
- Milyen videókártyát?
- A Linux megnégyszerezte magát a Steamen — a Microsoft ismét ígérget
- Milyen monitort vegyek?
- Meglepően árazta az AMD a Ryzen AI Halo minigépet
- Milyen billentyűzetet vegyek?
- Új padokkal vezeti el a hőt az Arctic
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Projektor topic
- 5.1, 7.1 és gamer fejhallgatók
- Steam Deck
-
Fórumok
PROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Új hozzászólás Aktív témák
-
 Pöttön
őstag
Pöttön
őstag
-
 nevemfel
senior tag
nevemfel
senior tag
Sziasztok!
Egy videó tutorial alapján szeretnék meg mókolni egy privát wow szervert, hogy legyenek plusz portálok.
A tutorialban elakadtam, sajnos a videó gyenge minősége miatt nehezen vehetőek ki a mysql parancsok.
HeidiSQL nevű programban van egy lekérdezés (Query) ide kellene a következőt beírnom:
SELECT + FROM gameobject_template WHERE NAME LIKE '%portal to%'Erre a parancsra hiába nyomok f9-et (futtatást) csak 1064-es hibát dob ki.
Rá google-ztam elvileg a program számára nem érthető a parancs, tehát valami elírás lehet benne.Az eleje az select all, legalábbis ezt hallani a videóban, de a srác valami + jelhez hasonlót ír be.
A végén az idéző jelek a shift+1-es idéző jelek lehetnek, a százalék jel meg a shift+5-el beírható százalék jel?Bocs az analfabétáskodásomért, nem vagyok jártas a témában.
A segítséget előre is köszi!
Az eleje az select all, legalábbis ezt hallani a videóban, de a srác valami + jelhez hasonlót ír be.
SELECT *lesz az. -
 bhonti
aktív tag
bhonti
aktív tag
Sziasztok!
Egy videó tutorial alapján szeretnék meg mókolni egy privát wow szervert, hogy legyenek plusz portálok.
A tutorialban elakadtam, sajnos a videó gyenge minősége miatt nehezen vehetőek ki a mysql parancsok.
HeidiSQL nevű programban van egy lekérdezés (Query) ide kellene a következőt beírnom:
SELECT + FROM gameobject_template WHERE NAME LIKE '%portal to%'Erre a parancsra hiába nyomok f9-et (futtatást) csak 1064-es hibát dob ki.
Rá google-ztam elvileg a program számára nem érthető a parancs, tehát valami elírás lehet benne.Az eleje az select all, legalábbis ezt hallani a videóban, de a srác valami + jelhez hasonlót ír be.
A végén az idéző jelek a shift+1-es idéző jelek lehetnek, a százalék jel meg a shift+5-el beírható százalék jel?Bocs az analfabétáskodásomért, nem vagyok jártas a témában.
A segítséget előre is köszi!Mindenesetre a SELECT * FROM ... forma elég gyakori, "SELECT +"...-ról én legalábbis még nem hallottam.

-
Pöttön
őstag
Sziasztok!
Egy videó tutorial alapján szeretnék meg mókolni egy privát wow szervert, hogy legyenek plusz portálok.
A tutorialban elakadtam, sajnos a videó gyenge minősége miatt nehezen vehetőek ki a mysql parancsok.
HeidiSQL nevű programban van egy lekérdezés (Query) ide kellene a következőt beírnom:
SELECT + FROM gameobject_template WHERE NAME LIKE '%portal to%'Erre a parancsra hiába nyomok f9-et (futtatást) csak 1064-es hibát dob ki.
Rá google-ztam elvileg a program számára nem érthető a parancs, tehát valami elírás lehet benne.Az eleje az select all, legalábbis ezt hallani a videóban, de a srác valami + jelhez hasonlót ír be.
A végén az idéző jelek a shift+1-es idéző jelek lehetnek, a százalék jel meg a shift+5-el beírható százalék jel?Bocs az analfabétáskodásomért, nem vagyok jártas a témában.
A segítséget előre is köszi! -
 biker
nagyúr
biker
nagyúr
-
 baracsi
tag
baracsi
tag
Kedves ügyfélnél összehányta magát a xampp alatti mysql-ben egy tábla
sem a szerkezet, sem az adatok nem nyerhetők ki, lockolva van, és sérültnek jelzi, restart megvolt, kézzel minden mókolás, hogy legalább a mysql szerver elinduljon, és a myadminba beléphessek megvolt, de a repair tables és a repair table táblaneve sem segít, nem tudja javítani, szerinte hiányzik az index
ha nem találnak egy backupot a xampp/mysql/data/táblaneve fileokból, akkor így jártak? google összes helpje eddig nem segített.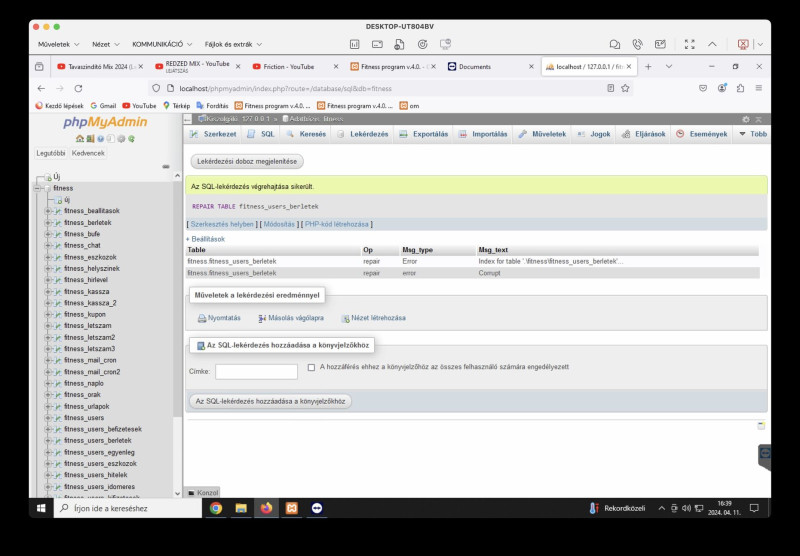
REPAIR TABLE [táblanév] USE_FRM; sem segít?
-
biker
nagyúr
Kedves ügyfélnél összehányta magát a xampp alatti mysql-ben egy tábla
sem a szerkezet, sem az adatok nem nyerhetők ki, lockolva van, és sérültnek jelzi, restart megvolt, kézzel minden mókolás, hogy legalább a mysql szerver elinduljon, és a myadminba beléphessek megvolt, de a repair tables és a repair table táblaneve sem segít, nem tudja javítani, szerinte hiányzik az index
ha nem találnak egy backupot a xampp/mysql/data/táblaneve fileokból, akkor így jártak? google összes helpje eddig nem segített. -
 szricsi_0917
tag
szricsi_0917
tag
Szia,
Megnézem majd és esetleg jelentkezek még, mert hátha másban is látható teljesítmény növekedés lesz, ha meglesz a probléma forrása, de egyelőre magát az importot sikerül megoldanom a workbench segítségével. Érdekes módon a majdnem 500.000 sor alig volt egy perc. -
nevemfel
senior tag
A fájl maga kb 40Mb.
Annyira nem vagyok profi a témában sajnos.
A phpmyadmin felülete a http miatt fut korlátba?
Az egész mögött amúgy egy ubuntu server van és azon egy aaPanel.
Próbáltam ezeket változtatni, de nem sok eredménye lett:
post_max_size
upload_max_filesize
max_execution_time
max_input_time
memory_limitMilyen beállításokat kéne még megváltoztatni?
A PHP error logot kellene megnézni.
-
szricsi_0917
tag
A fájl maga kb 40Mb.
Annyira nem vagyok profi a témában sajnos.
A phpmyadmin felülete a http miatt fut korlátba?
Az egész mögött amúgy egy ubuntu server van és azon egy aaPanel.
Próbáltam ezeket változtatni, de nem sok eredménye lett:
post_max_size
upload_max_filesize
max_execution_time
max_input_time
memory_limitMilyen beállításokat kéne még megváltoztatni?
-
 disy68
aktív tag
disy68
aktív tag
Sziasztok,
Egy kis segítséget szeretnék szeretnék kérni.
Mysql és phpmyadmin-t használok.
A phpmyadmin felületén szeretnék importálni egy táblát amiben 200.000 sor van.
1000-1500 sor után mindig megáll és a következő hibát dobja fel:
Merre induljak, hogy megtaláljam a probléma forrását?sokáig tart a művelet vagy túl nagy a fájl a szervernek
vagy kell több erőforrás alá vagy ne a phpmyadmin-on csináld, hanem parancssorból vagy pl. mysql workbench-ből (esetleg saját kód saját gépedről)
-
szricsi_0917
tag
Sziasztok,
Egy kis segítséget szeretnék szeretnék kérni.
Mysql és phpmyadmin-t használok.
A phpmyadmin felületén szeretnék importálni egy táblát amiben 200.000 sor van.
1000-1500 sor után mindig megáll és a következő hibát dobja fel:
Merre induljak, hogy megtaláljam a probléma forrását? -
biker
nagyúr
De, összevonhattam, simán megcsinálta. Csak ahogy írtam: minek?
SELECT COUNT(*) FROM `table1`UNIONSELECT COUNT(*) FROM `table1` WHERE MATCH( field1, field2, field3, field4 ) AGAINST( 'Lookforthis' IN BOOLEAN MODE);Eredmény:
count(*)
13500
238sZERK: KÖSZÖNÖM AZ ÖTLETEKET! (HÜJE cAPSlOCK)
de ez ettől még két lekérdezés, csak egybeágyaztad
-
 hellsing71
tag
hellsing71
tag
De, összevonhattam, simán megcsinálta. Csak ahogy írtam: minek?
SELECT COUNT(*) FROM `table1`UNIONSELECT COUNT(*) FROM `table1` WHERE MATCH( field1, field2, field3, field4 ) AGAINST( 'Lookforthis' IN BOOLEAN MODE);Eredmény:
count(*)
13500
238sZERK: KÖSZÖNÖM AZ ÖTLETEKET! (HÜJE cAPSlOCK)
-
nevemfel
senior tag
Valóban kihagyhatom, hogy össz hány rekord van a táblában, a lapozás anélkül is működik., csak furcsán jön ki, hogy szűrés nélkül a lapozó mellett az jelenik meg, hogy
Showing 1 to 20 of 1.212.509 entries (ennyi rekord van most a táblában)
... de szűréssel meg az, hogy
Showing 1 to 20 of 11.612 entries (filtered from 11.612 total entries) (ez a találatok teljes száma, és a második 11k helyén az 1.212.509-nek kéne megjelennie, mert így valótlan a filtered from utáni érték).
A tábla teljes hossza a "filtered from" helyes megjelenéséhez kell.
Valóban kihagyhatom, hogy össz hány rekord van a táblában, a lapozás anélkül is működik.
Nem hiszem, hogy a teljes táblára a COUNT queryt érdemes kihagyni, szerintem ez a leggyorsabb lekérdezés.
-
biker
nagyúr
Bocs, ez nekem nem jön át. Neked is 3 sql query-d van:
Összes rekord a táblában:
SELECT COUNT(*) AS allcount FROM fitness_naplo{$_SESSION['helyszin']}Szűrt rekordok teljes száma:
SELECT COUNT(*) AS allcount FROM fitness_naplo{$_SESSION['helyszin']} WHERE 1 ".$searchQuerySzűrt rekordokból a megjelenítendők tartalma:
SELECT * FROM fitness_naplo{$_SESSION['helyszin']} WHERE 1 ".$searchQuery." ORDER BY ".$columnName." ".$columnSortOrder." LIMIT :limit,:offsetÖsszevonhatnánk az első kettőt egy UNION-nal (mindig csak 2db szám az eredmény), de az 1db webszerver-db-webszerver kommunikáció elhagyásán gondolom csak századmásodperceket lehet nyerni, akkora terhelésem meg sohasem lesz, hogy ez bármit jelentsen.
nem vonhatod össze, mert más alapján számol. szerintem. de valóban, századokat jelent csak
-
hellsing71
tag
ennél egyszerűbb
Nálam több százezer soros táblák lapozóval
<script>
$(document).ready(function(){
$('#naploTabla').DataTable({
'processing': true,
'serverSide': true,
'serverMethod': 'post',
'ajax': {
'url':'ajax_naplo_file.php'
},
'columns': [
{ data: 'datum' },
{ data: 'esemeny' },
{ data: 'ertek' },
]
});
});
</script>a feldolgozó pedig
<?php
include("master.php");
// Create connection
try{
$conn = new PDO("mysql:host=$host;dbname=$adatbazis","$sql_felhasznalo","$sql_jelszo",
array(
PDO::MYSQL_ATTR_INIT_COMMAND => 'SET NAMES UTF8;',
PDO::ATTR_ERRMODE => PDO::ERRMODE_WARNING,
));
$conn->setAttribute(PDO::ATTR_ERRMODE,PDO::ERRMODE_EXCEPTION);
}catch(PDOException $e){
die('Unable to connect with the database');
}
## Read value
$draw = $_POST['draw'];
$row = $_POST['start'];
$rowperpage = $_POST['length']; // Rows display per page
$columnIndex = $_POST['order'][0]['column']; // Column index
$columnName = $_POST['columns'][$columnIndex]['data']; // Column name
$columnSortOrder = $_POST['order'][0]['dir']; // asc or desc
$searchValue = $_POST['search']['value']; // Search value
$searchArray = array();
## Search
$searchQuery = " ";
if($searchValue != ''){
if (substr_count($searchValue, " ")==0)
{
$searchQuery = " AND (datum LIKE :datum or
esemeny LIKE :esemeny ) ";
$searchArray = array(
'datum'=>"%$searchValue%",
'esemeny'=>"%$searchValue%"
);
}
else
{
$searchValue_arr=explode(" ", $searchValue);
$i=1;
foreach($searchValue_arr AS $expl_value) {
$searchQuery.= " AND (datum LIKE :datum$i or
esemeny LIKE :esemeny$i ) ";
$searchArray = array(
"datum$i"=>"%$expl_value%",
"esemeny$i"=>"%$expl_value%"
);
}
}
}
## Total number of records without filtering
$stmt = $conn->prepare("SELECT COUNT(*) AS allcount FROM fitness_naplo{$_SESSION['helyszin']} ");
$stmt->execute();
$records = $stmt->fetch();
$totalRecords = $records['allcount'];
## Total number of records with filtering
$stmt = $conn->prepare("SELECT COUNT(*) AS allcount FROM fitness_naplo{$_SESSION['helyszin']} WHERE 1 ".$searchQuery);
$stmt->execute($searchArray);
$records = $stmt->fetch();
$totalRecordwithFilter = $records['allcount'];
## Fetch records
$stmt = $conn->prepare("SELECT * FROM fitness_naplo{$_SESSION['helyszin']} WHERE 1 ".$searchQuery." ORDER BY ".$columnName." ".$columnSortOrder." LIMIT :limit,:offset");
// Bind values
foreach($searchArray as $key=>$search){
$stmt->bindValue(':'.$key, $search,PDO::PARAM_STR);
}
$stmt->bindValue(':limit', (int)$row, PDO::PARAM_INT);
$stmt->bindValue(':offset', (int)$rowperpage, PDO::PARAM_INT);
$stmt->execute();
$empRecords = $stmt->fetchAll();
//echo "ok";
$data = array();
foreach($empRecords as $row){
// echo "ok";
$data[] = array(
"datum"=>$row['datum'],
"esemeny"=>translated($row['esemeny'], $_GET['sel_lang']),
"ertek"=>$row['ertek']
);
}
## Response
$response = array(
"draw" => intval($draw),
"iTotalRecords" => $totalRecords,
"iTotalDisplayRecords" => $totalRecordwithFilter,
"aaData" => $data
);
echo json_encode($response);
?>nyilván testre kell szabnod, de az elv ennyi, ajaxxal hívogatja, és küldi melyik 10 vagy 25 vagy 100 sort kérje le
Bocs, ez nekem nem jön át. Neked is 3 sql query-d van:
Összes rekord a táblában:
SELECT COUNT(*) AS allcount FROM fitness_naplo{$_SESSION['helyszin']}Szűrt rekordok teljes száma:
SELECT COUNT(*) AS allcount FROM fitness_naplo{$_SESSION['helyszin']} WHERE 1 ".$searchQuerySzűrt rekordokból a megjelenítendők tartalma:
SELECT * FROM fitness_naplo{$_SESSION['helyszin']} WHERE 1 ".$searchQuery." ORDER BY ".$columnName." ".$columnSortOrder." LIMIT :limit,:offsetÖsszevonhatnánk az első kettőt egy UNION-nal (mindig csak 2db szám az eredmény), de az 1db webszerver-db-webszerver kommunikáció elhagyásán gondolom csak századmásodperceket lehet nyerni, akkora terhelésem meg sohasem lesz, hogy ez bármit jelentsen.
-
hellsing71
tag
Rosszul állsz hozzá. Mivel lapozást használsz, soha nem kell a teljes táblát listáznod. És biztosra veszem, hogy kettő lekérdezés elég.
Select akármi from tábla
Where feltételek (nyilván az alap eset, amikor még where sincs) queryEz az alap lekérdezésed, ami csak egy alap, de ilyen formában sose kell lefuttatnod.
1. lekérdezés: alap query count-ja, azaz maxmimum hány sornyi adatod van (ez is erőforrásigényes tud lenni, de amit mondtál 250k adatsor nudli, majd 6 milliárd sornál ráérhetsz ezen aggodni)
2. lekérdezés: alap lekérdezés az aktuális page-nek megfelelően (pl. 20-dik pagenek megfelelő 10 sor)azaz sose fogsz a megjelenített sorok számánál (pl. 10/20/50/100) többet elkérni a db-től. Hiszen pont erre való a pagelés.
Valóban kihagyhatom, hogy össz hány rekord van a táblában, a lapozás anélkül is működik., csak furcsán jön ki, hogy szűrés nélkül a lapozó mellett az jelenik meg, hogy
Showing 1 to 20 of 1.212.509 entries (ennyi rekord van most a táblában)
... de szűréssel meg az, hogy
Showing 1 to 20 of 11.612 entries (filtered from 11.612 total entries) (ez a találatok teljes száma, és a második 11k helyén az 1.212.509-nek kéne megjelennie, mert így valótlan a filtered from utáni érték).
A tábla teljes hossza a "filtered from" helyes megjelenéséhez kell.
-
biker
nagyúr
'reggelt! Optimalizációs kérdésem lenne.
A DataTables-t (DT) szerveroldali feldolgozással használva, a lapozás normális működéséhez 3 adat kell:
- az össz. rekordszám,
- a kereséssel elérhető rekordszám (akár 35-250k találat, amíg nem szűkítik),
- és a full-text keresés egy oldalon megjelenítendő találatai (pl. limit 100, 25).Mi a legjobb, ha 3 SQL-t futtatok:
- 1× COUNT, de MATCH és LIMIT nélkül (= összes rekordszám),
- 1× COUNT + MATCH, de LIMIT nélkül (= a találatok lehetséges max. száma),
- 1× nincs COUNT, de van MATCH + LIMIT (= az egy oldalon megjelenítendő adatok),...vagy van a 3 adat egylépéses kinyerésére jobb módszer? Le tudnám kezelni php-ből, de azzal is csak a 3. lépést úszom meg, és akár 250k találata is lehet egy keresésnek, ezért ez nem tűnik jó ötletnek. Az meg nem elegáns, ha kiírom, hogy "Túl sok találat, szűkítsen".
A környezet: procedurális php 8.2, mysqli, MariaDB 10.4.
ennél egyszerűbb
Nálam több százezer soros táblák lapozóval
<script>
$(document).ready(function(){
$('#naploTabla').DataTable({
'processing': true,
'serverSide': true,
'serverMethod': 'post',
'ajax': {
'url':'ajax_naplo_file.php'
},
'columns': [
{ data: 'datum' },
{ data: 'esemeny' },
{ data: 'ertek' },
]
});
});
</script>a feldolgozó pedig
<?php
include("master.php");
// Create connection
try{
$conn = new PDO("mysql:host=$host;dbname=$adatbazis","$sql_felhasznalo","$sql_jelszo",
array(
PDO::MYSQL_ATTR_INIT_COMMAND => 'SET NAMES UTF8;',
PDO::ATTR_ERRMODE => PDO::ERRMODE_WARNING,
));
$conn->setAttribute(PDO::ATTR_ERRMODE,PDO::ERRMODE_EXCEPTION);
}catch(PDOException $e){
die('Unable to connect with the database');
}
## Read value
$draw = $_POST['draw'];
$row = $_POST['start'];
$rowperpage = $_POST['length']; // Rows display per page
$columnIndex = $_POST['order'][0]['column']; // Column index
$columnName = $_POST['columns'][$columnIndex]['data']; // Column name
$columnSortOrder = $_POST['order'][0]['dir']; // asc or desc
$searchValue = $_POST['search']['value']; // Search value
$searchArray = array();
## Search
$searchQuery = " ";
if($searchValue != ''){
if (substr_count($searchValue, " ")==0)
{
$searchQuery = " AND (datum LIKE :datum or
esemeny LIKE :esemeny ) ";
$searchArray = array(
'datum'=>"%$searchValue%",
'esemeny'=>"%$searchValue%"
);
}
else
{
$searchValue_arr=explode(" ", $searchValue);
$i=1;
foreach($searchValue_arr AS $expl_value) {
$searchQuery.= " AND (datum LIKE :datum$i or
esemeny LIKE :esemeny$i ) ";
$searchArray = array(
"datum$i"=>"%$expl_value%",
"esemeny$i"=>"%$expl_value%"
);
}
}
}
## Total number of records without filtering
$stmt = $conn->prepare("SELECT COUNT(*) AS allcount FROM fitness_naplo{$_SESSION['helyszin']} ");
$stmt->execute();
$records = $stmt->fetch();
$totalRecords = $records['allcount'];
## Total number of records with filtering
$stmt = $conn->prepare("SELECT COUNT(*) AS allcount FROM fitness_naplo{$_SESSION['helyszin']} WHERE 1 ".$searchQuery);
$stmt->execute($searchArray);
$records = $stmt->fetch();
$totalRecordwithFilter = $records['allcount'];
## Fetch records
$stmt = $conn->prepare("SELECT * FROM fitness_naplo{$_SESSION['helyszin']} WHERE 1 ".$searchQuery." ORDER BY ".$columnName." ".$columnSortOrder." LIMIT :limit,:offset");
// Bind values
foreach($searchArray as $key=>$search){
$stmt->bindValue(':'.$key, $search,PDO::PARAM_STR);
}
$stmt->bindValue(':limit', (int)$row, PDO::PARAM_INT);
$stmt->bindValue(':offset', (int)$rowperpage, PDO::PARAM_INT);
$stmt->execute();
$empRecords = $stmt->fetchAll();
//echo "ok";
$data = array();
foreach($empRecords as $row){
// echo "ok";
$data[] = array(
"datum"=>$row['datum'],
"esemeny"=>translated($row['esemeny'], $_GET['sel_lang']),
"ertek"=>$row['ertek']
);
}
## Response
$response = array(
"draw" => intval($draw),
"iTotalRecords" => $totalRecords,
"iTotalDisplayRecords" => $totalRecordwithFilter,
"aaData" => $data
);
echo json_encode($response);
?>nyilván testre kell szabnod, de az elv ennyi, ajaxxal hívogatja, és küldi melyik 10 vagy 25 vagy 100 sort kérje le
-
 martonx
veterán
martonx
veterán
'reggelt! Optimalizációs kérdésem lenne.
A DataTables-t (DT) szerveroldali feldolgozással használva, a lapozás normális működéséhez 3 adat kell:
- az össz. rekordszám,
- a kereséssel elérhető rekordszám (akár 35-250k találat, amíg nem szűkítik),
- és a full-text keresés egy oldalon megjelenítendő találatai (pl. limit 100, 25).Mi a legjobb, ha 3 SQL-t futtatok:
- 1× COUNT, de MATCH és LIMIT nélkül (= összes rekordszám),
- 1× COUNT + MATCH, de LIMIT nélkül (= a találatok lehetséges max. száma),
- 1× nincs COUNT, de van MATCH + LIMIT (= az egy oldalon megjelenítendő adatok),...vagy van a 3 adat egylépéses kinyerésére jobb módszer? Le tudnám kezelni php-ből, de azzal is csak a 3. lépést úszom meg, és akár 250k találata is lehet egy keresésnek, ezért ez nem tűnik jó ötletnek. Az meg nem elegáns, ha kiírom, hogy "Túl sok találat, szűkítsen".
A környezet: procedurális php 8.2, mysqli, MariaDB 10.4.
Rosszul állsz hozzá. Mivel lapozást használsz, soha nem kell a teljes táblát listáznod. És biztosra veszem, hogy kettő lekérdezés elég.
Select akármi from tábla
Where feltételek (nyilván az alap eset, amikor még where sincs) queryEz az alap lekérdezésed, ami csak egy alap, de ilyen formában sose kell lefuttatnod.
1. lekérdezés: alap query count-ja, azaz maxmimum hány sornyi adatod van (ez is erőforrásigényes tud lenni, de amit mondtál 250k adatsor nudli, majd 6 milliárd sornál ráérhetsz ezen aggodni)
2. lekérdezés: alap lekérdezés az aktuális page-nek megfelelően (pl. 20-dik pagenek megfelelő 10 sor)azaz sose fogsz a megjelenített sorok számánál (pl. 10/20/50/100) többet elkérni a db-től. Hiszen pont erre való a pagelés.
-
nevemfel
senior tag
'reggelt! Optimalizációs kérdésem lenne.
A DataTables-t (DT) szerveroldali feldolgozással használva, a lapozás normális működéséhez 3 adat kell:
- az össz. rekordszám,
- a kereséssel elérhető rekordszám (akár 35-250k találat, amíg nem szűkítik),
- és a full-text keresés egy oldalon megjelenítendő találatai (pl. limit 100, 25).Mi a legjobb, ha 3 SQL-t futtatok:
- 1× COUNT, de MATCH és LIMIT nélkül (= összes rekordszám),
- 1× COUNT + MATCH, de LIMIT nélkül (= a találatok lehetséges max. száma),
- 1× nincs COUNT, de van MATCH + LIMIT (= az egy oldalon megjelenítendő adatok),...vagy van a 3 adat egylépéses kinyerésére jobb módszer? Le tudnám kezelni php-ből, de azzal is csak a 3. lépést úszom meg, és akár 250k találata is lehet egy keresésnek, ezért ez nem tűnik jó ötletnek. Az meg nem elegáns, ha kiírom, hogy "Túl sok találat, szűkítsen".
A környezet: procedurális php 8.2, mysqli, MariaDB 10.4.
Emlékszem, hogy régebben használtam mysql alatt a SQL_CALC_FOUND_ROWS + FOUND_ROWS párost. Ezzel a módszerrel egy lekérdezést meg tudsz takarítani a három közül, de mindenképp érdemes lemérni, melyik módszer mennyi idő-, esetleg egyéb erőforrás nyereséget hoz, mert el tudom képzelni, hogy manapság a mindenféle gyorsítótárazás korában gyakorlatilag semennyi különbség nem lesz.
-
hellsing71
tag
'reggelt! Optimalizációs kérdésem lenne.
A DataTables-t (DT) szerveroldali feldolgozással használva, a lapozás normális működéséhez 3 adat kell:
- az össz. rekordszám,
- a kereséssel elérhető rekordszám (akár 35-250k találat, amíg nem szűkítik),
- és a full-text keresés egy oldalon megjelenítendő találatai (pl. limit 100, 25).Mi a legjobb, ha 3 SQL-t futtatok:
- 1× COUNT, de MATCH és LIMIT nélkül (= összes rekordszám),
- 1× COUNT + MATCH, de LIMIT nélkül (= a találatok lehetséges max. száma),
- 1× nincs COUNT, de van MATCH + LIMIT (= az egy oldalon megjelenítendő adatok),...vagy van a 3 adat egylépéses kinyerésére jobb módszer? Le tudnám kezelni php-ből, de azzal is csak a 3. lépést úszom meg, és akár 250k találata is lehet egy keresésnek, ezért ez nem tűnik jó ötletnek. Az meg nem elegáns, ha kiírom, hogy "Túl sok találat, szűkítsen".
A környezet: procedurális php 8.2, mysqli, MariaDB 10.4.
-
martonx
veterán
Sziasztok!
Hogy lehet elérni mysql-ben, hogy ha az eeredmény egy sort se érint, akkor ne NULL legyen hanem 0 vagy 1?
Coalesc nem oldja meg, az csak azt oldja meg, hogy ha van benne null sor az átlagban, akkor beleszámolja az elemekbe vagy semMaga a lekérdezés naplóból a belépés-kilépés közti idők átlaga
$atl_bent=$db->query("SELECT AVG(SUBSTRING_INDEX(SUBSTRING_INDEX(esemeny,' ',-2),' ',1)) FROM fitness_naplo{$_SESSION['helyszin']} WHERE esemeny LIKE '%[ {$query_tomb['id']} ]%' AND esemeny LIKE '%bent töltött idő:%'")->fetchAll();A helyzet az, hogy kb 80-100 tárhelyen fut hibátlanul a kód, de egy új tárhelyen valami rejtélyes okból fatal errorral elszáll ha ez a sor benne van, mert a fetchall nem futtatható boolean elemen, azért boolean mert null az eredmény.
ha van idő, akkor hibátlan.Az egy dolog, hogy senki nem tudja, melyik php vagy mysql beállítás okozza a fatal errort, ha máshol nem okoz hobát, de valahogy át lehet-e írni hogy a NULL helyett 0 legyen ha nincs egy elem sem?
Gyanítom MySql-ben is létezik isnull, vagy ifnull, vagy coalesce vagy valami ilyesmi ami pont erre való, hogy null esetben valami értelmes értéket kapj vissza.
-
biker
nagyúr
Sziasztok!
Hogy lehet elérni mysql-ben, hogy ha az eeredmény egy sort se érint, akkor ne NULL legyen hanem 0 vagy 1?
Coalesc nem oldja meg, az csak azt oldja meg, hogy ha van benne null sor az átlagban, akkor beleszámolja az elemekbe vagy semMaga a lekérdezés naplóból a belépés-kilépés közti idők átlaga
$atl_bent=$db->query("SELECT AVG(SUBSTRING_INDEX(SUBSTRING_INDEX(esemeny,' ',-2),' ',1)) FROM fitness_naplo{$_SESSION['helyszin']} WHERE esemeny LIKE '%[ {$query_tomb['id']} ]%' AND esemeny LIKE '%bent töltött idő:%'")->fetchAll();A helyzet az, hogy kb 80-100 tárhelyen fut hibátlanul a kód, de egy új tárhelyen valami rejtélyes okból fatal errorral elszáll ha ez a sor benne van, mert a fetchall nem futtatható boolean elemen, azért boolean mert null az eredmény.
ha van idő, akkor hibátlan.Az egy dolog, hogy senki nem tudja, melyik php vagy mysql beállítás okozza a fatal errort, ha máshol nem okoz hobát, de valahogy át lehet-e írni hogy a NULL helyett 0 legyen ha nincs egy elem sem?
-
F1DO
senior tag
1. DECLARE sql_C VARCHAR(MAX); egyrészt hibás, másrészt nem kell
2. SET sql_C = helyett SET @sql_C =
3. SET sql_C = CONCAT('CREATE TABLE ', tabla, ' AS SELECT * FROM ', allomany); itt nincs az allomany változó deklaralva
4. PREPARE stmt FROM sql_C; helyett PREPARE stmt FROM @sql_C;BEGIN
DECLARE tabla VARCHAR(255);
-- DECLARE sql_C VARCHAR(MAX);
SET tabla = CONCAT('allomany_mentes_', DATE_FORMAT(NOW(), '%Y%m%d'));
SET @sql_C = CONCAT('CREATE TABLE ', tabla, ' AS SELECT * FROM allomany');
PREPARE stmt FROM @sql_C;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
ENDKöszönöm az útbaigazítást,
 ez alapján is:
ez alapján is:Közkinccsé:
tárolt eljárás, ami meghíváskor a paraméterben átadott névre (név_mentes_évhónap) illetve ugyanazon nevű forrástábla alapján úgy hozza létre az új táblát, hogy ellenőrzi az adandó táblanévvel létezik-e már tábla és ha nem, létrehozáskor megőrzi a forrás tábla beállításait (kulcs oszlop, stb):
DELIMITER //
CREATE PROCEDURE tabla_masolas(IN tablanev VARCHAR(255))
BEGIN
DECLARE uj_tabla VARCHAR(255);
SET uj_tabla = CONCAT(tablanev,'_mentes_', DATE_FORMAT(NOW(), '%Y%m%d'));IF NOT EXISTS (SELECT 1 FROM information_schema.tables WHERE table_schema = DATABASE() AND table_name = uj_tabla) THEN
-- Létrehozzuk az új táblát az eredeti tábla szerkezetével
SET @sql_code = CONCAT('CREATE TABLE ', uj_tabla, ' LIKE ', tablanev);PREPARE stmt FROM @sql_code;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
-- Másoljuk át az adatokat az eredeti táblából az új táblába
SET @sql_code = CONCAT('INSERT INTO ', uj_tabla, ' SELECT * FROM ', tablanev);PREPARE stmt FROM @sql_code;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
ELSE
SELECT 'A képzendő táblanév már létezik.';
END IF;
END //
DELIMITER ; -
baracsi
tag
Kicsit átírtam de nem lett jobb. Fontos infó lehet hogy 5.7-es a Mysql verzió
DELIMITER //
CREATE PROCEDURE allomany_masolas(allomany VARCHAR(MAX))
BEGIN
DECLARE tabla VARCHAR(255);
DECLARE sql_C VARCHAR(MAX);
SET tabla = CONCAT('allomany_mentes_', DATE_FORMAT(NOW(), '%Y%m%d'));
SET sql_C = CONCAT('CREATE TABLE ', tabla, ' AS SELECT * FROM ', allomany);
PREPARE stmt FROM sql_C;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END ;
//
DELIMITER ;#1064 - A Szintaktikai hiba a 'MAX))
BEGIN
DECLARE tabla VARCHAR(MAX);
DECLARE sql_C VARCHAR(MAX);
SET ta'-hez kozeli a 1 sorban

1. DECLARE sql_C VARCHAR(MAX); egyrészt hibás, másrészt nem kell
2. SET sql_C = helyett SET @sql_C =
3. SET sql_C = CONCAT('CREATE TABLE ', tabla, ' AS SELECT * FROM ', allomany); itt nincs az allomany változó deklaralva
4. PREPARE stmt FROM sql_C; helyett PREPARE stmt FROM @sql_C;BEGIN
DECLARE tabla VARCHAR(255);
-- DECLARE sql_C VARCHAR(MAX);
SET tabla = CONCAT('allomany_mentes_', DATE_FORMAT(NOW(), '%Y%m%d'));
SET @sql_C = CONCAT('CREATE TABLE ', tabla, ' AS SELECT * FROM allomany');
PREPARE stmt FROM @sql_C;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END -
nevemfel
senior tag
Kicsit átírtam de nem lett jobb. Fontos infó lehet hogy 5.7-es a Mysql verzió
DELIMITER //
CREATE PROCEDURE allomany_masolas(allomany VARCHAR(MAX))
BEGIN
DECLARE tabla VARCHAR(255);
DECLARE sql_C VARCHAR(MAX);
SET tabla = CONCAT('allomany_mentes_', DATE_FORMAT(NOW(), '%Y%m%d'));
SET sql_C = CONCAT('CREATE TABLE ', tabla, ' AS SELECT * FROM ', allomany);
PREPARE stmt FROM sql_C;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END ;
//
DELIMITER ;#1064 - A Szintaktikai hiba a 'MAX))
BEGIN
DECLARE tabla VARCHAR(MAX);
DECLARE sql_C VARCHAR(MAX);
SET ta'-hez kozeli a 1 sorban
VARCHAR(MAX) - a MAX egy mysql függvény, de ha más lenne a neve, akkor sincs definiálva, hogy mi az.
-
F1DO
senior tag
Kicsit átírtam de nem lett jobb. Fontos infó lehet hogy 5.7-es a Mysql verzió
DELIMITER //
CREATE PROCEDURE allomany_masolas(allomany VARCHAR(MAX))
BEGIN
DECLARE tabla VARCHAR(255);
DECLARE sql_C VARCHAR(MAX);
SET tabla = CONCAT('allomany_mentes_', DATE_FORMAT(NOW(), '%Y%m%d'));
SET sql_C = CONCAT('CREATE TABLE ', tabla, ' AS SELECT * FROM ', allomany);
PREPARE stmt FROM sql_C;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END ;
//
DELIMITER ;#1064 - A Szintaktikai hiba a 'MAX))
BEGIN
DECLARE tabla VARCHAR(MAX);
DECLARE sql_C VARCHAR(MAX);
SET ta'-hez kozeli a 1 sorban
-
biker
nagyúr
Sziasztok!
PhPMyAdmin-ban mysql tárolt eljárást szeretnék létrehozni, szintaktikai hibát jelez, nem jövök rá hol lehet a gond - tudnátok segíteni?
Egy szimpla táblamásolás - mentési célból feladat megoldása lenne, annyi hogy a táblanévben legyen benne az aktuális év hó nap
DELIMITER //
CREATE PROCEDURE allomany_masolas(allomany VARCHAR(255))
BEGIN
DECLARE allomany_mentes_ VARCHAR(255);
DECLARE sql_C TEXT;
-- Az új táblanév létrehozása az aktuális dátum alapján
SET allomany_mentes_ = CONCAT(allomany, '_', DATE_FORMAT(NOW(), '%Y_%m_%d'));
-- SQL parancs összeállítása
SET sql_C = CONCAT('CREATE TABLE ', allomany_mentes_, ' AS SELECT * FROM ', allomany);
-- SQL parancs végrehajtása
PREPARE stmt FROM sql_C;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END //
DELIMITER ;Az END után nincs pontosvessző, szerintem, utána // és DELIMITER ;
DELIMITER //
CREATE PROCEDURE allomany_masolas(allomany VARCHAR(255))
BEGIN
DECLARE allomany_mentes_ VARCHAR(255);
DECLARE sql_C TEXT;
-- Az új táblanév létrehozása az aktuális dátum alapján
SET allomany_mentes_ = CONCAT(allomany, '_', DATE_FORMAT(NOW(), '%Y_%m_%d'));
-- SQL parancs összeállítása
SET sql_C = CONCAT('CREATE TABLE ', allomany_mentes_, ' AS SELECT * FROM ', allomany);
-- SQL parancs végrehajtása
PREPARE stmt FROM sql_C;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END ;
//
DELIMITER ; -
martonx
veterán
És mi a hibaüzenet?
-
F1DO
senior tag
Sziasztok!
PhPMyAdmin-ban mysql tárolt eljárást szeretnék létrehozni, szintaktikai hibát jelez, nem jövök rá hol lehet a gond - tudnátok segíteni?
Egy szimpla táblamásolás - mentési célból feladat megoldása lenne, annyi hogy a táblanévben legyen benne az aktuális év hó nap
DELIMITER //
CREATE PROCEDURE allomany_masolas(allomany VARCHAR(255))
BEGIN
DECLARE allomany_mentes_ VARCHAR(255);
DECLARE sql_C TEXT;
-- Az új táblanév létrehozása az aktuális dátum alapján
SET allomany_mentes_ = CONCAT(allomany, '_', DATE_FORMAT(NOW(), '%Y_%m_%d'));
-- SQL parancs összeállítása
SET sql_C = CONCAT('CREATE TABLE ', allomany_mentes_, ' AS SELECT * FROM ', allomany);
-- SQL parancs végrehajtása
PREPARE stmt FROM sql_C;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END //
DELIMITER ; -
 Fire/SOUL/CD
félisten
Fire/SOUL/CD
félisten
Utolsó sor biztos ERROR...
![;]](//cdn.rios.hu/dl/s/v1.gif)
UI: akko' 2.-5.-ig kell csak és a
select *helyettselect line, account
UUI: Nem igazán értem, hogy az általad linkelt "tábla" (ami mezei Excel, Google, LO stb stb) mire volt jó... Kurvára nem az eredeti DB records... -
 laracroft
senior tag
laracroft
senior tag
Rég nem mysql-eztem, de talán így (ha a create/drop view-hoz van engedélyed)
create or replace view myview as
select *
from t1
group by line, account
having count(email)=0;
select t1.*
from t1, myview
where t1.line = myview.line and t1.account = myview.account
order by line, account;
drop view myview;Köszi a választ és hogy foglalkoztál vele, végül ez lett a megoldás:
SELECT DISTINCT CONCAT(line, '-', account)FROM customerWHERE CONAT(line, '-', account) NOT IN(SELECT CONCAT(line, '-', account)FROM customer WHERE email LIKE '%@%'); -
Fire/SOUL/CD
félisten
Sziasztok
egy kis segítséget szeretnék kérni.
Itt EZ a tábla (datas).
A line és az account mező határoz meg egyértelműen egy ügyfelet.
A name mező az ügyfél értesítendője.
Keresem azokat az ügyfeleket (line+account), akiknek egyik name mezőjéhez sem tartozik email cím.
Jelen esetben nálam ezek a 4-1000 és 7-1000.
előre is kösziRég nem mysql-eztem, de talán így (ha a create/drop view-hoz van engedélyed)
create or replace view myview as
select *
from t1
group by line, account
having count(email)=0;
select t1.*
from t1, myview
where t1.line = myview.line and t1.account = myview.account
order by line, account;
drop view myview; -
laracroft
senior tag
Sziasztok
egy kis segítséget szeretnék kérni.
Itt EZ a tábla (datas).
A line és az account mező határoz meg egyértelműen egy ügyfelet.
A name mező az ügyfél értesítendője.
Keresem azokat az ügyfeleket (line+account), akiknek egyik name mezőjéhez sem tartozik email cím.
Jelen esetben nálam ezek a 4-1000 és 7-1000.
előre is köszi -
biker
nagyúr
Mit szólnátok, ha olyan programkód kerülne elétek, amihez így néz ki az adatbázis?

CREATE TABLE `Kategóriák` (
`id` int(10) UNSIGNED NOT NULL,
`azonosító` tinytext CHARACTER SET ascii NOT NULL,
`szülö` int(10) UNSIGNED NOT NULL,
`kép` varchar(100) COLLATE utf8_hungarian_ci NOT NULL,
`háttérkép` int(11) NOT NULL,
`galéria` int(11) NOT NULL,
`sorrend` int(10) UNSIGNED NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_hungarian_ci;
CREATE TABLE `KategóriákNyelv` (
`id` int(10) UNSIGNED NOT NULL,
`nyelv` int(10) UNSIGNED NOT NULL,
`név` tinytext COLLATE utf8_hungarian_ci NOT NULL,
`leírás` text COLLATE utf8_hungarian_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_hungarian_ci;de a legjobb ahol keveri az ékezetes és ekezettelenul írt mezőket, és egy kis angolt is beletesz. nem, nem a file marad file, az fájl lett

CREATE TABLE `Termékek` (
`id` int(10) UNSIGNED NOT NULL,
`kód` varchar(30) COLLATE utf8_hungarian_ci NOT NULL,
`ár` int(10) UNSIGNED NOT NULL,
`beszerzesiar` int(11) NOT NULL,
`nyereseg` int(11) NOT NULL,
`marka` int(11) NOT NULL,
`markalink` varchar(300) COLLATE utf8_hungarian_ci NOT NULL,
`kiszereles` varchar(200) COLLATE utf8_hungarian_ci NOT NULL,
`akciósár` int(10) UNSIGNED DEFAULT NULL,
`nettoar` int(11) NOT NULL,
`beszerzesiar_huf` varchar(300) COLLATE utf8_hungarian_ci NOT NULL,
`beszerzesiar_eur` varchar(300) COLLATE utf8_hungarian_ci NOT NULL,
`cimkek` varchar(1000) COLLATE utf8_hungarian_ci NOT NULL,
`akciókód` varchar(200) COLLATE utf8_hungarian_ci NOT NULL,
`cikkszám` varchar(100) COLLATE utf8_hungarian_ci NOT NULL,
`áfa` int(10) UNSIGNED NOT NULL,
`darab` int(10) NOT NULL,
`készletinfó` varchar(300) COLLATE utf8_hungarian_ci NOT NULL,
`súly` int(11) NOT NULL,
`elektronikus` enum('NEM','IGEN') COLLATE utf8_hungarian_ci NOT NULL,
`fájl` varchar(300) COLLATE utf8_hungarian_ci NOT NULL,
`állapot` enum('AKTÍV','TÖRÖLVE','ELÖKÉSZÜLETBEN') COLLATE utf8_hungarian_ci NOT NULL,
`azonosító` tinytext CHARACTER SET ascii NOT NULL,
`idöpont` datetime NOT NULL,
`kiemelt` tinyint(4) NOT NULL,
`argep` tinyint(1) NOT NULL,
`arukereso` tinyint(1) NOT NULL,
`olcsobbat` tinyint(4) NOT NULL,
`hasznalati` varchar(300) COLLATE utf8_hungarian_ci NOT NULL,
`adatlap` varchar(300) COLLATE utf8_hungarian_ci NOT NULL,
`video` varchar(300) COLLATE utf8_hungarian_ci NOT NULL,
`videohasznalati` varchar(300) COLLATE utf8_hungarian_ci NOT NULL,
`kiemeltsorrend` int(11) NOT NULL,
`sorrendegy` int(11) NOT NULL,
`sorrendketto` int(11) NOT NULL,
`sorrendharom` int(11) NOT NULL,
`sorrendnegy` int(11) NOT NULL,
`title` varchar(300) COLLATE utf8_hungarian_ci NOT NULL,
`seogeneral` tinyint(4) NOT NULL DEFAULT '1',
`description` varchar(300) COLLATE utf8_hungarian_ci NOT NULL,
`sharetitle` varchar(100) COLLATE utf8_hungarian_ci NOT NULL,
`sharedescription` varchar(200) COLLATE utf8_hungarian_ci NOT NULL,
`shareimage` int(11) NOT NULL,
`osszehasonlito` tinyint(4) NOT NULL,
`osszehasonlitokategoria` int(11) NOT NULL,
`variacio` tinyint(4) NOT NULL,
`szulo` int(11) NOT NULL,
`variaciosorrend` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_hungarian_ci; -
nevemfel
senior tag
Persze a te eseteben a tábla neve nem `teszt`, hanem `kocsi`, illetve a `gpsdatetime` mező neve nem tudom, mi. Csak nem `datetime`?
-
nevemfel
senior tag
Ha 5.7 vagy frissebb verziójú a mysql, próbáld ki generált mezővel, és arra rakott indexszel:
ALTER TABLE `teszt` ADD (
`gpsdate` DATE GENERATED ALWAYS AS (CAST(`gpsdatetime` as DATE)) STORED,
KEY `gpsdateindex` (`gpsdate`)
) -
 Panhard
tag
Panhard
tag
gyanítom a cast-olás lassít még rajta, bár nem hiszem, hogy ezen drasztikusan tudnál még gyorsítani. Ha ennyire kritikus a sebesség, akkor érdemes lenne eleve úgy tárolnod az adatokat, hogy ne kelljen castolni.
Vagy ha kell datetime-ként is és date-ként is, lehet kipróbálnám, hogy mindkét módon redundánsan letárolnám ugyanazt az adatot.
Másik lehetőség, hogy tárold le ezt az adatot napokra groupolva is, ez persze megint redundáns tárolást jelent, de biztos, hogy gyorsabb lesz az így előre groupolt adatokat lekérdezni, mint on-the-fly groupolni sok millió adatot.Igen, próbáltam többféleképpen lekérdezni, de sokkal gyorsabb nem lett. Szerintem azt fogom csinálni, hogy letárolom a napokat groupolva külön táblában, ahogy te is írtad.
-
martonx
veterán
Sziasztok!
Van egy lekérdezésem, ami így nézni:select cast(datetime as DATE) as gpsdate from kocsi GROUP by gpsdate;
Napokat csoportosítja a datetime oszlop szerint. Kb: 1.8millio sor van az oszlopban. Egy napra kb: 2000.
Ez a lekérdezés jelenleg 1.9mp-ig tart.
Az oszlop indexelve van, Az explain lekérdezés szerint használja is. Az explain extra oszlopába ezt írja: "Using index; Using temporary; Using filesort".
Ideiglenes táblát hoz létre a lekérdezéshez. Lehet ezt másképpen csinálni, hogy sokkal gyorsabb legyen? Ne tartson majdnem 2 mp-ig?gyanítom a cast-olás lassít még rajta, bár nem hiszem, hogy ezen drasztikusan tudnál még gyorsítani. Ha ennyire kritikus a sebesség, akkor érdemes lenne eleve úgy tárolnod az adatokat, hogy ne kelljen castolni.
Vagy ha kell datetime-ként is és date-ként is, lehet kipróbálnám, hogy mindkét módon redundánsan letárolnám ugyanazt az adatot.
Másik lehetőség, hogy tárold le ezt az adatot napokra groupolva is, ez persze megint redundáns tárolást jelent, de biztos, hogy gyorsabb lesz az így előre groupolt adatokat lekérdezni, mint on-the-fly groupolni sok millió adatot. -
Panhard
tag
Sziasztok!
Van egy lekérdezésem, ami így nézni:select cast(datetime as DATE) as gpsdate from kocsi GROUP by gpsdate;
Napokat csoportosítja a datetime oszlop szerint. Kb: 1.8millio sor van az oszlopban. Egy napra kb: 2000.
Ez a lekérdezés jelenleg 1.9mp-ig tart.
Az oszlop indexelve van, Az explain lekérdezés szerint használja is. Az explain extra oszlopába ezt írja: "Using index; Using temporary; Using filesort".
Ideiglenes táblát hoz létre a lekérdezéshez. Lehet ezt másképpen csinálni, hogy sokkal gyorsabb legyen? Ne tartson majdnem 2 mp-ig? -
biker
nagyúr
Mintha a szerveren lenne egy globális default ‘’
Igen, a mysql használ gyári defaultokat, ha nincs megadva saját:
For data entry into a NOT NULL column that has no explicit DEFAULT clause, if an INSERT or REPLACE statement includes no value for the column, or an UPDATE statement sets the column to NULL, MySQL handles the column according to the SQL mode in effect at the time:
- If strict SQL mode is enabled, an error occurs for transactional tables and the statement is rolled back. For nontransactional tables, an error occurs, but if this happens for the second or subsequent row of a multiple-row statement, the preceding rows are inserted.
- If strict mode is not enabled, MySQL sets the column to the implicit default value for the column data type.
MySQL :: MySQL 8.0 Reference Manual :: 11.6 Data Type Default Values
Egyébként érdemes felkészülni arra, hogy a jövőben egyre több mysql szolgáltató tér át a mysql 8-ra, ahol alapból a strict mode van beállítva. Általánosságban azt tapasztaltam, hogy az a query, ami strict módban működik, az működik non-strict módban is, ezért lokálisan már strict mode-ban fut a mysql nálam is, sctrict módban tesztelek mindent, egy-két esetet leszámítva, amikor az adott, jellemzően régebbi web framework egyszerűen nem működik strict mode beállítással.
Köszi!
-
nevemfel
senior tag
Ezen elgondolkoztam, és sikerült rekonstruálni a sztut
Az installer script amit írtam eddig id ugyanaz volt, meg a query. Igenám, de lusta módon csak olyanok voltak benne hogy pl mezőneve text not null (default nélkül)
Érdekes módon ha ebbe a táblába beszúrtam egy sort ahol egy ilyen mezőbe nem adtam meg értéket, akkor mivel null nem lehet üres lett. Mintha a szerveren lenne egy globális default ‘’
A mai telepítéskor feltűnt hogy beszúráskor hibával nem ír be ha nem adok meg értéket, mivel not null mezőbe kért adatot. Én meg hülye módon default null és nem default ‘’ beállítással orvosoltam a beszúrást
És valoban ezért lett ezen a szerveren az érték nélküli mező és nem üresMintha a szerveren lenne egy globális default ‘’
Igen, a mysql használ gyári defaultokat, ha nincs megadva saját:
For data entry into a NOT NULL column that has no explicit DEFAULT clause, if an INSERT or REPLACE statement includes no value for the column, or an UPDATE statement sets the column to NULL, MySQL handles the column according to the SQL mode in effect at the time:
- If strict SQL mode is enabled, an error occurs for transactional tables and the statement is rolled back. For nontransactional tables, an error occurs, but if this happens for the second or subsequent row of a multiple-row statement, the preceding rows are inserted.
- If strict mode is not enabled, MySQL sets the column to the implicit default value for the column data type.
MySQL :: MySQL 8.0 Reference Manual :: 11.6 Data Type Default Values
Egyébként érdemes felkészülni arra, hogy a jövőben egyre több mysql szolgáltató tér át a mysql 8-ra, ahol alapból a strict mode van beállítva. Általánosságban azt tapasztaltam, hogy az a query, ami strict módban működik, az működik non-strict módban is, ezért lokálisan már strict mode-ban fut a mysql nálam is, sctrict módban tesztelek mindent, egy-két esetet leszámítva, amikor az adott, jellemzően régebbi web framework egyszerűen nem működik strict mode beállítással.
-
biker
nagyúr
-
martonx
veterán
Ezen elgondolkoztam, és sikerült rekonstruálni a sztut
Az installer script amit írtam eddig id ugyanaz volt, meg a query. Igenám, de lusta módon csak olyanok voltak benne hogy pl mezőneve text not null (default nélkül)
Érdekes módon ha ebbe a táblába beszúrtam egy sort ahol egy ilyen mezőbe nem adtam meg értéket, akkor mivel null nem lehet üres lett. Mintha a szerveren lenne egy globális default ‘’
A mai telepítéskor feltűnt hogy beszúráskor hibával nem ír be ha nem adok meg értéket, mivel not null mezőbe kért adatot. Én meg hülye módon default null és nem default ‘’ beállítással orvosoltam a beszúrást
És valoban ezért lett ezen a szerveren az érték nélküli mező és nem üresAkkor csak jól mondtuk, hogy nincs hiba, se hibás beállítás.

A bénácska MySql találkozott a user errorral. -
biker
nagyúr
Egyelőre úgy tűnik hogy a tábláknál a default null helyett default ‘’ megoldja a problémát
Igen, a megoldás így ezesetben jó lehet, illetve aktiv VARCHAR(1) NOT NULL DEFAULT '' még jobb.
Mert eddig mondjuk 150 helyen ez nem volt hiba, a 150 tár a roossz?
A NULL tudomásom szerint mindenhol így működik, ahogy leírtam, minden relációs adatbázis kezelőben, ugyanis ezt írja elő az SQL 92 szabvány.
Ezen elgondolkoztam, és sikerült rekonstruálni a sztut
Az installer script amit írtam eddig id ugyanaz volt, meg a query. Igenám, de lusta módon csak olyanok voltak benne hogy pl mezőneve text not null (default nélkül)
Érdekes módon ha ebbe a táblába beszúrtam egy sort ahol egy ilyen mezőbe nem adtam meg értéket, akkor mivel null nem lehet üres lett. Mintha a szerveren lenne egy globális default ‘’
A mai telepítéskor feltűnt hogy beszúráskor hibával nem ír be ha nem adok meg értéket, mivel not null mezőbe kért adatot. Én meg hülye módon default null és nem default ‘’ beállítással orvosoltam a beszúrást
És valoban ezért lett ezen a szerveren az érték nélküli mező és nem üres -
nevemfel
senior tag
Ezt a kódban kikeresni, hány lekérdezés érintett, kicsit gyilkos lenne
Egyelőre úgy tűnik hogy a tábláknál a default null helyett default ‘’ megoldja a problémátDe jó lenne tudni, az a tárhely mysql beállítás a hibás ahol ez hibás, vagy ahol ez jó
Mert eddig mondjuk 150 helyen ez nem volt hiba, a 150 tár a roossz?Egyelőre úgy tűnik hogy a tábláknál a default null helyett default ‘’ megoldja a problémát
Igen, a megoldás így ezesetben jó lehet, illetve aktiv VARCHAR(1) NOT NULL DEFAULT '' még jobb.
Mert eddig mondjuk 150 helyen ez nem volt hiba, a 150 tár a roossz?
A NULL tudomásom szerint mindenhol így működik, ahogy leírtam, minden relációs adatbázis kezelőben, ugyanis ezt írja elő az SQL 92 szabvány.
-
biker
nagyúr
Ezt a kódban kikeresni, hány lekérdezés érintett, kicsit gyilkos lenne
Egyelőre úgy tűnik hogy a tábláknál a default null helyett default ‘’ megoldja a problémátDe jó lenne tudni, az a tárhely mysql beállítás a hibás ahol ez hibás, vagy ahol ez jó
Mert eddig mondjuk 150 helyen ez nem volt hiba, a 150 tár a roossz? -
nevemfel
senior tag
Pontosan. =, !=, <> nem ad találatot NULL értékre.
Ha a mező NULL értéket vehet fel, akkor a te példád alapján az összes rekordot, ahol az aktiv mező nem 'n' értéket tartalmaz, úgy kaphatod meg, hogy:
WHERE aktiv != 'n' OR aktiv IS NULL
-
biker
nagyúr
szóval ha a mező NULL akkor a mező != 'n' nem ad találatot (az explainben látható okból)
HA a mező '' (két aposztrof közt semmi) tehát semmi nincs benne de nem null, akkor a mező != 'n' kiadja találatnak.Tehát NULL != semmi
 De máshol ezzel semmi gond nincs. Szuper....
De máshol ezzel semmi gond nincs. Szuper.... -
biker
nagyúr
Nem azt keresem, hanem azt hogy mező !=‘valami’
A null is nem egyenlő valami, de ezeket kihagyja, nem eredményes a lekérdezés. Ertem hogy nem hibaüzenet, de nekem hibás működést eredményez -
biker
nagyúr
a régi jó hányadék MySQL Ez 2012 óta ismert feature, nem bug. MySQL Bugs: #64197: "Impossible WHERE noticed after reading const tables" message
Csak szar az üzenet, ha jól értem nincs hiba, csak valószínűleg nem hozott találatot a WHERE.
Talán ideje lenne a garázs szolgáltatókat örökre elfelejteni a vicc MySQL-jeikkel együtt, és a felhőbe menni?
Értem, csak kb 150 tárhelyen futtatom a rendszert ahol ha üres a mező akkor a where !=‘valami’ az kiadja az üres mezőket, ezen az egy tárhelyen nem
Ha a mező ‘másvalami’ akkor a !=‘valami’ kiadja
Ilyet még nem láttam eddig, nekem új -
nevemfel
senior tag
Üdv, milyen szerver beállítás eredményezhet ilyen hibát? Eddig sosem láttam hasonlót
Példa: SELECT * FROM berletek WHERE aktiv!='n' ORDER BY berlet_neve ASC
és az aktiv mező NULL (üres) ha aktiv, ’n’ ha inaktív, akkor ha NULL a mező, akkor eldobja az sql-t. Ilyennel még nem találkoztam.
Explain mód: "Impossible WHERE noticed after reading const tables”
Vagyis ha a mező null, akkor lehetetlen benne where feltétellel keresni?
Próbálom a tárhelyest elérni, állítson valamit, de mit?Ez nem hibaüzenet, hanem EXPLAIN magyarázat.
Ha azt akarod keresni, hogy egy mező NULL vagy sem, akkor nem a !=, <> operátorokat kell használni, hanem az IS NULL vagy IS NOT NULL-t.
-
martonx
veterán
Üdv, milyen szerver beállítás eredményezhet ilyen hibát? Eddig sosem láttam hasonlót
Példa: SELECT * FROM berletek WHERE aktiv!='n' ORDER BY berlet_neve ASC
és az aktiv mező NULL (üres) ha aktiv, ’n’ ha inaktív, akkor ha NULL a mező, akkor eldobja az sql-t. Ilyennel még nem találkoztam.
Explain mód: "Impossible WHERE noticed after reading const tables”
Vagyis ha a mező null, akkor lehetetlen benne where feltétellel keresni?
Próbálom a tárhelyest elérni, állítson valamit, de mit? a régi jó hányadék MySQL Ez 2012 óta ismert feature, nem bug. MySQL Bugs: #64197: "Impossible WHERE noticed after reading const tables" messageCsak szar az üzenet, ha jól értem nincs hiba, csak valószínűleg nem hozott találatot a WHERE.
Talán ideje lenne a garázs szolgáltatókat örökre elfelejteni a vicc MySQL-jeikkel együtt, és a felhőbe menni?
-
biker
nagyúr
Üdv, milyen szerver beállítás eredményezhet ilyen hibát? Eddig sosem láttam hasonlót
Példa: SELECT * FROM berletek WHERE aktiv!='n' ORDER BY berlet_neve ASC
és az aktiv mező NULL (üres) ha aktiv, ’n’ ha inaktív, akkor ha NULL a mező, akkor eldobja az sql-t. Ilyennel még nem találkoztam.
Explain mód: "Impossible WHERE noticed after reading const tables”
Vagyis ha a mező null, akkor lehetetlen benne where feltétellel keresni?
Próbálom a tárhelyest elérni, állítson valamit, de mit? -
martonx
veterán
De hogyan ?
Ezekből a meglévő rekordokból kellene:
id,reading_time,N,V,A,W
123,2022-12-17 15:58:41,1,220,1,220
124,2022-12-17 15:58:41,2,230,2,460
125,2022-12-17 15:58:41,3,230,1,230
126,2022-12-17 15:58:41,4,235,1,235
127,2022-12-17 15:58:41,5,234,1,224
128,2022-12-17 15:58:41,6,233,3,699
Ilyet készíteni:
id,reading_time,V1,V2,V3,V4,V5,V6,A1,A2,A3,A4,A5,A6,W1,W2,W3,W4,W5,W6,
1,2022-12-17 15:58:41,220,230,230,235,234,233,1,2,1,1,1,3,220,460,230,235,224,699Áhá, csak kezded kinyögni, hogy mi is a konkrét problémád.
Én a helyedben a következő lépéseket tenném:
1. megcsinálnám az új táblát üresen
2. írnék egy adat migráló scriptet (te tudod milyen programnyelv áll hozzád a legközelebb ehhez, akár SQL is lehet egy kurzorral), ami minden egyes soron végigmegy, az azokban talált adatokat összefűzi az új struktúrának megfelelően, majd azt beleírja az új táblába
3. a régi táblát átnevezném régitáblanév_backup-ra
4. az új táblát átnevezném a régi tábla nevére
5. amikor látom, hogy minden szép és jó, akkor elpusztítanám a backup táblát (ez időben akár heteket, hónapokat, ha nem zavar ott a backup tábla akár éveket is jelenthet ). -
 mlaci01
tag
mlaci01
tag
De hogyan ?
Ezekből a meglévő rekordokból kellene:
id,reading_time,N,V,A,W
123,2022-12-17 15:58:41,1,220,1,220
124,2022-12-17 15:58:41,2,230,2,460
125,2022-12-17 15:58:41,3,230,1,230
126,2022-12-17 15:58:41,4,235,1,235
127,2022-12-17 15:58:41,5,234,1,224
128,2022-12-17 15:58:41,6,233,3,699
Ilyet készíteni:
id,reading_time,V1,V2,V3,V4,V5,V6,A1,A2,A3,A4,A5,A6,W1,W2,W3,W4,W5,W6,
1,2022-12-17 15:58:41,220,230,230,235,234,233,1,2,1,1,1,3,220,460,230,235,224,699 -
 Formaster
addikt
Formaster
addikt
Sziasztok! Kérnék szépen egy kis segítséget, nem tudom mit rontok el. Egy tábla text oszlopjait (A) szeretném átmásolni ugyanazon tábla másik text oszlopjába (B), de nem sikerül. Az alábbival próbálkoztam, két féle képpen is, de nem történik semmi.

UPDATE tábla SET oszlopB = oszlopAUPDATE tábla SET oszlopB=oszlopA
szerk: megvan a hiba, lemaradt a végéről a ;
-
martonx
veterán
-
mlaci01
tag
Köszi a szoftver már megvan, csak a meglévő adatbázist kellene úgy átalakítani, hogy az adatok megmaradjanak, és az új formában legyenek tárolva.
Magyarul, az egy mérésből származó meglévő minden 6 rekordból kellene 1-re átalakítani. -
martonx
veterán
Sziasztok,
Át kellene alakítanom egy adatbázist, de nem tudom hogyan fogjak hozzá.
Az eredeti így néz ki:
id,reading_time,Rd,Rt,N,V,A,W
Az "id" auto increment,az "N" egy szám 1 -től 6-ig, ezeket szeretném egyesíteni az alábbiak szerint.
id,reading_time,Rd,Rt,V1,V2,V3,V4,V5,V6,A1,A2,A3,A4,A5,A6,W1,W2,W3,W4,W5,W6,
Ezek érzékelő adatok (6 db), amiknek a leolvasása minden esetben egyszerre történik, az "n" jelöli az érzékelő sorszámát.
Ezeket szeretném egyesíteni, hogy 1 leolvasásnál ne 6 db rekord jöjjön létre, hanem csak egy.
Esetleg valakinek van ötlete, hogyan lehetne az adatbázist átalakítani ?
Előre is köszönöm.
L,Javaslom vegyél fel plusz mezőket a DB táblába, majd módosítsd az adatokat beíró szoftvert ennek megfelelően.
-
mlaci01
tag
Sziasztok,
Át kellene alakítanom egy adatbázist, de nem tudom hogyan fogjak hozzá.
Az eredeti így néz ki:
id,reading_time,Rd,Rt,N,V,A,W
Az "id" auto increment,az "N" egy szám 1 -től 6-ig, ezeket szeretném egyesíteni az alábbiak szerint.
id,reading_time,Rd,Rt,V1,V2,V3,V4,V5,V6,A1,A2,A3,A4,A5,A6,W1,W2,W3,W4,W5,W6,
Ezek érzékelő adatok (6 db), amiknek a leolvasása minden esetben egyszerre történik, az "n" jelöli az érzékelő sorszámát.
Ezeket szeretném egyesíteni, hogy 1 leolvasásnál ne 6 db rekord jöjjön létre, hanem csak egy.
Esetleg valakinek van ötlete, hogyan lehetne az adatbázist átalakítani ?
Előre is köszönöm.
L, -
nevemfel
senior tag
Sziasztok
Van egy tábla, amiben van egy számokat tartalmazó oszlop.
Ide szabadon választott számok kerülnek be 1 és 100 között (szerepelhet többször is).
Azt szeretném lekérdezni, hogy - a megadott lehetőségek közül - mely számokat nem írták még be?
Ezzel a paranccsal derült ki, hogy nincs köztük 100 db szám:select count(id) from naplo where id between 1 and 100Remélem jól fogalmaztam
előre is kösziHa Mysql 8.0.1=< vagy MariaDB 1.2.40=<, akkor CTE-vel viszonylag egyszerű:
WITH RECURSIVE cte AS (SELECT 1 AS value UNION ALL SELECT value + 1 FROM cte WHERE value < 100)
SELECT value FROM cte LEFT JOIN naplo ON cte.value = naplo.id WHERE id IS NULLCTE nélkül, pl. 5.7-es mysql alatt nem tudom, talán tárolt eljárással.
-
laracroft
senior tag
Sziasztok
Van egy tábla, amiben van egy számokat tartalmazó oszlop.
Ide szabadon választott számok kerülnek be 1 és 100 között (szerepelhet többször is).
Azt szeretném lekérdezni, hogy - a megadott lehetőségek közül - mely számokat nem írták még be?
Ezzel a paranccsal derült ki, hogy nincs köztük 100 db szám:select count(id) from naplo where id between 1 and 100Remélem jól fogalmaztam
előre is köszi -
meone
tag
-
martonx
veterán
Sziasztok!
Adott egy MySQL-es adatbázis mely perces mérési sorokat tartalmaz.
A sorok'YYYY-MM-DD hh:mm:ss'DateTime időbélyeggel vannak ellátva.A sorokat szeretném aggregálni.
Aggregációs intervallum: 10 perc
A mért értékeket átlagolni szeretném.
A létrejött eredményt pedig elszeretném tárolni egy új adattáblában.Valakinek valami ötlete, minta példa mi alapján el indulhatok meg valósítani a dolgokat.
Segítséget előre is köszönöm.
Group By-t javaslom
-
meone
tag
Sziasztok!
Adott egy MySQL-es adatbázis mely perces mérési sorokat tartalmaz.
A sorok'YYYY-MM-DD hh:mm:ss'DateTime időbélyeggel vannak ellátva.A sorokat szeretném aggregálni.
Aggregációs intervallum: 10 perc
A mért értékeket átlagolni szeretném.
A létrejött eredményt pedig elszeretném tárolni egy új adattáblában.Valakinek valami ötlete, minta példa mi alapján el indulhatok meg valósítani a dolgokat.
Segítséget előre is köszönöm.
-
disy68
aktív tag
Szia, ilyen string konkatenációval nem kellene értéket adnod az SQL-nek, mert ez az SQL injection melegágya.
Mi lehet a megoldás helyette, hogy lehet ezt elegánsan megoldani? -
 Harcipocok84
tag
Harcipocok84
tag
Szia, ilyen string konkatenációval nem kellene értéket adnod az SQL-nek, mert ez az SQL injection melegágya.
Mi lehet a megoldás helyette, hogy lehet ezt elegánsan megoldani? -
martonx
veterán
Sziasztok!
Nem igazán vagyok képben MySQL téren. Mondhatni kezdő vagyok, viszont egy projektemnek sajnos része a MYSQL is. Felvázolom a helyzetet:
- létrehozok egy táblát, hozzáadok 4 db mezőt.
- létrehozok egy user-t, akinek teljes jogot adok a táblához
- felépítem az adatbázis kapcsolatot:$db = new mysqli(DB_HOST, DB_USERNAME, DB_PASSWORD, DB_NAME);
Nyilván itt behelyettesítem a változókat, így az adatbázis kapcsolat megvan. Majd ezután egy külső eszközről HTTP Post utasításokat adok át a PHP-nek, és 3 db értéket adok át POST-al az alábbi linkkel:
http://weboldal.hu/data.php?vnev="Próba"&knev="Elek"&cim="fing utca 2"
A data.php pedig az alábbit tartalmazza:$sql = "INSERT INTO tabla_szemely(vnev,knev,cim,created_date)VALUES('".$vnev."','".$knev."','".$cim."','".date("Y-m-d H:i:s")."')";
Nyilván előtte a változók értékeit kiveszem a $_GET[]-ből
A 4. értéket nem adom át, azt szeretném ha azt az SQL saját maga adná hozzá a rendszeridő szerint.
Ezzel kapcsolatban lenne pár kérdésem:
1. Ez így működik ahogy leírtam, vagy kihagytam valamit?
2. Mi történik ha valaki meghívja a linket, és HTTP post üzenetet küld de hibásan? Tehát nem olyan változónévvel, vagy nem annyi paramétert amennyire vár a PHP?Szia, ilyen string konkatenációval nem kellene értéket adnod az SQL-nek, mert ez az SQL injection melegágya.
1. Ettől eltekintve az elképzelés jó, és működhet.
2. hibát fog dobni -
Harcipocok84
tag
Sziasztok!
Nem igazán vagyok képben MySQL téren. Mondhatni kezdő vagyok, viszont egy projektemnek sajnos része a MYSQL is. Felvázolom a helyzetet:
- létrehozok egy táblát, hozzáadok 4 db mezőt.
- létrehozok egy user-t, akinek teljes jogot adok a táblához
- felépítem az adatbázis kapcsolatot:$db = new mysqli(DB_HOST, DB_USERNAME, DB_PASSWORD, DB_NAME);
Nyilván itt behelyettesítem a változókat, így az adatbázis kapcsolat megvan. Majd ezután egy külső eszközről HTTP Post utasításokat adok át a PHP-nek, és 3 db értéket adok át POST-al az alábbi linkkel:
http://weboldal.hu/data.php?vnev="Próba"&knev="Elek"&cim="fing utca 2"
A data.php pedig az alábbit tartalmazza:$sql = "INSERT INTO tabla_szemely(vnev,knev,cim,created_date)VALUES('".$vnev."','".$knev."','".$cim."','".date("Y-m-d H:i:s")."')";
Nyilván előtte a változók értékeit kiveszem a $_GET[]-ből
A 4. értéket nem adom át, azt szeretném ha azt az SQL saját maga adná hozzá a rendszeridő szerint.
Ezzel kapcsolatban lenne pár kérdésem:
1. Ez így működik ahogy leírtam, vagy kihagytam valamit?
2. Mi történik ha valaki meghívja a linket, és HTTP post üzenetet küld de hibásan? Tehát nem olyan változónévvel, vagy nem annyi paramétert amennyire vár a PHP? -
F1DO
senior tag
Sziasztok, egy kérdésem lenne:
Ugye az order by záradék 'jellege miatt' ez a véletlenszerű tábla lekérdezés ismétlődés nélküli? (mondjuk 100-ból választunk véletlenszerűen 10 rekordot)
SELECT * FROM tábla WHERE valami = érték ORDER BY rand() LIMIT 10 -
laracroft
senior tag
Sziasztok
Van egy ilyen MySQL táblám.
Az id a primary key és auto increment.
Azt szeretném elérni, hogy ha új a rekord, akkor insert, ha létező, akkor update legyen.
Hogyan kéne a táblát beállítanom ahhoz, hogy a uniq_id-n belül ne fogadjon el már létező number rekordot (ekkor legyen update).
Egy ilyen paranccsal próbálkozok, de sosem update-el, mindig csak hozzáadja:INSERT INTO table (uniq_id, date, number)VALUES(acd0e7f0f6e2e6d5968f84d8fcb307b0, date=NOW(),3)ON DUPLICATE KEY UPDATE number = 3;Bocsánat, ha nem jól fogalmaztam
Előre is köszi -
 Agostino
addikt
Agostino
addikt
sziasztok
csoportot szeretnék lekérni a következőek szerint:
+----+----------+
| id | date |
+----+----------+
| 1 | 20210701 |
| 1 | 20210801 |
| 2 | 20210601 |
| 2 | 20210401 |
| 3 | 20210801 |
| 3 | 20210501 |
| 3 | 20210501 |
+----+----------+a 20210701 lenne az érdekes dátum, tehát minden egyes olyan sort szeretnék visszakapni, ahol az id ugyan az, ez jelentené a csoport alapját, de van olyan sora, ahol szerepel a 20210701. a fenti tábla tehát a móka után a lenti tábla szerint nézne ki (vagyis a 2-es id kiesik, hiszen ott egyetlen sor mellett sem szerepel a 20210701). igazán attól izgalmas az egész, hogy select only opcióm van, te se temporary table, se update se semmi. teljesen basic lehetőségek
+----+----------+
| id | date |
+----+----------+
| 1 | 20210701 |
| 1 | 20210801 |
| 3 | 20210701 |
| 3 | 20210501 |
| 3 | 20210501 |
+----+----------+ -
 Ablakos
addikt
Ablakos
addikt
(windows10 / Msql80)
Workbench-ben nem tudom megállítani/elindítani a servert. (Így igen: net start mysql80 )
Jó néhány okfejtést végignéztem, de nem találom a magyarázatot mit rontok el. -
 Dißnäëß
nagyúr
Dißnäëß
nagyúr
A MySql cache-e nagyon nem egyenlő egy Redis-el. Ettől még simán lehet felesleges a redis.
Nekem már önmagában az is fura, hogy ha a DB bőven belefér 10-30 gigába, akkor ehhez minek cluster?
Szóval fingom sincs, hogy mi a célotok, milyen egyéb cachelési stratégiát használtok rendszer szinten, egyáltalán mennyi request fog beesni percenként
Nem mindegy, hogy 20 vagy 2 millió. Ehhez képest a DB mérete kb. lényegtelen.Értem. Cluster csak HA miatt, nyilván nem csak performancia előnye akad.
De értelek, több adatom viszont nincs, így meg én sem vagyok előrébb, úgyhogy tárgytalan kb. -
martonx
veterán
Sziasztok Szakik !
MySQL (innoDB) cluster lenne a célpontja egy nagyobbacska adatbázisnak. Mennyire érdemes egy ilyen elé betenni egy Redis-t, cache-ként ? Szerintem ágyúval verébre lövés, de cáfoljatok.
Én úgy tudom, a MySQL-nek is elég fejlett a cache-ing mechanizmusa és az egyes node-ok ha komolyabb mennyiségű memóriával vannak ellátva, akkor a MySQL (cluster) ismétlődő, ugyanazon rekordokat érintő, 99%-ban READ lekérdezéseknél meglehetősen hatékonyan tud memóriából dolgozni, azaz marhagyors lenni, jól sejtem ? Túl azon, hogy a mysql router el-load-balance-olja a kéréseket a PRIMARY (R/W) és a két SECONDARY (R) között.
Csak általánosan érdeklődök, nincs a leendő DB-re vonatkozóan egyéb adatom, de az első sejtések alapján a DB mérete úgy 10-30 gigába bőven beférne.
Köszi.
A MySql cache-e nagyon nem egyenlő egy Redis-el. Ettől még simán lehet felesleges a redis.
Nekem már önmagában az is fura, hogy ha a DB bőven belefér 10-30 gigába, akkor ehhez minek cluster?
Szóval fingom sincs, hogy mi a célotok, milyen egyéb cachelési stratégiát használtok rendszer szinten, egyáltalán mennyi request fog beesni percenként
Nem mindegy, hogy 20 vagy 2 millió. Ehhez képest a DB mérete kb. lényegtelen. -
Dißnäëß
nagyúr
Sziasztok Szakik !
MySQL (innoDB) cluster lenne a célpontja egy nagyobbacska adatbázisnak. Mennyire érdemes egy ilyen elé betenni egy Redis-t, cache-ként ? Szerintem ágyúval verébre lövés, de cáfoljatok.
Én úgy tudom, a MySQL-nek is elég fejlett a cache-ing mechanizmusa és az egyes node-ok ha komolyabb mennyiségű memóriával vannak ellátva, akkor a MySQL (cluster) ismétlődő, ugyanazon rekordokat érintő, 99%-ban READ lekérdezéseknél meglehetősen hatékonyan tud memóriából dolgozni, azaz marhagyors lenni, jól sejtem ? Túl azon, hogy a mysql router el-load-balance-olja a kéréseket a PRIMARY (R/W) és a két SECONDARY (R) között.
Csak általánosan érdeklődök, nincs a leendő DB-re vonatkozóan egyéb adatom, de az első sejtések alapján a DB mérete úgy 10-30 gigába bőven beférne.
Köszi.
-
 bsh
addikt
bsh
addikt
üdv,
új kérdésem lenne, még az előbbi "projekthez". a bonyolult sok joines lekérdezés már frankón működik (és gyors is), de még kéne bele egy dolog, és ezt nem bírom megoldani.
adott egy tábla, amiben pdf fájlok helyei vannak (így gyorsabb mint fájlrendszerben keresgélni). van ebben egy RelativePath oszlop, ami ez elérési út fájlnév nélkül UNC formában, egy FileName oszlop, ami csak maga a fájlnév rész, és egy LatModified oszlop a fájl dátumával.
egy adott tétel pdf-jének a fájlneve elvileg 'rajzszám'+'revízió'+'.pdf' mintával generálható és lekérdezhető a táblából, hogy hol van a fájl.
több ugyanolyan nevű fájl is van (sajnos), különböző elérési utakon. ezekből úgy szoktam lekérdezni, hogy LastModified szerint csökkenő sorrendbe rendezve, és a legelső találat akkor a legújabb verziója a fájlnak.SELECT RelativePath, FileName, LastModified FROM pdflist WHERE FileName = 'valamiizébigyó.pdf' ORDER BY LastModified DESC LIMIT 0,1;ezt kéne valahogy join-nal beintegrálni a nagy bonyolult lekérdezésbe. ezt így próbáltam:
LEFT JOIN (SELECT FileName, CONCAT(RelativePath, '\\', FileName) AS hely FROM `pdflist` ORDER BY LastModified DESC) pdf ON pdf.FileName = CONCAT(t.rajzszam, t.revizio, '.pdf')
ezzel az a baj, hogy így visszaadja az összes találatot, ha több ugyanolyan fájlnév is van, nem tudom hogy lehetne itt is megoldani, hogy csak egy találatot adjon vissza fájnevenként. a LIMIT nem jó. próbáltam GROUP BY FileName is...
a másik probléma hogy ez így tetű lassú. -
 instantwater
addikt
instantwater
addikt
-
bsh
addikt
Akkor viszont tényleg kell egy kapcsolótábla 2 oszloppal.
Megrendelés ID, Szállítólevél IDMajd egy unique composite index a 2 oszlopra együtt, hogy garantálja, hogy egy megrendeléshez egy szállítólevél csak egyszer szerepelhessen.
A 2 oszlopon legyen foreign key a konzisztencia miatt.
Külön-külön is tegyél rájuk egy indexet, hogy megrendelés alapján gyorsan lekérdezhesd a szállítóleveleket, és szállítólevél alapján gyorsan lekérdezhesd az adott szállítólevélen szereplő megrendeléseket.
és az miért lesz úgy jobb?
-
instantwater
addikt
egy szállítólevél több több rendeléshez is tartozhat, mivel egy megrendelés kb. mindig több tételből áll (azaz több sor a táblában). ezeket ahogy egy nagyobb részmennyiség kész van és kiszállítható, csomagolják és egy fuvarlevéllel szállítják ki, de sokszor van olyan, hogy tételekre várni kell, ezért ezeket később egy másik fuvarlevéllel szállítják ki, és olyan is van, hogy mondjuk egy vagy több tételből csak X mennyiség van raktáron, ezeket kiszállítják, a maradékot meg később, amikro a hiányzó mennyiség beérkezik, akkor újabb szállítóval szállítják ki.
magyarán: egy szállítólevéhez több tétel is tartozhat (ez nem probléma), és egy tételhez tartozhat több szállítólevél is (jelen esetben max. 3)
próbáltam még olyat is, hogy:
... LEFT JOIN `szallitolevelek` sz ON m.Kisz1_flev = sz.id OR m.Kisz2_flev = sz.id OR m.Kisz3_flev = sz.id
de az úgy nemjó.
végülis működik a dolog, csak nem tudom, lehet-e "szebben".Akkor viszont tényleg kell egy kapcsolótábla 2 oszloppal.
Megrendelés ID, Szállítólevél IDMajd egy unique composite index a 2 oszlopra együtt, hogy garantálja, hogy egy megrendeléshez egy szállítólevél csak egyszer szerepelhessen.
A 2 oszlopon legyen foreign key a konzisztencia miatt.
Külön-külön is tegyél rájuk egy indexet, hogy megrendelés alapján gyorsan lekérdezhesd a szállítóleveleket, és szállítólevél alapján gyorsan lekérdezhesd az adott szállítólevélen szereplő megrendeléseket.
-
bsh
addikt
Ok, még kapcsolótábla sem kell amennyiben egy szállítólevél csak egy rendeléshez tartozhat.
Rakj be egy megrendeles_id oszlopot a szállítólevél táblába, és tegyél rá egy foreign keyt.
Így akármennyi szállítólevél tartozhat egy megrendeléshez, és megrendeles_id alapján könnyen le tudod kérdezni őket.
egy szállítólevél több több rendeléshez is tartozhat, mivel egy megrendelés kb. mindig több tételből áll (azaz több sor a táblában). ezeket ahogy egy nagyobb részmennyiség kész van és kiszállítható, csomagolják és egy fuvarlevéllel szállítják ki, de sokszor van olyan, hogy tételekre várni kell, ezért ezeket később egy másik fuvarlevéllel szállítják ki, és olyan is van, hogy mondjuk egy vagy több tételből csak X mennyiség van raktáron, ezeket kiszállítják, a maradékot meg később, amikro a hiányzó mennyiség beérkezik, akkor újabb szállítóval szállítják ki.
magyarán: egy szállítólevéhez több tétel is tartozhat (ez nem probléma), és egy tételhez tartozhat több szállítólevél is (jelen esetben max. 3)
próbáltam még olyat is, hogy:
... LEFT JOIN `szallitolevelek` sz ON m.Kisz1_flev = sz.id OR m.Kisz2_flev = sz.id OR m.Kisz3_flev = sz.id
de az úgy nemjó.
végülis működik a dolog, csak nem tudom, lehet-e "szebben". -
instantwater
addikt
SELECT (...) m.Kisz1_menny, m.Kisz1_datum, sz1.szam as Kisz1_flev, sz1.hely as Kisz1_hely, m.Kisz1_szla, m.Kisz2_menny, m.Kisz2_datum, sz2.szam as Kisz2_flev, sz2.hely as Kisz2_hely, m.Kisz2_szla, m.Kisz3_menny, m.Kisz3_datum, sz3.szam as Kisz3_flev, sz3.hely as Kisz3_hely, m.Kisz3_szla FROM `megrendelesek` m LEFT JOIN `szallitolevelek` sz1 ON m.Kisz1_flev = sz1.id LEFT JOIN `szallitolevelek` sz2 ON m.Kisz2_flev = sz2.id LEFT JOIN `szallitolevelek` sz3 ON m.Kisz3_flev = sz3.id WHERE m.id > 0;
ez csak a kérdéses rész, a többit kitöröltem.Ok, még kapcsolótábla sem kell amennyiben egy szállítólevél csak egy rendeléshez tartozhat.
Rakj be egy megrendeles_id oszlopot a szállítólevél táblába, és tegyél rá egy foreign keyt.
Így akármennyi szállítólevél tartozhat egy megrendeléshez, és megrendeles_id alapján könnyen le tudod kérdezni őket.
-
bsh
addikt
3 oszlop helyett esetleg egykapcsoló tábla megoldható lenne?
Jó lenne látni a lekérdezést és a struktúrát.
SELECT (...) m.Kisz1_menny, m.Kisz1_datum, sz1.szam as Kisz1_flev, sz1.hely as Kisz1_hely, m.Kisz1_szla, m.Kisz2_menny, m.Kisz2_datum, sz2.szam as Kisz2_flev, sz2.hely as Kisz2_hely, m.Kisz2_szla, m.Kisz3_menny, m.Kisz3_datum, sz3.szam as Kisz3_flev, sz3.hely as Kisz3_hely, m.Kisz3_szla FROM `megrendelesek` m LEFT JOIN `szallitolevelek` sz1 ON m.Kisz1_flev = sz1.id LEFT JOIN `szallitolevelek` sz2 ON m.Kisz2_flev = sz2.id LEFT JOIN `szallitolevelek` sz3 ON m.Kisz3_flev = sz3.id WHERE m.id > 0;
ez csak a kérdéses rész, a többit kitöröltem. -
instantwater
addikt
sziasztok.
lenne egy problémám, amit ugyan megoldottam, de nem biztos, hogy ez a jó/legjobb megoldás. ebben kérnék segítséget.
van egy tábla, amolyan megrendelés-áttekintő-összefoglaló akármi, aminek a lekérdezésekor több másik táblából jönnek product id-k, számlák, stb, több join is van. a probléma az ,hogy a megrendeléske kiszállításáról szállítólevelek is egy táblából jönnek. viszont előfordulhat olyan, hogy egy megrendelést több részletben szállítanak ki, ekkor több szállítólevél is tartozhat egy megrendeléshez. ezért minden megrendelés sorhoz 3 oszlop van, 3 lehetséges rész-kiszállítási szállítólevéllel. de ezek mind ugyanabból a táblából jönnek.
ezt úgy tudtam megoldani, hogy a lekérdezésben a szállítóleveles tábla háromszor is join-elve van, mindig az id oszlop, de 3 külön néven.
erre van esetleg más egyszerűbb megoldás? vagy ez így normális?3 oszlop helyett esetleg egykapcsoló tábla megoldható lenne?
Jó lenne látni a lekérdezést és a struktúrát.
-
martonx
veterán
sziasztok.
lenne egy problémám, amit ugyan megoldottam, de nem biztos, hogy ez a jó/legjobb megoldás. ebben kérnék segítséget.
van egy tábla, amolyan megrendelés-áttekintő-összefoglaló akármi, aminek a lekérdezésekor több másik táblából jönnek product id-k, számlák, stb, több join is van. a probléma az ,hogy a megrendeléske kiszállításáról szállítólevelek is egy táblából jönnek. viszont előfordulhat olyan, hogy egy megrendelést több részletben szállítanak ki, ekkor több szállítólevél is tartozhat egy megrendeléshez. ezért minden megrendelés sorhoz 3 oszlop van, 3 lehetséges rész-kiszállítási szállítólevéllel. de ezek mind ugyanabból a táblából jönnek.
ezt úgy tudtam megoldani, hogy a lekérdezésben a szállítóleveles tábla háromszor is join-elve van, mindig az id oszlop, de 3 külön néven.
erre van esetleg más egyszerűbb megoldás? vagy ez így normális?igen is és nem is. Egyrészt, ha ilyen a tábla struktúra, akkor normális. Másrészt elég gáz, hogy ilyen a tábla struktúra
-
bsh
addikt
sziasztok.
lenne egy problémám, amit ugyan megoldottam, de nem biztos, hogy ez a jó/legjobb megoldás. ebben kérnék segítséget.
van egy tábla, amolyan megrendelés-áttekintő-összefoglaló akármi, aminek a lekérdezésekor több másik táblából jönnek product id-k, számlák, stb, több join is van. a probléma az ,hogy a megrendeléske kiszállításáról szállítólevelek is egy táblából jönnek. viszont előfordulhat olyan, hogy egy megrendelést több részletben szállítanak ki, ekkor több szállítólevél is tartozhat egy megrendeléshez. ezért minden megrendelés sorhoz 3 oszlop van, 3 lehetséges rész-kiszállítási szállítólevéllel. de ezek mind ugyanabból a táblából jönnek.
ezt úgy tudtam megoldani, hogy a lekérdezésben a szállítóleveles tábla háromszor is join-elve van, mindig az id oszlop, de 3 külön néven.
erre van esetleg más egyszerűbb megoldás? vagy ez így normális? -
instantwater
addikt
Feltételezem, a kérdés nem valós
De ha mégis, attól függ, dilettáns módon csinálják-e. Sajnos még mindig látok olyan elvetemült, magát programozónak nevező embert, akinek a mínusz 1 hónap az, hogy levon 30 napot az aktuális dátumból

Pedig minden normális nyelv, a MySQL-t is beleértve tökéletesen csinálja.PS C:\> (Get-Date("2021-03-31")).AddMonths(-1)
2021. február 28., vasárnap 0:00:00
PS C:\>Szökőév:
PS C:\> (Get-Date("2024-03-31")).AddMonths(-1)
2024. február 29., csütörtök 0:00:00
PS C:\>Viszont ha már amúgy is MySQL:
MariaDB [(none)]> SELECT DATE_SUB(STR_TO_DATE("2021-03-31", "%Y-%m-%d"),INTERVAL 1 MONTH);
+------------------------------------------------------------------+
| DATE_SUB(STR_TO_DATE("2021-03-31", "%Y-%m-%d"),INTERVAL 1 MONTH) |
+------------------------------------------------------------------+
| 2021-02-28 |
+------------------------------------------------------------------+
1 row in set (0.001 sec)
MariaDB [(none)]>Köszi.
Erre voltam kiváncsi, hogy normálisan van-e megvalósítva -
 Keem1
veterán
Keem1
veterán
Mennyi március 31 minusz 1 hónap?
Feltételezem, a kérdés nem valós
De ha mégis, attól függ, dilettáns módon csinálják-e. Sajnos még mindig látok olyan elvetemült, magát programozónak nevező embert, akinek a mínusz 1 hónap az, hogy levon 30 napot az aktuális dátumból
Pedig minden normális nyelv, a MySQL-t is beleértve tökéletesen csinálja.PS C:\> (Get-Date("2021-03-31")).AddMonths(-1)
2021. február 28., vasárnap 0:00:00
PS C:\>Szökőév:
PS C:\> (Get-Date("2024-03-31")).AddMonths(-1)
2024. február 29., csütörtök 0:00:00
PS C:\>Viszont ha már amúgy is MySQL:
MariaDB [(none)]> SELECT DATE_SUB(STR_TO_DATE("2021-03-31", "%Y-%m-%d"),INTERVAL 1 MONTH);
+------------------------------------------------------------------+
| DATE_SUB(STR_TO_DATE("2021-03-31", "%Y-%m-%d"),INTERVAL 1 MONTH) |
+------------------------------------------------------------------+
| 2021-02-28 |
+------------------------------------------------------------------+
1 row in set (0.001 sec)
MariaDB [(none)]> -
instantwater
addikt
Mennyi március 31 minusz 1 hónap?
-
Keem1
veterán
-
Agostino
addikt
Srácok, valószínűleg nagyon egyszerű amit akarok, csak én nem látom a fától az erdőt.
Van egy timestamp-em (tstamp), kellene nekem a mindenkori "múlt hónap".Amim már van (a
WHERErészeként):
- ma:DATE(`tstamp`) = DATE(NOW())
- ebben a hónapban:YEAR(`tstamp`) = YEAR(NOW()) AND MONTH(`tstamp`) = MONTH(NOW())
- ebben az évben:YEAR(`tstamp`) = YEAR(NOW())Először valami ilyesmire gondoltam (gugli):
MONTH(CURRENT_DATE - INTERVAL 1 MONTH)De ebben az esetben nem fog kelleni (ha a mai napot nézzük, amikor is április van) a 2020-as március, csak a 2021-es március. A
YEAR(NOW()) AND MONTH(NOW()-1)meg elvérzik januárban.Tehát a kérdésem: hogy kapom meg azokat a sorokat, ahol a
tstampaz aktuális év előző hónapjának bármelyik napja? Annyi még, hogy a tstamp nem date, hanem timestamp, és egy napra akár több sor is lehet (2021 márciusára jelenleg 872 van összesen).Fontos: pure mysql kell, nem a host programozási nyelvben szeretném tovább filterezgetni, mivel a hívó program beágyazott kis teljesítményű hardveren fut, ami DB-related, azt végezze csak szépen a DB szerver. Ráadásul magának a programnak és a kapott DB query resultnak is robusztusnak kell lennie, éjjel-nappal futó service-ről van szó Linuxon, nem szállhat el egy hibás query miatt (pl. a fenti januári anomália). Ezért a legegyszerűbb, legegyértelműbb és legbiztonságosabb query-t kell megalkotnom, amit a futó service maga már nem igazán fog ellenőrizni.
Előre is köszi
-
Keem1
veterán
Srácok, valószínűleg nagyon egyszerű amit akarok, csak én nem látom a fától az erdőt.
Van egy timestamp-em (tstamp), kellene nekem a mindenkori "múlt hónap".Amim már van (a
WHERErészeként):
- ma:DATE(`tstamp`) = DATE(NOW())
- ebben a hónapban:YEAR(`tstamp`) = YEAR(NOW()) AND MONTH(`tstamp`) = MONTH(NOW())
- ebben az évben:YEAR(`tstamp`) = YEAR(NOW())Először valami ilyesmire gondoltam (gugli):
MONTH(CURRENT_DATE - INTERVAL 1 MONTH)De ebben az esetben nem fog kelleni (ha a mai napot nézzük, amikor is április van) a 2020-as március, csak a 2021-es március. A
YEAR(NOW()) AND MONTH(NOW()-1)meg elvérzik januárban.Tehát a kérdésem: hogy kapom meg azokat a sorokat, ahol a
tstampaz aktuális év előző hónapjának bármelyik napja? Annyi még, hogy a tstamp nem date, hanem timestamp, és egy napra akár több sor is lehet (2021 márciusára jelenleg 872 van összesen).Fontos: pure mysql kell, nem a host programozási nyelvben szeretném tovább filterezgetni, mivel a hívó program beágyazott kis teljesítményű hardveren fut, ami DB-related, azt végezze csak szépen a DB szerver. Ráadásul magának a programnak és a kapott DB query resultnak is robusztusnak kell lennie, éjjel-nappal futó service-ről van szó Linuxon, nem szállhat el egy hibás query miatt (pl. a fenti januári anomália). Ezért a legegyszerűbb, legegyértelműbb és legbiztonságosabb query-t kell megalkotnom, amit a futó service maga már nem igazán fog ellenőrizni.
Előre is köszi
-
Dißnäëß
nagyúr
Poénnak. De mint mindnek, a fele ennek is igaz
A tiszta technológián kívül amúgy nekem szvsz nulla, azaz 0 jó tapasztalatom van Oracle-el. Szóval szerintem ki fogják szépen lassan herélni a MySQL-t, ahogy telik az idô. -
 coco2
őstag
coco2
őstag
-
Dißnäëß
nagyúr
-
coco2
őstag
Kíséri valaki figyelemmel a fejlesztési trendet? Mennyi esélye lehet annak, hogy a memory engine-t kivezetik a jövőben a mysql free verzióból?
-
Dißnäëß
nagyúr
Köszönöm. Itthon bohóckodok vele teljesen kezdôként, szeretném szépen fokozatosan kitanulni egy kis privát, nem mission-critical projekthez.
InnoDB clustert már tudok telepíteni, mûxik is szépen, de minek tanultam meg biciklit építeni, ha nem tudok biciklizni ?
-
baracsi
tag
-
Dißnäëß
nagyúr
Sziasztok, mennyire MySQL ? MariaDB-ért köveztek ?
 Talán még nem nyílt nagyot az olló a kettô között.
Talán még nem nyílt nagyot az olló a kettô között. -
instantwater
addikt
ai, date, time oszlopok voltak az adatbázisban. Az ai volt az auto increment, csak a rendezés miatt kellett, más haszna nem volt. Ez a három oszlop helyett lett a datetime, a másik három majd törölve lesz.
A datetime mezőben soha nem lesz két egyforma adat. De ha mégis valamiért feltöltődne, a primary key index megakadályozza.
A datetime oszlop tartalmát a date és time oszlopokból generáltam. Csak az a baj, hogy 2018 előtt nem figyeltem arra, hogy ne töltődjön fel két egyforma adat, így most van egy pár táblázat, ahol kb: másfél millió sorból van átlagban 500 duplikált. Azokat kellen törölnöm.Én a SELECT DISTINCT környékén néznék körül.
-
Panhard
tag
Kérlek használj parameter bindinget, mert így sérülékeny a rendszer SQL injectionnel szemben.
Bármi SQL beküldhető a paraméterben és némi okoskodás után csúnya dolgokat lehet művelni.Sima indexet állíts be, ne unique indexet.
Egy időbélyeget nincs értelme unique indexbe tenni, hiszen egy adott pillanatban történhetett több minden amit el akarsz tárolni, és ha unique az index akkor hibát fogsz kapni.Korábban írtad, hogy a dátum meződ a primary key.
Erre van valami ok?
Primary key általában egy auto increment mező, az user email címe, uuid vagy hasonló szokott lenni.ai, date, time oszlopok voltak az adatbázisban. Az ai volt az auto increment, csak a rendezés miatt kellett, más haszna nem volt. Ez a három oszlop helyett lett a datetime, a másik három majd törölve lesz.
A datetime mezőben soha nem lesz két egyforma adat. De ha mégis valamiért feltöltődne, a primary key index megakadályozza.
A datetime oszlop tartalmát a date és time oszlopokból generáltam. Csak az a baj, hogy 2018 előtt nem figyeltem arra, hogy ne töltődjön fel két egyforma adat, így most van egy pár táblázat, ahol kb: másfél millió sorból van átlagban 500 duplikált. Azokat kellen törölnöm. -
instantwater
addikt
SELECT * FROM tabla WHERE datetime between '".$_GET["datum"]." 00:00:00' and '".$_GET["datum"]." 23:59:59' ORDER BY datetime DESC
Így működik.Viszont lenne még egy kérdésem: Van pár tábla, ahol elég sok duplikált bejegyzés van a datetime oszlopban, és ezért nem engedi beállítani az indexet. Neten találtam pár megoldást a duplikált bejegyzések törlésére, de egyik sem működik. Erre tudsz valami működő megoldást?
Kérlek használj parameter bindinget, mert így sérülékeny a rendszer SQL injectionnel szemben.
Bármi SQL beküldhető a paraméterben és némi okoskodás után csúnya dolgokat lehet művelni.Sima indexet állíts be, ne unique indexet.
Egy időbélyeget nincs értelme unique indexbe tenni, hiszen egy adott pillanatban történhetett több minden amit el akarsz tárolni, és ha unique az index akkor hibát fogsz kapni.Korábban írtad, hogy a dátum meződ a primary key.
Erre van valami ok?
Primary key általában egy auto increment mező, az user email címe, uuid vagy hasonló szokott lenni. -
Panhard
tag
Örülök, hogy sikerült.
Valóban kissé pseudocode amit írtam de végül sikerült felhasználnod.A castolás és stringhez hasonlítás egyenlőség vizsgálattal vagy LIKEval gátolja az indexek használatát.
Végül mi lett a megoldás pontos szintaktikával?
Hátha másnak hasznos lesz.SELECT * FROM tabla WHERE datetime between '".$_GET["datum"]." 00:00:00' and '".$_GET["datum"]." 23:59:59' ORDER BY datetime DESC
Így működik.Viszont lenne még egy kérdésem: Van pár tábla, ahol elég sok duplikált bejegyzés van a datetime oszlopban, és ezért nem engedi beállítani az indexet. Neten találtam pár megoldást a duplikált bejegyzések törlésére, de egyik sem működik. Erre tudsz valami működő megoldást?
-
instantwater
addikt
Örülök, hogy sikerült.
Valóban kissé pseudocode amit írtam de végül sikerült felhasználnod.A castolás és stringhez hasonlítás egyenlőség vizsgálattal vagy LIKEval gátolja az indexek használatát.
Végül mi lett a megoldás pontos szintaktikával?
Hátha másnak hasznos lesz. -
Panhard
tag
column BETWEEN dátum 00:00:00 AND dátum 23:59:59 ?
De MySQL 8 ban már vannak functional indexek, amikkel indexelni tudod a formázott tartalmat.
Vagy akár csinálhatsz egy virtuális generált oszlopot is amit lehet indexelni.
Épp ilyesmivel dolgozom. Fun
"column BETWEEN dátum 00:00:00 AND dátum 23:59:59 ?"
Így működik.
Köszönöm! -
Panhard
tag
"column BETWEEN dátum 00:00:00 AND dátum 23:59:59 ?"
ezt nem értem.Sajnos a tárhely szolgáltatóm nem használja a 8-as MySQL-t.
Vannak oszlopok is, amikben a dátum és idő van külön-külön, azokon az indexelés jól működik.
Gondoltam lecserélem őket egy datetime oszlopra. De akkor lehet marad ahogy van.A DATETIME oszlop PRIMARY KEY-nek van indexelve.
Kétféleképpen kérdeztem le, egyiknél sem használja az indexelést:
SELECT * FROM tabla where CAST(DATETIME AS DATE) = '2020-10-15'
SELECT * FROM tabla where DATETIME like '2020-10-15 %' -
Panhard
tag
column BETWEEN dátum 00:00:00 AND dátum 23:59:59 ?
De MySQL 8 ban már vannak functional indexek, amikkel indexelni tudod a formázott tartalmat.
Vagy akár csinálhatsz egy virtuális generált oszlopot is amit lehet indexelni.
Épp ilyesmivel dolgozom. Fun
"column BETWEEN dátum 00:00:00 AND dátum 23:59:59 ?"
ezt nem értem.Sajnos a tárhely szolgáltatóm nem használja a 8-as MySQL-t.
Vannak oszlopok is, amikben a dátum és idő van külön-külön, azokon az indexelés jól működik.
Gondoltam lecserélem őket egy datetime oszlopra. De akkor lehet marad ahogy van. -
instantwater
addikt
Sziasztok. Adatbázisban van egy oszlopom, ami DATETIME formátumú, így vannak benne az adatok: "2021-02-04 20:00:00". Én ebből az oszlopból mindig csak a dátumra kérdezek le így: CAST(DATETIME AS DATE).
Hogyan lehet indexelni ezt a dátumra történő lekérdezést? Ha az egész oszlopot indexelem, úgy nem jó, mert csak a dátumra kérdezek le, így az indexelés hatástalan.column BETWEEN dátum 00:00:00 AND dátum 23:59:59 ?
De MySQL 8 ban már vannak functional indexek, amikkel indexelni tudod a formázott tartalmat.
Vagy akár csinálhatsz egy virtuális generált oszlopot is amit lehet indexelni.
Épp ilyesmivel dolgozom. Fun
-
Panhard
tag
Sziasztok. Adatbázisban van egy oszlopom, ami DATETIME formátumú, így vannak benne az adatok: "2021-02-04 20:00:00". Én ebből az oszlopból mindig csak a dátumra kérdezek le így: CAST(DATETIME AS DATE).
Hogyan lehet indexelni ezt a dátumra történő lekérdezést? Ha az egész oszlopot indexelem, úgy nem jó, mert csak a dátumra kérdezek le, így az indexelés hatástalan. -
instantwater
addikt
1064 syntax, azért kell kétszer mert - bár ezek csak kitalált táblanevek - mindkét tábla ugyan olyan adatokat tartalmaz, viszont ki kell egészítsék egymást. mert lehet, hogy az egyik táblában ugyan azon id-hez nincsen adat.
Ha nagyon minden kötél szakad 2 külön UPDATE utasításba lehetne szétszedni.
igen, ez van mostMivel egy táblában egy mezőt updatelsz, esetleg meg lehet próbálni a 2 forrástáblát összekapcsolni UNIONnal vagy JOINnal, és azt átadninaz updatenek.
Mi a baj a 2 külön updatevel?
Az a baj, hogy látni kellene a valós neveket, célokat, és okokat.
Lehet, hogy te az updatet akarod megerőszakolni, de lehet, hogy a valóságban egy másik megközelítés lenne jobb. -
Agostino
addikt
Mi a hibaüzenet?
Miért kell 2x updatelni ugyanazt a mezőt?
Elegendő lenne csak a második subselect?Ha nagyon minden kötél szakad 2 külön UPDATE utasításba lehetne szétszedni.
1064 syntax, azért kell kétszer mert - bár ezek csak kitalált táblanevek - mindkét tábla ugyan olyan adatokat tartalmaz, viszont ki kell egészítsék egymást. mert lehet, hogy az egyik táblában ugyan azon id-hez nincsen adat.
Ha nagyon minden kötél szakad 2 külön UPDATE utasításba lehetne szétszedni.
igen, ez van most -
instantwater
addikt
sziasztok
az egyik updatemet szeretném továbbfűzni és sejtem is, hogy mi a baja, miért nem fut le, de azért ha lehetséges és van megoldás, akkor élnék vele. a következőt kell elképzelni:
UPDATE rendeles SET
datum = CONCAT(datum,'01'),
mennyiseg = (
SELECT rendeles_mennyiseg
FROM rendelestabla1
WHERE rendeles_id1 = mrendeles_id
) WHERE mennyiseg IS NULL, /*ez tudom fölös*/mennyiseg = (
SELECT rendeles_mennyiseg
FROM rendelestabla2
WHERE rendeles_id2 = mrendeles_id
) WHERE mennyiseg IS NULL;egyetlen oszlopot kellene kétszer updatelnem de mindig csak azokat a sorokat, ahol a mennyiseg NULL, azért, hogy a már lefutott első updatet a második ne bántsa. tippre az a baja, hogy zárójelben lévő select utáni WHERE nem jön be neki. ha külön-külön lemegy a három UPDATE nincsen semmi gond, egyszerűen csak jó lenne, ha egyetlen menetben lefutna minden.
Mi a hibaüzenet?
Miért kell 2x updatelni ugyanazt a mezőt?
Elegendő lenne csak a második subselect?Ha nagyon minden kötél szakad 2 külön UPDATE utasításba lehetne szétszedni.
-
Agostino
addikt
sziasztok
az egyik updatemet szeretném továbbfűzni és sejtem is, hogy mi a baja, miért nem fut le, de azért ha lehetséges és van megoldás, akkor élnék vele. a következőt kell elképzelni:
UPDATE rendeles SET
datum = CONCAT(datum,'01'),
mennyiseg = (
SELECT rendeles_mennyiseg
FROM rendelestabla1
WHERE rendeles_id1 = mrendeles_id
) WHERE mennyiseg IS NULL, /*ez tudom fölös*/mennyiseg = (
SELECT rendeles_mennyiseg
FROM rendelestabla2
WHERE rendeles_id2 = mrendeles_id
) WHERE mennyiseg IS NULL;egyetlen oszlopot kellene kétszer updatelnem de mindig csak azokat a sorokat, ahol a mennyiseg NULL, azért, hogy a már lefutott első updatet a második ne bántsa. tippre az a baja, hogy zárójelben lévő select utáni WHERE nem jön be neki. ha külön-külön lemegy a három UPDATE nincsen semmi gond, egyszerűen csak jó lenne, ha egyetlen menetben lefutna minden.
-
coco2
őstag
Sziasztok!
Használ valaki mysql ndb cluster-t mostanában? Üzemeltetési tapasztalatok / stabilitás érdekelne főleg, meg hogy a folyamatos frissítések mennyi hibával érkeznek hozzá?
Memory engine-t használok jelenleg, és a mysql doksik azt tanácsolják, érdemesebb átnézni az áttérés lehetőségeit, azért tettem fel a kérdést.
-
 sonar
addikt
sonar
addikt
működik köszönöm
elkerülte a figyelmem
esetleg azt hogyan tudom elérni hogy be is töltse a találatokat?
mert most engedi már görgetni de pár ezret azért hosszadalmas..
(20-30 at betölt és ahogy görgetek úgy tölti be folyamatosan)kodi adatbázisáról van szó
ami most még csak a gépemen fut
de tervezem hogy routerre teszem
ott tényleg nem lenne jó egyszerre mindent betölteni
köszi a fegyelmeztetéstÉn a workbenchet szoktam használni ott nincs ilyen betöltési gond.
-
 Hege1234
addikt
Hege1234
addikt
Workbenchnél ott a legördülő menü, ahol lehet variálni a limiteket. De ahogy nézem ennél az ETL-nél is ott a lehetőség, jobbra fent. Szerintem ha 0-ra állitod akkor nem lesz limit a lekérdezésnél.
De azzal legyél tisztában, hogy ha nagy a tábla akkor egy fullos lekérdezés meg tudja akasztani az adatbázis szervert.működik köszönöm
elkerülte a figyelmem
esetleg azt hogyan tudom elérni hogy be is töltse a találatokat?
mert most engedi már görgetni de pár ezret azért hosszadalmas..
(20-30 at betölt és ahogy görgetek úgy tölti be folyamatosan)kodi adatbázisáról van szó
ami most még csak a gépemen fut
de tervezem hogy routerre teszem
ott tényleg nem lenne jó egyszerre mindent betölteni
köszi a fegyelmeztetést -
sonar
addikt
Sziasztok!
a etl database browser-be megoldható valahogy a limit eltörlése vagy megnövelése?
most alapból 1000-en van
vagy a mysql workbench-nél van esetleg egyszerűbb és tudja a limit állítást?Workbenchnél ott a legördülő menü, ahol lehet variálni a limiteket. De ahogy nézem ennél az ETL-nél is ott a lehetőség, jobbra fent. Szerintem ha 0-ra állitod akkor nem lesz limit a lekérdezésnél.
De azzal legyél tisztában, hogy ha nagy a tábla akkor egy fullos lekérdezés meg tudja akasztani az adatbázis szervert. -
Hege1234
addikt
Sziasztok!
a etl database browser-be megoldható valahogy a limit eltörlése vagy megnövelése?
most alapból 1000-en van
vagy a mysql workbench-nél van esetleg egyszerűbb és tudja a limit állítást? -
SunyaMacs
aktív tag
A SET MYSQL=%MYSQLEXE% -h adatbázis név -u felhasználónév -pjelszó végére beírtam a -default-character-set=utf8mb4-et és így jó lett a phpmyadminban is.
Köszönöm szépen

Örülök, hogy megoldódott
Régebben a logout-on volt egy kisebb fanyalgásom a témáról, lehet érdekes lesz számodra. -
 Atomantiii
addikt
Atomantiii
addikt
A SET MYSQL=%MYSQLEXE% -h adatbázis név -u felhasználónév -pjelszó végére beírtam a -default-character-set=utf8mb4-et és így jó lett a phpmyadminban is.
Köszönöm szépen
-
SunyaMacs
aktív tag
Most nézem, hogy elvileg a cmd kódlapját is lehet állítani, most 852-esen (OEM - latin II)-őn van. De annak jónak kellene lennie, mert abban benne vannak a magyar karakterek.
Én a biztonság kedvéért a batch script elején a cmd kódlapját 65001-re állítanám, hogy egyezzen. A --default-character-set=utf8mb4 paramétert a #2125 hsz-ed utolsó sora szerinti kódhoz írnám a jelszó után, úgy remélhetőleg nem kéne hibát dobnia.
-
Atomantiii
addikt
Most nézem, hogy elvileg a cmd kódlapját is lehet állítani, most 852-esen (OEM - latin II)-őn van. De annak jónak kellene lennie, mert abban benne vannak a magyar karakterek.
-
Atomantiii
addikt
Most így van benne:
SET MYSQLEXE="c:\Program Files\MySQL\MySQL Workbench 8.0 CE\mysql.exe"
SET MYSQLDUMPEXE="c:\Program Files\MySQL\MySQL Workbench 8.0 CE\mysqldump.exe"Viszont akárhogy próbálom nem akarja elfogadni, hogy lefusson hiba nélkül. Bár biztos én bénázok.
Illetve utána így mondja meg neki, hogy melyik adatbázissal és felhasználóval csinálja meg.
SET MYSQL=%MYSQLEXE% -h adatbázis név -u felhasználónév -pjelszó
-
SunyaMacs
aktív tag
Win Server 2016-os-on egy bat fájl hívja meg az sql fájlt és a MySQL Workbench 8.0 CE\mysql.exe-t használja hozzá.
Ez a --default-character-set a bat fájlba kellene?
Igen, oda, ahol meghívja az exe fájlt és oda utána írva paraméterként.
-
Atomantiii
addikt
Az SQL queryt milyen környezetből / honnan futtatod? Pl. ha cmd-ből, akkor lehet, hogy régebbi Windowson az nem utf-8 módban van, vagy a csatlakozásnál valamilyen ok miatt nem utf8mb4 a charset az, amit a kliens használ és külön be kell állítani a
--default-character-setparaméterrel.Win Server 2016-os-on egy bat fájl hívja meg az sql fájlt és a MySQL Workbench 8.0 CE\mysql.exe-t használja hozzá.
Ez a --default-character-set a bat fájlba kellene?
-
SunyaMacs
aktív tag
Ugyanaz a helyzet MySql Workbenchben is, mint phpmyadminban. Ha sql-ként hozom létre nem jó, ha átírom utána jó lesz.
Az SQL queryt milyen környezetből / honnan futtatod? Pl. ha cmd-ből, akkor lehet, hogy régebbi Windowson az nem utf-8 módban van, vagy a csatlakozásnál valamilyen ok miatt nem utf8mb4 a charset az, amit a kliens használ és külön be kell állítani a
--default-character-setparaméterrel. -
Atomantiii
addikt
Megnézted pl. Mysql Workbenchben?
Ugyanaz a helyzet MySql Workbenchben is, mint phpmyadminban. Ha sql-ként hozom létre nem jó, ha átírom utána jó lesz.
-
 Ivy.4.Ever
őstag
Ivy.4.Ever
őstag
Kezdem feladni...
Ha sql-ből csinálok egy új táblát phpmyadminba egy már létezőbe beszútrva, akkor azt megcsinálja szépen, csak az ékezetes karakterek nem jelennek meg normálisan a komment részben az oszlop fejlécében.
Ha van egy másik táblám aminél jók phpmyadminban a komment résznél az ékezetek és úgy ahogy van átmásoltatom sql-ben egy másik táblaként, akkor ugyanúgy rosszak lesznek a komment részben a karakterek.
Ha az elrontott ékezetes betűket átírom phpmyadminban, utána szépen megjelennek az ékezetes karakterek ott is. Most már nem értem mi lehet a baja, miért nem jó ha sql-ből hozom létre.
Megnézted pl. Mysql Workbenchben?
-
Atomantiii
addikt
Benne van amit én akarok amúgy.
Kezdem feladni...
Ha sql-ből csinálok egy új táblát phpmyadminba egy már létezőbe beszútrva, akkor azt megcsinálja szépen, csak az ékezetes karakterek nem jelennek meg normálisan a komment részben az oszlop fejlécében.
Ha van egy másik táblám aminél jók phpmyadminban a komment résznél az ékezetek és úgy ahogy van átmásoltatom sql-ben egy másik táblaként, akkor ugyanúgy rosszak lesznek a komment részben a karakterek.
Ha az elrontott ékezetes betűket átírom phpmyadminban, utána szépen megjelennek az ékezetes karakterek ott is. Most már nem értem mi lehet a baja, miért nem jó ha sql-ből hozom létre.
-
Atomantiii
addikt
-
Agostino
addikt
Phpmyadminban annyit látok, hogy a server charset: UTF-8 Unicode (utf8), míg a server connection collation utf8mb4_unicode_ci-re van állítva
ALTER TABLE parancs nem kellene? emlékeim szerint pusztán a DB charset állítása nem húzza be TABLE-ben is a változtatást. de lehet rosszul emlékszem. megnézném azért a tábla mit csinál...
-
Atomantiii
addikt
Phpmyadminban annyit látok, hogy a server charset: UTF-8 Unicode (utf8), míg a server connection collation utf8mb4_unicode_ci-re van állítva
-
instantwater
addikt
Nézd meg terminálban vagy valami desktop klienssel.
Ha ott jó, akkor a PHPMYADMIN karakterkódolása a rossz.
Nézd meg a HTML és HTTP headert is, mindkét helyen UTF8nak kell szerepelni. -
nevemfel
senior tag
Nem ismerem a phpmyadmin-t, de valahogy nyilván abban is be kell állítani a charsetet és a collationt is.
Ja nem, ez más. A webszervert kell beállítani, hogy a standard fejlécbe ne tegyen content-type charset beállítást is.
-
Atomantiii
addikt
Igen így már elfogadja, köszi.
Viszont a végeredmény phpmyadminban sajnos ugyanaz.
-
nevemfel
senior tag
Köszi, sajnos nem szereti. Beírtam így:
DEFAULT CHARSET=utf8 COLLATE=utf8mb4_general_ci-ként beírtam, azt mondja rá, hogy COLLATION 'utf8mb4_general_ci' is not valid for CHARACTER SET 'utf8'
Van amit elfogad, de azok meg nem ismerik ugyanúgy a magyar karaktereket.
Az összes utf8mb4 kezdetű sorrendezés az utf8mb4 karakterkiosztáshoz tartozik. A te esetedben ez:
DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ciEgyébként ahogy olvasom, a
utf8mb4_general_ciheylett jobb azutf8mb4_unicode_ci -
Atomantiii
addikt
Nekem sima utf8-at nem ismer a MariaDB. Vagy használd a COLLATE szót is. Ilyen van hogy utf8mb4_general_ci pl azon belül. Egyébként az mb4-eseket ajánlott használni ha már utf8. Gyakori probléma forrás.
Köszi, sajnos nem szereti. Beírtam így:
DEFAULT CHARSET=utf8 COLLATE=utf8mb4_general_ci-ként beírtam, azt mondja rá, hogy COLLATION 'utf8mb4_general_ci' is not valid for CHARACTER SET 'utf8'
Van amit elfogad, de azok meg nem ismerik ugyanúgy a magyar karaktereket.
-
Ivy.4.Ever
őstag
Arra van ötlete valakinek, hogyan lehetne megoldani ékezetes problémát phpmyadminban a komment résznél?
Tehát sql-ben meg van írva a tábla szerkezete
CREATE TABLE IF NOT EXISTS `valami`.`valami` (
`oszlop1` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`oszlop2` varchar(40) NOT NULL COMMENT 'Név',
stb
CURRENT_TIMESTAMP COMMENT 'Módosítás időpontja',
PRIMARY KEY (`oszlop1`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=35 ;Ha megnézem az adott táblát phpmyadmin alatt, akkor az ékezetes karakterek helyett más jelenik meg a komment sorban, pedig phpmyadminban a kiszolgáló karakterkódolása: UTF-8 Unicode (utf8)-ra van állítva.
Nekem sima utf8-at nem ismer a MariaDB. Vagy használd a COLLATE szót is. Ilyen van hogy utf8mb4_general_ci pl azon belül. Egyébként az mb4-eseket ajánlott használni ha már utf8. Gyakori probléma forrás.
-
Atomantiii
addikt
Arra van ötlete valakinek, hogyan lehetne megoldani ékezetes problémát phpmyadminban a komment résznél?
Tehát sql-ben meg van írva a tábla szerkezete
CREATE TABLE IF NOT EXISTS `valami`.`valami` (
`oszlop1` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`oszlop2` varchar(40) NOT NULL COMMENT 'Név',
stb
CURRENT_TIMESTAMP COMMENT 'Módosítás időpontja',
PRIMARY KEY (`oszlop1`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=35 ;Ha megnézem az adott táblát phpmyadmin alatt, akkor az ékezetes karakterek helyett más jelenik meg a komment sorban, pedig phpmyadminban a kiszolgáló karakterkódolása: UTF-8 Unicode (utf8)-ra van állítva.
-
Panhard
tag
-
SunyaMacs
aktív tag
Sziasztok! Adatbázisban szeretnék utólag legenerálni egy új oszlopba, soronként unixtime-ot, meglévő dátum és idő mezőkből.
Addig megvan a kód, hogy fix dátum, idő értékből megcsinálja, de hogy tudom a dátum és idő helyére beírni a dátum és idő mezők értékeit?UPDATE database SET timestamp = UNIX_TIMESTAMP('2020-09-19 16:00:00') where sorszam < 100UPDATE idotabla t
SET t.timestamp = FLOOR(UNIX_TIMESTAMP(CONCAT(t.date, " ", t.time))) -
Panhard
tag
Sziasztok! Adatbázisban szeretnék utólag legenerálni egy új oszlopba, soronként unixtime-ot, meglévő dátum és idő mezőkből.
Addig megvan a kód, hogy fix dátum, idő értékből megcsinálja, de hogy tudom a dátum és idő helyére beírni a dátum és idő mezők értékeit?UPDATE database SET timestamp = UNIX_TIMESTAMP('2020-09-19 16:00:00') where sorszam < 100 -
 JohnD
tag
JohnD
tag
A mariadb szervert kapcsold le addig vagy az elérési portját állítsd be mindkettőnek ne legyen azonos és jegyezd meg, majd azt add meg a kód a connectnél.
Jó, azóta meglett már, köszi!
-
Ivy.4.Ever
őstag
Helló! Wampserver 3.2.0-t használva a következő probléma adódik: php-ből mysql parancsokkal csatlakoznék a mysql szerverhez, de a mariadb-hez csatlakozik, a phpmyadminban a mariadb alatt létrehozott adatbázishoz csatlakozik, az az alatti táblát tudom csak lekérdezni. Mi lehet a gond? Vmi konfigurációs probléma szerintem. Köszi a segítséget!
A mariadb szervert kapcsold le addig vagy az elérési portját állítsd be mindkettőnek ne legyen azonos és jegyezd meg, majd azt add meg a kód a connectnél.
-
mlaci01
tag
Sziasztok,
Hátha tud valaki segíteni.
Van két táblám:
T1: T1m1,T1m2,T1m3,T1m4,T1m5,T1m6,T1m7,T1m8
T2: T2m1,T2m7,T2m8
INSERT csak a T1 táblára van annak mikéntjére nincs ráhatásom.
Szeretném INSERT-kor ha a (T1m7+T1m8) megtalálható a (T2m7+T2m8)-ban,
akkor a T2m1 mező értéke automatikusan beíródna a T1m6-ba.
Remélem érthetően fogalmaztam.
Előre is köszönöm a segítséget.
L, -
JohnD
tag
Helló! Wampserver 3.2.0-t használva a következő probléma adódik: php-ből mysql parancsokkal csatlakoznék a mysql szerverhez, de a mariadb-hez csatlakozik, a phpmyadminban a mariadb alatt létrehozott adatbázishoz csatlakozik, az az alatti táblát tudom csak lekérdezni. Mi lehet a gond? Vmi konfigurációs probléma szerintem. Köszi a segítséget!
-
 bozsozso
őstag
bozsozso
őstag
Na elhamarkodtam, mert IBExpert-ben ezek a függvények nem működnek, de azért hasznos mindenképpen.





















 ez alapján is:
ez alapján is:


![;]](http://cdn.rios.hu/dl/s/v1.gif)






 De máshol ezzel semmi gond nincs. Szuper....
De máshol ezzel semmi gond nincs. Szuper....





















 Talán még nem nyílt nagyot az olló a kettô között.
Talán még nem nyílt nagyot az olló a kettô között. 













Új hozzászólás Aktív témák
-
Fórumok
PROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív

- Yettel topik
- Milyen videókártyát?
- Óra topik
- A Linux megnégyszerezte magát a Steamen — a Microsoft ismét ígérget
- Milyen monitort vegyek?
- Befellegzett a Destiny 2-nek, júniusban jön az utolsó frissítés
- Milyen okostelefont vegyek?
- Meglepően árazta az AMD a Ryzen AI Halo minigépet
- Milyen billentyűzetet vegyek?
- Xbox tulajok OFF topicja
- További aktív témák...

- Garanciális samsung galaxy watch 8 classic
- Samsung QVO 870 SSD (1 TB) 100/100%
- Új, bontatlan - Apple MacBook Air 13 M4 16/256GB - Sky Blue
- Új Dobozos ASUS VivoBook Go 15 Laptop 15,6" -20% Ryzen 5 7520U 16/512 Radeon Graphics FHD OLED
- Új HP ZBook Firefly 16 G10 Profi Tervező Vágó Laptop -50% i7-1355U 16/1TB FHD+ RTX A500 4GB
- AKCIÓ! Dell XPS 13 9305 13 FHD üzleti notebook -i5 1135G7 8GB DDR4 512GB SSD Intel IRIS XE W11
- Gamer PC-Számítógép! Csere-Beszámítás! I5 7600K / GTX 1070 8GB / 16GB DDR4 / 256 SSD + 1TB HDD
- Apple iPhone 14 Pro Max 128GB Purple - Megkímélt állapot - 100% akku
- Samsung Odyssey G3 S24AG320NU VA Monitor! 1920x1080 / 165Hz / 1ms / FreeSync
- BESZÁMÍTÁS! 8TB WD RED WD80EFAX HDD meghajtó garanciával hibátlan működéssel
Állásajánlatok

Cég: aiMotive Kft.
Város: Budapest

Cég: Laptopműhely Bt.
Város: Budapest