Új hozzászólás Aktív témák
-
válasz
 bambano
#6034
üzenetére
bambano
#6034
üzenetére
ahh, persze, kimaradt a group id. nem volt kedvem felhuzni egy php pdo-val, hogy kiprobaljam... amugy meg tenyleg teljesen rossz a sema, es persze a tablak letrehozasanak a sorrendje is szamit.
vsz most jol es kicsit egyszerubben//Create groups table - First table with shared ID - This table provides ID for suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
UNIQUE(id, group_name))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create suppliers table - Main table with shared ID - This table gets ID from supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT,
group_id INTEGER NOT NULL,
FOREIGN KEY (group_id) REFERENCES supplier_groups (id))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql1 = "INSERT OR IGNORE INTO supplier_groups (group_name) VALUES (:name);
SELECT id FROM supplier_groups WHERE group_name = :name)";
$sql2 = "INSERT INTO suppliers (supplier_name, group_id) VALUES (:name, :id)";
try {
$statement = $connection->prepare($sql1);
$statement->exec(['name' => 'jedi']);
$gid = $statement->fetchColumn();
$statement = $connection->prepare($sql2);
$statement->exec(['name' => 'Obi van Kenobi', 'id' => $gid]);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage(); -
válasz
 lanszelot
#6027
üzenetére
lanszelot
#6027
üzenetére
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT,
UNIQUE(id, supplier_name))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
FOREIGN KEY (id) REFERENCES suppliers (id))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql1 = "INSERT OR IGNORE INTO suppliers (group_name) VALUES (?)"
$sql2 = "SELECT id FROM group_name WHERE group_name = ?)";
$sql3 = "INSERT INTO suppliers (supplier_name) VALUES (?, ?)";
try {
$statement = $connection->prepare($sql1);
$statement->exec(['jedi']);
$statement = $connection->prepare($sql2);
$statement->exec(['jedi']);
$gid = $statement->fetchColumn();
$statement = $connection->prepare($sql3);
$statement->exec(['Obi van Kenobi', $gid]);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
} -
válasz
lanszelot
#6025
üzenetére
De, pont ugyanazt kell csinalni... Es az ordernel itt is meg kell adni a users.id-t.
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
username TEXT NOT NULL,
email TEXT)
CREATE TABLE IF NOT EXISTS order (
id INTEGER,
address TEXT,
FOREIGN KEY (id) REFERENCES users (id)) -
válasz
lanszelot
#6020
üzenetére
hogy lehetne autoincrement primary key, amikor foreign key is egyben?
Ebben a sorrendben kell letrehozni es feltolteni a tablakat:CREATE TABLE IF NOT EXISTS supplier_groups (
... group_id integer AUTOINCREMENT PRIMARY KEY,
... group_name text NOT NULL)
CREATE TABLE IF NOT EXISTS suppliers (
... supplier_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
... supplier_name TEXT NOT NULL,
... group_id INTEGER NOT NULL,
... FOREIGN KEY (group_id)
... REFERENCES supplier_groups (group_id))
INSERT INTO supplier_groups (group_name) VALUES ('Jedi')
INSERT INTO suppliers (supplier_name, group_id) VALUES ('Obi van Kenobi',1) -
-
-
-
A 3xx-as HTTP kódoknál nincs konkrét tartalom (mintha csak a HTTP headert kérnéd le) és a Location header mezőben van az URL (abszolút, vagy relatív), ahova a böngészőnek tovább kell dobnia a teljes eredeti kérést. Persze az egyéb header mezőket is fel kell dolgozni (pl SetCookie, de ez a kliensen futó kód szempontjából ireleváns).
Amennyiben pl az általad említett példában az ID alapján is továbbít és nem kell a query, az lehet valami régi logika maradéka, vagy lehet benne plusz infó is, amit pl a redirect során a szerver eltárol (pl referrer link).
A konkrét esetben így néz ki egy kliens-szerver kommunikáció:
1) kliens "betölti" az alábbi oldalt:
https://rd.hirkereso.hu/rd/39891270?place=6544&partner=hirkereso&url=https%3A%2F%2Fprohardver.hu%2Fhir%2Fjon_lg_elso_hibrid_projektora.html
2) "rd.hirkereso.hu" megkapja a kérést és betölti a logikát, ami a "/rd/39891270" path feldolgozásáért felel
3) a betöltött logika megkapja az eredeti kérést a query elemekkel együtt:
/rd/39891270?place=6544&partner=hirkereso&url=https%3A%2F%2Fprohardver.hu%2Fhir%2Fjon_lg_elso_hibrid_projektora.html
4) eltárolja az adatbázisba a megfelelő elemeket, timestamp-ot és betölti annak az oldalnak az URL-jét, ahova redirect-elni kell
5) a logika nem HTTP 200 választ ad, hanem HTTP 3xx-t és a Location headerbe beállítja a redirect URL-t: https://prohardver.hu/hir/jon_lg_elso_hibrid_projektora.html
6) kliens megkapja a 302-es üzenetet és a redirect URL-t: https://prohardver.hu/hir/jon_lg_elso_hibrid_projektora.html
7) a kliens elküldi a kérést redirected URL-nek:
https://prohardver.hu/hir/jon_lg_elso_hibrid_projektora.html
8) a "prohardver.hu" betölti a "hir/jon_lg_elso_hibrid_projektora.html" path feldolgozásához szükséges logikát
9) a betöltött logika legenerálja a felhasználó számára a tartalmat és egy HTTP 200 üzenetben elküldi a kliensnek
10) a klines megjeleníti a betöltött weboldalt (illetve letölti az oldalhoz szükséges többi erőforrást) -
-
-
válasz
 nyugis21
#5370
üzenetére
nyugis21
#5370
üzenetére
Mondjuk ha még mindig access 2007-el szenvedsz, akkor sok segítséged nem lesz (még a neten se nagyon), az már egy rég kivezetett verzió.
A Projekt template-hez úgy nézem nincs videó, csak szöveges bemutató:
https://support.microsoft.com/hu-hu/office/a-projects-access-adatb%C3%A1zissablon-haszn%C3%A1lata-87fdb02a-b109-4864-ab94-95e7ce1b6443Ezeket a plusz táblákat, amik neked kellenek, fel lehet venni a legyártott sablonokhoz, csak meg kell csinálni a hozzájuk tartozó formokat, ha nem akarod táblázatos módban kezelni az alapadatokat.
Törölni is lehet belőle táblákat, csak vele együtt célszerű törölni a hozzájuk tartozó formokat is, amik nem kellenek. Illetve ki kell szedni a megmaradó formokból a hozzájuk tartozó beviteli mezőket.
common tasks - fogalmam sincs, hogy mire jó, és csak az emberekkel van kapcsolata
Ezek olyan feladatok, amik nem tartoznak projektekhez, de valaki elvégzi. Mivel a template egy projektcég/projekt csapat munka kimutatására szolgál így célszerű nyilvántartani azokat a feladatokat is, amik nem kifejezetten projektekhez tartoznak, hogy lehessen látni a kollégűk leterheltségét (terhelhetőségét). -
válasz
nyugis21
#5365
üzenetére
Ezt a videót egyébként megnézted?
Ebben a template-ben vannak FORM-ok és RIPORT-ok is, szóval meg lehet nézni, mit hogyan kell csinálni egy form vagy egy riport készítésénél: https://support.microsoft.com/hu-hu/office/vide%C3%B3-az-asztali-feladatkezel%C3%A9si-adatb%C3%A1zissablon-haszn%C3%A1lata-9a9736a4-9aac-45a1-93dd-4eca934cf8ef -
-
-
-
Nem biztos, hogy értem, hogy mit szeretnél...
Egyrészt a tűblákat érdemesebb volna ID-val csinálni (mert mi van, ha van két ugyanolyan nevű Kis Péter), de ha eddig nem kézzel volt szinkronizálva a tábla, hanem valami automatizmussal, akkor működhet a mezők "összekötése" utólag is.
Amúgy a harmadik tábla csak egy query lenne, vagy ott is tárolnál valami plusz infót?
Valahogy így raknám össze, ha sokat nem akarnék vacakolni: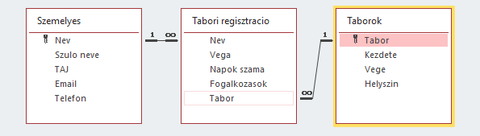
De rendesen, Id-kkal valahogy így nézne ki:
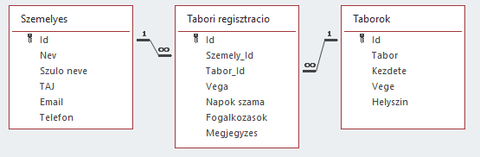
-
-
válasz
bambano
#5156
üzenetére
Ez viszont nem jól fogja számolni, lesz egy nap két DE (2*8 óra, hajnalban és éjszaka) és egy DU (1*16 óra napközben).
Valahogy így lehet jó:
SELECT
TRUNC(dateadd(hour,-8,datum)) AS nap,
CASE WHEN date_part('hour',dateadd(hour,-8,datum))>12 THEN 'DU' ELSE 'DE' END AS muszak,
SUM(szam)
FROM tabla
GROUP BY 1,2 ORDER BY 1,2;Így a hajnal még az előző naphoz fog tartozni mint DU műszak.
-
-
Simán meg lehet trükközni a lekérdezést, hogy pl csak a legfrissebb 1000-ben keresse az első ötöt (persze, ha lesz annyi és nem került be az összes a "rossz" kategóriába):
SELECT i.item_id, i.item_date
FROM (
SELECT item_id, item_date
FROM items
ORDER BY item_date DESC LIMIT 1000) as i INNER JOIN items_categories AS c ON i.item_id=c.item_id
WHERE
c.category_id NOT IN (1,3,13,7,20) AND
i.item_id NOT IN (117,132,145,209,211)
GROUP BY i.item_id, i.item_date
ORDER BY i.item_date DESC LIMIT 4 -
A létrehozott index sokat nem segít, mivel az egy 'compound index' (csak akkor működik, ha egyszerre használod a két mezőt inkluzív keresésre, és egyszerre tudja használni mind a kettőt). Két külön indexszel talán valamit javulna.
Amúgy akármit is csinálsz úgy tűnik a kapcsolótábla nagy mérete miatt - és mivel nem magát a táblát, hanem annak egy előszűrt nézetét használod - szinte biztosan lesz jelentős adatmozgás (ez látszik a "sending data" szekcióban).
Ahogy nézem a mariadb nem igazán tudja rendesen használni az indexeket (pontosabban a MERGE módot), DISTINCT és/vagy GROUP BY kifejezésekkel együtt, mindenféleképp temp táblát szeretne alkalmazni.
Ezért is kisebb az első esetben létrehozott temp tábla (mivel itt csak egy mező jön létre és ezzel hasonlítja össze az item_id-t). A második esetben meg létrehozza a joinolt temp táblát (három mezővel) és mivel utána group by/distinct van így nem MERGE-et használ, hanem csinál egy teljes table dump-ot :/Tényleg meg kell próbálni valami mással, mert még a MySQL doksiban is azt olvastam, hogy még pl a DISTINCT esetében is szépen kell működnie index-szel, ha a sorbarendezett mező sorbarendezett indexet használ.
-
Ahogy jobban megnéztem a probléma azzal van, hogy igazából nem sikerült rendes indexet létrehozni.
A primary indexhez lett hozzáadva a dátum, mint key oszlop, pedig saját indexet kellett volna csinálni:--
-- Indexes for table `items`
--
ALTER TABLE `items`
ADD PRIMARY KEY (`item_id`);
ALTER TABLE `items`
ADD INDEX (`item_date` ASC); -
Ha sorba szeretnéd rendezni, akkor majdnem mindegy, hogy ASC-ba, vagy DESC-be rakod az indexet, gyorsan kell működjön, Igazából az ASC azért lenne elméletileg jó a DESC sorbarendezésnél, mert az indexet növekvő sorrendben hozza létre így az index végén levő (legnagyobb értékek) rögtön rendelkezésre kell álljanak. Mondjuk egy-egy execution plan-t jó volna látni mindegyikre...
-
válasz
 sztanozs
#5123
üzenetére
sztanozs
#5123
üzenetére
és ha minden Itemhez csak egy dátum tartozik, akkor használható az index:
SELECT i.item_id, i.item_date
FROM items as i INNER JOIN items_categories AS c ON i.item_id=c.item_id
WHERE
c.category_id NOT IN (1,3,13,7,20) AND
i.item_id NOT IN (117,132,145,209,211)
GROUP BY i.item_id, i.item_date
ORDER BY i.item_date DESC LIMIT 4 -
Esetleg:
SELECT i.item_id, i.item_date
FROM items as i INNER JOIN (
SELECT item_id FROM items_categories
WHERE
category_id NOT IN (1,3,13,7,20) AND
item_id NOT IN (117,132,145,209,211)
GROUP BY item_id
) AS c ON i.item_id=c.item_id
ORDER BY i.item_date DESC LIMIT 4Ennél már nem tudom jobban bonyolítani

De egy item_date Sorted Index-szel szerintem többre mennél, ha mindenféleképp sorba szeretnél rendezni:
https://www.mssqltips.com/sqlservertip/1337/building-sql-server-indexes-in-ascending-vs-descending-order/ -
Ráadásul: "amire amúgy már az elején, az első Select-nél is meg lehetne csinálni, mert úgyis csak abban van a mező, ami alapján rendez, így kár a kibővített találati táblán rendezgetni."
Nincs olyan, hogy első Select. Amit te elsőnek nézel, az a külső select, tehát az hajtódik végre utoljára, tehát subselect először, külső select másodszor.Join+GroupBy nekem több rápróbálás után kb ugyanúgy (~500ms) működik, mint a subselect:
SELECT i.item_id, max(i.item_date) as max_date
FROM items as i INNER JOIN items_categories c on i.item_id=c.item_id
WHERE
c.category_id not in (1,3,13,7,20) and
c.item_id not in (117,132,145,209,211)
group by i.item_id
ORDER BY max_date DESC LIMIT 4 -
Az orderby csak a fő selectre hat, a subselect egyszer legenerálódik és azután csak újrahasznosítódik.
Az utolsó kérdésre:
A query mindig a motor optimális futása alapján történink, nincs értelme order by-nak belül (ha nincs limit is mellé), mert a subquery/temp tábla lekérdezése nem garantálja a rekordok sorrendjét. -
-
'NOT IN' elég pazarló (legalább is az én ismereteim szerint), persze lehet, hogy a modern motorok már átalakítják kevésbé lassabbakra.
A LIKE-ok meg szerintem mindegy milyen scope-ban futnak. Simán egybe lehet rakni az összes táblát és utána szűrni:SELECT * FROM (
SELECT * FROM table1
UNION ALL
SELECT * FROM table2
UNION ALL
SELECT * FROM table3
UNION ALL
SELECT * FROM table4
UNION ALL
SELECT * FROM table5
)
WHERE ((title LIKE '%szoveg%') OR (description LIKE '%szoveg%'))
ORDER BY date DESC -
válasz
 Diopapa
#4918
üzenetére
Diopapa
#4918
üzenetére
mysql/mariadb
select szttorzsszam, sztnev, group_concat(klnevhu) from szemelytorzs
left join bfkepzettsegimatrix on szemelytorzs.szttorzsszam = bfkepzettsegimatrix.kmtorzsszam
left join kepzettseglista on bfkepzettsegimatrix.kmkepzettsegid = kepzettseglista.klid where szttorzsszam = '1234'
group by szttorzsszam, sztnevmssql (2017+)
select szttorzsszam, sztnev, STRING_AGG(klnevhu, ',') from szemelytorzs
left join bfkepzettsegimatrix on szemelytorzs.szttorzsszam = bfkepzettsegimatrix.kmtorzsszam
left join kepzettseglista on bfkepzettsegimatrix.kmkepzettsegid = kepzettseglista.klid where szttorzsszam = '1234'
group by szttorzsszam, sztnevpostgres
select szttorzsszam, sztnev, array_to_string(array_agg(klnevhu), ',') from szemelytorzs
left join bfkepzettsegimatrix on szemelytorzs.szttorzsszam = bfkepzettsegimatrix.kmtorzsszam
left join kepzettseglista on bfkepzettsegimatrix.kmkepzettsegid = kepzettseglista.klid where szttorzsszam = '1234'
group by szttorzsszam, sztnev -
#4917
 sztanozs
veterán
Apollo17hu
#4915
sztanozs
veterán
Apollo17hu
#4915
válasz
 Apollo17hu
#4915
üzenetére
Apollo17hu
#4915
üzenetére
Az, hogy milyen példát hozott még nem jelenti azt, hogy ez a való életben is így lesz (lehet, hogy csak nem gondolt rá)...
-
válasz
 kw3v865
#4910
üzenetére
kw3v865
#4910
üzenetére
Ez már operációkutatás, nem adatbázis kérdés...
tegyük fel a következőt:
1 | 2 | 10 | 20
2 | 2 | 10 | 30
3 | 2 | 10 | 40
4 | 2 | 20 | 30
5 | 2 | 20 | 40
6 | 2 | 20 | 50
7 | 2 | 30 | 40
8 | 2 | 30 | 50
9 | 2 | 30 | 60
Ezzel a forrással milyen range-eket hozol létre és melyik melyikbe tartozna? -
válasz
 user112
#4579
üzenetére
user112
#4579
üzenetére
Igen, erre van a HAVING feltétel (aggregált kifejelzés ellenőrzésére, pl a darab több, min 3
kiscica).select
1 + 2 as harom,
null as ertek2,
created as letrehozva,
sum(user_id) as valami,
count(*) as darab,
'hello' as ertek3
from
dba_users
group by
created
having
count(*) > 3
order by
harom,
letrehozva -
válasz
sztanozs
#4570
üzenetére
Ja, ahogy nézem nem is kell subselect, simán mehet a végére is...
select 'adat' ad, ID, nev, ertek1, ertek2, ertek3, ertek4, ertek5
from tabla
union
select "osszesen" ad, ID, null nev, sum(ertek) ertek1, null ertek2, null ertek3, null ertek4,
null ertek5
from tabla
group by id
order by ID, ad -
válasz
user112
#4566
üzenetére
Hali, ennek tutira mennie kellene:
select 'adat' ad, ID, nev, ertek
from tabla..
union
select "osszesen" ad, ID, null nev, sum(ertek)
from tabla..
group by idha pedig van 5 érték, amiből csak az elsőt summázod, a többi meg üres lesz a végén:
select 'adat' ad, ID, nev, ertek1, ertek2, ertek3, ertek4, ertek5
from tabla
union
select "osszesen" ad, ID, null nev, sum(ertek) ertek1, null ertek2, null ertek3, null ertek4, null ertek5
from tabla
group by idSőt a végén még össze is rendezheted, hogy minden ID-hez a a felsprplás végére tegye az összeget, ne a tábla végére ID-nként:
select * from (
select 'adat' ad, ID, nev, ertek1, ertek2, ertek3, ertek4, ertek5
from tabla
union
select "osszesen" ad, ID, null nev, sum(ertek) ertek1, null ertek2, null ertek3, null ertek4,
null ertek5
from tabla
group by id)
order by ID, ad -
válasz
 haxiboy
#4316
üzenetére
haxiboy
#4316
üzenetére
Nekem SSIS-szel nem volt eddig gondom (igaz csak max 2-3 millió rekordos adatcsomagokat mozgattam vele eddig - viszont elméletileg batchben dolgozik, szóval memóriaprobléma nem nagyon lehetne vele.
Amúgy nem lett volna megoldás átnevezni a táblát és csinálni a régi névvel egy view-t, ami megfelelő sorrendben tartalmazz a mezőket? -
1-2) az adatbázis fájlban nem marad, de az SQLite nem igazán szereti a konkurens használatot.
a) ha az adatbázi fájl nincs nyitva más által, akkor nincs journal fájl sem és mindent kimásol.
b) ha lehalt az eredeti program és vannak bent ragadt módosítások, de nem korrupt az adatbázis, akkor az adatbázis megnyitáskor azokat végrehajtja és utána mindent kiír
c) ha korrupt az adatbázis, akkor a sémát és az olvasható adatokat is kiírja, de az sql dump vége regy rollback utasítás lesz. Ha ezt kézzel átírod egy commit-ra, akkor az adatbázis-t az aktuálisan olvasható adatokkal vissza tudod állítani.
3) szvsz nincs. Amúgy ez nem "kinyeri" az adatokat, hanem az egész adatbázist és a benne található adatokat és a sémát SQL utasításokká konvertálja. Az adataid eddig is megvoltak, csak máshogy tudsz hozzájuk férni. Ha csak az adatok kellenek, akkor inkább exportálj, de dumpolj: [link]Bónusz: Azért használnak ilyneket, mert ezekhez vannak sztenderd könyvtárak és gyakorlat, míg a szöveges fájlok (főleg ini) feldolgozását (és hibakezelést) kézzel kell megoldani.
-
válasz
bambano
#4148
üzenetére
ez elég fura, mert elvileg az exists-hez le kellene futtatni a subselectet minden sorhoz
Elméletileg pont fordítva. A NOT IN-hez kell iterálni, az NOT EXISTS anti-joinra konvertálható (csak ebben a formában szebb).Analyse jól írja, mert tényleg pont fordítva van, mert az exists és a left join + null is anti-joinra van optimalizálva, a not in pedig hashed subplan (mert az IN értéket és null-t is visszaadhat, ezért kétszer fut az iteráció - ki elemszámnál ez nem probléma, de nagy elemszámnál már lesz különbség, ráadásul a subplan miatt cache problémák lehetnek).
EXPLAIN ANALYZE
It is possible to check the accuracy of the planner's estimates by using EXPLAIN's ANALYZE option. With this option, EXPLAIN actually executes the query, and then displays the true row counts and true run time accumulated within each plan node, along with the same estimates that a plain EXPLAIN shows.



















 kapcsolat (több eseményhez tartozhat több személy). Kell hozzá egy kapcsoló tábla.
kapcsolat (több eseményhez tartozhat több személy). Kell hozzá egy kapcsoló tábla.







 kipróbáltad egyáltalán, amit írtam?
kipróbáltad egyáltalán, amit írtam?







Új hozzászólás Aktív témák
Hirdetés

- AlzaErgo ErgoArm D05B Tube - Akár 2db 32" monitorhoz
- Lenovo Thinkcentre M720s SFF,i3-8100,8GBDDR4,256GB NVMe SSD,WIN11
- Wacom Cintiq Pro 16 (4K) rajzmonitor teljes szett + Parblo állvány + Rajzkesztyű Újszerű állapotba
- HP Zbook 17 G6,17.3",FHD,i7-9850H,16GB DDR4,256GB SSD,WIN11
- 5 darab WIFI/LAN biztonsági kamera, 3 kültéri és 2 beltéri
- GAMER PC! Ultra 7 265 / RTX 5070 / 32GB DDR5 / 1TB NVMe / 750w Gold / BeszámítOK !
- AKCIÓ! Intel Core i9 12900KF 16 mag 24 szál processzor garanciával hibátlan működéssel
- Gamer/streamer mikrofon, állvány és USB HUB kitűnő árakon!
- Asrock Challenger RX 9070 XT // Felbontott // Számla // Garancia //
- Xbox Game Pass Ultimate előfizetések kedvező áron
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest