Hirdetés
- Tudjuk, de nem tesszük: a magyarok többsége nem törődik adatai védelmével
- Mesébe illő csodakábelt tervezett a GeForce-ok leégése ellen a Segotep?
- Irodát kért, de gyárat kapott Elon Musk a Samsungtól
- Nyílt forráskódú lett a legegyszerűbben használható AI tartalomgeneráló
- Hazavághatja a MicroSD memóriakártyák piacát a Biwin-féle Mini SSD
- Azonnali notebookos kérdések órája
- Mikrokontrollerek Arduino környezetben (programozás, építés, tippek)
- OLED TV topic
- Milyen notebookot vegyek?
- Azonnali informatikai kérdések órája
- Vezetékes FEJhallgatók
- Samsung LCD és LED TV-k
- Apple MacBook
- Apple asztali gépek
- Tudjuk, de nem tesszük: a magyarok többsége nem törődik adatai védelmével
Új hozzászólás Aktív témák
-
#9000
 hokuszpk
nagyúr
Petykemano
#8998
hokuszpk
nagyúr
Petykemano
#8998
hokuszpk
nagyúr
válasz
 Petykemano
#8998
üzenetére
Petykemano
#8998
üzenetére
ilyen limited edition lehetne, mittomen "AMD 54" csak hogy a bencheckben legyen par piros csik is legelol.
-
#8999
 paprobert
őstag
Petykemano
#8998
paprobert
őstag
Petykemano
#8998
paprobert
őstag
válasz
Petykemano
#8998
üzenetére
"Ha egy sokmagos asztali gépet MT teljesítményre húzol fel, az papíron jól hangzik, de egyrészt a 300W elég nevetséges. (1-2 generáció múlva ugyanezt fogja hozni egy 15W notebook)"
"Nagy" rendszert venni ezzel jár. Az elején jó, de idővel túl nagy, túl sokat fogyaszt, és nem öregszik méltóságteljesen. Azok veszik, akiknek kell az erő, és az is most kell.
A Threadripper vagy az Epyc is, egy mezei PC-hez képest egy traktor hatékonyságát tudja... 150W üresjárat, stb."Hasonló helyzetként lehetne emlegetni a Zen1 betörését, hogy hát ott is feleslegesen jöttek a plusz magok."
Egyetértek. A Zen1/Zen1+ egyetlen dologra viszont megoldást adott, a megjelenés után nem sokkal. Ár/értékben szétverte a 4c/8t konkurenciát többszálú feladatokban. Minden másban hamar öregedett a további fejlődés miatt, de ez az érdem elvitathatatlan."Intelnek ott van a fiókban a titkos új architektúra, amivel majd újra megszégyenítő vereséget mér az MT teljesítménnyel bohóckodó AMD-ra"
Az Alder Lake lett ez az architektúra, 4.5 évvel később, ami nagyon valószínűsíti, hogy a Zen-től megijedve kezdődött el a fejlesztése.És igen, otthoni felhasználásra a MT teljesítmény egy szinten túl már alig számít, számomra ezért nem imponál a Zen-dense vagy az E-core megléte. Értem hogy mi a célja, és mire szolgál, de egyszerűen a nyers number crunching nem mindennapos otthon.
Persze ha sok-sok évig használja valaki a CPU-t, akkor megtörténik, hogy a vásárlás elején parlagon heverő MT teljesítmény egyre több workload-nál használatba kerül, de addigra a ST teljesítmény már rég elavultatta a rendszert, és egy sokat fogyasztó irodai PC lett a gép.
Én sokkal jobban örülnék egy olyan rendszernek, ami a teljes rendszer fogyasztását ~5W-ra tudná redukálni üresjáratban, minden komponenst beleértve.
Ma csak a laptopok tudják ezt. -
#8998
 Petykemano
veterán
hokuszpk
#8997
Petykemano
veterán
hokuszpk
#8997
Petykemano
veterán
válasz
 hokuszpk
#8997
üzenetére
hokuszpk
#8997
üzenetére
Az a kérdés motoszkál bennem, hogy vajon számít ez?
Ha egy sokmagos asztali gépet MT teljesítményre húzol fel, az papíron jól hangzik, de egyrészt a 300W elég nevetséges. (1-2 generáció múlva ugyanezt fogja hozni egy 15W notebook) másrészt miközben kicsit talán bele is harap a Workstation piacba, desktopon valóban érdemben ki lehet használni?
Igazából ugyanezt gondolnám egy 3CCD-s Ryzenről is. Maximum akkor látnám értelmét, ha igazából a plusz magok (pontosabban a többlet MT teljesítmény) a régi sku-khoz képest grátisz és csuklóból jönnek és nem felárért. A 300W-os fogyasztás viszont némiképp izzadtságszagúvá teszi.
Hasonló helyzetként lehetne emlegetni a Zen1 betörését, hogy hát ott is feleslegesen jöttek a plusz magok. Annyiból látom másnak a helyzetet, hogy akkor azt gondoltuk, hogy a Skylake-en túl generációról generációra már csupán néhány százaléknyi IPC növekedésnek maradt szufla - legalábbis az x86 mikroarchitektúrákban -, így logikus volt azt gondolni, hogy nincs más út, mint növelni a magok számát.
Akkor persze sokan azt gondolták, hogy az Intelnek ott van a fiókban a titkos új architektúra, amivel majd újra megszégyenítő vereséget mér az MT teljesítménnyel bohóckodó AMD-ra, csak eddig cicázott vele. Végül nem lett.
De hát most minden jel arra utal, hogy a Zen5 is komoly ST előrelépést hozhat és 10-15% ST előny a desktop CPU-k terén mindig sokkal meggyőzőbb volt mint 10-15% MT előny - különösen ha annak a fogyasztásban is komoly ára van.
Ennélfogva bár az AMD valóban képes lehetne 3 CCD-t ledobni egy SKU-ba (nyilván lehet, hogy kellene hozzá új IOD és nyilván szükséges lenne hozzá valamilyen nagy frekvenciájú RAM is), de szerintem ez lényegesen kisebb sikerrel kecsegtetne, mint a Zen5.
-

S_x96x_S
addikt
lesz egy kis verseny ..( 300 Watton )
Intel Core i9-14900KF 6 GHz CPU Benchmarks Leak Out: Up To 20% Faster Than 7950X, 15% Faster Than 13900K
https://wccftech.com/intel-core-i9-14900kf-6-ghz-cpu-benchmarks-leak-up-to-20-percent-faster-7950x/ -
#8995
S_x96x_S
addikt
Petykemano
#8993
S_x96x_S
addikt
válasz
Petykemano
#8993
üzenetére
> Az M2-höz N4-en gyártott és és most
> az A17-ben debütált N3B-n gyártott lapkák egyszálas CPU teljesítménye
> szinte alig növekedett.lehet, hogy kezdenek átállni tik-tok -ra ..
( a GPU-ba jobban belenyultak )"Apple's A17 Pro SoC maintained the company's renowned six-core configuration and packs two high-performance cores functioning at up to 3.77 GHz and four energy-efficient cores operating at a lower frequency. When compared to the A16 Bionic (made on TSMC's N4), the A17 Pro boosts the maximum clock-speed of performance cores by 8.95% (from 3.46 GHz), which is in line with what TSMC's N3 (3nm-class) process technology offers compared to its 5nm-class counterparts (+10% ~ +15% compared to N5, about 10% compared to N4)."
--------------------
Single-Core
2914 A17 Pro ( up to 3.77 GHz )
2641 A16 Bionic
3223 Core i9-13900K
3172 AMD Ryzen 9 7950X ( up to 5.70 GHz )
2050 Snapdragon 8 Gen 2"When Apple formally introduced its A17 Pro system-on-chip (SoC) earlier this week, it said that its high-performance cores deliver a 10% increase in single-thread workloads compared to its predecessor. Apparently, this was an accurate estimate and the new processor delivers single-thread performance that is competitive with some PC processors while working at a considerably lower frequency. Meanwhile, it looks like Apple has made little to no architectural changes to its A17 Pro CPU cores and only boosted clocks."
via:
Apple's A17 Pro Within 10% of Intel's i9-13900K, AMD's 7950X in Single-Core Performance
https://www.tomshardware.com/news/apples-a17-pro-challenges-core-i9-13900k-ryzen-7950x-in-single-core-performance -
S_x96x_S
addikt
Az új linux kernel optimalizációknak pár programnál eléggé látható hatása lesz a szervereknél (zen4 - bergamo)- hogyha nagy a magszám ...
"lower core count desktop systems " -nél nem annyira látható ..Linux 6.6 Delivers Some Impressive Gains For AMD EPYC 9754 "Bergamo" Server Performance
https://www.phoronix.com/review/linux-66-bergamo"Needless to say, I am very excited about the Linux 6.6 prospects after this round of testing on the AMD EPYC 9754 "Bergamo". As mentioned on lower core count desktop systems I haven't seen such dramatic gains, so presumably much of this work is in regards to large gains from scheduler enhancements. The workqueue optimizations benefiting multiple L3 caches like with modern AMD CPUs may also be a contributing factor. I'll be running more Linux 6.6 kernel benchmarks on AMD EPYC Genoa(X) and other platforms like Intel Xeon Max in exploring the Linux 6.6 performance. Exciting times ahead with all of the new Linux 6.6 features."
-
#8993
Petykemano
veterán
Petykemano
veterán
Amikor megjelent az Apple M1 N5-ön gyártva, mindenki megijedt, hogy az arm tarol.
Azóta is persze minden iterációja nagyon remek, de elveszteni látszik - nem feltétlenül az előnyét, de a varázsát.
Az M2-höz N4-en gyártott és és most az A17-ben debütált N3B-n gyártott lapkák egyszálas CPU teljesítménye szinte alig növekedett.Vajon mi lehet az oka?
- az N4 és azt követően az N3B is annyira kis előrelépést biztosító gyártástechnológia, hogy nem fér bele több? Valóban azt tudjuk, hogy az IO és az SRAM skálázódása lényegében megállt, nem véletlen, hogy Nagy erőkkel folyik a fejlesztés a chipletezés irányába.
- ennyire hiányoznak a Nuviát megalapító chiptervezők?
- az Apple fókusza a GPU-n és az NPU-n van, és nemsokára olyan AI funkciókkal fognak előrukkolni, ami teljesen háttérbe szorítja a hagyományos CPU-t. Vajon lehetséges egy algoritmust AI segítségével.értelmeztetni, taníttatni és futtatni gyorsabban, mintha az hagyományos számítóegységeken futna? -
#8992
Petykemano
veterán
Petykemano
veterán
"Chips made for Apple and other TSMC clients in Arizona will still have to be shipped back to Taiwan for advanced packaging, therefore TSMC Arizona does not reduce America’s reliance on Taiwan" [link]
Jár a taps... /facepalm
-
#8991
S_x96x_S
addikt
Petykemano
#8989
S_x96x_S
addikt
válasz
Petykemano
#8989
üzenetére
> Arról szól a hír, hogy most találtak valami szoftveres megoldást,
> hogy az adatlokalitás optimalizálásával csökkentsék a késleltetést?csak egy még finomabb a hardveret jobban figyelembe vevő
szoftveres optimalizáció. -
#8990
Petykemano
veterán
Petykemano
veterán
-
#8989
Petykemano
veterán
S_x96x_S
#8986
-
#8987
 HSM
félisten
Petykemano
#8982
HSM
félisten
Petykemano
#8982
HSM
félisten
válasz
Petykemano
#8982
üzenetére
Sajnos nem vagyok jártas ilyen területen, de általánosságban minél gyorsabb egy interfész, annál kényesebb a jelvezetésre, hacsak nem változnak a technológia alapjai.
#8986 S_x96x_S: "This means that the impact of L3 cache locality is noticeable in these experiments"
Használva Ryzen 3600 majd Ryzen 5600-at illetve mobil Ryzen 4650U-t és 5850U-t (mindkét eset elsősorban az osztott/egyesített L3-ban különbözik) azt kell mondjam, bőven akad olyan feladat/felhasználás, ahol komoly jelentősége lehet ennek.
Bár sajnos az app szálkezelését ez önmagában nem fogja tudni megoldani, de az OS legalább segít majd, ahol tud.
-
S_x96x_S
addikt
többszörös ( chipletes ) L3 cache támogatás Linuxban
("multiple L3 caches like modern AMD chiplet-based systems." )Linux 6.6 WQ Change May Help Out AMD CPUs & Other Systems With Multiple L3 Caches
https://www.phoronix.com/news/Linux-6.6-Workqueue"Ryzen 9 3900x - 12 cores / 24 threads spread across 4 L3 caches. Core-to-core latencies across L3 caches are ~2.6x worse than within each L3 cache. ie. it's worse but not hugely so. This means that the impact of L3 cache locality is noticeable in these experiments but may be subdued compared to other setups."
-
#8985
Petykemano
veterán
hokuszpk
#8984
Petykemano
veterán
válasz
hokuszpk
#8984
üzenetére
Nem.vagy amatőr, nagyonis jól teszed, hogy azt várod.
Elméletben nagyon izgalmas, hogy a CCD-IOD kapcsolat szélessávúvá és - talán - alacsonyabb késleltetésűvé tétele milyen lehetőségeket hordoz magában.
De ha az AMD - ahogy egyes pletykák magyarázzák - az AI kereslet kielégítése érdekében hajlandó volt lemondani az RDNA4 chipletes változatairól, akkor ez a kapacitás-szűkösség érintheti a zen6-ot is. Ami ennek következtében, ha az AI kereslet fennmarad, akkor vagy nem, vagy csak drágábban lesz kapható. Emiatt azt mondják, hogy a zen5 sokáig lesz a zen3-hoz hasonló hosszan támogatott, olcsó változat.
De ez nem is biztos, hogy baj. Szerintem a zen6 alcsonyabb csíkszélességen elsősorban a zen5 fogyasztását fogja korrigálni és a MT teljesítményt fogja emiatt javítani. Viszont nem biztos, hogy ugyanakkora frekvencia ugrásra lehet számítani megint, mint a zen4 esetén.
-
#8984
hokuszpk
nagyúr
Petykemano
#8983
hokuszpk
nagyúr
válasz
Petykemano
#8983
üzenetére
én amatőr meg a Zen5-re várok.
de váltok Zen6 -ra várásra, nemkerül semmibe![;]](//cdn.rios.hu/dl/s/v1.gif)
-
#8983
Petykemano
veterán
Petykemano
veterán
AMD Venice - Zen6 [link]
- 384 mag
- 12-16 ch DDR5
- 2025
- azt mondják, a Zen5 lesz az új core, a zen6 pedig az új uncore, ami teljesen megújítja azt, ahogy a.chipletek kapcsolódnak egymáshoz. Azt mondják, a Mi300 úttörő és bár az RdNA4 chiplet változatait elkaszálták,.a technológiát továbbviszik a többi termékre. Tehát itt is hasonló várható.A roadmapen megjelenik a Mi400A, Mi400X és Mi400C. Utóbbi minden. Bizonnyal a csak CPU chipletekből álló HBM-es szerverchip.
-
S_x96x_S
addikt
AMD EPYC Venice SP7 12
AMD EPYC Venice SP7 16
https://twitter.com/yuuki_ans/status/1700146795899162699AMD Zen 6 Powered EPYC Venice CPUs To Feature Support On SP7 Platform With Up To 16-Channel Memory
https://wccftech.com/amd-zen-6-epyc-venice-cpus-feature-support-sp7-platform-16-channel-memory/ -
S_x96x_S
addikt
SP5
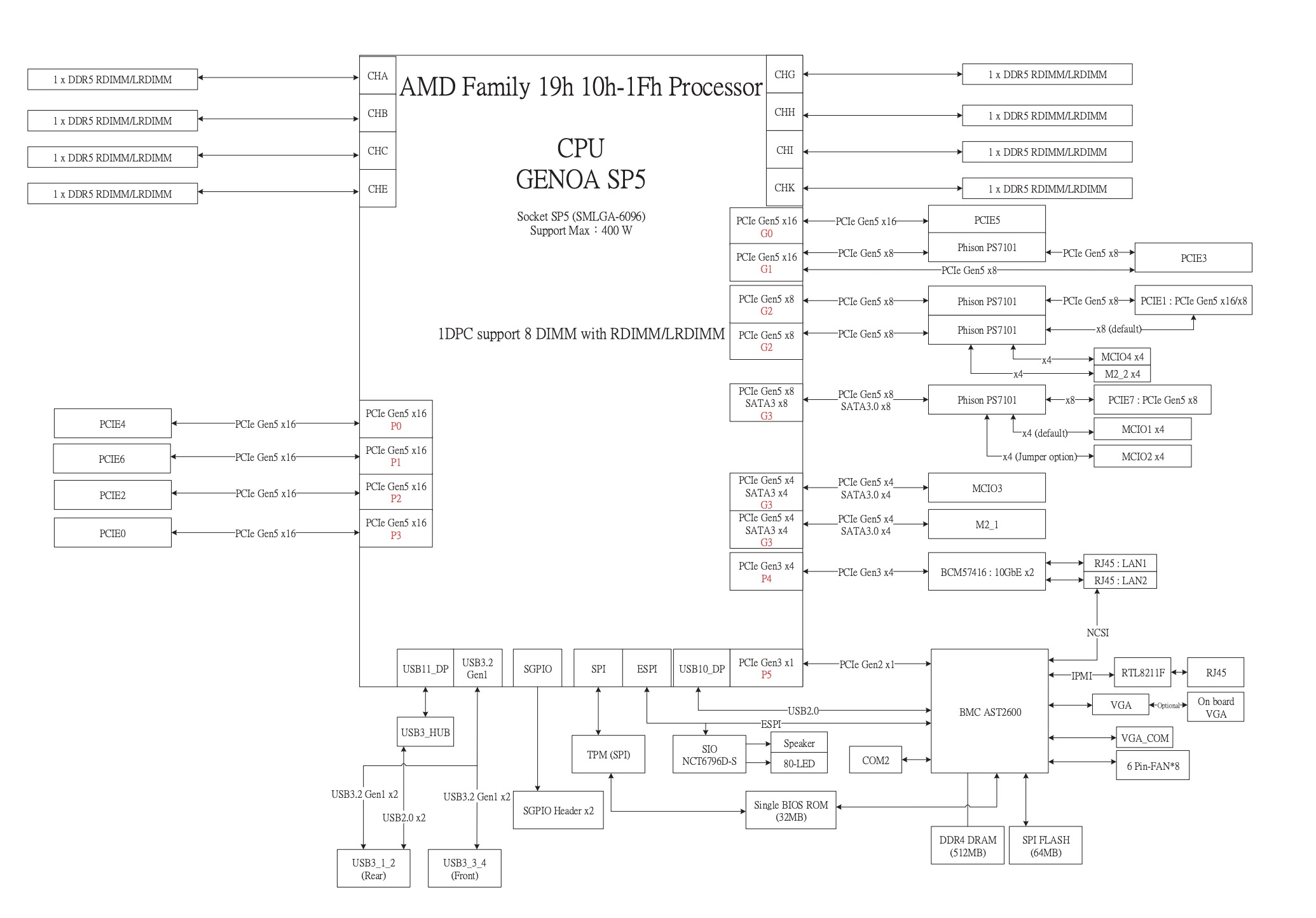
ASRock Rack GENOAD8X-2T/BCM Review An Uncomfortably Good Motherboard
https://www.servethehome.com/asrock-rack-genoad8x-2t-bcm-review-an-uncomfortably-good-motherboard-amd-epyc/ -
#8978
Petykemano
veterán
S_x96x_S
#8977
Petykemano
veterán
válasz
 S_x96x_S
#8977
üzenetére
S_x96x_S
#8977
üzenetére
Kicsit igazán lehettek volna bátrabbak, karakánabbak, határozottabbak annak megfogalmazásában, hogy a Zen4 működésében észlelt szűk keresztmetszetek (amik persze nyilván egyensúlyi döntések eredményei) milyen célszerű/praktikus fejlődési irányt jelölnek ki a Zen5 számára.
Nekem az állt össze, hogy bizonyos szélességű backend számára meghatározott mennyiségű cache és buffer elegendő. A cache és buffer méretek növelése - ahogy az az intelnél is látszik - 1-2%-ot számíthat a végső IPC-ben, de ha túllősz a célon, akkor tulajdonképpen pazarlás is lehet.
A zen5 48kB-os L1d engem arra enged következtetni, hogy szélesítették az architektúrát és 6 széles lett a backend.
-
S_x96x_S
addikt
Hot Chips 2023: Characterizing Gaming Workloads on Zen 4
https://chipsandcheese.com/2023/09/06/hot-chips-2023-characterizing-gaming-workloads-on-zen-4/ -
S_x96x_S
addikt
UE 5.3 apró lépések az AVX-512 optimalizáció felé ..

"Updated support for minimum cpu arch for x64 platforms.
Replaces ModuleRules.bUseAVX.
MinimumCpuArchitectureX64, valid values are None, AVX, AVX2, & AVX512."
https://docs.unrealengine.com/5.3/en-US/unreal-engine-5.3-release-notes/ -
S_x96x_S
addikt
A Mindfactory heti cpu stat-ban a top3 proci
- 7800X3D 890 db
- 5700X 410 db
- 5800X3D 421 db -
S_x96x_S
addikt
TRX50 WS
ASRock preparing AMD TRX50 Workstation motherboard for next-gen Threadripper 7000
https://videocardz.com/newz/asrock-preparing-amd-trx50-workstation-motherboard-for-next-gen-threadripper-7000 -
S_x96x_S
addikt
egy újabb picuri gép.
ASRock Industrial's New 4X4 BOX 7040 Series Mini PC: Sprint Faster and Run Longer with AMD Ryzen™ 7040U Series APU
https://www.asrockind.com/en-gb/article/170

-
#8972
Petykemano
veterán
Petykemano
veterán
Cisco Silicon One
Ez valami hálózati chip lehet. A név nem új, de lehet, hogy a felépítés, ami eléggé hasonlít a Graviton3-ra, újszerű.Persze ez is egy bizonányára méregdrága hálózati eszköz, aminek az árába belefér az egzotikus csomagolás. De azért remélem, hogy mihamarabb látunk hasonló megoldást az AMD-től is az IOD és más compute lapkák csatlakoztatására.
-
hokuszpk
nagyúr
válasz
S_x96x_S
#8970
üzenetére
"és az AVX2/AVX-512 elég sok helyet foglal."
hát. mert ilyen hülyesegekkel foglalkoznak, hogy segillyük meg a nullterminalt string vegenek megkereseset.
ahelyett, hogy vegre elfelejtenenk a nullterminalt stringeket a verbe ; mostmar van boven memoria, annyi mindenre elpazaroljak ; hat lehetne erre is.
semmilyen avx kiterjesztessel nem ubereli az strlen() -- mar bocs, de lemaradtam a turbo/borland pascal koraban -- a
mov al,[stringnulladikbyte]
sebességét. -
#8970
S_x96x_S
addikt
Petykemano
#8969
S_x96x_S
addikt
válasz
Petykemano
#8969
üzenetére
> Azért az nem hangzik rosszul,
> hogy egy Veyron V1 mag még a Bergamonál is 30%-kal kisebb.Szerintem van 2 kulcs mondat, hogy miért is kisebb:
- "V1 has no vector capability, " és az AVX2/AVX-512 elég sok helyet foglal.
- "Ventana (B1) hasn’t included die to die interfaces in their images"https://chipsandcheese.com/2023/09/01/hot-chips-2023-ventanas-unconventional-veyron-v1/
SPECInt -ben viszont nem rossz .. , persze a zen4/zen5 -höz képest kell mérni majd, mert azok lesznek a versenytársai.
 https://www.servethehome.com/ventana-veyron-v1-risc-v-data-center-processor-hot-chips-2023/
https://www.servethehome.com/ventana-veyron-v1-risc-v-data-center-processor-hot-chips-2023/Az mindenesetre jó hír, hogy egyre nagyobb a verseny :-)
-
#8969
Petykemano
veterán
Petykemano
veterán
Megérkezett a RISC-V is.
Van egy-két meglepő, jól hangzó állítás
pl:
"Ventana targets 3.6 GHz, but Veyron V1 can clock lower to reduce power consumption. At 2.4 GHz, the core pulls less than 0.9 W of power."Ami azért elég jól hangzik.
Még akár akkor is, ha ez csak a mag.
A GEnoa-t most hagyjuk, mert gondolom, hogy annak azért némieg cél a magasabb frekvencián üzemelés - a Bergamohoz képest. A Bergamonál viszont az energia és területhatékonyság a cél. A 100-as nagyságrendű magoknál persze már a tizedek is számítanak.A másik a terület:


Azért az nem hangzik rosszul, hogy egy Veyron V1 mag még a Bergamonál is 30%-kal kisebb. De ezt nehéz csak a méret alapján megítélni, hiszen nem tudjuk, hogy végülis milyen teljesítményt nyújt. Vagy legalábbis ebből nem derül ki.Viszont az, hogy egy 16 magos cluster kisebb, mint a Bergamo úgy, hogy magonként 2 helyett 3MB L3$ jut rá - mindezt ráadásul úgy, hogy egy mag számára is nem 16MB, hanem 48MB érhető elé, az objektíve jobbnak hangzik. Jó, persze nyilván itt is számít a workload.
Viszont a Bergamo mag Neoverse V2-vel való összevetése is érdekes. A Zen4c esetén az L2$ mérete még így is elég nagy. A Neoverse V2 közel ugyanakkora magterület mellett viszont kétszer akkora L2$-sel rendelkezik.
A Bergamoról már elvileg nem lehet elmondani, hogy jójójó, de lényegesen magasabb frekvenciával amennyivel több helyet foglal, annyival nagyobb is a teljesítménye.
Nekem úgy tűnik, hogy az AMD még a kicsinyített méretű Bergamoval is eléggé le van maradva - azonos csíkszélességen - a Cache sűrűség tekintetében.
Kiváncsi lennék, hogy ez kompetencia kérdése-e, vagyis arról van-e szó, hogy az ARM által tervezett SRAM ennyivel jobb és az AMD képtelen őket utolérni/lemásolni, vagy arról, hogy az AMD egy olyan SRAM designnal rendelkezik, ami a ~6Ghz elérésére is alkalmas. Ezt a designt HD libraryvel ennyire lehet összesűríteni. Ha átterveznék az SRAM designt, akkor képesek lennének elérni az ARM által mutatott sűrűséget, de az a design már mondjuk csak 4GHz elérése lenne alkalmas HP libraryval is. -
#8968
Petykemano
veterán
Petykemano
veterán
Strix Point
 [link]
[link] Több szempontból fura
- továbbra is 2x1MB L2$-t ír az "E" magokhoz. Ami nem valószínű, hiszen eddig arról volt szó, hogy az E magok belső felépítése a L3$-t kivéve megegyezik.
- AMD Strix - Internal GPU - GDDR6?7.61-es HWinfo-val olvasták le, az a legújabb beta.
Gondolom, hogy ezt majd egy frissebb HWinfo korrigálja. -
#8967
HSM
félisten
Petykemano
#8966
HSM
félisten
válasz
Petykemano
#8966
üzenetére
Igen, az IF sávszélessége visszafogja az AM5 cpu-kat gyors ramokkal elég jól láthatóan. A gyorsabb kapcsolat ott lehet kérdéses, hogy a fogyasztás kulcskérdés, ha sok CCD-t kell összekapcsolni. A nagy CCD lokális L3 ilyen téren is nagy segítség, csökken(het) a terhelés a memória felé, szinkronizálni is több sávszélesség marad(hat).
-
#8966
Petykemano
veterán
S_x96x_S
#8965
Petykemano
veterán
válasz
S_x96x_S
#8965
üzenetére
> Amúgy nem tünik rossznak a Grace ..
Nem mondtam, hogy rossz lenne. Sőt... ha nem így gondolnám, nem azt kérdeztem volna, hol lehet a szűk keresztmetszet, min kellhet javítani.LPDDR5X vs DDR5
Emlékszem, hogy Abu egyszer erről értekezett, hogy az LPDDR5X egy középút sávszélesség, fogyasztás és ár, nameg persze kapacitás tekintetében a DDR5 és a HBM között és akkor azt hiszem, azt mondta, hogy az LPDDR5X lehetőségét az AMD végülis a kapacitáskorlát miatt vetette el.Az az igazság, hogy ugyanakkor nem hiszem, hogy kizárólag erről lenne szó. Hiszen mennyiből tartana az AMD-nek csak az IOD helyett egy LPDDR5X-eset tervezni és azzal kínálni valami jelzéssel. Pont ez lenne a chipletezés egyik előnye, hogy ezt könnyen megteheted. Viszont szerintem a CCD-IOD kapcsolat sávszélessége (ami most talán valahol a 60-70GB/s-nál járhat [link] egy 7950X esetén, de nem biztos, hogy a Genoa is tud ennyit) sem biztos, hogy érdemben képes lenne a nagyobb sávszélességet a magok felé hasznosítani.
Persze az IOD és a CCD között létezhet dupla infinity fabric kapcsolat is, de azzal meg csökken a magok száma.
Talán ugyanez lehet - részben - a magyarázata annak is, hogy miért nincs L4$. Lehet, hogy kissé csökkenteni lenne képes a késleltetést, de a CCD és IOD között nincs meg az a sávszélesség, hogy valóban azt lehessen érezni, hogy az L4$ hasznos.
Viszont akkor ez azt is jelenti, hogy amíg nem változik meg a CCD-IOD kapcsolat egy aktív interposeres szélessávú megoldásra addig nem valószínű, hogy a memória alrendszerhez hozzányúlnának. Máskülönben meg ott HBM-es használó Mi300
-
#8965
S_x96x_S
addikt
Petykemano
#8964
S_x96x_S
addikt
válasz
Petykemano
#8964
üzenetére
> sávszélesség
talán az egyik ok .. a sok közül ..
a másik az általad is említett energia kérdése .. ( "hogy mennyi energia megy " )
és a link is jó, amit linkeltél ..
"Compared to an eight-channel DDR5 design, the NVIDIA Grace CPU LPDDR5X memory subsystem provides up to 53% more bandwidth at one-eighth the power per gigabyte per second while being similar in cost. An HBM2e memory subsystem would have provided substantial memory bandwidth and good energy efficiency but at more than 3x the cost-per-gigabyte and only one-eighth the maximum capacity available with LPDDR5X. "Tehát a DDR5 EPYC - kb 8x akkora energiát igényelhet ( Power / GBps )
mint a HBM és az LPDDR5x - GraceVagyis a [ sávszél * költség * energia ] alapján az Nvidiás mérnökök a DDR5-öt elvetették.
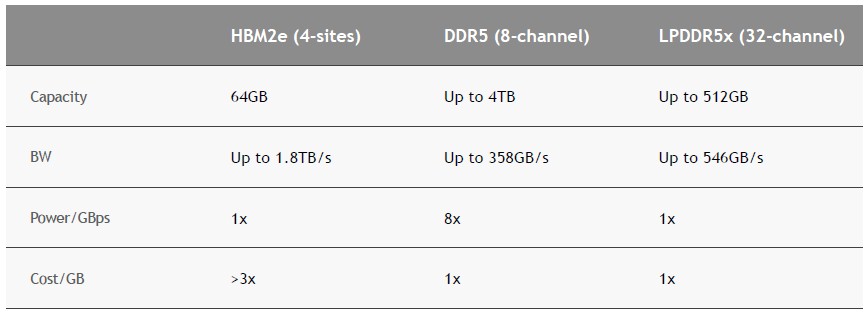
https://www.nextplatform.com/2022/08/29/details-emerge-on-nvidias-grace-arm-cpu/
----------------Amúgy az OpenFOAM -nak használ az AVX-512 ; vagyis a ZEN5 előrelépés lesz
https://www.phoronix.com/review/amd-epyc-avx512/9-------------------
Vagyis összefoglalva, ami számíthat az OpenFOAM szempontjából:
- Magok száma ( grace next : 144 )
- FPU hatákonyság ( itt gyengébb a grace , a zen5 meg ütős lesz .. )
- Memória sávszél , cache ( NVMe, 3Dvcache; 12 csatornás DDR5 )
- CPU Energia igény ( TSMC 4N ?? )
- Memória energia igény ( a DDR5 itt nem ideális )Amúgy nem tünik rossznak a Grace ..
-
#8963
S_x96x_S
addikt
Petykemano
#8962
S_x96x_S
addikt
válasz
Petykemano
#8962
üzenetére
közben már megválaszoltam ott ( is )
De az Intel XEON MAX -os teszt alapján
a HBMe eléggé rásegíthet a feladatra
és az új grace HBME3e -s.vagyis a 3D-Cache segít, de a HBMe még jobban ..
az új MI300 -al kell majd összehasonlítani a Next Gen Grace-t. -
#8962
Petykemano
veterán
Petykemano
veterán
@S_x96x_S
Láttam, hogy az Nvidia találgatósban megosztottad az aggályodat, hogy az Nvidia Genoa-t és nem Genoa-X-et használt a teszteléshez.
Csak kiváncsiságból kérdezem, hogy Te tudod-e, hogy pl az OpenFoam hogy működik:
- milyen utasításokat,
- milyen feldolgozókat (FP/INT) használ
- működése közben mekkora az interdependencia és adatmegosztás a szálak között?Azért kérdezem, mert nekem elsőre az jutott eszembe, hogy nem csak a Genoa, de akár a Bergamo is jobb ellenfél lehetett volna. De nem.
A Bergamo (9754) valójában még a Genoa-nál is gyengébb eredményt ad. [link]
Hiba több a mag. Pedig nem valószínű, hogy az OpenFoam szkálázódásával lenne a gond.A Genoa, Genoa-X és Bergamo eredményei között a legszembetűnőbb különbséget talán épp a L3$ mérete adja. De a Genoa és a Genoa-X L3$ mérete közötti nagy különbség ellenére is a teljesítmény differencia csak 14%, ami hasznos (és elképzelhető, hogy per socket gyorsabb is), de nem tűnik elégségesnek a Grace hatékonyság-előnyének behozatalára.
A Grace 72 maghoz 117MB egységes L3$-t kínál. Ami egyébként összességében kevesebb, mint amit egy Genoa összesen tartalmaz (384MB) és nem sokkal több annál sem, mint amit egy Genoa-X CCD birtokol (96MB)
De az mégiscsak egységes, emitt meg hiába van 1GB L3$, egy adattárból akkor is csak 8 mag tud dolgozni.
Persze egyáltalán nem biztos, hogy ez a meghatározó tényező. De akkor mi?Memória sávszélesség? Az mondjuk a Genoa esetén feleakkora
Feldolgozók száma? A Grace-ben 4x128b SVE2 FP feldolgozó van, az nem tűnik többnek, mint a Zen4-é
CPU chipfelépítés?Van itt egy táblázat: [link]
Azért persze van különbség
Míg a Grace mag 64+64KB L1$, addig a Zen4 csak 32+32
De mindkettőben magonként 1MB L2$ van.Régen az AT-en voltak ilyen mérések, amik azt mutatták meg, hogy mennyi energia megy a magokhoz és mennyi a package veszteség. És emlékeim szerint a kép azt mutatta, hogy a Milan esetén elég nagy.
Kiváncsi lennék, a Genoa esetén ez változott-e és hogy mikor terveznek lépéseket tenni ez ellen.
Pl:
- Lecserélni a szubsztráton keresztüli távoli, magas frekvenciás, de szűk sávos kommunikációt valamilyen modern csatlakozóra
- egységes L4$ az IOD-on a memóriasávszélesség kímélésére és CCD-k közötti adatmegosztásra
- CCD-k közötti adatmegosztásra szolgáló L4$ (megosztott L3$)Vagy lehet, hogy nincs ilyen terv, hanem majd a Zen5c-vel rákötnek 16 magot egy egységes L3$-re és akkor ismét kesz valamelyest érzékelhető teljesítményjavulás itt-ott, ahol a teljesítmény függ a szálak kommunikációjától.
Mit gondolsz?
-
S_x96x_S
addikt
AMD Siena Shown at Hot Chips 2023 A Smaller EPYC for Telco and Edge
https://www.servethehome.com/amd-siena-shown-at-hot-chips-2023-a-smaller-epyc-for-telco-and-edge/érdekes frissitett slide-ok.

-
S_x96x_S
addikt
válasz
 Busterftw
#8957
üzenetére
Busterftw
#8957
üzenetére
> Pedig jönnie kell valaminek mert itt a nyakunkon
> a Raptor Lake Refresh +3%-os teljesítménnyel. :DDDaz új Intel 66 thread/core -os prociról nem is beszélve.

Érdekes új trend .. teljesen más architektúra ..
Bár kísérleti, néhány dolog biztos le fog csorogni a consumer szintre isIntel Shows 8 Core 528 Thread Processor with Silicon Photonics
Hot Chips 2023;
- RISC ISA és nem x86 ; ( mielőtt valaki pánikba esne )
- kísérleti DARPA kutatás ( Defense Advanced Research Projects Agency )
- TSMC 7nm
- 8-core 75W CPU ; silicon photonics.https://www.servethehome.com/intel-shows-8-core-528-thread-processor-with-silicon-photonics/


-
#8956
 fatal`
titán
Petykemano
#8955
fatal`
titán
Petykemano
#8955
fatal`
titán
válasz
Petykemano
#8955
üzenetére
Nem hinném, hogy közeledne a Zen 5, pláne a 3D caches. Fél éves sincs a Zen 4 X3D.
-
#8955
Petykemano
veterán
Petykemano
#8949
Petykemano
veterán
válasz
Petykemano
#8949
üzenetére
7800X3D közel $100-ral akcióban [link]
Vajon ez eseti akció lehet, vagy futnak ki a szerveres megrendelések és halmozódik a készlet és/vagy közeledik a Zen5?
-
#8954
Petykemano
veterán
Petykemano
veterán
(Olrak29 szerint) a desktop Zen5 (Granite Ridge) ugyanazt az IOD-ot fogja használni, mint Zen4-es elődje. [link]
Ami elég fura, mert azt gondoltam volna, hogy ott is indokolt lehet az RDNA3-mal érkezett AI képességek bevezetése.
-
#8953
Petykemano
veterán
-
S_x96x_S
addikt
bővebb UCIe 1.1 leirás. - slideok
UCIe 1.1 Specs Announced for Chiplet Future
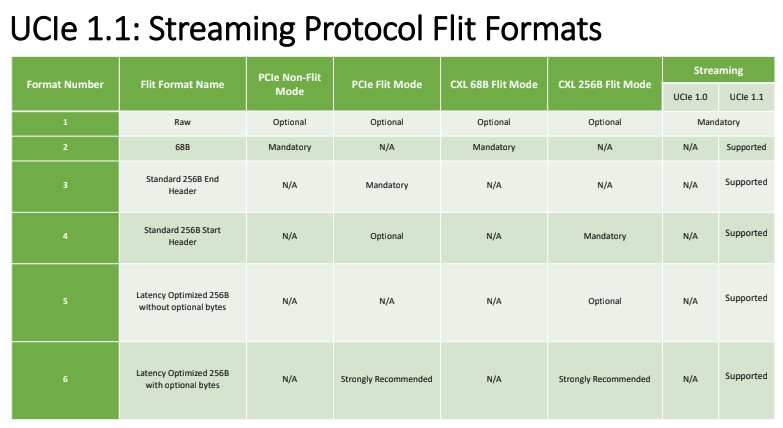
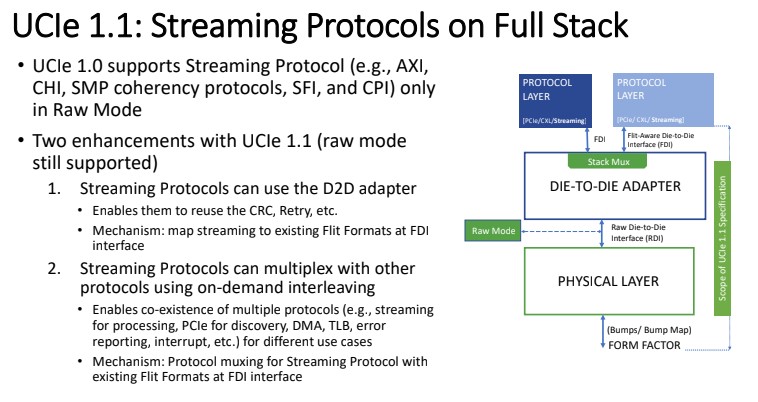
https://www.servethehome.com/ucie-1-1-specs-announced-for-chiplet-future/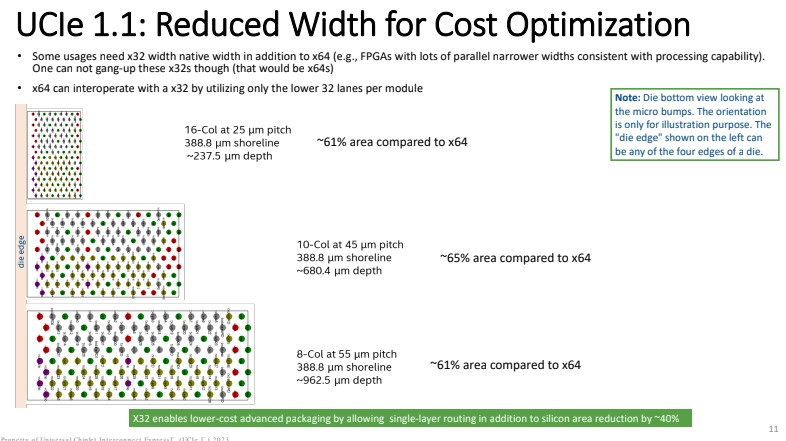

-
S_x96x_S
addikt
AMD Ryzen 7 7840U Windows 11 vs. Linux CPU Performance
https://www.phoronix.com/review/amd-7840u-windows-linux" the AMD Inception mitigation lowered the performance by about 5% while the other Linux 6.2 to 6.5 kernel differences represented the rest."
-
#8950
Petykemano
veterán
Petykemano
veterán
Nem mai hír... De legyen meg
Június 7-én jelent meg a Benchleaks által ez az azonosító, ami elvileg Zen5 Eng Sample:
100-000001290-11_N -
#8949
Petykemano
veterán
S_x96x_S
#8948
Petykemano
veterán
válasz
S_x96x_S
#8948
üzenetére
A MS Azure-ben június 13-mal vált elérhetővé a Genoa(-X) [link] NEm tudom, hogy hagyományos Genoa volt-e már előtte elérhető.
mindenesetre ha jól értem, akkor az AWS-ben a Genoa most, 2023-08-15 napon vált elérhetővé. [link]
Az a fura, hogy az Oracle is idén júliusban jelentette be az GEnoa-val szerelt E5 elérhetőségét [link]
A GCP-nél még nem találtakoztam sem Genoa, sem Genoa-X, sem Bergamo említésével.Több mint háromnegyed éve jelent meg a a Genoa és persze az asztali Zen4. Máskor is ilyen lassan szokott menni a terjedés, vagy most tényleg nem volt érte akkora kapkodás?
Lehetett valami korlátozó tényező? Pl DDR5 szerver ramok elérhetősége, vagy a új platform (szerver-alaplap) validálása? Vagy csak ennyire limitált mennyiségben tud az AMD Genoa-t szállítani, hogy mondjuk 2-3 havonta tud egy-egy nagyobb ügyfelet kiszolgálni csak?Még a GCP hátra van. De lehet, hogy ők sincsenek messze lemaradva.
És utána vajon mi fog történni? Tavaly tavasszal elég látványosan zuhantak be a zen3 árak - 5600G, 5700G, 5500, 5700X megjelenésével. Vajon ha a nagy cloud szolgáltatókat kiszolgálták, felszabadulnak az chipletek? -
S_x96x_S
addikt
"Amazon's New EC2 M7a AMD EPYC "Genoa" Instances Deliver Leading Performance In The AWS Cloud"
https://www.phoronix.com/review/aws-m7a-ec2-benchmarksperformance/cost -ban elég nagy végletek vannak ..
Azért a Graviton3 és a SPR -nak is vannak ideális tesztek, amelyeknél a zen4 eléggé le van maradva...viszont az Intel SPR erős AVX-512 / AMX teljesítménye látszik
pl. egy játék ...
És valamikor a Graviton3 is labdába rug ... a Zen4 meg a lista 2. felében ..
Persze az összesítésben jól áll az AMD zen 4
a verseny jó -
S_x96x_S
addikt
avx10 - újabb infók :
a cél
- az inkonzisztencia csökkentése
- és a több regiszterből valamaint a K-maszkokból eredő sebességnövekedés.
https://www.theregister.com/2023/08/15/avx10_intel_interviews/(intel) Van de Ven notes the new spec should address many of the frustrations raised by Torvalds back in 2020. "We listened very carefully to his feedback… part of his gripe was inconsistency," he said. "Inconsistency makes it harder for people to use it, and, if it's hard to use, it doesn't get used."
In terms of implementation, Van de Ven told The Register that once fully fleshed out, most applications should be able to take advantage of the new SIMD instructions with nothing more than a recompile. Though, of course, Intel says it will provide additional tools for the one percent that want to further optimize their code.
Another benefit of decoupling these features from AVX-512 is lower power overhead. "In terms of power and thermals, the extra registers and K-masks make the same code more efficient. That gives you a performance benefit, but the performance benefit is also a power benefit," Van de Ven said. "As an example, if your matrix multiply is suddenly 10 percent faster, you take 10 percent less time; your total power consumption is down by give or take 10 percent."
...Beyond a wider register width, AVX-512 has a couple of advantages over AVX2, SSE, and other SIMD instructions. Two of the biggest, according to Intel Fellow Arjan van de Ven, are its 32 registers, twice that of AVX2, and the introduction of K-masks. "A lot of the performance comes from those extra registers [and] from the K-masks; not so much the rest," he said.
Under the new spec, AVX10 compatible chips will, for the most part, share a common feature set
— including 32 registers, k-masks, FP16 support
— and minimally support 256 bit wide registers. -
#8946
 Alogonomus
őstag
Alogonomus
őstag
Alogonomus
őstag
Hát ezzel megadta az alaphangot Jim Keller...
"AMD Zen 5 is faster than Sapphire Rapids and faster than older Zen architecture according to Zen creator Jim Keller"Amihez passzol az RGT leak is, hogy 16 maggal a Cinebench R23 MT: 49.000 pont, vagyis 64 magos Zen 2 Epyc szint (Epyc 7702P), valamint az ST: " mid to high 2000", vagyis valahol 2500 és 2800 között lehet, amihez legközelebb a 13900KS jár most, de az is csak 2300-ig jut el.
-
S_x96x_S
addikt
Az Intel - eléggé kezd ráfeküdni a speciális hw-res gyorsításra
kíváncsi leszek, hogy mi lesz erre az AMD válasza ..pl. hw-res tömörítés támogatás:
- Intel® QuickAssist Technology Zstandard Plugin, an External Sequence Producer for Zstandard ( 08-16-2023 )
- https://github.com/intel/QAT-ZSTD-Plugin/releases/tag/v0.0.1 -
S_x96x_S
addikt
Az E-core + P-core ütemezés nem is olyan egyszerű ...
Future Intel CPUs May Dump Hyper-Threading For Partitioned Thread Scheduling
https://hothardware.com/news/future-intel-cpu-partition-threads"Basically, instead of scheduling on the application thread level, this new method analyzes the work required by a thread and then breaks application threads into segments using partitions. These partitioned threads are then scheduled onto processor cores based on their performance requirements. In other words, a program thread that is mostly simple ALU work but includes a crunchy AVX section may be scheduled onto an E-core, but have its AVX work thrown over to a P-core to make sure it gets completed within a certain time threshold."
-
#8943
Petykemano
veterán
Petykemano
veterán
Tachyum Prodigy - 192 mag [link]
Nem találkoztam ugyan még ténylegesen legyártott és használt Tachyum processzorral. (Tartok tőle, hogy ez ez egy olyan EU forrásból finanszírozott projekt, Aminek valójában nincs meg a gyakorlati felhasználásról szóló vége, nincsenek európai tech vállalatok, akikbek szintén támogatást nyújtva elő lehetne segíteni az európai infrastruktúra fejlődését)
Mindenesetre ha nekik sikerült, hamarosan másoknak is mehet (Ampere, Graviton) -
S_x96x_S
addikt
Inception ... Ajajj ... rosszabb a helyezet, mint ahogy vártam
 ..
..
még emésztenem kell ...Benchmarking The Performance Impact To AMD Inception Mitigations
https://www.phoronix.com/review/amd-inception-benchmarks----- ZEN3-----------
"
One of the real-world areas where the AMD Inception mitigations did hurt the performance was in code compilation speed. The EPYC 7763 server was showing various open-source projects taking a few seconds longer to build now with the safe RET mitigations. Interestingly the new CPU microcode didn't provide much of a difference over the pure kernel-only mitigation run. The alternative IBPB mitigation showed the worst performance penalties.""The PostgreSQL database server also recorded some slowdowns as a result of the mitigated kernel."
----- ZEN4 ------
"Overall it comes down to what workloads you are engaged in whether you may notice any performance difference when upgrading your Linux kernel (or otherwise being patched for Inception on your given OS) on an AMD Zen desktop or server. For the most part users are unlikely to notice anything drastic, aside from some sizable database performance hits in a few cases. It's unfortunate seeing some of these regressions due to the Inception mitigation but ultimately is unlikely to really change the competitive standing of AMD's latest wares on Linux. Most of the prior AMD CPU security mitigations have also not resulted in any performance degradation, so this Inception mitigation difference is a bit rare. It also was announced on the same day as Intel Downfall where there was again a sizable hit to Intel CPU performance. For those wanting to avoid the new mitigation, there is always the "mitigations=off" route or the "spec_rstack_overflow=off" as used in this round of testing (the "off" metrics) for only disabling the Inception/SRSO and leaving all other CPU security mitigations at their respective defaults. I continue to run more AMD Inception and Intel Downfall benchmarks in looking to uncover any other performance differences worth mentioning." -
#8940
S_x96x_S
addikt
Petykemano
#8939
S_x96x_S
addikt
válasz
Petykemano
#8939
üzenetére
> Nem tudom, hogy ezt hiányoltad-e.
érdekesnek érdekes ..
de ettől még nem leszek optimistább -
#8939
Petykemano
veterán
S_x96x_S
#8937
-
S_x96x_S
addikt
"Beelink GTR7 Pro Review a Faster AMD Ryzen 9 Mini PC"
https://www.servethehome.com/beelink-gtr7-pro-review-a-faster-amd-ryzen-9-mini-pc/-----------
az elmúlt pár hétben végignéztem jópár 7840HS, 7940HS Mini PC tesztet.
A hütés igencsak kényes pont, melegszik, throtlingol - mert a gyártók nem limitálták le a power-t, vagy mert az AMD driver is rossz, vagy eleve pici a házA tesztek szerint a Beelink a legjobb.
és a relative rangsor - hütés alapján:
1.) Beelink ( GTR7 ( PRO ))
2.) Minisforium ( UM780 Pro, UM790 Pro )
3.) Morefine ( M600 )Nehéz rendelni és általában 32GB RAM-ot adnak hozzá.
A Morefine M600 -asnál láttam 7840HS + 64GB verziót 2 TB SSD-bel - relative olcsón -
csak ennek a legrosszab a hűtése és az egyik usb4 -et kispórolták.
( 840 EUR-ért , németből rendeléssel - amúgy rebrandelt Morefine , KingnovyPC néven az amazon.de -ről. )A normál ASUS Expertcenteres 7840HS viszont még meg se jelent ..
lehet, hogy az ASUS - azt a kevés chipet amit kapott az AMD-től,
teljesen belenyomja a saját laptopjaiba.kezdem azt hinni, hogy a PhoenixAPU egy elátkozott széria ..
-
hokuszpk
nagyúr
válasz
S_x96x_S
#8932
üzenetére
hát. a 8008/8080 konverzion nemvitatkozom ; de ha jólemléxem pl. a 8008/8080/Z80 -on a "NOP" az $00 ( de inkabb a kor szellemeben 00h ) ; a 8086 -nál $90 ; ezeknel már az $00 valami add utasitast takarmanyoz.
ha megvan asm-ben a forras, akkor biztos fordithato ide / oda / amoda ; for example a homelab 3 monitora is volt ahol "mov" -ot hasznalt a Z80 -on "szabvanyos" ld helyett; de itt Intel cpukrol beszelunk, ahol a mov az mov
-
S_x96x_S
addikt
az X86 eredete ...
Tracing the roots of the 8086 instruction set to the Datapoint 2200 minicomputer
https://www.righto.com/2023/08/datapoint-to-8086.html"
The modern x86 architecture is descended from the Datapoint 2200's architecture. Because there is backward-compatibility at each step, you should theoretically be able to take a Datapoint 2200 binary, disassemble it to 8008 assembly, automatically translate it to 8080 assembly, automatically convert it to 8086 assembly, and then run it on a modern x86 processor. (The I/O devices would be different and cause trouble, of course.)" -
S_x96x_S
addikt
AMD Ryzen Threadripper 7995WX, 7985WX and 7945WX with 350W TDP spotted in transit
https://videocardz.com/newz/amd-ryzen-threadripper-7995wx-7985wx-and-7945wx-with-350w-tdp-spotted-in-transitSP6 -os foglalat.
-
#8930
S_x96x_S
addikt
Petykemano
#8929
S_x96x_S
addikt
válasz
Petykemano
#8929
üzenetére
> A chiplet kommunikáció késleltetésén
érdekesség:
Az UCIe - 2ns alatti késleltetést céloz be .."Meanwhile, it’s interesting to note just what the promoters are expecting in terms of latency and energy efficiency. For all package types, latency is expected to be under 2ns, which is especially critical in chiplet designs that are splitting up what would previously have been a monolithic chip design. "
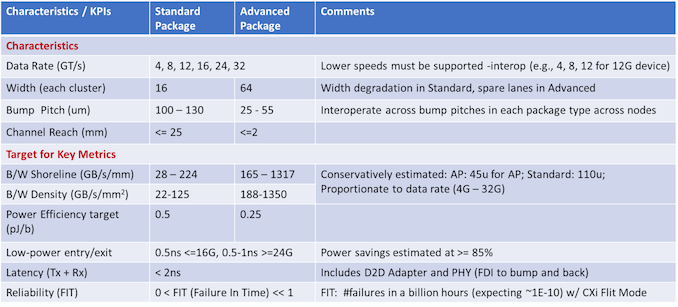 https://www.anandtech.com/show/17288/universal-chiplet-interconnect-express-ucie-announced-setting-standards-for-the-chiplet-ecosystem ( March 2, 2022 )
https://www.anandtech.com/show/17288/universal-chiplet-interconnect-express-ucie-announced-setting-standards-for-the-chiplet-ecosystem ( March 2, 2022 )------------------------------------
És a héten jelent meg az UCIe 1.1 - legalább valamit dolgoznak a háttérben ..
https://www.phoronix.com/news/UCIe-1.1-Specification
https://www.uciexpress.org/press-releasesA 3 nagy CPU gyártó ott van azok között - akik névvel is vállalták, hogy kiállnak mellette ..
Statements of Support for UCIe 1.1 Specification
AMD - Statement:
“The UCIe 1.1 specification, which adds new features to optimize silicon and packaging costs, additional protocol flexibility and automotive use cases, takes the first step towards establishing a chiplet ecosystem. We are proud of the UCIe Consortium’s progress so far and look forward to establishing a truly pervasive universal chiplet ecosystem.”
Nathan Kalyanasundharam, Corporate Fellow and AMD Infinity Fabric Lead Architect, AMDIntel - Statement:
“Intel is proud to be a founding member of the UCIe consortium. Chiplets are continuing to become a critical technology for the semiconductor industry. Intel Foundry Services (IFS) is focusing on UCIe to enable our foundry customers to build interoperable silicon solutions, based upon industry standards.”
Bob Brennan, Vice President of Customer Enablement, Intel Foundry ServicesArm - Statement:
“As compute requirements continue to grow and evolve across all industries, we must deliver scalable, cost-effective solutions and new approaches. Arm partners are already delivering chiplet-based solutions in infrastructure applications; in automotive, chiplets can reduce time to market, allow for new performance points and enable unique SoC designs in applications such as ADAS and infotainment, while still delivering the dedicated features tailored to the safety and real-time needs of the market. Arm will continue to work with industry leaders in the UCIe Consortium on standards and specifications like the UCIe 1.1 Specification as the Consortium expand to increase interoperability and address industry needs.”
Andy Rose, VP Technology Strategy and Fellow, Arm---------------------
és apró siker - az egyik cég már a 3nm-eren sikeresen tesztelte ..
"We are delighted to announce successful tapeouts on TSMC’s most advanced 3nm process including UCIe PHY IPs."
https://www.uciexpress.org/post/meet-ucie-consortium-member-alphawave-semi
-----------
(Board) UCIe Director -ok - van nVidiás és TSMC-s is.
https://www.uciexpress.org/board-representatives -
#8929
Petykemano
veterán
S_x96x_S
#8927
Petykemano
veterán
válasz
S_x96x_S
#8927
üzenetére
Az AMD egy újabb lépést tesz előre a témában a Bergamoval? Vagy a Bergamo 2x8 magos CCX-eket tartalmaz?
A chiplet kommunikáció késleltetésén pedig feltehetően lehetne javítani azzal, ha szubstrát helyett valamilyen modern chip2chip kommunikációt biztosító megoldást használnának. Csak az a kérdés, hogy elfér-e.annyi chiplet az IOD körül. Sztem nem.
Ha valaha látni fogunk valamit, akkor én egy olyan megoldásra számítanék, mint a mi300 esetén, hogy ráültetik a CCD-ket egy base die-ra. Ez a base die lehet egy cache die, ami összefog 2-3 CCD-t és az csatlakozik az IOD-hoz. Vagy lehet eleve az IOD is. Úgy persze addícionális megosztott cache nem lenne. De ezt már több éve várjuk hiába.
-
S_x96x_S
addikt
(mégegy Q2 ; néha nem árt újraolvasni egy másfajta tálalást .. )
"AMD FEELS THE SERVER RECESSION, TOO, BUT GROWTH IS LOOMING LARGE"
https://www.nextplatform.com/2023/08/11/amd-feels-the-server-recession-too-but-growth-is-looming-large/"
On a call with Wall Street analysts, chief executive officer Lisa Su said that AMD was on track to launch and deliver the MI300A hybrid GPU-GPU engines and the MI300X standalone GPUs in the fourth quarter and touted the fact that Amazon Web Services, Microsoft Azure, Oracle Cloud, and Alibaba Cloud had all launched instances based on the Genoa CPUs. There are over 30 instances based on Genoa worldwide, and all told, there are 670 instances worldwide powered by AMD CPUs and by the end of the year the company projects there will be nearly 900 – with the bulk of those new instances being powered by Genoa chips. Revenues from the Genoa CPUs doubled sequentially from Q1 to Q2, and the addition of “Bergamo” and “Genoa-X” variants will help drive sales further, and the “Sienna” Epyc CPU for hyperscalers will launch later this quarter and join the mix. Su added that AMD expects sequential growth in the double digits – which obviously can be anywhere from 10 percent to 99 percent growth, so that is a pretty wide bracket – in Q3.""AMD’s prognostications are for AI accelerators to drive over $150 billion
in revenues across the IT industry by 2027, and AMD is increasing its research, development, and go-to-market spending to try to capture a larger piece of this pie." -
S_x96x_S
addikt
azért nem olyan egyszerű ez a chiplet dolog ...
"Sapphire Rapids Core-To-Core Latency // AUG 7, 2023
https://jprahman.substack.com/p/sapphire-rapids-core-to-core-latency"It’s interesting to note that with the upcoming Emerald Rapids die shrink on Sapphire Rapids, Intel is actually somewhat back-tracking from chiplets (at least temporarily for ER), scaling back from 4 → 2 chiplets. I’d expect with ER undergoing 2 → 4 die reduction from Sapphire Rapids, combined with improvements to the EMIB interconnect, to flatten the latency hierarchy just as AMD did going from Rome → Milan → Genoa (which I still need to benchmark)."
előzmény: AMD CPU Topology - Rome + Milan // JUN 3, 2023
https://jprahman.substack.com/p/amd-cpu-topology-rome-milanés még: "AWS is running a 96-core, 192-thread, custom Xeon server"
Amid all the Graviton chat, cloud colossus still has a soft spot for Chipzilla
https://www.theregister.com/2023/08/03/aws_custom_xeon_m7i_instances/
"A reader took the M7I instances for a spin, queried the machine to learn its CPU type, and told The Reg it is a two-socket machine packing a 48-core Xeon Platinum 8488C processor." -
#8926
Petykemano
veterán
Petykemano
veterán
Zen5 (zen 5) Linux kernel patch [link]
znver5 -
#8925
HSM
félisten
Petykemano
#8923
HSM
félisten
válasz
Petykemano
#8923
üzenetére
Különös adalék, hogy úgy nem látjuk a piacon, hogy elvileg készült belőle egy fizikailag kisebb kiadás is az olcsóbb modellekhez...

-
#8923
Petykemano
veterán
S_x96x_S
#8922
Petykemano
veterán
válasz
S_x96x_S
#8922
üzenetére
"APU a gyorsító sávban"
LoL
"az is lehet, hogy a Zen5 -ös APU a gyorsító sávba került.
( valamiért nagy prioritást kapott Lisa Su-tól )"
Kaphatott.
A volumen az OEM-ektől jön. A magas volumenre teríthető R&D-től lehet az R&D vagy a profit magas, vagy az ár versenyképes. Az ok ami miatt a desktop megelőzte mindig az az, hogy az együtt jár a még fontosabb szerver termékkel.Egyébiránt pedig ha az asztali Raptor Lake refresh nem is lesz túl erős, a Meteor Lake érkezik az Inteltől - mobilba. És az sokat javíthat a fogyasztási és teljesítmény értékeken is. Tehát a Zen5 APU megjelenítése emiatt bizonyára elég fontos.
Az is lehet, hogy a PhoenixAPU -val valami gond van
.. nagyon lassan megy a launch.
és az AM5 -ös desktop-os Phoenix verzióról kevesebb a pletyka mint a Strix Point -ról.Milyen érdekes meglátás!
Erről volt már szó. Nem úgy van, hogy a Phoenix APU-t az AMD a ROG Ally-ba értékesíti Ryzen Z1 (extreme) néven?
Egy olyat olvastam, hogy 500e-1m között lehet az eladás [link]
Az mondjuk nem olyan hatalmas tétel az évi 150-250m eladott notebookhoz képest. -
#8922
S_x96x_S
addikt
Petykemano
#8921
S_x96x_S
addikt
válasz
Petykemano
#8921
üzenetére
> Bennem ez azt erősíti, hogy a 2024Q1-es Zen5 rajt sínen van.
az is lehet, hogy a Zen5 -ös APU a gyorsító sávba került.
( valamiért nagy prioritást kapott Lisa Su-tól )És ha arra gondolok, hogy most az AI az AMD Number 1 prioritása
akkor tényleg az APU-nak több értelme van,
A STRIX Point lényegében egy ideális MI300/MI400-as dev kit ROCm kompatibilitással.
És ha lesz belőle mini PC/notebook/... akkor veszik mint a cukrot ..Az én spekulációm:
Vagyis ami az MI300/MI400 - szoftveres ellátottságát segíti - az magas prioritást kap.
a sima ZEN5 CPU - pedig alacsonyabbat.
Legalábbis ez az én spekulációm - az én szubjektív nézőpontombólAz is lehet, hogy a PhoenixAPU -val valami gond van
.. nagyon lassan megy a launch.
és az AM5 -ös desktop-os Phoenix verzióról kevesebb a pletyka mint a Strix Point -ról.
Nyugtassatok meg, hogy minden rendben vele -
#8921
Petykemano
veterán
Petykemano
veterán
Zen5, Zen 5, CPUz, CPU-z, hwinfo, AMD eng sample
Hybrid 12-core config of AMD Ryzen 8000 “Strix Point” APU seemingly confirmed by leaked screenshots


Eredeti forrás: [link]
L1$:
- 4x32 + 4x48
- 8x32 + 8x48Amennyiben a képernyőkép valid, az igazolja a 48Kb-os L1d-re vonatkozó pletykákat.
Zen4 esetén az még 8way, itt már 12wayAmi még nagyon különös az az L2$!
8 magra 2x1M?
Hmm... nem, nem hiszem, hogy az AMD a normál és dense magok között változtatna a cache hierachián - legfeljebb az L3$ méretén. Gyanítom, hogy ez a HWinfo hibája, ami E magnak ismeri fel és az Intel E magjai esetében tényleg úgy van, hogy 4 magos clusterek vannak 1db L2$-re fűzve és csak rosszul ismeri fel.És míg a Zen4 esetén az L2$ is 8 way, addig itt már 16 way.
Azt gondolom, hogy a Zen4 esetén a L2$ méretének növelése valóban csupán azt a célt szolgálhatta, hogy elférjenek benne az AVX512-höz használatos nagyobb hosszúságú adatok és alig járt IPC növekedéssel. Addig az asszociativitás növelése viszont valóban hozzájárulhat ahhoz..A zen4-hez CPUz (CPU-z) 2022 szeptemberben jelent meg [link] De akkor már nem AMD Eng Sample volt a megnevezése.
Zen4-ről nem feltétlenül CPUz, vagy hwinfo jellegű leak pedig január és május között jelent meg. Vagyis 4-8 hónappal a szeptemberi release előtt.Bennem ez azt erősíti, hogy a 2024Q1-es Zen5 rajt sínen van.
-
#8920
HSM
félisten
Petykemano
#8918
HSM
félisten
válasz
Petykemano
#8918
üzenetére
Pusztán spekuláció, de azt gondolom, arányos lehet a felfedezés "piaci értéke" azzal, mekkora felhasználói bázist érint... Így minél több a Zen-es rendszer, annál inkább foglalkoznak vele. Már csak azért is, mert egyre több Zen-es gép lesz, amit a kutató kipróbálhatja tesztelni a potenciális sebezhetőségét....

#8919 Busterftw : Mivel eddig nem jelent meg javíthatatlannak tűnő súlyos sebezhetőség, így nincs ok "lyukas sajtozni"...

De tény, most átmenetileg jár a jelző a Zen2-nek, amíg nem jönnek rá széleskörűen a Zenbleed patch-ek. -
#8918
Petykemano
veterán
HSM
#8917
Petykemano
veterán
Nem érzem azt, hogy egyik vagy másik cég termékei jobban célpontja lenne ilyen kutatásnak, tehát nem sejtek részrehajlást. Olyan mintha általában ez a kérdés kevesebb nyilvánosságot, vagy kevesebb kutatást kapott volna a Zen előtt.
Persze nem kizárt, hogy arról van szó, hogy a cégek egymás lejáratása érdekében keresztfinanszírozzák egymás biztonsági réseinek felderítését, amit a Zen óta tudnak vagy érdemes megtenni. -
#8917
HSM
félisten
Petykemano
#8915
HSM
félisten
válasz
Petykemano
#8915
üzenetére
Szerintem most jobban figyelnek a kutatók a Zen architektúrára, ahogy egyre nagyobb méretekben terjed, akár szerver oldalról is.
A másik oldalon is miket találtak az elmúlt néhány évben, most úgy tűnik valamennyire felzárkózik a Zen ebben is...
Persze, ez Zen2 és Zen3 tulajként annyira nem villanyoz fel, de várható volt. -
#8916
S_x96x_S
addikt
Petykemano
#8915
S_x96x_S
addikt
válasz
Petykemano
#8915
üzenetére
Valami olyasmi .. öngerjesztő spirál.
- szerintem most a kormányok és a cégek is több pénzt áldoznak erre, és az egyetemek + kutatók jobban kapnak erre forrásokat. ( ~ több benne a pénz )
- és egyre gyakorlottabbak a kutatók is. Ugyanazt a trükköt sokszor csak egy picit elég módosítani - és néha szerencséjük van, mert működik.
- És minél inkább felkapja a sajtó .. annál több pénzt adnak rá a politikusok és a cégek ..
amelyek újabb sebezhetőségeket generálnak A hosszú távú hatása, hogy a CPU-k egyre biztonságosabbak lesznek.
-
#8915
Petykemano
veterán
S_x96x_S
#8914
-
S_x96x_S
addikt
AMD "INCEPTION" CPU Vulnerability Disclosed
https://www.phoronix.com/news/AMD-INCEPTION
( elméletileg erre a javításra is lesz Phoronix-es benchmark, meglátjuk ... )AMD's statement to Phoronix on the matter is:
"AMD has received an external report titled ‘INCEPTION’, describing a new speculative side channel attack. AMD believes ‘Inception’ is only potentially exploitable locally, such as via downloaded malware, and recommends customers employ security best practices, including running up-to-date software and malware detection tools. AMD is not aware of any exploit of ‘Inception’ outside the research environment, at this time.
AMD recommends customers apply a µcode patch or BIOS update as applicable for products based on “Zen 3” and “Zen 4” CPU architectures. No µcode patch or BIOS update is necessary for products based on “Zen” or “Zen 2” CPU architectures because these architectures are already designed to flush branch type predictions from the branch predictor.
AMD plans to release updated AGESA™ versions to Original Equipment Manufacturers (OEMs), Original Design Manufacturers (ODMs) and motherboard manufacturers listed in the AMD security bulletin. Please refer to your OEM, ODM or motherboard manufacturer for a BIOS update specific to your product.
"
-- > https://www.amd.com/en/resources/product-security/bulletin/amd-sb-7005.html------------------
"Updated AMD Family 19h Microcode Published Following "Inception"
https://www.phoronix.com/news/AMD-Microcode-Inception
-
S_x96x_S
addikt
válasz
hokuszpk
#8912
üzenetére
> ... AVX512 ...
// DOWNFALL //
pár napja ütött be a https://downfall.page/ az Intel oldalra, ami pont az AVX2/AVX-512 -es müveleteket érinti - és javítás ( a régebbi intel cpu-kon ) néha elég jelentős teljesítmény vesztéssel járhat disclaimer: felhőben vegyesen használok AMD-t és Intelt - úgyhogy érint engem is. És van még egy inteles 8250-es Thinkpad-em is ..
( Which computing devices are affected? : Computing devices based on Intel Core processors from the 6th Skylake to (including) the 11th Tiger Lake generation are affected. )
pár link:
Hacker News: https://news.ycombinator.com/item?id=37052586"Intel DOWNFALL: New Vulnerability Affecting AVX2/AVX-512 With Big Performance Implications" https://www.phoronix.com/review/downfall
"Initial Benchmarks Of The Intel Downfall Mitigation Performance Impact"
https://www.phoronix.com/review/intel-downfall-benchmarks
"Intel has reported up to 50% performance penalties in extreme cases but from my testing over the past day it thankfully has tended to be less than that but still significant. "
-
#8912
hokuszpk
nagyúr
Petykemano
#8907
hokuszpk
nagyúr
válasz
Petykemano
#8907
üzenetére
hm.
Zen1 = AVX2 128 bit. stimt.
Zen2 = AVX2 256 bit de ez ha jolemlexem vegrehajtasnal 2x128 bitre bomlott.
Zen3 = AVX2 256 bit, full.
Zen4 = AVX512 bit de vegrehajtasnal megint kette van bontva 2x256 bitre
szoval logikailag ZEN5 = AVX512 full -
#8911
S_x96x_S
addikt
Petykemano
#8910
S_x96x_S
addikt
válasz
Petykemano
#8910
üzenetére
> Két dolog miatt hiszek a 2024Q1-es rajtban:
legyen igazad !
-
#8910
Petykemano
veterán
S_x96x_S
#8909
Petykemano
veterán
válasz
S_x96x_S
#8909
üzenetére
Az egy szerver roadmap.Abból is látszik, hogy nem az asztali megjelenést látjuk, hogy a roadmap szerint a Raphael alapú AM5 platform előkészítése 2023 során zajlik és 2023Q4-ben kerül piacra vezetésre - miközben az asztali Zen4 már 2022 év vége óta elérhető.
Nem állítom persze, hogy mindent 1 évvel elcsúsztatva kell értelmezni, csak azt, hogy amit ezen az ábrán látunk az nem az asztali termék megjelenésére vonatkozóan mérvadó.
Abban sem vagyok biztos, hogy vajon ez a roadmap még pontos. A Bergamo emlékeim szerint például 2 hónapja jelent meg, tehát csúszott 2 negyedévet.
Elnézést, persze én is csak ködszurkálok. Meglátjuk majd.
Két dolog miatt hiszek a 2024Q1-es rajtban:
Egyrészt mert az architektúrák közötti intervallumszámítás alapján - figyelembe véve a Zen4 2 negyedéves csúszását - úgy jön ki.
Másrészt szerintem az üdvrivalgás is korai jelenség volna 1 évvel a kiadást megelőzően.De majd meglátjuk.
Szerintem CES-re remek téma lenne. -
#8909
S_x96x_S
addikt
Petykemano
#8908
S_x96x_S
addikt
válasz
Petykemano
#8908
üzenetére
> A 2024Q1-es rajt elég valószínű.
ki tudja ..
de a (May 15th 2023 -MLID-Videocardz alapján csak 2023Q1-ben kezdődik el a gyártása )
"More importantly, the slide shows when the product might enter production, which is between Q1 2024 and Q1 2025,"Az ábra alapján a "Turin Dense" és a "Turin Classic" kap nagyobb prioritást.
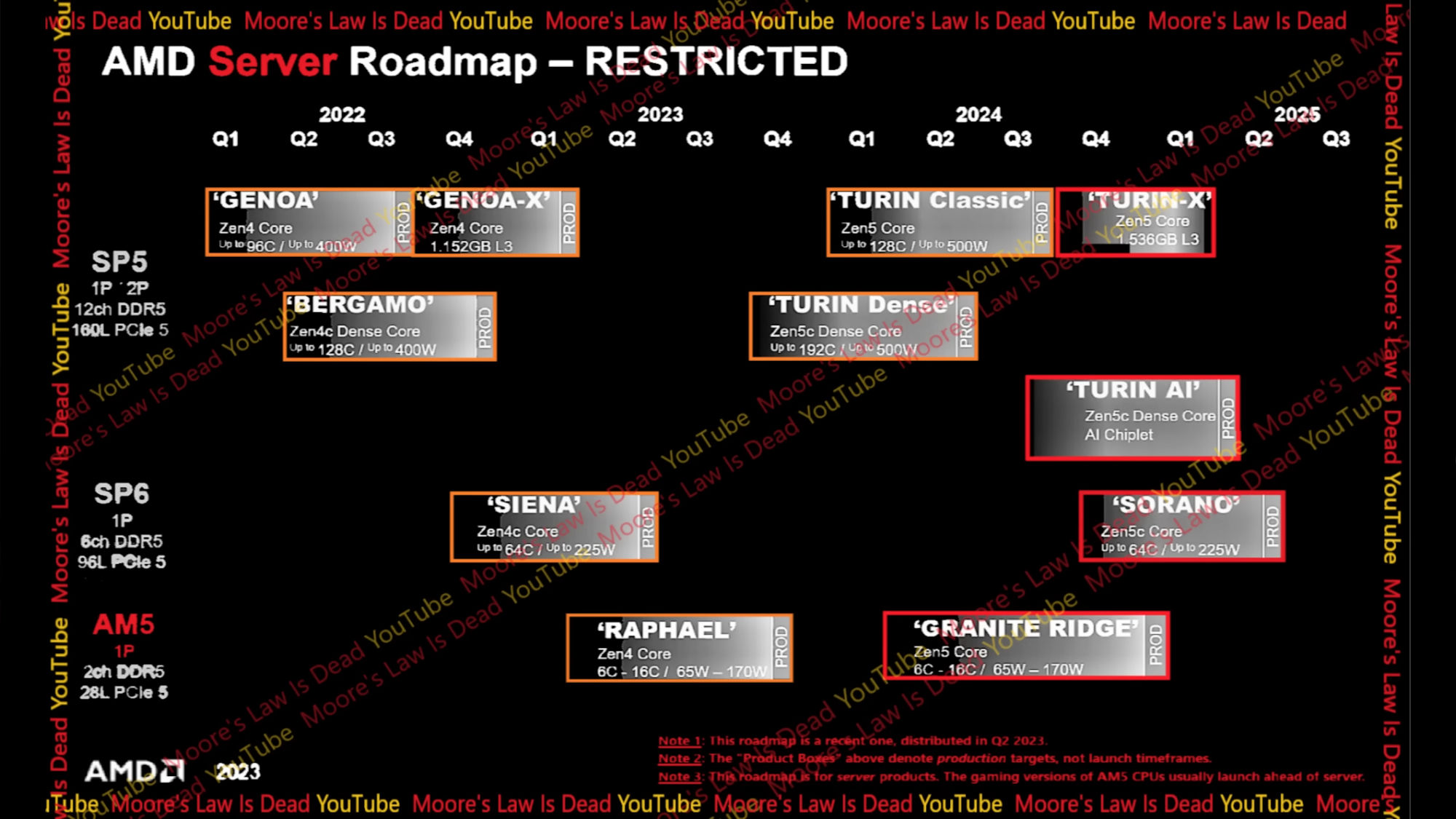
de amúgy én is örülnék, hogyha már januárban meg lehetne venni ..
-
#8908
Petykemano
veterán
Petykemano
#8907
Petykemano
veterán
válasz
Petykemano
#8907
üzenetére
Nagyon erősnek tűnik a hype és az elégedettség a zen5 tesztpéldányokkal.
Azt nézegettem, hogy Vajon mikor jelentek meg az első olyan leak-ek, amiket nem Mlid, RGT jelentettek meg, hanem a twitter sejtelmes közönsége is somolyogva lebólogatott. Szerintem nyáron ilyen már biztos történt.
A 2024Q1-es rajt elég valószínű.
Igazából persze a nép annak örülne, ha karácsonyra vihetne haza egyet.A 25% körüli ST teljesítménynövekedés valószínű. Bármi ennél jobb, legyen inkább meglepetés. A raptor lake refresh nem tűnik túl erősnek. Mivel az Intel árat akart volna emelni, ezért az árcsökkentés valószínűtlen, tehát minimum a zen3 borsos árazásához való visszatérés várható. Főleg a kisebb magszámú skuknál.
-
#8907
Petykemano
veterán
Petykemano
veterán
Vector Width
Znver1: AVX2 128 bit
Znver2: AVX2 256 bit
Znver3: AVX2 256 bit
Znver4: AVX512 512 bit
Znver5: AVX512 512 bit*2
[link] -
#8906
Petykemano
veterán
Petykemano
veterán
Zen5 (Zen 5) benchmarks leak - RedGamingTech
CineBench R23 (MT)
16 Core = 49000
12 Core = 36000
8 Core = 23000
6 Core = 17000Igen különös eredmények. A 16 és 12 magos változat rendre 27% és 23%-os előrelépést mutat. A 8 és 6 magos viszont csak 12%-ot. Ez igencsak meglepő. Azt jelenti, hogy a Zen5 tulajdonképpen relatív sokat fogyaszt és a 12-16 magos változatoknál a nagyobb TDP nagyonis ki van használva.
De ugyanakkor az energiaéhség nem meglepő, ha figyelembe vesszük azt, hogy jelenlegi tudásunk szerint a rendkívül Zen5 N4P gyártástechnológián fog készülni. Ennek megfelelően a target - a Zen3-hoz hasonlóan - a ST (+lightly threaded) teljesítmény növelése lehetett, miközben - a Zen3-hoz hasonlóan - a MT teljesítménybeli növekedése korlátozott. Ez majd az N3_ port esetén korrigálódik. A dense és mobil chip azon fog készülni.
A szöveg alapján a R23 ST mérésben 2500-3000 között teljesít. Ami egy elég tág intervallum. És persze ezt a tág meghatározást már akkor is teljesítik, ha a MT értékeknél látott 23-27%-os növekményt teljesítik.
És persze ne vegyük készpénznek a fent látott számokat.
-
#8905
S_x96x_S
addikt
Komplikato
#8904
S_x96x_S
addikt
válasz
 Komplikato
#8904
üzenetére
Komplikato
#8904
üzenetére
> Ezeket én is megtaláltam. Igazából engem az érkező alaplapok
>, azok felszreltsége és ára érdekelne.ha nem találod, akkor még nincs róla infó;
még korai ..> És mivel Am5 lapok is mocskos drágák,
> lehet az "olcsó" verzió a 64 PCIe lannel,
> meg a kevesebb memória csatornával megérnék.mire kell ?
- mert szerintem az AM5 átlagos árszintje felett lesz.- amúgy technikailag nincs akadálya - Gen4-es ( lebutított ) Threadripperes alaplapnak se
- vagy ránézhetsz az SP5 -ös lapokra és EPYC Gen4 -es CPU-t választasz.
https://geizhals.de/?cat=mbsp3&xf=644_SP5Supermicro H13SSL-NT retail - € 847,29 bis € 1011,50
- 12x DDR5 DIMM, 12-Channel PC5-38400R/DDR5-4800, max. 3TB (RDIMM), 3TB (LRDIMM)
- 3x PCIe 5.0 x16, 2x PCIe 5.0 x8, 2x M.2/M-Key (PCIe 4.0 x4/SATA, 22110/2280), 1x MCIO SFF-TA-1016 74-Pin (PCIe 5.0 x8), 2x MCIO SFF-TA-1016 74-Pin (PCIe 5.0 x8/SATA)Vagy Supermicro MBD-H13SSL-N-B : 352.034 Ft(277.192 Ft + ÁFA)
https://www.arukereso.hu/alaplap-c3128/supermicro/mbd-h13ssl-n-b-p977758878/És raksz bele egy olcsó EPYC procit ... $1200 EUR -tól.
https://geizhals.de/?cat=cpuamdam4&xf=12099_Server~16686_Epyc+9004 -
#8904
 Komplikato
veterán
S_x96x_S
#8898
Komplikato
veterán
S_x96x_S
#8898
Komplikato
veterán
-
#8903
Petykemano
veterán
Petykemano
veterán
Azt pletykálják, hogy a Strix Point 4P+8e összeállítású lesz ,míg a Strix Halo 8P+8P
Bár mintha valahol azt olvastam volna, hogy 8P+8eUtóbbi nem tűnik túl valószínűnek... kivéve, ha strix halo monolitikus lesz.
Jön a PS5 Pro is.Itt gondolkodtam el, hogy vajon mi lesz végül monolitikus és mi lesz chiplet?
A Strix Point persze valószínűleg monolitikus.
A Strix Halo esetén a 8P+8P egészen úgy hangzik mintha chipletes lenne: 2 hagyományos Zen5 chiplet + egy 40CU-t tartalmazó "IO" lapka. Egy 40CU-s IO lapkát nem volna praktikus úgy tervezni, hogy azt akár diszkrét kártya formájában is el lehessen adni? És akkor vajon a PS5 Pro is ilyen felépítést kap, vagy az marad monolitikus? Ha az monolitikus, akkor lehet-e a Strix Halo is monolitikus inkább?
-
S_x96x_S
addikt
"Azure Provides Excellent HPC Cloud Performance With HBv4 Series Powered By AMD EPYC Genoa-X"
https://www.phoronix.com/review/azure-hbv4-genoaxteszt:
HBv4 - The 176 vCPUs with the EPYC 9V33X Genoa-X.
HBv3 - The 120 vCPUs for Milan-X with the EPYC 7V3X processors.
HBv2 - The 120 vCPUs with the EPYC 7V12 Rome processors.
HC - The original 44 vCPUs with the Xeon Platinum 8168 Skylake processors."When taking the geometric mean of all the benchmark results, the HBv4 with 176 vCPUs was 2.1x the performance of the 120 vCPU HBv3 VM. For classic high performance computing workloads and especially for areas like CFD, FEM, and other memory bandwidth intensive applications, the HBv4 performance uplift can be dramatic thanks to AVX-512 and the larger 3D V-Cache with Genoa-X. The price increase in the HBv4 line-up is justified and still the HBv4 top-end VM tended to deliver the best value."









![;]](http://cdn.rios.hu/dl/s/v1.gif)















 ..
..







Új hozzászólás Aktív témák

- Thrustmaster t300 bázis
- Core I7 4K ERŐMŰ Lenovo P1 G3 (Core I7 10850H 32Gb 1 Tb) Tervező/vágó/gamer - Nvidia 4Gb!
- Bivaly Lenovo T14 gen5 (Core Ultra 7 32Gb DDR5 1 Tb SSD) laptopom eladó 30 hónap gyártói garanciával
- Eladó MEE audio T1 CMA Bluetooth fejhallgató rendszer, gyakorlatilag új!
- Acer Predator Helios 300 gamer notebook/QHD,165Hz/i9 11900H/RTX 3060/32GB/ beszámítás van
- Samsung Galaxy A53 5G 128GB, Kártyafüggetlen, 1 Év Garanciával
- Önerő nélkül is elvihető! Részletfizetés. 27 % Áfás számlával Dell Alienware QD-OLED gamer monitor
- AKCIÓ! Apple MacBook Pro 16 M4 Max 36GB RAM 1TB SSD macbook garanciával hibátlan működéssel
- Apple iPhone 15 Plus - Black - 256GB - Akku: 100% - Újszerű állapot!
- iKing.Hu - HONOR 400 Lite 5G Velvet Grey Vékony, könnyű, AI-kameragomb 8/256 GB- 2027. 07. 01
Állásajánlatok

Cég: BroadBit Hungary Kft.
Város: Budakeszi

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest