Hirdetés
- Három játékprofillal készült az új Arc meghajtó
- Befutottak a beágyazott rendszerekbe szánt, tempós Ryzenek
- Mi történik a szemeddel, ha napi 8 órát monitort nézel? | Orvos válaszol
- A Synology visszatáncolt a saját márkás HDD-k megkövetelésének kapcsán
- 350 Hz-es IPS kijelzővel gyarapodott a Samsung portfóliója
- Mini PC
- Jövőre jósolják a memóriahiányt, ami egy évtizedig is fennmaradhat?
- Fejhallgató erősítő és DAC topik
- Milyen billentyűzetet vegyek?
- SSD kibeszélő
- Projektor topic
- Azonnali notebookos kérdések órája
- Milyen alaplapot vegyek?
- Másodszor is nekifut az AI PC-k meghódításának a Qualcomm
- Milyen videókártyát?
Új hozzászólás Aktív témák
-
#5426
 Petykemano
veterán
S_x96x_S
#5425
Petykemano
veterán
S_x96x_S
#5425
-

HSM
félisten
válasz
 S_x96x_S
#5410
üzenetére
S_x96x_S
#5410
üzenetére
"mert ez az új "normális"
az Intel Alder-Lake-S akár 150W-os TDP-vel nyomulhat ..
de az is lehet, hogy ez csak az átlag - mert:
Intel: "TDP values are maintained at 125W (PL1) and 228W (PL2).""Intelnél máshogy van definiálva a TDP, mint AMD-nél, ezt itt nagyon fontos lenne figyelembe venni. Az Intel féle 125W PL1 és 228W PL2 a gyakorlatban azt jelenti, hogy a beállított időablakban (8-60 másodperc között modellfüggően) átlagosan nem mehet a PL1 azaz 125W fölé, és sehogyse mehet a PL2, azaz 228W fölé. Illetve ami fontos, itt a TDP = fogyasztás. Persze, imádják a lapgyártók a saját szájízük szerint megemelni a PL1, PL2-t, de ez egy egész más történet.
AMD-nél a TDP valami számolás eredménye, ők valahogyan a hűtő felől nézik, ott a 105W-os TDP-vel ellátot processzor vidáman fogyaszthat átlagosan 140W-ot hosszú távon is. Tehát, ha úgy tetszik, épp az AMD lépett kicsit feljebb az AM4-el a korábban szokásos max 65/95W fogyasztási keretből.
A lapgyártók persze itt is igyekeznek a konkurencia fölé kerülni, de mivel itt a gyári limiteket nem módosíthatják, így a processzor telemetriáját próbálják félrevezetni, tehát még szvsz rosszabb a helyzet, mint a konkurens processzorokon, ahol legalább két beállítás után visszakaphatod bármilyen alaplapon a gyárilag specifikált működést.#5419 Petykemano : "És azt mondom, hogy az csupán "véletlen", hogy ezt az Apple pont megengedheti magának és még így is brutálisan nyereséges."
Szerintem a véletlennek ehhez semmi köze. Azt gondolom, óriásit kaszálnak azzal, hogy a saját chipjükre zárták be a rendszerüket, és nem kell másoknak fizetniük a CPU-ért.
Így ebben a piaci helyzetben nem csoda, hogy minden pénzt megér nekik, hogy egy ideig előnyben legyen gyártástechnológiailag is, ezzel is erősítve a képet, hogy megéri váltani az új rendszerre a régiekről. -
válasz
S_x96x_S
#5414
üzenetére
Kellenek igen. Átfutottam a tesztet, de nem derült ki, hogy milyen fogyasztási limitek közé voltak a cpu-k szorítva. Továbbá érdekelne az is, hogy a tesztelt alkalmazásokat mennyien használják, mert a gimpen kívül még a többiről nem hallottam (tudom az én szegénységi bizonyítványom).
Az is megeshet, hogy felületes voltam a cikk olvasásakor
-

S_x96x_S
addikt
válasz
S_x96x_S
#5412
üzenetére
kapcsolódó Hacker News kommentek ...
https://news.ycombinator.com/item?id=27851314
"Perhaps a very smart move from Gelsinger, time will tell,
in the meantime I'll have a laugh at Intel buying AMD's old fabs :)"
A háttérben a "patent" portfolió és az IBM mint ügyfél megszerzése lehet .. -
#5405
Petykemano
veterán
S_x96x_S
#5403
Petykemano
veterán
válasz
S_x96x_S
#5403
üzenetére
Igen, én is ezt a kérdést pedzegettem magamban.
Az eddigi magyarázatok szerint a változó hosszúságú utasítások nagy fejtörést okoznak. Az agenda szerint ennek enyhítésére vezették be az opcache-t, ami viszont sok energiát használ és ezért se olyan széles nem lehet az x86, se olyan energiahatékony, mint az Arm.
Ehhez képest Az A77-ben szintén megjelenik az opcache. És a cikk - valamint Jim Keller - szerint a változó hosszúságú utasítás sem probléma.De akkor miért nem rukkolt elő már korábban az AMD vagy az intel egy az M1-hez hasonlóan széles architektúrával, ami ugyan csak 3-4Ghz-en ketyeg, de úgy is hozza az 5+Ghz-es konkurencia teljesítményét és persze egy 3-4Ghz-es proci fogyasztását.
Széles design nyilván több tranzisztort igényel. De Abu elmondása szerint a magas frekvencia sincs ingyen. Nem csak áramot használ, hanem tranzisztort is. Nem emlékszem, hogy a kifejezetten "speed demon" bulldozer esetén előny lett volna, hogy alacsony a tranzisztorigénye. (nagyjából ugyanannyi tranzisztorból állt a bulldozer, mint a 4 magos sandy)
Szerintem az M1-gyel való összevetést nem magyarázza az, hogy az X86 designok HPC piacra készülnek, míg az Arm-osak mobil piacra. Hiszen épp ez az, hogy az M1 hozza azt a teljesítményt. Tehát az, hogy egy "másfajta design választás", aminek "máshol vannak az optimumai" nem elég erős magyarázat.
Az M1 típusú design tervezőasztalon és szimulációkban már régóta álom, de a csak TSMC 5nm-es gyártástechnológiája tette fizikailag megvalósíthatóvá?
Az M1 egy valódi innováció lenne? Amire még senki se gondolt? -
HSM
félisten
válasz
S_x96x_S
#5397
üzenetére
Mit mondhatnék erre... Annyira csendben zajlik, hogy cirka 10 év leforgása alatt is csak néhány szoftver használja.

Ami eszembe jut, azok az RT gyorsított render szoftverek és talán egy tömörítő van/volt, ami OpenCL támogatott.Egyébként az egyértelmű, hogy hasznos lehetőségek rejlenek ebben a modellben, de úgy tűnik a PC eddig túl ingatag/fragmentált terep volt (nem volt pl. minden CPU mellett IGP) ahhoz, hogy ott is elterjedjen, mint pl. a konzoloknál, inkább megoldották amit kellett erőből a CPU-n.
#5399 Petykemano : A DDR5 és az új AM5 IOD kérdés, mennyit javít a memória alrendszer tempóján, ha sokat, akkor az óriás L3 jelentősége azért jelentősen csökkenhet, mivel a maximális magszámot (16) nem tervezik emelni és a jelenlegi alap 8mag/32MB sem éppen kevés.
#5402 Petykemano : Érdekes írás, köszi!

-
#5401
Petykemano
veterán
S_x96x_S
#5400
Petykemano
veterán
válasz
S_x96x_S
#5400
üzenetére
Elég valószínűtlennek tartom azt, hogy a zen4-es Raphael után 1 évvel (15hónap) zen5 következzen ráadásul az épp bevezetett 5nm helyett szintén rögtön 3nm-en.
(Feltéve persze, hogy a 3nm nem úgy jön össze, hogy az nem TSMC, hanem Samsung 3nm)És bár a Vega sokáig kitartott, valahogy azt se hiszem, hogy az RDNA2-t is olyan sokáig hurcolnák magukkal. Tehát szerintem úgy lenne pontos, hogy
- a granite ridge nem 2023, hanem legjobb esetben is 2024 (A Raphael és a granite ridge között persze lehet valami "filler", valami "-X" vagy "+")
- A strix point is csúszik 2025-re és 2024-ben valami zen4 + RDNA3 apu érkezik 5nm-en (esetleg 4nm-en)Hogy ez mennyire versenyképes az egy másik kérdés.
De szerintem az az érvelés, hogy erős a konkurencia és az eddigi 18-24 hónapos nagyobb fejlesztési ciklusokat (tehát ami nem "+") fel kell pörgetni és muszáj új maggal, meg új gyártástechnológiával előállni 15 havonta, az úgymond wishful thinking. -
HSM
félisten
válasz
S_x96x_S
#5393
üzenetére
"Valamint a legtöbb párhuzamosítást - át lehet lökni a GPU-ra ..
Vagyis a heterogén ( CPU + GPU ( + FPGA ))
programozásé a jövő"
Ezt nyomták a Caveri APU-nál is ezer éve... [link] Aztán a forradalom valamiért mégis elmaradt, pedig a hardver azóta is adott (lenne) hozzá.#5394 Busterftw : "a CCX desgin ellegge eltero volt mindentol ami addig megjelent es mainstream volt"
Az OS és a szoftverek szintjén teljes mértékben ugyanaz a megoldandó probléma, mint a Core2 Quadnál. Vannak magok, amik egymással gyorsan tudnak adatot cserélni (közös L2 a Quadnál, közös L3 a CCX-nél) és vannak, amik lassan, és ezt a feladatok kiosztásánál/ütemezésénél érdemes figyelembe venni.Fun fact, annak idején épp az AMD demózta bőszen, mikor megjelentek a világ első natív négymagosával, hogy ez bizony mennyivel jobb, mint a konkurencia kétszer kétmagos felépítése...

"Currently Intel’s quad core implementation relies on it having two Core 2 dies on a single package. It can easily pull this off because it doesn’t integrate the memory controller into the CPU. This allows more cores to be added as needed.
However, this creates an inherent performance problem, since both die are only connected only through the CPU front side bus (FSB). Sending data from core one to three means that it has to be sent out of the CPU to the northbridge and then back again creating a massive additional latency and reducing the bandwidth available for memory access.
Discussion between cores one and two or three and four is okay, because they are on the same piece of silicon, but still 50% of the time there’s a latency problem.
" [link]
Pontosan ez történik a CCX-ek esetén is, ha a szomszéd CCX-el kell adatot cserélni, arra csak a memóriavezérlőn keresztül van mód, hiába fizikailag egy csip. Ez a probléma "szűnt meg" az 5600X és 5800X modelleken, mivel azokon egy csip egy CCX, minden mag egyforma gyorsan fér az adatokhoz.Azzal viszont teljes mértékben egyetértek, hogy a fő probléma, hogy hogyan ütemezd a feladatokat a magok között, adott esetben power plan függően, a különböző elérhető kis/nagy magszámok mellett.
 Bár tegyük hozzá, 16 magot megfelelően skálázódó módon ellátni szálakkal egyébként sem feltétlenül egyszerű, hát még ilyen "egzotikus" felépítésű CPU-k esetén.
Bár tegyük hozzá, 16 magot megfelelően skálázódó módon ellátni szálakkal egyébként sem feltétlenül egyszerű, hát még ilyen "egzotikus" felépítésű CPU-k esetén. -
#5385
Petykemano
veterán
S_x96x_S
#5382
Petykemano
veterán
válasz
S_x96x_S
#5382
üzenetére
"AMD Raphael with up to 16 cores"
Én egy pár éve még nagy híve voltam a magszám emelésnek. Az szerintem kétségbevonhatatlan, hogy nagy felszabadító ereje volt az első 1-2 zen generációnak, hisz kiszabadított minket a 4/8 felső korlátból.Nem állítom, hogy sok értelme lenne a magszám emelésének a mainstreamben. Tehát az, hogy $200-300 szinten mondjuk ne 6 magos procit lehessen kapni jövő évtől, hanem már 8 magosat, az igen csekély előnyt jelentene. Ha úgymond ingyen jönne a következő generációk során, akkor persze nem mondanék nemet.
Annak viszont semmi értelme, hogy úgy emelgessék a magszámot, hogy közben az ár is emelkedik. Mármint 24 magos cpu-t most is lehet kapni- drágábban. És azt most is csak az veszi meg, akinek szüksége van rá.
A sokmagos forradalom szerintem egyelőre elmaradt.
Egyrészről úgy tűnik, nem valósul meg hardver oldalról. Vagyis nem kapunk mondjuk 3-4 évente 2-vel több magot ugyanazért a pénzért. Nagyjából az lett - és valószínűleg marad is - standard, amit az AMD beállított a zen1 megjelenésével.
Másrészről szinte minden téren megmaradt az a helyzet, hogy a +20% IPC az minden körülmények között +20% IPC, míg a +50% v +33% magszám az hát csak bizonyos speciális körülmények között ér tényleg annyit.
Nem éri meg azért magas magszámú cpu-t venni, hogy a magas magszám majd hosszútávon is kielégítő lesz, mert mire IPC szempontjából kiöregszik, addigra majd hozzáskálázódnak a programok a sok maghoz. Kivéve persze ha biztosan olyan programot használsz, ami biztosan ki is használja a magas magszámot.Számomra például nagyon elgondolkodtató a pletykált Monet. Reméljük olcsón fogják adni. Mindenesetre azt elég valószínű, hogy bucira fogja verni az 1600-tól 2700X-ig mindent, pedig csak négy magos.
"Mindenesetre kiváncsi leszek az 5950X utódjára ..
Vajon lesz-e +20% CB R20 eredmény?"
Egész pontosan a Raphael-re gondolsz, vagy a Vermeer-X-re? -
#5375
Petykemano
veterán
S_x96x_S
#5373
Petykemano
veterán
válasz
S_x96x_S
#5373
üzenetére
Én nem vonnék le messzemenő következtetéseket.
Az ilyen hirtelen ugrások általában nem valamilyen cpu piaci mozgás következményei.
Lehet, hogy elindult egy új játék, ami KÍnában népszerű
Lehet, hogy újranyitottak az internet kávézók, amik eddig "a covid miatt" zárva tartottak.
Lehet, hogy a lezárt bányászat miatt a gépeken adtak túl, és azok valami olcsó intel procik voltak.
Lehet, hogy a lezárt bányászat miatt a gépekből új internetkávézók nyíltak.Egyébként egy 4 magos GF12-es zen3 még talán engem is érdekelne. Bár az valószínűleg valami forrasztott cucc lenne, nem AM4.
-
válasz
S_x96x_S
#5373
üzenetére
Én majd arra leszek kíváncsi, ez is ilyen anomália féle a Steamben, vagy tényleg trendforduló. Játékosok között több a DIY vásárló szerintem, mindfactorynál nem igazán látszik, hogy lassítana az AMD. Arról meg nem hallottam, hogy OEM-eknél hiány lenne AMD-ből (ettől még lehet persze
 )
)Múltkori anomália Steam surveyben, de előtte is van egy pár százalékos elmozdulás, ami aztán vissza is állt következő hónapban az enyhén javuló AMD trendre.

Milyen érdekes a steam survey-ben ez is:
Bal oszlopban az egyik kategóriában meg van nevezve egy gyártó, AMD-nek esélye sincs.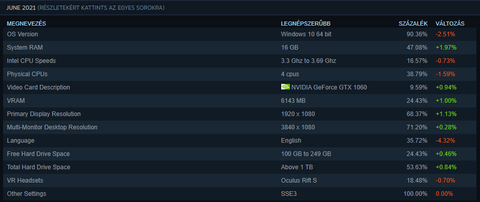
-

TRitON
aktív tag
válasz
S_x96x_S
#5358
üzenetére
Amit olvastam:
PH: "A vállalattól megtudtuk, hogy a korábbi generációs X470-es és B450-es vezérlőhidak támogatása az alaplapgyártóktól függ, ami annyit jelent, hogy a partnereknek nem kötelező kiadni egy kompatibilis BIOS-t, de a szükséges AGESA elkészült, így megtehetik, ha akarják."
[link]
TPU: "Built in the Socket AM4 package, the processors are compatible with AMD 500-series chipset motherboards."
[link]
Utóbbiban egyáltalán nem említik a régebbi alaplapokkal való kompatibilitást, ez volt, amit ellentmondásosnak találtam. Wishful thinking: ha az eddigi összes AM4 CPU (kivéve a Bristol Ridge-et muhaha) kapott az MSI-től támogatást a B450-es alaplapokhoz, bízom benne, hogy ez is fog. Nem szeretnék alaplapot is venni a jelenlegi árak mellett. -
#5356
Petykemano
veterán
S_x96x_S
#5354
Petykemano
veterán
válasz
S_x96x_S
#5354
üzenetére
Az apple egy kuriózum
Az már inkább érdekes, hogy a hagyományos arm miképp engedheti meg magának, hogy eldobjon régi fícsöröket, és az x86 meg miért nem.Azt gondolom, ez abdisztribúciós csatornán múlik.
Az android fő csatornája a play store volt. Nagyon ritkán forgott kézen apk. Vagyis végfelhasználó ritkán szembesült azzal, hogy a régi verzója nem megy.
Ehhez képest x86-on elég gyakori lehetett a nyafogás.De azért szerintem már így is vannak régi dolgok, amik nem működnek. Dosos játékok. Azokhoz már egy ideje dosbox kell.
A Windows 11 nem kompatibilis már az első generációs ryzenekkel sem. Talán lassan itt is elindul az elengeDés.
Bár jim Keller azt mondta, kezdetben azért gondolták, hogy a risc jobb, mert a cisc prociknak kellett egy nagy rom és ha az ahhoz szükséges tranzistorokat inkább számításra használjuk... de ma meg már olyan pici az a rom, hogy szabadszemmel alig kivehető.
-
#5352
Petykemano
veterán
S_x96x_S
#5350
Petykemano
veterán
válasz
S_x96x_S
#5350
üzenetére
Bocs, nem tudtam befejezni...
Az amazon egyben a legesélyesebb és a legkevésbé esélyes is. Valahogy összerakták a gravitont. Biztosan készül már a graviton 3 is a V1 v N2 magokra építve.
Annál persze a zen2+50% biztosan jobb. Ha jól emlékszem, akkor már a A77 elérte a x86 magok IPC-jét, csak nem éri el az 5GHz-et. Szerverben viszont épp azért versenyképes, mert ott minden 3-3.5GHz-et megy.
Ehhez képest az M1 alacsonyabb frekvencián versenyképes az 5GHz-es x86 magokkal.
Ez a zen2+50% elég jól.hangzik ma. De 2023-ban?
Azért számoljunk.
Zen2-höz képest a zen3 +15%. Jövő évben kijön a zen4, ami remélhetőleg rátesz a zen3-ra 15-20%-ot. És ott van még a v-cache is, ami itt-ott szintén jelenthet 15%-ot.
Tehát a peak performance előrelépés éppenséggel x86 oldalról is meglehet.
Viszont a fogyasztás egy érdekes kérdés.
A gyári Arm magok esetén szerintem nem igazán tapasztalható az, hogy lényegsen jobb fogyasztással rendelkezne az arm. Az M1 viszont igen erős. Nyilván mert annyival alacsonyabb frekvencián hozza.
Nyilván a Nuvia is széles designnel oldja meg.Szóval az a kérdés, hogy a TSMC 5nm-e vajon milyen előrelépést hozhat, illetve hogy nem viszi-e el a töbv tranzisztor.
Abu valahol mintha említette volna, hogy legnagyobb jelentősége annak van, hogy full EUV.A verseny mindenképpen örömteli.
Közben az Intel sem tétlenkedik. Elsők között lesznek megrendelői a TSMC 3nm-nek. Az szerintem 2023.
Amúgy ha már itt tartunk, meglepne, ha a nuvia chipeket 2023-ban nem 3nm-en gyártanák. És akkor az már lehet, hogy meg is magyarázza a fogyasztást. Persze én arra számítok, hogy az x86 magok picit mindig többet fognak.fogyasztani, mint az arm magok. -

hokuszpk
nagyúr
válasz
S_x96x_S
#5332
üzenetére
nemastam magam bele, de tippre a TSX az ilyen in-memory adatbazisoknal jatszana, es ha igazam van, akkor az Intel megint bealdozza a biztonsagot a sebessegert, de ez csak addig lesz oke, amig meg nem jonnek az elso hirek az inkonzisztenssé / korrupttá váló adatbazisokrol.
-
#5328
Petykemano
veterán
S_x96x_S
#5326
Petykemano
veterán
-
#5307
Petykemano
veterán
S_x96x_S
#5306
Petykemano
veterán
válasz
S_x96x_S
#5306
üzenetére
Figyelemre méltó ugrás a notebookok terén - még ha ez csupán benchmarkokat jelent is, akkor is arra utal, hogy több az AMD noti, többet tesztelnek, talán több van a polcokon is és többen veszik meg kipróbálni, hogy milyen. A benchmarkból persze mindenképp csak az enthusiast réteg látszik.
-
#5302
Petykemano
veterán
S_x96x_S
#5297
Petykemano
veterán
válasz
S_x96x_S
#5297
üzenetére
Kétféle véleményt láttam megjelenni:
1) "Báháháhá, az SMT letiltásával nyert egyszálas teljesítmény x86 utolsó halálhörgés kísérte próbálkozása, mielőtt az Arm végleg letaszítaná a trónról egyszálas teljesítményben különösen ha figyelembe vesszük a perf/W mutatót is."
2) Az elmúlt években a legnagyobb igyekezet ellenére is több SMT-vel kapcsolatba hozható sebezhetőség felbukkant. A szálak között megoszott erőforrások, cache-ek, bufferek, stb olyan sebezhetőséget rejtenek - most vagy akár a jövőben -, hogy bölcsebb és biztonságosabb már élből tiltani virtualizált környezetben, ahol nem biztosítható, hogy ugyanaz a mag biztosan ne kerülhessen kiosztásra két különböző szervezet vagy projekt számáraÉrdekes egyébként a megoldás.
a GCP-ben vCPU-t bérelsz, ami gyakorlatilag ez hardveres szálat jelent.
Állítólag az Amazonnál hardveres magot bérelsz, az SMT-t ingyen adják. -
#5301
Petykemano
veterán
S_x96x_S
#5299
Petykemano
veterán
válasz
S_x96x_S
#5299
üzenetére
aZ x86 dekóder limitációról:
"For a while we thought variable-length instructions were really hard to decode. But we keep figuring out how to do that. You basically predict where all the instructions are in tables, and once you have good predictors, you can predict that stuff well enough. So fixed-length instructions seem really nice when you're building little baby computers, but if you're building a really big computer, to predict or to figure out where all the instructions are, it isn't dominating the die. So it doesn't matter that much."
-
hokuszpk
nagyúr
válasz
S_x96x_S
#5299
üzenetére
ha jolertem az x86 -ot 8 biteskent emlegeti, nekem ez fura a 8008 meg a 8080 az 8 bites volt, a 8086 -os proci kivul - belul 16 bites, a 8088 amit a legtobb PC/XT megkapott, az meg valami 8 bites adatbusszal operalt, talan a 8085 -el labkompatibilis is volt, na az viszont tenyleg 8 bites...
-
#5294
Petykemano
veterán
S_x96x_S
#5291
-

carl18
addikt
válasz
S_x96x_S
#5274
üzenetére
Igen hát arra én is kíváncsi vagyok mikor lesz a piaci részesedés egyenlő. Steam felmérés szerint 30 %AMD 70% intel, azaz nem olyan gyorsan halad ez az AMD esetében.
A Meteor lake-S már valóban versenyképes lehet, mert 8 nagy és 16 kis mag akkár hogy nézzünk nem elhanyagolható mennyiséget tekintve.
Cinebench alatt biztos hogy durva eredményt guritana.Igen szerintem is ha a TSMC adna is az intelnek bérbe kapacítást nem fogja kiemelt ügyfélként kezelni. Mert nem hosszú távú ez a kapcsolat, az intel is bérgyártani kezd így a TSMC konkurenciája lehet.
Apple/AMD akik hosszú távon is velük maradnak, szóval a TSMC érdeke is hogy nekik legyen elég kapacítás.Bár a jövőbeli AMD termékekre vissza térve az mondjuk tény mindegy milyen jó terméket dob az AMD a piacra ha nem elérhető vagy csak arany áron akkor nem lesz réteg termék.
Mert a Ryzen 1600/1600AF 85 dollárért volt kiszorva, a Ryzen 3600 is 200 dolcsiról indult és volt ez alatt kis kicsit akcióban.
Azért most akkár hogy nézzünk nem is jött X-mentes Ryzen 5600.
És jelenleg az ár-érték arányt is figyelembe véve sokan vásároltam 10400F-t mert az AMD ára elég szépen elszált az utobbi időben.Csak itt a kérdés hogy mielőtt lezárja az AMD az AM4-et? Fog-e valami igazán jó ár-érték arányú processzort a piacra dobni?
Ryzen 5 5600 200 dollárért kéne a népnek!
Ameddig tart a chiphiány nem érdemes olcsóbb termékekre várni.
-
#5277
Petykemano
veterán
S_x96x_S
#5276
Petykemano
veterán
válasz
S_x96x_S
#5276
üzenetére
> szerintem a 3rd gen IA már a PCIe5.0 -re épül
> ( ~4.5 bandwith növekedés erre utal ; 0.5 -öt a latency csökkenésnek tudom be .. )
> Viszont valami ok miatt az AMD - nem PCIe5.0 -nak hivja.
> lásd az oszlopok elnevezését.
> Gen3->Gen4-> 3rdGen Infinity Architekture
Abu Trento és egyéb AMD titkos kódnevek kapcsán valami olyasmit mondott, hogy lesz olyan változat, amiben az AMD azt mondja, hogy toll a fületekbe, ebben nem lesz PCIe csatoló, hanem mindent Infinity Fabric köt össze.Szerintem az Infinity Architecture ezt az elképzelést használja.
Ez persze nem jelenti azt, hogy ne lenne PCIe5 is az asztalon. De én azt valószínűsítem, hogy a Frontier szuperszámítógépben nem lesz.Azt nem tudom megmondani, hogy a "3rd gen IF" milyen viszonyban van a PCIe5-höz és a CXL-hez képest. Mármint azon kívül, hogy értelemszerűen nem kompatibilis. De hogy milyen előnyt jelenthet PCIE5/CXL-hez képest, az előttem nem ismeretes. Azt sem tudom, hogy az IF működik fizikai PCIE4 csatlakozáson keresztül. Talán ennek első szárnybontogatása volna a "Smart Access Memory"?
-
#5270
 TESCO-Zsömle
titán
S_x96x_S
#5268
TESCO-Zsömle
titán
S_x96x_S
#5268
TESCO-Zsömle
titán
válasz
S_x96x_S
#5268
üzenetére
Ha jól tudom, a HBM közel sem az a sebesség, mint az S-RAM. Nyilván fordítva meg a kapacitás alakul így.
Mindenesetre érdekes jövőképet fest, hogy a hagyományos L3 és a DDR5 közé így most bekerül még 2 rétegnyi tár. Ember legyen a talpán, aki ezeknek a kezelését megkomponálja...
Vó'tmá' kategória, de én még mindig azt várom, hogy jöjjön egy legalább 200W-os gamer SOC 6c/12t + legalább 16-20CU + 4-8GB HBM. Lehetőleg midnezt 500$ plafonon. És akkor ott van egyben a 300$-os VGA meg a 200$-os proci egyben.
sz: Tisztában vagyok vele, hogy ez legkorábban is csak azután jöhet, ha már a Radeon vonalat is átállították chiplet dizájnra. Addigra remélhetőleg lesz annyira jó a 3D technológia, hogy a procin ülő S-RAM-on kívül megoldható legyen a GPU-n ülő HBM3 is.
Mivel közölték, hogy az AM5 foglalat bem támogatja a 4-csatornás DDR5 kialakítást, így arról letettem, hogy azzal buffolják a memóriasávszélt, amit egy a fentiekben írt erejű GPU követelne.
-
#5269
Petykemano
veterán
S_x96x_S
#5268
Petykemano
veterán
válasz
S_x96x_S
#5268
üzenetére
Én is olvastam olyan véleményt, hogy 256MB V-cache mellett (ez egyébként akár 3-4TB/s sávszélesség is lehet) nem.biztos, hogy szükséges/érdemes még a HBM is, pláne úgy, hogy közben épp érkezik a DDR5 is.
Nem hülyéség, csak megúszható.
Nem tudom, hogy egyébként költség terén ez mekkora tétel lenne. Korábbról úgy tudjuk, hogy az interposer illetve az arra való chip ültetgetés drága mulatság.
Az AMDnek brutális nagy interposerre lenne szüksége jelenleg.Én ezt csak az Intel féle tile megoldásban látom megvalósíthatónak. De tegyük össze, amit az AMD RDNA3-ról tudunk és a raphaelről.sejtünk:
Szerintem ez úgy tudna megvalósulni, hogy az AMD készít egy olyan lego elemet, ami egy interposerre tett 1-2-3 chiplet + IOD + HBM3. (Ezt akár külön is lehet árulni a desktop piacon. hBM-mel és anélkül, vagy' akár úgy is, hogy a chipletek valamelyike RDNA)
És ilyen legoelemeket rak egymás mellé két sorba úgy, felfűzi őket egy hosszanti irányban elhelyezett Infinity Cache chipletre (ahogy azt az RDNa3 esetén spekulálták)Ez az újrahasznosíthatóság szempontjából jól.hangzik, de amúgy elég fura, hogy egy HBM valójában közelebb van, mint a kapcsolódásért felelős Infinity cache.
Végülis ha a IOD zsugorodik 6nm-re, akkor eljéozelhető, hogy nem szükséges olyan hatalmas interposer, ha csak a HBM kerül rá, a chipletek nem.
Mindenesetre az intelnek azért ebben van előnye. Ha rápakolnak HBM-et a processzorra, akkor már nyugodtan mondhatják, hogy a DDR slotokba mehet csak optane. Az AMD-től eddig nem láttunk eltérő memóriarendszerek menedzselésére vonatkozó működést.
-

Cathulhu
addikt
válasz
S_x96x_S
#5246
üzenetére
Érdemes elolvasni a szerző további cikkeit is. Olyan elemző szavára nem szabad adni, aki nyilván valóan elfogult, mert még ha valós alapokon is nyugszik az érvelése, az csak válogatott tények, hogy alátámasszák az igazát.
Volt pár éve egy hasonló elemző, 2017 óta az AMD halálát jósolta, 15 dolláron, 25ön, 35ön, mindenhol az eladásra biztatott, mert mindenhol túlértékelt volt neki az AMD és az Intel bármikor elsöpörheti. Sajnos a nevére már nem emlékszem, de befektetési tanácsadóként ő emberek pénzével játszott, és rendszeresen vesztett az elfogultságának köszönhetően.
SA megvalógathatná kiket hagy publikálni, a reputációjuk múlik rajta -
#5249
Petykemano
veterán
S_x96x_S
#5246
Petykemano
veterán
válasz
S_x96x_S
#5246
üzenetére
Szerintem Arne Verheyde ugyanaz az személy, mint Twitteren witeken, aki eléggé elfogult az intel irányában.
Nem állítom, hogy nincs igazság a felsorolt pontokban.
-

Busterftw
nagyúr
válasz
S_x96x_S
#5246
üzenetére
Koszi, erdekes olvasmany.
Azert az evek soran ez latszott, hiaba volt/van (gyartas)technologiai foleny AMD-nel, kisebb volumen miatt az AMD nem tudott annyira ervenyesulni mint tudott volna normalis korulmenyek kozott.
Szerintem a korulmenyekhez kepest az Intel jol allta a sarat, mindezt ugy hogy 14nm-el kellett dolgozni. Ez latszott az evek alatt, a market share nagyon lassan kezdett megindulni AMD fele, ekozben kijott 4! Ryzen generacio.
En ezt mar az elejetol fogva mondtam, hogy az Intelnek a legfontosabb tenyezo az ido.Persze aztan ahogy lattuk, par ev alatt nagyon sok minden tud valtozni, teljesen realis, hogy a leirtak nem fognak bejonni. Az AMD sem fog egy helyben ulni.
-
#5247
Petykemano
veterán
S_x96x_S
#5243
Petykemano
veterán
válasz
S_x96x_S
#5243
üzenetére
A hősűrűség (thermal density) eddig is fokozódó problémát jelentett.
A hősűrűség azért jelent problémát, mert magas hőmérsékleten ugyannak a frekvenciának a tartásához magasabb feszültségre van szükség, ami növeli a hőtermelést.
Nem állítom, hogy a 14nm-es zen1 frekvencia skálázódása emiatt állt meg, de amikor a 12nm-re váltottak, akkor a hírekben arra hivatkoztak a fizikai kiterjedés megtartásával kapcsolatban, hogy így több a "hely" a hőt termelő tranzisztorok között és könnyebben hűl
Valamint a zen2 esetén is szó volt róla, hogy nagyon szép és szuper, hogy milyen sűrű a 7nm-es gyártástechnológia, de az intel abból a szempontból könnyebb helyzetben van, hogy a lapkái 2x akkora kiterjedésűek, és ennélfogva engedheti meg magának a ~2x akkora fogyasztást. másként megfogalmazva: a hősűrűség miatt az AMD ha akarná se tudná növelni a fogyasztást.Szerintem a 3D technológia terjedésével ez a probléma fokozódni fog. A rétegződéssel - gondolom valamelyest növekedni fog a lapkák magassága (Az ExecutableFix által megosztott/renderelt Raphael kupak például kifejezetten magasnak tűnik) A legalsó réteg biztosan távolabb kerül a hőelvezetést szolgáló hűtött felső felülettől. Tehát szerintem egyre kevésbé lesz megengedhető, hogy neked valahol a szilícium téglatestedben - főleg alul - legyen valami nagy hőkoncentrációt okozó részegységed.
Vannak elképzelések a 3D stacked chipek Z irányú hűtésére, de azért annál szerintem lényegesen egyszerűbb, ha a hőtermelést a frekvencia csökkentésével oldják meg. a chipek ma már tele vannak hőérzékelőkkel, tehát nem gondolom, hogy bármikor is alattomosan ki tudna alakulni valami hőtermelő központ, ami leégeti a chipet.
A másik fontos szempont ami megjelenik, hogy ha valahol nagy hő képződik, akkor oda a szükséges kakaót is el kell juttatni.Számomra minden szempontból előnyösebbnek tűnik az alacsonyabb feszültség és a frekvencia és a 3D stacking által kínált cache és feldolgozó szélesítési lehetőség.
Az Apple a példa rá, hogy ebben a vonatkozásban jelenleg az Arm tűnik előnyösebb pozícióban levőnek. És arról pedig volt már szó, hogy az x86 esetén az instruction decoder szélessége tűnik jelentős korlátozó tényezőnek a feldolgozók szélesítése kapcsán.
-
S_x96x_S
addikt
válasz
S_x96x_S
#5243
üzenetére
TSMC ..
June 8, 2021
An AnandTech Interview with TSMC: Dr. Kevin Zhang and Dr. Maria MarcedIC: As process nodes shrink, resistance on metal layers is becoming more problematic. With regards innovative solutions, and exotic materials versus copper interconnects, is it just a case of more research down that front? Or do we need to put more effort into increasing and routing higher metal layers?
KZ: I think in the research session at our advanced technology introduction, we did cover a little bit about the back end work. For example, we are continuing to optimize the copper grain boundary to bring a lower resistance metal line to our overall chip technology and new technology. Also, with dielectrics we continue to find innovative materials to improve the dielectric in parasitic capacitance. So, those things are being actively researched.
The 3D integration can also bring an alternative solution to this whole performance requirement in the back-end. You can instead route from A to B in a 2 dimensional space, or you can route A to B vertically in 3 dimensions. In some cases, by going vertical, you can reduce the overall length of the RC wire, and reduce pass delay significantly. So all those things have to be looked at going forward.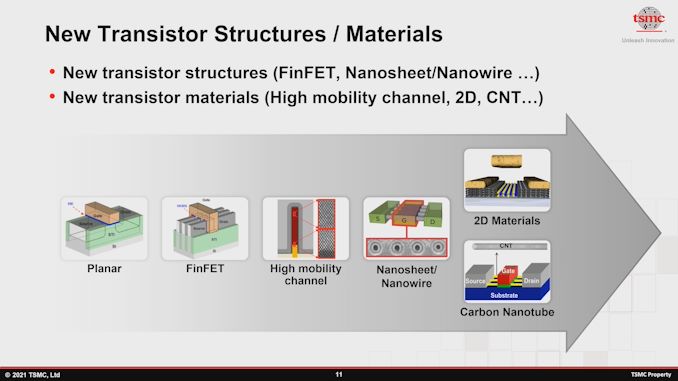
-
#5233
Petykemano
veterán
S_x96x_S
#4995
Petykemano
veterán
válasz
S_x96x_S
#4995
üzenetére
zen4 IPC
Sokmindent lehetett eddig olvasni
- volt ez a zen2 =>zen4 +45%
- volt zen3 => zen4 +29% (Milan => Genoe)
- MLiD utolsó videójában zen3 => zen4-re 20+%-ról írtDe az AMD jól megkavarta ezeket információkat.
Mi a zen3? plain zen3, vagy zen3D?
Mi a zen4? plain zen4, vagy a zen4-et már v-cache-sel együtt kell érteni? (Ami még nem jelenti azt, hogy minden sku-n lesz v-cache, de hát ugye "upto*" )És hol jön képbe a Rembrandtnál szereplő zen3+?
"AMD Ryzen 6000 Warhol could hit 5 GHz with 9-12% gains over Zen 3"
Ezeket 9-12%-os értékeket magyarázná, ha a v-cache-re vonatkozna. Bár ha frekvencia növekményt is nézzük, akkor a 9-12% meg elég konzervatív. (Bár lehet, hogy az AMD is azt a pár játékot emelte ki, ahol van létjogosultsága a V-cachen-nek)
Már olyat is olvastam, hogy a v-cache-nek semmi köze a Warholhoz. De olyat is, hogy a Warhol nem a B2-es stepping. Az is lehet, hogy mégis, de az is lehet, hogy az AMD csinált egy B2-es steppinget, ami képes a v-cache felépítmény fogadására, de a végleges termék a Warhol lesz 6nm-en gyártva és a 9-12% úgy jön össze - v-cache nélkül - hogy picit emelkedik a mag frekvencia és picit emelkedik a FCLK is.
Én még titkon reménykedem az új IOD-ben. Van egy olyan elméletem is, hogy a B2 stepping lesz a warhol végül, de 6nm-es IOD kapDe a lényeg, hogy innentől bármilyen hírt nehéz lesz értelmezni.
-
#5211
Petykemano
veterán
S_x96x_S
#5192
Petykemano
veterán
válasz
S_x96x_S
#5192
üzenetére
Feb 2022
a dátum - noha későbbi, mint amit én reméltem - nem irreális,.sőt.
A Vermeer megjelenéséhez képest 15 hónap - a szokásos termék-megjelenés-intervallum.
Lisa Su azt mondta a kísérleti zen3V-re, hogy év végén kerül gyártásba. Onnan még biztosan pár hónap, mire termék lesz.De vajon milyen termék?
Szerverbe nagyonis lenne értelme, ott bármilyen formában megfizettethető. =>Milan-X (Talán nem is nagyon lenne szükség v-cache nélküli termékre.)Viszont abból lenne értelme vajon új szériát csinálni, ha egyébként csak a legdrágább 8-12-16 magos darabokra kerül rá? Na nem mintha sok 8 magosnál kisébb zen3 létezne a piacon. Viszont egy olyan új széria, ami nagyobb drágulást hoz - mert a texhnológia drága - mint amennyi előnyt biztosít, az megint fölháborodást fog kelteni. Persze tudom, így is el fog fogyni.
Na de mindegy, nem is ide akartam kifuttatni, hanem az időzítésekhez. Ha ez az AMD 2022Q1-2023Q2-ig tartó terméke (ide értve a Vermeer-X és Milan-X is) akkor miért mondta Lisa Su, hogy eltökéltek az 5nm-es termékek 2022-ben való megjelentetését illetően?
Persze sokminden lehetséges. Pl:
- 2022 hosszú, a zen4 indulhat akár 2022Q4-ben is és még akkor is 2022. Azt gondolnám, hogy ez talán inkább a DDR5 és az 5nm elérhetőségétől függ, mint attól, hogy kész van-e. A Milan-X a meglevő alaplapokba akkor is remek drop-in-replacement lenne, ha egyébként egyszerre jelenne meg a Genoaval.
- én továbbra is azt remélem, hogy a 7nm-es (AM4) termékek olcsóbb változatként még pár évig a piacon maradnak. Ennek némileg ellentmond az, hogy a zen4-ről meg épp azt rebesgetik, mégsem emel magszámot.
- egy kísérleti terméket láttunk. A végleges 2022-ben megjelenő megoldás épülhet éppenséggel már zen4-re - újabb meglepetést okozva. Nem jött megerősítés arra vonatkozólag, hogy ez volna a Warhol
(Én erre látok legkevesebb esélyt) -
#5210
Petykemano
veterán
S_x96x_S
#5206
Petykemano
veterán
válasz
S_x96x_S
#5206
üzenetére
Jól értem, hogy a 36mm2 = 64MB és ez egy réteg?
Tehát nem 2x36mm2.Vajon.... mi érné meg jobban?
- hasonló rétegeket az L2$ és L1$ fölé építeni?
- a jelenlegi L3$ helyén az L2$ méretét növelni (hogy a V-cache továbbra is cache fölött legyen) és az L3$-t pedig kompletten kiszervezni többrétegű V-cache-be? -
HSM
félisten
válasz
S_x96x_S
#5206
üzenetére
"- As the V-Cache is built over the L3 cache on the main CCX, it doesn't sit over any of the hotspots created by the cores and so thermal considerations are less of an issue. The support silicon above the cores is designed to be thermally efficient."
Azért az nem túl bíztató, hogy "less of an issue". A nagy kérdés, hogy a hűtő és a tranzisztorok távolsága változott-e, ez sajnos ebből nem derült ki. Ha nőtt, akkor a hűthetősége elméletileg rosszabb lesz.#5208 paprobert : Azt lenne még érdekes tudni, a csip és kapacitás hiány miatt mennyi bevételtől esnének el, ha pl. ilyeneket gyártanának adott kapacitásokon Navi GPU-k és Zen3 CCD-k helyett. És ezt mondjuk mennyire lehet ellensúlyozni egy nyilván magasabban árazott prémium termékkel, amihez ezeket felhasználhatják. Persze, B-tervnek is jónak tűnik, ha az Alder Lake túl jól sikerülne.
-
#5204
Petykemano
veterán
S_x96x_S
#5201
Petykemano
veterán
válasz
S_x96x_S
#5201
üzenetére
Agner:
"A serious bottleneck is a decoding rate of 4 instructions or 16 bytes per clock. To compensate for this, the Zen 3 has a micro-op cache with 4096 entries after the decoder.
The increased throughput in terms of instructions per clock may be difficult to utilize if the software has long dependency chains (where each calculation must wait for the result of the preceding one). It is now more important than ever to avoid long dependency chains.
The bottleneck in the decoder appears to be difficult to overcome. This is a consequence of the messy x86 code structure where instructions can have any length from 1 to 15 bytes, and it is complicated to determine the length of each instruction. Intel processors have the same bottleneck and the same decoding rate. The programmer must make sure the critical part of a program fits into this micro-op cache if you want to get the maximum throughput. It is important to avoid loop unrolling where possible in order to economize the use of the micro-op cache. (The Clang compiler often makes excessive loop unrolling)"
[link]Az AT fórumon két elképzelés (patent) is fölmerült.
Én nem értek hozzá, nem tudom megmondani, hogy melyik mennyire jó vagy nem jóVirtualuizált uop cache [link]
A másik pedig a Tremont féle dual-decoder út [link]Persze lehet, hogy mindkettő módszer együttes használata adja a legjobb eredményt - és a legtöbb tranzisztor és fogyasztástöbbletet az Armhoz képest, ahol ilyen trükkökre nincs szükség.
Mindenesetre úgy tűnik ez alapján, hogy egyelőre hard Wall nincs, csak ha fejlődni szeretnének, akkor arra az Armhoz képest több tranzisztort és fogyasztást kell áldozni.
Egyelőre mindenki azt mondja, hogy az IPC szignifikáns növelésének legkézenfekvőbb módja a mag szélesítése lenne [link] aminek az x86 esetén az a korlátja, hogy a decoder nem tudják 4(-5)-nél szélesebbre venni.
Valószínűleg enélkül is lehet IPC-t növelni - valahogy úgy, ahogy az intel teszi, hogy a bufferek, regiszterek és cache-ek 25-50%-os növelése itt-ott ad 1-2%-os gyorsulást, ami végülis kiadhat egy valamirevaló 15%-os előrelépést egy generációban. De ez nem az a fajta ugrás, amit az igen vékony bulldozer magról az akkori értelemben széles ryzen magokra ugrás hozott és amivel utol lehetne érni az Apple M1-et.Úgy tűnik, hogy ennek az akadálynak az elhárítása a következő pár év nagy kihívása és beszédtémája lesz.
-
-
S_x96x_S
addikt
válasz
S_x96x_S
#5192
üzenetére
> - "Feb 2022 launch" -re jósolja a következő AMD cpu generációt.
> (feltételezem, hogy valami belsős infó alapján, Ian Cutress a kevésbé
> blöffölös fajta elemzők közé tartozik)rákérdezett:
"Confirmed with AMD that V-Cache will be coming to Ryzen Zen 3 products, with production at end of year."
https://twitter.com/IanCutress/status/1399766139769602058Az Intel ellen valamit ki kell állítani ..
Közben az interneten már találgatják a termékelnevezést:
"Ryzen 5950XT Pro Hyper V-Cache RX edition" -
hokuszpk
nagyúr
válasz
S_x96x_S
#5190
üzenetére
"Az AMD általában kevesebbet igér"
végülis a chiplet felépítést is elég jól leplezték, az Infinity Cacherol is csak nagyjabol a megjelenes elott picivel szivárgott info.
no mind1, ittvan ez az extended cache, 2TB/s ABU mondogatta, hogy a sugarkoveteshez kellenek a TB/secek, szoval most eppen az RDNA3 -at varom piszkosul.
oke, megvenni nemlehet majd, de varni ... igen ! -
#5196
Petykemano
veterán
S_x96x_S
#5192
Petykemano
veterán
válasz
S_x96x_S
#5192
üzenetére
- az új cache jó dolog, és 7nm-en .. ( nem 5nm! )
- "Feb 2022 launch" -re jósolja a következő AMD cpu generációt.
(feltételezem, hogy valami belsős infó alapján, Ian Cutress a kevésbé blöffölös fajta elemzők közé tartozik)
Elég érdekes felvetés. 2022-re tényleg zen4-et "ígértek". Persze nem kell minden szegmensben elindulnia. Viszont ha ez a Vermeer-X/Milan-X még csak 2022 elején rajtol, akkor hogy lesz ebből még abban az évben zen4?Szerver szinten egy Milan-X is szép előrelépést jelentene mindenképp.
On the performance, we’ve seen L3 cache depth improve gaming performance, both for discrete and integrated gaming. However, increased L3 cache depth doesn’t do much else for performance. This was best exemplified in our review of Intel’s Broadwell processors, with 128 MB of L4 cache (~77 mm2 on Intel 22nm), wherein the extra cache only improved gaming and compression/decompression tests. It will be interesting to see how AMD markets the technology beyond gaming.
Nem nevezném L4$-nek. Én azt olvastam róla, hogy tényleg 3D kiterjesztése a L3$-nek, vagyis nem egy újabb szint, csak a L3$ címzésének egy új dimenzió. Ezzel érdemben valószínűleg nem csökken a késleltetés sem - pont az új dimenzió miatt.
A Lisa SU által említett 2TB/s úgy jön ki, hogy 3x akkora az egész L3 komplexum sávszélessége.Ezzel együtt nyilván nem fog mindent gyorsítani.
-
HSM
félisten
válasz
S_x96x_S
#5175
üzenetére
Mindkettő nagyon szimpatikus.
És ne felejtsük el, hogy a korábbi APU tapasztalatok alapján az integrált IOD miatt várhatóan magasabb ram tempó érhető el, ami kompenzálhatja a kevesebb L3-at. És még egy jó IGP is lesz benne ajándékba.#5176 Petykemano : "Kicsit talán érthetetlen is, miért ennyire olcsó."
Gondolom itt nem kell versenyeznie/osztoznia az elkészült lapkáknak a legnagyobb profitú szerver termékekkel. Valamint feltételezhetően a gyártása is egyszerűbb (olcsóbb?), hogy egy helyen gyártják, egy csippel."Kicsit csalódást keltő, hogy 3x annyi L3$ csak 12-15% IPC növekedést hoz."
Pedig ez nagyjából megfelel a várhatónak. Nem véletlen rakott pl. az Intel is inkább kicsit kevesebb, de gyorsabb elérésű gyorsítótárakat a kliens CPU-ira. És pont ugyanezért nem gyorsult óriásit az 5000-es Zen sem, pedig praktikusan duplázták a "hasznos" L3 méretet.Egyébként azt gondolom, ez leginkább memória sávszélesség hiányos helyzetekben segíthet igen sokat, azaz szerverekben és a magas magszámú modelleken, asztaliaknál pl. 5900, 5950.
Ami szerintem itt még nagyon érdekes kérdés felmerülhet, hogy hogyan fog ez hatni a csip hűthetőségére? A 7nm magas teljesítménysűrűsége miatt eddig sem volt könnyen hűthető magasabb órajelen erős terhelésen, ha még raknak a hőtermelő magok és a hűtött felső felület közé egy plusz réteget, az izgalmas kihívások elé állíthatja a hűtőket és tuningra vágyó tulajokat.
-
carl18
addikt
válasz
S_x96x_S
#5160
üzenetére
Én igazán mázlista voltam akkor mert pont akkor vásároltam Ryzen mikor a Ryzen 5 1600 85 dollárért ment!
Viszont a jelenlegi korona vírusos helyzet és a TSMC készlet hiány is rájátszik a pocsék árazásra amin az AMD is emelt mert valszeg tudták így se tudnak eleget gyártani.
Szóval szerintem teljesen normális hogy nem gombokért adják jelenleg és keresnek is rajta kicsit .
Jelenleg nekik van jobb hardverük, és ahhoz képest 5900X/5950X nem lett sokkal drágább 550/800 dollár.
Elég csak megnézni az intel pár éve mennyiért adta a 16/18 magos hardvereket. Ha az AMD nem fogja közre nem nagyon csökkentettek volna ők árat.
6700K/7700K is kis órajel emelkedés volt.
Hát én is vártam egy 220 dolláros Ryzen 5 5600-at de fene tudta hogy ilyen készlet hiány lesz végül.
Persze így se panaszkodok, a 6/12 szál még mindig elég rengeteg dologra. Főleg egy RX 570 mellet szépen dolgoznak együtt.
Aztán mire lesznek normális árak, talán lehet egyszerre CPu-GPU csere is. -
#5159
Petykemano
veterán
S_x96x_S
#5157
Petykemano
veterán
válasz
S_x96x_S
#5157
üzenetére
Unalomig lehet magyarázni az okokat - amit mint figyelmes olvasó persze értek is, de azért az nem változtat azon a tényen, hogy akkor a top 6 magos $249 volt, most meg $299.
A zen1-gyel megjelenő magasabb magszámú széria nem trendszerűen állította be azt, hogy a core/$ szám növekedjen, hanem két lépésben (zen1, zen2) egy alacsonyabb ársávba sorolta be. Legalábbis ha igaznak bizonyulnak MLiD pletykái, hogy a zen4 esetén is megmaradnak a core/$ vonalak - erre pedig legnagyobb esély akkor van, ha tényleg nem indul 24 magos.
Mindez persze valóban azt jelenti: a verseny (vagy annak hiánya) és a kapacitások foglyai vagyunk.
> igazából Lisa Su
Nem tudom jobban kitenni az idézőjelet -
#5150
Petykemano
veterán
S_x96x_S
#5149
Petykemano
veterán
válasz
S_x96x_S
#5149
üzenetére
A 16 magra gondolsz?
Elég vicces... egy fél éve még attól harsogott a média, hogy a 8/16 magos konzol proci és az ssd vezérlő brutális terhelést fog róni a procikra.
Abu nemrég azt mondta, at FSR nagyobb terhelést dog róni a procikra.Az AMD meg nem akar több magot adni.
Megy a szerecsenmosdatás. Jójójó, a 8 magos kezdés tényleg nagyszerű volt, letörte a 6+ magos procik árát. De hát ugyanoda tartunk vissza. Jójójó, aztán letörte a 12-16 magosokat is
De a 6 magos procik az 1600/X megjelenése óta nem lettek olcsóbbak, sőt, drágultak is.:
-
S_x96x_S
addikt
válasz
S_x96x_S
#5146
üzenetére
> PCIe5
egy kicsit megnyugodtam ..
az AMD szerepel a "Launch Partners - Ecosystem" slide-on
az Intel és a Renesas mellett.
Van még remény

amúgy az STH -s cikk jobb mint az AT-s .. sok sok slide ...
https://www.servethehome.com/marvell-bravera-sc5-offers-2m-iops-and-14gbps-in-a-pcie-gen5-ssd/A Latency- csökkenés jó lesz .. meglássátok!

A Gen5 és a CXL - miatt a Szerverek gyors elavulását jósolja az STH. -
#5142
TESCO-Zsömle
titán
S_x96x_S
#5133
TESCO-Zsömle
titán
válasz
S_x96x_S
#5133
üzenetére
Szerintem valamit félreértelmeztek, mert az energiahatékonyság nem valami egyezményes dolig, ganem egy származtatott eredmény, ami számolható. A 170W-ot zabáló proci is is lehet energiahatékony, ha 2x annyit számol, mint a 100W-os.
Hasznos számítás/fogyasztás. Ennyit jelent az energiahatékonyság.
-
#5137
Petykemano
veterán
S_x96x_S
#5135
Petykemano
veterán
válasz
S_x96x_S
#5135
üzenetére
> technikailag kivitelezhető ..
> de Cloud-ban szerintem nem sok értelmét látom..
De hát ezt csinálja az Arm.
A V1 némileg magasabb egyszálas teljesítményre képes és 96 magos processzort lehet vele készíteni (referencia design) az N2 pedig az alacsonyabb egy és magasabb többszálas teljesítményre éleződik ki és 128 magos processzort lehet belőle csinálni.Ennek se látod értelmét?
Nem feltétlenül kellene vegyíteni a különböző lapkákat - cloudban. Sőt, ott lehet, hogy kifejezetten igény lenne arra, hogy eltérő árazással mérhessék a különböző típusú magokat.
Ugyanakkor - szerintem - a játékokon kívül más szoftvereknél is beüthet az Amdahl törvény - vagyis lehet, hogy nagyon hatékonyan tudja kiszórni szálakra a feladatokat, de lehet egy-egy olyan process, aminél az egyszálas teljesítmény limitáláltsága kihat az egész rendszer teljesítményére.
Ez persze már az ütemezés kérdése - ahogy mondod is. Az operációs rendszernek tisztában kell lennie azzal, hogy vannak olyan magok, amelyek más teljesítménnyel bírnak, mint a többi és azt is meg kell fontolnia, hogy egy szálat érdemes-e oda helyezni - vagyis hogy nem okoz-e azzal nagyobb lassulást, hogy ha egy másik CPU clusterbe helyezett programszál miatt megnövekszik a kommunikációs késleltetés.
Ez a probléma újra és újra visszaköszön, amit azért nem teljesen értek, mert az Intel Turbo boost 3 (vagy melyik) arról szól, hogy van 1-2 mag, amelyik magasabb frekvencia elérésére képes, mint a többi és a legdurvább programszálat oda ütemezi.
És a 2+1 chipletes zen2 és zen3 termékek is úgy működnek - ez a 3950X esetén elég világosan látszott - hogy az egyik CCD jobb minőségű és magasabb frekvencia elérésére képes "golden sample" és mellette van egy átlagos, gyengébb. Tehát az ütemezőnek már ebben az esetben is kutya kötelessége volt megtalálni, hogy ne akármelyik magon, hanem a legerősebbe(ke)n futtassa a programszálakat, amennyiben a program nem terhel minden szálat. Azt gondolnám, hogy itt nem megfelelő egy roundrobin száldobálás, hanem nagyonis tisztában kell lennie az ütemezőnek, hogy melyik cpu száltól milyen teljesítményre számíthat.
Azt mondod, hogy ez valójában nem így van, ez csupán szemfényvesztés, hogy papíron leírható legyen a magasabb frekvencia és az ütemezés szub-optimális működését meg elfedi a "mérési hiba"?
> akkor már inkább egy CCD-n belül kellene.
> - 8 core / CCD - amiből 2core extra (duplás) és 6 egyszerű.
> persze ez se ideális ..
> de legalább 1 chiplet-ből megoldható ..
> míg a tied 2 különböző CCD
Abból a szempontból igazad van, hogy egy ilyen esetben kevesebbet kellene "gondolkodnia" az ütemezőnek, hogy mi lesz a késleltetéssel, mert minden clusteren belül lenne "erős" mag, csak azzal kéne pluszban foglalkozni, hogy azokat a szálakat, amelyeket eddig is valamilyen megfontolásból egy clusterbe rakott, azok közül a legnagyobb igényűt a legerősebb magra tegye. "Csak azzal" - nyilván ez nem egyszerűViszont így nem lenne válogatási lehetőség, hogy melyikből mennyit kérek.
-
#5134
Petykemano
veterán
S_x96x_S
#5133
Petykemano
veterán
válasz
S_x96x_S
#5133
üzenetére
Ez már nagyon vagdalkozás részemről, de..
Azt nem tartom valószínűnek, hogy a zen4 CCD magszáma 8-ról 6-ra essen.
De azért amit mondasz,.szöget ütött a fejembe. Az A78 és az X1 lényegében feldolgozók számában és cache méretben különböznek egymástól.
Mennyire lenne bonyi csinálni
- egy zen4 heavy magot, ami 2 x AVX512, meg több cache stb. De csak 6 mag van a CCD-ben.
Célkeresztben a maximális teljesítmény.
- és egy zen4 light magot, ami utasítások terén ugyanazt tudja, csak kevesebb feldolgozó, kevesebb cache. Cserébe 8 mag / CCD. Célkeresztben a perf/W.Ennek már ugyan sok köze nincs ahhoz, hogy 3 CCD esetén -2 mag, de a Genoa 96 és 128 magos változatára magyarázat lenne. És lényegében ugyanezt látjuk az arm V1 és N2 esetében is.
-
#5131
Petykemano
veterán
S_x96x_S
#5128
Petykemano
veterán
válasz
S_x96x_S
#5128
üzenetére
> a mostani 2*8=16 power core - hoz képest
> nem valami nagy előrelépés.
Igen.
Most van ez hype a Milan-X-ről, amiről csak azt lehet tudni, hogy valami 3d stacked cucc (3DX) de azzal kapcsolatban, hogy pontosan mi van egymásra pakolva, csak találgatás zajlik.
Elég valószínű, hogy csupán arról van szó, hogy HBM lesz a zen3-as chipletek mellett használva, amire az elmúlt 1 év hírei alapján számítani is lehetett. De van aki felvetette, hogy vajon CCD-k vannak-e egymásra pakolva?- egyébként megmagyarázná, hogy hogy lenne 128 magos Genoa.
Mindenesetre ezen kezdtem gondolkodni, hogy vajon lehetséges-e, hogy ha már ekörül ekkora hype van, hogy a 2CCD az valójában 2x2 CCD, tehát a normál 24-32 magos és a 3 CCD az 3x2 CCD, de itt már max 7 mag / CCD - és akkor ezzel kijönne 42.
De ennek semmi értelme nem lenne.
Nem így ismerjük az új AMD-t.
Viszont értelmet nyerne a 170W-os TDP keret> meg, ha én tervezném, akkor csak 1 energiahatékony CCD-t
> raknék bele .. nem kettőt ..Miért?
Az energiahatékony az nem low power. Energiahatékony az az, hogy 3.5Ghz-en, amit 24-32 mag használata közben valószínűleg elérhet, a kevesebbet fogyaszt, mint a performance típusú.Abu mondta, hogy lesz RDNA és CCD lapkák cserélhetők lesznek.
A raphael esetén én arra számítok, hogy - és most maradjunk a leakben említett 3 CCD-nél - lesz
3 CCD
2 CCD + 1 IGP
1 CCD + 1 IGP
adabszurdum lehetséges volna 1 CCD + 2 IGP is, ami impozáns lenne, csak megint a memória sávszélesség jelentene probémát -
HSM
félisten
válasz
S_x96x_S
#5128
üzenetére
Nekem az nem világos, asztali gépbe mi a csodának energiatakarékos mag?
Korábban megmértem a Ryzen 5 3600-asom, egy mag fogyasztása az alap 3,6Ghz-en gyári feszültségen mindössze kb. 4-5W Cinebench R15 terhelés alatt, lásd 1 szál vs. 2 szál: [link]
Nem tűnik ésszerű célnak ez alá menni, amikor egy tipikus asztali gép üresjárati fogyasztása legalább 20-30W monitor nélkül. A memóriavezérlő/IF linkek sokkal inkább tűnnek lényeges fogyasztónak, ha nincs eszetlen paraméterekkel meghajtva a CPU.Egy notebooknál értem, amikor üresjáratban az egész fogyaszt monitorral együtt 5W körül, de asztalon más a nagyságrend, ahova az AM5-öt szánják.
A háttérfeladatok hatékony végzésére pedig sokkal inkább valami szoftveres megoldásnak látnám értelmét, ami ezekre nem aktiválja a magas, tipikusan nem energiahatékony turbó/boost órajeleket.
Nekem két 8 magos erős CCD és egy GPU csiplet tetszene, lehetőleg CXL-es PCIe5-el.
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
#5125
Petykemano
veterán
S_x96x_S
#5124
Petykemano
veterán
válasz
S_x96x_S
#5124
üzenetére
"persze most még ~90% -10% lehet az X86 - ARM megoszlás,
de 4-8 év múlva az ARM feljöhet 30 - 40% -ra is ."
Ezt nem vonom kétségbe, de ez csaknem az egyik évről a másikra ugrik meg. Nagyjából mindem évben történik beruházás a legújabb szerverekből. (Persze nem minden telephelyen az igaz.)
Ráadásul most elég nagy ugrások is vannak már generációról generációra -
#5120
Petykemano
veterán
S_x96x_S
#5117
Petykemano
veterán
válasz
S_x96x_S
#5117
üzenetére
Ezt a vitát egyszer már lejátszottuk.
Én valahogy nem tudom elképzelni hogy erre - hogy csak egyszer kelljen megvenni a procit,de a kupak alatt kétféle maximálisan profi rendszer legyen, amik között reboottal lehessen váltani - nem tudom ki akarna. Én nem gondolom, hogy ennyire bénakacsák lennének a cloud szolgáltatók, hogy annyira ne legyen elképzelésük, hogy milyen ISA-ra lesz igény 2-5 év múlva, hogy nekik egyenlő mértékben kéne különböző ISA-kból számítási kapacitásra beruházni, mert ki tudja, mit hoz a jövő. Szerintem ők ezt nem annyira lereagálni, mint inkább költség alapon irányítani szeretnék.Annak esetleg látnám értelmét, hogy olyan heterogén architektúra, amiben egyszerre van jelen az x86 és az arm processzor, mindkettő aktív, de persze csak az egyiket használja a host rendszer, a másik lehetőséggel csak tisztában van és ennek megfelelően tud rajta virtuális futtatási környezetet (VM-et) futtatni.
Ha jól emlékszem, az intelnek volt PCIe slotba dugható compute cardja
[link]Ha így nézzük, akkor a gpu is egy hasonló. Egy saját ISA-val rendelkező rendszer, amin ezért sajátos módon, sajátos kódot lehet futtatni. Tehát egy x86-os host rendszerbe dugott Arm kártyán miért ne lehetne Arm kódot futtatni? vagy fordítva.
Azt gondolnám, hogy ennek neked otthon, aki esetleg nem engedhetsz meg magadnak két számítógépet, még lenne értelme. De egy nagy cloud szolgáltató miért járna jobban?
Az persze hatalmas húzás lenne az AMD-től, ha kiderülne, hogy az architektúráit mindig is úgy készítette el, hogy ugyanabból a zen-ből létezett egy olyan változat is, ami nem x86, hanem Arm ISA frontenddel rendelkezik. De ha ilyennel rendelkezik, akkor szerintem azzal már előálllt volna, ha úgy gondolná, hogy előnyös a szerverpiacot két irányból támadni. Ha viszont visszatartja azért, hogy majd a megfelelő pillanatban rántsa elő, amikor az Arm adoptációja már erre készen áll, akkor az valójában azt jelenti, hogy valaki ezt az utat - az AMD x86-os törekvései ellenére - kijárta, kitörte, ha ennél nem jobbal áll elő az AMD, akkor ezen a piacon is elvesztette a versenyt, ha viszont jobbal rendelkezik, akkor minek várt vele?
-
-
#5111
Petykemano
veterán
S_x96x_S
#5110
Petykemano
veterán
válasz
S_x96x_S
#5110
üzenetére
Én ebből csak azt olvasom ki, hogy nek zárkóznak el az arm elől. (Semi custom?) Még akár azt is,.hogy xilinx területre nem próbálnák beerőltetni az x86-ot, csak mert ők most abban érzik.nyeregben magukat, ha egyébként annak ott nincs se hagyománya, se igénye.
De azt nem látom, hogy ez már egy komplett armos átállásra való felkészítés lenne. Mármint ez megtörténhet, de azt nem látom.ebből, hogy ennek az AMD úttörője lenne. Viszont ha úgy alakulnak az ügyféligények, akkor kiszolgálják.
5-10 éves távlatban szerintem az lehet meghatározó, hogy mennyivel.egyszerűbb armra programozni. Ebben számíthat az is, hogy önmagában arm, vs önmagában x86, és az is, hogy ugyanezek heterogén computinggal.
Ez viszont lehet, hogy már oneAPI vs CUDA vs ROCm terület. -

Devid_81
félisten
válasz
S_x96x_S
#5097
üzenetére
AMD AM5, the successor to AM4 is to feature an LGA1718 socket. AMD is apparently changing its socket type from PGA to LGA (land grid array), which means there be no pins on the next-gen AMD processors, instead, pins will be located on the motherboard socket.
Hoppa hoppa

-
#5098
Petykemano
veterán
S_x96x_S
#5097
Petykemano
veterán
válasz
S_x96x_S
#5097
üzenetére
Szerintem ez csak a CPU és a chipset közötti kommunikációt jelenti.
A pcie4 megjelenésekor volt szó arról, hogy régebbi alaplapba teszed az új pcie4 procit, akkor engedélyezik-e az amd és az alaplapgyártók (nyilván BIOS frissítés kellhet), hogy azok a sávok,.amiket a proci kezel pcie 4 sebességgel működjenek. Végül döntés alapján ez nem valósult meg, de Végülis a nextgen budget alaplapok így működtek.Bár lehet, hogy ugyanezt mondtad, csak nem "A"-s procikra, hanem "A"-s alaplapokra gondoltál.
-
HSM
félisten
válasz
S_x96x_S
#5094
üzenetére
Ezzel kapcsolatban a Cyberpunk esete volt pl. nagyon érdekes... [link]
Sok idő, mire ezek a kikopnak.Én egyébként óriási előnyként tekintek az X86 széleskörű, több évtizedes kompatibilitására. Az ember szabadon használhatja a jól bevált, adott esetben nem feltétlen "naprakész" szoftvereit is amíg csak szeretné.
Amúgy a Skylake architektúrában is bejött egy érdekes "újdonság", ami komoly optimalizálási nehézségeket okozhatott bizonyos szoftverekben, a PAUSE utasítás "energiatakarékosabbá" tétele [link] [link] .
-
#5075
Petykemano
veterán
S_x96x_S
#5074
Petykemano
veterán
válasz
S_x96x_S
#5074
üzenetére
Ez úgy hangzik, mintha cserélnék az IO lapkát TSMC-nél gyártottra, de az nem feltétlenül jelent előrelépést semmiben.
Egyébként az is előrelépésnek számít manapság, ha ugyanazt lehet megkapni, de nagyobb mennyiségben tudják előállítani (most itt nem a chipletre gondolok, hanem a packagingre) és így olcsóbban hozzáférhető. -
válasz
S_x96x_S
#5069
üzenetére
De ami a lényeges:
a PCIe GEN5 és a DDR5 -höz nem árt egy új alaplap is.
és akkor már új foglalat is kell.
és erről még semmi hír.Éppenséggel akad írás róla, pont ph!-n
A 2022-ben érkező Socket AM5-ös foglalat hozza a DDR5 támogatását, illetve a PCI Express 5.0-t, amelyeket az új IO hub biztosítja. -
#5058
Petykemano
veterán
S_x96x_S
#5057
Petykemano
veterán
válasz
S_x96x_S
#5057
üzenetére
3 év leforgása alatt $1.6b = évi $500m, vagyis negyedévente kb $130m
Ez szerintem már elég kis tétel az AMD jelenlegi negyedéves jelentéseiben, ennek kb 10x-esét elkölti a TSMC-nél.
Ez egyébként havi $45m
Mondjuk ha a 12/14nm-es waferekre költi, ami mondjuk waferenként $3000 (?) az havi 15000 wafer. Ez szerintem nem olyan vészesen sok, mérettől függően 2-4 millió lapkát jelent.Ebből kell kiszolgálniuk a Rome és Milan termékek IO lapkáját, ha cserélni kell, és ha megtarjták budget katerógiára a 7nm-es gyártást (Vermeer), akkor ott is keletkezik igény.
Azt mondják egyébként, hogy kevésbé cutting-edge igényű FPGA-kat gyárthatnak még ott.
Meg hát ugye az örökéletű Polarist.Egyébként a GF-nak előbb-utóbb biztos elkészül a frissített 12nm-e, ami papíron sokat javít a fogyasztáson.
Az persze igaz, hogy ezek a mai gondolataink erről. És a kérdés úgy hangzott, hogy 2024-ig mit fognak kezdeni ezekkel a waferekkel. De úgy is nézhetjük, hogy chiphiány van. Egy rosszabb gyártástechnológián elkészített lapka bizonyos szempontból még mindigjobb, mint egy nem elkészített lapka.
-
S_x96x_S
addikt
válasz
S_x96x_S
#5055
üzenetére
A Samsung az AMD-t is megemliti a sajtóközleményben.
úgyhogy van még remény .."Dan McNamara, senior vice president and general manager, Server Business Unit, AMD, added, “AMD is committed to driving the next generation of performance in cloud and enterprise computing. Memory research is a critical piece to unlocking this performance, and we are excited to work with Samsung to deliver advanced interconnect technology to our data center customers.”"
-
#5054
Petykemano
veterán
S_x96x_S
#5053
Petykemano
veterán
válasz
S_x96x_S
#5053
üzenetére
S=Silent
Abu előrejelzései alapján várható volt az emelkedés, hiszen alacsony magszámú szerverek terén most vették át a vezetést és - abu szerint - az eladások nagy része még mindig ez a terület.
Ebből a szempontból még az Ice lake bezavarhat. De biztosan egyre többen bátorodnak fel. -
#5048
Petykemano
veterán
S_x96x_S
#5044
Petykemano
veterán
válasz
S_x96x_S
#5044
üzenetére
"We're very excited about our next generation which is our 5nm roadmap, we're committed to have that in the market in 2022 "
Lisa Su - [link]Eddig is úgy volt, hogy 5nm 2022-ben lesz csak, de korábban azt reméltük, hogy mondjuk 2022Q1-ben érkezhet a zen4 és a zen3+ vagy Warhol, vagy akármi, az csak valami szolid refresh, egy filler a valamivel hosszabb zen3-zen4 várakozási időszakban.
Aztán jött a hír, hogy a Warholt elkaszálták - és vele együtt felcsillant a remény, hogy talán csak nem azért, mert a vártnál előbb jön a zen4?
De Lisa Su tisztázta: nem, nem jön 2021Q4-ben zen4.
(noha ugye azt is mondta, hogy zen4 ES példányokat már szállítanak kiválasztott partnerek számára) -
#5046
Petykemano
veterán
S_x96x_S
#5044
Petykemano
veterán
válasz
S_x96x_S
#5044
üzenetére
Szerintem az 5nm-es gyártókapacitás eleinte (még ha nem is vagyunk már az 5nm-es gyártás elején, sőt, jövőre "elavulttá" válik), szűkös lesz.
Rémlik, mintha egyszer abu is említette volna, hogy a zen4-et az AMD szerverbe hozza először.
Önmagában ez nem volna meglepő dolog. Se ez, se az, hogy a DDR5 és a CCD fejlesztése sokáig tart. Az tűnik egymásnak ellentmondó hírnek, hogy
- egyszer kilövik a filler Warholt, ami alapján azt feltételezné az ember, hogy akkor biztos a zen4 hamarabb jön, vagy valami
- ugyanakkor meg nem, dehogyis, sőt.De ahogy tanult kolléga megállapította a Radeon találgatósban: mindegy, hogy milyen architektúra és milyen gyártástechnológán nem érhető el emberi áron.
-

Mumukuki
aktív tag
válasz
S_x96x_S
#5024
üzenetére
Úgy látom, hogy most van verseny. Ha nem sikerül Amdnek és főleg az intelnek sávszélességgel versenyezni a közeljövőben az apple lefoglalt gyártással , akkor itt már kevésbé lesz verseny , inkább csak az egész PC ipar kivéreztetése.
Pillanat alatt az AMD is ott találhatja magát mint most az intel, durva csíkszélesség előnyt kell lefaragniuk.A verseny jó szerintem is és mindenkit szolgál.
-
#5023
Petykemano
veterán
S_x96x_S
#5020
Petykemano
veterán
válasz
S_x96x_S
#5020
üzenetére
Az MLiD videóban az egyik "forrás" azt állította - és én úgy értettem, hogy az egész műsor végülis erre futott ki - hogy Ő ugyan zen3+-ról nem hallott, de a Warhol egy valós kódnév, létező projekt.
Ez persze még nem jelenti azt, hogy
1) Az elhangzottak igazak. Azt például egyszerűen nem hiszem el - ugyanabból a videóból - hogy a 4700S az nem PS5 vagy xbox selejt, hanem egy Subor Z+-hoz hasonló "semi-custom" fejlesztés újrahasznosítása.
A kódnévről más leakerek viszont nem is hallottak.2) és azt sem feltétlenül jelenti, hogy a Warhol - amennyiben tényleg létezik - az, aminek eddig gondoltuk.
A 7nm megtartása mainstream/budget vonalra szerintem továbbra értelmes, logikus döntés lenne. Az 5nm-es gyártás biztos drágább és biztos van annak jobb helye is. Arról nem is beszélve, hogy abu mindig azt mondja, hogy a szerverpiacon sok évre előre kell vállalni azt, hogy adott lapkát fogják gyártani.
Ha nincs Zen3+, egy esetleges Warhol szempontjából akkor is szóbajöhető node a 6nm. Csak nem a compute lapkáknak, hanem az IO lapkáknak. Ha jól tudom, a zen4-et már 6nm-en készülő IO lapkákkal fogják párosítani. De máskülönben a 6nm-es Rembrandtban is 6nm-es lesz az uncore. Azt láttuk, hogy a 14nm-es IO lapka már elég sokat eszik és bizonyára limitációt jelent a FCLK szempontjából is. Logikus lenne, ha a zen3 6nm-es IO lapkával élne tovább.
Ezzel persze nem azt akarom mondani, hogy szerintem biztosan megvalósul. Éppenséggel kaphatott kaszát mondjuk amiatt, hogy a 6nm-es Rembrandtra kell a gyártókapacitás.
-









![;]](http://cdn.rios.hu/dl/s/v1.gif)



 Bár tegyük hozzá, 16 magot megfelelően skálázódó módon ellátni szálakkal egyébként sem feltétlenül egyszerű, hát még ilyen "egzotikus" felépítésű CPU-k esetén.
Bár tegyük hozzá, 16 magot megfelelően skálázódó módon ellátni szálakkal egyébként sem feltétlenül egyszerű, hát még ilyen "egzotikus" felépítésű CPU-k esetén. 














Új hozzászólás Aktív témák

- HP 14 Elitebook 640 G10 FHD IPS i5-1345U vPro 10mag 16GB 512GB SSD Intel Iris XE Win11 Pro Garancia
- HIBÁTLAN iPhone 14 128GB Purple -1 ÉV GARANCIA - Kártyafüggetlen, MS3530
- BESZÁMÍTÁS! 64GB (2x32) G.Skill Trident Z RGB 4000MHz DDR4 memória garanciával hibátlan működéssel
- Bomba ár! Dell Latitude E5550 - i5-5GEN I 8GB I 256GB SSD I 15,6" I W10 I HDMI I Cam I Gari!
- BESZÁMÍTÁS! Intel Core i5 4570 4 mag 4 szál processzor garanciával hibátlan működéssel
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest