- Milyen billentyűzetet vegyek?
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Gyártófüggetlen módon oldja meg a részletes geometria problémáját az AMD
- NVIDIA GeForce RTX 4060 / 4070 S/Ti/TiS (AD104/103)
- Rendkívül ütőképesnek tűnik az újragondolt Apple tv
- Micro Four Thirds
- A gyári kábelek fontosságára hívják fel a figyelmet az új GeForce-ok gyártói
- OLED TV topic
- Apple notebookok
-

PROHARDVER!
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#42212
 S_x96x_S
addikt
Quadgame94
#42206
S_x96x_S
addikt
Quadgame94
#42206
S_x96x_S
addikt
válasz
 Quadgame94
#42206
üzenetére
Quadgame94
#42206
üzenetére
> Miért olcsóbb a HBM mint a 3D V-Cache
talán még ez releváns - GPU szempontból ..
https://www.latent.space/p/flashattention#details
( 3D V-Cache == SRAM )"""
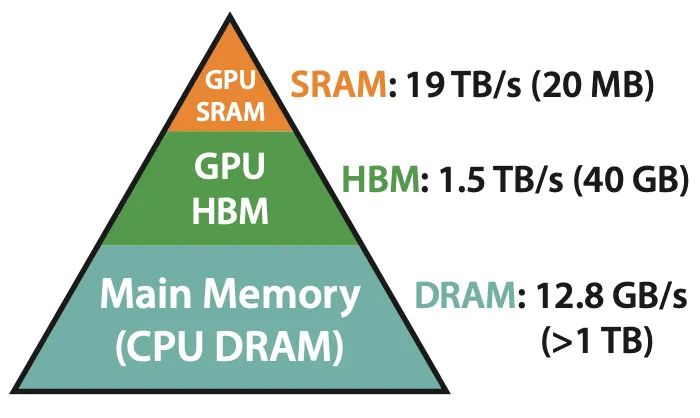
Tri: Yeah, for sure. This is kind of a caricature of how you think about accelerators or GPUs in particular, is that they have a large pool of memory, usually called HBM, or high bandwidth memory. So this is what you think of as GPU memory. So if you're using A100 and you list the GPU memory, it's like 40 gigs or 80 gigs. So that's the HBM. And then when you perform any operation, you need to move data from the HBM to the compute unit. So the actual hardware unit that does the computation. And next to these compute units, there are on-chip memory or SRAM, which are much, much smaller than HBM, but much faster. So the analogy there is if you're familiar with, say, CPU and RAM and so on. So you have a large pool of RAM, and then you have the CPU performing the computation. But next to the CPU, you have L1 cache and L2 cache, which are much smaller than DRAM, but much faster. So you can think of SRAM as the small, fast cache that stays close to the compute unit. Physically, it's closer. There is some kind of asymmetry here. So HBM is much larger, and SRAM is much smaller, but much faster. One way of thinking about it is, how can we design algorithms that take advantage of this asymmetric memory hierarchy? And of course, lots of folks have been thinking about this. These ideas are pretty old. I think back in the 1980s, the primary concerns were sorting. How can we sort numbers as efficiently as possible? And the motivating example was banks were trying to sort their transactions, and that needs to happen overnight so that the next day they can be ready. And so the same idea applies, which is that they have slow memory, which was hard disk, and they have fast memory, which was DRAM. And people had to design sorting algorithms that take advantage of this asymmetry. And it turns out, these same ideas can apply today, which is different kinds of memory. [00:13:00]Alessio: In your paper, you have the pyramid of memory. Just to give people an idea, when he says smaller, it's like HBM is like 40 gig, and then SRAM is like 20 megabytes. So it's not a little smaller, it's much smaller. But the throughput on card is like 1.5 terabytes a second for HBM and like 19 terabytes a second for SRAM, which is a lot larger. How do you think that evolves? So TSMC said they hit the scaling limits for SRAM, they just cannot grow that much more. HBM keeps growing, HBM3 is going to be 2x faster than HBM2, I think the latest NVIDIA thing has HBM3. How do you think about the future of FlashAttention? Do you think HBM is going to get fast enough when maybe it's not as useful to use the SRAM?
[00:13:49]
Tri: That's right. I think it comes down to physics. When you design hardware, literally SRAM stays very close to compute units. And so you don't have that much area to essentially put the transistors. And you can't shrink these things too much. So just physics, in terms of area, you don't have that much area for the SRAM. HBM is off-chip, so there is some kind of bus that essentially transfers data from HBM to the compute unit. So you have more area to essentially put these memory units. And so yeah, I think in the future SRAM probably won't get that much larger, because you don't have that much area. HBM will get larger and faster. And so I think it becomes more important to design algorithms that take advantage of this memory asymmetry. It's the same thing in CPU, where the cache is really small, the DRAM is growing larger and larger. DRAM could get to, I don't know, two terabytes, six terabytes, or something, whereas the cache stays at, I don't know, 15 megabytes or something like that. I think maybe the algorithm design becomes more and more important. There's still ways to take advantage of this, I think. So in the future, I think flash attention right now is being used. I don't know if in the next couple of years, some new architecture will come in and whatnot, but attention seems to be still important. For the next couple of years, I still expect some of these ideas to be useful. Not necessarily the exact code that's out there, but I think these ideas have kind of stood the test of time. New ideas like IO awareness from back in the 1980s, ideas like kernel fusions, tiling. These are classical ideas that have stood the test of time. So I think in the future, these ideas will become more and more important as we scale models to be larger, as we have more kinds of devices, where performance and efficiency become much, much more important. [00:15:40]
"""
Mottó: "A verseny jó!"


Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az NVIDIA éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.


Állásajánlatok

Cég: Marketing Budget
Város: Budapest