- Eladhatatlannak ítélt CPU-k eladásával javult az Intel node-ok kihozatala
- Az AI átformálja a Peugeot modelljeit is
- Ráműthető a Linux PlayStation 5-re, de csak egy boot erejéig
- Mindenféle környezeti behatásnak ellenállnak az ASUS új TUF tápjai
- A kínai felsővezetés blokkolhatta Mark Zuckerberg óriási AI üzletét
- Melyik tápegységet vegyem?
- Papírnehezékként használható csúcs-GeForce-ot árul egy francia viszonteladó
- OLED TV topic
- Mini-ITX
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Apple MacBook
- Eladhatatlannak ítélt CPU-k eladásával javult az Intel node-ok kihozatala
- Beolvad a Palitba a Galax a VGA-piac nehézségei miatt
- Azonnali fotós kérdések órája
- Milyen egeret válasszak?
Új hozzászólás Aktív témák
-

Sokimm
senior tag
Sziasztok!
A MsAccess fórum elég kihaltnak tűnik, ezért itt tenném fel a kérdésem:
Van egy gyermektábor, amiben 3 tábla adja az adatbázist.
Az első tábla, a gyerekek neve, szülők kapcsolattartó elérhetősége, extra adatai vannak.
A második tábla, a gyerekek egyedi táboros igényeit taglalja (vega, hány napot van, melyik foglalkozás érdekli, stb).
A 3. táblába szeretném a gyerekek információs táblájából kinyerni CSAK a nevüket, és mellé a második tábla opciós mátrixát dinamikusan hozzáilleszteni. (táborba érkezés regisztrációkor név: mit kér enni, mire jött, stb)
A problémám az, hogy míg az adatok lookup table szerű dinamikus változói szépen létrejönnek, addig a gyerekeket egyesével kell a rekordok közé felvenni, és rohadt fárasztó 100 gyereknél. Van rá valami mód, hogy a recordokat autofill módon feltöltse az első táblából?
Van rá valami mód, hogy a recordokat autofill módon feltöltse az első táblából?
Később jöhet még 1-1 gyerek, azokat már manuálisan hozzáadnám a 3. táblához, de a tömeget nem szeretném egyesével.
Ha ez túl Microsoft-os téma (szintaktika acces szinten), akkor kérlek ne haragudjatok, viszont ha szemantikailag (lehetetlen teljes adattáblákból oszlopok "copy"-ja másik táblában adatbáziskezelő programokban) vagyok lemaradva, kérlek világosítsatok fel, miként oldanátok meg a problémám.
A válaszokat előre is köszi. -

Taci
addikt
Adott ugyanaz a témakör, ami korábban is.
A kérdésem a következő lenne:Adott példának okáért ez a lekérdezés: DB Fiddle
Itt ami fontos lenne nekem, hogy ha egy kategóriára azt mondom, hogy nem érdekel (
category_id not in (27)), akkor azokat az elemeket ne jelenítse meg, amikhez ez a kategória hozzá van rendelve. (Pl. ha azt mondom, allergiás vagyok a mogyoróra, akkor ne mutasson olyan recepteket, amiben mogyoró van)Ezzel az adott lekérdezéssel viszont nem így működik.
Direkt úgy módosítottam a példát, hogy könnyen látni lehessen:INSERT INTO `items_categories` (`id`, `item_id`, `category_id`) VALUES(349, 117, 27),(350, 117, 26),(351, 117, 29)Tehát 117-es elem benne van a 27-es, 26-os és a 29-es kategóriában.
Ha én azt kérem, hogy azokat az elemeket ne jelenítse meg, amik a 27-es kategóriába tartoznak (
category_id not in (27)), azt várnám, hogy a 117-es elemet nem jeleníti meg egyáltalán.Viszont ebben a formájában ez nem így működik, mert ezzel csak azt érem el, hogy eredménybe visszaadja a 117-est is, mert a 3 rekordból kizárja azt az egyet, ami a 27-es kategóriás, viszont a maradék kettő miatt a találati listában marad.
Hogyan lehet megoldani ezt?
Köszönöm.
-

pch
senior tag
Ha már mysql lenne egy kérdésem

Van egy tábla amibe a dátumok vannak (meg egyéb adatok, de ez most nem lényeg)
Van egy másik tábla amibe egy adott dátumhoz hozzá van fűzve egy érték.
Meg van egy harmadik tábla amibe van egy kezdőérték.
Melyik az a számolási metódus amivel a kezdőértékhez ha hozzáadom a dátumnál letárolt értéket az lesz a következő kezdőérték, és ha talál egy későbbi dátum<>értéket azt az előzőhöz adja hozzá?
php alatt ugye a x=x+y
Azaz egyik táblába vannak mondjuk a hónap-napok egymás után (2021-08-01 ... 2021-08-31)
Másik tábla (2021-08-20 1500) (2021-08-23 3500)
A harmadik táblába az induló 5000
Akkor ezt szeretném kapni:
2021-08-01 től 2021-08-19 ig 5000,
utána 6500
majd 23-tól 10000
Köszönöm! -

nyunyu
félisten
Azt ne felejtsd ki a képletből, hogy a count() lekérdezésnek a végeredménye egy szám, míg a count() nélkülié egy adathalmaz, aminek a DB szerverről letöltése lényegesen tovább tart.
Tegnap kellett lementenem egy 850k soros táblához kapcsolódó adatokat CSVbe, eltartott vagy 20 percig, mire lejött a 160 mega adat a céges VPNről.
Ugyanez select count(*) from (eredeti query)-vel 5 másodpercig tart. -
Taci
addikt
Lehet, triviális a válasz, de:
Egy Count-lekérdezés végrehajtása ugyanannyiba kerül, mint pont ugyanannak a query-nek a Count nélküli változata?
Azért merült fel a kérdés, mert ha a Count nélkülivel eleve megkapom magukat az elemeket is, akkor ha csak a Count-ban tér el a két query, abban az esetben nincs értelme a Count-ot használni, hisz' az csak az elemek számát adja vissza, míg a másikkal megkapom az elemeket is, amiket aztán meg összeszámoltatok egyszerűen.
(Nyilván lehet millióféleképpen használni, én sem csak így használom, de amikor pont ilyen eset lenne, hogy a Count-on kívül minden más ugyanaz, akkor vajon ugyanannyi időt vesz igénybe mindkét lekérdezés? Tippem szerint igen, hisz' ugyanúgy kell elvégezni minden műveletet benne, így a Count csak összeszámolja az eredménytáblát "és kész".
De most már inkább rákérdezek.)
-
-
Taci
addikt
Sosem találkoztam még vele, úgyhogy ránéztem. És itt azt taglalják, hogy az SQL_CALC_FOUND_ROWS általában véve lassabb, mint a két külön query (az eredeti + a count).
Plusz ahogy olvasom, a jövőbeli verziókból már ki is szedik a támogatottságát:
The SQL_CALC_FOUND_ROWS query modifier and accompanying FOUND_ROWS() function are deprecated as of MySQL 8.0.17 and will be removed in a future MySQL version.
És hogy a COUNT(*)-ot ajánlják helyette.Köszönöm azért a tippet, legalább láttam, hogy ilyen is van (lassan: volt).
-
Taci
addikt
Illetve még azt kérdezném külön témaként, elméleti kérdésként:
Eddig úgy csináltam, hogy kértem 4 elemet (query, Limit 4), a kliens felhasználta, kért újabb 4 elemet, felhasználta és így tovább.
Tehát 4 elemenként volt egy query az adatbázisból. Per kliens.
Ez azért volt jó (inkább kényelmes), mert abban a pillanatban, hogy nem 4 elemet kapott a kliens vissza, megvolt, hogy nincs több elem, jöhet a no_more_items elem.Most azt nézem, hogy a Limit 64-gyel egyből betöltök 64 elemet. Ez nyilván 16-szor több (szöveges) adatot jelent egyben, viszont így is csak kb. 30 kB a Limit 4-nek a kb. 2 kB-jával szemben. 30 kB-nyi adat pedig semmi, és ezzel a query-k számát is drasztikusan leredukálhatom. (4 elemenkéti lekérdezés helyett csak 64 elemenkénti).
Viszont ezzel egy teljes szerkezeti változást meg kell csinálnom a PHP és a JS fájljaimban is. Amit persze szó nélkül megteszek, csak szeretnék előbb tanácsot kérni, hogy melyik a jobb út. Vagy van-e egy harmadik út, ami még jobb lenne.
Ha a szervernek "nem fáj" az ilyen sűrű lekérdezés (és nem is lassítja - több ezer felhasználó egyidejű lekérdezéseit figyelembe véve sem), akkor maradok a Limit 4-nél.
De ha ez a sűrű lekérdezgetés rossz hatással van a válaszidőre, és ezzel a felhasználói élményre is, akkor nézegetem a másik utat, hogy egyszerre több adatot kérek le, és az utolsó pár elemig azzal eldolgozgat a kliens lokálban, aztán a vége felé kéri az újabb adagot.
Vagy van valami más, jobb út?
Köszönöm.
-
Taci
addikt
válasz
 sztanozs
#5140
üzenetére
sztanozs
#5140
üzenetére
Ha az általad írt lekérdezés által visszaadott össz-elemszámot szeretném megtudni (a belső limit nélkül - hogy később tudjak vele számolni, a belső limit meddig nyújtózkodhat - szóval a belső Select-et ezért veszem ki, plusz ugye nem kell rendezni sem (Order By), és a végén lévő Limit sem kell)), akkor jelen tudásom szerint azt így kérdezném:
SELECT COUNT(*) AS result_count FROM(SELECT i.item_id FROM items AS iINNER JOIN items_categories AS c ON i.item_id=c.item_idWHEREc.category_id NOT IN (1,3,13,7,20) ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_id) AS tVan esetleg ennek hatékonyabb, gyorsabb, jobb módja?
Ezt találtam még:
SELECT COUNT(DISTINCT item_id) AS result_count FROM(SELECT i.item_id FROM items AS iINNER JOIN items_categories AS c ON i.item_id=c.item_idWHEREc.category_id NOT IN (1,3,13,7,20) ANDi.item_id NOT IN (117,132,145,209,211)) AS tItt elvileg a Distinct kiváltja a Group By-t.
Viszont sajnos Count-hoz a phpMyAdmin nem ír lekérdezési időt, így nem tudom, melyik a gyorsabb. Vagy jobb.
Ebben kérnék tanácsot.
Köszönöm. -
-
válasz
 bambano
#5156
üzenetére
bambano
#5156
üzenetére
Ez viszont nem jól fogja számolni, lesz egy nap két DE (2*8 óra, hajnalban és éjszaka) és egy DU (1*16 óra napközben).
Valahogy így lehet jó:
SELECT
TRUNC(dateadd(hour,-8,datum)) AS nap,
CASE WHEN date_part('hour',dateadd(hour,-8,datum))>12 THEN 'DU' ELSE 'DE' END AS muszak,
SUM(szam)
FROM tabla
GROUP BY 1,2 ORDER BY 1,2;Így a hajnal még az előző naphoz fog tartozni mint DU műszak.
-

tm5
tag
válasz
bambano
#5150
üzenetére
SELECT TRUNC(datum) AS nap,
CASE WHEN DATEPART(HOUR,datum)>11 THEN 'DU' ELSE 'DE' END AS napszak,
SUM(szam) AS osszeg
FROM tabla
GROUP BY nap,
CASE WHEN DATEPART(HOUR,datum)>11 THEN 'DU' ELSE 'DE' END
ORDER BY 1,2
Legyen neked Karácsony Nálunk 12 és 1 között ebéd szünet van, olyan senkiföldje. -
Sziasztok,
tudok valahogy időintervallumot group-olni?
Tehát van egy ilyen táblám, amiben vannak órák és egy hozzá tartozó értékeke kb így:
2021.06.01 06:00:00000000000 29
2021.06.01 07:00:00000000000 26
2021.06.01 08:00:00000000000 33
2021.06.01 09:00:00000000000 26
2021.06.01 10:00:00000000000 27
2021.06.01 13:00:00000000000 16
2021.06.01 14:00:00000000000 28
2021.06.01 15:00:00000000000 20
2021.06.01 16:00:00000000000 20
2021.06.01 17:00:00000000000 18
2021.06.01 18:00:00000000000 17
2021.06.01 19:00:00000000000 7
2021.06.01 20:00:00000000000 13
2021.06.01 21:00:00000000000 19
2021.06.01 22:00:00000000000 34
2021.06.01 23:00:00000000000 28Úgy szeretném az adatokat összegezni, hogy pl 12 óránként legyen összeadva. Van erre valami értelmes megoldás?
Előre is köszi -
-
Taci
addikt
válasz
sztanozs
#5140
üzenetére
 Na azért ez így hasít...
Na azért ez így hasít...
0.0096 secondsEzek szerint akkor nem kell "archiválni"? Akármekkorára is dagad a tábla, jobb egyben tartani? Vagy van egy határ valahol, ahol már szeletelni kell?
GROUP BY i.item_id, i.item_date
Itt miért kell az _id után a _date is, ha csak azért van a Group By, hogy egy-egy _id csak egyszer szerepeljen? (Csak szeretném megérteni.)Illetve még egy dolog jár ezzel a lekérdezéssel kapcsolatban a fejemben:
Ez egy nagyon jó és gyors lekérdezés. Azt hogyan lehetne legoptimálisabban megoldani, hogy ha a visszaadott rekordok száma kisebb, mint 4, akkor megnézze LIMIT 1000 helyett 2000-re is? Mert ha 2000-ben a talált rekordok száma nagyobb egyenlő mint 4, akkor onnan kell az eredmény, és akkor a következő görgetős lekérdezéshez is már a 2000-et kell használni, mert az 1000 nem volt elég.
Ehhez elég gyors ez a lekérdezés már, úgy gondolom, hogy kettő egymás után is beleférjen, ha kell.Hogy a gyorsabb/jobb?
1) Futtatom a query-t, aztán számoltatom php-ben a rekordok számát, és ha kisebb, mint 4, akkor jöhet az újabb query 2000-re?
2) Vagy előbb "üresen" csak egy Count, és az eredmény függvényében a valós (rekordokat visszaadó) lekérdezés?
3) Vagy van valamilyen COUNT-os utasítás (esetleg feltételes is) hozzá, amivel ezt még SQL-oldalon meg lehetne oldani? Ami akár egy lekérdezésen belül visszaadja, hogy az 1000-es limittel mennyi rekordot adna vissza, és ha 4-nél kevesebbet, akkor egyből futtatja 2000-re?Egy Count biztosan sokkal gyorsabb, mint az összes érintett mezőt visszaadni, és azt számoltatni, csak ezért jutott eszembe a kérdés.
-
Simán meg lehet trükközni a lekérdezést, hogy pl csak a legfrissebb 1000-ben keresse az első ötöt (persze, ha lesz annyi és nem került be az összes a "rossz" kategóriába):
SELECT i.item_id, i.item_date
FROM (
SELECT item_id, item_date
FROM items
ORDER BY item_date DESC LIMIT 1000) as i INNER JOIN items_categories AS c ON i.item_id=c.item_id
WHERE
c.category_id NOT IN (1,3,13,7,20) AND
i.item_id NOT IN (117,132,145,209,211)
GROUP BY i.item_id, i.item_date
ORDER BY i.item_date DESC LIMIT 4 -
Taci
addikt
válasz
sztanozs
#5137
üzenetére
Köszönöm szépen a részletes magyarázatot és okfejtést! (És mindenki másnak is, aki segített!)
Mindezt figyelembe véve még az az elméleti kérdés jutott eszembe, hogy:
Csakis és kizárólag a legfrissebb dátumú elemek vannak elől. Egyszerre mindig csak 4 elemet kap a felhasználó, mindig a (kiválasztott kategóriának stb. megfelelő) 4 legfrissebb dátumút. Mindig.
Ezek a rekordok pedig 5 percenként kerülnek az adatbázisba, kb. 5-10-esével / forrás, 20-30 helyről egyszerre.
Aztán ha görget a lap aljáig (mínusz X pixel), akkor következő 4 és így tovább. 25 görgetés 100 rekord. 250 görgetés 1000 rekord. 750 görgetés 3000 rekord. Ennyit nem fog senki soha egy huzamban végig pörgetni a szűrési feltételek módosítása, vagy ráfrissítés nélkül (ahol 0-ról kezdődik az egész).
Plusz a következő "4-esbe" az időközben bekerült új rekordok is benne kerülnek, szóval egyre kevésbé valószínű, hogy "túl mélyre ér" (a rekordok időbélyegzőit figyelembe véve).Így a tábláknak (items) nem kellene csak max 3 ezer (az items_categories-nak pedig átlag 3 kategória/item-mel számolva max 9 ezer) rekordot tartalmaznia. Tehát a mostani példa adatbázisomnak (300e / 900e) a század részét.
Most levittem erre a számra a rekordok számát, és így az eddigi 0,5 mp-es lekérdezés 0,01 mp-re (sőt inkább alá) szelídült. Azért ez már élhető. Még ha a duplájával számolnék (rekordszám) a biztonság kedvéért, akkor is.
A legfrissebb 3000 utáni rekordra pedig csak és kizárólag a szöveges keresésnél lehet szükség, ott pedig belefér egy lassabb (Union miatt) lekérdezés is.
Illetve még akkor is, ha mondjuk csak 1 kategóriát néz, és abban a legfrissebb 3ezerből csak kb. 100 rekord van (30+ kategória van), és 25-től többet scrollozik - ami azért nem olyan sok. Inkább megnéztem most gyorsan 6e/18e rekordra, 0,03 mp alatti a lekérdezés, és így "biztonságban is lennék" minden téren.A kérdésem az lenne, hogy:
1) ezt jó ötletnek tartjátok-e,
2) ha igen, akkor hogyan lenne jobb az "archív" rekordokat tárolni? Minden, ami nem a 3000 (vagy 6000) legfrissebben van benne, az legyen egyetlen egy darab (mondjuk items_archive) táblába áthelyezve? Mert ha jól emlékszem, azt mondtátok, hogy ahol ugyanazok a mezők vannak, nem jó ötlet szétszedni.
Viszont azt is mondták, hogy mindenképp kell "archiválni" is.
Tehát egy nagy archiv tábla legyen (items_archive), vagy legyen mondjuk évenkénti? (items_archive_2021, items_archive_2022 stb.)
Úgy gondolom, csak kereséseknél kellene használni az archívokat, normál használattal görgetve oda már "nem jut le senki" (de biztos ami biztos, felkészíteném arra is).@nyunyu: Az SQL Server Express-t most raktam fel, már a táblákat töltöm. Kíváncsi leszek az ottani eredményekre.
-
A létrehozott index sokat nem segít, mivel az egy 'compound index' (csak akkor működik, ha egyszerre használod a két mezőt inkluzív keresésre, és egyszerre tudja használni mind a kettőt). Két külön indexszel talán valamit javulna.
Amúgy akármit is csinálsz úgy tűnik a kapcsolótábla nagy mérete miatt - és mivel nem magát a táblát, hanem annak egy előszűrt nézetét használod - szinte biztosan lesz jelentős adatmozgás (ez látszik a "sending data" szekcióban).
Ahogy nézem a mariadb nem igazán tudja rendesen használni az indexeket (pontosabban a MERGE módot), DISTINCT és/vagy GROUP BY kifejezésekkel együtt, mindenféleképp temp táblát szeretne alkalmazni.
Ezért is kisebb az első esetben létrehozott temp tábla (mivel itt csak egy mező jön létre és ezzel hasonlítja össze az item_id-t). A második esetben meg létrehozza a joinolt temp táblát (három mezővel) és mivel utána group by/distinct van így nem MERGE-et használ, hanem csinál egy teljes table dump-ot :/Tényleg meg kell próbálni valami mással, mert még a MySQL doksiban is azt olvastam, hogy még pl a DISTINCT esetében is szépen kell működnie index-szel, ha a sorbarendezett mező sorbarendezett indexet használ.
-
Taci
addikt
válasz
sztanozs
#5126
üzenetére
SELECT item_id, item_dateFROM itemsWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))ORDER BY item_date DESC LIMIT 4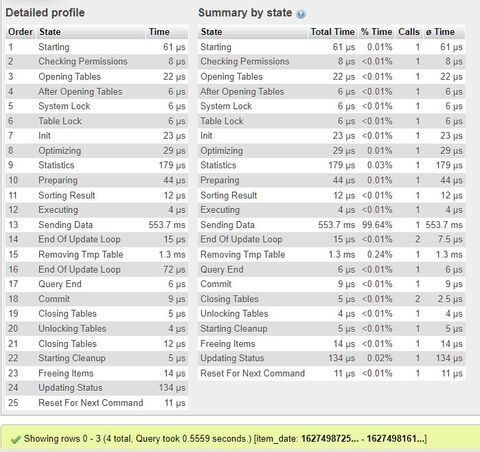

(valami régi kódból maradt benne a neve, a feed_id az az item_id az index nevében)
Mivel itt azt mondja, hogy az items_categories táblán nem használ indexet (key = NULL), ezért arra gondoltam, akkor létre hozok egy covering indexet ide:
CREATE INDEX idx_category_id_item_id ON items_categories (category_id,item_id)A sebességen nem javított, de most már így néz ki az explain:

----------
SELECT i.item_id, i.item_dateFROM items as i INNER JOIN items_categories AS c ON i.item_id=c.item_idWHEREc.category_id NOT IN (1,3,13,7,20) ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_id, i.item_dateORDER BY i.item_date DESC LIMIT 4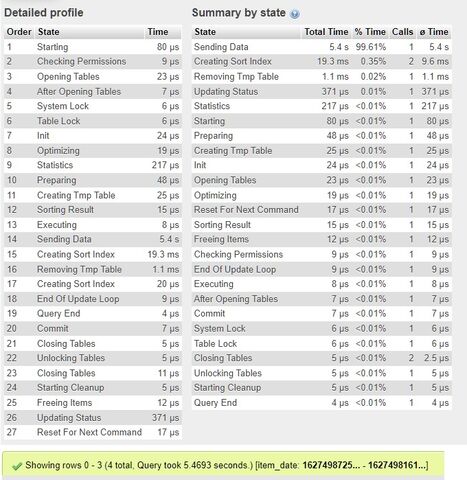

Itt ha a
GROUP BY i.item_id, i.item_date
helyettGROUP BY i.item_id
van, akkor ennyi a változás:
De időben semmit nem jelent.
-
Taci
addikt
válasz
 martonx
#5131
üzenetére
martonx
#5131
üzenetére
Már fontolóra vettem, ha másért nem is, hogy lássam, ott is ugyanez-e a sebesség. Plusz ugye a Weblap készítés topikban szolgáltatóválasztásnál az Azure-t ajánlottad.
Egyelőre nem köt semmi a MySQL-hez, csupán pár lekérdezésem van, aminek jól (gyorsan) kellene működnie (az itt tárgyalt a legfontosabb), ezekben meg annyira nem lehet semmi specifikus, vagy ha igen, akkor van alternatívája.
Teszek egy próbát vele. -
nyunyu
félisten
válasz
martonx
#5131
üzenetére
Kérdés, hogy azokból a free megoldások (Oracle XE, SQL Server Express) mennyire használhatóak az ő céljaira, hiszen pár magra meg pár GB RAMra vannak korlátozva, és az adatbázis lehetséges mérete is korlátozott, ez többmillió soros táblákhoz kevés lehet.
Oracle XE:
- 2 szál
- 2GB RAM
- 12GB tárterület
- 3 DB (séma?)SQL Server Express:
- 4 mag
- 1GB RAM
- 1MB puffer
- 10GB tárterületMindenesetre egy próbát megérnek, hogy melyik hogyan hasít a gépeden.
Más kérdés, hogy a MariaDBs szintaxist, adattípusokat biztosan át kell majd írni PL/SQL-re vagy T-SQL-re.
Amennyire múltkor nézegettem a MariaDBt, szintaxisa inkább az Oracle szintaxisához áll közelebb.Nem tudom, hogy hoztad létre az ID mezőket a táblákban, ha autoincrementesek, akkor egyszerűbb lehet az SQL Server Expresst használni, mivel Oracle még mindig szekvenciákat használ, amit neked kell manuálisan
kezelni.PostgreSQL-t nem vágom.
-
-
Ahogy jobban megnéztem a probléma azzal van, hogy igazából nem sikerült rendes indexet létrehozni.
A primary indexhez lett hozzáadva a dátum, mint key oszlop, pedig saját indexet kellett volna csinálni:--
-- Indexes for table `items`
--
ALTER TABLE `items`
ADD PRIMARY KEY (`item_id`);
ALTER TABLE `items`
ADD INDEX (`item_date` ASC); -
Taci
addikt
válasz
sztanozs
#5126
üzenetére
Mondjuk egy-egy execution plan-t jó volna látni mindegyikre...
Ezekre a fajta információkra gondolsz (a lekérdezés egyes részei mennyi ideig futottak, használt-e indexeket stb.), amit az Explain és a Profiling ad? (Google-ön rákeresve az execution plan-re phpMyAdminban ezeket dobta fel.)
Mert akkor megcsinálom.
-

bambano
titán
válasz
sztanozs
#5126
üzenetére
"az indexet növekvő sorrendben hozza létre így az index végén levő (legnagyobb értékek) rögtön rendelkezésre kell álljanak": szemben azzal, ha csökkenő sorrendben hozza létre, mert akkor az index elején áll rendelkezésre a legnagyobb érték.
normálisan az indexet egyféleképpen kell létrehozni, és ha csökkenő a lekérdezés, akkor egyszerűen reverse scan-t csinál. legalábbis a postgres ilyen, hogy más adatbáziskezelők mit csinálnak, nem tudom.
-
Ha sorba szeretnéd rendezni, akkor majdnem mindegy, hogy ASC-ba, vagy DESC-be rakod az indexet, gyorsan kell működjön, Igazából az ASC azért lenne elméletileg jó a DESC sorbarendezésnél, mert az indexet növekvő sorrendben hozza létre így az index végén levő (legnagyobb értékek) rögtön rendelkezésre kell álljanak. Mondjuk egy-egy execution plan-t jó volna látni mindegyikre...
-
Taci
addikt
válasz
sztanozs
#5124
üzenetére
Köszönöm szépen a sok energiát amit bele fektettél.
Az indexeléssel kapcsolatos módosítás nem hozott érezhető eredményt. (Amúgy ha Order By DESC van a lekérdezésben, akkor az indexet is DESC alapján kellene létrehozni, nem? Csak mert ASC-t írtál. De amúgy próbáltam mindkettővel, nincs változás sajnos.)
A Join-os lekérdezés sajnos minden formájában szörnyen lassú, ha van benne Group By is.
- Copy-past amit #5124-ben írtál: 7.6651 seconds.
- Group By nélkül: 0.0278 seconds. (Csak így egy-egy rekord (az amúgy jó eredményekből) többször is benne van, ami nem jó.)Közben hogy kiszűrjem, hogy nem-e az én lokál gépeimen (kettőn építettem fel és futtattam a lekérdezéseket) van-e a gond, kipróbáltam egy ingyenes szolgáltatónál is (000webhost.com, a célnak megfelelt tökéletesen).
Sajnos ugyanaz az eredmény.Elképzelhető, hogy ennél a 300e rekord az egyik táblában, és 900e rekord a másikban (és ezek összekötve), itt ez a max lekérdezési sebesség? A leggyorsabb helyes eredményt az #5112-ben leírt lekérdezés hozta, 0,5 mp. Ami lassú így is.
Szóval lehet, hogy ha majd elérek 100e bejegyzés környékére (az első táblában), akkor el kell gondolkodnom a régi rekordok "archiválásán"? Hogy a fő táblában ne legyen 100e rekord fölött, és akkor "megúszom" a lekérdezéseket (amik persze csak a fő táblából kérdeznek le, nem az "archivakból") kb. 0,2 mp alatt?Több ötletem nincs. És köszönöm szépen nektek ezt a sok segítséget és próbálkozást, nem akarok visszaélni a jóindulatotokkal.
-
válasz
sztanozs
#5123
üzenetére
és ha minden Itemhez csak egy dátum tartozik, akkor használható az index:
SELECT i.item_id, i.item_date
FROM items as i INNER JOIN items_categories AS c ON i.item_id=c.item_id
WHERE
c.category_id NOT IN (1,3,13,7,20) AND
i.item_id NOT IN (117,132,145,209,211)
GROUP BY i.item_id, i.item_date
ORDER BY i.item_date DESC LIMIT 4 -
Esetleg:
SELECT i.item_id, i.item_date
FROM items as i INNER JOIN (
SELECT item_id FROM items_categories
WHERE
category_id NOT IN (1,3,13,7,20) AND
item_id NOT IN (117,132,145,209,211)
GROUP BY item_id
) AS c ON i.item_id=c.item_id
ORDER BY i.item_date DESC LIMIT 4Ennél már nem tudom jobban bonyolítani

De egy item_date Sorted Index-szel szerintem többre mennél, ha mindenféleképp sorba szeretnél rendezni:
https://www.mssqltips.com/sqlservertip/1337/building-sql-server-indexes-in-ascending-vs-descending-order/ -
nyunyu
félisten
válasz
sztanozs
#5116
üzenetére
Nincs rá garancia, az igaz.
Gyakorlatban meg pont emiatt szívtam a mostani GDPR projektemen.
3 insert szedte össze a daráló érett szerződéseket, első leválogatta az egyik típusú szerződéseket, második az első szerződésekhez kapcsolódó másik típusúakat, harmadik meg a második típusúakból az önállókat.Aztán amikor beröffentettük az állami hivatallal való szinkronizációt, az első 20000db-os adatcsomagba kb. 19000 olyan rekord került, aminek az IDja 20000 alatti volt.
Végül a második típusú szerződések szinkronizációjára már csak akkor került sor, amikor az első típusúak teljesen elfogytak a táblából.Ez azért volt kellemetlen, mert mint kiderült, a második típusú szerződések nagy része nem kellett, hogy meglegyen az állami nyilvántartásban, azok sokkal gyorsabban darálhatóak lennének.
Első típusúak darálása meg nem ment olyan gyorsan a túloldalon, mint vártuk. -
Ráadásul: "amire amúgy már az elején, az első Select-nél is meg lehetne csinálni, mert úgyis csak abban van a mező, ami alapján rendez, így kár a kibővített találati táblán rendezgetni."
Nincs olyan, hogy első Select. Amit te elsőnek nézel, az a külső select, tehát az hajtódik végre utoljára, tehát subselect először, külső select másodszor.Join+GroupBy nekem több rápróbálás után kb ugyanúgy (~500ms) működik, mint a subselect:
SELECT i.item_id, max(i.item_date) as max_date
FROM items as i INNER JOIN items_categories c on i.item_id=c.item_id
WHERE
c.category_id not in (1,3,13,7,20) and
c.item_id not in (117,132,145,209,211)
group by i.item_id
ORDER BY max_date DESC LIMIT 4 -
Az orderby csak a fő selectre hat, a subselect egyszer legenerálódik és azután csak újrahasznosítódik.
Az utolsó kérdésre:
A query mindig a motor optimális futása alapján történink, nincs értelme order by-nak belül (ha nincs limit is mellé), mert a subquery/temp tábla lekérdezése nem garantálja a rekordok sorrendjét. -
Taci
addikt
Meg lehet azt valahogy csinálni, hogy ne a subquery-ben lévő Select-re (select item_id) alkalmazott fő Select-re (select item_id, item_date) alkalmazza az Order By-t, hanem csak a fő Select-re?
Ahogy írtam is a bejegyzésben, amire itt válaszolok most, külön-külön gyorsak a lekérdezés részei:
select item_idfrom items_categorieswherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211)
Showing rows 0 - 24 (768981 total, Query took 0.0232 seconds.)SELECT item_id, item_dateFROM itemsORDER BY item_date DESC LIMIT 4
Showing rows 0 - 3 (4 total, Query took 0.0057 seconds.)És ha egyben van, akkor pedig az egészre nézve az Order By lassítja le:
Order By benne:
SELECT item_id, item_dateFROM itemsWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))ORDER BY item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 0.5749 seconds.)
Order By nékül:
SELECT item_id, item_dateFROM itemsWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))LIMIT 4Showing rows 0 - 3 (4 total, Query took 0.0295 seconds.)
Ezért gondoltam arra, ha a Group By-t "le lehetne tudni hamarabb", akkor már kellően gyors lehetne az egész lekérdezés. Mert így a join-olt (ez így subquery-vel amúgy Join-nak számít?) táblán sokat időzik az Order By miatt - amire amúgy már az elején, az első Select-nél is meg lehetne csinálni, mert úgyis csak abban van a mező, ami alapján rendez, így kár a kibővített találati táblán rendezgetni.
Így lehetne optimális:
SELECT item_id, item_dateFROM itemsORDER BY item_date DESC -- <----WHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))LIMIT 4Persze ez itt a szintaktika nem helyes. Ahogy nézegettem, kb. ilyesmi módon lehetne helyesen lekérdezni:
SELECT item_id, item_dateFROM(SELECT item_id, item_dateFROM itemsORDER BY item_date DESC) AS iWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211)) LIMIT 4És ez már elég gyors is:
Showing rows 0 - 3 (4 total, Query took 0.0156 seconds.)Viszont itt van egy furcsaság:
Nálam a saját gépemen futtatva más eredményt ad a 2 változat. Az első (ahol a Group By a végén van) adja a helyes eredményeket, ez a legutóbbi pedig teljesen más rekordokat mutat, és nincsenek item_date alapján rendezve sem.VISZONT
DB Fiddle-ben ugyanazok az eredmények, tehát ott meg elvileg jó az új lekérdezés:
- Eredeti: [link] (item_id: 213, 212, 210,208)
- Új: [link] (item_id: 213, 212, 210,208)Erre az új fajta lekérdezésre, és a különböző eredményekre tudtok mondani valamit?
Esetleg finomítani ezen a változaton? (Ha pl. nem raktam bele az "AS i"'-t, akkor szólt, hogy "Every derived table must have its own alias". Így viszont a Where után lehet, hogy i.item_id kellene? Bár nem változtat az eredményen. Csak hátha ti láttok még benne valamit, azért írtam ezt a példát, hogy ez nekem csak Google-keresés eredménye. Hátha lehet csiszolni.) -
nyunyu
félisten
SQL99 óta azt javasolja a szabvány, hogy csoportosításnál, rendezéskor írd ki a teljes mezőt, függvényt, akármit.
Oszlopra sorszámmal hivatkozás az ennél régebbi szintaxis maradvány, már nem szabványos.Eddig csak Oracle kódokban láttam használatban, de ahogy nézem jó pár DB kezelő ismeri ezt a szintaxist.
-
Taci
addikt
válasz
sztanozs
#5107
üzenetére
Értem a logikát mögötte, és amúgy tök jó ötlet, köszönöm a tippet - de sajnos kb. 0,2 mp-cel lassabb, mint az előző.
Csak kíváncsiságként:
Itt az ORDER BY 2 ugye a második mezőt jelenti, ami jelen példában a MAX(item_date)? Ha sok mezőm lenne a SELECT-ben, és nem akarnám számolgatni, ide írhatnám azt is az ORDER BY 2 helyére, hogy ORDER BY MAX(item_date)? (Most így lefut a lekérdezés, az eredmény ugyanaz, csak nem tudom, az ORDER BY-os résznél is műveletnek veszi-e a MAX-ot, vagy már a fenti SELECT-ben elvégzettre hivatkozik?) -
-
Taci
addikt
Még annyi, hogy külön-külön a rész-lekérdezések gyorsak:
select item_idfrom items_categorieswherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211)
Showing rows 0 - 24 (768981 total, Query took 0.0232 seconds.)SELECT item_id, item_dateFROM itemsORDER BY item_date DESC LIMIT 4
Showing rows 0 - 3 (4 total, Query took 0.0057 seconds.)Szóval nem tudom/értem, összekapcsolva hogyan lesz ebből 0.8 mp.
-
Taci
addikt
válasz
bambano
#5104
üzenetére
Talán ez lehet a jó irány...
Most így néznek ki a lekérdezések:
Az "eredeti" (a javasolt változtatásod előtti):
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 10.8688 seconds.)
A categories tábla kivétele a Join-ból:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idWHEREic.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 5.0478 seconds.)
A subquery-s megoldás (WITH-et nem engedett használni, így most ezt a megoldást találtam a "helyettesítésére"):
SELECT item_id, item_dateFROM itemsWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))ORDER BY item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 0.7163 seconds.)
(És ide már nem is kell a Group By.)
Frissítettem a db-fiddle-t vele.
Mind a 3 változat ugyanazt a 4 rekordot adja vissza, helyesen.
Ez utóbbi, az általad javasolt valóban sokkal gyorsabb - bár (lehet, az én implementálásom miatt) még így is lassú (0,8 mp környéki lekérdezés).
(Furcsa mód ha kiveszem az Order By-t belőle (ami eddig csak lassította), a 0,8 mp-ből 6,6 mp lesz...)De ezzel talán már el lehet indulni ebbe (subquery) irányba.
Még valami ötlet esetleg ehhez az irányhoz?Köszönöm a tippeket és hogy ránéztél!
-
bambano
titán
további problémának látom a felesleges joinokat.
mivel az items_categories táblában a category_id egyenlő a categories táblában a category_id-vel, ezért csak abból a célból, hogy szűrni lehessen rá, tök felesleges összejoinolni a kettőt. az items_categories táblában pont ugyanúgy lehet szűrni a category_id-re, mint a categories táblában.pontosan ugyanez igaz az item_id-re.
tehát azt kellene csinálni, hogy az items_categories táblából leválogatod azt, ami kell, berakod egy subselectbe (ha a mysql vagymi tud olyat, nem ismerem), és utána ahhoz joinolod hozzá a végén a két plusz táblát.
ekkor a két plusz tábla joinját már csak a leszűrt termékekre csinálja meg, és sokkal gyorsabb lesz.valami ilyesmi postgresben az elmélet:
with tetelek as (select * from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211)) select * from items,tetelek,categories where
tetelek.item_id = items.item_id and
tetelek.category_id = categories.category_id;a lényeg, hogy a valódi szűrést a tetelek selectjében érdemes megcsinálni.
-
Taci
addikt
válasz
martonx
#5100
üzenetére
Próbáltam azt is, kicseréltem a *-ot 2 mezőre, de csak minimálisat gyorsult, annyit, amennyivel kevesebb adatot kellett visszaadnia. (Jelen lekérdezésnél 18mp helyett 17mp.)
Próbáltam azt is, hogy a most fent lévő xampp lite mellé felraktam a legfrissebb xampp-ot is, feltöltöttem adatokkal - és ugyanez a helyzet. Szóval nem a rendszer valamilyen hibája.
Annyit vettem észre "változást", hogy a "Copying To Tmp Table On Disk" helyett most a "Sending Data" veszi el a sok időt. De a végeredmény ugyanolyan lassú.
@bambano: Distinct-et nem használok, mert a join-olás miatt 1-1 bejegyzéshez az eredeti táblában (itt item) több kategória is tartozik, azok így több külön rekordba kerültek, és mivel így van több unique rekord ugyanahhoz az item_id-hoz, így sajnos nekem nem jó. (Mivel pont hogy az item_id-ra akartam volna használni a distinct-et.)
-----
Gondoltam, megnézem már, hogy a lekérdezés melyik része lassítja le az egészet amúgy.
Így néznek ki:Where, Group By, Order By nélkül:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idShowing rows 0 - 24 (901830 total, Query took 0.0165 seconds.)
Egy kérdés itt:
Amúgy az miért van, hogy habár azt írja ki, hogy 0.01 mp-ig tartott a lekérdezés, mégis, a lekérdezés indítása után kb. 5-7 mp-cel jelenítette csak meg ezt az eredményt?
A lekérdezés gyors, de mégis csiga lassan adja vissza az eredményt?
Most akkor a szememnek higgyek vagy az adatoknak?------
Group By, Order By nélkül:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)Showing rows 0 - 24 (768981 total, Query took 0.0351 seconds.)
------Group By nélkül:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)ORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 0.0420 seconds.)
------Minden benne:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 2.5095 seconds.)
------Szóval Group By (vagy Distinct) nélkül gyors a lekérdezés (bár mintha erre is lett volna cáfolat korábban, már nem tudom, annyi tesztet csináltam, már kavarodnak az eredmények).
Közben átmentem a másik (lokál) szerverre, és ott meg ugyanez a lekérdezés már az Order By-jal is belassul... Tök jó, hogy mindig változó eredményt kap, segít megtalálni a hibát...Még annyi ötletem van, hogy választok egy szolgáltatót, és reménykedem benne, hogy csak az én lokál telepítéseimen szerencsétlenkedik a kód (és én), és éles szerveren rendben lesz.
Egy kérdés:
Ha egyszer tényleg jó lenne a lekérdezés (mármint Group By vagy Distinct nélkül), hogyan tudnám "pótolni" azok funkcióját?Mert tegyük fel, ezeket a rekordokat adta vissza most eredményül:
item_id | category_id | item_date11 | 32 | 21111 | 27 | 21111 | 13 | 21135 | 7 | 165De így a 11-es item_id 3-szor szerepel, nekem pedig az kell, csak 1-szer legyen, akármi is van.
A Distinct nem jó, mert a különböző category_id-k miatt egyedi minden rekord, tehát szerepelni fog mind ugyanúgy külön.
A Group By nem jó, mert szörnyen lelassítja.Milyen megoldás jöhet még szóba?

 Van rá valami mód, hogy a recordokat autofill módon feltöltse az első táblából?
Van rá valami mód, hogy a recordokat autofill módon feltöltse az első táblából?



























Új hozzászólás Aktív témák
Hirdetés

- Dell Latitude 5430 14" Touchscreen i5-1235U 32GB 1000GB 1 év garancia
- Apple iPhone 15 Pro Max / 512GB / Kártyafüggetlen / 12HÓ Garancia / Akku: 84%
- Samsung Galaxy A05s / 4/128GB / Kártyafüggetlen / 12Hó Garancia
- HP ZBook Fury 15 G7,15.6,FHD,i7-10850H,16GB DDR4,1TB SSD,T1000 4GB VGA,WIN11
- CoolerMaster MM710 53gr pehelykönnyű gamer egér eladó
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest