Új hozzászólás Aktív témák
-

S_x96x_S
addikt
Zotac Zbox Pro CA622 nano barebone
(Ryzen R1505G dual-core CPU with 15 W TDP ; 2c/4t ; 14nm ; Vega3 )


-
S_x96x_S
addikt
válasz
 paprobert
#2648
üzenetére
paprobert
#2648
üzenetére
> ARM ... " néha már verik az x86-ot, akkor szerverben"
Az adaptáció mindig nehezebben megy; de a Cloud szolgáltatók eléggé nyomják.
Sőt ... Amazon már "marketinges" állításokat tett ...
+ remélem lesznek normál tesztek is.
Amazon AWS Graviton2:
- max 64 mag, 1MB L2 caches per core , 32MB L3 cache
- "memory subsystem: 8 DDR4-3200 channels; hardware AES256 memory encryption."
- "Peripherals of the system are supported by 64 PCIe4 lanes."
- 40% jobb ár/teljesítmény az (intel) X86-alapú instance-okhoz képest.
https://www.anandtech.com/show/15189/amazon-announces-graviton2-soc-along-with-new-aws-instances-64core-arm-with-large-performance-upliftsAmazon is also making some very impressive benchmark comparisons against its fifth-generation instances, supporting Intel Xeon Platinum 8175 processor of up to 2.5GHz:
- All of these performance enhancements come together to give these new instances a significant performance benefit over the 5th generation (M5, C5, R5) of EC2 instances. Our initial benchmarks show the following per-vCPU performance improvements over the M5 instances:- SPECjvm® 2008: +43% (estimated)
- SPEC CPU® 2017 integer: +44% (estimated)
- SPEC CPU 2017 floating point: +24% (estimated)
- HTTPS load balancing with Nginx: +24%
- Memcached: +43% performance, at lower latency
- X.264 video encoding: +26%
- EDA simulation with Cadence Xcellium: +54% -

paprobert
őstag
válasz
 S_x96x_S
#2642
üzenetére
S_x96x_S
#2642
üzenetére
Ettől a grafikontól függetlenül, méret és TDP limitált helyzetekben (mobil) azt látjuk, hogy az Apple még tud előre menni, a Qualcomm viszont egy helyben toporog lassan 3 generáció óta, ahogy a Samsung is.
Szerverben egyik limit sem létezik igazán, tehát ha valós lenne hogy a mobil megoldások néha már verik az x86-ot, akkor szerverben már át kellett volna venniük a vezetést a legtöbb tulajdonságot tekintve. De ez egyáltalán nincs így, tehát ebben a cikkben legalább egy nagy csúsztatás van.
-
S_x96x_S
addikt
A Clear Linux-os Intel fejlesztők azért próbálnak korrektek és transzparensek lenni.

( legalábbis az Intel marketing csapatához képest )
------------
a Kérdés ez volt:
"I am a developer and would love to use Clear Linux on my main machine but I am on AMD Ryzen and I am curious if Clear Linux makes any guarantees to not break non-Intel hardware(I understand the “optimized for Intel CPUs” part but things like LTO are helpful for everybody)?
I worry for sudden breakages.
It is safe to use on non-Intel, x86 hardware or you would not recommend it?"https://community.clearlinux.org/t/is-there-a-promise-to-not-break-non-intel-hardware/1810/2
és a válasz ...
2020 Január 10. "config: enable load AMD microcode"
https://github.com/clearlinux-pkgs/linux/commit/8965bd08e8b942083e3ab817e1ea1324365690102020 Január 11. "add AMD_MEM_ENCRYPT and AMD_NUMA"
https://github.com/clearlinux-pkgs/linux/commit/da5305d80a28117996eee00bb746e1162022e5f1Persze ettől függetlenül vannak még problémák.
https://github.com/clearlinux/distribution/search?q=AMD&type=Issues
-------------És persze az olcsóbb AMD-s CPU-k is gyorsabbak Clear Linux alatt.
"Intel Clear Linux outperforms Windows 10 and Ubuntu… on cheap AMD hardware"
https://www.techradar.com/news/intel-clear-linux-is-a-distro-that-outperforms-windows-10-and-ubuntu-on-cheap-amd-hardwareszóval akit érdekel:
https://clearlinux.org/ -
S_x96x_S
addikt
Ironikus, de az Intel "Clear Linux" -a a legoptimálisabb a Threadripper 3990X-re. ( köszönhetően annak is , hogy gcc-t használnak és nem saját zárt inteles forditót)
"Making The AMD Ryzen Threadripper 3990X Run Even Faster - By Loading Up Intel's Clear Linux"
https://www.phoronix.com/scan.php?page=article&item=3990x-clear-linux&num=1Egy extrém - grafikon - hogy mit is jelent egy általános optimalizáció:
( vagyis egyes esetekben hiába van 2x annyi core az AMD chipeken; ha a szoftvereket *akár* 2x sebességre is lehet optimalizálni -
Persze ezekkel a "mikro" optimalizációkkal rengeteg időt el lehet cseszni, de igazából a tanulság szerintem az, hogy nem csak tisztán hardverben kell gondolkodni .)és egy összesített:
( és ez már általánosságban szerényebb szórás ) -
S_x96x_S
addikt
válasz
 #82819712
#2643
üzenetére
#82819712
#2643
üzenetére
> Egy ideje már heggesztgetik az AMRszos windowst
not perfect ..
de a napokban elkészült egy barkács - málnás ( Rasberry pi 4/3) optimalizált windows is.
https://www.tomshardware.com/news/windows-10-raspberry-pi-4-arm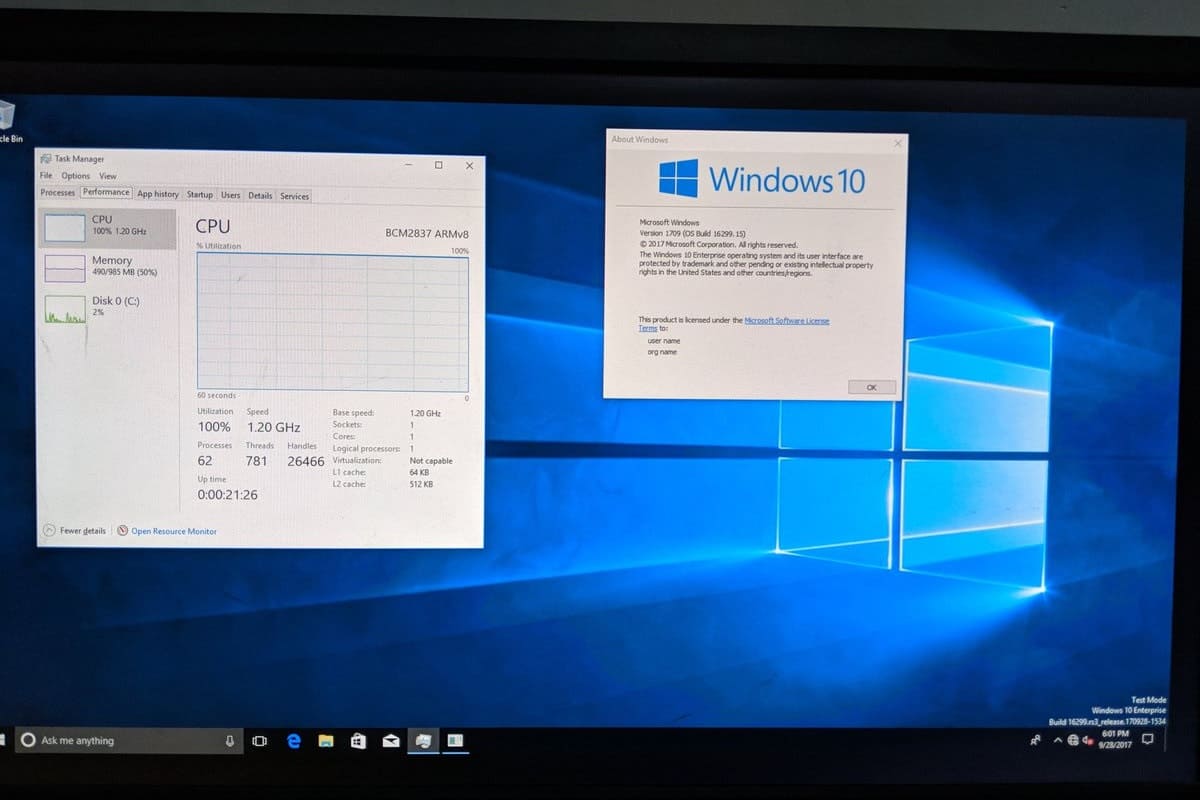
magyarul
https://pcworld.hu/pcwpro/mar-windows-10-is-fut-a-raspberry-pi-gepeken-259568.html -
#2644
 Petykemano
veterán
S_x96x_S
#2642
Petykemano
veterán
S_x96x_S
#2642
Petykemano
veterán
válasz
S_x96x_S
#2642
üzenetére
Bár ha jól látom, nem teljesen egyértelmű, hogy mit mutatnak a csíkok. Geekbench Single thread? körülötte IPC-t emlegetnek.
Mindenesetre azt gyaníom, hogy a fekete az Apple A13-mal a végén.
De ez nem lehet IPC. mert az A13 valójában már elég durván magasabb IPC-t hoz - legalábbis Geekbench5-ben.
A13: ~1350 @ 2660MHz
x86: ~1700 @ 5000MHzNem nehéz kiszámolni, hogy közel 50%-kal magasabb az IPC.
Más kérdés, hogy vajon magas frekvenciát is el tudna-e érni.
És más kérdés, hogy vajon az x86 a frekvencia néhány %-os elengedése mellett tudna ilyen 20-30%-os IPC-t hozni.Az biztos, hogy a frekvencia nem megy feljebb. Mindenki tegye meg tétjeit, hogy vajon a x86 tud-e a tranzisztorbüdzsé erre való áldozásával IPC-t növelni és hogy az ARM-nál ez a folyamat meredekebben tarthat-e anélkül, hogy hasonlóan elszállna a fogyasztás.
Ugye sok esetben sok energiát nem is a számítás elvégzése emészt föl, hanem hogy egy nagy lapkán belül az adat utazik. Ezért mondják, hogy a jövő a "Data locality" fejlesztésében rejtőzhet.
Mindenesetre ez valamilyen ST teljesítmény lehet. Abban meg tényleg nem volt jelentős előrelépés az x86 terén.
-

#82819712
törölt tag
válasz
S_x96x_S
#2642
üzenetére
Egy ideje már heggesztgetik az AMRszos windowst, a chiplet szemlélet elterjedése GPUban is jelentősen előnyhöz juttathatja őket, kérdés majd mi üt be előbb az 1nmnél a grafénra való átállás vagy a ARM igazán nagy teljesítményű változatai.
De ha így drágul minden akkor 5- 3 nm-en már alig valamit kapunk a pénzünkért (mm^2). -
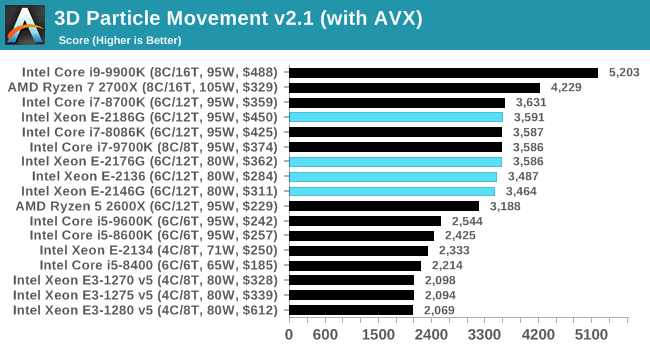
S_x96x_S
addikt
( versenytársfigyelő)
ARM vs. X86
( a grafikont egy ARM-ben érdekelt cég a "Nuvia" készítette valószínűleg a saját befektetőinek ...
persze az X86 (kék) vonalban - inkább az Intel trendje látható és nem az AMD-é ; ettől függetlenül az ARM jön fel mint a talajvíz ... )
https://www.nextplatform.com/2020/02/11/throwing-down-the-gauntlet-to-cpu-incumbents/ -
-
#2640
Petykemano
veterán
DraXoN
#2637
Petykemano
veterán
Az én tapasztalatom az, hogy a chrome egy átlagos weboldal megnyitásakor is több szálat.megmozgathat 2-nél, a javascipt intezív weboldalakra meg 2 mag kifejezetten kevés.
Világos persze, hogy élete nagy részében kihasználatlan és 2-nél több mag netezni már olyan pazarlás. De felhasználói élmény számít.
A "netezni jó lesz" is mára már elinflálódott.Pedig nemsoká jön a GF 12nm+, úgyhogy a raven velünk marad még egy ideig, az biztos.
-
#2639
S_x96x_S
addikt
Petykemano
#2634
S_x96x_S
addikt
válasz
 Petykemano
#2634
üzenetére
Petykemano
#2634
üzenetére
> Ejha, és mi van a 4900U-val?
- Lehet, hogy az Lenovo exclusive ?
https://www.techpowerup.com/263672/amds-mobile-ryzen-9-4900u-listed-by-lenovo
- vagy csak az első körben megjelenteket tartalmazza.
A 4900U az AMD honlapján se szerepel ( ~ nem találom)
de a 4800U igen )
-
Mintha olvastam volna, h Chromebookokba szánják, de nem esküszöm meg. Mondjuk biztos sokkal többet ér ez a 2/2 Athlon, mint az 1 modulos Stoney Ridge, amik kb 1 éve jelentek meg.

(#2633) S_x96x_S:
Nézegetem ezt a táblázatot, de nem jövök rá, mi benne az új. Az összes rajta lévő procinak van már egy ideje AMD holnapon adatlapja.
Ja, leesett, a kék konkurens nevesítése.
-

DraXoN
addikt
70-90eFt-os gép kategóriákba jó
 ..ha már E2 sorozatos és hasonszőrű (N3000.. de még Atomot is találni) holmik kifutottak... bár tuti feléjük lesz pozicionálva amíg van raktáron régi "olcsó" chip...
..ha már E2 sorozatos és hasonszőrű (N3000.. de még Atomot is találni) holmik kifutottak... bár tuti feléjük lesz pozicionálva amíg van raktáron régi "olcsó" chip...
bár talán befér.. azt nézem már van 100eFt körül Ryzen 3 2200U gép [link] (meg i3-makat)... -
#2635
 awexco
őstag
Petykemano
#2634
awexco
őstag
Petykemano
#2634
awexco
őstag
válasz
Petykemano
#2634
üzenetére
A kérdés jogos ...
-
S_x96x_S
addikt
https://twitter.com/momomo_us/status/1226810947567620096
* Ryzen 4000 Series Mobile Processors
* Athlon 3000 Series Mobile Processors

-
#2632
 joysefke
veterán
Petykemano
#2630
joysefke
veterán
Petykemano
#2630
joysefke
veterán
válasz
Petykemano
#2630
üzenetére
semmit
-
#2631
 Cathulhu
addikt
Petykemano
#2630
Cathulhu
addikt
Petykemano
#2630
Cathulhu
addikt
válasz
Petykemano
#2630
üzenetére
En sem ertek hozza, de a srac sem, aki irta cikket.
Eleve a screenshotja szerint nem 1db 12 magos peldanyrol beszelunk, hanem 2db 6 magosrol, masreszt geekbench4-et nezunk, nem az 5-ot, es 4-ben ezt a scoret egy 3900X is rohogve hozza, de a az idezett Intel Xeon Gold 6226 is boszen duplajat hozza, mint amit o irt.Klikkvadaszat?
-
S_x96x_S
addikt
(versenytársfigyelő ... IceLake 10nm Server )
kérdés, hogy mikorra tudja kihozni az Intel a 10nm -es szerver chipet ...
és erre mi az AMD válasza.Az Intel10nm Ice Lake szerver a ZEN3-al egy időben ( az év végén ) jön ki?
akkor legalább lesz egy kis verseny 
" Intel is working on a 10nm Ice Lake-based server CPU as part of its server lineup. The model spotted here is a dual-socket part with 12 cores and 24 threads.
It scored a stunning 27,926 in the multithreaded test. This is nearly as high as the 24-core 48-thread Cascade Lake Xeon Gold 6226, which scored 32,937. Intel's 10nm Ice Lake part delivered nearly the same performance with just half the core count.
....Intel's monolithic die design means that more cores cost exponentially more to manufacture. If Intel can bring Ice Lake Xeons to the market, delivering more performance with fewer cores, it could mean the end for AMD's server ambitions, even as Team Red preps EPYC Milan.
" -
S_x96x_S
addikt
kikerült a februári frissítés ... (PDF)
AMD Corporate Presentation
sok újdonság nincs benne ... -
joysefke
veterán
válasz
 joysefke
#2626
üzenetére
joysefke
#2626
üzenetére
disclamer:
mielőtt valaki azt hiszi, hogy valami SIMD veterán vagyok: csak a .NET Core 3.0 kapcsán játszottam vele (unsafe c# +intrinsics) illetve olvastam el pár könnyedebb SIMD/assembly optimalizációs könyvet. Pld a fenti linken
De amiket leírtam alapvetően alapvetések. -
joysefke
veterán
válasz
 Cathulhu
#2620
üzenetére
Cathulhu
#2620
üzenetére
Nem értem hogy egyáltalán min vitatkozunk. Azt sem értem, hogy mi a problémád az unrollingra írt két mondatommal.
Ha jobban tudod, hogy mi az unrolling, akkor kérlek írd le, hogy hol a probléma a kijelentésemmel és ne wikipediát idézz, mert én akkor meg a Mestert idézem: https://www.agner.org/optimize/optimizing_cpp.pdf (c.h 12.3)
Tehát még egyszer: A loop unrolling sok minden optimalizációra (lehet) jó, ezek közül az egyik, hogy lehetőséget ad(hat) automatikus vektorizálásra, mivel több (2-4-8-16 attól függően hogy mennyi adatelem fér egy vektorba) skalár adaton végzett ciklustörzset egyesít egy nagyobb ciklustörzzsé, ahol az egy-egy skalár adaton végzett műveletet helyettesíteni lehet nagyobb vektorműveletekkel.
Lehet hogy te arra gondoltál, hogy egy konstans hosszúságú loop
Ahhoz hogy ez a fordító által automatikusan megvalósítható legyen a kódnak egyszerűnek kell lennie: az egymás után következő ciklusok között csak könnyen feloldható függőség lehet. Bonyolult függőségeket és branchelést nem fog tudni magától feloldani/kezelni a fordító.
Attól függetlenül, hogy a compiler bizonyos egyszerű skalár kódrészleteket (pld for ciklussal egyenként végiggyalogolok egy tömb összes elemén és hozzáadok az aktuális elemhez valami konstansot) hatékonyan tud vektorizálni, ennek még zéró köze van egy SIMD- utasításokat használva kézzel optimalizált kódhoz.
Erre mondtam azt, hogy ha Pistike ír mondjuk egyszerű képmanipulációs szoftvert skalár műveletekkel, mondjuk egy Sepia filtert, ami ugye az egyik legegyszerűbb RGB adatokon dolgozó algoritmus, a compiler nem fog tudni a skalár kódból érdemi SIMD kódot generálni.
Az ok pedig annyi, hogy a hatékony SIMD kódhoz elengedhetetlen, hogy a bemeneti és köztes adatok struktúráját hozzáigazítsd a vektoros feldolgozáshoz. Ez nagy munka. Az RGBA adatokat pld transzponálni kell, hogy a bemeneti [RGBARGBARGBARGBA] helyett kapj valami ilyet:
[RRRR] [GGGG] [BBBB] [RRRR] [GGGG] [BBBB] stb stb (az A alapvetően nem kell a szépiához).Aztán ott van a branchelés. Ha a módosított képen valamelyik színkomponens nem 0-255 közé esik, akkor csonkolni kell. Ezt sem fogja tudni érdemben automatikusan skalárról vektorra fordítani a compiler.
stb stb stbAz MKL az intel sajat, zart forrasu kodja, kb termeszetes, hogy bunteti a nem intel procikat
Nem, nem természetes. Itt arról van szó, hogy ha a dispatcher nem intel procit detektál, akkor rá sem engedi az AVX2 kódra, akkor sem, ha a proci egyébként támogatja azt.
Ennyi erővel az intel fgv könyvtárak akár az x86-os kódot is tilthatnák AMD-n.
Egyébként attól, hogy egy kódot AVX2 -t használva írtak meg, az még nem lesz önmagában ideális egyszerre Skylakere és mondjuk ZEN2-re.
Az intel nyilván a saját AVX2-t tudó processzoraira fogja az AVX2 -t használó kódrészletet optimalizálni. Figyelembe veszi az L1/L2 cache méretét asszociativitását, adott SIMD utasításból hányat tud egyszerre végrehajtani a mag és mekkora az utasítás késleltetése stb. A sebességet mérik is, és nyilván úgy csiszolják, hogy a legjobb legyen a saját procijuknak. Tehát az AMD proci itt is hátrányban lenne, de legalább nincsen szándékosan kigáncsolva. (mintha skalár kódot futtatna enyhén szuboptimális vektorkód helyett)Tehát én azt várnám el az ilyen gyártói fgv könyvtáraktól, hogy ha a konkurens processzor tudja a szükséges utasításkészletet, akkor az is fusson rá az optimalizált útvonalra.
A fenti hosszú irományom lényege pedig az, hogy semmilyen compiler nem fog saját kútfőből skalár kódból vektor kódot csinálni eltekintve pár low hanging fruit leszedésétől.
-
S_x96x_S
addikt
válasz
joysefke
#2618
üzenetére
>> ... AVX-512 támogatás
> Feltételezem a gyakorlatban, ez leginkább csak bencsmárkokat jelent.ne feltételezz
https://github.com/search?p=2&q=AVX512&type=Repositories
----------ZEN2 : elméletileg már most is lehetne emulálni az AVX512-öt mikrókódokkal, de ez megtévesztő lenne és gyakran lassabb megoldást eredményezne mint a sima AVX2 -kódot futtatna a program.
Ráadásul ez a lassúság teljesen összezavarná a felhasználókat és a kód optimalizálókat. szóval nincs még AVX512 a ZEN -ben.-------------
Intelnél is néha csodálkoznak, hogy az AVX512 néha lassabb mint az AVX2
https://software.intel.com/en-us/forums/software-tuning-performance-optimization-platform-monitoring/topic/815069
Ha "# of AVX-512 FMA Units" == 1 és az AVX-512 -öt nem tudja turbozni mint az AVX2-öt , akkor értelemszerűen lassabb lehet a kód ..
----------------- -
Cathulhu
addikt
válasz
joysefke
#2623
üzenetére
Az unrolling nem azt jelenti amire gondolsz ezekszerint, masreszt nem arrol szol az egesz, hogy a standard lib-ben mi hogy van elore megirva.
Epp ezert szeretik sokan az icc-t, mert az relativ ugyesen veszi eszre a vektorizalhato muveleteket es optimalisabb kodot fordit (intelre) mint a tobbi fordito. -
joysefke
veterán
válasz
Cathulhu
#2620
üzenetére
Az MKL az intel sajat, zart forrasu kodja, kb termeszetes, hogy bunteti a nem intel procikat, de ennek semmi koze az 512-hoz, hiszen a legtobb intel proci se tamogatja azt.
Pontosan erről beszélek. Amikor vektorkódnál hátrányban van az AMD akkor nem azért van hátrányban mert "csak" AVX2-t támogat és nem AVX512-t mint a legmodernebb szerver/ws intelek, hanem azért, mert az AMD-proci nem fog ráfutni a számára legoptimálisabb kódútra, hanem egy csomó szoftverben skalár kódot fog végrehajtani, pedig futtathatná az AVX2-es kódutat is. ez az igazi hátrány
Ezen a problémán nem egy esetleges AVX512 támogatás fog segíteni, hanem ilyen olyan módon rá kell bírniuk a szoftvergyártókat, hogy gondoskodjanak róla, hogy az AMD is az AVX kódot futtassa, ha ez nem megoldható MKL alapon, akkor más libraryt kell keresni.
Nemelyik fordito kepes skalar kodot automatikusan vektorizalt kodra optimalizalni, es ehhez nincs szukseg a programozonak explicit SIMD kodot irnia, a forditonak kell eleg intelligensnek lennie (es itt megint felmerul az ICC partatlansaga).
A fordító soha nem fog helyetted vektorkódot írni.
Egyszerű for ciklusokat fog automatikusan unrollolni, ha nem érzékel az egymás után következő ciklusok között függőséget/branchelést, illetve egy csomó alap fgv van még vektorizálva (pld egy némely stringművelet).
Egy "skalár megírt Cinebench"-ből semmilyen fordító nem fog CB20-at csinálni...
-
Cathulhu
addikt
válasz
joysefke
#2619
üzenetére
Az az MKL "hibajabol" ered, es nem azert mert ha nincs AVX-512, akkor semmilyen AVX-et nem hasznal. Az MKL az intel sajat, zart forrasu kodja, kb termeszetes, hogy bunteti a nem intel procikat, de ennek semmi koze az 512-hoz, hiszen a legtobb intel proci se tamogatja azt. A matlab ott kovetett el hibat, hogy dobta az OpenBLAS es Lapack tamogatast es exkluziv modon allt at MKL-re ugy 10 evvel ezelott. De az MKL-t is at lehet verni az altalad linkelt modon es rogton AVX utat kezd el hasznalni AMD-n is. Open source libeknel ezzel nincs (nem feltetlen van) gond mint ahogy open source vagy gyarto fuggetlen forditokkal sem. Nemelyik fordito kepes skalar kodot automatikusan vektorizalt kodra optimalizalni, es ehhez nincs szukseg a programozonak explicit SIMD kodot irnia, a forditonak kell eleg intelligensnek lennie (es itt megint felmerul az ICC partatlansaga).
Ha az AVX 512 elterjed a kovetkezo generacios intelek miatt, majd megoldja az AMD ugy mint a Zen1-nel a 256-ot, emulalva. A magszambol eredo elonye miatt nem fog nagy hatranyba kerulni amig nem kap majd vegleges nativ megoldast.
-
joysefke
veterán
válasz
S_x96x_S
#2612
üzenetére
Minden olyan programnál, amit AVX-512 támogatással fordítottak
Feltételezem a gyakorlatban, ez leginkább csak bencsmárkokat jelent.
Az AMD-nek szerintem nem az lesz itt a baja, hogy az intel tud AVX512-t, ők meg csak 256 bites AVX-et, hanem a legtöbb problémás esetben az, hogy az intel procit a dispatcher ráviszi a legjobb AVX kódra, az AMD pedig a skalár kódot futtatja pedig tudna elég komoly órajel (és magszám előny mellett) mellett AVX2-t is. Az hogy az AVX kódot is az aktuális intelre felépítésre optimalizálták és nem AMD-re az már részletkérdés, ha az AMD ráfut a vektor kódra.
Ha ránézel a magszámokra, AVX-órajelekre, cache méretre és a teljes processzor memória sávszélességére, akkor szerintem nem az AMD-nek van szüksége AVX512-re, hogy pariban legyen az intellel, hanem az intelnek van szüksége az AVX512-re hogy egyrészt legyen valami marketingfegyvere illetve ne verje agyon a ZEN2/3, ha az éppen ráfut egy több szálon végrehajtott AVX2 kódra.
Mondom ezt úgy, hogy AVX512-vel még nem volt dolgom, és SSE/AVX-szel is csak pár egyszerűbb kódot írtam (önképzés jelleggel hobbiból), tehát ha valaki jobban rálát a dologra javítson ki
-
S_x96x_S
addikt
válasz
#82819712
#2605
üzenetére
> Ha a 3990X 3990 dollárba kerül
Eredetileg 3999 lett volna .. de ez az egyezőség csak kivétel és nem szabály.Az AnandTech-es srác intézte el
"A final thought. The AMD TR 3990X is amusingly priced at $3990. It’s a great marketing idea, and gets people talking. I’m proud to say that this price was my idea – AMD originally had it for something different. I don’t often influence change in the industry in such an obvious way, but this one was fun." ( link ) -
S_x96x_S
addikt
> Ez annyira nem nem méz ki rosszul.
de nem használható.
A te listádban mintha egyik proci se támogatná az AVX-512-öt.
Intel Xeon E-2186G : se támogatja.'Intel® SSE4.1, Intel® SSE4.2, Intel® AVX2'
Az Intel ARK listájában tudod megnézni a támogatott utasításkészleteket.@ #2610) joysefke
> Milyen AVX-es tesztekben van hátrányban a ZEN2?Minden olyan programnál, amit AVX-512 támogatással fordítottak.
Eddig csak egyes XEON / HEDT procikban volt ilyen támogatás ..
de most az Intel az új architektúrás ( értsd ~ 10nm ) desktop és laptop procikban is elérhetővé teszi ..
Nem könnyű implementálni, rengeteg chip területet elvesz .. és még elég képlékeny az AVX-512 utasításkészlet is. Emiatt az AMD inkább a magszám növelésére ment rá, mert abból több program tud hasznot húzni. A modern fordítók LLVM/Clang/GCC/MSVC/* már mind támogatják .. és az új Centaur proci is támogatja.Az AMD a ZEN2 -ben duplázta a lebegőpontos végrehajtó egységeket - de az még mindig csak AVX2-es ;
A ZEN3-ban meg várhatóan 50%-al tovább növelik a lebegőpontos teljesítményt, de ez még mindig kevés lehet az Intel kigyúrt AVX-512 -hez képest.
"AVX-512 is a set of 512-bit SIMD extensions that allow programs to pack sixteen single-precision eight double-precision floating-point numbers, or eight 64-bit or sixteen 32-bit integers within 512-bit vectors. The extension provides double the computation capabilities of that of AVX/AV2."Az Intel azért volt kénytelen nyomni az AVX-512 -öt mert nem volt rendes GPU-juk - és HPC területen elég éles harc megy az nVidiával.
https://www.anandtech.com/print/14466/intel-xeon-cascade-lake-vs-nvidia-turing ( ebben még csak ZEN1-es procik vannak )
De most már az Intel -nek is lesz rendes GPU-ja és a AI chipje. -
-
S_x96x_S
addikt
Feltételezve, hogyha a ZEN3 -as FP-je kb 50%-al lesz jobb ..
akkor még mindig hátrányban lesz az AVX--es tesztekben
( persze ez erősen programfüggő is. )
Valószínüleg ilyen esetben egy erős GPU-t tesznek a konfighoz .. és az végzi a hasonló számításokat .. ettől függetlenül néha jól jöhet az AVX-512.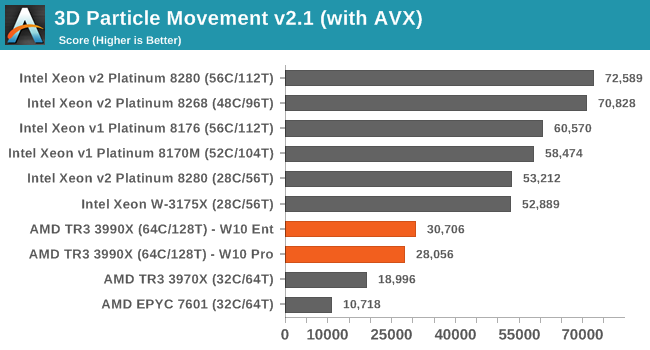
-
S_x96x_S
addikt
válasz
joysefke
#2600
üzenetére
>Ez a grafikon nekem nem áll össze...
szerintem rengeteg szoftver bug - optimalizálatlan kód lehet a háttérben.
- Egyrészt a Windows Pro/Enterprise furcsaságai - eltérései.
- Másrészt a tesztprogramok részéről.Eddig nem is volt nagyon hardver, amin tesztelhettek vagy tunninggolhattak volna.
( egy cpu - 128 Thread !!! szinte elképzelhetetlen még most is nekem ... )pl. itt azért látszik, hogy valószínüleg a POV-Ray ( tesztprogram ) nem jól kezeli a 128 szálat .
És a javításig érdemes lehet kikapcsolni az SMT-t.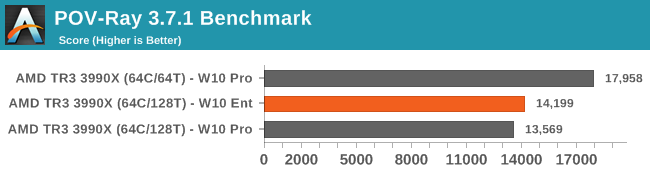
A következő fél évben - azért remélem a nagy részét javítják ezeknek.
-
joysefke
veterán
https://www.macrumors.com/2020/02/07/macos-catalina-amd-apu-references/
Simid: az eredmény
















 ..ha már E2 sorozatos és hasonszőrű (N3000.. de még Atomot is találni) holmik kifutottak... bár tuti feléjük lesz pozicionálva amíg van raktáron régi "olcsó" chip...
..ha már E2 sorozatos és hasonszőrű (N3000.. de még Atomot is találni) holmik kifutottak... bár tuti feléjük lesz pozicionálva amíg van raktáron régi "olcsó" chip...













Új hozzászólás Aktív témák
Hirdetés

- BESZÁMÍTÁS! ASRock B460M i5 10400 16GB DDR4 512GB SSD RTX 2060 Super 8GB Rampage SHIVA TT 500W
- ÚJ Lenovo Legion Pro 5 16IRX9 - 16" WQXGA 165Hz - i5 14500HX - 32GB - 1TB - RTX 4060 - 3 év garancia
- ÁRGARANCIA! Épített KomPhone i9 14900KF 64GB RAM RTX 5080 16GB GAMER PC termékbeszámítással
- Samsung Flip 2.0 PRO 65" WM65R + Connectivity tray + Gurulós állvány
- AKCIÓ! ASUS Z97-A Z97 chipset alaplap garanciával hibátlan működéssel
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: CAMERA-PRO Hungary Kft
Város: Budapest