- Fórumok
- Szoftverfejlesztés
- SQL kérdések
- (kiemelt téma)
- Megújult mobilos felület, fórumos ráncfelvarrás a PROHARDVER! lapcsaládon
- Eladhatatlannak ítélt CPU-k eladásával javult az Intel node-ok kihozatala
- Az AI átformálja a Peugeot modelljeit is
- Ráműthető a Linux PlayStation 5-re, de csak egy boot erejéig
- Mindenféle környezeti behatásnak ellenállnak az ASUS új TUF tápjai
- Milyen TV-t vegyek?
- Androidos fejegységek
- Intel Core Ultra 3, Core Ultra 5, Ultra 7, Ultra 9 "Arrow Lake" LGA 1851
- Azonnali informatikai kérdések órája
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Hobby elektronika
- OLED monitor topic
- Gaming notebook topik
- Eladhatatlannak ítélt CPU-k eladásával javult az Intel node-ok kihozatala
- Tápokról alaposan - mélyvíz
-
Fórumok
PROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Új hozzászólás Aktív témák
-
 epicdev
junior tag
epicdev
junior tag
Nem sql kérdés, Libreocce calc probléma, de talán valakinek van rá ötlete.

Két lista van, egyszerűek, megnevezés, kategória és leírás
Az első az általános lista, a másikban az a nagyon kevés van, ami az általános lista két vagy több eleméből jött létre és új definíciót eredményezett.
Úgy kellene megjeleníteni ezeket, hogy az alapelemeket is lehessen látni.
egyszerű példa:
alaplistában:
víz - kategória, leírás
gőz - kategória, leírásmásik listában:
vízgőz - kategória, leírás
(és ide kellene valahogy linkelni a fenti kettőt, hogy lehessen látni a forrásokat is)bonyolultabb probléma:
(egy egészen más listában)
pár tucatnyi elem vanEgy másik listában minden új tételben csak a fenti elemek némelyike fordulhat elő bennük, és valahogyan hivatkozni kell rájuk.
példa:
alaplista
A
B
C
Daz új lista
AB
ACA
BAC
DBBACBmindegyiknél azokra az elemekre is kell hivatkozás, amik előfordulnak bennük
remélem, érthető
-
 velizare
nagyúr
velizare
nagyúr
-
 lanszelot
addikt
lanszelot
addikt
Először is nagyon szépen köszönöm a segítséget mindenkinek

Látod, te is php-val oldottad meg.
 megválaszoltad saját kérdésed
megválaszoltad saját kérdésed bambano: ha csak azt írod le, hogy rossz séma, rossz séma, abból nem fogom tudni hol rontottam és hogyan kellene.

pch: sajnos abból egy szót se értek. Nekem az még túl bonyolult

-
 bambano
titán
bambano
titán
felvettél egy group_id mezőt, ami a hagyományos módszere az 1 : N kapcsolat tárolásának relációs algebrában.
És ezt mondta korábban: "Lehet pont azért látom meg a hibát a rendszerben, mert még nem rögzült belém, hogy ezt így kell, mert csak így lehet."Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis -
 sztanozs
veterán
sztanozs
veterán
-
bambano
titán
-
sztanozs
veterán
ahh, persze, kimaradt a group id. nem volt kedvem felhuzni egy php pdo-val, hogy kiprobaljam... amugy meg tenyleg teljesen rossz a sema, es persze a tablak letrehozasanak a sorrendje is szamit.
vsz most jol es kicsit egyszerubben//Create groups table - First table with shared ID - This table provides ID for suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
UNIQUE(id, group_name))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create suppliers table - Main table with shared ID - This table gets ID from supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT,
group_id INTEGER NOT NULL,
FOREIGN KEY (group_id) REFERENCES supplier_groups (id))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql1 = "INSERT OR IGNORE INTO supplier_groups (group_name) VALUES (:name);
SELECT id FROM supplier_groups WHERE group_name = :name)";
$sql2 = "INSERT INTO suppliers (supplier_name, group_id) VALUES (:name, :id)";
try {
$statement = $connection->prepare($sql1);
$statement->exec(['name' => 'jedi']);
$gid = $statement->fetchColumn();
$statement = $connection->prepare($sql2);
$statement->exec(['name' => 'Obi van Kenobi', 'id' => $gid]);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának... -
bambano
titán
Sehogy nem oldja meg, mert rossz az adatbázis sémája és nem akarja elhinni. De ez nem probléma, most a matematika ellen fogad, és megvárjuk, amíg megoldja.

A te megoldásod is rossz, mert ha az insert into suppliers utasításban egy oszlopot adsz meg, akkor a valuesben nem lehet két kérdőjel.
Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis -
sztanozs
veterán
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT,
UNIQUE(id, supplier_name))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
FOREIGN KEY (id) REFERENCES suppliers (id))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql1 = "INSERT OR IGNORE INTO suppliers (group_name) VALUES (?)"
$sql2 = "SELECT id FROM group_name WHERE group_name = ?)";
$sql3 = "INSERT INTO suppliers (supplier_name) VALUES (?, ?)";
try {
$statement = $connection->prepare($sql1);
$statement->exec(['jedi']);
$statement = $connection->prepare($sql2);
$statement->exec(['jedi']);
$gid = $statement->fetchColumn();
$statement = $connection->prepare($sql3);
$statement->exec(['Obi van Kenobi', $gid]);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának... -
sztanozs
veterán
-
 pch
senior tag
pch
senior tag
trigger amit keresel.
triggerrel oldható meg, hogy insert esetén a kapott iD-t egy másik táblába beírjuk.
https://sqlite.org/lang_createtrigger.htmlhttp://sb-soft.hu - "A" számlázó -
lanszelot
addikt
Rég óta próbálom az sqlite pdo php -t , de sehol sincs semmi róla.
Borzasztó nehéz bármit is találni. Mind hiányos, és felületes.
Vagy pont az ellenkezője. Egyik se jó egy kezdőnek.
Én is biztos vagyok, hogy a kód nem tökéletes, de működik.
Senki sem segít, így örülök ha működik.
Amit akarok az php-val simán meg lehet oldani.
Amiért akarom, mert hülyeségnek tartom, hogy azért hozzak létre plusz egy oszlopot minden táblába, plusz még egy táblát, hogy össze kössem a táblákat, mikor sokkal egyszerűbben meg lehet csinálni.
Lehet pont azért látom meg a hibát a rendszerben, mert még nem rögzült belém, hogy ezt így kell, mert csak így lehet.
Akkor marad a php. -
bambano
titán
Szerintem el kellene olvasnod pár alap irodalmat az adatbázis tervezésről, különös tekintettel a normálformákra, az 1 : N és az M : N kapcsolatok ábrázolására.
Mert amit akarsz, az NINCS. Ha pedig úgy akarod tárolni az adatot, amit abból a php kódrészletből ki lehet olvasni, akkor az úgy téves.Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis -
lanszelot
addikt
-
lanszelot
addikt
Köszönöm szépen a választ.
Nekem nem működik. Lehet én csinalok valamit rosszul ezért belinkelem a kódodt, és a hibát.
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT)";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
FOREIGN KEY (id) REFERENCES suppliers (id))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql = "INSERT INTO suppliers (supplier_name) VALUES ('Obi van Kenobi')";
$sql2 = "INSERT INTO supplier_groups (group_name) VALUES ('jedi')";
try {
$connection->exec($sql);
$connection->exec($sql2);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}Hiba: "Error: SQLSTATE[23000]: Integrity constraint violation: 19 NOT NULL constraint failed: suppliers.group_id"
-
sztanozs
veterán
De, pont ugyanazt kell csinalni... Es az ordernel itt is meg kell adni a users.id-t.
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
username TEXT NOT NULL,
email TEXT)
CREATE TABLE IF NOT EXISTS order (
id INTEGER,
address TEXT,
FOREIGN KEY (id) REFERENCES users (id))JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának... -
lanszelot
addikt
-
bambano
titán
-
sztanozs
veterán
ha azt irsz bele amit akarsz, akkor nincs ertelme a ket tablanak meg a foreign key-nek...
foreign key ugy mukodhet, hogy a user kivalasztja egy listabol az erteket (dropdown box), nem pedig szabad szoveges.JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának... -
lanszelot
addikt
-
sztanozs
veterán
hogy lehetne autoincrement primary key, amikor foreign key is egyben?
Ebben a sorrendben kell letrehozni es feltolteni a tablakat:CREATE TABLE IF NOT EXISTS supplier_groups (
... group_id integer AUTOINCREMENT PRIMARY KEY,
... group_name text NOT NULL)
CREATE TABLE IF NOT EXISTS suppliers (
... supplier_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
... supplier_name TEXT NOT NULL,
... group_id INTEGER NOT NULL,
... FOREIGN KEY (group_id)
... REFERENCES supplier_groups (group_id))
INSERT INTO supplier_groups (group_name) VALUES ('Jedi')
INSERT INTO suppliers (supplier_name, group_id) VALUES ('Obi van Kenobi',1)JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának... -
lanszelot
addikt
Köszönöm szépen.
Valamit nem jó; értek, mert eddig jutottam, de nem jó:
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
supplier_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
group_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
FOREIGN KEY (group_id)
REFERENCES supplier_groups (group_id))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
group_id integer PRIMARY KEY,
group_name text NOT NULL)";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql = "INSERT INTO suppliers (supplier_name) VALUES ('Obi van Kenobi')";
$sql2 = "INSERT INTO supplier_groups (group_name) VALUES ('jedi')";
try {
$connection->exec($sql);
$connection->exec($sql2);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
} -
 martonx
veterán
martonx
veterán
-
lanszelot
addikt
Köszönöm szépen a választ.
Oda írtam a példát. Az id pont úgy van ahogy írtad.
És azt is tudom hogy constraint és /vagy foreign key -t kell használom, de nem tudom hogyan.
Azért írtam le a kódot, hogy lehessen látni, hogy mit szeretnék.
Természetesen azid FROM usres(id)sort kellene javítani,
constraint és /vagy foreign használataval,
Csak nem tudom hogy.
Bárhogy próbáltam, sehogy se volt jó.Sqlite pdo php -val használom.
-
martonx
veterán
-
lanszelot
addikt
Hello,
Hogy kell létrehozni táblát úgy, hogy az id-je egy másik tábla id-je legyen? (Utolsó előtti sor.)CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
username TEXT NOT NULL,
email TEXT)
CREATE TABLE IF NOT EXISTS order (
id FROM users(id),
address TEXT) -
 Magnat
veterán
Magnat
veterán
Pl valamilyen sql-t, de ezt mondjuk a topik címe determinálja
Nem tudom mennyi bejegyzés van, de pár millió rekordot jó szervezés meg kulcsolás esetén kb bármilyen vason meg lehet oldani bármilyen sql szerverrel .. meg persze kell hozzá vmi frontend, jellemzően browseres megoldás a legelterjedtebb (ekkor persze kell webszerver, de az is van ingyé), de még excelben is meg lehet csinálni (ami a háttérben beszélget az sql szerverrel).Lehet pl MariaDB (azaz MySql), Transact (MS) Sql-nek is van ingyenes verziója olyan limitációkkal amit jó eséllyel nem fogtok elérni, meg még jó hosszan lehetne sorolni.
̿' ̿'\̵͇̿̿\з=(◕_◕)=ε/̵͇̿̿/'̿'̿ ̿ -
 shipfolt
kezdő
shipfolt
kezdő
Lexikon keszitesre milyen ingyenes es biztonsagos megoldast javasoltok?
pelda:
cimszo: fekete
def1: szin
jelentes: ide jonnek a szinnel kapcsolatos leirasok
kulcsszo: szindef2: lopott aru
jelentes: ide jonnek a peldak, leirasok
kulcsszo: szlengstb. stb.
Jelenleg a 0. fazisban vagyunk, mert a kezdetekben az adatgyujtok allandoan modositottak vagy (veletlenul) toroltek korabbi beirasokat, mert szovegfajlba irtak.
Most ott tartunk, hogy cimszo es jelentes es kudo neve szerint kuldik nekem hetente a gyujteseket, osszesitem oket ABC szerint egy Libreoffice Calc fajlba kiegeszitve a kuldes datumaval.
Majd egy okos csapat eldonti, hogy a kulonbozo jelentesek hanyfele kategoriaba tartoznak es milyen kulcsszavak tartozik hozza
A problema ugyanugy fennall, mert az okosok osszevonnak dolgokat, ezert a bekuldok ujra bekuldenek olyan dolgokat, amiket korabban az okosok mar kilottek vagy modositottak.
Olyan megoldas kellene, hogy a bekuldok lathassak, hogy korabban miket fogadott el az okos csapat, de ne tudjanak belepiszkalni.
-
bambano
titán
Ha fafejség ellen kell harcolni, arra a nézettábla megoldás.
Itt az az érdekes helyzet van, hogy a nézettábla két irányból is alkalmazható:
1. van egy pocsék tárolási struktúrád, és abból akarsz jó nézetet generálni.
2. csinálsz egy rendes tárolási struktúrát és abból generálsz pocsék nézetet.Én azt javaslom, hogy minél előbb át kell térni a rendes megoldásra, vagyis 2.
Tehát megcsinálod a 3 táblát, elkezded abba tölteni az adatokat, akár visszamenőleg is, és ráhúzol annyi nézetet, amennyi az aktuális helyzetben kell. Ráadásul nézetet ráhúzni és eldobni sokkal egyszerűbb, mint alaptáblát módosítani. Megcsinálod, hogy azok a programok, amik a rossz struktúrát használják, használják a nézettáblákat, amiket meg ezután módosítotok, már az új megoldást használják.
szerk: ha minden szenzor egy tábla rendszerben tárolod az adatokat és egy nézettáblába hozod össze a sok táblát, akkor ott problémás lehet, hogy egy új szenzor hozzáadásakor megcsinálod a szenzor saját tábláját, és amikor a nézettáblát módosítod, akkor le kell bontani a korábbi nézettáblát és feltenni az újat. Ha pedig minden szenzor egy tábla rendszer van, akkor az új nézettábla létrehozása nem befolyásolja a többi működését.
Itt kerül elő az alapkérdés, hogy milyen a kapcsolat a fafejűekkel, hogy nekik mi mindenről van döntési joguk és mi mindent kell tudniuk. Én csendben átírnám, oszt jónapot.
Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis -
 fjanni
tag
fjanni
tag
Értem a 3 tábla felépítését és ez a megoldás jónak tűnik. Megoldja azt hogy eltérő időbélyegekkel hogyan lehet összefűzni adatokat.
Az adat összefűzés azért kell mert ipari üzemről van szó ahol gázmérők regisztrálják a fogyasztást főmérők/almérők/mellérendelt mérők struktúrában. Minden időpontban meg kell tudni mondani pl. hogy az almérőkőn mért fogyasztás összege megegyezik-e a főmérőével. De ugyanígy az elektromos mérőknél pl. hogy a napelem általt termelt energia / a hálózatról vásárolt energia / visszatermelés hogyan viszonyul egymáshoz és pl. mennyi az üzem tényleges fogyasztása stb. és mindezeket összesítve órára/napra/hétre hónapra stb. Tehát különböző mérőpontoknál szerzett adatokkal műveleteket kell végezni, ezt pedig csak úgy lehet hogy összerendelem azokat.
Ez azonban egy jelentős struktúra váltás és egy német cégnél ezt nehéz átvinni, de megpróbálom.
Viszont nekem addig is kell egy megoldás és a korábban említett View jó lehet erre. Fogom a tábla adatokat, először is konvertálom az időt a legközelebbi negyed órás időre (00/15/30/45min) beleteszem a mérési pont azonosítóját (MPxxx) is az adat mellé és unionnal összefűzöm őket. Aztán ezt a view-t használom a Grafana Query-kben. -
 Jim74
nagyúr
Jim74
nagyúr
-
bambano
titán
"Valóban a mérő azonosító karaktereiben lehet betű is.": majd valami agyhalott kitalálja, hogy legyen benne ékezetes betű, pl. tulaj neve vagy címe rövidítve, esetleg bugos utf8 konverter az adatbáziskezelőben (mint ma a debianban...
) és akkor lefekszik az egész....Egyébként a számmal is az a gond, hogyha nem tudod a határait, nem biztos, hogy találsz hozzá természetes adattípust. Akkor eltárolod stringként, és vége. Vagy jöhet olyan történet is, mint egyszeri lakcímnél, hogy beépítenek egy telket, és hirtelen a természetes szám házszámból lesz egy /b.
Soha nem tudhatod, hogy egy architect miket képes elbarkácsolni
Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis -
Jim74
nagyúr
-
bambano
titán
Én is közüzemi cég szerűséget találgatok...
Szerintem a mérőket ki kell venni, mert stringek között keresni rosszabb, mint egész számok között, másrészt nem tudni, melyik mérő neve milyen hosszú.Archiváláson valóban érdemes gondolkodni, de a kötelező megőrzési idő, szerintem, elég nagy ahhoz, hogy archiválástól függetlenül meg lehet borítani a lekérdezéseket. Ha a jelentési teljesítmény nem jó, akkor nem jól tervezték meg az adatbázist.
Egyébként a nagy tábla a biztonsági mentéseket borítja meg leghamarabb...
Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis -
Jim74
nagyúr
Nekem az a gyanúm, hogy valami olyan feladatról lehet szó, mint egy közüzemi cégnél, hogy jönnek a mérőkről az adatok és két adott időpont között ki kell számolni az adott időszakban elfogyasztott (mért) mennyiséget.
Szerintem ehhez elegendő egy tábla (feltéve, ha a mérőkről nem szükséges további információ, pl. telepítési hely, lokáció, hitelesítési év, ilyesmi).
Viszont az adatok mennyiségétől függően már most érdemes elgondolkodni az időközönkénti archiváláson, mert egy ilyen tábla elképesztő nagyra tud "hízni", ami az esetleges riportolási performanciát megboríthatja.
Én nem vagyok data enginieer, csak egy mezei riportingos, ezért az irományomat ilyen kritikus szemmel nézd kérlek. -
bambano
titán
Én úgy értettem abból, amit írt, hogy össze akarja kötni az azonos időben különböző mérőkkel mért értékeket, és ezt nem lehet időbélyeg alapján, mert az mindig változik.
Tehát ha valamiféle egységben (gazdasági egység, megrendelő, számlázási egység) több mérő van, tudni akarja az egy időpontban mért értékeket. Találgatás: például nálam 5 hőmennyiség mérő van, ha simán leszeded a mért értékeket, különbözik az időpont, de bizonyos célokra tudni kell, hogy amikor az egyik mért valamit, pontosan akkor mit mért a másik.Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis -
fjanni
tag
Nem ugyanarra van, minden tábla más mérési pont adatát tárolja, valamelyik gáz fogyasztás és van amelyik villamos energia fogyasztás adatot tárol, és olyan is van ahol villamos teljesítmény adatot tárolnak adott timestamp-hez kötve.
Ha sikerülne elérni hogy újrafejlesszék akkor annak milyennek kellene lennie?
Jelenleg ilyen egy tábla, a tábla neve MP001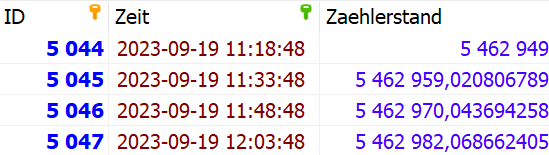
Egy másik tábla pedig: MP002
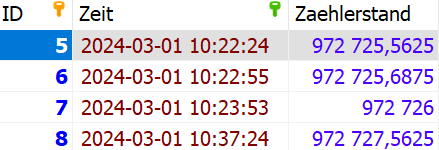
Látható hogy szinte minden táblában más az időbélyeg adat, van ahol rövid időn belül sok adat lett letárolva stb.
Ehelyett mi a jó megoldás?
Az hogy egy táblába írok úgy hogy minden adatnak van egy mérési pont azonosítója?
ID / MP_code / Zeit / Zaehlerstand - itt ügyelni kell arra hogy az időbélyeg adatok egy beírásnál megegyezzenek.
vagy
egy rekordba legyen írva az össze adat egy dátum mellé?
ID / Zeit / MP001 / MP002 / MP003 .... ahány mérési pont van?Ha elfogadják az új formátumok akkor pedig átkonvertáljuk a régi adatokat is ebbe az új formátumba.
-
 Louro
őstag
Louro
őstag
Uh, ilyen nálunk is van az egyik területen. Kb. 3-4 hetente felhívom a figyelmüket, hogy rendezzék már az adataikat. Ugyanarra a témára, naponta hoznak létre táblákat és van, hogy 1-2 rekord van csak benne. Mondtam nekik, hogy +1 oszlop, ami a napot jelöli, sokkal ideálisabb lenne. Ehelyett már 300+ táblájuk van csak egy célra és nekik így jó. Szerencsére csak két ilyen fafejű kolléga van. Persze panaszkodni tudnak, hogy ha az SSMS-ben lenyitják a táblák listáját, akkor van, hogy megnyekken a rendszer.
És nem egy DWH területről beszélünk. Kb. 100 táblában elférnének, de ehelyett 5000+ táblájuk van. Nekem fizikailag fáj, ha velük kell foglalkoznom. Hiába jelzem, hogy ha unique indexet akarnak trigger miatt, akkor ne 4 adatból rakják össze, amik ráadásul eltérő adattípusúak, hanem csináljanak egy dedikált unique mezőt és arra lehet indexálni.
De hát mi csak csóró üzemeltetők vagyunk és ők a détaendzsinírek.
Mess with the best / Die like the rest




![;]](http://cdn.rios.hu/dl/s/v1.gif)



 megválaszoltad saját kérdésed
megválaszoltad saját kérdésed 





















Új hozzászólás Aktív témák
-
Fórumok
PROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
- Fórumok
- Szoftverfejlesztés
- SQL kérdések
- (kiemelt téma)
Hirdetés
- Nintendo Switch 2
- Windows 10
- PROHARDVER! feedback: bugok, problémák, ötletek
- Milyen TV-t vegyek?
- Okos otthon - Home Assistant, openHAB és más nyílt rendszerek
- Egyéni arckép 2. lépés: ARCKÉPSZERKESZTŐ
- Mikrotik routerek
- Megújult mobilos felület, fórumos ráncfelvarrás a PROHARDVER! lapcsaládon
- Androidos fejegységek
- One otthoni szolgáltatások (TV, internet, telefon)
- További aktív témák...

- ASUS RTX 5070 Prime OC garis
- DELL Latitude 5520 Intel Core I7-1185G7, 32 GB, 512 SSD MAGYAR VILÁGÍTÓ BILLENTYŰZET
- PlayStation Portal - Midnight Black - Garanciával
- Új ASUS RYZEN 5 7600X GAMER ERŐMŰ PC 32Gb DDR5 512GB SSD NVIDIA RTX 3070TI 8Gb DDR6 750W TÁP 2ÉV GAR
- REDRAGON K530 TKL Draconic Compact RGB Red Switch
- iPhone 13 128GB Red -2 ÉV GARANCIA - Kártyafüggetlen, MS4570, 100% AKKSI
- 0PERCES BOSE QuietComfort Ultra Headphones, zajszűrős, Bluetooth fejhallgató!
- Tablet felvásárlás!! Apple iPad, iPad Mini, iPad Air, iPad Pro
- Dell Latitude 7390 13,3" FHD IPS, i5-i7, 8-16GB RAM, SSD, jó akku, számla, 6 hó gar
- Apple iPhone 17 256GB & 512GB Bontatlan Független Összes Szín / 27% áfás ár
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest