-

PROHARDVER!
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-
#22851
 Balala2007
tag
Balala2007
tag
Balala2007
tag
Zen3: 64c max, 2xHTT, 8c CCX, CCX=CCD, 32MB L3/CCX, DDR4, SP3, 7nm
[link] -
Balala2007
tag
válasz
 joysefke
#22554
üzenetére
joysefke
#22554
üzenetére
Kaptatok tesztpéldányt?
Kaptunk, meg foto is van.
Tudod a memória késleltetéseket kommentálni?
A hivatalos bejelentesig (ami jul 7-re van most utemezve tudtommal) semmit se
-
#22552
Balala2007
tag
Balala2007
tag
[ Módosította: mobal ]
-
Balala2007
tag
válasz
 Petykemano
#22264
üzenetére
Petykemano
#22264
üzenetére
Nem azt mutatja a VTune.
A CB15 nem full sse128, hanem skalar 64b SSE/SSE2, es a CB20 is ~90% skalar 64b AVX/FMA, a maradek is max 128b.
Az oszlopok tetejen az FP. Ops Packed es FP.Ops.Scalar, a MULSS es MULPS kozott kulonbseg pl.
Ez kifejezetten Zen1 barat kod (4x128b vs SKL 3x256b). -
Balala2007
tag
válasz
 Raymond
#22253
üzenetére
Raymond
#22253
üzenetére
IPC: megfeleloen EU korlatos esetekben kijohet a 4x256b vs 3x256b EU-k elonye is, csak kerdes, hogy mennyi ehhez szukseges AVX kod van.
az orajelek is ott lesznek
Ezt honnan lehet biztosan tudni? Eddig a csak a szokasos jocskan a celfreq alatti peldanyokrol volt szo, es mas magas freq-t 7nm-en meg nem gyartottak tudtommal. Nem veletlenul a nagy magszamu EPYC-kel akartak kezdeni, ahol nem csucs sebesseggel is tarolni lehetne. -
Balala2007
tag
válasz
Petykemano
#22249
üzenetére
Sztem tulzoak a varakozasok, Zen4-ig nem varhato semmi lenyeges valtozas ezekben.
-
Balala2007
tag
válasz
Petykemano
#22246
üzenetére
-
Balala2007
tag
válasz
Petykemano
#22243
üzenetére
Zen2-ben nem lesz:
- AVX512
- 8 magos CCX
- 4xHTTZen -> Zen2 valtas leginkabb a K8-> K10 valtassal analog. Szelesebb FPU es felzarkozas a Skylake-hez.
Semmi egetvero ujdonsag, a lenyegesebb es konnyen kommunikalhato fejleszteseket mar elmondtak, ami par dolog meg maradt azt vszeg majd a piacra dobassal egy idoben mondjak el. -
#21770
Balala2007
tag
Balala2007
tag
Zen3-ban se lesz AVX512:
-
#21682
Balala2007
tag
Balala2007
tag
Zen2 ujdonsagok a New Horizonts-bol:
- uj L1I
- nagyobb uop cache
- jobb branch predictor
- jobb data prefetch
- 128 helyett 256b L1D portok
- 128 helyett 256b FPU portok7nm miatt dupla suruseg fele fogyasztas, 1.25x teljesitmeny
Zen4 hivatalosan is utitervbe illesztve
-
-
Balala2007
tag
válasz
Petykemano
#21554
üzenetére
B2, csak nem Summit Ridge B2 (800F12) (ez az EPYC1-nek van fenntartva), hanem Pinnacle Ridge B2 (800F82)

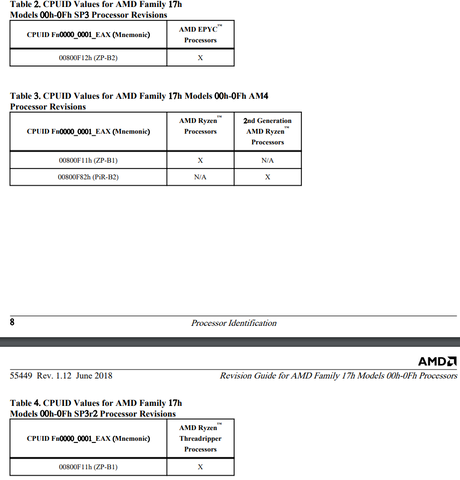
-
#21551
Balala2007
tag
Balala2007
tag
-
#21518
Balala2007
tag
Balala2007
tag
-
Balala2007
tag
válasz
 apatyas
#20900
üzenetére
apatyas
#20900
üzenetére
A 12 ciklusosnak mennyi a teljesítményelőnye? Jól látszik?
Persze, a 17->12 clk L2-hit csokkentes ugyanigy -5clk-kal huzza le a L2-miss/L3 hit szamokat is Nezd meg a velemenyeket a Pinnacle Ridge-rol, sokaknak tetszik a novekedes. A pontos aranyokat nehez megbecsulni, mert a hivatalos memClk is novekszik 2933MHz-re, de a PR javulasa nemigen szarmazhat masbol.
-
Balala2007
tag
válasz
joysefke
#20830
üzenetére
Eddig arról volt szó, hogy közel nulla sebezhetőség...
Meltdownra ez igaz is, de a Spectre elol nincs menekves, meg az InOrder POWER6-on is mukodik
Hivatalos AMD Spectre workarounds
-
#20606
Balala2007
tag
Z_A_P
#20602
-
Balala2007
tag
válasz
 Balala2007
#20489
üzenetére
Balala2007
#20489
üzenetére
Reszletesebb TechReport HP Envy x360 15z (Ryzen2500U) review
-
#20489
Balala2007
tag
Balala2007
tag
-
#20396
Balala2007
tag
Balala2007
tag
AMD Picasso, Matisse
Zen2 is AM4-be jon 2019-ben -
#20120
Balala2007
tag
Balala2007
tag
Mukodo dual socket, 64C/128T EPYC 7601 2.2GHz B2 core rev tunt fel a GB4.1 adatbazisaban:
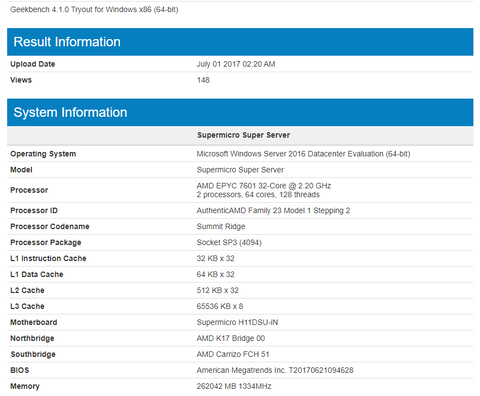
Nagyon alacsony ertekei vannak, azok most meg nem erdekesek, nyilvan meg erosen fejlesztes alatt all, de annyira mar kesz van, hogy felbootoljon egy WinServer2016-ot
-
#20114
Balala2007
tag
Balala2007
tag
Van publikus Ryzen Optim Guide:
http://support.amd.com/TechDocs/55723_SOG_Fam_17h_Processors_3.00.pdf
Azt sajnos nem tudom, hogy a tablazatokat tartalmazo, hozza jaro xls hol van
-
Balala2007
tag
válasz
Balala2007
#17216
üzenetére
Vegleges, hogy az FMA4 kimarad a Zenbol. Gyozott az eredeti SSE5 koncepcio.
....eees akkor egy utolso utani csavar: benne van az FMA4 a piaci 800F11-ekben, de nem jelenti a CPUID (Ez egy 1800X-bol van):
FMA4 :VFMADDPS ymm,ymm,ymm,ymm L: 1.39ns= 5.0c T: 0.28ns= 1.00c
FMA3 :VFMADD132PS ymm,ymm,ymm L: 1.39ns= 5.0c T: 0.28ns= 1.00c
FMA3 :VFMADD213PS ymm,ymm,ymm L: 1.39ns= 5.0c T: 0.28ns= 1.00c
FMA3 :VFMADD231PS ymm,ymm,ymm L: 1.39ns= 5.0c T: 0.28ns= 1.00cEbben az a jo, hogy ha egy kod lekerdezi, hogy mehet-e a FMA4, akkor nemleges valaszt kap, de check nelkul ra lehet eroltetni, cserebe viszont akar mar a kovetkezo steppingbol repulhet minden kulon ertesites nelkul.
-
#19972
Balala2007
tag
Balala2007
tag
-
Balala2007
tag
válasz
 shabbarulez
#19936
üzenetére
shabbarulez
#19936
üzenetére
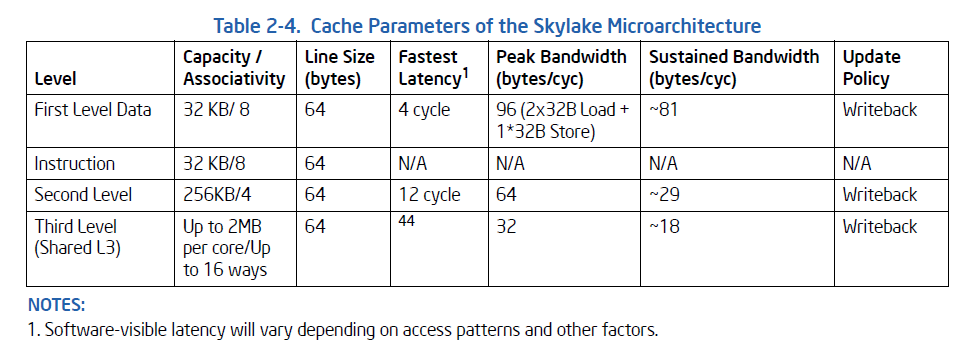
Az anomáliák a L2 és L3 cache-eknél jönnek elő. Ott lehet tudni hogy Intel esetén 64B széles az adatbusz, Zen esetén 32B-os.
Nem stimmelnek az adataid: SKL/KBL-nel az L1D read tenyleg 2x32 B/clk, de az L2 es az L3-nal mar nem.
Az L2 peakben ugyan 64 B/clk-ot tud, de nem tudja kitartani, ahogy az Intel optim guide-ban irjak ~29 B/clk a sustained L2 BW (azaz 32 B/clk lehet az elvi maximum).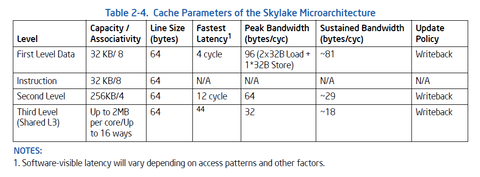
Az L3 -> L2 BW meg 32 B/clk iranyonkent, viszont a clk ott a "ring clock", ami gyakorlatban csak ~16 B/clk-ot jelent:
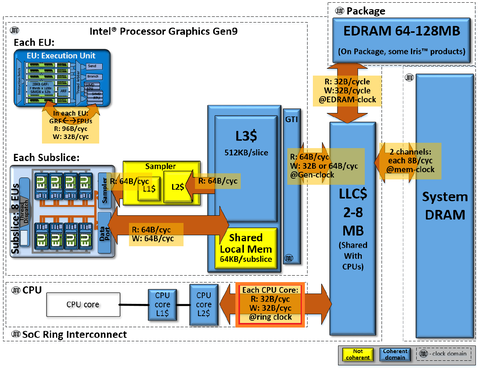
Ezzel szemben Ryzennel az L3 is core clk-kal megy, es csak a data fabrichoz fordulasnal (azaz masik CCX eleresnel) lassul memclkra:
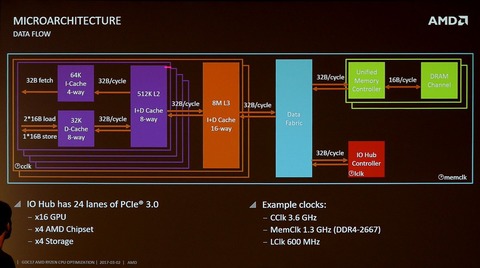
-
#19935
Balala2007
tag
Balala2007
tag
Van uj, Ryzen optimalizalt AIDA64 5.90. Mindenki orul?

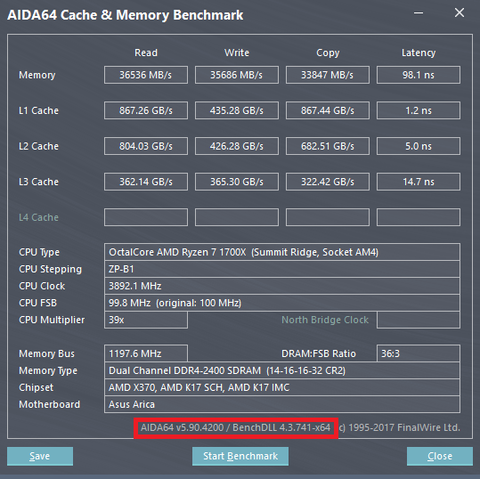
-
#19801
Balala2007
tag
Balala2007
tag
Allitolag Zen2 = Pinnacle Ridge, 2018 eleje
-
Balala2007
tag
válasz
shabbarulez
#19724
üzenetére
Ott lehet tudni hogy Intel esetén 64B széles az adatbusz
A SKL/KBL cache-ekrol ez az Intel hivatalos allaspontja (Optim Guide 24896635 p. 38):
Ezt meg most mertem egy 7700K-n, Read only, singlethread, TurboOff/C1EOff, 4200MHz:
L1D 268345.8MiB/s( 63.894B/c)
L2 133257.8MiB/s( 31.729B/c)
L3 67280.9MiB/s( 16.020B/c)
Mem 21858.9MiB/s( 5.205B/c) -
Balala2007
tag
válasz
Balala2007
#19704
üzenetére
A 128 bites lebegőpontos összeadás a szorzás időigénye 4 órajel
(V)ADDPS/PD: 3 lat
(V)MULPS: 3 lat
(V)MULPD: 4 lat
FMA: 5 lataz Intel-processzorok regiszterfájljának képessége, hogy önállóan felismerje és végrehajtó egység közreműködése nélkül lekezelje a regiszternullázó utasításokat, szintén kívánatos funkció
Ebbol a temabol leheto a legtobbet hozza a Ryzen, az osszes (P)XOR/ANDN/PCMPEQ/(P)SUB a maximumon mukodik benne.
-
Balala2007
tag
válasz
 Oliverda
#19701
üzenetére
Oliverda
#19701
üzenetére
Pazar, koszonom!
- Az L1D órajelenként legfeljebb két darab 128 bites memóriaolvasást és legfeljebb egy darab 128 bites memóriaírást tud végrehajtani; azaz összesen 3 hozzáférést kínál órajelenként, noha a két AGU órajelenként maximum két címet tud kiszámítani.
Nekem ez ugy jott le, hogy az Intelhez hasonloan az AGU csak a 3 operandusos cimszamitashoz kell, az leggyakoribb 2 operandusosakat barmelyik ALU ki tudja szamolni. Intelnel a Port7 is csak az egyszeru esetekben mukodik.
- A 128 bites lebegőpontos összeadás a szorzás időigénye 4 órajel
sztem nem, de holnaptol lehet majd nyiltan beszelni [asszem hianyzik egy "és" ]
- az Intel-processzorok regiszterfájljának képessége, hogy önállóan felismerje és végrehajtó egység közreműködése nélkül lekezelje a regiszternullázó utasításokat, szintén kívánatos funkció
ez mar a Jaguarban is szinte padlogazzal mukodott, holnap kiderul mit orokolt ebbol a Ryzen
- Ebben a hozzaszolasban elszurtam, ott a "Branch Fusion" a slide-on, de sajnos vmiert elsiklottam felette -
Balala2007
tag
válasz
Petykemano
#19374
üzenetére
#18516, az interleave miatt. Felezni, negyedelni lehet az L3-at, haromnegyedelni nem.
-
Balala2007
tag
válasz
Balala2007
#18388
üzenetére
Ez volt a terv L2/L3-ra, de a közelében sincsenek, amikkel minket megkerestek...
-
Balala2007
tag
válasz
max-pain
#19113
üzenetére
AVX nem lesz a kovetkezo SSE
Miert nem? Ha valami spigot, vagy mas SIMD kizaro algoritmus van, akkor mar az SSEn se jo, illetve csak a skalar utasitasok (xxxSS/xxxSD) hasznalhatok. Ezek az AVX-ben is megvannak, 3 operandusos tomor formaban, sot, 4op AVX512 verziojuk is van.
Ha meg egyszer mar megvan a SIMD verzio, akkor 4-rol 8-ra ritkan kihivas novelni a SIMD meretet. AVX meg kulon rasegit pl. VMASKMOV*-okkal a problemas esetekre is.
-
#19112
Balala2007
tag
lezso6
#19109
-
Balala2007
tag
válasz
Oliverda
#19030
üzenetére
Sajnos meg nem ismerem a Zen+(+) felepitreset, mindazonaltal vannak olyan nem magatol ertetodo szempontok, ami alapjan megis inkabb megerne a 256b muveleteket nativan tamogatni:
- A Ryzen pont ugy tordeli szet az x64 muveleteket, mint a Jaguar. Az Intel procijaval szemben 1 helyett 2 slotot foglal el a teljes core-ban, a dekodolastol a visszavonasig, igy nem csak a reorder scope felezodik, hanem a decode bandwidth is;
- Ha az egyik operandus memoria, akkor mar 4 uops-ot fogyaszt, es egy cimszamitas is tkpen feleslegesen tortenik;
- Mivel a 256b muvelet nem atomi, bevaghat egy megszakitas a ketto kozott, es akkor a rollbackrol is gondoskodni kell (nem tunik nagy ugynek, de ugy...)Ezek persze nem elsopro ervek, de hogy az AMD-t evek ota foglalkoztatja a tema, es kedvezo esetben azonnal ugrananak a lehetosegre, azt szerintem mutatja, hogy a 2013 májusi, 3.20-as Programmers Manual ota benne van a CPUID.8000_001Ah.EAX[2] bit, amit meg egyszer sem aktivaltak:
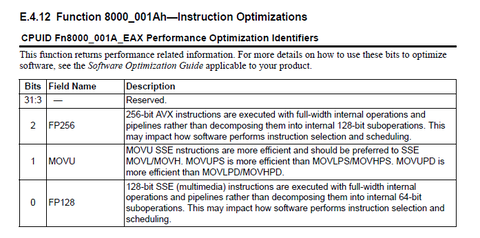
-
#18958
Balala2007
tag
Balala2007
tag
A Zen bezizzen, avagy ezek vszeg RavenRidge ES azonositok a Videcardz.com forumabol
AMD Eng Sample: 2M3001C3T4MF2_33/30_N with AMD 15DD iGPU
AMD Eng Sample: ZD3101AHM44AB_38/31/13/07_9874 with Radeon R7 -
#18940
Balala2007
tag
Balala2007
tag
-
#18828
Balala2007
tag
Balala2007
tag
-
Balala2007
tag
válasz
 Bucsi13
#18558
üzenetére
Bucsi13
#18558
üzenetére
reddites összefoglaló
omlesztve ami eszembe jutott errol:
- uop cache merete a CanardPC #31 ota ismert, 2048 SMR vs. 1536 SKL/KBL;
- a 64KB L1I jol hangzik, de mivel az 512KB L2 inkluziv, lejon belole ez meg a 32KB L1D, igy 416KB L1-tol garantaltan fuggetlen adat marad;
- SMR-ben a SIMD EU-k csak 128 bitesek, emiatt az ymm muveletekhez kapcsolodo uop-okbol dupla annyi kellhet, a dekodolastol a visszavonasig. Ez igy teljesen megegyezne a Jaguar mukodesevel;
- Szinten Fam16h orokseg lehet, hogy egyelore nem latom nyomat macrofusionnak. Branch intenziv kodban elonyben lehet emiatt az Intel;
- Mindezekhez kapcsolodik, hogy a SKL OoO ablaka 224 uops a SMR 192-jevel szemben;
- A SMR L1D savszelessege fele a SKL-nek. Tovabba kerdes, hogy a bank conflict-okkal csinaltak-e valamit (Intelnel HSW ota ez megoldott), mert ha nem, akkor ez igy csak az IVB szintje.
- Par uj trukk a Zenbe is jutott, a dupla AES-en kivul pl. itt a Linux-gore Linus mereng azon, hogy mekkora jelentosege lehet annak, hogy az SMR mar a dekodolasnel megprobalhatja elintezni a STLF-eket;Azaz egesz lenyege, hogy bar a Zen hozza az igert 40%-os IPC javulast az Excavatorhoz kepest, de 1 szalon meg mindig inkabb az Intel a favorit, illetve forditva nezve boven van meg fejlesztesi lehetoseg a Zen leszarmazottaihoz.
-
#18550
Balala2007
tag
Balala2007
tag
AMD says its Zen CPU architecture is expected to last four years
"Jim Anderson, senior vice president and general manager of AMD’s Computing and Graphics business, told PCWorld that Ryzen chips will be available from day one. “We’re not going to do a paper launch,”"
"Papermaster confirmed the four-year lifespan and tapped the table in front of him: “We’re not going tick-tock,” he said. “Zen is going to be tock, tock, tock.”"
-
#18549
Balala2007
tag
Yutani
#18517
Balala2007
tag
válasz
 Yutani
#18517
üzenetére
Yutani
#18517
üzenetére
Az AMD az FX-nél megoldott a core és L2$ letiltását úgy, hogy nem kellett az L3$-hez nyúlnia, az minden FX-ben maradt az eredeti méretű. Természetesen a Zen egy teljesen más design, de nem lehet, hogy itt is meg tudják oldani az FX-nél is alkalmazott letiltási lehetőséget?
Igy lehet, persze, ilyan core-only disabled demo darabok vannak/lesznek is elvileg. Csak kerdes, h gazdasagilag megeri-e piacra dobni, javit-e a kihozatalon, a kikapcsolando terulet eleg kicsi, nem hinnem hogy 1/16 reszenel nagyobb a die-nak. De BDZ-nel megerte, ugy latszik.
-
Balala2007
tag
válasz
Petykemano
#18426
üzenetére
Downcore: a magok fuggetlennek latszanak, ott nem latszik akadalya az egyenkenti lekapcsolasnak, inkabb az L3-mal van gond, ahogy a HotChips slide mutatja, az elso cimbitek alapjan interleave-et hasznal, igy kb. keptelenseg a negyedet kivenni. Felezni talan lehet, de az se tunik trivialisnak. Ha en mostanaban AMD lennek, elso korben biztos nem szivatnam magam ezzel.
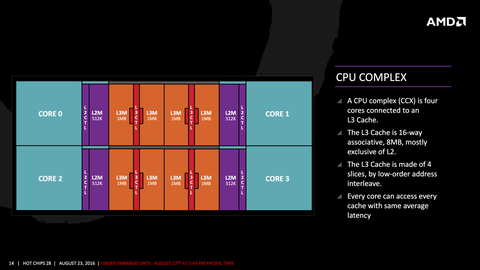
-
Balala2007
tag
válasz
 #85552128
#18502
üzenetére
#85552128
#18502
üzenetére
Zen sample 3.6 GHz-es alapórajellel az egyik CES demógépben
CanardPC-seknek eggyel ujabb van (F4), az 3,6GHz base, 4GHz turbot tudhat.
-
Balala2007
tag
válasz
Oliverda
#18389
üzenetére
Nem tul bobeszedu az Intel, tudtommal csak annyit mondtak errol, h cserebe a throughput novekedett, +50% a Bandwidth/Watt.
A szemelyes teoriam az, h ez a tile-based/2D Mesh protokoll mellekhatasa lehet. A BDW lehet az utolso 1D/Ring LLC-s proci, es a Skylake-ben (a slide-ok allitasa ellenere) mar a 2D cache elfajulo esete van, ami 2x2 eseten szinten egy gyuru. Ezt meg alatamasztja, h a Skylake die-on a core-ok a korabbi generaciokkal ellentetben mar nem sorban, hanem egymassal szembeforulva allnak. Tovabba: a Skylake-E(P/N/X)-oknal kiderult, hogy a 1024KB-os L2 mellett mindossze 1408KB/core az L3 merete. Ez eleg furanak latszik, a 2048-nak a 11/16-oda, plusz a L2:L3 arany kizarja, hogy az L3 a szokasos inclusive lehessen. Az biztosnak latszik, hogy a Skylake-E(P/N/X) a Knights Landinghoz hasonlo 2D tiled felepitest hasznalnak majd, core-onkent 640KB L3-at bealdozva a koherencia adminisztraciojara, es nekem ugy tunik a latencianovekedes valahogy ennek a mellekhatasa.
Remelem nem tul off ez itt...
-
Balala2007
tag
válasz
Petykemano
#18374
üzenetére
Nem fake, de ahogy irjak a bevezetoben is, a vizsgalt verzio meg tartalmaz sulyos bugokat meg workaroundjaikat, emiatt a mindenkit izgato "Milyen lett a Ryzen?" kerdes nem valaszolhato meg vele.
Nekem az a legerdekesebb, hogy a cikkben vegre leirtak 2 fontos szamot:.
Ryzen HSW/BDW SKL/KBL
L2 latency: 12 11 12
L3 latency: ~35 ~34 ~44Ezexerint a cache hatranyt ledolgozta az AMD
-
#18301
Balala2007
tag
Balala2007
tag
Talan annyira nem off, de erdekes lehet, Intel-fonok #2 a Zenrol:
"Our faith in 10 nm raising the bar for enthusiast PCs is why we see the threat presented by AMD’s Zen as being fairly manageable, with only short term disruption in 2017."Nem tul friss, meg iden Mikulas elott mondta
-
Balala2007
tag
válasz
 Laja333
#18180
üzenetére
Laja333
#18180
üzenetére
Ugy tunik, az AMD rajta van a teman, a most ervenyes AMD64 System Programming Manual ujdonsaga, a SEV-ES, mintha ezeknek a kifogasoknak menne valamennyire elebe. Ez a mostani Zen-ben persze meg nincs benne, sztem csak a Zen+-ban varhato.
-
#18178
Balala2007
tag
Balala2007
tag
-
Balala2007
tag
válasz
 golya87
#17681
üzenetére
golya87
#17681
üzenetére
Ez olyasmi (is) lesz, mint Intelnél az AES-NI és a QAT kiterjesztés/egység?
Nem. (AES-NI AMD-nel a Bulldozer/Jaguar ota van)
Az SME a nem-felejtos RAM-ok terjedese miatt kell, ha fizikailag sikerul hozzajutni egy ilyen titkositatlan modulhoz, ugyanugy siman kiolvashato belole barmilyen adat, mint egy HDD/SSD-bol. Az SME egy resetenkent valtozo random kulcsu AES128-sel titkositva tarolja az adatokat minimalis latency novekedes mellett. Ez tokfuggetlen az architekturalis AES-NI-tol, csak a titkositasi eljaras ugyanaz. Jo benne, hogy csak a laponkenti titkositashoz kell OS support, a teljes memoria titkositasa (TSME) sima BIOS kapcsolasbol megoldhato az AMD igerete szerint (bar ilyenkor a SEV nem hasznalhato).
A SEV meg a Hypervisor/VirtualMachine esetben a guest memoriajanak titkositasat oldja meg a SME-hez hasonlo modon, igy ha pl feltoltesz vmit egy Zen alapu cloud-ba, akkor megfelelo OS/HV tamogatas eseten az adataid csak titkositott formaban kerulnek ki a CPU-bol, meg a host sem fer hozza.Nekem ezek a feature-ok is azt mutatjak, hogy a Zen a desktop Core i7 helyett inkabb majd Xeon D-nek jelent majd konkurenciat, ahol dual socket/128 thread supporttal, SME+SEV-vel komoly ellenfel lehet meg alacsonyabb (<3GHz) freq-val is.
-
#17688
Balala2007
tag
lezso6
#17680
Balala2007
tag
válasz
 lezso6
#17680
üzenetére
lezso6
#17680
üzenetére
És a Keccak?
Az csak azota plane, hogy eloleptettek SHA3-nak, ez 2015 augusztusaban volt a wikipedia szerint, az Intel HW SHA-t meg mar 2013 juliusaban speckoztak.
Ami katalizalhatna az SHA3 ugyet az, ha pl. ARMv8.3-ba beraknak, az SHA1/2 is foleg a konkurencia miatt kerult be az x64-be tudtommal. -
Balala2007
tag
válasz
Balala2007
#16714
üzenetére
Van mar valami hasonlo Zen temaban?
Most mar van.
-
#17665
Balala2007
tag
Yutani
#17663
Balala2007
tag
válasz
Yutani
#17663
üzenetére
Nem latom ertelmet ilyesmit szamolgatni az ismeretlen freq (2900-1400 kozott barmi lehet), a HTT/SMT ismeretlen allapota, a HW SHA torzito hatasa, a nem karbantartott GB3, a gyatra skalazodas ismeretlen oka, a kerdeses topologia tamogatas, stb. miatt.
Az egeszbol az a lenyeg, hogy vegre felbootolhato allapotban van a 2x32 magos Zen, ami leginkabb a jelenleg max. 1x16 magos Xeon D-kre jelenthet majd komolyabb veszelyt.
-
#17662
Balala2007
tag
Balala2007
tag
-
Balala2007
tag
válasz
Balala2007
#16712
üzenetére
Az elso Zen-specifikus publikus doksi:
Secure Encrypted Virtualization Key
Management Technical Preview -
Balala2007
tag
válasz
 Goose-T
#17435
üzenetére
Goose-T
#17435
üzenetére
érdekes lehet ez a hír
Elegge Megerositi tkpen az osszes gcc-bol levonhato kovetkeztest.
A februari Citavia blogon megtippelt felepites meglepoen pontos. -
Balala2007
tag
válasz
Oliverda
#17365
üzenetére
Zen is a from scratch architectural design
Pikans ellentmondani a CEO-nak, de szerencsere ez nem igaz sztem. A Fam15h, na az volt from scratch.

A Fam17h egyertelmuen a Fam16h leszarmazottja, nem veletlenul all annyi Jag tervezo a hatterben.Nagyon durvan es teljesen szubjektiven igy latom most a Zent, (Zen-Jaguar ~= Penryn-Dothan):
{C}Zen(Fam17h) =
~50% Fam16h (XBox/PS4 Jaguar-szeru felepites, monolitikus LLC, single/double dekodolas, basic ALU, 128b FPU port, stb.)
+ ~25% Intel (HyperThreading, uop cache, HW SHA, RDSEED, ADX, CLFLUSHOPT, stb.)
+ ~15% Fam15h (FMA3, AVX2, 4x integer EU, stb.)
+ ~10% "ujdonsag" (5 szintu topologia, eddigi legjobb AMD cache-ek, CLZERO, dual HW AES, SME/SEV stb.) -
Balala2007
tag
válasz
Balala2007
#16807
üzenetére
5 szintu topologia
1 applikaciot mar tudok, ami megzavarodik tole...
-
#17216
Balala2007
tag
Balala2007
tag
#16816
Viszont az számomra érthetetlen, hogy miért nem tud FMA-t a 2-3 porton a Zen...Nyilvan design trade-off, azaz kompromisszum. FMA-nak teruleti es energiakoltesegei vannak, es ennyit gondoltak bealdozhatonak.
Most meg úgy néz ki, hogy FMA szempontjából teljesítményben egy Zen core=egy Bulldozer uarch modul (2x128 bit FlexFP)
Per core per clock alapon pont a Fam15h teljesitmenyet hozza, vszeg ez volt az also hatar, ami ala nem mehettek.
Vegleges, hogy az FMA4 kimarad a Zenbol. Gyozott az eredeti SSE5 koncepcio.
Az FMA4 kodolasa pocsek, a negyedik operandust egy hozzacsapott byte-al irja le, ahol az also 4 bit kihasznalatlan, pl. mar egy 3D skalar szorzasnal 2 byte elonye van az FMA3-nak:
AVX C4C12559CB vmulpd ymm1, ymm11, ymm11
FMA4 C4C31D69CC10 vfmaddpd ymm1, ymm12, ymm12, ymm1
FMA4 C4C31569CD10 vfmaddpd ymm1, ymm13, ymm13, ymm1
^^utolso 4 bit mindig 0
AVX C4C12559CB vmulpd ymm1, ymm11, ymm11
FMA3 C4C29DB8CC vfmadd231pd ymm1, ymm12, ymm12
FMA3 C4C295B8CD vfmadd231pd ymm1, ymm13, ymm13Ez a tomorsegre toro x64-nel brutalis pazarlas, az AIDA64 RayTrace-ben pl. ~0.7%-kal rovidebb az FMA3 verzio. Osszeveteskeppen: ugyanitt az FMA hasznalat 18-20%-os kodrovidulest jelent az AVX2-hoz kepest.
Az FMA3-nak az ad letjogosultsagot, hogy a legtobb gyakorlati esetben (matrix- es skalarszorzas, polinomhelyettesites, FFT, stb.) csak par %-ban kulonbozik mind a 4 operandus.#16812
FMA-t milyen alkalmazások használnak?Ahol nagy mennyisegu lebegopontos szamitas kell, gyorsan es pontosan, tkpen barhol a gazdasagban vagy a tudomanyos eletben.
(Karikirozva: ahol a gepekbol penzt csinalnak, nem pedig a gepekre koltik a penzt.)Itt egy hangsulyozottan toredekes lista a nepszerubb numerikus konyvtarakrol, amiket ilyen a celokra hoztak letre.
Itt meg egy meg toredekesebb, nem tul naprakesz, ami a SIMD tamogatasok szintjet reszletezi.
#16815
Eleg keves, legalabbis en konkretan, a benchmarkokon kivul nem tudok egyrol sem.Amit itt mindenki ismer az a Prime95. De ha csak GMPLib-bol indulunk ki, akkor hasznalja a Mathematica, a Matlab es a Maple is.
Elterjedeset neheziti, hogy ritkan lehet siman helyettesiteni, addig stabil eredmenyek szeteshetnek, pl. a klasszikus hogy FMA-val a 0.1*10.0-1.0 != 0.0.
Itt egy "elmenybeszamolo" a MatLab + FMA tapasztalatokrol. -
Balala2007
tag
válasz
 hugo chávez
#16810
üzenetére
hugo chávez
#16810
üzenetére
Ez ugye csak az AVX-512-re érvényes?
Ha azt is szamoljuk akkor mar 1:4 a Zen/Skylake arany, de a Zeppelin nem tud AVX512-t.
Tehát pl. 256 bites AVX-ben már kb. egál?
Igy talan szemleletesebb:
Zen/Zeppelin KNL/Skylake Xeon Zen/SKX
Port0 Port1 Port2 Port3 Port0 Port1 peak FLOPS ratio
SSEn: MUL128 MUL128 ADD128 ADD128 MUL128 ADD128 2:1
AVX: MUL256 ADD256 MUL256 ADD256 1:1
FMA: FMA256 - FMA256 FMA256 1:2
AVX512 (AVX2 FMA256) - FMA512 FMA512 1:4 -
#16813
Balala2007
tag
derive
#16809
-
#16808
Balala2007
tag
Yutani
#16778
Balala2007
tag
válasz
Yutani
#16778
üzenetére
Remélem, van alapja ennek a nyilatkozatnak.
FLOPS-ban konkretan a fele lesz a Skylake-nek per core. Ettol persze meg lehet relativ sikeres,
- ha az a "high bandwidth, low latency caches system" valosag lesz, akkor a fentebb emlegetett monolitikus LLC latency-je lehet jobb is, mint Skylake-e;
- FLOPS ugyan a fele, de legacy x64 koddal is teljesen ki lehet hajtani, nem kell AVX/FMA;
- ha a memoria hasznalata kompetitiv lesz;
- ha a freq kompetitiv lesz;
- ha emiatt az atlagos legacy programokkal jobb, mint pl. a WinRAR;
- mindez eleg fontos a usereknek; -
#16807
Balala2007
tag
Fiery
#16802
Balala2007
tag
a Bulldozer megfelelo kezelesehez is kellett egy Windows kernel patch
Ez eselyes a Zen-nel is az 5 szintu topologia megjelenese miatt:
1 level: Socket = Die = Core = Thread
2 level: Socket->Core (pl. AMD Dual K8), Socket->Thread (pl. Intel Northwood)
3 level: Socket->Die->Core (pl. AMD Magny Cours), Socket->Core->Thread (pl. Intel Nehalem)
4 level: Socket->Die->CU->Core (pl. AMD Interlagos)
5 level: Socket->Die->Complex->Core->Thread (pl. AMD Zen Server)Mindez vszeg a LLC (Last Level Cache) miatt szukseges. Egyreszt a Zen-ben nem 1D ringbe, plane nem 2D mesh-be szervezett LLC lesz, hanem a konzolos Jaguarokhoz hasonlo egyszerubb dual monolitikus LLC, masreszt az LLC masik fele egy die-on lesz ugyan, de valamivel lassabb eleresu, mint a kozelebbi, kvazi xMB L3 + xMB L4.
-
#16719
Balala2007
tag
F34R
#16718
Balala2007
tag
A friss linux kernelek fel lesznek ra keszitve
Efelol semmi ketsegem.
Nekem a NVRAM tamogatas divergenciaja a furcsa: egy ideje mar ismert a Cannonlake tamogatasa (user modu PCOMMIT+CLWB), de Intelnel nincs szo titkositasrol, a Zen egyetlen specifikus uj utasitasanak (CLZERO) tudtommal nincs koze az NVRAM-hoz, most meg hivatalos lett titkositassal egyutt (ami nyilvan implikalja az NVRAM tamogatast, de PCOMMIT/CLWB nelkul). -
#16714
Balala2007
tag
And01
#16710
Balala2007
tag
Már márciusban küldtek es-samplet a partnerek felé
Van arra valamilyen bizonyitek, hogy ezek nem csak mechanical sample-ek voltak? Arra gondolok, hogy amikor appokat futtatni kepes peldanyokat kiad a gyarto a kezebol, akkor altalaban kikerulnek infok. Pl. GB adatbazis tetelek, bugriportok, support keresek szoktak megjelenni. Itt pl. az latszik, hogy egy honappal ezelott egy 5065x Skylake Xeon mar Linuxot birt bootolni. Van mar valami hasonlo Zen temaban?
-
#16712
Balala2007
tag
Balala2007
tag
Zen SME/SEV support. Teljesen hivatalos.
A SME memoria tartalmanak AES128 titkositasa, pl NonVolatile DIMM-ek fizikai ellopasa esetere, SEV meg virtualis gepek memoriatartalmanak ugyanilyen titkositasa Hypervisoros kifurkeszes ellen. Minimalis latency romlast okoz csak allitolag.
-
#16707
Balala2007
tag
derive
#16703
Balala2007
tag
válasz
 derive
#16703
üzenetére
derive
#16703
üzenetére
Az egy 4 socketes ES Interlagos Opteron, csak a GB "kisse" osszekutyulja a cache es memoriadetektalast.
-
Balala2007
tag
válasz
 headhunter
#16700
üzenetére
headhunter
#16700
üzenetére
A Summit Ridge-nel csak az "AM4" info a biztosan jo.
-
#16663
Balala2007
tag
Balala2007
tag
Tudtommal az elso x86/x64 HW SHA eredmeny (ilyen lesz a Zenben is): Intel Broxton/Goldmont GB3 eredmenyek
-
Balala2007
tag
válasz
Petykemano
#16653
üzenetére
Tulajdonképpen a bulldozer 1 magja akkor képes volt extrém esetben kvázi 4 ALU szélesként funkcionáln
Csak az Excavator.FPU intenzív terhelés alatt "összeomlott".
A K15 szeria rengeteg reszletben le van maradva az Intelhez kepest a mar emlitetteken kivul is (pl. nincs uop cache, macrofusion gyengebb, stb), de az FPU-nal a donto az, hogy 3x128b EU all szemben 3x256b EU-kal.A rendelkezésre álló erőforrások kihasználtságát az SMT növelheti, hiszen ha két külön szálat futtat a mag, akkor kevesebbet kell bűvészkedni az utasítások párhuzamosíthatóságán.
Ha ket IP-tol jonnek a uop-ok, akkor azok implicit fuggetlenek, az mar TLP.FMAC egységet tartalmaz, ami tulajdonképpen 1-1 add + multiply egység, ha jól sejtem gyárilag összeolvasztott egysége.
Az FMAC-ban nagyon hangsulyos a Fused, azt jelenti, hogy a szorzas utan kimarad egy kerekitesi fazis, a szorzas eredmenyehez vegtelen pontosaggal adodik a harmadik operandus. Ezt SW-bol eleg nehez pontosan utanozni, az Intel SDE pl. nagysagrendileg ~100x lassabb a nativnal.Ezzel szemben a Zennél 2 FMUL és 2 FADD egység van, ami a leírás szerint egyenként 3ciklus késleltetéssel végeznek műveletet
Csak az ADD 3, az SP MUL 4, a DP MUL 5. Itt egy tablazat a gcc patch-ek alapjan, amit most a Zenrol tudni lehet.Itt már is kérdezném, hogy fenti azt jelenti, hogy azért választották-e vajon a különálló FMUL és FADD egységeket, mert a bulldozer esetén a 2 FMAC különálló FADD és FMUL műveleteket is csak ugyanazzal a késleltetéssel tudott végrehajtani, mint FMAC műveleteket és persze ezekből is csak egyszerre kettőt?
Nem, FMA-ra egyszerubb kulon muveletkent gondolni.egy bulldozer mag, pontosabban amikor egy szál futott egy bulldozer modulon, akkor vajon mindkét FMAC egységet tudta-e használni
Persze, latszik a throughput adatokon.1 szálas FPU teljesítményben milyen előrelépést tud majd felmutatni?
A jobb ADD/MUL latency-n mar nyer, es ha pl. a regiszteren beluli pack/shuffle/permute EU-t nem kapcsoljak ugyanarra a portra, mint az FMA (mint az Intel Port0-1 FMA, Port5 shuffle), akkor azon is, ha a store nem utkozik az elobbiekkel, az megint elony, stb.A gcc patchekbol sejtheto, hogy az AMD celja a Zennel a x64-hez hasonlo lehet: ahogy anno az Intel kihagyta a 64b-es x86 kiterjesztest az IA64 kedveert, ugy most a legacy x64-et hanyagolja a 256/512b-es SIMD-ekert. Bar sok reszlet meg hianyzik, az erzodik, h a Zeppelin core-t a legacy x64 kodok futtatasara optimalizaljak.
Peak Flopsban az Intel 2x erosebb, de ehhez a kodokat is ujra kell forditani -> kicsi Itanium szindroma.
Ket *szelsoseges* pelda szemlelteteskent:
Code1 (128b SSE):
mulps xmm1, xmm2
mulps xmm14, xmm15
addps xmm6, xmm7
addps xmm8, xmm10
Code2 (256b FMA):
vmfadd213pd ymm0, ymm1, xmm2
vmfadd213pd ymm3, ymm4, xmm5
vmfadd213pd ymm6, ymm7, xmm8
vmfadd213pd ymm9, ymm10, xmm11Code1 throughput Zenen 1clk, Skylake-en 2clk, Zen 2x gyorsabb Skylake-nel a 4 FPU port miatt.
Code2 throughput Zenen 4clk, Skylake-en 2clk, Skylake 2x gyorsabb a Zennel a 256b-es portok miatt.Nekem most ugy tunik, hogy ha kipofoztak a cache-eket, kapott egy nagyobb ROB-ot, egy turheto branch predictort es memoriakezelest, akkor a Zennel integerben ~Skylake, SSE2-SSE4 Skylake+, AVX-AVX2-FMA: XV+ szintet celozhattak meg. Aztan a tesztekbol majd kiderul, mi jott ossze ebbol.
-
Balala2007
tag
válasz
Petykemano
#16648
üzenetére
Jaguarnak 2
3, mint PProtol Penrynig, K7-tol K12-ig, meg Bonnell + Silvermont. 2clk-os L1D-je a Northwoodnak volt legutobb, azelott meg csak Socket7-eseknek.
nem tudom, hogy mi a jelentősége, hatása, hogy az AGU-k egy része ALU funkciókat is ellát.
Duplazodik az integer throughput. Clk-onkent 2x annyi fuggetlen egesz muvelet hajtodhat vegre,miért elég a Zennek 4 ALU + 2 AGU ?
Ki mondta, h eleg? Hoztak egy dontest a statisztikak, az energiakeret, a felulethasznalat, meg meg ki tudja milyen szempontok alapjan. Kompromisszum, mint minden ilyen.Esetleg arra gondolsz, hogy a K7-K12 korszakban 3 AGU volt? Ez ugyan jol nezett ki, de 3 dolog durvan behatarolta: az L1D ezekben mindig csak 2 portos volt, masreszt nem tudtak az AGU queue-k kozott ugralni az assignolt uop-ok, harmadreszt ott meg nem volt spekulativ a memoriakezeles.
Vagy esetleg arra, hogy HSW-SKL vonalon a Port2-3-7 AGU a 2R+1W portos L1D-hez? Ez igaz, de a Port7 csak az egyszeru, index regiszter nelkuli cimszamitasokat tudja (HSW-ben meg biztosan, nem tudom ezt fixaltak-e mar.)
Az lehet a megoldas, amit mar a K10 is tudott: az egyszeru cimszamitasokat tudja a 4 ALU is kezelni, es csak komplexekhez kell a 2 AGU. Ez a gyakorlatban jo lehet egy 2R+1W portos L1D-hez. -
#16647
Balala2007
tag
Balala2007
tag
4ns L1D-je a 750MHz-es K7-nek volt
, ez ma mar az L2 nagysagrendje. 4clk lesz az.Ez igy kiragadva elegge felrevezeto, MONITORX/MWAITX mar Excavatorban is van. Eddig 1db CLZERO nevu Zen specifikus utasitas ismert. Meglepne, ha lenne tobb, a Zennek pont ez a lenyege, csak a mainstream, semmi extra 3DNow/SSE4a/SSE5/XOP/TBM-szeru kiterjesztes. (Az FMA4 kerdeses, a legutolso verzio szerint lesz, de nem tudom hogy ez-e a vegso szo.)
Végső soron a XV-nak magonként 2-2 integer ALU-ja van
Dehogyis.
Bulldozer 600F1x, 2 AGU csak cimeket fordit:
22 X86 :MOV r32, r32 L: 0.28ns= 1.0c T: 0.14ns= 0.50c
23 AMD64 :MOV r64, r64 L: 0.28ns= 1.0c T: 0.14ns= 0.50c
72 X86 :ADD r32, r32 L: 0.28ns= 1.0c T: 0.14ns= 0.50c
73 AMD64 :ADD r64, r64 L: 0.28ns= 1.0c T: 0.14ns= 0.50c
Piledriver 600F2x, 610F01, 610F31, 2 AGU sima MOV-okat is kezel, decoder megosztott:
22 X86 :MOV r32, r32 L: 0.25ns= 1.0c T: 0.06ns= 0.25c
23 AMD64 :MOV r64, r64 L: 0.25ns= 1.0c T: 0.08ns= 0.31c
72 X86 :ADD r32, r32 L: 0.25ns= 1.0c T: 0.12ns= 0.50c
73 AMD64 :ADD r64, r64 L: 0.25ns= 1.0c T: 0.12ns= 0.50c
Steamroller 630F0x, 2 AGU sima MOV-okat is kezel, decoder dedikalt:
22 X86 :MOV r32, r32 L: 0.27ns= 1.0c T: 0.07ns= 0.25c
23 AMD64 :MOV r64, r64 L: 0.27ns= 1.0c T: 0.07ns= 0.25c
72 X86 :ADD r32, r32 L: 0.27ns= 1.0c T: 0.14ns= 0.50c
73 AMD64 :ADD r64, r64 L: 0.27ns= 1.0c T: 0.14ns= 0.50c
Excavator 660F0x, 2 AGU ADD/SUB/CMP/AND/OR/XOR/NOT/NEG/TEST/INC/DEC-t is tud:
22 X86 :MOV r32, r32 L: 0.36ns= 0.8c T: 0.12ns= 0.25c
23 AMD64 :MOV r64, r64 L: 0.36ns= 0.8c T: 0.12ns= 0.25c
72 X86 :ADD r32, r32 L: 0.48ns= 1.0c T: 0.13ns= 0.28c
73 AMD64 :ADD r64, r64 L: 0.48ns= 1.0c T: 0.13ns= 0.27cXV 0.8-as MOV latency-je az jelenti, hogy a MOV-ok legalabb egy reszet elliminalni tudja EU-k nelkul. Raw x86/x64 integer throughput mertekben mar az XV a Skylake szintjen van. Hogy ez miert nem erzodik? Write-through L1D, joval lassabb L2, az L3 hianya, kisebb Reorder Buffer, gyengebb branch prediction, gyenge memoria hatekonysag, stb.
Meg azert van ahol latszodik. Az AMD egy ideje nem frissiti a techdoc-okat (talan a leepites miatt?), igy mire kipofoztak a K15 sorozatot, hivatalos dokumentacio nem szuletett rola. -
#16406
Balala2007
tag
Balala2007
tag
-
#16403
Balala2007
tag
Balala2007
tag
-
Balala2007
tag
válasz
 leviske
#15826
üzenetére
leviske
#15826
üzenetére
Az AIDA mely benchmarkjai reflektálnak legjobban az átlag felhasználás során nyújtott teljesítményre?
A ZLib csak x86/x64 utasitasokat hasznal egy elegge elterjedt tomoritesi modszert tesztelve (pl. PNG formatum is ezt hasznalja) threadenkent 32MB-ot tomoritve, a VP8 meg csak SSE4.1-ig hasznalja ki a SIMD-et (AIDA64 mertekkel) eleg pocsek skalazodassal.
azért úgy tűnik, hogy több tesztben is sikerült komolyabbat javulni.
Leginkabb ezekbol jon az elony:
- L1D merete es asszociativitasa duplazopdott (16KB/4way-> 32KB/8way, de maradt WriteThrough, Intelnel Prescott ota csak WriteBack L1D-k vannak);
- L2 merete felezodott, de atlag latency 38->32clk (Intelnel Nehalem ota 256KB, de csak 10-12clk);
- A dekodolas tovabb javult a Steamrollerhez kepest, de reszleteket nem tudok;
- A Steamrollerhez kepest bovult a AGU portokon vegrehajthato utasitasok kore:Steamroller: 32+64b MOV reg, reg,
Excavator: MOV reg,imm/ADD/SUB/CMP/AND/OR/XOR/NEG/NOT/TEST/MOVZX/MOVSX;- Az AES ugras a AESENC/AESDEC utasitaspar gyorsulasanak koszonheto (9->6 clk), de ez semmi masra nem jo;
- A lassu FP utasitasok (DIV/SQRT) szepet gyorsultak (pl. VSQRTPD 44->25 clk), bar ezek eleg ritkan hasznalatosak; -
Balala2007
tag
válasz
 Vitamincsiga
#15380
üzenetére
Vitamincsiga
#15380
üzenetére
ennek tuti AVX-512 képesnek kell lennie!
Nem lesz az. A minapi gcc patch-bol keves biztos derul ki CPUID family erteken kivul, de ez alapjan valoszinu, hogy a Carrizohoz kepest kikerul a XOP, FMA4, TBM, LWP, bekerul az Broadwellbol az ADCX, RDSEED, Goldmontbol az SHA, Skylake-bol a CLFLUSHOPT, Zen specifikus meg egyelore a CLZERO lesz (1 utasitas osszvissz). Abszolut konzervativ designnak nez ki.
Az osszes tobbi ertekhez meg ezt kell alapul venni: "Costs and tunings are copied from bdver4, but we will be adjusting them later for znver1."
-
#15275
Balala2007
tag
Balala2007
tag
-
#15007
Balala2007
tag
Fiery
#15004
Balala2007
tag
Talan a mentheto CRZ-kbol probalnak meg vhogy penzt kisajtolni? Ez elegge ketsegbeejto lepes lehet, amig nem olvastam az alabbit, el se kepzeltem volna, hogy ilyesmivel probalkozzanak.
-
#14843
Balala2007
tag
Abu85
#14829
Balala2007
tag
A Broadwell-U átlagos sűrűsége 14,3 millió tranyó/mm2, míg a Carrizo esetében ez a paraméter 12,7 millió tranyó/mm2.
Tudtommal minden BDW P1272-vel keszul, ami a teljesitmenyorientalt Intel 14nm. A CherryTrail/Braswell/Broxton keszul P1273-mal, ami fogyasztas es surusegoptimalizalt eljaras.
A Silvermont ota tudtommal nem publikaljak a tranzisztorszamokat, de die size-ok megvannak:
BYT: 102mm2
BSW: 71mm2
BXT: 58mm2 (ez nem hivatalos, pixelszamolassal jott ki egy Intel slide-bol)
Illetve meg annyi info volt, hogy a Silvermontnal az AIrmont 64%-kal kisebb. -
Balala2007
tag
válasz
Oliverda
#14822
üzenetére
Fully inclusive cache design...
Be kell aldozni az exclusive cache kapacitasfolenyet. Gondolom ugyanaz lehet itt is az indok, mint amikor a Nehalemnel bejott az inclusive L3, egyszerubb a snoop, nem kell minden szintet vegigellenorizni. Ki tudja, talan meg gyorsulast is hoz.
Még ennél is érdekesebb lenne odatenni az AMD által alkalmazott 28 és 32 nanométert is.
Nekem ezek az adatok sajnos nincsenek meg, de barki kiegeszitheti a tablazatot.
(egyesítettem őket)
[ Módosította: Oliverda ]











































Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

- Okos Otthon / Smart Home
- Samsung Galaxy S23 Ultra - non plus ultra
- Samsung Galaxy S23 és S23+ - ami belül van, az számít igazán
- hcl: Döglött tabletből wifis kijelző kókány
- Motoros topic
- Külpolitika
- Videós, mozgóképes topik
- Kezdő fotósok digitális fényképei
- Hobby rádiós topik
- Melyik tápegységet vegyem?
- További aktív témák...

- AKCIÓ! HP USB C G5 Essential (5TW10AA) dokkoló hibátlan működéssel garanciával
- Eladnád a telefonod? KÉSZPÉNZES OKOSTELEFON FELVÁSÁRLÁS azonnali fizetéssel!
- LG 77B3 - 77" OLED - 4K 120Hz & 0.1ms - NVIDIA G-Sync - FreeSync Premium - HDMI 2.1 - 700 Nits
- Bomba ár! Dell Latitude 7280 - i5-7GEN I 8GB I 256SSD I 12,5" FHD I Cam I W11 I Garancia!
- BESZÁMÍTÁS! Asus TUF B365M i7 9700F 16GB DDR4 512GB SSD RTX 3060Ti 8GB Rampage SHIVA Zalman 600W
Állásajánlatok

Cég: Laptopszaki Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest