
- Milyen billentyűzetet vegyek?
- Intel Core Ultra 3, Core Ultra 5, Ultra 7, Ultra 9 "Arrow Lake" LGA 1851
- TCL LCD és LED TV-k
- Már az MSI-nek is van 500 Hz-es QD-OLED monitora
- Nvidia GPU-k jövője - amit tudni vélünk
- AMD GPU-k jövője - amit tudni vélünk
- A 3D V-Cache és a rengeteg memória lehet az új PlayStation fő fejlesztési iránya
- ASUS ROG Ally
- AMD vs. INTEL vs. NVIDIA
- Milyen széket vegyek?
Új hozzászólás Aktív témák
-

Teasüti
nagyúr
Számít ez a végeredmény szempontjából, hogy a professzor képzésében önmaga szerezte be a forrásokat vagy egy szponzor biztosította számára?
Amúgy megértem a példádat a könyveddel kapcsolatban. Engem sem hagyna nyugodni, ha bizonyíthatóan én lennék az értelmi szerzője annak a konkrét információnak. De milyen várható bevételtől esnék el? Ezt hogy bizonyítom? De ez ugye egy akadémikus területen kényes, ahol tudományosan megalapozott tudás cserél gazdát és visszakövethető az első tanulmányokig kitől származik egy publikáció ötlete. De azért egy fikciós történetnél ez nem annyira egyértelmű szerintem. Vagy én nem írhatnék könyvet egy varázsló iskoláról, csak mert más már írt egyet?

-

Vesa
veterán
Ebben semmi újszerű nincs, ami a szerzői jogi részt illeti. Elolvasol emberként egy scifi rgényt (meg még 10 másikat), majd semmit nem megismételve, de ötleteket merítve belőlük írsz egy másik scifi regényt. Az életben senki nem fog tudni beperelni, mert nincs alapja, nem másoltál ki 1:1-ben részeket az álatald olvasott könyvekből. Ugye pusztán attól, hogy egy űrhajón utaznak a szereplők a korábbi regényben is és a tiédben is, még lesz lopás a Te irományod. AI detto...'Elolvassa' azt a scifi regényt és a 10db másikat, majd csinál belőlük egy harmadikat. Ha nem másolt ki 1:1-ben részeket abból a 11 könyvből, és emelte be a sajátjába, akkor ennyi volt a történet, nincs jogsértés. Lényegtelen, hogy AI olvas vagy ember.
Amibe itt esetleg bele lehetne kötni véleményem szerint, az a nyilvánossághoz közvetítés jogi intézménye. De ott sem azért, mert ellopják a műveket, hanem mert olyan műveket használtak a trenírozásra, melyeknek szerzői nem adtak nyilvánossághoz közvetítési jogot, vagyis, csak akkor olvashatja el egy ember is és egy AI is, ha előtte megvásárol belőle egy példányt. Ennek azonban egészen más a jogkövetkezménye, mint a tartalommal kapcsolatos kvázi lopásnak. Más kérdés, hogy abban a mennyiségben amiben az OenAI felhasznált esetleg ilyen műveket, még a kisebb büntetési tétel is hatalmas lehet. Ezt a képet viszont nagyban éárnyalja, ha a művek elérhetőek voltak nyilvánosan.
-

nuke7
veterán
Egyrészt igen, mi is újrakeverünk, emberek.
Másrészt viszont nekünk vannak/lehetnek új ötleteink az LLM viszont csak azt tudja, amin tanították - nem véletlenül van programozásnál is korlátolt haszna, hiszen nem fogja fel a kontextust, az egész szoftvert majdnem bele kellene táplálnod, hogy aztán valószínűségi alapon kiadja azt a kódrészletet ami neked kellene épp pont... -
#21
 Gargouille
őstag
ddekany
#19
Gargouille
őstag
ddekany
#19
Gargouille
őstag
A gép és az ember közé valóban nem lehet egyenlőségjelet rakni, de szerintem ő nem is ezt mondta. Abból a szempontból, hogy egy alkotás plágium-e vagy sem, teljesen irreleváns, hogy gép vagy ember állította-e elő. Tehát kizárólag a végeredmény tekintetében van egyenlőségjel közöttük, ugyanis egy plagizálás nem attól lesz plagizálás, hogy ki követte el, hanem attól, hogy tényszerűen megállapítható, hogy már egy meglévő alkotás újrahasználatáról van szó. Szerintem ő erre gondolt, én inkább így értelmeztem.
-
Teasüti
nagyúr
Vajon jó ötlet lenne-e bekategorizálni az AI-generált tartalmakat a szerzői jog alá külön az emberi szerzőktől? Esetleg egyenest Public Domain-be tenni mindent, amit egy LLM generál? Vagy esetleg egy GNU-hoz hasonló licenc?
Ha mondjuk egy OpenAI-t nézünk ahol a jogsértés kérdése merült fel, akkor esetleg megoldás lehet-e a sértettek számára vmi olyasmi, mint anno az üres adathordozókra kivetett sarc a zeneipar jóvoltából?Filozófiai/érzelmi alapon már csak ezért sem fog ez menni, mert a legtöbb embernek csődöt mondanak az ilyen ösztönei, amikor ilyen újszerű dologról van szó.
Erről jut eszembe. Önvezető autók kapcsán hogy állnak a filozófusaink az olyan etikai vitákban, mint hogy két végzetes lehetőség közül melyiket válassza a gép? Ha jól emlékszem már vagy 10-15 éves kérdések ezek: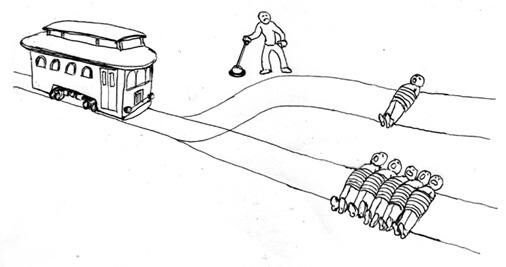 Mert hogy a feltételezés szerint egy AI-nak lesz ideje mérlegelni. Míg ugye egy emberi vezetőnél ez nem probléma abból a szempontból, hogy ott ösztönös választ kapunk abban a három tizedmásodpercben és lesz ami lesz alapon zajlik a dolog. Majd utána a bíróság eldönti egy másfél éves jogszolgáltatás keretében, amit a géptől elvárunk majd még a tragédia előtt.
Mert hogy a feltételezés szerint egy AI-nak lesz ideje mérlegelni. Míg ugye egy emberi vezetőnél ez nem probléma abból a szempontból, hogy ott ösztönös választ kapunk abban a három tizedmásodpercben és lesz ami lesz alapon zajlik a dolog. Majd utána a bíróság eldönti egy másfél éves jogszolgáltatás keretében, amit a géptől elvárunk majd még a tragédia előtt.
Én valahogy úgy tudom elképzelni, mint az Én A Robot c. filmben, ahol azt húzták ki a tóból, akinek több volt a túlélési esélye. -
#8
Gargouille
őstag
ddekany
#6
Gargouille
őstag
"Amúgy végsősoron az zavarja talán leginkább a szerzőket, hogy egyáltalán nem fog kelleni a művük, mert majd valami jövőbeni, mostaninál fejlettebb AI olcsóbban és jobbat írt."
Nagyon jó meglátás, én is ezt érzem mögötte hosszú távon, rövid távon meg azt, hogy most pörög az AI ipar, ömlenek bele a dollár milliók és nagyon szeretnének ők is odaférni a húsos fazékhoz.
-
Teasüti
nagyúr
Tehát akkor a példád szerint egy fizetős oktatás keretében előadó tanárok és professzorok lexikális tudása nem őket illeti, hanem az ő saját képzésük forrásainak szerzőit? Az egyetemet perelhetik azon kutatók és szakértők, akiknek az alkotásaiból specializált tudással felvértezve a professzor egy fizető tanulónak oktatást tart és kérdésekre válaszol?
Nem vagyok szakértője a szerzői jognak a tengeren túl, de nem erről szólna a fair használat elve? Amíg egy jogvédett tartalmat csak részben idéznek be egy önálló gondolat* alátámasztására, addig fair használatról beszélünk. A sajtó is például szabadon felhasználhat szerzői jogvédett tartalmat hírközlési céllal. Ez is fair használat. YouTuber-ek reakció videóiban bevágott szintén szerzői jogvédett tartalmat ugyancsak fair használat.
*Manapság létezik még egyáltalán eredeti/önálló gondolat?






 Mert hogy a feltételezés szerint egy AI-nak lesz ideje mérlegelni. Míg ugye egy emberi vezetőnél ez nem probléma abból a szempontból, hogy ott ösztönös választ kapunk abban a három tizedmásodpercben és lesz ami lesz alapon zajlik a dolog. Majd utána a bíróság eldönti egy másfél éves jogszolgáltatás keretében, amit a géptől elvárunk majd még a tragédia előtt.
Mert hogy a feltételezés szerint egy AI-nak lesz ideje mérlegelni. Míg ugye egy emberi vezetőnél ez nem probléma abból a szempontból, hogy ott ösztönös választ kapunk abban a három tizedmásodpercben és lesz ami lesz alapon zajlik a dolog. Majd utána a bíróság eldönti egy másfél éves jogszolgáltatás keretében, amit a géptől elvárunk majd még a tragédia előtt.Új hozzászólás Aktív témák
Hirdetés


- Peak Design - Everyday hátizsák 15L Zip v2 - éjkék
- National Geographic - Manfrotto fotós hátizsák
- Acer Nitro 5 - AN515 - 15,6"FHD IPS 144Hz - Ryzen 7 5800H - 24GB - 1,5TB SSD - RTX 3060 6GB - Win11
- BOMBA ÁR Új Dell Inspiron 16" Gamer Tervező Vágó Laptop -50% Ultra 7 155H 16/1TB RTX 4060 8GB 2,5K
- ASUS ROG STRIX RTX 4070 Ti SUPER OC Edition 16G (kishibás) videokártya garanciával
- BLUESUMMERS NVMe SSD adapter
- Xiaomi 12T Pro 256GB, Kártyafüggetlen, 1 Év Garanciával
- Apple iPhone 14 Pro / Gyárifüggetlen / 128GB / 12Hó Garancia / 88% akku
- HIBÁTLAN iPhone 14 Pro 256GB Space Black -1 ÉV GARANCIA -Kártyafüggetlen, MS3235
- Gamer PC-Számítógép! Csere-Beszámítás! R5 5600X / RX 7600 / 32GB DDR4 / 1TB M.2 SSD
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft.
Város: Budapest