Hirdetés
- Dedikált NPU-t tervezne az AMD?
- És akkor egy fejlesztőstúdió rájött, hogy vissza is élhetne a felskálázással
- Száguld a Meta és a Microsoft, 500 milliárd dollárral lőttek ki az AI-részvények
- Jól áll az ARM-os Windows helyzete, de a játékoknál nem jön az áttörés
- Kínai kézbe kerül a MediaMarkt áruházak tulajdonosa
- Milyen belső merevlemezt vegyek?
- Milyen processzort vegyek?
- TCL LCD és LED TV-k
- HiFi műszaki szemmel - sztereó hangrendszerek
- RAM topik
- Azonnali fotós kérdések órája
- Jól áll az ARM-os Windows helyzete, de a játékoknál nem jön az áttörés
- Dedikált NPU-t tervezne az AMD?
- Kettő együtt: Radeon RX 9070 és 9070 XT tesztje
- Épített vízhűtés (nem kompakt) topic
Hirdetés
Talpon vagyunk, köszönjük a sok biztatást! Ha segíteni szeretnél, boldogan ajánljuk Előfizetéseinket!
-

PROHARDVER!
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
Ezt értem - ez egy, a szokásosnál nagyobb szürkezóna, ahol megfelelő rutinnal és érzékkel lehet ügyesen navigálni.
(#25699) Abu85: igen, ez így világos. Innentől belemegy egy nagy adag szubjektivitás, hogy mit lehet, és mit nem. Van, aki óvatos lesz, és betűre betartja a leghülyébb kéréseket is, és van, aki feszegeti a határokat. Esetleg ráb***ik

-

Abu85
HÁZIGAZDA
Nem is hallottam olyanról, hogy valakin behúzták volna a pénzbüntetéseket. Nálam is volt olyan, hogy olyat írtam meg, amit nem lett volna szabad. Persze annak már 7-8 éve, de annyi történt, hogy ránk írt helyi PR, hogy nem kellett volna megírni, és hogy töröljük már le. Megtettük, utána picit nyaliztunk, hogy nem-e lehetne az, hogy figyelmen kívül hagyjuk ezt, és lényegében megtették, minden ment tovább, ahogy korábban. Tehát alapvetően rémisztőnek hangzik ami ezekben van, de még ha be is perelnek, akkor is kicsi az esélye, hogy fizetned kell a szabályok megszegéséért, mert túlmegy egy határon, amit kérnek. Ugyanakkor arra képesek, hogy legközelebb nem hívnak meg a briefingekre, ami eléggé kellemetlen egy médiának, és ott be se tudod őket perelni, mert szabadon eldöntheti egy gyártó, hogy melyik médiával akarja tartani a kapcsolatot. Szóval ezek nagyrészt nem jogi szinten problémásak, az levédhető, de ha sűrűn szeged meg a leírtakat, akkor ráraknak a blacklistre, és onnantól kezdve sokkal rosszabb lesz neked.
Ez addig működik, amíg kedvezőbbnek érzed azt, amit ők kínálnak, mint az NDA-n kívüli tevékenységet, és általában kedvezőbb az NDA-n belüli kapcsolattal dolgozni, mert egyrészt időre tudsz híreket, jobb esetben teszteket csinálni, másrészt nem írsz marhaságot a megjelenés előtt.
-

lenox
veterán
mind a titoktartási témakör jogi kereteivel
Nyilvan mindig lehet kerni, hogy valami hulyeseget irj ala, es ugy is alairhatod, hogy tudod, hogy nem lehet jogi kovetkezmenye egy reszenek. De itt olyan is van, hogy ha nem tartod be, akkor legkozelebb nem kapsz infot vagy hw-t, tehat valoszinuleg a jozan esz es a jogi kereteken tulmenoen is van aki betartja. -
Abu85
HÁZIGAZDA
Nincs kivétel. Lényegében az áll benne, hogy minden ami elhangzott a briefingen, benne van a press deckben, illetve a review guide-ban, kiemelve a terméknevek teljes vagy részletes közlését (fel vannak sorolva a számok és nevek), tilos. Semmi kivétel nincs. Az is ki van emelve, hogy más forrásra sem lehet hivatkozni/linkelni, amelyben benne vannak a tiltott részletek (fel vannak sorolva a számok és nevek).
-
Abu85
HÁZIGAZDA
De, azért a típusnévért mindig felelősségre vonható az NDA-t aláíró személy, amelyik típusnéven jön a hardver. Mindegy, hogy valaki ezt pletykálja, vagy ír hozzá még több betűt, hogy másként tüntesse fel. Ha aláírta, akkor nem írhatja le. Ezek a cégek nem amatőrök, egészen konkrétan meg van jelölve, hogy mit nem lehet csinálni, és az alapján Igor NDA-t sért, de valószínűleg nem is írt alá semmit, hiszen 99%-ban faszságokat írt, még a nevet sem találta el teljesen. Csak abból indulj ki, hogy ha állítólag tudsz mindent, akkor mi értelme marhaságot írni a megjelenés előtt? Az NDA-t már megsértette, hiszen leírta azt a jelölést, még ha nem is pontosan, ahogy jön.
(#25688) b. : De ezzel nem tudod magad felmenteni. Egészen konkrétan le van írva, hogy mit nem lehet leírni az NDA előtt, ha aláírtad. Nem úgy van megfogalmazva, hogy ha a bolygók együttállása úgy hozza, akkor egy adott pillanatban megjelentethető egy adott cikk, amiben plusz betűket hozzáírva benne lehet a konkrét terméknév. Nem, ilyen nincs. Konkrétan idézőjelben ott van, hogy ha leírod azt a négy számot, akkor megsérted az NDA-t, a bolygók együttállásától és a különböző földönkívüli forrásoktól függetlenül.
Nézd nem én írtam fals neveket a grafikonba. Ha tudná, hogy mi jön, akkor erősen kétlem, hogy ilyet kiad. Nem látom értelmét annak, hogy rossz terméknevekkel, rossz adatokat közöljek, gyakorlatilag pár alvásra a hivatalos bejelentéstől. Szerinted ennek mi értelme, ha mindent tud?
Mivel az AMD közös folderből dolgozik, így aki aláírta az NDA-t, azok ugyanannyit tudnak, tehát mi is ugyanazt látjuk, amit a többi média. Ezen belül ugye van briefing felvétel, press deck, review guide, képek és driverek. Na most a review guide alapján még becsülni sem kell a teljesítményt, hiszen ott van benne lemérve.
(#25690) Pipó: Azt is írhatod a végére, hogy a nagyon tisztánlátó öregapóm hallucinált, és onnan vannak az adatok. Ha aláírtad az NDA-t, akkor azt megsérted így is.
Én is pörgetnék amúgy ilyen híreket, mert nagyon sok olvasót hoz, de tényleg úgy van megfogalmazva az NDA az AMD és az NV esetében is, hogy erősen le vannak védve. Az NV-nél a múltkor az is része volt ennek, hogy ha azt leírod, hogy egy hajléktalan kicsi kínai szerint állítólag jön valami új. Ennyi, kész, még típust sem kell ott írni, és máris véged van. Szóval hiába hoz kattintást, nem véletlen, hogy mondjuk mi nem pörgetjük ezt, mert rohadtul le vannak védve, és marhára nagyot kell kamuzni ahhoz, hogy ne kapják el a nyakadat. De úgy meg minek írni bármit a megjelenés előtt, ha csak hazudni tudsz róla?
-
lenox
veterán
-

b.
félisten
gyakorlatilag ha elolvastad volna a cikket az első bekezdésben leírja a választa felvetésedre.
"Of course, I can’t leak anything that manufacturer A or N may have given me in terms of information. The so-called NDAs help against this. Whereby this is not seen so narrowly in Asia rather."
Mivel megjelöl forrásként oldalakat a cikkéhez, (WCC/ egy ázsiai site ) ezért azokat az elnevezéseket használja, mert ezzel nem szegi meg az NDA-t az eredményekre meg természetesen azt írja, hogy becsült, de ugye elég neves oldalról van szó ezért elég jó eséllyel vehető, hogy hasonló lesz a felállás, mert már képben van. Nem tudom miből gondolod, hogy te több infóval rendelkezel mint az igorslab,vagy fordítva, hogy egy ilyen menő site mint ő ( k) nem kap legalább annyi infót mint te a PH ról...
Toms'hardver újságírója . -
Nagyon jó. Tehát a kettő messze nem ugyanaz, jelen esetben pl. időzítés szempontból sem. Haladunk
Akkor már csak azt kell megugrani, hogy ha a WTFTech lehozza, hogy az AMD megjelenteti az 5500-at, az 5600-at, az 5800-at és az 5999-et, akkor onnantól kezdve senki nem vonható felelősségre ezen típusnevek használatáért. -
Abu85
HÁZIGAZDA
7 nm-es GPU-t drágább gyártani, mint 12/14 nm-est. Így marad mindkettő. Ha olcsóbb kell, ott a régi. A GlobalFoundries és a GDDR5 előnyös koncepció az ár tekintetében, amivel semmi sem tud versenyezni jelenleg, így megéri megtartani a régi hardvereket, mert gyártani is olcsó őket, így le lehet vinni az árat jelentősen. Olyan szintre, ahova a nem GlobalFoundriesnél gyártott megoldások nem tudják követni.
-
Abu85
HÁZIGAZDA
Miért égetnéd magad ezzel, amikor pár nap alatt kiderül, hogy hülyeséget írtál? Az NDA-t így nem lehet megkerülni, mert részleges névközlés is szabályozva van benne, vagyis ha egy terméket "Marikának" hívnak, de te úgy írod le, hogy "Marikának a bulája", akkor attól még megszeged az NDA-t, mert benne van a "Marikának" jelzés, amit tilos leírni.
-
Abu85
HÁZIGAZDA
Ha ezeket a típusokat írja fel gyakorlatilag alig a start előtt, akkor kétlem, hogy van bármilyen pontos infója. Nem véletlenül írtam, hogy ilyen Radeonok nem lesznek.
Még ha hetekre vagyunk a bejelentéstől, akkor elhiszem, hogy xy OEM ezeket mondja, de napok vannak hátra már csak.
-

Segal
veterán
Ez az én meglátásom hogy ha "muszáj" lenne kijönni valami új csúccsal akkor röhögve meg tudnák oldani holnapra is de mivel semmi sem indokolja ezért nem kell kapkodni.
Most a középkategória jön amd-től és egész véletlenül nvidiától is...
Ha az 5800-as jönne amd-től akkor viszont nem a középkategória jött volna nvidiától hanem a felsőkategória. -
b.
félisten
Na itt a várható felállás az érkező mid és low range kártyákról:
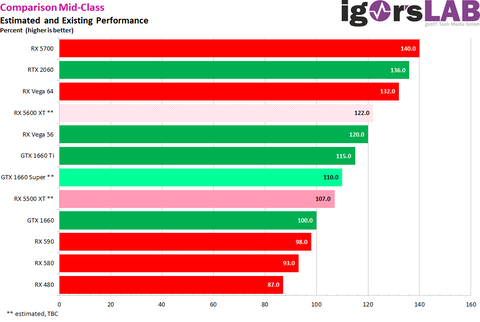
És egy elég fontos infó még innen [igorslab] ahonnan a kép jött:
"Whereby up to the half of the year 2020 Ampere should finally come (I had already written something about it from time to time). As a middle class offer, as it was said from various sources and then also with a smaller structure width. Because obviously Nvidia doesn’t dare to get close to the big guys right at the beginning, but practices with light sailors. "Tehát 2020 első felében itt lesznek az új kártyák:
-
Segal
veterán
Ez ugye leginkább az 5800-as bejelentésétől függ mert ha nagyon akarnák az nvidia már holnap is jöhetne az új szériával de ugye egyelőre minek ha nincs konkurencia. Inkább csiszolgatják, aztán ha az amd majd jön a "világverő" kártyájával ami izzadva picit erősebb mint a 2080Ti akkor nvidia kiröhögi az új szériával

-
Abu85
HÁZIGAZDA
válasz
 adamssss
#25657
üzenetére
adamssss
#25657
üzenetére
A Gen12 lehet más. A Gen11 csak az Ice Lake IGP-je marad, sosem lesz belőle dedikált GPU. A Gen12-ről meg nem lehet tudni sokat. Mármint az EU száma eléggé világos, de ugye pont nem ez a lényeg, hanem ami ezeken belül van. Ugye ez az RDNA-n is látszik. Ott is sokkal kevesebb multiprocesszor van a Navi 10-ben. Szám szerint 20, és veri a 64 multiprocesszoros Vega 64-et. Tehát pusztán a multiprocesszorok számából sok nem derül ki.
-
Abu85
HÁZIGAZDA
válasz
adamssss
#25655
üzenetére
Nem az a baja a Gen11-nek. A motorok is jól kezelik, ahogy a driver is elég jó. A Vulkan implementáció főleg. Viszont a hardver még mindig régi co-issue felfogású, ami lehet, hogy jó egy CS:GO esetében, de tök hasztalan egy modern játéknál, mert a feldolgozón belül az ALU-k fele címezhetetlen, tehát effektíve elveszti a teljesítmény felét. Egyedül címfordításra jó ilyenkor a másodlagos SIMD. Ezért is van az, hogy a régebbi játékokban jobb, mint a Ryzenben a Vega 10, míg az új játékokban rosszabb. Szóval alapvetően még mindig a nyers erő hiányzik, csak annyira sok tranzisztort elvisz a hatalmas regiszterterület, hogy nincs lehetőség több ALU-t beépíteni.
-
-

Cifu
félisten
válasz
adamssss
#25653
üzenetére
A "mindig" ugye egy próbálkozást jelentett, azt benézték, nem picit.
A notebook IGP terén pedig a Gen11 már elég ütős lett az Iris Pro jelölésű változatoknál, a 64EU-s G7-el felér az AMD féle Vega 10-el (notebook Ryzen 7), még ha bő egy évvel fiatalabb is annál.Persze az is tény, hogy az Intel még csak most bontogatja a szárnyait az Xe-vel, de egyszerűen másban már nem nagyon lehet bízni. Az nVidia kényelmesen elcsücsül a dVGA-k trónján, az AMD meg függően attól, hogy nézzük, 5-8 éve csak próbálja utolérni a zöldeket, mindig halljuk, hogy majd a Polaris, majd a Vega, majd a Navi, aztán mindig azt látjuk, hogy hiába a nagy ígéretek, valahogy sose sikerül a trónfosztás...
-
Cifu
félisten
válasz
adamssss
#25650
üzenetére
Semmi érdemi nem szivárgott ki, az Ampere kapcsán, annyi hír volt az elmúlt egy évben, hogy a Samsung 7nm-es gyártósorát (esetleg EUV-vel) is felhasználhatja a gyártásra az nVidia, de a hírek szerint a TSMC-nél is rendelt kapacitást.
Ennyi és nem több. Ray-Tracing terén sincs info tehát.
Én nagyon úgy látom (de hát én csak egy laikus vagyok), hogy az nVidia továbbra is akkora előnyben van a Turing-al, hogy még jövő év közepéig-végéig simán elhúzhatja az Ampere megjelenését, mert a Navi nem jelent valós veszélyt számára, maximum az extra profitot egy kicsit lejjebb engedik az árazásnál, de valódi árversenyre nincs esély, teszem hozzá sajnos...

Én már tényleg csak abban bízom, hogy az Intel Xe felkavarja végre ezt a poshadt állóvizet a dVGA-k piacán, és újra versenyt fogunk látni a gyártók részéről a vásárlókért...
-
b.
félisten
remélem így lesz, nagyon lecserélném a projektorra rákötött gépembe már a VGA-t ( 750 Ti) néha alkalmi játékra is jó lenne 2 méteren
Igazából az 1650 10-20 % kal gyengébb ( játéktól függően) mint az 570, szóval én kb annaka környékére várom az 1650 Ti-t vagy super mindegy hogy hívom.( optimistán azt remélem hogy azért az Rx 580 és 570 között lesz) Az szenzációs lenne 75 wattból,12 nm-n, elsők között venném meg. -

Z10N
veterán
-
Z10N
veterán
The leak from Gigabyte indicates that the rumored GeForce GTX 1650 Ti might, in fact, be called GTX 1650 SUPER.
According to the listing, GTX 1660 SUPER features 6GB of memory, while the GTX 1650 SUPER comes with 4GB onboard. -
b.
félisten
Jogos az észrevételed,Érdemesebb a 2070 super és a 2080 kártyákat összevetni inkább ott nem ilyen mérési hibahatárról beszélünk, hanem 15 % kal kevesebb az RT számolóegységek száma azonos GPu és sávszél mellett.
Itt talán jobban látszik a 2070 Super Vs 2080 közötti különbség az a 15 % kb a Port Royale benchben.
[link] -
lenox
veterán
Annyi a gond, hogy a ket kartyan (2070 vs 2080) ugyanaz a savszelesseg, 2070-en kisebb az fps, tehat ott a sugarkovetes se hasznal annyi savszelt, tehat nem a savszel a limit a 2070-en. Kiprobaltam a kedvedert a sajat gepemen (rtx 6000), 100 gpu load es 60% mem load van, nem savszel a limit.
-
Cifu
félisten
Szeleteli szépen a piacot az nVidia. Gondolom valami ilyen lesz a lineup karácsonyra:
GT 1030 ( Ennek kellene lassan egy utód )
GTX 1650 (Kifut az 1650 Ti / Super után?)
GTX 1650 Ti vagy Super
GTX 1660 (Szerintem marad)
GTX 1660 Super (gondolom a GTX 1660 Ti helyett érkezik)RTX 2060
RTX 2060 Super
RTX 2070 Super
RTX 2080 Super
RTX 2080 Ti
RTX Titan -
Z10N
veterán
ASUS confirms GeForce GTX 1660 SUPER is coming
The manufacturer is preparing at least 3 models from DUAL EVO, Phoenix and TUF3 series.
The GeForce GTX 1660 SUPER is believed to feature the exact same GPU as GTX 1660 non-SUPER. The difference lies in memory configuration. The SUPER variant is rumored to feature GDDR6 memory clocked at 14 Gbps (which is even faster than GTX 1660 Ti’s), whereas the non-SUPER variant only has GDDR5 clocked at 8 Gbps.
-

X2N
őstag
Otthon viszont nem probléma a memória. Én nem fogok milliárd geometriából álló víz/füst/tűz/robbanás effekteket csatajeleneteket stb szimulálni és renderelni. Azt be kell lássa mindenki hogy aki mozgóképet akar renderelni és komolyabb VFX-et renderel arra még a 4 kártyás rendszer is édes kevés. Állóképre a 4 kártya már közel realtime tud raytracinget. A másik dolog meg az hogy ezt a rengeteg effekt nagy részét nem lehet gpu-n szimulálni, így is kell hozzá erős processzor ami leszámolja. Én együtt tudok azzal élni hogy véges a memória a vga-ban, az új gépemben most 32GB ram van, ha esetleg a GPU 8GB-ja kevés lenne akkor majd leszámolja a cpu 10x lassabban, egye fene. Ezeket én rendereltem: LINK A képek 95%-át egy 980Ti-1 óra alatt bővel lerendereli 2K+ felbontásban. Processzorral ezeket 8+óra alatt lehetne lerenderelni. Ami nevetséges a GPU-hoz képest, ráadásul a GPU-val a viewportban is látom a közel végleges képet csak zajosan ami alapján tudok utánaállítani a fényeken. CPU-val erre nincs lehetőség, ott le kellene renderelni az egész képet majd utána állítani.
-
Abu85
HÁZIGAZDA
Bármit nem. A filmeknél igen erős probléma a VGA-k memóriája, hiszen poligonmilliárdokból álló adatokról van szó. Ezt például Hollywood azzal kezeli, hogy nagyrészt hozzá sem ér a VGA-khoz, de ugye a CPU-k lassabbak, tehát valamennyire rákényszerülnek. Megoldások vannak, felbontani a tartalmat, stb. Bár egyelőre Hollywood szintjén pénz van dögivel, tehát olyan nagyon nem dőlnek karóba, ha CPU-khoz kell nyúlni, kiépítenek egy új rendszert CPU-nként 4 TB memóriával és kész. Bollywoodban ez már sokkal problémásabb, ott azért már nincs pénz a klozetpapír helyén, így rákényszerülnek a VGA-kra. Nem véletlenül jegyzi meg egy bollywoodi stúdió fejese, hogy ezt a képet látja már évek óta. [link] - folyamatosan kifutnak a memóriából. Ez sajnos nem user error. Marha nagy az adat, amivel dolgoznak, és arra a VGA-k 99%-a nem elég jó.
-
X2N
őstag
Ez is csak programozás kérdése, az octane tudja az out of core geometry-t. Majd a többiek is felzárkóznak. Egy játékban nincs olyan komplex scene mint egy professzionális renderben, nem kell annyira sok memória mint ahogy azt gondolod. Egy mostani Quadro meg röhögve lerenderel bármit. Az már user error ha neked nem elég 96GB Vram se.
-
Abu85
HÁZIGAZDA
Ne keverjük a real time-ot, meg a professzionális kategóriában.
A valóságban a legtöbb picit is komplexebb scene elszáll out of memory-val, ha nem szeleteled fel manuálisan, vagy nincs olyan hardver alatta, ami ezt meg tudja oldani automatikusan. Emiatt minden hardvernek megvan a maga privilégiuma jelenleg. A Radeon VII-nek is, hiszen maximum 64 GB memóriát tud adni neked, és még fölötte sem szál el, csak akkor, ha a jeleneted 256 TB-nál nagyobb adatmennyiséget tartalmaz. Ezzel szemben a legtöbb többi VGA, még a professzionálisok is megpusztulnak, amint betelik a VRAM, ami ugye 8-12 GB körül van egy consumer hardvernél. Tehát aki Radeon VII-et vesz, az azért veszi, mert nem fér bele 8-12 GB-ba. Persze nem feltétlenül a 256 TB-os limit érdekli, de azért 100 GB-os jelenetek így is vannak. Egyébként, ha a 256 TB kevés lenne, akkor a Radeon Pro VGA-k limitje 512 TB. A 256 TB csak egy driverben meghúzott mesterséges határ a consumer modellekre.
A V-ray pedig nem ugyanazt a kódot futtatja a gyártók hardverein. Ott ezt a különbséget látod, nem a hardverek közöttit. Ugyanazt a kódot a Luxrender vagy a Luxcorerender futtatja például. Változik is a helyzet erősen.
-
Cifu
félisten
Ebből a diagramból azért nem biztos, hogy várakat építenék. A világoszöld részt veszed figyelembe, ami bekapcsolt DLSS mellett van. Ha megnézed, akkor DLSS nélkül viszont a 2070 még minimálisan lassabb is, mint a 2060 Super. Márpedig a logikád szerint a kettővel több RT mag miatt a 2070-nek gyorsabbnak kellene lennie, mint a 2060 Supernek ott is...
-
Abu85
HÁZIGAZDA
A marketing hívja magnak, de ugyanez a marketing egy szimpla FP32 ALU-t is magnak tekint, ami ugyanolyan hülyeség. Képzeld el, ha a procikat is eszerint számoznák. Egy Ice Lake-ben akkor 64 "mag" lenne. Ez a magozás a marketingnek egy dilije lett a GPU-k vonalán, de hát mit lehet csinálni.
A sugárkövetés nem csak bejárásból és ütközésvizsgálatból áll. A számítósok nagy részét még mindig az shading teszi ki, ahol a TFLOPS számít. Erre vannak a demoprogramok, ahol szándékosan kevés a shading, és ott már nincs akkora különbség a kártyák között, mert a limitet a bejárás és ütközésvizsgálat adja, nem pedig a shading, aminek pedig a limitje a memória-sávszélesség.
-
b.
félisten
A hivatalos források magnak hívják és szamszerusitik. 30/36/40/46/48 az RTX kártyákban ráadásul itt azonos felepitesű GPU kat merünk össze azonos multiprocesszor felepitessel.
A lényege a hozzászólásnak ezen egysegek számának az egymáshoz viszonyulása RT használata alatt ahol szamszerusitve kijon, hogy kevesebb RT maggal/mindegy hogy hivjuk/ ugyan az a GPU (RTX 2080 VS RTX 2070 Super) kisebb teljesitmenyre képes aktív RT alatt.
Ezert nem értem miért írod, hogy az RT magok számának nincs köze a teljesítményhez. Ha a memóriával korlátozva lenne ez a dolog, akkor hasonló eredmények lennének mint CPU limites VGA teszteknel.
Meg a tesztprogramokban is kijon az eltérés, legyen az Microsoft vagy bármi. -
Abu85
HÁZIGAZDA
Viszont a végeredmény sokszor nem lesz annyival jobb, hogy megérje bevállalni a sokkal több ideig tartó számítást. A magam részéről pont emiatt vártam az EEVEE-t, mert aki professzionális szinten csinál valami olyat, ahol iszonyatosan fontos, hogy minden részlet a helyén legyen, annak megéri akár cloud erőforrást is bérelni rá, aztán egy unbiased rendering engine-nel a végtelenségig számoltatni a képet. Nekem speciel nem. A Dazt is inkább egy eszköznek tekintem, amivel ki tudom egészíteni a Blenderrel való munkát, de a leképezést mindenképpen a Blenderben szoktam csinálni, mert minőségben és sebességben is jobb alternatívákat kínál. Persze nehezebbnek tűnik, de sokkal nagyobb is a tudása.
(#25624) b. : Ezek a dokumentumok azért vannak személyre szabva vízjelezve, hogy ne kerüljenek ki róla az információk. Ha ez nem számítana, akkor nem lennének jelszóval védve. Van más dokumentum is, amit nemrég kaptam. Például az AMD-nek a Q4 játéktervezete. Arról is bemásolhatnék mindent, de ugye az azzal ér fel, hogy csinálok egy képet a monitorról, és feltöltöm a vízjelezett dokumentumot. Ezeknél meg kell várni, hogy lejárjon rá az embargó. Valamikor ez pár hét csak, valamikor másfél év is.
Korábban már írtam, hogy itt nincs szó magokról. Egy nagy fixfunkciós blokk van a hardveren belül erre, és arra vannak a multiprocesszoron belül bemeneti és kimeneti pufferek. Ezeket hívja az NVIDIA magnak, de valójában köze sincs a maghoz. Az a baj, hogy a marketing borzasztóan leegyszerűsíti a hardverek valós felépítését. És ez általánosan igaz az NVIDIA és az AMD marketingjére is, mert szimpla ALU-kat tekintenek magnak, hogy minél nagyobb szám legyen a shadereknél. De ez butaság, nagyon is látszik a GCN-RDNA váltáson, hogy kevesebb maggal, ahogy ők hívják, jobb eredményt is lehet hozni. Ami valóban számít az a multiprocesszorok száma, csak azt már nehéz lenne elmagyarázni, hogy nem minden multiprocesszor egyforma képességű. Ezért van ez a rém egyszerű magosítás, aminek a valóságban köze sincs a hardver felépítéséhez. A másik véglet az Intel, ahol valóban a multiprocesszort adják meg egységnyi feldolgozóként, és ennek meg az a hátránya, hogy ezt a kis számot hasonlítják például az AMD és az NVIDIA nagy számaihoz.
-
b.
félisten
ne haragudj meg Abu,de ezek megint azok a dolgok, hogy csak te voltál jelen 9 másik újságíróval az AMD-s konferencián, ezt is csak te kaptad meg vízjelezett PDF ben a Microsofttól ( ettől függetlenül adatokat amiket lenox kér, pl a hitrátióról) bemásolhatnál ide hozzászólásban.
Itt jönnek azok a gondok amikor azt gondolom ezen bizonyítékok hiányában, hogy smafu ebben sok minden amit mondasz és az egészet beállítod tényként, miközben pusztán ez a te véleményed a saját rálátásod szerint. Még jobban azt gondolom, hogy semmit nem látsz bele abba, milyne fejlesztést fog eszközölni Nvidia a következő generációs kártyákon az RT szintemelésére.
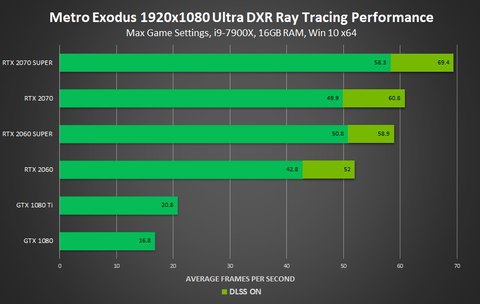
Egyre jobban csalódás minden ami itt zajlik a PH-n.A sávszél biztos probléma egy bizonyos szint fölött ,de jelenleg az van hogy a 2070 és a 2060 Super között 3 % különbség van kb RT magok számában ( a 2070 ben 36 RT mag van a Super 2060 ban 34 ) és pont ez jön ki az RT eredményekben is azonos GPU val. csak úgy mint a 2070 super ( 40 darab RT core ) és a 2080 között ahol (46 darab RT core )van.15 % kb a kölünbség a 2 kártya között bekapcsolt RT alatt, azonos GPU val ebből világosan lejön , hogy az RT gyorsítók száma hatással van az RT On teljesítményre és nem feltétlenül a memória a szűk keresztmetszet.
-
X2N
őstag
Az EEVEE biztos hogy kompromisszum, azt kell csak megérteni hogy a RT nem csak magáért az árnyékokért, a fényekért és a tükröződésekért van. Mondok egy példát talán így érthetőbb lesz. Ha van egy 3d karaktered, és megvilágítod 1-2 spotlámpával szemből akkor látod a bőrön a részleteket, amit a normal map bump map ad. Ha én csak annyit csinálok hogy kicsit megnövelem a fényforrás méretét a bőrön a mikro részletek máris tompábbak simábbak lesznek ahogy a való életben is. RT-vel minden felület "reagál" a fényekre. Egy raszterizált megoldás szerintem ezt nem fogja leszimulálni mert kvázi "1 mintavételes", miközben RT-vel rengeteg sugarat szimulálunk 1 felületre valós időben folyamatosan. Itt nincs olyan hogy befejezte a frame-t a gpu mert folyamatosan változik minden.
-
Abu85
HÁZIGAZDA
Pontosan. Viszont enélkül szarul van marketingelve, mert nincs elmagyarázva, hogy sugárkövetés és sugárkövetés között is lehet hatalmas különbség. Nem véletlen, hogy a hsz-ek többségen a DXR On/Off esetében arról szól, hogy fps On/Off. Persze, hogy úgy néz ki, hogy szart sem ér, ha nincs elmagyarázva, hogy ez nem olyan sugárkövetés, amilyen van a professzionális programokban.
A Quake 2-t pedig konkrétan hiba volt kihozni rá magyarázat nélkül, mert a felhasználók az összhatást nézik. Egyszerűen a sugárkövetés hardveres szinten nem tart ott, hogy számos sugárkövetéssel megoldott effekt mellett le tudja győzni a raszterizálás trükkjeit. RT vs. berserker mod. Összhatásban utóbbi lényegesen jobb, pedig el lehetne magyarázni, hogy persze az, mert a hardverek még nudlik a sugárkövetéshez, de számos előnye van, ami ugyan összhatásban még nem látszik, de majd úgy 3-4 generáció múlva már igen lényegesek lesznek.
(#25620) X2N: A refractionnel nyilván nem tud mit kezdeni, de sokezerszer gyorsabban van kész. Csodát nem tesz, viszont sokszor annyira közeli az eredmény, hogy az EEVEE egyszerűen egy nagyon jó kompromisszum.
-
X2N
őstag
AZ EEVEE az egy vicc bocs. Elég csak megnézni egy tükröződést pl egy üvegpoháron, köze sem lesz a valósághoz nem számol anyagon áthaladó sugarakkal ha EEVEE-vel rendereled. AZ EEVEE-nem használ sugárkövetést és ez látszik is. Persze látványos amikor realtime látod az eyecandy csúcs grafikát, de ennyi. Valakinek ez már tökéletes nincs ezzel semmi gond. De nem egy Octane vagy Redshift, minőség. Jelenleg ezek a leggyorsabbak. Ez a maximum amit meglehet csinálni most. Emberi bőrt, szemet talán a legnehezebb jól renderelni.
-
X2N
őstag
Igen ezt kellene jobban kihangsúlyozni. Ugyanis nagyon nem mindegy hogy van beparaméterezve a sugárkövetés. Lehet rengeteg dolgot állítani sugarak számát, a távolságot, a sugarak ütközését meddig számolja, caustic-ot szimuláljon-e esetleg dispersion-t, a színspektrumot szimulálja-e stb. Ezekben a játékokban kvázi interaktív módban működik csak a sugárkövetés nem photoreal módban. Megkockáztatom photoreal sugárkövetés caustic-al és egyéb effektekkel nem lesznek játékokban még sok sok évig.
-
Abu85
HÁZIGAZDA
A Blenderben viszont ott van már az EEVEE. Alig látható hátránya van és sokezerszer is gyorsabb. Persze jó dolog az Iray/ProRender/Cycles/Lux, de nem feltétlenül éri meg azt, hogy az egy másodperces renderidőről lemondjak, és percekig, vagy akár egy óráig várjak. Értem a lényegét a többinek, csak az EEVEE sok dologra bőven good enough. Érdemes kipróbálni, ha még nem tetted, én eldobtam az agyam tőle.
-
X2N
őstag
Lehet hogy jobb a Blender viewportban, de a DAZ-ban ott van az Iray ami sokkal jobb mint a Blender Cycles. Persze van Blender alá radeon prorender, Lux de azokkal sokkal körülményesebb dolgozni.... Itt Iray-nél ha jól tudom nincs a sugarak száma lekorlátozva, végtelenségig számolja. A sugarakat 10 eltérítésig legalább visszaköveti. 4 kártya már elég gyors már már realtime a jelenlegi modellekkel. Itt sokkal részletesebb modellek vannak mint egy játékban....
-
Abu85
HÁZIGAZDA
Olvasd el, amiről szó van, a memória-sávszélesség a bejárás és ütközésvizsgálat lépcsők szűk keresztmetszete. Itt sokkal gyorsabb a fixfunkciós hardver, mint amire a memória-sávszélessége egyáltalán képes a hardvereknek. Sugárkövetés viszont áll shading fázisból is, ahol már pusztán számítás van. Kivéve az árnyékokat, mert ott nincs shading, és amit írtam, hogy erre van egy nagyon jó példaprogram.

Amit senki sem vesz figyelembe, hogy maga a sugárkövetés nagyban paraméterezhető. Tehát el lehet érni azt, hogy még a szűkös sávszéllel is be lehessen állítani egy olyan korlátozott működést, hogy megfelelő sebességet kapj a mostani hardvereken is Full HD-ben. De akár 4K-ban is megoldható lenne ez, ha mondjuk négy pixelenként lenne egy sugár, például, tehát a lehetőségek nagyon tágak. A hardverek képességei szűkítik ezt le, és emiatt van az, hogy nem igazán látsz gyakorlati különbséget például a BF5-ben: [link] vagy a ME-ben: [link] - de mondjuk, ha nem kellene erősen visszafogni a paraméterezést, mert lenne hozzá elég sávszél, akkor viszont lényegi különbséget is lehetne mutatni, nem kellene hozzá állóképeket elemezni, hogy ezeket meglásd.
-
lenox
veterán
Mondjuk korabban azt irtad, hogy demoprogramokban lehet, hogy igaz, gyakorlatban nem, de akkor neked ezek szerint a peldaprogramok a gyakorlat.
Nem tudom, ami quake 2 benchmarkot nezem 2070 vs 2080 eseten ha igazad lenne, akkor egyforma teljesitmenyuk lenne, de nekem ugy tunt, hogy inkabb szepen skalazodik. Ez mondjuk a te fenti allitasodat, miszerint 'mindig a memória lesz a szűk keresztmetszet' cafolja. Persze nem jelenti azt, hogy sosem lehet a memoria a szuk keresztmetszet, de a 2070 vs 2080 ertekek jok kiindulasnak mas programokban is. Persze gondolom, hogy falra hanyt borso. -
Abu85
HÁZIGAZDA
Játékot nem vizsgáltak, csak példaprogramokat. Annyi van megjegyezve, hogy a játékokban ez jellemzően rosszabb. Az Imagination ezért fejlesztett például koherenciamotort a Wizardba, mert anélkül igazából pokoli mázli kell, hogy két egymás melletti pixelből kilőtt sugár egymás melletti texelt találjon el.
-
Abu85
HÁZIGAZDA
A hsz-t.
Közel 0.
PDF-et tudnék adni, de nem fogod tudni megnyitni, mert személyre szabott az állomány, és ha kinyitod a jelszavammal, akkor az én mailcímemmel vízjelezi tele. De szerintem te láttál már ilyet, és nyilván tudod, hogy ezeket a védett PDF-eket hiába osztod meg, rajtad kívül senki sem tudja megnyitni. Az NVIDIA is ilyen rendszerrel csinálja, és te közel állsz hozzájuk, tehát hiába adnád ide az egyik védett PDF-edet, semmit sem tudnék vele kezdeni.
-
lenox
veterán
Olvasd végig.
Mit? Szivesen olvasnek/neznek errol infot, ha lenne valahol, hogy melyik jatekban hogy alakul, de nem latom, hogy ilyet hivatkoznal.A jelenlegi kialakítással nincs messze a nullától a legtöbb effektnél. Hardveres koherenciamotor nélkül egyszerűen nincs lehetőség a sugarakat megfelelően csoportosítani.
Tehat akkor pl. Battlefield V, Quake 2 stb. mindnel 0?Én a Microsoft adatai alapján írom, amit írok.
Akkor vegre egy linket dobhatnal.
-
Abu85
HÁZIGAZDA
Olvasd végig.
A jelenlegi kialakítással nincs messze a nullától a legtöbb effektnél. Hardveres koherenciamotor nélkül egyszerűen nincs lehetőség a sugarakat megfelelően csoportosítani. De ez egyébként nem gond egy nulladik generációs hardvernél, meg úgy alapból sem, mert eleve elég sokat módosul a DXR futószalagja a következő körben.Én a Microsoft adatai alapján írom, amit írok.
(#25608) X2N: A valóságot nem érdekli, hogy mit hiszel.
A cuda magok száma szart sem ér, mert eleve egy ALU-ról van szó. Kb. annyira súlytalan, mint a GCN-nél a shader részelemek száma. Egy jó nagy marketingadat, ugyanakkor a valóságban a multiprocesszor képességei, illetve ezek száma határozzák meg a gyakorlati teljesítményt. Ezért van az, hogy hiába a sok ALU, az új architektúráknál többet ér a kisebb szám, lásd Pascal->Turing és GCN->RDNA váltás.
Négy kártya is kevés lesz. Az NVIDIA szerint 2030 után lehet majd ez real-time, de ugye ez is egy olyan tényező, amit nehéz belőni, mivel addigra sokkal több pixelt kell majd számolni, meg nem mindegy, hogy mennyi sugarat lősz ki egy pixelből, illetve ezek milyen hosszan vannak visszakövetve. Tehát kellően erős beállításokkal még 2030-ban sem lesz ez real-time.
Mondjuk a Daz Studio eléggé szar program, tehát az, hogy akad nem feltétlenül a hardver hibája. A Blender lényegesen jobb, főleg a 2.8-as, az odapörkölt keményen.
-
X2N
őstag
Az a baj hogy itt ezt csak te állítod senki más. Nincs forrás sem.
 Szerintem meg nem kell nagyob memória sávszélesség. Én most vettem egy RTX2060 Super-t és gyorsabban renderel mint a régi 980Ti, pedig a 980Ti-több cuda core-t tartalmaz. Sokat számítanak azok az RT magok(hívjátok aminek akarjátok). Ha pedig beletennék még egy 2060S-t 2x gyorsab lenne. Hiába nincs összekötve a memória nvlink-el. Iray render és UE4 RT. Egyszerűen számításigényes a RT, 4 kártyával már lehet közel realtime renderelni, kevesebbel nem, akkor kompromisszumos lesz. Az hogy milyen geometriai részletesség van egy mostani játékban lényegtelen. Nálam most a Daz Studioban egy komolyabb haj 12millió négyszögből áll. Már a viewportban akad a kép. Ezt vajon egy gyengébb kártya RT magok nélkül szerinted meddig számolná? Mondjuk ez még csak a beta változat ami már kihasználja az rtx kártyákat.
Szerintem meg nem kell nagyob memória sávszélesség. Én most vettem egy RTX2060 Super-t és gyorsabban renderel mint a régi 980Ti, pedig a 980Ti-több cuda core-t tartalmaz. Sokat számítanak azok az RT magok(hívjátok aminek akarjátok). Ha pedig beletennék még egy 2060S-t 2x gyorsab lenne. Hiába nincs összekötve a memória nvlink-el. Iray render és UE4 RT. Egyszerűen számításigényes a RT, 4 kártyával már lehet közel realtime renderelni, kevesebbel nem, akkor kompromisszumos lesz. Az hogy milyen geometriai részletesség van egy mostani játékban lényegtelen. Nálam most a Daz Studioban egy komolyabb haj 12millió négyszögből áll. Már a viewportban akad a kép. Ezt vajon egy gyengébb kártya RT magok nélkül szerinted meddig számolná? Mondjuk ez még csak a beta változat ami már kihasználja az rtx kártyákat. -
lenox
veterán
Nem én számoltam vs Amit én számoltam
Most akkor el kene donteni, hogy te szamoltal vagy nem. Ha igen, akkor legyszi adjal cache hit ratiot amivel szamoltal, ha nem, akkor linket, hogy ki hol szamolt. Amugy gondolom te kb. 0-val szamolsz egy talalgatas alapjan, illetve meg az is lehet, hogy talaltal egy programot ami alapjan azt hiszed, hogy mindig annyi.A cache-hit arány pedig attól függ, hogy koherensek-e a sugarak. A demoprogramokban lehet, a gyakorlatban nem.
Mi a gyakorlat? Egy jatek es egy demo ugyanugy korlatozott, tehat ezt nem tudom, hogy kene ertelmezni. Van tobb programhoz is adatod, hogy melyikben mennyi a chr, vagy csak egy demo program alapjan talalgatod, hogy mindig annyi? -
Abu85
HÁZIGAZDA
Nem én számoltam lényegében, hanem a Microsoft adta meg, hogy a mai VGA-kon, milyen mély BVH mellett, mekkora sávszélességre van szükség. Amit én számoltam az a BVH8, mert az rendben van, hogy egy demoprogramnak elég BVH4, de egy játéknak nem, elvégre ott azért nem százezer háromszög van egy jelenetben.
A cache-hit arány pedig attól függ, hogy koherensek-e a sugarak. A demoprogramokban lehet, a gyakorlatban nem.
-
Abu85
HÁZIGAZDA
válasz
 Jack@l
#25602
üzenetére
Jack@l
#25602
üzenetére
Mert a valóságban nincs is olyan, hogy RT mag. Az rendben van, hogy ezt számszerűsítik magokkal, de valójában egy nagy fixfunkciós hardverről van szó, ami a bemeneteket per multiprocesszor kapja. Kb. a raszterizálóhoz hasonló az egész. Csak ahogy itt leírtam: [link] - a sugárkövetésen nem segít a cache, mert nem alkalmazható rá a lokalitási elv, emiatt minden egyes mintáért menni kell a memóriába, míg raszterizálásnál hiába történik hasonló mennyiségű adat feldolgozása, akkor is nagyságrendekkel kevesebbszer kell a memóriába menni az adatért, mert nagyon jól működik a lokalitási elv. Emiatt mindig a memória lesz a szűk keresztmetszet, mert nem tudod igazán bevinni a számítást a lapkán belülre. Még koherenciamotorral sem, bár az sokat segít.
(#25603) b. : A chiplet nem igazán jó a sugárkövetésre, mert akkor meg a mintát szállítani kell a lapkák között. Azt is csak a memóriával tudod megtenni, különben alaposan túlterheled a buszt, amire a legkevésbé sem vágysz egy GPU-nál. Amikor mintavétel van, akkor az a lényege neki, hogy ott legyen a textúra gyorsítótárban az adat, az mindegy, hogy raszterizálással vagy sugárkövetéssel vetted a mintát. Ha ezt a problémát kihelyezed egy külön lapkára, akkor az történik, hogy az adat nem ott lesz, ahol kellene lennie, vagyis el kell menni érte egy lassú buszon keresztül. Ráadásul az adatlokalitás kifejezetten rossz sugárkövetéssel. A CPU-knál azért működik ez a chiplet dizájn, mert ott van magonként 2-4 szál, és a feldolgozás jellege is olyan, hogy nagyon lehet építeni a lokalitási elvre. Egy GPU multiprocesszor viszont dolgozik 10-32 wave-vel, wave-enként 32-64 lane-nel, vagyis hardvertől függően 500-1000 konkurens szál fut egy multiprocesszoron, ezeket pedig hardveresen vezérelni kell. Emellett a feladatok végrehajtása sem olyan, hogy ami ideális a chipletnek, mert amíg a CPU-nál eléggé nagy az esélye, hogy egy folyamat azon a magon fejezi be a munkát, amelyiken megkezdte, addig egy GPU-nál eléggé kis eséllyel történik meg az, hogy egy folyamat ugyanazon a multiprocesszoron végez, ahol kezdett. A chiplet úgy működne a GPU-knál, ha az API-ban lenne rá módosítás, ami egyébként létezik is - [link]. Alternatív megoldás lenne egy vezérlőlapka több GPU chiplet mellett, ami igazából azon dolgozna csak, hogy megpróbálja a futó folyamatokat egy chipleten belül tartani, mert ahogy kikerülsz onnan, megdöglik a chiplet buli a GPU-knál.
Azért ez nem atomfizika. A sugárkövetés egyáltalán nem olyan hardveresen, hogy annyira sok lehetőség lenne. Két lépcső van, amit lehet gyorsítani: a bejárás és az ütközésvizsgálat. Utóbbi igazából nem nehéz, és nem igazán kell rá programozhatóság, tehát érdemes gyorsítani. Előbbinél véleményes, hogy a gyorsítás, vagy a programozhatóság ér többet. Arra felé haladunk, hogy a programozhatóság, de a mai DXR verzióban még gyorsítva van. Ezeken kívül a koherenciamotor, amit még be lehet építeni, arra amit fentebb kifejtettem. Na most nagyjából ennyi. A futószalag többi rész shader, tehát a multiprocesszorok ALU-in fut.
Az, hogy mit várok és mi valósul meg, két különböző dolog, de ha már megkérdezted, akkor azt várom, hogy támogatni fogja a következő DXR verziót, így picit át fog alakulni a hardver, hogy jobban tudjon igazodni a programozható bejáráshoz. Az ütközésvizsgálat nyilván marad fixfunkciós. Ahhoz, hogy sebesség is legyen szükség lesz legalább ~1 TB/s-ra, de jövőre realitás a HBM3 is, tehát inkább érdemes ~1,5-2 TB/s közé ugrani. Ez már önmagában elég nagy előrelépés. A koherenciamotorban reménykedem, de nem várom feltétlenül a tranzisztorköltség miatt. Ugye amíg a memóriára vonatkozó változások jelentős előnyt jelentenek általánosan is, a koherenciamotor már nem, így ott van pár erős kontra érv is. Amit az RT-n kívül várok az a variálható warp-méret, amivel erősödhet az egy munkaelemre levetített IPC.
-
b.
félisten
De senki nem mondta hogy ez a gyorsító ugyan olyan elven fog működni mint a mostani RT vagy azt sem mondta senki, hogy a képen nem egy dupla GPu-s ( chipletes) megoldás lenne rajta.
Kb semmit nem tudunk az egészről, ez egy olyan terület amiről kb a megjelenése napjáéig nem is látjuk mit és hogyan módosítanak benne. valószínűleg látják Nvidiánál a problémákat nem csak te számolsz itt a pH-n és fedezed fel a limitáló tényezőket,hanem ők is megpróbálnak megoldást találni arra, ha nem HBM2 lesz a fedélzeten vagy bármi egyéb megoldást.
próbáld egyszer feltételezni azt magadban hogy az AMD-n kívül létezik más cég is aki alkalmaz közmunkaprogramon kívüli mérnököket is és használják az eszüket arra , amire kell, és hátha kitalálnak olyan dolgokat is,amire te nem gondolsz.![;]](//cdn.rios.hu/dl/s/v1.gif)
De ha már itt tartunk, kíváncsi lennék, te mit vársz mondjuk a következő generációs Nvidától, mondjuk legyen RTX 3080.
Biztos, hogy a dedikált hardver megmarad RT-re szerintem egyenlőre( és miért nem teszteltek Nvidia kártyákat önállóan ? csak a szokásos, ha már itt vagy....
) -

Jack@l
veterán
Akkor befejezem mert látom lepereg rólad a józan logikus gondolkodás.
Maradjunk annyiban hogy ray-, path-tracinghez nincs olyan hogy elég mag...
Majd 8k 120fps-nél 100 millio poligonnal el lehet gondolkozni hogy már elég.
Nem a memória a szűk keresztmetszet perpill, hiába is próbálod ész nélkül nyomni az amd-s hbm2-t.







































![;]](http://cdn.rios.hu/dl/s/v1.gif)

Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az NVIDIA éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.


- Bomba ár! Dell Precision 5530 - i7-8850H I 16GB I 512SSD I 15,6" FHD I P1000 I Cam I W11 I Gari!
- Bomba ár! HP EliteBook 850 G2 - i5-5GEN I 8GB I 256GB SSD I 15,6" FULL HD I Cam I W10 I Gari!
- Gamer PC-Számítógép! Csere-Beszámítás! I7 6700 / GTX 1660Ti / 16GB DDR4 / 500GB SSD
- LG 55G4 - 55" OLED evo - 4K 144Hz & 0.1ms - MLA Plus - 3000 Nits - NVIDIA G-Sync - FreeSync Premium
- BESZÁMÍTÁS! GIGABYTE B550M R5 5600 32GB DDR4 512GB SSD RTX 2070 SUPER 8GB ZALMAN I3 NEO Enermax 650W
Állásajánlatok

Cég: FOTC
Város: Budapest