Új hozzászólás Aktív témák
-
#4430
 Petykemano
veterán
solfilo
#4429
Petykemano
veterán
solfilo
#4429
Petykemano
veterán
válasz
 solfilo
#4429
üzenetére
solfilo
#4429
üzenetére
Hm, értem a kérdés élét.
Miért gondolod, hogy az Apple sajátos hardvermegoldás csak akkor lehet fenyegető a hasonló termékkategóriában induló x86 processzorra, ha a végtermék nem Apple márkával jelenik meg? A kérdésedből azt olvasom ki, hogy úgy véled, az Apple és nem Apple termékek vásárlói között nincs átjárhatóság és nem lehetséges, hogy valaki azért vásárolja be magát Apple készülékbe, mert - ha most még nem is , de idővel - objektíve jobb hardvert kap, mint amit más nem Apple gyártóktól kaphatna.
Jól értelek? -
#4428
Petykemano
veterán
Petykemano
veterán
/konkurencia/
Jön nemsokára az Apple M1X
Rocket Lake ~ 5800XUtóbbival kapcsolatban felröppent az a pletyka, esetleg MCM összeköttetésben nagyobb magszámot is tudhat. De lehet, hogy ha igaz is, csupán egy kísérlet, ami nem kerül kereskedelmi forgalomba. Mindenesetre nagyjából ott lenne vele az intel, mint az AMD 2017-ben a zen1-gyel.
Az M1X-szel a Cezanne valószínűleg csak korlátozottan lesz versenyképes.
VAlószínűleg mindkettő konkurens megjelenik jövő év első felében, vagy akár negyedévében.Csak azért mondom, hogy nekem nem tűnik úgy, hogy az AMD ráérne 2 évet (2x14 hónapot) malmozni, virítani kell a zen4-et.
-
#4426
Petykemano
veterán
S_x96x_S
#4415
Petykemano
veterán
válasz
 S_x96x_S
#4415
üzenetére
S_x96x_S
#4415
üzenetére
> https://erik-engheim.medium.com/why-is-apples-m1-chip-so-fast-3262b158cba2
A cikk első részével nem teljesen értek egyet. Mármint azzal persze igen, hogy a hardveres gyorsítók számítanak. Azzal nem, hogy a Dell-nek vagy a HP-nek abban bármiféle szerepe tudna lenni, hogy milyen hardveres gyorsítók épülnek be a termékeikbe. Jó, hozzáteszem, ez úgy igaz, hogy nem tudom, ezek a cégek mekkora tényleges befolyással tudnak lenni a szoftveres környezetre. Merthogy a hardveres gyorsítók kihasználhatósága sokkal inkább ezen múlik, mint azon, hogy a gép összerakója mit álmodik meg. Ha a Dell vagy a HP megálmodik valamilyen hardveres gyorsítót, akkor nem elegendő ARM IP-ből összedobálnia, megterveznie, VAGY megrendelni az AMD-től vagy inteltől. Vagy saját magának kell a szükséges szoftvert is hozzátenni, vagy megkörnyékezni az MS-ot, Google-t, hogy nézzétek, milyen jó lenne, ha.
Az idézetedhez pedig hozzátenném:
- Az ILP növelésében segít az Out of Order execution.
- Minél nagyobb a ROB (Re-order buffer), annál nagyobb a soron kívül, párhuzamosan végrehajtható utasítások száma
- A ROB-ot a decoder eteti "micro-op" utasításokkal.
Így összességében az M1-ben a lényegesen 3x nagyobb ROB-ot egy 2x akkora teljesítményű decoder eteti.És a magyarázatban ez a lényeg:
"This is where we finally see the revenge of RISC, and where the fact that the M1 Firestorm core has an ARM RISC architecture begins to matter.
You see, for x86 an instruction can be anywhere from 1–15 bytes long. On a RISC chip instructions are fixed size. Why is that relevant in this case?
Because splitting up a stream of bytes into instructions to feed into 8 different decoders in parallel becomes trivial if every instruction has the same length.
However on an x86 CPU the decoders have no clue where the next instruction starts. It has to actually analyze each instruction in order to see how long it is.Namost két dolgot nem értek.
Úgy tudom, hogy a az x86 processzorokban belsőleg már valóban nem CISC hanem RISC architektúrák, van egy belső fordító. A legújabb atom magban épp az pláne, hogy valódi CISC x86 végrehajtást csinál és így tud energiahatékony lenni alacsony teljesítmény mellett.
A másik dolog: nem tudom, hogy vajon micro-op cache nem pont ezért van-e?És miért ne lehetne valamikortól olyan x86 processzort csinálni, aminek van fix utasítás hossza. Nyilván egy úgy forgatott program nem futna régi processzorokon. De ez kb egy olyan átállást jelente, mint a 32bit vs 64bit. Egy új processzor nyilván tudna visszafelé kompatibilis lenni.
De vajon az Apple-nél nem kell minden programot újraforgatni? Vagy ha A MS úgy dönt, hogy akkor Arm, akkor nem kell mindent újraforgani?De azzal persze egyet kell értsek, hogy az Apple-nek beépíteni 8-16 magot valószínűleg könnyebb, mint az AMD-nek és az intelnek levezényelni az x86-ban egy ilyen változást.
Ugyanakkor ha ez ennyire triviális, hogyhogy csak az apple-nek jutott eszébe?
Egy választ a másik linked tartalmaz (ez nem az x86 utasítás hossz limitációval magyarázza)
"The answer of wide decode and deep reorder buffer gets much closer than the “tricks” mentioned in tweets. That still doesn’t explain how Apple built an 8-wide CPU with such deep OOO that operates on 10-15 watts.
The limit that keeps you from arbitrarily scaling up these numbers isn’t transistor count. It’s delay—how long it takes for complex circuits to settle, which drives the top clock speed. And it’s also power usage."Ahogy írtad is, az intel már most 5 decodernél jár 10nm-en.
A kommentben a hangsúly a késleltetésen, a tranzisztorok gyorsaságán van. Az 5nm ugye eleve sűrűbb és az Apple mindig is a legsűrűbb libraryt használta. Vajon elképzelhető-e, hogy a 8 decoder beépíte azért lehetséges, mert a sűrű 5nm-en elképesztően rövidek a késleltetések, kicsi a delay.
Ha ez igaz, akkor elképzelhető, hogy az intel és az AMD is képes lesz 5nm illetve 7nm-en előrelépni 5 vagy akár 6 decoder irányába.Az urak is jól elvitatkoztak azon, hogy az M1-gyel az Apple az elmúlt 10-20 év ILP növelhetőségének tudományos kutatását tette zárójelbe.
-
#4414
Petykemano
veterán
Petykemano
veterán
Na, lesz AM5 2021 végén?
-
#4413
Petykemano
veterán
S_x96x_S
#4411
Petykemano
veterán
válasz
S_x96x_S
#4411
üzenetére
"és az M1 után a Nuvia célja már nem is annyira valószínűtlen .."
Igen, természetesen. Főleg, hogy a Nuvia asszem 2022-re ígért terméket.
Ide is bedobom, hogy mennyire lehet játszani a zen3 magok energiahatékonyságával:
[link]
komment itt: [link]tl;dr
A zen3 mag teljesítménye és fogyasztása optimalizálható olyan szintre, amikor már csak ~30% választja el a M1 magjaitól. A zen3 lényegesen nagyobb package powerhez nyilván hozzájárul a 14nm-es IO és az MCM. Majd meglátjuk Cezanne-nal mit tud.az AT fórumon valaki spekulál, hogy mit hozhat a zen4, milyen cache bővítés fér bele, mi az ami már inkább ront a késleltetésen, stb. Felmerül annak lehetősége, hogy az L3$ mérete visszacsökken 16MB-re, és cserébe az 512KB-os L2$ bővül 1MB-ra.
-
#4408
Petykemano
veterán
Petykemano
veterán
[Konkurencia]
M1 postgresql benchmarkElég kemény
-
#4400
Petykemano
veterán
Petykemano
veterán
"AMD today announced that it will bring a technology that should make this processor a lot easier. AMD Precision Boost Overdrive 2 will have a new curve optimizer undervolting that will come with the AGESA 1180 firmware update for AMD 400-series and 500-series motherboards. This tool will allow users to track and adjust voltages for their CPUs. It will opportunistically reduce voltage where possible under heavy load, but also during low use. Instead of relying on a fixed offset for the whole range, it will read the data from internal sensors, such as temperature or socket limits to adapt the voltage when required. This should happen in the frequency of each millisecond."
Azt hiszem én ezt vártam eddig az AVFS-től.
-
#4393
Petykemano
veterán
Cathulhu
#4391
Petykemano
veterán
válasz
 Cathulhu
#4391
üzenetére
Cathulhu
#4391
üzenetére
Szerintem az ábra ellenére ez csak egy koncepció, amit bármelyik szinten be lehet vetni.
Azt nem tudom, hogy érdemes-e csak egy közbülső szinten bevetni? Csak L2 esetén, de L1és L3 esetén nem.De a koncepció azért érdekes, mert a késleltetés romlása elkerülhetetlen.
A zen esetén már az L2 esetén látható, hogy a második szelet 256KB késleltetése rosszabb. Ugyanez igaz a legtávolabbi L3 szeletre.A cache kapacitását növelni kell. Eldöntheted:
1) a cache méretét növeled? Ennek valószínűleg lineárishoz közeli lesz tranzisztor- és fogyasztásköltsége és minél nagyobb/távolabbi a cache szelet, annál inkább romlik a késleltetés.
2) beépítesz egy fixfunkciós tömörítő egységet. Ennek is lesz tranzisztorköltsége és fogyasztásköltsége is és bizonyosan rátesz valamekkora késleltetést is.Tehát mindenképpen lesz tranzisztorköltség, fogyasztás és késleltetés. Az a kérdés, hogy vajon melyik megoldással mennyi a nyereség és mennyi a költség?
Az L4$-ről:
Egyetértek. Ugyanakkor most elgondolkodtam.
A zen3 nagy újítása az, hogy 2db 4magos CCX-et egyesített 1db 8magos CCX-ben ezzel megduplázva az 1 mag számára elérhető L3$ méretét és eliminálva azt a kényszert, hogy 1 CCD-n belül elhelyezkedő CCX-ben levő magok az IOD-on, vagy leginkább a memórián keresztül legyenek kénytelenek adatot megosztani. Ez az elmélet.Egyébként az anandtechnek erre vonatkozóan voltak is mérései:
https://www.anandtech.com/show/16214/amd-zen-3-ryzen-deep-dive-review-5950x-5900x-5800x-and-5700x-tested/53950X vs 5950X
Nagyon szépen látszik, hogy már nem csak 4, hanem 8 mag között zöld a késleltetés.
De ami még érdekesebb, a zöld már nem 30ns-ot, hanem 17ns-on jelent két egy CCX-be tartozó mag között. Ez óriási előrelépés!És akkor a kérdés:
Rendben van, hogy ha ez az óriási előrelépést jelentene egy 6-8 magos generációváltás esetében. De Ha a játékokban tapasztalt intelhez képest gyengébb teljesítményt az inter-CCX kommunikáció okozta (ami ugye a 6-8 magos Vermeer lapkákon megszűnik), akkor miért nem tapasztaljuk ugyanezt a teljesítmény-regressziót az 5900X/5950X esetén, ahol továbbra is van CCX-CCX kommunikáció?Ha innen nézem, nem is biztos, hogy olyan sokmindent megoldana egy hatalmas L4$ az IO lapkán
-
#4390
Petykemano
veterán
Petykemano
veterán
L2$ compression
(zen4?) -
#4379
Petykemano
veterán
Petykemano
veterán
EPYC Milan 2021Q1
-
#4370
Petykemano
veterán
Petykemano
veterán
Egy érdekes szöveg jelent meg a redditen: [link]
mondom a Redditen...zen4 desktop:
- 2022Q3
- 4 x 8c
- DDR5
- L4$ az IOD-ban
- 3300Mhz FCLK (Infinity Fabric 2.0)
- +30-40% IPCAmi érdekessé teszi az ez a mondat:
"[infinity fabric 2:] What it actually is is the culmination of all of our efforts since Zen 1 in architecting a solution to instruction starvation."
" As of now, our total IPC improvement is a staggering 30% - About 4% of this is minor core optimizations and the rest is entirely the result of the IF and memory overhaul."
Mindez a redditen van, úgyhogy senki ne úgy olvassa, mintha Lisa Su kinyilatkoztatása lenne.Viszont 2 év távlatában 5nm-en a 30-40%-os IPC növekedést nem tudok kizárni.
Ugyanakkor nem tudnám az egészet csak egy L4$ számlájára írni, vagy a 2000-ről 3300Mhz-re emelkedő IF órajelre.
Ehhez én azt tartanám szükségesnek, hogy vastagítsák az L1 és L2 cache méreteket is. -
#4364
Petykemano
veterán
Ueda
#4363
Petykemano
veterán
A big.LITTLE, vagy hibrid multithreading szerintem nem elsősorban a magszám növelhetőségét célozza.
Szerintem arról van szó, hogy
1) vannak olyan szoftverek, amik 1 szálon, vagy legalábbis kevés szálon tudnak tudnak csak működni. Viszonylag kevés az olyan szoftver, ami sok magra egyenletesen skálázódik. A játékok egy olyan köztes terület, ahol ügyködnek a több magra való skálázódáson, de mindmáig meghatározó az, hogy a 1-2-3 szálon mennyire erős egy processzor.
2) az IPC növelése jelentős fogyasztás és területigénnyel rendelkezik. (valószínűleg a frekvencia növelése is)És a lényeg: ahhoz, hogy azoknál a programoknál teljesítménynövekedést érjenek el, amik rosszul skálázódnak, az IPC-t kell növelni. De azoknál a programoknál, amik jól skálázódnak a magok számával, nem feltétlenül szükséges az összes szál kezeléséhez magas IPC-jű mag. Azokhoz a programokhoz, amelyek jól skálázódnak, előnyösebb lehet 1 magas IPC-jű mag helyett 2-3 olyan, aminek az IPC-je 30%-kal alacsonyabb, de negyedakkora helyet foglal és negyedannyit fogyaszt.
Tehát a kényszer nem a magszám növelésének irányából jön, hanem az IPC növelés tranzisztor és energia költségeiből, amit azokban az esetekben, amikor több magot ki tud használni egy applikáció, hatékonyságra optimalizált magokkal kompenzálnak.
Nekem úgy tűnik, hogy az intel ezt az utat választotta. Nem állítom, hogy ez a helyes.
-
#4361
Petykemano
veterán
Mumee
#4359
Petykemano
veterán
/konkurencia/
M1
bár az AT deepdive többet mond.
Az apple 2-3x-szoros teljesítménynövekedésről beszél.
Persze várjuk meg a 3rd party méréseket
Meg nyilván persze saját OS-sel könnyű jót csinálni. Meg ott van az NPU is, amire szintén a saját OS meg az egyféle környezet sokat segít, hogy ki legyen használva
Meg 5nm.Na de mégis. Most egy pillanatra tegyük föl, hogy tényleg 2-3x gyorsabb, mint a 2018-as Coffee lake-kel szerelt elődje, pedig azért az is 4 magos i3 volt
Így mérték:
"A tesztelést az Apple 2020 októberében végezte a Mac mini Apple M1 chippel szerelt prototípusain, valamint 3,6 GHz-es, négymagos Intel Core i3 processzorral szerelt sorozatgyártott modelljein. A teszteléshez használt mindegyik modellben 16 GB memória és 2 TB-os SSD-tároló volt. A tesztelés a Final Cut Pro 10.5 kiadás előtti verziójával, egy 55 másodperces, 4096 x 2160 képpontos felbontású, 59,94 képkocka/másodperces sebességű 4K-s Apple ProRes RAW multimédiás anyagot alkalmazó projekt Apple ProRes 422 formátumra való átkódolásával történt. A teljesítménymérések adott számítógépes rendszerek használatával történtek, és a Mac mini hozzávetőleges teljesítményét tükrözik."
[link]
Jó, tehát 2x annyi mag, de azért a maradék az IPC-ből jön. Ráadásul ez csak 3Ghz-es, nem is 3.6.menjünk bele

Ez csak blokk diagram.
De itt látszik:
192KB L1i
128KB L1dEz a zen3 32KB/32KB-jához képest elképesztően sok
12MB L2$ a 4 magnak. Még ha ez az L2$ nem is éri el azt a késleltetést, mint a zen3 512KB L2$-e, viszont a zen2 16MB-os L3$-énél és egészen bizonyosan a zen3 L3$-nél is alacsonyabb a késleltetése. És a magok osztoztak rajta.Ezzel az Apple a leggyorsabb mag címét vindikálja magának.
De még a hatékonyságra optimalizált magok is
128KB L1i
64KB L1D
4MB shared L2$
paraméterekkel rendelkeznek.What really defines Apple’s Firestorm CPU core from other designs in the industry is just the sheer width of the microarchitecture. Featuring an 8-wide decode block, Apple’s Firestorm is by far the current widest commercialised design in the industry. IBM’s upcoming P10 Core in the POWER10 is the only other official design that’s expected to come to market with such a wide decoder design, following Samsung’s cancellation of their own M6 core which also was described as being design with such a wide design.
Other contemporary designs such as AMD’s Zen(1 through 3) and Intel’s µarch’s, x86 CPUs today still only feature a 4-wide decoder designs that is seemingly limited from going wider at this point in time due to the ISA’s inherent variable instruction length nature, making designing decoders that are able to deal with aspect of the architecture more difficult compared to the ARM ISA’s fixed-length instructions. On the ARM side of things, Samsung’s designs had been 6-wide from the M3 onwards, whilst Arm’s own Cortex cores had been steadily going wider with each generation, currently 4-wide in currently available silicon, and expected to see an increase to a 5-wide design in upcoming Cortex-X1 cores.
[link]"A +-630 deep ROB is an immensely huge out-of-order window for Apple’s new core, as it vastly outclasses any other design in the industry. Intel’s Sunny Cove and Willow Cove cores are the second-most “deep” OOO designs out there with a 352 ROB structure, while AMD’s newest Zen3 core makes due with 256 entries, and recent Arm designs such as the Cortex-X1 feature a 224 structure."
[link]"The four 128-bit NEON pipelines thus on paper match the current throughput capabilities of desktop cores from AMD and Intel, albeit with smaller vectors. Floating-point operations throughput here is 1:1 with the pipeline count, meaning Firestorm can do 4 FADDs and 4 FMULs per cycle with respectively 3 and 4 cycles latency. That’s quadruple the per-cycle throughput of Intel CPUs and previous AMD CPUs, and still double that of the recent Zen3, of course, still running at lower frequency."
[link]"We’re measuring up to around 148-154 outstanding loads and around 106 outstanding stores, which should be the equivalent figures of the load-queues and store-queues of the memory subsystem. To not surprise, this is also again deeper than any other microarchitecture on the market. Interesting comparisons are AMD’s Zen3 at 44/64 loads & stores, and Intel’s Sunny Cove at 128/72."
Késleltetések: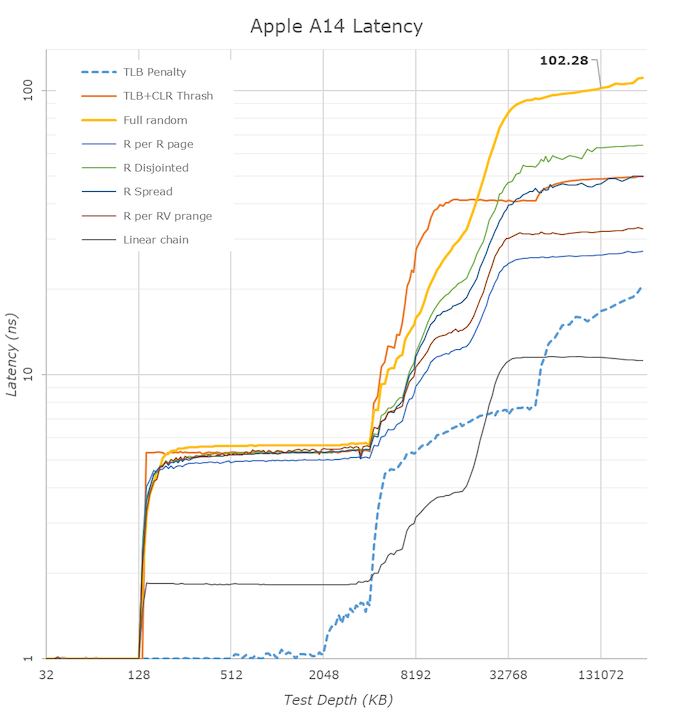
5950X:
A késeltetés az Apple M1 esetén 128KB-ig 1ns
Ugyanez az zen3-nál felugrik 32KB-nál 2-3-ra és ez 256KB-ig kitart. Tehát már a második szelet 256KB L2$ picit lassabb, mint az első. (mivelhogy összesen 512KB van a fedélzeten)Az apple-nél 128KB-től 4MB-ig végig 5ns. Világos, hogy ez a 4MB-os L2$ késleltetése.
A zen3-nál a 256KB-től 1024-ig fokozatosan emelkedik a késleltetés 8ns-ra, onnan 4MB-ig lassabban emelkedve 10ns-ra.
Az tökre világosan látszik, hogy 4MB-ig összességében jobb késleltetéseket nyújt az apple. A zen3 csak a 128KB és 512KB adatméret között ad jobb késleltetést.mindezt úgy, hogy ez csak 3Ghz-es, a zen3 meg 5ghz-es.
A hetekben asszem talán pinkyvel volt egy eszmefuttatásunk, amelyben ő kifejtette, hogy a magszám emelésnek a desktop vonalon semmi értelme és szervereknél is a magszám alapú szoftver licenc árazás eléggé betett annak az elképzelésnek, hogy majd kisfogyasztású, és kis helyigényű, de erős és sok maggal fogjuk megváltani a compute világot. Helyette az IPC növelés tűnik annak az útnak, amivel eladásokat lehet generálni.
Szóval itt van az apple példája. 3Ghz, remek késleltetések. Ha a magszámmal nem lehet nyerni, akkor a mag területigényét el kell engedni.
Jó, persze 5nm
Meg az Apple M1 nem szerverchip, hanem csak egy notebook-minipc. Igazi jó összevetés majd inkább a Cezanne-nal lehet.Nem állítom, hogy csak a hardver vonatkozásában jaj AMD/intel is dooomed. Az Apple most úgy gurított szépet, hogy rajta kívül még senki nem használ 5nm-es gyártástechnológiát. Ez mindenképp előnyt jelent persze. És ha az apple bevásárolja magát a 4 és 3nm-be is, akkor pont ugyanennyi előnyt meg is tarthat a későbbiekben is.
De az biztos, hogy az AMD nem ér rá totojázni a zen4-gyel, hogy humihumi, hát még ráérünk, hát hol az intel. Ilyen imac minit $699-ért bárki vehet, remekül helytállna bármilyen otthoni gépként, amivel történetesen játszani nem akarnak. Apropó, nem tudom, hogy áll az apple a nagyobb gpu-kkal, de mi akadályozná meg abban, hogy ugyanerre a lapkára (esetleg duplaekkára) ne csak munkára használható Mac Prokat készítsen, hanem kifejezetten játékosoknak szánt új termékvonalat?
Nyilván az MSI, meg az Acer, meg a HP nem fognak holnap előhúzni a kalapból egy ARm designt és nem tudnak Apple készüléket sem forgalmazni. És az is igaz, hogy az Apple-ön kívül nem biztos, hogy bárki más tudna 5nm-en gyártatni.
De szerintem azért kell iparkodni!És akkor még nem is beszéltünk a zárt ökoszisztéma előnyeiről. Tehát az AMD-nek és az intelnek extra/ingyen szilikont kellene áldozni arra, hogy rápakoljanak a procijaikra minimum gpu-t, de akár FPGA-t, vagy NPU-t is. Az apple ezzel élni fog nyilván. X86-on meg semmi elterjedtsége nincs.
-
#4360
Petykemano
veterán
Mumee
#4359
Petykemano
veterán
És lesz félidős refresh is.
Bár nem nevezte Warholnak. És a matisse 2-t sem nevezték annak hivatalosan.Nem fura, hogy még szinte meg se jelent és már erről beszélnek? Nem félnek az Osborne hatástól? Épp most üzenik: nem életbevágó a zen3/RDNA2-be beugrani, nyugodtan várd meg a következőt, az még jobb lesz.
-
#4354
Petykemano
veterán
Petykemano
veterán
-
#4350
Petykemano
veterán
Cathulhu
#4348
Petykemano
veterán
válasz
Cathulhu
#4348
üzenetére
A ps4 és ps4 pro cpuja 100-130gflops teljesítményt tudott.
Az AT mérései alapján az ps4 megjelenésekor már elterjedtnek mondhat 2500k is legalább másfélszer nagyobb cpu teljesítményt jelentett. Single threadben 2x is
[link]Tehát a ps4 megjelenésekor az elterjedt mainstream cpuk erősebbek voltak, mint a konzol CPU.
Ennek köszönhető az, hogy sok esetben egy mai 4/8 elegendő lehet egy játékra. És ennek köszönhető az is, hogy 8 teljes értékű magnál többet felvonultató CPU esetén nagyítóval kell keresni az előnyöket. Mert 7-8 mag a target.Én azt mondom, hogy 2-3 év múlva a 4/8, a 6/6 esetén biztosan és talán a mai 8/8 és 6/12 magos cpuk esetén is enyhén érezhető lesz, az a fajta lemaradás, amit ma a 2/4, 4/4 cpuknál tapasztalunk.
Azt senki nem mondja, hogy egy 8/16-os, későbbi generációs 8/8, 6/12 ne Lehetne elég a játékra,de ugyanolyan belépőszintnek fog minősülni, mint ma a 4/8.
-
#4328
Petykemano
veterán
BiP
#4323
Petykemano
veterán
Lehet, hogy mást gondolunk most a 16 magról, vagy más gondolunk arról, hogy Mit fogunk gondolni 2-3 év múlva.
Te ezt írtad:
"Az 5950x 16mag,32szál desktopra már tényleg olyan, hogy nincs játék, vagy hobbi otthoni felhasználás aminek több kell"
És hogy nem hiszed, hogy a 8 3GHz-es zen2 magtól változna a játékok CPU igénye. Nem tudom ezt jól értem-e? Vagy úgy értetted, hogy a játékok CPU igénye ha növekszik is, nem fog túlmenni a 16 magon (ezzel mondjuk egyet tudok érteni) és ha egy játék CPU igénye meg is ütné a 16 magot (most itt persze nem a minimum követelményre kell gondolni), akkor se, más alkalmazás (hobbi) végett se fognak 16 magnál többet kínálni desktop termékvonalban (AM5)Én azt gondolom, hogy ma egy 5600X vagy 5800X >megfelelően elég a játékokhoz<. A 12-16 magos változat a desktop >prémium<, azt a játékok nem indokolják, de otthoni hobbi felhasználásra elegendő.
A véleményünk talán abban különbözik, hogy szerintem a konzolok 4-5x-ös CPU teljesítménye fel fogja vinni pcn is a követelményeket és 2-3 év múlva a konzolokkal ekvivalens 6-8 mag inkább a belépő szint lesz és a konzoloknál erősebb 12-16 mag lesz a >megfelelően elég a játékokhoz<. (Ebben talán egyetértünk?) Viszont szerintem ha a 12-16 mag lesz már a mainstream, akkor is lesz majd egy >prémium< 24-32 maggal.
-
#4320
Petykemano
veterán
BiP
#4319
Petykemano
veterán
Az elképzelhetetlen, hogy a konzolok cpu teljesítményében bekövetkezett 3-4x-es gyorsulás ( [link] ) miatt 2-3 év múlva drasztikus hatással lesz arra, hogy milyen lesz a játékok CPU teljesítmény követelménye és hogy mit fogunk gondolni egy 16 magos prociról?
Mondjuk erre még mindig jelentős hatással lehet, hogyha teret veszít a kliensoldali játékfuttatás a cloud javára. Mindkét konzolgyártónak van valamilyen cloud szolgáltatása. Idővel dönthetnek úgy, hogy a következő generációs konzol cloud only és kapsz egy low power vékonyklienst.
-
#4318
Petykemano
veterán
Petykemano
veterán
-
#4317
Petykemano
veterán
Cathulhu
#4316
Petykemano
veterán
válasz
Cathulhu
#4316
üzenetére
Lehet, hogy igazad.van, ám abu a nyáron még arról cikkezett, hogy 5 és 3nm-en is dupláz az AMD. De a roadmapek persze változhatnak. A warhol beékelődése például nehezen illeszkedik abba, amit 14-15 hónapos kiadási ciklusok alapján várunk.
Amúgy persze mind a desktop, mind a szerver magszámmal kapcsolatban igazad van, utóbbinál cikk is született arról, hogy inkább az alacsonyabb magszámú termékekre van nagyobb kereslet. A SzerverMérnök szerint azért, mert a cégek a biztonsági parák miatt átálltak 7 helyett 3 éves csereciklusra. 3 évre meg nem éri meg drága, magas magszámú procit venni. Az alacsonyabb magszámú termékeken viszont vékonyabb a marzs, ezért csökkent az Intel marzsa. És ugyanez miatt jön az abu által emlegetett kicsi Epyc.
És ha ez igaz,.akkor valóban lehet vonzóbb egy 24 magos, ami jövőre 15 helyett 25%-kal nagyobb IPCt hoz, mint ha 48 magos lenne, amire a licenc is drágább.
Hát majd meglássuk.
-
#4315
Petykemano
veterán
Petykemano
veterán
-
#4298
Petykemano
veterán
yagami01
#4297
Petykemano
veterán
válasz
 yagami01
#4297
üzenetére
yagami01
#4297
üzenetére
A Warhol egy kakukk tojás.
Én egyaránt elképzelhetőnek - ám merésznek - tartom azt, hogy a Warhol egy filler a Vermeer és a Raphael között, ami az IOD-on javít, cserébe mondjuk valamivel hamarabb jön a szokásos 14-15 hónapos ciklusnál. Hasonlót láttunk már: zen+. A zen és zen2 közözz ugye több idő telt el.
Ha ez így lenne, akkor elképzelhető, hogy a Warhol még mindig AM4-be érkezzen.De azt is elképzelhetőnek tartom, hogy a Warhol már AM5 lesz és a Ryzen 6000 felső szintjét töltik csak fel zen4-gyel, az alsó szint zen3-as Warhol. Ha nem lennének pletykák arról, hogy a az 5000-es szériában egyaránt lesz Renoir és Cezanne, akkor persze ezt a lehetőséget elképzelhetetlennek tartanám. De így...
Nincs szó SMT4-ről.
Szerintem 4-gyel nem tudják növelni a magszámot. 8 magos most egy CCX. Ezt valószínűleg egy pár évig megint nem piszkálják. Az a kérdés, hogy a zen4-es CCD-be 1 8 magos CCX kerül, vagy 2, vagy bevetnek valamilyen speciális 3d tokozást .
-
#4289
Petykemano
veterán
Petykemano
veterán
Zen4 találgatások:
"I expect that Zen4 is very similar project to Zen2. It will widen the FP and L/S by 2x, add (most likely) 2x the cores per chiplet. I hope that AMD will go Zen3 route with regards to CCX and share a huge pool of (64MB?) L3 cache among 16 Zen4 cores. Similarly to Zen2, I think they will aim at around 15ish% IPC jump versus Zen3 - this would leave Zen5 with very optimistic (but obviously achievable) target of ~21% IPC improvement coming from Zen4, if they were to keep the 40% increases between their "tocks" (EX->Zen1; Zen1->Zen3 ; Zen3->Zen5?).
There are some rumors of further chiplet design evolution and some possible massive (L4?) caches, new memory controller + DDR5 support, shrinking of the IOD etc. Zen4 definitely looks like the next big core count increase and a major platform update."
[link]
"It will get difficult to scale the cache size larger without increasing latency. Some form of L4 may be more likely. I don't think they are going to jump to a 16 core CCX right after going to an 8 core. It may be possible that they would make a 16-core chiplet with 2 CCX on one die. I expect Zen 4 to be very similar to Zen3. Zen 3 is a new architecture, so I don't think we will see huge changes to most of the functionality. Using stacked chips allows for much higher bandwidth, so I wouldn't be surprised to see internal pathways widened significantly and much increased FP performance. Stacked chips can easily use 1024 bit links; a single HBM stack is 1024-bits, so I am wondering if internal paths will actually go up to 1024 bits to match."
[link]
"Here is some speculation. Due to recent AMD's graphics reveal and infinity cache, and that zen arch was inspiration for it, I think that zen4 could have L4 cache.
So CCD would have two octacore CCXes, each having its own 32MB L3 cache, both connected to CCD wide 64 MB L4 cache.
This way you get to reuse zen3 topology, but also save on latency. Also, cache, or to be more precise, SRAM is getting "cheaper" on smaller nodes.
I am not EE, so this could be nonsense, but thought it could sprout some discussion."
[link]
Az FP teljesítmény növeléssel egyetértek. Logikus volna, ha megint dupláznának és ezzel megérkezne az AVX512 támogatás is.
Azzal is egyetértek, hogy logikus lenne, ha 5nm-en duplázódna az egy CCD-ben elhelyezett magok száma. Viszont ezt egyelőre csak úgy tudom elképzelni, hogy 2 CCX kerül megint 1 CCD-be.A megvalósítás viszont kérdéses. Az eléggé tradícionális lenne, ha tényleg hagyományos módon csak simán bekerülne 2 8magos CCX 1 CCD-be, pont úgy, ahogy a zen1-2-nél volt. Miért csinálnának ilyet? Miért tennék egybe? Túl kicsi lenne 1 CCX-szel a lapka?
Másrészről ott vannak az advanced 3d tokozások.Én L4$ vonatkozásában hasznosabbnak gondolnám, hogy ha nem 2 8magos CCX-et kötne össze, hanem ha az IOD-ra kerülne és az összes CCX-et összekötné. Persze az elég nagy helyet igényelne. Pl: 128MB-os Infinity Cache 7nm-en 86mm2 lenne.
Pl desktop esetén a jelenlegi 12nm-en készülő Matisse IOD 125mm2. Ha ezt a zen4 esetében levinnék 7nm-re, akkor biztos csökkenhetne a mérete mondjuk 80-90mm-re (nem számolva persze azzal a lehetőséggel, hogy a DDR5 és PCIe5-nek milyen helyigénye van) ha ehhez hozzátennénk még a 128MB-os oo$-t akkor egy 160mm2-es IOD jönne ki. Ezzel ha a zen4 esetén továbbra is 8 magos CCX-eket 32MB L3$ köt össze, akkor kezelni lehetne 4CCX-et is.Ami a találgatásból fájóan hiányzik nekem az a Warhol.
Ami ugye még mindig zen3. És nem tudjuk a célját. Már a múltkor is pedzegettem azt kérdést, hogy a oo$-nek lehet-e köze a Warholhoz.Egy olyan lehetőséget például elképzelhetőnek tartok, hogy a Warhol egy olyan fejlesztés, aminek az IOD-ja már 7nm-en készül és rendelkezik mondjuk 64MB oo$-sel (ezzel nagyjából méretkompatibilis maradna a Matisse IOD-jal) és továbbra is ki tudná szolgálni az alapvetően zen3-as CCD-ket. (zen3+?)
-
#4281
Petykemano
veterán
Petykemano
veterán
-
#4272
Petykemano
veterán
Petykemano
veterán

A navi21-ben bemutatkozott infinity cache, ami ahogy a képen látható, egyrészt körülöleli a lapkát, másrészt az IF és a Memória vezérlő között helyezkedik el.
Navi21:
128 MB Infinity Cache = ~86.6 mm² = 1.48 MB/mm²
zen2 CCD:
32 MB L3$ = ~33.4 mm² = 0.96 MB/mm²Mi a valószerűsége/valószínűsége annak, hogy ez megjelenjen ha máshol nem is, de az EPYC IO lapkáján?
Mondjuk ha az IO lapkát 7nm-en gyártanák akkor 256MB infinity cache-sel a fedélzeten talán még mindig elférnének 450mm2-ben, nem?
-
#4263
Petykemano
veterán
Petykemano
veterán
Sisoft
5600X
"Overall the 6-core Zen3 is only about 16% faster than the old Zen2, as it can cannot rely on much faster Turbo as we’ve seen with its other siblings. While we may have hoped for more, the XT Zen2 have too good performance rather than Zen3 not improving enough."Executive Summary: Zen3 (6-core) is ~15-40% faster than Zen2 across all kinds of algorithms. Thus we’ll give it 9/10.
5800x
"We previously saw Zen2 40% faster than Zen+ and now Zen3 is a similar 40% faster than Zen2: in effect for the same number of cores (8C/16T), Zen3 is 2x faster than Zen+! Simply astonishing!""Executive Summary: Zen3 is ~25-40% faster than Zen2 across all kinds of algorithms. No choice but give it 10/10 overall!"
-
#4254
Petykemano
veterán
S_x96x_S
#4251
Petykemano
veterán
válasz
S_x96x_S
#4251
üzenetére
Hmm
Smart.Access ide vagy oda, a fusion lényege az volna, hogy nem csak közös címtérben dolgoznak, hanem tényleg közös memóriát használnak és se pcie-n keresztül, ad absurdum se memóriában nem kell másolgatni a feldolgozandó adatot."Full Access to gpu memory"
Arra utal, hogy a CPU úgy fogja látni a gpu memóriáját, mintha egy másik memory pool lenne.A sebességnövekedés.ott érhető tetten, hogy a gpunak alacsonyabb késleltetéssel fognak rendelkezésére állni az adatok, amiket a CPU feldolgozás/előkészítés után máskülönben a rendszermemóriában tárolna.
Szóval ez arra jó, hogy ha valami alapvetően a gpun fut, akkor annak alá tud dolgozni a CPU. Ez a CDNA esetében is szerintem kifejezetten hasznos lesz
Sőt, bármihez jó, ami valami gyorsítón.fut, akár gpu, akár fpga.De azt nem látom.ebbe bele, hogy ezzel megvalósítható lenne az AVX512 utasítások offloadolása.
De az irány persze mindenképp a heterogén feldolgozás, és azt értem, hogy ezzel egy programban meg lehet majd mondani, hogy egy parancs egy adathalmazon min fusson (vagy akár adattípustól függően automatizálni is lehet) csak én még azt nem értem, hogy egy-egy utasítást kiszervezése lehetséges-e egyáltalán.
-
#4243
Petykemano
veterán
Cathulhu
#4242
Petykemano
veterán
válasz
Cathulhu
#4242
üzenetére
hát igen, csak azért a Xilinx tulajdonosainak (bárki is volt) el kellett fogadnia az AMD részvényt fizetségként - nyilván abban a reményben tették ezt, hogy az AMD részvény
- magasabb tőkejövedelmet biztosít (függetlenül attól, hogy azt osztalék vagy részvényérték formájában teszi)Igazából azt nem tudom, hogy miért kellett felvásárolni.
- olcsóbb lesz így a wafer?
- ha feltételezzük, hogy a biznissz megy tovább, akkor az egy pontra fókuszálható fejlesztési kapacitás ettől nem lesz több, mert más üzletben utaztak együtt.
- A szinergia magasabb lesz, mintha külön cégként teszik össze amijük van?
- ellenséges kivásárlás megakadályozása?Kiváncsi vagyok, mire fogják használni az FPGA-kat, amihez a felvásárlás szükséges vagy érdemes volt.
-
#4241
Petykemano
veterán
S_x96x_S
#4240
Petykemano
veterán
válasz
S_x96x_S
#4240
üzenetére
"Revenue was $2.80 billion, up 56 percent year-over-year and 45 percent quarter-over-quarter driven by higher revenue in both the Enterprise, Embedded and Semi-Custom and Computing and Graphics segments."
Tényleg megjelent náluk az inteltől hiányzó $1mrd.
"Computing and Graphics segment revenue was $1.67 billion, up 31 percent year-over-year and 22 percent quarter-over-quarter."
"Enterprise, Embedded and Semi-Custom segment revenue was $1.13 billion, up 116 percent year-over-year and 101 percent quarter-over-quarter." => EPYC v konzol?
"For the fourth quarter of 2020, AMD expects revenue to be approximately $3.0 billion, plus or minus $100 million, an increase of approximately 41 percent year-over-year and 7 percent sequentially."
-
#4206
Petykemano
veterán
S_x96x_S
#4205
Petykemano
veterán
válasz
S_x96x_S
#4205
üzenetére
Itt két lazán kapcsolódó dologról beszélünk.
Az egyik a 7nm-es wafer ellátás
A másik pedig Charlie féle TCO, költségGondolataim:
1) chiplet IO
Ha jól emlékszem, a Rome IO die egyik jellegzetessége és hiányossága volt, hogy egy core nem tudja egyszerre minda 8 DDR4 csatornát használni, csak 2-t, azt, amelyik az IO lapka hozzá legközelebbi kvadránsában helyezkedik el. Ha ezt nem oldották fel, akkor nagy IO lapka helyett MCM módon raknak le IO lapkákat. A spórolás ott jön, hogy mindegyik sku-ra annyit raknak, amennyi ott szükséges.
Ennek persze akkor szerintem kevés jelentősége van, ha továbbra is 12/14nm-es IO lapkákat használnak. Bár annak is van egy ára ($20-100), de az így megspórolható összeg eladott EPYC chipenként pont ez a $50 körül van és nem is igazán segítene az ellátáson, csakis akkor , ha egyébként a Milan 7nm-es IO lapkával jönne.
A 7nm-es IO lapka egyébként indokolt - a fogyasztás miatt és esetleg a magas IF clock végett.
Namármost a chiplet IO azért nem hülyeség, merthogy ugye valójában a X570 chipset egy pont ugyanolyan IO lapka volt, mint a procik melletti, tehát tudnak kommunikálni egymással.2) kicsi EPYC
Forrest Norrod az egyik interjúban valami ilyesmit mondott, a TCO-ban nem a CPU ára a legmeghatározóbb, hanem a CPU teljesítménye. CPU-d hibahatáron túl, mondjuk 20%-kal erősebb a konkurenciánál, akkor a TE CPU-dból a vásárlónak kevesebb pont azzal a 20%-kal kell kevesebb szervert kell építenie, ami annyival kevesebb alaplapot, házat, memóriát, háttértárat, és helyet, hűtést igényel.
Ez alapján a kicsi EPYC ereje (mármint TCO szempontjából) nem abban fog megmutatkozni, hogy az IO lapka kisebb és ezért olcsóbban adható, hanem leginkább abban, hogy az egész platform lényegesen olcsóbb lesz - mintha ugyanazt olyan platformon adnák kevesebb maggal, ami a legütösebb sku-t is ki tudja szolgálni.Ha a kettőt összeteszem, akkor az jön ki belőle, hogy tudnak úgy kicsi EPYC platformot építeni, hogy nem kell egy köztes IO lapkát tervezni, mert össze lehet rakni két olyan IO lapkát, ami amúgy az AM4 platformra megy.
-
#4203
Petykemano
veterán
Petykemano
veterán
"AMD is also releasing its Radeon RX 6700 series, but not this month. The RX 6700 series will feature Navi 22 GPU. According to our sources, AMD has recently decided to launch these GPUs quicker than previously planned. The current plan is to launch them in January."
[link]
Akkor olyan nagy hiány csak nem lehet. Vagy januárra tényleg elmúlik. -
#4201
Petykemano
veterán
awexco
#4200
Petykemano
veterán
-
#4199
Petykemano
veterán
Petykemano
veterán
- AMD will talk in Nov about Zen 3 for servers
- please be prepared for a surprise
- Milan is divided in low-end and high-end
- low-end Milan not all/full based on TSMC 7nm
- reason: limited 7nm capacity at TSMCHanem vajon mi?
A samsung is gyárt Zen3 chipletet?
Vagy a GF12nm-en is készülne?
Valami backport?
Vagy erről szóltak az AMD-TSMC 5nm-es pletykák és már egyenesen 5nm-en készülne? De miért pont a low-end Milan?Vagy ez csak az IO lapkára vonatkozik?
High-End Milan => 7nm IO
Low-End Milan => 12nm IO
? -
#4193
Petykemano
veterán
awexco
#4192
Petykemano
veterán
Igen, azt kellett volna:
Sandy Bridge - architektúra
Ivy Bridge - node: 22nm
Haswell - architektúra
Corewell - ugrás 6 magra
Broadwell - node: 14nm
Skylake - architektúra
Kaby lake - ugrás 8 magraPersze világos, hogy azért sem lépegettek magokkal, mert igyekeztek minimalizálni a lapkaméretet. Részben a marzs miatt, meg a kapacitás. Mondjuk ennek némileg ellentmond, hogy közben meg több magnyi méretű IGP-t benne hagytak - sokszor feleslegesen, csak a részesedésért.
Arm:
The end is nigh -
#4191
Petykemano
veterán
awexco
#4190
Petykemano
veterán
Az csodálatos a zen3-ban, hogy miközben az x86-ot ugye temetjük és éljen az ARM, azonos node-on látható fogyasztásnövekedés nélkül értek el tekintélyes IPC növekedést. Legalábbis jelenleg így tűnik. A lapka méretéről nem tudunk semmit, tehát lehet, hogy tranzisztorköltsége volt, de ez nem jelentkezik a tranzisztorbüdzsé növekedésével arányos fogyasztásnövekedéssel.
-
#4189
Petykemano
veterán
awexco
#4187
Petykemano
veterán
AVX512
SMT4
Természetesen. 😃Zen4 = 2db zen3 mag összeolvasztva.
8 ALU
😃Semmi konkrétumról nem olvastmam.
Én azt gondolom, kell haladni az utasításkészlettel. AVX512, AMX irányba. De ez szoftveres kérdés is. Ha kitudják offloadolni ezt CU-kra, az is megoldás. Talán ezért van zöld navi blokk a Raphael alatt a roadmapen.A vastagabb backendben nem hiszek egyelőre. Mark papermaster azt nyilatkozta, a zen3 teljes újratervezése a zen mikroarchitektúrának. Ilyenkor a low hanging fruitokat szokták leszedni. Azt nem tudom, hogy egy új alu, vagy ilyesmi az annak számítana-e. Mivel a zen4 5nm-en készül, én elsősorban regiszterek és cachek növelésére számítanék.
-
#4188
Petykemano
veterán
Devid_81
#4186
Petykemano
veterán
válasz
 Devid_81
#4186
üzenetére
Devid_81
#4186
üzenetére
Hát fogalmam sincs.
Ahhoz vmi új technológia kellene szerintem. Az Intel is csak 10 magig.ment a ring busszal.
Azt nem tudom, az AMD mit használ 8 mag összekötésére. A probléma ugye az, hogy milyen messze vannak egymástól, hány ugrásra, a magok. Ha meg sok az összeköttetés az meg nehéz, meg fogyasztás... mittomén.Adoredtvnek volt egy érdekes videója, valami butterfly, hogy mi a Legjobb topológia összekötni chipleteket aktív interposerrel.
Amit én lehetséges útnak látnék erre az a 3d tokozás. Nem tudom, megoldható-e azzal, hogy a vertikálisan egymás alatti magok kommunikálni tudjanak egymással.
Persze akkor meg a hőtermelés...A ccx-ben levő magok számának növelése előbb utóbb nyilván muszáj lesz, nem maradhat örökkön örökké a 8 mag/ ccx
Én mégis azt gondolom, hogy előbb az jön - 5nm-en -, hogy két 8magos CCX egy CCD-be.
De aztán ki tudja?
-
#4185
Petykemano
veterán
awexco
#4184
Petykemano
veterán
Igen, azt is megtehetik, hogy az AM4-et és AM5-t egy generációra párhuzamosan futtatják úgy, hogy az AM5-be csak 16-24 magos zen4 procik érhetők el, viszont csinálnak (8-12 magos) zen4 sku-t AM4-re is, hogy elvigyék a gaming benchmark pálmát, miközben az AM4 eladások java továbbra is zen3.
-
#4182
Petykemano
veterán
awexco
#4181
Petykemano
veterán
"Lényegében Picit visszatáncolt az amd a monolitikusabb kevesebb ccx-ek felé"
Azt nem hiszem, hogy látnánk az AMD-től újra olyan monolitikus lapkát, amiben 2-nél több CCX van.Próbálok óvatosan fogalmazni, mert ki tudja, mi jön legjözelebb (Vermeer -> Warhol -> Raphael ?) és mikor (Warhol lesz-e a 14 hónap múlva esedékes termék, vagy a Warhol egy köztes termék és 14-15 hónap múlva 5nm-en zen4 jön?)
A szóbeszéd alapján az átlag felhasználónak nem hoz sokat a DDR5 a konyhára. Tehát ott lehet érdemes bepróbálkozni vele, ahol nem csupán kivagyiság miatt lehet eladni, hanem tényleg haszna van, még ha a felhasználói réteg szűk is.
Én azt gondolom, GB/s / core arány alapján, hogy akár már 16 magos zen3-mal el lehetne adni DDR5-öt. Mármint például ha történetesen a Warhol egy olyan fejlesztés lenne, ami DDR5-öt (AM5) hozza el. Mondjuk mennyi lehet jövőre majd 32GB DDR5 RAM $300-400? Az nem fér el egy $800-os proci mellett? Nem mondom, hogy ez lesz, csak azt, hogy szerintem eladható lenne úgy, hogy tudjuk, hogy ha mainstream teljesítmény kell, akkor ez a csúcs.
És ugyanez érvényes a Threadripperre is főleg a 64 magosra.
Az AMD-nek egyvalami tehet keresztbe, hogy ezeket bevezesse: saját maga.
Nem jöhet DDR5-ös TR, amíg azt meg nem előzi a DDR5-ös EPYC
és nem jöhet DDR5-ös csúcs AM5 proci, amíg azt meg nem előzi a TR DDR5-re frissítése -
#4174
Petykemano
veterán
Mumukuki
#4172
Petykemano
veterán
válasz
 Mumukuki
#4172
üzenetére
Mumukuki
#4172
üzenetére
Én 1700X-et vettem 1600X helyett azért, hogy majd később is jó legyen.
3 év telt el és egy zen3 viszont ~70%-kal jobb ST teljesítményt tud, még egy 6 magos zen2 is lenyoma MT-ben, nemhogy egy zen3.Ha a hosszútávra tervezésnek a jövőállóság a célja úgy, hogy ma nem biztos, hogy ki tudod használni, akkor lehet, hogy nem érdemes megreszkírozni a ma még kihasználatlan drágábbat abban a reményben, hogy majd a jövőben jól fog jönni.
3 év múlva mainstream (remélhetőleg ~$300-400) lehet olyan cpu, ami 30-40%-kal magasabb ST teljesítménnyel rendelkezik 12 (szélsőséges versenyhelyzetben akár 16) maggal.
-
#4167
Petykemano
veterán
awexco
#4165
Petykemano
veterán
"Ezért" - miért?
Az optimista magyarázatok szerint azért lett drágább a zen3 desktop, mert
- átvette az elsőséget és azért prémium marzs jár
- szűkös a 7nm-es gyártókapacitásAmi érthető, mert ezen készülnek a PS5, XSX, XSS lapkák, zen2, zen3, RDNA1, RDNA2, Renoir lapkák is. És ugye a konzol, meg az adatközpont (Epyc Rome, Epyc Milan) bizonyosan előnyt kap. Állítólag ha majd az Apple lekopik a 7nm-ről, meg ha majd lefut a konzol első hajtása, jobb lesz.
Sokan fel vannak háborodva egyébként ezért a név-választásért.
Azért lett 5000 a Vermeer, hogy ne keveredjen össze a vásárló, hogy a 4000-es Renoir még zen2, a 4000-es Vermeer meg már zen3, de közben meg jön pár hónap múlva az 5000-es Cezanne, ami szintén zen3. Rácsúszott a zen desktop a mobilra, úgy is mondhatnánk.
De ha ezért ugrasztották, akkor az önlábonlövés. Jó, persze a átlagJoe semmit nem fog érteni belőle. Azért vicces lesz, hogy a 5400U-nak a ST teljesítménye jobb, mint az 5700U, (ami egy rebranded 4800U)Fura
-
#4163
Petykemano
veterán
Petykemano
veterán
Azt mondják, a Cézanne túl nagy. Azért kell csak, hogy megnyerjék a benchmarkokat, de eladni nem Szeretnék.
-
#4161
Petykemano
veterán
Petykemano
veterán
"Cezanne 6-core 😋
2.3GHz base, 4.2GHz boost
7 CU @ 1.8GHz
10-25W TDP"
[link] -
#4133
Petykemano
veterán
S_x96x_S
#4132
Petykemano
veterán
válasz
S_x96x_S
#4132
üzenetére
Az új celeronokba és pentiumokba nyomja bele, amik fél éven belül megjelennek.
De az nem fog fél éven belül akkora penetrációt elérni, hogy a fejlesztők - maguktól - foglalkozzanak vele.De ha elérhető a hardver és elkezdik benyomni a játékokba meg más szoftverekbe is, akkor arra jó öszönző lehet, hogy újítsál és persze intelt vegyél, mert az AMD elavult.
Kicsit sajnálom, hogy AVX-512-re épít az intel, ahelyett hogy megcsinálta volna rendesen úgy, mint a SVE, hogy bármilyen proci jó, de az erős procikba vastag feldolgozót teszünk, az atomokba vékonyat.
-
#4113
Petykemano
veterán
solfilo
#4112
Petykemano
veterán
válasz
solfilo
#4112
üzenetére
Nem csak arra kell odafigyelni, hogy egy benchmark mekkora cache méretbe fér bele, amely esetben drasztikus (irreális) gyorsulás következhet be.
Hanem ennek megfelelően arra is, hogy egy-egy benchmark meddig terhelheti a procit. Az órajelet és hozzá a Tau időtartamát érdemes úgy meghatározni, hogy a tesztekben legkedvezőbben szerepeljen.
fél perc 4x-es túlhasználat egy 65W-os és eképp hűtött proci esetén talán még nem jármeltdownnalthrottlinggal.Persze korántsem szeretnék egyoldalúan cinikus lenni, ezzel mindenki játszik és meg is van a magyarázat rá: a felhasználók többsége impulzusszerű igénybevételnek teszi ki a gépet. Megnyit egy programot, lefuttat valamit.
-
#4104
Petykemano
veterán
.Ishi.
#4097
Petykemano
veterán
-
#4099
Petykemano
veterán
Petykemano
veterán
5950X
GB52000-es ST score-ral szépen átvette a vezetést.
Megtalálnató a top menüpontban is.Érdekes, hogy eddig csak 1400 körüli eredményeket tudott hozni. És most mekkora ugrás lett. Pedig a cacheéretek nem változtak, tehát elvileg nem arról van szó, hogy a benchmark befér a cachebe.
Érdekesség még, hogy a GB imacpronak ismeri fel.
Persze van teszt imacpro névvel 3900X-zal is.
Nen biztos, hogy ez azt jelenti, hogy az Apple amd cpura váltott. Bár indokolt volna. -
#4090
Petykemano
veterán
.Ishi.
#4089
Petykemano
veterán
Én kétlem, hogy a 4000 széria még bővülni fog.
Közben lassan már érkezik a Lucienne és a Cezanne.
Amit nem értek az az, hogy van egy pletyka, amely szerint az 5600U és 5800U Cezanne lesz (zen3), míg az 5500U és 5700U Lucienne.Namost a Lucienne nem lehet 4 magos, mert akkor nem lehetne 5700U
VAjon ennek mi értelme lehet?
Vagy valaki téved és nem Lucienne, hanem VanGogh.
Annak esetleg lenne értelme, hogy
5800U 8 erős cpu, 8 gyenge gpu
5700U 8 erős gpu, 8 gyengébb cpu
5600U 6 erős cpu, 6 gyenge gpu
5500U 6 erős gpu, 6 gyengébb cpu -
#4082
Petykemano
veterán
awexco
#4081
Petykemano
veterán
Akkor azt mondod, hogy a 3Ghz-es A13 1.5*x IPC-vel GB5-ben lehet, hogy jó eredményeket ad, de elvérezne mondjuk egy játékban egy x IPC-vel rendelkező, de 4.5Ghz-en ketyegő procival szemben?
Ebben lehet valami.
ÉRdemes ezekre az ábrákra vetni egy pillantást: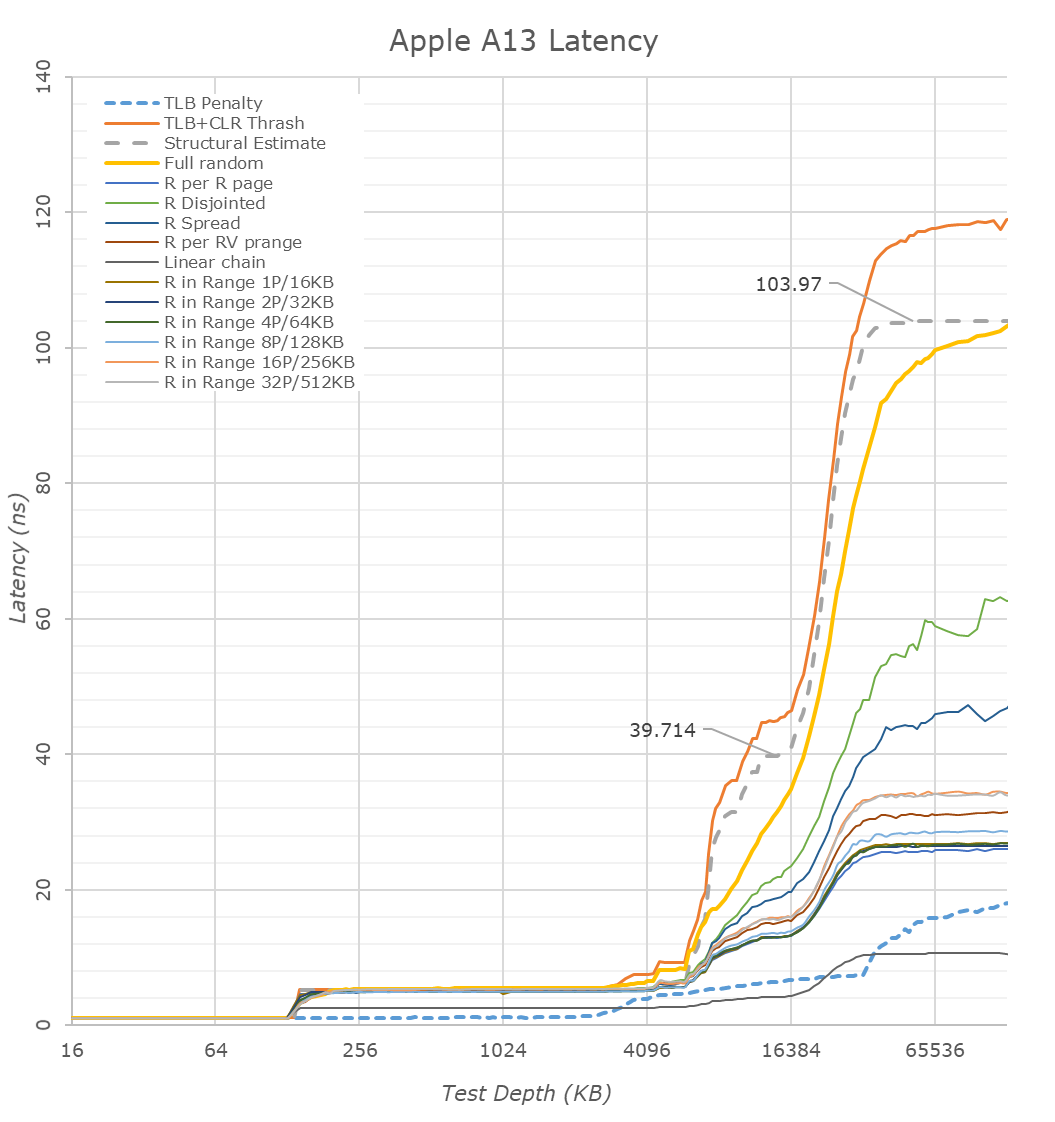
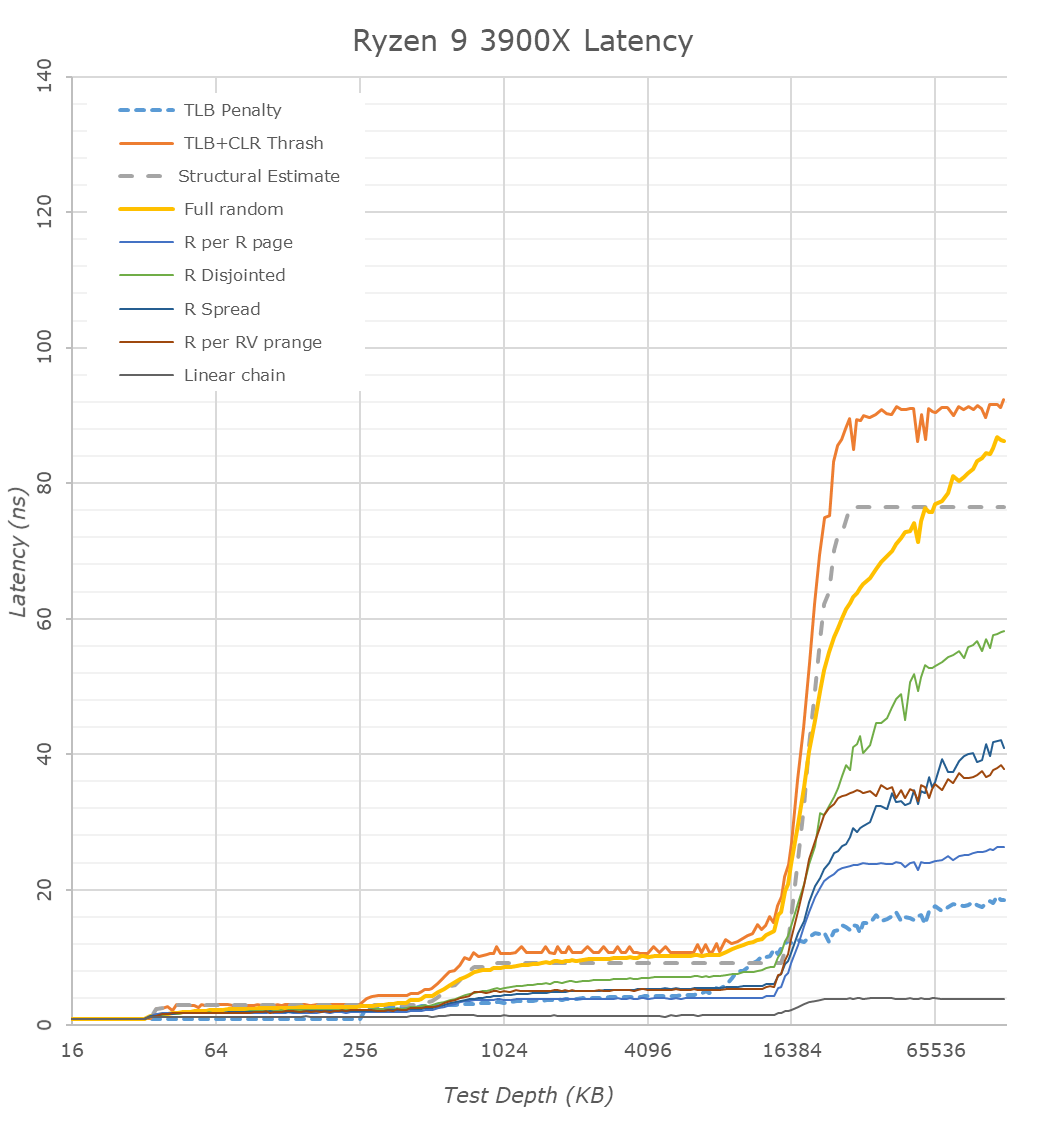

Szépen látszódnak a különbségek.
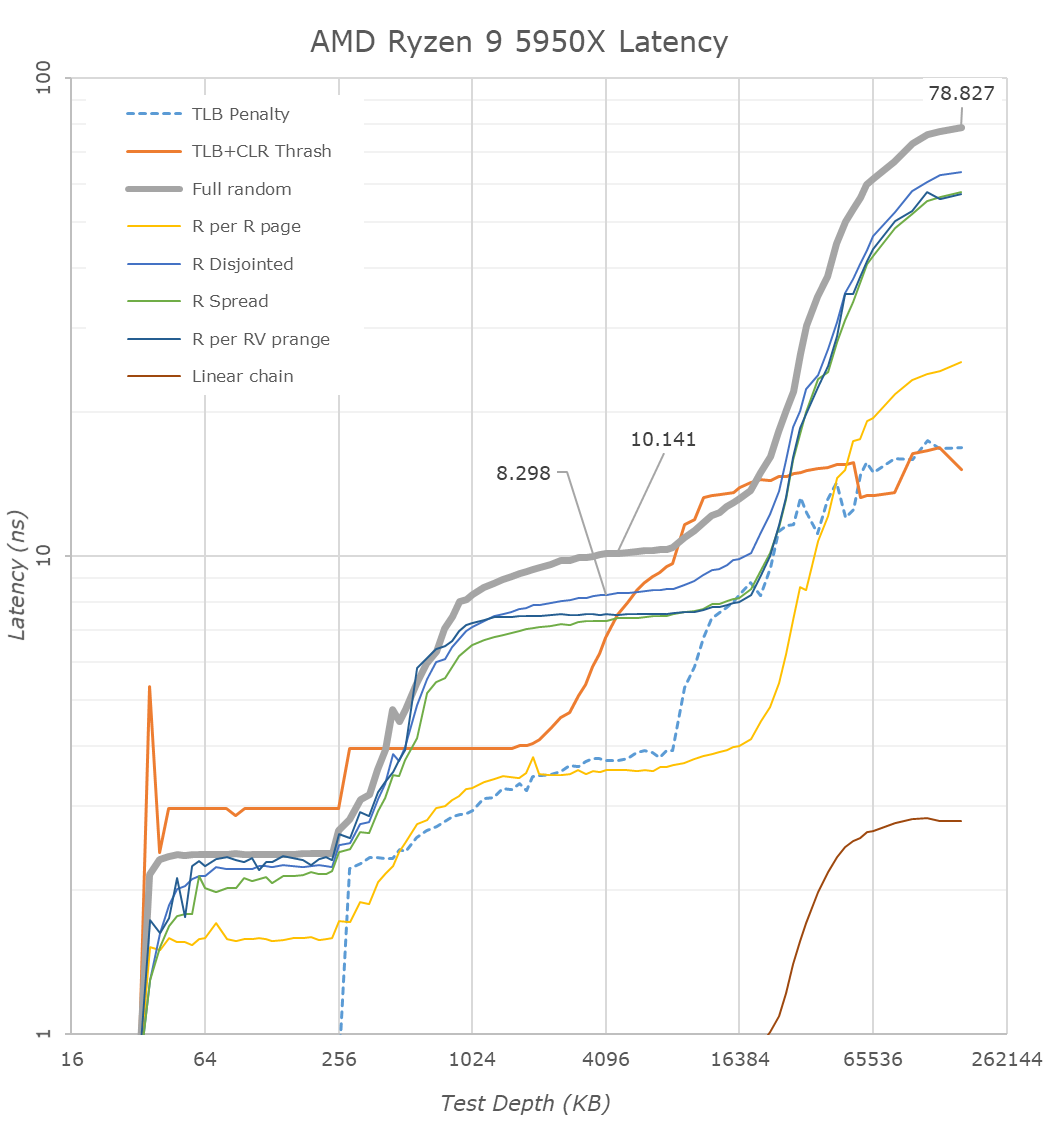
Az A13 nagy L1$-e gyönyörű késleltetést ad 128KB-ig. Szerintem ez eltanulható volna
Az L2$ viszont az AMD és Intel esetén 256KB-ig adnak nagyon szép 3ns körüli késleltetést.
A zen2 esetén a második 256KB-os szelet szerepe nem ennyire konzisztens, de legalább nem emelkedik tőle meredeken a késleltetés a L3$ szintjére.
Viszont az látszik, hogy az Apple L2$ késleltetése inkább 5ns körül van.
Az ábra alapján olyan, mintha a zen2 második 256KB-jának késleltetése inkább a A13 L2$-ére hasonlítana.
Az A13 L2$-e 512KB fölött 4MB-ig viszont jobb késleltetést biztosít, mint a zen2 és a CL L3$-e. Tehát esetleg a zen2-nél esetleg el lehetne tanulni. Tehát ha a 256KB-tól nem 512KB-ig adna olyan késleltetést, mint az A13, hanem 1024-ig vagy 2048-ig, az biztos hasznos volna.Az viszont látszik, hogy az A13 SLC-je messze nem olyan jó, mint az AMD vagy az Intel L3$-e.
Azt el tudom képzelni, hogy az Apple cpu mag olyan dolgokon dolgozik, ami ebbe a 8-16MB-ba belefér, erre optimalizálták és ez mérhető jó IPC-nek. Viszont nagyobb adat esetén látványosan összeomlik, ezért adatközpontba nem volna jó.
-
#4079
Petykemano
veterán
Cathulhu
#4078
Petykemano
veterán
válasz
Cathulhu
#4078
üzenetére
De akkor a Bulldozer érában hogy boldogult az Intel? Mindenkinek az 5Ghz-es bulldozert (piledriver) kellett volna venni, hiszen az 5Ghz, nem suta 3.5 meg 3.7Ghz-ek. Veszítenie kellett volna az 5Ghz-től megbabonázott vásárlók miatt.
Azonban mégis mindenki tudta, hogy
AMD => szar magok + 5Ghz => kazán
Intel => elképesztően hatékony magok => teljesítmény, energiahatékonyság
De mondok mást:
Miért nem próbálják meg azt, ami az ARM X1/A78-ban jött, hogy hát van egy alap design, amit még fel lehet turbózni itt-ott?Az intelnek sikerült a Turbo Boost 3 technológiával azt megoldani, hogy minden magról tudja a a rendszer (a szoftver), hogy meddig tud turbózni és a legmagasabb turbóra képes magra osztja a legdurvább ST feladatokat.
"Intel Turbo Boost Max Technology 3.0 is a feature used by some Intel CPUs to improve performance of lightly- or single-threaded applications by pushing those workloads to the processor’s two favored (or fastest) cores. Using both hardware and software, Intel claims Turbo Boost Max Technology 3.0 delivers “more than 15% better single-thread performance.” "
Az AMD eddig csak az L3$ méretével játszott
De miért nem csinálja azt az AMD, hogy minden CCX-be betesz +1 magot, ami mondjuk 32 helyett 64KB L1$, 512KB helyett 2MB L2$ (csak hogy ne szaladjunk egyből messzira) és most hogy már a CCX közös L3$-t használ, akár ezt is rá lehet csatlakoztatni a 32MB megosztott L3$-re.
Valamit csak számít. +15-20% IPC úgy, hogy mondjuk annak az egy szerencsétlen magnak a fogyasztás 2x nagyobb és a mag mérete is 2x nagyobb. Nagyjából ezt látjuk az A78/X1 esetében is.Hiába hogy a szervereknél több a MT workload, Amdahl törvénye ott is él, vannak szűk keresztmetszetek ott is, amit ST erővel lehet legyőzni.
-
#4077
Petykemano
veterán
Petykemano
veterán
Azt mondják, az új Apple A14 GB5-ben eléri a Tiger lake ST pontját. ~1600
Ha összehasonlítjuk az Apple A13-at és a zen2-t, akkor azt látjuk, hogy
a A13-nak 4x akkora L1$ (128KB) és 8x akkora L2$ (4MB) áll rendelkezésre magonként. És nem mellesleg 6 ALU-ja van 4 helyett.Persze nyilván nem olyan egyszerű, hogy felnyomom a cache méreteket és röpköd az IPC emelkedés magától. De már önmagában érdekes, hogy hogy tud ennyi cache-t belepakolni.
A zen2 512KB-os L2$-e 0.8mm2, vagyis 4MB-hoz 6.4mm2 kéne, míg a A13-ban 4MB L2$ csupán 1.92mm2.
A zen2 16MB L3$-e 17mm2, miközben az A13 szintén 16MB-os System Level Cache csak 6.5mm2-es.
Majdnem 3x annyi helyet foglal a zen2 cache, mint az A13-hoz!Nyilván a méret nem független a sűrűségtől és azt tudjuk, hogy az apple eléri a névleges 100Mtr/mm2 sűrűséget a TSMC 7nm-en.
A sűrűség meg nyilván nem független attól, hogy milyen frekvenciát kell elérni.
És eddig a zen esetében a magas frekvencia cél volt.Azon gondolkodtam el, hogy vajon az AMD és az Intel miért nem indul el ebbe az irányba?
- lőjenek meg kisebb célfrekvenciát
- az eleve alacsonyabb fogyasztással jár és kevesebb tranzisztorral (According to Abu: A vega esetén abu azt mondta, hogy a vega tranzisztortöbbletének nagy részét arra lőtték el, hogy magasabb frekvenciát tudjon elérni. Tehát elvileg a magas frekvenciának is lehet tranzisztorköltsége)
- legyen sűrűbb a design, így több cache-t lehet belepakolni.Persze ahogy mondtam, nyilván nem ennyire egyszerű. De vajon arról lenne szó, hogy x86 esetén nem lehet megvalósítani, hogy holnaptól 3x annyi cache lesz és másfélszer több ALU, akkor mit és hogyan kell változtatni a mag többi részén, hogy kiaknázható is legyen?
Az Apple megtalálta a szentgrált?Azért is érdekes kérdés ez, mert a szerver cpu-k nem nagyon mennek 3.5Ghz fölé amúgy se. Tehát ott az, hogy magas frekvencia elérésére képes a mag, ki sem használható.
-
#4073
Petykemano
veterán
S_x96x_S
#4072
Petykemano
veterán
válasz
S_x96x_S
#4072
üzenetére
Bár a cpukat válogatják, de azt nem tudom, hogy a minősítés aktív tesztelés alapján történik-e, vagy csak ilyen mintavétel alapján, hogy hát az ostya közepén általában ilyen, a szélén meg olyan. Azt feltételezem, hogy azért valamilyen aktív tesztelésnek kell lennie, hogy legalább a működésképtelen példányokat kiválogassák, vagy megállapítsák, hogy hol hibás. De valószínűleg itt cél a gyorsaság. A CTR finomhangolása viszont ha jól tudom, több tízpercen keresztül is tarthat. Emiatt elég valószínűtlen, hogy ilyet csináljanak. Pedig amúgy mekkora jó lenne már - az AMD-nek - ha minden a cpu-kat ennyire finomhangolva tudná legörgetni a gyártósorról.
De azt igazán megtehetné az AMD, hogy megveszik ezt a programot és beemelik a Ryzen Masterbe. Viszont az meg abból a szempontból nem érdekük, hogy jobb terméket kapj, mint amit megfizettettek veled.
Az a 67% kemény!
-
#4067
Petykemano
veterán
Mumee
#4066
Petykemano
veterán
Nem teljesen világos, milyen dealre gondolsz

Az 5600X 200Mhz-el több, mint a 3600X volt (turbó) +$50-ért és -1 cooler tier
A 3600 4.2Ghz-es volt. fentihez képest az, hogy ha ez is +200Mhz-et kap +$20-ért és azonos hűtővel, az már így is "ajándék".(Én úgy próbálom nézni, hogy a logikus + perf/$ vonatkozásban vonzó +
ge*itopdog faktor) -
#4065
Petykemano
veterán
Mumee
#4064
Petykemano
veterán
4.5Ghz túl sok. Ha az 5600X 95W lenne, akkor lehetne az 5600 4.5Ghz turbó, mert jóval alacsonyabb lenne az allcore frekvencia.
De már az 5600X is 65W-os. Nincs hová lejjebb adni.Szerintem:
- Vagy 4.3, jobb esetben 4.4Ghz, tehát érezhetően alacsonyabb frekvencia
- vagy megkockáztatom, hogy 6C/6T lesz és akkor lehet 4.5Ghz a frekvenciaUgyanezt meg merném kockázatni az 5700X-re is... Bár a fene tudja, lehet, hogy ezúttal az 5700_ helyet a Cezanne-nak hagyják ki. Itt a Renoir kapcsán ponthogy felmerültek ezek a kérdések.
-
#4063
Petykemano
veterán
Mumee
#4062
-
#4059
Petykemano
veterán
Petykemano
veterán
"Van Gogh | FF3 is a BGA-1385 package
Die Size: 12,19 mm × 13,34 mm ≈ 162,61 mm²"
[link]
Mennyire lehet messze a bemutató, ha már valaki ismeri a méretet? -
#4047
Petykemano
veterán
awexco
#4045
Petykemano
veterán
Szerintem pont ugyanaz történik, mintha Így másik cég tulajdonolná. Abban az esetben a tulajdonjogot birtokló cég megbízott képviselője gyakorolja a tulajdonosi jogokat: vesz részt a közgyűléseken és szavaz.
Például az igazgató tanácsi tagokról. Az igazgatótanács meg CEO-t nevez ki.
Belterjes lesz. -
#4044
Petykemano
veterán
awexco
#4043
Petykemano
veterán
Rocket Lake jön jövő tavasszal.
8 mag, < Tiger lake IPC, 14nm => magas TDP,
Játékokban versenyképes lehet
Tiger Lake H jöhet talán év elején
8 mag, 10nm
Gamer.notikban versenyképes lehet.Aztán a következő előrelépés az alder lake lesz legkorábban 2021Q4, de inkább 2022-ben.
-
#4021
Petykemano
veterán
S_x96x_S
#4013
Petykemano
veterán
válasz
S_x96x_S
#4013
üzenetére
De miért gondolod, hogy ellátási gondokkal küzdenének?
Chiplet. Nem új nodeon készül, kiváló a kihozatal, apró a chiplet és látszólag nem is nagyobb. Eközben a matisse gyártása leállhat/csökkenhet.
Persze ha másra is kell a wafer, lehet szűkös.A szűkösség magyarázná azt is, miért a legnagyobb volumenben fogyó sku drágult legnagyobb mértékben.
Akkor is bunkóság! Álomgyilkosok!

Nem is arra gondoltam, hogy aki 3600X-ről váltana, hanem valami régebbi prociról. Eddig dédelgetted az elképzeléséidet, hogy $200-250-ért kapható 3600/X, számolgatod, mivel nyernél többet, de majd milyen jó lesz, hogy már mindjárt itt van az új széria és juhúúú. Erre kiderül, hogy a perf/$ nem javul.
Ha így nézed, akkor az történt, hogy betoltak egy új szintet, pont úgy, mint at XT példányokkal
-
#4008
Petykemano
veterán
Devid_81
#4007
Petykemano
veterán
válasz
Devid_81
#4007
üzenetére
persze, csak ugyanaz az $50 az 5950 esetén 7%, a 5600X esetén meg 20% drágulást jelent.
Persze nyilván az 5600X lenyomja multiban a 3700X-et vagy akár a 3800X-et is és ezzel magyarázható.Azt fontolgattam, hogy esetleg cserélek, de valami kisebb magszámra. De vajon megéri másfélszer drágábban az 5600X a 3600X-hez képest? Mármint nem csak nekem, bárkinek.
Következő generációnál mi lesz? lejjebb adom a lécet, legyen akkor 4 magos és de addigra már az is olyan áron jön, hogy úgy fogom megítélni, hogy nem éri meg lecserélni a jelenlegit?Persze értem: átvették a koronát, akkor most bestgamingriget szeretne, ezt fogja venni, no matter the price.
Aztán majd jön tavasszal a Következő lake és lehet némi árkorrekció. -
#3963
Petykemano
veterán
Mumee
#3955
Petykemano
veterán
">>AMD would be focusing on the transition to DDR5 and AM5 socket for Zen4 next year.<<
Ezek szerint az is lehet, hogy AMD is DDR5-ön lesz jövő év végén.
Viszont, akkor nem tudom mi lesz a Warhol-al."Abu azt mondta, hogy a zen4 először a szerverekbe jön, desktopra csak később.
Namost mivel egy chipletre építenek, ezért így ez furcsa lenne.két eset lehetséges:
A fenti kiemelt - következtetett - állítás nem igaz, vagyis jövő évben sem jön még AM5.
Vagy a roadmap nem helyes.Nekem az tűnne logikusnak, hogy jövőre jön a Genoa zen4-gyel és zen4 chipletekkel fedik le a TR és az AM5 felső részét is. A TR és az AM5 alsó részét pedig 7nm-es Warhollal, ami AM5 tokozású és semmi más nem változik, mint az IO lapka DDR5 képessége. Ez azért lehet indokolt, mert jövőre talán az 5nm kapacitás még korlátozottan állhat rendelkezésre.
De ez ellentmond a roadmapnek, mert aszerint ezeknek egymás utáni években kéne érkeznie.Az lehetséges, hogy a Warhol egy olyan termék, ami aztán vagy lesz, vagy nem lesz attól függően, hogy elég olcsó lesz-e már a DDR5 ahhoz, hogy mainstreamben is el lehessen adni.
-
#3950
Petykemano
veterán
S_x96x_S
#3948
Petykemano
veterán
válasz
S_x96x_S
#3948
üzenetére
Kezdetben biztos drága lesz a DDR5. Tehát ha most nem is ruházol be DDR4-es rendszerre, akkor sem biztos, hogy jövő ilyenkor már értelmes, mai DDR4-gyel versenyképes áron lehet majd hozzájutni. Ha persze a pénz nem annyira számít, akkor érdemes várni.
Pont emiatt én azt gondolom, hogy lesznek már jövőre DDR5-ös alaplapok az AMD-től is.Mármint ha már most tudná a DDR5-öt a Vermeer, akkor végképp nem érteném, hogy mi a cél a Warhol generációval. Úgy adná magát, hogy jövő nyár felé jöhetne egy félgeneráció, ami olyan, mint a Matisse 2 volt, apró bütykölés, kicsit magasabb all-core frekvencia, de DDR5-ös IOD és AM5 foglalat X670 alaplappal.
Abban, hogy már most be van építve, azért nem hiszek, mert biztos több láb is kéne hozzá, ha meg már úgyis más cpu package kell ahhoz, hogy ddr5-öt használhass, akkor már rákerülhet egy másik IOD is.
De abban teljesen igazad van, hogy a DDR5-ös 16 magos zen3 interferálhat a TR-rel, ha azt nem eleve DDR5-tel adják ki.
-
#3947
Petykemano
veterán
Petykemano
veterán
(#23159) Z_A_P
"Hat en barmikor inkabb egy 10Ghz 6/12 -t valasztanek mint egy 5Ghz 12/24.
Persze tudom, ez nem lesz megvalosithato, technologiai/fizikai korlatok miatt. Sajnos"
A frekvencia emelése a szilícium fizikai tulajdonságai miatt nem lehetséges. Egy pár éve láttam egy videót, amiben azt hiszem a grafént, vagy szén nanocsövet emlegették, mint amivel lehetséges a terahertzes frekvencia elérése. De nyilván ez csak akkor lehet a jövő, ha a számítógép alapvető működése nem változik.Több szempontból is változhat.
1) Egyrészt itt a topikban is volt már említve a neuromorphic computing
2) Másrészt ha például a jelenlegi DL/AI számításokra gondolunk, és egyre inkább minden afelé megy el (nem tudom, hogy miképp) akkor ott valószínűleg kevésbé fog számítani a frekvencia.Az új programok egyre jobban építenek a többszálúságra, de nyilván ez szoftverfoggü.
A következő nagy dobás szerintem a ML/DL többszálúsítás. A fordító, vagy valami fordítás vagy futás közben elemzi az együgyü programozó által írt soros kódot és ahol lehet párhuzamosít(va fordítja le)
Amdahl törvénye miatt persze az IPC és frekvencia emelése és/vagy a ST bottleneckek kiszűrése sose áll le.
-
#3946
Petykemano
veterán
Petykemano
veterán
Bár továbbra sem kristálytiszta számomra, hogy mi a szerepe a Warholnak, mit hoz, vagy miért indokolt a 7nm-es zen3-mal az időhúzásnak.
De ez alapján jövő ilyenkor már akár lehetne DDR5-öt kapni. Drágán, de talán lehetne. -
#3927
Petykemano
veterán
hokuszpk
#3925
Petykemano
veterán
válasz
 hokuszpk
#3925
üzenetére
hokuszpk
#3925
üzenetére
Úgy tűnik, az 5800X 8 magos, ez alapján ha lesz 10 magos, akkor az inkább 5900 lesz.
Persze a számozáson az utolsó hetekben is lehet változtatni
De ezzel együtt én nem tartom valószínűnek, hogy az AMD feljebb tolná a magszámokat. Legalábbis most.Annak persze lehet, hogy lenne értelme, hogy a Threadripperek számozása ne szoruljon be az 5960-5990 közé.
Fogalmazzunk úgy, hogy nekem nincs olyan érzésem, hogy a $200-250 mainstream szegmensbe az AMD most betolna 8 magot.
Szerintem ezt majd a Warhollal fogják meglépni
akkor lesz majd 6600/X 8 magos
6700/X 10 magos
6800/X 12 magos
6900/X 16 magosÉs abu azt mondta, hogy a zen4-et először a szerver piacra viszi. De az nem jelenti azt, hogy ne készülne el ütem szerint 14-15 hónap múlva és ne lehetne top-tier termékeket építeni rá, mint például Threadripperek és egy 24 magos 6950X
Persze sok a kérdőjel. Ehhez a Warholnak már DDR5-ös AM5-nek kéne lennie kompletten, hogy ne legyen kavarodás.
Mindenesetre én magszám emelkedésre most nem számítok. Ha meg az árakat is csúsztatná, vagyis a 8 magos 5600X $300-350 körüli lenne, akkor azzal nem okozna nagyobb kavarodást (vigyázat! Áremelés!!)?
-
#3924
Petykemano
veterán
Petykemano
veterán
Cpu monkey
Nem tudom, valós-e, vagy fake, vagy placeholderFigyelembe véve, hogy abu azt mondta, hogy az AMD egyelőre nem készül a 16 magos 5950X-szel, azt mondanám, inkább fake/placeholder kalkuált értékkekel.
Erre utal, hogy az R20 multithread értékek hiányoznak - azt nehezebb kalkulálni IPC-ből max turbó frekvenciából. -
#3915
Petykemano
veterán
Petykemano
veterán
Új infót nem igazán tartalmaz, csak egy teljesebb képet mutat.
A tartalomhoz:
A mobil részt értem.
A Renoir-ból készítik a Van Gogh-ot, ami RDNA2 IGP-vel rendelkezik, a Cezanne-t, ami zen3 magokkal és a Lucienne-t, ami a Dalit váltja és a Renoir még kisebb változata (4 mag, ilyesmi)A mobil következő lépcsőjét is értem. Fogják a Van Gogh-ot és cserélik abban is a zen2 magokat zen3-ra és portolják az egészet a 6nm-nek nevezett node-ra.
Amit nem értek az a desktop vonal.
A rekonstruált roadmap-en jelzett évhatárok alapján a Vermeer eleve késésben van pár hónappal.
Majd ezt követően jön egy új zen3+7nm verzió, ami látszólag semmilyen újítást nem kínál.
Elvileg a Vermeer az utolsó AM4 foglalatos cpu, ez alapján lehetne azt gondolni, hogy biztos a Warhol DDR5 verzió, de mindenki azt mondja, hogy annak semmi értelme nem lenne, hiszen a DDR5 drága.
Lehetne még arra gondolni, hogy biztos emelik a magszámot és mondjuk nem 2, hanem akár 3 chiplet is elfér a foglalaton. De ahhoz meg akkor épphogy indokolt lenne a DDR5.
Vagy csak simán faraghatnak az IO lapkán? Nyilván azt is lehet jobb node-on készíteni, csökken a fogyasztás, jobb fclk érhető el, stb. De nem felesleges úgy portolni az IOD-t, hogy közben nem cseréled DDR5-re a memóriavezérlőt?
Lehet valami más egzotikum? 3d Stacking, vagy ilyesmi?Abu azt mondta, hogy a zen4-et az AMD először szerverbe hozza. A Warholra valószínűleg azért lehet szükség, mert a zen4 5nm-en készül és nincs elég kapacitás. De így meg bukják azt, hogy a selejtes lapkákat a desktop piacon lehet kiszórni.
-
#3909
Petykemano
veterán
Petykemano
veterán

5800X leakkel összefüggésben valaki megosztott egy vtune eredményt
[link]Ez lehet az 5800X-é, vagy csak valami összehasonlítás?
-
#3905
Petykemano
veterán
Mumee
#3904
Petykemano
veterán
Hát jó, de nemsokára jön a Rocket lake. Az biztos hozza majd ezt az eredményt
gyári OCvelalapjáraton. Persze, kérdés, mennyi az a nemsokára.
Mindenesetre az valószínű, hogy ha esetleg egyértelműen és minden kétséget (OC és egyéb fine tuning) kizáróan nem is lépi meg a zen3 az intel aktuális és közeljövőben elérhető kínálatát, azért zárul az olló. -
#3902
Petykemano
veterán
Yutani
#3900
Petykemano
veterán
valóban
itt van egy 5800X @ 1080p eredmény is.A cpu fps-re nincs hatással a gpu is?
-
#3899
Petykemano
veterán
Mumee
#3896
Petykemano
veterán
Én nem különösebben érte az AOTS benchmarkhoz. Az OC-s eredmények hogy lettek olyan magasak? Hogy lett az OC-s 10700K értéke majdnem másfélszer jobb, mint a 10900K-é?
Jól látom, hogy az OC-s oszlop valójában 2080Ti és nem is látszik, hogy milyen preset?
Nem vagyok meggyőződve róla, hogy az OC oszlop valóban szintén crazy_4K. -
#3891
Petykemano
veterán
Petykemano
#3890
Petykemano
veterán
válasz
 Petykemano
#3890
üzenetére
Petykemano
#3890
üzenetére
Nem mondanám kifejezetten nagy előrelépésnek, ha az armos útvonaltervekhez hasonlítjuk, de tisztességes. Ez Végülis megfelel a várakozásaimnak
Ha ezzel megelőzik a rocket lake-et - mind időben, mind teljesítményben - akkor nyertek.
A rocket lake ugye valami willow cove származék, magasabb IPC és a pletykák szerint 5.5ghz turbó.Illetve kérdés, hogy ez elég-e a Cézanne-Nak előzni a tiger lake-t?
Én azért remélem, hogy ezt nem 150W tdpvel tudja.
-
#3890
Petykemano
veterán
Petykemano
veterán
5800X vs 10900k aots
(2080, DX12, crazy 4k)5800X: 133.6 (+16% vs 10900k, +26.5% vs 3800X )
10900k: 114.8 (+9% vs 3800X)
3800X: 105.4
[kép] -
#3882
Petykemano
veterán
Petykemano
veterán
-
#3878
Petykemano
veterán
Petykemano
veterán
Amúgy az Oracle Cloud-hoz mit szólunk? Emlegették a Milant.
Vajon már rég szállítják és idén ősszel debütál? -
#3877
Petykemano
veterán
S_x96x_S
#3875
Petykemano
veterán
válasz
S_x96x_S
#3875
üzenetére
"+40-50% IPC increases over Zen2 for only a third of the power."
Nagyon impozáns.
MLiD is arról beszélgetett az egyik vendégével - kicsit messziről indítva -, hogy a szoftverek haladnak a konténerizált-virtualizált futás irányába, aminek megvan az az előnye, hogy ilyen virtuális csomagokat lehet futásidőben migrálni egyik eszközről a másikra és hogy ez felhasználói élmény szempontjából milyen cool lenne. És hogy az apple is errefelé igyekszik nyilvánvalóan az Armmal, mert intel alapon nem tudták (rendesen) megoldani.És hogy az új kulcsszó az edge computing, vagyis cégek arrafelé haladnak, mármint ilyen google, MS, Amazon, stb, hogy a végfelhasználóhoz közel biztosítsanak relatív nagy számtási teljesítményt. Abban az értelemben, hogy lehet, hogy pár év múlva nem lehet majd Threadripper workstationt kapni, hanem lesz majd minden nagyobb városban valami adatközpont és onnan lehet bérelni a hardvert és fogod és odamozgatod a notebookodról a VM-et/konténert, amiben a photoshopod fut és használod a kapacitást.
Na és most jön a lényeg, hogy azt mondta MLiD, hogy jó, de hát látjuk, hogy mekkora fejlődés van az alacsony fogyasztású processzorok között, most 8 mag befér 15W-ba, 5nm-en lehet, hogy már 16 magos U szériás procik is jöhetnek. (Nem feltétlen jövőre)
Hogy ez milyen viszonyban áll az edge computinggal, és hogy mi mit vált le vagy ki, azt most hagyjuk, mert nem erre akarnám rátekerni, hanem a 16magos 15W-os cumókra.
A nuvia terméke vajon mikor lesz elérhető? 2021-2022?
Ezek az összehasonlítások azért félrevezetők picit, mert addigra feltehetően az AMD-nek is lesznek már fejlettebb termékei. 2022-ben az intel Alder Lake is kijöhet, ami a jelenlegi Cometh Late-nél 40-50%-kal magasabb IPC-t ígér. És a feltehetően akkortájt érkező zen4 is 30%-kal magasabb IPC-vel rendelkezhet, mint a zen2 (és akkor ez egy olyan konzervatív alacsony szám, amit ha nem sikerül meglépni, akkor az lemaradást eredményez az AMD számára)És gondolom nem is ugyanazon a gyártástechológián fog készülni.
Azért érdekes lesz.
Annál is inkább érdekes a hír, hogy az Nvidia felvásárlás után történt.
-
#3874
Petykemano
veterán
Petykemano
#3870
Petykemano
veterán
válasz
Petykemano
#3870
üzenetére
"Ryzen 5 5500U : Lucienne (Renoir Refresh)
Ryzen 5 5600U : Cezanne
Ryzen 7 5700U : Lucienne (Renoir Refresh)
Ryzen 7 5800U : Cezanne"
Vajon miért csinálná ezt az AMD?
Az 5600U bizonyára közel olyan jó eredményeket adhat, mint a 5700U, ST biztosan. -
#3870
Petykemano
veterán
Petykemano
veterán
-
#3868
Petykemano
veterán
Petykemano
veterán
A roadmap nem tudom, mennyire hiteles.
Ez persze ugyanaz, már láttuk.
De a Feltételezett Vermeer és a Renoir - Cézanne vonal egymáshoz képesti elcsúsztatása nem jön ki.
Figyelembe véve, hogy a Renoir közepén van a 2020 és Renoir kár év elején óta van, ezért joggal feltételezhető, hogy a Vermeernek már év közepe óta kéne lennie. -
#3866
Petykemano
veterán
S_x96x_S
#3865
Petykemano
veterán
válasz
S_x96x_S
#3865
üzenetére
"A DPU is essentially PCIe on one side and Ethernet on the other. "
Én a Mellanox-szal látok hasonlóságot.
[link]Azt gondolom valami ilyesmire az AMD-nek is biztos szüksége lehet.
Ha nem abban a világban élnénk, hogy a cégek elképesztő vagyonokkal rendelkeznek, a versenyhatóságon meg pár yachtozásért kábé minden átmegy, akkor azt is mondanám, hogy lehetne partnerségben is gondolkodni. De úgy tűnik, hogy erős a "piacról való kiszorítás" igénye és ennek nyilván a fentiek miatt egy ellenséges felvásárlás remek eszköze lehet.

























Új hozzászólás Aktív témák
Hirdetés
- Napelem
- Feketehalálra váltja a kékhalált a Microsoft
- Soundbar, soundplate, hangprojektor
- Futás, futópályák
- Melyik tápegységet vegyem?
- Mini-ITX
- Motorola Edge 30 Neo - wake up, Jr...
- Kerékpárosok, bringások ide!
- M0ng00se: Hardvert áruhitelre?
- Debrecen és környéke adok-veszek-beszélgetek
- További aktív témák...

- Lenovo ThinkVision P27U-10 3840 x 2160 4K monitor - PIVOT - HDMI - USB- C - több db - gari + számla
- Eladó ASUS ROG STRIX GTX1080Ti 11Gb videókártya
- Nothing Phone 1 128GB, Kártyafüggetlen, 1 Év Garanciával
- Gamer/Multimédia PC Eladó - GTX 1070 + Ryzen 5 + 16GB RAM
- Xiaomi Redmi Note 14 Pro 5G 256GB, Kártyafüggetlen, 1 Év Garanciával
- Csere-Beszámítás! Asus Rog Strix RTX 3070Ti 8GB GDDR6X Videokártya!
- BESZÁMÍTÁS! ASRock Z370 i5 8500 16GB DDR4 512GB SSD 2060 Super 8GB Zalman Z9 Plus Enermax 750W
- Xiaomi Redmi 13128GB Kártyafüggetlen 1Év Garanciával
- AKCIÓ! Lenovo Legion Slim 5 16AHP9 notebook - R7 8845HS 16GB RAM 512GB SSD RTX 4060 8GB Win11
- BESZÁMÍTÁS! Dell Latitude 5550 üzleti -Intel Ultra 7 165U16GB DDR5 RAM 1TB SSD Intel Graphics WIN11
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: PC Trade Systems Kft.
Város: Szeged