Hirdetés
- Milyen egeret válasszak?
- Menekül a HEVC licencdíja elől a HP és a Dell
- AMD Navi Radeon™ RX 9xxx sorozat
- AMD Ryzen 9 / 7 / 5 / 3 5***(X) "Zen 3" (AM4)
- Szeretne nagyobb versenyt a Microsoft, de nem szeretne túl sok gyártót a piacon
- Steam Deck
- Házimozi belépő szinten
- Milyen TV-t vegyek?
- Gaming notebook topik
- Philips LCD és LED TV-k
Új hozzászólás Aktív témák
-
#6878
 Petykemano
veterán
S_x96x_S
#6874
Petykemano
veterán
S_x96x_S
#6874
Petykemano
veterán
válasz
 S_x96x_S
#6874
üzenetére
S_x96x_S
#6874
üzenetére
/zen5/
Ha tippelnem kéne, azt mondanám, hogy az Apple-t követik:
privát L1 + L2 és megosztott L3 (zen3)
 ( [link] )
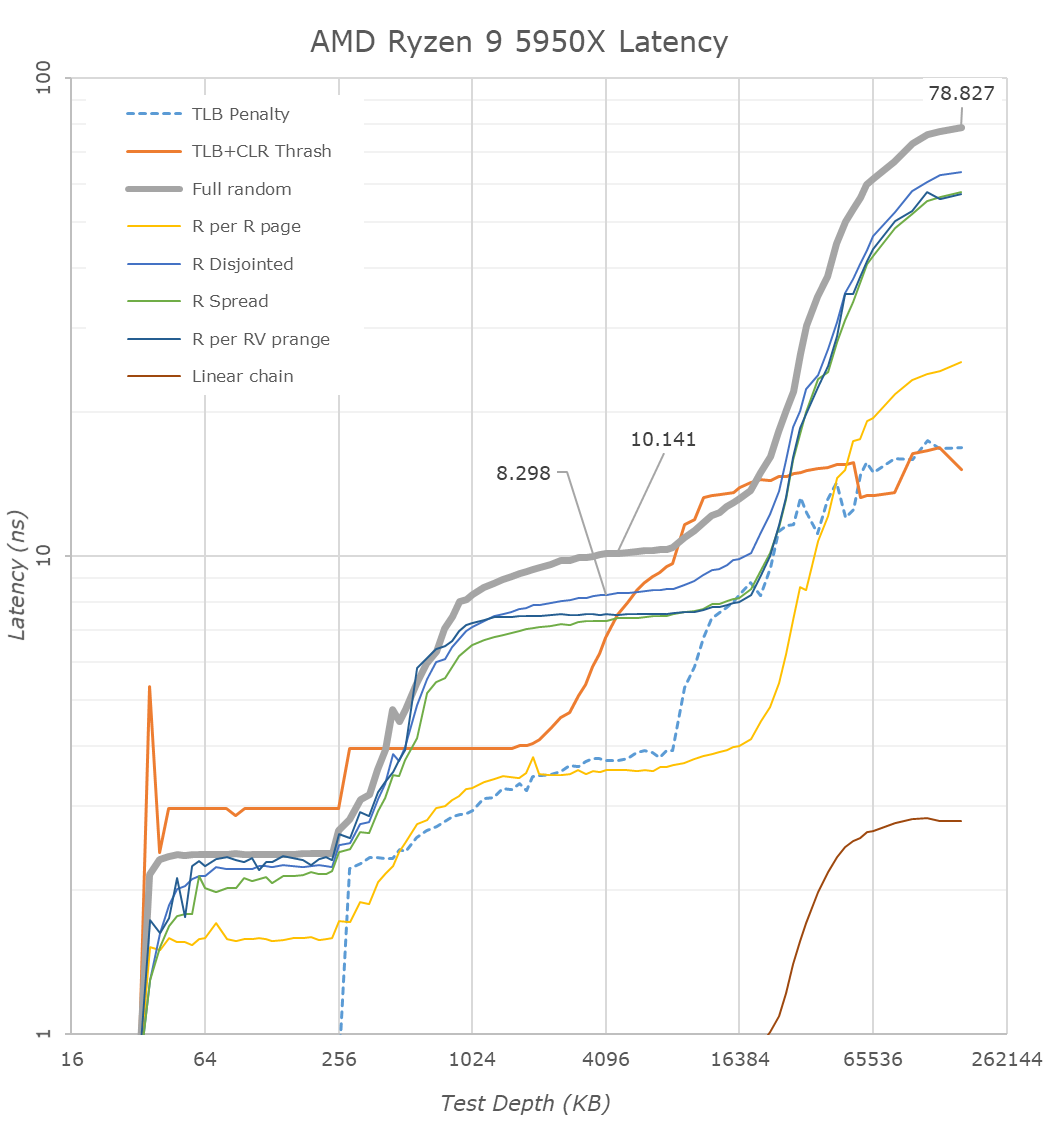
( [link] )Látszik, hogy 32KB-ig 1ns a késleltetés, aztán az L2$ feléig még mindig alacsony, aztán szépen felkúszik 10ns-ra, ami az L3$ közel eső szeletének késleltetése, majd az is feltörik.
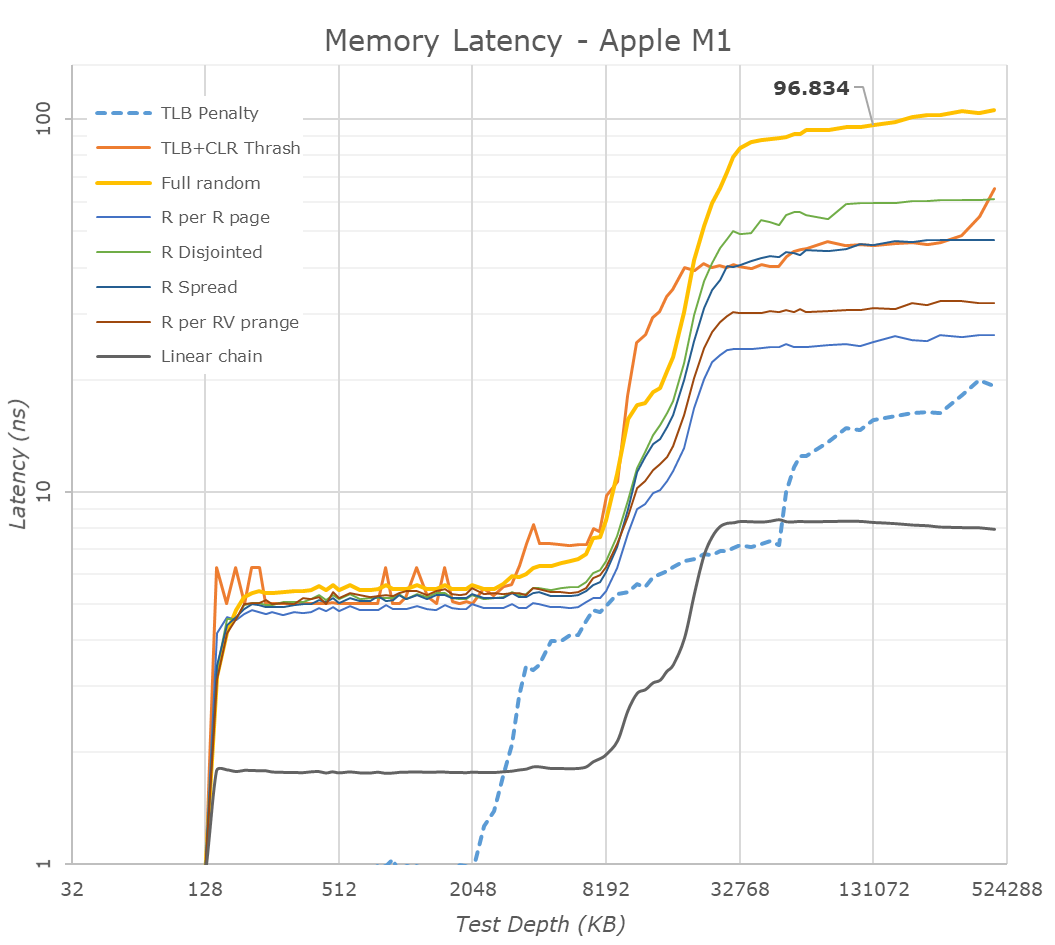
Ehhez képest az M1:
A késleltetés 128KB-ig nagyon alacsony és utána 8MB-ig 5ns (noha valójában 12MB az L2$)
Ha ezt meg tudják csinálni, akkor valóban kevesebb szükség lehet L3$-re.
Bár az Apple is alkalmaz L3$-t (System Level Cache néven), de ha jól emlékszem,. akkor azt már nem csak a CPU, hanem az IGP is tudja használni.Ez viszont csak akkor valósítható meg, ha a az L3$-t kompletten kiemelik a CCX-ből, összecsúsztatják az L2$ részeket és végül egységesítik az L2$-t úgy, hogy stacked L3$ rápakolására még mindig lesz lehetőség. Abban az esetben ha az L3$ stacked azzal sincs probléma, hogy a stacked L3$ rész késleltetése picit magasabb.
Ezzel egyébként egy roadmapet is felvázoltunk.
Szerintem nem volt akkora hülyeség a wccf által publikált rajz [link] [link]
Csak nem arra vonatkozik, amire ők gondolták.
Szóval a roadmap szerintem:
- zen4: az új zen3 architektúra finomítása, megnövelt L2$ (aminek hatására kisebb a nyomás az L3$-en), új gyártástechnológia, FPU duplázás
- zen4c/zen4d: L3$ kiemelése (legalább felezése, de inkább kiemelése) a CCX-ből. Az L2$ összecsúsztatása (privát 1MB vagy 2 mag által megosztott?), 3D Stacked L3$, visszaállás 2 CCX / CCD-ra (16 magra egységesített L3$, vagy 2x 3D stacked L3$ lapka )
- zen5: új architektúra: architektúra szélesítése, megnövelt L1$, L3$ kiemelése a CCX-ből, L2$ összecsúsztatása és egységesítése (=> megosztott, 8MB)Azt gondolom, hogy az L3$ kiemelése a designból és az L2$ összecsúsztatása nem egy nagy kunszt, tehát a zen4d/c és a zen5 fejlesztése ebből a szempontból lehetett párhuzamos. A wccf cikk fő mondanivalója ugye az, hogy két zen4 mag fog osztozni 1MB L2$-n. Ebből a szempontból a zen4d/c egy pilot projekt is lehet(ett) a zen5 egységesített L2$-éhez.
Az a kérdés merült föl bennem, hogy azt mondják, hogy nem véletlen, hogy az Apple M1 olyan, amilyen és a zen valamint az intel processzorok is olyanok, amilyenek cache felépítés szempontjából. Konkrétan: az M1 egy konzumer eszköz, ahol jellemző az egy programos használat (nem feltétlenül egyszálas, de hogy a rendszert döntően egy program veszi igénybe egyszerre), amely esetben jól jöhet, hogy megosztott L2$, amin keresztül az egy programhoz tartozó szálak adatot tudnak megosztani egymással. Ehhez képest a szerverek terén inkább jellemző az, hogy egymástól teljesen független programszálak futnak, amiknél meg inkább a privát cache hasznos. Persze elképzelhető, hogy ki lehet kapcsolni a megosztást. Tehát konzumer termékben 8MB L2$ látható, szerver termékben magonként 1MB L2$.


Új hozzászólás Aktív témák
- Hardcore café
- AliExpress tapasztalatok
- Milyen egeret válasszak?
- BMW topik
- Menekül a HEVC licencdíja elől a HP és a Dell
- Kerékpárosok, bringások ide!
- PlayStation 5
- AMD Navi Radeon™ RX 9xxx sorozat
- AMD Ryzen 9 / 7 / 5 / 3 5***(X) "Zen 3" (AM4)
- Kodi és kiegészítői magyar nyelvű online tartalmakhoz (Linux, Windows)
- További aktív témák...

- GYÖNYÖRŰ iPhone 13 Pro 256GB Sierra Blue -1 ÉV GARANCIA - Kártyafüggetlen, MS3361, 100% Akksi
- AKCIÓ! Intel Core i7 6700K 4mag 8szál processzor garanciával hibátlan működéssel
- 2025.11.22 - Frissített Lenovo Gamer árlista (RTX 5090 / 4090 / 5080 / 4080 / 5070Ti / 4070 / 5060)
- iPhone 13 mini 128GB Green -1 ÉV GARANCIA - Kártyafüggetlen, MS4052, 100% Akkumulátor
- AKCIÓ! DELL PowerEdge R630 rack szerver - 2xE5-2680v4 (28c/56t, 2.4/3.3GHz), 128GB RAM, 1G, áfás
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopműhely Bt.
Város: Budapest