
- Szomorú jövőt vetít előre a dedikált GPU-knak a Jon Peddie Research
- NVIDIA GeForce RTX 5070 / 5070 Ti (GB205 / 203)
- AMD Navi Radeon™ RX 9xxx sorozat
- iPad topik
- Autós kamerák
- Hamarosan szárba szökken a hardverpalánta
- Vezeték nélküli fülhallgatók
- OLED TV topic
- Amlogic S905, S912 processzoros készülékek
- Fejhallgató erősítő és DAC topik
-

PROHARDVER!
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#57699
 kisfurko
senior tag
Petykemano
#57698
kisfurko
senior tag
Petykemano
#57698
kisfurko
senior tag
válasz
 Petykemano
#57698
üzenetére
Petykemano
#57698
üzenetére
Lehet, hogy azért kisebb a cache az MCD-ben, hogy csökkentsék a latencyt. Azt se tudjuk, hogy a GCD-vel való kapcsolat mennyi helyet igényel. Simán valami gazdaságossági dolog is lehet, hogy pl. 10-20 százalék die area aránytalanul több időt/pénzt igényelne, vagy sokkal nagyobb kihozatalt akarnak.
Eddig a cache chipen belül volt, nyilván a belső busz gyorsabb, mint a két chip közötti, tehát valamivel kompenzálniuk kell a sávszélesség-veszteséget, ezért a másfélszeres busz, szerintem. -
#57698
 Petykemano
veterán
hokuszpk
#57697
Petykemano
veterán
hokuszpk
#57697
Petykemano
veterán
válasz
 hokuszpk
#57697
üzenetére
hokuszpk
#57697
üzenetére
Idővel lesz 16GB cache 😃
Viszont érdekesek a számok.
Az angstronomics cikk alapján az MCD 37mm2 (legyen 35-40)
Azt állítják, hogy ebben már benne van 16MB Infinity Cache.Locuza Navi21-es számai alapján 64bit GDDR6 ~13mm2, 32MB IC pedig ~23mm2, vagyis 35-40mm2-ből nagyjából 32MB is kijön és akkor még nem is beszéltünk arról, hogy ez N7 számok, az MCD pedig N6.
Miért és hogyan kerülne bele csak 16MB?Az a fura, hogy külön gyártva lényegesen nagyobb sűrűséget értek el a V-cache esetén - ott 64MB belefért ~36mm2-be. Tehát ha az MCD v-cache-t kapna, annak is valamivel kisebbnek kéne lennie a 23mm2-nél, ha csak 32MB, vagy ha nincs kitöltő szilícium, akkor 64MB is kijöhetne az MCD teljes méretéből.
Így meg aztán tényleg érthetetlen a spórolás.Ezzel együtt hihetőnek tűnik az, hogy nem skálázódik jól tovább a cache. Szerintem az infinity cache nem egybefüggő volt eddig se. Legjobb esetben is 2db 64MB-os szelet volt, de valószínűbb, hogy 32MB-os szelet szolgált ki 64bit memóriavezérlőt (sőt, lehet, hogy 16MB egy 32bites sávot)
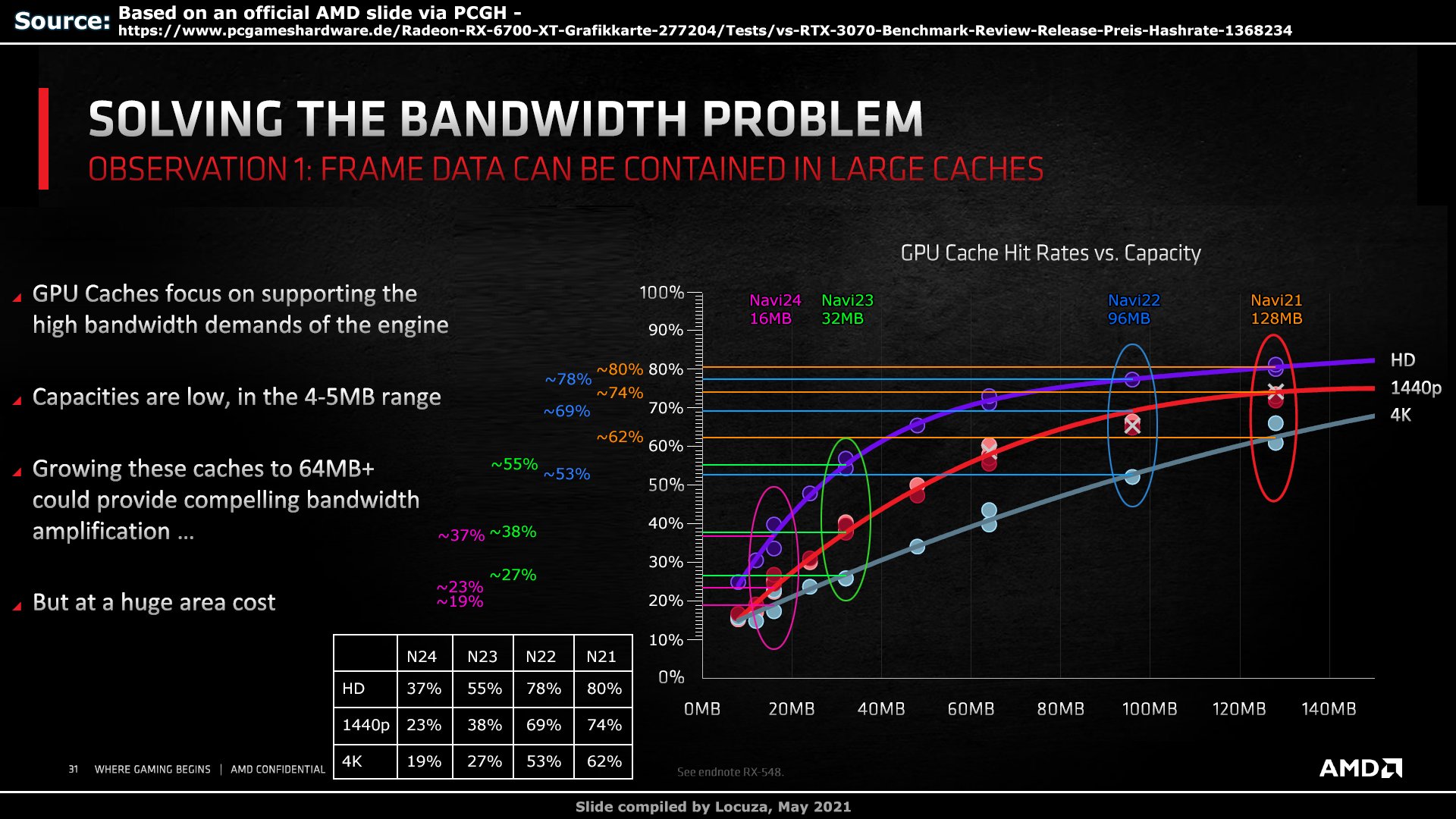
A grafikon alapján látható, hogy 1080p-hez a felezett mennyiség is.elég. 1440p lehet,.hogy vállalható felezett cache mellett. De a 4K-Nak jót.tenne a több cache.
Kissé érthetetlen, hogy az AMD miért döntött a jó iránynak tűnő.cache helyett a memóriabusz szélesítése mellett.
Két dologra tudok gondolni:
- nem csak az számít, hogy mennyi a cache méret. Tehát mondjuk hiába lenne nagyobb a cache mérete, ha a csatoló (InFO_oS) által kínált sávszéleség limitált.
Ez Megmagyarázná miért döntött az amd a több cache helyett a több MCD mellett.
- a GCD-ben az nvidiához.hasonlóan növelték az L2$ méretét (sajnos itt a kitöltő szilícium szükségessége miatt valószínűtlen a 3D megoldás), ami jelentősen enyhítette a L3$-re nehezedő nyomást. -
#57697
 hokuszpk
nagyúr
Petykemano
#57696
hokuszpk
nagyúr
Petykemano
#57696
hokuszpk
nagyúr
válasz
Petykemano
#57696
üzenetére
kamu duma. ha beletolnának 16GB infinity cachet, 100% hit rate.
-
#57696
Petykemano
veterán
hokuszpk
#57694
Petykemano
veterán
válasz
hokuszpk
#57694
üzenetére
csökkenő határhasznosság
Lehet, hogy úgy lesz majd a szegmentálás, hogy az (esetleg később jövő) YY50XT megkapja a plusz sávszélt és vagy "true 4K"-val vagy RayTracinggel, vagy épp PRO kékséggel fogják eladni, míg a kisebb IC-vel rendelkező példányok mennek a kevésbé vájtszemű kispolgároknak.
-
válasz
hokuszpk
#57694
üzenetére
Szerintem mérlegelnek a kihozatal/ teljesítmény / árazás koordinátákon és ez lett az origo.
Okosan hoznak mostanában fejlesztési döntéseket, nincs kétségem afelől ,hogy felső házas termék lesz így is a konkurenciával szemben és ha így jobb áron jöhet egyben kihúzza a használt piac méregfogát is. Legalább is mérsékli a hatását az új genre. -
-
#57692
Petykemano
veterán
Alogonomus
#57691
Petykemano
veterán
válasz
 Alogonomus
#57691
üzenetére
Alogonomus
#57691
üzenetére
Ezen infók alapján én a navi33-at a 6700XT / 3070/Ti szintre várnám.
Egy 237mm2-es navi23 teljesítményét hozni N6-on gyártott ~200mm2 navi33-mal nem lenne nagy kunszt.Gondolom a dupla mennyiségű ALU azért valahol érezteti majd a hatását.
Ha a 335mm2-es lapkájú navi22-t elérnék az már szép eredmény lenne. Ha ez Így történne, akkor szerintem oda áraznák, ahol most a 6600XT van (nem számolva recessziós árkedvezménnyel)
-
#57691
 Alogonomus
őstag
Devid_81
#57689
Alogonomus
őstag
Devid_81
#57689
Alogonomus
őstag
válasz
 Devid_81
#57689
üzenetére
Devid_81
#57689
üzenetére
Igen, az biztos, hogy végül használat közben rendben lesz az RDNA 3 kártyák teljesítménye, mert egyébként nem a kis IC irányába mentek volna el, hanem maradtak volna a 256 bit és 384 MB IC vonalán. Talán tényleg az az AMD szándéka, hogy a chiplet design miatt nagyon olcsón kiadható kártyákkal piaci részarányt javítson, és nem kezd el versenyezni a rengeteget fogyasztó Lovelace csúcskártyával. Majd talán a refresh kapcsán.
Érdekes ősznek nézünk elébe.
Egyedül a Navi 33 specifikációi lehangolóak, mert a 128 bites memóriabusz egyértelműen kizárja a 12 GB-os pletykált verzió létezését, a "Navi33 outperforms Intel’s top end Alchemist GPU" pedig azt jelzi, hogy nagyjából egy RX 6600 XT lesz erőben, bár a fogyasztása valószínűleg kedvező lesz, de egyáltalán nem Navi 21 teljesítményszintre jön.
-
#57690
Petykemano
veterán
Devid_81
#57689
Petykemano
veterán
válasz
Devid_81
#57689
üzenetére
Biztosan most is többféle variációt kipróbáltak.
Ez a 96/192MB lehet szegmentációs célzatú is.
A raytracingben pl tudtommal sokat számít. Tehát pl a 192MB-os változat lehet PRO, vagy valamilyen más célzattal feláras.De az sem kizárt, hogy változott a cache hierarchia.
(Abu azt mondta, az oo$ eddig nem is volt része.) Csupán egy victim cache volt. Ha ezen változtattak, akkor kevesebb is elég lehet.A leírás szerint az AMD PPA-ra optimalizált, vagyis vagy kellően szűkösek a kapacitásaik, vagy az AMD piaci részesedés szerzését tervezi.
Ezek a lapkák tényleg elég kicsik. Reméljük ez az áraikban is reflektálódni fog.
-
#57689
 Devid_81
félisten
Alogonomus
#57687
Devid_81
félisten
Alogonomus
#57687
Devid_81
félisten
válasz
Alogonomus
#57687
üzenetére
Sztem van ott meg valami amire a leakerek sem latnak ra.

AMD-tol nagyon keves info jon, az RDNA2.0-rol is vegig keves info jott es egy jo eros RTX2080Ti szintig vartuk a vacak 256bitjevel, aztan mi lett belole? -
#57688
 Yutani
nagyúr
Alogonomus
#57687
Yutani
nagyúr
Alogonomus
#57687
válasz
Alogonomus
#57687
üzenetére
Vagy 384 bithez elég a 96MB IC
-
#57687
Alogonomus
őstag
Devid_81
#57686
Alogonomus
őstag
válasz
Devid_81
#57686
üzenetére
Minimum meglepő az AMD jelenlegi sorozatának komoly előnyt biztosító Infinity Cache méretének negatív irányú változása. Vagy az állítólagos OREO technológia mellé nagyon kevés Infinity Cache is elég, vagy valami nagyon nem stimmel a leak kapcsán.
Eddig ilyen 384, vagy akár 512 MB-os Infinity Cache meglétét jósolták, ami abszolút logikus is lett volna a megcélzott 4K és 8K mellé, valamint a játékok egyre méretesebb textúracsomagjaihoz igazodva. -
-
#57685
Petykemano
veterán
Petykemano
veterán
Korszakos lehetőséghez érkezett az AMD.
Nem, vagy nem feltétlenül a chiplet miatt. Az biztosan sokat segít majd a válogathatóságban és így hozzájárulhat, hogy megbízhatóan jó minőségű sku-kat is össze tudjanak rakni.
Valamint persze javíthat a selejtarányon, összességében segítheti az AMD-t abban, hogy egy kellően jó kártya esetén ne annyira kelljen kapacitás-problémákkal küzdeni, amiatt magasan.árazni, és/vagy lemondani piaci részésedésről.Még csak nem is feltétlenül azért, mert a pletykák szerint az RDNA3 energiahatékonysága jobb lesz. Ez lehet, hogy csak a túlhajtott legmagasabb szféra esetén lesz igaz. De ha igaz, akkor az lehetővé teheti, hogy az AMD benyomuljon az OEM piacokra. - ahonnan szerintem az nvidia meghatározó piaci részesedése származik.
Hanem amiatt, hogy az elmúlt hetekben kiadott az AMD egy újraírt DX11 és egy újraírt openGL illesztőt. Régóta ismert, hogy az nvidia ezeken a területeken brillírozott nagyon és ha DX12/Vulkan terén egálban is voltak, akkor.számos régi.játék eredménye ronthatta az összképet, ami miatt lehetett az a konklúzió, hogy aki régebbi játékkal is akar játszani, annak.azért előnyösebb az nvidia kártyát választani.
Most a jónak ígérkező RDNA3-mal és a új driverekkel az AMDnek törtélmi esélye nyílik, hogy a benchmarkokban megszabaduljon a régi játékok lehúzó terhétől és a teljes palettán győzelmet arasson.
-
#57684
Alogonomus
őstag
Devid_81
#57683
Alogonomus
őstag
válasz
Devid_81
#57683
üzenetére
Azok a 320 és 384 bites modellek érdekes új spekulációk. Eddigi pletykákban csak 256 bites 16 és 32 GB-os modelleket emlegettek. A jelenlegi generációban szerintem a 384 bit helyett csak 256 bites memóriabusz okozhatja a 4K-ban jelentkező lemaradás nagy részét, mert 4K-hoz már kevés az Infinity Cache kapacitása.
Az alsóbb felbontásokban az új 8-as és 9-es kártyákhoz várt 384 vagy akár 512 MB-os Infinity Cache valószínűleg továbbra is eldönti majd a versenyt. Sőt egyes pletykák szerint a csúcs Navi 31 esetén az MCM kialakítás eredményeként több részre lehet majd bontva az IC, így többszörözött sávszélességet biztosít. -
Devid_81
félisten
-
#57682
Yutani
nagyúr
Alogonomus
#57680
válasz
Alogonomus
#57680
üzenetére
Jó lenne egy tesztet látni, mennyire segíti meg a 8GB memória.
-
#57681
Petykemano
veterán
Alogonomus
#57680
Petykemano
veterán
válasz
Alogonomus
#57680
üzenetére
nájsz
-
#57680
Alogonomus
őstag
Alogonomus
őstag
Ez a 8 GB-os RX 6500 XT kártya megkavarhatja az állóvizet a belépőszinten. Persze nem lesz ettől RTX 3050 erejű, de a kártya legjelentősebb gyengeségét ezzel orvosolják is.
-
#57679
Petykemano
veterán
Petykemano
veterán
Greymon szerint a Navi31 GCD chiplet mérete: 350mm2
Ez elég kicsinek tűnik, de persze ehhez még hozzájön 6db N6-on gyártott MCD. -
#57678
 Hellwhatever
aktív tag
Hellwhatever
aktív tag
Hellwhatever
aktív tag
-
-
#57674
Alogonomus
őstag
olymind1
#57672
Alogonomus
őstag
válasz
 olymind1
#57672
üzenetére
olymind1
#57672
üzenetére
A hitelesebb leakerek már régóta utalnak rá, hogy az AMD is be fog vetni csak a saját kártyájában elérhető funkciókat az FSR technológiához, ahogy az Intel is pluszként adja az XMX megoldást a saját kártyáiban, míg a többi gyártónak ott van a DP4a az XeSS használatához.
Kérdés, hogy az állítólagos kb. 150% gyorsulás az ilyen WMMA típusú optimalizálások eredményeként jelentkezik, vagy ez csak még további gyorsulást hoz a kompatibilis alkalmazásokban? -
-
#57671
Petykemano
veterán
szmörlock007
#57670
Petykemano
veterán
válasz
 szmörlock007
#57670
üzenetére
szmörlock007
#57670
üzenetére
Annak látnám némi esélyét és előnyét, hogy bizonyos chipleteket a samsungnál ggyártsanak
De az az igazság, hogy a Samsung gyártástechnilógia bár tr sűrűségben versenyképes, high perf fogyasztásban és talán kihozatalban nem.
Ebben lehet, hogy az EUV és az ahhoz kapcsolódik szűrőfólia késése játszik szerepet. -
#57670
 szmörlock007
aktív tag
Yutani
#57669
szmörlock007
aktív tag
Yutani
#57669
szmörlock007
aktív tag
válasz
 Yutani
#57669
üzenetére
Yutani
#57669
üzenetére
Amd amúgy simán átvihetne pár dolgot (pl. laptop cpu-k) a Samsung 3nm-re, amúgy is együtt dolgoznak, hiszen ők adják a Samsungnak az igp-t a csúcstelefonokba. Emiatt gondolom alapból van információjuk az aktuális legfrissebb node-ról is. És akkor a kínzó gyártásbeli hiányt kb ki is ütnék.
-

Abu85
HÁZIGAZDA
Lényegében igen. A 3 nm problémája az, hogy a Samsungnál GAAFET van, ami ismeretlen, tehát kockázatos, míg a TSMC-nél még nincs GAAFET, miközben a FinFET már nem skálázódik ilyen csíkszélességre, ami megint kockázatos. Nyilván átváltanak majd, de most nem túl jó döntés ezt elsietni.
Egyébként a Samsung 3 nm-je jobban áll, ami nyilván azért van, mert ők már nem FinFET-et használnak. És valószínű, hogy gyorsabban is fog javulni nekik a kihozataluk.
-
Abu85
HÁZIGAZDA
A TSMC-nek az 5 nm-es node-ja (plusz ennek a 4 nm-es half-node-ja) azért elég jól sikerült. Igen kellemes már a kihozatal is a kisebb lapkáknál, a nagyobbaknál nem tökéletes, de ez benne van eleinte. Sokkal több baja van a 3 nm-en a TSMC-nek. Ott már kezd visszaütni, hogy a FinFET túlment a határon.
-
#57665
 b.
félisten
Petykemano
#57664
b.
félisten
Petykemano
#57664
válasz
Petykemano
#57664
üzenetére
Az hogy helyes döntés a chiplet nem kérdés,ez a jövő.Az hogy korai e és erre rátervezni egy egész generácíót mindjárt az elején az a kérdés főleg üzletileg..Kockázatos.Miért nem elég egy csúcs MCM tapasztalatszerzésnek alá pedig biztosra menni?
.A példa azt mutatja hogy nem sikerül kompletten kihozni a tervezett SKU kat és így 2022 ben kiadni a csúcs RDNA3 at tehát ha a pletyka igaz nem nehéz sommás véleményt alkotni,ha AMD ezzel fél év előnyt ad a felsőházban az Nvidiának,aki közben nyugissan elesz a csúcson és fejlesztgeti a Hoppert MCM dizájnt.
Ha a pletyka nem igaz akkor persze más az aspektus de akkor is még nagyon sok a kérdőjel teljesítmény ,ár és egyéb mutatók szempontjából és nem csak AMD nél,Nvidiánál is.Egyre több jel utal afelé,hogy(pletykák szerint )a kezdeti lemaradásuk már előnnyé vált.Tehát nem látom mi értelme van kockáztatni.
Ráadásul azért az a tsmc 5 nem lett azért igazi.Az öreg és Intel is kisebb csíkszélre tervezik az MCM hatékony megvalósithatóságát.3nm? -
#57664
Petykemano
veterán
Alogonomus
#57663
Petykemano
veterán
válasz
Alogonomus
#57663
üzenetére
Igen, ez igaz.
Én abból az aspektusból kívántam körbejárni a kérdést, hogy vajon a látott eredmények a szokásos mutatók (perf, perf/W, perf/$) alapján fogják-e egyértelműen megválaszolni azt a kérdést, hogy előnyös volt-e már chipletre menni, vagy helyes döntés volt-e még várni vele. b ugyanis sommásan mintha az utóbbit állapította volna meg (többedszer). -
#57663
Alogonomus
őstag
Petykemano
#57662
Alogonomus
őstag
válasz
Petykemano
#57662
üzenetére
A chipletes megoldás a minőségbeli válogatáson felül a célhoz igazodó optimális node kiválasztását is lehetővé teszi.
Míg egy monolitikus GPU egységesen egy bizonyos nodeon készül, vagyis szükségtelenül nagy kapacitást emészt fel a rendelkezésre álló drága node kapacitásból, addig a chipletes kialakítással csak a feltétlenül szükséges részegységek (jellemzően a compute egységek) készülnek a drága node alkalmazásával, míg a többi elem (IO, SRAM) simán készülhet 7/6, de az IO talán még 14/12 nm-en is. Ez pedig nem csak a legyártható mennyiséget növeli, de a legyártási költséget is csökkenti.
Sőt adott esetben a kártya "tuningját" is egyszerűsíti, mert chipletes kialakítás esetén sokkal könnyebb később "hozzácsapni" egy extra külső - de az MCD/MCM fizikai keretein belüli - gyorsítótárat, ahogy az például az 5800X3D esetén is történt. -
#57662
Petykemano
veterán
Alogonomus
#57659
Petykemano
veterán
válasz
Alogonomus
#57659
üzenetére
Greymon mai tweetjében (megint) azt állíttotta, hogy a jelenlegi állás szerint 1GCD + cache+IO kialakítású, a korábbiakhoz képest visszafogottabb specifikációval rendelkező Navi31 nem a csúcs RDNA3 modell lesz. Hanem egy 2023-ban érkező modell (2GCD?) lesz a zászlóshajó.
Meglátásom szerint a chipletes megoldás elsősorban a gyárthatóságon segít. Egy adott teljesítményű processzor amennyiben elkészíthető monolitikus felépítéssel, valószínűleg átlagosan* kisebb fogyasztással rendelkezhet.
* Direkt írtam, hogy átlagosan. Mert ha már kisebb chipletekkel számolunk, mint amilyen az Epyc esetén a Zen CCD, úgy már a lapkák minőségbeli válogatása is sokat nyomhat a latba, de a pletykált 1GCD + körítés esetén ez nem játszik.
Amiben a chiplet design segít az az, hogy mondjuk az AMD - mivel kevesebb N5 wafert használ egy adott lapkához, ezért elképzelhető, hogy ugyanannyi N5 waferből kétszer annyi lapkát legyárt. Más kérdés, hogy az Nvidia általában több wafert foglal és többet gyárt, de ha az AMD-nek kapacitás problémái lennének, akkor ez egy olyan lépés, ami azon enyhíthet.
-
#57659
Alogonomus
őstag
b.
#57658
Alogonomus
őstag
A tweet arról szól, hogy az AMD esetleg nem is lesz rákényszerítve az MCM kialakításra ahhoz, hogy az AD102 "huge power consumption" változatával felvehesse a versenyt most ősszel.
Az MCM váltás maximum azért tekinthető korainak, mert a tweet alapján a konkurenciát már MCD kialakítással is belekényszerítette egy "huge power consumption model" létrehozásába.
Ez mondjuk megkérdőjelezi annak a széles körben terjesztett állításnak a valóságtartalmát, hogy a konkurensek állítólag eléggé pontosan tudják a másik termékének a képességeit. -
Az előző tweet júni 15: [link]
"There seems to be 16384SP 8SE navi3x, but I don't know if it really exists or if it's a gaming card?"Mai tweet: 2023 Specifications to be determined.[link]
"It was planned in response to the AD102's huge power consumption model, so there is a lot of uncertainty about power consumption and scale, if the N31 is good enough to deal with the AD102, it may not come out, just like the GH202."ezért emelik a fogyasztását a kész tervezett SKU-knak. vajon elég lesz a felső házban NV ellen?
lehet korai volt még az MCM váltás, jensen megint jól gondolta ki a dolgokat. -
NV megijedt, feljebb srófolta a fogyasztást. Most AMD ijedt meg, és ők is toltak rajta egy kicsit. Remélem, itt megállnak mindketten.

-
-
#57653
Petykemano
veterán
paprobert
#57651
Petykemano
veterán
válasz
 paprobert
#57651
üzenetére
paprobert
#57651
üzenetére
> Az AMD rendelkezik a default library-vel.
Nyilván, persze> De ha belegondolsz, a Bergamo (Zen dense) tekinthető egyfajta
> szélesítésnek-sűrítésnek, package és mag szinten.
Abból a szempontból, ahogy én kérdeztem nem. A frekvencia és az IPC is hatással van egy processzor mag egyszálas teljesítményére. A Bergamo lehet, hogy alacsonyabb frekvenciát célozva ugyanúgy magasabb tranzisztorsűrűséget fog hozni, de csak a magszámot fogja emelni. -
#57651
 paprobert
őstag
Petykemano
#57649
paprobert
őstag
Petykemano
#57649
paprobert
őstag
válasz
Petykemano
#57649
üzenetére
Az AMD rendelkezik a default library-vel.
A "nagy tempó, nagy fogyasztás" piacot célozza jelenleg az AMD. Valamekkora fogyasztáshátrány szinte biztosan megmaradna az ARM-mal szemben, egy teljesen más filozófia szerint felépített új x86 CPU-val is.
De ha belegondolsz, a Bergamo (Zen dense) tekinthető egyfajta szélesítésnek-sűrítésnek, package és mag szinten.
-
#57650
Abu85
HÁZIGAZDA
Petykemano
#57649
Abu85
HÁZIGAZDA
válasz
Petykemano
#57649
üzenetére
Mert olyat akarnak csinálni, amit el tudnak adni. Olyat nem, ami csak az Apple-nek jó, de az Apple nem veszi meg.
-
#57649
Petykemano
veterán
Abu85
#57648
-
#57648
Abu85
HÁZIGAZDA
Petykemano
#57647
Abu85
HÁZIGAZDA
válasz
Petykemano
#57647
üzenetére
Mert van olyan performance libjük, amivel ezt megtehetik, ellentétben az Apple-lel, amely cég a gyári libeket használja.
-
#57647
Petykemano
veterán
Abu85
#57646
Petykemano
veterán
mi az oka, hogy az AMD (és az Intel is) a szűkebb, de magas órajelen működő architektúra irányába megy és nem követi az Apple-t a széles, alacsony órajelen és alacsony fogyasztással való működés felé?
Nyilván az IPC (architektúra szélesítése) nem egyszerű, azért azt kimondhatjuk, hogy az AMD és az Intel is egy nagyon (egy évtized óta) bejáratott ösvényen halad a processzoraik jelenlegi felépítésével kapcsolatban és toldozgatás-foltozgatás, bufferek, pufferek, cache-ek kisebb-nagyobb bővítése volt (manapság főleg inkább az intelnél) de az alapvető felépítés nem nagyon változott.
Nyilván a magasabb IPC elérése széles architektúrával jelentékeny tranzisztorköltséggel jár. De mint mondod, a magas frekvenciát elérni képes architektúra sincs ingyen tranzisztor szempontjából. Nem is beszélve arról, hogy a magas frekvenciához magas feszültség kell, ami növeli a tranzisztorok melegedését, a hősűrűséget ez pedig azt eredményezheti, hogy az architektúra tranzisztorsűrűsége messze elmarad a névlegestől. -
#57646
Abu85
HÁZIGAZDA
Petykemano
#57641
Abu85
HÁZIGAZDA
válasz
Petykemano
#57641
üzenetére
Fene se tudja, de ugye a saját performance libjük manapság erőteljesen órajelre megy. Szóval ez bele van tervezve a dizájnba. Valószínűleg 5 nm-en már lehet rá elég tranzisztort áldozni. Alapvetően az órajel is egy dizájnkérdés manapság. Rá tudsz tervezni egy lapkát.
-
#57645
b.
félisten
Petykemano
#57644
válasz
Petykemano
#57644
üzenetére
Nem tudni.Tippelgetnu lehetne .
Azt gondolom ,az egy GCD-s tud nagy orajelen menni,igy kisebb GPU,magas orajel,jobb kihozatal ,olcsobb gyartas es csucs közeli teljesitmény.
Nvidianal 18000+ feldolgozó lesz a csúcs Ada .Tegnap kopite mar azt irta a 2,8 Ghz nem kihívas neki azaz 3 Ghz Biztos megy ami hatalmas előrelépés.Azt gondolom,hogy tokéletesen tudják megint,mit hoz a másik és hol tart,mit változtat. egymashoz igazitjak a Csucs kategoriat.
lehet meglepő lehetett az Ada monolitikus teljesitménye AMD nek,ezért lépniek. -
#57644
Petykemano
veterán
b.
#57642
Petykemano
veterán
Időbeli lefolyást nézve vajon mi történhetett?
Az első 2 GCD-s tervek nem működtek, ezért történt egy fallback 1 GCD-re, de Végülis egy későbbi designban sikerült megoldani, vagy megcsinálják a 2 GCD-s megoldást, de csak compute célokra?
Vagy azért vetették el a 2 GCD-s terveket, mert 3-3.5GHz-en egy nagyobb GCD is elég és wafer kapacitás tekintetében így hatékony? De prémium (Pro Duo) terméknél beléfér?
-
#57643
Alogonomus
őstag
b.
#57642
-
#57642
b.
félisten
Alogonomus
#57638
válasz
Alogonomus
#57638
üzenetére
Ez nem feltétlenül gamer kártya, írja is a szivárogtató.
-
#57641
Petykemano
veterán
Abu85
#57639
Petykemano
veterán
Hogyan küzdötték le a hősűrűséget?
Pár éve még azt mondogatták minden csövön, hogy a sűrűség növekedésével degradálódni fog az elérhető frekvencia. Lényegében ez volt anno a 20nm problémája is.(Ha tippelnem kéne arra tippelnék, amit az Intel 4-nél is lehet olvasni, hogy a rézről kobaltra váltás ugyan nem vált be, de valamilyen kobalt-réz ötvözet, vagy Kobalt bevonatú réz viszont nagyonis [link] )
-
Abu85
HÁZIGAZDA
Közben volt 3D matyi futás. Egyelőre eredmény nélkül, de a maximum elért órajel 3,8 GHz volt.
Ez amúgy lehet reális, ha tényleg ugyanazzal a performance library-vel készül, amivel a Zen 4, az is tud 6 GHz-re turbózni.
Valszeg a tipikus órajel az AMD-nél prociban 5-5,5 GHz közötti lesz, míg GPU-ban 3-3,5 GHz közötti.
-
#57638
Alogonomus
őstag
Petykemano
#57637
Alogonomus
őstag
válasz
Petykemano
#57637
üzenetére
Igen, ez lehet majd az RX 7950/70 XT a táblázatban, amiket az RTX 4090 fogyasztásához közelebb engednek.
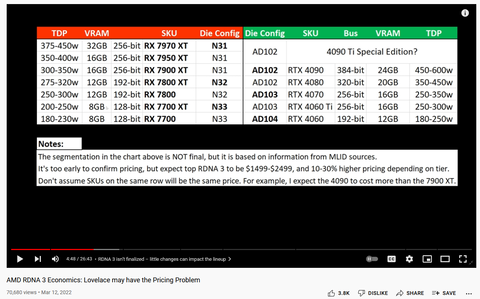
-
#57637
Petykemano
veterán
Petykemano
veterán
Helyükre kerülnek a dolgok:
AMD rumored to be working on another Navi 3X GPU with 16384 Stream Processors [link] -
Abu85
HÁZIGAZDA
válasz
Yutani
#57631
üzenetére
Igen, bele van rakva egy rakás munka. A Valve előadásai nagyon jól mutatták ezt. Ők ugye kényszerűen AMD hardveren fejlesztettek, mert akkora kódmennyiséget az NV debug eszköze nem tudott kezelni. Szétfagyott az egész a picsába.
Itt van a dia, ami azt írja le, hogy miért az AMD fejlesztőeszközét használták:

Ezt az előadást láttam is, és Rich azt is hozzátette, hogy ha nincs a GPU PerfStudio 2, akkor sose lett volna OpenGL módja az említett két játéknak. Egyszerűen kivitelezhetetlen lett volna egy ekkora kódbázisra az egész, mert egyénileg kellett volna minden egyes függvényt ellenőrizni, hogy az hogyan fordul le xy hardverre, és ott pontosan mit csinál. Az pedig akár 5-6 évnyi munka is lett volna, és olyan időtávban felesleges dolgozni, mert mire ellenőrzik xy hardverre, addigra két-három generációval későbbi hardverek jönnek, amelyekre szintén ellenőrizni kell, vagyis ismét jöhet a munka, bár nem 5-6 évnyi, de folyamatosan patch-ek kellenének, amelyek az érkező hardvereket 1-2 év csúszással támogatják csak.Ezen túlmenően a szabványos kódjuk, meg se moccant az NV hardvereken. Egyszerűen sűrűn szétfagyott, illetve kaptak egy rakás stallt. Ezt úgy oldották meg, hogy a kódot mindig elküldték az NV-nek, amely cég egy új driverrel együtt visszaküldte a kívánt módosítást. Tehát nem csak egy másik kódút kellett, hanem egy specializált driver is, amit mindig használtak, mert ha nem, akkor a módosított kódút is szétfagyott a picsába, és a teljesítménye is kb. a tizede volt annak, amire szükség volt.
Alapvetően ezek voltak az OpenGL bajai, és évek óta ismertek, csak a Khronos egyszerűen nem fordított erőforrást a kijavításukra, mert feltettek mindent a Vulkan API-ra. Ezzel együtt pedig a Valve is befejezte az OpenGL mód supportját. A Vulkan mellett nem volt értelme.
Tehát amikor valaki OpenGL-re dolgozik egy igen nagy programot, akkor igazából gyártói segítség nélkül azt nem fogják összehozni. És a gyártók is egyedi kódokat javasolnak, gyártói kiterjesztésekkel, amit a Valve szintén említett, hogy használják is bőven, mert az ARB-vel sokkal lassabb a program. Ilyen szintű együttműködés ugyan megoldható, de végül lesz gyártónként két-három kódút, és specializált driverek, és a kódutakat úgy kell karbantartani, hogy új driver kell a módosításokhoz. Ma már ezzel nem éri meg foglalkozni. Az egyetlen működő OpenGL debugert sem fejleszti már az AMD. Persze a forráskódját kiadták, hogy aki szeretne dolgozni, az elmaszatolhat vele, de sokkal-sokkal könnyebb Vulkan API-ra váltani.
#57632 b. : Ami ugye Linux alatt megint úgy sikerült, hogy a Valve a saját programjaihoz módosította a meghajtót, vagyis ez sem szabványos teljesen.
A szabványhitelesítés lényegtelen OpenGL alatt, mert az a gond, hogy maga a dokumentáció nem fogalmaz egyértelműen, hogy mik a követelmények. Egy-egy dolog implementációjára több út is van, és a gyártók ezt ki is használják. Itt változott nagyon sokat a Vulkan. Amikor átvették a Mantle API-t, akkor vele átvették az AMD dokumentációját is, és az nagyon szigorúan fogalmazza meg, hogy mit hogyan lehet implementálni. Ezt a Vulkan vitte tovább, tehát alig van olyan tényező, hogy valamiben kérdés merülne fel. Ha van is, azt is nagyon gyorsan egyértelműsítik, hogy ne álljon be az a helyzet, ami az OpenGL-nél.
Az OpenGL dokumentációjával simán lehet olyan meghajtókat írni, amelyek mind átmennek a hitelesítésen, de eközben ugyanazokat a kódokat nem úgy értelmezik. És ez az API hibája, nem egyértelmű a specifikáció, és ezt a gyártók szándékosan félreértelmezik, hogy gyorsabb legyen a meghajtó, csak nem eszi meg a szabványos kódot.
Érdekes módon a workstation piacon mindenki tudja, hogy mi a szabványos és mi nem. Ott eléggé egységesen van kezelve minden, akármilyen gyártói drivert dobsz fel, megeszi a szabványos kódot. Tehát nem hülyék a gyártók sem, csak tetetik, hogy hülyék, mert csak az AMD hozza át a workstation meghajtóját Windows alatt a gaming driverbe. Ez változik meg a következő nagy batch-csel, de ezzel együtt már az AMD meghajtója sem lesz szabványos.#57633 Petykemano : Igen jól érted. Az új meghajtóval a régi játékok OpenGL módja problémás lehet, de mivel alig van OpenGL program, így nagyon egyszerű per alkalmazás szintjén leprofilozni az egészet, és akkor az új meghajtó problémáit célirányosan lekezelni úgy, hogy az AMD még a fordítás előtt kicseréli a programkódot egy olyanra, amit a nem szabványos meghajtó megeszik. Ezt csinálja az NV is. Csak ugye az ilyen modell megöli az API-t, mert így fejleszteni lehetetlen rá, lásd fentebb Valve.
-
#57634
b.
félisten
Petykemano
#57633
válasz
Petykemano
#57633
üzenetére
Szerintem az van amit Husky is és tulajdonképpen Abu is irt,csak ugye ő cukormázba foglalta,Husky meg a vegeredmenyt jelentette ki egy kerdessel megspekelve.
AMD tulajdonkeppen nem foglalkozott OGL gyorsitasaval eddig pont az a fazis ami ahogy irtad belul tortenik nem volt kezelve naluk.Hogy most miert kerult porondra dx11 es az OGL a fene tudja.Szerintem nem kuka az csak lassu es bugos,de szabvanyos.
Abu szerint az Nvidia azert gyors mert sok szempontból nem szabvany szerint kezelte a dolgot megkerult check in fazisokat AMD meg igy elmeletileg stabilabb de lassabb.Most ez ellen az szól hogy rengeteg bug volt es van OGL jatekokkal AMD nel,nem cdak a sebesseg es evek ota az elso hitelesiteseket Nvidia szerzi meg,ami igy eleg erdekes mert Abu szerint az AMD fejlesztoeszkozokket hasznaljak.Kisse ellentmondasos de mindegy is ezek ilyen parttalan vitak. -
#57633
Petykemano
veterán
b.
#57632
Petykemano
veterán
Bocsánat.Elnézést.
Abu nem válaszolta meg a kérdésemet.Jól értem, hogy az OpenGL valójában nem egy API, hanem csak egy API-speficikáció, amire minden hardver gyártónak írnia kell egy implementációt. És az AMD-nek eddig volt valamilyen implelemtációja, de most csinált egy újat, ami elvileg jobb. De csak elvileg.
Merthogy Abu kritikája szerint az OpenGL specifikációja annyira pontatlan, elnagyolt, hogy valójában egy-egy implementáció bemeneti és kimeneti eredménye (mivelhogy épp annak nem kéne számítania, hogy belül mi történik) annyira más, hogy ahhoz egy-egy alkalmazás kénytelen alkalmazkodni és ha az AMD új implementációja másként viselkedik, akkor az eddigi AMD openGL implementációra való optimalizációk az összes alkalmazásban kuka.Jól értem?
A másik kérdésem pedig az volna, hogy tulajdonképpen egy ilyen API-nak nem az lenne a lényege, hogy függetlenítse az alkalmazást a hardvertől és/vagy a hardverhez tartozó drivertől? Vagy ez jelen esetben csak olyan mértékben történik meg, hogy mondjuk az AMD és az Nvidia openGL implementációja is megoldja azt, hogy az alkalmazásnak ne kelljen foglalkoznia azzal, hogy miylen amd vagy milyen nvidia kártya van benne, de a két gyártó openGL implementációja azért annyira eltér egymástól, hogy az alkalmazás attól már ne tudjon elvonatkoztatni, hogy melyik gyártó openGL imlementácójával kommunikál?
Jól értem?
-
válasz
Yutani
#57631
üzenetére
Linux alatt amúgy egyáltalán nem rossz az AMD OGL futasa Nvidiához nézve,sőt.De ott nyílt forráskód ugye.Tehat szinte csak driveren mulik a sebesseg.Ott megoldjak a fuggetlen fejlesztők.
Igen valószínűleg ez van mögötte.Évek óta az első szabványhitelesítéseket pont az Nvidia szerzî meg,tehát annyira nem mennek ők szembe ezzel a dologgal se driveresen se fejlesztői eszközök terén. -
Én a #57629-ben azt látom leírva, hogy miért sz@r az OpenGL, miért lassú az AMD, és miért gyors az NV implementáció.
Viszont azt nem értem, hogy miként lehetett mindig is gyors az NV OGL alatt, ha annyit kellett minden alkalmazásra optimalizálni a drivereket. Ennyi erőforrást tett vajon bele, hogy minden jól fusson? -
Egyszer érném meg hogy így érvelsz Intel és Nvidia oldalán....( nem fogom)
![;]](//cdn.rios.hu/dl/s/v1.gif)
Ott általában azt olvassuk mért szar amit csinálnak még ha jónak is tűnik,( lásd eza hozzászólás) itt meg azt hogy azért szar valami az AMD től mert közben jó, mint mindig. Egyszerűen nem tudnak hibázni náluk, na.
-
#57629
Abu85
HÁZIGAZDA
huskydog17
#57625
Abu85
HÁZIGAZDA
válasz
 huskydog17
#57625
üzenetére
huskydog17
#57625
üzenetére
Évek óta ismert problémát írtam le. Ez végezte ki az OpenGL-t.
#57626 Hellwhatever : Leginkább úgy, hogy amikor az OpenGL-t specifikálták, akkor már a fejlesztésébe bele volt kódolva, hogy el lehet szarni.
Rich elég sok előadást tartott anno, amikor a Valve motorját portolta natívan OpenGL-re. A lényege ezeknek mindig az volt, hogy hiába beszélünk egy API-ról, a gyártók az egyes függvényeket másképp implementálják. Egyszerűen a specifikációban leírtak nem egyértelműek.
Többször utalt rá, hogy az NV-vel gyorsan működhetnek a dolgok, de a kód, amit így megírsz nem lesz szabványos, és az NV-nek a fejlesztőeszközei pontosan ezért használhatatlanok, mert a debug eszközökkel összevesznek, ugyanis a debug nem azt várja, amit kap, egy nem szabványos kódot. A fejlesztéshez tehát nem tudott a Valve mást használni, csak AMD hardvert, mivel a GPU PerfStudio és a CodeXL eléggé szabványos eszközök voltak, és kompatibilisek szabványos debug eszközökkel is, illetve az AMD workstation drivere is szabványosan kezeli az API-t, de ha erre megírsz egy kódot az nem jó az NV-nek, mert az meg más kódot vár. Olyat, ahogyan az NV értelmezte a szabványt. Emellett az AMD workstation drivere pont azért workstation driver, mert arra van kigyúrva, hogy a specifikációknak megfelelően kezelje az API-t, és ilyenkor nem csinál olyat, amitől az alkalmazás összeomolhatna, nem értelmezi szabadon a függvények specifikációit, hogy kihagyjon teljesítményigényes ellenőrzéseket. Utóbbitól lesz egy performance driver gyors, egyszerűen a nagyon lassú munkafolyamatokat koncepció szintjén kihagyja, még akkor is, ha a specifikáció előírja az erőforrások ellenőrzését, annak érdekében, hogy ne alakulhassanak ki hazardok. Viszont ilyenkor nagyon sok múlik a játékra szabott meghajtón, mert ott kell olyan ellenőrzési rutinokat beépíteni, ami ezt megakadályozza, ha már az API működését nem követik. És ez az, amiért a performance driverekkel lehetetlen a nagy OpenGL alkalmazások debugolása és profilozása. Egyszerűen a meghajtó még nem ismeri az alkalmazást, és az ellenőrzések kihagyásával tele lesz az egész munkafolyamat hazarddal.Ezen túlmenően nagy gond volt még a shader fordítás. Az OpenGL programban magát a shader forrást kellett szállítani, és azt a meghajtó fordította le a GPU-nak. De az egyes meghajtók más kódokat igényeltek, attól függően, hogy miképpen értelmezték a specifikációt, ezért kellett külön shader az összes gyártónak, sőt, az egyes architektúrák sem mindig fogadták el a gyártóspecifikus shadert, így hiába beszéltél szabványról, akkor is egy gyártóra két-három kódutat szállítottál OpenGL-ben, vagyis mindent kb. 7-9-szer kellett megírni. És mivel más megoldás nem volt, ez egy leülős-gépelős feladat volt.
Nem véletlen, hogy a Vulkan API már sokkal egyértelműbben fogalmaz a specifikációk tekintetében. Kevésbé félreérthető. Alapvetően a dokumentációját az AMD-től emelték át, és azt módosították, tehát helyből már egy olyan alap állt rendelkezésre, amit hozzáértők írtak meg. És így már jól lehetett építeni erre az alapra. A shader fordítást is megváltoztatták, mostantól nem lehet forrást szállítani, hanem IR-t kell, és az IR-re gyári fordító van, vagyis nincs olyan, hogy az NV/AMD/Intel "véletlenül" máshogy értelmezte a specifikációt. Az IR-ig hozzá sem tudnak szagolni a fordításhoz, tehát ők már csak az IR után dolgozhatnak, és ez a köztes nyelv nem magas szintű, így sokkal-sokkal egyértelműbb, mint magas szintű nyelvről gépi kódot fordítani.
Röviden, az volt a gond, hogy OpenGL-re nagy applikációkat lehetetlen volt írni egy kódútból. Egyszerűen több kellett. Emiatt meg is pusztult az API. A Valve is áttért később a Vulkan API-ra, mert igazából nagyon-nagyon drágává tette az OpenGL mód karbantartását az, hogy 7-8-szor volt megírva minden.
#57628 morgyi : Igazából a gyártóspecifikus kiterjesztések egyszerre voltak hasznosak és katasztrofálisak. Az egyik előadáson Rich meg is említette, hogy ARB kiterjesztésekkel lehetetlen gyors kódot írni, egyszerűen azok túl rosszak. Emiatt a Valve is a lehető legtöbb dologra gyártóspecifikus kiterjesztéseket használt. Ha ezek nem lettek volna, akkor az OpenGL a DirectX leképező teljesítményének a huszadát sem szedte volna össze, annyira el van szarva az egész. A kiterjesztésekkel lehet hozni bele teljesítményt.
Nincs azon mit csodálkozni, hogy manapság nem igazán jön OpenGL-re semmi. Néhányan a régi kódutakat még karbantartják, de a Vulkan akkora átütő siker, és a Khronos annyira leállt az OpenGL fejlesztésével, hogy ez a kérdés már rég eldőlt.
-
#57626
Hellwhatever
aktív tag
Abu85
#57624
Hellwhatever
aktív tag
Hogy lehet az hogy egy szabványt nem a specifikáció szerint implementálnak (hiszen ettől szabvány), illetve alkalmazás szintjén hol és hogyan lehet hibázni? Tényleg érdekel a dolog, akár egy külön cikket is szívesen olvasnék a témában úgyis uborkaszezon van hardver fronton.
Nagyon leegyszerűsítve gondolom megvannak az OGL interface-ek, ezeket kell megvalósítani majd a megfelelő értékkel visszatérni.
Alkalmazás szintjén pedig ezeket a függvényeket hívják.
-
#57625
 huskydog17
addikt
Abu85
#57624
huskydog17
addikt
Abu85
#57624
huskydog17
addikt
Most hosszasan leírtad a te saját nyelveden, hogy az AMD valamiért képtelen volt normális OGL drivert írni, ezt tudjuk, látjuk másfél évtizede.
Ha annyira szar a performance, akkor az NV-nél miért nem volt soha gond a nagyságrendekkel nagyobb teljesítménnyel?
2004-ben kezdték újraírni? Na akkor ott k*rták el az egészet. 2004-ben még jó volt a teljesítmény, 2007-től nagyjából fos lett, szóval jó munkát végeztek, a performance-t kinyírták, de 15 évvel később úgy tűnik visszahozzák.
Ha annyira bugos a performance mód, akkor miért hozzák most vissza 15 évvel később?
Hogy lehet az NV-nek nem voltak gondjai a jó teljesítménnyel?Állandóan azt szajkózod, hogy a programok a sárosak így meg úgy és nem szabványosak. Érdekes, hogy az NV-nek nem okozott gondot, minden OGL programmal gond nélkül működött jó teljesítménnyel, viszont az AMD-nél nagyon súlyos problémák voltak az elmúlt bő évtizedben (személyesen is tapasztaltam elég sokszor), de az alkalmazások a szarok, ezzel egyidőben azt is állítod, hogy minden fejlesztő, aki OGL-re programozott, hülye volt és nem vette figyelembe a szabványt és szándékosan úgy írta meg a játékot, hogy AMD-n szarul fusson.
VAAAGY
van egy olyan lehetőség is, hogy a fejlesztők megtettek mindent, hogy mindenen jól fusson, szabványos kódot írtak, de az AMD fos driverével nem tudnak mit kezdeni.
Ez utóbbi sokkal valószínűbbnek tűnik nekem.
Ha pedig figyelembe veszem, hogy például a Teardown fejlesztői hónapokat, rengeteg időt és pénzt égettek el arra, hogy AMD-n valahogy értelmes teljesítményt érjenek el (külön kódutat írtak), hogy valamennyire megközelítsék az NV driver out of the box tempóját, akkor pláne őrültségnek hangzik az elméleted.A legvalószínűbb inkább az, hogy az NV csinált szabványos drivert, míg az AMD valami fost odahányt 2007-ben, amihez nem nyúltak hozzá 15 évig. Ja de hozzányúltak, mert a A Doom 4 OGL teljesítményt is az AMD k*rta el driverből. Gondolom Tiago Sousa és az id Software is figyelmen kívül hagyták a szabványt.
Ha szerinted az AMD annyira szabványos, akkor miért módosítják most 15 évvel később és miért akarnak kismillió bugot (ahogy te írtad)?
Adj légyszi egy linkeket, ahol programozók írásban megerősítik az elméleted. Ha nem tudsz ilyeneket adni, akkor csak egy újabb őrültséget olvashattunk tőled és akkor részemről bejeztem ezt a diskurzust.
-
#57624
Abu85
HÁZIGAZDA
huskydog17
#57623
Abu85
HÁZIGAZDA
válasz
huskydog17
#57623
üzenetére
Egyrészt az AMD meghajtójának OpenGL drivere egy workstation driver. Nem pedig performance. Másrészt az OpenGL baja az, hogy ha ezt átrakják performance driverré, akkor keletkezik kismillió bug, mert maga az OpenGL nem jól működik. Hiába szabvány, ha mindenki úgy értelmezi a specifikációt, ahogy akarja. Ergo minden egyes OpenGL program úgy van megírva, hogy van külön kód minden gyártóra. Erre mondjuk a kódcsere áthozható, de amint hozol egy új programot, rögtön ott fogja találni magát a fejlesztő, hogy kell egy külön kód az új AMD driverre, és egy másik a régire. Emiatt értelmetlen az egész OpenGL, mert egy ilyen drivercsere már gyártón belül is gyakorlatilag kompatibilitási gondokat eredményez. Az AMD tudna erről mesélni, mert ők rendelkeznek a legfrissebb OpenGL driverrel. 2004-ben döntötték el, hogy újraírják a nulláról, és 2007-ben lett kész. Ekkor csinálták meg azt, hogy a régi performance drivert kicserélték workstation driverre, hogy masszívan a szabvány specifikációját kövesse a rendszer. Viszont a játékok többsége szart a szabványra, emiatt ennek haszna nem volt, maximum annyi, hogy ha valaha is szabványos kódot akartál OpenGL-re, akkor nem mentél tovább az AMD OpenGL driverénél. A performance driverek mások. Azoknál szabadabb a szabvány értelmezése, és ezt ki is használják a cégek, mert teljesítményt nyernek velük. Persze annak az árán, hogy a saját értelmezésük eltér a konkurens értelmezésétől, és cserébe két kód kell, vagy több, ha per driverben is gondolkodsz. Ezért döglött meg az OpenGL, nincs senkinek sem türelme 5-6 különböző kódutat fenntartani, amikor Vulkan API-ra elég egy kódút.
-
#57623
huskydog17
addikt
huskydog17
addikt
Radeon's targeting poor OpenGL performance with a future AMD Software release
Tudjuk, "az OpenGL-be senki nem öl erőforrást...oh wait"
Szerencsére és csodával határos módon az AMD-nek eszébe jutott rendbe tenni a katasztrofális OGL driverét bő másfél évtized után. Végül is jobb későn, mint soha.
Ez a D3D11 driver rendbe rakása után logikusnak tűnt, de én elkönyveltem magamban, hogy az AMD már soha többé nem fogja rendbe tenni, ezt leginkább az itteni propaganda miatt hittem el, de hála az égnek hogy én is és a propaganda is tévedett (utóbbi számomra nem meglepő)!Úgy tűnik Lisa mama végre rendbe akarja tenni a driveres lemaradásokat és hajlandó erőforrást ölni abba, amibe senki nem akar erőforrást ölni, legfőbb ideje volt!
-
válasz
paprobert
#57621
üzenetére
$500 alatti szegmensben lehet értéksíteni a már létező megoldásokat. Oké, a Navi24 egy kalap 57@®, de a Navi23 is egy sokáig piacon tartható termék szerintem, akár tovább vágva is (RX 6600 "LE/SE").
Ami biztos: a Navi24 még évekig velünk lesz: kicsi, olcsó (a gyártónak), szükség kártyának megteszi, főleg az OEM-eknek.
-
paprobert
őstag
Szerintem is, még mindig ebben a szegmensben van a vásárlók 70 százaléka.
Nézd, ha amiatt nem tervez az AMD $500 alá, mert az új gyártástechnológia "drága", azon az APU sem segít.
-Max. a GDDR phy-t lehet megspórolni
-egységnyi teljesítmény egy dedikált GPU-val olcsóbb(vagy azonos áron gyorsabb)
-az összetett APU gyártási hibára hajlamosabb mint egy GPU package
-az Infinity Cache egyaránt gyorsít egy GPU-t is
-egy APU hőmérsékletileg limitáltabb a CPU jelenléte miatt
-elavult node-ot használni APU-ban problémásabb.Én alig látok pozitívumot akár költség, akár teljesítmény, akár felhasználási szempontból.
-
#57620
Petykemano
veterán
paprobert
#57618
Petykemano
veterán
válasz
paprobert
#57618
üzenetére
Ez egy régi teória, ahogy mondod, és bár mindig felcsillant valami, az idővel.letekerődött.
Most a csillanás az elérhető árú APU-hoz az infinity cache, ami kihúzhatja a memória sávszesség méregfogát egy közepes IGP esetén. De HBM használathoz is ott az EFB, ami egy nagyobb IGP esetén nagy interposer.nélkül biztosít sávszélt.
Mellesleg az egész már lehet chiplet, nem feltétlenül kell monolitikusnak lennie.De közepes IGP-hez ebben a genben is ott lett volna az IFC és mégis inkább Navi24 lett. Abu azt állítja, ennek fő oka az volt, hogy az bekerülhetett inteles gépbe is.
Szerintem nem fog megszűnni az $500 alatti gpu piac. Legfeljebb nem kap fókuszt, vagyis 5nm-es RDNA3 nem lesz ilyen áron. De az oemeknek mindig fog kelleni olyan relatív olcsó de szar dgpu, Amivel nyerhetnek még pár dollárt ha közben kinyírják a memória sávszélességet 1 memória modullal.
-
-
#57618
paprobert
őstag
Petykemano
#57617
paprobert
őstag
válasz
Petykemano
#57617
üzenetére
Rosszat linkeltem az előzőben, itt a forrás:
https://prohardver.hu/tema/re_bemutatta_eddig_titkolt_fejleszteseit_az_intel/hsz_36-36.htmlEbben a kommentben néhány érdekesség van elrejtve.
Egyrészt az óriás APU-ról még nem hallottam sehol, ez egy meglepő leak Abutól.
Másrészt az "$500 alatti piac döglött" kijelentés... kell ezt cáfolnom?
kell ezt cáfolnom?
És ennek az alapgondolatnak a továbbvitele, miszerint az érkező erősebb APU-k fogják az $500 alatti szegmenst lefedni, felidézik bennem a Kaveri-várás időszakát.Az eredeti, költői kérdésem az lett volna, hogy az emberek által tömegében elérhető "AMD GPU-k jövője" az APU lesz?

-
paprobert
őstag
"Nem véletlen, hogy sem az AMD, se az NV nem csinál a következő körben 500 dollár alá GPU-t. Az a piac megdöglött. Az AMD viszont csinál bivaly APU-t (tényleg nagy teljesítményű kiadás, nem klasszikus IGP vonal), hogy tudjon reagálni a Core+Arc kombóra. Az NV is csinálna, ha lenne processzoruk."
[link]
Ez a hír előbb jön Abu-tól, mint hogy a nemzetközi leakerek beszélnének róla.#57617 Petykemano
Edit: marad a last gen $500 alatt, talán. -
#57615
Petykemano
veterán
Petykemano
veterán
-
#57614
Petykemano
veterán
Petykemano
veterán
Navi3 will be in preproduction this month and is expected to be handed over to AIB after August for a final release in October/November.
[link] -
Devid_81
félisten
Ha nem felsz a hasznalt VGA-ktol (mining positive) akkor Angolna foldrol mar lehet szerezni ezt azt egeszen jo aron.
Sztem utazoban amennyiben latszik rajta, hogy hasznalt (bontott doboz) viheto es nem vamolnak.
Mondjuk szamomra a hasznalt Ampere kartya most olyan mint a friss kutya sz@r a jardan, elkerulom inkabb, mert tutira ment honapokat/evet ki tudja milyen korulmenyek kozott -
válasz
Devid_81
#57610
üzenetére
3080 volt a héten többször több darab Gigabyte pl neweggen 699$ ért. Én azt gondolo m ( reménykedem) nagyon le foge sni az áruk nyár közepére ezeknek a kártyáknak és akkorát a mortizálodik az értékük, hogy havi x euroért nem fogja megérni az egész.
Én ennek szorítok, szeretnék egy 3080 12 GB karit -
#57611
Abu85
HÁZIGAZDA
Petykemano
#57609
Abu85
HÁZIGAZDA
válasz
Petykemano
#57609
üzenetére
Ha a hit erős, akkor a profit másodlagos.

-
#57610
Devid_81
félisten
Petykemano
#57609
Devid_81
félisten
válasz
Petykemano
#57609
üzenetére
Mar eleg sokan feldobaltak a VGA-kat amugy Angliaban Ebayre.
Meglepo de RTX 3080 Ti van £612-ert, RTX 3090-es meg £590-ert
Nagyon bele sem merultem, mert ennyiert sem erdekelne egyik sem
Szerk: ehhez kepest RX 6900 XT-k meg inkabb £759+ magassagban vannak
Gondolom azert is, mert ezekbol joval kevesebb ment banyaba, igy nincs akkora nagy keszlet a hasznalt piacon sem.
Bar teljesitmeny szempontbol akkor mar inkabb vennek egy RTX 3090-et, 24GB ram es meg olcsobb is, de csereben tobbet is eszik -
#57609
Petykemano
veterán
Yutani
#57607
Petykemano
veterán
válasz
Yutani
#57607
üzenetére
kemény.
Pedig a profitability tényleg nagyon alacsony.
[link]De hát ha még a jelenlegi energiaárak mellett is 1 font/nap, akkor a meglevő infrastruktúrát érdemes járatni.
Vagy a fene tudja. Lehet, hogy érdemes elgondolkodni, hogy a hardver amortizációja havi szinten több-e mint 30 font? Mert ha igen, akkor ugye ma többért el lehet még passzolni, mint 1 hónap múlva. (Ugye most egy 3090-ről beszélünk, ami pár hónap múlva jelentős árcsökkenésen mehet át) -
Devid_81
félisten
válasz
Yutani
#57607
üzenetére
Gondolom boldog boldogtalan banyaszik (meg) hatha csurran cseppen, mar mindent bedobnak meg a Casio szamologepet is, hatha valahogy megis meglehet elni dolgozas helyett
Ekozben a profitability meg az ETH arak mennek le, szoval halott ugy.Annyira "megeri banyaszni", hogy jelen UK villanyarak mellett majdnem 1 fontot termelne naponta egy db RTX 3090 jelenleg...teljesen kedvet kaptam hozza
Vegulis ha lenne 1000db RTX 3090-em akkor tok jol elhetnek -
#57607
Yutani
nagyúr
Petykemano
#57601
válasz
Petykemano
#57601
üzenetére
Persze meg kell jegyezni, hogy a kriptovaluta bányászat nem omlott be, vagyis nem ömlött a használtpiacra rengeteg rendkívül olcsó bányászkártya.
Annyira nem omlott be, hogy éppen all-time csúcsot dönt az ETH hashrate:
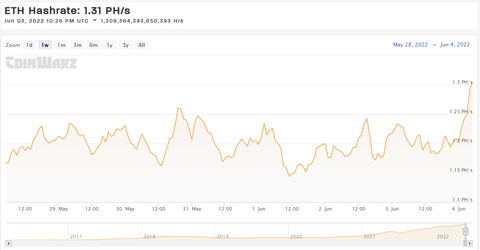
-
#57606
Yutani
nagyúr
Petykemano
#57605
válasz
Petykemano
#57605
üzenetére
És mégis valahogy pont beillik a sorba. Ez a modern chiptervezés csodája.
-
#57605
Petykemano
veterán
Yutani
#57604
Petykemano
veterán
válasz
Yutani
#57604
üzenetére
Elnézést. A kártya nem RX.
Gyanítom ez alapján, hogy valójában nem AMD által specifikált hivatalos termék.
(És nem Navi 23, hanem 22)Vélhetően arról lehet szó, hogy a sapphire megállapodott az AMD-vel, hogy a hibás példányokkal azt kezd, amit akar. Ebben a formában ez selejtszórás, semminthogy mesterséges szegmentáció lenne.
-
#57604
Yutani
nagyúr
Petykemano
#57603
válasz
Petykemano
#57603
üzenetére
Tudták előre, hogy lehet ezektől majd megszabadulni.
-
#57603
Petykemano
veterán
Komplikato
#57602
Petykemano
veterán
válasz
 Komplikato
#57602
üzenetére
Komplikato
#57602
üzenetére
Afféle...
VCZ megfejtette:
"Sapphire BC-2235 GPRO X080 cryptomining card vs Sapphire Radeon 6700
Both 36 CU, 10 GB 160-bit.
Must be a coincidence "
[link] -
#57602
Komplikato
veterán
Petykemano
#57601
Komplikato
veterán
válasz
Petykemano
#57601
üzenetére
Mindenki várja az RX7000 meg az Rtx 4000 szériát remegve, erre kijönnek ilyenek mint az RX6x50 sorozat, az RX6700 10GB vagy a GTX1630. Ez már GPU raktársöprés?
-
#57601
Petykemano
veterán
Petykemano
veterán
RX 6700 - talán már erre is jut.
Ez elmúlt napokban megjelent egy JPR jelentés, ami negyedéves szinten 6%, éves szinten 19%-os dGPU forgalom csökkenésről számolt be.
Feltehetőleg a következő nagy teljesítményugrást ígérő generációt övező várakozás, valamint a kriptovaluták árfolyamának (a bányászat jövedelmezőségének) megtorpanása, hovatovább csökkenése miatt csökkenhetett a nyomás az eladási csatornákon. Ennek hatására az árak belesimultak a normál, msrp árakba.Persze meg kell jegyezni, hogy a kriptovaluta bányászat nem omlott be, vagyis nem ömlött a használtpiacra rengeteg rendkívül olcsó bányászkártya. Mivel ez nem következett be, így a bolti árak is összeomlás helyett csak szépen belesimultak az ajánlott fogyasztói árba.
Elképzelhető, hogy a következő hetekben bekóstolnak az msrp alá is. Az persze megjósolhatatlan, hogy meddig megy le, ezt meg sem kísérlem.
Ami a hírben érdekes, az az, hogy amíg a kereslet nagyon nagy volt, az volt az álláspont, hogy a cégek igyekeznek a rendelkezésükre álló wafer kapacitásokat olyan termékekre allokálni, amin minél magasabb árrést tudnak elérni. Ennek köszönhető az a lépcsőzetes termékbevezetés (amennyiben nincsenek gyártási/kihozatali nehézségek), hogy szűk kapacitás esetén először a drágább piacokat szolgálják ki, majd azok telítődése esetén kezdenek kisebb, olcsóbb termékeket gyártani.
Ez a lépcsőzetesség lapkán belül is érvényes. Amennyiben nincsenek kihozatali nehézségek, úgy egy lapkát érdemesebb teljes értékű termékként eladni és csak akkor értékesíteni vágott termék formájában akár mesterséges szegmentáció révén, amennyiben a legyártott lapkákat a teljesértékű termék formájában és árán nem lehet eladni.Érdekes kérdés, hogy vajon az RX 6700 összegyűjtött selejtek kiszórása, limitált széria, vagy pedig a legyártott Navi 23 lapkák alacsonyabb áron való értékesítítése arc (árcsökkentés) nélkül?





































![;]](http://cdn.rios.hu/dl/s/v1.gif)






Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Egyéni arckép 2. lépés: ARCKÉPSZERKESZTŐ
- Óvodások homokozója
- Szomorú jövőt vetít előre a dedikált GPU-knak a Jon Peddie Research
- Fotók, videók mobillal
- Audi, Cupra, Seat, Skoda, Volkswagen topik
- Milyen program, ami...?
- NVIDIA GeForce RTX 5070 / 5070 Ti (GB205 / 203)
- Nintendo Switch 2
- Villanyszerelés
- Xbox Series X|S
- További aktív témák...

- Samsung Galaxy S23 128GB, Kártyafüggetlen, 1 Év Garanciával
- ÁRGARANCIA!Épített KomPhone Ryzen 7 5700X3D 32/64GB RAM RX 7800 XT 16GB GAMER PC termékbeszámítással
- AKCIÓ! Apple iPad Pro 11 2024 1TB WiFi + Cellular tablet garanciával hibátlan működéssel
- BESZÁMÍTÁS! MSI MAG321QR 32 165Hz WQHD 1ms monitor garanciával hibátlan működéssel - használt
- Telefon felvásárlás!! iPhone 12 Mini/iPhone 12/iPhone 12 Pro/iPhone 12 Pro Max
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: PC Trade Systems Kft.
Város: Szeged