- Fórumok
- Szoftverfejlesztés
- SQL kérdések
- (kiemelt téma)
- Megújult mobilos felület, fórumos ráncfelvarrás a PROHARDVER! lapcsaládon
- Eladhatatlannak ítélt CPU-k eladásával javult az Intel node-ok kihozatala
- Az AI átformálja a Peugeot modelljeit is
- Ráműthető a Linux PlayStation 5-re, de csak egy boot erejéig
- Mindenféle környezeti behatásnak ellenállnak az ASUS új TUF tápjai
- NVIDIA® driverek topikja
- Milyen asztali (teljes vagy fél-) gépet vegyek?
- Dell notebook topic
- Azonnali VGA-s kérdések órája
- Melyik hordozható audiolejátszót (DAP, MP3, stb.) vegyem?
- Mini-ITX
- Milyen billentyűzetet vegyek?
- NVIDIA GeForce RTX 5080 / 5090 (GB203 / 202)
- Milyen egeret válasszak?
- A jövőben nem csak a gazdagok kiváltsága lehet az Intel CPU-k tuningja
-
4500 - 4401
6041 - 6001 6000 - 5901 5900 - 5801 5800 - 5701 5700 - 5601 5600 - 5501 5500 - 5401 5400 - 5301 5300 - 5201 5200 - 5101 5100 - 5001 5000 - 4901 4900 - 4801 4800 - 4701 4700 - 4601 4600 - 4501 4500 - 4401 4400 - 4301 4300 - 4201 4200 - 4101 4100 - 4001 4000 - 3901 3900 - 3801 3800 - 3701 3700 - 3601 3600 - 3501 3500 - 3401 3400 - 3301 3300 - 3201 3200 - 3101 3100 - 3001 3000 - 2901 2900 - 2801 2800 - 2701 2700 - 2601 2600 - 2501 2500 - 2401 2400 - 2301 2300 - 2201 2200 - 2101 2100 - 2001 2000 - 1
-
Fórumok
PROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Új hozzászólás Aktív témák
-
 Szmeby
tag
Szmeby
tag
"ez nem fontos a fejeseknek"
Nem értem. Miért nem fontos a fejeseknek?
Inkább másképp kérdezem. Akkor mi a fontos a fejeseknek? A fejesek számára fontos dologhoz ennek nincs köze? Akkor neked miért fontos? Azon kívül, hogy téged szórakoztat ilyesmivel foglalatoskodni.
De tudok még tovább is menni. [irony on ] A fejeseket nem zavarja, hogy olyan felesleges dolgokkal töltöd a (munka)időd, ami számukra nem fontos? Mivel foglalkozhatnál helyette a fontos dolgokkal is. Remélem nem jönnek rá, hogy titokban nem a céges irányelvek és vízió mentén végzed a munkád, még a végén lapátra kerülsz.
] A fejeseket nem zavarja, hogy olyan felesleges dolgokkal töltöd a (munka)időd, ami számukra nem fontos? Mivel foglalkozhatnál helyette a fontos dolgokkal is. Remélem nem jönnek rá, hogy titokban nem a céges irányelvek és vízió mentén végzed a munkád, még a végén lapátra kerülsz. -
 Louro
őstag
Louro
őstag
Én a DBA-ra nem haragszok, mert lehet rá számítani, csak sajnos más feladatokat is ellát. (Munkaszervezésbeli hiba az IT részlegen (szerintem).)
Én egy kicsit IT vénával megáldottüzleti elemző vagyok. Nem csak megírom a SELECT-et, hanem a teljesítményre és az olvashatóságra is igyekszek figyelni. De amúgy értem amire utalsz.
@nyunyu (4497): Elvileg a 2008->2012 átállás már jóvá lett hagyva és jönne az UAT, de se neki nincs erre ideje, se nálunk, mert persze ez nem fontos a fejeseknek. Tesztelés nélkül biztos nem engedném. Az nagyon amatőr lenne. A jelenlegi helyzetben meg a VPN döcög. Amúgyis nehezebben halad a munka

-
Louro
őstag
Szia,
ha jól értem lesz két tábla. A kettő között a kapcsolatot a "gyógyszerkészítmény" fogja adni.
Egyik táblában az összetételek lesznek. Feltételezem soronként. Kicsit furcsa lenne olyan struktúra, hogy összetétel1, összetétel2, összetétel3,.... .
Másik táblában a tulajdonságok lesznek. Feltételezem itt is soronként lesznek felsorolva a hatások.Ha a számomra "furcsa" megoldás van, akkor simán JOIN-nal összeköthetőek. Ugyanaz, mint a VLOOKUP az Excelben

A másik megoldás esetén simán mellé tenni, LEFT JOIN-nal nem érdemes, mert összes lehetséges párosítást adná vissza, ami biztos nem jó. PIVOT kicsit macera kezdőként.
Én személy szerint soronként tárolnám mindkét táblát. Az összetevőket és a tulajdonságokat is katalogizálnám. Azaz bevezetnék egy táblát, amiben egyes adatok kapnának egy azonosítót és a két táblában csak az azonosítókat kellene eltárolni. Később lehet meghálálja a rendszer és a tárhely. Például a penicilin szót eltárolni 9 karakter, de ha ez a 17-es kódú összetevő, akkor ez egy sokkal kisebb helyet igénylő adat.Példa:
1-es azonosítójú gyógyszerkészítmény eseténElső tábla
1 - összetevő: por
1 - összetevő: víz
1 - összetevő: penicilinMásik tábla:
1 - tulajdonság: Fejfájás
1 - tulajdonság: HányingerHa ezt kötöd össze, akkor ilyet kapnál:
1 - összetevő: por - tulajdonság: Fejfájás
1 - összetevő: víz - tulajdonság: Fejfájás
1 - összetevő: penicilin - tulajdonság: Fejfájás
1 - összetevő: por - tulajdonság: Hányinger
1 - összetevő: víz - tulajdonság: Hányinger
1 - összetevő: penicilin - tulajdonság: HányingerNa ez jó hosszú lett. Jó lenne ismerni a kiindulási alapot. Akár fake adatokkal összedobsz egyet a Google Drive-on, talán könnyebb lenne a megoldást megtalálni.
-
 nyunyu
félisten
nyunyu
félisten
Egy 2008->2012 frissítésért is kuncsorogni kellett
Mielőtt Móricka azt képzelné, hogy régi DBn backup, aztán új szerveren restore, és máris megy minden, mint a karikacsapás, ennél nagyobbat nem is tévedhetne.

Annó egyik ügyfelünk nagyon nyüstölt minket az SQL Server 2000 miatt, hogy 2011-ben nem kéne már használni, aztán új DB szerver telepítésekor upgradeltette a rendszerét 2008R2-re.
Akkor a DBAink vagy egy fél hónapot reszelhették a régi kódot, hogy normálisan működjön a hárommal újabb DB verzióval, mivel felülről kompatibilitás ide vagy oda, az új DB motor sokmindent másképp optimalizált/futtatott, mint a régi.
Úgyhogy lehetett végignyálazni az indexeket, hinteket, meg utánaolvasni a 2008R2 újításainak, mivel a DBAnk főleg 2000-hez értett, meg kisebb részben 2005-höz. -
 martonx
veterán
martonx
veterán
-
martonx
veterán
Sőt igaziból on-the-fly kellene replikálni, az a vicc, hogy az ugyan folyamatosan dolgoztatja a két szervert, viszont folyamatosan alacsony terheléssel.
Ezek a napi 1 megoldások viszont ugyan az éles szerveren kb. semekkora plusz terheléssel nem járnak (nem mintha az on-the-fly replika komoly terheléssel járna), viszont a teszt szerver arra az időre full használhatatlan. -
 formupest
csendes tag
formupest
csendes tag
Szevasztok
segítséget kérek, egy excel táblában gyógyszerkészítmények összetételét mig egy másik táblában a készitmények tulajdonságait leiró adatokat rögzitem. A tulajdonsághalmaz a gyógyszertipustól (baletta, kenőcs, kúp, szirup stb, függően változik azaz annyi tulajdonságtábla van ahány gyógyszertípus. Kérdés: milyen kapcsolatokat kell a táblák között kiépiteni illetve milyen SQL lekérdezéssel lehetne a táblákból a legegyszerűbb módon kiolvasni az információkat. -
Louro
őstag
A rendszer egy dobozos termék. Az adatbázisa is adott. Azon változtatni nem tudunk. Ezért a második opció az életképes. Egy 2008->2012 frissítésért is kuncsorogni kellett
De így is lassan 10 éves lesz az új szoftver is. (Multikulti probléma.)A DBA-nk optimalizálásba próbál segíteni, de mivel nem csak ezen dolgozik, így elég kevés ideje jut az ilyen dolgokra. Úgymond ránk bízza, hogy milyen kódot írunk. Ha több millió sor törlését indítjuk el vagy deadlock-ba botlunk, akkor természetesen jön és segít. De nem fér bele az idejébe, hogy monitorozza a tevékenységeinket.
Elvileg mi is meg tudjuk nézni a query plan-t és tudunk eszközölni javításokat. (De a felhasználók közül csak én vagyok olyan beteges, akinek számít a futási idő. Többieknek csak az számít, hogy lefusson.) Mondjuk meg szoktam osztani praktikákat, de onnan az ő felelősségük, hogy alkalmazzák-e.
A partícionáláson én is gondolkodok, mert van jó pár gyakran használt nagy táblánk, amin segítene. Csak elmagyarázni a többi felhasználónak, hogy mit hogyan.... IF vagy egy WHILE ciklusnál is teljes sötétség. Vagy, ha kell, inkább kézzel töltenek be 100 külső forrást, semmint ciklussal BULK INSERT-tel.
(Desszert: Egyik korábbi munkahelyemen meg VIEW-kat kezdtük el visszafordítani, hogy miből is épül és a 13. szint után feladtuk. VIEW-ra VIEW-t, majd arra VIEW-t építeni...Sok a szakbarbár a piacon, de persze ők sírnak a legjobban a pénzért.).
Bocsi a hosszért... Megyek eszek sütit. Nem panaszkodom. A replikációt biztos megbeszélem az DBA-val és a partícionálás nagyon terítéken van, mert sokat nyernénk vele.
-
nyunyu
félisten
Ha jól értem, itt kőkemény gazdaságossági kérdések is bejátszanak.
Nektek kell eldönteni, hogy mire akartok költeni:
- újabb, erősebb vas
- toldozzátok-foltozzátok a régi kódot, hátha jobban fut az elégtelen vasonÍrtad, hogy van DBAtok.
Nem az ő dolga lett volna eddig kielemezni a rendszer gyenge pontjait, és azon optimalizálni?
Akár úgy, hogy megnézi, mi fut túl lassan, és a végrehajtási terv alapján kitalálja, milyen indexszel vagy hintekkel lehetne jobban futtatni ugyanazt, vagy akár úgy, hogy nyakára lép a trehány fejlesztőknek, hogy gondolkozzanak, mielőtt telibejoinolnak két sokmilliós táblát.Vagy azon is el lehet gondolkozni, hogy valami mentén partícionáljátok a táblákat.
Mittudomén, van egy folyamatod, aminek van egy azonosítója, akkor célszerű lehet az összes a folyamatban használt táblát a folyamat azonosító mentén partícionálni, és az összes joinba betenni a partíciókulcsot, így mindig csak az aktuális partíció pártíz-ezer során dolgozik a DB, nem az egészre megy a full table scan...[szerk:]Ja, hogy dobozos? Akkor a beszállítót kell rugdosni, ha még garis a termék, de sejtésem szerint már fizetős a support
Pénz meg szokás szerint nincs.Én sok kis lépéssel próbálok javítani. Igazából szorgalmiként, mert mellette ott vannak a feladataim is :/
Sajnos volt ilyen munkahelyem.
Amikor sikerült sok hónap munkával eloltanom egy évek óta lángoló tüzet, amit az egyik vezető fejlesztő nemtörődömsége okozott, akkor még vállveregetést sem kaptam érte, nem hogy fizuemelést.
Aztán még én voltam a szemét, amikor leléptem onnan... -
Louro
őstag
Nem saját termékről van szó, hanem egy dobozos termékről, ami kötöttségekkel jár. Ezért az SQL server is. Rendelkezésre áll a SAS is, de arra átállni (backup esetén) meg idő lenne, amire persze nem szánnak időt. Rengeteg idő lenne a meglévő jobokat átírni
Én sok kis lépéssel próbálok javítani. Igazából szorgalmiként, mert mellette ott vannak a feladataim is :/
-
Szmeby
tag
Nem léteznek már eleve elosztott működésre képes megoldások?
Ami hirtelen eszembe jut, egy mongo is könnyedén szét tudja szórni az új adatot a cluster összes node-ján. Real time. A relációs DB-k erre nem képesek? Vagy olyan a felhasználási mód, ami mellett ez a megoldás nem jó ötlet?
-
Louro
őstag
Amire nekünk kell, arra jó a T-1 napi adat. Így is csoda, hogy él a rendszer. Napközben nem nyüstöljük az éles rendszert. Én próbálkozok, hogy nyerjek egy kis erőforrást, mert amikor átvettem, akkor borzasztóan rosszul megírt szkriptek futottak ütemezetten
A következő kérdés lehetne, hogy a változásokat azonosítsuk. A rendszer olyan, hogy frissít több mezőbe szinte folyamatosan. Bár jogos, hogy azzal tudnánk nyerni, de a régi adatok beazonosítása, törlése, majd áttöltése lehet időigényesebb lenne.
-
 tm5
tag
tm5
tag
-
Louro
őstag
Köszi az infót. Általában éjfél után fél perccel indítjuk jelenleg is az átmásolást és van, hogy 7-ig is eltart :/ Az éles is lassan 1 terra. De ennek egy töredékéről készítünk tükörmásolatot.
Úgyis lassan várható egy kis fejlesztés a 2012-re. Lehet ezt a repikációt bedobom. A DBA-nk szerencsére jó szaki. Lehet tud is erről, csak több, mint 10 éve nem nyúltak a jelenlegi rendszerhez :/
Köszi mindkettőtöknek!
-
nyunyu
félisten
Replikáció erre való, hogy ha megváltozik egy adat, akkor a változás automatikusan át legyen víve a másolatra is.
Persze arra oda kell figyelni, hogy a táblák egyedi azonosítóit populáló szekvenciákat nem szokta szinkronizálni, így pl. ha kiesik az eredeti adatbázis, és ideiglenesen a replikát akarod használni helyette, akkor manuálisan léptetned kell a másolat DBben lévő szekvenciákat, hogy nagyobb értékről induljanak, mint a táblában lévő aktuális ID, különben egyedi kulcs sértést kapsz, amikor írni próbál a rendszer a replikába.
(aztán a kiesett eredeti DBre visszaálláskor is el lehet ezzel játszani.)Nyilván a replikációt elindítani sem munkaidőben kell, ha akkorák a tábláid, hiszen jó pár óráig eltarthat, mire nulláról felépíti a másolatot.
Kollégáimnak annó elég sok bajuk volt az SQL Server 2000 replikációjával, de a 2005, aztán a 2008 már jóval stabilabban működött.
-
Louro
őstag
Több 20gb+ tábla is van az átmásolandók között, ami emiatt több órát igényel. Szimplán csak át kell másolni a tábla teljes tartalmát. (Az oka, hogy ne az éles környezetet terheljük elemzési célból, hanem egy másolatot. Egy kartéziánus szorzat és megfektetjük az élest és hamar tartós szabadságra küldenek
. )Lassúnak nem biztos, hogy lassú, de ha egy kicsit is tudok spórolni, akkor én hajlamos vagyok időt tenni bele. Kicsit kattanásom, hogy ha lehet jobban, akkor miért ne.
Az SQL replikációról megkérdezem a DBA-nkat. Én ezt nem használtam. Ennek is kicsit utánajárok
-
tm5
tag
SQL Szerver replikáció nem játszik? Nem használtam sose. De ez elég régóta egy elérhető feature. Szóval ha olyat kellene csinálnom amit írtál, én ezt (a beépített replikációt) nézném meg először, hogy hogy működik.
Amúgy pontosan mi a lassú? Konkrétan a rekordok átmásolása, vagy nagy a késleltetés (latency) a két szerveren lévő adatok állapota között?
SSIS-t sem használtam, de azzal is megpróbálnám, ha ez csak olyan batch/bulk jellegű másolás lenne. Általában ezek az integrációs eszközök elég jók. -
Louro
őstag
Sziasztok!
Adott két SQL Server 2008 R2. A kettő össze van kapcsolva (Linked Server). Az lenne a kérdésem, hogy ha a két szerver között akarok olyat, hogy A szerverről másolja át a táblákat napi szinten a B szerverre, mint egy backup, akkor melyik a gyorsabb a megoldás? T-SQL vagy a SSIS?
Jelenleg az előbbi van alkalmazásban, de ha tudok időt nyerni, akkor annak örülnék. Rengeteget gugliztam már a témában, de sajna nem találtam egyértelmű választ.
Köszi előre is a válaszokat!
-
 bambano
titán
bambano
titán
-
tm5
tag
Jogos, azt zavart be, hogy 32 karakteren ábrázolják/tárolják, nem pedig egy 128 bites számként.
Viszont még az is eszembe jutott, hogy ha valahol letárolod, hogy mi volt a legnagyobb dátum amit még beszúrtál, akkor a log file olvasáskor figyelmen kívül hagyhatsz minden olyan sort ami annál régebbi. Az újabbakat meg simán inzertálod. Csak ne felejtsd el letárolni az új MaxRowLoadDate-et a log feldolgozás végén.
-
nyunyu
félisten
A hasht tároló oszlopra rakj rá egy unique megszorítást, és akkor magától hibát dob, ha már bent lévő értéket próbálsz megadni:
CREATE TABLE "logs" (
"id" INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
"level" INTEGER,
"tstamp" TEXT,
"message" TEXT,
"location" TEXT,
"userid" TEXT,
"hash" TEXT UNIQUE
);Nem vágom az SQLiteot, de az insert szintaxisát elnézve lehet benne olyan upsertet írni, hogy:
insert or ignore into tábla values (értékek) on conflict do nothing;Ekkor figyelmen kívül hagyja a hibára futó insertet, és nem hajtja végre.
-
 Keem1
veterán
Keem1
veterán
Mekkora az MD5 hash mérete?
Ezt nem értem Simán a normál MD5 16 bájtos mérete, hexában.
Simán a normál MD5 16 bájtos mérete, hexában.Miért nem másolod el egy másik fájlba azokat amit nem akartsz törölni [...]?
Alapvetően az lett volna, hogy nap végén: logs.txt -> logs001.txt, de külső elérés kell a loghoz, ezért (+ a kereshetőség miatt) a DB.Most van egy AI PK, de az a fájlbéli logbejegyzéstől független. Arra is gondoltam, hogy hátha lenne egy int alapú hash algoritmus, de itt is fontos a gyorsaság (az MD5 előállítása minimális erőforrást igényel), a hash-re csak az adatbázisba írás miatt van szükség, a feladat többi szemszögéből irreleváns.
Így néz ki a tábla schema:
CREATE TABLE "logs" (
"id" INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
"level" INTEGER,
"tstamp" TEXT,
"message" TEXT,
"location" TEXT,
"userid" TEXT,
"hash" TEXT
);A logfájl mindegyik sora egy határoló string alapján kerül feltördelésre, a log level pedig a megfelelő string indexe lesz (NONE->0, ERROR->1, DEBUG->2, ...).
Egy log sor így néz ki:
DEBUG - 2020-04-05 16:00:04 - No IP change detected, no need to update - [itt az adott namespace.class.method van] - [devicename/userid]Tranzakcióra nincs esetleg valami (sematikusan) ilyesmi?
IF SELECT ...
INSERT INTO ...
ENDIF -
tm5
tag
Mekkora az MD5 hash mérete? Mert ha nagyon nagy akkor le kéne cserélni egy INT-re mint kulcs. Azzal gyorsabb keresni.
Pontosan mit/hogy szeretnél tárolni az adatbázisban?
Kicsit homályos az a rész, hogy nap végén beszúrod a napi log bejegyzéseket egy táblába, majd kiüríted a logot néhány bejegyzés kivételével és másnap újból ugyanabba a fájlba írnál új logokat? Miért nem másolod el egy másik fájlba azokat amit nem akartsz törölni és akkor a log fájl tartalmából mindig insert lenne csak?
Amúgy ami a kérdéseidet illeti (bár nem ismerem az SQLiteot):
- tennék egy indexet a kulcsra, úgy a leggyorsabb keresni illetve kéne rá a primary key megszorítás és akkor nem szúrhatná be ugyanazt a sort kétszer.
- Mindenképpen INSERT rögtön, nem kell SELECT előtte és valamilyen try - catch jellegű dolog köré elkpani a hibaüzenetet. BTW, UPDATE lenne a benn lévő soron vagy nem? -
Keem1
veterán
Helló emberek, iránymutatást szeretnék kérni. Mivel IoT rendszerről (Raspberry Pi) van szó, minden megspórolt millisec számít.
Adott egy már jól működő service, de ami még debug módban megy, ezért rengeteget loggol file-ba (egyelőre kell is, az alapján csiszolom), viszont minden nap végén a log file-t kiürítené, tartalmát SQLite adattáblába zsuppolná (keresés, kiértékelések miatt). Sajnos egyelőre vannak logbejegyzések, amiket bent hagynánk a fileban, és nem lenne jó naponta újra és újra beírni az adatbázisba, ezért egyszerűen tárolunk ott egy MD5 hasht is (vizsgálva, hogy a hash bent van-e már az adatbázisban). A helyzetet "bonyolítja", hogy tranzakcióval megy a beírás (napi 200-1000 log tranzakció nélküli beírása [csak az adatbázisművelet] 1-2 sec, tranzakcióval 40-80 ms).
Hogy lehet a legjobban, legelegánsabban megoldani?
- letárolás előtt a hash értékek kiolvasása egy tömmbe/listába programozottan (C#)?
- INSERT helyett SELECT(?) + INSERT annak csekkolására, hogy már bent van-e a hash, a db-re bízva? Ha igen, itt kérnék iránymutatást, fogalmam sincs, ez miképp kivitelezhető egy tranzakció belsejében, a COMMIT parancsot megelőzően.Az első pont fizikailag készen van, működik is, csak nem tudom, ez így mennyire vehető jó megoldásnak egy IoT rendszernél.
Javaslatot szeretnék kérni!

-
bambano
titán
"NOT IN vs LEFT JOIN?": értem, amit írsz, de.
a calendar tábla évi nagyságrendileg 20 rekorddal bővül, és mivel a subselectben van dátumra való korlátozás, így amikor ez végrehajtódik, akkor néhány rekord kerül a not in (...) -be. ennyivel boldoguljon már.annak utána fogok járni, hogy az áthelyezett szombat az én problémám szempontjából minek számít. kösz a felvetést.
-
nyunyu
félisten
Nem elég azt nézni, hogy benne van-e a dátum a calendarban, hanem azt is kéne nézni, hogy az extra nap milyen napnak számít, különben elveszted a soknapos ünnepek körül elcserélt szombati munkanapokat.
Ezért volt plusz egy oszlop az ügyfeleinknél használt naptár táblákban, ahova a munkanapcserés szombatokat is fel kellett vennem péntek értékkel, előtte pénteket meg csütörtökkel, amikor egy évre előre felvettem az ünnepnapokat.NOT IN vs LEFT JOIN?
Annak idején úgy tanultuk, hogy jobb az anti join teljesítménye, de nem tudom ez a mai DB kezelőknél mennyire áll még fenn.
Oracle optimalizálója alapból anti joinná alakítja a not in-t, hacsak nem tiltod meg neki, így ott már nincs különbség teljesítményben. -
bambano
titán
logikáját tekintve valóban az, amit nyunyu írt, de ezt én is leírtam már (#4469) (eltekintve attól, amennyivel butább az oracle...
 ) . amit te írtál, az teljesen más. te keresnél egy számolótáblát az adatbázisban, amit nem tudok értelmezni, és azzal számolnál. ezzel szemben a postgresql (ami kikötés volt), on the fly képes sorozatokat generálni és record-setként kezelni. a hétvégéket nem modulo 7 alapján számolja, ami egyébként is lehetetlen, mert a kiinduló napnál hiába akarnál modulo7-et számolni, hanem a beépített naptár funkcióval, ahogy nyunyu is.
) . amit te írtál, az teljesen más. te keresnél egy számolótáblát az adatbázisban, amit nem tudok értelmezni, és azzal számolnál. ezzel szemben a postgresql (ami kikötés volt), on the fly képes sorozatokat generálni és record-setként kezelni. a hétvégéket nem modulo 7 alapján számolja, ami egyébként is lehetetlen, mert a kiinduló napnál hiába akarnál modulo7-et számolni, hanem a beépített naptár funkcióval, ahogy nyunyu is.lelassulhat? miért is?
-
 Apollo17hu
őstag
Apollo17hu
őstag
-
bambano
titán
én erre jutottam:
1. generálom a következő napok dátumait
2. ebből kidobom, ami szerepel a calendar táblában
3. kilistázom a maradékból a munkanapokat, sorbarendezve
4. a listából az n. elemet lekérdezemamiben nagyon más: van generátor függvény, ami többek között dátum típusra is működik, és az ünnepeket egy not in subselect halmazzal szedem ki.
kb. így néz ki postgresql-ben:
select l.nap,date_part('dow',l.nap),to_char(l.nap,'YYYYMMDD') as kompaktdatum from(select date_trunc('day',generate_series(now()+'1 day'::interval,now()+'30 days'::interval,'1 day'::interval)) as nap ) lwhere l.nap not in (select distinct date from calendar where date>now()and date<now()+'30 days'::interval)and date_part('dow',l.nap) in (1,2,3,4,5) order by l.nap limit 1 offset 5; -
bambano
titán
-
nyunyu
félisten
-
bambano
titán
-
nyunyu
félisten
Oracle:
with extra_nap as (
select '20200410' datum, '7' nap from dual
union
select '20200413' datum, '7' nap from dual
union
select '20200501' datum, '7' nap from dual),
szamok as (
select level l
from dual
connect by level <= 1000),
datumok as
(select to_char(sysdate+l,'yyyymmdd') datum,
case when nvl(e.nap, to_char(sysdate+l,'d')) in ('1','2','3','4','5') --hétfő..péntek
then 'Y'
else 'N'
end munkanap
from szamok l
left join extra_nap e
on e.datum=to_char(sysdate+l,'yyyymmdd'))
select datum, row_number() over (order by datum) rn
from datumok
where munkanap='Y';Extra_nap "táblába" felvettem a nagypénteket, húsvéthétfőt, május elsejét vasárnapi munkarenddel.
Aztán legenerálom a következő 1000 nap dátumát, és melléteszek egy munkanap flaget, ami az extra_napban beállítottból vagy a hanyadik nap a héten értéktől függ.
Végül leválogatom a munkanapokat és melléteszek egy sorszámot, hogy ő hanyadik. -
martonx
veterán
-
Apollo17hu
őstag
-
bambano
titán
ennél sokkal egyszerűbbet szeretnék.
-
Apollo17hu
őstag
Jaaa... Az szívás. Ahol én dolgoztam, ott a calendar tábla minden naptári napot tartalmazott talán 1900-tól 2040-ig. Külön flag volt a munkanapokra, hóvégekre, hét melyik napja, mi a köv. munkanap stb.
Szóval akkor egy ilyen segédtáblát kellene megképezni, és felhasználni ahhoz, amit fentebb írtam. Legyen mondjuk ez a calendar_2! Valahogy így állítanám elő calendar_2 -t:
1. Keresnék egy számláló táblát az adatbázisban, ami 0 és egy nagyon nagy szám között tartalmazza az egész számokat. (Ha nincs ilyen, akkor tetszőleges táblán row_number-t képeznék, és azt használnám.)
2. A számláló tábla rekordjaihoz megképezném a calendar_day mezőt, ami a naptári napokat tartalmazza. Az 1. naptári nap a bemenő dátum, az összes többi pedig ez a dátum növelve a számlálóban lévő értékkel (date_add, ha van ilyen postgresql-ben).
3. Szintén új mezőben megjelölném a szombatokat és vasárnapokat. (modulo 7 eredménye alapján)
4. A 2. pontban létrehozott listához gyengén (LEFT JOIN) hozzákötném a calendar táblát, amiben csak a rendkívüli munkarend napjai vannak benne.
5. A 3. és 4. pontban lévő információ felhasználásával létre lehetne hozni a végleges workday_fl mezőt.Így állna elő a calendar_2 halmaz, amiből calendar_day-t és workday_fl-et lehetne felhasználni a megoldáshoz.
-
bambano
titán
a calendarban csak a rendkívüli munkarend napjai vannak benne.
-
Apollo17hu
őstag
Fognám a calendar táblát, raknék rá egy "nagyobb, mint a bemenő dátum" ÉS "legyen munkanap" szűrést, majd a kapott halmazon valamilyen rank() függvénnyel (van ilyen postgresql-ben?) egy sorszám mezőt generálnék, ami dátum szerint növekvő sorrendben osztaná ki a sorszámot. Ahol a sorszám n, az a keresett dátum.
Ehhez mondjuk az is kell, hogy az ünnepnapokból és a munkanap áthelyezésekből rendelkezésre álljon egy munkanap flag ['I', 'N'] is. Ha ilyen nincs, azt mondjuk egy CASE WHEN-nel külön le kell még kezelni.
-
bambano
titán
Érdekelne a ti megoldásotok postgresql-ben:
Előre adott n-re annak a napnak a dátuma EEEEHHNN formátumban, amelyik a lekérdezéstől számítva az n. munkanap úgy, hogy a lekérdezés napja a nulladik, a másnapja az első. Segítségként van egy calendar nevű tábla, amiben rekordonként benne vannak az ünnepnapok és a munkanap áthelyezések, egy date nevű mezőben.tehát ha ma lefuttatom 6 napra, akkor 20200415-öt ad eredményül.
kösz
-
nyunyu
félisten
Mi volt a baj az eredeti elképzeléseddel?
FOR nem a mögé írt query által visszaadott sorrendben megy végig a sorokon, mint ahogyan a kurzorok tennék? De.
Indexelős ötleted nagyon elborult, egyrészt nehéz megvalósítani, pl. mi van akkor, ha jön egy új elem a táblába, akkor minden sort megupdatelsz az aktuális sorrend alapján?
Iszonyúan nagy overheadet produkálnának az ehhez szükséges triggerek.Ha csak annyi lenne a kérdés, hogyan tudod megmondani egy sorról, hogy ő valamilyen rendezés szerint hanyadik a táblában, akkor a row_number() over (order by x,y) függvényt tudod használni.
Egyébként meg a relációs adatbázisok mindig halmazokkal dolgoznak, nem egy-egy elemmel, így a más programnyelvek procedurális gondolkozásmódja (ciklusok, kurzorok...) SQLben sosem ad jó teljesítményt.
Próbálj inkább úgy gondolkozni, hogyan lehet egy queryvel az összes adatot egyszerre frissíteni/beszúrni.Előző projekten amúgy belefutottam hasonlóba, mint amit most szeretnél.
Örököltem egy kódot, ami egy táblából csinált egy rendezett kurzort, majd azon ment végig egyesével, és dinamikus SQLben kért új értéket egy szekvenciából, majd updatelte rá a tábla soraira, kvázi új indexet vezetett be.
Persze, hogy 15000 sor esetén húsz percig szöszmötölt rajta az Oracle.
Megoldás az lett, hogy egy segédtáblába leválogattam a fő tábla azonosítóit, meg a row_number() over (order by x,y) rn-t, aztán következett egy jól irányzott merge a fő táblára.
Egyből lefut 10 másodperc alatt... -
 kw3v865
senior tag
kw3v865
senior tag
Átgondoltam és kicsit máshogy közelítem meg a kérdést: adott egy tábla, melynek van egy ID mezője. Ehhez nem akarok hozzányúlni (később még szükség lehet rá). Azonban, szeretnék egy másik ID-t, ami természetesen szintén egyedi kell, hogy legyen. Erre azért van szükség, mert jelenleg nem a számomra megfelelő sorrendben vannak az adatok. Azaz, lényegében azt szeretném, hogy ORDER BY "ClassID", "Valami" ASC. Ez alapján legyen kiosztva az új ID, növekvő sorrendben.
Szerinted ezt hogyan lehetne megvalósítani a legegyszerűbben? Új táblát nem akarok, a már meglévővel kell dolgoznom.
Index-eléssel vajon megoldható? https://www.postgresql.org/docs/10/indexes-ordering.html
Ezáltal lenne egy indexem, de én egy új mezőt is akarok.
Ha megvan az index, majd csinálok egy CLUSTER-ezést: https://www.postgresql.org/docs/10/sql-cluster.html
Végül csak simán hozzáadok egy új serial mezőt, az jó megoldás lehet? -
martonx
veterán
-
kw3v865
senior tag
Sziasztok!
PostgreSQL-es kérdésem lenne, FOR ciklussal kapcsolatban:
Adott egy tábla, melyen végig akarok menni egy FOR-ral, de olyan sorrendben, hogy két mezőt vegyen figyelembe. Vannak csoport ID-k és azon belül az egyedi ID-k.
Az lenne a lényeg, hogy növekvő sorrendben menjen végig rajtuk, úgy, mint ORDER BY "ClassID", "ID".
Szerintetek ez így jó PostgreSQL-ben? Azaz helyesen írtam meg?DO $$<<first_block>>DECLAREi int;BEGINFOR i IN SELECT "ClassID", "ID FROM table ORDER BY "ClassID", "ID"LOOPEND LOOP;END first_block $$; -
 MrSealRD
veterán
MrSealRD
veterán
Így önmagában semmi... Az 1 képernyős karbantartást meg lehet oldani több tábla esetén is. Én csak megosztottam az érvelést amit kaptam.
nyunyu : Ez mondjuk nem adattárház lesz. Viszont mivel tervezési fázisban vagyunk ezért én próbálok minden esetleges vonatkozást megvizsgálni. Most a Hibernate is elgondolkodtatott... Ott is vannak kérdőjelek az egyesített tábla miatt.
-
Szmeby
tag
-
nyunyu
félisten
Normalizálásnak megvan a maga helye és az ideje, de ez az eset nem tűnik annak.
Mostanában már nem annyira a tárhely (memória, vinyó, szalag...) a szűk kapacitás, mint tizenévekkel korábban, így már nem feltétlenül érdemes a normalizációval megspórolható helyre gyúrni.Adattárházaknál például bevett szokás a csillag séma, amikor egy nagyon széles, sokmillió soros ténytáblához joinolnak sok kicsi dimenziót, viszont a dimenziótáblák tartalmát nem nagyon szokták normalizálni, hogy minél kevesebb joinnal gyorsabban lekérdezhető legyen a nagy mennyiségű adat.
Vannak olyan mondások is, hogy a dimenziókat nem ártana normalizálni, azt hívják hópehely sémának, de az általában ront a lekérdezések, adattranszformációk sebességén.Előző projektünkből kiindulva az sem ideális, amikor tizen-huszon, alig pár rekordot tartalmazó paramétertáblát kell kerülgetned, hogy mi az amit a következő shipmentbe bele kell tenned, és mi az amit nem szabad.
Olyankor valami mindig kimarad, vagy éppen felülírod az éles beállításokat egy alsóbb környezetre érvényes teszt beállítással.
Ráadásul fél évvel később az üzemeltetési doksi írásakor már nem is emlékeztem arra, hogy kollégák melyiket mire használták, sokat úgy kellett kitúrni a kódból, amikor az üzemeltetők rákérdeztek valami egyedi beállítási lehetőségre.Azon a projekten a fontosabb paraméterek állítására például az Üzlet kért egy képernyőt, ahol Excelben letöltheti a fontosabb paramétertáblák tartalmát, majd szerkesztés után visszatölthesse.
Azokat a táblák tartalmát például tilos volt dumpként a shipmentbe adni, nehogy felülírjuk a felhasználók beállításait.
Ha új sorok kellettek, akkor azokat élesítéskor insertekkel kellett beszúrni. -
MrSealRD
veterán
Persze, semmiképp sem akarom keverni. Én fejlesztési oldalról vagyok érintett. A PM akivel az alapokat tesszük le meg, hát PM meg üzleti oldalról érintett. Ezért nézzük két szemszögből. Itt az a nagy kérdés, hogy mi legyen az elhatározás. Az oké, hogy egyik legyen, de melyik?
-
 Ferfiu
tag
Ferfiu
tag
-
MrSealRD
veterán
Először is köszi az észrevételeket.
bambano : A fenti szerkezet csak egy kivonat. Pontosan ez volt az érvelés mögötte amit te is írsz. Ettől biztosan több lesz a karbantartandó adat. Az ehhez kapcsolódó implementáció nem akkora overhead. Inkább felhasználói oldalról volt ez vizsgálva. Hogy ne kelljen sok képernyőn keresztül kiigazodnia a user-nek, hogy karbantartsa ezeket az adatokat. Így egy képernyőn el tudja intézni. Persze az implementáció is szóba került, hogy egyszerűbb 1 képernyőt megcsinálni.
Objektíven nézve nekem ez egy új megoldás...és úgy érzem ez ellentéte a normalizálásnak.whYz A tovább bontás az már meglévő gondolat. Igazából az egész állapot egy piszkozat. Szóval ez még nem a végleges. Sok kérdés tisztázás alatt van még.
A TYPE+ID esté type-onként lenne egyedi az ID. Ezért kell együtt PK-nak lenniük.
Én a szétbontás mellett vagyok, ahogy az ábrán is rajzoltam. Viszont látok realitást is a másik ötletben is...nyunyu A hibernate nem kőbe vésett dolog. De abból amit írsz nekem inkább egy rosszul konfigurált és rosszul működtetett Hibernate réteg körvonalazódik... Ezt a fejlesztőkkel kell lejátszani, mert ez így nem fenntartható. Széles körben alkalmazott technológia. Nem tökéletes, semmi sem az, de viszonylag jó vélemény van róla többségében.
-----
Visszatérve a DB szerkezetére. Nem nagyon tudok érvelni a közös tábla ellen. Mondjuk kódból kell nagyon undorító dolgokat csinálni. Mert egy közös típus lesz különböző dolgokra. A pókösztönöm azt mondja ez nem egészséges hosszú távon. -
nyunyu
félisten
Ha az a cél, hogy enumokat tárolj, akkor egy szótártábla elég, amiben van enum_neve, sorszám, érték.
(Aztán utána lehet hitvitákat folytatni, hogy nullától vagy egytől indexeljünk, lásd java vs sql)Ha viszont Hibernateet akarsz használni DB kezelésre, akkor jól gondold meg, hogy mire vállalkozol, mert az arra tökéletesen alkalmatlan.
Előző projekten alapvetően Oracle DBben fejlesztettünk egy üzleti alkalmazást, afölé lett Javaban írt frontend-backend téve, aztán az eredeti elképzelés az volt, hogy a Hibernate közvetíti az DBben lévő adatokat a Java GUI felé.
Aha, iszonyúan erőforráspazarló, nem gyors, de legalább az összes adatműveletnél lockolja az összes érintett táblát, tábla szinten.
Gyakorlatban totálisan alkalmatlannak bizonyult többfelhasználós célokra, mert folyamatosan homokórázott a rendszer a Hibernate hülyeségei miatt lockolt táblák miatt.
Végül az össze 3 táblából összejoinolok egy táblázatot kérdésre az lett a válasz, hogy a GUI meghív egy tárolt eljárást, ami elvégzi a joint, és az eredményt visszaadja egy kurzorban, aztán annak a tartalmát húzták be a kliens oldalon tovább szűrhető gridbe.
Vagy natív query.A másik nagy kedvencem a késleltetett írás témája.
Felhasználó képernyőn kitölt egy táblázatot, amit egy az egyben a Hibernate ment egy DB táblába.
Elmélet az, hogy a táblázat soráról elvéve a fókuszt azonnal menti a módosult sort a DBbe.
Gyakorlatban? Ha a felhasználó rábökött a Tovább gombra, ami meghívott valami tároltat, ami a frissen töltött táblát használta, akkor az esetek 20%-ában nem volt elmentve az utoljára szerkesztett sor, és a DBben implementált logika emiatt hülyeséget csinált.
Én meg nyomozhattam, hogy mi a francért van jó adat a forrástáblában, az adattranszformáció végén meg rossz. (Hibernate végül mégiscsak elmentette, miután a DB már felhasználta a rossz adatot...)
Végeredmény? Javas kollégákkal veszekedtem pár napot, hogy a DB tárolt hívása előtt MENTSÉK el a táblát.Ez vajon megoldotta a problémát?
A fenéket, méréseim szerint még mindig 3% adathibát okoz, hogy a SaveAndFlush() sem ment azonnal.
Utolsó ötletük a javas kollégáknak a probléma megoldására a Thread.Sleep(500) beiktatása volt a SlaveAndFlush() és a DB tárolt hívás közé...
Mivel az ilyen hókuszpókuszokban nem bízom, inkább beraktam egy összehasonlítást a transzformáció végére, hogy ha inkonzisztenciát lát, azonnal fusson újra az időközben mentett adatokra.Harmadik agybaj meg az volt, hogy a Hibernate konkrétan lebénul attól, ha olyan táblába kell sorokat beszúrnia, ahol a tábla egyedi kulcsát képező szekvencia egyesével lépked. (ami ugye a DB default beállítás...)
Javas kollégák magyaráztak valami marhaságot arról, hogy a Hibernate húszasával becacheli előre a leendő ID értékeket, így a szekvencia lépésközét ennél nagyobbra kell állítani, hogy ne akadjon össze a DBvel egy-egy insertkor.Szóval csak óvatosan a Hibernatetel, mert attól erősen csökken a savassága a DBnek.
-
 whYz
őstag
whYz
őstag
A diagramod teljesen okesnak tunik, sot en meg a player tablat tovabb is bontanam egy contracts tablara.
Szerintem ez a javaslat olyan olvasszunk ossze ket tablat, hogy kevesebb tablank legyen otletnek tunik, mindenfele logika nelkul.
Ket teljesen kulon dolgot ne akarj 1 tablaba eroszakolni, mert nem ersz el vele semmit. Ha 1 tabla csak egy egyszeru akar statikus adatot tarol 2 darab oszloppal akkor abban nincs semmi rossz. Ha a ContractTypes es a Level egyutt letezik, osszetartozik akkor mehet egy tablaba, ha viszont vagy egyik vagy masik, akkor legyenek kulon.
Raadasul TYPE + ID kombinacioval nem tudsz hatekony composite primary keyt alkotni, mivel az ID folyamatosan no, ergo mindig egyedi lesz, gyakorlatilag ugyanaz mintha csak az ID lenne PK.
-
bambano
titán
-
MrSealRD
veterán
Először is igen. Normalizáció. Én is ebben a hitben éltem eddig. Mivel érzékeny adatokról van szó, ezért meg kellett változtatnom a kontextust. Viszont a lényeg, érthető maradt.
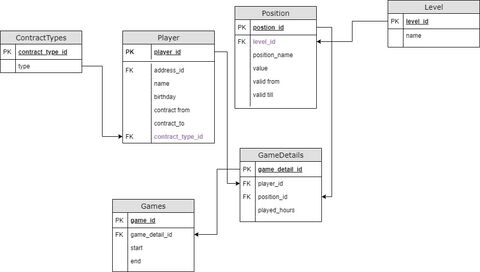
Ez egy gyors kivágás és átírás, ezért az ehhez kapcsolódó hibákat és a kapcsolat típusát most ne firtassuk.
Szóval a lényeg, a ContractTypes és a Level táblák. Ezekbe legfeljebb néhány rekord lenne, de részben ősfeltöltés részben a működés közbeni módosíthatóság miatt kapna CRUD felületet. ContractTypes lehet állandó, vagy ideiglenes...stb A Level, meg amatőr, haladó, profi..stb.
Na most erre kaptam egy olyan javaslatot, hogy legyen 1 tábla.
Aminek az első oszlopa legyen TYPE ide kerülne be a ContractTypes vagy Level értéként.
Második oszlop ID ami lenne valami inkrementált szám.
Majd jönne LEVEL_NAME ami Level típusnál kapna értéket.
Végül A CONTRACT_TYPE ami csak ilyen típusnál kapna értéket.Ezt nem tudom lerajzolni, mert nekem is fura. De a olyasmi mint egy általános tábla amibe több értékkészlet van összevonva és a TYPE + ID együttesen adja a PK-t.
-
whYz
őstag
Inkabb itt valaszolok mert ez sql.
Normalizacio, normalizacio, normalizacio. Nem tudom elegszer mondani. Attol, hogy 1 tablaba pakolod az osszes adatod nem lesz gyorsabb a lekerdezes, ha jol van megdesignolva akkor akar rakas joint is pakolhatsz bele, gyors lesz.
Ha mutatsz egy konkret peldat, akar uml diagrammot, akkor tobbet tudunk segiteni.
-
MrSealRD
veterán
-
 Laca0
addikt
Laca0
addikt
-
 DrojDtroll
veterán
DrojDtroll
veterán
-- Table: public."neighborStationLine"-- DROP TABLE public."neighborStationLine";CREATE TABLE public."neighborStationLine"("lineId" integer NOT NULL,"stationId" integer NOT NULL,"nextStationId" integer NOT NULL,"travelTime" time without time zone NOT NULL,index integer,CONSTRAINT "neighborStationLine_pkey" PRIMARY KEY ("lineId", "stationId", "nextStationId"),CONSTRAINT lineneighborfk FOREIGN KEY ("lineId")REFERENCES public.line (id) MATCH FULLON UPDATE NO ACTIONON DELETE NO ACTION,CONSTRAINT stationfk3 FOREIGN KEY ("stationId")REFERENCES public.station (id) MATCH FULLON UPDATE NO ACTIONON DELETE NO ACTION,CONSTRAINT stationfk4 FOREIGN KEY ("nextStationId")REFERENCES public.station (id) MATCH FULLON UPDATE NO ACTIONON DELETE NO ACTION)WITH (OIDS = FALSE)TABLESPACE pg_default;ALTER TABLE public."neighborStationLine"OWNER to postgres; -
nyunyu
félisten
SELECT DISTINCT s.szerzodesID,
CASE
WHEN s1.tetel IS NOT NULL AND s2.tetel IS NOT NULL THEN 'Mindkettő megvan'
WHEN s1.tetel IS NOT NULL AND s2.tetel IS NULL THEN 'Csak az első'
WHEN s1.tetel IS NULL AND s2.tetel IS NOT NULL THEN 'Csak a második'
ELSE 'Egyik se'
END tetelek
FROM szerzodesek s
LEFT JOIN szerzodesek s1
ON s1.szerzodesID = s.szerzodesID
AND s1.tetel = 'Tetel1'
LEFT JOIN szerzodesek s2
ON s2.szerzodesID = s.szerzodesID
AND s2.tetel = 'Tetel2'
WHERE s.datum>SYSDATE-30
ORDER BY s.szerzodesID;Főnököm mondjuk megölne a distinct miatt, meg nem árt egy index a szerzodesID mezőre, ami mentén joinolod önmagával a táblát, különben elég elborult végrehajtási terve lenne.
-
bambano
titán
-
martonx
veterán
Nem lehet, hogy csak a hibaüzenet rossz, és azok valójában FK-k is, de közben meg ilyen PK-kkal nem létezik sor (36, 37), és valójában ez a hiba?
https://www.db-fiddle.com/ -be csinálhatnál egy példát.
-
Szmeby
tag
DDL? Főleg a tábla és a constraint lehet érdekes.
Ha nem a táblában van a hunyó, akkor nyilván valami másban, amit a constraint használ. Teszemazt egy oszlopra akasztott sequence, ami nem olyan értéken áll, ami az insertedet megenné. Bár a hibaüzi félrevezetően nem erről szól, de bele lehet képzelni, ha nagyon akarom. Amúgy nem értek a postgreshez, csak tippelgetek.
-
DrojDtroll
veterán
Egy kis postgre wtf:
nem tudok rekordot felvenni mert elvileg megsértem a primary key kényszert:INSERT INTO "neighborStationLine" ("lineId", "stationId", "nextStationId","travelTime", index)VALUES ( 29, 36, 37, '00:01:00 ', 1);a primary key a lineId, stationId és nextStationId együtt
ERROR: duplicate key value violates unique constraint "neighborStationLine_pkey"DETAIL: Key ("lineId", "stationId", "nextStationId")=(29, 36, 37) already exists. SQL state: 23505a következő lekérdezésre egyetlen sor eredmény sincs, szóval kizárt, hogy megsértsem a kényszert
select * from "neighborStationLine" where "lineId" = 29Valakinek van ötlete mitől lehet ez?

-
 disy68
aktív tag
disy68
aktív tag
üdv, valóban nem része az alap pogstgresql szervernek
select * from pg_available_extensions;ezzel lekérheted az elérhető kiegészítőket.
a dblink mellett a postgres-fdw is használható arra, amit szeretnél -
Laca0
addikt
PgadminIII-ban szerettem volna ezt a műveletet elvégezni úgy, hogy már csatlakozva vagyok a szerverhez. A dblink-nek csak adatbázis paramétert adtam meg, mert ugyanaz a connection. De igazából fel sem ismerte a D link függvényt/eljárást. Szerintem ez alapból nem része a rendszernek.
-
bambano
titán
-
Laca0
addikt
-
bambano
titán
-
Laca0
addikt
-
bambano
titán
szerintem csinálni kell egy temporális táblát, abba belerámolni a szűrt adatokat, azt kidumpolni, betölteni a másikon ugyanolyan temporális táblába majd onnan berakni a helyére.
egyszerűbbet én sem tudok, mert a pg_dump nem tud válogatva dumpolni.
de lehet, hogy mégis tudok egyszerűbbet: újabb postgreseken lehet olyat, hogy az adatbázisszerver beloginel egy másik postgresbe, és úgy éred el a táblákat, mint a helyi táblákat. ezt megteszed, és akkor csinálhatsz olyat, hogy insertálod a helyi szerveren a távoli táblából szelektált sorokat.
-
Laca0
addikt
Sziasztok!
Először azt hittem, triviális lesz, de mégsem... vagy egy PostgreSQL szerver 2 egyforma szerkezetű adatbázissal. Hogyan tudok szűrt adatot átemelni egyik adatbázis X táblájából a másik adatbázis X táblájába? -
Apollo17hu
őstag
sztem amit irtam, az teljesen jo neki, csak nem vette eszre
-
 velizare
nagyúr
velizare
nagyúr
-
tm5
tag
Még esetleg a PIVOT is jó lehet neked:
SELECT * FROM
(SELECT szerzodesID, tetel FROM szerzodesek)
PIVOT
(COUNT(*) for tetel('tetel1' tetel1, 'tetel2' tetel2)
)
Így a szerződés azonosító mellett 1-1 oszlopban jelenik meg, hogy volt-e 'tetel1' illetve 'tetel2' érték hozzárendelve.
Az meg hogy sokáig fut, hát filterezni kell. Ez a query 1 táblát olvas végig. Ha ettől összeszakad, akkor alul van méretezve az a szerver. -
martonx
veterán
Légyszi ide dobj be egy konkrét példát. https://www.db-fiddle.com/
Hogy konkrétumokról tudjunk beszélni. -
 BuktaSzaki
tag
BuktaSzaki
tag
-
Apollo17hu
őstag
Valahogy igy:
...
WHERE ...
AND CASE
WHEN tetel = 'egyik ertek' THEN 1
WHEN tetel = 'masik ertek' THEN 1
END = 1
... -
tm5
tag
SELECT szerzodesID, tetel
FROM szerzodesek
WHERE tetel = 'tetel1' OR tetel = 'tetel2'
ORDER BY szerzodesID -
BuktaSzaki
tag
Sziasztok, megint egy kis segítség kéne... Van egy szerződések tábla. Van benne egy szerződés szám oszlop, meg egy szerződés tétel. (meg egy csomó másik, de az most nem releváns) egy szerződéshez sok tétel tartozhat, de max egyszer.
Azt szeretném leválogatni, hogy egy adott szerződésen 2 adott tétel rajta van-e vagy nincs, minden konstellációban, tehát, hogy mindkettő rajta van, (ez ok). Csak az egyik, csak a másik, vagy egyik sem. Na ezt nem sikerült összehozni... -
 McNamara
Ármester
McNamara
Ármester
Sziasztok!
MySQL szeretném elindítani de ez a hibaüzenet fogad. Még csak most kezdek vele ismerkedni szóval lővésem sincs az egészről Köszi előre is!
Köszi előre is!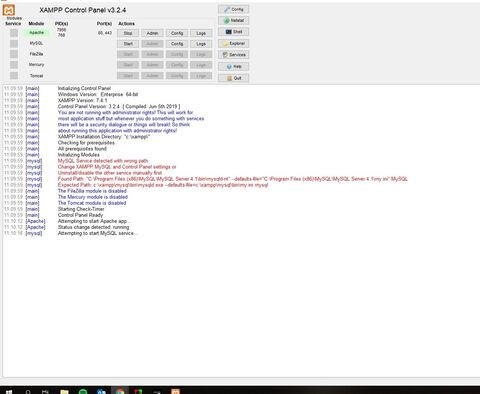
-
 bpx
őstag
bpx
őstag
Tipikus probléma, hogy a JDBC driveren keresztül nem működik a futó query megszakítása.
Azt most ne kérdezd, hogy melyik verzió és milyen csillagállásnál gond, mert nem tudom, régi verziónál szokott baj lenni vele. SQL Developerben is akkor működik megbízhatóan, ha JDBC helyett Oracle kliens van használatban. -
BuktaSzaki
tag
Sziasztok, használ valaki dbeavert oracle-el? Rohadtul nem működik a cancel query, a dbeaver-nél azt írják, hogy ezt a database driver kezeli, és csak sql developerhez találtam valami megoldást... Elég idegesítő állandóan kirántani alóla a kapcsolatot....
-
Apollo17hu
őstag
-
 peterr85
tag
peterr85
tag
Koszonom szepen mindenkinek, javitom es csekkolom!
-
 Jim74
nagyúr
Jim74
nagyúr
-
 Ispy
nagyúr
Ispy
nagyúr
-
Jim74
nagyúr
-
Ispy
nagyúr
-
Jim74
nagyúr
-
Ispy
nagyúr
-
Jim74
nagyúr
-
Ispy
nagyúr
És a dátumokban a pontot cseréld ki kötőjelre.
Egyébként ha SSMS-t használsz, akkor a queryben van egy fekete pipa gomb az exec mellett, az leellenőrzi a szintaktikát, hogy rendben van-e.
Illetve először írd meg a lekérdezést sum nélkül, annak gyorsan le kell futnia, de a dátum okozhat gondot, ha nincsen rajta index. Legyilkolni ezzel nehezen fogod a szervert szvsz, vagy akkor futtasd, amikor kevesen használják a programot.
-
tm5
tag
-
martonx
veterán
Ránézésre igen, de futtasd le és gyorsan kiderül. 7 millió sor nem nagy ügy, arra figyelj oda, hogy ha gyanúsan sokáig futna a lekérdezésed (mondjuk 1 percig), akkor inkább állítsd le a futtatását, és akkor biztos nem dögleszted be a DB-t.
Ez a kérdezősködésed így teljesen parttalan.
-
peterr85
tag
-
martonx
veterán
Select-el nem ronthatsz el semmit, noha olyan select-et futtathatsz, ami legyilkolja az egész DB-t, és az lelassul, vagy szélesőséges esetben akár újra is kellhet indítani.
De ez csak elég nagy DB-knél fordul elő, sok milliós, milliárdos adatsorokkal.Szóval a kérdéseidre te magad is gyorsan választ kaphatsz, ha lefuttatod a lekérdezésed.
-
peterr85
tag
Sziasztok,
Munkahelyemen szeretnék 1 sql lekérdezést készíteni, de egyelőre nincs tapasztalatom a témában. Dynamics NAV 2016 rendszert használunk, a feladat pedig a következő. Egy tétel táblából szeretnék adatokat lekérni, adott időszakra, szummázva az egy adagszámhoz tartozó mennyiség és költségösszeg sorokat (ahol egy-egy adagszám több sorban is szerepelhet). Mindezt úgy, hogy a kapott eredményben egy adagszám csak egyszer jelenjen meg. A lekérdezsést futtató platform Microsoft SQL server 2014.
Ezt sikerült összeraknom, kérdés, hogy működőképes lehet-e így?
SELECT CONVERT(date, [Posting Date]) AS 'Könyvelési dátum'
,[Item no.] AS 'Cikkszám'
,[Lot No.] AS 'Adagszám'
,SUM[Quantity] AS 'Mennyiség'
,SUM[Cost Amount (Actual)] AS 'Költségösszeg(tényleges)'
FROM [adatbazis].[dbo].[Item Ledger Entry]
GROUP BY 'Adagszám'
WHERE [Posting Date] > '2017.11.30' AND [Posting Date] < '2019.12.31'További kérdés, hogy amennyiben csak 1 táblából szeretnék adatot kinyerni, mint jelen esetben, a SELECT résznél szükséges-e megadni a tábla nevét azokban az esetekben, ha 1-1 mező (pl. Item No. )több, másik táblában is azonos néven található?
Végül az is érdekelne, hogy egy rosszul megírt SELECT utasítással okozhatok gondot az adatbázisban?
Előre is köszönöm a segítséget!
-
martonx
veterán
Egyrészt ebben az esetben biztos mysql kell-e neki? Nem elég egy sqlite?
A fejlesztés be kell látni, hogy valamennyire gép igényes feladat, 15 éves P4-el nem biztos, hogy érdemes belekezdeni.
Amúgy itt van egy tutorial szerűség: https://stackoverflow.com/questions/42301953/how-to-install-a-light-version-on-mysql -
 #68216320
törölt tag
#68216320
törölt tag
Urak, van a mySQL-nek valami light verziója, ami semmi felesleges kacatot nem tesz fel csak a DB kezeléshez minimálisan szükséges cuccokat? Csak fejlesztéshez kellene 1-1 weboldal elkészítéséhez egy ismerősömnek windows-os gépre. Valami kis gyenge laptop. PhpMyAdmin-ból fogja használni, illetve amikor segítek neki én fogom konzolból. Szóval olyan verzió/konfigolás kellene, ami nagyon kis terhelésre/hardverre megfelelő.
Szerintem mysql5 elég is lenne neki.
Update:
közben eszembe jutott, hogy egy régi backup-omban van valami MySQL5 cucc, ami alacsonyra van konfigolva. Azt átrakom neki. -
BuktaSzaki
tag
Úgy értem hibásat nem dob ki, pedig bizti van. Amúgy mintha most jó lenne, annyit változtattam, hogy a count után * helyett csak szolgazon van.


 ] A fejeseket nem zavarja, hogy olyan felesleges dolgokkal töltöd a (munka)időd, ami számukra nem fontos? Mivel foglalkozhatnál helyette a fontos dolgokkal is. Remélem nem jönnek rá, hogy titokban nem a céges irányelvek és vízió mentén végzed a munkád, még a végén lapátra kerülsz.
] A fejeseket nem zavarja, hogy olyan felesleges dolgokkal töltöd a (munka)időd, ami számukra nem fontos? Mivel foglalkozhatnál helyette a fontos dolgokkal is. Remélem nem jönnek rá, hogy titokban nem a céges irányelvek és vízió mentén végzed a munkád, még a végén lapátra kerülsz.















 Simán a normál MD5 16 bájtos mérete, hexában.
Simán a normál MD5 16 bájtos mérete, hexában.


 ) . amit te írtál, az teljesen más. te keresnél egy számolótáblát az adatbázisban, amit nem tudok értelmezni, és azzal számolnál. ezzel szemben a postgresql (ami kikötés volt), on the fly képes sorozatokat generálni és record-setként kezelni. a hétvégéket nem modulo 7 alapján számolja, ami egyébként is lehetetlen, mert a kiinduló napnál hiába akarnál modulo7-et számolni, hanem a beépített naptár funkcióval, ahogy nyunyu is.
) . amit te írtál, az teljesen más. te keresnél egy számolótáblát az adatbázisban, amit nem tudok értelmezni, és azzal számolnál. ezzel szemben a postgresql (ami kikötés volt), on the fly képes sorozatokat generálni és record-setként kezelni. a hétvégéket nem modulo 7 alapján számolja, ami egyébként is lehetetlen, mert a kiinduló napnál hiába akarnál modulo7-et számolni, hanem a beépített naptár funkcióval, ahogy nyunyu is.


































Új hozzászólás Aktív témák
-
4500 - 4401
6041 - 6001 6000 - 5901 5900 - 5801 5800 - 5701 5700 - 5601 5600 - 5501 5500 - 5401 5400 - 5301 5300 - 5201 5200 - 5101 5100 - 5001 5000 - 4901 4900 - 4801 4800 - 4701 4700 - 4601 4600 - 4501 4500 - 4401 4400 - 4301 4300 - 4201 4200 - 4101 4100 - 4001 4000 - 3901 3900 - 3801 3800 - 3701 3700 - 3601 3600 - 3501 3500 - 3401 3400 - 3301 3300 - 3201 3200 - 3101 3100 - 3001 3000 - 2901 2900 - 2801 2800 - 2701 2700 - 2601 2600 - 2501 2500 - 2401 2400 - 2301 2300 - 2201 2200 - 2101 2100 - 2001 2000 - 1
-
Fórumok
PROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Hirdetés
- NVIDIA® driverek topikja
- Brogyi: CTEK akkumulátor töltő és másolatai
- Gumi és felni topik
- Vigneau interaktív lokálblogja
- Megújult mobilos felület, fórumos ráncfelvarrás a PROHARDVER! lapcsaládon
- Parfüm topik
- Spórolós topik
- Autós topik
- Milyen asztali (teljes vagy fél-) gépet vegyek?
- Kiszivárgott a Xiaomi 17T és 17T Pro teljes specifikációja és eurós ára
- További aktív témák...

- Erős, !GARANCIÁLIS! Acer Nitro 16 AI gamer laptop! -Ryzen AI 9 365, RTX 5070 8gb, 32gb DDR5, 1tb SSD
- Xreal Beam
- Gigabyte Z170X-Gaming 7 Rev 1.1 / Beszámítás OK!
- Apple MacBook "BlackBook" (2007) - 2,16GHz Core2Duo, 4GB RAM, gyári töltővel (Retro / Projekt gép)
- Realme Realfit F3 ANC aktív zajszűrésű Bluetooth fülhallgató
- HP 200W töltők (19.5V x 10.3A) kis kék, kerek, 4.5x3.0mm, 928429-002
- Lenovo Legion Slim 5 Ryzen 7 7840HS 16GB 1000GB RTX 4060 OLED 120Hz 1év garancia
- HIBÁTLAN iPhone 13 128GB Green-1 ÉV GARANCIA - Kártyafüggetlen, MS4347
- HIBÁTLAN iPhone 12 Pro Max 256GB Pacific Blue -1 ÉV GARANCIA - Kártyafüggetlen, MS4533
- Samsung Galaxy Watch Ultra LTE / 32GB / Kártyafüggetlen / 6Hó Garancia
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest