Hirdetés
- Mini PC
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- Hobby elektronika
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Pánik a memóriapiacon
- Milyen egeret válasszak?
- Nem indul és mi a baja a gépemnek topik
- Azonnali alaplapos kérdések órája
- Xiaomi Mi Box androidos médialejátszó 4K és HDR támogatással
- Milyen videókártyát?
Új hozzászólás Aktív témák
-

P.H.
senior tag
Nem igazán értem, mire gondolsz, a számok valósak.
- a Sandy Bridge egy FPU-val futtat 2 szálat, egy FPU órajelenként 2 128 bites (8 FLOP) vagy 2 256 bites műveletet (16 FLOP) képes végrehajtani, azaz ráerőszakolva a gondolatmenetedet, szálanként 4 vagy 8 FLOP jut.
- a Bulldozer egy FPU-val futtat 2 szálat, egy FPU órajelenként 2 128 bites (8 FLOP) vagy 1 256 bites műveletet (ugyancsak 8 FLOP) képes végrehajtani, azaz a gondolatmenettel szálanként 4 FLOP jut.
Nekem 128 bites végrehajtás mellett ez azonosnak tűnik, nem "fele akkora peak" értéknek, AVX esetén a a Sandy Bridge 2x erősebb. Érdekes, nem érdekes, ez van. Ezenkívül 100 más dolog határozza meg azt, hogy mennyire lehet megközelíteni az elméleti maximumot.
Például K8 és K10.5 egyaránt 2 FLOP/órajel tempóval tudja végrehajtani az x87-es kódokat, mégis ennyi különbség van köztük ugyanannál a kódnál: c1 oszlop az IPC (1.6 vs 2.1), a soronkénti c2/c0 hányados megadja az órajelenként végrehajtott átlagos x87-műveleteket: 0.8 vs 1.05; (itt az alsó a program).Nem azt írták, hogy magonként négyszerezik a számítási kapacitást a K8-hoz képest, hanem FPU-nként.
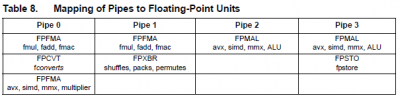
Abból a teljes szövegből lehet tudni, amit #120-ba bemásoltam az Opt. Guide-ból, illetve innen (234. oldal):



Új hozzászólás Aktív témák

- Mibe tegyem a megtakarításaimat?
- Mini PC
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- sziku69: Fűzzük össze a szavakat :)
- Luck Dragon: Asszociációs játék. :)
- Exkluzív órák
- A fociról könnyedén, egy baráti társaságban
- Milyen okostelefont vegyek?
- Hobby elektronika
- Kerékpárosok, bringások ide!
- További aktív témák...

- Xiaomi Redmi Note 12 Pro 5G 128GB, Kártyafüggetlen, 1 Év Garanciával
- HP EliteBook 840 G10 - 14"WUXGA - i7-1360P - 16GB - 512GB - Win11 - MAGYAR - 3 év garancia
- Telefon felvásárlás!! Samsung Galaxy A14/Samsung Galaxy A34/Samsung Galaxy A54
- iKing.Hu - Apple iPhone 14 Stílusos megjelenés, megbízható teljesítmény
- Xiaomi Redmi Note 9 Pro 128GB, Kártyafüggetlen, 1 Év Garanciával
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopműhely Bt.
Város: Budapest