Hirdetés
- Kormányok / autós szimulátorok topikja
- Amlogic S905, S912 processzoros készülékek
- Félkörpanorámás Thermaltake ház, ezúttal faberakással
- AMD Navi Radeon™ RX 9xxx sorozat
- ThinkPad (NEM IdeaPad)
- Milyen asztali (teljes vagy fél-) gépet vegyek?
- Nem tetszik pár profi eSport játékosnak, hogy Intel CPU-val kell játszaniuk
- A firmware okozhatja a Windows 11 augusztusi frissítésével kapcsolatos SSD-hibát
- OLED TV topic
- Milyen TV-t vegyek?
Új hozzászólás Aktív témák
-
#5702
 Petykemano
veterán
S_x96x_S
#5697
Petykemano
veterán
S_x96x_S
#5697
Petykemano
veterán
válasz
 S_x96x_S
#5697
üzenetére
S_x96x_S
#5697
üzenetére
Ugyanez audio-vizuális formában
Talán én nem olvastam elég figyelmesen az AT cikk végét, ezért engem most meglepetésként ért, hogy nagyjából ugyanazt mondta az interposeres megoldásra, mint amit én.
Hogy van egy interposer, azon rajta van 3 CCD. Az így kialakított szigeteket nem 1-1-1, hanem 3 IF link köti össze az IOD-dal és az interposeren keresztül nem csak az azonos lapkához tartozó magok, hanem a CCD-k közötti kommunikáció is természetesen gyors. -
#5700
Petykemano
veterán
Petykemano
veterán
"Úgy tudjuk, hogy az AMD elsősorban az egyes 7 nm GPU-it, illetve a szintén 7 nm-es, semi-custom üzletágon belül értékesített lapkáit vinné át 6 nm-re. A meglévő CPU chipletek és APU-k viszont maradnának 7 nm-en, azokat relatíve gyorsan leváltják a modernebb fejlesztések, így nincs értelme áttervezni őket."
A Cezanne-t valóban a pletykák szerint 2 negyedév múlva leváltja a Rembrandt*
De hát eddig úgy tudtuk, hogy a Zen3D az egy real thing. Most itt vajon akkor mi a csúsztatás? Az, hogy a Vermeer-t valójában nem azért marad 7nm-en, mert hamar váltja valami modernebb, hanem mert az a modernebb az önmaga?
Ez lehet indokolt, mivel lehet, hogy a "7nm on 6nm" 3d packaging nem működik. (UGye az 5nm on 5nm-t is csak 2022H2-re mondják)Pedig egyébként biztos itt is meg tudták volna oldani azt, amit a 14->12 átmenetnél, hogy a lapkaméret ugyanakkora.
Na mindegy, érdekes Abu megjegyzése.
* Rembrandt
Ez is roppant érdekes. a Rembrandt zen3+@N6. A fejlesztés célja persze nyilván az RDNA2 integrálása volt. Viszont ezzel jelentős hátrányba kerülhet az AMD a mobil piacon - megint.
A Cezanne-nal és a Renoir nagy előrelépésnek számított a 6-8 maggal a korabeli 4 magos Tiger lake-kel szemben, de épphogy állja a versenyt a 8 magos Tiger lake-kel szemben.Nem tudjuk, mit hoz a Rembrandtnak a zen3+-ság, meg az N6-on való gyártás. Mondjuk 5-8%-ot. Tartok tőle, hogy a versenyképesség megtartása érdekében a Rembrandt-nak azzal kell majd "újítania", hogy nem lesz felezett az L3$ a Vermeerhez képest. Ez azért nem kevés lapkaterület, de talán így elérhető 15%-os előnyt a Cezanne-hoz képest ST-ben is.
De ez azért még lehet, hogy kevés lesz az Alder Lake-kel szemben. Egy 6|8+4-es konfigurációban a 4 kis mag valószínűleg azért sokat fog segíteni az üzemidőn. Belépőszinten meg egy 2|4+4|8-as konfig elég nagy aduász lehet.
-
#5699
Petykemano
veterán
Petykemano
veterán
Frontier vs Aurora
Nem állítom, hogy ugyanakkora a teljesítményük, csak annyit tudunk biztosan, hogy mindkettő exa.
De elég nagy a különbség a fogyasztás.terén:
29 vs 60
[link]
Ráadásul úgy, hogy az aurora csúszik
-
#5698
Petykemano
veterán
S_x96x_S
#5697
Petykemano
veterán
válasz
S_x96x_S
#5697
üzenetére
Nekem az első kérdésem az volt, hogy tulajdonképpen miért kellene az AMD-nek növelnie a CCX-ben a magszámot?
A cikkben arra tesznek utalást, hogy jelenleg úgy jön ki a 64 mag, hogy a 8 magos gyűrűs vagy legalábbis gyűrű alapú topológiát használó (szerintem a bemutatottak közül a Twisted Hypercube az esélyes) CCX-ek vannak felfűzve egy újabb gyűrű, vagy gyűrű alapú topológiát követő IO lapkán belüli kommunikációs körre.
A cikk gondolom azt fejtegeti, hogy hogy hát a CCX-en belül megnövelni a magok számát nehézkes gyűrű topológiát használva - ugye ezzel küzdött az intel is a Comet Lake esetén.
És hát a külső gyűrűnél is ugyanazok a problémák jelentkezhetnek, ha az ottani 8 megállót kellene bővíteni.Szerintem a témában nagyon tanulságos AdoredTV egy 3 évvel ezelőtti videója:
https://www.youtube.com/watch?v=G3kGSbWFig4
már akkor arról beszélt, hogy a kisebb magszámú lapkákban gyártott CCX-eket aktív interposerrel kellene összekötni.Szerintem az AMD azt fogja majd csinálni - nagyjából ezt említik egyébként a mai cikk végén is. De abban nem vagyok biztos, hogy az AMD fogja növelni a magok számát a CCX-ben.
Teszemhozzá, azt nem tudom, hogy a Bergamo (Genoa+) esetén miként oldották meg a 96 magot...
Amit most mondok, az nem arra válasz, hanem az eredeti, az AT által feszegetett kérdésre.
Szerintem az AMD azt fogja csinálni (és mégegyszer mondom, ez nem a Bergamo), hogy meghagyja a 8 magos CCX-eket és ráteszi őket egy aktív interposerre. Így az egy interposeren helyet kapó processzorok közötti késleltetésnek le kellene csökkenie.
Az aktív interposer egyrészt összekötné szintén valamilyen gyűrű topológiával a rajta levő mondjuk 3-4 CCD-t, de ha lehetséges, akkor át lehetne építeni abba az Infinity Fabric-ot, ami szintén nem kevés hely és biztos nagyon rosszul skálázódik

Ilyetén módon a jelenlegi 8x8 helyett egy 8x(3-4)x8 topológia alakulna ki.
Az interposerre rá is lehetne tenni HBM-et, amit mondjuk 3 CCX együtt használ. -
#5695
Petykemano
veterán
Petykemano
veterán
AMD Ryzen 5000 series are getting cheaper ahead of Intel Alder Lake release
[link] -
#5682
Petykemano
veterán
Petykemano
veterán
-
#5680
Petykemano
veterán
S_x96x_S
#5679
Petykemano
veterán
válasz
S_x96x_S
#5679
üzenetére
Elég érdekes koncepció.
A zenről az elején azt feltételeztük,.hogy a CCX-ek között van infinity fabric kapcsolat. És hogy azon keresztül legalább olvasásra megosztott a CCX-ek L3$-e. Nem állítom, hogy nem lehetett az AMDnek erre vonatkozólag terve, de mérések nem igazolták vissza, hogy ez létezik, vagy hogy ha létezik, akkor.lenne érdemi hatása.A cikkből kiderül, hogy ha nem egy Next level cache,.akkor egy low latency high bandwidth interconnectnek kell lennie, ami összeköti a magokat. Meg is említik, hogy a lapkán belüli magok között van ilyen és a magok közötti L2$-hez való hozzáférés +12ns késleltetést ad hozzá.
Késleltetést persze nyilván ugyanúgy hozzáad egy valódi L3$-ben való turkálás. A különbség ha jól értem annyi, hogy az L3$ vezérlő nem egy neki dedikált tárterületben turkál, hanem a magok amúgy privát L2$ tárterületében.
Ügyes, valóban újszerű megközelítés - különösen az AMD "szilíciumpazarló" v-cache megközelítéséhez képest.
Kíváncsi vagyok, viszont fogjuk-e látni valahol másutt.Azért biztos lehetnek hátrányai is. Az impresszív számok egyszálas terhelés során érvényesek. De amikor az összes mag fullra van terhelve, akkor mindenkinek van 32MB L2$, de senkinek nincs L3$.
Persze ezzel biztos kalkuláltak.
Azért a 256MB cache lényegesen több 8 magra, mint amennyivel egy 8 magos zen3 CCD rendelkezik. Még. Ha majd az is kap 4 layer L3$-t akkor már igazán érdekes lesz összehasonlítani. -
#5674
Petykemano
veterán
Petykemano
veterán
Nagyot esett az AMD processzorok aránya a Steam HWS-ben
Ezzel együtt breaking news, hogy feljövőben van a Windows 7!
[link]Egyébként az oldal alján található Other Settings elég érdekes így az utasításkészletek szempontjából.
-
#5670
Petykemano
veterán
Petykemano
veterán
Az árazással kapcsolatban én mindig feltételesen fogalmaztam:
ha az intel verseng az alder lake-kel, akkor mehetnek lejjebb az árak, de ha úgy gondolja, hogy a konkurensénél jobb termékét adhatja drágábban, akkor a jövőben lehet, hogy mindenki minden új generációval (a konkurensénél remélhetőleg jobb termékkel) árat fog emelni.Megjelent egy árazás az ADL-kel kapcsolatban: [link]
legolcsóbb adó nélkül:
10600K: 233 eur
11600K: 242 eur
12600K: 287 eur10700K: 329 eur
11700K: 376 eur
12700K: 294 eur10900K: 489 eur
11900K: 499 eur
12900K: 540 eurPersze az 12600K ~$300-os ár mellett valószínűleg mind egyszálas, mind többszálas teljesítmény vonatkozásában jobb lesz mint az 5600X - tehát inkább egy 5800X-nek felelne meg, és ha így nézzük, akkor egész jó ajánlatnak is tekinthető.
De azért szép lassan, de emelkednek az árak.
Ez alapján azt lehet jósolni, hogy
1) ha az AMD semmi mást nem csinál, csak ráteszi a v-cache-t mondjuk a 6 magos lapkákra is, ami átlag +15%-ot hoz játékokban, esetleg +100MHz, akkor a $299-es ár szerintem marad.
A v-cache nélküli változat lehet $249.
2) ha az AMD a v-cache mellett még mást is bütyköl (Warhol, zen3+, új IOD, stb), ami a v-cache-en kívül még további pár százalékokat hozzáad, akkor akár emelkedhet is az ár. Mondjuk $329 és a v-cache nélküli verzió (ami szintén jobb valamivel, mint az 5600X) $279Ezek az én tippjeim.
-
#5667
Petykemano
veterán
regener
#5666
Petykemano
veterán
válasz
 regener
#5666
üzenetére
regener
#5666
üzenetére
5600X
= 5800X - 3% @gaming + általános felhasználás
= 5800X -30% "ipari" felhasználásA HWBU legutóbbi két teszjéből, amikor intel procikat próbálgattak 6, 12, 16 és 20MB cache-sel azonos magszámmal, abból kiderül, hogy kb 6 mag fölött a cache-többlet többet számít, mint mag-többlet. (Persze nyilván ez sem a végtelenségig igaz, mert a cache-re is érvényes a csökkenő határhasznosság elve.)
Ami a találgatást illeti:
- megy a latolgatás, hogy vajon 5600XT, 5800XT, stb néven fog-e megjelenni (vagy XV), vagy 6000-es szériaként. A tét nem kicsi. Érdemes-e AM4-be 6000-es néven indítani egy új szériát csak a látszat kedvéért, és tartozzon-e ugyanebbe a 6000-es szériába a kicsivel később AM5-be érkező Rembrandt?
- Vajon csak a legdrágább példányok kapnak v-cache-t vagy alsóbb szegmensekben is megjelenik?A Moore's Law is Dead nevű youtuber állítása szerint az AMD már a zen2-nél tervezte a v-cache bevezetését az XT vonallal, ami annak elmaradása miatt lett olyan fing. Mindenesetre volt 3600XT, ami arra utal, hogy talán 6 magos sku is indult volna v-cache-sel.
Én azt gondolom, hogy az AMD kénytelen lesz 6 magost is indítani v-cache-sel, mert az ADL 12600K elég jónak ígérkezik, jó esélye van arra, hogy megverje a gamerek között népszerű 5600X-et. Persze ez manapság leginkább kínálat függvénye.
A legutolsó információk szerint a korábbi Warhol, meg 6nm-es zen3 respin dolgokat elkaszálták, tehát elvileg ugyanaz a 7nm-es lapka fog forgalomba kerülni, ami tavaly is (pontosabban annak B2-es steppingje), csak lesz olyan, amelyiken lesz v-cache.
Ez alapján én 6000-es szériára számítok úgy, hogy mai $299-ért (valójában olcsóbban) kapható 5600X megy mondjuk $249 árral a 6600 pozícióba. És a $299-es pozícióban pedig egy v-cache-sel rendelkező példány kerül.
- persze feltéve, hogy tényleg nincs N6-on készülő / zen3+-os / Warhol (ilyesmire újabban semmilyen jel nem utal)
- és persze az árak leginkább attól fognak függni, hogy hogyan árazza az intel az ADL-ket, valamint hogy az ADL árazása mellett az AMD cpu eladásai meginognának-e. Ha nagyon nagy a kereslet, akkor előfordulhat, hogy az ADL mellett az AMD még mindig mindig elad és akkor áremelés lesz. De azt gondolnám, hogy mivel már a jelenlegi zen3 procikat akciózzák, az áremelésre nem biztos.Ez persze csak az én véleményem, semmilyen insider információm nincs.
-
#5665
Petykemano
veterán
regener
#5664
-
#5663
Petykemano
veterán
Petykemano
veterán
"The 3d cache versions of Zen 3 CCDs have to be thinned, which they're not going to do on a per die basis so anything already fabricated and diced won't be eligible to be used. Most likely the fab is doing the thinning so any wafers already sent to AMD are also probably not eligible. That's not to say AMD couldn't already have produced thinned wafers in preparation, but any 'standard flow' dice won't be used. The cache layer fab time should be more or less the same as the CCDs."
[link]Ebben van ráció. Valóban úgy hatékony, ha nem lapkákra való szétvágás után egyesével, hanem még szétvágás előtt, wafer állapotban történik meg a vékonyítás és a 3D felépítmény elhelyezése.
+ valószínűleg nagyobb volument lehet így kipumpálni, mintha egyesével csinálnák
- így nem biztos, hogy lehet előre válogatni a jó lapkákat, amikre ráteszed az extra V-cache-t és előre kiválogatva kiszórni a selejtet, hanem a selejt a 3D felépítménnyel együtt jelenik meg.Ez persze még nem jelent semmi biztosat.
Egyrészt nem kell minden gyártósort ilyenre átállítani. Tehát ha ez így működnek, akkor is biztos folytatódik a hagyományos zen3 lapkák gyártás - vékonyítás nélkül.
Másrészt a 12 magos verziókban a 6 magos selejteket el lehet lőni. Itt legfeljebb az a kérdés, hogy előfordulhat-e, hogy a v-cache selejtes és 64 helyett 48 vagy 32MB kapacitás kapcsolható csak be. -
#5658
Petykemano
veterán
Petykemano
veterán
"3D packaging devices arrived at China last week, and ZEN3D has a chance to be available around Christmas.😙"
-
#5657
Petykemano
veterán
Petykemano
veterán
A 7773X csak $1000-ral drágább, mint a 7763
[link]
(Az persze még csak feltételezés, hogy ez X=v-cache) -
#5648
Petykemano
veterán
S_x96x_S
#5646
Petykemano
veterán
válasz
S_x96x_S
#5646
üzenetére
> vagy most még csak vegyes konstrukció lesz.
> pl. a 8 magos chipletből csak 4 magot tunningolnak fel,A jelenlegi CCX-ek közösen/megosztottan érik el és használják a L3$-t.
Az én értelmezésem szerint a V-cache nem L4$ lesz, hanem az L3$ kibővítése.
De sehogyse értem, hogy miképp lenne megvalósítható, hogy 8-ból 4 mag látja csak a kibővített - v-cache - területet.Azt esetleg el tudom képzelni, hogy egy 2CCD-s kialakításban csak az egyik kap v-cache-t. Ez mondjuk a 2 CCD-s Ryzenek esetén talán kevésbé lenne látványos/jelentős lépés, de ha egy Threadripper épülne fel úgy, hogy 4-ből csak 1 kap tornyot az már eléggé a big.LITTLE irányába hatna. És nyilván ahogy mondod, szükség is lenne a megfelelő megkülönböztetésre.
Ilyenkor az emberek mindig megijednek, hogy na itt ette meg a fene, de hát valahogy eddig is kitalálta a hardver és az ütemező együtt, hogy melyik az a mag, amelyik a legmagasabb frekvenciára tud boostolni és hogy oda akkor mit érdemes ütemezni a maximális teljesítmény elérése érdekében.
Ezzel együtt én valószínűbbnek tartok egy v-cache méreten alapuló szegmentációt. egy CCD felett 64 v 32
-
#5641
Petykemano
veterán
Petykemano
#5640
Petykemano
veterán
válasz
 Petykemano
#5640
üzenetére
Petykemano
#5640
üzenetére
-
#5640
Petykemano
veterán
-
#5635
Petykemano
veterán
S_x96x_S
#5633
Petykemano
veterán
válasz
S_x96x_S
#5633
üzenetére
> de főleg a core alapján licenszelt szoftvereknél lehet ez hátrány.
> valami árazással ki kell egyensúlyozni.Nem tudom, hogy a sapphire rapids esetén az AVX512 használata jár-e még órajelcsökkentéssel. De ha esetleg az AMD megoldotta - ahogy az AVX2 esetén is tette - hogy órajelcsökkenés nélkül tudja a mag használni, akkor már az is kompenzálhatja azt, hogy kevesebb az 512b feldolgozó.
> #5634 HSM
> Pedig ez tűnik a legjobb megoldásnak.
> A kis mag utasítás szinten kompatibilis az AVX512-vel is, csak csiga lassú,
> ha tempó is kell, majd átrakja az ütemező a nagyobb magokra.Szerintem azért nem így lesz (kis mag érti az AVX512 utasítást, de vékony feldolgozókkal rendelkezik és egy AVX512 utasítást több órajelciklus alatt tud csak végrehajtani), mert az Intel számára az E mag nem Low Power, amely esetén kényszerből, de minél olcsóbban megvalósítják a utasítás-parítást. Az E magokat az intel throughputra akarja használni.
Nem tudom megmondani, hogy mi az ideális, de azt feltételezem, hogy nem a minimum. Nyilván attól is függ, hogy milyen a kód, amit futtatni kell.
Jelenleg a Gracemont magok AVX2-ot tudnak, elvileg 256b feldolgozókkal -
#5632
Petykemano
veterán
Petykemano
veterán
Már a zen2-t is felkészítették V-cache fogadására
A Warholt akkor kaszálhatták el, amikor sikerült összerakni. -
#5631
Petykemano
veterán
S_x96x_S
#5628
Petykemano
veterán
válasz
S_x96x_S
#5628
üzenetére
Az N2 sok szempontól vastagabbnak tűnik, mint a zen3, más szempontból viszont nem. [link]
És mégis nagyon pici.Mondjuk nehéz összehasonlítani.
7nm-en 1.1-1.4mm2 az N1 [link]
Ehhez képest a zen3 brutálisan nagy, több mint 3mm2 [link]
(A számok csak a core részeket tartalmazzák)
Persze az IPC-je is másfélszeres és nyilván az elérhető frekvenciában is jelentős különbség van [link]az N2 kiterjedése 5nm-en nem változott az N1-hez képest.
Elvileg egyébként a zen4 lapkaméret is csökkent. Ha jól emlékszem olyan 70mm2 - annak ellenére, hogy az L2 a duplájára nőtt és az AVX512 is eléggé helyigényes - azt mondják 0.5mm2 a core részből csak az.> És szerintem min +10% IPC csak össze tudnak kaparni
> Elég nagy változás önmagában
> az AVX-512 kielégítő implementálása.Nem kívántam lekicsinyleni. Csupán megállapítottam, hogy ha volt egy design goal listájuk a zen4-re vonatkozóan, akkor annak első helyén az AVX512 implementálása lehetett. Emellett persze nyilván dolgoznak,csiszolnak-reszelnek más részegységeket is és ha valamilyen fejlesztés elkészül, akkor az bekerülhet a release-be. (ahogy anno a zen2-be is bekerült valami Tage branch predictort, amit eredetileg a zen3-ba terveztek)
Szerintem 10%-nál több lesz az IPC növekedés - a szokásos módon ahol az L2$ számít, ott nagyobb.
> Akkor a ZEN4-ben fele annyi lesz.
De dupla annyi mag.Lehet, hogy innen érdemes ágaztatni.
A zen5 újdonsága lehet, hogy az lesz, hogy a backend szélesedik. -
#5627
Petykemano
veterán
S_x96x_S
#5625
Petykemano
veterán
válasz
S_x96x_S
#5625
üzenetére
Ahogy a Ch&Ch elemzésben is írták, a zen4 fundamentálisan nem különbözik a zen3-tól. AZ AVX512 utasításcsalád és a 256bit helyett 512bites feldolgozók persze a vektor egységen nagy előrelépésnek számít, de más vonatkozásban inkább csak csiszolgatás-reszelgetés.
A viszonylag jelentősnek mondható L2$ méretnövekedését is e kettő kategóriába sorolnám. Úgy értem, hogy el tudom képzelni, hogy ezzel a cél nem az IPC gyorsítás volt - Na nem mintha nem nőne tőle az IPC -, hanem elsősorban a duplázódó adatméretek tették indokolttá.
Példaként a Golden Cove magokat szokták felhozni, reszelgetés (+10%) helyett elég komoly (+50+%) méretnövekedésen esnek át bizonyos alegységek, mint pl a reorder buffer. De ahogy a múltkor is mondtam, ha a zenből e nélkül is lehet IPC növekedést elérni az jó jel, mert arra enged következtetni, hogy van még benne tartalék.
Engem amúgy meglepett, hogy az L1$-t egyáltalán nem növelték. Én arra számítottam, hogy 48kB-ra nő az is.
-
#5624
Petykemano
veterán
S_x96x_S
#5623
Petykemano
veterán
válasz
S_x96x_S
#5623
üzenetére
> persze a jövőben - az AMD-nek is meg kell oldania - az AVX-512 - Big-Little architektúrát
> ( remélhetőleg nem kiherélten - mint az Intel Alder Lake )Nekem nem lenne bajom azzal, ha csak a kompatibilitás végett úgy oldanák meg ,hogy 128 bites feldolgozók vannak a kis magokban és 4 órajelciklus alatt hajt végre egy AVX512-es utasítást.
De szerintem nem ez lesz. -
#5622
Petykemano
veterán
-
#5621
Petykemano
veterán
TESCO-Zsömle
#5619
Petykemano
veterán
válasz
 TESCO-Zsömle
#5619
üzenetére
TESCO-Zsömle
#5619
üzenetére
van új jelölés: Intel 7
-
#5606
Petykemano
veterán
S_x96x_S
#5602
Petykemano
veterán
válasz
S_x96x_S
#5602
üzenetére
Én is azt néztem a táblázatban, hogy azokban a számokban, amiknek sokan az M1 magas IPC-jét tulajdonítják, a zen3 alacsony értékekkel rendelkezik. Persze nem mindenben.
De az a ROB pl alacsony a Sunny/Willow Cove magokhoz képest.
Ez szerintem azért jó, mert van még hová növekedni.
Persze nyilván minden egyes duplázás megtérülése IPC-ben csökkenő mértékű és külön-külön minden elhanyagolható mértékű.
Mindenesetre én is arra számítok, hogy a jövőben ezeknek az értékeknek a növekedését fogjuk látni.
Ja igen, azt elfelejtettem mondani - a másik threadben - hogy az intel IPC növekedése nagyjából a sandy bridge-től a skylake-ig azért volt szerény - összehasonlítva azzal, hogy most néhány év leforgása alatt duplázást terveznek - mert akkoriban az intel - konkurencia hiányában - a lapkaméret csökkentésére is koncentrált. (=> gyártási volumen ^^ és profit ^^)
Ami a Gracemontot illeti...
Szintén a táblázatban azt írják, hogy 2.5-ös az IPC szintje, ami kb annyi, mint a skylake és igazából csak 20%-kal (~1 generáció) van lemaradva a zen3 mögött. Nyilván nem volna jó, ha csak ebből állna egy cpu, de azért kis prüntyögőnek sem mondható.Ilyen magokból lesz 4db egy nagy mag helyén. A maximális frekvencia pedig kb 1Ghz-cel lesz lemaradva. Én arra számítok, hogy 2 Gracemont mag teljesítmény nagyjából 1 Cove mag 2 szálas teljesítményével fog felérni, viszont 4 Gracemont mag fogy annyit fogyasztani, mint 1 cove mag.
Most sokan morognak amiatt, hogy az AVX512 támogatás kikerült az Alder Lake-ből.
Fenti ábrából számomra nem derül ki, hogy a Gracemont hány és milyen méretű FPU porttal, vagy pipe-pal rendelkezik. (Egy helyet találtam, ahol azt írták, hogy a gracemont fpu port size 256b) Ha jól tudom a Zen eredetileg 4x128b volt, amivel tudott AVX2-es utasításokat végrehajtani úgy, hogy két portot összeolvasztott. Aztán ez a zen2-ben bővült 4x256b-re.
Korábban pedig beszéltünk arról, hogy az Arm SVE esetén is megoldható az, hogy egy hosszabb vektorutasítást rövidebb feldolgozóval több órajelciklus alatt hajtson végre.Remélem, hogy a raptor lake-ben megoldják, hogy AVX512 visszajöjjön
1) vagy úgy, hogy összeolvasztással, vagy több órajelciklus alatt történő végrehajtással.
De szimpatikus lenne egy olyan megközelítés, mint a zené, hogy 4x128bit a feldolgozó képessége, amivel lightweight taskokat gyorsan tud kiszolgálni, de kompatibilis tudna maradni akár AVX512 utasításokkal egy órajelciklus alatt is.2) Nem tudom, emlékszel, hogy az új Low-power Arm magoknál a "Compex" kifejezésre
[link]
Lényegében az amd bulldozer köszönt vissza: megosztott, összeolvasztható FPU
Na ez még elég ütős lenne -
#5595
Petykemano
veterán
Petykemano
veterán
AM5 [link]
A cikk szerint a Raphael csak DDR5-4800 és PCIe4 támogatást kap.
Valahogy nehezemre esik elhinni, hogy ez egy 2022Q4-ben megjelenő termék.
Tehát:
2021Q4: Alder lake - DDR5+pcie5
2022Q1: zen3d - DDR4+pcie4
2022Q4: zen4 - DDR5+pcie4A DDR5 csúsztatása költségoldalról értelmes, a vcache kompenzálhatja.
Természetesen nem gondolnám, hogy konzumer piacon kapkodni kellene a pcie5-tel, szerintem a pcie4 ssdk pláne videokártyák penetrációja sem magas. Nem feltétlenül gondolnám azt, hogy 2022-ben bárki azért döntene az alderlake mellett, mert az gyorsabb pcie5.
Lehet magyarázni, de techpress oldalról cikizve lesz - ahogy már most is - ha az Intel első pcie5 képes terméke után 1 évvel megjelenő friss termék se fogja tudni.De szerverpiacon ez esetleg számíthat.
Az AMD direkt szállítana gyengébb pcie csatolót, hogy inkább az infinity acrhitecture 3.0-t válaszd?
Vagy a zen4 lapka tud pcie5-öt, de desktopban csak 4-et engednek?Egyébkéntár megint mért az elvileg másfél év múlva megjelenő zen4/raphael cuccokról jön infó és nem a fél év múlva esedékesről?
-
#5592
Petykemano
veterán
Petykemano
#5582
Petykemano
veterán
válasz
Petykemano
#5582
üzenetére
Ez a videó elgondolkodtató: [link]
A HWBU tesztelte az Intel 6-8-10 magos cpuit 6, illetve 8 maggal úgy, hogy az eredeti L3$ cache mennyiség (12-16-20MB) megmaradt.
Azt találták, hogy a játékok, legalábbis amelyek skálázódnak, jelentősen magasabb mértékben jobban reagáltak a cache méret különbségre (12-16-20) azonos -6- magszám mellett, mint a magszám emelkedésére.Az Intel 6-8-10 magos cpukhoz képest az AMD cpuk között lényegesen kisebb differencia látható, mivel mindegyiknél azonos az elérhető l3$ cache mérete.
Egyrészt ez megerősíti azt, hogy a v-cache várhatóan nagy siker lesz - ott ahol ez számít - és valószínűleg tényleg remek szegmentciós tényezővé lehet tenni.
Másrészt ezt a magszámokról folytatott vitát is átalakíthatja: egy év múlva lehet, hogy azzal fogok érvelni, hogy érdemes volna inkább $200-300-ért a hardvergyártónak előrebocsátania a omegacache-t, hogy tudjanak rá optimalizálni a fejlesztők.
-
#5591
Petykemano
veterán
S_x96x_S
#5588
Petykemano
veterán
válasz
S_x96x_S
#5588
üzenetére
> azért a 8C+16c is necces lehet 2 csatornás DDR5 mellett ..
> de a "40 (8C+32c)" ( Arrow Lake ) -et már végképp nem értem."2016-ban 4 mag volt a desktop maximuma 2ch mellett, és 6-8-10 magot kaptál 4 csatornával. Pedig szerintem már az is DDR4 volt akkor.
Jóllehet csak 2400. Ennek ma leginkább másfélszerese a széleskörben elterjedt, ugyanakkor 2 csatornával már 16 magot is elérhetsz.A magyarázat szerintem ott keresendő, hogy mennyi L3$ volt a 4 magos skylakeben és mennyi a 16 magos ryzenben.
-
#5583
Petykemano
veterán
Petykemano
veterán
"The file shows that the IO die power consumption of zen4 is basically the same as that of 14nm, which should not be the performance of 6nm at all. Personally, I think the information in the file is not necessarily correct."
[link]
"It seems pretty correct to me. I feel the following changes could definitely offset the efficiency gains moving from 14HP to N6. 1.5x the memory channels + DDR5 instead of DDR4. 2x the PCIe bandwidth. 50% more GMI PHYs. Infinity Fabric 3.0."
[link]
Mindenesetre ezek szerint az IOD fogyasztása a szerverben nem fog csökkeni.
Viszont ha tényleg a felsorolt új fícsörök növelik a nodeváltás ellenére, akkor desktopon némileg akár csökkenhet is (feltéve, hogy azt is 6/7nm-en gyártják majd) hiszen legalább a 1.5x DDR vezérlő kihagyható.Egyébként ez egy érdekes kérdés. Az eddigi IOD-ok esetén megfigyelhető volt, hogy a szerver/TR IOD 4 kvadránsát nagyjából kiadja 4db desktop IOD.
Vajon a 4 kvadráns ugyanúgy megmaradt és egyenként 3 CCD kapcsolat és 3 DDR5 vezérlőt tartalmaz? (Ebben az esetben a desktop is)
vagy 4 kvadráns helyett a szerver IOD 6 db desktop IOD-ra fog emlékeztetni? -
#5582
Petykemano
veterán
S_x96x_S
#5579
Petykemano
veterán
válasz
S_x96x_S
#5579
üzenetére
> a desktopon
> a jövő "kövér - szteroidos - kigyúrt magoké"
> lásd Apple M1 ; AVX-512 / AMX
Igen, ebben egészen biztos vagyok én is. Jim Keller is mondta az Intel designokról, hogy hízni fognak. És abban is biztos vagyok, hogy a szteroridos magok hízását szeretnék a big.LITTLE koncepcióval ellensúlyozni - Multithread felhasználáshoz tényleg nem kell minden magnak gyorsnak és kövérnek lennie.De szerintem csak a desktopon lehet sikere/helye a big.LITTLE-nek, vagyis annak, hogy a fürge, de optimális hely és energiahatékonyságú magok mellett vannak kövér, szteridos magok is. Egyrészt a cloud gamingben szerintem lehet szerepe a desktophoz hasonló -- big.LITTLE - felépítésű, de szerver minőségű processzoroknak. másrészt pont azokban a szegmensekben, amikről Abu mesélt, hogy <32 mag az igény, ott is lehet nagyon hasznos, hogy egy hosszantartó/main processre erős mag jut, míg a kisebb, jobban szálasítható folyamatokat elviszik a kismagok.
> Az AMD előreszaladt egy kicsit a sok*sovány mag irányába,
> ami a szerveres/cloud szinten jó ..
> de a desktop-on a szoftveres integráció le van maradva.
> emiatt nem éri meg mindenáron tovább növelni.
Nem tudom, hogy az AMD magjait illik-e soványnak nevezni. Talán az Apple M1 magjainak árnyékában lehet - ha majd kiderül, hogy mennyi lesz egy zen4 5nm-en.
De soknak sok.Természetesen nem állítom, hogy ha a mai árszínvonalon lehetne egy tierrel magasabb cpu-t (ez általában +2 magot magasabb szinten +4 magot jelent) kapni, akkor azt holnap már ki is lehetne használni.
Ahhoz, hogy a többmagos kompatibilitás kiáradjon, valakinek meg kell tennie az első lépést.
Vagy a hardvergyártó kínál - eleinte persze kihasználatlan - többletmagokat a vásárlónak és a többletmagokat látva követi a szoftver, vagy a szoftvert készítik el előre úgy, hogy 1-2-4 magnál jobban skálázódjon, hogy majd sok évvel később széleskörben elérhetővé váljanak azok a hardverek, amelyeken ez a skálázódás meg tud történni.szerintem az első megközelítés működik, mert a több magot ki lehet írni, az lehet egy selling point az emberek mohóságára bazírozva.
> De az egy memória-csatornára eső CPU számot nem lehet büntetlenül növelni
> .. a szük keresztmetszet átmegy a memória elérésre.
> .. és a magszám növelésének haszna elolvad
> a ZEN4/Epyc -nél a 96 mag / 12 mem csatorna = 8
> A ZEN3/AM4 -nél 16 mag / 2 mem csatorna = 8
> vagyis most a 8core/1memCsatorna
> a mágikus szám, amit nehéz átlépni.
> Vagyis a magszámok növelése nem lineáris
> .. a memória csatorna visszafogja.Ezt a problémát szerintem mindig is a cache-sel oldották meg.
Itt van egy érdekes ábra arról, hogy időben állandó a bandwidth / core: [link]Tehát két szempontból is érdekes a 8c/1ch
Egyrészt mert zen4 esetében már elvileg nem DDR4, hanem DDR5 lesz.
Másrészt meg a 3D stacking miatt épp a cache méretek áttörésének küszöbén lehetünk - a növekvő cache méretek pedig csökkenthetik a rendszermemóriára nehezedő terhet.
Vagy lényegesen magasabb - egyszálas - teljesítményt tehetnek lehetővé.Apopó, ha már itt tartunk. Megintcsak megjegyezném.
Ezek az információk nyilván a Gigabyte-tól származnak. De összességében nem fura, hogy mennyi infó érkezik a zen4-ről mostanság és mennyire semmi a zen3D-ről? -
#5576
Petykemano
veterán
Armagedown
#5575
Petykemano
veterán
válasz
 Armagedown
#5575
üzenetére
Armagedown
#5575
üzenetére
> növelje az AMD a versenyképességét az Intelel szemben
Ez elgondolkodtatott.
Sokáig azt vártuk, hogy az 5nm ismét lehetőséget ad majd a mag szám növelésére - Nem azért, mert hogy a 16 mag a mainstreamben ne lenne bőven elég és bárkinek is tényleg életbevágóan 24 magra lenne helyette szüksége, hanem azért, hogy az egész product stack lejjebb csússzon az árlétrán. Mivel hogy ugye a 6 magos $200-250-ről felcsúszott $300.
Na mindegy, nem akarom megnyitni azt a vitát újra, hogy szükságes- vagy indokolt-e a olyasfajta előrelépés, hogy $250-300-ért már ne 6 magot, hanem 8 (friss) magot lehessen kapni. Csak azt akartam mondani, hogy a jelenlegi várakozás az, hogy a magszám maximuma marad 16.Nem hiszem, hogy a 170W-os TDP keret ST felhasználás terén számítana. Viszont a 170W-os azért bőven ad többletlehetőséget arra, hogy mondjuk 3.5Ghz helyett 4-4.5 között pörgessék a 16 magos csúcs processzort.
Már látom a szemeim előtt a zen3 vs zen4 tesztet, hogy mivel tud többet gyári beállítások alapján és mennyivel jobb a zen4 azonos, 105W-os TDP keretbe korlátozva.
Ha ezt összetesszük - ezen gondolkodtam el - valójában legalább annyira fontos lehet az AMD-nek, hogy extra CCD nélkül kínáljon a vásárlóknak extra MT teljesítmény - persze ha így nézzük, akkor leginkább a vásárló költségére.
Én azért persze még titkon remélem, hogy ez nem csak a "hardkór" mainstream felhasználók, hanem a big apu-ra várakozók örömét is szolgálni fogja.
-
#5574
Petykemano
veterán
Petykemano
veterán
-
#5573
Petykemano
veterán
Petykemano
#5572
Petykemano
veterán
válasz
Petykemano
#5572
üzenetére
A videokardz már le is hozta: [link]
-
#5572
Petykemano
veterán
-
#5569
Petykemano
veterán
hokuszpk
#5568
Petykemano
veterán
válasz
 hokuszpk
#5568
üzenetére
hokuszpk
#5568
üzenetére
Hát igen, eléggé low-hanging fruit, én is ezt szajkózom már egy ideje. Megfelelő méretű Infinity cache mellett az AMD gyakorlatilag eliminálhatná az IGP teljesítményéből a rendszermemória sávszélességének problematikáját.
Persze elég sok lehetőséget el tudok képzelni.
Itt mindig a költség volt a szűk keresztmetszet. Különben HBM-mel is meg lehetett volna oldani.
Vajon mondjuk 16MB elég? Annyit talán még a lapka méret szempontból is elvisel.
32MB embedded SRAM már azért elég nagy lenne. Persze mihez képest. Mert azzal nyilván nem 8db kisméretű Vega CU-t kellene meghajtani, hanem 10-12 RDNA2 WGP-t. Tehát ahhoz, hogy infinity cache beépítésének legyen értelme a APU-nak önmagában is nagyobbnak kell lennie.Vannak akik azt mondják, a Zen vonal esetén a 3D stacking mainstream lesz. Hasonlóan ahhoz, ahogy valaha volt frekvencia-verseny, és volt magszám-verseny, most a cache-verseny fog majd beindulni.
3D stackelve elég sok cache-t lehetne hozzáadni.
Majd figyelni kell, hogy a Remrandt kap-e a Vermeer-hez hasonló TSV előkészítést.
Az is egy izgalmas szempont, hogy vajon lehetséges és kívánatos volna-e 3D stackelt SRAM hozzáadása egy APU-hoz úgy, hogy azt akár a CPU akár a GPU is használhatja (legrosszabb esetben BIOS beállítás alapján) Ennek megvalósítása most nyilván nem triviális és az Intelnél a közös cache használat pont nem jött be.Én legalábbis azt gondolnám, hogy az RDNA3 esetén is a nagy méretű infinity cache-t majd 3D stack eljárással oldják meg.
Ez még nagyon a jövő zenéje persze. Valahogy van egy olyan érzésem, hogy mindezeket majd a PS5 Pro alakjában fogjuk először látni ~2 év múlva.
-
#5561
Petykemano
veterán
S_x96x_S
#5555
Petykemano
veterán
válasz
S_x96x_S
#5555
üzenetére
ITt van már annotáció is:
[link]"AMD didn't utilized the area which became free because of it, there is quite a lot of white space. Without the apparently empty spaces, Cezanne would be only 9% larger and not 16%."
"Moreover, simply based on the area, it would have been possible to fit 3 additional GCN5 compute units (11 in total, as on Raven Ridge) while pushing everything else down. 4-8x PCIe3 PHYs could also been added. But obviously, this ignores power limits, extra work, etc."
-
#5559
Petykemano
veterán
S_x96x_S
#5558
Petykemano
veterán
válasz
S_x96x_S
#5558
üzenetére
> ... és 2-3-5 év múlva képesek az M1/2/3/4 -et is lekörözni - innovációban;
Azért ez jelenleg elég merész gondolat.
Nem azért, merthogy azt gondolnám, az intelnél butább emberek ülnek, hanem mert
- az Apple-nek a bőre alatt is pénz van.
- az x86 (legalábbis azok a magok, amiket ma látunk) jelenleg azért úgy tűnik, nincs annyira közel az M1-hez. -
#5548
Petykemano
veterán
Petykemano
#5546
Petykemano
veterán
válasz
Petykemano
#5546
üzenetére
AT fórmon is latolgatják a több stack lehetőségét. Mondhatnám úgy is, hogy van, aki készpénznek veszi, hogy elsőre is lehet több stack.
Mindenesetre az a kérdés is felvetődött, hogy mit hozhat.
Abu upto 25%-ot mondott - játékokban
Nyilván olyan alkalmazások esetén, amik nem függnek az L3-tól, nem fogjuk tudni mérni, láthatatlan, érzékelhetetlen lesz.
Pl a Cinebench esetén az 5600X és az 5600G között pont akkora (4.5%) különbség van ST módban, amekkora az egyszálas órajelkülönbség. (4.4 vs 4.6)Játékban viszont ennél nagyobb tapasztalható.
A fő különbség az 5600X és 5600G között az órajelen kívül a 32MB helyett csak 16MB-os L3$A HWBU tesztje szerint 10 játék átlagát figyelembe véve a két proci között (+3090) ~16% a különbség. Ebből írjunk jóvá 4.5%-ot az órajelnek. (Mindazonáltal megjegyezném, hogy érdekes módon az 5600G-nek a bázis órajele 3.9Ghz, míg az 5600X-nek csak 3.7Ghz)
Tehát az L3$ különbség kb 11%-ért lehet felelős. Legyen csak 10%.az AT fórumon nagyon lelkes JOE NY nevű user szerint vehetjük úgy, hogy az L3$ minden duplázással hozzáadhat 10%-ot. [link]
Ez persze nyilván nem igaz a végtelenségig - biztosan minden programnál van egy olyan méret, aminél már minden fontos dolog befér az L3$-be.De azért játszuk le:
- 16MB => 32MB: +10%
Ez ugye eddig 5600G és 5600X különbsége. De legyen a 32MB a bázis
- 32MB => 64MB: +10%
Ez azt jelenti, hogy már egy felében letiltott v-cache is hozhat 10%-ot.
Egy teljes 64MB-os stack (32MB+64MB) ennél valamivel többet, mondjuk akár 16%-ot is.
- 64MB => 128MB +10% => szumma +21%
128MB persze csak úgy jöhetne ki, hogy az embedded 32MB + 2Hi stack, ami 64MB-ról le van tiltva egyenként 48MB-ra. Két teljes stack ennél akár többet is.
- 128MB => 256MB +10% => szumma +33%
Ehhez persze már 4Hi stack kéne.Ha belekalkuláljuk azt egyre erősödő és nem pedig ilyen végtelenségig lineáris diminishing return jelleget, akkor azt láthatjuk, hogy nagyjából kijön az Abu által mondott 15-25%-os érték (játékokban), ami ebben a számításban persze a stackek számától nem független.
HSM-mel a minap arról értekeztünk, hogy az AMD valószínűleg azért legalább 5950X esetében valószínűleg azért nem spórolt a lapka minőségén. Arra azért lehet számítani, hogy a top Ryzen SKU-k esetén sem fog spúrkodni.
Ha ezek a számok bejönnek (egyrést az Abu által mondott, másrészt a számításos alapú), akkor lehet, hogy esetleg a cinebench elsőséget az AMD el is veszti, mindshare-ért igazán felelős a játékokban betöltött elsőségét nemhogy megőrizheti, de még erősítheti is az Alder Lake-kel szemben.
-
#5546
Petykemano
veterán
poci76
#5543
Petykemano
veterán
Igen.
A bemutatott darab elvileg 1 layert tartalmazott.
A daytona biosban viszont az látszott, hogy 1-2-4 layer lehet aktív. (már ha persze nem volt kamu a képernyőkép)Mindenesetre jelenleg nem tudjuk biztosan, hogy az AMD első körben 1 layerrel próbálkozik. vagy már első körben is lehetséges a több layer. Nyilván minél több layer, annál több a hibalehetőség.
Én azt gondolnám, hogy ha már el kell vékonyítani a szilícium tetejét és alá kell vetni a 3D packaging eljárásnak, akkor azon már kár spórolni, hogy mennyi layert telepítenek. Persze attól függ, hogy mit jelent a hibás, vagy sikertelen illesztés. Anno a Fiji / FuryX esetén Abu azt mondta, hogy ha nem sikerül a HBM-mel való illesztés, akkor az egész kuka. Ha ez így van, akkor érdemesebb inkább óvatosan csak 1 layert pakolni.
Ha viszont félig sikeres illesztések esetén is működőképes lehet a 4db 64MB-os layer közül valamennyi, vagy valamennyi valamilyen kapacitással, akkor az bőven adhat lehetőséget a válogatásra, a selejtes példányok felhasználására.Jó lenne azt gondolni, hogy utóbbi igaz - a daytona bios alapján -, mert akkor ugye vélhetően több csurranna-cseppenne lefelé is. De a konzervatív énem azt mondatja velem, hogy csak 1 layer lesz.
Attól függetlenül természetesen abból is lehet vágott, ahogy mondod. (Az se feltétlenül azértm mert hibás, hanem csupán szegmentálási célból)
-
#5542
Petykemano
veterán
HSM
#5540
Petykemano
veterán
"De valamit kezdeni kell azokkal is, amik se különösebben magas órajelet, se különösebben jó fogyasztást nem hoznak.
 Én ezeket gondolnám ideálisnak pl. az 5900X-ek második CCD-jének elszórni. TDP tartalék van bőven, két mag kikapcsolható, és kb. csak a base clock van, mint kötelező specifikáció, amit a nem túl szoros TDP-n belül hozni kell."
Én ezeket gondolnám ideálisnak pl. az 5900X-ek második CCD-jének elszórni. TDP tartalék van bőven, két mag kikapcsolható, és kb. csak a base clock van, mint kötelező specifikáció, amit a nem túl szoros TDP-n belül hozni kell."
Természetetesen, pontosan.
De lehet, hogy az 5950X második lapkája is is ilyen átlagos / semmilyen kiemelkedő jó karakterisztikával nem rendelkező. Sőt, szerintem az 5600X és akár az 5800X is ilyen lapkákat kaphat, ahol szintén van bőven TDP keret és nem is feltétlenül kell a legkiemelkedőbb frekvencia-képesség.
A 6 magos lapkák többsége szerintem nem azért 6 magos, mert hibás, hanem mert 8 magosként túl sokat fogyasztana.Erre mondtam, hogy a desktopra a nyesedék/hulladék/forgács jut. Nem abban az értelemben, hogy amúgy a szemétbe kerülne, de ha ezeket az átlagos / semmilyen kiemelkedően jó karakterisztikával nem rendelkező lapkákat nem tudnák ilyen helyen ellőni, akkor ugye kénytelenek lennének vagy kidobni, vagy az epycekben felhasználni, ami mondjuk magasabb TDP-t, vagy 1-200mhz-cel alacsonyabb frekvenciát eredményezne az SKU-kban.
Ezzel nincs baj, nem azt mondom, hogy a desktopra kellene a legjobb lapkákat felhasználni.
Csak azt, hogy hát pont így - nyesedék/hulladék/forgács - formájában jutnak el a fejlesztések is a desktopra, amit lelkesítő marketingszövegekkel adnak el az itteni közönségnek.Ugyanezen logika mentén gondolom azt, hogy lesz majd V-cache-sel szerelt forgács is, amit majd úgy adnak el a desktop piacon, hogy "gyerekek, ez csakis nektek készült, játékra"
-
#5541
Petykemano
veterán
Petykemano
veterán
Ez nagyon érdekes:
Cezanne vs Renoir power-performance curve[link]
Alacsonyabb teljesítményszinten a Renoir nagyon picivel kevesebbett fogyaszt, magasabb teljesítményszinten viszont az inflexiós pontnál meredekebben ugrik fel a fogyasztás.
Szerintem megmagyarázza, miért van Renoir/Lucienne az U sorozatban és miért erősebb a CEzanne jelenléte a desktop (DIY) piacon.
-
#5538
Petykemano
veterán
S_x96x_S
#5537
Petykemano
veterán
válasz
S_x96x_S
#5537
üzenetére
Szerintem legalább kétféle válogatási szempont (minőségi jellemző) létezik.
1.) Fogyasszon alapfrekvencián (3-4ghz) minél kevesebbet minden mag használata mellett
2.) Tudjon elérni minél magasabb frekvenciát legalább néhány magon.A kettő szerintem nem feltétlenül esik egybe, vagyis nem biztos, hogy alapjáraton az a lapka fogyaszt keveset, ami egyébként 1-2 maggal magas frekvencia elérésére képes.
A 64 magos epycekhez biztosan Azokat válogatják,.amik rendkívül.jó fogyasztási mutatókkal rendelkeznek'
A 12-16 magos ryzenekhez pedig valószínűleg Azokat, amik nagyon magas frekvenciát el tudnak érni.De az pl már megállapításra került, hogy a 16 magos ryzen esetén csak az egyik lapka jó minőségű max frekvencia szempontból, a másik tök "átlagos"
-
#5533
Petykemano
veterán
S_x96x_S
#5532
Petykemano
veterán
válasz
S_x96x_S
#5532
üzenetére
> Vajon mit jelenthet a "ZEN4D" -ből a "D" ?
> Persze ha a ZEN3 3D-V-cache - ZEN3D -nek nevezik majd összel, akkor
> közelebb leszünk a megfejtéshez.
Én úgy emléskszem, hogy az AMD nem nevezte a V-cache-sel elláttott zen3-at zen3D-nek, hanem ezt a kivejezést a rajongótábor aggatta rá.
Ami inkább az AMD-hez (vagy AMD-hez közeli szivárogtatókhoz) kötődik, az inkább a "Milan-X" kifejezés, aminek szerintem szintén egy nem AMD, hanem közönség általi mutációja a Vermeer-X.Az elnevezés kérdése érdekes.
Nagyjából tudható - csak mindig megfeledkezünk róla - hogy a fejlesztések nagy része, irányában és mértékében a szerverpiacnak és a notebookok piacának szól. A PR és a marketing viszont a nagyon lelkes "gamer" rajongótábornak.
A V-cache-ről is lehet sejteni, hogy elsősorban nem a játékosoknak készült, hanem a memóriaintenzív HPC alkalmazások alá. Persze akár szerver, akár desktop szegmensben is egy remek húzás lehet a V-cache-sel szerelt "olcsó" DDR4-es platformmal menni a drága DDR5-ös ellenfelekkel szemben. Tehát mégegyszer: a Milan-X szerintem érhet el komoly sikereket azzal, hogy olcsóbb DDR4-gyel ér el jó eredményeket.A desktopra mindig a nyesedék és hulladék érkezik. Nem mondom, hogy a szemét, de a termelés gyengébbik része.
Ha meg tudják oldani, akkor nem csak mag szám, hanem V-cache méret vonatkozásában is lesz szegmentáció.
Mondjuk:6600: szokásos6600X: szokásos6600XT: V-cache6800: szokásos (OEM only)6800X: szokásos6800XT: v-cache6900: szokásos, (OEM only)6900X: szokásos,6900XT: v-cache6950X: szokásos,6950XT: v-cachePersze azt sem szabad kihagyni a számításból, hogy a Daytona biosban már láttuk, hogy az AMD elvileg nem csak 1 layer v-cache-sel készül, hanem upto 4. Tehát nem csak olyanfajta szegmentáció lehetséges, hogy van-e layer, vagy nincs, hanem hogy mennyi működőképes/aktív.
Pl:
6600 : cache nélkül6600X: cache nélkül6600XT: 1 layer6800: cache nélkül (OEM only)6800X: 1 layer6800XT: 2 layer6900: cache nélkül (OEM only)6900X: 1 layer6900XT: 2 layer6950X: 1 layer6950XT: 3 layerA desktop elnevezéssel kapcsolatban abban egészen biztosak lehetünk, hogy valami olyan lesz, ami hangzatos és lelkesítő a nyesedéket megkapó gamer közösség számára. Ezt olyan elnevezésekkel érik el, amivel elhitetik, hogy mintha a fejlesztés nekik készült volna. Mint pl a gaming cache.
Frame Rate Stabilizer Buffer
Gaming Cache Cube (that improves your gaming experience with a new dimension)
3D Game Cache -
#5529
Petykemano
veterán
Petykemano
veterán
Erősen kezdett a 5600g/5700g
[link] -
#5528
Petykemano
veterán
S_x96x_S
#5527
Petykemano
veterán
válasz
S_x96x_S
#5527
üzenetére
Szerintem a uop (L0).cache megjelenése tette lehetővé az L1$ méretének csökkentését és a cél szerintem épp a késleltetés caökkentése lehetett.
Én a zen4 esetén... hmm elgondolkodtató. Max.egy szolid emelést tartok valószínűnek (48KB) L1$ terén. És 1MB-os L2-t.
Aztán a komoly áttervezés - Almásra - majd inkább a zen5. Azt gyanítom, nem véletlen, hogy a zen5 mellett jelenik meg a "zen4D"*, ami azt sejteti, hogy lesz egy zen vonal a zen4-ből, ami a jelenlegi egyensúlyi pont optimalizációja, és ágazik egy nagyobb mag.
* elvileg Abban a környezetben a zen4d nem a v-cache -sel szerelt változatot jelentette
-
#5523
Petykemano
veterán
S_x96x_S
#5519
Petykemano
veterán
válasz
S_x96x_S
#5519
üzenetére
Szerintem Amikor tranzisztorsűrűségről beszélünk, az fizikai kiterjedést is jelent és cache esetén szerintem ennek nagyonis van hatása a késleltetéssel. Vagyis amikor növelsz egy cache-t, akkor szerintem a fizikai kiterjedése hozzájárul ahhoz, hogy mekkora a késleltetés. Nagyobb sűrűség mellett a fizikai kiterjedés kisebb, tehát csökkenhet a késleltetés.
Az Apple cache-e egyébként nemcsak nagy kapacitású, hanem ráadásul fizikailag kicsi is.
Azt nem tudjuk, hogy forradalmi cache design vagy csupán a 5nm sűrűsége tette lehetőve.
Mindenesetre én arra számítok, hogy növekedni fog legalább az L2, de talán az L1 is és az 5nm miatt nem fog nőni a késleltetés.
A 3d cache épp azért lesz forradalmi, mert úgy tudod növelni a cache kapacitását, hogy a fizikai kiterjedés nagyon minimálisan nő.
-
#5514
Petykemano
veterán
S_x96x_S
#4912
Petykemano
veterán
-
#5511
Petykemano
veterán
S_x96x_S
#5510
Petykemano
veterán
válasz
S_x96x_S
#5510
üzenetére
De fura, hogy a 3600X-et beköltöztették az "others" kategóriába. Tavaly november-december környékén az csúcsosodott - drága lett az 5600X, ezért mindenki gyorsan lecsapott a 3600X-re.
> nagyon hiányzik az "olcsó" kategória ..
IgenÉrdekelne egy hasonló kimutatás GPU-k terén.
Nyilván a mindfactory nem reprezentatív, de azért érdekes lenne látni, hogy darabra ugyanannyit vásárolnak az emberek, csak drágábban, vagy a drágulással az eladási volumen is letört? - CPU-knál ez látszik.És ha az eladott volumen GPU-k terén is kisebb, mint 1 éve, akkor vajon hová, vagy milyen ellátásái láncon keresztül történik az értékesítés? Mert az Nvidia és az AMD bevételei nem csökkentek.
-
#5503
Petykemano
veterán
S_x96x_S
#5502
Petykemano
veterán
válasz
S_x96x_S
#5502
üzenetére
>> Brecken Ridge
>érdekes mintha a festők és a földrajzi helyek??
>váltakoznának a jövőben ..
>lehet, hogy valami tick-tock szerüség?Azt mondák már a múltkor is, hogy van a CCD-nek is saját kódneve: [link]
> Amúgy a 3DStack főleg a gyártástechnológiáról szól. És lehet, hogy ezután sokkal nagyobb
> változtatásokat is beleraknak - ami már megérdemel egy külön elnevezést ?Arra gondolsz, hogy az AMD fejlesztései (sem) node-agnisztikusak, tehát hogy van egy rahedli fejlesztésük tervezés szintjén készen, de az implementáláshoz (ahhoz, hogy megérje), szükséges a nagyobb tranzisztorsűrűség (Hasonló okokból láttunk az Intelnél is megtorpanást, amit végül a Rocket Lake formájában igyekeztek oldani) és aztán miután lementek 5nm-re utána egy ideig gyorsabban tudnak új designokat kiadni?
-
#5501
Petykemano
veterán
Petykemano
#5401
Petykemano
veterán
válasz
Petykemano
#5401
üzenetére
Nemrégiben megjelent a köztudatban ez a slide. Ennek a lényege a Warhol helyett Brecken Ridge említése volt:
Én akkor kifejeztem egyet nem értésemet azzal kapcsolatban, hogy az AMD felgyorsítaná fejlesztéset és gyors egymásutánban új node-okon hozná a zen4-et majd a zen4-öt: [link]
Ma Greymon újra kiírta ezeket az információkat:
phoenix 2023
granite ridge 2023
strix point 2024
[link]Lényegében ugyanaz, mint az ábrán, nincs új információtartalom.
-
#5497
Petykemano
veterán
Petykemano
veterán
"AMD Mendocino | MDN-A0
Zen 2 | socket FT6
CPUID 0x8A0F00"
[link]Talán.vágott xbox chip?
Esetleg hibás steamdeck? (van gogh) -
#5484
Petykemano
veterán
solfilo
#5481
Petykemano
veterán
válasz
 solfilo
#5481
üzenetére
solfilo
#5481
üzenetére
> "Arra van tippetek, hogy Cezanne miért jöhet DIY-re, mikor a Renoirt nem mutatták itt be? "
Volt Renoir desktop, csak de csak PRO 4750G néven. Tudom, az nem DIY, de volt asztali változat.Nem túlmagyarázva: az én tippem az, hogy a Cezanne minimum fogyasztása nem annyira jó, mint a Renoir volt, illetve a Lucienné most. Tehát szerintem több lehet a túl sokat fogyasztó selejt.
Egyébként természetesen ha nem "hibás egyedek, ami rendeltetésszerű helyén eladhatatlan", akkor a kapacitás határoz meg mindent.
Viszont HSM megjegyzését ("Szerintem a Cezanne-t egyszerűbb gyártani és nem von el lapkákat a legdrágábban eladható szerver CPU-któl.") Közvetlenül nem von el lapkákat, de egy Cezanne-ból kijönne két zen3-as lapka is terület alapon. Logikus lenne inkább még két zen3-as lapkát gyártani és akár 5600X-től 5950X-ig bármilyen formában eladni.A kérdés tehát az, hogy ha a 7nm kapacitásról dönthetnek, miért arra fordítják. Tehát az lehet még, hogy kevés az IO lapka, vagy azoknak az összeszerelő gyártósoroknak a kapacitása is fullon lehet, ahol az IO lapkákat és a CCD-ket összeszerelik. Ilyen esetben hiába tudnál még CCD-t gyártani és akkor talán érdemesebb Cezanne-t, amit ennélfogva "egyszerűbb gyártani"
-
#5480
Petykemano
veterán
solfilo
#5479
Petykemano
veterán
válasz
solfilo
#5479
üzenetére
Elég messze van még az AMD.
Itt most arról beszélünk tulajdonképpen 3 technológia szempontjából sikeres év után $2b-ról sikerült $3-4b-ra emelni az árbevételt úgy, hogy ők szolgálják ki a DIY piacot, a konzolokat, és a Top500 szuperszámítógépeket is.
Ehhez képest az Intel még mindig 6-8-szor akkora árbevétellel rendelkezik, az AMD növekményét szinte meg se érezték.
Van még hová nőni. Eközben viszont a másik oldalról arról beszélünk, hogy hát az AMD nem igazán tud több gyártókapacitást venni. -
#5474
Petykemano
veterán
S_x96x_S
#5473
Petykemano
veterán
válasz
S_x96x_S
#5473
üzenetére
Ez nagyon kemény.
És az is,.hogy még egy ilyen szép számokat tartalmazó grafikont is kozmetikáznak: 2x nagyobb érték 3x hosszabb csík.Ú és a margó is nőtt. Ezt a céget megviselte a covid...
"AMD began initial shipments of their first CDNA 2 architecture-based Instinct accelerators in Q2"
Kár, h nem derül ki, hogy ryzen v gpu mennyi,.és hogy a az epyc vagy konzol mennyi -
#5472
Petykemano
veterán
HSM
#5464
Petykemano
veterán
Abu a v-cache-ről:
"Kódolási feladatokban már számottevő előnye van, 15-40%-os gyorsulás is realizálható a gyakorlatban, és hasonló módon tündököl a rendszer a modernebb játékokban. Úgy tudjuk, hogy a 3D V-Cache a frissebb címekben 15-25% közötti, gyakorlatban is kimérhető előrelépést biztosíthat, sőt, az Unreal Engine 5-ben akár 30-40%-nyi extra teljesítményt is érhet."
"Az asztali termékek tekintetében csak olyan területre hoznak friss processzorokat, ahol az extra gyorsítótárnak valóban haszna van, így az erre építő Ryzenek kizárólag a játékosokat célozzák majd. Sajnos ezeknek valószínűleg az árát is meg fogják kérni."
[link]Ez alapján azt tippelném, hogy Threadripperből nem lesz v-cache verzió,
legalábbis zen3-ból nem,
legalábbis egyelőre nem, merthogy a Threadripper egyre jobban csúszik.A szövegezés - miszerint új verzió csak ott lesz, ahol a v-cache-nek értelme van - arra utal, hogy a döntő újítás mégiscsak a v-cache és nem lesz zen3+/Warhol jellegű ráncfelvarrás, új IOD. (Persze 100-200Mhz többlet nem kizárt)
Úgy értem, hogy a megfogalmazás nem azt mondja, hogy a v-cache-t csak ott vetik be, ahol értelme van, hanem hanem hogy új processzort oda hoznak.Viszont ha ez tényleg a játékosok a célpiac, akkor ha Neked van igazad és csak az eleve drágább 12-16 magos példányokra teszik rá, akkor az PR-nak természetesen kiváló, mert biztosan minden reviewer lecseréli az addig tesztelésre használt 5950X-et, de a gyakorlatban szemfényvesztés, mert 12-16 magosokat leginkább az veszi, aki valamilyen munka jellegű célra is használja, de kevésbé az átlag gamer.
Ezzel együtt nem mondom, hogy ne történhetne meg, sőt.
-
#5468
Petykemano
veterán
Petykemano
veterán
5(6|7)00G: Augusztus 5.
-
#5465
Petykemano
veterán
Valdez
#5463
Petykemano
veterán
Sok volt az össze-vissza irányú információ, ezért nem lehet tudni semmi sem biztosan.
Volt szó arról, hogy Warhol, és hogy az zen3 7nm, aztán hogy az zen3+, aztán hogy mégse, aztán hogy 6nm, aztán hogy nem is lesz Warhol.Nem tudjuk, mi lesz vagy lett volna a Warhol és azt se, hogy mi lesz az, amit zen3+-ként emlegetnek még mindig a Rembrandtban.
A Rembrandtban minden elkészül, ami 7 helyett 6nm-es és zen3 helyett úgynevezett zen3+ magos CCD-khez szükséges és ami 12nm helyett 6nm-es IOD-hoz.
A másik oldalról viszont ott van, hogy vajon érdemes-e ilyenekkel vesződni az életpályája végén levő AM4 platformba (A Rembrandt AM5) ? -
#5462
Petykemano
veterán
HSM
#5461
Petykemano
veterán
> És ezen szvsz nem fog javítani a V-cache egy cseppet sem.
Ok, értem.
De ha a v-cache hatása ennyire csak egy niche szoftver-szegmenst érint és a költsége viszont ehhez képest nagy, akkor az inkább kéne, hogy egy olyan új termékkategóriát jelentsen, ahol az előny kihasználható, és annyira nagy is, hogy hajlandóak a magasabb költséget kifizetni.De ha - költség és a niche hatás miatt - nem cél, hogy mainstream legyen, akkor az az AMD-nek is némiképp problémát jelent.
Eddig kényelmesen szórták ugyanazt a CCD-t minden piacra.Lehet, hogy igazad van és tényleg csak a drágább modelleken vetik be.
Pl: 6900X(V) és 6950X(V)
És akkor a 6 magos lapkák is megjelennek a mainstream vonalon. -
#5459
Petykemano
veterán
HSM
#5458
Petykemano
veterán
A pletykák szerint [link] a 6+4 magos Alder Lake (12600K) ST kb 10%-kal lesz lassabb, mint az 12900K.
Persze sok a kérdőjel. Lehet, hogy a 12900K valójában csak golden sample, amiből kb annyit válogatnak le, amennyit el kell küldeni a reviewereknek.Mindenesetre nem tűnik úgy, hogy az 12900K-hoz képest az Intel középkategóriája (bár manapság ez már felső-közép), az 12600K a megszokott differenciától nagyobb mértékben lenne lassabb. Ez a pletykák szerint akár 750 pontot is jelenthet a CB20ST mérésben az 12600K-nak
Ha az így van, akkor az AMD sem igazán engedheti meg magának azt, hogy a középkategóriája nagyon lemaradjon. Az 5600X jelenleg 600 körüli eredményt produkál.
Ha ezen tényleg csak annyit javítanak, hogy reszelnek picit az órajelen, akkor 650-660-ra felmehet, de azért ez még kevéske.Persze sok a kérdőjel. Mert ha az Intel az 12900K-t $750-ra árazza mondván, hogy annyit megér az, mint az 5950X, akkor persze mindennek az ára mehet feljebb és lehet az 12600K is $400-450, ami alá elfér (sőt, még kedvezőnek is tűnhet) $300-ért egy 10%-kal lassabb 6 magos az AMD-től.
Viszont ebben az esetben az AMD-nek is egy $100-ral nagyobb kerettel gondolkodhat azon, hogy akar-e v-cache-sel szerelt 6 magost.Én egyébként tartok tőle, hogy ez fog történni.
-
#5457
Petykemano
veterán
HSM
#5451
Petykemano
veterán
Mindennel.egyetértek azon kívül, hogy olcsóbb termékekre nem fogják elsütni.
4 magos persze már nem lesz. Arra ott a picasso+++, vagy vangogh selejt, később a pletykált Monet.
De szerintem hatmagoson még lehet. $300-ba azért már csak bele kéne férjen +10$ költség. A 3d.stacking akkor lesz olcsó, ha nagy a volumen.
Nyilván ennek is lehet selejtje. Ha az igp nélküli ps5 lapkákat eladják...(Ugyanakkor az ember hiába gondolja azt, hogy valami kevés, annál több kéne gyakorlat sokszor azt igazolja, hogy annál kevesebb fog csak jönni.)
-
#5449
Petykemano
veterán
S_x96x_S
#5448
Petykemano
veterán
válasz
S_x96x_S
#5448
üzenetére
> inkább január az AlderLake-el
Szerinted az Alder Lake csak akkor fog megjelenni?
Nyár közepe van. A mostani AL hírek alapján (Qualicifation Sample), meg hogy kínában már lehet venni a mintákat feketepiacon, azt gondolnám, hogy ez ősszel - legalábbis papír formában - elrajtol.
Az várakozásom/elképzelésem ez és hogy erre az AMD némi árcsökkentéssel, vagy XT verziók kiadásával (és árcsökkentéssel) válaszol még a 5k sorozatban. Amire majd finnyázunk, hogy hát ez kevés, de legalább jó áron van. A v-cache verziót 6k szériának mondják.(Persze én is csak találgatok)
-
#5445
Petykemano
veterán
tlac
#5444
Petykemano
veterán
Engem kellemesen meglepne.
Az AMD az utolsó előadáson azt mondta, hogy a v-cache-sel szerelt processzorok (abban most már nem is vagyok biztos, hogy megnevezték, hogy egészen pontosan milyen típus, csak a bemutatott zen3-as kísérleti darab miatt gondoljuk, hogy zen3-ra épül) idén év végén kerülnek gyártásra. Abból idén új termék feltehetőleg nem lesz.
Amire szerintem lehet számítani az az, hogy a Van Gogh (SteamDeck) selejtjét is kiárulja úgy mint a PS5 selejtet.
Valamint ha megjelenik az Alder Lake és az AMD wafer ellátottsága megengedi, akkor esetleg megjelenhet egy 5600-as sku.Máskülönben az év hátralevő részében az AMD az olcsóbb jellegű RDNA2-kel lesz elvileg elfoglalva.
-
#5443
Petykemano
veterán
S_x96x_S
#5441
Petykemano
veterán
válasz
S_x96x_S
#5441
üzenetére
Tehát azt mondod, hogy egy 1060 vagy AMD oldalról egy RX 470-580 középkategóriának számít. (Nem kérdőjelezem meg)
Az AMD tavaly(előtt) hozta a navi 14-gyel, ami 22CU, az RX 580 szintjét. Ez volt 1800Mhz körül.
Az RDNA2-ra épülő és 2500Mhz körül járó 6700XT ennek 232%-át tudja.
Vagyis RDNA2 alapon, ami 2500Mhz körül ketyeg, erre a teljesítményre már akár 16-18CU is képes lehet.
A 32CU-s Navi23 (RX 6600/XT) 32MB oo$-sel rendelkezik és 128bit G6-tal (~250GB/s)Ezt most csak azért mondom, mert hogy amikor azt mondom, hogy szerintem a DDR4/5 lassúságát (a 128bit G6-hoz képest) feleannyi (16-20) CU-hoz szerintem elfedheti ugyanaz a 32MB oo$.
(A Rembrandt, ami elvileg oo$ nélkül jön DDR5-re elvileg 12CU-val fog rendelkezni.)
Sajnos az árak alapján egy ilyen kártya (én kb ide várom a Navi24-et) nem vált belépőszintű, tehát ilyen $100-120 környékivé, legalábbis az utóbbi időben. De amúgy én ezt a szintet ma már inkább belépőszintnek tekintetném, nem középkategóriának.
-
#5440
Petykemano
veterán
S_x96x_S
#5438
Petykemano
veterán
válasz
S_x96x_S
#5438
üzenetére
Mi számít manapság ""középkategóriának"?
Kezd olyan lenni a kérdés, mint Magyarországon (és nyilván más kelet-európai országban is ) a középosztály kérdése.
- van egyszer egy képünk arról, hogy hogy él, mit csinál, hogy gondolkodik egy középosztálybeli
- és van az, hogy statisztikai számítás alapján ki tartozik a középső tizedekbe.
És hát a probléma az, hogy a statisztika alapján vett középosztály itt valójában nem engedheti meg magának a ideálkép szerinti középosztálybeli létformát, életvitelt, gondolkodást.Tehát mondjuk az $500-os 6700XT a középkategória teteje és a remélhetőleg $300-os 6600 az alja?
Az a $300-os kártya, amire a kolléga a másik topikban azt mondta, hogy így néz ki a $100-150-os rx 460-a.Na de mindegy.
-
#5436
Petykemano
veterán
Petykemano
veterán
Az mindenVS-ben már megjelent:
Alderlake:
ST: >810
MT: >11600
[link]Ami 26% és 11% Az 5950X-re
Most már csak abban kell reménykednünk, hogy
- ez nem egy kirakat / golden sample termék lesz, amit egyébként nem lehet majd kapni.
- az intel nem fogja úgy gondolni, hogy hát ez így akkor megér $700-800-tHa a jövőben mindenki úgy fogja gondolni, hogy a jobb termékemmel nemhogy alá kéne vágnom a konkurenciának, hanem épphogy inkább többet is elkérhetek érte, akkor nekünk végünk.
Mindenesetre az a 26% elég komoly. Igaz persze, hogy a 11900K által a 10900K-hoz képest papíron hozott növekményt sem tudta például a játékokban egyértelműen realizálni. Tehát lehet, hogy ez a 26% a gyakorlatban nem annyi. Mindenesetre csak a v-cache nem biztos, hogy elegendő lesz megkérdőjelezhetetlenül megtartani a koronát.
Az a gyanúm, hogy talán az AMD-t kissé váratlanul (bár nem feltétlenül felkészületlenül) érte az, hogy az Alder lake hirtelen ilyen jó frekvenciákat ért el. Mármint hogy talán az Alder lake - előlegezzük meg - jó szereplése okozhatta az AMD-nél azt a kavarodást a kiszivárgó információk terén, hogy most zen3+ vagy nem zen3+, Warhol vagy nem Warhol.
-
#5435
Petykemano
veterán
S_x96x_S
#5434
Petykemano
veterán
válasz
S_x96x_S
#5434
üzenetére
> de azért teljesítményre az nem sokat dob ..
Ezt nem teljesen értem.
Az AMD amikor bemutatta az infinity Cache, akkor egy olyan slide-ot mutogatott, hogy a 256b GDDR6-höz képest több mint 3x, a 384b GDDR6-höz képest pedig 2.17x nagyobb sávszélességet tudnak elérni a 384b GDDR6-nál kevesebb energiahasználat mellett 128MB oo$ segítségével.256b GDDR6 kb 500GB/s, tehát 128MB oo$-sel együtt a sávszélesség 1.6TB/s lehet
Ha azt feltételezzük, hogy negyedennyi cache csak negyedennyi sávszélességetjelent és a biztonság kedvéért előtte kivonjuk belőle a GDDR6 sávszélességét, akkor is legalább 250-300GB/s-mál járhatunk.Ha azt gondoljuk, hogy 32MB oo$ ki szolgálni 32 CU-t 128bit GDDR6-tal (~250GB/s) 1080p-re, akkor én azért azt gondolnám, hogy ugyanúgy 32MB-nak elegendőnek kellene lennie 16-24CU kiszolgálására 2 csatornás DDR5 (~80GB/s) mellett.
Ez egy érdekes twitter thread a témában:
[link]
Effektív BW számítás:
[link]Ezért mondom én a 32MB-ot. 32MB-tal biztosan megvan a 300-500GB/s gyakorlatilag bármilyen memóriarendszer mellett ( [link] )
Bár a navi 24-re történetesen 16MB-ot mondanak/jósolnak. Szerintem az azért kevés.És hát 32MB oo$ mérete kb 23mm2, ami nem kibírhatatlan méret
[link]
cserébe semmilyen más költség nincs. Se packaging (LSI/interposer), se memória (HBM)Ez nagyjából ugyanaz a vita, amit a zen4 + HBM kapcsán lefolytattunk.

Azt természetesen nem zárnám ki, hogy bizonyos termékekben lehet létjogosultsága. Akár úgy is, hogy egy viszonylag pici cache nem ér semmit (lásd bányászat), akár abból a szempontból is, hogy belefér a költségbe.De ha csak a low-end grafikát nézzük, akkor költséghatékonyabb és kielégítő megoldásnak gondolnám, a oo$-t a HBM-nél.
-
#5433
Petykemano
veterán
S_x96x_S
#5432
Petykemano
veterán
válasz
S_x96x_S
#5432
üzenetére
Szerintem a HBM-nél egyszerűbb és olcsóbb megoldás, ha tesznek az IGP elé 32MB infinity Cache-t.
De a következő lépés még mindig csak a sima DDR5 lesz.A roadmapen a desktop vonalon a nagyon minimál, apu vonalon pedig ez a 8-12CU-s irány jelenik meg - ami mindenféle extra nélkül szériamegoldásokkal kiszolgálható. Annak ellenére, hogy évek óta mondják, hogy az apuk fel fogják falni a low-end gpukat, valamiért ez a big apu vonal mindig semi-custom maradt.
-
#5430
Petykemano
veterán
Petykemano
veterán
IOD
Vajon az AMD ezúttal is külön IO lapkát készít 2-4-8 memóriavezérlőkre?
Vagy egységes 6nm IO lapkát készít, ami 2 csatornás, és benne van egy IGP is? (Raphael)
Majd ezeket szükség szerint kapcsolja össze LSI-vel csempeszerűen? -
#5428
Petykemano
veterán
S_x96x_S
#5427
Petykemano
veterán
válasz
S_x96x_S
#5427
üzenetére
Biztos, hogy az asztalon van.
De azért sok a kérdőjel.
Mit nyerhetnek vele, amit chipletenként 64+X MB v-cache nem biztosít?
A HBM lényege az volna, hogy nagy sávszélességet biztosít. Viszont hová csatlakozatod? Ha az IO-hoz, akkor az IO-CCD közötti kapcsolat sávszélességét is meg kell növelni. Ha pedig az egyes CCD-khez, akkor abba kell HBM vezérlő. -
#5426
Petykemano
veterán
S_x96x_S
#5425
-
#5423
Petykemano
veterán
HSM
#5421
Petykemano
veterán
"Szerintem a véletlennek ehhez semmi köze. Azt gondolom, óriásit kaszálnak azzal, hogy a saját chipjükre zárták be a rendszerüket, és nem kell másoknak fizetniük a CPU-ért.
Így ebben a piaci helyzetben nem csoda, hogy minden pénzt megér nekik, hogy egy ideig előnyben legyen gyártástechnológiailag is, ezzel is erősítve a képet, hogy megéri váltani az új rendszerre a régiekről."Talán nem volt szerencsés szóválasztás a "véletlen"
Átfogalmazom.
Az csupán egyedi felállás (kemény munkát követő "rámosolygó szerencse"), hogy az Apple finanszírozza a TSMC új gyártástechnológiát és még így is nyereséges.
Ezzel azt akartam mondani, hogy ha a Intel nem tolja bele hasonlóképp ugyanazt az összeget a fejlesztésbe, akkor le fog maradni. Ha nem tudja, az persze érthető, de ha csupán azért nem teszi meg, hogy a saját számai - ideig-óráig - fényesebbnek tűnjenek, akkor az hosszútávon káros lehet saját magára nézve.
Szóval a lényeg ez: az Apple helyzete egyedi, nem biztos, hogy az Intel is megengedheti magának azt, hogy behúzza a nagy profitokat, miközben elengedi a gyárai kezét, hogy majd oldja meg az új fejlesztések finanszírozását ahogy tudja, de ne az én profitomból. -
#5419
Petykemano
veterán
hokuszpk
#5418
Petykemano
veterán
válasz
hokuszpk
#5418
üzenetére
Értem. Hát... lehet. Nem pontosan tudom, hogy az intel hol csúszott el a saját 10nm-es fejlesztésével. Kósza pletykák nevezték meg a túl ambíciózus csíkszélességcsökkentést. (ami ugye ilyen 1.8x többtranzisztort jelentett volna generációnként szemben a TSMC által alkalmazott 1.4x-es szorzóval, amit még félgenerációk is megszakítanak.) Meg hát a kobalt is felmerült.
Nem tudom, hogy ezek közül a GF tudott-e valamit megoldani. az IBM-től elvileg egy fullos csomagot kaptak 7nm-re. Nem kizárt, hogy lehetett közte olyan info, ami hasznos a továbbiakban.Többen megint azt mondogatják, hogy valójában nem az intel veszi meg a GF-et, hanem az intel ilyen többlépcsős módon választja le magáról a saját gyárait.
Ugye ennek akkor lenne értelme az Intel részéről, ha üzletileg jobb eredményeket tudna kimutatni gyárak nélkül.
De ha a gyárak valójában veszteségesek, akkor szerintem bukta lesz. Pont úgy, ahogy az AMD-nek sem jött be az, hogy a saját leválasztott gyáraiban gyártat - a GF kénytelen volt egész más irányt venni.
Ha viszont nyereséges tud lenni a gyárbirodalom (lásd GF), akkor miért kéne leválasztani?Szerintem be kell látni, hogy ha az intel abból a megfontolásból választja le a saját gyárait, hogy magasabb marzsot mutathasson ki és ezzel csökken a drága cutting edge gyártósorok fejlesztésének finanszírozása (Vagyis a design nem finanszírozza a foundry-t), akkor a gyártósorok le fognak maradni a versenyben és az Intel is kénytelen lesz minden releváns üzleti tevékenységét a TSMC-nél gyártatni és ezzel kiszolgáltatni magát.
Az csupán a véletlen műve, hogy a TSMC esetében az Apple pont bármit kifizet azért, hogy a legújabb node-ot kétévente két évre kizárólagosan használhassa. VAlójában ez a finanszírozás. És azt mondom, hogy az csupán "véletlen", hogy ezt az Apple pont megengedheti magának és még így is brutálisan nyereséges.
-
#5417
Petykemano
veterán
hokuszpk
#5415
Petykemano
veterán
válasz
hokuszpk
#5415
üzenetére
Az lehet, de a GF 7nm közelebb állt az Intel 10nm-éhez.
Az elkövetkező években biztosan nagy szükség lesz kapacitásra. Az évi 20%-os teljesítménynövekedés biztos növeli a keresletet mindenféle CPU iránt.
Ugyanakkor nehéz elképzelnem, hogy a GF kapacitás miatt kellhetne az intelnek. Hiszen nem igazán rendelkezik különösebben modern gyártástechnológiával.Ami a GF-nél számíthat az talán az, hogy van amerikai és európai gyártelepe. Ez fontossá válhat a jövőben a kínával éleződő helyzetben. Kína annektálhatja Taiwant, később délkoreát is befolyása alá vonhatja.
Az intelnek fel kell készülnie a kínai térségen kívüli világ ellátására. A GF gyártelepeit talán meg lehet tölteni intel gyártósorokkal talán könnyebben és gyorsabban,.mint újakat felhúzni. És persze van hozzáértő szakállomány is.
Meg ami még van és az IDF2-höz.fontos lehet: szakértelem.third party megrendelők kiszolgálására.A másik ami még érdekes lehet a chiplet/tile.érában
Az az FDSOI. Ami lényegében egyszerűbb tervezést tesz lehetővé alacsony fogyasztás mellett, némileg drágább gyártási folyamat árán. De ezt se feltétlenül gondolnám, hogy az Intel saját magának szeretné behúzni. -
#5409
Petykemano
veterán
awexco
#5408
Petykemano
veterán
Hát nem tudom, tudni kéne, hogy mire vonatkozik a 15W és mire a 4W.
Ami a TSMC megrendeléseket illeti...
MLiD utolsó híradásaiban azt állította, nem annyira a wafer v megmunkálás kapacitás hiánycikk, mint a szubstrát. Ha ez igaz, akkor elvileg lehet szolídan növelni a lapkák méretét.És hát az is igaz, hogy nem nagyon van más módja a teljesítmény növelésének, mint a több tranzisztor.
TDP növelés szerintem:
- ez azért jelentős MT perf növekedést jelenthet a 16, de akár a 12 magos verzióknak. Mondjuk 10-15% is lehet akár, amennyivel magasabb frekvencián ketyeghet.
Ezzel nyilván reagálni is akartak a intel elszállt fogyasztási értékeire.
- valószínűleg egy új alaplap tier is
- remélem, hogy valami csinos méretű 170W-os apu is belefér. -
#5407
Petykemano
veterán
-
#5406
Petykemano
veterán
Petykemano
veterán
Elég durva, hogy a TSMC bevételének 20%-át az 5nm adja, miközben arra elvileg még csak egy tényleges megrendelő van (Apple)
-
#5405
Petykemano
veterán
S_x96x_S
#5403
Petykemano
veterán
válasz
S_x96x_S
#5403
üzenetére
Igen, én is ezt a kérdést pedzegettem magamban.
Az eddigi magyarázatok szerint a változó hosszúságú utasítások nagy fejtörést okoznak. Az agenda szerint ennek enyhítésére vezették be az opcache-t, ami viszont sok energiát használ és ezért se olyan széles nem lehet az x86, se olyan energiahatékony, mint az Arm.
Ehhez képest Az A77-ben szintén megjelenik az opcache. És a cikk - valamint Jim Keller - szerint a változó hosszúságú utasítás sem probléma.De akkor miért nem rukkolt elő már korábban az AMD vagy az intel egy az M1-hez hasonlóan széles architektúrával, ami ugyan csak 3-4Ghz-en ketyeg, de úgy is hozza az 5+Ghz-es konkurencia teljesítményét és persze egy 3-4Ghz-es proci fogyasztását.
Széles design nyilván több tranzisztort igényel. De Abu elmondása szerint a magas frekvencia sincs ingyen. Nem csak áramot használ, hanem tranzisztort is. Nem emlékszem, hogy a kifejezetten "speed demon" bulldozer esetén előny lett volna, hogy alacsony a tranzisztorigénye. (nagyjából ugyanannyi tranzisztorból állt a bulldozer, mint a 4 magos sandy)
Szerintem az M1-gyel való összevetést nem magyarázza az, hogy az X86 designok HPC piacra készülnek, míg az Arm-osak mobil piacra. Hiszen épp ez az, hogy az M1 hozza azt a teljesítményt. Tehát az, hogy egy "másfajta design választás", aminek "máshol vannak az optimumai" nem elég erős magyarázat.
Az M1 típusú design tervezőasztalon és szimulációkban már régóta álom, de a csak TSMC 5nm-es gyártástechnológiája tette fizikailag megvalósíthatóvá?
Az M1 egy valódi innováció lenne? Amire még senki se gondolt? -
#5402
Petykemano
veterán
Petykemano
veterán
-
#5401
Petykemano
veterán
S_x96x_S
#5400
Petykemano
veterán
válasz
S_x96x_S
#5400
üzenetére
Elég valószínűtlennek tartom azt, hogy a zen4-es Raphael után 1 évvel (15hónap) zen5 következzen ráadásul az épp bevezetett 5nm helyett szintén rögtön 3nm-en.
(Feltéve persze, hogy a 3nm nem úgy jön össze, hogy az nem TSMC, hanem Samsung 3nm)És bár a Vega sokáig kitartott, valahogy azt se hiszem, hogy az RDNA2-t is olyan sokáig hurcolnák magukkal. Tehát szerintem úgy lenne pontos, hogy
- a granite ridge nem 2023, hanem legjobb esetben is 2024 (A Raphael és a granite ridge között persze lehet valami "filler", valami "-X" vagy "+")
- A strix point is csúszik 2025-re és 2024-ben valami zen4 + RDNA3 apu érkezik 5nm-en (esetleg 4nm-en)Hogy ez mennyire versenyképes az egy másik kérdés.
De szerintem az az érvelés, hogy erős a konkurencia és az eddigi 18-24 hónapos nagyobb fejlesztési ciklusokat (tehát ami nem "+") fel kell pörgetni és muszáj új maggal, meg új gyártástechnológiával előállni 15 havonta, az úgymond wishful thinking. -
#5399
Petykemano
veterán
Petykemano
veterán
Warhol helyett Brecken ridge néven emlegetik az idei Vermeer utódot.
[link]
Ez állítólag nem a csomag, hanem a CCD kódneve.Fura. Ott van a sor.végén egy Granite ridge is.
Most vagy az is CCD kódnév,
Vagy változik az AMD nevezéktana (esetleg vele együtt a komplett roadmap) és végül a Raphael sem Raphael lesz. Vagy a kódnév csak időbeliséget jelöl és a zen 3D egy új megoldás.
Az is különös, hogy azt követően már sehol nincs jelölve, hogy valamelyik gen 3d Stacked lenne. -
#5387
Petykemano
veterán
HSM
#5386
Petykemano
veterán
"Szerintem annak még épp van/lenne értelme felhasználói oldalról, hogy 6 helyett 8 magot kapj ugyanannyiért."
Úgy értettem, hogy ha ez így lenne, akkor a növekvő felhasználói értéknek mindenki örülne, de persze a mindennapokban kevés hasznát látná. Tehát a több mag (6-=>8) nem kell úgy, mint egy falat kenyér, mint régen (1=>2, 2=>4)Én arra számítottam, hogy a zen4-gyel majd magszámot emelnek és szépen csúszik le a stack. $200 alá a 6 mag, $200-300 közé a 8 mag, $300-400 közé a 12 mag.
Azt, hogy nem éri meg úgy értettem, hogy egy felhasználónak nem biztos, hogy megér $50-100-t 6 helyett 8 magot venni. A mai 8 magos ugyanolyan elavult lesz 3 év (2 generáció) múlva mint a valamivel olcsóbb 6 magos.
Legalábbis én ezt látom, szerintem nincs lényeges különbség egy 1600X és egy 1800X között. Mindkettőt kenterbe veri egy 5600X.Az üzleti részét értem.
Azt is, hogy az árakat leginkább az befolyásolja, hogy mennyire megy el amit gyártanak azon az áron, amin kínálják. És ebben értelemszerűen a TSMC és más beszállítók árai és keresleti-kínálati viszonyai meghatározók.Azt mondják, a Monet is azért készül, mert "túl jó" a kihozatal. Nem éri meg 4 magosként eladni a lapkákat, ami működnek 6 v 8 magosként is és eladhatók is akként, annyiért.
Akkor lesz változás az árazásban, ha olyan híreket hallunk, hogy túltermelés van a félvezetőpiacon és a TSMC leállít vagy elhalaszt valamilyen gyárépítést és Abu azt írja majd: "hiába szeretné az Apple jövőre a legújabb -1nm-es gyártástechnológián kihozni új processzorát. Lehet, hogy az Apple bele is tolná a fejlesztéshez szükséges pénzt, de utána a TSMC nem tudná megtölteni a gyárakat rendeléssel. Mindenki igyekszik maradni a magas volumennel rendelkező, olcsóbban gyártó és olcsóbban tervezhető gyártósorokon."
"Esetleg az Alder Lake hozhat a maga módján 6+ magot olcsón, de a kis magos megoldásnak is meglesznek szerintem a maga buktatói, szoftveres oldalról a sok kis mag érzékenyebb lehet a programok skálázódási korlátaira, mint ugyanannyi, vagy akár kevesebb nagy."
Ezért fejleszttette az Intel a Windows 11-et, nem? -
#5385
Petykemano
veterán
S_x96x_S
#5382
Petykemano
veterán
válasz
S_x96x_S
#5382
üzenetére
"AMD Raphael with up to 16 cores"
Én egy pár éve még nagy híve voltam a magszám emelésnek. Az szerintem kétségbevonhatatlan, hogy nagy felszabadító ereje volt az első 1-2 zen generációnak, hisz kiszabadított minket a 4/8 felső korlátból.Nem állítom, hogy sok értelme lenne a magszám emelésének a mainstreamben. Tehát az, hogy $200-300 szinten mondjuk ne 6 magos procit lehessen kapni jövő évtől, hanem már 8 magosat, az igen csekély előnyt jelentene. Ha úgymond ingyen jönne a következő generációk során, akkor persze nem mondanék nemet.
Annak viszont semmi értelme, hogy úgy emelgessék a magszámot, hogy közben az ár is emelkedik. Mármint 24 magos cpu-t most is lehet kapni- drágábban. És azt most is csak az veszi meg, akinek szüksége van rá.
A sokmagos forradalom szerintem egyelőre elmaradt.
Egyrészről úgy tűnik, nem valósul meg hardver oldalról. Vagyis nem kapunk mondjuk 3-4 évente 2-vel több magot ugyanazért a pénzért. Nagyjából az lett - és valószínűleg marad is - standard, amit az AMD beállított a zen1 megjelenésével.
Másrészről szinte minden téren megmaradt az a helyzet, hogy a +20% IPC az minden körülmények között +20% IPC, míg a +50% v +33% magszám az hát csak bizonyos speciális körülmények között ér tényleg annyit.
Nem éri meg azért magas magszámú cpu-t venni, hogy a magas magszám majd hosszútávon is kielégítő lesz, mert mire IPC szempontjából kiöregszik, addigra majd hozzáskálázódnak a programok a sok maghoz. Kivéve persze ha biztosan olyan programot használsz, ami biztosan ki is használja a magas magszámot.Számomra például nagyon elgondolkodtató a pletykált Monet. Reméljük olcsón fogják adni. Mindenesetre azt elég valószínű, hogy bucira fogja verni az 1600-tól 2700X-ig mindent, pedig csak négy magos.
"Mindenesetre kiváncsi leszek az 5950X utódjára ..
Vajon lesz-e +20% CB R20 eredmény?"
Egész pontosan a Raphael-re gondolsz, vagy a Vermeer-X-re? -
#5378
Petykemano
veterán
Petykemano
veterán
Itt egy másik érdekes kép az eladott PC példányszámokról:
[link]Ha jól értem, akkor a 2020 februári előrejelzés és a 2021 februári előrejelzés között évi 100millió gép különbség van. Nyilván az előrejelzés tényadatokra épül, de arra nem vállalkoznék ez alapján, hogy megmondjam, 2020 és 2021 eddigi hónapjaiban mennyivel volt magasabb tényleges eladásszám / kereslet az előző évekhez képest.
-
#5377
Petykemano
veterán
Petykemano
#5375
Petykemano
veterán
válasz
Petykemano
#5375
üzenetére
ITt egy érdekes kép ehhez:
[link]
Az intel processzorok arányával együtt nőtt a korábban csökkenőben levő GTX 1060 is.
Úgy tűnik, talán tényleg csak internetkávézók nyitottak újra. -
#5375
Petykemano
veterán
S_x96x_S
#5373
Petykemano
veterán
válasz
S_x96x_S
#5373
üzenetére
Én nem vonnék le messzemenő következtetéseket.
Az ilyen hirtelen ugrások általában nem valamilyen cpu piaci mozgás következményei.
Lehet, hogy elindult egy új játék, ami KÍnában népszerű
Lehet, hogy újranyitottak az internet kávézók, amik eddig "a covid miatt" zárva tartottak.
Lehet, hogy a lezárt bányászat miatt a gépeken adtak túl, és azok valami olcsó intel procik voltak.
Lehet, hogy a lezárt bányászat miatt a gépekből új internetkávézók nyíltak.Egyébként egy 4 magos GF12-es zen3 még talán engem is érdekelne. Bár az valószínűleg valami forrasztott cucc lenne, nem AM4.









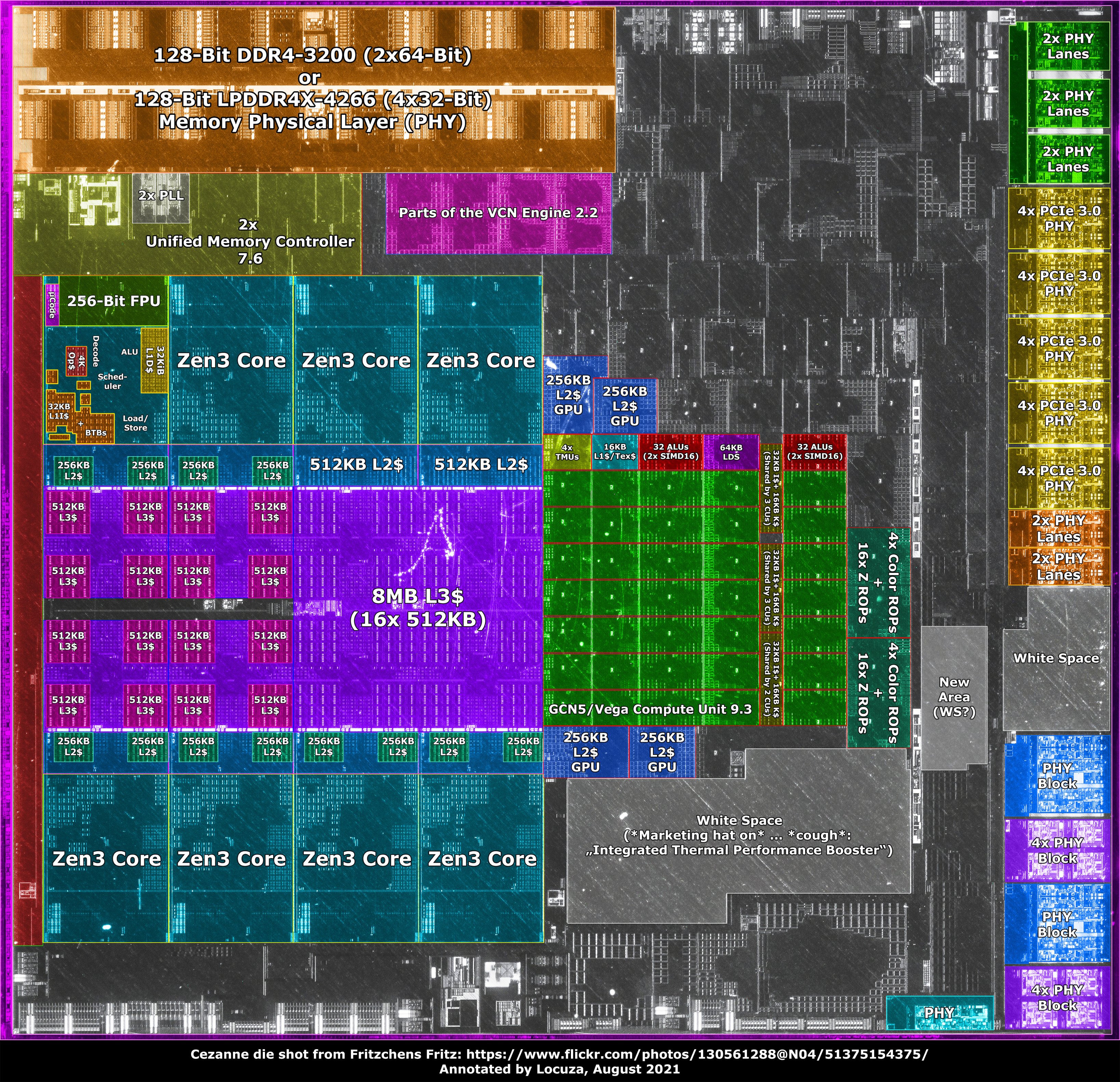

 Én ezeket gondolnám ideálisnak pl. az 5900X-ek második CCD-jének elszórni. TDP tartalék van bőven, két mag kikapcsolható, és kb. csak a base clock van, mint kötelező specifikáció, amit a nem túl szoros TDP-n belül hozni kell."
Én ezeket gondolnám ideálisnak pl. az 5900X-ek második CCD-jének elszórni. TDP tartalék van bőven, két mag kikapcsolható, és kb. csak a base clock van, mint kötelező specifikáció, amit a nem túl szoros TDP-n belül hozni kell."
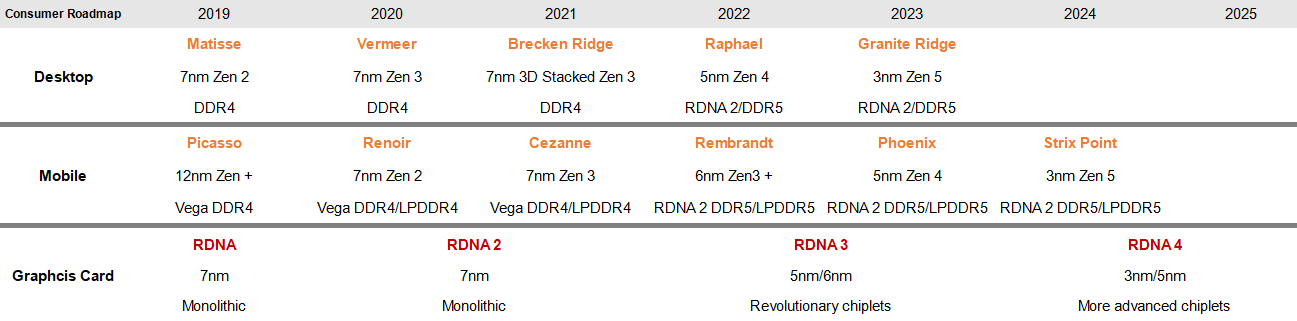


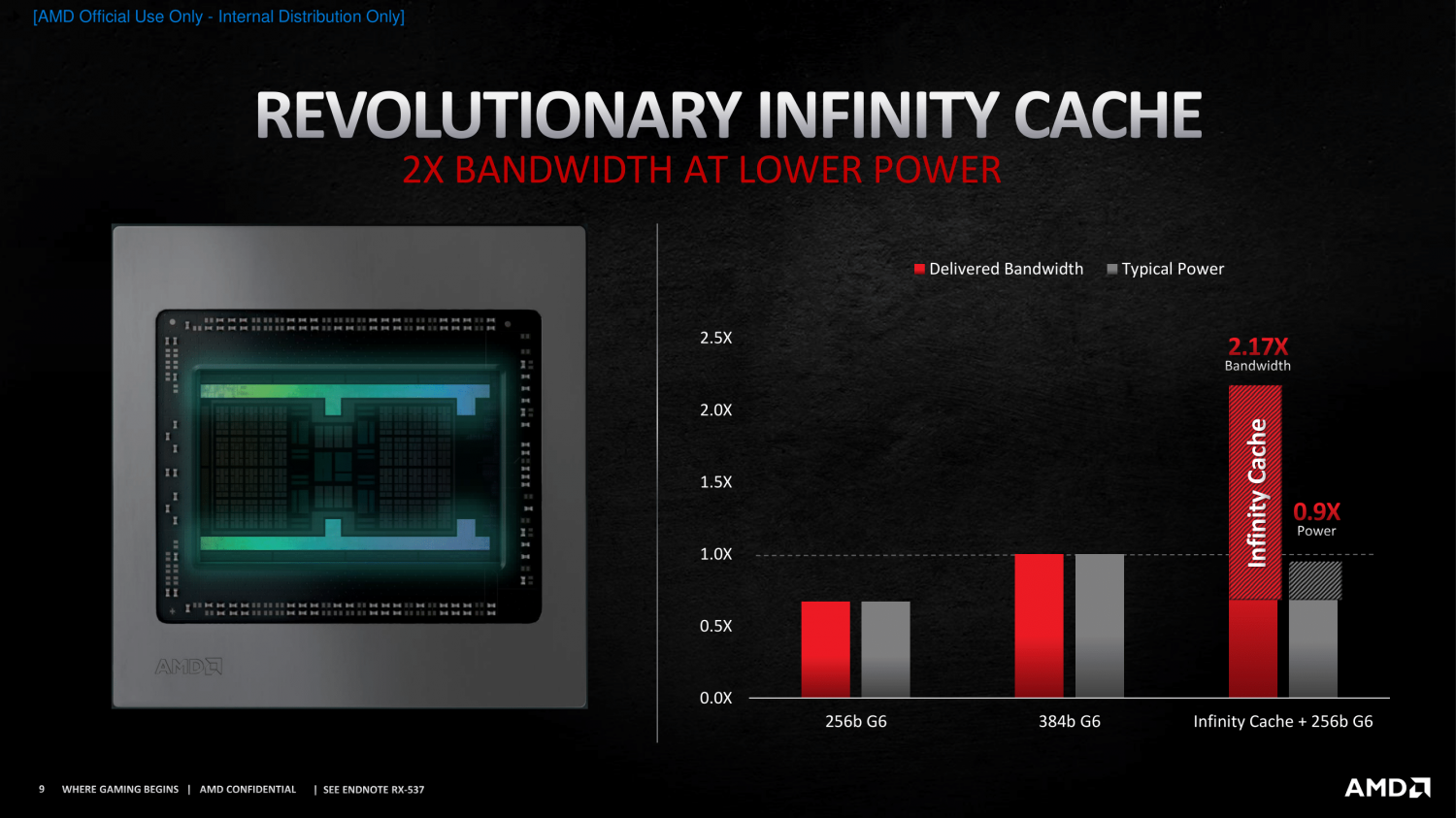


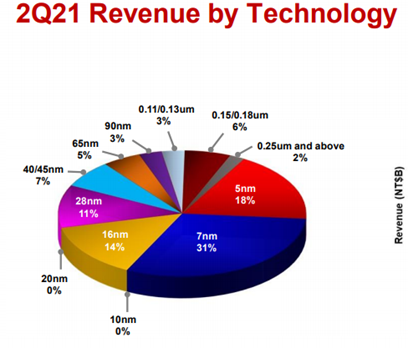

Új hozzászólás Aktív témák
- Elektromos autók - motorok
- Kormányok / autós szimulátorok topikja
- Amlogic S905, S912 processzoros készülékek
- Kerti grill és bográcsozó házilag (BBQ, tervek, ötletek, receptek)
- Tőzsde és gazdaság
- Argos: Az vagy, amit megeszel
- Ubiquiti hálózati eszközök
- eBay
- Szinte csak formaság: bemutatkozott a Pixel 6 és Pixel 6 Pro
- Félkörpanorámás Thermaltake ház, ezúttal faberakással
- További aktív témák...

- iPhone 16 Pro Max 256GB black titanium fekete titán független Apple 3 év garancia
- újszerű iPhone 15 Pro 128GB blue titanium kék titán független Apple ajándék tok
- ASUS TUF F15 FX506 - 15,6"FHD IPS 144Hz - i5-11400H - 32GB - 1TB - RTX 3050 Ti - Win11 - MAGYAR
- Asztali PC , R7 8700F , RTX 3080 , 32GB DDR5 , 512GB NVME , 1TB HDD
- SAPPHIRE PULSE Radeon RX 7800 XT GAMING 16GB
- Eladó szép állapotban levő Apple iPhone SE2020 64GB / 12 hó jótállás
- BESZÁMÍTÁS! 4TB Western Digital Purple SATA HDD meghajtó garanciával hibátlan működéssel
- ÁRGARANCIA!Épített KomPhone Ryzen 7 9700X 32/64GB RAM RX 7800 XT 16GB GAMER PC termékbeszámítással
- Samsung Galaxy S24 Ultra Titanium Black Titán dizájn, 200 MP Pro kamera, S Pen
- Azonnali készpénzes AMD CPU AMD VGA számítógép felvásárlás személyesen / postával korrekt áron
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest