Hirdetés
Új hozzászólás Aktív témák
-

tm5
tag
Mondjuk a főnök minden hétfő reggel 8-ra kér valami riportot excelben a mailboxába.
Lehet menne SQLből is, de ez pythonban tényleg csak egy pár sor. Mondjuk kell valami ütemező is. OK, ez épp pont nem data analysis , hanem csak egy kis automatizáció, de pont azt mutatja, hogy mennyi mindenre jó.
Én is most kezdek majd belemélyedni pythonba a sok SQL-ezés mellett, mert össze akarok rakni egy dashboardot arról, hogy 1. megy a rendszer 2. jók az adatok.
De ha nagyon tanulni akarsz valamit az SQL mellett akkor lehet érdemes megnézned az AWS-t vagy Azure-t. Most ezek a menő dolgok...a python mellett persze.
-

Louro
őstag
válasz
 martonx
#4596
üzenetére
martonx
#4596
üzenetére
Köszönöm. Nekem is ez a legizgalmasabb a jelenlegi munkámban, bár többnyire SQL-ben oldom meg. Persze a vizualizáció Excel-ben történik - sajnos.
Esetleg tudsz mondani egy példát, hogy mi az, amit SQL-ben nem lehet vagy rosszabbul, mint Python-ban? De érzem, hogy pont a vizualizáció lesz a kulcs
-

martonx
veterán
A Python ott jön a képbe, hogy a Data Science szakmának maga az adatlekérdezés része a legkevesebb, senki nem ettől lesz data scientist. Hanem utána jön az adatok elemzése, vizualizálás, statisztikák, és erre jelenleg a legelterjedtebb a Python (megjegyzés: kb. bármilyen nyelv is jó erre pl. java, c#). Ettől még csomó esetben Python nem is kell a gépre, mert különböző IDE-kben, GUI-kon keresztül elég megírni pythonban a cuccokat, és az majd úgyis a szerveren fog futni.
-
Louro
őstag
Most jövök a kérdéseimmel
A képzések kapcsán végül a felhő alapú BI-t kezdtem el a M$ oldalán.De párhuzamosan Python-t is.
Ezutóbbival kapcsolatban lenne egy olyan kérdésem, hogy mi lehet a Python mellett erős érv, amivel meg lehetne indokolni, hogy "kell a Python a gépekre"? Este a Stackoverflow-t olvasgatva nem nagyon találtam érvet a Python mellett. Értem, hogy az egyik egy lekérdező nyelv, másik pedig programozási. De mégis rengeteg adattudós (, de csúnya így magyarul) használ Python-t. Csak még nem látom hol jön a képbe. Aggregáció során SQL nyert. ETL során az adatok manipulálását SQL-ben is el tudnám végezni.
Elnézést, ha láma kérdés, de inkább kérdezek. (Tanulnom kell valamit, mert már pár éve csak toporgok az SQL-ben és nem hinném, hogy 20 év múlva is piacképes maradnék csak SQL-lel.)
-

nyunyu
félisten
Jut eszembe, MS platform téren meg a NetAcademiának voltak képzései.
Nem tudom az SQL Server 2017 Admin képzésük milyen lehet. -

bpx
őstag
Ezek az Oracle saját tanfolyamai. Mindenhol ennyi lesz az ára nagyságrendileg és a tananyag is ugyanaz lesz. Az Oracle Hungary az oktatási részlegét leépítette, az oktatási partnerek tartják nekik a tanfolyamokat.
Több helyen is vannak egyedileg egyeztetett tematikájú ás formátumú oktatások is. Ezek ár/értékben kedvezőbbek. Talán.
De igazából egyik változattal sem vagyok megelégedve.
Az említett Webváltónál dolgozom, 10 éve. Nem foglalkozom oktatással, csak ha nagyon muszáj.
-
nyunyu
félisten
Utóbbi pár évben járt nálunk pár webváltós arc, többek között Oracle fejlesztők és egy DBA is.
Fő profiljuk elvileg az oktatás, céges tanfolyamok szervezése, de szoktak cégekhez szakértőket és/vagy frissen képzetteket kölcsönözni is. (Kb. mint a csapból is csöpögő IT gyorstalpalók: GreenFox, Training360)
[szerk:]Hmm, fél misi náluk egy egyhetes (40 óra) Oracle DBA tanfolyam?
Kb. annyi, mint a feljebb linkelt Számalknál. -
tm5
tag
Hát akkor lehet váltanék a helyedben egy olyan helyre ahol DBA-t keresenek és elfogadják az SQL-es múltadat és a szándékot, hogy te ebbe az irányba akarsz fejlődni.
A DBA-s tanfolyamok elég drágák, életszerű tudást úgyis meg munka közben lehet felszedni.
Tippre azt mondanám, hogy Oracle-s DBA-t többet keresnek, mint MSSQL-est. Mivel mind a két dialektussal foglalkoztál érdemes mind a két irányba próbálkozni, aztán amelyiknél hamarabb beesik a munka abban elmélyedni... -
Louro
őstag
Bár multi, de a smucig fajta. Inkább önerőből oldom meg. A VBA-t és az SQL-t is autodidakta módon tanultam meg. De úgy érzem eljutottam arra a szintre, hogy ezt nem oldom meg önerőből.
Ahogy este olvasgattam, az SQL Server képzések szimpatikusabbnak tűnnek. Persze oda is kell más alapozó ismeret.
Eddig csak bőszen írtam az SQL-eket és próbáltam figyelni a performanciára.
-
tm5
tag
Iskola alatt tanfolyamos cégekre gondolsz? Olyanok vannak, illetve, hát, az Oracle-nak vannak különböző adminisztrációs tanfolyamai aranyárban. Szerintem ezeket olyanok tarthatják csak akik tudnak hozzá infrastruktúrát (sandbox-okat) biztosítani, akárki nem. Én kb. ezekkel kezdeném:
12c administration , Grid infrastructure
Lehet vannak újabbak is belőle. Viszont nem 2 fillérek. Valahogy a cégedet, ahol dolgozol, kéne rávenni, hogy finanszírozzák. Illetve ha multi akkor be kellene rotálni a DBA csapatba. -
Louro
őstag
Én is mellőzöm a right join-t, mert az agyunk balról jobbra értelmez. De, amikor mondja, hogy mi a feladat és hogyan kezdet neki, akkor ott volt,hogy right kellett volna. Amikor nagyon junior voltam, szégyeltem volna olyan kérdéseket feltenni, mint amiket én kapok manapság.
A senior-nak is már ajánlottam az sqlzoo.net oldalt és tegnap találtam az Oracle oldalán is egy tök jó leírást kezdőknek, ahol elég sok példa mentén van elmagyarázva.
Kicsit ON is legyek. Már 8 éve SQL-ezek. Bár nem tartom magam veteránnak kódismeret szintjén, de 5 év Oracle és most 3 év T-SQL a hátam mögött kicsit tovább lépnék. DBA irány szimpatikus. Van olyan iskola, ami különösen ajánlott vagy nagyon kerülendő?
-
nyunyu
félisten
Egyáltalán kellhet valamihez a right join?
Vagy csak én kezdem mindig a fix adattartalmú táblákkal a lekérdezést, és ahhoz left joinolom az opcionálisakat?
Legalábbis az én fejemben ez a kettő ekvivalens:
select a.*,b.*
from a
right join b
on b.id=a.id;
select a.*,b.*
from b
left join a
on a.id=b.id;(Sima select * esetén az adattartalom ugyanaz lenne, csak a táblák oszlopainak sorrendje változna.)
-
Louro
őstag
Abszolút jogos a kérdés, mert van kollégám, aki senior elemző és a left join-t és a right join-t nem ésszel használja. Nem érti a különbséget. (Amúgy a bérsáv miatt lett senior :/ )
Ha nem adatbázis beállítása a kérdés, hanem egy lekérdezés, akkor szerintem sokan tudunk itt segíteni.
-
válasz
 user112
#4579
üzenetére
user112
#4579
üzenetére
Igen, erre van a HAVING feltétel (aggregált kifejelzés ellenőrzésére, pl a darab több, min 3
kiscica).select
1 + 2 as harom,
null as ertek2,
created as letrehozva,
sum(user_id) as valami,
count(*) as darab,
'hello' as ertek3
from
dba_users
group by
created
having
count(*) > 3
order by
harom,
letrehozva -
bpx
őstag
Konstans értéket nem kell a group by-ban felsorolni.
De, tud alias alapján rendezni.
Nem, nem tud oszlopszám szerint csoportosítani.select
1 + 2 as harom,
null as ertek2,
created as letrehozva,
sum(user_id) as valami,
count(*) as darab,
'hello' as ertek3
from
dba_users
group by
created
order by
harom,
letrehozva
;
HAROM E LETREHOZVA VALAMI DARAB ERTEK
---------- - ------------------- ---------- ---------- -----
3 2020-04-16 19:04:45 6442450869 6 hello
3 2020-04-16 19:04:46 13 1 hello
3 2020-04-16 19:06:12 43 2 hello
3 2020-04-16 19:06:18 23 1 hello
3 2020-04-16 19:07:31 2147483638 1 hello
3 2020-04-16 19:08:08 36 1 hello
3 2020-04-16 19:15:29 48 1 hello
3 2020-04-16 19:15:31 49 1 hello
3 2020-04-16 19:15:37 101 2 hello
3 2020-04-16 19:18:29 61 1 hello
3 2020-04-16 19:18:41 62 1 hello
3 2020-04-16 19:20:21 70 1 hello
3 2020-04-20 20:51:53 73 1 hello -

user112
senior tag
Bocsánat mindenkitől, a group by-ba tévesen Erteket írtam. Ott egy második mező van, amely szintén kell az összegzés
select 'adat' ad, ID, nev, nev2, ertek1, ertek2
from tabla
union
select "osszesen" ad, ID, null nev, ID2, sum(ertek) ertek1, null ertek2
from tabla
group by id, id2
order by ID, ad -
nyunyu
félisten
válasz
 sztanozs
#4573
üzenetére
sztanozs
#4573
üzenetére
Group by után minden olyan mezőt fel kell sorolni, ami nem szerepel az oszlopfüggvények paraméterében.
Ha van egy fixen 'kiscica' oszlopod, akkor azt is.
Értelmes interpreterrel bíró DBken valahogy így nézne ki:
select "osszesen" ad, ID, null nev, sum(ertek) ertek1, null ertek2, null ertek3, null ertek4,
null ertek5
from tabla
group by id, ad, nev, ertek2, ertek3, ertek4, ertek5;Kevésbé értelmeseken valahogy így:
group by id, 1, 3, 5, 6, 7, 8;(Ha már a hülye Oracle nem tud alias alapján rendezni, csoportosítani, csak oszlopszámmal...)
-
válasz
sztanozs
#4570
üzenetére
Ja, ahogy nézem nem is kell subselect, simán mehet a végére is...
select 'adat' ad, ID, nev, ertek1, ertek2, ertek3, ertek4, ertek5
from tabla
union
select "osszesen" ad, ID, null nev, sum(ertek) ertek1, null ertek2, null ertek3, null ertek4,
null ertek5
from tabla
group by id
order by ID, ad -
válasz
user112
#4566
üzenetére
Hali, ennek tutira mennie kellene:
select 'adat' ad, ID, nev, ertek
from tabla..
union
select "osszesen" ad, ID, null nev, sum(ertek)
from tabla..
group by idha pedig van 5 érték, amiből csak az elsőt summázod, a többi meg üres lesz a végén:
select 'adat' ad, ID, nev, ertek1, ertek2, ertek3, ertek4, ertek5
from tabla
union
select "osszesen" ad, ID, null nev, sum(ertek) ertek1, null ertek2, null ertek3, null ertek4, null ertek5
from tabla
group by idSőt a végén még össze is rendezheted, hogy minden ID-hez a a felsprplás végére tegye az összeget, ne a tábla végére ID-nként:
select * from (
select 'adat' ad, ID, nev, ertek1, ertek2, ertek3, ertek4, ertek5
from tabla
union
select "osszesen" ad, ID, null nev, sum(ertek) ertek1, null ertek2, null ertek3, null ertek4,
null ertek5
from tabla
group by id)
order by ID, ad -
user112
senior tag
Több union is van, kötött sorrendben a group by-os union elött. Szerettem volna az adott oszlopba tenni az összegzés eredményét. Ahogy próbálom, az elsőt még át lehet hidalni:
select ' ', id,sum(Ertek)
működik, de a Erteket már nem tudom arrébb tolni egy, két oszloppal.
Úgy látszik két összegző mező között nem lehet "üres" mező. -
tm5
tag
válasz
user112
#4566
üzenetére
UNION-nál a benne lévő SELECT-ek oszloplistáinak meg kell egyeznie legalább darabszámra és adat tipusra. Olyan nincs hogy "select a,b union select c".
Ha meg nem akarsz group by-olni valamilyen oszlopra, akkor meg ne tedd bele azt az oszlopot a select listába.
Vagy nem értem a problémádat... -
user112
senior tag
Sziasztok!
Szeretnék további union-nal bővíteni egy lekérdezést, amiben viszont group by is lenne.
Hogyan tudom kihagyni azokat a mezöket amelyek nem group by -osak?
pl.select 'adat' ad, ID, nev, ertek1, ...unionselect null, id, null, sum(Ertek)from..group byid,Ertekde így nem jó.
-

vamzi
senior tag
Sziasztok,
Adatbázis a régi: [kép]
Feladat szövege: Definiáljon egy olyan nézetet, amely kilistázza azoknak az áruházaknak a nevét, ahonnan a legtöbb fajta társasjátékot vásárolták!
Működő megoldásom:
CREATE OR REPLACE VIEW TOP_aruhazak AS
SELECT nev
FROM(
SELECT
aruhaz.nev, COUNT (DISTINCT tarsasjatek_id) egyedi_jatekok_szama
FROM t_vasarlas vasarlas INNER JOIN
t_aruhaz aruhaz
ON vasarlas.aruhaz_id = aruhaz.id
GROUP BY aruhaz.nev
ORDER BY egyedi_jatekok_szama DESC
)
FETCH FIRST 1 ROWS WITH TIES
;Van jobb, logikusabb megoldás?
Köszönöm!
-
nyunyu
félisten
Jut eszembe, ezt is lehetne egyszerűbben írni:
SELECT
y.nev,
MAX(ar) max_ar
FROM t_cikk x
INNER JOIN t_tarsasjatek y
ON x.tarsasjatek_id = y.id
GROUP BY y.nev
ORDER BY MAX(ar) DESC;De amennyire emlékszem Oracle nem nagyon szokta szeretni, ha számolt oszlopokra próbál rendezni az ember, sokszor kaptam hasonló próbálkozásokra szintaktikai hibát, emiatt írtam inkább köré egy másik selectet a rendezéssel.
Más adatbáziskezelők rugalmasabbak ebben.
-
nyunyu
félisten
Alapvetően jó az elképzelés, de ezt lehet egyszerűbben is írni, mivel joinolt táblákat is tudsz szummázni:
SELECT
vasarlo.id,
vasarlo.nev,
sum(vasarlas.darab*vasarlas.vetelar) koltes_osszesen
FROM t_vasarlo vasarlo
INNER JOIN t_vasarlas vasarlas
ON vasarlas.vasarlo_id = vasarlo.id
GROUP BY vasarlo.id, vasarlo.nev; -
vamzi
senior tag
Adatbázis ugyan az: [kép]
Feladat: Írjon egy SQL utasítást, amely kilistázza a vásárlók azonosítóját és nevét, valamint azt, hogy mennyit költött az adott vásárló társasjátékokra a vásárlásai során! Az összeg meghatározásakor a vásárlás vételárát és a vásárolt termékek darabszámát is vegye figyelembe!
Erre ez a megoldásom:
SELECT
vasarlo.id,
vasarlo.nev,
vasarlas.koltes_osszesen
FROM t_vasarlo vasarlo INNER JOIN ( SELECT
vasarlo_id,
sum(darab*vetelar) koltes_osszesen
FROM t_vasarlas
GROUP BY vasarlo_id) vasarlas
ON vasarlas.vasarlo_id = vasarlo.id;Ránézésre jó adatokat ad vissza a kérdésem inkább arra vonatkozna, hogy logikusan építettem fel a lekérdezést vagy van ennél kézenfekvőbb megoldás?
Köszönöm!
-
-
vamzi
senior tag
Sziasztok,
Adott az alábbi adatbázis:
[kép]
Szeretném megkapni a legdrágább társasjátékok neveit. Az első fele megy, kitudom gyűjteni a legdrágább árakat:SELECT
tarsasjatek_id, MAX(ar)
FROM t_cikk
GROUP BY tarsasjatek_id
order by tarsasjatek_id;Viszont nem tudom hogy húzzam be a társasjátékok neveit ID alapján a t_tarsasjatek táblából.
Sejtem, hogy egy beágyazott select kell, de nem tudom összerakni a logikáját fejben

-
#4552
user112
senior tag
Apollo17hu
#4551
user112
senior tag
válasz
 Apollo17hu
#4551
üzenetére
Apollo17hu
#4551
üzenetére
Tökéletes köszönöm.

-
user112
senior tag
Sziasztok!
Egy táblából összesített adatokat szedek le, de lenne köztük pár egyedi feltételnek megfelelő adat is: pl: select id, sum(adat1), sum(adat2),adat3, adat4 ahol adat3 csak pl a ho=2 adatsor értéke legyen, az adat4 pedig a ho=9-é.
Hogyan tudom ezt megcsinálni? Belső select? Szeretném egy sorban megjeleníteni. Oracle
Köszönöm. -
nyunyu
félisten
válasz
 Jim Tonic
#4548
üzenetére
Jim Tonic
#4548
üzenetére
Ja tényleg, ablakozó függvényekkel lehet, hogy egyszerűbb, mivel ott összetett rendezést is tudsz alkalmazni:
select
p.product,
p.price
from products p
join (select
p1.product,
nvl(p2.valid_from, to_date('0000-01-01')) valid_from,
nvl(p1.valid_to, to_date('9999-12-31')) valid_to,
row_number() over (partition by p1.product
order by nvl(p2.valid_from, to_date('0000-01-01')) desc,
nvl(p1.valid_to, to_date('9999-12-31')) asc) rn
from products p1) b
on b.product = p.product
and b.valid_from = nvl(p.valid_from, to_date('0000-01-01'))
and b.valid_to = nvl(p.valid_to, to_date('9999-12-31'))
and b.rn = 1;Ezzel sorszámozod az egy termék rekordjait kezdő dátum szerint csökkenő és azon belül érvényességi dátum szerint növekvő sorrendben, majd veszed a legelső rekordot minden termékhez.
-
nyunyu
félisten
válasz
Jim Tonic
#4545
üzenetére
Ezeket egy selectben nem tudod összeszedni, mivel az oszlopfüggvények egymástól függetlenül értékelődnek ki.
Tehát nem max(valid_from)-hoz tartozó min(valid_to) értéket kapod vissza, hanem a globálisat.Maximum azt tudod tenni, hogy egy belső selectben leválogatod a max(valid_from)-okat minden termékhez, majd az a köré írt másik selectben kiveszed a min(valid_to)-t.
Valahogy így:
select product,
price
from products p
join (select
p1.product,
a.max_valid_from,
min(nvl(p1.valid_to, to_date('9999-12-31'))) min_valid_to
from products p1
join (select p2.product,
max(nvl(p2.valid_from, to_date('0000-01-01'))) max_valid_to
from products p2
group by p2.product) a
on a.product = p1.product
and a.max_valid_from = p1.valid_from
group by p1.product, a.max_valid_from) b
on b.product = p.product
and b.max_valid_from = nvl(p.valid_from, to_date('0000-01-01'))
and b.min_valid_to = nvl(p.valid_to, to_date('9999-12-31'));Oszlopfüggvények alapból figyelmen kívül hagyják a nullokat!
-
válasz
 bambano
#4544
üzenetére
bambano
#4544
üzenetére
Ki kell szednem a valid_from értékekből a legmagasabbat, ami kisebb vagy egyenlő, mint az aktuális dátum, majd ezek közül a legkisebb valid_to, ami nagyobb vagy egyenlő, mi ma. Ezt nekem nem szedte össze az sql server (tsql) egy select-ben.
Most ezt a rank() függvényt nézegettem.
-
-

#68216320
törölt tag
válasz
martonx
#4540
üzenetére
Természetesen, otthon használatra megy, tanulásra - hobby célokra. Vagyis kb. zéró terhelés, max 1-2 user egyidejű kiszolgálása lesz. Eddig max 3000-es táblám volt a legnagyobb (retro számítógép program kategorizálásnál). De ez sem jellemző.
Szóval tényleg nem kell sok. Viszont most felhőbe menne majd cucc és jelenleg 1GB RAM-ot bérelek, szeretném, ha ennyi is maradnaDesktop gépen (win10) sikerült még az 5.7-est leszorítanom alapjáratban 30MB körüli értékre. [kép]
A 8-ast is megpróbálom valamennyire visszavenni (win10 / linux), de majd kiderül hogy sikerült. -
-
nyunyu
félisten
válasz
martonx
#4538
üzenetére
Egyébként MySql-nek (meg amúgy bármelyik SQL-nek) tök jól lehet paraméterezni a memória foglalását.
A teljesítmény rovására.
Nézz meg egy ingyenes, egy procimag+1GB RAMra limitált MS SQL licenszet, meg a rendes verzióját.
DB tipikusan olyan alkalmazási terület, ahol a több RAM mindig jobb.
Persze ha van három táblád, 10-10 sorral, akkor az 1GB is elég lehet, de párezer soros táblák joinolgatásánál már észreveszed a különbséget.
-
martonx
veterán
válasz
 #68216320
#4537
üzenetére
#68216320
#4537
üzenetére
Egyébként MySql-nek (meg amúgy bármelyik SQL-nek) tök jól lehet paraméterezni a memória foglalását. Emlékeim szerint a MySql defaultban nagyon is visszafogottan foglal memóriát (rendszergazdák első MySql optimalizációja szokott lenni, átírni a memória foglalást valami egészségesebbre).
Szóval szerintem tedd fel nyugodtan. -
-
#68216320
törölt tag
Urak. Van a MySQL 8-nak valami memória kímélő konfigurációja kis terhelésű haszálathoz? Programozás tanuláshoz kellene feltenni, de jó lenne minél kevesebb erőforrást, ez esetben memóriát adni neki.
Valami developing ini található esetleg hozzá valahol? -
#14069248
törölt tag
Sziasztok!
2010-ben kiszedtem az internetről a Dupal honlapomat. Azóta a gépemen működik. (Jelenleg 20.04-es Xubuntut használok.) Múlt évben még ránéztem, de mára elfelejtettem az Admin jelszót. A kérdésem az lenne, hogy a Mysql adatbázis alatt az sql fájlból ki tudom szedni valahogyan? Előre is köszönöm a segítséget!
-
#4530
 Apollo17hu
őstag
Jim Tonic
#4527
Apollo17hu
őstag
Jim Tonic
#4527
Apollo17hu
őstag
-
Egy lekérdezésben kérném segítségeteket.
Hogyan tudom megírni úgy a lekérdezést, hogy válasszak két rekord közül.
Van egy árlista tábla. Elég hülyén van kitöltve, de ez most mindegy.
Van egy árnak kezdő érvényességi dátuma, ez kötelező, és lehet befejező dátuma, ez nem kötelező. Az indexelés úgy van belőve, hogy lehet olyan rekord, hogy azonos a kezdő dátum, azonos lehet az ár is, de nem feltétlenül, de az egyiknél van záró dátum, másiknál nincs. Na, ha ilyen duplikációk vannak, akkor azt kell vennem, ahol van záró dátum, ha nincs duplikáció, akkor jó a záró dátum nélküli is. Soha nem láttam még ennyire hülye megoldást, de ezzel kell élni. -

Ispy
nagyúr
Használ valaki itt mssql-hez schema compare toolt?
Átraktuk az adatbázist a .net source controlba, és a módosításokat az sql schema comparrel töltjük vissza, de iszonyat lassú, és nem igazán találok rá megoldást. Pedig remek eszköz lenne, ha normálisan lehetne használni, de egy pár tábla módosítás visszaírása is 25 percig fut, ami hát nem túl hatékony. De egy check/unchek is el tud futni percekig...
-

cekkk
veterán
válasz
 velizare
#4519
üzenetére
velizare
#4519
üzenetére
Szia!
Az az. Köszönöm.
Ezt a kódot írtam be, hogy : status = resolved AND assignee = currentUser() viszont így pl nincs benne a tegnapi lezárt hiba, csak a mai. Nem teljesen értem még a működését.
Ha pl a címet akarok lekérdezni, hogy adress szolnok akkor azt, hogyan adjam meg neki? -
cekkk
veterán
Sziasztok!
Egy elég alap lekérdezést szeretnék csinálni. Ma kaptunk a cégnél egy hibakezelő rendszer ahol egyben van az összes lezárt hiba.
status=resolved ezzel megkapom a megoldott hibákat de a "Dealer name" oszlopból ki akarom választani az én kódomat és csak azokat akarom látni amikhozzám tartozik akkor ezt a kódot hogyan folytassam? Dealer name=kód ? Közel 10 éve nem foglalkozta sql lekérdezéssel.
Azt még nem írtam le, hogy JQL.
Köszi a segítséget! -

bambano
titán
válasz
 Petya25
#4509
üzenetére
Petya25
#4509
üzenetére
a probléma pár órás tojtorozása után nekem úgy tűnik, hogy a legegyszerűbb megoldás a következő:
csinálsz egy táblát, olyan szerkezettel, ami neked tetszik, plusz hozzáadsz egy oszlopot, pl. sor néve, text típussal:tmp=> \d merestmpTable "public.merestmp"Column | Type | Collation | Nullable | Default--------+------------------+-----------+----------+--------------------------------------id | bigint | | not null | nextval('merestmp_id_seq'::regclass)subid | bigint | | |azon | text | | |meres1 | double precision | | |meres2 | double precision | | |meres3 | double precision | | |meres4 | double precision | | |sor | text | | |utána belemásolod az input fájljaidat úgy, hogy a szövegből minden sort egyben tegyen bele a sor mezőbe:
\copy merestmp(sor) from '/tmp/mteszt.txt';Majd adatbáziskezelős függvényekkel szétszeded a sorokat.
update merestmp set subid=id,azon=trim(both from sor) where array_length(regexp_split_to_array(sor,' +'),1)=1;ezek után a subid-t beállítod az előtte levő sorra:
update merestmp m1 set subid=(select max(subid) from merestmp m2 where m2.id<m1.id) where array_length(regexp_split_to_array(sor,' +'),1)=5;
ennél a megoldásnál nyilván van szebb is, windowing funkciókkal...
utána már csak regexp-ekkel ki kell szedni a mezőket a sorból és betenni a helyükre. -
bambano
titán
válasz
Petya25
#4509
üzenetére
nem ismerem az mssql-t, postgresql-ben így csinálnám:
csinálnék egy táblát, amiben van egy id mező, aminek serial (más adatbáziskezelőkben autoincrement), meg van benne egy másik id2 mező, aminek a defaultja egy serial aktuális értéke, van egy text mező, meg négy real.
tennék rá egy szabályt, hogyha mind a négy real mezője null, akkor a második mezőt növelje egyel és úgy húzza be a többi sort.szerk: persze a triviális megoldás az, ha awk-val insert-té alakítod a fájlokat.
szerk2: esetleg dobj fel valahova 3-4 ilyen kis fájlt, amivel kísérletezni lehet.
-

Petya25
őstag
Igen ez is megoldható valami külső eszközzel.
Eredetileg egy rakás kis egyedi fájlneves fájlban figyelnek ezek az adatok, csak össze lett mergelve. Visual studióban megnézem hátha tudok valamit alkotni, a fájokat egyesével fel tudom dolgozni, de tömegesen automatikusa nem, legalábbis most. -
#4511
Petya25
őstag
Apollo17hu
#4510
Petya25
őstag
válasz
Apollo17hu
#4510
üzenetére
Nem a mezőket nehéz megtalálnom, hanem azt hogy hol kezdődik a következő adatcsoport.
-
Petya25
őstag
MS SQL-ben valami ötlet erre? Azonosító+dátum és adat sorok követik egymást.
Többszáz megás textben van de így tagolva be tudom tenni egy táblába.
A következő azonosítóig tartanak a hozzá tartozó adatok.
Full változó az adadatsorok száma egy blokkon belül.
Na ebből kellene egy select azonosító, dátum, mező1....5 végül.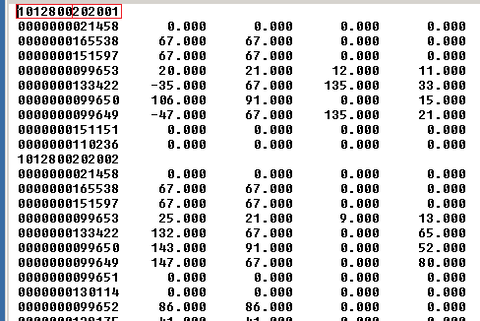
-
#4504
Apollo17hu
őstag
Szmeby
#4503
Apollo17hu
őstag
Bocs, hogy beleszólok, de Lourohoz hasonló munkakörben dolgoztam, és csak megerősíteni tudom:
- High-level menedzsernek nem fogod tudni elmagyarázni. Nem érdeklik a részletek ilyen mélységben, és nem is akarja megérteni, mert nincs ideje rá. A közvetlen vezetődnek mondhatod, de ő nagyon jól tudja, hogy a nála nagyobb emberek az ilyesmit egyszerűen lesöprik az asztalról. Csak az eredmény számít.
- A másik dolog pedig az, hogy felsőbb szinten a vezetők hajlamosak (sőt, néha kötelező az előmenetel miatt) rotálni szervezeten belül. Tehát, ha 3-5 évig működik a toldozás-foldozás, akkor nyert ügye van, mert úgyis dobbant máshova....és ennek analógiájára: az a fejlesztő balek, aki próbál prudensen, hosszú távban gondolkodva végezni a dolgát. Ahhoz képest mindenképp, aki összehányja a munkát, de feleannyi idő alatt eredményt mutat fel, és 2-3 évente munkahelyet vált (aminek következményeként nem kell saját maga után takarítani).
-

Szmeby
tag
Oké, azt hiszem nem jól fogalmaztam. Ígérem, ez az utolsó off.
Az, hogy az optimalizálatlan lekérdezések miatt lassú a szolgáltatás, gondolom kimeríti a fejesek felett állók igényeinek kielégítését. Az, hogy nincs elég kapacitás tesztelni, optimalizálni, backupot készíteni ínségesebb időkre, ésatöbbi, mind mind a szolgáltatás színvonalát befolyásolja. Ha az ún. fejes (vagy a felette álló) azt hiszi, hogy nem, akkor vagy hülye vagy igénytelen. Szerény véleményem szerint.
Azzal takarózni, hogy valami túl kocka, ezt nem tudom hova tenni. Ha valami kocka, akkor nincs köze a szolgáltatás színvonalához? Az igényességhez? Ha fejesnek ez túl kocka, akkor miért használ számítógépet? Dolgozzon kockás füzetben, és szolgáltasson abból! Vagy ha az is túl kocka, akkor vonalas füzetből.Bocsánat a kirohanásomért, csak pont ebből lett elegem az IT szférában, és érzékenyen tudok reagálni a hasonló hozzáállásra. Kiborító, amikor azt hallom egy menedzsertől, hogy csak dobj össze valamit, csak működjön; menjen élesbe, mindjárt határidő; ezeknek így is jó lesz, és hasonló szóvirágok. Többnyire ugyanez a menedzser kongatja a vészharagot, hogy nagy baj van a projekten, több erőforrást kell bevonni; azonnali tűzoltásra van szükség; lehalt az éles szerver, mindenki hétvégézik; ha ez ma nem lesz kész, holnap már nem kell bejönnöd; ha ezt megcsinálod még ma, holnap kapsz egy sütit. A fejlesztő meg nyilván megtörik, és inkább hekkel, drótoz, gányol. Mert azt jutalmazzák, aki vilámgyorsan összedob valamit, aki tüzet olt, még ha a saját gányolását is javítja valójában. Ahogy te is mondtad, fontosabb a jó munkánál a "mindenki fel akar valamit mutatni". És aztán eljön az a pont, amikor többségbe kerülnek a valamit felmutatni akaró egyedek a jó terméket gyártó egyedekel szemben. Csodálkozunk, ha kiég az ember?
Csak arra akartam célozni, hogy így látatlanban szerintem a te igényeid nincsenek összhangban a fejesek igényeivel, ami hosszú távon eléggé lélekölő. Persze ha neked (még) tetszik, akkor folytasd nyugodtan. Minden tiszteletem a tiéd, én már eljutottam arra a pontra, hogy az általad lefestett fejeseket nem akarom elviselni.
Mindenesetre sok sikert kívánok és bocs, hogy elkanyarodtam a témától. Ahhoz nem tudok hozzászólni.
-

formupest
csendes tag
Szia Louro,
köszönöm a választ. Gyakorlatilag részben eltaláltad ,hogy mi a feladat és tetszik nagyon a javaslatod. Kicsit bonyolultabb a dolog, mert gyógyszertípusonként más és más tulajdonságokat kell megadni, de vannak olyan tulajdonságok is amelyek minden vagy legalábbis több gyógyszertípusnál szerepelnek. Így például a sűrűség minden készítménynél fontos paraméter, míg például az emulzióstabilitás csak bizonyos esetekben mérhető stb. Ezért mondtam azt, hogy annyi tulajdonságtábla van ahány gyógyszertípus. Holnap este összerakok egy DEMO-t , azaz táblázatokat adatokkal együtt.
üdv -
Louro
őstag
[Személyes vélemény on]
Ez témába nem vág, csak a kérdésre válasz
:
A feladatok el vannak látva. Még plusz is. Többieknek segítek. Megosztom az infót és a társosztályoknak is segítek, amitől az osztály reputációja is nő. A fennmaradó időben próbálom javítani a rendszerünket, spórolni erőforrásokat. Amikor a jelenlegi helyemre kerültem, annyira nem volt kapacitás, hogy folyamatosan jobokkal dolgozott az adatbázisszerver. Volt, ami több, mint 3 órát futott. Kis átírással 10 perc alatt lefutott. (Több nagy tábla összekötve egy lekérdezésben, indexek nélkül. Ezeket szedtem szét több kisebb lépésre.)A fejeseknek az a fontos, hogy az ő felettük állók igényei ki legyenek szolgálva és persze mindenki fel akar valamit mutatni, de azzal nem foglalkozik, hogy a meglévő rendszerrel faragjon, mert túl kocka terület. Sajnos ilyennek miatt olyanok a nagyobb cégek rendszerei, amilyenek. Szívás minden fejlesztés.
[Személyes vélemény off]













![;]](http://cdn.rios.hu/dl/s/v1.gif)
































Új hozzászólás Aktív témák
Hirdetés
- WLAN, WiFi, vezeték nélküli hálózat
- Vezetékes FEJhallgatók
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- Gitáros topic
- Szívós, szép és kitartó az új OnePlus óra
- Kerékpárosok, bringások ide!
- Filmvilág
- Battlefield-film készülhet - Michael B. Jordan is képben van
- Kínai és egyéb olcsó órák topikja
- World of Tanks - MMO
- További aktív témák...

- ÚJ Acer Nitro V 17 AI - 17.3"QHD 165Hz - Ryzen 7 260 - 16GB - 1TB - Win11 - RTX 5060 - 3 év Gar - HU
- Lego replika Tokyo 20051 építőkészlet doboz nélkül
- 27% - HEIGAOLA MiniPC - / 10.1" Érintőképernyő! Intel J4125 / 8GB RAM /128GB SSD
- Dell Vostro 5410 14" i5-11320H 16GB 512GB 1 év garancia
- Samsung Galaxy Z Flip 7 256 GB Kék Használt állapot 12 GB RAM 6 hónap garancia
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest