Hirdetés
Új hozzászólás Aktív témák
-
#10077
 Petykemano
veterán
hokuszpk
#10076
Petykemano
veterán
hokuszpk
#10076
Petykemano
veterán
válasz
 hokuszpk
#10076
üzenetére
hokuszpk
#10076
üzenetére
Dehogyis. A zen4c esetén a mag és az L2 együtt is 35%-kal kisebb helyet foglalt el.
Ez olyan 1.3mm2-t jelentett magonként.Ha a 8-at megoldani macera is, az egyik oldali 6 mérete ponthogy lehetne ennyivel kisebb. Mivel server first, nekem így lenne logikusabb.
Aztán a fene tudja, lehet, hogy így meg hamarabb lesz belőle termék. -
#10070
 Alogonomus
őstag
hokuszpk
#10069
Alogonomus
őstag
hokuszpk
#10069
Alogonomus
őstag
válasz
hokuszpk
#10069
üzenetére
Elsődlegesen az AM5 ihs-e azért lett vastag, hogy a teljes CPU magassága kompatibilis legyen az AM4 hűtőkkel.
Aztán hogy még milyen előnnyel járhat ez a jövőben, arra sok ötlet lehet. Például a vastag ihs miatt a Zen 4 és Zen 5 hőháztartása is szuboptimális, amit bizonyított például der8auer is azzal, hogy az ihs jelentős részét lecsiszolva a vékonyabb ihs eredményeként a Zen 4-es processzora 20 fokkal hűvösebb lett, miközben érdemi mértékben gyorsult is. -
#9989
Alogonomus
őstag
hokuszpk
#9988
Alogonomus
őstag
válasz
hokuszpk
#9988
üzenetére
A magyarázó szöveg alapján az ASUS 2503-as biosával teszteltek és PL1=PL2=253 wattal. Szóval nem a legfrissebb bios, de azért valamennyi javítás már benne volt. Viszont a degradáció miatti javítások a tesztek alapján annyira nem ártottak a játékok teljesítményének.
A kialakult átlagot jobban befolyásolta, hogy a tesztelt játékok nagy részénél az APO aktív volt. Erős cherrypicking történt. -
#9978
Alogonomus
őstag
hokuszpk
#9976
Alogonomus
őstag
válasz
hokuszpk
#9976
üzenetére
A Core Ultraval szemben már a 7800X3D teljesítménye is bőven elég lenne a korona megtartásához, hiszen az Intel saját diája szerint a csúcs Core Ultra is szűken elmarad a 14900K játékok alatti teljesítményétől, és a 14900K is elmaradt már a 7800X3D-től. Ez alapján a 285K már a 7800X3D-hez képest is szűken 10% környéki lemaradást mutathat majd, ami a 9800X3D-hz képest átlagosan már egy bő 10% fölötti lemaradássá növekedhet 1080p esetén, és talán 1440p esetén is ott marad 10% környékén. A 4K persze már legtöbb esetben GPU-limites szituáció. ott főleg csak az 1% low értékeken javít az X3D technológia.
Az AMD valószínűleg a 9800X3D-t is "ellazsálja", mert nincs rákényszerülve a "hardver végletekig kifacsarására". -
#9967
Petykemano
veterán
hokuszpk
#9966
Petykemano
veterán
válasz
hokuszpk
#9966
üzenetére
Tegnap néztem.
Ha jól értettem, akkor maga az L3$ cellák mérete nem változott. Beszél.valami sűrűbb pakolásról, de a lényegi elem az, hogy a TSV helyigénye csökkent drasztikusan.Az L3$ felület persze mindenképp csökkent.
Nekem épp az jutott eszembe, hogy mi van, ha - igazodva az alapfelület méretének csökkenéséhez - épphogy csökkentették egy v-cache lapka kapacitását 32MB-ra, de már több rétegben helyezik el. A 3 vagy 4 aktív réteg magyarázná a kapacitás számokat. -

fatal`
titán
válasz
hokuszpk
#9964
üzenetére
De te említetted a 7800X3D-t a blenderes grafikonnal kapcsolatban, én arról beszéltem most, nem arról, amit nekem címeztél, az 55 kapcsán írtál 7800X3D-t az 57-ben..
A scheduler egyébként most is csak annyit csinál, hogy CCD-n belül tartja (illetve játékot fixen az elsőre oszt, ez a része viszont nem fog változni). Ha a második CCD is vcachet kap, szerintem nem segít semmin, főleg ha így lassabb órajele lesz. De majd meglátjuk. Szerintem ugyanaz lesz az új X3D-kkel, mint a sima 9-es sorozattal, minimális előrelépés lesz. De megkövetem magam, ha nem így lesz.
Ha növelnek az egy CCD-re eső cachen akkor az még okozhat sebességnövekedést.
-
fatal`
titán
válasz
hokuszpk
#9962
üzenetére
Az eredeti hozzászólásodban szó nem volt 9800X3D-ről, nem is lehetne a grafikonon mert nem jelent meg:
#9957
******* jah itt a garfikonban van 5800X3D; ... 7950X3D ; de sehol nemlatom a 7800X3D -t. szvsz azert valahol az 5950X es a 7950X3D között lenne.Erre reflektáltam, hogy ez szinte kizárt azon a Blender charton.
-
fatal`
titán
válasz
hokuszpk
#9957
üzenetére
******* jah itt a garfikonban van 5800X3D; ... 7950X3D ; de sehol nemlatom a 7800X3D -t. szvsz azert valahol az 5950X es a 7950X3D között lenne.
Ez durván meglepő lenne rendernél. Több, mint valószínű, hogy valahol az 5800X3D és az 5950X között. A 16 magos 5950X azért nem olyan gyenge cucc.
Annyit kell megoldani, hogy ccd-n belul tartsuk
Attól függ milyen processt. Úgy értettem, hogy mégnagyobb lesz a késés a cacheből pakolászás miatt, ha rosszul ütemez. -

S_x96x_S
addikt
válasz
hokuszpk
#9954
üzenetére
> nem feltétlen kell magasabb frekit tudnia.
Akkor általános felhasználásra is ideális lenne.
Sajnos nem minden program - X3D cache - érzékeny,
és az alacsonyabb freq miatt ilyenkor - csak "pain" van "gain" nélkül.Még a játékprogramoknál is van X3D -re nem annyira érzékeny program,
aminél a freq veszteség nagyobb - mint az X3D nyereség.------------
Amúgy a Blender például nem értékeli annyira az X3D-t, hogy a freq veszteséget kompenzálja.
https://www.phoronix.com/review/amd-ryzen9-7950x3d-linux/14
-----------Amúgy fogyasztásban teljesen ideális lesz a két X3D -s 9950X3D.
-
S_x96x_S
addikt
válasz
hokuszpk
#9901
üzenetére
Linux-on már van sok program, ami használja az Inteles AMX-t.
és azért aki komoly mérnöki/tudományos számításokat végez,
az biztos halott is már erről.De amúgy az AI/ML hullám elején vagyunk
és valamilyen X86-64 - Mátrix támogatás kell majd a jövőben.
és mivel az Intel csinált már egy ilyet ( AMX ) valószínüleg az lesz X86 oldalon.
(mégha nem is tökéletes)Az Armv9.2-A - már tartalmazza az SME/SME2 (Scalable Matrix Extension)
(May 23, 2024) https://newsroom.arm.com/blog/scalable-matrix-extension
És mintha az Apple M4 is megkapta volna az új (szabványos) SME-t
https://github.com/tzakharko/m4-sme-exploration
Az új Snapdragon 8 Gen4 (Oryon/Nuvia) viszont mintha még nem lenne SME képes. -
S_x96x_S
addikt
válasz
hokuszpk
#9898
üzenetére
(AMX)
az (Intel) AMX támogatás mintha már be lenne integrálva az LLVM és a GCC -be,
és sok minden másba is https://www.phoronix.com/search/Intel+AMXAz Apple ( M1/M2/M3/.. ) viszont már 2020 -óta támogat ( egy hasonló mátrixos utasításkészletet - persze az ARM alapú és nincs rendesen dokumentálva.
AI-re és pl. a CPU-n futtatott https://ollama.com/ ( lokális chatbot ) futtatásához lenne praktikus egy átlag usernek. Persze ott vannak a GPU -k és az NPU-k, de szerveres környezetben azok nem mindig érhetőek el.
pár random link:
1.) Advanced Matrix Extensions (AMX) Guide
https://github.com/mikeroyal/AMX-Guide2.) "Contrasting Intel AMX and Apple AMX"
https://www.corsix.org/content/contrasting-intel-amx-and-apple-amx3.) "Explore AMX instructions: Unlock the performance of Apple Silicon"
https://zhen8838.github.io/2024/04/23/mac-amx_en/
"""
Since 2020, Apple has published M1/M2/M3. They have at least four different ways to perform high-intensity computing tasks.
- Standard arm NEON instructions.
- Undocumented AMX (Apple Matrix Co-processor) instructions. Issued by the CPU and performed on the co-processor.
- Apple Neural Engine
- Metal GPUIf we use ARM NEON instructions to accelerate the sgemm kernel on the single core of the M1 Max, It can achieve a performance of around 102 GFLOPS. But if use AMX instructions it can achieve 1475 GFLOPS!
...
""""4.) "Accelerate PyTorch* Training and Inference Performance using Intel® Advanced Matrix Extensions (Intel® AMX) " ( Intel )
-
S_x96x_S
addikt
válasz
hokuszpk
#9887
üzenetére
> hm. te mint programolo,
> fejtsuk mar meg, az if -ben minek is van break aztan utana a zaro '}' utan meg1 ?<tippelek>
mert lesz valamikor egy "znver6"-os kód is beszúrva.
és ha jól értem - ez egy ajánlás K&R -től - amolyan defenzív programozás.
https://stackoverflow.com/a/26139061
From The C programming language - Second edition (K&R 2) Chapter 3.4 Switch:
"As a matter of good form, put a break after the last case (the default here) even though it's logically unnecessary. Some day when another case gets added at the end, this bit of defensive programming will save you."amúgy nézd meg a teljes kódot is,
és ha ez a gyakorlat az LLVM kódokban, akkor felesleges ezen vitatkozni.
( amúgy tényleg érdemes belenézni a zen1, zen2,zen3,zen4,zen5 definiciókba. )
https://github.com/llvm/llvm-project/blob/b68bcc1415151bd84b5868aa2c98663069f45469/compiler-rt/lib/builtins/cpu_model/x86.cdisclaimer: adatbázisokkal foglalkozom. A C-ből nem tudnék megélni, úgyhogy ne vedd a véleményemet szentírásnak.
-

Z_A_P
addikt
válasz
hokuszpk
#9889
üzenetére
Persze, vagom, ha eszreveszed ki lehet (kell) szedni onnan. Ott maradt, gondot nem okoz.
Ha meg valaki if utan meg berak valamit, és nem veszi eszre break-et, na AZ mar hiba
Ugyanugy a CPU is ugyanazt az erteke kapja if-en belul is ujra.
Lehet a Subtype-nak mar van default erteke, vagy ures alapbol, es csak if cpu eseten lesz erteke. -
#9858
Petykemano
veterán
hokuszpk
#9850
Petykemano
veterán
válasz
hokuszpk
#9850
üzenetére
Azt írták, eltérő (CPU specifikus?) kódutakat használ.
Ezért én nem gyanakodtam bugra.Egyébként ilyen talán régebben is volt, talán az Intel fordítójával, hogy Intel esetén AVX2 használatba került, az AMD-t meg a processzorgenerációtól függetlenül generikus processzornak vette.
-
#9766
Petykemano
veterán
hokuszpk
#9754
Petykemano
veterán
válasz
hokuszpk
#9754
üzenetére
Szerintem az Intel gyártástechnilógiája frekvenciában jobb. Fogyasztásban viszont talán inkább gyengébb.
Ezért én arra számítanék a tsmc-nél gyártott Intel cumóknál, hogy sokat javul az energiahatékonyság, de romlik az Fmax. Így ugyanolyan felemás érzést fog kelteni.mint a Zen5. Ha ez így lesz, lehet, hogy érthetővé válik az is, miért olyan lett a Zen5, amilyen.
-
#9763
Alogonomus
őstag
hokuszpk
#9761
Alogonomus
őstag
válasz
hokuszpk
#9761
üzenetére
Ha előzetesen tippelni kell, akkor egyetlen szálon az Arrow Lake nyers teljesítménye szerintem is valószínűleg a Zen 5 előtt lesz. Persze a teljes képhez az is hozzátartozik, hogy az Arrow Lake maximális változata csak 8 "P" szálat és 16 "L" szálat biztosít majd, amivel összteljesítményben csak a felső-középkategóriás 16 szálas 9700X felülmúlása lehet a valós célja csúcsmodellként. Mindezt egy sokkal drágább node segítségével elérve.
-
#9759
Alogonomus
őstag
hokuszpk
#9754
Alogonomus
őstag
válasz
hokuszpk
#9754
üzenetére
"ha ezt az Intel leviszi olyan technologiara, ami redukalja a fogyasztast"
Lévén az Arrow Lake nem a Raptor Lake "P" magjait használja, így annyira mégsem világszenzáció az a "P" mag. Talán pont az a hibája, hogy a stabil működéséhez kell az a magonként legalább 30 watt neki, amit 3 nm-en is biztosítani kellett volna a magnak, szóval nem lehetett volna takarékosabb.
-
#9752
Alogonomus
őstag
hokuszpk
#9751
Alogonomus
őstag
válasz
hokuszpk
#9751
üzenetére
Az Intel valószínűleg a TSMC kiemelt partnereit követően tudott a megmaradt 3 nm-es kapacitásra licitálni a többi kisebb céggel közösen. A válaszommal főleg arra akartam utalni, hogy az AMD terveit nem az húzta keresztbe, hogy "de az Applen kivul bejott meg 1 nagy megrendelo a kepbe, ugy hívják, hogy INTEL", mert kiemelt stratégiai partnerként az AMD – minden valószínűség szerint – az Intel előtt lefoglalhatta azt a 3 nm-es kapacitást, amennyire szüksége volt. Sőt az AMD ki is ad 3 nm-es Zen 5c magokkal Epyc processzort.
Az viszont legkésőbb a Raptor Lake bemutatkozásától kezdve nyilvánvalóvá vált, hogy az alacsonyabb piacokra szánt CCD-khez elég lesz a sokkal olcsóbb 4 nm-es gyártósort használni.
Az persze valószínű, hogy valamikor 2019 magasságában, amikor megnyílt a 3 nm-es kapacitásra jelentkezés, akkor felmerült opcióként a teljes Zen 5 termékskála 3 nm-en gyártásának a forgatókönyve, de az valószínűleg gyorsan le is került az asztalról, mivel nem voltak szorongatva az Intel által.
Az Intel talpa alatt volt nagyon forró a talaj, ezért vásárolt egyáltalán az inteles Bob Swan kapacitást a TSMC 3 nm-es gyártósorán. Bob Swan a belső bizalmas inteles állapotjelentések alapján előre láthatta, hogy az inteles gyártósorok 2024-ig sem lesznek képesek olyan "effektív csíkszélességre", amit 2024-ben a TSMC nyújtani tud majd. -
#9731
Alogonomus
őstag
hokuszpk
#9730
Alogonomus
őstag
válasz
hokuszpk
#9730
üzenetére
Ez a magyarázat már ott hibás, hogy megfelelő méretű leszerződött 3 nm-es TSMC gyártási kontingens hiányában az AMD nem is tervezte volna 3 nm-re a Zen 5-öt. Amennyiben pedig rendelkezésre állt megfelelő méretű leszerződött 3 nm-es TSMC gyártási kontingens az AMD tulajdonában, azt az Intel legfeljebb megvásárolni tudta volna az AMD-től csillagászati áron, de a TSMC nem adhatta át az Intelnek csak úgy.
Az Intel legfeljebb a még le nem szerződött 3 nm-es kapacitásra jelentkezhetett be.A 3 nm-es Arrow Lake esetét sokkal jobban megmagyarázza ez a verzió két megfogalmazásban 1, 2.
A Pat Gelsinger előtti Bob Swan az Intel kikászálódását nem az Intel saját gyárainak a felfejlesztésében látta, hanem az AMD-hez hasonlóan egy fabless megközelítésben. Ezért Bob Swan nagy mennyiségű 3 nm-es waferre adott le megrendelést a TSMC felé még 2019 környékén. Aztán jött Gelsinger, de a szerződésből már Gelsinger sem tudott visszalépni, ezért bármennyire is fájt Gelsinger számára, de az IDM 2.0 szekerének irányítgatása mellett a jelenlegi időszakban kénytelen volt valamit gyártani a TSMC 3 nm-én is, mert a Swan által 2024-es szállítással lekötött wafereket akkor is kiszámlázta volna nekik a TSMC, ha azok üresen futnak végig a TSMC gyártósorán. -
#9561
Petykemano
veterán
hokuszpk
#9559
Petykemano
veterán
válasz
hokuszpk
#9559
üzenetére
Nem lepne meg, ha a MT teljesítmény nem nőne olyan nagy mértékben. Ezzel együtt tartok tőle, hogy ahogy gigantikus IPC emelkedés sem volt, úgy gigantikus hatékonyságnövekedés sem lesz.
A Zen3 elég hasonló képet mutatott: ST teljesítményen volt a fókusz és közel azonos gyártástechnológián készült. A Zen3 esetén volt egy sandbagging elem, a 8 magra egyesített CCX, ami játékok esetén a nominális IPC számítási metódushoz képest jobb eredményt adott a felhasználók kezébe. Nem is beszélve a X3D változatról.
A zen4 esetén a szokásosnál nagyobbat ugró frekvencia volt a meglepi.Kíváncsi vagyok, most lesz-e.
(Esetleg a versenyhelyzetben épp elvárt energiahatékonyság lesz?) -
S_x96x_S
addikt
válasz
hokuszpk
#9559
üzenetére
és Blenderes
AMD Ryzen 9 9950X “Zen 5” ES CPU Outperforms Intel Core i9-14900K In Blender At Just 120W"In terms of performance,
the AMD Ryzen 9 9950X ES CPU scored
268.7 points in the Monster test,
177.5 points in the Junkshop test, and
129.8 points in the Classroom test in Blender.
Compared to the Core i9-14900K, the Zen 5 CPU at 120W not only matches it in the Monster test but is also able to outperform it in Junkshop and Classroom tests.
The CPU also comes close to the Ryzen 9 7950W which has a peak PPT of 230W or almost twice as much as this Zen 5 ES CPU.
Compared to the 90W configuration, the 120W PPT tune delivers close to a 19% gain in performance with a 33% increase in power." -
S_x96x_S
addikt
válasz
hokuszpk
#9475
üzenetére
A P+E miatt vették ki az AVX-512 az Intel consumer cpu-kból,
de a szerver fronton a Sapphire és az Emerald -nak elég jó az AVX-512 -es implementációja.
" The difference in peak frequency with AVX-512 enabled and disabled was minimal. With it on, the Xeon Platinum 8592+ hit 2.95 GHz on all cores compared to 3.01 GHz when AVX-512 was off. The 64-core Emerald Rapids chip hit the 3.9 GHz boost clock regardless of whether AVX-512 was on or off."sőt ... annyira jó, hogy a Microsoft(Azure) - az AMD's MI300X - mellé
nem EPYC-et választott, hanem Sapphire Rapids -ot."Support for a wide spread of AVX-512 instructions is a primary selling point of Emerald Rapids. Although the CPU loses out to AMD's 4th Generation EPYC Genoa chip with 96 cores in raw performance, as seen in our Emerald Rapids review, AVX instructions can change the dynamic between Intel and AMD's server CPUs, especially for AI. It's one of the probable reasons Microsoft chose last-generation Sapphire Rapids chips over EPYC to pair with AMD's MI300X GPUs."
( forrás )
úgyhogy az AVX-512 teljesítménye
szerver fronton sokkal fontosabb mint desktop-on
és a ZEN5 fejlesztési célja így jobban érthető is, -
#9452
Petykemano
veterán
hokuszpk
#9451
Petykemano
veterán
válasz
hokuszpk
#9451
üzenetére
Ó, de ravasz, ezt nem is néztem...
Mármint persze más szempontból korrekt, és az Intel tolta túl, csak hát a számok így nem egyértelműek.
Úgy rémlik egyébként nekem, hogy a baseline config nem volt annyira nagy hatással a játékokra: 2-3%
Merthogy játékok alatt viszonylag normális fogyasztása volt.Szerintem meg a "szerény" frekvencia, ami talán a gyártéstechnológia következménye, velünk marad.
A Zen6 biztosan ezeket a low hanging fruitokat fogja leszedni, hogy N3-on ki lehet majd tömni picivel több regiszterrel, cache-sel, és 2-300Mhz-cel lehet magasabb frekvencia.Lineárisan skálázódik a TDP a magok számával. Szerintem nincs itt már értelmesen kiaknázható tartalék.
Másrészt persze a TDP-t azért is kellhet alacsonyan tartani, mert a Qualcomm irányából épp a hatékonyság irányából fog jönni a támadás.
-
S_x96x_S
addikt
válasz
hokuszpk
#9406
üzenetére
szerintem a PS6 kompatibilitáson azt érthették,
hogy a régebbi játékok ne fussanak lassabban az új hw -en.
mert ha akár 1% esélye van, hogy egyes játékok rosszabbul futnak az írtó ciki lenne.
és ezt az se kompenzálná, hogy a több 99% -al nincs semmi baj,
a sajtó az 1% -on csámcsogna.![;]](//cdn.rios.hu/dl/s/v1.gif)
-
#9402
Petykemano
veterán
hokuszpk
#9401
Petykemano
veterán
válasz
hokuszpk
#9401
üzenetére
Én is kíváncsi vagyok, vajon a játékok skálázódnak-e 8 magon túl. Valószínűleg most még nem nagyon. Emiatt 3dCache ide vagy oda, tartok tőle, hogy a többletmag egyelőre nem érné meg a frekvenciadeficitet.
Úgy lenne jó ez a cucc, ha a 16 magból 2-4 azért mégiscsak eredeti felépítésű.
-

HSM
félisten
-
S_x96x_S
addikt
válasz
hokuszpk
#9397
üzenetére
> én még a Zen5CX3d -t várom
ezt fejtsd ki bővebben

én úgy értelmezném amit te javasolsz ..
hogy
az 5C -ben eleve kisebb a cache ..
és emiatt ezt visszapótolnád extra X3D -vel?
vagyis végül ugyanakkora cache-e lenne
mint a normál Zen5 magnak, csak 2x több mag?vagyis "Zen5CX3d" CPU core == 2x annyi Zen5 CPU core -al ?
de mivel sűrűbb a zen5c, amiatt biztos nem tud ugyanakkora Ghz -et - mint a normál zen 5.
-
S_x96x_S
addikt
válasz
hokuszpk
#9366
üzenetére
> még a Zen5 se jelent meg, de már hátizé.
a notebookcheck dekódolásában
A zen6 és a zen6c mellett lesz egy még jobban sűrített variáns is ( ~ még több mag )
( én zen6cc -nek nevezném el )"The Zen 6 architecture reportedly has three flavors: Standard, Dense Classic, and Client Dense."
"MLID suggests that Zen 6 “Client Dense” takes the Zen Xc formula even further by increasing the core count even further but incurring an energy penalty in the process." -
válasz
hokuszpk
#9328
üzenetére
Na igen csak két dolgot nem veszel figyelmbe. A noverdehez majd aztán odakerül a 2700 x meg 3700x és így tovább, generációs CPU előrelépések vannak azonos foglalaton belül. Intelnél a noveredhez bekerülehett volna egy 1700 nál max 10 % kal erősebb CPu aztán ha onnan tovább akar lépni akkor vesz egy használt deszkát is akitől megveszi az meg egy újat.
A másik hogy közben te ugyan úgy nem vettél új alaplapot ahogy írtam, miközben töb generáción át kb 2x olyan gyors csúcs vagy közép porcit tettél abba az alaplapba.
Ez régen 2 alaplapváltás lett volna neked Intelnél és legalább további 1 a használtpiacon továbbadottaknál.
Persze lehet rossz a gondolkodásom,de olvastam is erről redditen anno az EVGA kapcsán egy ottani illetékestől. -
válasz
hokuszpk
#9321
üzenetére
Szerintem pusztán üzleti oka van, nem a gyártási drágulás áll mögötte, bár bizonyos mértékig az is biztos. Ezt már anno kifejtettem több topikban szerimtem mi a probléma. Az hogy ha egy deszkába sok genrációnyi processzor jön, az nem tesz jót az alaplapgyártóknak mert évekig nem cserélnek a felhasználók deszkákat .
Mivel AMD átvette a vezető szerepet eladásokban sok szempontból az AIB partnereknek ugyan azt a bevételt kellene behozniuk lénygesen kevesebb alaplapeladásból. mint anno az Intelnél aki maximum 2 generációt engdett egy foglaltba, azok sem voltak igazán eltérőek. Amúgy én ezért nem örülök annak ha sokáig ki van tartva egy foglalat, mert közben sok egyéb dolog frissül, például a ram támogatás, a PCIE, az SSD is vele együtt. és egy jobb alaplap annyiba kerül mint egy középkategóriás Proci.... -
#9319
Petykemano
veterán
hokuszpk
#9318
Petykemano
veterán
válasz
hokuszpk
#9318
üzenetére
Zen4 problémák alatt pont azt értettem, amit leírtál: drága platformváltás.
Szerintem azért a teljesítmény előrelépés / költség nem elhanyagolható tényező. Persze nyilván nem is kizárólagos, hiszen ahogy mondod is, remekül elketyeg a zen3 is.Nem állítom, hogy a zen4 korai áresése mögött kizárólag ez a tényező állt, de közfejátszhatott. Valószínű, hogy ezt a problémát kevéssé hatékonyan lehet kezelni a teljes költség 20-30%-át kitevő proceszor 20-30%-os árcsökkentésével. De szerintem az, hogy 30% helyett 40% ponthogy meggyőző lehet a költségek vállalásához. Azért gondolom ezt, mert nagyon hasonló történik, ha egy generációt kihagysz és úgy növekedik a képlet számlálójának értéke.
A DDR6 állítólag 2024 végén, 2025 elején fog megjelenni. Ez azt jelenti, hogy földi halandók számára 2026 táján lesz inkább elérhető.
Arra is lehet számítani, hogy a zen5 és zen6 között eltelik 2 év, tehát 2026-ban várható a megjelenés.De persze én is örülnék, ha alacsony magszámú példányokat kiadnának AM5-re is. A chiplet illesztés és stacking fejlődése (v-cache) éppenséggel eredményezhetné azt is, hogy kevésbé szorul rá a proci a memória fejlődésére. (Lásd: 5800X3D)
De ismerve az AMD eddigi üzleti gyakorlatát, valószínűbbnek tartom, hogy nem lesz zen6 am5-be.
-
-
S_x96x_S
addikt
válasz
hokuszpk
#9190
üzenetére
> Samunak van chipletfelheggeszto technologiaja,
packaging?
le vannak maradva, de szeretnének
https://www.businesskorea.co.kr/news/articleView.html?idxno=117558
"""
(2023.07.03)
Samsung has also launched an all-out effort to develop advanced packaging technology that will take chip performance to the next level. At the Samsung Foundry Forum 2023 held on June 27, Samsung Electronics announced an all-out packaging war with TSMC, saying that it will not only advance its packaging technology but also grow related ecosystems. To this end, the Korean semiconductor giant even introduced the concept of a one-stop packaging service. It plans to provide customized packaging services for customers that want to improve the performance of their chips. In the long term, it will create a new line dedicated to packaging.
In order to overtake TSMC’s CoWoS, Samsung is also developing a more advanced concept of I-cube and X-cube packaging technologies. In particular, the Korean chipmaker is reportedly focusing its research on three-dimensional (3D) packaging in which multiple chips are stacked vertically to boost performance. “Samsung is preparing a more advanced way, the three-dimensional packaging of semiconductors,” a semiconductor industry insider said. “Soon there will be a head-on collision between Samsung and TSMC in packaging.”
출처 : Businesskorea(https://www.businesskorea.co.kr)
""" -
#9081
Petykemano
veterán
hokuszpk
#9080
Petykemano
veterán
válasz
hokuszpk
#9080
üzenetére
Valamivel mérni kell és még azért nem annyira sok natív cross-platform eszköz van, amivel ez megtehető.
Szerintem vitán felül áll az, hogy az Apple chipje jó.
Legfeljebb arról lehet vitatkozni, hogy tényleg jobb-e annyival, mint amennyit a grafikonok mutatnak, de biztosan nem rosszabb, mint az X86-os versenytársak.
És eközben szerintem az is vitán felül áll, hogy a nagyonis versenyképes ST teljesítmény leadása közben azért észrevehetően kevesebbet fogyaszt.mondhatjuk, hogy a különbséget tulajdonképpen az eredményezi, hogy az Apple procija széles feldolgozókkal közepes frekvenciára van tervezve, míg ehhez képest az x86 processzorok hagyományosan vékonyabbak, cserébe magasabb frekvenciával kompenzálják a szűkösséget. A magas frekvenciához pedig magasabb feszültség kell, ami négyzetesen emeli a fogyasztást
MT teljesítményben ennek megfelelően a teljesítmény és hatékonyságbeli különbség már nem látványos, vagy szinte el is tűnik. A lapkaméreten persze továbbra is lehet vitatkozni.
De ezzel megint ott vagyunk, hogy egy mobil 8 magos Zen4 APU-ban - vagy akár CCD-ben is - tulajdonképpen szinte feleslegesen foglal el az összes Zen mag teljes kiterjedést. Persze nyilván nem annyira egyszerű, mert nem lehet tudni előre, hogy a 8 közül melyik lesz az, amelyik majd a kívánt legmagasabb frekvenciát eléri.Azért is ködös számomra, hogy miért a magas frekvenciát választják tervezéskor a széles design helyett, hiszen a processzorok fő felhasználási területe, ahová ténylegesen és igazából készül az a szerver, ahol meg nem szükséges a magas frekvencia.
Valószínű, hogy azért nem annyira egyszerű jó széles architektúrát építeni. Ha elengedik a frekvenciát, akkor azzal sok helyet nyerhetnek (tehát kisebb lehet a lapkaméret), de nem biztos, hogy az ALU-k, FP pipe-ok, és gyorstótárak méretének növelésével együtt magától megérkezik az Apple chipben látható magasabb IPC is.
Engem például meglep, hogy a Zen5-ben, csak az L1d növekszik 48kB-ra 32-ről, miközben az Apple cpu-ban 192kB + 128kB van.
-
#9070
Petykemano
veterán
hokuszpk
#9069
Petykemano
veterán
-
#8998
Petykemano
veterán
hokuszpk
#8997
Petykemano
veterán
válasz
hokuszpk
#8997
üzenetére
Az a kérdés motoszkál bennem, hogy vajon számít ez?
Ha egy sokmagos asztali gépet MT teljesítményre húzol fel, az papíron jól hangzik, de egyrészt a 300W elég nevetséges. (1-2 generáció múlva ugyanezt fogja hozni egy 15W notebook) másrészt miközben kicsit talán bele is harap a Workstation piacba, desktopon valóban érdemben ki lehet használni?
Igazából ugyanezt gondolnám egy 3CCD-s Ryzenről is. Maximum akkor látnám értelmét, ha igazából a plusz magok (pontosabban a többlet MT teljesítmény) a régi sku-khoz képest grátisz és csuklóból jönnek és nem felárért. A 300W-os fogyasztás viszont némiképp izzadtságszagúvá teszi.
Hasonló helyzetként lehetne emlegetni a Zen1 betörését, hogy hát ott is feleslegesen jöttek a plusz magok. Annyiból látom másnak a helyzetet, hogy akkor azt gondoltuk, hogy a Skylake-en túl generációról generációra már csupán néhány százaléknyi IPC növekedésnek maradt szufla - legalábbis az x86 mikroarchitektúrákban -, így logikus volt azt gondolni, hogy nincs más út, mint növelni a magok számát.
Akkor persze sokan azt gondolták, hogy az Intelnek ott van a fiókban a titkos új architektúra, amivel majd újra megszégyenítő vereséget mér az MT teljesítménnyel bohóckodó AMD-ra, csak eddig cicázott vele. Végül nem lett.
De hát most minden jel arra utal, hogy a Zen5 is komoly ST előrelépést hozhat és 10-15% ST előny a desktop CPU-k terén mindig sokkal meggyőzőbb volt mint 10-15% MT előny - különösen ha annak a fogyasztásban is komoly ára van.
Ennélfogva bár az AMD valóban képes lehetne 3 CCD-t ledobni egy SKU-ba (nyilván lehet, hogy kellene hozzá új IOD és nyilván szükséges lenne hozzá valamilyen nagy frekvenciájú RAM is), de szerintem ez lényegesen kisebb sikerrel kecsegtetne, mint a Zen5.
-
#8985
Petykemano
veterán
hokuszpk
#8984
Petykemano
veterán
válasz
hokuszpk
#8984
üzenetére
Nem.vagy amatőr, nagyonis jól teszed, hogy azt várod.
Elméletben nagyon izgalmas, hogy a CCD-IOD kapcsolat szélessávúvá és - talán - alacsonyabb késleltetésűvé tétele milyen lehetőségeket hordoz magában.
De ha az AMD - ahogy egyes pletykák magyarázzák - az AI kereslet kielégítése érdekében hajlandó volt lemondani az RDNA4 chipletes változatairól, akkor ez a kapacitás-szűkösség érintheti a zen6-ot is. Ami ennek következtében, ha az AI kereslet fennmarad, akkor vagy nem, vagy csak drágábban lesz kapható. Emiatt azt mondják, hogy a zen5 sokáig lesz a zen3-hoz hasonló hosszan támogatott, olcsó változat.
De ez nem is biztos, hogy baj. Szerintem a zen6 alcsonyabb csíkszélességen elsősorban a zen5 fogyasztását fogja korrigálni és a MT teljesítményt fogja emiatt javítani. Viszont nem biztos, hogy ugyanakkora frekvencia ugrásra lehet számítani megint, mint a zen4 esetén.
-
S_x96x_S
addikt
válasz
hokuszpk
#8912
üzenetére
> ... AVX512 ...
// DOWNFALL //
pár napja ütött be a https://downfall.page/ az Intel oldalra, ami pont az AVX2/AVX-512 -es müveleteket érinti - és javítás ( a régebbi intel cpu-kon ) néha elég jelentős teljesítmény vesztéssel járhat
disclaimer: felhőben vegyesen használok AMD-t és Intelt - úgyhogy érint engem is. És van még egy inteles 8250-es Thinkpad-em is ..
( Which computing devices are affected? : Computing devices based on Intel Core processors from the 6th Skylake to (including) the 11th Tiger Lake generation are affected. )
pár link:
Hacker News: https://news.ycombinator.com/item?id=37052586"Intel DOWNFALL: New Vulnerability Affecting AVX2/AVX-512 With Big Performance Implications" https://www.phoronix.com/review/downfall
"Initial Benchmarks Of The Intel Downfall Mitigation Performance Impact"
https://www.phoronix.com/review/intel-downfall-benchmarks
"Intel has reported up to 50% performance penalties in extreme cases but from my testing over the past day it thankfully has tended to be less than that but still significant. "
-
HSM
félisten
válasz
hokuszpk
#8611
üzenetére
A nagy L3-nak mindig is ez volt a baja... Néhány specifikus helyzetben csodát tesz szó szerint, míg másokban csak minimális hátrány a pár órajelnyi extra késleltetése révén. Én az MSRP szerinti 50 dollár felárat szó nélkül kicsengetném érte.
Jó példa egyébként a Renoir. Használok egy 15w-os hatmagost belőle, és többnyire szépen szedi a lábát 2x4MB L3-al is, főleg ahhoz képest, hogy ez milyen kevésnek tűnik.
-
#8607
Petykemano
veterán
hokuszpk
#8606
Petykemano
veterán
válasz
hokuszpk
#8606
üzenetére
> az L3 ha jóltévedek victim cache. azaz az előtte lévő szintekből kicsorgó adatokat tárolja.
> Szvsz dupla méretú L1 -ből kevesebb adat csorog le.
Igen, de ez magonként csak +0.5MB, egy CCX-ben összesen 4MB többlet. Ez magonként 0.5MB-nyi adat gyorsabb hozzáférését teszi lehetővé, mivel az a 0.5MB nem az L3$-ben, hanem az L2$-ben van.De a Zen architektúra achilles sarka nem ez, hanem a chiplet felépítés miatt magasabb késleltetésű memóriaelérés. (Nem tudom esetleg a sávszélesség jelenthet-e bármilyen limitációt, mindenesetre itt van olyan Genoa konfiguráció felvázolva, ahol 2 GMI linken kereszül csatlakozik egy CCD) Az, hogy a memóriavezérlő elérése nem valamilyen belső buszon közelre történik, hanem szubsztráton keresztül, biztosan limitáló tényező.
A lényeg, hogy a 32MB helyett 96MB L3$ viszont nem 4MB valamiyel gyorsabb elérését teszi lehetővé, hanem 64MB-ét pont azon a ponton, ahol a legérzékenyebb.
Persze nyilván az L3$ cache méretére igaz a csökkenő határhasznosság elve.
> Zen5 -re volt valami hír, hogy összevonják az L2 -t ;
> ha igaz a hír megkockáztatom, hogy bazi nagy közös L2 mellett akár el is tűnhet az L3.Szerintem 8 mag számára közös L2$-t csinálni megfelelő gyorsaságban és hogy akkor is kielégítő teljesítményt nyújtson, amikor a magok nem valami közös problémán dolgoznak, nehéz lehet.
A szóbeszéd szerint a szerverek szeretik a gyors privát L2$-t.Az L3$ eltűnhet, de valószínűbbnek tartom, hogy 3D stackelik.
Az még esetleg lehetséges út, hogy elengedik a szubsztráton keresztüli kapcsolatot (SerDes) és az IOD és a CCD között a NAvi31-nél látott módon (MCD-GCD) teremtenek szélessávú kapcsolatot. Ebben az esetben a stacked L3$ már mehetne az IOD-ra is és akkor az minden CCD-t ki tudna szolgálni. Ez abból a szempontból is, jó volna, hogy a CCD helyett az IOD-nak lehet kliense egy GCD is, vagyis egy IGP és akkor máris sikerült megoldani az APU-k 3D stackelt v-cache/infinity cache kérdését is.Azt persze nem tudom, hogy ez tényleg jó irány-e. L3$ nélkül azért az egész félkarú óriás. EGy ilyen bonyolult packaging drága is lehet, meg növelheti a hibaarányt is, meg volumenkorlátos is lehet ahhoz képest, ha van egy közepesen jó, de minden extrát nélkülöző alap lapkád, amit végtelen mennyiségben, hibátlanul, olcsón tudsz kipumpálni és szükséges esetén, kisebb volumenben ezzel-azzal dekorálni.
Az AMD eddig megfigyelt kockázatvállalási hajlandósága mellett azt gondolnám, hogy inkább valószínűtlen a kizárólag egzotikus kialakításra, 3D packagingre építő megközelítés nagy volumenben, olcsón gyártható jó mainstream bázislapka nélkül. (És szerintem L3$ nélkül nem lenne jó)
-
#8604
Petykemano
veterán
hokuszpk
#8603
Petykemano
veterán
válasz
hokuszpk
#8603
üzenetére
Fene tudja
Azt biztos, hogy a frekvencia-regresszióval kapcsolatos gyermekbetegségek javítására vonatkozó előzetes hírek félreértésnek bizonyultak.
Az AMD saját bevallása szerint 1% IPC növekedést tulajdonít önmagában a L2$ duplázott méretének. Ami laikusoknak egyrészt meglepő, másrészt viszont mindenhonnan azt hallani, hogy cache méretének egyszerű növelésétől ritkán változik a teljesítmény nagymértékben, hanem a megnövelt cache mérete köré kell tervezni a processzor többi aspektusát is és úgy aknázható ki a nagyobb cache nyújtotta előny (most azt a részét, hogy a cache méretének növelése késleltetés növekedésével is együtt jár és azt a trade-off-ot is figyelembe kell venni, hagyjuk)Az a gyanúm, hogy a 3D V-cache haszna is félig-meddig úgymond "véletlen". Nem emlékszem olyan programra, ahol egyszálas teljesítmény nőtt volna annak hatására. A kellemes hatását ott fejti ki, ahol a magok között adatmegosztás zajlik és a megnövelt v-cache már kellően nagy ahhoz, hogy durván sokminden beleférjen.
Mivel nem hallottunk arról, hogy a V-cache-t bármi módon tweakelték volna, ezért az én várakozásom az, hogy pontosan ugyanúgy fog működni, és ugyanakkorát fog dobni a teljesítményen is, mint az 5800X3D.
HA jól megy a hybrid mód a 12 és 16 magos példányok esetén, akkor el tudok képzelni egy olyan szituációt, hogy ha a független programszálakat a v-cache nélküli CCD-n az adatmegosztókat pedig a v-cache-sel szerelt magokon futtatja, akkor nagyobb is lehet az előny. -
#8519
Petykemano
veterán
hokuszpk
#8518
Petykemano
veterán
válasz
hokuszpk
#8518
üzenetére
There are three modes the chips can run in. One will be that there can be HBM Only, where no DIMM slots are populated. That limits memory capacity to 64GB per CPU but saves the power and cost of DDR5 as an offset. The HBM Flat mode treats HBM seperate from DDR memory giving a fast and a slower tier of memory. Finally, there is HBM Caching mode where data is cached in the HBM memory and that is transparent to the host. [link]
-

#36531588
törölt tag
válasz
hokuszpk
#8471
üzenetére
tádám
MSI Shows Off Spatium M570 PRO and M570 PCIe Gen 5 NVMe SSDs
GIGABYTE Shows Off AORUS Gen5 10000 NVMe SSD with a Large Heatsink
Mire piacon lesznek az X3D procik úgy néz ki lesz gen5 ssd is.....
-
HSM
félisten
válasz
hokuszpk
#8485
üzenetére
Az 5800X3D-nél beszéltek róla, hogy el lett vékonyítva a CCD, hogy ráférjen a korábbi kupak alá a plusz L3-al is.
Úgy tűnik, amit régebben mutattak 5900X3D prototípust, az egy generációval később mégis eljött... [link]
#8486 paprobert : Vagy van egy spagetti motor, aminek néhány szálának nagyon jól jönne a magas órajel, de más szálaknak meg jól jönne a nagy L3, de az egészet így agyonvágná a CCD-k közti kommunikáció?

Szerintem amúgy a játékoknak a legjobb, ha mennek a nagy L3 felé és kész, minden más meg marad a gyors CCD-n. Productivity appok pedig tipikusan nem annyira kényesek erre.Az asszimetria szerintem nem okozna gondot, ahogy írod, a victim cache jelleg miatt.
-
S_x96x_S
addikt
válasz
hokuszpk
#8397
üzenetére
> a tervezesi koltsegek is emelkeódnek, az AMD azert is
> igyekszik 1 maggal lefedni mindent is ;valószínüleg eljött az AMD-nél az az időszak,
amikor a növekedéshez nem lehet mindent 1 foglalattal ( pl. szerver )
vagy 1 CPU maggal lefedni.De az alapok hasonlóak:
A ZEN4 az alapja a ZEN4X3D és a ZEN4C -nek is.
És szerintem a ZEN4C sok mindenben visszahathatott az alap ZEN4-re is.
feltételezve, hogy a zen4c-ben is lesz avx-512 .. akkor az AVX-512 kialakításával kapcsolatos döntésekhez is.
Szerintem sok mindent automatizálhattak és lehet, (spekuláció) hogy a zen4c -t alapból ki tudják generálni a tervekből.Amúgy a tervezési idő ( + költségek ) csökkentése
a TSMC egyik célja az új "3DFabric Alliance" -al.
( meg hogy magához láncolja az ügyfeleket .. )
https://www.tsmc.com/english/dedicatedFoundry/oip/3dfabric_alliance
https://3dfabric.tsmc.com/english/dedicatedFoundry/technology/3DFabric.htm
"TSMC's 3DFabric offers our customers the ultimate flexibility in product design, brings packaging technologies to the forefront for innovation, and are critical to a product's performance, function and cost:
Time-to-Market: Customers can reuse technology blocks that do not change frequently or do not scale well to develop "chiplets" which allow for faster innovation and shorten the time-to-market
Performance and Efficiency: 3DFabric allows the integration of high density interconnected chips into a packaged module delivering improved bandwidth, latency, and power efficiency
Form Factor: Integrate varied logic, memory, or specialty chips with SOCs to deliver smaller form factors for various applications.
Cost: Customers can reuse blocks, such as analog IO, RF, and those that do not change frequently nor scale well, on more mature and lower cost semiconductor technologies. Customers can focus logic designs that scale well on TSMC’s most advanced semiconductor technologies" -
HSM
félisten
válasz
hokuszpk
#8397
üzenetére
"ha masik konyvtarral ujratervezed"
Ezt pont géppel szokták, kézzel csak legtöbbször csak belejavítgatnak. Nekem nem ez tűnik a "drága" lépésnek. Főleg, ha kb. ugyanazt a csipet módosítják, csak bizonyos részegységekből kevesebbet raknak bele, vagy picit másmilyet. Ha meg komoly versenyelőny, illetve mennyiségi előny (kisebb lapka esetén több csip/wafer!) lehet belőle HPC/Datacenter vonalon, ahol vastag a haszonkulcs, könnyen megérheti.
-
#8398
Petykemano
veterán
hokuszpk
#8397
Petykemano
veterán
válasz
hokuszpk
#8397
üzenetére
Szerintem ez egy mítosz.
Iparági modell - de nem gyakorlat
Ha nincs semmid és nekiállsz egy teljesen új chip teljesen új node-ra való fejlesztésének és mást nem is csinálsz, akkor talán tényleg annyi.Ennek a folyamatnak része lehet akár több teszt jellegű tape-out is.
De variánsokat tervezni meglevő blokkokoat újrahasznosítani mutálni valószínűleg néhány, vagy komolyabb átalaktás esetén néhány tíz misiből már megvan.
Abu nemrég mondta, hogy a >$100 GPU szegmens, hová évek óta tervezik az új GPU-kat csupán néhány milliárd dollár negyedévente. Szerintem nem terveznének 4-5 chipet, ha mindnek az elkészítése külön-külön többszázmillió dolláros tétel lenne.
-
HSM
félisten
válasz
hokuszpk
#8389
üzenetére
A mostani 15W-os 8-magos U-procik is éppen így működnek. Egy szálon terheled? Kifutja a BOOST-ot. Legyen 5Ghz. Kap egy durvább terhelést, lecsökkenti, hogy beleférjen a keretbe, legyen 3Ghz. Nem kell ehhez új mikrokód.
Egyébként bizonyos feladatokra nyilván sokkal hatékonyabb lehet, ha külön van energiatakarékosságra optimalizált mag, főleg mobil felhasználásra gondolok, a gond ugyanaz lehet, mint a kékek megoldásánál, miszerint egyáltalán nem biztos, hogy a szoftver/OS megfelelően képes lesz ideális, a felhasználó elképzeléseivel is összevágó magot választani a feladathoz.
Én személy szerint szívesebben játszom magam a laptopomon az energiatakarékossági beállításokkal (pl. max engedélyezett órajel, vagy a különböző TDP limitek), hiszen én tudom, hogy sietek vagy éppen ráérek, én nem örülnék, ha ezt egy szerintük "okos" megoldás önhatalmúlag konfigurálná aszerint, mit tart fontosnak és mit ráérősnek.
-
#8390
Petykemano
veterán
hokuszpk
#8389
Petykemano
veterán
válasz
hokuszpk
#8389
üzenetére
Ezzel valóban megoldanád az energiahatékonyságot.
De PPA-ra (Power-Performance-Area) optimalizálnak. Egyrészt annak a magnak, amelyik csak max 4Ghz-ig megy el nem is kell olyan nagynak lenni, lehet sűrűbb. Azon kívül lecsippentenek az egyébként legtöbb helyet elnyelő L3$-ből is. Ezzel szerintem a helyigényt közel megfelezhetik.LEgalábbis az eddig ismert infók alapján a Zen4c nagyjából ez.
(Ami egyébként fura, merthogy nagyjából ezt a mobil lapkáknál eddig is megtették és nem illették külön processzormag névvel. Tehát biztos van valami más is még a kalapban) -
-
#8193
Petykemano
veterán
hokuszpk
#8191
Petykemano
veterán
válasz
hokuszpk
#8191
üzenetére
Az az érzésem, hogy az általad hozott use case egy jó példa arra, amikor eleve kifejezetten célszerű és hasznos magas magszámú processzort venni, amire már most is jó megoldás egy 64 magos Milan és annál jobb lehet a 96 magos Genoa, vagy 128 magos Bergamo.
De közben meg valakik valamilyen célból nagy számban veszik a <=40 magos Intel szerver procikat.
Fogalmam sincs, hogy az általad említett use case tipikus PHP.felhasználásnak minősül-e azok körében,.akik szervereket vesznek. Lehet, hogy nem jó példát hoztam. A felhősödés, virtualizáció nyilvánvaló trend, biztos, hiogy egyre kevesebben vásárolnak saját célra hardvert és egyre gyakoribb az erőforrásmegosztás a költségtakarékosság és/vagy magasabb fokú biztonság/redundancia céljából.
De valakik veszik az Intel szervereket és ha nem valami megrögzött brand-hűség miatt, és mivel tudtommal a 4-8 utas szerverek annyira nem gyakoriak, ezért azt gondolnám, hogy ennek.magyarázata talán az lehet, hogy nincs is szükségük annyi magra, mint amennyi már most is kínálnak a csúcs szerver processzorok.
-
#8190
Petykemano
veterán
hokuszpk
#8189
Petykemano
veterán
válasz
hokuszpk
#8189
üzenetére
Én nem teszteltem a vhostonként külön fpm környezetet. De dockeres tapasztalataim alapján így ilyen szétbontásnak a memória footprintje nagyobb. Persze ha lecsökkented a spare workerek számát, akkor eltüntetheted ezt a memória footprintet.
Viszont a biztonsági szempontot félretéve azonos request szám esetén mi alapján gondolod, hogy a multi-fpm-es megoldás számára előnyösebb a több, de valamivel gyengébb mag? Hol keletkezik az overhead?
Én a PHP-t egyébként csak a phoronix PHPbenmark 0.8.1 eredményei alapján emlíettem meg.
-
S_x96x_S
addikt
válasz
hokuszpk
#8127
üzenetére
> ha az atlag annyi, akkor az neha boven benezhetett a 200 folotti tartomanyba.
egyeseknek úgyis hiába magyarázod,
mert sokan nem értik,
- hogy "mit jelent" és mire használható az "átlag".
- és mi a különbség az "adat" és az "információ" között.ráadásul ha a KSH-ra (
TechPowerup-ra) hivatkozok,
akkor még jobban össze is zavarom őket.
pl.
Ha a KSH szerint 2021-ben Budapest éves "Átlagos középhőmérséklete" 12.3 °C
- akkor miért vesznek az emberek légkondicionálót ?
- és miért fagynak meg egyesek télen?Vagy ha tudjuk, hogy
egy átlagos embernek 1 heréje és 1 melle van,
akkor mi a francért árulnak dupla melltartót?vagy másképpen:
"ne kelj át egy folyón, csak ezért mert az átlagosan 1 méter mély"de a lényeg, amit nehéz szemléltetni és sokan még így se értik meg ..
A 13900K hűtését sose a 12 átlagos játék alapján - kimért 139W-ra méretezd.
mert arra ott a "peak power"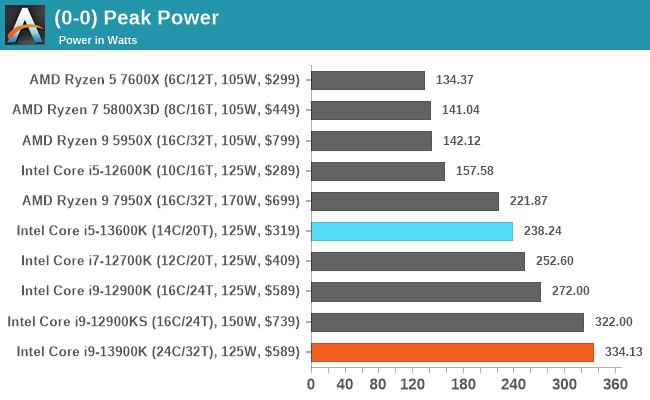
> ha az atlag annyi, akkor az neha boven benezhetett a 200 folotti tartomanyba.amúgy a 330-350W teljesen normális a csúcsfogyasztás az Intelnél.
és ezzel +100W -al van a 7950X -hez képest. ( via Anandtech )A +100W napi 10 óra Extrém esetben 1 hónapra a jelenlegi lakossági "Átlag feletti fogyasztás" áron akár havi +2100 Ft áramköltség is lehet. ( bank360 rezsi kalkulátorral számolva )
ami két évre 2100*24 = 50 400 Ft TCO különbséget is eredményezhet.Ha valaki átlagosan napi 20 órában renderel, akkor dupla
és így két évre +101e az üzemeltetési felár.
négy évre meg +202e
( ha valaki pesszimista akkor kalkulálhat még extrémebb árakat )
Vagyis aki extrém módon használja, az a +40e Ft jelenlegi 7950X-es feláron ( vs. 13900K)
nem akad ki.szóval megéri az ECO mód a RaptorLake-nél is ..
ahogy az Anandtech is irta a 13900K-ra.
"Given the rise in energy costs this year (especially in Europe), this probably isn't great timing for a 335W consumer CPU."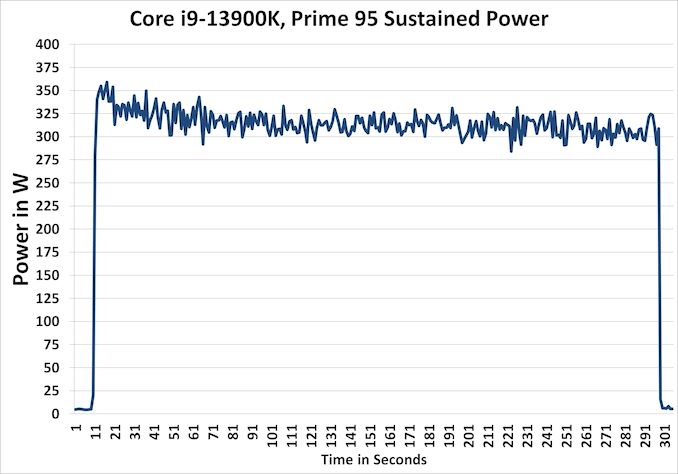
-
-
#36531588
törölt tag
válasz
hokuszpk
#7897
üzenetére
"A Sapphire mire megjelenik, mar talan a Zen4 -es motyoval kell versenyezzen, kicsit olyan ez, mint a Zen4 procikat a 12xxx -hez mérni, de ha egyszer az van piacon..."
Ezzel nem lehet vitázni, bár úgy tudom kiemelt partnerek már idén kapják, csak széles körben lesz 2023-ban elérhető....de mi a véleményed a zen4 diáival kapcsolatban, amit az amd az alder-hez hasonlít?
"igen, viszont akkor melyik iranyba ? 52 maggal nekem nem adja ki a 224 szalat, viszont ha 56 mag, akkor meg lehet ujraszamolni a mag/pont es a perf/w -t is."
Ennek gyorsan utána nézhettél volna:

Csak akkor nem lehet beírni hogy ét kell számolni a mag/pont-ot. -
#36531588
törölt tag
válasz
hokuszpk
#7894
üzenetére
Gondolom hibás a tábla. Emberek vannak ott is.
"* S_x96x_S nemlátom, hogy kommentált volna bármit, csak betette, hogy van egy ilyen leak. Néha kicsit többet látsz bele."
Ehhez nem kell semmit hozzáfűzni: "Sapphire Rapids HBM2E CPUs Fall Behind EPYC 3D V-Cache CPUs In Leaked Benchmarks" ebből kiderül hogy a xeon az epyc mögött végzett, mit írt volna még? A részletek csak akkor derülnek ki, ha elolvassák a cikket, hogy ez nem is annyira így van. Ha korrekt lett volna, és nem csak instant copy paste az intelre kedvezőtlen hír, akkor legalább a magok számát odateszi....
"azzal a leakkel nemstimmel valami."
Igen, ez nem jó leak. Na majd ha lesz olyan amiben egyértelműen jobb az epyc, akkor majd jó lesz a leak is.




















![;]](http://cdn.rios.hu/dl/s/v1.gif)
 +1 pont, ami csúnyán félremehet.
+1 pont, ami csúnyán félremehet.













Új hozzászólás Aktív témák

- DELL PowerEdge R730xd 16LFF 160TB+400GB 2U rack - 2xE5-2683v4 (16c/32t),256GB RAM,2x10G NET,HBA330
- HPE Aruba switch, 48G PoE+, 4SFP+, L3, Smart managed
- REFURBISHED - DELL Performance Dock WD19DCS (210-AZBN)
- BESZÁMÍTÁS! Asus H370 i7 8700K 16GB DDR4 512GB SSD RTX 2070 8GB RAMPAGE Shiva A-data 600W
- HIBÁTLAN iPhone 14 Plus 128GB Purple -1 ÉV GARANCIA - Kártyafüggetlen, MS3659, 100% Akksi
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopműhely Bt.
Város: Budapest