Hirdetés
- Kompakt vízhűtés
- Bluetooth hangszórók
- NVIDIA GeForce RTX 4080 /4080S / 4090 (AD103 / 102)
- NVIDIA GeForce RTX 5070 / 5070 Ti (GB205 / 203)
- Milyen billentyűzetet vegyek?
- Szédületes tempót rejt a OneXPlayer 3 az 1-ben kézi PC-je
- HP notebook topic
- Melyik tápegységet vegyem?
- L bajonett, Panasonic, Sigma, Leica
- Milyen asztali médialejátszót?
Új hozzászólás Aktív témák
-

Froclee
őstag
kettes feladvány megoldása ez lett végül:
EXEC sp_MSforeachdb
'Begin
USE [?]
IF EXISTS(SELECT name FROM [?]..sysobjects WHERE name = ''titkostablanev'')
BEGIN
DECLARE @rowCounter INT
SELECT @rowCounter = row_count FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID(''titkostablanev'');
Print ''?'' + ''-> number of rows of titkostablanev table: '' + cast(@rowCounter as NVARCHAR(20))
END
End'sp_spaceused-al nem tudtam volna printelni. spaceused is innen (sys.dm_db_partition_stats ) szedi ki az infókat és így lehetett printelni is.
a backupolásról még beszélek valakivel, nem merem még a select into-t lefuttatni, nehogy legyilkolja.

-

martonx
veterán
válasz
 Froclee
#2897
üzenetére
Froclee
#2897
üzenetére
Ja vár, elsiklottam a felett, hogy te csak egy darab táblát akarsz backupolni. A backup az a komplett DB backupra jó, bár lehet, hogy meg lehet neki mondani, hogy csak egy táblát akarsz backupolni, még sose próbáltam csak egy táblát backupolni vele.
Másrészt ha ugyanazon DB-n belül akarsz backupolni, akkor miért nem:
insert into backuptabla
select *
from eredetitablavagy select * into backuptabla from eredetitabla
hirtelenjében nem tudom melyik a nyerő szintaxis.
-
martonx
veterán
válasz
Froclee
#2895
üzenetére
1. ne viccelődjünk már, MS SQL-t rohadtul nem generate scripttel kell backupolni, hanem a backupolás funkcióval, ami meglepő módon pont erre van kitalálva. Akár még tömöríti is neked közben az adatot. Tudom durván el van rejtve, a te képernyőmentéseden pl. a totál váratlan Back Up menü pont néven szerepel 5-tel a Generate Script felett.
2. a select count nem erre való, noha rossz gyakorlatként gyakran használják erre. Nálunk pl. a legnagyobb táblában lévő pár milliárd sornál, ha kiadsz egy select count-ot, akkor simán leáll a 64 magos, 256Gb-s szerver is. Ellenben van egy rakás analitikai beépített függvény, simán le tudod kérni az összes tábla adatait. Mondjuk így: [link]
-
Froclee
őstag
sziasztok.
1) létezik valami hatékony módszer lebackupolni egy táblát, amiben 86 millió rekord (16GB) van? ms sql-ről van szó.
ma elindítottam egy generate script félét, ami ugye sql fájlba menti ki. fél óra után szóltak hogy gáz van a szeróval, persze a query nyomatta 100%-on a procit. 20gb volt a fájl, mikor cancelt nyomtam neki.2) más adatbázisban is le akarom csekkolni, hogy van-e ilyen gázos tábla. egy select count is ennyire proci igényes, hogy legyilkolja a szerót?
egyébként production szerverről van szó -

DNReNTi
őstag
Sziasztok,
Paraméterezhető MySQL tárolt függvényben van e lehetőség foglalkozni az SQL injection elleni védelemmel, illetve kell e foglalkozni vele? Próbáltam keresni a témában de csak PHP-related topikokat találtam, konkrétan arra példát, hogy pusztán SQL oldalon, hogy lehet prepared statement-eket használni, olyat nem. Valaki tud egy ilyet linkelni?
Thx. -

Iginotus
addikt
ÉS a végső megoldás ez lett!
select row_id, daten
from
(select row_id,
replace(
replace(
replace(
xmlserialize(XMLAGG(XMLELEMENT(NAME "x", daten) ) as varchar(32672))
, '</x><x>', ',')
, '<x>', '')
, '</x>', '') as DATEN
from DB.TÁBLA
where mand_id = 'VALAMI'
and scito_tst_ab > current timestamp -5 hour
group by row_id)
where daten like '%2233%COMO%9601201%2233%INT%U_AVS_W_750000%2233%ISIN%DE0007500001%2233%VALO%412006%2233%WM%750000%'
; -
#2890
Iginotus
addikt
Apollo17hu
#2888
Iginotus
addikt
válasz
 Apollo17hu
#2888
üzenetére
Apollo17hu
#2888
üzenetére
Nem egyetlen sajnos.
Ez lesz a megoldás, csak még ki kell googlizzam hogy is viszem be ezt db2 őbe..
(Egy barátom segített...)define finIdents as varchar[2000]
define inPayLoad as boolean
quere_result is
select * from XXX.scito
where mand_id = 'VALAMI'
and scito_tst_ab > current timestamp -1 hour
and operationname = 'sendDelivMgtExec'
order by sub_row_id
inPayLoad = 0
for row in query_result
do
if (finIdents == '' and exists(row.daten, '<finIdentDetailsList>'))
then
finIdents = replace(row.daten, '%<finIdentDetailsList>', '<finIdentDetailsList>')
inPayLoad = 1
continue
end
if (inPayLoad == 1)
then
if (exists(row.daten, '</finIdentDetailsList>'))
then
finIdents = concatenate(finIdents, replace(row.daten, '</finIdentDetailsList>%', '</finIdentDetailsList>'))
break
else
finIdents = concatenate(finIdents, row.daten)
end
end
end
echo finIdents -

Wyco
aktív tag
Sziasztok,
Gyors kerdes - tudom ez picit random igy, de tesztfeladat....az alabbi scriptet kellene optimalizalni.
Osszessegeben annyi a gond, h nem tudom hogyan.
Gondolom vagy az indexet kellene modositani (a PK-nak maradnia kell, ezert max uj indexet tudunk csinalni), vagy pedig valahogy a join-t megoldani h effektivebb legyen.
Otletek?
Elore is koszi.
-
Iginotus
addikt
Na mivel banki rendszer, így a kiírást nem tudom befolyásolni.
Le kell kérdezzem, hogy valóban kiírta-e az adatokat. Úgy ahogy elvárják.Beírom ide mi a baj jelenleg.
Jelen példa: Ez van a 3. Sorbanelőtte persze az ami számomra lényegtelen...:
"><element><FinIdentSchemeCode
tableNo='2233'>COMO</FinIdentSchemeCode><FinIdent"Itt a sortörés, és ez van a 4. sorban
"No>9601201</FinIdentNo></element><element><FinIdentSchemeCode tableNo='2233'>INT</FinIdentSchemeCode><FinIdentNo>U_AVS_W_750000</FinIdentNo></element><element><FinIdentSchemeCode tableNo='2233'>ISIN</FinIdentSchemeCode><FinIdentNo>DE0007500001</FinIdentNo></element><element><FinIdentSchemeCode tableNo='2233'>VALO</FinIdentSchemeCode><FinIdentNo>412006</FinIdentNo></element><element><FinIdentSchemeCode "
Ha csak egy sorban lenne akkor sima like.
Ez a lényeg:
like '%2233%COMO%9601201%'
like '%2233%INT%U_AVS_W_750000%'
STB...De random, hogy melyik sort töri meg, random, hogy 2 vagy 5 sorba írja ki az adatokat. Tehát egy kicsit nehéz a dolog.
-

Ispy
nagyúr
válasz
 Iginotus
#2876
üzenetére
Iginotus
#2876
üzenetére
Milyen adatok ezek, hogy ilyen hosszúak? Nem lehetne a betöltés pillanatában ellenőrizni a keresési feltételeket? Vagy csinálni egy temp táblát, ahová eleve értelmezhető bontásban tárolnád az adatokat? És akkor arra lehetne keresni is.
A lényeg, hogy túl kevés az info a megoldáshoz.
-

bambano
titán
válasz
Iginotus
#2880
üzenetére
a másik ötlet, hogy két lépésben keresel, egyszer simán az adatokon, másodszor minden adatmező elejéről és végéről levágsz egy-egy stringet, ami olyan hosszú, mint a keresési string, ezeket megfelelően összekonkatenálod és ezen kerestetsz.
lehet, hogy erre akár egy nézettáblát is fel lehetne húzni.
-
bambano
titán
válasz
Iginotus
#2880
üzenetére
kérdés: ha olyan nagy mennyiségű adatot kell tárolnod, hogy úgyis eltöri az sql, akkor miért nem töröd a maximális mezőméret felére, és akkor tudnád konkatenálni a mezőket és simán ellenőrizni?
tehát pl. ha az ms sql 65536 bájtot tud tárolni egy mezőben (csak hasraütéssel, a példa kedvéért), és neked így kell 4 sor az adathoz, akkor miért nem veszed le a mezőméretet 32768-ra, akkor kellene 8 sor, viszont két egymás utáni sorban levő adatot egymás mellé tudnál rakni és akkor könnyen tudnál keresni.
-
Iginotus
addikt
Köszi sajnos, töri a sorokat, (Ahogy bambano is írta) így ez nem megoldás. (Illetve az lenne, ha előbb össze tudnám vonni.)
Realradical: Köszi nézem. Ezzel az lesz a bajom, hogy olyan nagy adatmennyiség van a sorban, hogy nem képes kiírni az SQL, pont ezért töri a sorokat, mert nem képes több adatot egy sorban tárolni.
Megnézem hogy lehet ezt esetleg megnövelni. Akkor jöhet ez a megoldás. -
Iginotus
addikt
Sziasztok, kéne egy lekérdezés nekem.
Meg kell keressem egy DATA oszlopban több adott kifejezést. Ez a DATA oszlop viszont 4 sorból ál. Egy adatfolyamot ment bele de mivel limitált az egy cellába írható adatmennyiség, így tördeli. 4-5-6 de van hogy csak 3 sorban írja ki. Természetesen van hogy amit keresek az 1 es sorban van és van hogy a 5 ösben. De van hogy 2-3 as is érintett. Mivel lehetséges, ha lehetséges ennek a lekérdezése, hogy sorrendben legyenek?Valami összevonásra gondoltam először, (Hogy csináljon minden sorban lévő DATA oszlopból egyet és abban kérdezzem le.) de ilyet nem találtam.
Köszi előre is. -
martonx
veterán
válasz
 half333
#2871
üzenetére
half333
#2871
üzenetére
Ja várjál már, ne viccelődjünk. Nem írtad, hogy te eddig SQL 2000-rel szórakoztál, fel se tételeztem, hogy SQL 2005-nél régebbit bárki is használ manapság pár nagybankon kívül (vagy talán már ők sem).
Hát ez zseniális




Miért nem akarsz rögtön clipper-es adatbázist - vagy mi is volt annak idején a dos-os förmedvények alatt - futtatni a 2015 augusztusában kijött win10 alatt?
De hogy konstruktív is legyek, én a helyedben tennék fel egy virtuális gépben windows XP-t, arra simán fel kell tudnia menni az SQL 2000-nek. Más kérdés, hogy jó sok erőforrásba fog kerülni a gépeden csak azért virtuális gépet futtatni, hogy végül azon fusson az SQL 2000, és még jóval lassabb is lesz, mint eddig.
-

half333
őstag
Üdv! olyan kérdésem lenne h: eddig Windows 8.1 volt fent a gépemen és bírtam használni az sql servert. Most h Windows 10-re frissítettem,nem bírom elindítani,mert sqlunirl.dll nem tudja megnyitni,vagy hiányzik,vagy nem tudom. Tudna esetleg valaki segíteni? próbáltam a 2014-es változatát,de az teljesen más és nem tudtam használni.
-
#2867
martonx
veterán
BigBlackDog
#2865
martonx
veterán
válasz
 BigBlackDog
#2865
üzenetére
BigBlackDog
#2865
üzenetére
Nem az a kérdés, hogy mennyi adatot kellene tárolni NoSql-ben (jelzem havi 100 millió adat nudli, bármelyik TSQL-nek is, már ha nem egy Pentium 4-esen futtatod, 1Gb ram mellett), hanem az a kérdés, hogy milyen komplex lekérdezéseitek, riportjaitok lesznek.
Addig aranyos dolog a NoSql, amíg csak tolja bele az ember az adatokat, de amikor azokat ki is kellene szedni, netán bizonyos relációkat megvalósítani, akkor elég gyorsan ki fog derülni, hogy csodák nincsenek.
Ettől még igenis van létjogosultsága a NoSql-nek bizonyos területeken, csak jelezni akartam, hogy amikor döntötök, akkor több szempontot is vegyetek szemügyre, ne csak a havi 100 millió rekordot, ami egyébként abszolút nem sok, még ha nektek soknak is tűnik elsőre.
Ha meg a hype miatt szeretnétek NoSql-t, akkor érdemes megnézni a NewSql-eket is, mert ez a legújabb hype: [link] -

bdlackoo
tag
válasz
BigBlackDog
#2865
üzenetére
mongoDB?
-
#2865
 BigBlackDog
veterán
BigBlackDog
veterán
BigBlackDog
veterán
NoSQL adatbázis rendszerekkel van valakinek tapasztalata? Napi ~0,5-1 Gb adat (kb. ~100 millió rekord/hónap) tárolásához kéne. Oracle KVLite NoSQL megoldásáról mik a vélemények?
-

Diopapa
addikt
Plz help! Van egy nagyon noob kérdésem, nem értem, miért azt az eredmény kapom amit.
Van két táblám. "telepulesek" és "utcak"
Ha az utcak táblából lekérdezek:
select telepulesid, nev from utcak where telepulesid = '12300' and nev like 'Ác%'
ezt kapom:
telepulesid;nev
12300;Áchim András tér
12300;Ács utcatehát két sor.
A telepulesek táblából lekérdezek:
select id, telepulesnev from telepulesek where id = '12300'
ezt kapom:
id;telepulesnev
12300;VeszprémViszont ha joinnal csinálom:
select telepulesid, irsz , utcak.nev as utcanev from telepulesek
inner join utcak on utcak.telepulesid = telepulesek.id
where telepulesnev = 'Veszprém' and utcak.nev like 'Ác%'telepulesid;irsz;utcanev
12300;8200;Ács utcaAz első pár betűre szűrést csak azért raktam bele, hogy ne legyen olyan hosszú az eredmény. Kipróbáltam több id-vel is, a legelső sort lehagyja. Ilyenbe eddig még nem futottam bele. Valami ötlet?

-
#2862
 TomyLeeBoy
tag
sztanozs
#2857
TomyLeeBoy
tag
sztanozs
#2857
TomyLeeBoy
tag
válasz
 sztanozs
#2857
üzenetére
sztanozs
#2857
üzenetére
Válaszolva a felmerülő kérdésekre:
Igen belegondoltam mit szeretnék, eddigi kódjaimban én is ezt a módszert követtem, hogy legeneráltam a megfelelő sql kérést, így ami nem kell az nincs ott a where-ben. Most viszont a sok táblakapcsolat és a sok where feltétel miatt gondoltam hogy jó lenne ha mindig minden ott lenne, megfelelő paraméterrel.
Egyébként sztanozs "WHERE T.mezo IN (SELECT mezo FROM Tabla)" megoldásával sikerült megoldani a problémát, és minden variációban jól működik így a lekérdezés.
Köszönöm!
-
válasz
 martonx
#2859
üzenetére
martonx
#2859
üzenetére
Jó kérdés, mit csinál az IN.
IN-t átalakítani nem túl egyszerű, ha konkatenált értékek vannak, szvsz egyszerűbb megírni valami ilyesmire (php):
WHERE (T.mezo IN ($elemek) OR " . strlen($elemek) . " = 0)Persze SQL Injection ellen még mindig meg kell védeni a query-t. És nem elég az, hogy az értékek a form checkbox-okból jönnek - legfeljebb az, ha felasználó által nem manipulálható másik lekérdezésből...
-
#2859
martonx
veterán
TomyLeeBoy
#2856
martonx
veterán
válasz
 TomyLeeBoy
#2856
üzenetére
TomyLeeBoy
#2856
üzenetére
Belegondoltál-e már abba, hogy amit szeretnél, azt nem így kellene megoldani? Gondolom PHP-ban ügyködsz, és van egy összekonkatenált sql query-d, aminek a végén mindig ott van ez a where.
De miért van ott, amikor bizonyos esetekben egyszerűen nem kellene, hogy ott legyen? Alakítsd át a kódodat, és ha már átalakítod, akkor a konkatenálást is csináld meg normálisra. -
#2857
 sztanozs
veterán
TomyLeeBoy
#2856
sztanozs
veterán
TomyLeeBoy
#2856
válasz
TomyLeeBoy
#2856
üzenetére
WHERE T.mezo IN (SELECT mezo FROM Tabla)
-
#2856
TomyLeeBoy
tag
martonx
#2855
-
#2855
martonx
veterán
TomyLeeBoy
#2854
martonx
veterán
válasz
TomyLeeBoy
#2854
üzenetére
szerintem az üres karakterrel ezt fogod elérni, de azért joker karakternek nem nevezném.
-
#2854
TomyLeeBoy
tag
TomyLeeBoy
tag
Sziasztok!
MySQL-el kapcsolatban remélem jó helyen kérdezek.
WHERE IN-ben létezik joker karater? Pontosan arra gondolok, hogy pl. a következőben:
WHERE T.mezo IN ($elemek)
ha azt szeretném hogy ne legyen szűrés, csak a $elemek változónak adnék egy "joker" értéket, hogy minden rekord belekerüljön a lekérdezésbe.
-

Szmeby
tag
válasz
pittbaba
#2851
üzenetére
Tele van inner joinnal. Rendesen indexelt táblákkal nincs ebben semmi kíméletlen.
Az adatbázistól elkérheted egy lekérdezés execution plan-jét (legalábbis Oracle alatt biztosan), abból ki lehet bogarászni, hogy hogyan optimalizálja azt, és hol lehet gyorsítani rajta.Természetesen ha nem használod pl. a kategória3-mat, nem kell belevenni a lekérdezésbe. Továbbá biztosan nem lesz szükséged az összes tábla összes mezőjére, így a select * helyett a szükséges mezőnevek felsorolása célszerű.
Az ember mindig elszúrja valahol, ez természetes dolog. Azért gyakorlunk, hogy minimalizáljuk ezt.
Egy normális adatbázis több tíz, száz, ezer táblát tartalmaz - sémákba rendezve -, mindegyiknek megvan a célja. Egyes táblák akár sokszáz oszloppal rendelkezhetnek, bennük több milliárd rekorddal. Ha ezen táblák tartalmát egy táblába gyűjtenénk az adatbázis szerintem már az indexelésnél összeomlana.Viszont ezzel, hogy mindent "belehánysz" egy táblába, azt éred el, hogy borzasztóan sok _felesleges_ adattal duzzasztod azt fel. Szerencsétlen adatbázis minden teszemazt ingatlanos lekérdezésnél kénytelen végigfutni az autós meg az összes többi irreleváns hirdetések adatain/indexein is. Egy kicsit is tágabb szűrést adsz meg véletlenül, és csodálkozol, hogy miért lett ez ilyen tetü lassú.
Én úgy vélem, hogy ne hagyjuk az adatbázist feleslegesen dolgozni, ha van más lehetőség. Nagyon könnyen teljesítmény problémákba futhatsz bele, és azokon már nehezebb javítani, mint pár elrontott lekérdezésen. -
válasz
pittbaba
#2849
üzenetére
Szvsz, mindent vigyél fel, mint általános kategóriát valahogy így:
Hirdetés
hirdetés_id, feltöltő_id, hirdetés_típusa_id, hirdetés_címe, hirdetés_szövegHirdetés típus
hirdetés_típus_id, hirdetés_típus_szövegKategória_típus
kategória_id, hirdetés_típus_id, kategória_név, kategória_leírásHirdetés_kategória_értékek
hirdetés_id, kategória_id, értékLekérdezés
SELECT
h.hirdetés_id,
h.hirdetés_címe,
h.hirdetés_szöveg,
t.hirdetés_típus_szöveg,
k.kategória_név,
e.érték
FROM
hirdetés h
JOIN Hirdetés_kategória_értékek e ON h.hirdetés_id = e.hirdetés_id
JOIN Hirdetés típus t ON h.hirdetés_típusa_id = t.hirdetés_típusa_id
JOIN Kategória_típus k ON e.kategória_id = k.kategória_id
WHERE
h.hirdetés_id IN (
SELECT hi.hirdetés_id FROM
hirdetés hi
JOIN Hirdetés_kategória_értékek ei ON hi.hirdetés_id = ei.hirdetés_id
JOIN Kategória_típus ki ON ei.kategória_id = ki.kategória_id
WHERE
ki.kategória_név = "Szobák száma" AND ei.érték = 3
) -
Szmeby
tag
válasz
pittbaba
#2849
üzenetére
Ilyesmire gondoltál?
select *
from hirdetes h
inner join user u on u.id = h.userid
inner join kategoria1 k1 on k1.id = h.kategoria1
inner join kategoria2 k2 on k2.id = h.kategoria2
inner join kategoria3 k3 on k3.id = h.kategoria3
inner join custom c on c.hirdetes_id = h.id
where c.mezo_neve = 'szobak_szama' and c.ertek = 3;Egyébként nem lenne ésszerűbb az egymástól független fogalmakat külön táblában tárolni?
Vagyis külön tábla az ingatlan hirdetéseknek, külön az autóknak, stb.
És akkor lehet minden szépen field. Az úgy már csak nem olyan sok. -
pittbaba
aktív tag
Sziasztok!
Elég érdekes kérdésbe futottam:
Apróhirdető oldal, szűrések.
Vannak kategóriák, a kategóriáknak pedig sajátos mezői, pl ha ingatlant választ, akkor kijön h szobák száma, ha autót választ akkor futott kilóméter stb, kb ezer ilyen custom mező jelenhet meg.
Mivel ez nem lehet egy táblában termékenként 1000 oszlopban tárolni, ezért a custom paramétereket úgy tárolom, hogy egy külön táblában elmentem az adott hirdetés id-ját, az adott paraméter nevét (custom_szobakszama, custom_kilomterek), és a hozzá tartozó értéket.
Ez rendben is van, menti szépen, visszatölti szépen szerkesztésnél stb stb...Kérdésem az lenne, hogy hogy tudok ez alapján szűrni, keresni?
Pl:
Hirdetések tábla:
id,feltöltő_id,hirdetés címe,hirdetés szövege,dátum,kategória1,kategória2,kategória3,
1,110,Ingatlan hirdetés,Hirdetésem szövege,2015.10.10,45
2,110,Autó hirdetés,Hirdetésem szövege,2015.10.11,48Custom mezők tábla
id,hirdetés_id,mező_neve,érték
1,1,szobak_szama,3
2,1,terulet,32
3,2,kmora,10000
4,2,loero,10Ossze van joinolva 3 kategora tabla, es a user tabla is, ebbe a lekérdezésbe kellene megoldani, hogy WHERE-el keresni tudjak a customs mezők tábla alapján is. Pl ha az összes olyan hirdetést akarom ahol a szobak_szama =3 azt hogy tudom lekérni?
Előre is köszi.

Esküszöm megkeresném, mint mindig mindent, de ezt most fogalmam sincs hogy írjam be -
#2848
 PumpkinSeed
addikt
dellfanboy
#2847
PumpkinSeed
addikt
dellfanboy
#2847
PumpkinSeed
addikt
válasz
 dellfanboy
#2847
üzenetére
dellfanboy
#2847
üzenetére
-
#2847
 dellfanboy
őstag
dellfanboy
őstag
dellfanboy
őstag
sziasztok
van egy select lekérdezésem és szeretném automatizálni hogy:
pl. minden hét hétfő reggel lefusson és az eredményt lementse xls formátumban a merevlemezre.
ezt hogy tudnám kivitelezni. a számitógépem ki lenne kapcsolva és a szerveren kellene automatikusan futnia. -
Szmeby
tag
válasz
 bambano
#2845
üzenetére
bambano
#2845
üzenetére
A redundancia növeli a biztonságot, az integritást.
Ugyan hibát nem javít, de jelzi, ha teszemazt valaki kézzel belenyúlt és átírt egy összeget (és persze trehány módon elfelejtette átírni a többi hivatkozott összeget is).
Egy "hús-vér" (vagyis papír) számlán is szerepelnek tételesen a részösszegek, és a végösszeg is.
Nem érzem ezt annyira ördögtől valónak. -
Szmeby
tag
válasz
 jocomen
#2840
üzenetére
jocomen
#2840
üzenetére
Talán azért van ez így, mert nincs különösebb oka a beavatkozás és a számla tétel táblák szétválasztásának. Vagy mégis?
Például a díjszabás forintban kerül megállapításra, a beavatkozás ezen leíró tábla alapján egyértelműen beárazható (szerintem a lehető leghamarabb érdemes jelölni a kiszabott árat). Viszont az ügyfél eurós számlát kér, vagyis a számla tételben már euróban kell szerepelnie az összegnek. Az meg már tiszta sor, hogy a számla fejen lévő összeg a számla tételeket összegzi.
És ha már a valutakonveziónál járunk, ahhoz asszem illene egy teljesítés dátuma mező, ami alapján meghatározható, hogy melyik napi árfolyam alapján történt a konverzió.
Ha jól látom, a rendszer jelenleg nem kezeli a sztornó és helyesbítő számlát sem, ehhez is elkelne majd pár új mező (pl. számla típusa, számlák egymásra hivatkozása, ilyesmi).
Vagy a proginak nem lesz köze a számlázáshoz?Formailag nekem pl. nem tetszik, hogy bizonyos táblanevek egyes számban, mások meg többes számban szerepelnek, és nem látom az okát. Kevés olyan tábla van egy adatbázisban, amiben csak egy sor van, totál felesleges belekeverni a számosságot a táblanévbe, bátran lehet mindegyik egyes számú.
Ha nagyon zavar a kerülő útvonal, hát egyesítsd a táblákat. Pl. úgy, hogy eltörlöd a kategóriát (az legfeljebb a fogon szerepel mint plusz információ), a díjakat pedig foganként adod meg. Nincs olyan sok fogunk, hogy ez drasztikus mértékben rontaná a teljesítményt. Persze ha igény van arra, hogy kategóriához adunk meg árat, akkor ne tedd.
Megjegyzem, hogy mindig is utáltam a normalizálós feladatokat a suliban, és nincs is benne gyakorlatom, ezért csak módjával hallgass a hülyeségeimre.
-

jocomen
aktív tag
válasz
bambano
#2838
üzenetére
Köszönöm az észrevételeket, a hibákat javítom. Az "sz.j." mező mit takarna?
#Apollo17hu: Nem tuodm, hogy jó-e, számomra az a fura, hogy a [dijszabas] táblából az összeg nem jelenik meg a [beavatkozas] táblában, a [szamla_tetel] táblában viszont már igen.
Az `osszeg` nem külső kulcs a [szamla_tetel] táblában, ezért nem éreztem úgy, h közvetlen kapcsolat kellene, és oda tettem, ahová leginkább valónak éreztem.A fő problémámra, a kerülő útvonal megszüntetésére akkor nincs senkinek ötlete?
-
-
jocomen
aktív tag
válasz
jocomen
#2835
üzenetére
Bocsánat!
Ezek voltak eredetileg, kapcsolatok nélkül (így kellett lekérdezéseket írjanak):PACIENS
p_id
nem
szuldat
KATEGORIA
hely
fog_nev
kategoria_nev
DIJSZABAS
kategoria_nev
muvelet
osszeg
BEAVATKOZAS
id
p_id
irany
szint
hely
orvos
muvelet
datumVagyis semmi sincs kőbe vésve, csak legyen jó a szerkezet és a kapcsolatok.
-
#2835
jocomen
aktív tag
Apollo17hu
#2834
jocomen
aktív tag
válasz
Apollo17hu
#2834
üzenetére
Igen. A mintapélda alapján, kategórián (metsző, kisörlő, nagyörlő) végzett műveletenként (húzás, tömés) van megállapítva a díj.
Eredetileg 4 tábla volt a példában, kapcsolatok nélkül (fogak, műveletek, díjszabás, beavatkozás). Én bontottam külön a kategória táblát redundancia miatt, ill. egészítettem ki egyéb táblákkal, h minél közelebb legyen a valósághoz. -
jocomen
aktív tag
MySQL adatbázis-szerkezettel kapcsolatos kérdésem lenne: jó-e a következő szerkezet?
Főleg a `dijszabas` tábla kapcsolatai nyugtalanítanak, mert így 2 tábla közt elkerülő út jön létre, ami tudtommal hiba. Vagy melyik másik táblába lehetne elhelyezni a `dijszabas.osszeg` oszlopot?
Egy barátomnak segítenék, aki most fog vizsgázni.
-
#2832
 beni26k
csendes tag
Apollo17hu
#2831
beni26k
csendes tag
Apollo17hu
#2831
beni26k
csendes tag
válasz
Apollo17hu
#2831
üzenetére
Azóta hál istennek minden érettségi forrás jó volt. Szerintem ott valamit elcsesztek. A másik dolog, előre félek attól, hogy kitől fogok kapni az MySQLhez adminpwt, mert kétlem, hogy az ott jelenlévő magyaros/matekos/földrajzos felügyelőtanár tud majd nekem ebben segíteni..
-
#2830
beni26k
csendes tag
Apollo17hu
#2827
beni26k
csendes tag
válasz
Apollo17hu
#2827
üzenetére
csvként megnyitottam libreoffice calcban ott frekvencia és teljesítmény oszlopot kijelöltem és átírtam a cellaformátumot standard magyar számról standard amerikaira és utána normálisan beimportálta. Pedig a kettő teljesen ugyanúgy néz ki
 Nem kellett pontozni, se semmi.
Nem kellett pontozni, se semmi.Ha véletlenül előjön az érettségin legalább tudom mit kell tenni.
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
#2829
beni26k
csendes tag
Apollo17hu
#2827
beni26k
csendes tag
válasz
Apollo17hu
#2827
üzenetére
Ha a Basenél nem MySQLt használok, hanem a gyári HSQL motort, akkor simán engedi decimálissá való változtatást. Itt valami SQLel van. A másik dolog, hogy egy későbbi érettségiben, a 2013-masban is van egy olyan tábla, amiben területek vannak, vesszővel (pl 1215,36) és ott engedi importálni decimálisba, pedig ott is MySQLt használtam. Kipróbálom majd a ponttá alakítást előtte excelben (csvként importálom excelbe utána beillesztem basebe). Mindegyik szöveg UTF-8 kódolású.
-
#2828
Diopapa
addikt
Apollo17hu
#2827
Diopapa
addikt
válasz
Apollo17hu
#2827
üzenetére
Pontosan ez a gond. A vesszőket át kell konvertálni pontra és utána jó lesz.
-
#2827
 Apollo17hu
őstag
beni26k
#2826
Apollo17hu
őstag
beni26k
#2826
Apollo17hu
őstag
válasz
 beni26k
#2826
üzenetére
beni26k
#2826
üzenetére
Csak egy nagyon távoli tipp, hátha valakinek beugrik, mi okozza a problémát:
Nem lehet, hogy az alkalmazások eltérő tizedesjelölőt használnak, és ami az egyikben szám, azt a másik csak szövegként tudja értelmezni? (Munkahelyen volt ilyen gondom, ott a Windows területi beállításai tértek el az adatbáziskezelő nls-paramétereitől.) -
#2823
 zolynet
veterán
-=Flatline=-
#2822
zolynet
veterán
-=Flatline=-
#2822
zolynet
veterán
válasz
 -=Flatline=-
#2822
üzenetére
-=Flatline=-
#2822
üzenetére
select kvizid,name,time, substring(convert(char(20), time,120),12,2) DT,
case when substring(convert(char(20), time,120),12,2) between '01' and '08' then '150'
when substring(convert(char(20), time,120),12,2) between '08' and '16' then '100'
when substring(convert(char(20), time,120),12,2) between '16' and '23' then '50' end [DT_point]
from prohardver
where helyes=1 -
#2821
zolynet
veterán
-=Flatline=-
#2820
zolynet
veterán
válasz
-=Flatline=-
#2820
üzenetére
Először próbáld meg, aztán ha nem megy segítünk.
CASE
-
-=Flatline=-
tag
válasz
 zolynet
#2818
üzenetére
zolynet
#2818
üzenetére
Hello!
Odáig már megvan a dolog általatok, hogy megkeressük az adott napi első válaszadási időpontot per júzer per day per kvízID. Az időponttól függően, azaz, ha éjféltől nyolcig, nyolctól délután négyig és négytől éjfélig jött a helyes válasz, különböző pontokat írunk bele a végeredmény egy sorunkba. 150et 100at és 50et respectively.
Zsolya: Azért nem ilyen egyszerű a képlet, mert ez egy sokkal összetettebb adatbázis része, amiből ezt emeltem ki, mert erre van szükség. Nem elég csak a helyes mezőt használni, ez egy kvízrendszer része. És a kvízrendszer pluginja olyan hivatkozásokat küld, aminek nem megfelelő eredményt ad, ha csak a helyes mezőket váltogatom és bentmaradnak a nem helyes, vagy több instance helyes válaszok.
Kizárólag az segít, amit a legelső posztban kértem és tisztában vagyok vele, hogy nem törlünk direktben, de nem is a "lecke" része volt a cél, így akármilyen unorthodox, azt szeretném elérni, amit fent leírtam. Mély tisztelettel:
Flat
-
-=Flatline=-
tag
válasz
zolynet
#2818
üzenetére
Egyetértek, de nincs más megoldás és ez egy relatíve átmeneti megoldás, míg a plugint továbbfejlesztik... Mivel az adott struktúra, ha bennehagyom megzavarja a leaderboard kéréseket és gagyi eredményt adna, muszáj törölni. (Esetleg egy deleted 0 / 1 oszlopot be tudok varázsolni egye fene, de akkor kérek szépen kiegészítést az előző megoldáshoz, ami updateli mindet, kivéve a várt eredményt. tehát a várt eredmény a deleted=0, a tÖbbi deleted=1)
-
#2818
zolynet
veterán
-=Flatline=-
#2817
zolynet
veterán
válasz
-=Flatline=-
#2817
üzenetére
Első alapvető tézis: DB-ban nem törlünk!
Ott van a helyes (0,1) indikátor, pont jó erre. Inkább azt update-d."pontozás 3 update-je megoldható egy körben?" - ezt teljesen nem értem hogy mit szeretnél
-
zolynet
veterán
válasz
 rum-cajsz
#2814
üzenetére
rum-cajsz
#2814
üzenetére
Még 1 megoldás:
select top 1 * from prohardver
where helyes=1
order by time descsorszám oszlop bővítéssel, itt még nincs leszűrve arra hogy 1 rekordot adjon 1 user-re, de view-nak jó alap:
select *,ROW_NUMBER() over (order by time desc) sorszam
from prohardver
where helyes = 1
order by sorszamIdőre lehet használni a MAX függvényt is ha nem top 1-el akarunk játszani.
még1
select kvizid,name,
convert(char(10),time,120) as időpont
from prohardver
where helyes=1
group by kvizid,name,convert(char(10),time,120) -
#2814
 rum-cajsz
őstag
-=Flatline=-
#2810
rum-cajsz
őstag
-=Flatline=-
#2810
rum-cajsz
őstag
válasz
-=Flatline=-
#2810
üzenetére
Ha jól értelek, akkor felhasználónként a legkorábbi helyes tipp kell, az ez (kicsit bőbeszédűen):
select kvizid,name,
DATE_FORMAT(time, '%Y-%m-%d') as Day,
min(time) as Időpont
from prohardver
where helyes=1
group by kvizid,name,DATE_FORMAT(NOW(), '%Y-%m-%d'); -
#2813
Ispy
nagyúr
-=Flatline=-
#2809
Ispy
nagyúr
válasz
-=Flatline=-
#2809
üzenetére
Most akkor egy view kell neked, vagy egy tárolt eljárás?
-
-=Flatline=-
tag
válasz
Apollo17hu
#2811
üzenetére
Sajnos SQL a szerver...
-
#2811
Apollo17hu
őstag
-=Flatline=-
#2810
Apollo17hu
őstag
válasz
-=Flatline=-
#2810
üzenetére
MySQL-t nem vágom, Oracle-ben a rank() függvénnyel lehetne megoldani valahogy így:
select rank() over (partition by t.kvizid, t.name, trunc(t.time) order by t.time) as sorrend
Ez egy olyan oszlopot generálna neked, ahol kvízenként, azon belül userenként, azon belül naponta minden egyes választ sorba rendez időpont alapján. Erre az oszlopra szűrve - ha előtte rászűrtél, hogy a teljes listából csak a helyes válaszokra van szükséged - elég csak az '1' értékeket megtartani, mivel ezek lesznek adott kvízhez adott napon adott user első helyes válaszai.
Tehát a dolgod, hogy keress valami sorrendfüggvényt MySQL-ben...
-
-=Flatline=-
tag
válasz
-=Flatline=-
#2809
üzenetére
No szép, az updatelt fiddlet már nem tudtam beleszerkeszteni, ímhol:
-
#2809
-=Flatline=-
tag
-=Flatline=-
tag
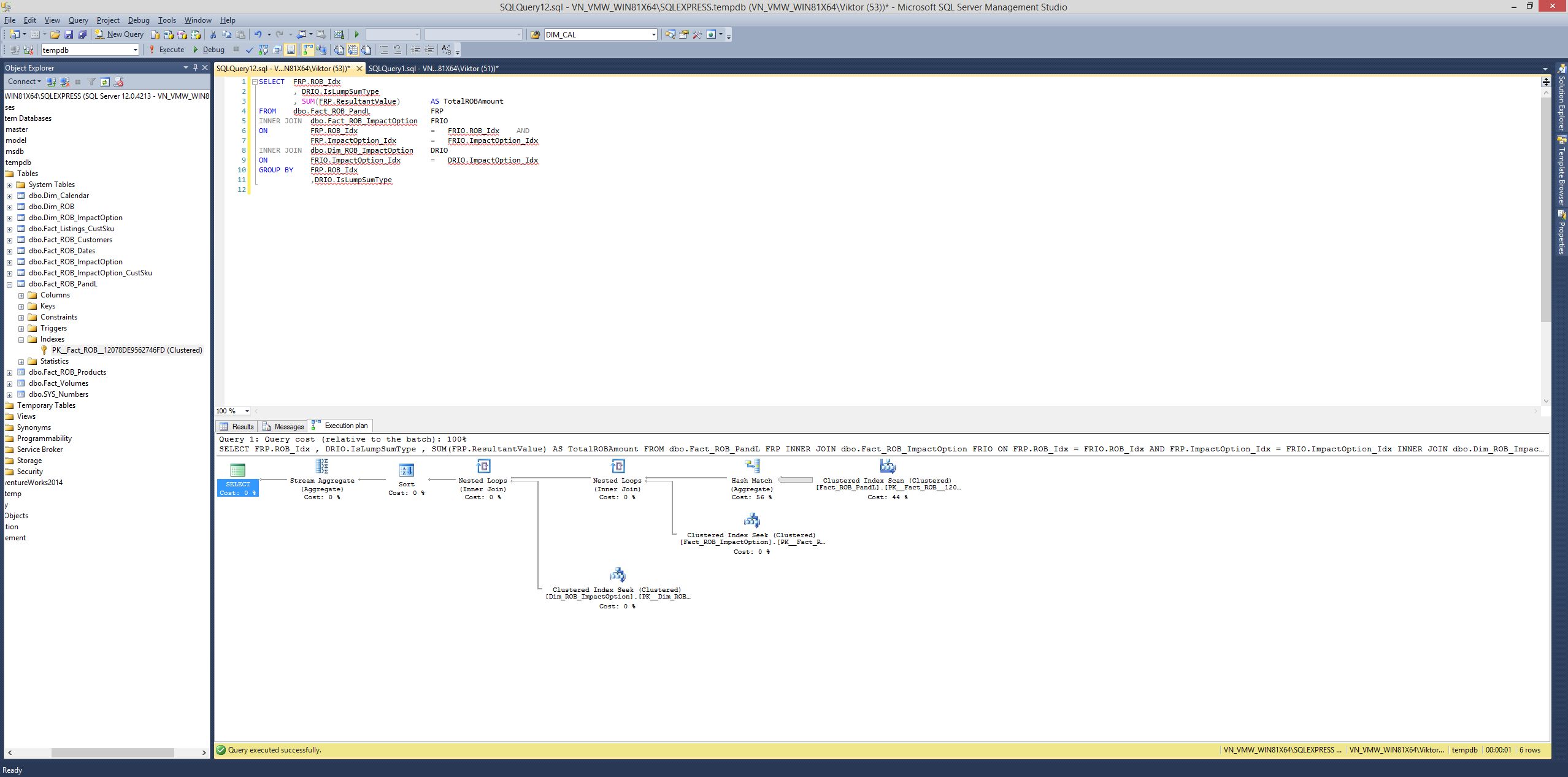
Sziasztok!
Előre is köszönöm a segítséget. Viszonylag (nekem) komplex queryt kellene építenem és a segítségeteket kérném. Egy free wordpress plugin hiányosságait szeretném adatbázisban fixelni és attól tartok egyedül nem fog menni. Az most sajnos kivitelezhetetlen, hogy maga a plugin kód változzon és ez a query ami hiányzik csak egyszer, pont éjfélkor fut le, szóval nem folyamtos nyilván.
Itt az SQLfiddle, az adatbázis struktúrával. A következőt szeretném elérni:
http://sqlfiddle.com/#!9/1c3b4
Meg kell keressek minden felhasználót név alapján, aki ugyanazon a napon, adott kvízID-vel HELYES=1 rekordot kapott. Jelen esetben ez
SELECT * FROM prohardver WHERE kvizID=4 AND time >= '2015-04-01 00:00:00' AND time <= '2015-04-01 23:59:59'
Amennyiben egy felhasználó több helyes értékkel is rendelkezik adott napon, vagy akár mellé helyes=0 sorral is, szeretném törölni mindegyik nem helyes sort ÉS egyetlen egy helyes=1 sort megtartani, amelyik a legkorábbi az adott napi dátum alapján. A fiddle-ben ez azt jelenti, hogy a végeredmény táblában az ötös sort tartjuk meg, míg az összes többi Flatline nevű törlődik.(Adott napra vonatkozólag) Mivel a query-nek minden nevet végig kellene néznie, ezért a Funny nevű is pontszámot kap, míg Lacey nem, mert az nem adott napon történő rekord.
Ezen felül, amint már csak egy sor van adott névhez, a PONT oszlopot ezen egy megmaradt sorban szeretném updatelni az alapján, hogy a time mező mit mutat., azaz 8 óránként eltérő pontszám, így:
SET pont = 150 WHERE time >= '2015-04-01 00:00:00' AND time <= '2015-04-01 08:00:00'
SET pont = 100 WHERE time >= '2015-04-01 08:00:00' AND time <= '2015-04-01 16:00:00'
SET pont = 50 WHERE time >= '2015-04-01 16:00:00' AND time <= '2015-04-01 23:59:59'Tudom ez egy picit sok, de a segítségeteket kérem, remélem a fiddle könnyebbé teszi.
Much appreciated!
-
#2808
Apollo17hu
őstag
gerg0
#2807
Apollo17hu
őstag
Valamivel kötnöd kellene a 3 lekérdezést (--> táblát).
Nekem elsőre az az ötletem, hogy vedd azt a lekérdezést, ahol COUNT(*) értéke a legnagyobb, egészítsd ki egy sorszám oszloppal - akár rank() analitikus függvénnyel, de talán a rownum is alkalmas rá -, majd a másik két lekérdezést - szintén sorszám oszloppal kiegészítve - kösd az előbbihez gyengén.
-
gerg0
aktív tag
Sziasztok,
Szükségem lenne egy kis segítségre, adott 3 lekérdezés, amik különböző result set-eket adnak (csak a where feltételek mások), a 3 result set-et szeretném egy temp táblában megjeleníteni egymás mellett.
Egy példa:
'a' lekérdezésben ezek az eredmények vannak: 1,2,3,4
'b' lekérdezésben pedig ezek: 5,6
'c'-ben pedig ezek: 7,8,9Én azt szeretném, ha ez így jelenne meg:
a-b-c
1-5-7
2-6-8
3-null-9
4-null-nullTudnátok segíteni, hogyan lehetne megoldani?
Köszönöm -
#2806
 DS39
nagyúr
sityupityka
#2798
DS39
nagyúr
sityupityka
#2798
DS39
nagyúr
válasz
 sityupityka
#2798
üzenetére
sityupityka
#2798
üzenetére
engem érdekelne milyen számokat fognak kihúzni szombaton (5-ös lottó)





























 Még nem biztos a NoSQL mellett döntés, csak feljött mint opció, emiatt kérdeztem. De asszem ezek alapján kicsit más oldalról is körbejárjuk még a dolgot.
Még nem biztos a NoSQL mellett döntés, csak feljött mint opció, emiatt kérdeztem. De asszem ezek alapján kicsit más oldalról is körbejárjuk még a dolgot.

























 Nem kellett pontozni, se semmi.
Nem kellett pontozni, se semmi.![;]](http://cdn.rios.hu/dl/s/v1.gif)







Új hozzászólás Aktív témák
Hirdetés

Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest