Hirdetés
- TCL LCD és LED TV-k
- Az AI-piac kivégezte a Micronhoz tartozó Crucialt
- Azonnali fotós kérdések órája
- Ha a koreaiakon múlik, még évekig ingünk-gatyánk rámehet a memóriákra
- Sony MILC fényképezőgépcsalád
- Projektor topic
- Videós, mozgóképes topik
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- Milyen széket vegyek?
- 5.1, 7.1 és gamer fejhallgatók
Új hozzászólás Aktív témák
-

Taci
addikt
válasz
 lanszelot
#21294
üzenetére
lanszelot
#21294
üzenetére
Jobb (napra készen tartott) helyről tanulj, és nézd a dokumentációt is, szépen le van írva minden:
https://www.php.net/manual/en/function.define
Warning
Defining case-insensitive constants is deprecated as of PHP 7.3.0. As of PHP 8.0.0, onlyfalseis an acceptable value, passingtruewill produce a warning.Tehát 7.3.0-s verziótól kezdve a case-insensitive ki van vezetve, 8.0.0-tól pedig már csak a false (alapérték) van elfogadva, a true figyelmeztetést dob, amit te is megkaptál.
-
Taci
addikt
válasz
 liksoft
#21161
üzenetére
liksoft
#21161
üzenetére
Sajnos tapasztalat híján csak linkekkel tudlak segíteni. Pl. ezek a példák hátha hasznosak: [link]
De amúgy minden függvénynek megvan a saját leírása is, pl.: move_uploaded_file.Viszont ha nem másolsz be példakódot, a többiek sem fognak tudni segíteni. Szóval szerintem másold be a kódodat, írd át a privát részeket publikusra (mármint személyes adatot, ip címet, jelszót, bármit, szedd ki), és akkor hátha könnyebb lesz a debug.

-
Taci
addikt
válasz
liksoft
#21159
üzenetére
Én még nem használtam fájlfeltöltésre, de ha használni szeretném, innen indulnék ki:
PHP File Upload
Amúgy javaslom az oldal (W3Schools) PHP-tananyagának és -gyakorlatainak végigvitelét, mert nagyon sok hasznos (és alap) dolgot tanulhatsz belőle. -
#21073
Taci
addikt
hellsing71
#21072
Taci
addikt
válasz
 hellsing71
#21072
üzenetére
hellsing71
#21072
üzenetére
Szia!
Ha olyan változót akarsz használni, ami nincs definiálva, és emiatt szól a PHP, akkor a megoldás az, hogy definiálod a változót.
Vagy eleve úgy építed a kódot, hogy
if (isset($valtozo) {
//...
}És akkor ha nincs is definiálva, hibára sem fog futni (ill. warningot sem fog adni), mivel az érintett kódrész se fog lefutni.
-
Taci
addikt
Sziasztok!
.htaccess-hez ért valaki esetleg közületek?Már egy ideje elakadtam vele, de eddig volt más amit csinálni kellett - most viszont már hátráltat, hogy nem megy.
Azt szeretném elérni, hogy
- awww.pelda.hu/site1, .../site2, .../site30
és awww.pelda.hu/category1, .../category2, .../category50
URL-ekre a szerveren lévő tartalmat hozza be, tehát simán nyissa meg az oldalakat,
(ezzel ugye nincs teendő a fájlban, de a "feladat" talán így jobban érthető)- viszont amikor van site és category is (ebben a sorrendben), pl.:
www.pelda.hu/site1/category1, .../site1/category50, .../site30/category50stb.
akkor az irányítson át a főoldalra (index.html).(Minden mást ami nem valid, futtasson 404-re.)
Csak egy olyan megoldásig sikerült eljutni, ami a
.../site, illetve a.../site/categoryválozatokat (úgy ahogy) jól kezeli (de nem tökéletesen azokat sem - pl. ha/van az url végén (pl.www.pelda.hu/site1/), akkor azt hibásnak veszi, és 404-re dob).DirectoryIndex index.htmlRewriteEngine On# If the request is not of the form# "/site" or "/site/category" then stop hereRewriteRule !^[^/.]+(/[^/.]+)?$ - [L]# Validate "site" (first path segment)RewriteCond $1 !=site1RewriteCond $1 !=site2RewriteCond $1 !=site3# etc.RewriteCond $1 !=site30RewriteRule ^([^/.]+) - [R=404]# Validate "category" (second path segment)RewriteCond $1 !=category1RewriteCond $1 !=category2RewriteCond $1 !=category3# etc.RewriteCond $1 !=category50RewriteRule ^[^/.]+/([^/.]+)$ - [R=404]# Front-controllerRewriteRule . index.html [L]Ért valaki közületek annyira ehhez, hogy tudna ebben segíteni?
Köszönöm.----------
Esetleg egy ilyen egyszerű megoldás? Még csak most leltem rá:RewriteRule ^/?(site1|site2|site3)/(category1|category2|category3)/?$ index.html [L] -
Taci
addikt
Jellemzően kihagyja a dinamikus rész előállításához szükséges JS betöltését a Google, így nincs tartalom sem az általa indexelt verzióban. (Néha viszont behúzza, és szépen összerakja, de jellemzően inkább nem. Van, hogy egyik nap azt látom a Search Console-ban, hogy ott a tartalom is (nem csak a keret), másnap meg azt, hogy írja, a JS-t kihagyta, így tartalom sincs.)
Ezért kell statikus tartalom a szerver oldalra is, hogy nehezebb napjain is legyen mit indexelnie. -
Taci
addikt
JS-alapon tartalmat generáló az oldal, így a tényleges tartalom csak a kliensen látható, a szerveren az index.html csak egy üres váz. A Google pedig ezt nem szereti (nem akarja indexelni), ezért kell szerverre is kvázi statikus tartalmat generálnom. És ezt valamennyire frissen tartani, ezért az 5 percenkénti ismétlődés.
\site1\category1
..
\site1\category50
..
\site30\category1
..
\site30\category50A 30 x 50 = 1500 html oldal viszont sok, már változtattam a koncepción, "csak" 30 + 50 = 80 oldal van. És talán azt is elég csak óránként. Szóval az meg főleg nem nagy feladat már a szervernek. (És nekem is egyszerűbb.)
De érzésre a problémát rosszul közelíted meg.
Én sajnos tudom is, csak nem találok jobbat (a funkciók csorbítása nélkül), és valamit viszont csinálnom kell. -
Taci
addikt
Nem programozás, egyelőre ott még nem tartok a témában, viszont a vége az lesz, ezért ez a topik.
Ha (legrosszabb esetben) le kell mondjuk 5 percenként generálnom 30 x 50 .html oldalt szerver oldalon (ahol 1 .html 100kB méretű), ez mennyire erőforrásigényes?
Lehet "bajom" belőle (rám szól a szolgáltató, hogy ez túlságosan lehúzza szervert), vagy csak egy kis task egy átlag szervernek?
150 MB-nyi adat, azért ez nem a világ vége, viszont minden 5 percben, és mindegyik generálása külön-külön adatbázis-lekérdezésekkel is jár.
Még nem kezdtem hozzá, mert ha vakvágány, akkor keresek más utat.
Köszönöm. -
Taci
addikt
Sziasztok!
Iránymutatást szeretnék kérni a következő témában:
Adott a weblapom, ami egy HTML keret (felső és oldalsó panelek, menük), amihez a szerverről érkezik az adat a content részhez, amit a kliens rak össze és jelenít meg JS segítségével. Tehát client side rendering (CSR).
Az elmúlt 2 hónap tapasztalata alapján úgy néz ki, hogy a Google ezt a fajta megoldást nagyon nem szereti, össze-vissza indexel kb. random részeket belőle, így a SEO is ugrik, nagyon rossz az egész. Valószínűleg ez a dinamikus tartalomhozzáadás az üres vázhoz nem a kedvence.
Azt a tanácsot kaptam, hogy próbálkozzak meg server side renderinggel (SSR).
Dinamikus az oldal, görgetek, jön az újabb tartalom, a lap alja közelébe érek, tölti a többit stb. Ezért azt a tanácsot kaptam, csináljam úgy, hogy legenerálom 1-2 percenként szerver oldalon az első pár megjelenítendő elemre a teljes oldalt, ami pedig görgetés után jönne, azt ezután is rakhatom dinamikusan JS-tel. Így a Google is nagyjából fix tartalmat kapna (legalábbis a content részt így már JS-töltés nélkül is láthatja és indexelheti), és megmaradna az oldal dinamikus mivolta is.A kérdésem az lenne, hogy ez kb. hogyan néz ki működés közben?
- 1-2 percenként legenerálom szerver oldalon azt a teljes index.html-t, ami a jelen változatban a keretből, és a JS-által összerakott elemekből áll?
- És eddig csak a megjelenítendő első pár elem adatait adta vissza a szerver, ezután pedig a teljes, tartalommal feltöltött index.html kódját?Tehát ha jól értem, a cél az kellene hogy legyen, hogy az első HTML kód ami a kliensre érkezik, abban már legyen tartalom is (a mostani üres keret + azután JS-en keresztül behúzott tartalom helyett). Jól értem?
Azért ebbe a topikba írtam, mert gondolom, a mostani index.html-t cserélnem kell index.php-ra. (De ebben nem vagyok biztos. Csak félek attól, ha ugyanígy .html-en hagyom, amiben lesz egy szkripthívás, amivel a szerver oldalon generált html tartalmat áthúzom, akkor a Google szemében az nem lesz más, mint a mostani. Hisz' igazából ugyanazt csinálja: van egy keret, és szerverről tölti fel a hiányzó részt. Csak a mostani változatban kevesebbet, az újban meg kb. mindent. Szóval ha úgy nézem, akkor még kevesebb tartalomból tudna indexelni a Google... Nem tudom... Nagyon össze vagyok most ezzel kapcsolatban zavarodva.)
De ez a .html --> .pho amúgy a Wordpress jutott az eszembe, ami szintén ha jól tudom, szerver oldalon renderel, és az is index.php-vel operál.Nem örülök neki, hogy az eddig felépített szerkezetet kb. teljesen át kell írnom, de a Google nagyon mostohán bánik a jelenlegi szerkezettel, szóval muszáj vagyok lépni.
De amit már megcsináltam eddig, azt szeretném megtartani, tehát magát az oldalt nem szeretném új alapokra helyezni, az már készen van - csak másképp eljuttatni a kliensekre.Ebben kérnék iránymutatást, mert nagyon nem látom, merre van az előre.
Köszönöm. -
Taci
addikt
Sziasztok!
A php error logban sok ilyen bejegyzést találok:
PHP Warning: Error while sending STMT_PREPARE packet. PID=123456Van, amikor a szkript teljesen elején lévő legelső lekérdezésre mutat, van, amikor a közepére, változó.
Kerestem, mi lehet, de egyértelmű választ nem találtam. A megoldási javaslatokból viszont úgy tűnik (és ebben erősítsetek vagy cáfoljatok meg, kérlek), hogy nálam esetleg az a baj, hogy minden cron job-ot (kb. 20 db) egyszerre hívok meg, így kvázi egyszerre terhelik le a szervert, és néha egyszerűen ez talán túl sok neki.
Jó a sejtésem, vagy tévúton járok?
Ha jó, megoldás lehet erre, hogy a cron jobokat (amik amúgy most 5 percenként futnak) eltolom valahogy? Tehát most mindegyik lefut egyszerre minden 5 percben. De mondjuk minden másodikat eltolnék, hogy ugyanúgy 5 percenként fusson, de ne 00-kor kezdje, hanem 01-kor, és akkor a következő 06-kor stb. Aztán minden harmadikat 02-es kezdettel stb.
Így valamelyest tehermentesebb lenne a szerver, még ha csak 1-1 perccel is eltolva a szkriptek indulását. (Vagy akár inkább másfél perccel, mert úgyis 90mp a futási limit.)Vagy más lehet az oka ennek?
Kódot azért sem írtam, mert változó, hogy melyikkel van épp "baja", de már a legegyszerűbb 2 paraméteresre is írja ki néha, szóval nem a "bonyolultságán" múlik szerintem.Köszi!
-
Taci
addikt
Sziasztok!
Tanácsot szeretnék kérni adatbázis backupolással kapcsolatban.
Amíg az itthoni tesztkörnyezetben dolgoztam (fejlesztettem),
mysqldump-pal ésmysqladmin-nal (flush-logs) csináltam egy nagyon jól működő inkrementálisan backupoló rendszert.
Aztán átköltöztem a szolgáltatóhoz, ahol kiderült, hogy sajnos se abinary lognincs engedélyezve, sereloadjog nem elérhető, így ez a módszerem ott nem működőképes.
Azóta csak kézzel tudok (cPanelen keresztül) backupolni, nyilván azt is csak akkor, amikor épp odaérek. Ez pedig így nem jó.Tudnátok tanácsot adni, hogy az elérhető tool-okkal milyen automatizált backupoló megoldást tudnék létrehozni?
Ezeket tudom használni:
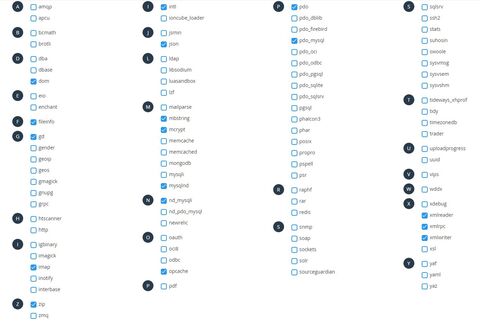
Köszönöm.
-
Taci
addikt
Ha inkognitó módban (vagy Edge-ben) próbálod, akkor is előjön ez a hiba (és a 2 fájl)?
Mert fura ez az extension-ös rész, ha feltelepíted, ugye engedélyt is adsz neki (arra amire kér). Szóval nézd meg egy másik böngészőben (vagy tiltsd le a Chrome-beépülőt), hátha úgy már rendben lesz. -
Taci
addikt
válasz
 pelyib
#20965
üzenetére
pelyib
#20965
üzenetére
The __DIR__ can be used to obtain the current code working directory.
Ezzel az a "baj", hogy más mappákba is be kell "látnom" (hozzáférni fájlokhoz), így nem indulhatok ki mindig az éppen aktuális mappából. Ezért is volt jó a Document_Root, amíg (lokálban) működött.
nem lehet h a script meghiv egy http szervizt es az hasal el?
Van a require_once előtt 3 db direkt változó értékadás, és ennyi az egész szkript, tényleg nincs benne semmi más.
Aztán az azon belül meghívott szkript már millió dolgot csinál, viszont amíg addig eljut, rengeteg kellene logolnia is, de semmi. Ebből gondolom, hogy a belső szkripthez el sem jut, és hogy ezért csak azzal az egy sorral lehet a gond:require_once $_SERVER['DOCUMENT_ROOT'] . "/almappa/php/main.php"; -
Taci
addikt
Segítségre lenne szükségem.
Szolgáltatónál vagyok végre, de szenvedek a cron jobok beállításával. Folyamatosan ezt a hibát kapom:
Status: 500 Internal Server Error
Content-type: text/html; charset=UTF-8A php fájl amit meghívok, tartalmaz egy hívást egy másik php fájlra. És ahogy utánanéztem, talán itt hibázhat, mert amíg ez lokál szerveren tökéletesen működött, a szolgáltatónál ez talán már máshova mutat, vagy eleve nincs értéke a $_SERVER-nek sem:
require_once $_SERVER['DOCUMENT_ROOT'] . "/almappa/php/main.php";Próbáltam visszakövetni, itt mi a document root, és kicseréltem rá, erre:
require_once "/home/sitename/public_html/almappa/php/main.php";De így is ugyanazt a hibát kapom.
Ez lehet a hiba egyáltalán? Mert meghívni így hívom amúgy cron-ból:
php /home/sitename/public_html/almappa/php/elso.php
(az időt érintő részeket nem másoltam be, nem releváns, kattintgatva van amúgy is cPanelben).Hogyan lehet ezt működésre bírni? Sajnos nem jutok előrébb.
Hogyan tudom belinkelni a szükséges fájlokat? (már ha ez a baja egyáltalán)
Köszi. -
Taci
addikt
A PHP szerver oldalon fut, nem tud kliens oldalon csinálni semmit. A kliens oldalról kell adatot "várni" a szerver oldal felől. Tehát a PHP kód, amit a Submit aktivál, annak a visszatérési értékét kell, hogy kiértékelje a kliens a JS segítségével, és annak függvényében tudod a HTML tartalmát változtatni.
A Submit-tel triggerel valamit az oldalad a szerver (PHP) irányába. A PHP kód lefut, és visszaad egy általad megadott értéket, amivel kliens oldalon a JS-tel dolgozni tudsz tovább.
Én erre az Axios-t használom:axios.get("sajat_kodod.php?v=" + js_oldalrol_atadott_valtozo).then(function (response) {// handle successconsole.log(response);}).catch(function (error) {// handle errorconsole.log(error);}).then(function () {// always executed});})És itt a response-ban lesz a PHP kód által visszaadott érték.
-
-
Taci
addikt
Abban tudnátok esetleg segíteni, hogy ha a
get_headersés agetimagesizesem ad visszacontent-length-et, akkor a "maradék" adatból hogyan lehet kiszámítani hozzávetőlegesen pontosan a fájl (kép) méretét?Pl. ezekből:
[0] => 800
[1] => 600
[2] => 2 (IMAGETYPE_GIF, IMAGETYPE_JPEG, IMAGETYPE_PNG or IMAGETYPE_BMP)
[3] => width="800" height="600"
[bits] => 8
[channels] => 3 (3 for RGB or 4 for CMYK)
[mime] => image/jpegEnnek a képnek a mérete 114077 bájt a valóságban.
Úgy indultam neki, hogy (szélesség * magasság * bitmélység) / 8. De ez 480000.
Eloszthatnám 4-gyel, akkor nagyon közel lennék (a többi képfájnál is), de egyrészt sehol nincs 4, másrészt miért is osztanék vakon akármennyivel is?Nyilván ebbe beleszól a tömörítés típusa is, a színtartomány is, de azokat sem tudom alkalmazni.
Arra gondoltam még, hogy letöltöm a fájlt ideiglenesen, aztán a
filesize-zal lekérdezem a méretét, és törlöm. De ez így eléggé nyakatekert megoldás, főleg sok ezer képhez.Hátha van ötletetek.
Köszi!
-
Taci
addikt
Szeretnék tanácsot kérni ebben a témában is:
Adott egy link forrása, pl.: [link]
Melyik módszerrel gyorsabb, hatékonyabb a feldolgozása? (keresés benne, pozíciótól pozícióig kimásolás stb.)
1.file()függvény, így minden sor egy tömbelem, és azon belül foreach, és így soronként (tömbelemenként) keresni, aztán a műveletek
2.file_get_contents()függvény, ami sztringként menti a tartalmat, és abban simán elvégezni a műveleteket.Most direkt csináltam egy tesztet, és nekem ugyanannyi másodpercre jött ki mindkét függvénnyel / módszerrel. Szóval nem tudom, melyik lehet a jobb választás. (A file-lal dolgoztam eddig, csak lassúnak találom néha, ezért gondoltam, megnézem, mivel lehetne gyorsítani.)
Köszönöm.
-
Taci
addikt
Ne haragudj, hogy 100+1-edjére is visszakérdezek
 , de ez tényleg a legelső találkozásom szinte mindennel, amikről eddig beszéltünk, és nem szeretném "rosszul kezdeni", érteni szeretném a miérteket.
, de ez tényleg a legelső találkozásom szinte mindennel, amikről eddig beszéltünk, és nem szeretném "rosszul kezdeni", érteni szeretném a miérteket.Ha csak mentesz akkor ne php-ból futtasd mert felesleges.
Cron job-ként fog futni a backup, viszont ott .php szkriptet hívok majd meg, és minden példában így is láttam. (Ezt is csak szolgáltatónál tudom majd élesben kipróbálni.) Mire érted azt, hogy ne php-ból futtassam? Php-ban írtam meg mindent hozzá, kapcsolódás az adatbázishoz, backup, tömörítés, felhőbe feltöltés stb. Ez van egy .php szkriptben, ezt fogom majd valamilyen időközönként futtatni:* * * * * /usr/bin/php /home/user/public_html/index.php > /dev/null 2>&1
(csak copy-paste egy sample linkről)Ha mentés előtt valamit csinálsz, pl. takarítasz
Takarítani? Bocs, tényleg olyan balféknek érzem magam, de nem értem, mire gondolsz. Az egész processzben, de még az egész életciklus alatt sem volt takarítás "betervezve". Milyen takarításra gondolsz?Én csak örülök és hálás vagyok, ha tippeket kapok, hogy hogyan kell ezt jól csinálni. Szóval ha előtte takarítani kell (vagy előtte-utána bármi mást), kérlek, terelj a helyes irányba.
Köszönöm.
-
Taci
addikt
Hogy érted, hogy mit csinálok?
Még semmit, de igazából nem is terveztem. Mármint (ha jól értem a kérdésed lényegét) a singe-transaction (és a skip-lock-tables) miatt az adatbázis továbbra is elérhető lesz, így nem kell az oldalt maintenance módba raknom. Az új bejegyzések (SQL Insert) pedig sorban állnak addig, amíg a mysqldump nem végez.
Kihagytam valamit? Vagy mit tanácsolsz?
-
Taci
addikt
bár exec helyett a backupot php-ból oldanám meg.
Ez mit jelent? Mármint most is php kódban van az egész (hisz' sok más mindent is csinálok még előtte-közben-utána vele), és a mysqldump az exec()-en keresztül van meghívva (így találtam példakódokban).$cmd = "mysqldump" . " --skip-extended-insert --complete-insert--single-transaction --skip-lock-tables --user=" . $username ." --password=" . $password . " " . $dbname . " > " .$backup_folder . $backup_filename_sql;exec($cmd, $return_array, $return_code);Ezen kívül még shell_exec()-et láttam használva, illetve passthru()-t, de az böngészőnek adja át elvileg csak.
Hogyan máshogy lehet/érdemes használni?
-
Taci
addikt
válasz
 nevemfel
#20931
üzenetére
nevemfel
#20931
üzenetére
az viszont a fizetős mysql enterprise csomagban van
Ez az infó nem került a szemem elé, így akkor nem is forszírozom. Köszönöm.
Amúgy azt a doksit már végignéztem, már kezdtem is összerakni a parancsot, amikor észrevettem, hogy nem dump a vége, hanem backup. (Öregszem, plusz már a betűk is összemosódnak ilyenkor.)
(Öregszem, plusz már a betűk is összemosódnak ilyenkor.)Neked is köszönöm, mobal.
Akkor marad így, backup, tömörítés, feltöltés, régiek törlése (egy idő után).--------------------
Még esetleg abban adjatok tanácsot, kérlek, hogy mire készítsem fel a szkriptet. Mikor mondhatom azt, hogy "baj van" az adatbázissal, és a "hibás" adatbázisról ne csináljon backup-ot.
if ($return_code == 0){}
Ha sikeresen lefutott, akkor jön a tömörítés, és ha az is sikeres, akkor a feltöltés.
Nem tudom, állhat-e elő olyan helyzet, hogy 0-ás return code-dal tér vissza az exec() annak ellenére, hogy baj van az adatbázissal.Eredetileg arra gondoltam, hogy mivel nagyon max 3-6 óránkénti (vagy ritkábbi) backupolásra állítanám be, ezért ha még kézzel valamiért pár rekordot törölnöm is kellene, nyugodtan beállíthatok egy olyan feltételt, hogy egy új backup fájl csak akkor valid, ha nagyobb, mint az előző. (5 percenként futnak cron jobok, amik tartalmat húznak be kb. 30 forrásból, így esélytelen, hogy abban a 3-6-akármennyi órás periódusban ne legyen új rekord.)
Ha pedig valamiért mégsem kerülne be egy új rekord sem, akkor sem bántja az előző backupot, hiszen csak akkor valid az új backup, ha nagyobb, mint az előző - tehát egyenlőnél invalid.Jó ez a gondolatmenet?
Mire készítsem még fel, mi "romolhat el"? Nyilván ha a szolgáltatónál valami kiesik, akkor a cron jobok, így a backup sem fog futni. Vagy ha az adatbázissal van baj, akkor a mysqldump az exec-ben nem 0-ás return code-dal tér vissza. Másra a saját tapasztalataimből (ami ebben a témában a nullához konvergál alulról) nem tudok gondolni.
Köszi.
-
Taci
addikt
Kerestem megoldást az incremental backup-ra, de
mysqldumpnem támogatja, csakmysqlbackup, ez utóbbi viszont nem elérhető (a tesztszerveren, a szolgáltatónál nem tudom, de abból kell kiindulnom, hogy ott sem).Sokkal jobb lenne így csinálni, egy kezdeti full backup hetente, ahogy te is írtad, aztán bizonyos időközönként mondjuk 1-1 cumulative.
Te mivel, hogyan csináltad? Van esetleg egy "best guide"-od hozzá? (Egy jól összeszedett oldal, példákkal, hogy értsem is, mi-mit-miért csinál, hogy testre tudjam szabni.) -
Taci
addikt
$data = file_get_contents($backup_folder . $backup_filename_sql);$gzdata = gzencode($data, 9);file_put_contents($backup_folder . $backup_filename_sql_gz, $gzdata);A
gzencodepontosan ugyanazt a fájlméretet eredményezi, mint aZipArchive, 1 kB-nyi különbség se nagyon van.Ha ugyanazt az sql fájlt 7-zip-pel Ultra tömörítéssel .gz-be tömörítem (Windows alatt), akkor 260 kB-tal kisebb fájl lesz csak. Ha ugyanígy Ultrával, de .7z-be, akkor lesz egyedül a 8,9 MB-ból 5,1 MB, ami már azért jelentős különbség.
Szóval max még azt tudom valahogy elérni, bár nem tudom, hogyan, egyelőre nem találok rá semmit. Nem hiszem, hogy ebben több lenne. Szerintetek? -
Taci
addikt
Köszönöm, a tippet is az inkrementális backuppal, utánakeresek, hogyan kell.
Meg akkor megnézem még, mit tudok kezdeni a tömörítéssel. Így gyorsan (munka mellett egy percre félre nézve) ezt találtam, ami beépített, és talán pont ide való: [link] De majd ha lesz időm, alaposabban utánajárok.Köszi.
-
Taci
addikt
Már csak pár apróbb simítás kell (köztük az RClone is, ami azért nem lesz olyan hamar meg), aztán költözök szolgáltatóhoz. Ott lesz cron is majd.
Köszönöm a megerősítést, hogy a backup rész így akkor rendben lesz.
Az alatt mit értettek, hogy sok a 8 MB? 54 MB-ról tömörítette a ZipArchive (ezt találtam, ami egyből működött). Biztos van kapcsolója is, hogy hatékonyabb legyen a tömörítés, de éjfél környékén fejeztem be, első változat, nem tudom, mi lenne a "jó fájlméret".
Vagy más miatt mondjátok?Azt tervezem, hogy napi pár alkalommal futtatom ezt a backup szkriptet, ami backupol, tömörít, aztán feltölt (felhőbe). És mivel így tömörítéssel csak ilyen minimális méretekkel kell számolnom, nyugodtan megcsinálhatom úgy, hogy meghagyok akár 1 hétnyi backupot is, és mindig csak a legrégebbit törlöm (a megfelelő ellenőrzések után).
Ha mondjuk 2 óránként fut (csak példa), akkor az napi 12 backup, heti 84 fájlt kell tárolnom - persze egyre nagyobbakat, de bőven van helyem.
Vagy mi az ajánlásotok ezzel kapcsolatban?Köszi.
-
Taci
addikt
válasz
 supercow
#20876
üzenetére
supercow
#20876
üzenetére
A
mysqldump-hoz lenne pár kérdésem:Az adatbázis mostani felépítése szerint a backuphoz (mysqldump) generált user Select és Lock Tables jogokat kapott. (Előbbivel kezdtem, de hibára futott, és a logban írta, hogy az utóbbi is kell neki.)
Kellhet esetleg még más jog is a "későbbiekben"? Ahogy néztem, Show View és Trigger van még említve, de az előbbit nem használom, utóbbit pedig még soha nem használtam, szóval így gondolom, egyik sem kell.Ezt a parancsot futtatom (
exec()):$cmd = "mysqldump" . " --skip-extended-insert --complete-insert--single-transaction --skip-lock-tables--user=" . $username . " --password=" . $password . " " . $dbname ." > " . $backup_folder . $backup_filename_sql;Amit megértettem ezekből:
- InnoDB adatbázis, ezért a single-transaction, így elvileg nem lock-olja a táblákat.
- Viszont van néhány kapcsoló (bár itt nincs használva most), ami aktiválhatja a lock-tables-t, ezért biztos ami biztos, ott van benne a skip-lock-tables, hogy ezt kiüsse mindenképp.
- skip-extended-insert: Ilyenkor minden műveletet külön sorba tesz, szétszed. Ha kiszedem belőle, akkor viszont pl. egy sorban, 1 db Insert-ben ott van egy teljes tábla tartalma. És tapasztalatom szerint így a gyorsabb (sokkal). Szóval lehet, ezt ki kell inkább szednem.
- complete-insert: a mezőnevek is szerepelnek, enélkül kihagyja őket.Van még esetleg más, amit megérne használnom?
Még tömörítem a végén, így a jelenleg 54 MB-ba backup-olt adatbázist kb. 8 MB-ra tömöríti össze a ZipArchive. (Aztán majd ezután nézem az RClone-t, hogy feltöltsem felhőbe tárhelyre.)
Köszönöm.
-
Taci
addikt
Köszönöm a tanácsot és a segítő szándékot, de sztanozs "unszolására" (jó értelemben véve persze
) átnéztem újra, és meglett, hogy az SQL-es Update miatt volt lassú, amúgy nagyon gyors a logikai/ellenörzős rész.
A lassúság oka az volt, hogy egyesével futtattam rekordonként az Update-et... - de most már átírtam arra, hogy csak egyszer a végén, az összeset bind_param-mal átadva, egy lépésben futassa, és így már repül.
(Érdekes volt így kilogoltatni, hogy hogyan is néz ki egy darab, 23e rekord adataiból összerakott lekérdezés. )Köszönöm azért így is a tanácsot!
-
Taci
addikt
válasz
 sztanozs
#20912
üzenetére
sztanozs
#20912
üzenetére
Nagyon szépen köszönöm a felajánlásodat, de nem foglak privátban zaklatni ezzel. Az egy dolog, hogy beírom ide, aztán ha valaki épp rálát és rá is ér, ad 1-2 tanácsot - de amíg van mit átéznem saját kútfőből is, semmiképp nem fogok mást piszkálni ezzel.
Kb. 1100 rekord / 80 mp-ről indultam optimalizálni, kb. 18e / 80 mp körül van most, de ha azt mondod, ez még mindig nem az igazi, átnézem a többi részt is. (Igazából élvezem, persze sok időt elvisz egy olyan területre, amiről azt hittem, már készen van, de attól még élvezem.
)Köszönöm még egyszer a felajánlást!

-
Taci
addikt
foreach ($rekord_kategoriai as $rekord_kategoriai_value){if (array_key_exists($rekord_kategoriai_value, $kulcsok){//}}A $kulcsok tömbben kb. 3000 elem (kulcsszó - kategória páros) van.
A $rekord_kategoriai-ban átlagban 5-10 elem.Itt mi lenne az elérendő cél sebességben? Tényleg még csak viszonyítási alapom sincs.
Ahogy írtam, most kb. 6500 elem 80 mp alatt.Ez tehát 1 mp alatt 80 elem. 80 elemnél elemenként mondjuk 10 kulcsszó, ezeket egyesével 3000 kulcsszó-kategória párossal összehasonlítani. (bár ugye az array_key_exists-tel ez elvileg gyors)
Bocs, hogy ezzel nyaggatlak titeket, de tényleg nem tudom, meddig is lehet ezt javítani. Lehet, már elértem ezzel egy ideális sebességet? Lehet, a 1/100-át sem.
-
Taci
addikt
Átírtam, most már a megadott 80 mp alatt kb. 6500 elemmel végez (az eddigi 1100-hoz képest). Igazából nagyobb ugrásra számítottam, mert egy 1 milliós táblát nézve ezt bizony elég sokszor kell hívogatnom.

Megpróbálok "lekapcsolni" részeket belőle, hogy lássam, mi fogja vissza ennyire. -
Taci
addikt
válasz
sztanozs
#20898
üzenetére
Tehát ha jól értem, akkor ebből
$kategoriak = array('szorakozas' => ['elozetes', 'film', 'sorozat', 'hbo', 'mozi'],'kultura' => ['mozi', 'szinhaz', 'múzeum', 'koncert', 'film'],'masszázs' => ['eufória']);ezt csináltad:
$kulcsok = array("elozetes" => "szorakozas","film" => "szorakozas","film" => "kultura","sorozat" => "szorakozas","hbo" => "szorakozas","mozi" => "szorakozas","mozi" => "kultura","szinhaz" => "kultura","múzeum" => "kultura","koncert" => "kultura","eufória" => "masszázs",);És akkor azt mondod, hogy így ezen belül az array_key_exists (key_exists) gyorsabban megtalálja az értéket, és egyből ott van hozzá a kategória neve is értékként.
Kipróbálom, köszi.Reggel amúgy rákerestem arra, hogy "php in_array slow performance", és volt egy válasz valahol, ahol azt ajánlotta, hogy a
$categories_szorakozas = array("elozetes","film","sorozat","hbo","mozi",);helyett legyen:
$categories_szorakozas = array("elozetes" => true,"film" => true,"sorozat" => true,"hbo" => true,"mozi" => true,);és így array_key_exists-tel ellenőrizni. Átírtam, futtattam egy tesztet (előzővel és ezzel is ugyanúgy 10 mp-re limitálva), és az in_array 10mp alatt 77 rekordot tudott feldolgozni, míg ez a másik fajt az array_key_exists-tel csak 38-at... Szóval vissza is írtam.
De a te változatodnak sokkal több értelme van, szóval teszek azzal is egy próbát.
Meg amúgy (bár nem hiszem, hogy túl sok időbe kerül az a kezdeti, "kulcsok" táblát feltöltő művelet, de) megcsinálhatom eleve úgy a "kategoriak" tömböt, hogy eleve abban a formában legyen. -
-
Taci
addikt
válasz
sztanozs
#20893
üzenetére
#20894: Ah, az azért már nem elhanyagolható sebességbeli különbség...
 Csak jó lenne tudni ki is használni.
Csak jó lenne tudni ki is használni. A Pythonba nem kezdenék bele, bőven elég ez is, köszönöm. Látod, ezzel sem haladok épp villámtempóban.
A tömbbe a kulcsszavakat kézzel írom bele. Jönnek külső forrásból a bejegyzések, hozzájuk az általuk megadott kulcsszavak, tagek, kategóriák, én pedig azokat rendezgetem magamnak a saját kategóriáimba. (Enélkül nagyon össze-vissza lenne minden, átláthatatlanul.)
Ezen a táblázatos tároláson el kell gondolkodnom, ki kell próbálnom. És igazán nem is értem.
Most simán csak in_array()-jel nézem meg, hogy az adott kulcsszó benne van-e valamelyik kategóriához tartozó kulcsszavai között. De ehhez ugye végig kell mennem a külső forrásból megadott kulcsszavakon (foreach), aztán a kategóriákhoz beállított kulcsszavakon is (foreach).
Ha táblázat van tömb helyett, az én tapasztalatommal kapásból feltöltenék egy tömböt a táblázat adaival, és foreach-et használék, hogy bejárjam. De sejtésem szerint nem ez az ajánlásod lényege. (A linkeket átnézem alaposan, amint odaérek. Köszönöm.)
Upd.: És azt is, amit most küldtél, még csak most látom, a hozzászólás elküldése után. Köszönöm szépen ismét a segítségedet és a türelmedet!
-
Taci
addikt
válasz
sztanozs
#20888
üzenetére
Mindenek előtt köszönöm, hogy kódot is írtál!
Viszont talán nem egy dologról beszélünk. (simán benne van, ti látjátok a jó utat, én meg továbbra is vakon vagyok)
SQL-lel nem lehet (jelen pillanatban) ezt megcsinálni, mert a kulcsszavak nem táblázatban vannak, hanem simán egy tömbben.
De amúgy ha a kulcsszavak táblázatban lennének, akkor sem lenne gyorsabb szerintem, sőt, hiszen azért csak gyorsabb egy kész tömbön végigmenni, mint előtte a tömb elemeit SQL-ből lekérni.Mutatok egy éles példát:
Külső forrásból ez a sztring érkezik:
$rekord_kulcsszavak = "Kultúra,előzetes,eufória,filmtv,hbo,második évad,rév marcell,sam levinson,sorozat,zendaya";Ezt szétbontom tömbbe, elemenként.
Ezeket az elemeket egyesével megnézem, milyen kategóriákhoz tartoznak (a kategóriákhoz tartozó kulcsszavak alapján), és azokat írom be a KUlcsokKAtegóriák táblába:
- Kultúra --> kultura
- előzetes --> szorakozas
- eufória --> nincs ilyen kulcsszó
- filmtv --> nincs ilyen kulcsszó
- hbo --> szorakozas, már benne van a kategóriában, skip
- második évad --> nincs ilyen kulcsszó
- rév marcell --> nincs ilyen kulcsszó
- sam levinson --> nincs ilyen kulcsszó
- sorozat --> szorakozas, már benne van a kategóriában, skip
- zendaya --> nincs ilyen kulcsszóTehát a rekordhoz a kultura és a szorakozas kategóriák kerülnek mentésre.
@biker: Amikor bekerül egy rekord a fő táblába, az az infó is mentve van vele, hogy milyen verziójú kategória tömb alapján lett kategóriákba besorolva. Így amikor ez a szkript elindul, elsőnek csak azt ellenőrzi, melyik rekordnál van más (régebbi) verzió. Így csak azokat a rekordokat nézi át, amik régi verzióval készültek. Nincs felesleges művelet.
Viszont ha aztán frissítenem kell a kategóriákhoz tartozó kulcsszavakat, akkor muszáj vagyok emelni a verziószámot is, mert nem tudhatom, melyik rekord fog új/más kategóriá(k)ba kerülni.A fenti példánál maradva:
Mondjuk azokkal a kulcsszavakkal az 1.0-s verzióban a következő kategóriákba kerülne a rekord: kultura, szorakozas, és mondjuk az "eufória" miatt a masszazs kategóriába (csak egy példa).
Aztán ezt észreveszem, hogy hopp, az "eufória" kulcsszó nem jó a masszazs kategóriába, úgyhogy kiszedem onnan.
Ekkor ha nem emelek verziót (1.0 marad), akkor az a rekord skippelve lesz, így marad a masszazs kategóriában, hibásan.
De verziót emelek (1.1 lesz), így újra ellenőrzive lesz, és kikerül a rossz kategóriából. De ennek sajnos az az ára, hogy verzióemelésnél mindet újra át kell nézetnem, mert nem tudhatom, melyik fog változni, addig, amíg nem ellenőrzöm újra. Viszont a következő változtatásig ez a szkript skippelni fogja az összeset már, mert 1.1-re át lett írva mind. -
Taci
addikt
válasz
sztanozs
#20883
üzenetére
Már csak rákérdezek, mert ezt a feladatot nem látom máshogy (könnyebben, főleg gyorsabban) megoldhatónak:
Adott 40 kategória. Minden kategóriában vannak kulcsszavak, van, amiben csak 20, van amiben 240, van amiben 600.
Minden rekordhoz tartoznak szintén kulcsszavak, egy, vagy akár több is.A szkript ezeket a rekordokhoz tartozó kulcsszavakat vizsgálja végig a kategóriák kulcsszavain, az összesen, és ha valamelyikben egyezés van, azt a kategóriát bejegyzi neki.
Így alakul ki a végére, hogy az adott rekord milyen kategóriákba kerül.
Aztán ezek a kategóriás kulcsszavak változhatnak, bekerül pár, kikerül pár, és ez alapján a rekordokat is módosítani kell.A 90 mp jelenleg arra elegendő, hogy ezeket az ellenőrzéseket és bejegyzéseket megcsinálja kb. átlag 1200 elemhez.
Lefuttattam 3 mp-cel, 32-re volt ideje.Ezen akárhogy nézem, gyorsítani csak úgy tudnék, ha vagy kategóriákat törölnék, vagy kulcsszavakat. Egyiket sem akarom, sőt, kulcsszavakból egészen biztosan még több lesz.
Ez amúgy csak pár egymásba ágyazott
foreach, semmi több:-- foreach - a kategóriák listájából a kategóriák neveire
---- foreach - a kategóriák neveihez tartozó tömb elemeire, amik a kategóriák kulcsszavai
------ foreach - a rekordokhoz tartozó kulcsszavakraEzután már csak a megfelelő rekordot hozza létre, módosítja vagy törli.
Ebben a kontextusban, ezekkel a számokkal is olyan szörnyűnek hangzik? Csak mert 0 viszonyítási alapom van, nem látnám, hogy bárhol "pazarolnék", nem tudom, hogyan lehetne ezen gyorsítani.
-
Taci
addikt
válasz
sztanozs
#20883
üzenetére
*Naprendszeren kívül - nagyban gondolkodom.
Ezért is írtam, hogy ez a része nem lényeges most. Nyilván átnézem újra, mindent logolva, mi tart mégis ennyi ideig.
Előbb futtat egy lekérdezést, ahol csak a rekordhoz tartozó verziószámot ellenőrzi. Ha nem a legfrissebb (amit egy tömbből ellenőriz a legelején), akkor ezekből visszaad egy listát (id-k).
Aztán ezen a nem legfrissebb verziójú rekordokon végig futtat pár ellenőrzést, sztringekből, és JOIN-olt táblákból dolgozik, aminek a végén kap egy eredményt, és attól függően kell a JOIN-olt táblákban update-elni, törölni vagy hozzáadni (vagy mindet).Ez legutóbb 6 percig tartott 8150 rekordnál.
Ahogy a részletes logot nézem, azt látom, hogy van olyan rekord, ahol akár 4 mp-be is kerül a processz, máshol meg 1 mp-en belül megvan 2-3.
Én is szívom a fogam, mert azért tényleg nem DNS-t vizsgál a szkript... De ezt úgyis átnézem, mert ez így sok.
Lehet, itt az én gépem (tesztkörnyezet - XAMPP) teljesítménye a szűk keresztmetszet, és szolgáltatónál repülni fog.De ettől függetlenül...
...csak annak az elvére szeretnék ráérezni, hogyan lehet vajon ezt megcsinálni, ha mindenképp kezelnem kellene ezt a helyzetet (szkript futása nem fér 90 mp-be bele).
Ma reggel az jutott eszembe, hogy vajon ha a Cron job meghívja a szkriptet, aztán azt 85 mp-nél commit-olom, majd meghívatom vele rekurzívan saját magát addig, amíg végig nem megy minden elemen, akkor vajon a 2. hívás (és a többi) még a Cron job-hoz tartozik?
Ezt fogom majd kipróbálni. -
Taci
addikt
A szolgáltató 90 mp-ben maximalizálja a Cron Job-ok futási idejét.
Viszont van 1 szkriptem, aminek az összes elemen végig kell mennie néha, számolni, átírni stb. (ez a része most nem lényeges). És ez már most, 20e elem környékén sem fér bele a 90 mp-be. (duplájába se)Hogyan tudom ezt megoldani? Az oké, hogy mondjuk 85 mp-nél azt mondom, na most egy commit, aztán vége. De aztán valahogy triggerelnem kellene újra ezt a szkriptet, hogy folytassa, ahol az előbb abbahagyta. Viszont ilyenkor már a cron job le lesz állítva.
Nem állíthatok be 10-20-30 cron jobot, hátha mindre szükség van, hogy végig menjen az összes elemen.Hogyan lehet ezt megoldani?
Hátha van valalmilyen ötletetek. -
Taci
addikt
Van esetleg bevált módszeretek / keretrendszeretek SQL adatbázis (táblák) biztonsági mentésére (php-alapon, hogy cron jobként futtathassam)? Elsősorban MS OneDrive-ra szeretném bizonyos rendszerességgel a kiválasztott táblák backupjait kimenteni, de ahogy olvastam, abba az irányba talán nincs annyira kiforrott megoldás, mint Google Drive-ra. De ott is van elég tárhelyem, szóval az is jó lenne.
Tudtok valami bevált megoldást ajánlani?
-
Taci
addikt
Ezzel a kódolásos dologgal valami nincs rendben nálam, kérnék egy kis segítséget.
Adott egy saját függvény, hogy szépen logoltatni tudjak. A lényegi része:
error_log($message_to_log, 3, $log_file_custom_path);
(vagy jobb lenne simán csak file_put_contents használatával a fájlba írogatni?)A .log fájlok, ahova mennek az adatok UTF-8 kódolással vannak elmentve.
De pár napja azt vettem észre, hogy egyszer csak fogja, és többet nem UTF-8-as kódolású a fájl, hanem átállítja a már tartalommal bőven feltöltött fájlt is ANSI-ra, és minden magyar ékezetes szöveg "szétesik".
Azok is, amiket előtte láttam, hogy rendben, utf8-asként, normálisan kódolva szerepeltek.
(Pl. tegnap még azt volt benne utf8-asként, hogy Találat kategóriára, ma meg már Találat kategĂłriára...)Adatbázis oldalon és kapcsolódásnál is minden szépen be van állítva (pl. $conn->set_charset("utf8mb4"); ).
Gondolom, ezért is kerül rendben minden az adatbázisba, még akkor is, ha a logban a "szétesett" verzió szerepel.Az ini_get('default_charset') azt mondja, UTF-8.
Gondolom, így a php.ini-ben nincs dolgom.Hogyan lehet ezt megoldani? Máshol nincs jele szerencsére ennek az UTF8-->ANSI váltásnak, csak a logban, de ez is zavaró, mert keresek bennük. (Plusz nem tudom, máshova bekavar-e.)
Szívesen vennék valamilyen hasznos tanácsot, hogy mit kell még beállítani, vagy hogy hogyan kaphatom el, mi csinálja ezt az utf8-->ansi cserét.
Köszönöm. -
Taci
addikt
UTF-8-ban van minden, és direkt úgy csináltam meg, hogy amit nem abban kapok, először azt is átalakítom azzá. Amúgy azóta minden más linknél jól működik (normálisan adták meg, normál ékezetekkel -amiben épp van-, szóval az egy egyszeri "valaminek" tűnik csak), plusz módosítottam is a függvényen:
1. FILTER_VALIDATE_URL-rel teszt. Ha false, akkor
2. a header-ös ellenőrzéses teszt (200 OK). Ha ezen is megbukna, akkor kuka.Plusz így átgondolva ha még 3. lépésnek bevonnám az ékezetes betűk ellenőrzését, (hogy ha az van benne, akkor jóhiszeműen átengedem, mert biztos csak amiatt nem volt jó az első 2 teszt), akkor igazából ha a link annyi lenne csak, hogy "é", azt is átengedné.
Szóval jó ez így, nem is ér további energiaráfordítást.
Köszi azért, hogy írtál.
-
Taci
addikt
Kérnék egy kis segítséget.
Olyan szinten vért izzadtam ezzel...
$str1 = "Névtelen";$str2 = "Névtelen";$pattern = "/á|é|í|ó|ö|ő|ú|ü|ű/i";echo preg_match($pattern, $str1) . "<br>";echo preg_match($pattern, $str2) . "<br>";Az output pedig ez:
01Az elsőt (str1) én gépeltem be, a másodikat egy link címéből másoltam ki ( [link] ).
Aztán kb. fél óra idegőrlő próbálgatás után (kb. annyi kellett, hogy a link részeit külön-külön megnézve megtaláljam, mi nem stimmel) megnéztem a link forrását, ahol azt láttam, hogy aNévtelenaz ott valójábanNe%CC%81vtelen.Ezt találtam róla:
e%CC%81 (U+0065 U+0301): Combining character e + ́Még a Notepad++ is furcsán "kezeli", mert amikor kijelölném (normál é betűnek látszik), akkor elsőre csak a feléig jelöli, aztán következő lépésben (Shift + jobbra) a másik felét.
Ide be tudom most csak azt a karaktert másolni: é
És fura módon ha a sima é-re keresek, ezt is találatnak dobja. De amikor egyet visszatörlök: e lesz.Találtam egy ilyen patternt, ami "beugrik" mindenre:
/\p{L}+/u
Viszont én kifejezetten azt szeretném, hogy csak akkor adjon találatot, hogy magyar ékezetes betűk vannak benne.Amihez használnám:
Linkeket ellenőrzök vele.if (filter_var($link, FILTER_VALIDATE_URL, FILTER_NULL_ON_FAILURE))
Ez hibásnak dobja, ha ékezetes karakter van a linkben (works as designed), ezért egy újabb lépcsőben ellenőrzöm, hogy a magyar ékezetes betűk vannak-e benne, és ha igen, akkor tovább engedem.Na ez eddig működött, most ezzel a "fura ékezetes megoldással" már nem.
Hirtelen ötlettől vezérelve megnéztem a header-jét, és bár böngészőben 200-as státuszú, a get_headers által visszaadva HTTP/1.1 404 Not Found.
Hogyan lehetne ezt megoldani?
Egy másik linkben © karaktert fogott meg a szkriptem... hát legyen az ő bajuk, aki így enged ki egy linket. Bár ennél speciel 200-as a státusz a headerben, de hát akkor is.
-
Taci
addikt
Köszönöm a választ mindenkinek, átnézek mindent! Még biztos lesz kérdésem ezzel kapcsolatban, de most nekiülök alaposan átnézni a témakört, mert elsőre nem gondoltam, hogy ennyit kell majd ezzel (is) foglalkozni. De ahogy látom, ez a .htaccess-es dolog azért csúnyán félre is tud menni - viszont nagyon hasznos is tud lenni, szóval jobb, ha ebbe is belerázódom.
@Mr. Y:
Meg tudnád mutatni a .htaccess-ed tartalmát (akár csak az ide vonatkozó részt)? Persze csak a publikus részeket, szenzitív infók nélkül.
mobal adott már egy jó példát erre (köszönöm), szeretnék még esetleg egy másikat is látni, összehasonlítani. -
Taci
addikt
index.html van - bár gondolom ez esetben mindegy. (Azt még meg kell keresnem, hogyan kell átirányítanom - amúgy is, mert almappában vannak a fájlok, és amúgy is azt szeretném, hogy ha www.weblap.hu/index.html-t írja be, kiírva a címsorban akkor is www.weblap.hu legyen stb. De ezeket megkeresem.)
Eddig ezeket találtam:
Options -Indexes- így már nem lehet listázni a mappákat.RewriteCond %{HTTP_REFERER} !^weblap_linkje [NC]RewriteRule \.(gif|jpg|jpeg|png|webp|ico|
php|js|css|xml|log|txt|html)$ - [F,L]
- Ezzel pedig a fájlokhoz való direkt hozzáférés van tiltva, csak a weblapon keresztül lehet őket elérni. (ide talán a html nem kell, mert bár a lapon keresztül megnyitja ezeket a belső linkeket is, külön beírva már nem)Még valamit érdemes ide felvennem, figyelnem valamire?
-
Taci
addikt
Amikor pár hete azt kerestem, hogyan kell/lehet védeni egy PHP-alapú weboldalt, többek között szerepelt a "hide files from the browser". Több helyen is feltűnt, de igazán jó leírást még nem sikerült találnom róla.
Ez amúgy azt jelenti, hogy ezt megelőzzük?

Ami biztos, hogy a weblaphoz szükséges fájlok ne legyenek a gyökérkönyvtárban.
Plusz a .htaccess fájllal is van teendő - bár ez nem egyértelmű, hogy mit-hogyan. Ahogy láttam, a fő cél ezzel az, hogy a .php fájlokhoz hozzáférést letiltsa.Tudnátok esetleg egy megfelelő linket, jól összeszedett, alapos cikket mutatni, amit átolvashatok, hogy a jó irányba tereljen, ha lehet, példákkal kiegészítve, hogy értsem, mit-miért?
Köszönöm.
-
Taci
addikt
Jó pár cron job-om ugyanazt a php fájlt használja (jelenleg require-rel). Függvényt ugye nem lehet újra deklarálni, ezért hogy ne legyen PHP Fatal error: Cannot redeclare fuggvenynev(), néztem, mi lenne a legjobb megoldás.
1) require_once
2) require és if (!function_exists('fuggvenynev'))A leírás szerint egyértelmű, hogy a
require_oncepont erre van kitalálva:
The require_once expression is identical to require except PHP will check if the file has already been included, and if so, not include (require) it again.De inkább rákérdezek, hogy tényleg ez-e a jó megoldás.
Csak mert ez olyan fura nekem. Én úgy értelmeztem (lehet, rosszul), hogy a require(_once) az kvázi olyan, mintha a behúzott fájl tartalma a behúzott helyre lenne másolva.
De mint ilyen, nem lenne szabad hogy látszódjon másik fájl futásából. Tehát ha én 10szer húzom be ugyanazt a fájlt 10 különböző kódba, és ezek egyszerre futnak, ezek nem kéne hogy "lássák egymást", így a "Cannot redeclare" hiba sem állhatna fent.
Viszont mégis adott, így gondolom, talán memóriában tárolásról lehet szó, és ott ellenőrzi, hogy az adott függvény deklarálva van-e. (De akkor pedig az csak addig él, amíg az eredetileg hívó szkript fut. Ha befejezte a futását, akkor törlődik a memóriából. Mi van akkor, ha közben egy másik szkript épp használná valamelyik függvényt az első require_once-ból, de mivel az a másodiknak már nem engedte a require-et, viszont időközben kilépett, mi történik ekkor? Logikus az lenne, ha látja, hogy volt másik require_once, amit elutasított, de az azt hívó még fut, addig a memóriában tartja neki.)Kusza ez nekem, ezért kérnék tanácsot, hogy végülis melyik a jobb, az 1) vagy a 2)?
Köszi.
-
Taci
addikt
$slash_character_array = array("%2F","/","/","/","/","/","/","/","/","/","/","/","/","\x2f","\u002f");foreach ($slash_character_array as $slash) {if (stripos($dataToCheck, $slash) !== FALSE){//kezelés}}Ha
$dataToCheck = "https://mobilarena.hu/tema/php_kerdesek_2/friss.html";
akkor erre is találatot ad, és nem értem, miért.És amikor logoltatom, hogy mégis mire talált rá, azt mondja, hogy a
/karakterre.Ennek mi az oka? Nincs benne a
/karakter ebben a formájában. Mégis miért talál rá? Van tippetek esetleg? Valamiért automatikus átalakítja? Ha igen, melyiket, miért? -
Taci
addikt
Egy példán keresztül könnyebben átlátható:
$_ = array("Notes"=>"35", "Dont"=>"37", "Lie"=>"43");echo $_['Notes'];Az output pedig az lesz, hogy:
35pelyib pedig leírta, hogy mi-miért:
_--> valid változónév,['Notes']--> asszociatív tömb Notes nevű eleme,$_['Notes']--> Az "aláhúzás nevű" asszociatív tömb Notes nevű elemének értéke. -
Taci
addikt
Illetve alig hogy megírtam a hozzászólást, rátaláltam még a "Double Encoding" kifejezésre, és azzal erre a példára is (pontosabban előbb a példára, aztán a kifejezésre):
%253Cscript%253Ealert('XSS')%253C%252Fscript%253E
Úgyhogy ezt lekezelendő az 0. és az 1. lépés közé még beleraktam egy sztring cserét,%25-ről%-ra, és még beleírtam pluszban, hogy ne csak a < karaktert kódolásait alakítsa vissza, hanem a>és a/karaktereket is.
Így a fenti sztringből a feldolgozás végén (a dirty content check előtt) ez lesz:<script>alert('XSS')</script> -
Taci
addikt
Amit terveztem, és ami idő közben még képbe került az XSS elleni védelemben, azzal nagyjából készen vagyok (ezer köszönet a sok segítségért, sztanozs!), összeállt a függvény.
Ki szeretném kérni a véleményeteket, hogy van-e még esetleg valami aspektus, amit nem vizsgálok, és kellene / jó lenne / megérné.
A témában az utóbbi napokban/hetekben átolvasott cikkek, átnézett YT-videók alapján összeszedtem egy példa listát, hogy mik ellen kell leggyakrabban védekezni, milyen támadások/próbálkozások érhetnek. Ezt kiegészítettem még ebből a listából azokkal, amiket úgy láttam, korábban még csak hasonlót sem próbáltam: XSS Vectors Cheat Sheet.
Jelenleg csak keresőmezőben van user inputom, azt első körben kliens oldalon validálom, de persze megkerülhető, szóval azt a kérelmet ezen is végig ellenőriztetem.
Ezen kívül RSS-ekből érkező következő 3 típusú tartalmat vizsgálok vele:
- title (cím)
- description (rövid leírás)
- link (weblap és kép)Így néz ki a függvény, lépésről lépésre:
0. lépés (a függvény hívása előtt):
html_entity_decode($abc, ENT_QUOTES);1. Ha van találat a
&#párosra, akkor preg_replace használatával kiegészíteni az esetlegesen hiányzó pontosvesszőt (by sztanozs)
2. Pár példában az unicode kódolással kapcsolatban is találatot, így vizsgálom azu+és\utalálatokat. Ha van találat, mb_convert_encoding segítségével dekódolás.
3. Rákeresek a<karakter összes lehetséges formájára, és ha megtalálta,<-re cseréli.
4. Ha linket ellenőriz, rákeres pár előre beállított, nem linkbe illő karakterre, pl.( ) \ ; , < > { } @ $aztán még a különböző féle aposztrófokra és idézőjelekre is.' " ‘ ’ ” “. Itt csak logbejegyzést csinálok egyelőre, hogy vizsgáljam, hogyan működik. Ha a megfelelő találatokat ez is jól szűri, akkor már ez is átbillentheti az xss_found-kapcsolót.
5. Aztán ezeket a nem normál idézőjeleket és aposztrófokat a "normál" változatukra cseréltetem.
6. Ugyanígy a\n-t és\r-t (és máshogy kódolt változatukat is) is lecserélem, de üres sztringre. Ugyanígy a&Tab-ot és a null karaktert is\0.
7. Ezek után van egy nagyon hosszú lista, amiben a "dirty content" van listázva. Ezekre a kifejezésekre keresek, és ha bármelyikre találat van, átbillent egy változóértéket, és az adott komplett bejegyzés skippelve lesz. A listában az összes HTML tag benne van, illetve az összes event handler is (pl. onError). Plusz persze a "javascript", "script", "noscript" stb. stb sztringek is. Az összes, amit a példákon keresztül támadhatónak láttam, és amiknek semmi helyük se egy linkben, se egy normál szövegben (cím, leírás). (Ha mégis fals pozitív találat lenne, majd külön kezelem.)
8. Ha linket vizsgál, és nincs dirty content-re találat, akkor a biztonság kedvéért megvizsgálom mégfilter_varsegítségével (FILTER_VALIDATE_URL).Ez a függvény tartalma. Ezután a korábban már megírt és használt processzek vannak, ahol még a linkkel kapcsolatban fontos, hogy ha a protokol csak
http, akkor kiegészítihttps-re, ellenőrzi, hogy valid-e, és ha igen, https-ként tárolja, amúgy skippeli.Ami átment minden szűrőn, az így lesz (_decode-dal) tárolva. Megjelenítésre pedig minden esetben minden érték
htmlspecialchars($xyz, ENT_QUOTES); használatával lesz átadva.Lehet, erősen overkill, de az is lehet, hogy hiányzik még valami, amit nem vettem észre, hogy figyelni kellene. Lehet, soha senki nem fog "megtámadni", de jobb félni és felkészülni.
Van esetleg még valami, amire figyelnem kellene?
Köszönöm. -
Taci
addikt
válasz
sztanozs
#20817
üzenetére
A regex (a minta) mégsem tökéletes még.
Ránéznél erre a példára, kérlek? Remélhetőleg neked hátha hamar szemet szúr, mi lehet a hiba.[link] (Csak két helyen kell a kommentelést
//leszedni/beírni.)Adott a
–(hosszabb kötőjel) karakter, aminek a kódja:–.1. változat:
- Ha nincs a végén pontosvessző, és a te kódodat ({1-9}{0-9}*) használom, nem rakja végére a pontosvesszőt. (helytelen)
- Az "enyém" ([0-9]*) igen. (helyes)2. változat:
- Ha van pontosvessző, és a te kódodat használom, akkor nem bántja, marad minden jó a formában, és a végén a _decode átalakítja a megfelelő hosszú kötőjelre. (helyes)
- Az "enyém" viszont ezt csinálja belőle:̵1;, a 3. számjegy után berak egy pontosvesszőt. És nem értem, miért. (helytelen)És a
{ }és[ ]közötti különbségre sem tudtam még rájönni. Te az előbbivel írod, én azt a formát viszont csak a számosságnál találtam meg, az általad használt formában nem:
n{x,y} Matches any string that contains a sequence of X to Y n'sRá tudnál nézni erre, kérlek?
-
Taci
addikt
válasz
sztanozs
#20820
üzenetére
Asztali legfrissebb Chrome-ban, Firefox-ban és Operában is néztem, ugyanaz mindenhol. Ami fura, \-rel írva (pl. \047 az aposztróf) már jól fordítja.
megszünteted az injection lehetőségét
Pontosan hogyan? Hisz' eddig csak megkönnyítettem a dolgát azzal, hogy nem a böngészőnek kell dekódolnia, nem?Mármint itt van példának ez:
$link = "jAvAsCriPT:alert(\047Hacked!')";
A regexet használva, majd dekódolva a böngészőnek már semmi dolga nincs, mert egyből ezt kapja:jAvAsCriPT:alert('Hacked!')Ez hogy szüntette meg az injection lehetőségét?
Mert eredetileg azért akartam ezt csinálni, hogy megtalálhassam a potenciálisan veszélyes kifejezéseket (javascript, script, onerror stb stb stb - nagyon hosszú lista, de talán megéri), amiknek amúgy semmi keresnivalójuk nincs egy linkben - aztán vagy csak ezeket a talált "rossz" kifejezéseket törölni, vagy az egész linket skippelni. (valószínűleg ez utóbbi)
De ha csak a decode --> regex --> decode lépéseket csinálom, az hogyan szünteti meg a támadási felületet?
-
Taci
addikt
Kapkodtam, bocsánat...
A 039 az nem 8-asban (Oct) van, hisz' ott a 9-es szám benne...
De az zavar be igazán, nem nagyon látok példát rá, hogyan lenne 8-asban (Oct) leírva bármelyik karakter is.Itt van pl. ez a táblázat: [link]
A 039 azért az aposztróf, mert a 39 Dec-ben az. És valamiért a '-et őt átalakítja '-cé.
Én azt gondoltam (mert mint írtam, sajnos példát nem találtam rá), hogy ha 0-val kezdődik, akkor 8-as számrendszerbeli (Oct). És hogy az ellenőrzésed is ezért van így megcsinálva, hogy ha 0-val kezdődik, akkor már csak 0 és 7 közötti számokat vizsgálsz.
De itt van pl. a
047. Ez ugye megfelelne a feltételnek, mert 0-val kezdődik, és utána 0 és 7 közötti számok vannak. A kódod szépen le is zárja ;-vel, a böngésző viszont/-t ír ki, mivel a 47 a/karakter decimális kódja. Szóval ott is a 047-et 47-ként kezeli, Dec-ként.
Viszont Oct-ban a 047 az aposztróf lenne'.Az Oct-kódolásúakat tényleg &# kezdéssel kell meghívni? Ezért ellenőrzöd így? Tehát hogy ha
�-val kezdődik, akkor 8-as számrendszerbeli (Oct)?És amit írtál példát sem értem már:
ϻblabla
Itt is a kódod azért rakja a pontosvesszőt a 0101 után, mert meghúztad neki a 0-7 határt (0[0-7]+). Ezért lesz ebelőle, és azeazekarakter, így kiírni is azt írja, hogye9blabla
Szóval ezt is a Dec-kódolásként veszi.És te azért írtad azt, hogy a kimenet
A9blablalesz, mert a 101 az Oct-kódja azAkarakternek.Viszont mégsem így működik. Nem lehet, hogy azért, mert a Oct-kódokat nem
&#kezdettel kell írni? (Nem tudom, sehol nem találok példát rá.)Mert ez így most már nagyon össze-vissza számomra, és rosszul érzem magam, hogy ennyi kommentet írok, és spammelek...
 .
. -
Taci
addikt
válasz
sztanozs
#20817
üzenetére
Pont azért írtam azt a példát az előbb, mert annál sajnos még hibázik a kódod.
De ennél így leegyszerűsítve is:$link="'";
A'az aposztróf (').Ez a kimenete a kódodnál:
9
És a böngésző így jeleníti meg: [ismeretlen karakter]9Esetleg annyi változtatás kellhet, hogy
0[0-7]+
helyett0[0-7]{2,}
legyen?
Mert a 8-as számrendszerbeliek ha jól láttam, talán minimum 3 karakteresek. -
Taci
addikt
válasz
sztanozs
#20815
üzenetére
Köszönöm szépen!
Első lépésként _decode-ot hívni tényleg nagyon jó ötlet.Ha ehelyett:
$pattern = '/(&#(?:X[0-9a-f]+|0[0-7]+|[1-9]\d*)(?!;))/i';
így lenne:$pattern = '/(&#(?:X[0-9a-f]+|[0-9]+)(?!;))/i';
akkor miben hibázhatna? Mert így igazából a 2. feltétel le is fedhetné a 8-ast és a 10-est is.Sőt, most találtam egy példát is, amiben az első hibás eredményt ad, a második pedig jót:
$link="javascript:alert('Hacked!')";Itt az elsővel az output (_decode előtt):
javascript:alert(9Hacked!')
A másodikkal pedig (_decode előtt):javascript:alert('Hacked!')Persze ez lehet csak egy egyszeri "mázli", de biztos okkal csináltad úgy az elsőt, ahogy, és csak szeretném megérteni.
Köszönöm.
-
Taci
addikt
És nem is úgy működik, ahogy gondolnám/szeretném, hogy működjön.
Adott pl. ez a sztring:
$link = 'jAvAsCript';Itt a
jugye már eleve ;-re végződik, szóval skippelnie kellene. Ebből lenne ajkarakter.
AA-öt zárnia kellene ;-vel, de nem teszi. Ebből lenne azAkarakter.
AA-t jól kezelni. Szintén azAkarakter.
És aC-t is zárni kellene ;-vel, de ezt sem teszi. Ez lenne aCkarakter.Próbáltam átírni, hogy működjön, de nem tökéletes:
$pattern = '/(&#(?:X[0-9a-f]{2,}|[0-9]{2,})(?!;))/i';
Kipróbálható verzióban: [link]Itt az a baj, hogy "beragad" két karaternél, és nem nézi, hogy zárva van-e pontosvesszővel.
Pl. aj-nél csak
-ig veszi, mögé rak és pontosvesszőt, és kilép, mint aki jól végezte dolgát. Eredményül pedig ezt adja:[sortörés]6;AvAsCriptSzóval a két megoldás között lenne az igazság - nyilván sztanozs megoldásához sokkal közelebb.
-
Taci
addikt
válasz
sztanozs
#20799
üzenetére
Mint kiderült, mégsem értem...
Ez a sor nekem elég összetett:
$pattern = '/(&#(?:X[0-9a-f]*|0{0-8}*|{1-9}{0-9}*)(?!;))/i';Részekre szedve:
-&#ezzel kezdődő mintákat keres
- amik így folytatódhatnak:
-X[0-9a-f]*: tehát a következő karakter az X (a végén lévő /i miatt kis- és nagybetű is), utána pedig a 16-os (HEX) számrendszer miatt 0-9 és a-f karakterek szerepelhetnek, a * miatt 0 vagy több számban. Szóval ez a része azt hiszem, rendben (mármint értem), ezzel van lekezelve, ha Hex kódolásban lennének a karakterek.
-0{0-8}*: Ez a rész nem teljesen tiszta. Ha jól értem, ez azt jelenti, hogy a&#után hány darab 0 karakter állhat, és itt az van megadva, hogy 0-tól 8 db-ig akármennyi. Tehát ez alapján a minta lehetne&#,�,�, ...,�? Ezt nem értem, hogy mire való - vagy rosszul értelmezem.
-{1-9}{0-9}*: Ezt a részt egyáltalán nem értem. Kapcsos zárójel elvileg azt jelenti, hogy az előtte álló karaktert hányszor ismételje meg. De a|miatt a&#van előtte. Szóval nem értem.- A végén van még a
(?!;). Ezt sem értem, hogy mit csinálhat.- És a legeljén lévő
?:-ról pedig csak a nevét találtam: Non-Capturing Groups. De a működését nem bírom felfogni. Talán "csak" a művelet sebességéhez van köze?
(?: ), in contrast to ( ), is used to avoid capturing text, generally so as to have fewer back references thrown in with those you do want or to improve speed performance.-
$replacement = '${1};';Itt pedig az $1 a backreference lenne. A kapcsos zárójeleknek itt a Non-Capturing Groups-hoz van köze? Ezt sem igazán értem. Mert ugye itt adod meg, hogy ha megtalálja a mintát, akkor mire cserélje: eredeti + zárja le pontosvesszővel.
Az én felületes "tudásommal" ha magam írtam volna, akkor ezt írtam volna:$replacement = '$1' . ';';Miben különbözik az általad írt?Összességében a cél nyilván az, hogy felismerje, ha Dec vagy Hex kódolású karakterekről van szó (Dec:   Ẁ ♦ - Hex: ~ ˆ ∼ ), és ha nincs pontosvessző a végén, akkor egészítse ki vele.
Csak a részletekben vesztem el, és szeretném érteni, mi-mit-miért csinál. (Bocsánat, ha evidens dolgokra kérdezek rá, próbáltam megérteni a részleteket, utána járni, de ez egy számomra elég bonyolult "képlet".)
Ezt a pár dolgot pár mondatban el tudnád, magyarázni, kérlek?
-
Taci
addikt
Igen, így van. Több helyről érkezik, különböző formákban (van, ahol már eleve a forrás is escape-elt, encode-olt, össze-vissza), ezeket visszaalakítom "olvasható" formátumra, és így vannak letárolva. Ugyanígy a karakterkészlettel is, UTF-8-ra van konvertálva mind, és így van tárolva.
-
Taci
addikt
Szerintetek hogyan jobb adatbázisban tárolni az adatokat?
Adott mondjuk egy sztring, ami a forrásból idézőjellel jön, pl.:
Az almaecet "finom" és egészséges.1. opció:
Ezt tároljam így, ahogy van, majd a megjelenítésre adjam át htmlspecialchars() segítségével?2. opció:
Eleve már htmlspecialchars() használatával tároljam le? Így ez kerülne az adatbázisba:
Az almaecet "finom" és egészséges.Ez utóbbinál a keresésben látok problémát (ami persze nem megoldhatatlan), mert itt ha arra keresnek rá, hogy "quot", akkor minden idézőjelet helyettesítő html entity-re is találatot fog adni.
Így (egyelőre csak a keresés miatt) az 1. opciót tartom jobbnak, de szeretném kikérni a ti véleményeteket is. Melyik az ajánlott, bevált út? És hogy esetleg ha van még valami "jó ha tudom" dolog, azt is szívesen venném.
Köszönöm.
-
Taci
addikt
válasz
sztanozs
#20796
üzenetére
Igen, persze.
Egy "PHP Fiddle"-szerű helyen meg is csináltam egy kipróbálható és szerkeszthető példát: [link]
@disy68: Igen, és az alapján
Alenne azAkarakter. [link]
A "baj" az, hogy a böngésző értelmezni tudja, aA-bőlAkaraktert fordít, és így értelmezni is tudja. Ezt szeretném én is "elkapni", ellenőrizhetővé tenni, de nem megy. -
Taci
addikt
válasz
pelyib
#20793
üzenetére
De király, köszönöm, ez nagy segítség lesz (FILTER_VALIDATE_URL).
A lenti problémát viszont továbbra is meg szeretném oldani.
@sztanozs:
Sajnos a html_entity_decode sem működik (írtam is az eggyel korábbi hozzászólásban).Még egy furcsaság:
$link = "A";$dirty_content = "a";$link = htmlspecialchars($link);if (stripos($link, $dirty_content) !== FALSE){echo "XSS-találat";}Erre meg bejelez...
De hát pont hogy a _decode-nak kellene ezt csinálnia... De nem, a _decode szépen kiírja, hogy ez bizony azAkarakter, viszont a változónak továbbra sem ez az értéke.Nagyon nem értem, mi folyik itt.
-
Taci
addikt
Bocsánat a sok posztért, de igazából ez az egy probléma, ami megakaszt csak (és ez most XSS-től független, lehetne itt a string tartalma
Almafa(Almafa) is, ugyanúgy nem menne):$link = "jAvascript:alert('Hacked!')";$link = htmlspecialchars_decode($link);echo $link;
Ez kiírja, hogy:jAvascript:alert('Hacked!')
És az oldal forrásában is ez van. Tehát aA-et visszaalakítottaA-ra.Viszont magának a változónak mégsem ezt adja értéknek, ott megmarad a A karakteres.
És ebbe az if-beif (stripos($link, $dirty_content) !== FALSE){echo "XSS-találat";}
csak akkor lép be, ha$dirty_content = "jAvascript:";
arra nem, hogy$dirty_content = "javascript:";(se jAvascript-re persze)Ennek az egy rejtélynek a feloldásában kérnék csak segítséget, mert akárhogy keresem, próbálom, nem megy, nem értem.
-
Taci
addikt
Amúgy ajánlják ezt a fajta megközelítést is:
Another good prevention method is user’s input filtering. The idea of the filtering is to search for risky keywords in the user’s input and remove them or replace them by empty strings.
Those keywords may be:
<script></script> tags
Javascript commands
HTML markupÁrtani mindenesetre nem fog.
Ezt le tudom kezelni:
$link = "%3cScriPt%3ealert('Hacked!')%3c/script%3e";
(<ScriPt>alert('Hacked!')</script>)
mert először is visszaalakítom:$link_urldecode = urldecode($link);
aztán máris működik rá a keresés:$dirty_content = "<script>";if (stripos($link_urldecode, $dirty_content) !== FALSE){echo "XSS-találat: " . htmlspecialchars($dirty_content);}Ezt viszont továbbra sem tudom visszaalakítani:
$link = "jAvascript:alert('Hacked!')";(jAvascript:alert('Hacked!'))
Se az urldecode(), se a htmlspecialchars_decode(), se a html_entity_decode() nem alakítja át ezt:Оzzé:A.Ez alapján ez HEX. Jó lehetne az urldecode() ide is, de az csak az
\X41-re ugrik be, aA-re nem.Nem foglalkoznék ez utóbbi esettel, csak hát ha az adatbázisban az egyik bejegyzés linkjét kicserélem erre
jAvascript:alert('Hacked!'), akkor bizony kattintás után egyből látszik, hogy ha a böngésző nem fogná meg (about:blank#blocked), akkor futna, tehát valid kód. -
Taci
addikt
válasz
sztanozs
#20787
üzenetére
Arra gondoltam, megcsinálom azt, hogy szűröm az adott kontextusban rosszindulatúnak számító kifejezésekre, és ha van benne ilyen, akkor megpróbálom "tisztítani" (vagy simán csak skip, mert ha már "fertőzött", akkor valid tartalomrész amúgy sem nagyon lesz benne).
Pl. ha kép linkjét várom, akkor abban nem lehet javascript, onerror, onfocus stb.
Viszont mivel nem csak a
javascript:alert('Hacked!')
valid, hanem ajAvascript:alert('Hacked!')
is, ezért így gondoltam az ellenőrzés (egy részét) megcsinálni:if (stripos(htmlspecialchars_decode($linkToCheck), $dirty_content) !== FALSE){echo "XSS-találat!";}Ettől azt várnám, hogy ha
$linkToCheck = "jAvascript:alert('Hacked!')";
akkor ahtmlspecialchars_decodeezt visszaírjajAvascript:alert('Hacked!')-re,
astripospedig mivel case insensitive, így ha arra keresek, hogy "javascript:"$dirty_content = "javascript:";
akkor sikerül elkapni.De nem, a _decode nem, vagy nem úgy működik, ahogy várnám, és találatot itt továbbra is csak akkor ad, ha a speciális HTML entity-re keresek, pl.:
jAMit rontok el?
-
Taci
addikt
válasz
sztanozs
#20785
üzenetére
Köszönöm (a JS topikban is) a linkeket. Ezeket már megtaláltam, átnéztem, értelmeztem (legalábbis folyamatban van.)
Ha html tagbe illesztesz be, akkor mindent célszerű kódolni, ami nem lehet URL-ben...
Itt erre gondolsz?
htmlspecialchars()&(ampersand) becomes&"(double quote) becomes"'(single quote) becomes'<(less than) becomes<>(greater than) becomes>----------
Az adatbázisba raktározó részt már régen csináltam, így most meg kellett néznem, mi-miért van.
És azt találtam, hogy mivel a különböző források eltérően kezelik a tartalmakat, össze-vissza kapom az adatot. Pl.:
Egyik helyről így kapom:
szöveg első része – szöveg másik része(ez a "hosszabb" kötőjel: –)A másik helyről pedig már így:
szöveg első része – szöveg másik részeUgyanígy az idézőjelekkel is pl.
Ezért eredetileg úgy csináltam, hogy mindegy, melyik forrásból érkezett az adat, így tároltam el:
htmlspecialchars_decode($description, ENT_QUOTES);Megjelenítésre pedig így adtam át:
htmlspecialchars($description, ENT_QUOTES);Ez mondjuk a "hosszabb" kötőjelen pont nem segített, de az a legkevesebb, átíratom majd, ha ilyet talál, írja át normál kötőjelre.
A kérdésem most az lenne, mivel már eléggé bekutyultam magam a sok új infóval és teendővel:
Ez-e a jó irány, hogy
htmlspecialchars_decodehasználatával tároljam, és a megjelenítéshez menjen ahtmlspecialchars?
Vagy eleve már a decode --> encode után kaptottat tároljam?Bocs, ha túl kézenfekvő dolgot kérdezek, de már nem látok tisztán.
Ez egy tisztább példa lesz:
$description = "&" . ' "' . " '" . " <" . " >" . " –"
. " &" . " "" . " '" . " <" . " >" . " –"
. " <b>bold text</b>";
Tehát mindkét változatban megkapom ezeket a karaktereket. Nekem ami fontos lenne, hogy:
- kijelezve "szépen" legyenek
- viszont a kódolás miatt ahtmlspecialcharsis használva legyen.Ezt jelenleg így tudom elérni.
$description = htmlspecialchars_decode($description, ENT_QUOTES);$description = htmlspecialchars($description, ENT_QUOTES);echo $description;
Kivéve a hosszabb kötőjelet, de az nem érdekel.
Az output:& " ' < > – & " ' < > – <b>bold text</b>Mentsem akkor ezt a tartalmat (előbb dekód, aztán kód) az adatbázisba, és simán adjam át a HTML kódba illesztésre?
Bocs a hosszú megfogalmazásért.
-
Taci
addikt
Eljutottam oda, hogy az XSS elleni védelemmel is foglalkozni tudjak. Mivel egyelőre csak 1 user inputos rész van a weblapon, ez pedig a kereső, a kliens oldali része miatt a Javascript-topikba írtam.
Viszont aztán beugrott, hogy mivel RSS-csatornák tartalmával dolgozom, kvázi azok is külső források, amikből származó tartalmat ugyanúgy fenntartásokkal kell kezelnem. Hiszen ha a külső forrást támadják, és mondjuk átírják kártékony kóddal az RSS tartalmát, akkor ha ellenőrzés nélkül tárolom és használom az onnan származó adatokat, akkor azzal én is "fertőződöm".
Ennek szeretnék így hát elébe menni.
Ezeket az adatot szúrom be (jelen pillanatban ellenőrzés nélkül) a HTML kódba, ami ezekből a külső RSS forrásokból származik:
- cikkhez tartozó link
- képhez tartozó link
- cikk címe, leírásaItt ugye pl. az <img> tagnél lehet máris probléma, amit egyből reprodukálni is tudtam, mert ha az
<img src="után egy eltérített "link" kerül be (pl.:http://url.to.file.which/not.exist" onerror="alert('Hacked!')"), akkor máris bajban vagyok.
És ez ugyanúgy igaz lehet millió másik tagre, képnél, szövegnél, az összes ponton, ahova csak beszúrom ezeket a tartalmakat a HTML kódban.Van esetleg bevált megoldásotok ennek a problémának a kezelésére?
Így első keresésre ezt találtam: Sanitize filtersOlyasmi (talán-)megoldást tudok saját kútfőből, hogy csinálok egy funkciót, ahol az érintett adatokat átszűröm, és kiszedem belőle az összes lehetséges HTML tag-et és event-et. Ez egy hosszú lista lesz, viszont mivel egyik adatban (cikkhez tartozó link, képhez tartozó link, cikk címe, cikk leírása) sem szerepelhet ilyen (illetve leírásban már találtam, de az már ki van szedve), ezért ez talán egy jó módszer lehet.
Aztán olyanra is gondoltam, hogy ha az előbbi ("Hacked") példát nézem, hogy ott (<img src-nál) arra játszanak, hogy maguk rakják a záró idézőjelet (" vagy ' is lehet, gondolom), és utána a saját kódjukat hívják valamilyen event mögé pakolva. Így ha találok egy (elvileg csak) linkben " vagy ' karaktert, akkor azzal kezdődően levágom, és kész.
De ezek ilyen első gondolatos megoldási kísérletek. Ha van esetleg bevált megoldás rá, akkor nem pazarolnám erre az időt.
Köszönöm.
-
Taci
addikt
Működik szépen.
Arra kellett figyelni, hogy ha lett volna más paraméter is az id-k után, akkor a "..." operátor használata után azokat már (valamiért) nem engedte felsorolni (Cannot use positional argument after argument unpacking). Így azt úgy oldottam meg, hogy az elején csináltam egy tömböt, azt szépen sorban feltöltöttem minden változóval (push) és tömbbel (array_merge), amit paraméterként át akarok adni, és így a bind_param() funkcióban már csak ezt az új tömböt kellett átadnom.
Hátha ez később segít majd valakinek. -
Taci
addikt
-
Taci
addikt
7.3-as PHP-n vagyok (tesztgép).
Így viszont:
PHP Parse error: syntax error, unexpected '...' (T_ELLIPSIS)
(Elvileg 7.4-től működik csak a ... operátor.)Hogyan tudnám ezt helyettesíteni 7.3-ason?
Illetve hát nem értem. Itt azt írja, hogy ez az operátor már 5.6-os verzió óta működik.
-
Taci
addikt
Ezt a ...-os részt nem nagyon értem. (vagy csak megerősítésre lenne szükségem)
Eredetileg így hívtam (példa):
$stmt->bind_param("i", $limit);Most, hogy belekerül az id-s rész is, első próbálkozásra így hívnám (példa):
$stmt->bind_param("i" . $bindString, $limit, ...$idArray);Ez így jó lehet?
Mert ha jól értem, úgy kellene működnie, hogy ha mondjuk a $bindString-ben van három id-hoz tartozó integer-jelölés ("iii"), akkor ez egyenértékű lenne ezzel:
$stmt->bind_param("iiii", $limit, ...$idArray);Az első "i" menne a $limit változónak, a maradék háromhoz pedig elvileg a ...-tal "rendelné hozzá" az $idArray elemeit.
Szóval ha a $limit = 4, az $idArray = array(0,1,2);
akkor ezzel lenne egyenértékű:$stmt->bind_param("iiii", 4,0,1,2);Jól látom? Helyes lehet a hívás?
$stmt->bind_param("i" . $bindString, $limit, ...$idArray);
Ha nem, kérlek, javítsatok ki.Köszönöm.
-
Taci
addikt
Kifutottam a szerkesztési időből. Nem bind_params, csak bind_param.
És ahogy látom a leírásában
bind_param(string $types, mixed &$var, mixed &...$vars)
a típusok ($types) valóban sztring típusú, szóval akkor generálhatom is kedvem (szükség) szerint. -
Taci
addikt
$bindString = str_repeat('i', count($ids));$stmt->bind_params($bindString, ...$ids);Nem is tudtam/gondoltam, hogy a paraméter típusát jelölő karaktereket generálni is lehet...
Tehát ha mondjuk három elemű az id-kat tartalmazó tömböm, akkor generálok három i betűt ("iii") és kész?
Na amint a közelében leszek, megnézem, hogy tényleg ennyire egyszerű lenne-e...@Mike: Igen, átgondoltam, és azok kívülről érkeznek. Saját JS kódból, de akkor is kívülről. A kliensen generálódik, onnan jön - szóval abba bele lehet nyúlni.
@nevemfel: Igazából minden más tökéletesen működik vele, már csak ennyi hiányzik. Szóval ha nem muszáj, nem váltanék. Szóval ha csak a bonyolultsága miatt érné meg a PDO (és a linkelt cikkből így látom, és korábban más forrásból is néztem már a különbségeket), akkor ha már egyszer megírtam így, és jól is működik, nem bántom.
Köszönöm.
-
Taci
addikt
Mármint hogy ne legyen paraméterezés? Vagy nem értem. Pont a paraméterezés lenne a lényeg, mert így ha valahogy az egyik érték helyére bejuttatnak egy kártékony kódrészletet, akkor bajban leszek. (a pár hozzászólással ezelőtt tárgyalt SQL injection-támadhatóság)
Azt látom itt problémának, hogy ugye mivel dinamikusan változik a változók száma, nem tudom ráhúzni a sémát, és simán beírni, hogy
$stmt = $mysqli->prepare("... WHERE id NOT IN (?,?,?)");$stmt->bind_param('iii', 0,1,2);(vagy változókkal, most mindegy, csak példa)És így ha valamelyik érték helyett bekerül egy "rossz kód", akkor általa támadva lehetek.
Ugye erre lenne védelem a paraméterezés, csak mivel változó, hogy mennyi elem van ennél a résznél átadva, nem tudom, hogyan lehet paraméterezni. -
Taci
addikt
bind_param, ezzel kapcsolatban kérdeznék.
Adott egy olyan lekérdezés, amiben van egy változó tartalmú rész, pl.:
WHERE id NOT IN (0), máskor NOT IN (0,1,2,3), vagy NOT IN (0,1,2,3,4,5,6,7,8,9) stb.Tehát a zárójelen belül lehet akár 1, akár 11 érték is, változó.
Ha simán csak stringként adom át, akkor nem működik. Pl.:
$id_list = "0,1,2,3,4,5,6,7,8,9";$stmt = $mysqli->prepare("... WHERE id NOT IN (?)");$stmt->bind_param('s', $id_list);(Nincs előttem a kódom most, de kb. így lehet. Plusz azok az id-k belső kódból jönnek, így lehet, le sem kellene védenem őket, de talán jobb lenne biztonságban tudni.)
Itt látok pont most talán egy ide illő megoldást: ReflectionClass (sose láttam még).
https://www.php.net/manual/en/mysqli-stmt.bind-param.phpComing to the problem calling mysqli::bind_param() with a dynamic number of arguments via call_user_func_array() with PHP Version 5.3+, there's another workaround besides using an extra function to build the references for the array-elements.
You can use Reflection to call mysqli::bind_param(). When using PHP 5.3+ this saves you about 20-40% Speed compared to passing the array to your own reference-builder-function.
Example:
<?php$db = new mysqli("localhost","root","","tests");$res = $db->prepare("INSERT INTO test SET foo=?,bar=?");$refArr = array("si","hello",42);$ref = new ReflectionClass('mysqli_stmt');$method = $ref->getMethod("bind_param");$method->invokeArgs($res,$refArr);$res->execute();
?>Otthon utána olvasok majd (munkanap végén).
Van ezzel tapasztalatotok? Hogyan lehetne ezt megoldani?











 , de ez tényleg a legelső találkozásom szinte mindennel, amikről eddig beszéltünk, és nem szeretném "rosszul kezdeni", érteni szeretném a miérteket.
, de ez tényleg a legelső találkozásom szinte mindennel, amikről eddig beszéltünk, és nem szeretném "rosszul kezdeni", érteni szeretném a miérteket.
 (Öregszem, plusz már a betűk is összemosódnak ilyenkor.)
(Öregszem, plusz már a betűk is összemosódnak ilyenkor.)




 Csak jó lenne tudni ki is használni.
Csak jó lenne tudni ki is használni.  .
.Új hozzászólás Aktív témák
- One mobilszolgáltatások
- TCL LCD és LED TV-k
- Az AI-piac kivégezte a Micronhoz tartozó Crucialt
- Vivo X300 Pro – messzebbre lát, mint ameddig bírja
- Azonnali fotós kérdések órája
- World of Tanks - MMO
- ASUS routerek
- Ha a koreaiakon múlik, még évekig ingünk-gatyánk rámehet a memóriákra
- Sony MILC fényképezőgépcsalád
- Projektor topic
- További aktív témák...

- KFA2 RTX 2060 Super 8GB
- Ryzen5 5600X/ RTX 3060Ti/ 32GB DDR4 alapú konfig/ garancia/ ingyen foxpost
- Apple MacBook Air 13 M1 8GB RAM/256 SSD Asztroszürke
- 4ÉV GAR!! Lenovo X1 Carbon 11th Gen OLED KIJ. i7-1365U 16GB/512GB Intel Iris Xe Graph Magyar v.bill
- iPhone 16e 128GB One/Voda "ÚJ" 2026.05.18. Apple jótállás
- Bomba ár! Lenovo IdeaPad Slim 3 - i7-13620H I 16GB I 512SSD I 15,6" FHD I HDMI I Cam I W11 I Gari!
- Lenovo Thinkbook 16 G6 WUXGA IPS Ryzen7 7730U 16GB 512GB SSD Radeon RX Vega8 Win11 Pro Garancia
- Lenovo magyar laptop billentyűzetre van szükséged? Akármelyik verzióban segítünk!
- REFURBISHED - DELL Performance Dock WD19DCS (210-AZBN)
- Samsung Galaxy S22 8/128 GB Phantom White ÚJ, gariban cserélt! 6 Hónap Jótállás
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: BroadBit Hungary Kft.
Város: Budakeszi