Hirdetés
-

PROHARDVER!
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-
#9999
 Oliverda
félisten
Plazmacucci
#9998
Oliverda
félisten
Plazmacucci
#9998
Oliverda
félisten
válasz
 Plazmacucci
#9998
üzenetére
Plazmacucci
#9998
üzenetére
-
#9998
 Plazmacucci
félisten
Oliverda
#9997
Plazmacucci
félisten
Oliverda
#9997
-
#9997
Oliverda
félisten
Plazmacucci
#9995
Oliverda
félisten
válasz
Plazmacucci
#9995
üzenetére
Ki és hol harangozta be úgy? Úgy látom ebből megint egy urban legend lesz, sőt már van is.
"c2c gyengébb az Intelnél, akkor annyira lesz csak létjogosultsága mint a 12 magos "
Nincs kedvem másodjára is belinkelni houset(
 ), de szerintem felesleges belefolyni ebbe úgy, hogy sok részletet figyelmen kívül hagysz, vagy éppen nem is vagy tisztában azzal. Mondjuk pont mostanában volt szó itt is a különböző utasításkészletekről, amit egyelőre semmilyen más CPU nem támogat.
), de szerintem felesleges belefolyni ebbe úgy, hogy sok részletet figyelmen kívül hagysz, vagy éppen nem is vagy tisztában azzal. Mondjuk pont mostanában volt szó itt is a különböző utasításkészletekről, amit egyelőre semmilyen más CPU nem támogat. -
#9996
 Roxbury
őstag
Plazmacucci
#9995
Roxbury
őstag
Plazmacucci
#9995
Roxbury
őstag
válasz
Plazmacucci
#9995
üzenetére
Itt csak a Bull. mögött kullog az Intel.
-
#9995
Plazmacucci
félisten
atti_2010
#9989
válasz
 atti_2010
#9989
üzenetére
atti_2010
#9989
üzenetére
Modul, mag, mindegy, ha egyszer már arra az álláspontra jutottunk, h c2c gyengébb az Intelnél, akkor annyira lesz csak létjogosultsága mint a 12 magos Opteronnak. Ne érts félre én örülnék a legjobban, ha a Bullok ütőképesnek bizonyulnának, de egyre több negatív pletyka terjeng. Pláne annak fényében, h annó úgy lett beharangozva, hogy mindent lemos a pályáról.
-
#9992
 Zeratul
addikt
Plazmacucci
#9985
Zeratul
addikt
Plazmacucci
#9985
Zeratul
addikt
válasz
Plazmacucci
#9985
üzenetére

-

stratova
veterán
válasz
 Oliverda
#9983
üzenetére
Oliverda
#9983
üzenetére
Megnézném végül milyen TDP-keretbe szorították be azt a 8-16 magot.
Az új Xeonokkal összevetve a 8 magosat órajelben körülöleli a E5-2680 és E5-2690 az egyetlen 3 GHz feletti E5-2687W pedig 150 W-os.
Tudjuk azt, hogy jelenleg szerver környezetben milyen hatékonysággal használják ki az Intel féle Hyper-Threading-et? Úgy látom Turbo csak az 1P Szerverbe szánt Xeonoknál (E3-ak és E5 1620, 1650, 1660) van de ott derekas az alap órajellel együtt. -
#9989
 atti_2010
nagyúr
Plazmacucci
#9985
atti_2010
nagyúr
Plazmacucci
#9985
atti_2010
nagyúr
válasz
Plazmacucci
#9985
üzenetére
Nem is mag hanem modul, ha már blamálod csináld rendesen.
-
#9987
Oliverda
félisten
Plazmacucci
#9985
Oliverda
félisten
válasz
Plazmacucci
#9985
üzenetére

-
#9986
 kleinguru
addikt
Plazmacucci
#9985
kleinguru
addikt
Plazmacucci
#9985
válasz
Plazmacucci
#9985
üzenetére
Még jó, hogy ezek nem "gamer" procik, max 3 szálon ugye
 , hanem szerver környezetbe készített erősen többszálú dolgok kiszolgálására
, hanem szerver környezetbe készített erősen többszálú dolgok kiszolgálására
-
#9985
Plazmacucci
félisten
VaniliásRönk
#9984
válasz
 VaniliásRönk
#9984
üzenetére
VaniliásRönk
#9984
üzenetére
Szerintem gyászos vége lesz a történetnek. Ez így hurka, hiába ezer mag.
-
Oliverda
félisten
-
#9982
 VaniliásRönk
nagyúr
Oliverda
#9981
VaniliásRönk
nagyúr
Oliverda
#9981
VaniliásRönk
nagyúr
válasz
Oliverda
#9981
üzenetére
Pontosan ez az, amiben nem latok raciot.
Amig mondjuk egy ketmagos, shared L2 Core procin csinalja ezt, addig rendben van, hogy nem nagy problema, de egy olyan procin, amiben az L3-on vagy az (int.) NB-n keresztul kommunikalnak a magok, vagy ne adj isten egy regi dual-die quad eseteben az FSB-n keresztul, ott ugy gondolom ennek ara van. -
#9981
Oliverda
félisten
VaniliásRönk
#9980
Oliverda
félisten
válasz
VaniliásRönk
#9980
üzenetére
Azért mert alapvetően a Windows kernel így működik, ha nincs konkrétan beállítva, hogy melyik szálon/szálakon fusson a cucc.
-
#9976
 Hakuoro
aktív tag
VaniliásRönk
#9970
Hakuoro
aktív tag
VaniliásRönk
#9970
Hakuoro
aktív tag
válasz
VaniliásRönk
#9970
üzenetére
Win 7 alatt is van "Windows Classic" téma. Kétlem, hogy XP lenne.
-
#9975
Oliverda
félisten
VaniliásRönk
#9972
Oliverda
félisten
válasz
VaniliásRönk
#9972
üzenetére
Azt nem hiszem, ellenben az XP-t még biztosan támogatja. Mondjuk egy megfelelő windows update vagy driver nélkül ez megint semmit sem ér még akkor sem ha W7. Márpedig esélyes, hogy a Zambezi kapni fog valami ilyesmit az optimálisabb szálkezelés érdekében, és akkor máris nem fogja így dobálgatni a szálakat a kernel.
-
#9973
 Jack@l
veterán
VaniliásRönk
#9970
Jack@l
veterán
VaniliásRönk
#9970
Jack@l
veterán
válasz
VaniliásRönk
#9970
üzenetére
Nem akarok belevauvau, de honnan látjátok ennyire biztosra, hogy ez xp???
Igen jól szemlélteti a turbo-t, díjazom a videót. -
#9971
Oliverda
félisten
VaniliásRönk
#9970
Oliverda
félisten
válasz
VaniliásRönk
#9970
üzenetére
Igen, mert így 2011 végén azzal kell tesztelni az új processzorokat.
A következő OBR-rel kapcsolatos posztot szépen csendben törölni fogom.
-
Hakuoro
aktív tag
AMD FX-8150 Turbo (how its working)
CzechPCTuning=OBR
Érdekes hogy dobálja a szálakat a modulok között. Ez miért van?
-
#9967
 Abu85
HÁZIGAZDA
TESCO-Zsömle
#9966
Abu85
HÁZIGAZDA
TESCO-Zsömle
#9966
Abu85
HÁZIGAZDA
válasz
 TESCO-Zsömle
#9966
üzenetére
TESCO-Zsömle
#9966
üzenetére
Ha tudnám a megoldást a problémákra, akkor már ott ülnék az NV vagy az AMD VGA üzletágának vezetői székében.
-
#9965
Abu85
HÁZIGAZDA
TESCO-Zsömle
#9964
Abu85
HÁZIGAZDA
válasz
TESCO-Zsömle
#9964
üzenetére
Fogalmam sincs, hogy mennyi lesz az ára. Szerintem ez a dolog az NV-től is függ. Összességében lényegtelen. Ezen a piacon komplett reform segítene, lehetőleg árnövelés nélkül.
-
#9964
 TESCO-Zsömle
titán
Abu85
#9963
TESCO-Zsömle
titán
Abu85
#9963
TESCO-Zsömle
titán
Te, mint bennfentes meg tudod erősíteni azt a gyanúmat, hogy a New Zeland +100$-t rátesz a HD6990-es nyitó árára?
Mert a tendencia azt motatja, hogy generációról generációta kúszik felfele a legdrágább kártya ára, és az alatta levők meg követik.
Ez persze vásárlói szempontból nem jó, de a piac szűkülését figyelembe véve teljesen megérthető...
Azt sejtem, hogy itt is 999$-ig fog skálázódni a piac, akár csak a CPU-knál.
-
Abu85
HÁZIGAZDA
-
stratova
veterán
De, arra alapoznak. Ezt a persze költőien túlzó 400 W TDP-re írtam. Már az sem rossz, hogy HD 6950 szintű GPU befér majd 100W alá (PowerTune nélkül is); azaz egy nagyobb notebookba (< 300W és < 225W helyett).
A HD7900 viszont új lesz, igaz enni is kér (150-190 W-ról pletykálnak).
Abu: te magad is írtad, hogy továbbviszik a Cayman alapot Szerintem semmi baj nincs azzal, ha egy viszonylag energiahatékony felépítés alacsonyabb csíkszélességen újul meg, felette meg ott lesz az új lapka. Alatta pedig az APU-k Barts-Cayman keverékkel. -
Roxbury
őstag
-
válasz
Oliverda
#9953
üzenetére
1-2 halara optimalizalt cimnel talan. Annyit nem lehet rajta huzni, hogy ez az uj jatekok tobbsegere igaz legyen. Talan elerheti egy 5670 teljesitmenyet, de 1080p-hez minimum egy 5750 kellene, az mar kis kompromisszumokkal vallalhato Crysis2, Bad Company 2 alatt. Opitimistan azt remelem, hogy a Trinity majd eleri ezt a szintet maximum 100W fogyasztas mellett.
-
stratova
veterán
Ha minden igaz HD 7850 HD 6950-es, HD 7870 pedig HD 6970-es szintje felett teljesíthet 90 W illetve 120 W-os TDP-vel. Messze van ez még az APU-ba integráltságtól, de szép fogyókúra.
Annak sincs sok értelme, hogy pár notebookgyártó a Sandy Bridge i3 és i5-ök mellé HD 6370-et tesz.
-
#9951
 frescho
addikt
VaniliásRönk
#9884
frescho
addikt
VaniliásRönk
#9884
válasz
VaniliásRönk
#9884
üzenetére
Ez kicsit tulzasnak tunik. Egy kb 5570-el egyenrangu IGP-hez a jatekok tobbsegenel a grafikat le kell butitani, hogy 1080p-ben stabil, akadas mentes jatekod legyen.
-
Oliverda
félisten
Az átlagember meg a Raytracing... Az OpenCL-ről beszéltél miközben a CUDA-ra gondoltál. Előbb szerintem nézz utána pár alapvető dolognak mert itt is nagyon kiütközött, hogy nem igazán vagy tisztában azzal amiről beszélsz. Ugyanez volt a helyzet korábban a magok/modulok történetével, valamint amikor a SuperP alapján szerettél volna az új CPU-k között erősorrendet felállítani. Gondolom ezt is Szirmay javasolta.
-

dezz
nagyúr
Tudom én, csak az a nem mindegy, milyen API van ott. Lényegében a DirectX és az OpenGL a gond, még ha ezt így nem is mondjuk ki.
Mindkettő arra lett kitalálva, hogy megkönnyítse a 3D grafika leprogramozását, miközben biztosítja persze a kompatibilitást is a hw-ek között valamilyen szinten. Bár a DirectX játék-orientáltabb, közel sem eléggé hw-közeli, és sok függvénye amúgy sem valami fényes megvalósítású. (Egy ismerősöm már évekkel ezelőtt inkább megkerülte az egészet, mert lassú volt egy képfeldolgozási feladatra, a CUDA-val együtt.)(#9898) Jack@l: Nagyon nem mindegy, hogy van megírva az a ray-tracer. Ha simán ugyanazt a kódot futtatja mindkettőn, akkor nyilván ez lesz az eredmény. Azonban, bár ray-tracingben nagyon sok a számolás, de a feltételes ugrásokból is igen sok van, ezenkívül különféle kiértékelési részfeladatok is vannak, amik a CPU-nak sokkal jobban fekszenek, de az adatcsere latencyje "betesz" a dolognak. Egy igazán heterogén ray-tracerben igen sűrű adatcsere lehet, amiben egy közös címterű APU igencsak remekelhet, sokkal jobban megközelítve a kevésbé magas peakjét, mint a dGPU a sajátját.
Ugyanezen okokból, pl. x264 fejlesztői is sokkal jobban bíznak egy ilyen APU enkódolásbeli felhasználhatóságában, mint a dGPU-kéban. Az utóbbiakra (legalábbis a maiakra) csak egyes részfeladatokat bíznának, amiket hiába hajt végre gyorsan, az összteljesítmény ezzel nem nő drasztikusan. (Már ha a minőség is szempont).
Nem tudom, hogy a HD7000-esek (nagyobbak) vagy a Fermi megjelenése mennyit változtat majd ezen. Valamennyit biztos, de azért azok is GPU-k.
(#9901) Remusz911: LOL, ezek nem tudnak grafikont olvasni? Az ott nem 70%, hanem 70x...
(#9912) Abu85: Bizonyára belejátszik a driver, de ennyire biztos nem rossz az Intelé sem. Szerintem arról van szó, hogy Intelen szoftveresen kell emulálni az FMA-t a kerekítési hiba kiküszöbölése végett.
Azért is hasznos az FMA támogatása CPU-k esetén (amellett, hogy bizonyos algoritmusokhoz fontos), mert az újabb GPU-k is támogatják, és ha már FMA-ra építő kódot ír valaki, CPU-n sem szeretné újraírni máshogy...
-
Jack@l
veterán
válasz
Oliverda
#9942
üzenetére
Linkeltem feljebb a progit, ott az eredményt is, olvasd el. OpenCL-ről beszéltem végig. Raytracing és a videokódolás a két legelterjedtebb felhasználás, amit "átlagember" használ, és sokáig még az is marad. Befejeztem, mert nem látom ennek így értelmét. Járj be Szirmay óráira, mindent más színben fogsz látni.
-
Oliverda
félisten
Szerintem valami ilyesmire gondolhatott:

Ez talán megvalósítható lenne, de egyrészt növelné a tokozás és az egész gyártás költségét, plusz a chipek sincsenek ingyen. Valamint pluszban kellene egy külön memóriacsatorna a GPU részhez, hogy jól tudja kezelni ezt. Összességében megdobná a költségeket ami a termék árára lenne a vásárló szempontjából rossz hatással, ergo nem biztos, hogy megérné, vagy inkább biztos hogy nem.
-
Oliverda
félisten
Megint ott tartunk ahol tegnap. Bizonyos dolgokkal kapcsolatban erős sötétség dereng nálad, ami önmagában még egyáltalán nem is lenne probléma, ha nem próbálnád folyamatosan pont az ellenkezőjét bizonygatni. A HPC-hez pl. hogy jön a Raytrace? Szerintem sehogy.
"Raytrace-es renderelőknél a sok magos processor teljesítménye mondhatni mérési hibányit számít egy erősebb gpu-hoz képest. Magyara lefordítva: heterogén, de minek..."
Ebből pedig szerinted egyenesen következik, hogy egy másik API-val egy bármilyen más felhasználási területen vagy alkalmazásban is ez pontosan így működik.
Egy kicsit sincs igazad mert az eredeti téma az OpenCL volt és nem a CUDA. Ezzel kapcsolatban pedig gyakorlatilag csak olyan dolgokat írtál le amik nem állják meg a helyüket. Egy kalap alá vetted a kettőt ami finoman szólva sem jó húzás. Attól hogy a CUDA-hoz valamennyire értesz, még jól láthatóan nem jelenti azt, hogy az OpenCL-hez is konyítanál valamennyire. Vagy arra már programoztál? Vannak konkrét teszteredményeid? Amennyiben igen akkor ide velük!
Volt itt egy cwn (alias vers) nevű tag. Na ő jutott most eszembe ezekről a hozzászólásokról.
-
Jack@l
veterán
válasz
Oliverda
#9934
üzenetére
De, az.
4.0-tól...
Abbahagyom ,mert látom inkább félremagyarázod a dolgokat, minthogy kicsit is igazam lehessen, kb 2 éve foglalkozok ilyen renderelőkkel, és kicsit a programozásukkal is, a sok elméleti ppt helyett konkrét sebesség tapasztalatokról beszéltem. Téma nagyon offtopic, a lényeg hogy azért hozták létre, hogy a nagyon párhuzamosítható vektor/mátrix számolós munka nagy részét a gpu végezhesse. Raytrace-es renderelőknél a sok magos processor teljesítménye mondhatni mérési hibányit számít egy erősebb gpu-hoz képest. Magyara lefordítva: heterogén, de minek... (hacsaknem arra, hogy hasonló okos marketingábrákat lehessen gyártani vele) -
Abu85
HÁZIGAZDA
Attól függ, hogy a Future Implementation mit jelent. Ha az architektúra integrálás, akkor az 2013-2014-re van előrevetítve. Ha a végső lépcsőt, vagyis a rendszerintegrálást, akkor az 2016 előtt semmiképp nem lehetséges. Talán az Intel hamarabb megcsinálja a rendszerintegrálást, mivel ők valamilyen szinten kihagyják az architektúra integrálás lépcsőjét. A Larrabee miatt ez megalapozott.
-
-
Abu85
HÁZIGAZDA
válasz
 #95904256
#9933
üzenetére
#95904256
#9933
üzenetére
Azért fejleszti az Intel az FMA-t, mert nagy előny, nem kell kivégezni senkit. Az AMD azért van FMA-ban előrébb, mert az ATI-tól elég komoly szakemberek érkeztek, és ezért van hamarabb FMA-juk.
De amúgy, én még mindig azt mondom, hogy abban az up to 56x-ben csúnyán benne van az Intel OpenCL drivere. Sokszor a harmadát tudja sebességben, mint az AMD drivere. Ez saját mérés, és a processzor ugyanaz (Core 2 Quad 9550). Itt a szoftveres részleget kellene gatyába rázni, de amúgy az AMD sem állt jobban, amikor elkezdte ezt az OpenCL-t, csak annyi az előny, hogy három évvel hamarabb láttak neki az alapoknak. Ez szoftverben számottevő különbség. -
Oliverda
félisten
Heterogén.
A CUDA és az OpenCL pedig két eléggé különböző API. Legalább most már azt tudjuk, hogy mivel keverted az OpenCL-t.
A CUDA pl. baromira nem heterogén."Olyan programot még nem láttam ami először cpu-ra lett fejlesztve, és azért pakolják át opencl-re hogy azt csak cpu-n futtassák. "
Senki sem mondta, hogy létezik ilyen.
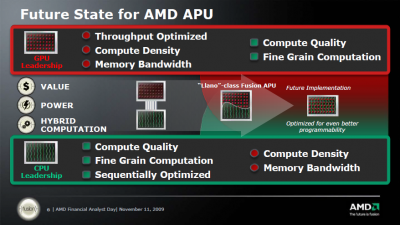
Ezt pedig nézegesd, hátha olyan szerencséd lesz, hogy egyszer csak koppan valami.
akosf: Ugyan kicsit más, de elég ha pl. megnézed AES alatt a VIA Nano-t, meg mondjuk egy alapvetően hasonló számítási teljesítményű AES támogatás nélküli CPU-t. Ott is hasonlóan nagy a különbség.
-

#95904256
törölt tag
Értem. Ez leolvasható az ábráról? Csak azért kérdem, mert ha komplex számokkal tényleg képes "up to 56x" gyorsabban számolni a Bulldozer, mint a Sandy Bridge, akkor már sejtem, hogy mely utasításokat fogom górcső alá venni ha lesz Bulldozerem...
Egyelőre erősen kétlem, hogy az "up to 56x" a Bulldozerből származik...
Ez akkora szám, hogy az Intelnél fejbelövik a matematikusokat, ha ez így van. -
Abu85
HÁZIGAZDA
Ez sajnos nem teljesen van így. Vannak olyan kódok, amik alkalmasabbak a processzorra, mint a mai GPU-kra. Nyilván a GPU-k fejlődésével ez változhat, de jelenleg nem ez a helyzet. Az aktuális GPU architektúrák ebből a szempontból még mindig elég gyengék. A nextgen már erős lesz, persze 20x-ről ott sem lehet beszélni. Max 10x, de a jelenlegi 2-3x-nél ez is jobb.
-
Jack@l
veterán
válasz
#95904256
#9924
üzenetére
Nem, a lényeg, hogy az opencl programok kb 10x-20x lassabban futnak cpu-n mint gpu-n, intelen meg még lassabb kicsit.
Pont az a probléma a diával, hogy nincs ott az platform, amihez elsősorban kitalálták, Opencl-t az ATI szeretné minél jobban elterjeszteni a régebbi kiforrottabb CUDA ellenfeleként. -
Jack@l
veterán
válasz
Oliverda
#9922
üzenetére
Oké, biztos igazad van, a lényeg, ahogy én tudom, és ez pusztán gyakorlati oldalról megközelített ismeret, az OpenCL-t épeszű ember a GPGPU gyorsításra használja. Olyan programot még nem láttam ami először cpu-ra lett fejlesztve, és azért pakolják át opencl-re hogy azt csak cpu-n futtassák. Lehet a másfél évet kevertem a cuda-val. A lényeg ugyanaz, gpu programozásra használják elsősorban. ( és API
) -
Abu85
HÁZIGAZDA
válasz
#95904256
#9924
üzenetére
Nem, itt az AMD megmutatta, hogy az OpenCL-t használó Mandelbrot FMA4-re fordított verziója mennyivel gyorsabban fut az FMA4 és az XOP mellett a Bulldozer architektúrán mint a Sandy Bridge-en, amiből hiányzik az FMA4 és az XOP. A GPU-nak ehhez semmi köze. Azt persze valószínűnek tartom, hogy az AMD a Sandy Bridge-hez az Intel OpenCL driverét használták a sajátjuk helyett, ami sebességben kapásból hátrány az Intelnek.
Egyébként a konkurencia is ki tudja használni a GPU-t. Az OpenCL képes arra, hogy más gyártó termékein futtasson egyszerre egy programot. Kell hozzá egy OpenCL CPU és egy GPU driver. Persze a szoftver szempontjából nem árt, ha az a két driver nem haklis egymásra, de ez nem sebességben szokott kiütközni, hanem fagyásban. Manapság szerencsére egyre ritkább, de bekövetkezhet. Jobb együttműködés kell a gyártóktól, de a konkurens termék kvalifikálása senkinek sem az érdeke.

-
#95904256
törölt tag
Ha jól értem, akkor ezen az ábrán az AMD megmutatta, hogy az OpenCL-t használó Mandelbrot gyorsabban fut egy több száz gigaflops teljesítményű GPU-val megtámogatott Bulldozeren, mint a konkurencia CPU-ján ami nem használja ki a GPU teljesítményét.
Ez így rendben is van, de ez nem igazán a Bulldozer érdeme...
-
Abu85
HÁZIGAZDA
Az FMA4 utasítás nem csak gyorsít, hanem pontosít is az eredményen, mert egyszer kerekít a Mul-Add kettő kerekítése helyett. Nagyjából hat éve kérik a fejlesztők a támogatást a processzorok oldaláról. A GPU oldaláról a FMA támogatása a DirectX 11-ben került be, de ez nem pont ugyanaz, mint a CPU-s támogatás.
Az OpenCL egy heterogén API a kezdetek óta. Egyébként az FMA4 nincs az OpenCL-hez kötve, csak az OpenCL alatt mutatta be az AMD ezt a funkciót. Gyanítom azért, mert az Intel OCL drivere egy nagy rakás nulla jelenleg, sebességben szerintem nagyon sokat lehet még rajta javítani. Az AMD CPU-s OpenCL driverével az OpenCL alkalmazások jelentősen gyorsabban futnak a Core 2 Quad procimon. Az Intel drivere nagyon lassú.
Elsődlegesen az FMA-t nem a sebességérét kérik a fejlesztők, hanem a pontosságáért. -
Oliverda
félisten
"Opencl-re kb 1-1,5 éve hozták be a heterogén cpu támogatást"
Tévedés. Már az első 1.0-s API-ban is benne volt a CPU támogatás mivel ez egy heterogén rendszer. Még hír is volt róla majd három éve.
The language specification describes the syntax and programming interface for writing compute kernels that run on supported accelerators, such as AMD GPUs and multi-core CPUs.
Az általad linkelt anyagból pedig:
Devices
There can be more than a single device on a platform.
The list of device IDs can be queried with clGetDeviceIDs(). You can filter the devices using CPU, GPU and ACCELERATOR flags. -
Jack@l
veterán
-
Oliverda
félisten
-
Jack@l
veterán
válasz
Oliverda
#9916
üzenetére
Gondolom FMA4 az opencl kód gyorsítására szolgál(szóval azt abban a formában egyik se), de annyira nem vágom ám...
Mindenesetre a grafikon egy nagy hülyeség, egy GPU-ra szánt api-n demonstrálni mennyire ütős is valami. Simán beállíthattak volna egy 6870-et is hogy legyen mihez a csíkokat igazítani.
Lehet tesztelni mi mennyit nyom, de gondolom ők mással mértek: [link] -

Remus389
veterán
válasz
Oliverda
#9910
üzenetére
na akkor mégse írtam hülyeséget, video tömörítésnél, esetleg konvertálásnál felmoshatja az intellel a padlót egy jól megírt progival
azért valljuk be lassan minek venni CPU-t, játékok alatt a videokártya számít(full HD-ban), a rendszer sebessége inkább SSD minőségétől
tehát egy új CPU gyakran nem is gyorsít sokat egy gépen
ellenben videokonvertálásnál meg hasonlóknál pont hogy kell, ott megérezni
-
Abu85
HÁZIGAZDA
válasz
#95904256
#9909
üzenetére
Szerintem a Mandelbrot set szimplán újra van fordítva, hogy kezelje az XOP-t és az FMA4-et. A HPC piacon kiemelten fontos lehet, de a desktopon nem hiszem. Ami probléma még, hogy az Intelnél az OCL driver egy híg fos. Persze ez nem meglepő, alig pár hónapja fejlesztenek OCL-t, míg az AMD lassan három éve. Nem hiszem, hogy a különbségekben csak a hardver játszik szerepet, az AMD az OpenCL támogatásában meglépet a konkurenciától. Már az NV is lemarad mögöttük, mondjuk ők valószínűleg szándékosan, hogy a CUDA stratégia előnyben legyen.
-
Oliverda
félisten
válasz
 Remus389
#9908
üzenetére
Remus389
#9908
üzenetére
Szerintem ennek főleg HPC-nél lesz haszna, azaz az Opteronok esetében. A XOP ellenben jól jöhet pl. videó tömörítésnél. Az x264 lehet kap ilyen jellegű optimalizálást a jövőben.
XOP:
- Numeric applications
- Multimedia applications
- Algorithms used for audio/radiomod: most úgy fest, hogy egyre valószínűbb a támogatás.
-
#95904256
törölt tag
válasz
Oliverda
#9907
üzenetére
Még nem találtam róluk semmit.

Addig én is eljutottam, hogy OpenCL, Mandelbrot, FMA4. Ezekről még tudom is, hogy melyik micsoda. De ettől még nekem csak színes oszlopok virítanak a képernyőn.
Pl. mi a különbség a "18 float_vector_fma" és a "19 float_vector_fma" közt?
Hm... 8 piros egységgel jobb a Bulldozer. Ja, elnéztem van az 60 is...
-
#95904256
törölt tag
-
#9905
Remus389
veterán
FireKeeper
#9904
Remus389
veterán
válasz
 FireKeeper
#9904
üzenetére
FireKeeper
#9904
üzenetére
-
Remus389
veterán
válasz
Remus389
#9901
üzenetére
ha megnézzük a diákat, látható hogy játékok esetén(gondolom FULL HD-ba van) jól tartja magát a Bull és igazi különbség nincs
ha megnézzük viszont a második diát az intel core i5 2500-2600K között lehet(ezek kihasználják a többmagot)
harmadik dián porig alázza az Intelt bonyolult matematikai műveleteknél
erősen propaganda ízű, de tegyük fel mindennel együtt egy 2500K-2600K szintű processzor, ami azért nem gyenge[link]
tehát énszerintem versenyképes termék
, jó oké nem mosatja fel az Intellel a padlót, mert ők is frissítenek, de azért korrekt[link]Ráadásul, órajelben is fognak javulni pár hónap múlva(C stepping) illetve árban is(csökken), tehát jó lesz ez, nem veri meg az Intelt csak a szokásos lemaradással kullog utána






 Szerintem az lesz úgy is amit intel bácsi akar, utasításkészletek ide vagy oda.
Szerintem az lesz úgy is amit intel bácsi akar, utasításkészletek ide vagy oda.














































![;]](http://cdn.rios.hu/dl/s/v1.gif)

Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

- Anglia - élmények, tapasztalatok
- A Xiaomi 15S Pro a Qualcommnak és a MediaTeknek szól
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Ukrajnai háború
- Házimozi belépő szinten
- Politika
- Víz- gáz- és fűtésszerelés
- VGA hűtő topik
- Fejhallgató erősítő és DAC topik
- EAFC 25
- További aktív témák...

- Csere-Beszámítás! Asus Rog Strix B550-F Gaming Wi-Fi II Alaplap + Ryzen 7 5800X3D Processzor!
- AMD Ryzen 9 9950X 16-Core 4.3GHz ( 64M Cache, Up to 5.7 GHz) AM5 Box Processzor! BeszámítOK
- AMD Ryzen 9 5900X CPU + 32GB RAM + B450 alaplap (akár külön is)
- Intel Core i7-6700K 4-Core 4GHz LGA1151 (8M Cache, up to 4.20 GHz) Processzor
- Intel Xeon Processzor E5-2680 v4
- PowerColor AMD RX5700XT 8GB / Újszerű állapotban / 6 hónap jótállással / számlával
- BESZÁMÍTÁS! Apple iMac Pro (2017) 5K - Xeon W-2140B 64GB DDR4 RAM 1TB SSD Radeon PRO Vega 56 8GB
- Bomba ár! HP EliteBook 820 G3 - i5-6GEN I 8GB I 256GB SSD I 12,5" FHD I Cam I W10 I Garancia!
- BESZÁMÍTÁS! GIGABYTE H77-DS3H H77 chipset alaplap garanciával hibátlan működéssel
- BESZÁMÍTÁS! 1TB WD Black SN750 NVMe SSD meghajtó garanciával hibátlan működéssel
Állásajánlatok

Cég: Liszt Ferenc Zeneművészeti Egyetem
Város: Budapest