
- Radeon RX 9060 XT: Ezt aztán jól meghúzták
- Atomenergiával dübörögnek tovább az Amazon adatközpontok, SMR-ek is jöhetnek
- Macron betiltatná az EU-ban a közösségi médiát a 15 év alattiaknak
- Az NVIDIA ipari AI-felhőt épít a németeknek, együtt az OpenAI és a Google
- Két új Ryzen közül választhatnak a kézikonzolok
-

PROHARDVER!
"A Proxmox Virtual Environment (röviden: Proxmox VE, PVE vagy proxmox) egy szerver virtualizációra optimalizált nyilt forráskódú Debian alapú Linux disztribúció. Lehetővé teszi a virtuális gépek és konténerek egyszerű telepítését és kezelését web konzol és command line felülettel. A programcsomag két LXC és OpenVZ konténerek, valamint a KVM alapú virtualizáció kezelését támogatja" (Wikipédia)
Hivatalos oldal: https://proxmox.com/en/
Hivatalos fórum: https://forum.proxmox.com/Véreshurka hozzászólásából

Új hozzászólás Aktív témák
-

amargo
addikt
válasz
 Kurrens
#3878
üzenetére
Kurrens
#3878
üzenetére
Azért ZFS alatt pl ilyen nem igazán van, nyilván ott is van olyan, hogy elszáll a kötet, de többnyire valamilyen hardveres probléma van akkor. Nyilván tanulni is kell és tud szívás lenni, ha nincs jól beállítva.
Ezt csak azért írom, hogy léteznek megoldások, de az alap, hogy önmagában az áramszünetek nem tesznek jót a gépnek, azaz érdemes ezt megoldani. -
-
#3281
amargo
addikt
zebrasügér
#3280
amargo
addikt
válasz
 zebrasügér
#3280
üzenetére
zebrasügér
#3280
üzenetére
Használd ezt: [link]
Amúgy nem tudta a wget feloldani a címet, így valamilyen DNS gondod van.
-
amargo
addikt
-
amargo
addikt
nekem semennyire nem tetszik a plex, pedig próbálkoztam, van lifetime license-em is.. de maradok az emby-nél sokkal jobban az én világom. A jellyfin-t is jobban szeretem, de emby mellett felesleges. Mindenre van kliense az emby-nek és jók.
szerk: tudom jól, hogy sokan nagyon szeretik a plex-et, amúgy a core része nagyon jó, de a külseje nekem nem tetszik ez sajnos egy szubjektív dolog..

-
-
amargo
addikt
válasz
 tasiadam
#3167
üzenetére
tasiadam
#3167
üzenetére
eddig egy 0,5TB-os volt ott, kb 3 hete, de egészség pontosan a 0, 1 slotban volt 0,5-0,5. Most lett először 2TB majd + 4TB.
ViZion: Nálam nem tiltja egyik SATA portot sem (máshol én is olvastam, de itt nem). 4db van, amúgy én is olvastam ilyet. kb 2-2,5 éve fullra tömve ment, mindenféle probléma nélkül, most amúgy szabad is az egyik sata port.
Egy hp elitedesk 800 g4 twr az áldozat. Van egy pcie bővítőm, ha továbbra is gond lenne, átrakom oda, mert akkor magán a pcie sávon szűkül a kettő ssd és ezért lehet probléma.
-
amargo
addikt
Köszönöm az elismerő szavakat, viszont a hardware közeli dolgoknál eléggé a le vagyok maradva hozzátok képest

Én még amire gondoltam, hogy figyelmetlenségemben nem csatlakoztattam megfelelően az alaplaphoz (?), de akkor miért 3 nap után jelentkezik a hiba, ma 2x is előjött.. mikor beraktam a gépbe, akkor frissítettem a pve-t is és a FW-t is.
Most megpróbáltam, hogy kikapcsolom a PCIe energia gazdálkodását, amit írtam is (itt is erre jutottak: [link] , amúgy nem tudom mennyit jelent fogyasztás szempontjából.. ). Még arra is gondolta, hogy majd felcserélem és átrakom a nvme1-be, mert kettő slot van a lapomon.
). Még arra is gondolta, hogy majd felcserélem és átrakom a nvme1-be, mert kettő slot van a lapomon.Most ezt tudtam eddig tenni:
nvme get-feature -f 0x0c -H /dev/nvme0
get-feature:0x0c (Autonomous Power State Transition), Current value:00000000
Autonomous Power State Transition Enable (APSTE): Disabled -
amargo
addikt
Sziasztok,
Van egy kis problémám. Raktam a gépbe egy nagyobb nvme-t és azóta mintha a pci csatolóval lenne gond.
Nov 30 16:44:00 home-pve.local kernel: pcieport 0000:00:1b.0: AER: Correctable error message received from 0000:00:1b.0
Nov 30 16:44:00 home-pve.local kernel: pcieport 0000:00:1b.0: PCIe Bus Error: severity=Correctable, type=Physical Layer, (Receiver ID)
Nov 30 16:44:00 home-pve.local kernel: pcieport 0000:00:1b.0: device [8086:a340] error status/mask=00000001/00002000
Nov 30 16:44:00 home-pve.local kernel: pcieport 0000:00:1b.0: [ 0] RxErr (First)Nov 30 16:44:31 home-pve.local kernel: nvme nvme0: controller is down; will reset: CSTS=0xffffffff, PCI_STATUS=0xffff
Nov 30 16:44:31 home-pve.local kernel: nvme nvme0: Does your device have a faulty power saving mode enabled?
Nov 30 16:44:31 home-pve.local kernel: nvme nvme0: Try "nvme_core.default_ps_max_latency_us=0 pcie_aspm=off" and report a bug
Nov 30 16:44:32 home-pve.local kernel: nvme 0000:01:00.0: Unable to change power state from D3cold to D0, device inaccessible
Nov 30 16:44:32 home-pve.local kernel: nvme nvme0: Disabling device after reset failure: -19
Nov 30 16:44:32 home-pve.local kernel: I/O error, dev nvme0n1, sector 4396784544 op 0x1:(WRITE) flags 0x0 phys_seg 1 prio class 0
Nov 30 16:44:32 home-pve.local kernel: zio pool=samsung4tb vdev=/dev/disk/by-id/nvme-Samsung_SSD_990_PRO_with_Heatsink_4TB_S7DSNJ0WC06179Z-part1 error=5 type=1 offset=1671746883584 size=16384 flags=1572992
Nov 30 16:44:32 home-pve.local kernel: zio pool=samsung4tb vdev=/dev/disk/by-id/nvme-Samsung_SSD_990_PRO_with_Heatsink_4TB_S7DSNJ0WC06179Z-part1 error=5 type=2 offset=2251152637952 size=4096 flags=1589376
Nov 30 16:44:32 home-pve.local kernel: zio pool=samsung4tb vdev=/dev/disk/by-id/nvme-Samsung_SSD_990_PRO_with_Heatsink_4TB_S7DSNJ0WC06179Z-part1 error=5 type=1 offset=1671746998272 size=16384 flags=1572992
Nov 30 16:44:32 home-pve.local kernel: zio pool=samsung4tb vdev=/dev/disk/by-id/nvme-Samsung_SSD_990_PRO_with_Heatsink_4TB_S7DSNJ0WC06179Z-part1 error=5 type=1 offset=1671746899968 size=16384 flags=1572992
Nov 30 16:44:32 home-pve.local kernel: zio pool=samsung4tb vdev=/dev/disk/by-id/nvme-Samsung_SSD_990_PRO_with_Heatsink_4TB_S7DSNJ0WC06179Z-part1 error=5 type=2 offset=2251152633856 size=4096 flags=1589376
Nov 30 16:44:32 home-pve.local kernel: zio pool=samsung4tb vdev=/dev/disk/by-id/nvme-Samsung_SSD_990_PRO_with_Heatsink_4TB_S7DSNJ0WC06179Z-part1 error=5 type=1 offset=1072442052608 size=61440 flags=1572992
Nov 30 16:44:32 home-pve.local kernel: zio pool=samsung4tb vdev=/dev/disk/by-id/nvme-Samsung_SSD_990_PRO_with_Heatsink_4TB_S7DSNJ0WC06179Z-part1 error=5 type=1 offset=1671747047424 size=16384 flags=1572992
Nov 30 16:44:32 home-pve.local kernel: zio pool=samsung4tb vdev=/dev/disk/by-id/nvme-Samsung_SSD_990_PRO_with_Heatsink_4TB_S7DSNJ0WC06179Z-part1 error=5 type=2 offset=2165064114176 size=12288 flags=1572992
Nov 30 16:44:32 home-pve.local kernel: zio pool=samsung4tb vdev=/dev/disk/by-id/nvme-Samsung_SSD_990_PRO_with_Heatsink_4TB_S7DSNJ0WC06179Z-part1 error=5 type=2 offset=2183058460672 size=65536 flags=1074267>
Nov 30 16:44:32 home-pve.local kernel: zio pool=samsung4tb vdev=/dev/disk/by-id/nvme-Samsung_SSD_990_PRO_with_Heatsink_4TB_S7DSNJ0WC06179Z-part1 error=5 type=2 offset=2183058526208 size=131072 flags=1572992
Nov 30 16:44:32 home-pve.local kernel: WARNING: Pool 'samsung4tb' has encountered an uncorrectable I/O failure and has been suspended.
Nov 30 16:44:32 home-pve.local kernel: WARNING: Pool 'samsung4tb' has encountered an uncorrectable I/O failure and has been suspended.
Nov 30 16:44:32 home-pve.local kernel: WARNING: Pool 'samsung4tb' has encountered an uncorrectable I/O failure and has been suspended.
Nov 30 16:44:32 home-pve.local kernel: zio pool=samsung4tb vdev=/dev/disk/by-id/nvme-Samsung_SSD_990_PRO_with_Heatsink_4TB_S7DSNJ0WC06179Z-part1 error=5 type=2 offset=2183058657280 size=131072 flags=1572992
Nov 30 16:44:32 home-pve.local kernel: WARNING: Pool 'samsung4tb' has encountered an uncorrectable I/O failure and has been suspended.Most megpróbálom ezt persze:
GRUB_CMDLINE_LINUX_DEFAULT="quiet pcie_aspm=off nvme_core.default_ps_max_latency_us=0"Valakinek volt már ilyen gondja? Eddig egy kisebb ssd volt itt, lehet hogy ez a Samsung túl éhes?
Az ssd-nek semmi baja, minden smart adat jó.
-
amargo
addikt
Az én javaslatom, a te oldaladon. Lehet LXC vagy VM, ennek adjál oda egy szeletet a hdd-ből, ez tudod a PVE-n belül annyiszor és úgy menteni, ahogy szeretnéd.
Majd syncthing ebbe az LXC/VM-be és azt nálad is oda mented ahova akarod és nála is felrakod + ott service-ként indítod. Még verziózást is tudsz állítani, stb. [link]
Itt nem kell nyitni semmit NAT mögül is összetalálkoznak, persze lassabb lesz, mintha tudnának egymásról, de ez csak akkor gond, ha folyamatosan sok adat mozog. -
amargo
addikt
Nálam a mosógép nem akkor indul, mert tipikusan azt valakinek ki kell onnan szednie, de a bojler az igen és egyszerűen csak azt nézem, hogy termel-e egy fázisra (azaz aktuális terhelés/3) az elmúlt 20 percben megfelelő mennyiségű energiát.
Ugye ez nem jelenti azt, hogy pl 5 percen belül ne állhatna meg a termelés. -
#2990
amargo
addikt
inspiroyhome
#2987
amargo
addikt
válasz
 inspiroyhome
#2987
üzenetére
inspiroyhome
#2987
üzenetére
[link]
Nálad nem valami raid controller volt?KaqXar19: Igen, én mindig id alapján kezelem a disk-eket.
-
#2985
amargo
addikt
inspiroyhome
#2984
amargo
addikt
válasz
inspiroyhome
#2984
üzenetére
Ezt hogy érted? Az alaplapi controller esetén bármelyik port-on lévő drive-ot önmagában át tudom adni egy VM-nek passtrougth-al.
-
amargo
addikt
Most már kezdem úgy érezni, hogy kicsit sok lettem, de itt a megoldás:
Tehát az említett leírásokat követve vagy akár ezt a script-et is: [link] egy unprivileged LXC alá remekül be lehet húzni a dolgokat (én is kevertem nálam miként is fut..), de nekem az emby privileged módban fut és amit 2x is benéztem annak más a uid és groupid-ja
PVE host (UID=100000/GID=110000) <--> unprivileged LXC (UID=0/GID=10000)Szóval ebben az esetben (privileged) ezt kell kiadni (amúgy pont itt vettem észre, mert több leírás is keveri [link] ):
pct exec $lxc_id -- groupadd -g 110000 lxc_sharesSzóval ez a megfejtés
-
amargo
addikt
Hopp megnéztem a gépemet és meglepődve tapasztaltam, hogy 999/999-el szerepelnek nálam az fstab-ban a mount-ok:
//192.xxx/movies/ /mnt/lxc_shares/movies cifs _netdev,x-systemd.automount,noatime,uid=999,gid=999,dir_mode=0770,file_mode=0770,credentials=/root/.smb 0 0ez a 999 pedig az LXC-ben lévő emby user uid/gid.
Már nem emlékszem, de mintha unprivileged container esetében valamiért nem akart menni ez a 100000/110000 megosztás. Ezért most elég bénán a time syncd -vel vannak felcsatolva.. a lényeg, hogy esetedben a felcsatolást akkor arra a uid/gid-re kell rakni, amivel az lxc-ben fut az alkalmazás.De utána nézek más megoldásnak, mert amúgy zavaró ez.
-
amargo
addikt
sorry lehet pont azt nem nyitottam már meg így nem emlékeztem erre a linkre.
Én pár éve használom a zfs-t, kezdeti bénázásaimon túl nincs vele bajom, sőt csak egy példa, ahol leginkább csak szöveges adatok vannak tárolva a 200GB-ből kb 100GB-t csinált (lz4), használom még 1-2 adatbázis alatt is, mert azok nagy részét úgy is memóriába kapja. Most az egyik hdd alá bekerült egy ssd cache-nek, de itt is az van, hogy amikor csak lehet a memóriát használja és nincsenek akadások.
-
amargo
addikt
Jobban nyírja, de valamit valamiért, ha van UPS-ed, akkor lehet érdemes kikapcsolni pár dolgot: [link]
zfs set atime=off sync=disabled xattr=sa compression=lz4 rpoolÉn most pro ssd-re cseréltem a gépben lévőt. QLC-s ssd-re 2 év alatt ment 65TB írás, itt van egyedül romlás csak 73%-os a kondíciója.
Másikok (ezek csak sima TLC-ek), amelyeken csak a rendszerek futottak 18TB írás van majd 3 év alatt. 100% a kondíciójuk -
amargo
addikt
Megszivattam magam.. külső usb-n csatoltam fel egy hdd-t, hogy majd wipe-jam. 1 hete még ezen lógott az új hdd. Most meg 5-10 perc alatt "kinyírta "a host-ot (újra kellett indítani), mert a syslog-ot telenyomta hibával, igen a /var/log -om meg egy kisebb 80GB-os disken van. Kiderült, hogy a külső táp ment tönkre ezért a lemez csak ilyen fél állapotban indult el és szórta a hibákat.
Tanulság igazából annyi, hogy ne este álljon neki az ember
A durva az volt, hogy még pár LXC log-ban is megtaláltam, amit csak azért vettem észre, mert nem indultak el, hely hiány miatt. -
amargo
addikt
Sziasztok!
Csináltam egy kis tesztet, nem tudom mennyire volt értelme (a cache miatt), a lényeg pve alatt felcsatolt tárból adtam oda egy VM-nek egy zfs volume-ot, amit a VM alatt is zfs-ként kezeltem 1GB-os fájllal dolgoztam, de lehet megnézem majd nagyobbal is. Csináltam egy ext4-es tesztet is, de az nagyon kiábrándító volt.
A lényeg, hogy pve alatt ilyen beállításokat használtam:
[kép]Itt vannak az eredmények chart-ba rakva
Read: [kép]
Write: [kép]Én ezek alapján scsi7-io választottam, itt nem kapcsoltam be a writeback-et.
Mit gondoltok mire érdemes beállítani vagy ki hogyan használja, akár ext4 esetén is?
-
-
amargo
addikt
Sziasztok!
Tudom már többször felmerült és tök szubjektív is tud lenni a dolog, de kérdeznék, mert bízok a tanácsokban
Szeretnék a gépből 2 hdd-t (2-4TB) és egy ssd-t kipakolni. Szóval beszereztem pár komolyabb háttértárolót..
Gyakorlatilag mindenhol ZFS-t használok már elég régóta (4-5 éve) és bár az elején PVE alatt megszívatott ssd-n a ZFS, de mára tudom miket kell beállítani és alapból bele került egy csomó disztróba is. Jelenleg is van kb állandó 20GB szabad RAM-om, tehát ez sem gond.
Az utóbbi 1 évben atom stabil volt a PVE, de tényleg, semmi gond semmivelÖsszegezve én alapból simán maradnék ZFS-en, de hátha van valami ajánlottabb, XFS esetleg vagy simán csak ext4. ZFS-ből nem használom ki a raid-et, csak a tömörítést és copy-on-write, ami azért fontos.
Vélemények, köszönöm előre is?
-
amargo
addikt
Tegnap egy érdekes dolog történt, volt egy VM-em, amit már vagy 1 éve nem inditottam el, csak teszt miatt volt korábban, de most gondoltam újra elindítom, erre az egész pve kifogyott konzolba be tudtam lépni qemu-ban leállítottam a VM-et, de addigra szétesett minden, csak a host újraindítása rakta helyre.
Annyi különbség volt ezzel a VM-el, hogy egy GPU volt átadva neki, amit azóta kiszedtem, továbbá volt egy 7-ről 8-ra upgrade is közben.
Mással is történt már hasonló, mármint egy VM indítás ledöntötte a host-ot is.
-
amargo
addikt
válasz
 bpmcwap
#2449
üzenetére
bpmcwap
#2449
üzenetére
Alapjában véve nem hiába ajánlottam megoldást a problémádra, de persze nem kell elfogadni..

Ahogy írták iGPU is tud gyorsítani.Helyettesíteni lehet csak nem erre a feladatra vagy cloud-ot fog használni, stb. Ha kikapcsolod az object detection -t itt sem fog semmit enni.
-
amargo
addikt
válasz
 Pista0001
#2349
üzenetére
Pista0001
#2349
üzenetére
Nekem egy HP (elitedesk G4) MT házban vannak a cuccok, most jelenleg van benne 3db 3.5 és 2db 2.5 van benne, +2-3db NVME.
Alapból 4db SATA port van a lapon, ami nagyon kényelmes.
Tehát csak azt akartam alátámasztani, hogy mezei brand gépet is fellehet szerelni, persze biztos a gyártó nem erre szánta.. -
amargo
addikt
válasz
Pista0001
#2275
üzenetére
Valamit félreértés van, a javasolt megoldásnál pont az a gond, hogy ha leáll a VM, akkor semmilyen mentésed nem lesz, azaz hiába van három helyen a nemlétező mentésed, ha egyszer sem létezik.
KaqXar19:
Alapjában véve mindenki maga érzi, mi az, ami megfelelő a számára és mi nem. Az, hogy egy a proxmoxban futtatott VM-nek adott disk van visszaadva a pve-nek, az számomra nem tűnik túl robosztus megoldásnak, az említett probléma miatt. -
amargo
addikt
válasz
tasiadam
#2232
üzenetére
Nálam LXC-ben fut, de a lényeg pont ugyan ez, van ami onedrive van ami azure storage-be megy. Viszont mennyivel egyszerűbb lenne, ha nem kellene futnia külön semminek, hanem maga a backup támogatná ezt is.
jahh, hogy pl az aws cli-t szeretnéd a proxmox-os gui-ban látni?
-
amargo
addikt
válasz
tasiadam
#2230
üzenetére
Igen (azure-nak is van) is és nem is, össze mostam a mondatot. Értem az on-premises célját, de akkor már a hybrid cloud, ahogy írod is. Viszont nem tudom, hogy proxmox alatt ezt, hogy képzeld? Vagy milyen támogatára gondolsz?
Nekem elég lenne csak maga a backup-ot menteni egyből cloud-ba, én már erre is örülnék
-
amargo
addikt
Én pont ezért használok csak a PVE-re egy kicsi gyors HDD-t és nem kell még külön a partícióval vesződni, stb. Ez lehet csak az én meglátásom, és hibás elgondolás is lehet.
Tehát nálam a PVE egy külön kicsi HDD-n van direkt nem SSD-n gyakorlatilag betöltés után semmi nem használja. Minden más SSD-n van vagy a nagyobb adatok HDD-n.
-
amargo
addikt
válasz
tasiadam
#2061
üzenetére
Igen, ehhez szerintem sok üzleti szempontot kell tudni, hogy valaki megfelelően tudjon dönteni egy ilyen kérdéskörben.
#2062 szpeti40 Az adatok manapság mindig érzékenyek, bár az orvosi, banki azért még megüt egy magasabb mércét szerintem is, az on-prem környezett szokott inkább kevésbé biztonságos lenni, ugye a cég belső szabályzatától és a kollégáktól függ innentől, ami nyilvánvalóan lehet nagyon jó is
persze ugyan úgy a cloud-ot lehet aztán nyitni a vakvilágba főleg public cloud esetében, de egy hosted private cloud-nál már megint kapunk pár extra lehetőségeket.Otthon ki mit tesz amúgy meg az adatok védelme érdekében, az illetéktelen behatolók ellen?
-
amargo
addikt
válasz
 szpeti40
#2056
üzenetére
szpeti40
#2056
üzenetére
Most license változásról eltekintve, én nem gondolnám olcsóbbnak főleg a fejlesztését, mert itt még az üzemeltetést is ki kell fizetned a kezdeti költségekről nem is beszélve, ha meg a skálázhatóságot nézem, akkor lesznek kifizetett, de fel nem használt erőforrásaitok, de lehet tévedek. Egy cloud provider-nél probléma, hogy régionként mondjuk milyen vasak érhetőek el, de akár ideglenesen másik régióból kölcsönözhetsz. Ha ez on-prem-ben van, akkor a vasat előbb be kell szerezned, ha a piacon nincs, akkor megint csak extra feladatok jönnek be.
Én ezt a megoldást, csak olyan helyen tudom elképzelni, ahol viszonylag egyenletes a terhelés vagy jól előre tervezhető. Tényleg érdekel ez a téma és nem vitatkozásként írom -
-
amargo
addikt
-
-
amargo
addikt
Itt hagyok én is egy kis infót, mert már többször észrevettem a logokban, de nem foglalkoztam vele, mert nem mindig volt jelen.
A lényeg, hogy LXC mentésekor, amiben használok docker-t ott fordult elő. Nálam egy ZFS-es pool-ba történik a rsync és onnen tömörít ugye (tar.zst).
Többször láttam ilyen hibaüzenetet az rsync-től:
rsync: [generator] set_acl: sys_acl_set_file(var/log/journal, ACL_TYPE_ACCESS): Operation not supported
failed: exit code 23A megoldás pedig, hogy be kell kapcsolni a tmp mappára, ahova történik az rsync a posixacl-t (
zfs set acltype=posixacl pool/tmp) -
amargo
addikt
milyen címen próbálod meg elérni?
Ha megcsináltad, amit leírtak és a root CA bekerült a trusted store-ba, akkor utána, ha a cert-ed önmagában valid, azaz pl: nem járt le és megfelelő az url azaz a subject alternative names között ott van, akkor be kell jönnie az oldalnak. -
amargo
addikt
Még én is nézem mit érdemes használni ebből a PVE integrációból, meglátjuk
Mi és miért nem engedi sleep-be a lemezeket, ez most nem volt világos.
Szép felület egészen letisztult és érdemes exclude-ni a nem szükséges dolgokat a DB-ből, mert valaki nem rég írta, hogy 16M rekordja van, ami azért karcos egy ilyen rendszernél.áhh Huawei B525, van egy feledékeny példányom, ha valakit érdekel odaadom neki, mert nekem nincs rá időm..
-
amargo
addikt
Most én is felraktam ezt az addon-t, mert mindenhol minden friss. Nekem pont jól jön, hogy tudom a host-ot kapcsolhatni, mert így áramszünet esetén egyszerűen csak ezen keresztül hívom meg a shutdown-t
(nem kell a custom command)Kérdésedre válaszolva, nekem az integráción kellett egy restart és utána vette észre az új jogosultságokat.
-
amargo
addikt
Én most egy régóta halogatott 7 -> 8(.1) upgrade-et ugortam meg, látszólag minden OK. Egy apróságot kivéve az emby elvesztette az iGPU-hoz a jogot.
Nem tudtam még megfelelően utána olvasni ezért kapott teljes hozzáférést :drwxr-xr-x 3 root root 100 Nov 28 17:41 .
drwxr-xr-x 10 root root 660 Nov 30 16:13 ..
drw-rw-rw- 2 root root 80 Nov 28 17:41 by-path
crw-rw-rw- 1 root video 226, 0 Nov 28 17:41 card0
crw-rw-rw- 1 root kvm 226, 128 Nov 28 17:41 renderD128Még nincs jobb ötletem mi történt vele, de így legalább van HW transcoding továbbra is.
-
amargo
addikt
válasz
tasiadam
#1540
üzenetére
jellyfin logja fog ebben segíteni, kell ott lennie egy külön transcoding lognak is (emby-ben van). Ugye csak akkor fogja elkezdeni, ha valamiért a tartalmon alakítani kell.
A transcoding-ot nem tudod kikapcsolni, csak azt, hogy HW-ból próbálja vagy minden más esetben CPU-ból fogja. -
amargo
addikt
válasz
 5leteseN
#1512
üzenetére
5leteseN
#1512
üzenetére
tehát azt szeretnéd, hogy egy meglévő desktopos rendszert, ami eddig natívan futott egy gépen azt a proxmox alá költöztetni?
Ha igen, akkor kb persze lehet, én a régi gépeimet mindig Ghost -al mentettem. A régebbi rendszerek esetében be kellett állítani, hogy éppen HW-t cserélsz alatta és akkor a virtuális gép alatt is simán elindultak. Most annyi plusz kell, hogy a mentett image-et pl vmdk-t qcow2-re alakítasz.
-
amargo
addikt
plusz kiegészítés, ha unprivileged LXC-ben szeretnéd az smb megosztást használni, akkor kicsit trükközni kell még, hogy a write jogod is legyen. Én a pve-n csatoltam fel közvetlenül ezt az smb-t és onnan adtam tovább. Most hirtelen nem találom telefonon a leírást, de ha megmagyarázhatatlan permission denied -ba futsz, akkor emlékezz majd rá
(majd megpróbálom megkeresni a leírást is) -
amargo
addikt
válasz
 Ranger^41
#1446
üzenetére
Ranger^41
#1446
üzenetére
mariadb-t nem raknám alá, "könnyen" kilehet szervezni onnan backup/restore. LXC alá rakd inkább.
Utána pedig egy mentés a HA-ra a google addon-al majd egy full új VM-en restore.
Így pl, egy "blue green" deployment -et is tudsz otthon nyomni.
szerk, de persze egy loggolás pl glances-el érdemes lenne, influxba küldheted az adatokat, ami persze kívül fut egy másik VM/LXC-ben.
hálózat rendben van? csak onboard nic van? -
#1445
amargo
addikt
inspiroyhome
#1444
amargo
addikt
válasz
inspiroyhome
#1444
üzenetére
Nálam van/volt, de ilyennel nem találkoztam. Milyen GPU? Volt olyan, hogy egy bizonyos driver verzió volt jó nálam, de nem erre a hibaüzenetre emlékszem.
-
amargo
addikt
Nálam a HA külön VM-ben fut OS verzióként. Teljesen stabil, igaz csak kb 1,5 éve van így.
Nincsnek benne nagyon addon-ok, esphome, z2m és ssh, + mentés, semmi extra. A HACS az egyedüli komolyabb dolog benne, minden más lényeges dolog kint van.Előtte debian-on volt az is stabil volt (maga az OMV nem stabil virtualizálásra). Mint írtam nálam egyedül eddig csak egy rosszul megírt könyvtár tudott ilyen erőforrás fogyást produkálni, de annak sem volt köze magához a HA-hoz. Ha magában az OS-ben nem kavarnak el valamit, akkor jelenleg ez a legtámogatottabb megoldás.
Én amit tudok szeparálok/csoportokba szervezem és külön kezelek inkább, mert jobban egyedire tudom szabni a mentést, bármint.
-
amargo
addikt
válasz
Ranger^41
#1433
üzenetére
Mi fut a HA-ban? Biztos, hogy ott fekszik meg valami.
Nálam még nagyon az elején volt egy HACS repó amit futtattam és a rosszul implementált BT driver miatt leakelt az egész ezért ott is bizonyos időközönként az összes erőforrást felemésztette.
Itt lenne segítség, ha vannak logok, hogy mikor kezdett megzuhanni a gép. -
amargo
addikt
-
amargo
addikt
válasz
tasiadam
#1363
üzenetére
on-premises EKS-re csak gyakorlás miatt van szükség? Azért, abból a pénzből pár hónapig a cloud-ban is simán lehet játszani, de ezt amúgy a cégnek kellene fizetni vagy vesznek inkább gépeket Neked? IAM roles-t is össze lehet összekapcsolni? Ennek sosem néztem utána
rgqjx: Nincs mit
ViZion: Nálam pont egy ilyen proci van a gépben, alapjában véve, ma már "olcsó" és nem árt a tartalék
-
amargo
addikt
válasz
tasiadam
#1361
üzenetére
Igen, én nagyon hittem a T-ben, de a non-T szerintem jobb választás, ha van megfelelő hűtés.
minikube-ot rakjál fel, az mindenen is elfut.
Ha valami specifikus dolog (AKS vagy EKS) arra pedig remek dokumentációk vannak, de ezekhez már érdemes egy előfizetés alatt játszadozni és akkor már terraform/terragrunt alatt kezelni.
-
amargo
addikt
Nekem van/volt I7-8700 és i7-8700T is.
A non-T semmivel nem fogyaszt többet alapjáraton mint a T-s. Annyi a különbség, hogy a T-s proci hamarabb van leszabályozva azaz a non-T engedi tovább magasabb órajelen dolgozni, meg a T-t nem.Én eléggé befürödtem ezzel, mert azt gondoltam minden képen kell egy T-s proci aztán a tesztek és az utánaolvasás kiderítette, hogy tök felesleges ezen szenvedni. Ha a lapod támogatja, akkor a feszt lejjebb veszed azzal jársz a legjobban.
-
#1353
amargo
addikt
inspiroyhome
#1352
amargo
addikt
válasz
inspiroyhome
#1352
üzenetére
hetente fut a trim, de persze lefuttattam.
Itt most ezen talán még jobban látszik (bocs a sok különböző output miatt): [kép]
az sdb a 6TB hdd az sdc pedig az ssd.
Látszik, hogy az ssd az szépen kimaxolja a HDD képességeit, amúgy most is amikor futottak a tesztek egyszer sem volt elérhetetlen másik VM minden futott szépen. -
amargo
addikt
válasz
szpeti40
#1350
üzenetére
6TB diskkel is a SMART alapján minden OK.
qbittorrent, korlátozva van 8GB, de most az új verzióval az 1GB-ot is csak ritkán éri el.
A probléma, azzal van amikor az ssd-ről másolja át a disk-re: Itt példaként 10GB másolását indítottam el.
Itt példaként 10GB másolását indítottam el.
Tehát a nincs másolás, akkor olyan 3-4% között van az iowait. -
amargo
addikt
-
amargo
addikt
Sziasztok!
Lenne egy kérdésem, mert ilyet még nem tapasztaltam, tegnap kb egy 5-10 percre a cluster-en belül lévő gépek még hálózati szinten is elérhetetlenek voltak.
Az alábbi képen látszik: [kép] , hogy az egyik VM (omv) elfoglalt elég sok erőforrást, aminek következtében a wait (I/O ?) pedig az egekbe szökött.
[kép] [kép] látszik, hogy valami írás kezdődőt el egy belső disk-en, letöltődött egy torrent.
A setup itt: van egy 500GB-os ssd, amire a letöltés megy, innen letöltés után átkerül egy 6TB-os diskre (ez közvetlenül van odaadva a VM-nek)Ilyet még korábban nem tapasztaltam, az omv-t 1-2-3 hete frissítettem fel (előtte vagy félévig nem volt..), lehet, hogy volt ilyen korábban is, csak nem vettem észre ez alatt az 1-2 hét alatt, de előtte biztos nem volt.
Ami a furcsa, hogy a többi VM is elérhetetlen volt.
Látszólag valami nem jó, mert többször is van ez az elég magas I/O wait a pve-n:
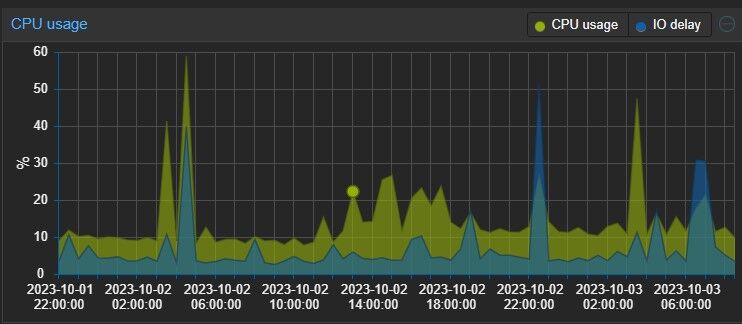 omv:
omv:

Mit érdemes jobban megnézni?









 ). Még arra is gondolta, hogy majd felcserélem és átrakom a nvme1-be, mert kettő slot van a lapomon.
). Még arra is gondolta, hogy majd felcserélem és átrakom a nvme1-be, mert kettő slot van a lapomon.


















 Itt példaként 10GB másolását indítottam el.
Itt példaként 10GB másolását indítottam el. omv:
omv:
Új hozzászólás Aktív témák
Hirdetés

- Windows, Office licencek kedvező áron, egyenesen a Microsoft-tól - Automata kézbesítés utalással is!
- ASUS ROG GL552VW - 15.6"FHD IPS - i7 i7-6700HQ - 8GB - 128GB SSD + 1TB HDD - GTX 960 4GB -
- KIÁRUSÍTÁS - REFURBISHED és ÚJ - Lenovo ThinkPad Ultra Docking Station (40AJ)
- LG 55G4 - 55" OLED evo - 4K 144Hz & 0.1ms - MLA Plus - 3000 Nits - NVIDIA G-Sync - FreeSync Premium
- Okosóra felvásárlás!! Samsung Galaxy Watch 6, Samsung Galaxy Watch 7, Samsung Galaxy Watch Ultra
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest