Hirdetés
- Bambu Lab 3D nyomtatók
- TCL LCD és LED TV-k
- Régi CPU újrakiadásával ünnepelné a Socket AM4 tizedik évfordulóját az AMD
- ThinkPad (NEM IdeaPad)
- Nem indul és mi a baja a gépemnek topik
- 5.1, 7.1 és gamer fejhallgatók
- Milyen asztali (teljes vagy fél-) gépet vegyek?
- Vezetékes FEJhallgatók
- HDD probléma (nem adatmentés)
- Apple asztali gépek
Új hozzászólás Aktív témák
-

nyunyu
félisten
Szerintem nem akarod tudni, hogyan generáltam dinamikus SQLlel másik dinamikus SQLt, ami generálta helyettem a végleges kódot, ami ~500 táblából vasvillával hányja ki a GDPR érett ügyfelek összes kapcsolódó rekordját.
(Nem volt kedvem kézzel végignyálazni a foreign keyeket, plusz megírni a szükséges joinokat.)
-
-
nyunyu
félisten
Tarzan erős jeligére:
create table tabla (
ID number,
month number,
country char(2),
ertek number);
insert into tabla (ID, month, country, ertek)
values (1, 1, 'HU', 100);
insert into tabla (ID, month, country, ertek)
values (1, 2, 'HU', 200);
insert into tabla (ID, month, country, ertek)
values (1, 3, 'HU', 300);
insert into tabla (ID, month, country, ertek)
values (1, 1, 'AT', 50);
insert into tabla (ID, month, country, ertek)
values (1, 3, 'AT', 500);
insert into tabla (ID, month, country, ertek)
values (1, 1, 'DE', 100);
insert into tabla (ID, month, country, ertek)
values (1, 2, 'DE', 1000);
commit;
declare
v_orszagkod varchar2(4000);
v_sql varchar2(4000);
begin
select listagg('''' || country || '''', ', ')
within group (order by country)
into v_orszagkod
from (select distinct country from tabla);
--dbms_output.put_line(v_orszagkod);
v_sql := 'create table pivot_table as' || chr(13) || chr(10) ||
'select *' || chr(13) || chr(10) ||
'from tabla' || chr(13) || chr(10) ||
'PIVOT (' || chr(13) || chr(10) ||
' SUM(ertek)' || chr(13) || chr(10) ||
' FOR country' || chr(13) || chr(10) ||
' IN (' || v_orszagkod || ')' || chr(13) || chr(10) ||
')' || chr(13) || chr(10) ||
'where ID = 1' || chr(13) || chr(10) ||
'order by month';
--dbms_output.put_line(v_sql);
execute immediate v_sql;
end;
select *
from pivot_table;
-
-

user112
senior tag
Sziasztok!
Egy ilyen táblából:
ID, month, country, value
szeretnék úgy szűrni ID-re, hogy az oszlopokban az összes olyan országkód bent legyen, ahol van érték adat, amit nem tudok előre:
month, country1, country2, country3, ...
Egy ID, egy hónapban többször előfordulhat, akárhány országkóddal.
Gyakorlatilag Pivot lenne, de nem ismerem előre az oszlopok értékét.
Köszönöm a segítséget. Oracle sql developer -

DopeBob
addikt
Olyan minimalis terheles, hogy nem lesz vele gond. Nalunk 5x ennyi emberrel is vidaman fut. Db meretkorlattol is messze vagyunk, igaz eleve ugy terveztunk, hogy tobb Vault van. De maguk a fajlok nem is a db-ben vannak. Ha a sima free Vaultrol van szo, mi 10+ eve hasznaljuk az ingyenes sql szerverrel.
-
nyunyu
félisten
Memory meg core limitek nem úgy értendőek, hogy tökmindegy, mennyi van a gépben, akkor is legfeljebb 4 magot, meg ~2GB RAMot használhat?
(Windows feladatkezelőben meg tudod nézni, hogy éppen mennyit használ.)Ettől persze lényegesen lassabb lesz combosabb lekérdezéseknél, mint a fizetős SQL Serverek, amik a gépben lévő összes procihoz, RAMhoz hozzáférnek. (olcsóbbik Web edition 16 mag, 64GB RAM limites? Átlag asztali PCben nincs annyi.)
-

MTbc
senior tag
Sziasztok, szeretném megtudni hogy az SQL Express limitációit elérjük-e, lehetséges ez van erre valami jó megoldás, milyen logokat érdemes bogarászni?
A 10Gb adatbázis korlátot azt könnyű megnézni, de a Buffer pool memory-t és a CPU core limitet lehet valahogy ezt jól elemezni? tablazat express vs standard
Úgy érzem nagyon penge élen táncolunk és szeretnék pontosabban látni. Költség fontos, de ha tudok prezentálni kézzel fogható számokat, akkor hamarabb lesz rá pénz. Autodesk rajznyilvántartó szoftverről beszélünk és csak 4 user használja abból is csak 3 aktívan.
Autodesk rajznyilvántartó szoftverről beszélünk és csak 4 user használja abból is csak 3 aktívan.
Köszönöm -

szabeska
addikt
Sziasztok!
Adott 3 db Windows 8.1-es pc, az egyiken sql express telepitve egyetlen egy adatbazis fajllal, amit egy fapados kis programmal hasznalunk mindharom gepen evek ota problemamentesen. Szeretnenk windows 11-re frissiteni a gepeket, ezert csinaltunk egy szuz w11-es gepet, rajta csak a kis programmal, de sehogyan sem latja a 8.1-en levo adatbazist. Probaltunk meg egy gepet felhuzni 11-el, sql expresst feltelepitettuk ra, de a ket w11-es gep kozott sem erjuk el az adatbazis fajlt. Fajlmegosztas mukodik, a halozaton latjuk a gepet, de nem mukodik az adatbazis fajl elerese, napok ota kuzdunk vele. Van valamilyen w11 specifikus oka/beallitas esetleg, hogy mi okozhatja? Virusirtokat, tuzfalakat kikapcsolva sem megy, ami 8.1-es gepek kozott igen.
-
kw3v865
senior tag
válasz
 kw3v865
#5681
üzenetére
kw3v865
#5681
üzenetére
Na, most mégiscsak megakadtam a logikai replikációnál: triggert (vagy rule-t, mindegy) szeretnék rakni arra a táblára, ahová replikálódik az eredeti tábla tartalma. Egyelőre nem tudtam működésre bírni. Hibát nem dob, csak egyszerűen nem csinál semmit.
Egy tök egyszerű triggerről van szó a példa kedvéért: egy másik táblába insertál valamit, ha meghívódik (insertre van ráállítva).CREATE OR REPLACE FUNCTION valami()RETURNS TRIGGERLANGUAGE PLPGSQLAS $$BEGININSERT INTO t2 (c) VALUES ('xyz');RETURN NEW;END;$$CREATE TRIGGER trgAFTER INSERT ON t1FOR EACH ROWEXECUTE PROCEDURE valami()
Azt találtam, hogy külön engedélyezni kell ilyen esetben a triggert:ALTER TABLE t1 ENABLE ALWAYS TRIGGER trig;
Ez megtörtént, de hiába.Ha nem az "eredeti", hanem a replikátum táblába insert-álok, akkor meghívódik. Viszont én azt szeretném, hogy akkor is működjön, ha az eredeti táblába insert-álok valamit. Rule-lal sem megy.
Vajon mi lehet ennek az oka? -

bugizozi
őstag
Sziasztok!
Van egy Veeam szerverünk, amire domain felhasználóval lépünk be. Ki szeretnénk venni a domain-ból a szervert, ezért létrehoztam egy local usert, beletettem az Administrators csoportba, be is tudok vele lépni, viszont az MSSQL-ben csak az egyik adatbázist (VeeamOne2) látom, a másikat (VeeamBackup) nem.
 (nem vagyok egy nagy SQL guru, nézzétek el nekem
(nem vagyok egy nagy SQL guru, nézzétek el nekem  )
)
Itt hozzáadtam a local user-t, beállítottam ugyanúgy mint ahogy a domaines user van, mégse jó. Azt se tudom az egyik db-t miért látja, és azt se hogy a másikat miért nem.
Van esetleg valakinek valami ötlete erre?Köszi!
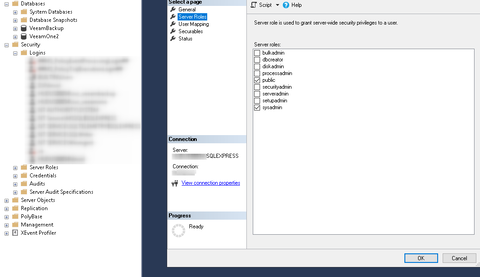
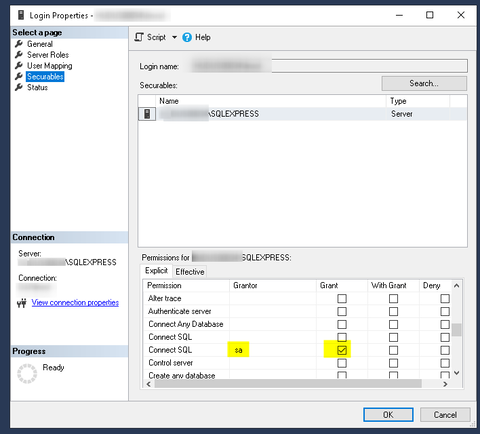
-
kw3v865
senior tag
Sziasztok!
PostgreSQL-lel kapcsolatos kérdésem lenne: adott egy tábla az egyik adatbázisban, amelynek a tartalma folyamatosan változik (elég gyakran insert-álódnak bele rekordok). Van egy másik adatbázisom (ugyanazon a szerveren), amelyben szintén lennie van egy ilyen tábla azonos struktúrával (ugyanazok a mezőnevek stb.). A cél az lenne, hogy az "A" tábla tartalma szinkronizálódjon a "B" táblába automatikusan. Nem baj, ha nem azonnal, úgy is jó, ha mondjuk csak 5 percenként. Csak egyirányú szinkronizációra van szükség, és elég, ha csak az insert-ekre vonatkozik.
A kérdésem az lenne, hogy szerintetek hogyan lehet ezt a legegyszerűbben megoldani? A replikáció kicsit bonyolultnak tűnik számomra egyelőre, a másik amit kinéztem az a db-link + trigger kombinációja és elméletileg talán jó lehet. Vajon utóbbi működhet? Esetleg van jobb ötletetek?
-

cog777
őstag
Lenne egy hulye kerdesem:
ha van egy project tablam (ID (serial), Nev)
es van egy Naplozas tablam (ID (serial), Nev, ... Project_ID (foreign key)
Ezek a tablak a projetc_id-n keresztu ossze vannak kapcsolva.
Jobb otlet lenne ha a Naplozas tablaban a primary key az nem serial hanem project_id+Nev?
Tehat osszetett kulcsot hasznalok azonositani a rekordokat es az a Project table ID-je + Naplozas tabla neve?
Szerintem az utobbi esetben tul nagy lenne az elsodleges kuklcs, mivel a nev az TEXT tipus, es ha fel akarom hasznalni egy harmadik tablaba az Naplozas elsodleges kulcsot (project id + nev) az tul nagy meretu?
Pl harmadik tabla:
Adatok tabla ahol:
Elsodlege kulcs: ID
Foreign key: Naplozas.project id + nev? -

Panhard
tag
Sziasztok! Segítséget szeretnék kérni. Van egy ilyen lekérdezésem:
select cast(datetime as DATE) as datum from tabla1 group by datum desc
Ez csoportba rendezi a dátumokat és kilistázza. Szeretném ezt öt táblára megcsinálni egy lekérdezéssel. Tehát az öt táblában az összes egyforma dátumot csoportba teszi, és sorrendben kilistázza. Tudnátok ebben segíteni? -

bambano
titán
a tábla szerkezetét az adatstruktúra normalizálása alakítja ki és nem más.
a másik alapvető dolog, hogy a redundanciából és a szinkronizálásból *MINDIG* baj lesz inkább előbb, mint utóbb.egyébként postgresben fel lehet csatolni másik adatbázist, végszükség esetén ez is jó lehet. a te tábládat a kolléga felcsatolja egy saját adatbázisba és mellérakja külön táblában a saját mezőit.
-
-
cog777
őstag
Remelem belefer egy DB kerdes ide. Szoval implementaltunk egy schema-t (postgresql), par table, adatok stb.
Egyik kollega jon hogy o most szeretne hozzaadni 2 plussz adatot az egyik tablahoz. Total nem kapcsolodik a mostani projekthez. Mondtam neki hogy csinaljon egy sajat DB-t abba rakja bele a sajat tablajat. Ennek ellenere ragaszkodik ahhoz hogy a mi DB-k be rakja bele, mondvan igy gyorsabban meg van csinalva. Lesz egy mitingunk a nagyobb fonokokkel nemsokara.Ti hogy csinaljatok? 1 DB ala tobb egymashoz szorosan nem kapcsolodo dolgokat is beletesztek (persze a termekhez azert kapcsolodik) vagy kulon DB-t csinaltok 1-1 nem kapcsolodo funkciohoz?
Koszi a tanacsokat.Eddig azt az elvet vallottam hogy minden nagyobb funkcionak sajat fuggetlen DB-t csinaljuk, igy pl tranzakciok nem zavarjak egymast, illetve a verzio kezeles konnyebben megvalosithato.
-
nyunyu
félisten
Nálunk úgy van megoldva az Oracle alatt megváltozott szerződések továbbítása, hogy rá van téve egy-egy insert meg update trigger a szerződések táblába, ami kiírja egy temp táblába a módosult rekord rowid-ját.
Aztán van egy eljárás, ami a temp táblába kiírt azonosítójú rekordokból felépít egy material viewt a szerződés+kapcsolódó ügyféladatok aktuális tartalmával, majd törli a tempet, ezzel azt érjük el, hogy a matviewban csak az utolsó szinkronizáció óta megváltozott rekordok tartalma lesz meg.
Amikor az SQL Servert használó dokumentumkezelő rendszernek olyanja van, a DBConnectoron keresztül meghívja ezt az eljárást, aztán a matviewban látható aktuális adatokkal megupdateli a saját tábláit.
Nyilván ha két szinkronizáció között többször változik egy rekord (pl. frissül az ügyfél címe, aztán az igazolványszáma), akkor többször fog bekerülni az azonosítója a tempbe, de a belőle épített matviewban már csak egyszer fog szerepelni, a legfrissebb adattartalommal.
-

syC
addikt
Sajnos az nem jó, mert olyan intenzitással jönnek az adatok hogy másodpercenként kb 100x változik a tábla. Végül megoldottam temporary table-lel, favágó módon: Kiszedem az egyik gépből az adatokat, majd a másik gépen felépítek belőle egy temporary table-t, amivel már tudok joinolgatni. Szerencse, hogy a szolgáltatás, amihez kell, nem fix periodikus futású, hanem prompt. De mindenesetre köszönöm az előző tippet.
-
nyunyu
félisten
Összejoinolod a 3 táblát, majd a wherebe írod a gépnév feltételt.
select g.gepnev, t.*
from gep g
join gep_tartozek gt
on gt.gep_id = g.id
join tartozek t
on t.id = gt.tartozek_id
where upper(g.gepnev) = 'KALAPÁCS';Régi szintaxissal nem írom le, tessenek a szabványt használni.
-

Kommy
veterán
Sziasztok!
3 tábla:
-tartozékok
-gépek
- melyik géphez melyik tartozék tartozikegy olyan lekérdezésre lenne szükségem ami listázza az összes tartozékot és az adott gépet amire szűrnénk.
igazából az lenne a problémám, hogy ha nem szűrnék gépre akkor meglenne a lekérdezés, de akkor az összes gép benne van. Tehát csak adott gépre kellene, ott kellene lennie az összes tartozéknak
-

martonx
veterán
válasz
 Gergello
#5662
üzenetére
Gergello
#5662
üzenetére
A többi alternatíva, amit ajánlottam sem fizetős. Más kérdés, hogy azoknak a hosztolását meg kell oldanod valahogy, ami végülis pénzbe kerül. Nekem pl. MeiliSearch lakik egy 1 magos Azure linux VM-en, kemény havi 15 EUR-ért (plusz áfa).
Hidd el, ezek a kereső cuccok sokkal jobbak, mint amit magadnak raksz össze, pl. typo tűréstől kezdve csomó mindent tudnak. -

Gergello
addikt
válasz
 martonx
#5661
üzenetére
martonx
#5661
üzenetére
Ez az 1 keresés van az egész oldalon, egy nem túl bonyolult query, szerintem én is normálisan megírtam. Miért rontsam le a Google-essel ? Megjelenítésbe nem is tudom, hogyan illeszthető.
Fizetősöket meg se néztem. Ott láttam, hogy egy konkurencia használja a findologic-ot.
-
martonx
veterán
válasz
Gergello
#5660
üzenetére
Inkább javaslom erre beüzemelni egy ElasticSearch-öt / MeiliSearch-öt, vagy legfapadosabb megoldásnak a Google Custom Search Engine-t behúzni az oldaladra, és azzal keresni. De majd mindjárt jönnek az SQL szakik, és jól ledorongolnak, hogy nem SQL-ben oldanám ezt meg.
-
Gergello
addikt
Sziasztok !
Nem igazán ismerem ezt a fulltext keresési módot, de találtam egy lekérdezést, amivel kísérletezek és én is írtam egyet saját kútfőből.
Egy webshop keresést szeretnék megvalósítani, úgy hogy a találatokat relevancia szerint csökkenő sorrendben adja vissza.
Van egy products nevű tábla mindenféle lényegtelen mező mellett a lényegesek:
product_model
product_name
product_description
Ezekből egyedül a product_model-en van btree index. /van id mező is, de azt most nem vettem bele ebbe/
Ezekben szeretnék keresni.Amit találtam fulltext lekérdezés, annál azt talapasztalom, hogy bárhogy próbáltam a * karakterrel feljavítani az illesztést, nem tudok vele úgy keresni, hogy pl.
a keresőszó: "fúró", akkor a "fémfúró"-t tartalmazó sort nem adja vissza, de a "fúrókészlet"-t igen, csak a szavak kezdetére tudok illeszteni.Fulltext keresés, nem saját munka: Lehet ezt módosítani, hogy a szavak végére is illesszen? Hiába raktam az elejére (is) csillagot.
SELECT
product_name,
(
(
1.3 *(
MATCH(product_name) AGAINST(
'lyukfúró*' IN BOOLEAN MODE
)
)
) +(
0.6 *(
MATCH(product_description) AGAINST(
'lyukfúró*' IN BOOLEAN MODE
)
)
)
) AS relevance
FROM
products
WHERE
status = 1
AND
(
(MATCH(product_name, product_description) AGAINST('lyukfúró*' IN BOOLEAN MODE))
OR
LCASE(product_model) LIKE '%lyukfúró%'
)
ORDER BY
relevance DESC,
LCASE(product_name) ASCErre találtam ki az alábbi megoldást: Mi erről a véleményetek, nagy baromság ?
Itt a példa keresőszó a "bmw vezérlés benzin", mindegyik szóra csinálok egy ilyen kis csoportot (3 case when) és az where-ben az AND-al kapcsolt részek.select*,(case when product_model like '%vezérlés%' then 10 else 0 end) +(case when product_name like '%vezérlés%' then 5 else 0 end) +(case when product_description like '%vezérlés%' then 2 else 0 end) +
(case when product_model like '%bmw%' then 10 else 0 end) +(case when product_name like '%bmw%' then 5 else 0 end) +(case when product_description like '%bmw%' then 2 else 0 end) +
(case when product_model like '%benzin%' then 10 else 0 end) +(case when product_name like '%benzin%' then 5 else 0 end) +(case when product_description like '%benzin%' then 2 else 0 end)as priorityfromproductswhere(product_model like '%vezérlés%'orproduct_name like '%vezérlés%'orproduct_description like '%vezérlés%')AND(product_model like '%BMW%'orproduct_name like '%BMW%'orproduct_description like '%BMW%')AND(product_model like '%benzin%'orproduct_name like '%benzin%'orproduct_description like '%benzin%')order bypriority desc,LCASE(product_name) ASC -
nyunyu
félisten
Alternatív megoldások az, hogy időnként kiírod a változást mondjuk csv-be, átmásolódik a másik gépre, az meg beolvassa? Elég idejétmúlt megoldás, de még mindig működik.
Esetleg MQ, webszerviz.Webszervizért szoktak nálunk a legkevésbé harapni, mondván az illik a legjobban a mikroalkalmazás architektúrába.
Konkrétan még azt se szeretik, ha azonos instanceon lévő másik sémából kéne olvasni ("grant select on tabla to másikséma;"), inkább írattak rá a javásokkal egy új szervizt, amit meg lehet pingelni, aztán az olvassa a választ a másik sémából, vagy írja amit a hívó szeretne.
-
nyunyu
félisten
Azonos gyártójú adatbázisok között DBLink?
Eltérők között valami 3rd party DB connector megoldás?De ott az IT biztonsági felelősnek is lesz hozzá pár keresetlen szava, tűzfal kivételek, grantok, stb. konfigurálása miatt.
Utána viszont tudsz olyanokat írkálni, hogy
select *
from tabla t
join tabla2@linkneve t2
on t2.id = t.id;Nem én üzemeltetem, így nem tudom, nálunk hogyan vannak konfigurálva az SQL Serverek, meg az Oraclek, de van olyan is, hogy nekem kell Insert ... into tabla@dblink után MS SQL eljárást hívnom, hogy dolgozza fel a külső rendszer, de olyan is bőven akad, hogy SQL Server hívogatja az Oracle eljárásainkat.
-
syC
addikt
Sziasztok. Szerintetek hogyan lehetne megoldani egy "joint" két különböző gépen lévő adatbázisbeli tábla között? Valahogy lekérném a kisebbik táblát, eltárolnám valami nézetben vagy temporary table-ként és a másik selectnél pedig beolvasom a megfelelő értékeket. Nagy Bármi ötlet?
-
-
nyunyu
félisten
SELECT nev,
sum(case when jelenlet NOT IN ('99') AND hianyzas NOT IN ('1') then 1 else 0) AS 'hianyzasoknelkul',
sum(case when jelenlet NOT IN ('99') then 1 else 0) AS 'hianyzasokkal'
FROM tabla
group by nev;Count a nemnull értékek számát adja vissza! (then 1 else null kellene hozzá)
Sum meg az összegét. -

Ispy
nagyúr
válasz
 Fundiego
#5647
üzenetére
Fundiego
#5647
üzenetére
Akkor a két select egy-egy subquery, amiket joinnal kell összekötni. De ebből 3 kell:
- lekérdezés 1 inner join lekérdezés 2, mindent visszaad, ami mindkét lekérdezésben benne van
- lekérdezés 1 left join lekérdezés 2, ahol lekérdezés 2 aznosítója null, minden, ami csak lekérdezés 1-ben szerepel
- lekérdezés 2 left join lekérdezés 1, ahol lekérdezés 1 azonosítója null, minden, ami csak lekérdezés 2-ben szerepelEzt a 3 lekérdezést kell union allal összerakni egy selectben, de csak akkor lesz jó, ha van minden sornak egyedi azonosítója, pl. a név mező, ha az garantáltan egyedi, vagy egy egyedi id a névhez.
-

Fundiego
tag
Sziasztok!
Az alábbi két lekérdezést összelehet gyúrni egybe valahogy?
SELECT nev, count(Fizetes) AS 'hianyzasoknelkul' FROM tabla WHERE jelenlet NOT IN ('99') AND hianyzas NOT IN ('1')
group by nev;SELECT nev, count(Fizetes) AS 'hianyzasokkal' FROM tabla WHERE jelenlet NOT IN ('99')
group by nev;köszi
-
nyunyu
félisten
válasz
 Pürrhosz
#5643
üzenetére
Pürrhosz
#5643
üzenetére
1:1-nél mindegy, melyik oldalon van a külső kulcs, működhet az, amit eredetileg elképzeltél.
(Még mindig nem értem az adatmodelledet, ez valami adatpiac akar lenni csillag sémával, ahol A a hub, B, C meg a különböző dimenziói? Akkor eleve A-ba kellett volna tenni a B_index és C_index oszlopokat.)
Akkor:
A-ba B_index felvétele:
ALTER TABLE A ADD COLUMN B_index INTEGER FOREIGN KEY REFERENCES B(B_index);A.B_index mező feltöltése
MERGE INTO A
USING B
ON (A.A_index = B.A_index)
WHEN MATCHED THEN
UPDATE SET A.B_index = B.B_index;Ha nem 1:1 volt eredetileg a kapcsolat, akkor hibaüzenettel el fog szállni!
B-ből a felesleges A_index kidobása:
ALTER TABLE B DROP COLUMN A_index; -

Pürrhosz
csendes tag
Ezek valójában 1-1 relációk, nem kell N-M-re átalakítani.
Vannak az A rekordok amik kétfélék lehetnek(b és c), az A-ban vannak azok a tulajdonságok amik a B-nek és a C-nek is közös tulajdonságai.
Tehát egy B vagy egy C az pontosan egyféle A-hoz van hozzárendelve.
Most lenne egy D tábla ami ugyancsak használná a B és C rekordokat. Itt is egy B sor vagy egy C sor pontosan egyféle D-hez kapcsolódna(vagy A-hoz).
pl. vannak az emberek(ez az A)
B - hím tulajdonságok
C - nőstény tulajdonságok
D - ez lenne most az állatok, ami szintén használná a B és C táblákat. -
nyunyu
félisten
válasz
Pürrhosz
#5641
üzenetére
Eléggé félremehetett a DB tervezése, ha mindenhol 1 : N reláció lett implementálva. (1 A objektumhoz tartozhat N féle B tulajdonság, ekkor kerül az A_index oszlop a B táblába.)
Igen, ha az A-C viszonyt/kapcsolatot/relációt is N : M-re akarod átalakítani, akkor oda is kell egy új kapcsolótábla, értelemszerűen A_index és C_index oszlopokkal.
-
-
nyunyu
félisten
válasz
Pürrhosz
#5639
üzenetére
Ha jól értem, akkor neked inkább egy új, AB tábla (a_index, b_index) kéne, az kapcsolná össze az A táblában leírt objektumokat, és a B táblában leírt tulajdonságaikat.
Így tetszőleges N:M kapcsolatot le tudnál írni: egy A-hoz több B tulajdonság is tartozhatna (pl. alma lehet piros, zöld és sárga is), és B tulajdonság tartozhatna több A objektumhoz is. (alma és citrom is sárga).Kapcsoló tábla létrehozása A-ra, B-re mutató külső kulcsokkal:
CREATE TABLE AB (
A_index INTEGER FOREIGN KEY REFERENCES A(A_index),
B_index INTEGER FOREIGN KEY REFERENCES B(B_index)
);
Törölni az AB táblából bármikor tudsz, viszont a külső kulcsok miatt sem az A-ból, sem a B-ből nem fogsz tudni olyan értéket törölni, amire az AB hivatkozik!Feltöltése a meglévő B táblából:
INSERT INTO AB (A_index, B_index)
SELECT A_index, B_index
FROM B;(B táblában ezután már felesleges az A_index mező, el lehet dobni:
ALTER TABLE B DROP COLUMN A_index;
Helyette mindig az AB táblát kell majd joinolni.)Új kombó, pl. zöld alma beszúrása (ha már külön-külön létezik az alma és a zöld is):
INSERT INTO AB (A_index, B_index)
SELECT A.A_index, B.B_index
FROM A
JOIN B
ON 1=1
WHERE A.A_name = 'Alma'
AND B.B_name = 'Zöld';Milyen színű répa van?
SELECT B.B_name
FROM A
JOIN AB
ON AB.A_index = A.A_index
JOIN B
ON B.B_index = AB.B_index
WHERE A.A_name = 'Répa';Melyik gyümölcs sárga?
SELECT A.A_name
FROM B
JOIN AB
ON AB.B_index = B.B_index
JOIN A
ON A.A_index = AB.A_index
WHERE B.B_name = 'Sárga'; -
Pürrhosz
csendes tag
Sziasztok!
Egy valószínűleg nagyon egyszerű kérdésem lenne.
Adott 2 tábla A és B.
A tábla:
A_index (UNIQUE INTEGER)
A_name (TEXT)
B tábla:
B_index (UNIQUE INTEGER)
B_name (TEXT)
A_index (ez hivatkozik az A tábla A_index-ére)
A B táblát máshol is fel szeretném használni így az A_index-et szeretném belőle kivenni és az A táblából hivatkoznék a B táblára valahogy így:
A tábla:
A_index (UNIQUE INTEGER)
A_name (TEXT)
B_indexB tábla:
B_index (UNIQUE INTEGER)
B_name (TEXT)A kérdésem az lenne, milyen UPDATE SET paranccsal tudnám feltölteni az A táblában a B_index oszlopot?
kb. ezt szeretném:
A
1, alma
2, korte
3, citrom
4, narancs
5, meggy
B
101, zöld, 2
102, sárga, 3
103, vörös, 5A'
1, alma, NULL
2, korte, 101
3, citrom, 102
4, narancs, NULL
5, meggy, 103
Előre is köszönöm! -
-

pch
senior tag
Üdv!
mariadb 10.9.3 re frissítve a 10.5.8 ról nagyon lelassult a többszörös join lekérdezés.
Másnál nem fordult elő ez a hiba? -=A lekérdezés 349.2095 másodpercig tartott=-
Soknak érzem
Tábla méretek: cikktábla: 5930 rekord
Tétel tábla: 36715 rekord
Készletfej tábla: 9599 rekord
Szerintem nem sok.
Lekérdezés:SELECT t5.cikk_id,t4.menny,t4.cikkszam,t4.megnevezes from cikk as t5LEFT JOIN(SELECT tetel.cikk_id,SUM(IF(tetel.tetel_id < COALESCE(t2.setid, 0),0,IF(tetel.mozgasnem < 200, tetel.menny, 0 - tetel.menny))) AS menny ,cikk.cikkszam , cikk.megnevezesFROM keszletfej,cikk,tetelLEFT JOIN(SELECT cikk_id, MAX(tetel_id) AS setid
FROM tetel
WHERE mozgasnem = 100
GROUP BY cikk_id
) AS t2ON (tetel.cikk_id = t2.cikk_id)WHEREkeszletfej.teljesites<='2022-11-05'AND cikk.cikk_id=tetel.cikk_idAND keszletfej.keszletfej_id=tetel.keszletfej_idAND cikk.keszletre='i'AND cikk.status='aru'GROUP BY tetel.cikk_idORDER BY tetel.cikk_id) AS t4ON t4.cikk_id=t5.cikk_idWHERE t4.menny<>0
Cikk tábla ami releváns (cikk_id, cikkszam, megnevezes, keszletre, status)
Készletfej tábla (keszletfej_id, teljesites)
Tétel tábla (tetel_id, keszletfej_id, cikk_id, menny, mozgasnem)
Mozgásnem: Ha 200 alatt van akkor beszerzés ha 200 felett akkor értékesítés ha 100 akkor nyitó azaz akkor onnantól annyi a készlet.
Ezzel a lekéréssel az összes cikk készlete kellene aminek a mennyisége nagyobb mint 0.Van ötletetek mi lehet a hiba, vagy tudtok valamit mi változott?
Már kezdek megőrülni lassan egy hónapja sz@p@k veleKöszi!
-
-
nyunyu
félisten
Akkor mindenki alapesetben a saját helyi DBjébe írja a koordinátáit, adatait, aztán föléje tesztek egy Java/C# alkalmazást, ami a neten kommunikál a központi DBvel, és ha van net, akkor beszúrja a még fel nem töltött adatokat, majd letölti a többiekét egy másik lokális táblába. *
Ha sikerült a központi szerverről letöltenie a saját koordinátáit, akkor az ahhoz az időbélyeghez tartozó rekordokat meg törli a lokális temp táblából.Arra nyilván figyelni kell, hogy ne legyen ID ütközés: adatok központba feltöltésénél NE a lokális szerver IDját/szekvenciáját használjátok, hanem kérjetek a központi DBből újat, különbön összeütköznének a különböző eszközökről jövő adatok.
Térkép helyi megjelenítésénél meg gondolom a helyi, még fel nem töltött adatokat tartalmazó tábla ÉS a központi szerverről leszinkronizált adatokat tartalmazó táblák unióját kell majd megjelenítened.
Nyilván ha éppen nincs net a hótolón, akkor a többiek által takarított felületből csak annyit tud megjeleníteni, amennyit az előző netkapcsolat idején sikerült letöltenie.
Meg az iroda is csak akkor fog valós idejű adatokat látni, ha éppen van net, kiesett időszakot csak utólag, ha megint net közelbe ér a munkagép.*: Elvileg DB oldalon is fel lehet konfigurálni DB linkeket, interfészeket, és a távoli szerveren lévő táblákat is meg tudja címezni, így akár (percenként) időzített jobokkal is meg lehetne csinálni az adatszinkronizációt, de jártam már úgy Oracle alatt, hogy hálózati hiba miatt leszakadt a DBlink, aztán egyből invalid lett miatta a package a táblanév@DBlink hivatkozás nem létezik címszóval.

Aztán lehetett rugdosni az üzemeltetőket, hogy nyomjon már egy recompile-t az élesen, mert nekem nincs jogom hozzá. -
cog777
őstag
válasz
 bambano
#5627
üzenetére
bambano
#5627
üzenetére
"inkább oldjátok meg, hogy legyen net. mibe se kerülne egy építési területre saját wifit telepíteni..."
Minden gep 4G modemmel rendelkezik azonban bizonyos orszagok, bizonyos teruletein nincs net, pl hegyekben, kint a tajgan, oserdoben stb.
Pl Alpokban a ho'tolo'k allomasanal van internet, de amikor kimennek, akkor vannak foltok ahol total nincs net es nem fognak telepitgetni nagy tavolsagu wifi allomasokat."ne kelljen multimastert csinálni, mindig pontosan egy irányba menjenek az adatok "
jah, egyetertek, 1 master eseten sokkal konnyebb lenne az elet.@tobbieknek: koszi az eszreveteleket.
-
nyunyu
félisten
válasz
bambano
#5627
üzenetére
az külön necces, hogy egyes gépen hol van net, hol nincs, ahelyett, hogy ilyenkor másik gépen keresztül küldi az adatot, inkább oldjátok meg, hogy legyen net. mibe se kerülne egy építési területre saját wifit telepíteni...
Mondjuk egy Paks2 alapozását ássa 25 munkagép jellegű témánál macerás lehet a saját wifi kiépítése, de mobilnettel megoldható.
-
bambano
titán
én még nem láttam olyat, hogy postgres kész applikációval úgy működjön, ahogy te leírtad.
nevezzük nevén a gyereket: gyári multimaster postgres tudtommal nincs.
tehát vagy csináltok valami cuccot, amitől multimaster lesz a postgres, és komolyan hiszek benne, hogy nem fogjátok tudni normális költséggel normális idő alatt megoldani,
vagy megváltoztatjátok az adatszerkezetet úgy, hogy ne kelljen multimastert csinálni, mindig pontosan egy irányba menjenek az adatok.az külön necces, hogy egyes gépen hol van net, hol nincs, ahelyett, hogy ilyenkor másik gépen keresztül küldi az adatot, inkább oldjátok meg, hogy legyen net. mibe se kerülne egy építési területre saját wifit telepíteni...
-
-
cog777
őstag
válasz
bambano
#5621
üzenetére
Koszi a valaszt!
A gepek rendkivul pontos helyzete van naplozva es abbol terkep felepitve, igy nem igazan van mas valasztasunk mint szinkronizalni az adatokat. Tudom hogy nagy szivas az ilyen , szerencsere van egy DB expert is velunk, hat majd meglassuk.
, szerencsere van egy DB expert is velunk, hat majd meglassuk.Sok adat keletkezik es a leheto leggyorsabban kell atkuldeni, hogy a gepek lassak a tobbi poziciojat es az irodaban ulo menedzser is

Elertuk azt a pontot amikor elkezdtuk hasznalni a syslog-ot is

-
bambano
titán
biztos, hogy ezt akarod? nekem nagyon rossz érzésem van a kérdéseddel kapcsolatban, az ilyen megoldásoknak szinte biztosan nagy kavarodás lesz a vége.
mondjuk jó lenne tudni a probléma részleteit is, hogy pl. mennyi adat keletkezik, mennyi idő alatt kell feldolgozni és van-e olyan más gépen keletkezett adat, amit vissza kell tölteni a gépekbe.szerintem naplózásra a syslog való, és annak van olyan verziója, ami kezeli az általad írt problémákat is. Balabit vagy Balasys vagy hogy hívják őket a héten, fejlesztette, pénzes.
táblák szinkronizálására vannak postgreses cuccok, én nem kezdenék velük
Slony és társai. -
cog777
őstag
Udv! Van valamilyen kulcskesz megoldas ketiranyu DB szinkronizaciohoz vagy ki kell fejlesztenunk egyet?
Utobbira keszulunk, de megprobalok rakeresni/rakerdezni az elobbire.
Tobb gepunk (markolo, epitoipari gepek stb) naploz bizonyos adatokat es kuldi el a kozponti szervernek. Viszont most jon be az a forgatokonyv hogy nem mindig van internet egy bizonyos gepen, illetve bizonyos gep nem a szerverrel hanem csak a szomszedos geppel van kapcsolatban. Igy szinkronizalni kell az adatokat a szerverrel es egymas kozott is.
PostgreSQL-t hasznalunk es erdeklodom hogy valaki talakozott-e mar ezzel a problemaval es akar fizetos megoldast talaltatok.
Ha nincs mas, akkor a reconciler pattern-t fogjuk kiprobalni: [link] -

Louro
őstag
válasz
 sztanozs
#5617
üzenetére
sztanozs
#5617
üzenetére
Én a T-SQL megoldást jobban csíptem. Nem voltak túlbonyolított jobok. Kisebb ellenőrző riportok, töltések. Csak most kitalálták az anyacégnél, hogy mindent át kell ültetni.
Az okot nem tudom. De mivel akad néha valami módosítás, ami igényli, hogy hozzányúljuk meglévő folyamatokhoz. Eleve nem túl gyors és viszonylag sűrűn omlik össze a Visual Studio. Félek, hogy ez durván lassítani fog. Ezért gondoltam ,hogy a tárolt eljárás kiskapu lehetne, hogy gyorsan szűrhessek. Anno Excelbe elkezdtük adminisztrálni, hogy melyik job mit tartalmaz, de hamar hamvába halt, hogy nem cska ketten csináltuk. Vagy mindenkinek kellene vagy senkinek. -
-
Louro
őstag
Sziasztok!
Újabb SQL szerveres kérdés. Elgondolkodtam egy dolgon. Nálunk van egy kezdeményezés, hogy a meglévő jobokat ültessük át SSIS package-ekre. Ezzel nem is lenne gond. Hisz copy-paste a nagy része. De!
Ha volt valami változás a forrásban vagy szűrést kell bővíteni, akkor az msdb.dbo.sysjobsteps hamar kidobta, hogy hol kell a változásokat lekövetni.
Az SSIS-szel viszont ez megszűnik.Van értelme annak, hogy a lekérdezéseket kimentem tárolt eljárásokba és csak az import-exportokat hagyom meg az SSIS számára? (Bevallom nem teszteltem még, de lehet holnap megpróbálok 2-3 jobot csinálni és megnézni, hogy mekkora a különbség.)
-

dudikpal
senior tag
Első mongodb sématervezésemmel el is akadtam szépen, ahogy illik, ebben kérném a segítségeteket.
Van a két képen szereplő entitásom, valamint egy Garage, amiben PlayerCard-ok vannak. Login után be kell töltenem a garaget. Na most hogy lenne ez gyorsabb?
- Garage <= List<String>(PlayerCardok ID-je)- PlayerCard <= (String)Card ID-jevagy
- Garage <= List<PlayerCard>- PlayerCard <= CardElső esetben ugye PlayerCardCount * 2 lekérdezéssel tudom kiolvasni a garaget.
Másodikban meg garageId alapján ott van izibe.
De ha azt mondom, hogy egy Cardból 1 playernek lehet több példánya is, amik természetesen PlayerCard szintjén egyediek, de ezt még meg kell szorozni a playerek számával is. Nem tudom ez mennyire elnézett/nem javasolt mongoban. Nekem annyira nem tetszik.Egybe tenni azért nem tudom a cardokat, mert a Card-on vannak az alap/kezdőértékek, a PlayerCardban meg a playerenként és PlayerCard-onként eltérő módosító értékek. A fronton az ezekből kalkulált érték fog megjelenni.
Pl: topSpeed * tuningEngine * ENGINE_MULTIPLIERMeg ez utóbbi esetben, ahol nested entitásként tárolok mindent, ha esetleg változik vmelyik Card vmelyik értéke, akkor mit csinálok? Végigmegyek mindenkinek minden playerCardján, h ha olyan card van benne, akkor updatelje?
Az első esetben ilyenkor beupdatelem a cards táblában levő Cardot, és annyi, onnantól már az új értékkel kerül majd mindenkihez a következő lekérdezéskor.Így leírva sztem maradnék az első verziónál. Szerintetek?
Még talán annyi, h Card lesz kezdésnek vagy 1-2000, player meg 2 biztosan, én a fiammal, de ki tudja mi lesz? Lehet leszünk vagy ezeren
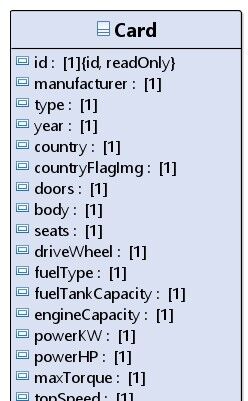

-
martonx
veterán
Külön programmal. A DB csak tegye ki egy külön táblába, hogy kiknek kell emailt küldeni.
Aztán majd egy külön program ez alapján kiküldi a saját workflowja alapján.
Így a DB is csak azt teszi, amihez ért, és majd a programozó is azt teszi amihez ért (rem,élhetőleg). Ráadásul az email küldés egészen bonyolult is lehet retry policy-vel, fogadottság ellenőrzéssel stb....
A mindent DB-vel megoldatásban óhatatlanul ott van a deadlockok, bármilyen más okból db lockok okozása, amivel vicces módon mondjuk egy sima email küldéssel akár a komplett DB-det is bedöntheted, pedig de jó ötletnek tűnt emailt küldeni a DB-ből (mondom ezt úgy, hogy bármikor elismerem nem vagyok DB szakértő, de régebben láttam már MS SQL-t megállni, valami ilyen huszadrangú jó ötletnek tűnt feature megakadása miatt).
De nyilván mindenki akinek kalpácsa van, az utána mindent azzal akar megoldani, klasszikus probléma. Rám is igaz lehet az előbbi, hogy minél több mindent inkább külön programmal oldanék meg, simán lehetnek esetek, amikor nem ez a jó megközelítés pl. irdatlan adatmennyiségek esetén. -
nyunyu
félisten
Értsd már meg, hogy ezt nem engedi a Szent Mikroalkalmazás Architektúra.
Cipész maradjon a kaptafánál, ablakpucolás nem az ő feladata!Hasonlóval szívtam, csak Oracle oldalon: automatizált GDPR törlésekről kellett volna hibajelzéseket küldenem az érintett osztályoknak, hogy vizsgálják ki, milyen adathiba miatt akadt el a folyamat.
Van egy tömeges SMS+email küldő alkalmazásunk, ami feldolgozza a webservicére érkezett kéréseket, így az első ötlet az volt, hogy DBből kéne meghívni a webservice-t.
Oracle persze ebben nem remekel, de azt meg lehet oldani, hogy indít egy shell szkriptet, ami meghívja a servicet.
Mivel minden is agyon van tűzfalazva, így kéne nyitni egy lyukat a DB szerver és az alkalmazásszerver között.
Természetesen ezt a felettesek azonnal letiltották, erről szó sem lehet éles banki környezetben.Második ötlet az volt, ha már az üzenetküldő alkalmazás fizikailag ugyanazon a DBn lóg, mint amin az adatokat törlöm, és a webservice oda pakolja, hogy mikor kinek, mit kell küldeni, akkor használjam direktbe.
Kb. 2 óra volt kisakkoznom, melyik táblájába mit kell írni, hogy menjen az email küldés tőlem.
Jelentem készre a fejlesztést, erre a code reviewn kivágta a biztosítékot az, hogy grant insert on emailszerver.emailtorzs to gdprtorles.
Egyből le lettem ugatva, hogy ezt mégis hogy gondolom hogy csak úgy másik sémába akarok írni, meg hápogtak sokat a Szent Mikroalkalmazás Architektúráról, miszerint az alkalmazások, szerverek nem véletlenül vannak fizikailag és logikailag is elszeparálva, nem kommunikálhatnak csak úgy random össze-vissza egymással.Végül az architektek, rendszerszervezők, üzemeltetők kiokumulálták megoldásnak azt, hogy a saját sémámban csináljam meg az emailtörzs, címzett táblákat, ezt pollozni fogja a DB sémámon lógó Java alkalmazás (amit a többi alkalmazás kérdezget, hogy mik a már törölt azonosítók), aztán az hívja meg az emailküldő servicet, ha kimenő hibaüzenet emailt lát nálam.
Bő 3/4 évvel később élesbe is állt ez a nice to have feature, mert akkor ért rá a javás kolléga ezzel a minor requesttel foglalkozni.
De legalább nem sérült a Szent Mikroalkalmazás Architektúra.
-
-
Louro
őstag
Sziasztok!
EGy kicsit speciálisabb kérdéssel jönnék. Adott sql server 2019. Csomagot kellene készítenem SSDT segítségével. Visual studioban a send mail nem opció, mert ahhoz su jog kellene. Így marad a Script task, ahol a system.net.mail segítségével tudnék levelet küldeni.
Ami a gondom, hogy igyekeznék hatékony kódot írni. A feladat annyi lenne, hogy van egy leválogatás. Egy hibalista az érintetteknek. Egy felhasználó egy rekordon szerepel és neki kellene levelet küldeni. Erre kurzort gondolnám a leghatékonyabbnak. De nem tudom miképp rakjam össze. Execute SQL task-ban a kurzort meg tudnám írni, de miképp "hívom meg" a script task-ban található emailküldést?
Remélem sikerült röviden összefoglalni a dilemmám
-
pch
senior tag
Üdv!
Mariadb 10.9.3-nál másnál is belassult a join utáni like '%keresés%' ?
Van egy eléggé sokrétű lekérdezés. Eddig simán ment max 0.5mp volt. Ez a legutolsó update során felment 4.5mp-re.
Így áttértem a match against-re beállítva az egy karakteres limitet.
Viszont ez ugyen csak a szó elejétől keres, és az ügyfelek eléggé hogy is mondjam.. nem tetszik nekik.
Szóval másnál is előfordult?



![;]](http://cdn.rios.hu/dl/s/v1.gif)










 Autodesk rajznyilvántartó szoftverről beszélünk és csak 4 user használja abból is csak 3 aktívan.
Autodesk rajznyilvántartó szoftverről beszélünk és csak 4 user használja abból is csak 3 aktívan.

 (nem vagyok egy nagy SQL guru, nézzétek el nekem
(nem vagyok egy nagy SQL guru, nézzétek el nekem  )
)























 , szerencsere van egy DB expert is velunk, hat majd meglassuk.
, szerencsere van egy DB expert is velunk, hat majd meglassuk.







Új hozzászólás Aktív témák
Hirdetés

- AMD Ryzen 5 1600X AM4
- Eladó Apple iPad (2020) 2. generáció Cellular + WiFi 512 GB
- iPhone 16 128GB gyári független hibátlan 2028.10.20. Apple jótállás
- iPhone 17 256GB gyári független hibátlan 2029.02.13. Apple jótállás
- Ryzen 7 7800X3D +ASRock X870 PRO RS WIFI +32GB 6000MHz DDR5 kit! GAR/SZÁMLA (a Te nevedre kiállítva)
- AKCIÓ! LENOVO ThinkPad P15 Gen1 - i7 10850H 16GB DDR4 512GB SSD Quadro T1000 4GB WIN11
- 263 - Lenovo ThinkBook 16p (G6 IAX) - Intel Core U9 275HX, RTX 5060
- Vállalom telefonok,tabletek javítását ,(szoftveres hibát is,frp lock-ot is)márkától fügetlenűl
- Dell XPS 15 9500 - 15,6" hibás kijelző, i7 10750H, 8GB RAM, Nvidia GTX 1650 Ti 4GB VGA
- GYÖNYÖRŰ iPhone 11 Pro 64GB Silver -1 ÉV GARANCIA - Kártyafüggetlen, MS3565
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest