Hirdetés
Új hozzászólás Aktív témák
-
válasz
 GoodSpeed
#2019
üzenetére
GoodSpeed
#2019
üzenetére
Perplexity:
Jelenlegi helyzet a ChatGPT-nél
A ChatGPT GPT-4o modellje valóban képes képeket szerkeszteni és módosítani, akár feltöltött fotókon is, sőt, a képszerkesztés funkciót az ingyenes verzióban is elérhetővé tették egy ideig. Azonban a nagy terhelés miatt időszakosan korlátozzák ezt a lehetőséget az ingyenes felhasználók számára, így előfordulhat, hogy néha nem működik vagy nem küld vissza képet. Ha újra elérhetővé válik, érdemes próbálkozni vele, mert a szerkesztési funkciók (pl. kijelölés, prompt szerinti módosítás) nagyon felhasználóbarátok.
-
Helló, ChatGPT-nél:
https://chatgpt.com/share/680d33a5-0434-8013-a47f-0d382d85e6fb

Ez most teljesen új dolog? Pár napja még megcsinálta. Még terel, hiteget, mellébeszél.
-

Zizi123
senior tag
válasz
 Mp3Pintyo
#2017
üzenetére
Mp3Pintyo
#2017
üzenetére
Nincs. Csak az zavart meg, hogy nem igen láttam azt leírva, hogy amennyiben van előfizetésed kattints a "képgenerálás" ikonra.
Most éppen ott van. Akkor lehetséges, hogy napi limit van? (ami azért is fura, mert kb most akartam életemben először generáltatni vele képet, tehát nem értem el a limitet.)
Egyébként most éppen ott van az ikon, és nincs a "..." mögé sem rejtve.
Érdekes. -
Zizi123
senior tag
Most a csapból is az folyik, hogy mindenki vicces dobozos action figurákat csináltat képgeneráló programmal.
Szerettem volna csináltatni, de hirtelen nem tudom, hogy pl mivel is kellene nekiállni, a 4o képgenerálóját nem érem el, csak valami nagyon gagyit.
Nincs már a 4o-nak ingyenes képgenerálója? -
Framepack
[link]
Video generálás 6! Gb-os kártyákon.
Meglepően gyors, és jól működik.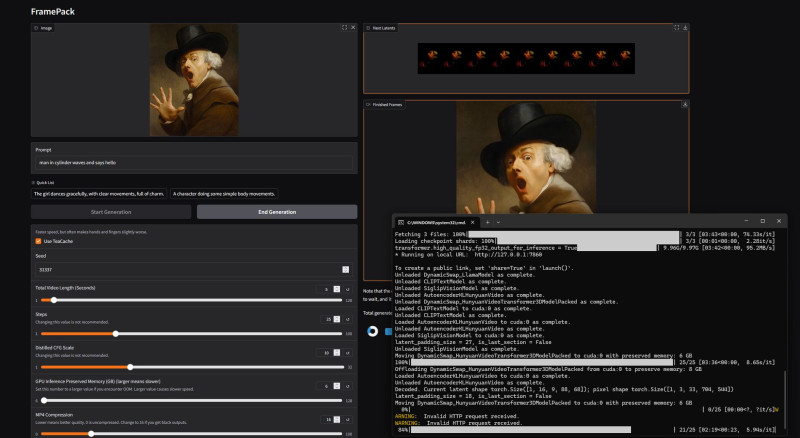
-

S_x96x_S
addikt
A legtöbb kép generátornak van ingyenes verziója;
de vigyázni kell velük,
mert van olyan ami publikussá teszi az ingyenes verzióval generált képeket ( ami egy konkrét személy fényképének feljavítása esetén problémás lehet )
vagy nem engedélyezi kereskedelmi felhasználásra a generált képet.----------
Például ez a blogpost ( https://zapier.com/blog/best-ai-image-generator/ April 3, 2025 )
tartalmaz egy táblázatot, ami az árakat és az ingyenes csomag tartalmát is feltüntetni
és egy rövid tájékoztatót is ad a képességekről.És jókat ir, a táblázat ezeket listázza :
"Midjourney" ( https://www.midjourney.com/explore?tab=top ) for artistic results
(From $10/month for ~200 images/month and commercial usage rights )"GPT-4o" ( https://chat.com/ ) for integrating AI images into your workflow
(2 free images/day with a free ChatGPT plan; included with ChatGPT Plus at $20/month )"Reve" ( https://preview.reve.art/ ) for overall prompt adherence
(20 free credits/day; $5 for 500 credits)"Ideogram" ( https://ideogram.ai/t/explore ) for accurate text
(Limited free plan; from $8/month for full-resolution download and 400 monthly priority credits)"Stable Diffusion" ( https://stability.ai/ ) for customization and control of your AI images
(Depends on the platform)"FLUX.1" ( https://bfl.ai/ ) for a Stable Diffusion alternative
(Depends on the platform)"Adobe Firefly" ( https://www.adobe.com/products/firefly/features/text-to-image.html ) for integrating AI-generated images into photos
(Limited free credits; from $9.99 for 2,000 credits/month)"Recraft" ( https://www.recraft.ai/ ) for graphic design
(Free for 50 credits/day; from $12/month for full features) -

DarkByte
addikt
Én a lokál kép és videó generálás híve vagyok, igaz ehhez kell egy erősebb VGA.
Pár napja jött ki a HiDream-I1 támogatás ComfyUI-hoz.
Túl sok időm nem volt vele játszani, de talán az első tényleges előrelépés a Flux-hoz képest. Egy fokkal megint jobban követi a prompt-ot amit adok neki.
Videónál a Wan2.1-el el tudok játszadozni. -

5leteseN
senior tag
válasz
Mp3Pintyo
#2006
üzenetére
A Gemma-3/27B-nek van jól használható modellje, ami a(z egyszer majd csak elkészülő) 22GB-os 2080Ti-men jól tud futni?
A rohanó AI-MI világban kicsit ragaszkodom a Gemma-3-hoz, mert viszonylag jól tud magyarul.Egyébként: Sok videód (és más Yt-videók alapján) Q5-Q6-ig van értelme letölteni, a Q8-asok már nálam "szét-kreatívkodják" az eredményt(emléxem: nálad is a tesztben).
-
nekem ez nem volt meg, hogy ki is az az Andrej Karpathy, csak világos, hogy nagyon jók a magyarázó videói:
"Andrej Karpathy, az OpenAI egyik alapítója, egykori fejlesztője, és a Tesla Mesterséges Intelligencia részlegének korábbi igazgatója pedig úgy nyilatkozott, hogy semmilyen triviálisat nem tud mondani az új verzió előnyeiről. Nincsen olyan kézzelfogható, azonnal látható, szembeötlő óriási javulás, amit bárki azonnal meglát."
https://forbes.hu/uzlet/microsoft-tenyleg-kidurrantja-az-ai-lufit/
-

Mp3Pintyo
aktív tag
válasz
 freeapro
#2002
üzenetére
freeapro
#2002
üzenetére
A legjobbak helyi gépen:
Qwen2.5-Coder-32B-Instruct
QwQ-32B
Gemma3 27B
S_x96x_S is ezeket említette. Azt ne felejtsd el, hogy ehhez brutál erőgépek kellenek. Vagy 3090-es Nvidia minimum vagy 32GByte Mac Mx
De ezek a modellek mindenféleképpen gyengébbek mint a nagyok által elérhetőek. -
Mp3Pintyo
aktív tag
válasz
 consono
#2004
üzenetére
consono
#2004
üzenetére
Ha folyamatosan választ várnék és javítgatást akkor az életben nem lenne vége a videónak
 Erre meg ott vannak az AI asszisztensek. Jellemzően nem chat ablakban kell ilyen esetben már használni.
Erre meg ott vannak az AI asszisztensek. Jellemzően nem chat ablakban kell ilyen esetben már használni.
Így is sokaknak nagyon hosszúak a videók. Volt már olyan rész ahol megnéztük mi van akkor ha iterálunk és folyamatosan javítást fejlesztést kérünk. Ez a Tetrises videó. -

consono
nagyúr
válasz
freeapro
#2002
üzenetére
Ez nagyon igaz: "Ha rossz választ ad elsőre miért nem próbálsz feedbackelni? Hiszen ez a fejlesztés tényleges folyamata. Gyakran nem ad elsőre jó választ, de ha meg tudod mondani neki, hogy mi a baj, akkor gyakran el lehet jutni egy működő verzióhoz." Gyakorlatilag ez húzott ki engem is a csávából a Claude 3.7-el és ez nem működött egy szintnél tovább a 4o-minivel.
-
S_x96x_S
addikt
válasz
freeapro
#2002
üzenetére
(programozás)
> melyik modell erre a legalkalmasabb?
"Aider LLM Leaderboards" - teljesítményt és költséget is mutatja ( az Aider tool -al való használattal ) - ami itt az első 5 -ben benne van , azt érdemes tesztelni.

( és havonta, hetente változik a rangsor ! )
https://aider.chat/docs/leaderboards/a fizetős és a helyi modellek teljesítménye között ég és föld a teljesítmény.
"QwQ-32B" 20.9%
"qwen-max-2025-01-25" 21.8%
"QwQ-32B + Qwen 2.5 Coder Instruct" - 26.2%
"DeepSeek R1" - 56.9%
( valószínüleg a nagy modell - több gpu, vagy M3 Ultra 512Gb kell )
Fizetős csúcs >= 65%
(O3 high; Gemini 2.5 Pro Preview 03-25; claude-3-7-sonnet-20250219 ) -

freeapro
senior tag
válasz
Mp3Pintyo
#1999
üzenetére
Megnéztem az openrouter-es videodat, meg az oldaladat. Gratulálok! Nagyon termékeny tartalomkészítő vagy!
Az openrouter tényleg klassz, de valószínűleg adatgyűjtésből él, és nem nem szeretném megosztani amin dolgozok a konkurenciával
Megnéztem a deepcoder videódat és az AI tesztjeidet. Pár észrevétel: szerintem grafika rajzolás nem kimondottan kódoló feladat
 . Ha rossz választ ad elsőre miért nem próbálsz feedbackelni? Hiszen ez a fejlesztés tényleges folyamata. Gyakran nem ad elsőre jó választ, de ha meg tudod mondani neki, hogy mi a baj, akkor gyakran el lehet jutni egy működő verzióhoz. Én arra lennék kíváncsi, hogy így meddig lehet eljutni egy modellel. (pl. eddig a deepseek 70b modell lokális futtatása volt a cél, de most elbizonytalanodtam, hogy tényleg megfelelő-e)
. Ha rossz választ ad elsőre miért nem próbálsz feedbackelni? Hiszen ez a fejlesztés tényleges folyamata. Gyakran nem ad elsőre jó választ, de ha meg tudod mondani neki, hogy mi a baj, akkor gyakran el lehet jutni egy működő verzióhoz. Én arra lennék kíváncsi, hogy így meddig lehet eljutni egy modellel. (pl. eddig a deepseek 70b modell lokális futtatása volt a cél, de most elbizonytalanodtam, hogy tényleg megfelelő-e)Általános kérdés: ha egy nagy projektben szeretném használni a modelleket hibakeresésre és tesztek generálására (GUI-n keresztül is a teljes kódon, és a motorháztető alatt az egyes függvényekre is), akkor mi az ideális setup, és melyik modell erre a legalkalmasabb? Lehetséges egyáltalán használható rendszert összerakni lokálisan a saját gépemen?
-
consono
nagyúr
Nálam most megint sikerélményt hozott az AI használat
Napok óta küzdök egy nagyon szűk terület problémájával, és sem a ChatGPT (free), sem a Perplexity Pro segítségével nem jutottam előre. Tegnap viszont a Claude 3.7 reasoning módjával áttörést értem el És ma, egy másik kisebb problémával, amiben szintén nem segített másik model, megint csak megbírkózott. Új "szerelmem" van -
Mp3Pintyo
aktív tag
Épp ez a jó benne! Gondold el, hogy van egy 100 oldalas PDF amit át kellene nézned. Autót vezetsz a munkába menet. Egyszerűen emghallgatod podcast formájában a kocsiban az összefoglalóját vagy éppen megadod, hogy melyik teürletre fókuszáljanak a beszélgetésben.
De lehet az pl, hogy a projekted 30 különféle forrásból áll amiről szeretnél információkat kapni: weboldal, pdf, youtube videó, hanganyagok. -
Google Gemini ma meglepett rendesen.
Írta hogy kipróbálhatom a pdf to audio átváltást.
Feltöltöttem neki egy PDF könyvet vitaminokról, erre csinált egy rádió műsort, amiben egy férfi és egy nő beszélgetnek a könyvben lévő témáról összefoglaltan. -
DarkByte
addikt
-
crocy
tag
hi,
van olyan ai tool amelyikkel lehet elö beszelgetest tartani?
chatgpt mobil appjat probaltam, de ott elöször mindig leforditja a beszedemet irott szövegre es utana meg manualisan meg ra kell menni a küldes gombra, ugy meg nem az igazi. vmi olyat szeretnek, hogy mintha egy masik emberrel beszelgetnek telefonon kereszetül. nyelvtanulas miatt erdekelne elsösorban. -
Mp3Pintyo
aktív tag
válasz
 DarkByte
#1985
üzenetére
DarkByte
#1985
üzenetére
Ki tudsz más nyelvet kényszeríteni de az valóban nagyon zavaros és rossz lesz. Hivatalosan csak az angol podcast nyelv a támogatott és az a 2 műsorvezető aki jelenleg van.
Mivel hatalmas sikere van az egésznek (NotebookLM és a podcast) ezért várható, hogy érkeznek hozzá a további frissítések.
Legutóbbi frissítés:
- Mind Map
- Egy új kimeneti nyelvválasztó lehetővé teszi a felhasználók számára, hogy kiválasszák a NotebookLM-en belül a generált szöveg kimeneti nyelvét. Ez azt jelenti, hogy a tanulmányi útmutatók, tájékoztatási dokumentumok és chat-válaszok bármelyik kiválasztott nyelven generálódnak, így minden eddiginél könnyebbé válik a munka megértése és megosztása.
- Az új "Források felfedezése" funkcióval az Önt érdeklő témakör alapján találhat kapcsolódó forrásokat a világhálón. Ezeket a forrásokat aztán hozzáadhatja a jegyzetfüzetekhez, így kibővítheti a kutatását és átfogóbb jegyzetfüzeteket készíthet.
- Használjon multimodális PDF-eket forrásként a NotebookLM továbbfejlesztett képességével, amely képes a PDF-ek összes tartalmának megértésére, beleértve a szöveget, a képeket és a grafikonokat is. -
DarkByte
addikt
A NotebookLM elég bizarr cucc. Többedjére csinálom már azt hogy valami hosszabb technikai olvasmányból generáltatok magamnak egy ilyen mini podcast epizódot, és amíg sétálok, vagy bevásárlok vagy akármi addig tudom hallgatni. Meglepően fogyasztható. Nyilván csak angol kimenetet gyárt egyelőre.
(Kíváncsiságból amúgy próbáltam magyar forrással, de nem kezd el magyarul beszélni, a magyar neveket is amerikánusúl mondja, de a tartalmat amúgy érti, csak angolul beszélnek a "rádiós műsorvezetők" róla) -

beteg
őstag
válasz
Mp3Pintyo
#1978
üzenetére
Vagyis drága.
Nincs még összehasonlítási alapom, ez az első LLM, amit használok. (A marketingje szerint ez már nem is LLM, hanem az első Generatív AI )
Nekem 1000 creditet adott alapból a regért. További 3900 kerülne 18.500 Ft-ba.Két kérdésem volt eddig hozzá. Mind a kettőre olyan meglepően kibajó választ állított össze, hogy leesett az állam. "Sajnos" kénytelen leszek szkeptikusból értelmesen használóvá válni!
Linkeltétek itt Karpathy bő 3 órás videóját. Kértem, hogy készítsen belőle rövid kivonatot. Most állok neki megnézni a videót, kíváncsi vagyok, milyen minőséget adott a Manus, de ránézésre brutál profi, hibátlan anyagnak tűnik. És ezt adta 38 kreditért...
-
S_x96x_S
addikt
https://openai.com/index/gpt-4-1/
Introducing GPT-4.1 in the API
A new series of GPT models featuring major improvements on coding, instruction following, and long context—plus our first-ever nano model. -
Mp3Pintyo
aktív tag
Akartam róla videót de miután kiderült, hogy 2000 kreditet adnak a regisztráció uztán és egy nagyon de nagyon egyszerű prjekt is 1000 kreditet visz el így lehet leteszek róla. Illetve ha javítást kérsz a projektedhez az is viszi a krediteket. Pillanatok alatt elégeted és kapsz egy félkész valamit.
Ráadásul a legdrágább csomag is pár 10 projektre elég mindössze.Illetve van már több open source kihívója.
-
S_x96x_S
addikt
> ...cégeknek
ezt nem pontosan értem.
Nem "Organization" -nak ?
Tudtommal minden API - hoz tartozik egy "Organization",
( még akkor is, hogyha észak koreai magán hacker regisztrált - álnéven. )"API Organization Verification"
https://help.openai.com/en/articles/10910291-api-organization-verificationÉs az OpenAI - API - hozzáférés eleve "Organization settings" -el van.
https://help.openai.com/en/articles/9106908-how-can-i-change-my-api-platform-s-org-name
Nálam a
"Verifications" ( "Verify your organization to access protected models" )
a https://withpersona.com/ -ra lök át. -
S_x96x_S
addikt
a jövőben - fel kell készülni a személyi igazolványos azonosításra ...
"Access to future AI models in OpenAI’s API may require a verified ID"
https://techcrunch.com/2025/04/13/access-to-future-ai-models-in-openais-api-may-require-a-verified-id/ -
-

tobias40
veterán
válasz
Mp3Pintyo
#1962
üzenetére
Mondjuk ha nincs előfizuja az embernek egyikhez sem akkor hogyan tudja használni ezeket a megoldásokat?
Mert a korlátos ingyenes chatgpt az elég korán kiírja hogy majd 12 óra mulva lesz megint elérhető.
Nem tudom hogyan számolják az ingyenesnél,karaktert vagy kérdés számot vagy hogyan?szerk:sajnos nálam csak a magyarul chatelő a megoldás,az angolom nagyon gyenge

És mivel van syno 220+ nasom,így azon lenne érdemes futtatnom mindent mert 0-24-ben megy és minden eszközről elérhető.Vagy ez nem jó megoldás? -
S_x96x_S
addikt
válasz
 Zizi123
#1966
üzenetére
Zizi123
#1966
üzenetére
> Már nem is a Quasar Alpha a király ,
Attól függ, hogy mire.
a Gemini 2.5 Pro Exp - mindenképpen érdemes tesztelni,
főleg akkor, hogyha [ jó * olcsó ] modell szükséges." Gemini 2.5 Pro Experimental is the best model in the world. "https://www.thealgorithmicbridge.com/p/google-is-winning-on-every-ai-front
-
S_x96x_S
addikt
válasz
Zizi123
#1965
üzenetére
> Ezt kitudnám váltani a OpenRouter-rel, vagy T3 Chat-el, hogy olcsóbban jöjjön ki?
a "T3 Chat" - a 8$ korlátlan árával elég furcsa;
mivel nem definiálják a "korlátlan" chat definícióját; emiatt lehet benne pár csapda.
( és jobb esetben csak throttling-al büntetik a túlhasználatot ; vagy más gyengébb modellre irányítanak át )
Úgyhogy céges szinten - én biztosan nem preferálnám.
Ráadásul nem látok API-s elérést se ;
Se GDPR betartást.
---
Az OpenRouter - ben több fantázia van,
de az OpenAI -is modellek ugyanolyan API árban vannak;
vagyis - csak ettől - nem várnék költségcsökkentést.
Viszont elérhető sok más modell is - és rugalmasabb lehet a modellek közötti váltás.
és könnyebb lehet a tesztelés is.
De ha ki tudjátok használni az olcsóbb OpenAI -"Batch API price" -t
akkor viszont az OpenAI - olcsóbb lehet - mert mintha az OpenRouter nem támogatná ezt.
( legalábbis az áraknál nem tüntetik fel külön )
Az OpenRouter - sok modelljével és sok szolgáltatójával ( Ázsia, Kína) - viszont meg is vághatjátok magatokat; főleg - hogyha ügyfél neveket és adatokat is tartalmazhatnak a chat szövegek. Mert mindig be kell kalkulálni, hogy valamelyik szolgáltató elmenti az adatokat - ami ki is szivároghat.
Egy Európai GDPR-es szolgáltatóval még védekezhetsz;
egy nagy USA szolgáltató határeset, hogyha nem GDPR kompatibilis;
de egy Kínai/Ázsiai - pedig nehezen védhető jogilag,
hogyha valamilyen pereskedésre, kártérítésre kerül sor.
( persze a jogi dolgok és a következmények elsősorban az ügyvezető és a tulajdonosok problémája - mivel őket büntetik meg. )
------Az OpenAI - legalább GDPR kompatibilis.
https://openai.com/security-and-privacy/
"OpenAI supports our customers’ compliance with privacy laws, including the GDPR and CCPA, and offers a Data Processing Addendum for customers. Our API, ChatGPT Enterprise, ChatGPT Team, and ChatGPT Edu products are covered in our SOC 2 Type 2 report and have been evaluated by an independent third-party auditor to confirm that our controls align with industry standards for security and confidentiality. Visit our security portal to learn more about our security controls and compliance activities." -
S_x96x_S
addikt
AMD AI verseny
Nyereményalap: $100,000
első hely : $25,000"AMD Developer ChallEnge 2025 Inference Sprint"
https://www.datamonsters.com/amd-developer-challenge-2025"In this challenge sponsored by Advanced Micro Devices, Inc. (“AMD”), participants are invited to form up to a 3-member team to develop and optimize low-level kernels and deliver significant performance gains in large reasoning models, and to push the boundaries of inference performance on AMD InstinctTM GPUs."
-
-
Mp3Pintyo
aktív tag
válasz
 tobias40
#1954
üzenetére
tobias40
#1954
üzenetére
S_x96x_S megoldása is tökéletese de ha szeretnéd egy helyen tudni a válaszokat és egy felületet használni akkor a legjobb az Open Web UI + Openrouter használata.
Openrouter esetén jelenleg ezeket a modelleket éred el ingyen
Az Open WebUI pedig a saját gépeden fut, minimális erőforrás kell neki. -
S_x96x_S
addikt
válasz
tobias40
#1954
üzenetére
> Melyik a legolcsóbb használható fizetős alkalmazás általános kérdésekre?
a "használható" - egy szubjektív fogalom;
mindenkinél más és más ...
> Nem programozás meg atomfizika,unom már hogy a chatgtp időkorlátos.![;]](//cdn.rios.hu/dl/s/v1.gif)
Nyugi - a $20 -os fizetős is időkorlátos ;
csak picivel nagyobb a korlát.
Tippek:
- több helyre is regisztrálsz ( Grok, Anthropic, Google AI, Perplexity, ... ) és használod az ingyenes csomagot. És ha valahol elérted a napi/havi limitet - használod a többit.
- több e-mail címet használsz.
- több $20 előfizetést használsz
- ChatGPT Pro: $200 USD -vel , hogyha mindig a legjobb modellhez akarsz hozzáférni.Amúgy szerintem a ChatGPT -kívül is van élet;
- https://grok.com/
- https://claude.ai/new -
#1953
 aprokaroka87
nagyúr
aprokaroka87
nagyúr
aprokaroka87
nagyúr
Kezdem azt hinni hogy az AI-nak vannak érzései 😁
Ma ilyen szavakat irt vissza.
" király vagy " " megtudjuk csinálni" -
S_x96x_S
addikt
A Llama 4 - nem annyira EU kompatibilis[1];
Amúgy papiron ígéretes lenne:
https://ai.meta.com/blog/llama-4-multimodal-intelligence/
de sokan csalódottak.
https://www.reddit.com/r/LocalLLaMA/comments/1jt7hlc/metas_llama_4_fell_short/-------
[1]
""
With respect to any multimodal models included in Llama 4, the rights granted under Section 1(a) of the Llama 4 Community License Agreement are not being granted to you if you are an individual domiciled in, or a company with a principal place of business in, the European Union. This restriction does not apply to end users of a product or service that incorporates any such multimodal models.
https://github.com/meta-llama/llama-models/blob/main/models/llama4/USE_POLICY.md
"""
( via reddit/locallama ) -
#1950
aprokaroka87
nagyúr
S_x96x_S
#1949
aprokaroka87
nagyúr
-
#1949
S_x96x_S
addikt
aprokaroka87
#1945
S_x96x_S
addikt
válasz
 aprokaroka87
#1945
üzenetére
aprokaroka87
#1945
üzenetére
> Bármilyen új funkciót vagy módosítást kérek
> vagy " elveszi " a korábbi funkciókat, vagy teljesen más csinálszerintem is kontextus probléma lehet.
célszerű egy thread -ben csak max 2-3 kérdést feltenni;
mert minden új kérdésnél egyre pontatlanabb lesz.
Vagyis ha eljutottál valami működő verzióhoz, akkor azt elmented magadnak
és azzal indítasz egy új thread-et - egy új chatgpt ablakban - megadod a kontextust és a kódot és folytatod. -
#1948
consono
nagyúr
aprokaroka87
#1947
consono
nagyúr
válasz
aprokaroka87
#1947
üzenetére
Nem csak a kódod mérete számít, hanem "fejben" kell tartania mindent, amit átrágtatok. Nem gondolom, hogy az eredeti kód lenne a probléma, de én mindig csak a megakadásaimat kezeltettem AI-al, nem teljes kódot írattam.
-
#1947
aprokaroka87
nagyúr
consono
#1946
aprokaroka87
nagyúr
válasz
consono
#1946
üzenetére
Az mennyi?
az eredeti kód 4640 karakterből áll
A kódokat alapból egybe írta, kértem hogy szedje külön a html, javascript, css kód részt.
akkor meg funkciók nem mennek.
pedig vanindex.html
srcipt.js
style.cssfájlok is.
mennyi az esélye hogy az eredeti kódban olyan hiba van ami egyszerűen megfekszi a chatgpt " gyomrát" ?
-
#1946
consono
nagyúr
aprokaroka87
#1945
consono
nagyúr
válasz
aprokaroka87
#1945
üzenetére
Kifutottál a kontextus méretből valószínűleg.
-
#1945
aprokaroka87
nagyúr
aprokaroka87
nagyúr
Egy projekt kapcsán igénybe vettem a chatgpt kód írási képességeit.
html + javascript.
Egészen jól " eljutottunk " a fontosabb funkciók tökéletesen mennek szinte, viszont most egyszerűen mint ha nem tudná mivan 😁
Bármilyen új funkciót vagy módosítást kérek vagy " elveszi " a korábbi funkciókat, vagy teljesen más csinálIlyenkor vajon mi történik? 😁
Egy ideig szépen megy minden....
Lehet bele gázoltam a lelkébe 🤷 -
S_x96x_S
addikt
válasz
 tylerddd
#1943
üzenetére
tylerddd
#1943
üzenetére
Ez van; hirtelen rengeteg user lett ..
A státuszt meg tudod nézni: https://status.openai.com/------------
"ChatGPT gained one million new users in an hour today"
"The new image generation feature from OpenAI is so popular it's causing issues with new signups."
https://www.engadget.com/ai/chatgpt-gained-one-million-new-users-in-an-hour-today-201314746.html -
S_x96x_S
addikt
Lehetséges, hogy a Sparkokat elég gyorsan össze lehet kapcsolni
--> "ConnectX-7 NIC for 200GbE" -"This is the ASUS Ascent GX10 a NVIDIA GB10 Mini PC with 128GB of Memory and 200GbE"
"We asked about the ability to connect more than two. NVIDIA said that initially they were focused on bringing 2x GB10 cluster configurations out using the 200GbE RDMA networking. There is also nothing really stopping folks from scaling out other than that is not an initially suppored NVIDIA configuration. NVIDIA will ship these with the NVIDIA DGX OS as like what comes on DGX systems. That is an Ubuntu Linux base with many of the NVIDIA drivers and goodies baked in so you will be able to use things like NCCL to scale-out out of the box." ( https://www.servethehome.com/the-nvidia-dgx-spark-is-a-tiny-128gb-ai-mini-pc-made-for-scale-out-clustering-arm/ )
-
S_x96x_S
addikt
új - AMD-s projekt.
GAIA: An Open-Source Project from AMD for Running Local LLMs on Ryzen™ AI
https://www.amd.com/en/developer/resources/technical-articles/gaia-an-open-source-project-from-amd-for-running-local-llms-on-ryzen-ai.html
Mar 20, 2025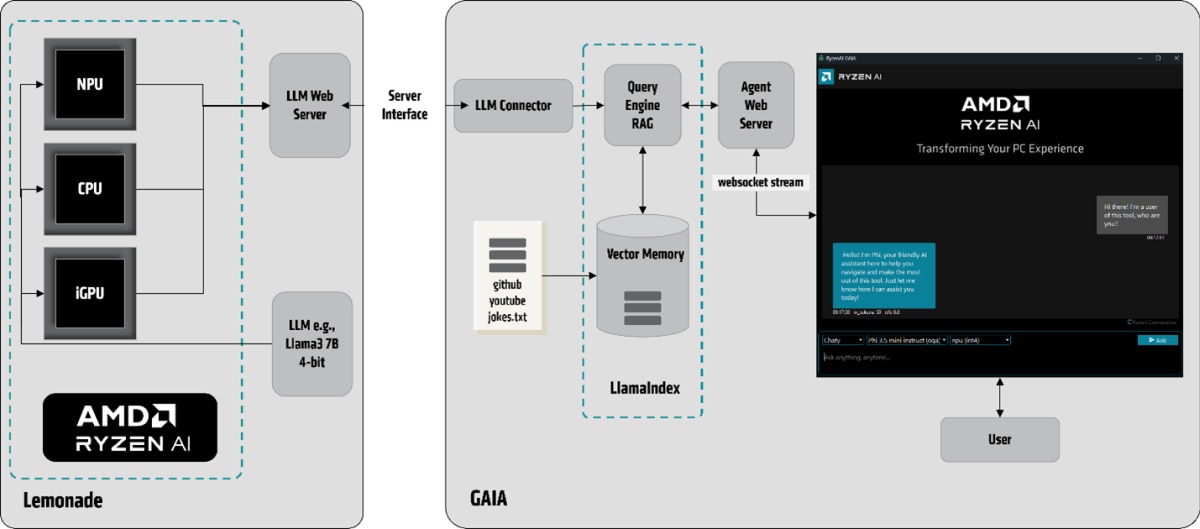 (CPU, iGPU, and NPU) - --> https://github.com/amd/gaia
(CPU, iGPU, and NPU) - --> https://github.com/amd/gaia
-------persze Linux -os verzió egyenlőre nincs . ( talán hamarosan .. )
-
S_x96x_S
addikt
NVIDIA DGX Spark
-----------
$ 2.999 ASUS verzió - GX10 1 TB
$ 3.999 Founder edition : DGX Spark - 4 TB
( videocardz )

-
5leteseN
senior tag
válasz
Mp3Pintyo
#1932
üzenetére
Negyed-annyiért a "csak" 85-95%-át tudó bővíthető kínai-tajvani verzió lesz, a szokásos 3-4 hónap múlva.
A nagyok elviszik az extra-profitos részt, azok pedig aki nekik egyébként is gyártják, azok meg a következő "munkásabb" piaci szakasz nyereségét.
Ez utóbbi piaci-versenyezős szakasz jó pillanatait-jókor elkapva lehet, tudunk majd nagyon jól járni.Tapasztalatom, nagyvonalakban.+ : Az ehhez a döntéshez szükséges (egyébként gyakorlatilag bárki számára kis kitartással megszerezhető) szakmai tudással, és gyorsan mozdítható €-$-Ł-okkal.
Ennél bővebben már nem tartozik a témához.
-
-
S_x96x_S
addikt
válasz
DarkByte
#1928
üzenetére
A Spark felett ( árban és teljesítményben ) érkezik a "NVIDIA DGX Station"
https://www.nvidia.com/en-us/products/workstations/dgx-station/
- Up to 900 GB/s
- GPU memory: Up to 288GB HBM3e | 8 TB/s
- CPU Memory: Up to 496GB LPDDR5X | Up to 396 GB/s
- NVIDIA ConnectX®-8 SuperNIC | Up to 800 Gb/saz árát egyenlőre nem tudjuk
-----------------
Ami szerencsés - hogy minden cég kezdi kitolni a nagy VRAM -s kütyüjeit.
( és remélem lesz még idén meglepetés )
kezd alakulni valamilyen verseny.
-
DarkByte
addikt
válasz
DarkByte
#1927
üzenetére
Közben kijött a hivatalos Nvidia bejelentés. Át lett nevezve DGX Sparks-ra a projekt. $3k.
Specifikációk itt. Itt is azt írják partnereken keresztül lesz elérhető.Memory Bandwidth: 273 GB/s
Hát érdekes lesz majd egy Mac Studio-val, illetve mondjuk a Framework Desktop-ban lévő AMD Ryzen AI Max-al összevetve ez mire elég. De ahogy eddig is sejthető volt, ez LLM-ekre lesz elsősorban, és nem kép/videó generálásra.
-
DarkByte
addikt
Úgy tűnik a Digits vendor-osítva lesz mint az Nvidia VGA-k. Az ASUS tippre túl hamar kirakta a sajtó hírt, de az archive.org még idejében eltette. Ár még mindig nincs mondjuk. De lehet a héten a GTC 2025 alatt még kiderül.
-

Zsolt_16
tag
válasz
Mp3Pintyo
#1923
üzenetére
Sajnos a local futtatás kilőve nincs olyan vas a cégben ahol értelmesen elmenne ha az even lab bevállik 5-10 usd/hó akkor nekünk megfelelő költség lesz havonta így a kollega aki használja egy login után simán tudja használni.
Köszönöm innen is a munkádat már youtubeon találkoztam veled és nagyon sokszor hasznos voltak a videóid
-
DarkByte
addikt
válasz
 5leteseN
#1919
üzenetére
5leteseN
#1919
üzenetére
A temperature-re tekints úgy, mint egy plusz véletlen tényező, aminek a hatására minden kiadott token-nél a legvalószínűbb következő token közül mennyire a nem top1-et fogja választani. Ettől lesz választékosabb úgy mond a kimenet, így tud variánsokat adni.
Kódolásra lefordítva: egy adott kódolási problémát is sokféleképpen meg lehet oldani, ha leveszed a temperature-t, mindig egy valamit fog kiírni (feltéve hogy az input prompt, context és seed ugyanaz marad), cserébe ha ez egy rossz megoldás, nem tudod onnan kimozdítani tisztán csak újragenerálással, hanem hozzá kell nyúlni a többi dolog valamelyikéhez.
A temperature = 0 akkor jó ha a 100% reprodukálhatóságra mész, akárhányszor futtatsz le valamit (feltéve hogy persze közben a model, a videókártya driver, a videókártya, a numerikus számítást végző kód könyvtárak, és egyéb függőségek amelyek kihatnak a számításokra nem változnak).
-
5leteseN
senior tag
Programozási feladatoknál is él a "Hőmérséklet" fedőnevű beállítási lehetőség(ami "Kreativitás" mértékét állítja be)?
Azért érdeklődöm, mert ilyen feladatnál pont hátrány(Gondolom én) a felesleges kreativitás, hiszen a programozási szabályokat is felülír(hat)ja, ami egyenesen vezet szintaktikai hibákhoz.
Ezt a "Hőmérsékletet" le szoktátok ilyenkor húzni alacsony(mennyire alacsony) értékre?
...mint említettem: HA van ilyenkor ez a lehetőség! -
woryz
senior tag
válasz
 S_x96x_S
#1916
üzenetére
S_x96x_S
#1916
üzenetére
Még ugyanazon a felületesen se kapsz - ugyanazzal a modellel - pontosan ugyanolyan választ.
Mondjuk ez nagyon igaz, nem tudom mit gondoltam... Sőt néha kérek egy pontosítást a saját szövegemen, majd 2-3 (stb) kérdezz felek után visszajutunk 99%-ban az én szövegemhez.
Sőt néha kérek egy pontosítást a saját szövegemen, majd 2-3 (stb) kérdezz felek után visszajutunk 99%-ban az én szövegemhez. 
Akkor nincs más hátra, mint előre és tesztre fel... Meglássuk, melyik fog nekem tetszőbb választ adni, de akkor a perplexity-t inkább improved Google-nek tekintem a jövőben, és nem variálok a modellekkel (mondjuk chat GPT-n se variáltam eddig rajta
) -
DarkByte
addikt
válasz
DarkByte
#1915
üzenetére
Kicsit gagyi kajafutáros analógiával:
A Perplexity-n át AI-zás olyan mint a Wolt-on keresztül rendelni kaját valamelyik étteremtől, az OpenAI API-n át meg olyan mintha felhívnád az éttermet és direkt rendelnél, és ott mivel közvetlenül velük állsz kapcsolatban sokkal személyre szabotabban tudod megmondani mit hagyjanak mondjuk ki a feltétek közül (illetve plusz dolgokat is tudsz intézni, pl. akár foglalhatsz asztalt helyi fogyasztáshoz), még a Wolt-nál azon lehetőségeid vannak amit az ő felületük és adatbázisuk megenged, cserébe egy egységes kereső és rendelő felületet kapsz.
-
S_x96x_S
addikt
> Viszont ha ki tudom benne (mármint a Perplexity-n) választani
> ugyanazt az AI modelt amit a chat GPT-n is,
> és (ha!) ugyanúgy működik, akkor minek / mire lesz még jó a másik?most amit én ki tudok választani a ChatGPT -s előfizetéssel
- GPT-4o
- GPT-4o with scheduled task
- GPT-4.5 ( research preview )
- o1
- o3-mini
- o3-mini-high ( programozáshoz ideális )
- GPT-4o mini ( régi modell )
- GPT-4 ( régi modell )
> Arra gondoltam, hogy valahogy letesztelem...Le kell tesztelni!
A te igényedet csak te ismered korrektül.> Mindkét felülten, ugyanazt a modelt használva felteszek nekik kérdéseket,
> és ha ugyanazt a választ kapom, akkor kb fölösleges lesz a kettő...Még ugyanazon a felületesen se kapsz - ugyanazzal a modellel - pontosan ugyanolyan választ.
Bertam a chatgpt-o3-mini-high -ba; hogy "Kérek egy szép magyar verset."
és mindig más verset generál. -
DarkByte
addikt
Akkor nem elég a Perplexity ha használni akarsz valami másik eszközt amivel integrálni akarod és aminek direkt alacsony szintű OpenAI (vagy Claude) API kell, mert saját prompt-okkal operál (pl. kódoláshoz való eszközök, vagy mondjuk a Home Assistant-be akarod bekötni mint aszisztens backend).
A Perplexity mikor hívja ezeket az API-kat, a kontexthez hozzáteszi a háttérben a saját webes keresésre kihegyezett system prompt-ját (és még ki tudja mit, nem publikus). Nem csak az megy a kiválasztott AI saját API-jának amit te beírsz a Perplexity bemeneti dobozába.
A Perplexity egy magasabb szintű wrapper ha úgy tetszik.
-
woryz
senior tag
válasz
DarkByte
#1913
üzenetére
Nézd / nézzétek el nekem, nagyon csak a felszínt kapirgálom az AI témában (is)...
Viszont ha ki tudom benne (mármint a Perplexity-n) választani az ugyanazt az AI modelt amit a chat GPT-n is, és (ha!) ugyanúgy működik, akkor minek / mire lesz még jó a másik?Arra gondoltam, hogy valahogy letesztelem... Mindkét felülten, ugyanazt a modelt használva felteszek nekik kérdéseket, és ha ugyanazt a választ kapom, akkor kb fölösleges lesz a kettő... De ha ezt már kipróbáltátok, akkor nem futok fölösleges köröket...

-
woryz
senior tag
válasz
consono
#1855
üzenetére
Tök jó, a Telekom adott egy éves Pro előfizetést a Perplexity Pro-ra. Viszont ahogy néztem, ott is ki lehet választani a Open AI 4o modeljét, szóval lehet, hogy akkor azt az előfizetést le is lehetne mondanom.
Vagy tapasztaltál különbséget a kettő között (mármint, hogy ott választottad ki esetleg a GPT-4o modelt)? -
freeapro
senior tag
válasz
S_x96x_S
#1907
üzenetére
Én ezt a kérdést dobtam be chagpt, deepseek r1, és grok-3 -nak. A chatgpt válasza állt legközelebb ahhoz amit én is gondoltam. A grok-3 is hasonlót adott, a deepseek viszont nem teljesen standard megoldást javasolt #pragma once paranccsal a standard define guardos megoldás helyett. (Nem rossz az sem, csak minek. Jobb a standard út)
Egy windowsos programon dolgozom. C nyelven készül a visual studio projekt. A program kódja nagyon doménekre (domain) bontható, mint a WinMain ablakkezelés, Editor az adatbászis létrehozására és módosítására és a RUN, ami az adatbázison futtat bizonyos feladatokt. A domainben vannak függvények, amik interfacek, és másik domainből meghívhatók, és vannak belsős (internal) függvények, amik a domain belső működéséhez szükségesek. Azt szeretném, ha a domének között kis csatolás és korlátozott láthatóság lenne, de a domainben használt közös változókat egy struct változóban összegyűjteném amit a domainben mindenki elérhet. Hogyan szervezzem a header filekoat és mit tegyek láthatóvá a domainen kívül és hogy legyenek láthatóak a belső függvények a domainen belül? Mutass példákat.
-
DarkByte
addikt
Szerintem ez nagyon felhasználási terület függő, próbálgatni kell, szinte mindegyiknek van ingyenes tier-je.
Én most pl. a napokban a Cursor-t próbáltam. Előfizetve $20/hótól indul (plusz gondolom ÁFA ráértendő). Durván ilyen áron megy a többi is.
Ez egyébként egy integrált megoldás, egy fork-olt vscode-on át teszi elérhetővé magát, kiegészítve az ágens elemekkel, így az egész projektet képes látni. (Sajnos emiatt vannak limitációi is, pár Microsoft vscode add-on nem megy vele, bár szerencsére ami engem érdekel, pl. WSL2 igen.)
Az alatta lévő modelleket is lehet váltogatni.
A szokásos dolgokat tudja amúgy, tab-ra kód kiegészítés, blokkok átírása, illetve chat-elni lehet a kódbázissal. Kb. az összes ennyit tud jelenleg. Amiben talán extrább, hogy képes indexelni a kódbázisodat (gondolom valami RAG-et épít a háttérben), így kicsit elvileg jobban érti a projektedet, nem csak egy-egy kiragadott fájlszakaszt kap meg mikor kérdezgeted.Sajnos sokat nem volt még időm vele játszani. Egy saját HTMX/Dart projektemre eresztettem rá és kíváncsi voltam felismeri-e benne a komponenseket amiket én írtam (tehát nincs benne meglévő framework használat, pont ezért is voltam kíváncsi rá, hogy ezzel mit tud kezdeni; jobban szimulálja hogy ráereszted egy legacy kódbázisra amiben ki tudja milyen régi taknyolt dolgok vannak).
Megkérdeztem tőle hogyan venne fel egy új alkalmazás oldalt, és egész jól láthatóan felfedezte magának a projekt struktúrát, és még használható template-et is tudott adni új oldal elkészítéséhez. (Persze ez egy relatíve kis projekt, néhány ezer sor. Köze nincs mondjuk ahhoz a több millió soros Java kódbázishoz amit munkában rugdosunk.)Itt sajnos megszakadt az ismerkedésünk, nem volt rá azóta több időm.
Nem is valami gyors, bár ez gyanúsan az ingyenes fiók miatt van.(Egyébként állítólag kódolási feladatokra a Claude még mindig jobban teljesít összességében. De saját tapasztalat hiányában ezt inkább csak lábjegyzetbe.)
-
S_x96x_S
addikt
> Milyen mesterséges inteligenciát érdemes használni programozásra
Attól függ ...
- Milyen programozási feladat.
- Milyen AI Editor: cline, cursor, windsurf, aider, v0 , ....
- Melyik modell : Claude 3.7 , OpenAI ( o3-mini-high , o1 ) , Grok3, Gemini 2.0, ...
- ....A modelleknél lehet: csomag és api előfizetés
( mert ha komolyan tolod - napi 10-12 órában, akkor a csomag is kevés )Az aider programozási bechmark -ból látszik, hogy - ma - mi a legjobb.
( de a következő hónapban már más lesz .. nagyon gyorsak a változások )
Költség alapján talán valamilyen okos openrouter -es vagy kombinált ( Claude3.7+DeepSeekR1) megoldás a legköltséghatékonyabb.
https://aider.chat/docs/leaderboards/Nekem már több mint 1 éve van:
- Claude - havi előfizetésem ( most váltottam évesre )
- ChatGPT ( havi + API credit )
- Copilot ( havi )
És még mindig kezdőnek érzem magam a témában.
Programozásra nekem a Claude a kedvencem;
de párhuzamosan sok más modellt is használok és tesztelek;> és melyik a legolcsóbb ha előfizetek,
Szerintem a minőség fontos.
1.) és bár a Claude ingyenesen is elérhető pár kérdésig - tesztelgetésre,
a saját teszt után - én egy claude -előfizetést javasolnék.2.) ha sok különböző modellt szeretnél egy helyen elérni,
és használat után akarsz fizetni - akkor érdemes
a https://openrouter.ai/models?order=pricing-high-to-low -t megnézni.
( claude, openai, gemmini flash 2.0, ... )
és itt látszik az is, hogy melyik a legnépszerűbb - programozásra:
https://openrouter.ai/rankings/programming?view=week
és vannak extrém olcsó és ingyenes modellek is.A használat után fizetéssel óvatosan - akár 1 nap alatt el tudsz verni 50 USD-t
-----------
Amúgy az utóbbi pár hétben az MCP-k nagyon trendik lettek:
"BlenderMCP connects Blender to Claude AI through the Model Context Protocol (MCP), allowing Claude to directly interact with and control Blender. This integration enables prompt assisted 3D modeling, scene creation, and manipulation."
- https://x.com/minchoi/status/1900379164454101154
- https://github.com/ahujasid/blender-mcp




















 Erre meg ott vannak az AI asszisztensek. Jellemzően nem chat ablakban kell ilyen esetben már használni.
Erre meg ott vannak az AI asszisztensek. Jellemzően nem chat ablakban kell ilyen esetben már használni.


 . Ha rossz választ ad elsőre miért nem próbálsz feedbackelni? Hiszen ez a fejlesztés tényleges folyamata. Gyakran nem ad elsőre jó választ, de ha meg tudod mondani neki, hogy mi a baj, akkor gyakran el lehet jutni egy működő verzióhoz. Én arra lennék kíváncsi, hogy így meddig lehet eljutni egy modellel. (pl. eddig a deepseek 70b modell lokális futtatása volt a cél, de most elbizonytalanodtam, hogy tényleg megfelelő-e)
. Ha rossz választ ad elsőre miért nem próbálsz feedbackelni? Hiszen ez a fejlesztés tényleges folyamata. Gyakran nem ad elsőre jó választ, de ha meg tudod mondani neki, hogy mi a baj, akkor gyakran el lehet jutni egy működő verzióhoz. Én arra lennék kíváncsi, hogy így meddig lehet eljutni egy modellel. (pl. eddig a deepseek 70b modell lokális futtatása volt a cél, de most elbizonytalanodtam, hogy tényleg megfelelő-e)














![;]](http://cdn.rios.hu/dl/s/v1.gif)










 Sőt néha kérek egy pontosítást a saját szövegemen, majd 2-3 (stb) kérdezz felek után visszajutunk 99%-ban az én szövegemhez.
Sőt néha kérek egy pontosítást a saját szövegemen, majd 2-3 (stb) kérdezz felek után visszajutunk 99%-ban az én szövegemhez. 

Új hozzászólás Aktív témák
Hirdetés
- TCL LCD és LED TV-k
- gban: Ingyen kellene, de tegnapra
- Autós topik
- Gaming notebook topik
- Android alkalmazások - szoftver kibeszélő topik
- Azonnali notebookos kérdések órája
- Kamionok, fuvarozás, logisztika topik
- Realme 9 Pro+ - szükséges plusz?
- Kerékpárosok, bringások ide!
- Samsung Galaxy A54 - türelemjáték
- További aktív témák...

- AmD - Ryzen5 - ös Gamer - Pc1 - Eladó - Számla - Ready !!
- Új Apple MacBook Pro 14 M4 Pro 2024 - SpaceBlack (3év garancia)
- Macbook Air M2 15,3 512GB SSD Ezüst
- Xbox Series X, dobozában, kitisztítva+újrapasztázva, 6 hó teljeskörű gar., Bp-i üzletből eladó!
- Apple Gyorstöltők / 20W ADAPTER / Type-C / Lightning kábelek
- REFURBISHED és ÚJ - Lenovo ThinkPad Ultra Docking Station (40AJ)
- Apple iPhone 12 Pro 128GB, Kártyafüggetlen, 1 Év Garanciával
- Huawei Watch GT2, 1 Év Garanciával
- BESZÁMÍTÁS! MSI B450M R5 5500 16GB DDR4 512GB SSD RTX 2060 6GB Rampage SHIVA Zalman 600W
- BESZÁMÍTÁS! MSI Z690 i7 12700K 32GB DDR4 1TB SSD RX 6800 16GB Phanteks P600S Cooler Master 750W
Állásajánlatok

Cég: Laptopszaki Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest