Hirdetés
- Androidos tablet topic
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Milyen házat vegyek?
- A Cherry többé nem gyárt kapcsolókat
- Milyen videókártyát?
- Rémisztő árakkal szembesülnek a notebookgyártók az új mobil platformoknál
- 3D nyomtatás
- Apple MacBook
- Soundbar, soundplate, hangprojektor
- AMD Navi Radeon™ RX 9xxx sorozat
Új hozzászólás Aktív témák
-

hokuszpk
nagyúr
válasz
 S_x96x_S
#5299
üzenetére
S_x96x_S
#5299
üzenetére
ha jolertem az x86 -ot 8 biteskent emlegeti, nekem ez fura a 8008 meg a 8080 az 8 bites volt, a 8086 -os proci kivul - belul 16 bites, a 8088 amit a legtobb PC/XT megkapott, az meg valami 8 bites adatbusszal operalt, talan a 8085 -el labkompatibilis is volt, na az viszont tenyleg 8 bites...
-

S_x96x_S
addikt
sok érdekes téma Jim Keller-el ..
hosszú .. szánj rá egy kis időt !
An AnandTech Interview with Jim Keller: 'The Laziest Person at Tesla'pl.
- AMD, Zen, and Project Skybridge
- CPU Instruction Sets: Arm vs x86 vs RISC-V
- Chips Made by AI, and Beyond Siliconpl
"
IC: So going back to ISA question - many people were asking about what do you think about Arm versus x86? Which one has the legs, which one has the performance? Do you care much, if at all?
JK: I care a little. Here's what happened - so when x86 first came out, it was super simple and clean, right? Then at the time, there were multiple 8-bit architectures: x86, the 6800, the 6502. I programmed probably all of them way back in the day. Then x86, oddly enough, was the open version. They licensed that to seven different companies. Then that gave people opportunity, but Intel surprisingly licensed it. Then they went to 16 bits and 32 bits, and then they added virtual memory, virtualization, security, then 64 bits and more features. So what happens to an architecture as you add stuff, you keep the old stuff so it's compatible.
So when Arm first came out, it was a clean 32-bit computer. Compared to x86, it just looked way simpler and easier to build. Then they added a 16-bit mode and the IT (if then) instruction, which is awful. Then [they added] a weird floating-point vector extension set with overlays in a register file, and then 64-bit, which partly cleaned it up. There was some special stuff for security and booting, and so it has only got more complicated.
Now RISC-V shows up and it's the shiny new cousin, right? Because there's no legacy. It's actually an open instruction set architecture, and people build it in universities where they don’t have time or interest to add too much junk, like some architectures have. So relatively speaking, just because of its pedigree, and age, it's early in the life cycle of complexity. It's a pretty good instruction set, they did a fine job. So if I was just going to say if I want to build a computer really fast today, and I want it to go fast, RISC-V is the easiest one to choose. It’s the simplest one, it has got all the right features, it has got the right top eight instructions that you actually need to optimize for, and it doesn't have too much junk." -
S_x96x_S
addikt
AnandTech: Google Cloud Tau - Milan alapon
Google Announces AMD Milan-based Cloud Instances - Out with SMT
vCPUs?érdekes a teljesítmény és a teljesítmény/árazás kapcsolata.
mindenesetre az AMD határozottan versenyképes.
az Intelhez képest majdnem 2x ár-teljesítmény
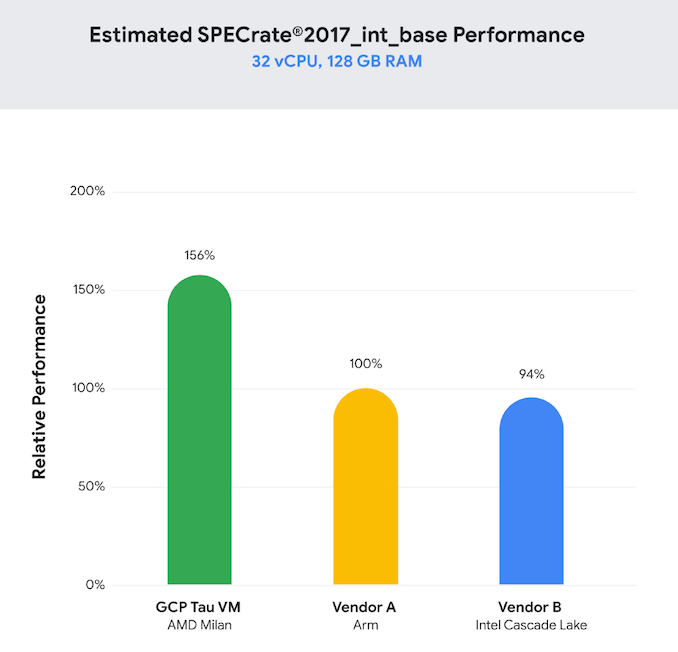
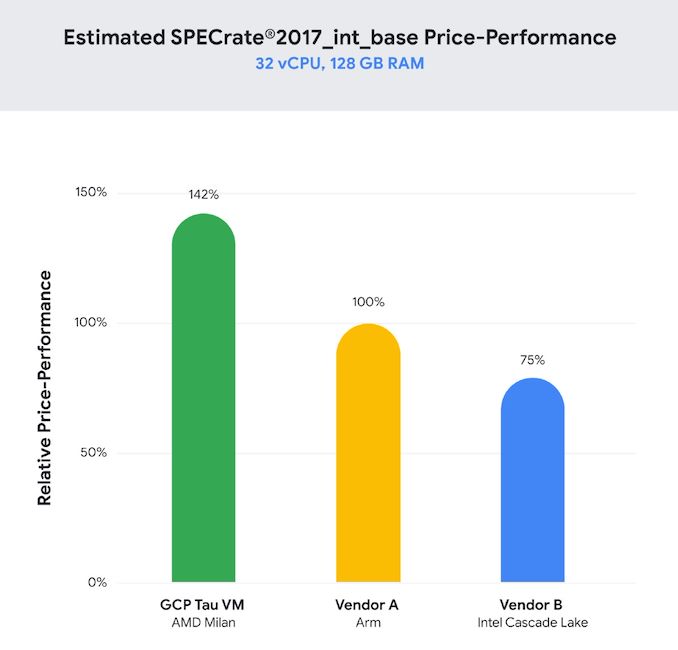
STH cikk: https://www.servethehome.com/google-cloud-tau-instances-featuring-amd-epyc-7003-milan/
-
#5296
S_x96x_S
addikt
Petykemano
#5295
S_x96x_S
addikt
válasz
 Petykemano
#5295
üzenetére
Petykemano
#5295
üzenetére
> Csodáljuk itt az ARM SVE2-t, hogy hűűű, meg háá,
> milyen jó, hogy az utasításhossza független
> a hardver feldolgozó-hosszától.
> De hát ez eddig is létezett az x86-ban is.az én leegyszerűsített megértésem szerint:
szerintem az lehet a probléma az, hogy az AVX-512 - nem csak egyszerűen a szélességről szól
- hanem rengeteg új funckionalitást is belepakoltak - amit a 128 vagy 256 bites feldolgozónak is tudnia kellene,
emiatt nehéz skálázni.
Az ARM-en a hardveres skálázás a fő hangsúly,
ezért a végrehajtó egység hosszát és a funkcionalitást nem katyvaszolják össze.
Ha definiálnak egy új funkcionalitást, akkor azt skálázhatóan teszik.
SVE - 128 to 2048 bits
SVE2 - 128 to 2048 bitsAz X86-os világban a váltás egy evolúciós lépés is .. nem lehet egyszerűen emulálni.
128b (SSE-SSE4.2 & AVX)
256b (AVX & AVX2)
512b (AVX512)Vagyis az ARM sokkal inkább vector-width-agnosztikus ..
mig az X86 egyáltalán nem.A RISC-V vektor utasításai még az ARM-nél is rugalmasabbak,
nem véletlenül, hogy az AI/HPC világban elég nagy jövőt adnak neki .. -
#5295
 Petykemano
veterán
Petykemano
#5288
Petykemano
veterán
Petykemano
#5288
Petykemano
veterán
válasz
Petykemano
#5288
üzenetére
big.LITTLE híradó
Hát tiszta hülyék vagyunk! Csodáljuk itt az ARM SVE2-t, hogy hűűű, meg háá, milyen jó, hogy az utasításhossza független a hardver feldolgozó-hosszától.
De hát ez eddig is létezett az x86-ban is.Emlékszünk?
"A Jaguar ennek támogatását egy 128 bites FADD és egy szintén 128 bites FMUL egység segítségével oldja meg, vagyis a 256 bites AVX utasításokat két 128 bites részre osztva hajtja végre a rendszer, tehát gyorsnak nem nevezhető, de egy alacsony fogyasztású processzormag esetében ez is jóval több a vártnál. Természetesen a 128-128 bites FADD és FMUL egység a 128 bites SSE utasításokra pozitív hatással lesz, hiszen azokat a Bobcattel ellentétben a Jaguar már nem osztja két részre."
[link]
Tehát a Jaguar képes volt 256bites AVX utasítások végrehajtására, csak 2 órajelciklusra volt hozzá szüksége.
Aztán nem is olyan rég:"The key highlight improvement for floating point performance is full AVX2 support. AMD has increased the execution unit width from 128-bit to 256-bit, allowing for single-cycle AVX2 calculations, rather than cracking the calculation into two instructions and two cycles. This is enhanced by giving 256-bit loads and stores, so the FMA units can be continuously fed."
[link]
Tehát a Zen is 4db 128 bites FP feldolgozóval rendelkezett, amiket össze tudott vonni 1db 256 bites AVX2 utasítás egy ciklusban történő végrehajtására. Akkoriban még volt is szó arról, hogy ennek annyi előnye van az akkor már 256bit hosszú FPU-val rendelkező skylake-kel szemben, hogy akár két különböző 128bites utasítást is végre tud hajtani 1 órajelciklus alatt.Tehát valójában biztos megvalósítható lenne az, hogy
a) 4db 256bites fpu feldolgozó helyett 8 db 128 bites legyen és ezeket vonja össze. a zen1 => zen2 váltás esetén azonban 4db 128bites feldolgozó helyett 8db 128bites feldolgozó használata biztosan bonyolultabb és nehezebb lett volna, mint 4db 256 bites feldolgozó arról nem is beszélve, hogy nem is biztos, hogy ki lehetett volna használni. De ez most mindegy is
b) Az AMD valószínűleg most is képes lenne 4db 256bites feldolgozót összevonva egy órajelciklus alatt végrehajtani 512bites AVX-512 utasításokat.
Vagy akár arra is képes lehetne, hogy összevonás nélkül, 2 órajelciklus alatt hajtsa végre.
(Más kérdés, hogy ennek van-e értelme)Mindenesetre az látszik, hogy akár x86 alapon is megvalósítható lenne az, hogy a kismag csak 2db 128bites FPU-t kap és ennek ellenére feature-kompatibilis marad AVX512 tekintetében az akár 4db 512bit hosszú FPU-val rendelkező nagy maggal. Csak ugyanazt az utasítást lényegesen lassabban képes végrehajtani.
"The current rumored specs for Big.Little appear more or less like this in my opinion:
Small Zen4 cores with 128-bit SIMD and big Zen5 cores with 512-bit SIMD.
Zen4 4-track on 3nm => lower leakage, same frequency capability (smaller FPU requires less current)
Zen5 5-track on 3nm => higher leakage, higher current capability (to feed larger FPU), thus higher frequency support at low/mid SIMD capability.8 Zen5 cores(Big core CCX), 4 Zen4 cores(Small core CCX) => similar strategy as Apple."
[link] -
#5294
Petykemano
veterán
S_x96x_S
#5291
-
#5293
 carl18
addikt
Petykemano
#5290
carl18
addikt
Petykemano
#5290
carl18
addikt
válasz
Petykemano
#5290
üzenetére
Engem legjobban az érdekel hogy jön-e még idén év végén egy Zen 3+ Warhol.
 A Raphael érdekes lehet.
A Raphael érdekes lehet.
Mondjuk az Intel az LGA 1700-al Socket V végett nem lesz kompatiblis a régi hűtésekkel. Ez azért törhet fejlesztés előtt borsot az emberek óra alá.

-
S_x96x_S
addikt
AMD EPYC 7343 / EPYC 7443 Linux Performance
https://www.phoronix.com/scan.php?page=article&item=epyc-7343-7443&num=1"In any case, the AMD EPYC 7003 series line-up continues exhibiting very strong performance and will be interesting in time to put the EPYC 7343/7443 against similarly priced 3rd Gen Xeon Scalable processors.
The Linux support for the AMD EPYC 7003 series remains in good standing and has been running well across all modern Linux distributions. The only caveats to mention are the AMD SEV-SNP support for upstream still on its way and the (silly) controversy with the AMD Energy driver.
"
"Lastly is the geometric mean for all of the benchmarks carried out on these different processors. From the 115 tests used, the dual AMD EPYC 7343 configuration came out around 3% faster than a single Xeon Platinum 8380. Not bad at all considering the EPYC 7343 2P configuration should retail for around $3k combined compared to $8k for a Xeon Platinum 8380, but it largely depends upon the particular workload(s) of interest to you for how competitive such a configuration would be and if AVX-512 comes into play, etc." -
#5291
S_x96x_S
addikt
Petykemano
#5290
S_x96x_S
addikt
válasz
Petykemano
#5290
üzenetére
> AM5 @ 2022Q2
Talán április?
és akkor ~ 1-2 negyedévvel az Intel után jelenik meg.
Remélem lesz benne rendes Gen5
és rendesen ki lesz tesztelve.ez van ...

De az is lehet, hogy a szervert/threadrippert ennél korábban hozzák ki.
( értsd: ~ kiemelt OEM-ek, Cloud partnerek ) -
#5290
Petykemano
veterán
Petykemano
veterán
AM5 @ 2022Q2
Hát ez elég érdekes lenne.
(Nem is sorolom a kérdéseket és lehetőségeket.) -
#5289
Petykemano
veterán
Petykemano
veterán
Erről nem is volt szó
Arm A510 - Merged Core Architecture: The Complex
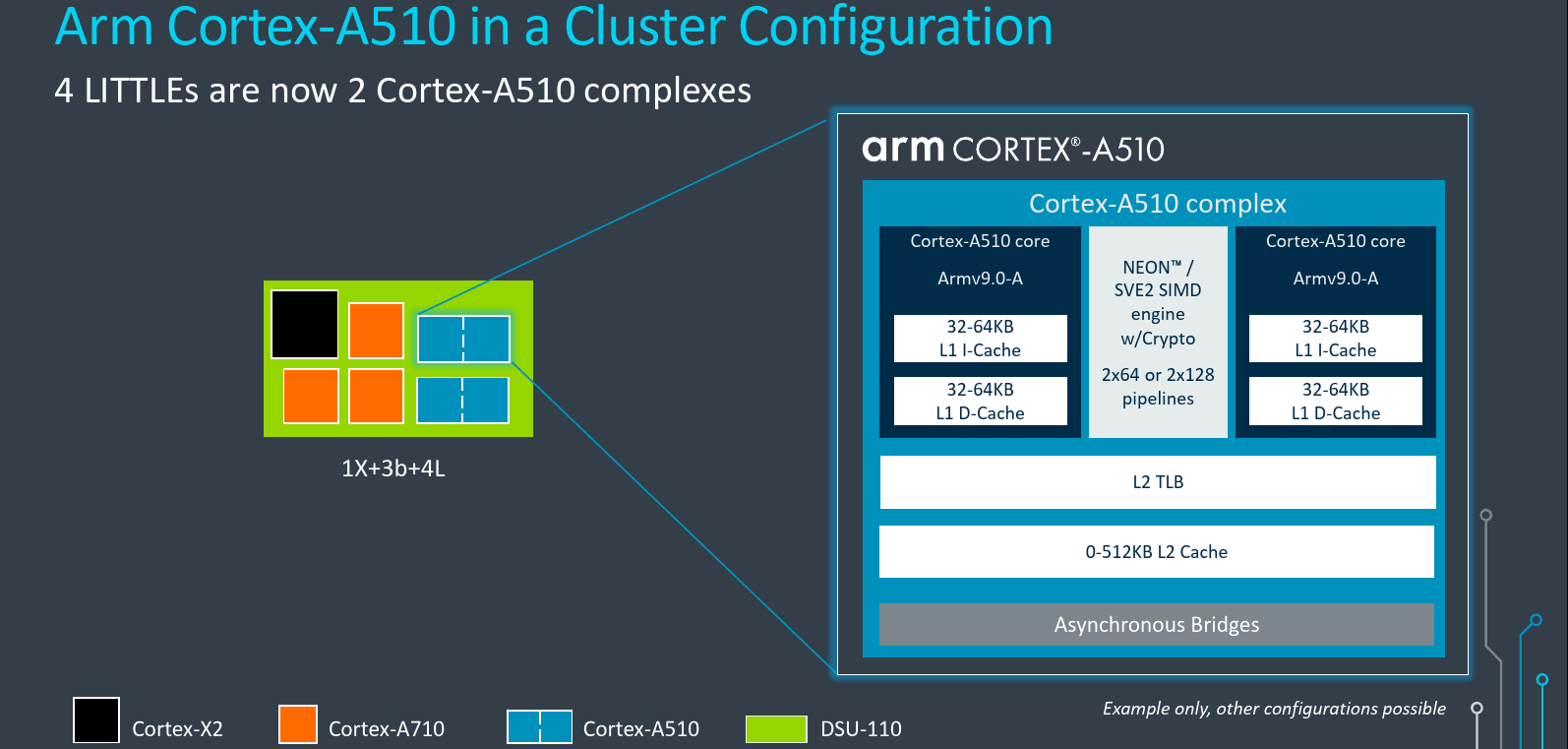
Soha nem gondoltam volna, hogy a bulldozer-féle megközelítés (CMT) még vissza fog köszönni valaha.
Persze ez sem teljesen olyan, mert nem osztoznak a frontenden. A bulldozer olyan, mintha egy 2 szálat kezelni képes SMT-s zen mag az integer erőforrásokat mindenképpen statikusan partícionálva érte volna csak el.
Itt viszont csak az SIMD egységeken osztoznak.Mindenesetre azért érdekes.
-
#5288
Petykemano
veterán
Petykemano
veterán
(Ha jól értem)
Az AMD olyan szabadalmakat jelentetett meg, amely a kis és nagy magok közötti váltást Hardveresen, az OS vagy az App tudta nélkül valósítja meg.
[link]"TL;DR;
With these patents AMD is solving two things, which is a very ingenious approach
1. big.LITTLE architecture that is virtually indistinguishable to the OS scheduler with thread migration done in HW (in contrast to ARM approach)
Using perf monitor to migrate CPU registers, thread state and execution to big core in HW itself without OS knowledge https://www.freepatentsonline.com/y2021/0173715.html Issue here is that only the big or small core is available at any time not both, but not really an issue on desktop if you already have 16 cores to begin with 2. Big and small cores have different levels of ISA support (i.e the small cores cannot support AVX for example and the big cores can). ( in contrast to Intel ADL approach )
Using illegal opcode exception in small core to seamlessly migrate the thread state and execution to big core without OS knowledge https://www.freepatentsonline.com/10698472.html "Nekem egy kicsit fura. Olyan, mintha az AMD több big.LITTLE projektet is futtatna egyszerre.
Legutóbbi ábrán inkább úgy tűnt, mintha lenne big cluster + LITTLE cluster és a fabrichoz kapcsolódnak.Ez a megfogalmazás, hogy a programszál költöztetése úgy történik meg, hogy valójában a kis és nagy mag nem elérhető egyszerre, ez sokkal inkább arra emlékeztet, ami ezt megelőzően "low-feature / high feature core" címszóval jelent meg. De egyébként ez utóbbi tulajdonképpen miben különbözik attól, mintha mondjuk egy mag áramtalanítaná az AVX512 vagy egyéb részeit (regisztereket, cache-t, ALU-kat stb), amit épp nem használ?
Egy ilyen megközelítés a fogyasztáson valószínűleg segít, de a tranzisztorigénye a "kis mag" működésnek nem kisebb.van ellenérv is:
"This sounds terrible from the OS kernel point of view. The physical CPU suddenly getting faster or slower without OS intervention is exactly what you don't want to do. This already happens with hardware-controlled turbo, but this will make this even more complicated (previously you could figure out performance by comparing clock speed, now you have no idea how the little core stacks against the big core)."
"It seems like you are possibly massively over-estimating the amount of floating point used in a JavaScript execution thread vs. the amount of all integer used in actually displaying the GUI. The amount of work to display the GUI is often huge compared to what is actually running in the GUI. Also, I don’t know if anyone is talking about having a core with absolutely no FP resources. If you have a separate small core with a scalar FP unit or even just a small narrow 128-bit unit, that could be used to handle any floating point instructions. Technically they could emulate any vector instructions with a scalar unit; it would just be slow. You could actually emulate floating point units with integer units, but that would be excruciatingly slow.
[...]
Perhaps we are going excavator style with multiple small cores sharing the vector execution resources. It could have a small scalar FPU that handles everything except actual vectorized instructions such that the big vector units stay powered down. Intel has certainly had power issues with processors supporting AVX512, so it would make sense to handle very light loads with a small unit, even if it takes multiple clocks, instead of taking the time to wake up the big unit."
Ez is érdekes ehhez. De ebből nekem nem igazán jön ki a "zen 5 + Zen4D" -
S_x96x_S
addikt
ez érdekes[1]
van egy olyan gyanúm, hogy egyes ügyfelek - alaplapgyártók miatt kerülhetett be a Zen4-es support a HWiNFO-ba.
pl. a PCIeGen5 -höz a perifériákat hitelesíteni kell .. vagyis a partnereknek sem árt ha tesztelni tudnak az AMD-re is.A hirtelen megugrott információ szivárgás is ezt valószínűsíti.
Én akár egy ~"paper launch" szerüséget is elképzelhetőnek tartok .. 2022Q1-ben.
[1]
HWiNFO 7.05 (4490) Changelog:
"Enhanced early support of some Zen4-based systems."" The changelog lists ‘enhanced early support for some Zen4-based systems’ but it does not explain exactly which systems are to be supported."
https://videocardz.com/newz/hwinfo-lists-enhanced-support-for-zen4-systems-in-upcoming-changes
-

HSM
félisten
"árazást nézve prémium a 11900K de natív teljesítmény /harci erő szinten elégé elmarad egy 5900X/5950X mellet"
Ebben az a kellemetlen, hogy a házon belüli elődjétől is elmarad.... (10900K)
Nem mondom, ettől még nem tartom rossznak, de nem épp ideális.#5281 Petykemano : "Eközben ez a 4 atom mag kb kétszer akkora teljesítményt ad le multithread felhasználás esetén, mint 1 Cove mag miközben nemom kb feleannyit fogyaszt"
Hát azért... A dupla tempó azonos fogyasztáson van csak meg, ha jól értem az ábrát [link] , és némileg nagyobb is a 4 atom, mint egy Sunny Clove, bár az ábrán nem látszik tökéletesen.A legnagyobb tervezési öngól pedig asztalon, hogy be van építve a nagy magba a durván tranzisztorevő AVX512, és nem lehet kihasználni, ha mennek a kis magok, erre Anandék is kitértek [link] .
#5282 hokuszpk: Ezért nem látom értelmét egy ilyen CPU-nak asztali felhasználásra, szvsz csak a számok fognak jól mutatni a marketing anyagon. Kb. mint amennyire nyolcmagos volt a jóhírű Bulldozer 10 évvel ezelőtt, csak ne nézd a kisbetűs részt....

#5283 carl18 : Azért itt gyorsan álljunk meg egy szóra, a Cinebench tempó erősen optimális eset többszálú feldolgozás tekintetében, életszagúbb mindennapi használatnál azért nem biztos, hogy minden olyan jól fog skálázódni a többféle erősségű magokon.
 Nekem már a korai Ryzenek 4-magos CCX-es felépítése sem nyerte el maradéktalanul a tetszésem, de itt sokkal több problémát tudok elképzelni.
Nekem már a korai Ryzenek 4-magos CCX-es felépítése sem nyerte el maradéktalanul a tetszésem, de itt sokkal több problémát tudok elképzelni.
Egy mobilon/tableten tökéletesen értem, miért jó, ha vannak extrém energiatakarékos magok, a sok háttérfeladatra, bőven megéri az ütemezési kompromisszum, de PC-n.... Még notebookon is túlzásnak és felesleges bonyolításnak hat számomra. Sőt, egyenesen úgy fest, mintha ez azért jönne, mert sehogy máshogy nem tudnak villantani valamit, ami legalább távolról hasonlít a nagyobb AM4 processzorokra.
Még notebookon is túlzásnak és felesleges bonyolításnak hat számomra. Sőt, egyenesen úgy fest, mintha ez azért jönne, mert sehogy máshogy nem tudnak villantani valamit, ami legalább távolról hasonlít a nagyobb AM4 processzorokra.#5285 Petykemano : Egyébként még szép kis tartalékok lehetnek a mostani Zen-ekben is, pl. egy 64MB-os Vcache-es 5950X egy modernizált IOD-el, amivel mondjuk 10-15%-al magasabb FCLK-t és ezáltal memória órajelet lehetne elérni azzal még szépen lehetne hozni ám a konyhára.

-
#5285
Petykemano
veterán
carl18
#5283
Petykemano
veterán
Egyetértek a számításaiddal. Nekem is kábé ez a várakozásom.
Viszont ez az épphogy 9000 score azt jelenti, hogy talán elérik a 3950X-et és az 5900X-et, de az 5950X-nek nincs mitől tartania - ahogy HSM fogalmazott.
Ezért mondtam, hogy valójában keveslem a kis magok számát. Az alder-lake-ből pont az a 8 mag fog hiányozni, amit a raptor lake hoz, hogy megfoghassa MT-ben a max 16 magos zen3-akat. De az alder lake fókusza valószínűleg inkább mobil volt.
Az Alder Lake-kel kb együtt az AMD-től is várunk egy termékrajtot. A worst case scenario az, hogy lesz pár V-cache-sel ellátott sku és nem is tudjuk, hogy hogy reagál a megnövekedett L3$-re.
A best case scenario pedig az, hogy 6nm-es gyártástechnológián készül valami, ami így pár száz mhz-cel magasabb frekvenciát kap és az FCLK is hasonlóképp növekszik, esetleg az IOD is megújul és még v-cache-t is kap (a top SKU) Tehát nincs kizárva, hogy az AMD már 12000 táján landoljon.Aztán jön a raptor lake, ami zárja ezt a különbséget, viszont addigra az AMD már megteheti, hogy 24 magos designokat dobjon piacra.
-
S_x96x_S
addikt
Az Intel publikálta a DPU terveit .. az AMD szerintem a Xilinx megoldását fogja használni ~DPU-nak ( hasonlóan FPGA alapon)
Intel IPU is an Exotic Answer to the Industry DPU
https://www.servethehome.com/intel-ipu-exotic-answer-to-industry-dpu/"We do not have Intel’s exact implementation details from today’s IPU disclosure, but we generally put FPGA-based NICs in the “Exotic” category. "
vagyis az AMD+Xilinx is "Exotic" lesz - az FPGA miatt.
-
#5283
carl18
addikt
Petykemano
#5281
carl18
addikt
válasz
Petykemano
#5281
üzenetére
Szerintem már a 8 energia takarékos mag is szépen dobni fog a Cinebench eredményen. Ebben biztos lehetsz

Cinebench R20 alatt ha csak 2000-3000 pontot dob már jobban fog kinézni a tesztekben hogy az intel mennyit fejlődött.
Az inteles szivárgásokba már az intel igy jósol hogy 1,5-2X teljesítmény többletet hozz az Alder Lake-S.
Viszont 20-30%-al lehet erősebb a Big Golden Cove mag maximum.
Szóval az intel már most is belekalulálja a kis magok teljesítményét.
Azért írtam egy ha nagy magok magukban guritanak 6000-6500 pontot Cinebench R20 alatt netto és erre rámegy egy 2000-3000 pont a kis magókból hála akkor már igen is szép eredmény lesz a 9000 Cinebench R20 az inteltől. És ha még olcsóbb is lesz mint egy R5950X akkor azért tud majd vevőket bevonzani.( Itt az én kalkuláciom)
Nos jelenleg egy 11900K tud R20 alatt 5896 pontot.
15-20%-ot minimum nőni fog a teljesítmény 8 magszám mellet.
Ez 6800-7100 pont csak a nagy magok erejét tekíntve.
Egy Régi i5-3470 1000 pontot tud R20 alatt, szóval ettől nem lesz gyengébb az energia takarékos mag sem.
2000 pontot minimum tudnia kell az energia takarékos magoknak 8 mag mellet.
így nekem az a joslásom hogy 8000-9000 R20 pontot generál a nagy és kis mag együtt. 9000 fölött már szerintem nem tud hozni
Meg hát itt az a kérdés ha intelnek is lesz 12900K 8+8 maggal az mennyiért fog menni?
Van rá esély az árakat emelni 700-800 dollára ha valóban jól teljesít. -
-
#5281
Petykemano
veterán
carl18
#5280
Petykemano
veterán
A kis magok előnye az, hogy
- 4 atom mag kb ugyanakkora helyet foglal, mint 1 Cove mag.
- Eközben ez a 4 atom mag kb kétszer akkora teljesítményt ad le multithread felhasználás esetén, mint 1 Cove mag
- miközben nemom kb feleannyit fogyaszt.Az alder lake szerintem egyértelműen mobil fókusszal érkezik. A 8 kis mag inkább értelmezhető Low-Power célokra, semminthogy érdemi segítséget nyújtson a nagy magok mellett a MT teljesítmény növelésében. Éppen ezért nagy valószínűséggel a kis magokat nem nagyon fogják használni desktop környezetben. Mobilon meg ne számoljál AVX512-t.
Ettől függetlenül biztos lesz átfedés, de nem fog nagy hangsúlyt kapni az, hogy az energiahatékony magok mennyivel megdobják desktop környezetben a MT teljesítményt.A Raptor lake esetén már inkább beszélhetünk ilyen célról. A 16 magot épp ezért én még keveslem. 32 mag esetén elmondhatánk: ugyanannyi helyet foglal, mint másik Cove mag foglalna, de MT teljesítmény szempontjából 16 Cove magot helyettesít, miközben 8 Cove magánál is kevesebbet fogyaszt.
Ezzel mondjuk már fel tudnák venni a versenyt egy akár 24 magos Ryzennel is (most az IPC különbségektől tekintsünk el), amely esetén a 8 fölötti magok szintén csak a MT teljesítményhez adnak hozzá. -
carl18
addikt
Hát ezt még a jövő zenéje! Hogy mit tud vagy mit nem tud még azt nem lehet eldőnteni, viszont ha jön a nagy magok IPC emelkedése és a kismagok is tudnak számítani 3 ghz környékén azért nem olyan lehetetlen hogy beérjék a jövőben a több magos 5950X-et!
A fő problémára mire jön a meteor lake-S már 2023-at írunk, és addig már piacon a Zen 4 is. (Sőt talán Zen 5 is)
Itt azzal a gond hogy a Zen 3 már létező processzor, de az intel fejlesztései nagy ígéretek amikből nem tudni lesz-e valójában valami.
Mert azt bevett szokás intelnél a 30% ipc emelkedés gyakorlatban csak 15% amit még órajel csökkenés is kövez.Azért a Rocket Lake-S most jött idén év elején és hát egyáltalán nem nevezném konkurenciának. Mert árazást nézve prémium a 11900K de natív teljesítmény /harci erő szinten elégé elmarad egy 5900X/5950X mellet.
-
HSM
félisten
"A Meteor lake-S már valóban versenyképes lehet, mert 8 nagy és 16 kis mag akkár hogy nézzünk nem elhanyagolható mennyiséget tekintve. "
Bár nem látok a jövőbe, de egy ilyentől én már a mostani 5950X-et sem félteném. Szvsz csak papíron mutat jól, hogy hűha, 24 mag.... Főleg, ha megmarad az az önszivatás, hogy a kis mag nem tudja az AV512-t, és így a nagyon sem használhatod, amíg nem kapcsolod le a 16 kis magot. -
carl18
addikt
válasz
S_x96x_S
#5274
üzenetére
Igen hát arra én is kíváncsi vagyok mikor lesz a piaci részesedés egyenlő. Steam felmérés szerint 30 %AMD 70% intel, azaz nem olyan gyorsan halad ez az AMD esetében.
A Meteor lake-S már valóban versenyképes lehet, mert 8 nagy és 16 kis mag akkár hogy nézzünk nem elhanyagolható mennyiséget tekintve.
Cinebench alatt biztos hogy durva eredményt guritana.Igen szerintem is ha a TSMC adna is az intelnek bérbe kapacítást nem fogja kiemelt ügyfélként kezelni. Mert nem hosszú távú ez a kapcsolat, az intel is bérgyártani kezd így a TSMC konkurenciája lehet.
Apple/AMD akik hosszú távon is velük maradnak, szóval a TSMC érdeke is hogy nekik legyen elég kapacítás.Bár a jövőbeli AMD termékekre vissza térve az mondjuk tény mindegy milyen jó terméket dob az AMD a piacra ha nem elérhető vagy csak arany áron akkor nem lesz réteg termék.
Mert a Ryzen 1600/1600AF 85 dollárért volt kiszorva, a Ryzen 3600 is 200 dolcsiról indult és volt ez alatt kis kicsit akcióban.
Azért most akkár hogy nézzünk nem is jött X-mentes Ryzen 5600.
És jelenleg az ár-érték arányt is figyelembe véve sokan vásároltam 10400F-t mert az AMD ára elég szépen elszált az utobbi időben.Csak itt a kérdés hogy mielőtt lezárja az AMD az AM4-et? Fog-e valami igazán jó ár-érték arányú processzort a piacra dobni?
Ryzen 5 5600 200 dollárért kéne a népnek!
Ameddig tart a chiphiány nem érdemes olcsóbb termékekre várni. -
#5277
Petykemano
veterán
S_x96x_S
#5276
Petykemano
veterán
válasz
S_x96x_S
#5276
üzenetére
> szerintem a 3rd gen IA már a PCIe5.0 -re épül
> ( ~4.5 bandwith növekedés erre utal ; 0.5 -öt a latency csökkenésnek tudom be .. )
> Viszont valami ok miatt az AMD - nem PCIe5.0 -nak hivja.
> lásd az oszlopok elnevezését.
> Gen3->Gen4-> 3rdGen Infinity Architekture
Abu Trento és egyéb AMD titkos kódnevek kapcsán valami olyasmit mondott, hogy lesz olyan változat, amiben az AMD azt mondja, hogy toll a fületekbe, ebben nem lesz PCIe csatoló, hanem mindent Infinity Fabric köt össze.Szerintem az Infinity Architecture ezt az elképzelést használja.
Ez persze nem jelenti azt, hogy ne lenne PCIe5 is az asztalon. De én azt valószínűsítem, hogy a Frontier szuperszámítógépben nem lesz.Azt nem tudom megmondani, hogy a "3rd gen IF" milyen viszonyban van a PCIe5-höz és a CXL-hez képest. Mármint azon kívül, hogy értelemszerűen nem kompatibilis. De hogy milyen előnyt jelenthet PCIE5/CXL-hez képest, az előttem nem ismeretes. Azt sem tudom, hogy az IF működik fizikai PCIE4 csatlakozáson keresztül. Talán ennek első szárnybontogatása volna a "Smart Access Memory"?
-
#5276
S_x96x_S
addikt
Petykemano
#5275
S_x96x_S
addikt
válasz
Petykemano
#5275
üzenetére
> lesz 128 magos zen4/Genoa
végre egy pozitiv "mag-inflációs" hír :-)
Szerintem az AMD oldaláról minden lehetséges
tartalékot igyekeznek felhasználni.
És biztos az Intelnek is lesz 1-2 meglepetése
.. amit legalább a magszámmal ellensúlyozni lehet ...
Az AMD ~1 évvel ezelőtt nyilvánosságra hozta az "Infinity Architecture"
tervét [1] .. Ezzel elméletileg a CPU-s chipleteket is skálázni lehet.[1]
March 5, 2020
AMD Moves From Infinity Fabric to Infinity Architecture: Connecting Everything to Everything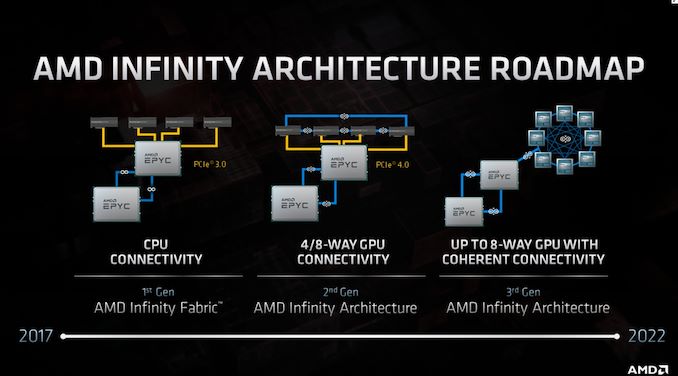 + https://www.amd.com/en/technologies/infinity-architecture
+ https://www.amd.com/en/technologies/infinity-architecturepersze ezen az ábrán gondolkodtam egy kicsit
szerintem a 3rd gen IA már a PCIe5.0 -re épül
( ~4.5 bandwith növekedés erre utal ; 0.5 -öt a latency csökkenésnek tudom be .. )
Viszont valami ok miatt az AMD - nem PCIe5.0 -nak hivja.
lásd az oszlopok elnevezését.
Gen3->Gen4-> 3rdGen Infinity Architekture
-
#5275
Petykemano
veterán
Petykemano
#5123
Petykemano
veterán
válasz
Petykemano
#5123
üzenetére
Egy pár hete AdoredTV bedobta, hogy lesz 128 magos zen4/Genoa
Felrobbant az internet, fel is került AdoredTV leak listájába élből "false" státuszban
most:
"Wow, ZEN4 is really more than 96 cores.I was skeptical when I first saw this news in Chiphell. Now I can also confirm that ZEN4 is up to 128 cores."
[link]Mások szerint lehet, hogy létezik 128 magos zen4, de az továbbra sem Genoa.
-
S_x96x_S
addikt
> Zen 5? ... Intel destroyer.
(Szerintem): még teljesen nyilt a verseny.
ráadásul az Intel totális ellentámadásba próbál átmenni
a 2023-as Meteor Lake-el
és ez már a "büszkeségről" szól, a pénz kevésbé számit.
legalábbis a vásárolt TSMC 3nm-es kapacitásból erre következtetek.
Az új vezető mindent el fog követni, hogy tudják tartani az ütemtervet.De az talán kiszámítható, hogy a TSMC-nek se érdeke, hogy az Intel rövidtávú bérlése, kiüsse az egyik legnagyobb - hosszú távú ügyfelét az AMD-t. Vagyis szerintem az AMD-nek is biztosítja majd a 3nm-ers technikát ( feltéve ha az AMD akarja .. )
de amúgy ..
a (tisztességes) verseny jó - mindenkiből a legjobbat hozza ki.
-
#5273
S_x96x_S
addikt
Petykemano
#5271
S_x96x_S
addikt
válasz
Petykemano
#5271
üzenetére
> Egy új AMD big.LITTLE patent
ha jól értem, akkor ezt csak
2 generációval később vezeti be az AMD a mobil processzoroknál
- mint az Intel.Vagyis ezen a területen (~mobil)
az AMD követő stratégiát alkalmaz ..Az Intel mellett még az ARM-es kütyük
(~ chromebook, arm-es windows laptop) lesznek veszélyesek, és akkor ott van még az Apple Silicon (M3?)Szerintem várható, hogy szoftveresen és hardveresen is összeolvad a notebook a tablet és a mobiltelefon ( ~consumer része )
de legalább az, hogy nem lesznek éles határok.pl. az új Ipad Pro -ban már M1-es proci van - ThunderBolt-al!
egy billentyűvel "elméletileg" tökéletesen tudná helyettesiteni a MacBook Air-t. És talán nem lenne gond a "macOS Big Sur" futtatásánál se.
Persze csak elméletileg. Valahol olvastam valami Apple mérnök nyilatkozatát, hogy jelenleg nincs ilyen terv. ( feltételezem, hogy azért mert akkor 3 kütyü (telefon, tablet, MacBook) helyett elég lenne
csak 1-2 kütyű sokaknál )
Persze a piac ki fogja kényszeriteni ..
( valamikor ) -
#5272
carl18
addikt
Petykemano
#5271
carl18
addikt
válasz
Petykemano
#5271
üzenetére
Zen 5? Szép ígéretesnek tünik.
Intel destroyer. 
-
#5271
Petykemano
veterán
Petykemano
veterán
-
#5270
 TESCO-Zsömle
titán
S_x96x_S
#5268
TESCO-Zsömle
titán
S_x96x_S
#5268
TESCO-Zsömle
titán
válasz
S_x96x_S
#5268
üzenetére
Ha jól tudom, a HBM közel sem az a sebesség, mint az S-RAM. Nyilván fordítva meg a kapacitás alakul így.
Mindenesetre érdekes jövőképet fest, hogy a hagyományos L3 és a DDR5 közé így most bekerül még 2 rétegnyi tár. Ember legyen a talpán, aki ezeknek a kezelését megkomponálja...
Vó'tmá' kategória, de én még mindig azt várom, hogy jöjjön egy legalább 200W-os gamer SOC 6c/12t + legalább 16-20CU + 4-8GB HBM. Lehetőleg midnezt 500$ plafonon. És akkor ott van egyben a 300$-os VGA meg a 200$-os proci egyben.
sz: Tisztában vagyok vele, hogy ez legkorábban is csak azután jöhet, ha már a Radeon vonalat is átállították chiplet dizájnra. Addigra remélhetőleg lesz annyira jó a 3D technológia, hogy a procin ülő S-RAM-on kívül megoldható legyen a GPU-n ülő HBM3 is.
Mivel közölték, hogy az AM5 foglalat bem támogatja a 4-csatornás DDR5 kialakítást, így arról letettem, hogy azzal buffolják a memóriasávszélt, amit egy a fentiekben írt erejű GPU követelne.
-
#5269
Petykemano
veterán
S_x96x_S
#5268
Petykemano
veterán
válasz
S_x96x_S
#5268
üzenetére
Én is olvastam olyan véleményt, hogy 256MB V-cache mellett (ez egyébként akár 3-4TB/s sávszélesség is lehet) nem.biztos, hogy szükséges/érdemes még a HBM is, pláne úgy, hogy közben épp érkezik a DDR5 is.
Nem hülyéség, csak megúszható.
Nem tudom, hogy egyébként költség terén ez mekkora tétel lenne. Korábbról úgy tudjuk, hogy az interposer illetve az arra való chip ültetgetés drága mulatság.
Az AMDnek brutális nagy interposerre lenne szüksége jelenleg.Én ezt csak az Intel féle tile megoldásban látom megvalósíthatónak. De tegyük össze, amit az AMD RDNA3-ról tudunk és a raphaelről.sejtünk:
Szerintem ez úgy tudna megvalósulni, hogy az AMD készít egy olyan lego elemet, ami egy interposerre tett 1-2-3 chiplet + IOD + HBM3. (Ezt akár külön is lehet árulni a desktop piacon. hBM-mel és anélkül, vagy' akár úgy is, hogy a chipletek valamelyike RDNA)
És ilyen legoelemeket rak egymás mellé két sorba úgy, felfűzi őket egy hosszanti irányban elhelyezett Infinity Cache chipletre (ahogy azt az RDNa3 esetén spekulálták)Ez az újrahasznosíthatóság szempontjából jól.hangzik, de amúgy elég fura, hogy egy HBM valójában közelebb van, mint a kapcsolódásért felelős Infinity cache.
Végülis ha a IOD zsugorodik 6nm-re, akkor eljéozelhető, hogy nem szükséges olyan hatalmas interposer, ha csak a HBM kerül rá, a chipletek nem.
Mindenesetre az intelnek azért ebben van előnye. Ha rápakolnak HBM-et a processzorra, akkor már nyugodtan mondhatják, hogy a DDR slotokba mehet csak optane. Az AMD-től eddig nem láttunk eltérő memóriarendszerek menedzselésére vonatkozó működést.
-
S_x96x_S
addikt
Az Intel a HBM-el nyomul [1] - és a Linux integrációt is elkezdte.
de a Consumer szegmensbe nem valószinű, hogy most az első körben lehozzák ( ".. in select Xeon Sapphire Rapids SKUs." )
viszont az AMD-s V-cahe valószínüleg a 6900X -ben benne lehet.amúgy a "3D V-Cache" vs. "3D HBM" - nem pont ugyanaz a kategória.[2]
Elméletileg a TSMC-nek is van hasonló HBM-es technológiája.
vagyis jövőre akár az Epyc-ek / Threadripperek is kaphatnának HBM-et.
( a V-Cache mellé )--------------
[1]
Linux Kernel Prepares For Intel Xeon CPUs With On-Package HBM Memory
"The patches do spell out quite clearly, "On package memory is coming (in the future)...A future Xeon processor will include in-package HBM (high bandwidth memory). The in-package HBM memory controller shares the same architecture with the regular DDR memory controller. Add the HBM memory controller devices for EDAC support."
So far all indications are that on-package HBM memory will be found in select Xeon Sapphire Rapids SKUs."
-----------------
[2]
"""
>AMD: 64MB SRAM (1-layer 3D V-Cache)
>Intel: 64GB DRAM (8-layer 3D HBM)
This is only true for one CCD and just one layer of SRAM. If we are talking 8 CCDs and four layers, that’s 2 GB of a very fast L3$ addition. Also: HBM runs over the IMC, while the SRAM is much closer/faster. That’s not apples to apples.
https://twitter.com/i/lists/1228697405509554176
"" -
S_x96x_S
addikt
válasz
 Cathulhu
#5262
üzenetére
Cathulhu
#5262
üzenetére
> de a v-cache-t is a TSMC fogja gyartani?
igen ; spéci TSMC 7nm -es integráció - TSMC's CoW (Chip-on-Wafer)
Anandtech:"The TSV interface is a direct die-to-die copper interconnect, meaning that AMD is using TSMC’s Chip-on-Wafer technology. " [link]
-->
https://www.tsmc.com/english/dedicatedFoundry/technology/platform_HPC_tech_WLSI
> Az nem mehet 12 nanon a GF-nel?minden lehetséges, de szerintem nem éri meg.
ráadásul úgy, hogy még az idén meg is jelenjen a közös integráció ..és extrém bonyolult lenne.
egyben kellene látnia és kezelnie a rendszernek
a TSMC-s 7nm -es belső L3Cache -t a GF12nm-es ráépülő L3Cache-el.
Mégha együtt is tudna müküdni, még a sebességnek is hasonlónak kell lennie. Ráadásul több pontos - függőleges integrációval
és hogy ez müködjön a két cég mérnökeinek nagyon együtt is kellene dolgoznia, gyártási titkokat kellene megosztani, ...
és ha nem müködik, ki a felelős?
Most a TSMC felel érte .. Ha az AMD erösködik, hogy legyen benne a GF is a buliban .. akkor az AMD lesz a felelős .. a TSMC és a GF egymásra mutogat majd ..
sőt szerintem a TSMC akarja a jövőben az I/O Die-t is gyártani N6-on!
"Zen 4 chips are stated to feature two Zen 4 CCD's based on the TSMC N5 process node and a CIOD (I/O die) based on the TSMC N7 process node however the latest reports suggest that the I/O die has been moved to a 6 nm process node." [link]ráadásul most úgy tünik, hogy a GloFO eléggé
elhanyagolta a fejlesztéseket.
friss hír: Az IBM már perelni akarja.
"WHY IBM IS SUING GLOBALFOUNDRIES OVER CHIP ROADMAP FAILURES"
https://www.nextplatform.com/2021/06/10/why-ibm-is-suing-globalfoundries-over-chip-roadmap-failures/amúgy a cikkben van egy AMD - GF spekuláció is.
"What we don’t know is if AMD decided to jump over 10 nanometer processes to 7 nanometer processes to get an edge on Intel or if it really had no choice to do so because GlobalFoundries was pulling the plug to focus on its dual-prong 7 nanometer effort. We think AMD was hit by the same 10 nanometer surprise that IBM was, but AMD never said anything about that and put the best spin on it. Much as IBM did with the difficulties that GlobalFoundries apparently had bringing 14 nanometer processes and IBM never said much at all about 10 nanometer issues. AMD, of course, used 14 nanometer processes from GlobalFoundries for its first generation “Naples” Epyc 7001 chips and still uses 14 nanometer processes in the I/O and memory hub at the heart of the Rome and Milan server processor packages. The Rome and Milan cores are etched by TSMC in 7 nanometers, and Infinity Fabric links hook hub and the cores together in a single package."
-
S_x96x_S
addikt
konferencia anyag:
2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA)
Pioneering Chiplet Technology and Design for the
AMD EPYC™ and Ryzen™ Processor Families
https://conferences.computer.org/iscapub/pdfs/ISCA2021-4ghucdBnCWYB7ES2Pe4YdT/333300a057/333300a057.pdftömény - 14 oldalas PDF.
created: Mon 07 Jun 2021 07:17:46 PM CEST ( PDF metadata)
keywords: Chiplets, Moore's Law, Processors, Industry, AMD, EPYC, Ryzen, Modular, Modularity, MCM"
...
In response, the industry is now seeing a trend toward revers-
ing direction on the traditional march toward more integration.
Instead, multiple industry and academic groups are advocating
that systems on chips (SoCs) be “disintegrated” into multiple
smaller “chiplets.” This paper details the technology challenges
that motivated AMD to use chiplets, the technical solutions we
developed for our products, and how we expanded the use of
chiplets from individual processors to multiple product families.
" -
#5264
Petykemano
veterán
awexco
#5261
Petykemano
veterán
Itt volt, hogy az "AMD lelassult" [link]
De ez nyilván csak egy percepció.A zen4 megjelenése szerintem az 5nm elérhetőségének függvénye.
/// Figyelem, wishful thinking következik ///
//////////////////////////////////////////////////////////////A magam részéről elégedett lennék az AMD által végrehajtott ütemmel, ha 2021Q4-2020Q1-ben ha az alsóbb szegmensben kapható termékek árai visszamennének. Tehát mondjuk a 6 magos nem $299 lenne, hanem visszamenne $249-re. (Ez mondjuk már majdnem teljesül az 5600G-vel) és ha a nem emelkedő árszínvonal mellett minden szegmenst ellátnák v-cache-sel. Tehát a 6 magos is kapna csak legfeljebb kevesebbet.
(Én erre azért látnék némi esélyt, mert valószínűleg az Alder Lake is minden szegmensben meg fog jelenni) -

poci76
aktív tag
Nem kell 2-3x annyi chip hozzá. A 64 MB cache, ami egy CPU chipletre kerül, az 36 mm2, ami kevesebb mint a fele a chipletnek, és a CPU+cache együtt is jóval kisebb, mint egy APU. A cache mellé rakott kitöltő "szerkezeti" Si pedig nagyon olcsó, nincs megmunkálva 7 nm-es technológiával, gyakorlatilag korlátlan mennyiségben áll rendelkezésre. Korábban írták, hogy egy ilyen v-cache lapka 7 dollárba kerül. Ahogy jön az 5 nm meg a 3 nm, gondolom a 7 nm ára valamennyivel csökken, így egy egész CPU+cache még ennyivel sem lesz drágább, tehát igazából marketingdöntés, hogy drágábban adják-e egyáltalán a v-cache-es CPU-kat, mint a jelenlegi 5000-es sorozatot, vagy ez lesz az új generáció változatlan áron, és az 5000-ek árát csökkentik.
De a v-cache lehet "végre" egy új eszköz a szegmentálásra. Régen a processzor órajele szerint elég szépen lehetett ugyanazt a chipet különböző árkategóriákban eladni, de ma az van, hogy "ne vegyél 3600x-et, hanem vegyél 3600-at, és húzd fel, ugyanott vagy". Most csak a magok számával lehet játszani, az 5000-es családban kizárólag ez alapján vannak szegmentálva a procik. Viszont, ha a sima procin nem lesz v-cache, az X-en meg lesz, akkor ott szépen lehet szegmentálni.
-

Cathulhu
addikt
egyreszt tajekozatlan vagyok, mert nem olvastam utana, de a v-cache-t is a TSMC fogja gyartani? Az nem mehet 12 nanon a GF-nel?
masreszt a memoriatombok sokkal konnyebben gyarthato, egyszerubb chipek masreszt joval nagyobb redundanciaval is birnak, szoval sokkal kisebb selejtarannyal kell szamolni.
mondjuk ennek ellenere is csak a felsohazba jonnek majd ilyen procik, gondolom nem veletlen
-
#5261
 awexco
őstag
Petykemano
#5236
awexco
őstag
Petykemano
#5236
awexco
őstag
válasz
Petykemano
#5236
üzenetére
Nem találom , de valahol irtad , hogy amd cpu fronton túlon túl visszafogott lett. Alapvetően szerintem ennek oka a sok sok évvel ezelőtti szűkös gyártói szerződések állnak TSMC-vel. De én is ezt látom . De ennek ellent mond masszivan , hogy v-cache az kb annyit tesz hogy proci 2-3x annyi felhasznált sziliciummal . Bár lehet , hogy mivel a hüvej jövőbeni megrendelt kapacitásás is átvették más vizeken eveznek , de szerintem egy -két spec Gamer HEDT editiont leszámitva értelmetlen . Mivel 2 proci vagy 1 ? beszerzése ugyan annyi kb ... csak nem mind 1 mennyit kapnak érte .
-
S_x96x_S
addikt
Best CPUs for Workstations: June 2021
https://www.anandtech.com/show/11891/best-cpus-for-workstations"For AMD, Threadripper on Zen 3 (probably likely to be called Threadripper 5000) is expected to be coming this year – some were predicting early June due to the annual Computex trade show, however that has been and gone with no insights. As Zen 3 chiplets are straight drop-ins for Zen 2 chiplets, bring-up should go smoothly. But, those chiplets will initially be served in AMD’s EPYC processors first, because that is where the higher margins are. Demand for Zen 3 Enterprise is high, and with the current semiconductor demand for EPYC compared to the size of the Threadripper market, then next-gen Threadripper might have to wait a little bit longer."
-
S_x96x_S
addikt
(versenytárs/piac)
Az Intel kezd merészeket lépni .. RISC-V ...
az Nvidia az ARM-re.
az AMD ????-----------------------
"Intel offers $2bn for RISC-V pioneer SiFive says report"
https://www.eenewseurope.com/news/intel-offers-2bn-risc-v-pioneer-sifive-says-report -

A.Winston
tag
válasz
Petykemano
#5253
üzenetére
Nem tudom mennyire lesz szerencses ez pasztazasnal majd?
-
#5255
 Devid_81
félisten
Petykemano
#5253
Devid_81
félisten
Petykemano
#5253
Devid_81
félisten
válasz
Petykemano
#5253
üzenetére
Orom lesz majd pasztazas utan tisztitani a procit, mar alig varom a szivast vele kitakaritank a pasztat a lyukakbol es az smd-k kozul
-
#5254
 TRitON
aktív tag
TESCO-Zsömle
#5250
TRitON
aktív tag
TESCO-Zsömle
#5250
TRitON
aktív tag
válasz
 TESCO-Zsömle
#5250
üzenetére
TESCO-Zsömle
#5250
üzenetére
Természetesen tudom, hogy ez egy torz statisztika, viszont ha őket is bele vesszük, akkor a helyzet csak romlik. Mondandóm lényege az volt, hogy a helyzet legalább ennyire rossz.
-
#5253
Petykemano
veterán
Petykemano
veterán
Egy pár hete jelent meg Executablefix rendere a Raphael nevű processzorról.
Akkor az első ami feltűnt nekem az az volt, hogy kicsit mintha magas lenne, magasabb, mint szokott. Ezt talán kevesen említették. Sokkal nagyobb figyelem övezte a kupak megszokottól eltérő formáját, a "lábait" és a "lábak" között elhelyezkedő kondenzátorokat
Összehasonlításképp itt egy kép egy kupaktalanított chipletes ryzenről:

Akkor nem értettem, hogy ennek mi lehet a jelentősége annak, hogy a lábak között kondenzátorok vannak, vagy hogy látszanak. Nem néztem össze.milyen magyarázatai lehetnek?
- Megmondom őszintén nem értek hozzá, de azért nem zárom ki. Volt szó arról, hogy AM5-be kerülő Raphael 120W, de lehet akár 170W-os megoldás is. Tehát nem zárható ki, hogy ilyen áramfelvételhez szimplán több kondenzátorra van szükség.
-Nem emlékszem, hogy találkoztam volna olyan infóval, hogy az AM5 fizikai kiterjedése hogyan viszonyul az AM4-hez. Arról viszont volt hír, hogy a chipgyártásban nem csak chiphiány van, hanem substrate hiány is. (Ha jól tudom a subsrate az a zöld felületű sárga lapka, amin a chipek elhelyezkednek és aminek érintkezők vannak az alján) Tehát az sem kizárt, hogy az AMD szimplán csak egy az AM4-nél kisebb AM5-öt ad ki, hogy takarékoskodjon a substrate összetevővel, ne az legyen a szűk keresztmetszet.
Elnézést, közben előkerült: [link]
Ez alapján az AM5 fizikailag ugyanakkora, mint az AM4 40x40-es.
- Felmerült egy olyan gondolat is, hogy azért volt szükség egy picit a szélhez közelebb elhelyezni a kondenzátorokat, mert a kupak alatt kellett a hely egy nagyobb interposernek
[link]Érdekes elképzelés. Az biztos, hogy az IF relatív sokat fogyaszt és lehetne harapni - főleg a szerver termékek esetén - a fogyasztáson, ha egy energiahatékonyabb módját használnák az adatkommunikációnak.
Persze nyilván ezt az AMD eddig költség okokból nem tette meg eddig. -
#5252
Petykemano
veterán
Petykemano
#5249
Petykemano
veterán
válasz
Petykemano
#5249
üzenetére
[link] a videó az Intel alder lake és raptor lake termékeiről szól, de említésre kerül az amd is, hogy milyen lehetőségei vannak.
Szokás azt mondani, "Intel is coming Back, but AMD isn't slowing down either"
De nekem most mégis egy lassulás érzésem van az amdvel kapcsolatban. Persze lehet, hogy megcsalnak az érzékeim. Hisz a zen után se 15 hónappal jött a zen2. Talán épphogy a viszonylag gyors zen2->zen3 váltás volt egyedi.
Na mindenesetre oda akarok kilyukadni, hogy a 2022 végén érkező zen4 szerintem egy nyitott ablak az intelnek, hogy felzárkózzon. -
Cathulhu
addikt
válasz
S_x96x_S
#5246
üzenetére
Érdemes elolvasni a szerző további cikkeit is. Olyan elemző szavára nem szabad adni, aki nyilván valóan elfogult, mert még ha valós alapokon is nyugszik az érvelése, az csak válogatott tények, hogy alátámasszák az igazát.
Volt pár éve egy hasonló elemző, 2017 óta az AMD halálát jósolta, 15 dolláron, 25ön, 35ön, mindenhol az eladásra biztatott, mert mindenhol túlértékelt volt neki az AMD és az Intel bármikor elsöpörheti. Sajnos a nevére már nem emlékszem, de befektetési tanácsadóként ő emberek pénzével játszott, és rendszeresen vesztett az elfogultságának köszönhetően.
SA megvalógathatná kiket hagy publikálni, a reputációjuk múlik rajta -
#5250
TESCO-Zsömle
titán
TRitON
#5244
TESCO-Zsömle
titán
Azzal ugye tisztában vagy, hogy a fenti statisztikából hiányzik egy csomó melós, aki rontaná a statisztikát? Nincsenek benne se a 4 fős vagy annál kisebb cégek alkalmazottai, a részmunkaidős munkavállalók, valamint a közmunka-programban résztvevők sem.
Nem mintha ez változtatna a dolgokon... Én 4 éve kevesebb, mint 2 havi béremből vettem az AMD legerősebb videókártyáját. Azóta a bérem nagyjából 40%-al nőtt, az említett kategóriájú videókártya MSRP-je pedig 100%-al*. 🤣
* - Ehhez ugye még jön a forint gyengülése is, mert az MSRP az $.
-
#5249
Petykemano
veterán
S_x96x_S
#5246
Petykemano
veterán
válasz
S_x96x_S
#5246
üzenetére
Szerintem Arne Verheyde ugyanaz az személy, mint Twitteren witeken, aki eléggé elfogult az intel irányában.
Nem állítom, hogy nincs igazság a felsorolt pontokban.
-

Busterftw
nagyúr
válasz
S_x96x_S
#5246
üzenetére
Koszi, erdekes olvasmany.
Azert az evek soran ez latszott, hiaba volt/van (gyartas)technologiai foleny AMD-nel, kisebb volumen miatt az AMD nem tudott annyira ervenyesulni mint tudott volna normalis korulmenyek kozott.
Szerintem a korulmenyekhez kepest az Intel jol allta a sarat, mindezt ugy hogy 14nm-el kellett dolgozni. Ez latszott az evek alatt, a market share nagyon lassan kezdett megindulni AMD fele, ekozben kijott 4! Ryzen generacio.
En ezt mar az elejetol fogva mondtam, hogy az Intelnek a legfontosabb tenyezo az ido.Persze aztan ahogy lattuk, par ev alatt nagyon sok minden tud valtozni, teljesen realis, hogy a leirtak nem fognak bejonni. Az AMD sem fog egy helyben ulni.
-
#5247
Petykemano
veterán
S_x96x_S
#5243
Petykemano
veterán
válasz
S_x96x_S
#5243
üzenetére
A hősűrűség (thermal density) eddig is fokozódó problémát jelentett.
A hősűrűség azért jelent problémát, mert magas hőmérsékleten ugyannak a frekvenciának a tartásához magasabb feszültségre van szükség, ami növeli a hőtermelést.
Nem állítom, hogy a 14nm-es zen1 frekvencia skálázódása emiatt állt meg, de amikor a 12nm-re váltottak, akkor a hírekben arra hivatkoztak a fizikai kiterjedés megtartásával kapcsolatban, hogy így több a "hely" a hőt termelő tranzisztorok között és könnyebben hűl
Valamint a zen2 esetén is szó volt róla, hogy nagyon szép és szuper, hogy milyen sűrű a 7nm-es gyártástechnológia, de az intel abból a szempontból könnyebb helyzetben van, hogy a lapkái 2x akkora kiterjedésűek, és ennélfogva engedheti meg magának a ~2x akkora fogyasztást. másként megfogalmazva: a hősűrűség miatt az AMD ha akarná se tudná növelni a fogyasztást.Szerintem a 3D technológia terjedésével ez a probléma fokozódni fog. A rétegződéssel - gondolom valamelyest növekedni fog a lapkák magassága (Az ExecutableFix által megosztott/renderelt Raphael kupak például kifejezetten magasnak tűnik) A legalsó réteg biztosan távolabb kerül a hőelvezetést szolgáló hűtött felső felülettől. Tehát szerintem egyre kevésbé lesz megengedhető, hogy neked valahol a szilícium téglatestedben - főleg alul - legyen valami nagy hőkoncentrációt okozó részegységed.
Vannak elképzelések a 3D stacked chipek Z irányú hűtésére, de azért annál szerintem lényegesen egyszerűbb, ha a hőtermelést a frekvencia csökkentésével oldják meg. a chipek ma már tele vannak hőérzékelőkkel, tehát nem gondolom, hogy bármikor is alattomosan ki tudna alakulni valami hőtermelő központ, ami leégeti a chipet.
A másik fontos szempont ami megjelenik, hogy ha valahol nagy hő képződik, akkor oda a szükséges kakaót is el kell juttatni.Számomra minden szempontból előnyösebbnek tűnik az alacsonyabb feszültség és a frekvencia és a 3D stacking által kínált cache és feldolgozó szélesítési lehetőség.
Az Apple a példa rá, hogy ebben a vonatkozásban jelenleg az Arm tűnik előnyösebb pozícióban levőnek. És arról pedig volt már szó, hogy az x86 esetén az instruction decoder szélessége tűnik jelentős korlátozó tényezőnek a feldolgozók szélesítése kapcsán.
-
S_x96x_S
addikt
egyes tőzsdei elemzők szerint már nem fenyegeti az Intelt az AMD ..
de majd meglátjuk .. Azért az Intelnek se lesz egyszerű dolga .."
Intel: AMD Threat Is Finished
SummaryAlthough competition from Arm is increasing, AMD remains Intel’s biggest competitor, as concerns of losing market share weigh on Intel’s valuation.
AMD's short-lived laptop competitiveness is already waning. Intel will further crush AMD with its (up to) 16-core Alder Lake: going from half the core count, to double in one generation.
Intel is also re-investing in the (high-end) desktop, could leapfrog AMD in the data center, and seems to be overtaking AMD-Xilinx for FPGA leadership.
AMD is slow to transition to the leading edge in process technology. For example, AMD will not launch 5nm laptop CPUs until 2023, when Intel might have outsourced (TSMC) 3nm.Given all the above, the Intel bear thesis of AMD benefiting from Intel's stumbles, gaining a large tech advantage and taking much market share, is finally finished.
"
a csoda-stratégia:
"
By 2023, with Meteor Lake Intel will have a "breakthrough" (as Intel called it) CPU architecture that might leapfrog AMD, perhaps reaching Intel's goal of "unquestioned leadership". Built on TSMC's 3nm and its own 7nm, it will be about half node to a full node ahead of AMD's 5nm portfolio."
-
S_x96x_S
addikt
válasz
S_x96x_S
#5243
üzenetére
TSMC ..
June 8, 2021
An AnandTech Interview with TSMC: Dr. Kevin Zhang and Dr. Maria MarcedIC: As process nodes shrink, resistance on metal layers is becoming more problematic. With regards innovative solutions, and exotic materials versus copper interconnects, is it just a case of more research down that front? Or do we need to put more effort into increasing and routing higher metal layers?
KZ: I think in the research session at our advanced technology introduction, we did cover a little bit about the back end work. For example, we are continuing to optimize the copper grain boundary to bring a lower resistance metal line to our overall chip technology and new technology. Also, with dielectrics we continue to find innovative materials to improve the dielectric in parasitic capacitance. So, those things are being actively researched.
The 3D integration can also bring an alternative solution to this whole performance requirement in the back-end. You can instead route from A to B in a 2 dimensional space, or you can route A to B vertically in 3 dimensions. In some cases, by going vertical, you can reduce the overall length of the RC wire, and reduce pass delay significantly. So all those things have to be looked at going forward.
-
#5244
TRitON
aktív tag
TESCO-Zsömle
#5241
TRitON
aktív tag
válasz
TESCO-Zsömle
#5241
üzenetére
A magyar bruttó átlagfizetés jelenleg ~410.000Ft, ami ~273.000 nettó fizetést jelent, a medián (aminél a "keményen dolgozó kisemberek" fele kevesebbet keres) bruttó ~300.000Ft, ami nettó ~200.000Ft. Egy valamire való játék-PC összerakása (monitor nélkül) jelenleg kb. 2 havi átlag-, vagy 3-4 havi medián fizetésbe kerül; persze ez nagyban függ attól is, hogy pontosan mit szeretnénk vele játszani. Nyilván, ha átlépjük a Lajtát, ezek kb. feleződnek, de szerintem még a nyugati világban is igen durva, hogy pl. egy középkategóriás videokártyáért jelenleg 1000USD-t kérnek, egy valódi gaming PC, amin elfutkosnak a legújabb játékok, simán bele kerülhet 4-5-6.000$ba.
Egy játékkonzol lazán kijön egy havi magyar medián fizetésből is. Szóval ja, a PC gaming igen kemény luxussá vált. -
#5243
S_x96x_S
addikt
Petykemano
#5242
S_x96x_S
addikt
válasz
Petykemano
#5242
üzenetére
> Tényleg mi lenne, ha skálázható lenne egy chiplet.
> És ebben a skálázhatóságban a L3$ csak az első lépés.valami lesz
habár szerintem az ARM-es design-oknak lesz egy kis előnyük a 12-es szendvich formációnál..
( kisebb fogyasztás .. kisebb hő .. kisebb gond )
És szerintem a következő Apple silicon is kaphat V-cache szerűséget."A single slide at the Technology Symposium shows it all off. TMSC is currently probing 12-Hi configurations of SoIC. Each of the dies within the 12-Hi stack has a series of through silicon vias (TSVs) in order for each layer to communicate with the rest of the layers, and the idea is that each layer could be a different element of logic, of IO, of SRAM, or could be passive to act as a thermal insulation layer between other active layers."
-
#5242
Petykemano
veterán
Petykemano
veterán
Érdekes olvasmány:
[link]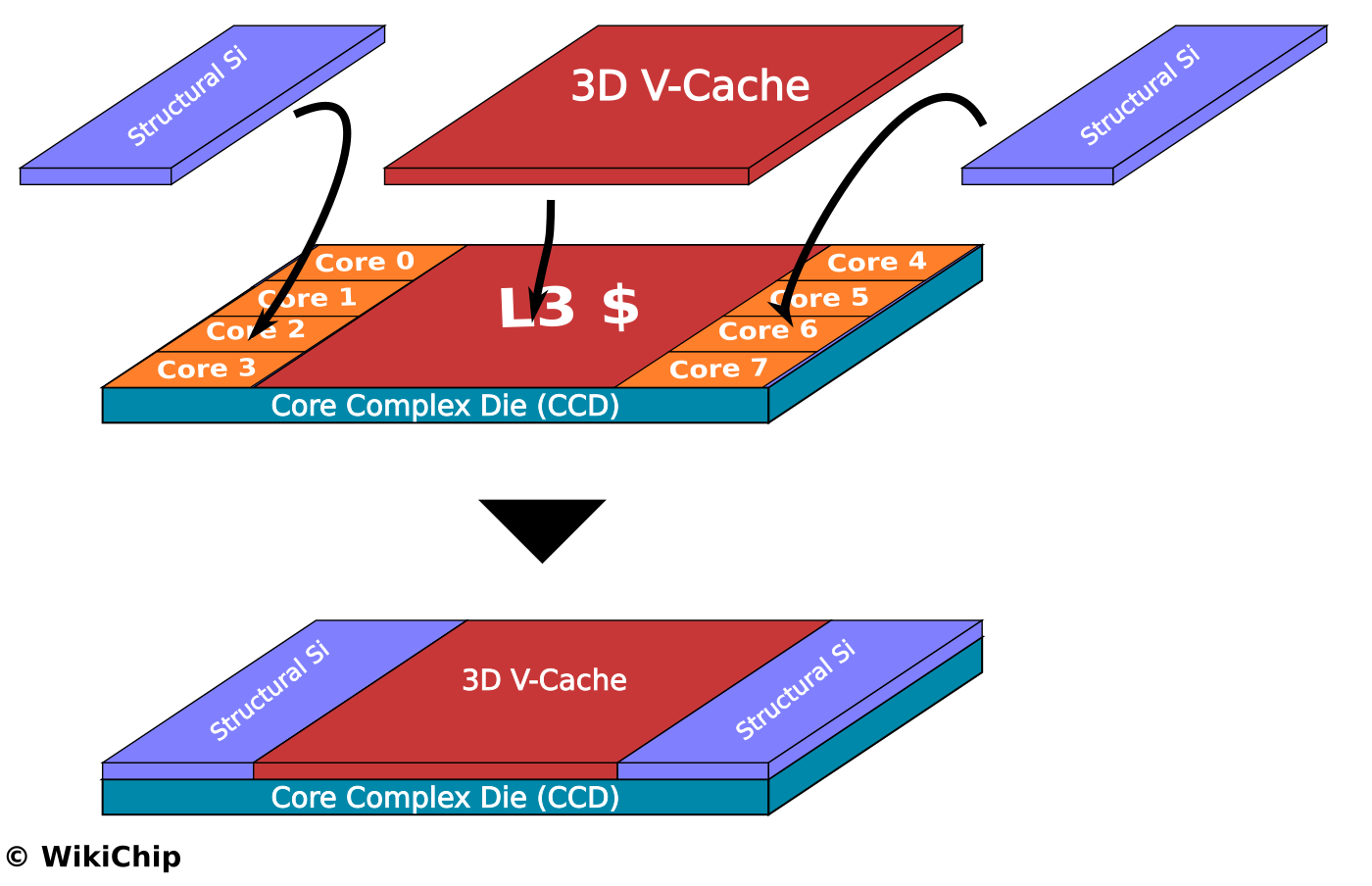
Azon gondolkodtam el, hogy vajon fogják-e lehetne-e valahogy a Structural Si elemeket hasznosítani."Schor speculates that the dummy dies may include thick copper traces to aid heat transfer. However, why not put all that copper to use? I see an opportunity to put fat vector engines in these dies. Instead of squeezing 512-bit wide SIMD units and data paths into the core below to support AVX-512, instead put (perhaps even wider) vector units in the dies above."
[link]
Az első reakció nyilván az: Hát az lehetetlen (és egyébként szentségtörés is volna), hiszen a hő a CCD-ben a logikai részeken keletkezik, amit a Structural Si fed, aminek épp az a célja, ahogy elvezesse az alul képződött hőt, nem pedig, hogy maga is hőt termeljen.De ezen az első felhorgadáson lépjünk túl.
Tényleg mi lenne, ha skálázható lenne egy chiplet. És ebben a skálázhatóságban a L3$ csak az első lépés. A structural Si minden rétege tartalmazhatna L2$-t, vagy akár L1$-t. Vagy ha már AVX, akkor lehetne úgy is, hogy minden egyes réteg tartalmaz egy AVX512 feldolgozót. Ha 4 magas a felépítmény, akkor 4xAVX512 pipeline van, ha nincs felépítmény, akkor meg egy se.
a processzor lelke persze továbbra is a CCD-ben maradna, csak az egyes részegységek elhelyezése/kiterjesztése/skálázása 3D irányban történne, ráadásul opcionálisan. -
carl18
addikt
-
#5237
carl18
addikt
Petykemano
#5236
carl18
addikt
válasz
Petykemano
#5236
üzenetére
Van egy megfigyelés, amely szerint
- a mobil az új desktop
- a desktop az új workstationEz egy elég jó megfigyelés, bele gondolni 12-16 mag már elérhető átlag felhasználó számára elég durva.
Az intel is idén már árulni fogja az Alder Lake-S mellet a 16 magot, az már tény hogy 8 nagy és 8 gyenge mag lesz egymás mellet.
Hát azért rengeteg youtuber/streamer lett akiknek fontos az erős cpu videózás szempontjából. -
#5236
Petykemano
veterán
awexco
#5234
Petykemano
veterán
V-cache alsó házba túl drága
Ez is egy érdekes kérdés egyébként, hogy valójában kit mit gondol alsó háznak?
Nyilvánvalóan nincs egyértelmű meghatározá. Amit látunk az régóta az, hogy az alsó-felső ház
- elsősorban feldolgozószámot jelent. Ez akár 50-100-150%-os különbség is lehet.
- kisebb részben tierenként pár százalékot jelentő eltérő maximális frekvenciát
- és az Intel sokáig láttunk kihagyott/letiltott utasításkészletetA mobil procik egyre inkább fejlődnek. Beérik, vagy beérték a desktop számítógépeket.
Legalábbis abban az értelemben, amire az átlag felhasználó használni akarja. VAnnak, akik arra készülnek, hogy kidobják a(z akármilyen kis) dobozos számítógép gondolatát és csak leteszik a telefont a monitor és a billentyűzet mellé és úgy használják. Persze AAA játékra nyilván nem megfelelő, de számlát befizetni, internetezni, excel táblázgatni kicsi helyett nagy kijelzőn és kicsi billentyűzet helyett emberi klaviatúrán elegendő.Van egy megfigyelés, amely szerint
- a mobil az új desktop
- a desktop az új workstationAz Apple-t hagyjuk, mert bár az M1 kimagasló teljesítényt nyújt, de a 300+eFt-os Mac mini semmiképp nem tartozik az alsó házba. De mondjuk mi van, ha jövőre a Qualcomm beforgatja a Nuvia fejlesztését egy az X2-nél 30-40%-kal gyorsabb processzormagba. Abból már lehetne csinálni - az Apple-nél - olcsóbb 4+4 magos miniPC-ket.
Biztos vannak páran, akiknek nem feltétlenül szükséges 16-24 mag, hanem kicsi, de fürge cpu-t szeretnének. És akkor az AMD azt fogja mondani, hogy ezekkel a 12-16 magos felsőházunk tud versenyképes lenni.
Vagy ott van pl a friss 4 magos Tiger Lake az inteltől, ami GB5-ben 1700 pontot ér el. Ehhez képest az 5600U csak valami 1300, az 5600G meg csak 1500 körül mozog.
Szóval ilyen kemény verseny mellett tényleg lehet azt mondani, hogy az alsó-felső ház nem csak magszámot jelent, hanem az egyszálas teljesítmény erőteljesebb differenciálását is?
-
#5235
HSM
félisten
Petykemano
#5233
HSM
félisten
válasz
Petykemano
#5233
üzenetére
Valamelyik APU-hoz volt írva régebben Zen3+, az pedig nem valószínű, hogy a plusz V-cache lett volna, tehát valószínűleg van még hiányzó része a kirakósnak.
Illetve a tervek is változhattak idő közben, ezt se felejtsük el. -
#5234
awexco
őstag
Petykemano
#5233
awexco
őstag
válasz
Petykemano
#5233
üzenetére
V-cache alsó házba túl drága . Kérdés az alkalmazásoknál mennyire fog számítani ?
-
#5233
Petykemano
veterán
S_x96x_S
#4995
Petykemano
veterán
válasz
S_x96x_S
#4995
üzenetére
zen4 IPC
Sokmindent lehetett eddig olvasni
- volt ez a zen2 =>zen4 +45%
- volt zen3 => zen4 +29% (Milan => Genoe)
- MLiD utolsó videójában zen3 => zen4-re 20+%-ról írtDe az AMD jól megkavarta ezeket információkat.
Mi a zen3? plain zen3, vagy zen3D?
Mi a zen4? plain zen4, vagy a zen4-et már v-cache-sel együtt kell érteni? (Ami még nem jelenti azt, hogy minden sku-n lesz v-cache, de hát ugye "upto*" )És hol jön képbe a Rembrandtnál szereplő zen3+?
"AMD Ryzen 6000 Warhol could hit 5 GHz with 9-12% gains over Zen 3"
Ezeket 9-12%-os értékeket magyarázná, ha a v-cache-re vonatkozna. Bár ha frekvencia növekményt is nézzük, akkor a 9-12% meg elég konzervatív. (Bár lehet, hogy az AMD is azt a pár játékot emelte ki, ahol van létjogosultsága a V-cachen-nek)
Már olyat is olvastam, hogy a v-cache-nek semmi köze a Warholhoz. De olyat is, hogy a Warhol nem a B2-es stepping. Az is lehet, hogy mégis, de az is lehet, hogy az AMD csinált egy B2-es steppinget, ami képes a v-cache felépítmény fogadására, de a végleges termék a Warhol lesz 6nm-en gyártva és a 9-12% úgy jön össze - v-cache nélkül - hogy picit emelkedik a mag frekvencia és picit emelkedik a FCLK is.
Én még titkon reménykedem az új IOD-ben. Van egy olyan elméletem is, hogy a B2 stepping lesz a warhol végül, de 6nm-es IOD kapDe a lényeg, hogy innentől bármilyen hírt nehéz lesz értelmezni.
-
#5232
 Mumukuki
aktív tag
Petykemano
#5227
Mumukuki
aktív tag
Petykemano
#5227
Mumukuki
aktív tag
válasz
Petykemano
#5227
üzenetére
Mióta kijött az M1 én azt mondom hogy szerintem az x86 -nap szépen lassan egyre kisebb szelet jut , perifériára szorul nagyon .
Eleve apple ami elég sok embernek , nem is lett annyira szar , a marketingje máris jó -
#5231
S_x96x_S
addikt
Petykemano
#5227
S_x96x_S
addikt
válasz
Petykemano
#5227
üzenetére
> Gondolhatnánk, hogy tök jogos az áremelés,
> meg hogy csak a drágább modellek kapják meg,
> mert hát drága technológia.- még nem biztos, hogy lesz áremelkedés.
- ráadásul az Inteltől is függ, hogy milyen árat lő be.
( amit az AMD bizonyára figyelembe vesz )nekem a Gen5 a sötét ló , vajon mi az AMD stratégiája?
mert ha ZEN3XT - hez nem lesz Gen5-ös lehetőség, akkor
az sokaknak fájhat..A prémium gamer / mini workstation-t keresők körében szerintem tarolni fog a Gen5.
- főleg a Gen5-ös GPU-k sokkal alacsonyabb latency-je miatt
- valamint a több GPU-s CXL összekötés, ami annó "Coherent Multi-GPU" néven futott, habár nem tudom, hogy melyik CXL verzió mire képes .. ( Ez valami általános SLI szerűség utódja )vagyis 2 középkategóriás Gen5-ös Intel GPU .. _akár_ le is verheti,
a csúcs nVidia / Radeon (Gen4)-es kártyákat .. ( ~ elméletben )"If CXL can seamlessly scale GPUs, then the economics of the market would also change completely. People would be able to buy a cheaper GPU first and then simply add another one if they want more power. It would add much more flexibility in buying decisions and even alleviate buyers remorse to some extent for the gaming class. If CXL mode trickles down to the consumer level anytime soon, then we might even see motherboard designs change drastically as multiple sockets and multiple GPUs become a feasible option. Needless to say, it looks like things are going to get pretty exciting in a few years."
( a coherent multi-gpu-s linkről másolva ) -
#5229
Busterftw
nagyúr
Petykemano
#5227
Busterftw
nagyúr
válasz
Petykemano
#5227
üzenetére
Ebbol ahogy irtad csak a CPU lesz max maceras, bar ez attol is fugg az Alder Lake hogy sikerul.
RDNA3 meg elegge adja magat, 2 eves ciklus meglesz az RDNA2-nel es a konkurencianal is. -
S_x96x_S
addikt
 látom - lassabb vótam ... ( de ezért itthagyom )
látom - lassabb vótam ... ( de ezért itthagyom )
---------
Jajj .. 2022-Q4 ! - akkor az egyik variáció:
2022Q1: ZEN3 XT
2022Q4: ZEN4AMD ZEN4 and RDNA3 architectures both rumored to launch in Q4 2022
https://videocardz.com/newz/amd-zen4-and-rdna3-architectures-both-rumored-to-launch-in-q4-2022 -
#5227
Petykemano
veterán
Petykemano
veterán
AMD ZEN4 and RDNA3 architectures both rumored to launch in Q4 2022
[link]Ebből elég nagy blama/zúgolódás (=> idővel térvesztés) lesz. Szerintem.
... amennyiben az AMD a Vermeer-X-et (Zen3 refresh) nem úgy fogja bevezetni, hogy minden chiplet kap egy v-cache-t, hanem csak a 12,16, esetleg a legerősebb 8 magos kapja meg és az is komoly áremelkedéssel.Gondolhatnánk, hogy tök jogos az áremelés, meg hogy csak a drágább modellek kapják meg, mert hát drága technológia. Persze, érthető.
Akár nevethetnénk is, hogy ugyan minek kéne erőlködni, az intel sehol sincs, a Vermeer-X bőven elég lesz az Alder Lake ellen (a lényeg úgyis az, hogy chartokon folyó versenyt ki nyeri )
Ahogy az is lehetséges, hogy az AMD az 5nm-hez előbb ha akarna se férne hozzá.
És persze az is érthető, hogy minek gyártsanak jobb terméket, ha még abból se tudnak eleget gyártani, amijük most kapható.De közben Apple oldalról érkezik az M1X meg az M2.
Ha az Apple hoz 10-15% generációs növekményt, akkor azzal még mindig megőrzi az előnyét és ha 4+4 helyett komolyabb konfigurációt hoz, az nagyon el fogja halványítani az AMD erőfeszítéseit. Mindezt ráadásul úgy, hogy lényegesen kisebb TDP-ből kijön.
Mondjuk egy 16+4-es konfigurációban (az apple kis magjai emlékeim szerint nem efficiency, hanem Low Power magok) még az sem feltétlenül biztos, hogy az AMD marad a desktop környezet megkérdőjelezhetetlen királya.A Nuvia a saját csodáját 2023-ra ígérte. A Qualcomm felvásárlással esetleg felgyorsulhatott annyira, hogy 2022-ben ledobjanak valamit, ami emlékeztet az M1-re.
Valahogy azt érzem, hogy ebből az lesz, hogy az AMD küszködik itt a kapacitásokkal, meg az intellel való küzdelemben és az ARM-os megoldások a külső íven fogják előzni mindkettejüket.
-
S_x96x_S
addikt
LINUX ..
fixálnak egy ryzen boot problémát ..
Linuxosok - óvatosan !CPU: Ryzen 7 3700xMB: Asrock X470 Taichi bios P4.70Have been unable to boot 5.13 rc kernels but bisected the issue to this commit:"Linux x86/x86_64 Will Now Always Reserve The First 1MB Of RAM"
"The motivation now for Linux 5.13 in getting that 1MB unconditional reservation in place for Linux x86/x86_64 stems from a bug report around an AMD Ryzen system being unbootable on Linux 5.13 since the change to consolidate their early memory reservations handling. Just unconditionally doing the first 1MB makes things much simpler to handle."
https://www.phoronix.com/scan.php?page=news_item&px=Linux-Always-Reserve-1MB
-
#5225
 Yutani
nagyúr
Petykemano
#5222
Yutani
nagyúr
Petykemano
#5222
Yutani
nagyúr
válasz
Petykemano
#5222
üzenetére
Biztos, hogy fake, 66MHz-es EDO RAM van mellette.
-
#5223
 Z10N
veterán
Petykemano
#5222
Z10N
veterán
Petykemano
#5222
Z10N
veterán
válasz
Petykemano
#5222
üzenetére
Fake. Abu szerint 8 mag lesz a belepo
-
#5222
Petykemano
veterán
Petykemano
veterán
AMD Ryzen 3 6100 [link]
4 mag
5ghz
Nem valami magas eredmény értékek...
Könnyen lehet, hogy fake -
S_x96x_S
addikt
Simply NUC Ruby R8 (CBM1r8RB) AMD NUC Review
https://www.storagereview.com/review/simply-nuc-ruby-r8-cbm1r8rb-amd-nuc-review
van több config ... R3/R5/R7
https://simplynuc.eu/ruby/
Ruby R3
AMD® Ryzen™ R3-4300U CPU (4c/4t) passmark: ~7667
AMD® Radeon™ Vega 5 Graphics
4GB DDR4 Memory
128GB SSD
1x 2.5GbE NIC + 1x 1GbE NIC + Intel Wi-Fi 6 AX200
Free OS installation
FULLY CONFIGURED
From €439 Ex.VAT -
HSM
félisten
válasz
 paprobert
#5214
üzenetére
paprobert
#5214
üzenetére
"Nyilván azért csinálják, mert megéri csinálni."
Nyilván, de nem mindegy, milyen szempontból éri meg... Pl. az is lehet a cél, hogy megtartsák a "leggyorsabb gaming CPU" címet, miközben nyilván a tömeg nem 5950X "triple L3" kiadásokat fog vásárolni.... #5218 S_x96x_S : A videók enkódolását/dekódolását azért már elég régóta szokás célhardverre vinni (tipikusan GPU/IGP), mivel jól gyorsítható ilyesmikkel.
-
S_x96x_S
addikt
CPU trend: VCPU specializálódás ..
Az általános x86 CPU feladatot - egyre inkább specializált chipek veszik át."Google New Custom Silicon Replaces 10 Million Intel CPUs | Google Argos VPU"
https://semianalysis.substack.com/p/google-new-custom-silicon-replaces
"if we assume that Google’s servers are utilized at 100% (they aren’t), all YouTube/Google Photos/Google Drive footage video is 1080p 30FPS, and the target is H264, the workload would require ~904,000 Intel Skylake server CPUs to encode. Google switching to VP9 with the same set of assumptions would require ~4,193,000 Intel Skylake server CPUs. If the ingest footage is 4k 60FPS, then the number of CPUs required for H264 is ~7,205,000, and VP9 requires ~33,407,000."
-
S_x96x_S
addikt
AMD Rembrandt will not get Infinity Cache
AMD has recently updated the Linux kernel with information on the upcoming Yellow Carp APU.
https://videocardz.com/newz/amd-ryzen-6000-rembrandt-yellow-carp-apu-will-reportedly-not-feature-infinity-cache
"
The APU will require a new FP7 socket, which will force laptop makers to adopt existing designs for new motherboards and possibly power and thermal characteristics of the “Yellow Carp” APU series. This is understandable, as Rembrandt brings major changes not only to the CPU and GPU core but also I/O. Rembrandt will be the first AMD APU to support DDR5 and LPDDR5 memory standards. It will also enable PCIe Gen4 support, which is something that Cezanne currently does not.
According to some new information, Rembrandt will not have Level3 (L3) cache, at least there is no such entry in the recent Linux kernel update (only L1 and L2 cache).
Furthermore, instead of 8 Compute Units per ShaderArray, Rembrandt will have 6. The code does not confirm the full number of CUs in the APU though. The Zen3+ and 6nm fabrication processes have not yet been confirmed either, but they have been repeated in rumors for quite a while, so it would be surprising if they turn out to be false.
"
 Source: @Broly_X1
Source: @Broly_X1 -
S_x96x_S
addikt
válasz
paprobert
#5214
üzenetére
> CPU-ból már túltermelés van,
ezt hogy érted?
- vagy erre milyen adatokból/jelekből következtettél?
- vagy ezt csak az OEM és a Cloud-ra érted?mert a Consumer hazai piacon:
- én "G"-s és "Athlon" procit nem is nagyon látok.
- és AthlonG-s pedig még ritkább. ( Athlon 3000G, 200GE, 240GE )ha csak a 7nm-resekre .. azért ott is lenne igény ..
és várják az új olcsó 5600G-t. ( meg ha lenne Ryzen3 -as ZEN3-as ) -
#5215
Petykemano
veterán
Petykemano
#5211
Petykemano
veterán
válasz
Petykemano
#5211
üzenetére
"In fact, the AM5 schedule is inconsistent with the V-Cache Zen3. This is one of the reasons why AM5 will only appear on ZEN4."
[link] -

paprobert
őstag
Abban a termékszegmensben, ahol az egyre jobb termékek már 200-300 dollárokkal lépkednek felfele árban, kigazdálkodják valahogy.
Nyilván azért csinálják, mert megéri csinálni.Egyébként lassan vége a kapacitáshiánynak.
CPU-ból már túltermelés van, és amint az eladatlan termékeken realizálódó kieső profit egyenlőséget tesz a GPU részleg eddigi 30%-os dollár/mm2 hendikepje között a CPU-hoz viszonyítva, a GPU termelés is helyre fog állni.
Gyakorlatilag mindegy lesz anyagilag, hogy melyiket gyártja majd az AMD. -
#5213
Petykemano
veterán
Petykemano
veterán
Megszakítjuk adásunkat...
IDT => Intel FRED vs AMD SEE
Linux szerint "és"
[link]Kiváncsi vagyok, hogy lesz-e a jövőben valamilyen közös megoldás például a mostanában sokat emlegetett utasítás-hossz problémára, ami szakértők szerint egy objektív akadálya a mag szélesítésének.
-
#5212
S_x96x_S
addikt
Petykemano
#5211
S_x96x_S
addikt
válasz
Petykemano
#5211
üzenetére
> Lisa Su azt mondta a kísérleti zen3V-re, hogy év végén kerül gyártásba.
én már azzal a gondolattal is eljátszottam,
hogy a következő Threadripper (zen3-as) _TALÁN_ már ilyen lesz ..
De szeptemberre még semmi esély ..
-
#5211
Petykemano
veterán
S_x96x_S
#5192
Petykemano
veterán
válasz
S_x96x_S
#5192
üzenetére
Feb 2022
a dátum - noha későbbi, mint amit én reméltem - nem irreális,.sőt.
A Vermeer megjelenéséhez képest 15 hónap - a szokásos termék-megjelenés-intervallum.
Lisa Su azt mondta a kísérleti zen3V-re, hogy év végén kerül gyártásba. Onnan még biztosan pár hónap, mire termék lesz.De vajon milyen termék?
Szerverbe nagyonis lenne értelme, ott bármilyen formában megfizettethető. =>Milan-X (Talán nem is nagyon lenne szükség v-cache nélküli termékre.)Viszont abból lenne értelme vajon új szériát csinálni, ha egyébként csak a legdrágább 8-12-16 magos darabokra kerül rá? Na nem mintha sok 8 magosnál kisébb zen3 létezne a piacon. Viszont egy olyan új széria, ami nagyobb drágulást hoz - mert a texhnológia drága - mint amennyi előnyt biztosít, az megint fölháborodást fog kelteni. Persze tudom, így is el fog fogyni.
Na de mindegy, nem is ide akartam kifuttatni, hanem az időzítésekhez. Ha ez az AMD 2022Q1-2023Q2-ig tartó terméke (ide értve a Vermeer-X és Milan-X is) akkor miért mondta Lisa Su, hogy eltökéltek az 5nm-es termékek 2022-ben való megjelentetését illetően?
Persze sokminden lehetséges. Pl:
- 2022 hosszú, a zen4 indulhat akár 2022Q4-ben is és még akkor is 2022. Azt gondolnám, hogy ez talán inkább a DDR5 és az 5nm elérhetőségétől függ, mint attól, hogy kész van-e. A Milan-X a meglevő alaplapokba akkor is remek drop-in-replacement lenne, ha egyébként egyszerre jelenne meg a Genoaval.
- én továbbra is azt remélem, hogy a 7nm-es (AM4) termékek olcsóbb változatként még pár évig a piacon maradnak. Ennek némileg ellentmond az, hogy a zen4-ről meg épp azt rebesgetik, mégsem emel magszámot.
- egy kísérleti terméket láttunk. A végleges 2022-ben megjelenő megoldás épülhet éppenséggel már zen4-re - újabb meglepetést okozva. Nem jött megerősítés arra vonatkozólag, hogy ez volna a Warhol
(Én erre látok legkevesebb esélyt) -
#5210
Petykemano
veterán
S_x96x_S
#5206
Petykemano
veterán
válasz
S_x96x_S
#5206
üzenetére
Jól értem, hogy a 36mm2 = 64MB és ez egy réteg?
Tehát nem 2x36mm2.Vajon.... mi érné meg jobban?
- hasonló rétegeket az L2$ és L1$ fölé építeni?
- a jelenlegi L3$ helyén az L2$ méretét növelni (hogy a V-cache továbbra is cache fölött legyen) és az L3$-t pedig kompletten kiszervezni többrétegű V-cache-be? -
HSM
félisten
válasz
S_x96x_S
#5206
üzenetére
"- As the V-Cache is built over the L3 cache on the main CCX, it doesn't sit over any of the hotspots created by the cores and so thermal considerations are less of an issue. The support silicon above the cores is designed to be thermally efficient."
Azért az nem túl bíztató, hogy "less of an issue". A nagy kérdés, hogy a hűtő és a tranzisztorok távolsága változott-e, ez sajnos ebből nem derült ki. Ha nőtt, akkor a hűthetősége elméletileg rosszabb lesz.#5208 paprobert : Azt lenne még érdekes tudni, a csip és kapacitás hiány miatt mennyi bevételtől esnének el, ha pl. ilyeneket gyártanának adott kapacitásokon Navi GPU-k és Zen3 CCD-k helyett. És ezt mondjuk mennyire lehet ellensúlyozni egy nyilván magasabban árazott prémium termékkel, amihez ezeket felhasználhatják. Persze, B-tervnek is jónak tűnik, ha az Alder Lake túl jól sikerülne.
-
paprobert
őstag
-
#5207
awexco
őstag
Petykemano
#5197
awexco
őstag
válasz
Petykemano
#5197
üzenetére
Ez egy nagyon sok ismeretlenes egyenlet . Sok dologot nem tudunk .
Az biztos , hogy alapjában véve nagyon durván pazarló megoldás ebben a kivitelben . De nem feltétlenül rossz . Megnyitja a lehetőségek tárházát . Annak van értelme , hogy a legnagyobb asztali cpu kapjon belőle. Mert vannak olyan gamerek akik nem az árat nézik és megvesznek bármit ami a csúcs .
Laptop téren elgondolkoztam egy picit . Teszem azt a kissebb cpu-kra rátesznek 8gb a nagyobbakra mondjuk 16gb ramot . Lehet kissebb chippet is tervezhetnek és maga komplet termék kissebb , olcsóbb is lehet . Mivel az integrációnak hála sok minden elhagyható lesz a nyákról .
Ez az egész egy opció . Annak is fügvénye lesz , hogy mennyi gyártó kapacitása lesz az amdnek . Ha kevés termék fogy véletlen és fel kell használni a gyártó kapacitást , hogy értéknövelt terméet áruljanak arra jó ...
Vajon menyibe kerülhet amdnek csak a szilicium gyártása (2x36) mindenféle járulékos költség mentesen ? -
S_x96x_S
addikt
V-Cache - Anandtech részletes frissítés:
Update June 1st:
In a call with AMD, we have confirmed the following:- This technology will be productized with 7nm Zen 3-based Ryzen processors. Nothing was said about EPYC.
- Those processors will start production at the end of the year. No comment on availability, although Q1 2022 would fit into AMD's regular cadence.
- This V-Cache chiplet is 64 MB of additional L3, with no stepped penalty on latency. The V-Cache is address striped with the normal L3 and can be powered down when not in use. The V-Cache sits on the same power plane as the regular L3.
- The processor with V-Cache is the same z-height as current Zen 3 products - both the core chiplet and the V-Cache are thinned to have an equal z-height as the IOD die for seamless integration
- As the V-Cache is built over the L3 cache on the main CCX, it doesn't sit over any of the hotspots created by the cores and so thermal considerations are less of an issue. The support silicon above the cores is designed to be thermally efficient.
- The V-Cache is a single 64 MB die, and is relatively denser than the normal L3 because it uses SRAM-optimized libraries of TSMC's 7nm process, AMD knows that TSMC can do multiple stacked dies, however AMD is only talking about a 1-High stack at this time which it will bring to market.
-
#5204
Petykemano
veterán
S_x96x_S
#5201
Petykemano
veterán
válasz
S_x96x_S
#5201
üzenetére
Agner:
"A serious bottleneck is a decoding rate of 4 instructions or 16 bytes per clock. To compensate for this, the Zen 3 has a micro-op cache with 4096 entries after the decoder.
The increased throughput in terms of instructions per clock may be difficult to utilize if the software has long dependency chains (where each calculation must wait for the result of the preceding one). It is now more important than ever to avoid long dependency chains.
The bottleneck in the decoder appears to be difficult to overcome. This is a consequence of the messy x86 code structure where instructions can have any length from 1 to 15 bytes, and it is complicated to determine the length of each instruction. Intel processors have the same bottleneck and the same decoding rate. The programmer must make sure the critical part of a program fits into this micro-op cache if you want to get the maximum throughput. It is important to avoid loop unrolling where possible in order to economize the use of the micro-op cache. (The Clang compiler often makes excessive loop unrolling)"
[link]Az AT fórumon két elképzelés (patent) is fölmerült.
Én nem értek hozzá, nem tudom megmondani, hogy melyik mennyire jó vagy nem jóVirtualuizált uop cache [link]
A másik pedig a Tremont féle dual-decoder út [link]Persze lehet, hogy mindkettő módszer együttes használata adja a legjobb eredményt - és a legtöbb tranzisztor és fogyasztástöbbletet az Armhoz képest, ahol ilyen trükkökre nincs szükség.
Mindenesetre úgy tűnik ez alapján, hogy egyelőre hard Wall nincs, csak ha fejlődni szeretnének, akkor arra az Armhoz képest több tranzisztort és fogyasztást kell áldozni.
Egyelőre mindenki azt mondja, hogy az IPC szignifikáns növelésének legkézenfekvőbb módja a mag szélesítése lenne [link] aminek az x86 esetén az a korlátja, hogy a decoder nem tudják 4(-5)-nél szélesebbre venni.
Valószínűleg enélkül is lehet IPC-t növelni - valahogy úgy, ahogy az intel teszi, hogy a bufferek, regiszterek és cache-ek 25-50%-os növelése itt-ott ad 1-2%-os gyorsulást, ami végülis kiadhat egy valamirevaló 15%-os előrelépést egy generációban. De ez nem az a fajta ugrás, amit az igen vékony bulldozer magról az akkori értelemben széles ryzen magokra ugrás hozott és amivel utol lehetne érni az Apple M1-et.Úgy tűnik, hogy ennek az akadálynak az elhárítása a következő pár év nagy kihívása és beszédtémája lesz.
-
-
S_x96x_S
addikt
válasz
S_x96x_S
#5192
üzenetére
> - "Feb 2022 launch" -re jósolja a következő AMD cpu generációt.
> (feltételezem, hogy valami belsős infó alapján, Ian Cutress a kevésbé
> blöffölös fajta elemzők közé tartozik)rákérdezett:
"Confirmed with AMD that V-Cache will be coming to Ryzen Zen 3 products, with production at end of year."
https://twitter.com/IanCutress/status/1399766139769602058Az Intel ellen valamit ki kell állítani ..
Közben az interneten már találgatják a termékelnevezést:
"Ryzen 5950XT Pro Hyper V-Cache RX edition" -
S_x96x_S
addikt
ISA architektúrák .. X86 vs. ARM
RISC vs. CISC Is the Wrong Lens for Comparing Modern x86, ARM CPUs
https://www.extremetech.com/computing/323245-risc-vs-cisc-why-its-the-wrong-lens-to-compare-modern-x86-arm-cpusAGner Fog
"
ISA is not irrelevant. The x86 ISA is very complicated due to a long history of small incremental changes and patches to add more features to an ISA that really had no room for such new features…
The complicated x86 ISA makes decoding a bottleneck. An x86 instruction can have any length from 1 to 15 bytes, and it is quite complicated to calculate the length. And you need to know the length of one instruction before you can begin to decode the next one. This is certainly a problem if you want to decode 4 or 6 instructions per clock cycle! Both Intel and AMD now keep adding bigger micro-op caches to overcome this bottleneck. ARM has fixed-size instructions so this bottleneck doesn’t exist and there is no need for a micro-op cache.
Another problem with x86 is that it needs a long pipeline to deal with the complexity. The branch misprediction penalty is equal to the length of the pipeline. So they are adding ever-more complicated branch prediction mechanisms with large branch history tables and branch target buffers. All this, of course, requires more silicon space and more power consumption.
The x86 ISA is quite successful despite of these burdens. This is because it can do more work per instruction. For example, A RISC ISA with 32-bit instructions cannot load a memory operand in one instruction if it needs 32 bits just for the memory address."----------------------------------------
és mégegy Kapcsolódó cikk az elmúlt hetekből -
Emulációnál viszont az ARM(AArch64) - 2x annyi regiszterének és a 3 operandusos utasításkészletének van valami előnye.
Valamint energiahatékonyabb is az M1. ( de ez az 5nm miatt is )
"Temptation of the Apple: Dolphin on macOS M1""AArch64 does have its advantages, though. Namely, the processors have 31 registers, compared to the 16 available in x86-64 processors. The PowerPC processor we are emulating has 32 registers, and while it is rare for all of them to be used within a single code block, more registers is always nice to have. Another difference is that AArch64 and PowerPC have 3 operand instructions while x86-64 only has two.
PPC: A = B + C AArch64: A = B + C x86-64: A = B, A = A + C
As you can see, it makes emulating some instructions much cleaner and easier than on our x86-64 JIT. Alright, enough with the boring details. How does the M1 hardware perform when put up against some of the beasts of the GameCube and Wii library? ..."







 A Raphael érdekes lehet.
A Raphael érdekes lehet.





 Nekem már a korai Ryzenek 4-magos CCX-es felépítése sem nyerte el maradéktalanul a tetszésem, de itt sokkal több problémát tudok elképzelni.
Nekem már a korai Ryzenek 4-magos CCX-es felépítése sem nyerte el maradéktalanul a tetszésem, de itt sokkal több problémát tudok elképzelni. Még notebookon is túlzásnak és felesleges bonyolításnak hat számomra. Sőt, egyenesen úgy fest, mintha ez azért jönne, mert sehogy máshogy nem tudnak villantani valamit, ami legalább távolról hasonlít a nagyobb AM4 processzorokra.
Még notebookon is túlzásnak és felesleges bonyolításnak hat számomra. Sőt, egyenesen úgy fest, mintha ez azért jönne, mert sehogy máshogy nem tudnak villantani valamit, ami legalább távolról hasonlít a nagyobb AM4 processzorokra.























 látom - lassabb vótam ... ( de ezért itthagyom )
látom - lassabb vótam ... ( de ezért itthagyom )


Új hozzászólás Aktív témák

- ASTRO A50 5th gen LIGHTSPEED WIRELESS HEADSET + BASE STATION fejhallgató
- Új Steelseries Arctis Nova pro vezeték nélküli gamer fejhallgató
- Samsung Galaxy Z Fold4 Graygreen Duplakijelzős produktivitás, 120 Hz, Garancia 2026. 03. 22-ig
- Samsung Galaxy A23 5G / 4/128GB / Kártyafüggetlen / 12 Hó Garancia
- GYÖNYÖRŰ iPhone XR 128GB Red-1 ÉV GARANCIA - Kártyafüggetlen, MS3984, 100% Akkumulátor
Állásajánlatok

Cég: ATW Internet Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest