
- Gaming notebook topik
- AMD Navi Radeon™ RX 9xxx sorozat
- Házimozi belépő szinten
- Vezeték nélküli fülhallgatók
- Milyen asztali (teljes vagy fél-) gépet vegyek?
- LG LCD és LED TV-k
- CPU léghűtés kibeszélő
- Fejhallgató erősítő és DAC topik
- Samsung Galaxy Tab S11 - tizenegyes
- Azonnali processzoros kérdések órája
Új hozzászólás Aktív témák
-

MineFox54
őstag
válasz
 MineFox54
#1999
üzenetére
MineFox54
#1999
üzenetére
Solved.
A megfejtés így néz ki a valós táblámnál:
(nem biztos hogy a legjobb megoldás, ha tudtok jobbat, hallgatom)SELECT indulas,
beerkezes,
tav,
nev,
Find_in_set(beerkezes, (SELECT Group_concat(beerkezes ORDER BY beerkezes
ASC)
FROM beerkezes
INNER JOIN versenyzo AS x
ON beerkezes.rfiddata = x.rfiddata
WHERE beerkezes <> '00:00:00'
AND v.tav = x.tav)) AS rank
FROM beerkezes
INNER JOIN versenyzo AS v
ON beerkezes.rfiddata = v.rfiddata
WHERE beerkezes <> '00:00:00'
ORDER BY beerkezes DESC -
#1999
MineFox54
őstag
Apollo17hu
#1997
MineFox54
őstag
válasz
 Apollo17hu
#1997
üzenetére
Apollo17hu
#1997
üzenetére
Köszönöm.
Nos, lenne még egy kérdésem.
Azt kellene megtudnom hogy az éppen vizsgált sor hányadik helyen szerepel, ha a táblát szűrjük bizonyos feltételekre.Tehát kifejtve:
tábla:id|sorrendalkoto|feltétel
1|1250|false
2|1235|true
3|1345|true
4|561|false
5|6235|trueTegyük fel, van egy select-em, amivel ebből a táblából olvasok adatokat. Ebbe a selectbe szeretnék generálni egy olyan mezőt, amellyel megtudom, hogy: egy
WHERE feltétel=true ORDER BY sorrendalkoto descfeltételek alapján hanyadik helyen szerepel a táblában. Fontos lenne hogy on-the-run működjön a dolog.
Várt result:id|sorrendalkoto|helyezés
5|6235|1 -
#1998
MineFox54
őstag
Apollo17hu
#1997
MineFox54
őstag
válasz
Apollo17hu
#1997
üzenetére
Igen, a GROUP BY megoldás, de a feldolgozási oldalon macerásabb (nem csak egy echo-ba megy
 ). Mindegy, megcsináltam, így marad.
). Mindegy, megcsináltam, így marad. -
#1997
 Apollo17hu
őstag
MineFox54
#1996
Apollo17hu
őstag
MineFox54
#1996
Apollo17hu
őstag
válasz
MineFox54
#1996
üzenetére
SELECT
SUM(CASE WHEN keresett = 7 THEN 1 ELSE 0 END) AS "7cnt",
SUM(CASE WHEN keresett = 14 THEN 1 ELSE 0 END) AS "14cnt",
SUM(CASE WHEN keresett = 22 THEN 1 ELSE 0 END) AS "22cnt"
FROM tabla...vagy próbálkozhatsz a PIVOT funkcióval is.
Amúgy biztos nem egy mezei
GROUP BY keresett-re lenne szükséged? -
MineFox54
őstag
Sziasztok!
Úgy látom nem túl aktív a topik, de megpróbálkozom.
Van egy táblám.
leegyszerűsítve (jóval több oszlopról beszélünk de most ennyi a lényeges)tábla -> id|keresett
Ebből szeretném megtudni egy lekérdezéssel, hogy hány előfordulása van az keresett oszlopban bizonyos stringeknek, ez most legyen "7","14","22".Tehát ha a tábla
1|7
2|14
3|22
4|22
1|7
Akkor a lekérdezés végén azt kapjam vissza hogy pl
7cnt|14cnt|22cnt
2 |1 | 2Jelenleg ezzel próbálkoztam, de ez csak azt dobja vissza hogy hány sor volt ami a feltételeknek megfelelt.
COUNT("7") as 7cnt,COUNT("14") as 14cnt,COUNT("22") as 22cnt -

sonar
addikt
-

martonx
veterán
válasz
 baracsi
#1991
üzenetére
baracsi
#1991
üzenetére
Az oké, hogy ebben a linkelt listában a Facebooktól kezdve egy csomóan benne vannak, de vajon ők tényleg MySql-t használnak out-of-the-box? Vagy az itt szereplő felhasználók döntő többsége már rég saját storage engine-el megy MySql alatt, mint pl. a Facebook is, csak épp lehet rájuk hivatkozni, hogy szegről-végről némi közük van a MySql-hez.
-

SaNyEe
aktív tag
válasz
baracsi
#1991
üzenetére
Ami a számomra furcsa az optimizerben, hogy preferálja a komplett adathalomhoz való hozzáférést az adott where záradékban, mert olyan oszlopokat sorolok fel a select záradékban, amik végül a select statement eredményeként megjelen(het)nek.
Nyilván ez sokkal-sokkal több szekvenciális és random IO-val jár, mintha csupán az indexekből táplálkozna, majd random hozzáférne a kiadni szükséges blokkokhoz (csupán egyszer egy adatblokkhoz), ahogy a példa jól mutatja is.MySQL ide vagy oda, biztos vagyok benne, hogy ez beállítási kérdés lesz
Ekkora multinál, mint aminél felmerült a téma, egy release upgrade még sztem min 1 évet várat magára, addig maradnak a patchek max (:Megszakértetem a hivatalos supporttal is úgyamúgy, ha valami eredménye lesz azt majd megosztom, csak sokszor szakértői fórumokon néha jön gyorsabban is válasz.
-

baracsi
tag
Az index problémára nem tudok mit mondani, lehet tényleg régi a MySQL-ed és azért csinálja, érdemes egy friss verzión megnézni, hogy hogyan viselkedik, másrészt pedig igazad van, elég sok komoly cég használja a MySQL-t ([link]), és valóban elveszik a PH!-s MySQL topic komolyságát az itt megjelenő "móricka projekt"-es hozzászólások. Egy "szerintem" hozzá nem értő véleményét olvassa egy másik hozzá nem értő, majd jövünk mi programozók, hogy MySQL fut a cége rendszere alatt, akkor bizony a másik hozzá nem értő megkérdőjelezheti azt, hogy jó lóra tesz-e adott szoftver választásával, úgyhogy tényleg óvatosan a meggondolatlan kijelentésekkel!
-
SaNyEe
aktív tag
válasz
 martonx
#1989
üzenetére
martonx
#1989
üzenetére
Már látom, hogy nem a megfelelő fórumhoz fordultam
Enterprise üzemet nem bíznál rá? Hm, titoktartási szerződés miatt nem nyilatkozhatok, de meglepődnél mekkora vállalatok, milyen rendszerei futnak mysql felett Bár kinek mi a móricka szint az relatív
Bár kinek mi a móricka szint az relatív(Attól, hogy valahogy konfigurálva van perpill az innodb engine s az optimájzer, nem jelenti azt, hogy más beállításokkal ne működne jobban, vagy épp optimálisan)
Az Oracle-t is be tudom neked úgy állítani exadatán akár, hogy arcpirongatóan gyorsnak tűnjön mellette egy access "adatbázis"
-
martonx
veterán
Simán lehet, de ha megtennéd, hogy pontokba szedve cáfolod (több szinten is  ), nem pedig pont hogy az igazamat bizonyítod, a szimpla select, index nem használós bizonyítással? Ettől még persze nincs baj a MySql-lel móricka projektekhez simán jó, és ingyenes, de komoly enterprise üzletmenetet biztos, hogy soha nem bíznék rá. Szerintem.
), nem pedig pont hogy az igazamat bizonyítod, a szimpla select, index nem használós bizonyítással? Ettől még persze nincs baj a MySql-lel móricka projektekhez simán jó, és ingyenes, de komoly enterprise üzletmenetet biztos, hogy soha nem bíznék rá. Szerintem. -
martonx
veterán
Egyrészt úgy rémlik mintha írtad volna a MySql verziót, és mintha valami elég elavult verziót használnál. Másrészt a MySql közismerten az Oracle ingyenes alternatívája, és nyilván nem véletlenül ingyenes
Ha mindenképpen az ingyen vonalon akartok mozogni akkor MariaDB vagy PostgreSql sokkal jobb választás, mint a MySql. Szerintem. -
SaNyEe
aktív tag
Nem segitett, force index kellett, ugy lett 1.65s a futasi ido. Az alkalmazas forrasahoz nincs hozzaferesem, elegans modjat (db szintu) szeretnem valasztani a problema megoldasanak.
Ehhez egy uj app release kene es az is csupan egy szepsegtapasz lenne
Masik erdekesseg amibe botlottam es nagyon meglepett oracle utan A+B tabla inner joinnal letrehozott, mindket tabla oszlopait tartalmazo rendezett, limitalt lista letrehozasanak koltsege iszonyat magas volt. A tabla 4 millio, b tabla 4db rekordot tartalmazott.
Az eredmeny eloallitasa kb 60 sec volt, ha csak a tabla oszlopait jelenittettem meg az kb instant megjelent. (1db where clause volt a tablara, indexelt)
-
SaNyEe
aktív tag
Sziasztok,
Találkoztam egy érdekes problémával (mysql "újonc" vagyok, Oracle vonalon mozgok alapvetően)
Egy Select rettenet hosszú ideig fut, a problémás selectet "redukáltam" a problémás részre. Ennek explainje a következő:
mysql> explain SELECT a.clock
-> FROM alerts a, events e
-> WHERE e.eventid=a.eventid;
+----+-------------+-------+--------+---------------+---------+---------+------------------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+---------+---------+------------------+---------+-------------+
| 1 | SIMPLE | a | ALL | alerts_3 | NULL | NULL | NULL | 3723509 | NULL |
| 1 | SIMPLE | e | eq_ref | PRIMARY | PRIMARY | 8 | zabbix.a.eventid | 1 | Using index |
+----+-------------+-------+--------+---------------+---------+---------+------------------+---------+-------------+
2 rows in set (0.00 sec)a tábla alerts_3 indexe nem kerül használatba. A csatolt mezők bigint(20) unsigned típusúak. Baloldali tábla 166 millió, a jobboldali tábla 3,7 milliós rekordmennyiségű.
Not null constraint van mindkét mezőn, de default null be van állítva (5.6 verzió)
A táblák innodb tárolómotort használnakAmikor nincs alerts_3 index használatban a query futási ideje 48sec.
A force index(alerts_3) megadásával 1.65sec-re redukálódik a futási idő.
Statisztikákat ma frissítettem közvetlen tesztelés előtt, azok aktuálisak.Miért nem használja a mysql a rendelkezésére álló indexet? Ott van és mikor kényszerítem, működik.
Miután elkezdtem játszani a selecttel és kivettem a tábla oszlopát (vagy betettem az index-el rendelkező oszlopot) a select clause-ból így alakultunk át:
mysql> explain SELECT a.eventid
-> FROM alerts a, events e
-> WHERE e.eventid=a.eventid;
+----+-------------+-------+--------+---------------+----------+---------+------------------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+----------+---------+------------------+---------+-------------+
| 1 | SIMPLE | a | index | alerts_3 | alerts_3 | 8 | NULL | 3723507 | Using index |
| 1 | SIMPLE | e | eq_ref | PRIMARY | PRIMARY | 8 | zabbix.a.eventid | 1 | Using index |
+----+-------------+-------+--------+---------------+----------+---------+------------------+---------+-------------+
2 rows in set (0.00 sec)Hogy lehetne a forrás SQL átírása nélkül rábírni a mysql-t, hogy az a.eventid oszlopon is használja az indexet annak ellenére, hogy valóban a tábla minden sora candidate row és jó ötletnek tűnhet első körben felolvasni mindent a blokkokból?
-

Male
nagyúr
Köszi a tesztet!
Akkor csak jól logikáztam, hogy nem számít igazán, sőt, ahogy látom, még a két külön mezős gyorsabb is volt egy picivel ( v1 vs. v3 másodikja, ez volt az eredeti kérdésed, ha akkor jól értettem )
(amikor még én próbálgattam időszükségleteket, akkor a JOIN volt a legdurvább, nagyságrendi eltéréssel a többihez képest... bár ott más volt a teszt, egy weboldal lett kielemezve, hogy milyen lekérések hányszor fordulnak elő a működés során, és ezek mennyi időt visznek el.. a JOIN ritka volt, pár százalék, de az össz időben mégis sokkal többet vitt el, mint bármi más) -

biker
nagyúr
Na, kipróbáltam, remélem mindent jól következtettem ki
Leginkább az ÉS lassítja.
Ha ugyanazt keresem 1x, vagy 2x, vagy 2 mezőben egyszer, akkor OR esetén mindegy.
AND esetén ha ugyanazt keresem, nem gond, de ha két külön feltételt AND-el, akkor mindkét esetben lassulPersze, ez a saját gépemen, ahol minden erőforrás itt van a mysql-nek, vhoston lehet hogy jobban kijön a különbség, hogy nem 0,0030 vs 0,0020 hanem egy tizedessel beljebb jövünk, de nem lényeg.
mysql teszt, 242,7mb tábla
v1: 744.000 sor szöveg keresés egy mezőben, egy feltétellel
SELECT * FROM `fitness_naplo_dup` WHERE `esemeny` LIKE '%rendszer%'
Sorok megjelenítése 0-24 (összesen 68691, A lekérdezés 0.0032 másodpercig tartott.)v2: 744.000 sor szöveg keresés egy mezőben, két feltétellel
SELECT * FROM `fitness_naplo_dup` WHERE `esemeny` LIKE '%rendszer%' OR `esemeny` LIKE '%törölt%'
Sorok megjelenítése 0-24 (összesen 100520, A lekérdezés 0.0030 másodpercig tartott.)SELECT * FROM `fitness_naplo_dup` WHERE `esemeny` LIKE '%rendszer%' AND `esemeny` LIKE '%törölt%'
Sorok megjelenítése 0- 0 (összesen 1, A lekérdezés 2.1407 másodpercig tartott.)v3: 744.000 sor szöveg keresés két mezőben, egy feltétellel
SELECT * FROM `fitness_naplo` WHERE `esemeny` LIKE '%rendszer%' AND `esemeny2` LIKE '%rendszer%'
Sorok megjelenítése 0-24 (összesen 68691, A lekérdezés 0.0018 másodpercig tartott.)SELECT * FROM `fitness_naplo` WHERE `esemeny` LIKE '%rendszer%' OR `esemeny2` LIKE '%rendszer%'
Sorok megjelenítése 0-24 (összesen 68691, A lekérdezés 0.0026 másodpercig tartott.)v4: 744.000 sor szöveg keresés két mezőben, két feltétellel
SELECT * FROM `fitness_naplo` WHERE `esemeny` LIKE '%rendszer%' AND `esemeny2` LIKE '%törölt%'
Sorok megjelenítése 0- 0 (összesen 1, A lekérdezés 1.3561 másodpercig tartott.)SELECT * FROM `fitness_naplo` WHERE `esemeny` LIKE '%rendszer%' OR `esemeny2` LIKE '%törölt%'
Sorok megjelenítése 0-24 (összesen 100520, A lekérdezés 0.0026 másodpercig tartott.) -
Male
nagyúr
3 mező 3 keresés? Szerintem ez nem darabra megy, mivel szövegben keresel... hogy az három mezőre van szétosztva egymás mellé vagy egyben van, mindkét esetben ugyan annyi szöveget kell betölteni, és ugyan annyit kell átnéznie hozzá ...de sonar jól mondja, csinálsz egy próbát, és kiderül
...viszont ha megcsinálod, majd írd be az eredményt, kíváncsi vagyok
( értem, hogy te a 3 cellás megoldásnál beírod OR-ral, és az szemre olyan, mintha háromszor annyi munka lenne a MySQL számára, de nem hinném, hogy ennyire "buta" lenne a MySQL motor, hogy így is hajtja végre, hanem betölti azt a három egymás melletti mezőt, ami esélyes, hogy fizikailag is egymás mellett lesz, és végignézi a szöveget az első találatig, ez pedig szerintem a mérhetetlen különbség tartományába fog esni ) -
biker
nagyúr
Lenne egy elméleti kérdésem. Keresés-sebesség kapcsán.
Ha van egy tábla, mondjuk
id, text, date
és ebben keresek szabad szavasan a text mezőben, akkor az ugye egy időegységHa ezt így készítem többnyelvűre, hogy
id, text_hu, text_en, text_de, date
és minden nyelvben keresek előfordulást, az 3 időegység, vagy esetleg kettő, de mindenképpen több mint egy!De ha a többnyelvű szöveget egy text mezőben tárolom pl {:hu}szöveg{:en}text{:de}sprache{:} módon, akkor hiába lesz kbyte-ra ugyanannyi a tábla, mivel minden szöveg egy oszlopban van, a keresés ideje szintén egy időegység nem? és egy keresési parancsal tudok minden nyelvre előfordulást keresni
Persze százezer sorokról beszélünk, több nyelven.
-

cidalain
veterán
válasz
 cidalain
#1974
üzenetére
cidalain
#1974
üzenetére
Az a verzio lesz valoszinuleg, hogy mivel a bejovo adathalmazban nem osszevissza vannak idopontok, es az adatok fejreszeben benne van a kezdo es vegidopont, igy le fogom kerdezni az adatbazisbol elore a start-end idopont kozotti hibas erteku bejegyzeseket.
Ez jo esetben 0 bejegyzest fog tartalmazni, rossz esetben ugye sokat. De a bejovo adathalmaz 80%-ban nem tartalmaz 250-nel tobb adatot, igy az arra az idopontra vonatkoztatott hibas adatok sem lehetnek tobben
A bejovo adatok fajlban vannak soronkent kell feldolgozni, igy tudom csekkolni az elore lekerdezett hibas ertekesek idopontjanal, hogy lett e jo ertek helyette.
Igy ossze tudok allitani egy INSERT IGNORE-t az adatok nagy reszere, es egy REPLACE beszurast azokra amiknel hibat tartalmazott a bazis.Igy egy SELECT lenne csak, egy INSERT IGNORE, es adott esetben egy REPLACE utasitas, ami azert meg vallalhato, a PHP-ban a check sem lesz talan veszes idoben.
A check-et parameterezhetore irom, igy ha nagyon sok adat jonne, vagy valami, akkor ki tudnam kapcsolni.
-
cidalain
veterán
válasz
martonx
#1973
üzenetére
igen ettől félek én is
azt kell mérlegelnem, hogy mi a fontos, a gyorsaság, vagy az alaposság.
simán előfordulhat hogy a beszúrandó adathalmaz csak 100 értéket tartalmaz, így ez esetben az adatbázisból lekérdezés, és elemzés PHP-ban még vállalható idő alatt lemegy. Viszont az is lehet hogy 15000 adat jön be egyszerre, akkor viszont úgy lekérdezni, és elemezgetni, majd válogatni és úgy beszúrni problémás... -
cidalain
veterán
lenne kis szakmai jellegű kérdésem.
legyen egy egyszerű adatbázis:
timestamp | data, ahol timestamp datetime, és data float, timestamp az elsődleges kulcs.
ebbe értékpárokat szúrok be. az érték lehet jó, és lehet rossz. a rossz érték kódja -9999, minden más esetben jó (ez egy tudatosan választott rossz érték, jellemzően -300 nál nincs kisebb jó érték). a rossz értéknek is van információtartalma az időpont miatt, tehát mindenképpen szerepelnie kell.az adatbeszúrás egy bejövő adathalmaz alapján történik, előfordulhat, hogy jön olyan adat is újra, ami már korábban bekerült az adatbázisba. ezért INSERT IGNORE INTO -val tenném a dolgokat az adatbázisba.
ez szuper.ugyanakkor jöhet olyan jó adat is később, aminél az első beszúrásnál hibás érték volt, és ott jelenleg -9999 van az adatbázisba. itt jó lenne ha ez lecserélődne a jó értékre. erre jött a REPLACE INTO ötlet, ami az új adatokat simán beszúrja, a már meglévőket kérdés nélkül update-eli. ezzel viszont az a bajom, hogy egy meglévő jó értéket felül tudja írni ha az új adathalmazban ott rossz érték van.
igazából a kettő kombinációja lenne jó, hogyha van már olyan időpont az adatbázisban, és az értéke jó, akkor hagyjuk, ha nem jó az érték akkor cseréljük. ha nincs még ilyen időpont akkor szúrjuk be, bármilyen érték is tartozik hozzá.
lehetőség szerint, mivel az adatbázis nagyon nagy lesz, nem szeretném előbb lekérni az adathalmazban szereplő időpontokra a bázis aktuális tartalmát, és kiemelezve eldönteni, hogy melyik adatot kell insert-elni/update-elni, hanem csak úgy bezuttyantani, de jó lenne ha replace egy feltétel függvényében futna le.
van lehetőség ilyesmire?
vagy csináljam azt, hogy a bejövő adathalmazt kétfelé veszem?
ha az érték jó, akkor REPLACE INTO
ha az érték rossz, akkor IGNORE INTO
és így ha rossz érték van, akkor csak abban az esetben kerül be, ha ahhoz az időhöz még nem volt semmi? -
#1971
 Keem1
veterán
Apollo17hu
#1970
Keem1
veterán
Apollo17hu
#1970
Keem1
veterán
válasz
Apollo17hu
#1970
üzenetére
Mindig tanul az ember valamit!

-
#1970
Apollo17hu
őstag
Keem1
#1968
Apollo17hu
őstag
Szia!
Még annyi, hogy az OR operátor használata bizonyos esetekben lassíthatja a leválogatást, ezért - ahol lehet - célszerű CASE WHEN -nel kiváltani. Pl. így:
SELECT * FROM tabla WHERE
CASE
WHEN mezo2=0 AND mezo1 LIKE 'kifejezes%' THEN 1
WHEN mezo2=1 AND mezo1 LIKE 'kifejezes' THEN 1
END = 1 -
Keem1
veterán
Sziasztok!
Adott egy sematikus query-m, jelenleg így néz ki:SELECT * FROM tabla WHERE mezo1 LIKE 'kifejezes%'Szeretném, ha ez úgy működne, hogy a
mezo1 LIKE 'kifejezes%'a tábla egy másik értékétől (legyen mezo2) függően nyitott végű vagy zárt végű lenne.mezo2 értéke lehet 1 vagy 0. Ha mezo2=1, akkor nyitott a LIKE:
SELECT * FROM tabla WHERE mezo1 LIKE 'kifejezes%'ellenben ha mezo2=0, zárt a LIKE:
SELECT * FROM tabla WHERE mezo1 LIKE 'kifejezes'Töröm a fejem, de a megoldás nem ugrik be.

Furcsa egy kicsit, mert a lekérdezés egy értéktől függ, de az a baj, hogy ez fontos, hogy így legyen. És épp ezért nem áll össze nálam.Szerk
Átfogalmazom!
A lekérdezésünk változatlan lenne:SELECT * FROM tabla WHERE mezo1 LIKE 'kifejezes%'Azonban ma mezo2=1, az eredményhalmazból kizárnánk az olyan találatot, ami csak LIKE 'kifejezes%' esetén adna eredményt, míg LIKE 'kifejezes' esetén viszont nem. Ha az eredmény mezo2 értéke 0, akkor ha amúgy a lekérdezésnek megfelel, akkor mindegy, hogy a % ott van-e vagy sem, találatként értelmezzük.
-
martonx
veterán
válasz
 Panthera
#1963
üzenetére
Panthera
#1963
üzenetére
Mindenképpen érdemes latest stable-re váltani, ha már úgyis dolgozni kell vele. Viszont ez esetben picit izgi tud lenni a DB migrálás, illetve ha szarul megírt PHP használta (más komolyabb programnyelvet nem tudok elképzelni, ami MySql-re alapozna
), akkor lehet annak is lesznek bajai egy újabb MySql verzióval. -
Üdv!
Van tapasztalat arra vonatkozóan, hogy Windows Server 2012/2016 alatt a MySQL szerver fut-e rendesen?
Manapság [MySQL Community Server] néven kell keresni?Köszönöm!
-

B.A.T.
tag
Így már megvan mi a gond. Beírtam a lekérdezést, amit adtál. Alapból minden sorban ugyanazt az értéket vették fel az azonosítónak szánt oszlop mezői. A dolgot meg ott szúrtam el, hogy utólag akartam primaryt csinálni a mezőkből. AUTO_INCREMENT-et nem tudtam beállítani mert ahhoz alapból primarynak kellett volna lenniük, így viszont csak akkor működött volna ha egyenként átírom a sorokat.
Aztán észrevettem, hogy amikor hozzáadok a táblához egy új oszlopot (kövezzetek meg, de phpMyAdmin így hívja
) akkor kell az Indexet Primaryra állítani, és így már az A_I-t is engedi. Szóval először jöl csináltam, aztán meg nem Köszi a helpet
-
Male
nagyúr
Siettem, benéztem... a tábla elemei között az adott oszlopban van legalább két azonos.
Próbáld meg így:
SELECT `amitprimarynekakarsz`, COUNT(*) FROM `tablaneve` GROUP BY `amitprimarynekakarsz` ORDER BY 2 DESC;Ha bármelyiknél több lesz, mint egy a COUNT, akkor megvan miből van több, és mi akadályoz.
-
B.A.T.
tag
Ugyanazt importáltam, jópárszor újranyomtam a dolgot, a szerkezetet is néztem, nem volt benne elsődleges kulcs.
Arra is gondoltam, hogy zavarja az első adatbázis, amit létrehoztam, és vmiért ütköznek egymással, de ez nem lehet mivel ezeknek elméletileg és gyakorlatilag is teljesen függetlennek kell lenniük egymástól + akkor a többi táblában sem hagyná, hogy ugyanazt állítsam be primary-nak, mint amit az első esetben.
-
B.A.T.
tag
Sziasztok!
A következő kérdésre szeretnék választ kapni: Létrehoztam egy adatbázist MySQL-ben, amibe importáltam néhány táblát. Az egyik táblához hozzáadtam egy új sort, amit elsődleges kulcsként definiáltam. Minden jól működött, megcsináltam néhány lekérdezést stb. mivel ezt egy feladat alapján kellett végignyomni, minden működött. Gondoltam megcsinálom még1x ugyanezt gyakorlásképpen.
Most másodjára viszont valami nem klappol. Amikor importálom azt a táblát, amihez hozzá kell adni egy sort nem engedi hogy elsődleges kulcsnak állítsam be. Ezt a hibaüzenetet kapom: "#1062 - Duplikalt bejegyzes '' a 'PRIMARY' kulcs szerint."
Párszor már újra próbáltam és mindig ugyanez, ami azért érdekes, mert mindent ugyanúgy állítottam be, mint az első adatbázisnál. Ráadásul ott hagyja hogy az a sor legyen az elsődleges kulcs.
Mi lehet a bibi?
-
Male
nagyúr
Ha másnak is ilyen gondja lenne: Winben le lehet rövidíteni a TIME_WAIT állapotot az alap 240 másodpercről akár 30 másodpercre is... valóban segít rajta, de az igazi megoldás a persistent connenction... szépen megy azóta
-
Male
nagyúr
Azzzz, most van hozzáférésem, nézem... 3306-os port 50023 - 54367 közti kimenő porttal mind TIME_WAIT-en van... pedig most épp nyugis időszak van. Ehhez jön még a 80-ashoz várakozó kupac. Hogy rohadna meg, legalább írná azt, hogy nincs szabad kimenő port, akkor egyből kiderül... kinyomozom hogyan lehet ezt a 4 percet lecsökkenteni, a tizede is bőven elég lenne (eleve nem tudom, ha close-zal zárok egy kapcsolatot, akkor mi a fenének kell még 4 percig váratni... bár lehet, hogy van valami a protokollban, de bármi is az, a 4 perc rengeteg manapság).
...aha, másodpercenként ez 18 darab port nyitásnak felel meg... nem is tippeltem rosszul a terheléssel kapcsolatban
Megint volt gond, a statot megnézve:
Aborted_connects 0
Connection_errors_accept 0
Connection_errors_internal 0
Connection_errors_max_connections 0
Connection_errors_peer_address 0
Connection_errors_select 0
Connection_errors_tcpwrap 0
Connections 7031142
Max_used_connections 6
Performance_schema_session_connect_attrs_lost 0
Ssl_client_connects 0
Ssl_connect_renegotiates 0
Ssl_finished_connects 0
Threads_connected 2 -
Male
nagyúr
Köszi!
Délután férek hozzá, akkor nekiállok nyomozni ez alapján.A max_connections-t már belőttem 10.000-re a hiba után, mert nem volt beállítva egyáltalán. Viszont gugli szerint ha azt érem el, akkor más hibakódot kapnék (12xx, nem emlékszem pontosan, de nem 2002).
A query-ket átnézem, de alapvetően kétféle megy ilyen gyakorisággal:
- egy kis méretű, mindössze 10-20 soros, és 3 oszlopból álló (int, tinyint, timestamp) táblában kell keresnie, ráadásul pkey alapján a legutolsót. ( mondjuk ezen kicsit lehet még javítani, mert kizárólag az utolsó sorra van szükségem, tehát új beírásakor akár kukázhatnám is az összes korábbi bejegyzést ). Ugyan ezekbe a táblákba írás nagyjából naponta 1-2 van.
- a bonyolultabbnál már van egy MAX és egy MIN keresés is:SELECT MIN(`tv1p`), MAX(`tv1p`), `emelkedo` FROM `{$sql}` WHERE `vastagitas_ido` != '0' AND `emelkedo` = '0' UNION SELECT MIN(`tv1p`), MAX(`tv1p`), `emelkedo` FROM `{$sql}` WHERE `vastagitas_ido` != '0' AND `emelkedo` = '1'
...a tv1p int, és indexelve is van. Ebben tippre szintén max pár száz sor van, de délután ellenőrzöm. ( ebbe írás/update napi 4-5 van )Az egésszel adatokat osztok meg programok között a gépen belül, és ami furcsa, hogy egyszerre jelentkezik mindegyik ebből olvasó programnál, és ilyenkor pont ugyan annál a táblánál (köv. eset másik tábla, de megint ugyan az mindegyik programnál)... pedig a connectnél még nem is tudhatja, hogy melyik táblából fogok olvasni
Igaz, eddig mindössze háromszor fordult elő, szóval lehet véletlen is.Gugli közben olyan tippet is adott (miután megtaláltam az angol verzióját a hibaüzenetnek... a francnak kell ezeket lefordítani), hogy igazából nem is a MySQL-nél van a gond, hanem a Windows limitációja okozza a problémát: a nyitott portot én hiába zárom, ő még 4 percig váratja, és emiatt simán kifogyok a felhasználható portokból.
-
sonar
addikt
Én a következő dolgokon mennék végig:
Tudni kéne, hogy mekkora a "mysql server" terhelése
MySQL Workbench progival sokmindent meg lehet nézni, de wamp-pal még nem házasítottam sose (linux user vagyok) vagy parancssorból (talán phpmyadmin is tudja)mysql> show status like '%onn%';
+--------------------------+---------+
| Variable_name | Value |
+--------------------------+---------+
| Aborted_connects | 7 |
| Connections | 6304067 |
| Max_used_connections | 85 |
| Ssl_client_connects | 0 |
| Ssl_connect_renegotiates | 0 |
| Ssl_finished_connects | 0 |
| Threads_connected | 7 | <---- No of currently open connections
+--------------------------+---------+
7 rows in set (0.00 sec)
Mennyi process futshow processlist;Illetve mennyi a max connection amit a szerver elfogad
show variables like "max_connections";
Ha változtatni szeretnéd akkor ez a parancsset global max_connections = 200;Aztán meg elkezdeném analizálni a query-ket... kulcsszó: EXPLAIN
Ez egy nagyon jó leírás: [link]Kb ennyi.
-
Male
nagyúr
Sziasztok!
Talán valaki tud segíteni ezen... WAMP 2.5-öt használok, helyi gépen belül. Amikor nagyobb terhelés van ( nem hatalmas, csak másodpercenként 50-100 tippem szerint ), akkor a csatlakozásnál ( PHP-ból mysqli_connect -tel) a következő hibaüzenetet kapom: "Az összes szoftvercsatorna-cím használatának általában csak egy módja (protokoll/hálózat cím/port) engedélyezett.", a hibakód pedig: 2002.
Mit lehet ezzel kezdeni?
-
#1941
B.A.T.
tag
fordfairlane
#1940
B.A.T.
tag
válasz
 fordfairlane
#1940
üzenetére
fordfairlane
#1940
üzenetére
És igazad lett
 A 2013-al tényleg műxik. Köszönöm a segítséget!
A 2013-al tényleg műxik. Köszönöm a segítséget! 
-
#1940
 fordfairlane
veterán
B.A.T.
#1939
fordfairlane
veterán
B.A.T.
#1939
fordfairlane
veterán
A Visual C++ 2013-as redistributable csomagot még kipróbálom, bár sztem ha 2015-el nem ment jó eséllyel ezzel se fog.
Jó eséllyel menni fog a 2013-mal. Ezek a runtimeok nem felülről kompatibilisek, ezért is lehet belőlük több verziót feltelepíteni egymás mellé.
Egyébként igazad van, a 6.3.9-től kezdve nincs 32 bites letölthető bináris:
Changes in MySQL Workbench 6.3.9
- Windows: Zip packages and 32-bit binaries are no longer published. The .NET Framework version 4.5 is now required.
-
B.A.T.
tag
Köszi mindenkinek a választ. Szóval igazából azért a Win7 32bit, mert ezt virtuál gépnek használom, amolyan kísérletezős, mindent kipróbálós telepítésként. A Visual C++ 2013-as redistributable csomagot még kipróbálom, bár sztem ha 2015-el nem ment jó eséllyel ezzel se fog. A 6.3.9 x64-es, így ezen a windowson nem műxik. Mondjuk annyira már nem lényeg, mert közben másik gépre (Win10) feltoltam, ott sima ügy volt.
-
#1938
fordfairlane
veterán
B.A.T.
#1936
fordfairlane
veterán
Vagy rakd fel a Visual C++ 2013 redistributable csomagot [link], vagy használd a Mysql Workbench 6.3.9 változatát.
Requirements for Windows:
- Microsoft .NET Framework 4.5
- Microsoft Visual C++ 2015 Redistributable PackageNote:
The 2013 version was changed to 2015 with MySQL Workbench 6.3.9. -
B.A.T.
tag
Sziasztok!
A következő lenne a problémám: Adott egy Windows 7 SP1 32 bites op. rendszer, amire MySQL Workbench-et próbáltam telepíteni. Letöltöttem a program 6.3.8-as x86-os verzióját, elkezdtem telepíteni, de a telepítéshez kérte a Visual C++ 2013 redistributable csomagot. Letölttöttem, és feltelepítettem a 2015-öset (most az a legújabb), de továbbra sem érzékeli. A Win7 .Net framework-jét is frissítettem, ez szokott még probléma lenni, de már ez sem lehet. Mi lehet a gebasz? Ötletek?
-
#1935
 trisztan94
őstag
trisztan94
őstag
trisztan94
őstag
Sziasztok!
Valószínűleg itt relevánsabb a kérdésem LOAD DATA INFILE-al kapcsolatban: [link]
Tudtok erről valamit?
-
#1934
 Anonymusxx
senior tag
Anonymusxx
#1933
Anonymusxx
senior tag
Anonymusxx
#1933
Anonymusxx
senior tag
válasz
 Anonymusxx
#1933
üzenetére
Anonymusxx
#1933
üzenetére
Vagy akár megadhatom neked az adataimat, ha túl bonyolult lenne megcsinálni....
-
#1932
 DNReNTi
őstag
Anonymusxx
#1931
DNReNTi
őstag
Anonymusxx
#1931
DNReNTi
őstag
válasz
Anonymusxx
#1931
üzenetére
Mi lenne ha a kepeket fajlkent tarolnad? Peldaul?
-
#1931
Anonymusxx
senior tag
Anonymusxx
senior tag
Sziasztok!
Csináltam egy képfeltöltős oldalt, és a probléma az az hogy a képek a Mysql táblákba is felkerülnek, így meg elég nagy lesz a mérete… Próbáltam onnan egyet kitörölni, de akkora weboldalamról is törlődött.. Reservot használok…
Szóval hogyan lehetne megcsinálni hogy a képek ne kerüljenek bele a mysql adatbázisba?
Próbáltam gogleba rákeresni, de nem nagyon tudtam angolul megfogalmazni, hogy hogyan is keressek rá…
-

Dilikutya
félisten
Ezzel mit lehet kezdeni? Egyik javasolt megoldás sem vezetett semmire. XLS táblázatból importálnék adatokat, főleg szöveges mezők vannak, és az össz karakterszám egy ezressel meghaladja ezt a 8126-os limitet.
Row size too large (> 8126). Changing some columns to TEXT or BLOB or using ROW_FORMAT=DYNAMIC or ROW_FORMAT=COMPRESSED may help. In current row format, BLOB prefix of 768 bytes is stored inline.
-
#1927
martonx
veterán
toth_janika
#1926
martonx
veterán
válasz
 toth_janika
#1926
üzenetére
toth_janika
#1926
üzenetére
-
#1926
 toth_janika
őstag
toth_janika
őstag
toth_janika
őstag
Sziasztok!
Szerenték kérni egy teszt adatbázist, ami fel van töltve adatokkal és a lekérdezéseket tudom tesztelni. Szeretném megtanulni a mysql-t és ehhez kellene nekem egy teszt adatbázis, hogy ne nekem kelljen kitalálgatni a táblákat, adatokat, stb. Tudtok ilyet?
A https://dev.mysql.com/doc/index-other.html oldalon találtam adatbázist, de az üres
-

bozsozso
őstag
Sziasztok,
Van egy mysql adatbázisom nas-on. Láttam olyan opciót, hogy ki tudom exportálni. PC-n mivel tudom ezt szerkeszteni, hogy ne egyből az eredetibe nyúljak bele? Mondjuk csak annyit szeretnék, hogy az egész adatbázisban ahol egy megadott útvonal részt talál azt cserélje ki egy másikra. Szóval egyelőre csak valami programot szeretnék amit pc-n futtatok és oda beimportálva ezt az adatbázis próbálkozzak. Megoldható ez?
-

MPowerPH
félisten
Sziasztok! Ha minden igaz, akkor szeptembertol elkezdek egy mysql kepzest UK-ban. 10 eve mar tanitottak ra, akkor ez a resze annyira nem erdekelt, es sajnos csak 1 evig, nem fotantargy volt. Alapok megvannak, fel kell oket eleveniteni. Az angolul tanulas reszetol is felek a dolognak, szoval arra gondoltam, hogy elotte onszorgalombol kicsit kepeznem magam, es elindulnek a nullarol egy konyv segitsegevel. Tudtok nekem ajanlani olyan konyvet, amivel az alapjaitol elindulhatok? Van meg 3 honapom, es tengernyi szabadidom. Sokat talaltam neten, konyvesboltokban, de en nem tudom eldonteni, melyik lenne az idealis, ami mind elmeleti, mind gyakorlati sikon vegigvezet.
-

adika4444
addikt
válasz
 DNReNTi
#1919
üzenetére
DNReNTi
#1919
üzenetére
Köszi! Ezt összekötném PHP-vel... Ilyenkor van egyszerűbb megoldás annál, mint hogy distincttel kiválasztom a dátum szerint sorrendezve a topikokat, majd a forum_topics táblából lekérem a nevüket?
szerk: ez már nagyon PHP, de egy helyen legyen az egész kérdés... A Distinct alapból a mysqli_fetch_all tömbben egy elemben ,-vel elválasztva adja vissza az eredményeket, jelen esetben a topic id-ket, vagy külön tömbelemenként, amit egy for-ral bejárok és mindegyikhez lekérem a nevét? -
DNReNTi
őstag
válasz
 adika4444
#1918
üzenetére
adika4444
#1918
üzenetére
En ezt teljesen maskepp oldanam meg:
SELECT post_date
FROM forum_posts
WHERE topic = 1
ORDER BY id DESC
LIMIT 1;Feltetelezve hogy van
idmezod, ami auto increment-es.
Magyarul ez kivalaszt egy darab post_date mezo erteket a forum_posts tablabol ahol a topic mezo egy, id szerint csokkeno sorrendben (tehat a legfrissebbet).Kottaknal meg erdemes hasznalni a "Programkod" gombot.
-
adika4444
addikt
válasz
DNReNTi
#1917
üzenetére
Értem, köszi!
más:
Van egy táblám, a fórum hsz-jeivel, és van egy másik a témákkal.
Hogy tudok olyat hogy a témáknál az adott téma utolsó hozzászólás oszlopa mindig a
select max(pdate) from `forum_posts` where topic = 1;
parancs kimenete legyen?
Itt 1-es a topic id-je, de valahogy azt is kellene hogy a megfelelő témához nézze a legnagyobb dátumot... A dátumot integerben tárolom, unixos formátumban tehát az eltelt másodpercek 1970 óta...
Hallottam valamit arról hogy valami foreign key amivel ezt meg lehet oldani, de normális leírást nem találtam hogy miként tudnám megoldani...
Köszi előre is! -
DNReNTi
őstag
-
adika4444
addikt
válasz
adika4444
#1914
üzenetére
Na most működőnek látszik, már 1--2 órája küzdök vele, mire eljutottam hogy nem tudom megoldani, rá 20 percre kb jó lett. De az az as postAlias miért kell? Miért kell alias-t csinálni? Ahogy elnézem az az alias később nincs használatba. Ha kiveszem akkor valami targetes hibát dob, így arra rájöttem hogy kell a lefutáshoz, csak nem értem miért...
-
-
-
DNReNTi
őstag
-
adika4444
addikt
Sziasztok!
Miért nem megy az alábbi kód? Hogy kéne helyesen megoldani?
insert into `posts` (`localid`, `topic`, `post`) values ((select * from `posts` where topic = 1) + 1, "1", "a tartalom");
Tehát azt szeretném hogy insertnél egy parancs előállítsa beszúrás közben az 1-gyel nagyobb localid-t az adott topic-ra nézve. PHP-val csinálom a fórumot, de sztem az SQL parancs hibázik mert adminer-ben próbáltam és nem megy -

henny
csendes tag
Közben a jelenlegi tárhelyemmel felvettem a kapcsolatot és segítettek. Azt írták, h felülírta a helyessel és így most működik, megkérdeztem, h mi volt a gond és azt a választ kaptam, h "USE (felhasználó nevem)".
Gondolom az volt a gond, h kolibrip_db volt az adatbázis neve.. -
henny
csendes tag
Sziasztok!
Most költöztettem el a weboldalamat egy másik szolgáltatóhoz, a Domain nevemet is átköltöztettem, úgyh ugyanaz maradt, viszont az MySQL adatbázis importálásánál kaptam egy hibaüzenetet.
Az oldalam egy Wordpress-es oldal, amennyiben ez fontos info. Sajnos nem értek az egészből semmit, hogy mi lehet a gond. Vki aki ért hozzá, tudna nekem segíteni ?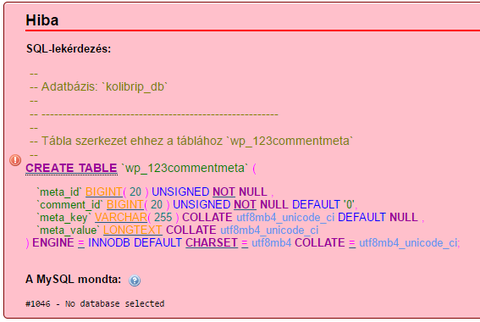



 ). Mindegy, megcsináltam, így marad.
). Mindegy, megcsináltam, így marad.







 Bár kinek mi a móricka szint az relatív
Bár kinek mi a móricka szint az relatív
 ), nem pedig pont hogy az igazamat bizonyítod, a szimpla select, index nem használós bizonyítással? Ettől még persze nincs baj a MySql-lel móricka projektekhez simán jó, és ingyenes, de komoly enterprise üzletmenetet biztos, hogy soha nem bíznék rá. Szerintem.
), nem pedig pont hogy az igazamat bizonyítod, a szimpla select, index nem használós bizonyítással? Ettől még persze nincs baj a MySql-lel móricka projektekhez simán jó, és ingyenes, de komoly enterprise üzletmenetet biztos, hogy soha nem bíznék rá. Szerintem.





















 A 2013-al tényleg műxik. Köszönöm a segítséget!
A 2013-al tényleg műxik. Köszönöm a segítséget! 




















Új hozzászólás Aktív témák

- GYÖNYÖRŰ iPhone 13 mini 128GB Green -1 ÉV GARANCIA - Kártyafüggetlen, MS3338
- Bomba ár! Lenovo 14W Gen2 - AMD 3015e I 4GB I 128SSD I 14" FHD I HDMI I Cam I W11 I Garancia!
- ÚJ HP ProBook 445 G11 - 14" WUXGA - Ryzen 5 7535U - 16GB - 256GB - MAGYAR - 2+ év garancia
- LG Gram 14 WUXGA IPS i7-1360P 5.0Ghz 12mag 32GB DDR5 1TB SSD Intel Iris XE 10óra Akku Win11 Garancia
- HIBÁTLAN iPhone 13 mini 256GB Pink -1 ÉV GARANCIA - Kártyafüggetlen, MS3441, 92% Akkumulátor
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: NetGo.hu Kft.
Város: Gödöllő