
- Fórumok
- Szoftverfejlesztés
- SQL kérdések
- (kiemelt téma)
- Végre elérhető az új Steam Controller
- Milyen egeret válasszak?
- VR topik
- Eladhatatlannak ítélt CPU-k eladásával javult az Intel node-ok kihozatala
- Milyen házat vegyek?
- iPad topik
- Nem annyira csodás az ASUS csodakábele
- Bemutatkozott a OnePlus Pad 4
- Mindenféle könyves (és olvasós) Off topic
- OLED monitor topic
- lkristóf: Prohardver fórum userscript – hogy lásd, mikor neked válaszoltak
- Luck Dragon: Alza kuponok – aktuális kedvezmények, tippek és tapasztalatok (külön igényre)
- bitpork: Meglátjuk mit hoz a jövő
- ubyegon2: Airfryer XL XXL forrólevegős sütő gyakorlati tanácsok, ötletek, receptek
- btz: Internet fejlesztés országosan!
-
Fórumok
PROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Tabletek, E-bookok Nyomtatók, szkennerek PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Új hozzászólás Aktív témák
-
 nyugis21
csendes tag
nyugis21
csendes tag
Köszönöm!
Sajnos megfertőztek coviddal, eltart egy ideig, amíg túlleszek rajta.:-(
Ráadásul a webbel is bajok vannak, levelező weboldalnak lejárt valami tanúsítványa, napok óta nem kapok leveleket, nagy nehezen be tudok lépni, küldeni tudok, de válaszok "kézbesíthetetlenek"?
yt-ről se tudom a videókat letölteni, még azokat se, amik korábban letölthetőek voltak, a letöltök nem találják a fájlt, vagy időtúllépés.:-(
-
 DeFranco
nagyúr
DeFranco
nagyúr
-
 Ispy
nagyúr
Ispy
nagyúr
-
 nyunyu
félisten
nyunyu
félisten
dupla
-
nyunyu
félisten
tripla

-
nyunyu
félisten
Egyáltalán a from után táblákat vesszővel felsorolós ősrégi szintaxist tanítják még valahol?
Mikor ~20 éve halogattam DB témájú tárgyakat a BMEn, akkor már csak a szabvány szintaxis Oracle és SQL Server implementációját mutogatták.
Legacy Teradata nyelvjárásba csak később futottam bele, amikor 10-15 éves ETL jobokat kellett visszafejtenem, és vizualizálnom.
-
nyunyu
félisten
Metszet nélküli az a left/right join is null-lal kombinálva.
select a.*
from tabla a
left join temp b
on b.id = a.id
where b.id is null;Ez szerintem ekvivalens ezzel:
select a.*
from temp b
right join tabla a
on a.id = b.id
where b.id is null;Ezeket a szörnyűségeket le se merem írni:
select a.*
from tabla a, temp b
where a.id = b.id (+)
and b.id is null;select a.*
from temp b, tabla a
where b.id (+) = a.id
and b.id is null;
-
nyunyu
félisten
Szerintem sok különbség nincs köztük, ha megfordítod a táblák sorrendjét, akkor right lesz a left-ből, és fordítva
Nekem olyan logikátlannak tűnik, hogy egy kicsi vagy lyukacsos táblához joinoljak egy nagyobbat / tömöret, így én sem szoktam right joint használni, helyette mindig nagy táblához left join.
-
 Pulsar
veterán
Pulsar
veterán
-
Ispy
nagyúr
-
nyunyu
félisten
-
 bambano
titán
bambano
titán
-
Pulsar
veterán
a keresendő adatom egy adatpár. van egy A és egy B oszlopom. Csak azokat az egyezőségeket keresem ami A oszlopban pl az egyes sorba van. Tehát A1-et B1-el. A elvileg nem ismétlődhet, de B igen.
nyunyu: rendben, köszi
 kb 10k sorom volt, és 7 darabbal lett több. Distinctet direkt nem írtam az ID-ra, mert állítólag az ID-ban nincs ismétlődés, de majd leellenőrzöm.
kb 10k sorom volt, és 7 darabbal lett több. Distinctet direkt nem írtam az ID-ra, mert állítólag az ID-ban nincs ismétlődés, de majd leellenőrzöm. 
-
nyunyu
félisten
-
 sztanozs
veterán
sztanozs
veterán
-
Pulsar
veterán
igen, bár az elsőben ismétlődés nem lehet, mert egyedi azonosító. Egy azonosítóhoz tartozhat sok dátum, de én csak azt keresném ami mellette van. És persze előfordulhat olyan, hogy egy másik azonosítóhoz ugyan az a dátum van rendelve. Ezt szeretném kiszűrni, és csak úgy lekérdezni az adatokat, hogy csak a mellette lévő dátummal keressen
ez így baromság?and (azonositok.ids = temp.column1 and azonositok.dates = temp.column2)
-
sztanozs
veterán
-
Pulsar
veterán
-
nyunyu
félisten
Sosem szerettem az ősrégi szintaxist, mert nem bírtam megjegyezni, hogy az Oracle a feltétel melyik oldalán várja a (+)-t a left illetve right joinnál.
select t1.*, t2.*
from tabla1 t1, tabla2 t2
where t1.id = t2.id (+);Aha, amelyik oldal nem kötelező / lehet null, oda kell tenni a (+)-t.
Vagyis a fenti példa egy left join.Arra meg egyáltalán nem emlékszem, hogy Teradatában volt-e ilyen left/right szintaxis.
Csak annyi rémlik, hogy update közben is tudott implicit joinolni, amit rajta kívül egyik DB motor sem ismert:update tabla1
set valami = tabla2.valami
where id = tabla2.idSzabvány SQL mindenesetre jóval olvashatóbb, mint ezek az elfajzott példák.
-
nyunyu
félisten
Mondjuk join feltételnek megadod mindkét mezőt AND-dal?
SQL-92 szintaxis:
select t1.*
from tabla1 t1
join temp t2
on t2.valami = t1.valami
and t2.masikmezo = t1.masikmezo;Szabvány előtti ősrégi szintaxis:
select t1.*
from tabla1 t1, temp t2
where t2.valami = t1.valami
and t2.masikmezo = t1.masikmezo;Utóbbit csak a nagyon régi DB gyártók (Oracle, Teradata), illetve az újabbak közül csak páran (MS SQL 2008-tól, MySQL?) ismerik csak.
Nagyon nagy (100k+ rekord) tábla esetén sokat lehet gyorsítani rajta, ha legalább az egyik joinolt oszlopon van index.
(Esetleg partícionálod a táblát az egyik kulcs mentén, de az már nagyon advanced megoldás, és nem minden ócó/ingyenes DB motor tudja) -
Pulsar
veterán
Sziasztok,
egy kis segítséget szeretnék kérni. Vagy egy tömeges adatlekérésem. Ez úgy szoktam megoldani, hogy a kért ID-kat betöltöm egy temp páblába, a temp táblát beírom a from-ba, és a where-be beírom, hogy azonosito = temp.column1
Mi olyankor az eljárás, hogy a temp táblám két oszlopot tartalmaz, és azt szeretném, hogy csak az egymás melletti megfelelőségekre kapjak eredményt, és ne minden mindennel végigpróbálva.
Remélem érthetően sikerült megfogalmaznom
-
 Szmeby
tag
Szmeby
tag
-
nyugis21
csendes tag
Mondanál egy Móricka-példát arra, hogy mi lehet egy Projekt < több esemény < több feladat?
5374 első mondatában leírtam, a projekt az eseményekből áll, amik megtörténtek, a feladatok az elintézendőek, amik jövőbeli dolgok.
Először azokat is be akartam venni, hogy lehessen látni az összes történést, de rájöttem, hogy az túl sok lenne, így azt majd csak ki kell pipálni, hogy még élő dolog, vagy már befejezett.
A Móricka példa a kedvedért:
projekt (ügy):
az osztályban lévő lányokat virágesővel köszönteni 1 hét múlva.
1. esemény:
gyűlés, résztvevő Móricka, Ottó, a tizedes, meg a többiek
leírás: Megalakult a "LáViKö" csoport, a lányokat virágesővel köszöntők csoportja.Feladatok:
1. feladat felelős: Móricka, teendő: megtudni, hol a legolcsóbb a cserepes virág - kipipálva
2. feladat felelős: Ottó, teendő: létrát szerezni - kipipálva2. esemény:
gyűlés, résztvevő Móricka és Ottó
leírás:
Móricka közli, hogy 13 virágkereskedést hívott fel, a legtávolabbinál van a legolcsóbb cserepes virág, így autó kell a beszerzéshez
Ottó közli, hogy megszerezte a szomszéd villanyszerelő létráját, de sietni kell a visszaadással, mert az illető a csavarhúzójába kapaszkodva maradt.Feladat:
1. feladat: pénzt összeszedni a tagoktól - kipipálva
2. feladat: cserepes virágokat gyorsan elhozni - kipipálva
3. feladat: virágesőt lebonyolítani- kipipálva
4. feladat: létrát visszavinni- kipipálva3. esemény
résztvevők: Móricka, Ottó, a tizedes, meg a többiek
leírás: 600 ft-ért megvették a virágokat, 200 ft-ért elhozták taxival, virágeső létra tetejéről megvolt, annyira sikeres lett, hogy a lányok a földön fekve sikongattak4. esemény
Ottó a létrát visszavitte, a villanyszerelő a földön feküdt aléltan, így a létrát ratette, hogy balesetnek látszódjonEz egész érthetőnek és jól felépítettnek tűnik a leírás alapján.
Nekem nem úgy tűnik, pl. hova írom be az eseményekhez a résztvevőket? Az ESET táblába nem tudom betenni, mert onnan az ID-vel kell kapcsolódnom a M táblához, akkor az M táblába kell felvennem egy résztvevők rubrikát?
Valamint a Feledat-okat is jelezni kell, hogy élő, vagy megoldva, ezt talán logikai Y/N mezővel meg lehet oldani, de akkor valahogy kezelni kell, hogyha megoldva, akkor ne legyen megjelenítve a lekérdezésben később, de jelentésekben szerepeljen, ha a feladatok is érdekesek lesznek.Adatbevitellel próbálkoztam, de úgy tűnik, az access nem szereti, ha egy id-hez egynél több tábla kapcsolódik, erre még megoldást kell találnom.
-
sztanozs
veterán
-
nyugis21
csendes tag
Megpróbáltam az összes szempontot figyelembe véve megoldani, de túl bonyolult lett, így egyszerűsítettem, lemondtam a feladat-esemény bonyolultságáról, külön kezelem őket.
(5294-ben és 5370-ben volt a két különböző séma)A feladatnál az lesz a lényeges, hogy lezáruljon, és ha fontos, akkor eseménylistába be lesz írva, mint egy fontos történés.
Itt az első változat, szerintetek ez a logika jó, vagy még mindig van vele valami gond?
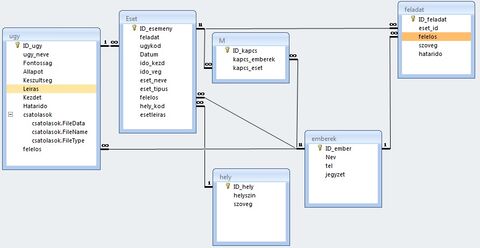
Az UGY (project)-nek lehet egyetlen felelőse és sok eseménye (ESET).
Az eseményeknek (ESET) csak egyetlen felelőse és egyetlen helyszíne, de M kapcsolóséma révén sok résztvevője lehet, és sok FELADAT tartozhat hozzá.
Egy FELADAT csak egyetlen eseményhez (ESET) kapcsolódhat és csak egyetlen felelőse lehet, a határidő a lényeg, és az, hogy nyitott vagy lezárult. (Hopp, ezt a mezőt elfelejtettem felvinni.)
Minden UGY-nek, ESET-nek és FELADAT-nak egy felelőse lehet, de M révén sok eseményen (ESET) vehet részt és egy eseményen több résztvevő lehet.
-
sztanozs
veterán
-
nyugis21
csendes tag
Az esemény az, ami megtörtént, a feladat az, ami elintézésre vár, el kell őket különíteni, ráadásul egészen más kapcsolatokra van szükség, lásd lentebb.
A példát csak hirtelen írtam, de nyilván minden az, amit meg kell tenni a közeljövőben.
Azt még nem tudom, mi lesz, ha a feladat meghiúsul, majd kiderül, ezért kellene végre eljutnom odáig, hogy legyen egy minimálisan működő séma és elkezdhessem tesztelni.A táblák közötti kapcsolatot továbbra se látom tisztán, az eseménynél egy eseményhez kell több személy, a résztvevők, míg a feladatnál egy személyhez több feladat kell, pont az ellenkezője.
Nem jövök rá, hogyan lehet az egészet kezelni, ebben kérek segítséget.
-
 martonx
veterán
martonx
veterán
Az 1-es sémára szavazok. Viszont tényleg van ezt értelme ennyire mikroszkopikus felbontásban, ultra részletesen adatbázisban ábrázolni?
Feladat és eseményenként? Ennyi erővel akkor már az is feladat és persze esemény lehetne, hogy a találkozóra menet kimész az utcára, felülsz a villamosra, veszel egy menetjegyet stb...Szóval szerintem továbbra is túlbonyolítod.
-
nyugis21
csendes tag
Furcsa ez a fórum, elvileg segítőkészséget ígértek, de ahogy visszaolvastam, a nekem írt "tanácsok" nagy része nem a témához tartozik, vagy félrevezető.
![;]](//cdn.rios.hu/dl/s/v1.gif)
Utána néztem, az acces is sql alapú, ami 1992-es megegyzés (szabvány?) alapján jött létre, majd 1999-ben volt egy újabb verzió, de azt már nem mindenki fogadta el. Akkor most nem mindegy, hogy a program 2007-es vagy frissebb, ha évtizeddel korábbi kódot használ?
Legyen lényeges téma is:
Agyalok egy ideje a megoldáson, szerintem táblák közötti kapcsolat mindennek a kulcsa, azt kellene valahogy összehozni, ebben lenne szükségem segítségre, az pedig még a programtól független megoldásnak tűnik.Amin elakadtam:
A project minta adatbázisban van egy jónak látszó megoldás, hogy a projekt-hez lehet feladatokat csatolni, amihez felelőst lehet kinevezni, de ha jól értem, ez csak úgy működik, hogy a projektnek is van felelőse (tulajdonosa?).Az én megoldásomban a projekt az eseményekből áll, amihez sok résztvevő tartozik - azaz ellentétes a példával, ahol csak egy felelős van - és az eseményekhez kellene feladatokat csatolni, amiknek lenne felelőse.
DE: a feladat megvalósításával az is eseménnyé válik.(Példa:
esemény: telefonhívásos megbeszélés 2 személy között, megegyeznek, hogy az egyik megvesz valamit, majd elviszi a másiknak, aki azt majd később visszaadja neki.Erre két megoldást látok:
1.séma
Az egyik megoldásnál van egy esemény 2 fővel, telefonos megbeszélés, majd lesz egy újabb esemény 2 fővel a találkozóról, ahol a lényeg az, hogy az egyik átad valamit a másiknak.Az első eseményhez kapcsolódik két feladat, az első feladatnak az egyik személy a felelőse, és a téma a bevásárlás.
A másik feladatnak mindkét személy a felelőse és a téma adott helyen és időben találkozni.A második esemény már a megvalósult találkozó lesz, ahol adott helyen és időben a két személy találkozik és megtörténik az átadás.
Ehhez rögtön kapcsolódik egy újabb feladat, a második személy a felelőse, és adott határidőre vissza kell adnia a dolgot az első személynek.Ekkor kell két külön tábla, az egyik az esemény, amikhez feladatok kapcsolódhatnak, a másik a feladat, ahol csak az a lényeg, hogy megvalósult, vagy sem.
A hátránya, hogy néha ugyan az a dolog feladat és esemény is lesz, lekérdezésnél esemény és feladat sorrendet kell választani.2.séma
A fenti folyamat azzal a különbséggel, hogy a feladatok a sikeres teljesüléskor eseménnyé válnak.
Ekkor a lekérdezés (megjelenítés) egyszerűbb lesz és nem lesz párhuzamos adat, de fogalmam sincs, hogyan lehet ezt megvalósítani - talán kell egy "kód" mező, hogy ez feladat vagy esemény?A másik problémám az, hogy a feladathoz egy felelős kell, ami a ms projekt mintában látszik, hogy csak egy személy kapcsolódik hozzá, DE! amint eseménnyé válik, akkor már ellenkező irányú kapcsolat kell, mert akkor már több résztvevője lehet az eseménynek.
Tehát, ha az ms projekt sémáját követem, akkor a második feladatot, amikor két személynek kell találkoznia, mindkét személynek ki kell osztani, személyenként lehet egy feladat, és mindkettőnek teljesülnie kell, hogy létrejöjjön a két feladatból az egy esemény.Ez önellentmondásnak tűnik számomra, ti ezt hogyan oldanátok meg? (vagy fel, ha az ellentmondást fel kell oldani.)

-
sztanozs
veterán
Mondjuk ha még mindig access 2007-el szenvedsz, akkor sok segítséged nem lesz (még a neten se nagyon), az már egy rég kivezetett verzió.
A Projekt template-hez úgy nézem nincs videó, csak szöveges bemutató:
https://support.microsoft.com/hu-hu/office/a-projects-access-adatb%C3%A1zissablon-haszn%C3%A1lata-87fdb02a-b109-4864-ab94-95e7ce1b6443Ezeket a plusz táblákat, amik neked kellenek, fel lehet venni a legyártott sablonokhoz, csak meg kell csinálni a hozzájuk tartozó formokat, ha nem akarod táblázatos módban kezelni az alapadatokat.
Törölni is lehet belőle táblákat, csak vele együtt célszerű törölni a hozzájuk tartozó formokat is, amik nem kellenek. Illetve ki kell szedni a megmaradó formokból a hozzájuk tartozó beviteli mezőket.
common tasks - fogalmam sincs, hogy mire jó, és csak az emberekkel van kapcsolata
Ezek olyan feladatok, amik nem tartoznak projektekhez, de valaki elvégzi. Mivel a template egy projektcég/projekt csapat munka kimutatására szolgál így célszerű nyilvántartani azokat a feladatokat is, amik nem kifejezetten projektekhez tartoznak, hogy lehessen látni a kollégűk leterheltségét (terhelhetőségét). -
nyugis21
csendes tag
Most látom, hogy már lelkes újonc vagyok, a moderátorok adnak kategóriákat?
------
1. Nem, az oldalon nem tudok semmit megtalálni, bármit keresek, az első tiz találatot megjeleníti - ami többnyire aktiváld-töltsd le, stb. - és nem enged továbblépni a többire.2. amennyit értek a videóból, az már 2016-os access példafájl, képpel, és csak a task-employee két táblából áll.
ennél jobb a projects adatbázis - lásd lentebb a képet - ha megtalálnád az azt bemutató videot, megköszönném, ott nem értem, miért van külön task és common task tábla is, eltérő kapcsolatokkal.3. Ez volt az első kérdésem, hogy hogyan lehet access példa adatbázisokat összehozni, de nem volt rá válasz. Végignéztem mindet, ami 2007-ben volt, a project adatbázis volt a legjobb, de nagy része felesleges nekem, más részét nem értem, mire jó és miért így vannak a kapcsolatok, és van, ami nekem hiányzik belőle, ezért kellett nekem több tábla.
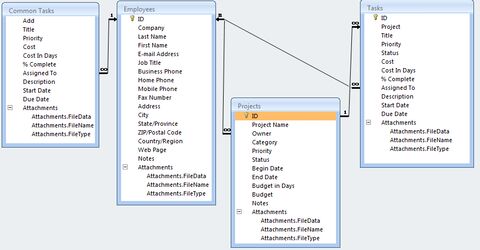
Itt van
project - ami nálam ügy,
tasks - ami nálam feladat
employees - ami nálam emberek
common tasks - fogalmam sincs, hogy mire jó, és csak az emberekkel van kapcsolatahiányzik az
eset - vagyis a project/ugy egyes lepesei
hely - esetek valahol történnek (vagy virtuálisak, pl. telefonhívás)Valamint itt úgy látszik, hogy mind a project, mind a task csak egy emberhez tartozhat, míg ténylegesen többen vesznek benne részt, és gyakran mindig mások.
-
sztanozs
veterán
Ezt a videót egyébként megnézted?
Ebben a template-ben vannak FORM-ok és RIPORT-ok is, szóval meg lehet nézni, mit hogyan kell csinálni egy form vagy egy riport készítésénél: https://support.microsoft.com/hu-hu/office/vide%C3%B3-az-asztali-feladatkezel%C3%A9si-adatb%C3%A1zissablon-haszn%C3%A1lata-9a9736a4-9aac-45a1-93dd-4eca934cf8ef -
sztanozs
veterán
-
 pch
senior tag
pch
senior tag
Szerintem jobban járna egy mysql-el. Annak ott a phpnyadmin. Ott tud adatot bevinni meg sql-t lekérni.
Wamp-al felmegy pár klikkre. -
sztanozs
veterán
-
nyugis21
csendes tag
Kérlek nézd el nekem, hogy utoljára valamikor 2010 táján Access-eztem, és nem is hiányzik.
Ezt nem értem, megsértődtél, mert gratuláltam, hogy találtál egy extra megoldást, amit eddig mások nem vettek észre, hogy táblán belül is lehet kapcsolat?
Ezen miért sértődtél meg?Egy dolgot kell megoldanod, hogy amikor egy újabb eseményt felviszel a formon, akkor ki tudj (de ne legyen muszáj) választani egy szülő eseményt, pl. az előzőleg felvittet. Így tudod logikailag megoldani, hogy a jövőbeli események kapcsolódnak az őket kiváltó eseményhez, azaz a tábla önmagához kapcsolódik.
Sejtettem, hogy nem accessel van a gond, ezek szerint nem is az adatbevitellel, hanem még a táblák egymáshoz kapcsolásával.
5295-nél tartunk, eddig jutottam, ezek szerint ez így nem jó?
Itt egy példa, mondjuk a mostaniak alapján:
1. esemény:
találkozó X.20 21-23 között, résztvevők: nyugis, martonx, ispy
leírás: access adatbeviteli form probléma megbeszélése
feladatok:
nyugis - acces-ben adatbeviteli formok végigpróbálása
ispy - acces és vba kapcsolati videok listájának kigyűjtéseVagyis a következő két esemény az lesz, hogy
nyugis mondjuk X.21 9-13 között végigteszteli az access formokat, mikor milyen hibák jönnek elő
majd a harmadik esemény az lesz, hogy ispy mondjuk X.22 14-22 között webes keresgéléssel listát csinál.Ezek az események még nem léteznek, még csak feladatok, de el van döntve, hogy ezek lesznek a következők, amik az 1-es esemény, a találkozó következményei.
Vagyis nekem előre kell beírnom, hogy mi(k) lesz(nek) a következő lépés(ek) és majd akkor lesznek véglegesítve (kezdő-vég dátum, résztvevők, leírás) amikor megvalósult.
Akkor a 5295 táblák közötti kapcsolat így nem jó?
Ispy:
Mi a trükköd, hogy te tudsz kétszer is írni egymás után?Kössz, de nyugdíjas fejjel nem akarok nekiülni programozni, az egyetlen életcélom most ezt a megoldást megvalósítani, legkésőbb a karácsonyi ünnepekig, ez a nagy projektem.
-
martonx
veterán
Kérlek nézd el nekem, hogy utoljára valamikor 2010 táján Access-eztem, és nem is hiányzik.
A gépemen is csak azért van, mert múltkor a kedvedért feltelepítettem, hogy bebizonyítsam hogy lehet Accessben egy táblát önmagához kötni."Ezért kérdeztem, hogy adatbevitelt hogyan oldod meg ott?
Nem értem, ha egyszer egy táblában egy rekordot kezdek bevinni, hogyan tudok ugyan abba a táblába egy vagy több újabb rekordot úgy beszúrni, hogy még nem zárom le a rekordot, ráadásul rögtön kapcsolat lesz az újonnan bevitt rekordokkal?"Fingom sincs (régen is VBA-t programoztam Access mögött, nem az adatbeviteli formokkal tökölődtem), hogy kell az adatbeviteli formokat összenyomkodni varázslóban.
VISZONT: háttal ülsz a lovon logikailag. Adatbevitelnél lényegtelen a kapcsolat az esemény, és a jövőbeli esemény között, mert nyilván ekkor még nincs is kapcsolat. Felviszed az eseményt, és kész. Ez az esemény lesz a szülő eseményed.
Egy dolgot kell megoldanod, hogy amikor egy újabb eseményt felviszel a formon, akkor ki tudj (de ne legyen muszáj) választani egy szülő eseményt, pl. az előzőleg felvittet. Így tudod logikailag megoldani, hogy a jövőbeli események kapcsolódnak az őket kiváltó eseményhez, azaz a tábla önmagához kapcsolódik.
Fogalmam sincs, ezt hogy kell csinálni a formon, de biztos, hogy elég csak a form varázslójában kattintgatni.Sok sikert, részemről téma lezárva.
-
Ispy
nagyúr
De lehet szimplán data bindingel hozzákötni a sourcet a táblához, a controlokba megadod tervező nézetbe melyik hova kapcsolódik és akkor auto save van, sajnos már nem emlékszem a részletekre vagy 12 éve nem dolgoztam vele...hála égnek.
Szóval valami olyasmi rémlik, hogy a form tervező nézetben a propertiek között meg tudod adni a táblát és utána mondjuk egy textboxnak ami kiraksz rá ki tudod választani a fieldet a táblából, amit kezelnie kell, szóval ha csak ilyen fapad kell, azt talán meg lehet úszni vba kód nélkül.
-
Ispy
nagyúr
Az access backend sql, de a frontend vba, azaz visual basic kódokat kell írni a formokhoz. A formok és a controlok pedig eseményvezéreltek. Nekünk a programunk 14 évig accesben futott, több 10000 sornyi programkód volt mögötte, ez nem triviális.
Nézd meg udemyn hátha van fent pár euróért anyag fent access frontendhez.
De ez már vegytiszta programozás, nem egy ilyen fórumba válaszolok rá pár sorba dolog.
Egyébként a youtubon van egy rakat videó.
-
nyugis21
csendes tag
Taci:
nem hiszem, hogy "kattintgatással" végig lehet vinni egy projektet.
Nem is, projektet csak ésszel lehet végigvinni.Talán próbálj meg kisebb területeket lefedni a kérdéseiddel, mert ezek talán túl általánosak, megfoghatatlanok, vagy nehezen megválaszolhatóak.
Vagyis nem értettétek meg, hogy egyetlen részletkérdés volt a probléma, és nem jeleztetek vissza, hogy nem értitek.Számomra a te javaslatod volt érthetetlen, értelmetlen nekiállnom sql programozási példáknak, amikor csak egyetlen részprogramra keresem a választ:
Hogyan lehet adatot bevinni az eset táblába jövőbeli feladatként, hogy az rögtön ugyan annak a táblának egy még nem létező rekordjára hivatkozzon?És azt kérlek, ne feledd,
Kérlek, ne feledd, hogy a fórum korlátoltsága miatt csak egyetlen beírás lehetséges, ha hetekig nincs válasz, vagy újabb beírás, hetekig kell várnom, hogy esetleg rákérdezzek, miért nincs válasz, mert még a beírást se tudom utólag módosítani.Próbáld ki, milyen érzés naponta többször ránézni a fórumra csak azért. hátha végre valaki írt valamit, hogy lehessen folytatni a munkát.
Kínzótábornak is elmegy ez a fórum.
martonx:
Ez egy SQL fórum, nem pedig MS Access fórum.SQL kérdésem volt, nem access - amúgy az acces is sql alapú, csak vizuális megoldású, de van sql nézet nézete is.
Hogy táblák között milyen kapcsolatok vannak, SQL query-kben mit-hogy érdemes megcsinálni, abban tudunk segíteni, de szerintem itt senki nem használ MS Access-t (többek között ezért is próbáltalak volna lebeszélni róla).
Pontosan ez volt a kérdésem, az általad javasolt megoldásra irányult, hogyan lehet vele adatot bevinni, mert nem értem és nem találtam rá sehol példát, pedig végignéztem az acces helpjének a részeit és letöltöttem és végignéztem az access2007 videókat yt-ról, még az angol nyelvűeket is.Sőt, letöltottem az elmúlt tíz év access érettségi feladatait is, de azok nem foglalkoznak adatbevitellel, csak lekérdezésekkel és jelentésekkel.
Mindenhol csak 1-sok, sok-1 vagy sok-sok kapcsolat van, de az utóbbinál is két különböző tábla között, te viszont ugyan abba a táblába tetted vissza a kapcsolatot, amire sehol sincs példa.
Ezért kérdeztem, hogy adatbevitelt hogyan oldod meg ott?
Nem értem, ha egyszer egy táblában egy rekordot kezdek bevinni, hogyan tudok ugyan abba a táblába egy vagy több újabb rekordot úgy beszúrni, hogy még nem zárom le a rekordot, ráadásul rögtön kapcsolat lesz az újonnan bevitt rekordokkal?A mi szemszögünkből nézve az MS Access form készítés mizériája egy szinten van az MS word-ös példámmal.
Igen, a könyvben is pár oldalon vannak az adatokkal kapcsolatos dolgok, majd sok-sok oldalon, hogy milyen betűtípus, szín, meg sok minden lehet és hogyan lehet logot használni képként, stb. amik nem érdekelnek.

Remélem így már érthető, hogy miért állt itt meg a segítségünk. Olvass MS Access doksikat, nézz MS Access form gyártó youtube videókat, ha létezik olyan, akkor írj direktben MS Access fórumokra, és biztos meg lesz a kérdésedre a megoldás.
Lásd a fentieket, úgy tűnik, egy sql megoldást javasoltál, amit az access könyvek nem ismernek, erre kérdeztem rá.
A könyvek, help és videok alapján arra tippeltem, hogy az adatbevitelnél talán egy lekérdezést kell meghívni, ami létrehoz egy új rekordot, és utána lehet az adatot bevinni, de nem értem, hogyan, ha egyszer még a tábla korábbi rekordját nem zártam le. (Sőt, több jövőbeli feladat lehet, úgyhogy sok új feladatot kell beszúrni a táblába.)Lehet, hogy jelentkezhetnél a megoldással a ms-nél is, hogy nem csak különböző táblák között lehet sok-sok kapcsolatot létrehozni.

-
martonx
veterán
Ez egy SQL fórum, nem pedig MS Access fórum. Hogy táblák között milyen kapcsolatok vannak, SQL query-kben mit-hogy érdemes megcsinálni, abban tudunk segíteni, de szerintem itt senki nem használ MS Access-t (többek között ezért is próbáltalak volna lebeszélni róla).
Azaz a formok gyártásában, mi itt nem fogunk tudni segíteni neked.
Ahogy azt is hiába kérdezed meg itt, hogy MS Wordben, hogyan formázzuk hupililára egy bekezdés hátterét, miközben felhőcskés szegélye legyen. A mi szemszögünkből nézve az MS Access form készítés mizériája egy szinten van az MS word-ös példámmal.Remélem így már érthető, hogy miért állt itt meg a segítségünk. Olvass MS Access doksikat, nézz MS Access form gyártó youtube videókat, ha létezik olyan, akkor írj direktben MS Access fórumokra, és biztos meg lesz a kérdésedre a megoldás.
-
 Taci
addikt
Taci
addikt
Én ahogy láttam, elég sok segítséget, tanácsot és iránymutatást kaptál a fórumtársaktól.
Részemről továbbra is az alapok tanulmányozását javaslom, mert előbb-utóbb szükséged lesz rá, nem hiszem, hogy "kattintgatással" végig lehet vinni egy projektet.
Kezdetnek én mindig ezt ajánlom, mert egyből gyakorolni és kipróbálni is lehet:
https://www.w3schools.com/sql/Talán próbálj meg kisebb területeket lefedni a kérdéseiddel, mert ezek talán túl általánosak, megfoghatatlanok, vagy nehezen megválaszolhatóak. (Számomra, sőt igazából nekem az egész témád az. Ezért sem igazán tudtam eddig érdemben segíteni.)
És azt kérlek, ne feledd, itt mindenki saját idejéből, önszántából segít, válaszol, senki sem kötelez senkit, hogy segítsen neked vagy másnak. És te sok választ és segítséget kaptál eddig is. Úgyhogy talán nem a legjobb "taktika" egy ilyen hozzászólás ezek után. De ez csak az én véleményem.
-
nyugis21
csendes tag
-
Taci
addikt
Köszönöm a gyors választ mindkettőtöknek.
Még egy kezdő kérdés:
Jelen tudásommal az index újraépítése az az index törlése és újrakreálása. Van ennek esetleg jobb/más/hatékonyabb módja? (MySQL, MariaDB)A REINDEX INDEX, REINDEX TABLE és OPTIMIZE TABLE opciókat találtam.
Ebből csak az utóbbi működik, viszont ezzel az üzenettel:
Table does not support optimize, doing recreate + analyze instead -
sztanozs
veterán
-
pch
senior tag
-
Taci
addikt
-
pch
senior tag
-
Taci
addikt
Sziasztok!
Van egy "kategóriás" táblám, amibe cikkehez tartozó kategóriák kerülnek be. Ha egy cikkhez 3 kategória tartozik, akkor az 3 rekord ebben a táblában.
Ez a szám (kategória egy cikkhez) azonban módosulhat, bekerülhet új kategória, és ki is kierülhet olyan, amihez mégsem tartozik.
Így elkerülhetetlen, hogy "lyukak" legyenek a táblában (ha mondjuk 3 kategória volt egy cikkhez, és csak 2 maradt, akkor ott lesz egy "lyuk", mert az a rekord ki lesz törölve).
A kérdésem az lenne, hogy megéri ezeket a lyukakat feltöltenem? Van bármilyen hátránya ilyen "kis lyukaknak" a táblában?
Mert ha úgy oldom meg, hogy az új elemeket előbb a lyukas részekre töltöm fel, akkor bár "szét lesznek szórva", de hát arra van az indexelés.
De ha az új elemek mindig csak "felülre" kerülnek, akkor idővel nagyon foghíjas lehet - bár ezek max 1-2 rekordnyi "lyukak".
Mit ajánlotok? Kezeljem, és a lyukas részeket töltsem fel előbb az új elemekkel, vagy ekkora lyuk az nem számít, hagyhatom?
(Mindkét módszert meg kell még írnom, ezért kérdezem, mert mindegy, melyiket csinálom, az egyikkel foglalkoznom kell így is - úgy is. Csak akkor már jó lenne a megfelelővel.)Köszönöm.
-
nyunyu
félisten
-
 Szigii
csendes tag
Szigii
csendes tag
-
nyunyu
félisten
-
Szigii
csendes tag
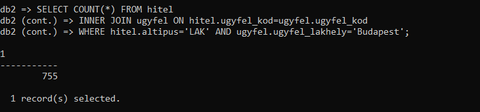
Köszi a segítséget, ki is jött egy eredmény
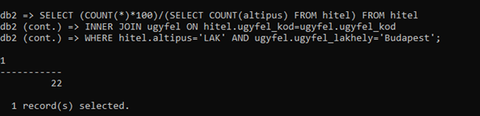
Viszont itt a hitel.altipusnál a teljes összeggel kell osztani nem csak a a 'LAK' típusokra, nem?
Azért gondolom így, mivel megkapjuk a 755db ügyfelet, akiknek lakáshitelük van és budapesti lakosúak
Ezt szorozzuk 100al és osztjuk az összes létező hitel típussal (ami ebben a feladatban 3333, amiből a 'LAK' 1972db), amire ki jön a 22%
Bocsi, ha egy kicsit bonyolultan írtam le a gondolatmenetem.
-
nyunyu
félisten
Kezdésnek jó.
Ennek az értékét szorozd százzal, aztán oszd el a select count(*) from hitel where hitel.altipus='LAK' értékével.
select p.db*100/o.db pesti_szazalek
from
(select count(*) db
from hitel h
join ugyfel u
on u.ugyfel.kod = h.ugyfel.kod
where h.altipus = 'LAK'
and u.ugyfel.lakhely = 'Budapest') p
join
(select count(*) db
from hitel h
where h.altipus = 'LAK') o
on 1=1;Vagy akár egy menetben is lehet, ha egy alselectben strigulázod a hiteleket, és abból a pestieket, aztán a külsőben summázod őket, és számolod a százalékot:
select sum(pesti)*100/sum(db)
from (select 1 as db,
case when u.ugyfel_lakhely = 'Budapest'
then 1
else 0
end pesti
from hitel h
join ugyfel u
on u.ugyfel.kod = h.ugyfel.kod
where h.altipus = 'LAK'); -
Szigii
csendes tag
Sziasztok,
A segítségeteket szeretném kérni.
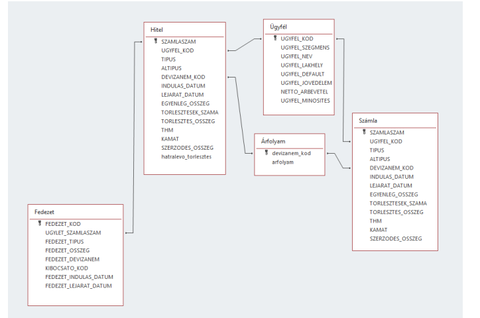

Ennél a feladatnál akadtam meg, nem tudok rájönni, hogy százalék formában, hogy kéne megadnom a lekérdezést.
Én eddig tudtam személy szerint eljutni. -
nyugis21
csendes tag
Óh, köszönöm, én az eset táblával próbálkoztam, mert annak van minden táblával kapcsolata, de az "a kapcsolat másik végén" van.
Egyenlőre csak azt akarom valahogy tesztelni, hogy ez az elrendezés működik-e, és igen, akkor miért nem, ezért akarok pár adatot bevinni.
Ha működik, akkor akarok nekiállni a beviteli űrlapot megcsinálni, ahhoz már most segítséget kérek, eddigi tudásom alapján azt sejtem, hogy a feladat-okat csak lekérdezéssel lehet majd bevinni, amire eddig semmilyen példát se találtam. Igazából nem is nagyon értem, mert úgy látom, hogy a táblába beviszek egy rekordot, majd a feladat "virtuális tábla" révén ugyan abba a táblába viszek fel újabb rekordokat, amik egyenlőre üres sorok lesznek, hoszen csak később realizálódnak.
Ennek emésztéséhez kérnék segítséget, mit olvassak el, hogy ezt a megoldást megértsem. -
Ispy
nagyúr
-
sztanozs
veterán
-
nyugis21
csendes tag
Igen, igazatok volt, csak megjelenítése ilyen furcsa.
Azóta viszont elakadtam, sehogyan se tudok adatokat bevinni a táblákba.
Egy hete bújom a könyveket és oktatóanyagokat, de semmit se találtam rá.
Hogyan tudok legalább két sornyi adatot bevinni minden táblába, hogy kipróbálhassam a lekérdezéseket?
-
 velizare
nagyúr
velizare
nagyúr
-
Taci
addikt
-
martonx
veterán
-
Taci
addikt
Na nagy nehezen csak tudtam lockolni a táblát (phpMyAdminból nem volt olyan egyszerű), adtam hozzá egy 30 másodperces sleep-et.
Abban a 30 mp-ben valóban nem volt hozzáférés a táblához, ez viszont a weboldal felőli oldalon abban mutatkozott meg, hogy új adatot nem tudott behúzni. De ami cache-elve volt, azt szépen hozta újra, mintha semmi se történt volna.Viszont így bár lehet, hogy maga az UPDATE processz hamar lefutna (sőt, igazából folyamatosan azt nézem, hogy futtatom, és közben privát böngészésben nézem, hogy ne cache-ből szedjen adatokat, de így is gond nélkül betölt mindent) inkább napi 1x futtatom csak (az UPDATE-et használó karbantartó szkriptet), azt is valami hajnali órában, így biztosan nem fog "bad user experience"-t okozni.
Köszönöm ismételten a segítséget!
Amúgy jó lenne, ha valahogy ezt a rengeteg segítséget meg tudnám hálálni. Nem szeretek csak kérni, úgy vagyok rendben magammal, ha viszonozni is tudom.
-
Ispy
nagyúr
-
nyunyu
félisten
2) pontban egyáltalán nem vagyok biztos.
Mostani banki GDPR projektemen kb. harmadannyian vagyunk, mint kéne, Üzlet meg csodálkozik, hogy miért tart annyi ideig a projekt, miért nem lesz idén se kész.
Csak hát a többi projektről elszállingózó emberek pótlása nagyobb prioritású.
Plusz közben szórakoztatják a fejlesztőcsapatot olyan derült égből vis majorokkal is, mint pl. moratórium, ami tavaly+idén totálisan megborította a futó IT projektek ütemezését, határidejeit, mert plusz ember az nincs a kormány ad hoc ötleteléseinek záros határidőre lefejlesztésére.
Előzőleg meg telconak dolgoztam, az se volt sokkal különb.
-
martonx
veterán
"Na kipróbáltam, futott az update(-elő szkript) kb. fél percig, addig mint az őrült kattintgattam a weblapon (ezzel select lekérdezéseket generálva), és nem volt megakadás sehol sem."
Erről beszéltem, hogy igen, ezek a problémák, amik itt felvetődnek jogosak, és léteznek, de a te rendszered mire ide elér, hogy DB szinten lock stratégiákon kell gondolkoznod, és erre optimalizálnod lehet, hogy:
1. sose fog megtörténni
2. ha mégis akkor meg te leszel a következő magyar bank / telko ez esetben zokszó nélkül fel fogsz tudni venni egy komplett fejlesztő csapatot Szóval elvileg nem haszontalan ezeken itt pörögni, gyakorlatilag viszont az
-
Taci
addikt
Na kipróbáltam, futott az update(-elő szkript) kb. fél percig, addig mint az őrült kattintgattam a weblapon (ezzel select lekérdezéseket generálva), és nem volt megakadás sehol sem.
Próbáltam direktben lockolni is a táblát (LOCK TABLE cikkek WRITE), de egyrészt ez alatt is ment minden, másrészt a SHOW OPEN TABLES által visszaadott adatokban azt láttam, hogy nincs is lockolva. (Szóval lehet, ez nem is volt jó teszt ehhez.)
Úgy csináltam anno meg amúgy (a kategóriás karbantartó szkriptet), hogy 100 rekordonként tol egy commit-ot. Nem tudom, ebben a kontextusban ennek köze van-e bármihez.
Annyit találtam még (SQL oldalon), hogy talán lehet csak az érintett mezőket lockolni:
SELECT ... FROM your_table WHERE domainname = ... FOR UPDATE
Ezzel van tapasztalatotok? Jó lehet ide?Az indexeket létrehoztam az érintett mezőkre. Viszont ott észre vettem egy "érdekességet":
Azt mondta az egyik mezőnél (utf8mb4), hogy Warning: #1071 Specified key was too long; max key length is 767 bytes. Ennek utána olvastam, és értem is az okát.A kérdésem az lenne ezzel kapcsolatban, hogy amikor ránézek az indexre, ezt látom:
varchar(255)-ből varchar(191) lett. (ugye 767 / 4).
Ez azt jelenti, ha az eredeti sztring 255 karakter hosszú, indexelve ebből csak az első 191 lesz? Vagy ez pontosan hogyan "manifesztálódik"?"bár szemlátomást, ő magával is ezt teszi
"
Ott a pont. Bár hidd el, nem szánt szándékkal teszem. -
martonx
veterán
Nem csak Hibernate létezik ORM-ként, és nem csak ORM szinten lehet cachelni
Maximális respect a DB tudásodnak, de nem kell mindig mindent DB szinten megoldani.Ez itt nagyon off topic, de minek görcsöltetitek, és csuklóztatjátok szegény kezdő kollégát (bár szemlátomást, ő magával is ezt teszi
) olyan problémák, olyan technológiai szintű mélységében, amikkel egyrészt jó eséllyel a való életben találkozni se fog (vagy végül elég lesz egy hiányzó indexet feltennie), másrészt, ha nem is DB szinten, hanem kód szinten de, tök simán kezelni lehet. -
nyunyu
félisten
-
nyunyu
félisten
csomó lehetőséged van tehermentesítened az adatbázist, anélkül, hogy belegörcsölnél az SQL minden mélységébe. Pl. cachelés
Hibernate cachelésétől ments meg Uram minket.
Olyan szinten telibeszarja a DBk többfelhasználós jellegét, hogy öröm nézni.
Addig konzisztens csak önmagával, amíg rajta kívül nincs senki más, aki módosíthatja ugyanazt az adatbázist!Ha a háttérben megupdatelsz egy rekordot, azt a Hibernate nem szokta észrevenni, és a felette lévő alkalmazásban módosul a becachelt verzió, akkor szemrebbenés nélkül hülyeséggel írja felül a már megváltozott rekordot.
Nesze neked tranzakciók függetlensége.
-
Taci
addikt
Persze, amint gép elé kerülök, lock-olom a táblát, és megnézem, mi történik web oldalon. Ezt még sosem néztem meg.
Az milyen megoldás lenne amúgy, hogy amíg fut az update, addig a select egy erre beállított view-t használna? Vagy így a lock-olt táblára támaszkodó view sem "érhető el"?
(Az indexet mindenképp megcsinálom - ha esetleg nem lenne. Csak ez most eszembe jutott.)
-
martonx
veterán
"Egy index a cikk_id-ra" - itt alapból is kellene indexnek lennie, mivel ez Foreign key. Probléma megoldva
Egyébként meg ez ugyan SQL fórum, de mivel egy web alkalmazásról beszélünk, csomó lehetőséged van tehermentesítened az adatbázist, anélkül, hogy belegörcsölnél az SQL minden mélységébe. Pl. cachelés
-
Taci
addikt
Ez nagyon hasznos információ, köszönöm!
Tehát ilyenkor sorbanállás van? Tehát egy sima Select is sorban áll, és a (honlapot használó) user nem kap vissza addig adatot, amíg az update nem végez?
Akkor csak lenne még kérdésem:
Melyik a jobb megoldás ezt a helyzetet kezelni?
- Egy index a cikk_id-ra (ezt kapja vissza a kategóriakarbantartó szkript),
- vagy mégiscsak egy külön tábla ennek a mezőnek?Nem fér bele semennyi várakozás, sorbanállás, hogy a user megkapja a tartalmat (a honlap a kért adatokkal betöltődjön). Most oké, még pár 10ezer rekordnál a karbantartó szrkipt hamar végez, de később ez csak lassulni fog.
Tényleg nagyon köszönöm ezt az információt!
-
nyunyu
félisten
Nem tudom ki volt, de szerintem arra gondolhatott, hogy az update, delete az egész táblát szokta lockolni, amíg le nem fut, ha a where feltételeihez nem talál használható indexet.
Ilyenkor az összes többi select, insert addig vár, amíg a tábla fel nem szabadul.Ha van olyan index, ami alapján meg tudja határozni, hogy melyik sorok érintettek az update vagy deleteben, akkor csak azokat a sorokat lockolja a DB, tábla többi része használható marad.
De ez erősen DB motor függő, nem mindegyik kezeli ugyanúgy a tábla meg sor lockokat.
-
Taci
addikt
De most kiderült, hogy ezekről szó sincs, hanem a kategoria_verzio az ellenőrző szkriptednek egy flag, hogy az adott cikket már ne kelljen vizsgálnia?
Igen, pontosan.
Akkor marad úgy, ahogy eredetileg volt felépítve. Csak pár héttel/hónappal ezelőttről emlékszem, hogy valaki írta itt, hogy az úgy nem jó, ha ez a két mező, amit folyamatosan frissítve lesz így vagy úgy (kategória verziója, illetve cikkhez tartozó kategóriák írott nevei, vesszővel elválasztva - amikre "rá tudok nézni"), a többi adat mellett van, ugyanabban a táblában.
Sajnos már nem találok rá arra a válaszra. De ezért tettem fel a nyitó kérdést, hogy maradhat-e így, ahogy most van (amit most Te is megerősítettél), vagy esetleg rakjam külön táblába.Köszönöm szépen még egyszer a sok segítséget!
-
nyunyu
félisten
Eddig az hittem, hogy van több kategória táblád, amikben nem biztos, hogy ugyanolyan id tartozik ugyanahhoz a kategórianévhez, ezért verziózod őket.
.
Ekkor logikusan vagy a cikkek-ben kellene tárolnod a kategoria_verzio-t, ha egy cikkhez egyszerre csak az egyik halmazból/táblából tartozhatnak kategóriák.Ha előfordulhat az, hogy adott cikkhez az egyik kategória az egyik halmazból, másik meg a másik halmazból származik, akkor meg a cikk_kategoria-ban van a helye.
Utóbbi esetben ez NEM lenne redundáns!Ezért írtam azt, hogy a mi a francért nem vonod össze a kategória tábláidat, hogy csak egyféle id tartozzon ugyanahhoz a kategória névhez.
De most kiderült, hogy ezekről szó sincs, hanem a kategoria_verzio az ellenőrző szkriptednek egy flag, hogy az adott cikket már ne kelljen vizsgálnia?
Mivel itt 1:1 kapcsolat van a cikkekkel, így szerintem felesleges kitenni új táblába, jó helyen van az a mező ott.Ekkor viszont túlbonyolítottam az előzőekben írt queryket, felesleges volt a sok case when, meg kategoria_v1/v2/v3 join.
Túlzottan beszédes volt a kategoria_verzio név, csak nekem teljesen mást mondott, mint amire a költő eredetileg gondolt.Igazából neked csak arra van szükséged, hogy néha szemmelverd a cikk-kategória összerendeléseket, aztán ha egy cikkhez rossz kategória van rendelve, akkor vagy törlöd a cikk_kategoria rekordot, vagy megupdateled benne a kategoria_id-t a megfelelő kategóriáéra, ahogy a #5318-ban írtam.
-
Taci
addikt
Átnéztem, köszönöm a belefektetett időt és energiát.
Ami kérdésem még lenne, az csak elméleti, szeretném érteni a dolgokat.
A cikkek és kategóriák kapcsolata egy külön táblában van (az előbbi példákban
cikk_kategoria ck). Itt egy-egy cikkhez több kategória is tartozhat, ekkor ennyi rekord van létrehozva hozzá. (csak az id-k).
Logikailag ide tartozna a korábban tárgyalt verzió (amivel a kategóriák vannak ellenőrizve,kategoria_verzio). Viszont mivel egy cikkhez több rekord is tartozhat, így ha itt lenne a verzió is, akkor ez az adat redundáns lehetne.Megéri ezért ezt egy külön táblába kivinni, ahol csak a
cikk_idés akategoria_verziolenne?
Adatbázis szempontjából melyik a jobb?Illetve még egy kérdésem lenne, amit az eleje óta nem értek:
Ha ez akategoria_verzioacikkek(a fő) táblában maradt volna, az miért lett volna baj? Az miben okozott volna gondot (adatbázis szempontjából), hogy abban a táblában kellett volna azt a mezőt frissítgetni?Csak szeretném érteni.
Köszönöm. -
Taci
addikt
Az első fele meg is van, a GROUP_CONCAT volt a megoldás rá. (Hamarabb is meglettem volna a teszttel, csak GROUP_CONTACT-ot írtam...
)Ez lett végül kb. belőle:
create view cikkek_vw asselect c.id cikk_id,c.cim cim,c.create_date datum,c.creator cikk_iro,GROUP_CONCAT(k.nev) AS kategoriakfrom cikkek cjoin cikk_kategoria ckon c.id = ck.cikk_idJOIN kategoriak AS kON ck.kategoria_id = k.idGROUP BY c.id cikk_id;Köszönöm!
A másik kérdéskörhöz (és a válaszaid feldolgozásához) picit több időre lesz szükségem.
De ott talán nem voltam teljesen egyértelmű azzal, mit szeretnék, miért is volt a verziózás használva.
Ha csak pár cikkről lenne szó, nyilván meg tudnám kézzel is csinálni a módosításokat. De 2 nap alatt kb. 1000 rekordnyi cikk jön, és ezt csak egy karbantartó szkripttel tudom kezelni.
Kategóriát nem nagyon tervezek hozzá adni, de ha úgy alakulna, hogy kell, az nem gond.
Viszont azt, hogy egy-egy cikk milyen kategóriába tartozik, már nem ilyen egyszerű. Ha észreveszek (vagy bejelentenek) egy anomáliát, hogy egy nem megfelelő / többértelmű kategória-szó miatt egy cikk rossz kategóriába is belekerült, azt az összes cikknél ellenőriznem kell. (Mint pl. az előbb láttam: alapból az Ünnepek kategóriába kerül egy cikk, ha a karácsony szó a cikkel kapott kategóriák közt van - viszont most jó pár cikk, ami politikai irányzatú, a szó miatt szintén az Ünnepek kategóriába került, pedig ott nincs helye). Ilyenkor azt a kategória-szót vagy ki kell vennem, vagy egy exclude-tömbbe rakni (HA karácsony ÉS politika, akkor NEM ünnepek). Ezeket nyilván nem lehet egyesével kezelni, visszamenőleg is át kell nézni az összes cikket. Erre van egy szkriptem, szépen működik.Erre írtam, hogy ez a verziót figyeli, mert ami a legfrissebb kategóriatömb-verzióval került az adatbázisba, azt nem kell nézni, mert az már jól van mentve. A többit viszont át kell nézni.
Ez az ellenőrző szkript óránként lefut. Mivel ettől sokkal ritkábban frissítem csak a kategória-tömb tartalmát, ezért a legtöbbször csinál egy gyors ellenőrzést, látja, hogy minden rekord a legfrissebb verziójú kategória-tömbbel van kezelve, úgyhogy nincs dolga.De ha ezt a verziózást kiveszem belőle, akkor óránként végig kell mennie az összes rekordon, ott mindehol legenerálni, hogy az aktuálisan legfrissebb verziójú kategória-tömb szerint milyen kategóriákba kell tartoznia a cikknek, ellenőrizni, hogy úgy van-e elmentve az adatbázisban, és ha nem, cserélni.
Napi kb. 500 új cikk kerül be (és ez csak több lesz), valahogy muszáj vagyok skippelni azokat a rekordokat az ellenőrzésből, amiket nincs értelme ellenőrizni, mert az aktuálisan legfrissebb változat szerint kerültek be. Másképp sosem lenne vége, és a szolgáltató is kidobna, plusz annyi ideig tartana, hogy a max execution time-ot is túllépném bőven.Lehet, már megírtad a jó választ erre a kérdésre is az előbbiekben, még át kell néznem alaposan.
De ha esetleg mégsem, akkor talán mégis az lesz a legegyszerűbb, ahogy most van megcsinálva:
A cikkek táblában egy mező a verziónak, amivel a rekord kategóriái fel lettek töltve, egy másik mező pedig a rekord kategóriáinak, szövegesen.
Ha változik a verzió, mert javítani kellett kategória-szavakat (lásd az előbbi példa), akkor frissítés az összes nem-legfrissebb rekordon ezen a két mezőn.Amúgy az én hibám, visszaolvastam, ezt a verziós dolgot nem írtam az elején, pedig fontosabb, mint az, hogy a kategóriák nevét lássam.
Gondolom, túl nagy gondot nem okoz a rendszernek, hogy két mezőt frissítgetni (UPDATE) kell.
-
nyunyu
félisten
-
Taci
addikt
-
nyunyu
félisten
-
nyunyu
félisten
Ja, hogy egységesíteni akarod a cikk_kategoria összerendeléseket?
Akkor
1) öntsd bele egy közös táblába az összes eddigi kategórianevedet (legyen kategoria_uj a példa kedvéért)2) csinálj egy cikk_kategoria_uj táblát, amiben már nincs kategoria_verzio oszlop, többi ugyanaz, mint az eddigi cikk_kategoria-nal.
3) töltsd fel tömegesen a cikk_kategoria_uj táblát:
merge into cikk_kategoria_uj i
using (
select a.cikk_id,
a.cim,
a.kategoria_nev
a.kategoria_verzio,
a.kategoria_id kategoria_id_regi
k.kategoria_id kategoria_id_uj
from (
select c.id cikk_id,
c.cim,
ck.kategoria_id,
ck.kategoria_verzio,
case
when ck.kategoria_verzio = 1 then k1.nev
when ck.kategoria_verzio = 2 then k2.nev
when ck.kategoria_verzio = 3 then k3.nev
end kategoria_nev
from cikkek c
join cikk_kategoria ck
on ck.cikk_id = c.id
left join kategoria_v1 k1
on k1.id = ck.kategoria_id
left join kategoria_v2 k2
on k2.id = ck.kategoria_id
left join kategoria_v3 k3
on k3.id = ck.kategoria_id) a
join kategoria_uj k
on k.kategoria_nev = a.kategoria_nev) x
on (i.cikk_id = x.cikk_id and i.kategoria_id = x.kategoria_id_uj)
when not matched
then insert (cikk_id, kategoria_id)
values (x.cikk_id, x.kategoria_id_uj);4) ELLENŐRIZD az új táblákat:
select c.id,
c.cim,
ck.kategoria_id,
case
when ck.kategoria_verzio = 1 then k1.nev
when ck.kategoria_verzio = 2 then k2.nev
when ck.kategoria_verzio = 3 then k3.nev
end kategoria_nev
from cikkek c
join cikk_kategoria ck
on ck.cikk_id = c.id
left join kategoria_v1 k1
on k1.id = ck.kategoria_id
left join kategoria_v2 k2
on k2.id = ck.kategoria_id
left join kategoria_v3 k3
on k3.id = ck.kategoria_id;
vsselect c.cid,
c.cim,
ck.kategoria_id,
k.nev kategoria_nev
from cikkek c
join cikk_kategoria_uj ck
on ck.cikk_id = c.id
join kategoria_uj k
on k.id = ck.kategoria_id;5) ha egyeznek, akkor átnevezed a régi táblákat valami másra.
ha nem, akkor átgondolod, mit szúrtál el/mi maradt ki.6) új táblákat átrakod a régiek helyére:
rename cikk_kategoria_uj to cikk_kategoria;
rename kategoria_uj to kategoria;7) ha már mindent 3x ellenőriztél, akkor eldobhatod az 5)-nél átnevezett táblákat.
8) itt jön az előző hozzászólásom.
NAGYON bátrak már az 5) pontnál tolhatják drop table-t.
Aztán utólag ne panaszkodjanak, hogy DDLre nincs undo. -
nyunyu
félisten
Nem teljesen értem, mit akarsz feleslegesen verziózni rajta.
Vedd a legfrissebb kategória táblázatodat, aztán annak az ID-it használd minden cikkhez.
Aztán ha jön egy új kategória, akkor csak egy helyre kell beszúrni egy új rekordot, és annak az IDját használod az új cikkhez.Ha meg egy cikk rossz kategóriába került, és utólag kézzel kell javítani?
Akkor átütöd a rossz cikk_kategoria rekordot.De az erősen kézi hajtány:
merge into cikk_kategoria u
using (
select c.id cikk_id,
c.cim cim
k1.id rossz_kategoria_id,
k2.id jo_kategoria_id,
from cikkek c
join kategoria k1
on k1.nev = 'rossz kategória'
join kategoria k2
on k2.nev = 'jó kategória') x
on (u.cikk_id = x.cikk_id and u.kategoria_id = x.rossz_kategoria_id)
when matched
then update
set u.kategoria_id = x.jo_kategoria_id;(nem mertem sima update szintaxissal írni, mert tuti belegabalyodnék és/vagy egy sor helyett a fél táblát updateelné az Oracle
) -
Taci
addikt
És lenne még egy kérdésem, de ezt külön írom, nem is igazán SQL-es. (Átraktam off-ba, de alig bírom kiolvasni..)
Eddig úgy csináltam, hogy a rekordok amikor az adatbázisba kerültek, be lett jegyezve, hogy melyik verziójú kategória tömbből lettek feltöltve a kategóriái.
Ezeket a verziókat mindig növeltem, ha változtatni kellett benne. Az új bejegyzések mindig a legújabbal kerültek be.A cikkek kategóriáit ellenőrző és módosító szkript pedig azzal kezdte a futását, hogy megnézte, melyik az aktuális kategória-verzió, indított egy egyszerű lekérdezést, ami visszaadta a nem ezzel a kategóriaverzióval "kezelt" cikkek id-jait, és így csak ezeken kellett az ellenőrzéseket és az esetleges módosításokat megcsinálni. A végén átírta a kategória-verziót az aktuálisra, az új rekordok pedig már az újjal kerültek be. És így tovább.
Most viszont így ez a plusz adatom (kategória-verzió) már nincs többé. Így nem látok más módot, csak azt, hogy minden egyes elemnél legeneráltatni, hogy az aktuális kategória-verzió szerint milyen kategóriákba tartozik egy-egy cikk, és ellenőrzöm egyenként, és ahol nem egyezik, átírom az újra.
Viszont ez rengeteg idő és energia, és azt hiszem tipikus példája az erőforráspazarlásnak.
Ha benne hagynám a kategória-verziót, akkor azt folyamatosan frissíteni kellene, szóval visszajutnék az eredeti kérdésemhez:
A kérdésem az lenne, hogy hol tartsam ezeket a "kiírt" kategórianeveket?
1) Legyen az "A" táblában a többi adattal együtt,
vagy
2) legyen egy külön "C" tábla, amiben csak ez a pár adat van, ami ahhoz kell, hogy rossz kategóriakiosztás esetén gyorsan át tudjam nézni, mi ment félre?És ugye itt a redundancia miatt inkább az 1)-es opció lenne a jobb.
Van esetleg más ötletetek, hogy ne legyen feleslegesen erőforráspazarló a dolog?
@nyunyu: Most látom, hogy írtál közben. Köszönöm, ránézek majd nemsokára.
-
nyunyu
félisten
Oracle alatt lehet még használni egy rakat aggregáló függvényeknél az over (partition by valami) záradékot, akkor dinamikusan csoportosítja a rekordokat, és nem kell a lekérdezés végére a kemény group by:
create view cikkek_vw as
select c.id cikk_id,
c.cim cim,
c.create_date datum,
c.creator cikk_iro,
listagg(ck.kategoria_id, ', ') within group (order by ck.kategoria_id) over (partition by c.id) kategoria_id,
listagg(k.nev, ', ') within group (order by ck.kategoria_id) over (partition by c.id) kategoria_nev
from cikkek c
join cikk_kategoria ck
on c.id = ck.cikk_id
join kategoriak k
on ck.kategoria_id = k.id;De pl. az előbb linkelt MS SQL doksiban explicite leírják, hogy náluk kötelező a group by a string ragasztó függvényhez.
-
nyunyu
félisten
Valahogy meg lehet csinálni, hogy 1 cikk csak egyszer szerepeljen (ezt a distinct vagy a group by megoldja), és hogy a különböző kategóriák vesszővel elválasztva egy új mezőben legyenek az adott egy darab cikk rekordjában?
Persze, ha a nézetben aggregálod a rekordokat valamilyen függvénnyel:
Oracle alatt valahogy így nézne ki:
create view cikkek_vw as
select c.id cikk_id,
c.cim cim,
c.create_date datum,
c.creator cikk_iro,
listagg(ck.kategoria_id, ', ') within group (order by ck.kategoria_id) kategoria_id,
listagg(k.nev, ', ') within group (order by ck.kategoria_id) kategoria_nev
from cikkek c
join cikk_kategoria ck
on c.id = ck.cikk_id
join kategoriak k
on ck.kategoria_id = k.id
group by c.id, c.cim, c.create_date, c.creator;listagg() függvény nem része az SQL szabványnak, nem tudom, a Te DB motorod alatt van-e hasonló aggregálási lehetőség, illetve milyen szintaxissal.
(MySQL alatt GROUP_CONCAT, MS SQL alatt STRING_AGG)Ilyenkor a végére KELL a group by, mert az fogja megmondani, hogy milyen mezők alapján csoportosítsa/vonja össze a sok találatot egy-egy rekordba.
within group (order by valami) meg azt mondja meg, hogy a vesszővel felsorolt elemek mi szerint legyenek sorbarakva.
(gondolom IDnál és a névnél is ugyanazt a rendezést akarod használni ) -
Taci
addikt
Köszönöm szépen, ezzel így már szépen alakul.
Viszont még lenne benne csavar:
3 tábla van (példád alapján írom):
- 1.: cikkek (c.cim, c.create_date stb.)
- 2.: kategoria (k.id, k.nev)
- 3.: cikkek_kategoriak (ck.cikk_id, ck.kategoria_id): Mivel egy cikk több kategóriában is lehet, ezért javaslatotokra ezt külön szedtem ebbe a táblába, így minden rekord 1-1 kapcsolat a cikk és a kategória között. Ha egy cikkhez 3 kategória tartozik, akkor 3 rekord van hozzá.Amit írtál, az szépen visszaadja a kért adatokat, de csak a kategóriák id-ját, és ha egy cikkhez több kategória van, akkor annyi rekordot ad vissza.
Pl.: ha a cikk_id = 5 -höz van kategória 3, 15 és 22, akkor így adja most vissza:cikk_id ... kategoria_id5 35 155 22Viszont úgy szeretném, hogy cikkenként csak egy rekordot adjon vissza, és a kategoria_id-khoz tartozó szringeket (neveket) sorolja fel, vesszővel elválasztva.
Tehát ha a 3-as kategória a "belfold", a 15-ös a "kulfold", a 22-es pedig a "sport", akkor ezt adja vissza:cikk_id ... kategoria_nevek5 belfold,kulfold,sportEddig arra jutottam, hogy:
create view cikkek_vw asselect c.id cikk_id,c.cim cim,c.create_date datum,c.creator cikk_iro,ck.kategoria_id cikk_kategoria_id,k.nev kategoria_nevfrom cikkek cjoin cikk_kategoria ckon c.id = ck.cikk_idJOIN kategoriak AS kON ck.kategoria_id = k.id;(Lehet, ide most nem a legpontosabban írtam át, de a lényege ez, és nálam a valós kód szépen hozza.)
Tehát ez kiírja több rekordban, ha egy cikkhez több kategória is van, viszont így már odaírja a kategória nevét is, nem csak az id-ját.
cikk_id ... kategoria_id kategoria_nev5 3 belfold5 15 kulfold5 22 sportValahogy meg lehet csinálni, hogy 1 cikk csak egyszer szerepeljen (ezt a distinct vagy a group by megoldja), és hogy a különböző kategóriák vesszővel elválasztva egy új mezőben legyenek az adott egy darab cikk rekordjában?
Mert ez így valóban egy az egyben az lenne, mint a mostani külön tábla tartalma.@Ispy: Már megvolt, a sokadik is, már a ló túloldalon vagyok lassan...
-
Ispy
nagyúr
-
nyunyu
félisten
create view cikkek_vw as
select c.id cikk_id,
c.cim cim,
c.create_date datum,
c.creator cikk_iro,
k.id kategoria_id,
k.nev kategoria
from cikkek c
join kategoria k
on k.id = c.kategoria_id;Aztán ezt már úgy kérdezed le utólag, ahogy akarod:
select *
from cikkek_vw
where kategoria = 'receptek'
order by cim;Aztán libasorban felsorolja neked a krumplileves, mákos guba, pejsli, töltött paprika receptes cikkek fő adatait.
Az már egyéni ízlés vagy munkahelyi megszokás kérdése, hogy a nézetek elnevezésénél V_ előtagot, vagy _VW utótagot használsz.
-
Taci
addikt
-
Ispy
nagyúr
-
Taci
addikt
Van egy kategória tábla (a cikkek és kategóriák kapcsolatairól), amiben a cikkek id-ja, és a kategóriák id-ja van, semmi más. Azt nem is szeretném bántani, mert 1-1 cikk id-hoz több kategória id is tartozhat, és ha mind után még odaírom szövegesen a kategóriák neveit, az egyrészt túl sok felesleges adat oda, plusz a "másik oldalról" is hiányozna ehhez a taskhoz adat, mert csak a cikk id-ját látom, a címét, szövegét nem.
Amit írtok (Ispy és DeFranco), ahhoz az kellene, hogy szerepeljen ez az adat (a "kiírt" kategórianév) valamelyik mezőben. De pont ez a kérdésem alapja, nem tudom, hol lenne jó helyen.
Viszont mivel kell lennie valahol, és a redundancia nem jó dolog, akkor talán az 1)-es megoldás a jobb.
-
DeFranco
nagyúr
nem vagyok adatbázisguru csak tanultam alapszinten meg használom, de elvileg nem ismételünk szükségtelenül adatokat, mert ahogy írtad is, redundáns.
erre egy view-t hoznék létre én is, ami lekérdezi és összekapocsolja az adatbázistáblákból az adatokat ott tudod szemrevételezni, hogy minden OK-e
-
Ispy
nagyúr
-
Taci
addikt
Tanácsot kérnék a következő témában:
Adott az "A" tábla, benne a megjelenítéshez (HTML) szükséges adatokkal (cím, szöveg, kép linkje stb.
Adott a "B" tábla, amiben az ajánlásotokra csak az előző táblában szereplő rekordok ID-ja, és a hozzájuk kapcsolódó kategóriák ID-jai szerepelnek.
Ezzel nincs is gond, hála nektek tökéletesen működik.Viszont továbbra is szükségem van rá, hogy ne csak az ID-ját lássam a kategóriáknak, hanem a "kiírt" változatát is (pl. "politika"). Néha (gyakran) egy-egy cikkhez rossz kategória kerül, ilyenkor meg kell néznem a címet, a linket, a leírást, és a hozzá rendelt kategóriákat, hogy aztán tudjam módosítani a kategóriák keresőszavainak tömbjét (ami alapján a kategóriák meghatározásra kerülnek), hogy utána a karbantartó szkript updatelni tudja a frissített tömb alapján (cron job - ellenőrzi, milyen verziójú kategória tömbbel lettek a rekord kategóriái létrehozva, és ha van frissebb, ellenőrzi, kell-e változtatnia).
A kérdésem az lenne, hogy hol tartsam ezeket a "kiírt" kategórianeveket?
1) Legyen az "A" táblában a többi adattal együtt,
vagy
2) legyen egy külön "C" tábla, amiben csak ez a pár adat van, ami ahhoz kell, hogy rossz kategóriakiosztás esetén gyorsan át tudjam nézni, mi ment félre?Mindenképp szükségem van ezekre az adatokra, mert amúgy csak a kategóriák id-jait látnám, aztán azt mire visszakeresem mindet, hogy most az 4542. rekordhoz tartozó 3, 12, 25 és 42-es kategória mi, és melyik került "hibásan" oda, az túl sok idő lenne.
Sokkal egyszerűbb az, hogy látom a cikk címét, szövegét és linkjét, látom kiírva, hogy milyen kategóriákba kerültek, és látom, hogy a karácsonyi vásárról szóló tudósító cikk egy nem megfelelő kategóriatömb-bejegyzés miatt került az auto-motor kategóriába, és egyből tudom, mit kell módosítanom.Azért nem jutok ezzel dűlőre, mert, folyamatosan frissítenem kell a rekordokat, hogy a jó "kiírt" kategórianevek szerepeljenek benne.
Ha az 1)-est választom, akkor emiatt az amúgy sehol sem használt adat ("kiírt" kategórianév) miatt kell folyamatosan update-elgetnem a fő táblát - bár annak csak ezt a sehol nem használt mezőjét. (És úgy rémlik, erre azt mondta itt valaki anno, hogy nem jó ötlet.)
Viszont ha a 2)-est választom, akkor redundancia lesz, mert az "A" táblában már szerepel pár mező, amire az ellenőrzéshez szükségem van mindenképp (cím, szöveg, link). És a redundancia nem jó adatbázisban, ha jól sejtem. Ezek az adatok mondjuk sosem lesznek többet frissítve, szóval abból nem lehet gond, hogy csak az egyik helyen frissülnének.Egyik megoldás sem ideális, de nem tudom, melyik a jobb (vagy kevésbé rosszabb).
Tudnátok ebben tanácsot adni? Készen van már mindkét változat, kipróbálva, működik, csak nem tudom eldönteni, melyikkel menjek tovább.
Köszönöm. -
Taci
addikt
-
 Mike
veterán
Mike
veterán
-
Taci
addikt
-
sztanozs
veterán
-
 nevemfel
senior tag
nevemfel
senior tag
Van értelme annak, hogy a weblappal kapcsolatos műveletekhez (rekordok felvétele, lekérdezése és frissítése) létrehozzak egy másik felhasználót, aminek csak a valóban elengedhetetlen jogokat adom meg?
Van. Security alapelv, hogy pont annyi jogosultságot adsz az adott alkalmazásnak, amennyi a működéséhez szükséges.






















 kapcsolat (több eseményhez tartozhat több személy). Kell hozzá egy kapcsoló tábla.
kapcsolat (több eseményhez tartozhat több személy). Kell hozzá egy kapcsoló tábla.

![;]](http://cdn.rios.hu/dl/s/v1.gif)

















 (Mentségemre, még mindig nem jutottam se reggelihez, se kávéhoz...)
(Mentségemre, még mindig nem jutottam se reggelihez, se kávéhoz...)



Új hozzászólás Aktív témák
-
Fórumok
PROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Tabletek, E-bookok Nyomtatók, szkennerek PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
- Fórumok
- Szoftverfejlesztés
- SQL kérdések
- (kiemelt téma)

- PlayStation 5
- Megújult mobilos felület, fórumos ráncfelvarrás a PROHARDVER! lapcsaládon
- Végre elérhető az új Steam Controller
- Folyószámla, bankszámla, bankváltás, külföldi kártyahasználat
- Abarth, Alfa Romeo, Fiat, Lancia topik
- Milyen autót vegyek?
- Milyen egeret válasszak?
- Jövedelem
- VR topik
- Eladhatatlannak ítélt CPU-k eladásával javult az Intel node-ok kihozatala
- További aktív témák...

- DJI Mini 3 pro Fly More Combo RC drón szett 2 akkuval +extrák
- P15 Gen2i 15.6" FHD IPS i7-11850H RTX A3000 32GB 512GB NVMe magyar vbill ujjolv IR kam gar
- DJI Mavic Air 2 Fly More Combo drón szett kofferben, szűrőkkel
- 100.000 ft tól elvihető RÉSZLETRE Lenovo Pro 7 16IRX9H 4090
- G.SKILL Trident Z5 Neo RGB 32GB (2x16GB) 6000MHz CL30 - Alza élettartam garancia
- MSI Pulse 15 B13VFK i7 / RTX 4060 140W / QHD 165Hz 16GB DDR5 1 TB SSD
- Apple iPhone SE (2020) / 64GB / Kártyafüggetlen / 12Hó Garancia / Akku:82%
- ÁRGARANCIA!Épített KomPhone i5 14600KF 32/64GB DDR5 RAM RTX 5070Ti 16GB GAMER PC termékbeszámítással
- Bomba ár! Lenovo ThinkPad T14 G2i - i5-11G I 16GB I 512GB SSD I 14" FHD I Cam I W11 I Garancia!
- ÁRGARANCIA! Épített KomPhone Ultra 9 285K 64GB RAM RTX 5090 32GB GAMER PC termékbeszámítással
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest