
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Internet Rádió építése (hardver), és programozása
- Milyen egeret válasszak?
- ThinkPad (NEM IdeaPad)
- OLED TV topic
- Sugárkövetés nélküli sugárkövetés felé menetel az új PlayStation
- Autós kamerák
- TCL LCD és LED TV-k
- Videós, mozgóképes topik
- Amlogic S905, S912 processzoros készülékek
Új hozzászólás Aktív témák
-
#614
 Petykemano
veterán
lezso6
#613
Petykemano
veterán
lezso6
#613
Petykemano
veterán
Igen, ez igaz.
De nem az a nagy kükönbség, hogy anno... volt ez az FSB, Front Side Bus frekvencia, ami ilyen 100-133MHz volt (és akkor 3-4-5MHZ-cel ezt is lehetett húzni.) És akkor a CPU frekvencia az FSB-nek valamilyen szorzata volt. A nagy találmány az integrálás során Gondolom az volt, hogy rövidebb utak mellett magasabb frekvencián tudott menni a belső bus. Ha jól tudom, az Intel ring busa például a magok frekvenciáján megy (ami mondjuk így fura, mert az nem fix)
Ha az AMD megoldotta, hogy az IF, vagyis az IO frekvencia nagy távolságra is tudjon magas frekvencián üzemelni, például a RAM frekvenciáján, ami 1200-1800MHz most, akkor máris 10-15x gyorsabb, mint régen a northbridge. Ha esetleg az IF2-vel megoldották, hogy a RAM névleges frekvenciájával (2400-3600) szaladjon akkor azzal a késleltetéseken is jelentős mértékben javíthatnak, hiszen azonnal el tudják kapni a felszálló és leszállóági adatcsomagot. (Esetleg hasonló trükkel)Mindenesetre érdekes.
-
#612
Petykemano
veterán
lezso6
#611
Petykemano
veterán
Az jövő évi amd lineup olyan, hogy tök könnyen lehet rá hihető elképzeléseket felvázolni.
Számomra ennek megfelelően hihető, nagyjából ilyesmire számítanék én is.
Lesz új apu, a Picasso, de arról Fiery eddig végig azt mondta, 14nm.
Ahol szerepel még IGP, zen2 magok mellett, az nyilvánvalóan nem apu, de egy chiplet felépítés mellett ráköthetnek az IO mellé egy Vega 20 (Vega12) lapkát.Más kérdés, hogy az a 14/20CU mire lenne alkalmas 2ch DDR4 sávszél mellett, de ettől függetlenül nem.kivitelezhetetetlen. ebben egyedül az hihetetlen, hogy ezért csupán $20-al kérnének többet.
Máskülönben a frekvenciák hihetők - minden spekuláció arra megy, hogy a kis lapkaméret és az egységes gyártás komoly válogatási lehetőséget biztosít, ami lehetővé teszi a 20-25%-kal jobb frekvenciát elérő lapkák termékké tételez.
Az árak is nagyjából, de csak nagyjából. Talán 10-15%-kal tényleg nyomottabbak, mint amire egy új termék megjelenésekor szokásos. De a 2700X most is $300 körül megy, az 1800X $499-ért debütált. Talán abban igazad van, hogy ha sikerül egyszálon is lenyomni az intelt, akkor azért akár kérhetne többet is - ez szokott lenni a Céges magatartás.Az 5GHz base utolsó sorokat én se hiszem el.
-
#608
Petykemano
veterán
Petykemano
veterán
-
#606
Petykemano
veterán
Cathulhu
#605
Petykemano
veterán
válasz
 Cathulhu
#605
üzenetére
Cathulhu
#605
üzenetére
"As for AMD, in 2016 it launched what remained of the Arm chip it was working on with Amazon, the Opteron A1100 codenamed Seattle. The clue was in the name, we note. Today, AMD is all in with its much more successful Zen-based x86 processors, Ryzen and Epyc, and no one talks about the A1100."
"Here's what we know about the Graviton right now. Its CPU cores are based on Arm's 2015-era Cortex-A72 designs, and are clocked at 2.3GHz. They are 64-bit, Armv8-A, little endian, non-NUMA, and feature hardware acceleration for floating-point math, SIMD, plus AES, SHA-1, SHA-256, GCM, and CRC-32 algorithms.
"Other benchmarks put the Graviton on the same footing as a Qualcomm Snapdragon 835, in terms of single-core performance. CPU benchmarks don't tell the whole story: there's always networking, latency, storage access, and so on, to worry about in the cloud."
Itt még lesz fejlődés.
-
#604
Petykemano
veterán
S_x96x_S
#591
Petykemano
veterán
válasz
 S_x96x_S
#591
üzenetére
S_x96x_S
#591
üzenetére
"Pro: everything just works. Literally. I used my unmodified deployment scripts I use to install a fresh Linode VPS for WikiChip to install and configure the servers. Everything just worked (minor config differences due to using RHEL on AWS and Fedora on Linode, but that's it)."
"The con: it's too damn slow. It does well on the Phoronix Test Suite. It does poorly benchmarking our website fully deployed on it (nginx + php + MediaWiki and everything else involved). This is your "real world" test. All 16 cores can't match even 5 cores of our Xeon E5-2697 v4"
(Src)
-
#593
Petykemano
veterán
lezso6
#592
Petykemano
veterán
Az szerintem nem lesz, amíg az ARm ökoszisztéma nem gyorsulja le az x86-ot (nem feltétlenül sebességben, hanem lendületben)
AZ AMD legalábbis pontosan tudja, hogy X86 piacon csak az intellel kell versenyeznie, ha teret kap az ARM, ott legalább féltucat, de inkább tucat versenyző szállhat be a ringbe nem is beszélve arról, hogy a legnagyobb ügyfelek (Amazon, Google, Microsoft, Baidu, stb) meg is tehetik, hogy fejlesztenek maguknak valamit, ami lehet, hogy nem olyan jó, mint az Apple évek alatt összepakolt chipje, de van olyan jó, mint bárki másé a piacon és biztosan olcsóbb összeollózni a kész IP-ket, mint fejleszteni.
Az Arm licencdíja darabszámra megy (nem?), márpedig biztos nem fognak annyi szervercpumagot eladni, mint a mobil piacon. Tehát erre az Armnak még szerintem ki kell találnuia valamit. Talán az interconnect drága? -
#588
Petykemano
veterán
Petykemano
veterán
16x16MB L3 => 4C/CCX
? -
#567
Petykemano
veterán
Petykemano
veterán
-
#556
Petykemano
veterán
Petykemano
veterán
mérnök úr most arra jutott, a 420mm2-es io chipbe, ha levonjuk belőle a ddr4 és pcie4 méretét, valamint a zeppelin lapka kitöltő részeit, nem marad hely L4$ számára
-
#555
Petykemano
veterán
lezso6
#551
Petykemano
veterán
ITT egy elemzés az Intel i gen1-gen8 "ipc" eredményei és a memória sávszélesség közötti összefüggésről.
A HT eléggé rontja a grafikont... vagyis értelemszerűen egy kezelt szálra kevesebb sávszélesség jut; a HT magok több sávszélességet igényelhetnek.
A videó csak érinti, hogy a CPU magok feldolgozóképességének fejlődésétől elmaradó memóriasávszélesség bővülést a processzorok többszintű cache bevetésével kezelik. Ez kell, hogy adattal tudják elég gyorsan etetni a feldolgozókat. (Ez nem újdonság.Ez az SMT4 érdekes dolog, mert ha megvan a backend 4 szál kiszolgálásához ... de ugye az is hogy? kb 2-3 ILP elérése egyszerű. Most ha jól tudom, 4 integer és 4 128bites fp feldolgozó van. (Bevallom itt már rezeg a léc, hogy fejből mit tudok) tehát mondjuk az SMT4 hatékony kihasználáshoz a zen backendjét meg kéne másfélszerezni? Vagy lehetséges, hogy a 256 bitesre bővítést már eleve úgy hajtották végre, hogy 8 128 hites, amiből 2-2 összeáll 256bites utasítás egy órajel alatti végrehajtására, mint a bulldozerben? Mert mondjuk így elfér az SMT4...
Nade oda akartam kilyukadni, hogy ezt etetni is kell. Akkor itt még durvább cache méretekre és. Sávszélességre lehet számítani.
Illetve ami még segíthet az a tömörítés.
-
#550
Petykemano
veterán
Petykemano
#549
Petykemano
veterán
válasz
 Petykemano
#549
üzenetére
Petykemano
#549
üzenetére
Ugyanakkor persze annyi különbség van, hogy az SE-k mögötti L2 és HBCC mellett az előttük levő Command processor és Workload distributor is közös. De miért ne lehetne ez az IO chipen?
Fogj meg egy aput, vágd ki belőle a cpu magokat és a CU-kat és kösd hozzá kívülről, skálázd. Voilà.
Ugyanakkor valamiért Dávid Wang mégiscsak azt mondta, ez nem olyan egyszerű nem compute taskok esetén.
(A gput folytassuk a radeon találgatósban) -
#549
Petykemano
veterán
Cathulhu
#548
Petykemano
veterán
válasz
Cathulhu
#548
üzenetére
De és ez a csomó késleltetés ez biztos?
Mert ha igen, akkor az meg is adja a választ arra, hogy a következőkben miért is lenne indokolt imterposer használata. Lezso azt mondta, az IF nem széles, nem szükséges az IP, de az IP miközben rövidít, aközben szélesebb buszt is lehetővé tesz. Ha az irány az IF javításán vezet, akkor az IP a későbbiekben elkerülhetetlen.Mindenesetre az jó hasonlat, hogy mintha csak közvetlen memóriaelérés nélküli TR lapkák lennének. Az biztos kolönbség, hogy az IF órajele magasabb kell legyen, ez máris csökkenthet a késleltetesen.
Viszont ha ebben igazad van, az megint csak indkolja, hogy az IO lapkán egy bazi nagy cache legyen, hogy egy útvonal minél inkább megúszható legyen. (Eddig: cpu<->ram, most: cpu<->io), amibe a prefetchelést maga az IO lapka végezze. Pont úgy, ahogy a Vega HBCC-nél láttuk. (Lehet, hogy a technológiát ott csak kipróbálták)
Az, hogy ezt a struktúrát fel lehetne használni gpuknál, nem egyedi gondolat. Sőt, kicsit a 4 Shader engine már eleve ez. De mennyivel jobb lenne minden shader enginet külön gyártani és IF-fel össszekapcsonil? Akár külön célra. Akár válogatva.
(Via) -
#541
Petykemano
veterán
lezso6
#540
Petykemano
veterán
Annak esetleg látnám létjogosultságát, hogy az egymás melletti chipletek közvetlen módon kommunikáljanak egymással ezzel megtartva valamiféle strukturális visszafelé kompatibilitást az EPYC1-gyel, ahol szintén volt olyan, hogy lapkán belüli magok a lapkán kívüli magokhoz viszonyítva gyorsabb eléréssel rendelkeztek. Így minden optimalizálást, amit az EPYC 1 megkap, áthozható a ROME-hoz is és vica versa, minden ROME optimalizálás értelmet nyer az EPYC1-nél is.
Amúgy looncraz is rajzolt egyet:
![[link]](http://files.looncraz.net/Zen_2_AMD_Rome_IOLayoutTheory.jpg "[link]")
"Decided to throw together a roughly scaled (probably should have been wider and slightly shorter) version of the IO chip using the Zepplin die shot.
This includes everything we know (ahem.. or believe) to exist on the IO die (8 IFOPs, 128 PCI-e lanes, 8 DDR4 channels, etc...) and all of the strange unknown blocks from the Zepplin die. And there was enough room to add 128MiB of L4.. using the L3 from the CCXes directly.
I estimated ~26ns nominal latency to any IFOP from the L4, which is half the latency as to main memory - and with potentially more than double the bandwidth reaching a chiplet (400GB/s). Latency to the L4 from a core would be hard to estimate, but it would be 20~30ns faster than going to main memory, so it's a big win."
-
#535
Petykemano
veterán
Simid
#534
Petykemano
veterán
zennél 2x8MB L3$ van
Egyik CCX-től a másikig elég magas a késleltetés
Azért gondoljuk, hogy a CCX-ek közötti elérésben, adattranszferben valahol a memória közrejátszhat, beépülhet, mert az inter-CCX latency általában a mérésekben magasabb, mint a memory latency.,
Itt tökre jól látszik, hogy 8MB felett emelkedik a késleltetés

Egy L4$-sel pedig ezt lehetne kb elérni, amit az 5775C-nál látsz:
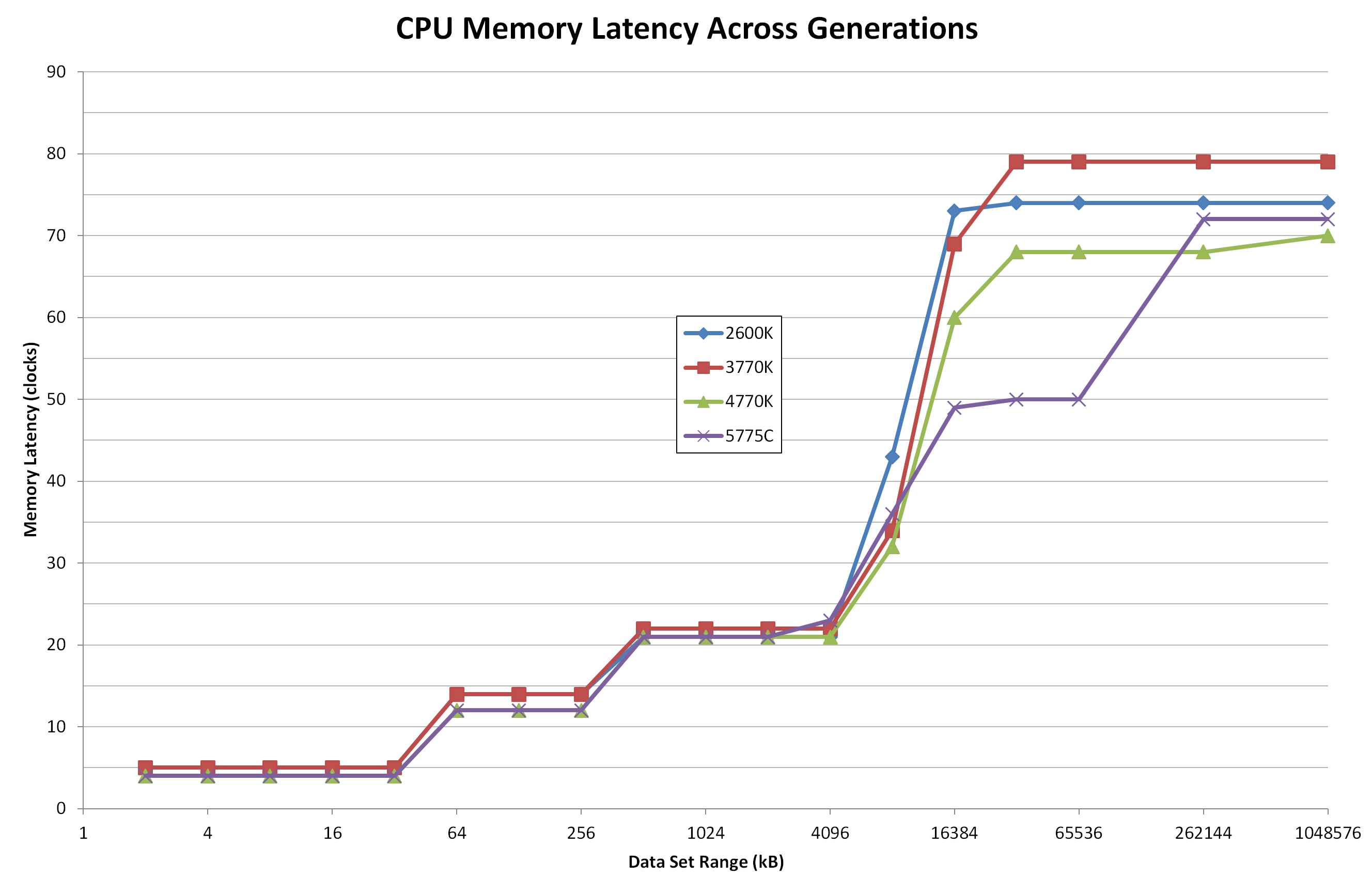
-
#529
Petykemano
veterán
Simid
#528
Petykemano
veterán
két lehetőség:
- 2 CCX közötti adatkommukáció meggyorsítása úgy, hogy az adatot ne a memórán keresztül kelljen cserélni (ez a feltétezés jelenleg az alapján, hogy a 2 CCX közötti késleltetés magasabb, mint a memóriahozzáférésé)
- memóriahozzáférés gyorsítása hagyományos cache funckióként.De a L4$ létezése még nem bizonyos.
-
#527
Petykemano
veterán
lezso6
#526
Petykemano
veterán
1000 az egész
65-80 között becsülgetik a chiplet méretét, ahhoz képest szemre ~5x nagyobb az IO chip.
75x8=600
75x5=375Ezek nem az én méréseim, becsléseim, csak amik szembejöttek.
Volt egy számítás, ami szerint a zen1ben a CCX 44mm2, kettő együtt mondjuk 90mm2 a maradék ~100 az uncore. Ebből 4 volt a naplesben. A kérdés az, hogy mennyi lehetett a redundancia az önállóan is működőképes zeppelin chipek miatt, amit ki lehetett vágni (usb, northbridge, huzalozás), aminek a helyére esetleg elfér eDRAM.
Ennek persze csak akkor van létjogosultsága, ha a zen2 chiplet mérete inkább nagy. Ha kisebb, az uncore is kicsi -
#524
Petykemano
veterán
S_x96x_S
#522
Petykemano
veterán
válasz
S_x96x_S
#522
üzenetére
Arra gondolsz, hogy a kifelé 8 csatornás DDR4 (később DDR5) megtartása mellett lepakolnak a feltételezett eDRAM helyére és/vagy üres helyre 4 stack HBM2-t (lásd Vega20) és HBCC-vel vidáman cachelgetnek 32GB-ban 1-1.2TB/s sávszélesség mellett?
Végülis könnyen lehet, hogy egy ilyen megoldással is könnyen tudnának.etetni 8-nél több chipletet.
-
#519
Petykemano
veterán
S_x96x_S
#517
Petykemano
veterán
válasz
S_x96x_S
#517
üzenetére
Ez az egész nagyon flexibilis.
A Rome socket kompatibilis lesz a naples-szel. SP3. 8ch DDR4De most, hogy a cpu chipletek készek, bármi máshoz csak az IO chippel kell játszani. Lefelé quarter IO - ian cutress szerint.
Ha már ennyire nagy szám az intel 12ch ddr4 cascade lakeje...
Mennyi esélyét látod annak, hogy az amd később, csináljon egy sp3+/sp4 foglalatot, ami értelemszerűen még nagyobb , és ami 12ch DDR4 (esetleg már ddr5) Memóriát támogat és a lapkán 12 chiplet kapna helyet?
-
#516
Petykemano
veterán
HSM
#514
Petykemano
veterán
Szerintem belefér AM4-be 2 chipletes 12 v 16 magos változat is. Méret, fogyasztás szempontjából mindenképp.
Ha az összekötő IO chipbe még EDramot is tesznek, azzal mindenképp megoldják a CCX-ek közötti kommunikációt és a 32MB/CcX és az edram együtt biztos jelentős mértékben tompíthatja a 2ch DDR terhelését.
Az ár még fontos. Frekvenciát még nem tudunk.. de ha a IF2, és az esetleges L4 kiküszöböli az eddigi CCx felépítésből adódó hátrányokat (latency) akkor már a 1x8 magos változattal is verhető a 9900K és a 2x6 és 2x8 változat is mehet a $400-700, ahol az ilyen magszámú TR1 jelenleg is vannak.Ha van L4, threadripperben biztos kisebb lesz az IO...
-
#507
Petykemano
veterán
lezso6
#506
Petykemano
veterán
L4$ két okból lenne hasznos.
Egyrészt úgy tűnik, hogy a zeppelin esetén a 2 egy lapkán levő CCX között is nagy késleltetés volt. Az IF ugyan kezelte, hogy 2db L3 tömb van, de a másik CCX L3-ból olvasni úgy tűnik nem volt gyors.UGyanez igaz most az epyc2-re is. Lehet, hogy egy CPU-nak egy másik CCX-ből kellő adat pont ott van a másik CCX L$-ban és a lokalizációt az IF lekezeli, de mégiscsak gyorsabb lehet, ha a IO lapka vissza adja, mintha át kell nyúlni a másik CCX L3-ába, és onnan vissza az IO-hoz és onnan az eredeti adatkérő cpu maghoz.
Másrészt segíthet önmagában a memóriaelérés gyorsítótárazásában is.
Ha jól emlékszem a broadwell használta L4.-ként a eDRAM-ot és némileg hasznára vált
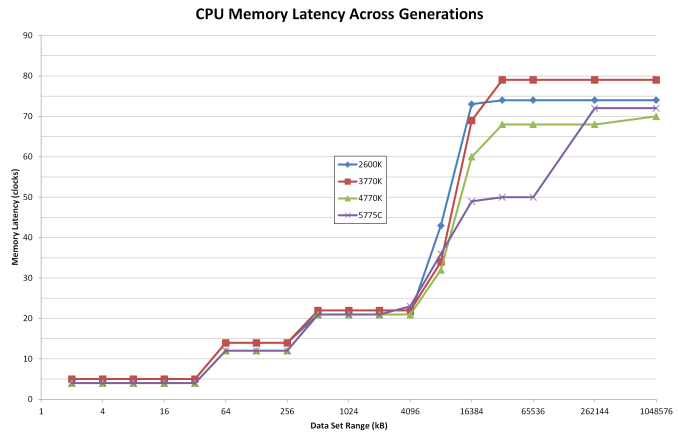
AT -
#501
Petykemano
veterán
lezso6
#500
Petykemano
veterán
Ott készül a Subor+ chipje, és a vega12 is (az apple-nek) 14nm-en. És a raven ridge is.
12-n a polaris30, a pinnacle ridge még fél-háromnegyed évig (bár szerintem ez ugyanaz a gyártósor, csak újabb maszk vagy ilyesmi)
Ezzel együtt a GF 14 még mindig olcsóbb lehet egy ilyen amúgylóbaszónagy méretű chipnél, mint a TSMC 16. Ez az IO lapka nagyobb, mint a vega10! -
#499
Petykemano
veterán
Cathulhu
#497
Petykemano
veterán
-
#495
Petykemano
veterán
Cathulhu
#494
Petykemano
veterán
válasz
Cathulhu
#494
üzenetére
Biztosan.
De ha minden jól megy, egy chiplet már 1 CCX osztatlan 32MB-os L3-mal.Az sok helyütt felvetődött, hogy a közel 500mm2-es IO chip azt tartalmazza-e, ami a 4 zeppelin chip uncore része volt, vagy abban volt nem használt redundancia (pl USB, South bridge), ami felhasználásra került
Ezen a képen sok rész (kék) nincs külön megnevezve, én nem tudom megállapítani, hogy az nem megnevezett uncore rész, vagy csak huzalozás, vagy mi. Szóval a sok helytütt felvetődött kérdés, hogy vajon az IO chip tartalmaz-e L4$-t (és HBCC-t?)Az előző bejegyzés alapján "8MiB L3 block on its own is 16mm^2." könnyen kiszámítható, hogy mondjuk 256MB L4$ 500mm^2 lenne, ami képtelenség. Ennél kisebbnek, tehát bárminek, amiben nem fér el az összes CCX L3$ tartalma, pl 128MB-nak nem tudom lenne-e értelme.
A dolog elvileg nem értelmetlen, mert a Broadwell is kapott 5-10% előnyt a 128MB eDRAM hatására.
-
#493
Petykemano
veterán
TRitON
#492
Petykemano
veterán
Szerintem a chipletben nincs IO. Az előadásban el is mondták, hogy az IO vezérlők nem skálázódnak jól és nem is annyira igényelnek alacsonyabb csíkszélességet, nem annyira kritikus a sűrűség, mint a CPU magok esetén. Ezért maradtak azok az - olcsón tervezett és olcsón gyártott - 14nm-en.
Egy másik számítás:
"Each 4-core CCX on GF 14nm is 44mm^2 (including L3); the 8MiB L3 block on its own is 16mm^2. Some back of the envelope math puts 2x 4-core CCX's + another 16MiB (for 32MiB total) L3 at around 120mm^2 on GF, so roughly 60mm^2 on TSMC 7nm, with the remaining 18mm^2 or so accounting the doubled FPU and load/store width, the overhead of unifying 8 cores, and whatever I/O is necessary to communicate with the IOX (and also to the 2x transistor density being optimistic).
" -
#491
Petykemano
veterán
Petykemano
veterán
"AMD's Mark Papermaster spoke in detail about its new 7nm Zen 2 core and partnership with TMSC, which will be manufacturing it. From the outset, he claims a doubling of core density and halving of power consumption for the same performance, both potentially indicating that we'll see increased core counts in future from its CPUs. He also claimed that Zen 2 will offer a 1.2x performance boost in IPC over current Zen+-based CPUs helped along by using a second generation Infinity Fabric."
Ez némi tárgyi tévedéssel együtt, vagyis akár frekvenciaemelkedéssel együtt sem rossz
"Estimated increase in instructions per cycle (IPC) is based on AMD internal testing for “Zen 2” across microbenchmarks, measured at 4.53 IPC for DKERN +RSA compared to prior “Zen 1” generation CPU (measured at 3.5 IPC for DKERN + RSA) using combined floating point and integer benchmarks."
Saját maguk ebben az egyetlen (részrehajló) tesztben 30%-ot mértek. Annál biztosan kevesebb! Meg ez Zen2 vs Zen1 és nem Zen+.
-
#486
Petykemano
veterán
TRitON
#485
Petykemano
veterán
Szerintem 1ccx saját ioval Apu formában lesz csak. Ha lesz. Az IF a zeppelin lapkán belül is eredményezett késleltetést. Meglátjuk, milyenek lesznek a számok. Akárhogy is, de több kisebb (akár különböző nodeon készülő ) lapkát legyártani olcsóbb, mint egyben.
Arra leszek kíváncsi, hogy lesz-e 8c + valami közepes gpu kombó. Mobilba nyilván igen.
-
#461
Petykemano
veterán
Petykemano
#450
Petykemano
veterán
válasz
Petykemano
#450
üzenetére
-
#460
Petykemano
veterán
Petykemano
veterán
Találgatások
1. ipc improvement is still higher than expected
2. Focus on improving memory delay
3.avx performance enhancement (but it is estimated that it does not support 512)
4.7nm frequency preview (engineering sample frequency has been higher than expected)
5. More refined boost frequency step Progress (pbo and xfr are smarter)
6. It is not clear whether ryzen will put pcie-4.0
7.one more thing......(ray tracing?!?!) -
#459
Petykemano
veterán
S_x96x_S
#455
Petykemano
veterán
-
#456
Petykemano
veterán
Cathulhu
#453
Petykemano
veterán
válasz
Cathulhu
#453
üzenetére
Én nem értek a lovakhoz, de azt olvastam, hogy az AMD-nek avx512 impelemtálása helyett praktikusabb lenne inkább az ilyen hosszú tömbök kezelésére gpu-t bevetni.
Pontosan nem tudom, mi a különbség a vliw, meg simd, meg avx512 között, de Elvileg mindegyiknek az a lényege, hogy minél sűrűbben tömbösített adatokon tudjál végrehajtani utasítás(oka)t.
Én meglepődnék ha az AMD mégis belemenne ebbe.az utcába.
-
#452
Petykemano
veterán
Cathulhu
#451
Petykemano
veterán
válasz
Cathulhu
#451
üzenetére
Ja hogy arra gondolsz, hogy halo product lenne? Papíron létezik, a 1000W-os chillerrel gyönyörűen le is tudják hűteni, kapni nem nagyon lehet majd, ha esetleg valakinek tényleg kéne, de ha mégis, inkább zárt ajtók között átbeszélik a 2S 28 magos megoldásra?
Én arra gondoltam, hogy bűzlik, hogy abból tényleg kézzelfogható, értelmes termék legyen, nem valami marketing-hack. Az nvidia például úgy szokta csinálni.
A linkpack állítólag nagyon AVX512
"The Next Platform that the 48-core Cascade Lake chip will have 21 percent more oomph on Linpack than the top-bin Skylake Xeon SP-8180M Platinum chip with 28 cores running at 2.5 GHz, and if you do some rough math, that puts the clock speed of the Cascade Lake AP at around 1.8 GHz. "
"On the STREAM Triad test, the future Cascade Lake AP MCM will beat the top-bin Skylake Xeon SP SCM by 83 percent, which is pretty good, but will only be 30 percent better than the AMD Epyc 7601."
Ha a az elég "kezdetleges" 7601-hez képest +30%-ot tud csak ebben a tesztben, azt gondolnám, hogy akkor ezt a 7nm-en készülő epyc2 még 48 maggal is megugorná.
-
#450
Petykemano
veterán
S_x96x_S
#449
Petykemano
veterán
válasz
S_x96x_S
#449
üzenetére
Nekem egy kicsit bűzlik. Az intel nem szokott ilyen megelőző csapásokat intézni.
Nem tudjuk, hogy az AMD mit főzött, de furcsa, miért adna 12 memóriacsatornát az intel, amikor ha a rome csak 48 magos 8 csatornával, akkor 2x4 csatorna is elég lenne az intelnek is. vagy legalábbis egyelőre. Nyilván idővel a 2x4 letiltott magot is felszabadíthatják, ha szükséges. Abban biztosan igazad van, hogy presztízs, itt már a TDP, meg a perf/W nem számít. Pontosabban, ha az abszolút elsőséget meg tudják tartani, akkor ennek marketing-értékéért dobjáka többi szempontot - hogy ez milyen fogyasztással jár és mennyibe van alá lapot rakni, stb.Azt tudjuk már, hogy az AMD Next Horizon(s) eventje CET idő alapján mikor kezdődik?
-
#443
Petykemano
veterán
Petykemano
veterán
ezért nincs olyan sok ryzen apuval szerelt notebook:
We looked at the whole series of AMD APUs and when you factor in cost and thermals in addition to performance the Bristol Ridge family came out on top. Thermals are a much bigger deal in a consumer product than in a typical PC. Yes, on paper the Ryzen family is technically better but without increasing the cost and having a higher thermal capacity, a Ryzen APU would never run at full performance. When the Ryzen is operating in a thermally limited environment its performance is only marginally better than Bristol Ridge. We figured any additional cost would be better spent on more memory in an optimal bank layout to maximize bandwidth as this benefits everybody all the time. A thermally-limited but higher performance APU adds some performance here and there but it’s not a universal gain. We will continue to maximize the thermals to allow the Bristol Ridge APU to run at maximum speed.
-
#440
Petykemano
veterán
Petykemano
#439
Petykemano
veterán
válasz
Petykemano
#439
üzenetére
Úgy tűnik, egy CCX 8 mag lesz. 32MB L3$
Kicsit tartok attól, hogy innentől minden cpu lapka mellé kell IO lapka is és innentől minden lapkaközi kommunikáció lapkán kívül történik (core-core, core-ram)es az is igaz, hogy így contol chipből is többet kell majd tervezni.
De az így biztosra vehető, hogy a mainstream LEHET 16 magos. És az is valószínű, hogy a control chiphez fog csatlakozni az igp is nagymértékű flexibilitást biztosítva.ZenX - ezmiez?
-
#439
Petykemano
veterán
Petykemano
veterán
Talán így fog mutatni az epyc2 és ryzen3
-
#432
Petykemano
veterán
Petykemano
veterán
Fiery, kommentálnád?
-
#426
Petykemano
veterán
Cathulhu
#425
Petykemano
veterán
válasz
Cathulhu
#425
üzenetére
De csak ezzel kéne kezdeni valamit. Mert ha az amd el is éri az 5GHz-et, akkor is alulmaradhat ezek miatt a bakik miatt. Akár gaming, akár valami többszálas production programban. Mindig lesz majd olyan, ami nincs a ccxre optimalizálva, és ezért a késleltetések miatt bukó.
Akárhogy is nézzük, ez ha nem is low hanging fruit, de musthave. Bizonyos magszám fölött ugye már az intel sem ring bust használ, hanem mesht, ami ugyanolyan rossz, mint az IF. Pontosabban magas magszámot tesz lehetővé. Tehát kB 8 mag esetén kellene csak megoldani jobbra a késleltetéseket, afölött már kB versenyképes az intel megoldásával. -
#423
Petykemano
veterán
HSM
#422
Petykemano
veterán
Én is valami ilyesmire gondoltam. De ez azt jelenti, hogy lényegében a memórián keresztül kommunikálnak, nem közvetlenül.
Azt hallottuk abutól is, hogy az L3$ mérete négyszereződik (?) A zen2 (?) esetén, de az még mindig nem igazán segít a inter-CCX kommunikáció késleltetésén. Kivéve persze ha valamilyen writeback (amikor az írást nem várja meg) módon egy CCX L3$-e több más CCX victim L3$-e is egyben.
Akárhogy is, felvetődhet a kérdés, miért hagytak ki egy csak CCX-ek közötti megosztást célzó L4-et a lapkából? Vagy a zen2-nél ez miért nem pálya? -
#421
Petykemano
veterán
HSM
#420
Petykemano
veterán
Igen, az igaz, hogy 2 lapkás TR esetén is előfordulhat távoli elérés, de ez nyilván kevésbé égető probléma, mint memóriaelérés nélküli lapkáké.
Ami viszont érdekes, hogy ha jól emlékszem a L3$ késleltetésekre, akkor mintha az lett volna a sima Zeppelin esetén, hogy a másik CCX L3$-éből pont ugyanannyi késleltetéssel tud olvasni, mint memóriából.Ezeken az ábrákon gyönyörűen látszik, milyen késleltetéseket ad hozzá a blokkon kívüliség:
Mennyivel jobb jobb memóriával:

Összehasonlítás:

Én azt nem értem (és ennek megoldását várom), a következő zen verzióban, hogy a CCX-ek közötti és a lapkák közötti interconnect miért függ a memória frekvenciájától.
Azt sem értem, hogy hogy lehetséges az, hogy ha az lokális L3$ késleltetése 45-50ns, a memória elérésének késleltetése mondjuk 60-80ns, akkor hogy lehet, hogy a szomszédos L3$ elérése 120-150ns (memóriasebességtől függően) ? Kicsit olyan, mintha a két CCX a memórián keresztül kommunikálna. (Persze nyilván nem, mert akkor lapká belüli két CCX egymáshoz képesti elérésének késleltetése pont ugyanannyi lenne, mint két különböző lapka CCX-é a a TR-ben) Az világos, hogy a elméletileg A CCX-ek között és a memória felé is az IF a kapcsolódást megoldó alkatrész, csak nem világos, hogy miért a memóriaelérés késleltetése alacsonyabb a szomszédos L3$-nél?Nincs ezen mit trollkodni, ezek tények, ezen ha lehet javítani kell.
-
#419
Petykemano
veterán
HSM
#418
Petykemano
veterán
Ez a probléma csak a 4 lapkás Threadrippert érinti, nem? 24/32 mag. Ezt ajánlják HEDT gamer gépnek? Én azt hittem, az a 16 magnál megáll. a 2 lapkás Threadrippernek meg minden lapkára van memória elérése. Persze nyilván a memóriaelérés és késleltetések szempontjából még így is rosszabb, mint a 2700X, ami szintén rosszabb, mint az intel ring busa.
De azért azt valljuk be, hogy az intel HEDT procijainak teljesítményének kihasználását ugyanaz az ok akadályozta, ami azt is, hogy a 8 magos bulldozer származékok rendre lemaradtak a 4, 4/8 magos intelektől.
Láttam valamelik nap egy táblázatot, de nem találom.
De ez is elég jól mutatja: https://techreport.com/review/34192/intel-core-i9-9900k-cpu-reviewedHa az érték valamilyen "lokális elérés" késleltetése, akkor van hová fejlődni.
Ha azonban valamilyen átlagérték, ami a kellően jó késleltetésű lokális elérés mellett egybeméri a CCX-ek közötti kommunikációt, akkor ezen legjobb esetben is csak a CCX magszám emelése segíthet.Előbbi tűnik helyesnek, mert
itt és itt az 1db CCX-el rendelkező raven ridge is hasonló késleltetéssel éri el a memóriát.Ha nem függ össze a CPU frekvenciával, akkor szerintem ennek a késleltetésnek a javítása fontosabb lenne, mint a frekvencia növelése.
-
#404
Petykemano
veterán
solfilo
#403
Petykemano
veterán
-
#383
Petykemano
veterán
S_x96x_S
#382
Petykemano
veterán
válasz
S_x96x_S
#382
üzenetére
A 32 magos TR2-re gondoltak, nem az egyébként jó frissítésnek számító 16 magosra.
De egyetértek: a TR2 a TR4 foglalatba jön, ami tud, amit tud. Ha ennél többet tudna és ténylegesen jól skálázódna a 32 magon mindenütt, arra ott az EPYC. Úgy tűnik, hogy az irány az, hogy a magok számával nem feltétlenül fognak fukarkodni, csak a magok irányában az adatkapcsolattal a UHEDT platformokon. Ez és nem a magszám fogja lényegesen megkülönböztetni a szerverektől.
-
#379
Petykemano
veterán
Petykemano
veterán
Jim Anderson leaves AMD, heads to Lattice Semiconductor as CEO
Állítólag a Threadripper 2 miatt kell mennie, merthogy papíron jól mutat, de szűkös a pálya, ahol tényleg skálázódik.
-
#378
Petykemano
veterán
Petykemano
veterán
A legújabb GF hírek szerint....
A matisse vagy nem 7nm, vagy nem a GF gyártja.
Ha tehát a matisse nem zen2, hanem zen++ egy 12nm+ gyártástechnológián a GF-nél gyártva, akkor a kaby lake frekvenciatartomány +2-3% IPC elég reális kilátás.
Utóbbira meg elég kicsi az esély -
#374
Petykemano
veterán
Cathulhu
#373
Petykemano
veterán
válasz
Cathulhu
#373
üzenetére
Hát... ezek ilyen nagyon pletykák, de azt mondják, hogy a zen+ eleve azért lett, mert az AMD látván azt, hogy az intel felbukott a 10nm-en, kapva kapott az alkalmon és előrehozta a zen2-re azt a fajta moduláris felépítést, hogy már nem komplett önmagukban is működő lapkákból áll össze az MCM, hanem cpu magokat tartalmazó lapkákból és egy központi, az adatkommunikációért felelő - akár más gyártástechnilógián előállított - egységből ezeket IF-fel összekötve.
Ha ez igaz, akkor nincs kizárva, hogy a Matisse nem zen2, hanem zen++, nem 7nm, hanem 12nm+.
Nagyjából ilyesfajta számokat látunk.Aztán lehet, hogy olyan sandbagging mint amit Jensen csinált, hogy az új geforce még naaagyon távoli.
-
#372
Petykemano
veterán
Petykemano
veterán
birdy
(Kicsit kár, ha igaz) -
#370
Petykemano
veterán
Cathulhu
#369
Petykemano
veterán
válasz
Cathulhu
#369
üzenetére
Vagy hogy megmérd és a mérési eredményeidet publikáld, hogy
- valaki más megtegye az összehasonlítást
= akár saját korábbi eredményekkel
= akár konkurens termékkel
(- gépjárművek esetén, hogy más is megnézhesse, hogy a mért érték tényleg megfelel-e és milyen mértékben az előírtaknak) -
#368
Petykemano
veterán
S_x96x_S
#367
Petykemano
veterán
válasz
S_x96x_S
#367
üzenetére
Ez nem tudom, mennyiben kapcsolódik az AMD-hez azon kívül, hogy az AMD is a CPU-ig hasonlíttotta az inteléhez. De ezt tette mindenki más is. Az intel is. Ez itt azt írja, hogy egyáltalán nem szabad benchmarkot vagy összehasonlító tesztet publikálni. Se az AMD-nek, se tech újságnak, se senkinek.
Nem?Ezek szerint a hatás drámai lehet...
Beteszem az intel találgatósba is -
#360
Petykemano
veterán
Petykemano
veterán
Ez itt elképesztően sokatmondó ábrákat tartalmaz az infinity fabricről. Huhh, már a 2700X nagyon durva, de az epyc pláne!
-
#359
Petykemano
veterán
Petykemano
veterán
-
#352
Petykemano
veterán
Mahrenburg
#1
Petykemano
veterán
válasz
 Mahrenburg
#1
üzenetére
Mahrenburg
#1
üzenetére
Ez biztos drága, de remélhetőleg jó jel abba az irányba, hogy lesz/legyen ryzen minipc
-
#348
Petykemano
veterán
Petykemano
veterán
Eléggé ígéretesen hangzik.
Röviden:
A monolitikus chippel szemben a kisebb elemek összeragasztása két előnnyel jár: a kisebb chip kisebb hibaaránnyal, tehát olcsóbban lehet gyártani. A kisebb chipeket válogatva könnyebb jobb frekvenciatartományokat elérő terméket összerakni, mint monolitikusból.
A hátrány természetesen a chipek és interposerek összeiötéséből fakadó késleltetés. A bemutatott kutatásban azt fejtegetik, ezt milyen módszerekkel és topológiákkal lehet leküzdeni. -
#343
Petykemano
veterán
Petykemano
veterán
Lisa su a computexen azt mondta, 5m ryzen processzor került gazdához az elmúlt egy évben. Ez a cikk szerint soknak hangzik, de az összes eladott pchwz képest (260m) elenyésző.
Érdekes. A 14nm GF fab8 gyártja, a wkii szerint 60000wafer/hónap kapacitással bír. Persze itt gyártják a polarist és a vegákat is. De mondjuk akkor felezzüm meg, és legyen egy igen alacsony 100lapka/wafer kihozatal. Az is 3 millió lapka havonta. Hova sütik el ezt a memnyiségű wafert? Vagy a 60000/hó nem is mind 14nm
-
#335
Petykemano
veterán
Petykemano
veterán
Azt mondják, a 28 magos 5GHz-es (turbó) cascade lake x megjelenik a HEDT platformban.
Nyilván nem nagy kunszt 4 lapkás threadrippert csinálni. De vajon elég lesz?
-
#329
Petykemano
veterán
S_x96x_S
#327
Petykemano
veterán
-
#325
Petykemano
veterán
Petykemano
veterán
Nemrég volt egy táblázat a SOC-ok fogyasztásáról az egyik Mediatekes hír alatt:
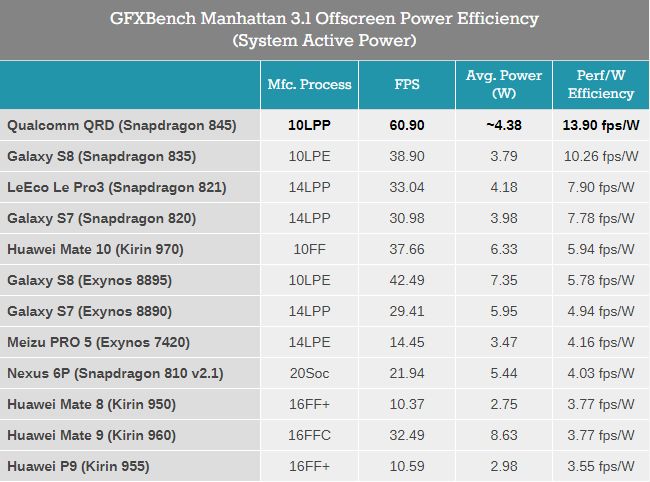
Most jelenteték be a Cortex A76-ot. ERről írnak:_
"ARM says that three A76 cores with larger cache (7nm) would fit inside one Skylake core (14nm) and comes to within 10% of the IPC of the 3 year old architecture. I feel obliged to point out that you'll never see an A76 at even half of Skylake's 7GHz overclocked frequency."
srcJóhogy ez nem ma lesz, hanem legalább jövő évig kell várni az első cortex A76-okra. És jóhogy ez még mindig 10%-kal van a skylake IPC alatt. És jó, persze a 3Ghz, meg a 3.5Ghz ugyanúgy csak rövid turbó azon az 5-15W-os szinten, mint a x86-os procik esetén és aztán jön a throttling
De ez már elég közel van.Vajon mit fog tudni hozni ehhez képest 7nm-en az AMD?
-
#322
Petykemano
veterán
Petykemano
veterán
Atari VCS bristol Ridge. Kár, ha igaz.
-
#321
Petykemano
veterán
S_x96x_S
#318
Petykemano
veterán
válasz
S_x96x_S
#318
üzenetére
Gondolod, hogy nem fogják tudni megoldani úgy, h egyik designt gyártják itt a másikat ott?
Ha nem, cpu esetén még meg tudják oldani a ráaggatott címkékkel. De gpuból ritka, hogy ugyanaz a chip csak frekvenciában térjen el.
Az mindenképp jó hír, ha ilyen sok eladott termékre számítanak. -
#313
Petykemano
veterán
Yutani
#312
Petykemano
veterán
Hát egyrészt én úgy emlékszem, hogy a haswell idején az intel kifejezetten kényszerített a partnereit jobb gyártástechnológián gyártani az alkatrészeket, hogy a platformfogyasztás csökkenjen a mobil gépeken. Nyilván persze asztali gépnél a 11W vagy 8W nem számít.
Másrészt viszont azt gondoltam, hogy ahogy szabadul fel a cutting-edge-1 gyártástechnológia, úgy minden megy át eggyel újabbra néhány éven belül és a legutolsókra, legrégebbiekre az igény egyre csökken és azokat szüntetik is meg. Persze ez is évtizetes távlat, tudom, hogy 65, meg 90nm-en is zajlik még gyártás. Csak azt gondoltam, hogy egy vadiúj tervezésű chipset valamivel újabb gyártástechnilógián készül.
mindegy egyébként.

-
#299
Petykemano
veterán
Petykemano
veterán
Érdekes fejlemények: ahelyett, hogy AMD EPYC-re váltanának inkább IBM POWER-re váltanak bizonyos cégek. Ennek az openpower az oka és az nvidia, vagy más?
-
#297
Petykemano
veterán
HSM
#296
Petykemano
veterán
Logikus, csak azt furcsállom, hogy a hardver képességei és a program igényei között nem az operációs rendszer közvetít, hanem kvázi ilyen "driveres hekkeléssel" kell kitrükközni, hogy a program ne kapjon szuboptimális erőforráskiosztást.
Vagy: ezt az egészet közvetlenül a program intézi saját hatáskörben? -
#295
Petykemano
veterán
Tyrel
#294
Petykemano
veterán
Én nem hallottam.
DE ha ennek a SMT letiltós gaming módnak van létjogosultsága, akkor az csak ütemezési-erőforráskiosztási hiba lehet. Az nyilvánvaló, hogy ha egy 8/16 magos/szálas proci esetén egy 9. programszálat kioszt egy nem terhelt szálra, akkor az akkor is SingleTread teljesítményt von el attól a procitól, amelyet a két szál megoszt, a throughput így nagyobb. Ennek akkor nem nagyon kéne problémának lennie, ha tényleg a 9. programszálat osztja ki, mert ha nincs 9. cpu szá, akkor egy olyan cpu szálra osztja, ami már futtat egy programszálat amúgy is. Probléma akkor van, ha a program/oprendszer nem tudja, hogy melyik cpu szál terhelésével okoz vagy nem okoz más programszál futásában lassulást, mert nem tudja, mely magok vannak szabadon.
A magasabb órajelet meg egyáltalán nem értem. Ha nem futtat két szálat egy cpu mag, akkor most is tudna magasabb órajelet elérni. Az a hardveres ütemező valami, ami az egy cpu magon való két szál futtatását lehetővé teszi annyira korlátozna, vagy annyira sokat fogyasztana, hogy kiiktatásával magasabb órajelet lehet elérni? Ez érdekes koncepció.
Threadrippernél egyébként már most is van ilyen, bár az nem az SMT-t tiltja, hanem ponthogy az ütemezést alakítja át úgy, hogy a a késleltetést minimalizálja a programszálak között.
-
#289
Petykemano
veterán
Petykemano
veterán
Az AMD hozzáigazította az MSRP árcímkéket a valósághoz: Ryzen 1000 price cut
-
#229
Petykemano
veterán
solfilo
#226
Petykemano
veterán
Hát szerintem ennek az lehet az oka, hogy a GPU-k tekintetében jelenleg az intel rendelkezik 70%-os piaci részesedéssel. A maradékon osztozik az AMD és az nvidia kb fele-fele arányban. Azt is tudjuk, hogy az nvidia 2/3 1/3 arányban viszi az asztali és mobil dgpu-k piacát. Tehát a 15%-15%-os teljes piaci részesedésből az AMD-nek a fele lehet dgpu, a többi IGP. Ebben persze benne vannak azok a beema, meg egyéb termékek is, amelyek nem HSA kompatibilisek. (Kérdés, hogy ebben benne vannak-e már a konzolok) Összességében tehát legjobb esetben is 2-3% szerintem. ha a teljes gpu részesedésben benne vannak a konzolok, akkor <1% a Kaveri, meg Carrizo, meg stb termék piaci részesedése, amire a HSA épülhetne.
Nem csoda, hogy nem lett belőle semmi.Az ARM is HSA tag, Akár még onnan is érkezhet valami. Ez nagyban függ attól, hogy az ARM mikor érkezik el oda, hogy már nem egyszerű, nem olcsó az IPC és a frekvencia további növelése.
De igen, nagy valószínűséggel nem lesz semmi, vagy nagyon nyögve-nyelve történhet bármi is 30-40%-os TAM nélkül.
-
#224
Petykemano
veterán
leviske
#223
Petykemano
veterán
Elképzelésem sincs, hogy a HSA mennyire bonyolult. Nyilván átírni valamit mindig bonyolult, főleg ha még ki is kell találni, hogy a százmillió kódsorból mit lehetne inkább GPU-n futtatni. Kínkeserves refaktoring.
De igen, ha mondjuk egy DX12-be és/vagy vulkan rálépne a HSA-ra, az komoly fegyvertény lehetne. De ehhez még hosszú és nehéz utat kellene bejárni. Abu sokat beszélt az IGP hasznosításáról, de úgy tűnik, hogy az intel IGP általános célú hasznosítása nem kellően megtérülő. Ezért mondom, hogy nem tudom, hogy HSA mennyire bonyolult, nem tudom, hogy ha nem intel IGP lenne (hanem GCN5), és/vagy az intel IGP HSA kompatibilis lenne, akkor más lenne-e a helyzet.
De én is arra számítok, hogy a GCN-es APU-k komolynak mondható terjedésével a HSA erőre kaphat. Ez biztos, hogy még a következő néhány év zenéje. A konzolokon szerintem kb még csak most kezdik el ezt a fajta optimaizálási munkát.Az intelnél én egyébként azt vártam, hogy FPGA-kat fognak beépíteni - idővel - a desktop/mobil chipekbe is. Azt gondolnám, hogy FPGA-ra lehet építeni olyan intelligens, öntanulló dolgokat, hogy a CPU szépen beállítgatja az FPGA-kat arra,ahogy Te használod általában és akkor abban gyors lesz.
-
#222
Petykemano
veterán
leviske
#221
Petykemano
veterán
Nehéz megítélni.
Egyrészt meg kell győzni egy felhasználói réteget, akiknek öregecskedő gépeik vannak, hogy de de maradj a PC vonalon, ne mondj le a PC-ről, frissítsd fel, használd. Nyilván lesznek, akiket meg lehet győzni azzal, hogy olcsón kapnak nagyon jót, másokat meg az PC formai átalakulásával lehet PC vásárlóként megtartani (Brix, Nuc, stb) De az egységesen elmondható, hogy a PC-ből, a PC fejlesztésből féllábbal már kintlevő emberek meggyőzése nem egyszerű.
Másrészt van nagy halom ember, aki i3, i5, i7 gépekkel tevékenykedik, akik eddig egy magasabb szintnek örülnének ugyan, de annak költséget drágállották (i3 -> i5, i5->i7, i7 -> i7X). De továbbra is igaz, hogy kellően kedvezőnek kell lennie a többletteljesítményhez az árazásnak, hogy megérje váltani. Például ha nekem egy ivy i5 van, akkor nem biztos, hogy egy "csak" 4/8-as Ryzen-re való váltás előnye megéri a platformváltással járó költségeket még akkor se, ha egyébként a 4/8-as Ryzent azon az áron kapom meg, amennyiért csak 4/4 skylake i5-öt kaptam volna. Ezt persze embere válogatja, de mindenképpen fontos a jó, kedvező ajánlat ahhoz, hogy emberek milliói dobják el még egyébként jól szolgáló i szériás gépeiket.
Harmadrészt ott vannak azok, akik mindenképp szeretnének nagyobb teljesítményt, de nem bármi áron. Talán ők a legkönnyebb menet. De a jó, versenyképes teljesítmény akkor is csak belépő szint jelenleg a komolyan vehetőség piacára.
A kérdés az, hogy mi a cél.
- Versenyképes termékekkel békés egymásmellett élés és közös küzdelem az X86-ot veszélyeztető törekvések ellen
- Optimális profit
- Intel megroppantásaSzerintem ez utóbbi sem lehetetlen. Az AMD valószínűleg el tudná látni olyan mennyiségű termékkel a piacot, ami komolyan visszavetné az intel eladásait és árazását. Ez persze kockázatos és nyilván nem is menne egyik napról a másikra.
Arra is gondolnia kell az AMD-nek, hogy ha jó olcsón teleszórja a piacot már az elején akkor azzal kicsit saját maga alatt is vágja a fát, hiszen akkor neki is fel lesz adva a lecke a következő évekre, hogy olyat kínáljon, amit meg is vesznek. TEhát szerintem valahol az optimális profitnál alacsonyabb, de részesedés és ár tekintetében az intelt nem teljesen "kifektető" árazásra lehet számítani. Igen, arra, hogy 8/16 $400 felett.
-
#213
Petykemano
veterán
Petykemano
veterán
Kering egy pletyka hogy a következő utáni generációs Intel processzorokból az Intel ki fogja Vágni a régi utsításokat ezzel egyfelől megszüntetve a visszafelé kompatibilitást, másfelől - azt nem teljesen értem, hogy és miért - új speciális és exkluzív utasításkészletek bevezeésével egyúttal megakadályozná az AMD -t "Intel kompatibilis processzor" készítésében. (És hogy ehhez a Microsoft asszisztál pl azzal, hogy folyamatosan darabka a win32-És alkalmazásokat)
Én azt nem értem, hogy ha szakít a visszafelé kompatibilitással, akkor minek megtartani az x86-ot?
Vagy lehet-e ezt úgy csinálni, hogy ennek hatására csak nagyon régi programok ne működjenek csak?
Valami ilyesmi is volt, hogy az avx3 tudná emulálni a kikerülő utasításokat...Mennyiben lehet ez igaz és ez vajon milyen hatással lesz az amdre néhány éven belül?
-
#191
Petykemano
veterán
leviske
#190
Petykemano
veterán
Engem a gcn hws/ace egységeire emlékeztetett.
Egyetértek, hogy úgy hangzik, hogy ez a magszám skálázódási falát hivatott áttörni.Kíváncsi lennék, mennyi a határ jelenleg. Abu nem valami olyasmit mondott, hogy a xeon phi magszámát úgy lehetne már csak növelni, ha tovább tömné az Intel a magokat cache-sel?
Mindenesetre nyilván nem véletlenül dolgozott ezen az Intel, tuti beleütköztek ebbe a phivel. -
#176
Petykemano
veterán
Fiery
#175
Petykemano
veterán
Mit gondolsz a napokban szárnyra kelt jayz xfx 480 gtr tesztről? Kamu? Vagy borzasztóan szerencsés válogatás? Vagy javított változat, rev2? 20nm-es print volt a polaris 14nm-en gyártva? Vagy a GF fejlődödött? Bíztató-e a zen órajeleire nézve, vagy épphogy összefügg azzal, hogy túl van a borzasztóan alacsony órajelen?
-
#174
Petykemano
veterán
Fiery
#173
Petykemano
veterán
Készséggel elhiszem, hogy vannak tudatos vásárlók is. De egyrészt szerintem mindenki befolyásolható, ha egy kicsit felületes, mert közvetlen (értsd forintosítható) érdeke nem fűződik hozzá. Másrészt Te is tudod, milyen fontos a királykategória. Én például szoktam teszteket olvasgatni úgy, hogy gyakorlatilag nincs a tesztesetek között általam játszott játék.
De ez tényleg részletkérdés.
szóval akkor 3,5-3,7Ghz?
-
#172
Petykemano
veterán
Fiery
#168
Petykemano
veterán
Tartok tőle, hogy a Média majd olyan benchmarkokat és realworld alkalmazásokat fog igyekezni előkaparni, amiben épphogy nem csillog majd a SR.
Míg eddig úgy teszteltek pl videokártyát, hogy jól belenyúltak a régi megoldásokba, mivelhogy most akarok játszani vele, nem jövőre, addig most majd Elő fog majd kerülni a legújabb cinebench és más 256bites utasításokat használó alkalmazások, mert hát nem a tegnapi programoknak vásárolok, hanem sok éves használatra. Eddig az volt a divat, hogy a legerősebb terméket a legerősebb termékkel hasonlítunk, teljesen mindegy, hogy egyébként 2-3-4-5-10x-szeres árkülönbség van. Most úgy dívik majd, hogy hát az azonos árfekvésű i7-7700k-val kell hasonlítani, olyan alkalmazásokban, amelyek használatára ilyen árfekvésben venni szoktak processzort. Mellékesen persze azokban a HEDT programokban versenyképes lenne, de nem tudja megverni a 8-10 magos intelt, a királyhoz ezért nem hasonlítjuk.
Stb.Meg lesz a prohardver, a részrehajló.
-
#160
Petykemano
veterán
Petykemano
veterán
-
#159
Petykemano
veterán
Simid
#158
Petykemano
veterán
Amiket olvasgattam a témában:
- Állítólag AoTS nem feltétlenül helyesen jeleníti meg a tényleges órajelet
Egy elég komoly vita alakult ki arról, hogy belinkeltek 6700(K) eredményeket, aminél 100CPU FPS eredményeket is mutattak, ami ugye jóval magasabb, mint a mostani ZenES CPU fps eredményei. Van aki azt mondta, hogy ez amiatt van, mert a DX12 képes kiaknázni az AVX2 utasításkészletet. Ugyanakkor ez nem látszott a skylake i5 eredményein.
- Állítólag az AoTS 6 magig skálázódik jól. Utána 8 szálig még kicsit nő, de már nem jelentős. Ez nagyjából egybevág a DX12 6 szálig skálázódásának pletykájával. Ezzel együtt persze még mindig nem elhanyagolható az egyszálas teljesítmény. -
#149
Petykemano
veterán
Petykemano
veterán
Steamroller FX szerintem két okból nem jött. Egyfelől azért, mert 28nm-re tervezték, de nem arra a 28nm-re, amin végül kijött. (A GF elkaszálta a 28nm-es SOI-t (valószínűleg PD SOI lett volna), így maradt a bulk), amin viszont nem érték el azt az órajelet, mint amit a 32nm hozott. Tehát hiába volt nagyobb IPC-je kicsit a Steamrollernek, azt elbukta órajelben. Szinte semmilyen előrelépést nem jelentett volna.
Másrészt a szerverpiacon, ahol még inkább számít a throughput, a szoftverlicenceket magszámra árazták. És throughputban ámbátor ha versenyképes volt a Piledriver a korabeli i7-tel (És látjuk, hogy a DX12 megjelenésével a játékokban is szépen felzárkózott), de mivel az AMD 8 magosként árulta, ezért perf/$ messze alulmaradt a licencköltségek vonatkozásában, mint a 4 magos i7, ill xeon megfelelője.
Steamroller és excavator fx persze azért nem készült, mert opteron se.
Nyilvánvalö, hogy az előbbi licenc okból a zen akkor is jobb lesz, ha elméletben csinálnánk egy finfetre leshrinkelt 16 magos excavator cpu-t. Pedig annak a throughputja lehet, hogy még jobb is lenne.
A HSa szerintem a B terv volt. Látták, hogy pár évig nem lesz versenyképes cpu a kezükben, ezért megpróbáltak előnyt faragni a gpu-ból. Nem öncélúam persze. A zen nem teszi zárójelbe a hsa-t, hiszen annak koclncepciójába nagyin jól illik az erős egyszálú végrehajtással rendelkező cpu. Az egész hpc törekvéseiknek ez a lényege.
-
#148
Petykemano
veterán
Petykemano
veterán
-
#142
Petykemano
veterán
Thrawn
#141
Petykemano
veterán
Persze, hogy bonyolultabb. Különben már tudnánk. És különben nem szólnának viták róla. The stilt meg van győződve róla, hogy a 14llp mobil node, és alacsonyan van a sweet spot frekvencia, nagyon magas lesz a fogyasztásbeli ára az annál magasabb frekvenciának, ezért a zen esetén is olyan nagy különbséggel dolgozó turbóra kell számítani, mint a bristol ridge.
Looncraz szerint viszont a low power csak azt jelenti, kevesebb feszültség kell ugyanakkora frekvenciához, ami ugyan végül az am3-hoz képest pl komolyabb terhelést fog tenni az alaplapi áramkörökre (áramerősség), de kevesebbet fog fogyasztani, ami jó. Az elérhető frekvencia pedig inkább azon múlik, mennyire gyorsan tud állapotot váltani a tarnzisztor, ebben pedig a finfet önmagában jó.És hát ott az élő példa is a maxwell, ami bizonyítja, hogy mennyire design kérdés az elérhető frekvencia, ezt a pascal tsmc ff+-on elért 2ghz-cel továbbviszi. Persze az még nem 4ghz, de pl ma olvastam, hogy el lehetne érni vele a 2.5ghz-et is, de az ezen a frekvencián termelődő hőmennyiség elvezetéséhez és leadásához túl kicsi a gp104.
-
#140
Petykemano
veterán
Petykemano
veterán
Ez egy igen érdekes kép arra vonatkozólag, hogy milyen ipc-t kell hoznia a Zennek.
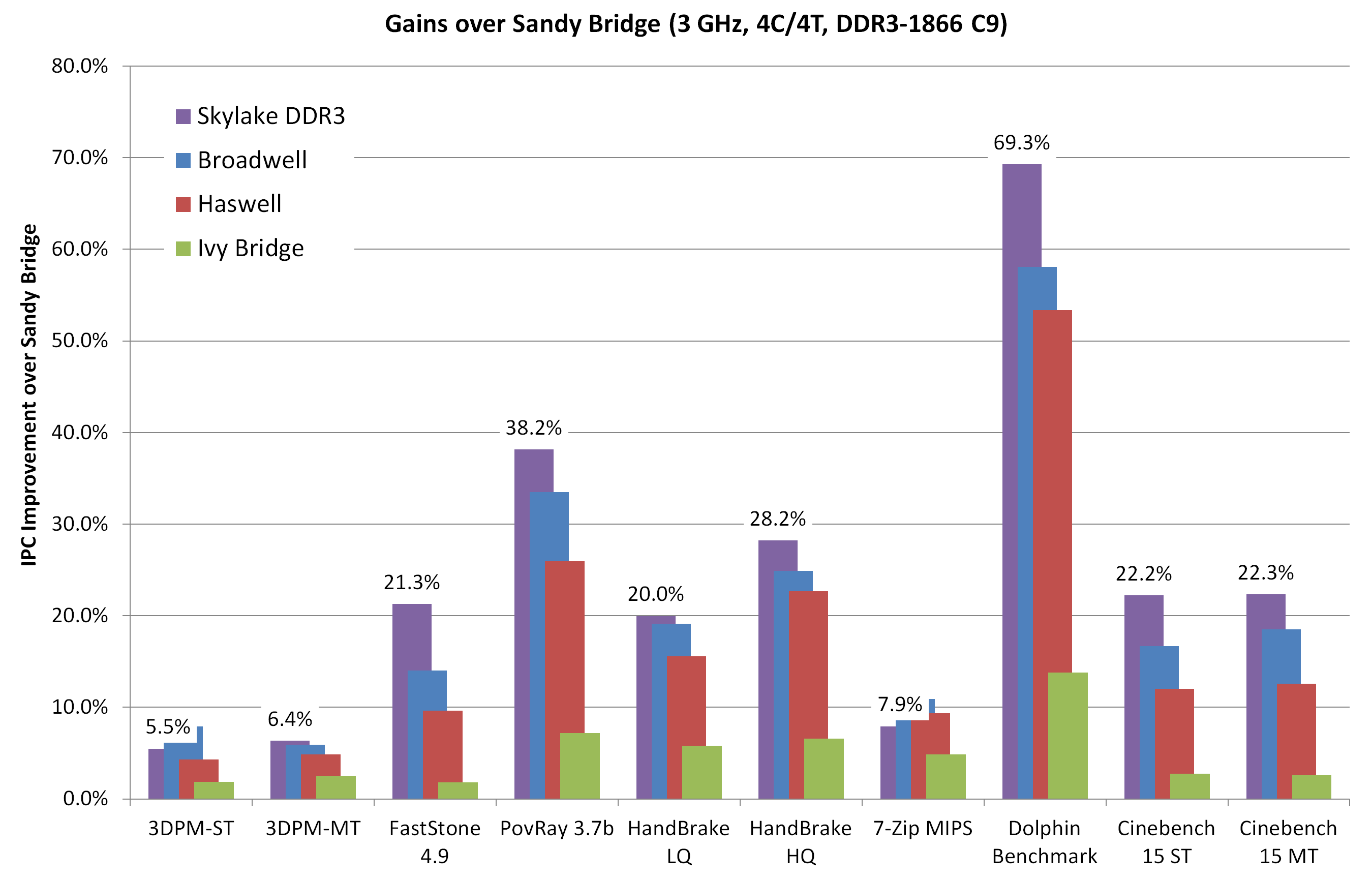
Arról persze nem mond sokat, hogy milyen órajellel. 😃
Tehát ha ivy ipct elér már tök jó, csak az órajelen múlik, ami persze sokat javult azóta.Vajon egy olyan node-on, amelyiken gpu és mobil csip könnyedén eléri a 2-2.8ghz-et, mennyire nehéz elérni a 4GHz -et?
-
#138
Petykemano
veterán
Petykemano
veterán
" ZEN represents a hard-core reboot. Our sources quoted that the performance magnitude is very similar to when the K7 550 silicon came out, and pummeled Intel’s incumbent Pentium III by 30%, clock-per-clock – starting the second Megahertz wars. "
Szerk :
Párdon, nincs itt semmi látnivaló, csak theo valich... -
#131
Petykemano
veterán
dezz
#130
Petykemano
veterán
Nem tudom megítélni:
A kép nem tudom mennyire hivatalos.
A kép felosztása nem tudom mennyire hivatalos, pontos, szakmai és helyes, vagyis igaz. Lehet hogy a pötyözött vonallal keretezett rész semmi.
Ha a kérdés mindezek ellenére helyes és odaillő, akkor is válaszolni az tud szakmailag korrektül aki tudja a választ (nyilvánvalóan őt titoktartás kötheti), minden más tulajdonképpen csak találgatás bármennyire megalapozott is.Tudom, hogy kicsit cinikus voltam, de igyekszem betartani a kialakított rendet, hogy a konkrét infó nélküli találgatós beszélgetést itt folytassuk le.
-
#129
Petykemano
veterán
solfilo
#128






















Új hozzászólás Aktív témák
Hirdetés
- Path of Exile 2
- Gumi és felni topik
- World of Tanks - MMO
- sziku69: Fűzzük össze a szavakat :)
- Egyéni arckép 2. lépés: ARCKÉPSZERKESZTŐ
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Internet Rádió építése (hardver), és programozása
- Kerékpárosok, bringások ide!
- Android alkalmazások - szoftver kibeszélő topik
- BestBuy ruhás topik
- További aktív témák...

- Új, Gamer félgép - ASUS PRIME B860M-A WIFI + Intel Ultra 5 245KF + Corsair 2x16GB DDR5 6000MHz
- Eladó iPad 9th Generation + tok + digitális toll (nem Apple Pencil) kitűnő állapotban
- Gamer PC-Számítógép! Csere-Beszámítás! I9 9900K / RTX 3070Ti / 64GB DDR4
- ASUS TUF Gamer Laptop: Ryzen 5 4600H / GTX 1650 Ti / 16GB RAM / 144Hz
- XFX Speedster SWFT210 Radeon RX 6600 8GB Garanciával!
- ÁRGARANCIA!Épített KomPhone i5 14600KF 32/64GB RAM RTX 5060Ti 16GB GAMER PC termékbeszámítással
- Bowers/Wilkins Px7 S2 fejhallgatók
- AKCIÓ! Apple Macbook Pro 16" 2019 i9 9980HK 64GB 500GB Radeon Pro 5500M notebook garanciával
- Bomba ár! Lenovo ThinkPad L460 - i5-6GEN I 8GB I 256GB SSD I 14" FHD I Cam I W10 I Garancia!
- Új Dell 13 Inspiron 5310 FHD+ IPS i5-11300H 4.4Ghz 8GB 256GB Intel Iris XE Graphics Win11 Garancia
Állásajánlatok

Cég: FOTC
Város: Budapest

Cég: CAMERA-PRO Hungary Kft.
Város: Budapest