
Új hozzászólás Aktív témák
-
-
#145
 wayne1
senior tag
hampidampi
#144
wayne1
senior tag
hampidampi
#144
wayne1
senior tag
válasz
 hampidampi
#144
üzenetére
hampidampi
#144
üzenetére
Kár. Annyiból lett volna jó, hogy a párom is olvas könyvet és nem szereti használni a Calibre-t és mivel Duokan van az olvasón manuálisan kell felmásolni mindent. Így könnyebb lett volna neki válogatni a könyvek között, de majd mindig lementem neki mert a Mentés Lemezre menüvel megcsinálja úgy ahogy szeretném neki.
-
wayne1
senior tag
Oké. Köszi. És az megoldható, hogy a merevlemezre is így mentse el alapból, vagy ott mindenféleképpen úgy csinálja, hogy Szerző szerint?
Arra már rájöttem, hogy a Mentés Lemezre menünél be lehet ezt állítani, de megoldható ez úgy is, hogy a merevlemezen lévő Calibre Könyvtár is ilyen formában legyen lementve? -
wayne1
senior tag
Hali
Lehet, hogy volt már róla szó, de hiába kerestem rá itt a fórumon és a Calbire-ben is nézegettem, de nem találtam a megoldást. A lényeg az, hogy elkezdtem a könyveimet rendezgetni, de véletlenül szerzőnként mentettem el a könyvtárba. Meglehet valahogy oldani, hogy újra csinálja a könyvtárat nekem úgy, hogy Címke/Szerző/Szerző-Cím ???
Előre is köszi a választ. -
#140
 snowdog
veterán
hampidampi
#135
snowdog
veterán
hampidampi
#135
snowdog
veterán
válasz
hampidampi
#135
üzenetére
A docx input plugin igazából már nem szükséges, a Calibre egy ideje alapból támogatja a docx-et.
Igazad van, annak idején a frissítések között olvastam is róla, csak azóta elfelejtettem. Most meg már lustaságból nem törlöm a plugin-ek közül.
What's new
Release: 0.9.34 [07 Jun, 2013]
Conversion of Microsoft Word documents (.docx files generated by Word 2007 or newer)
DOCX files created with Microsoft Word 2007 or newer can now be converted by calibre. The converter has support for lists, tables, images, all types of text formatting, footnotes, endnotes and even dropcaps. A sample docx file showing the capabilities of the converter is available: http://calibre-ebook.com/downloads/demos/demo.docx Note that this code is still very new, so there are more than likely a few bugs waiting to be squashed. -
#139
 drmotto
őstag
hampidampi
#135
drmotto
őstag
hampidampi
#135
drmotto
őstag
válasz
hampidampi
#135
üzenetére
Az elválasztós plugin az hogy kellene, hogy működjön?
Nekem "calibre, version 0.9.43
HIBA: Ismeretlen hiba történt: <b>LookupError</b>:unknown encoding:
"
üzenettel leáll. -

Degeczi
nagyúr
MOBI = PRC = AZW
Picit pontosabban: a MOBI-hoz az Amazon saját DRM-et illesztett, ez lett az AZW. Ezért ilyet házilag nem tudsz gyártani!Egyébként elég buta formátum - bár a könyvek többségéhez persze tökéletesen megfelel
Idővel létrehozott egy teljesen új formátumot az Amazon, amit KF8-nak nevezett el, és a tavalyi év folyamán a legtöbb e-book readerét alkalmassá tette a használatára (Paperwhite, Touch, K4 / K5 és végül a K3 Keyboardot is. A K1, K2 illetve a DX-et nem, mert azokban túl kicsi az operatív memória)
Ezt hívja a Calibre AZW3-nak, ilyet már tud gyártani - de az előbbiek miatt ne keverjük a sima AZW-vel, nem az!
Ez már sokkal többre képes, az EPUB mellett nincs szégyenkezésre oka (végre van pl. feltételes elválasztás is, ami egy ok lehet az alább említett plugin használatára. Ez lehet egy komoly érv a használata mellett, egyébként nem muszáj, mert hátránya is van: egyrészt jóval nagyobb a helyigénye, mert kompatibilitás miatt opcionálisan a régi formátumot is tartalmazza, másrészt legalábbis Calibre-vel legyártva nagyobb a sortávolság, mint MOBI-ban. Nemrég volt itt erről szó)
-
#136
drmotto
őstag
hampidampi
#135
drmotto
őstag
válasz
hampidampi
#135
üzenetére
Köszi neked is.
Az azw formátumot a Kindle 5 is viszi? Érdemes ebbe konvertálni epub-ból, vagy inkább a mobi? -
#135
 hampidampi
őstag
drmotto
#133
hampidampi
őstag
drmotto
#133
hampidampi
őstag
Az apnx generátor csak mobira működik. A másikat én pl. pdf-eknél szoktam használni, hogy oszlopban is láthassam, hány oldal egy adott könyv.
@snowdog:
A docx input plugin igazából már nem szükséges, a Calibre egy ideje alapból támogatja a docx-et.Hasznos lehet még a hyphenate this! plugin. Azw és epub könyvek szövegének elválasztását lehet vele megcsinálni.
-
snowdog
veterán
ount Pages.zip = kész könyv oldalszámlálása a Calibre-ben
lugin_apnx_generator-1.1.0.zip = oldalszám generálása már a gépen található könyvekhezItt a kettő között mi a különbség? Illetve mikor generálja az oldalszámot, amikor mobi-t csinálok belőle?
Akkor nézzük hogyan is működik a Calibre oldalszámozás.

Ha egy könyvet a Calibre-vel küldünk az olvasóra, akkor a program az oldalszám fájlt (apnx) automatikusan létrehozza, és rámásolja az olvasóra.
De ettől még a Calibre-ben a könyvtárban a könyveknél nem látszanak az oldalszámok. Ehhez való a Count Pages.zip plugin.
Ha egy könyvet egy file manager-rel másoltunk az olvasóra, akkor ahhoz az olvasón nem lesz oldalszám fájl. Ezt a Calibre-vel is létrehozhatjuk (plugin_apnx_generator-1.1.0.zip), majd az apnx fájlt felmásolva az olvasóra a könyvben az oldalszámok láthatók lesznek.
Összegezve, ez három különböző eljárás. És akkor lássuk a gyakorlatban hogy is néz ki a Calibre-ben az oldalszám kijelzés.
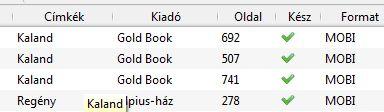
A "Kaland" véletlenül került a képre, az egér valamin állt.
-
drmotto
őstag
Antikvarium_hu_1.0.1.zip, Libri_hu_1.0.4.zip, Moly_hu_1.0.1.zip = metaadatok letöltése
Ez van nekem is, nagyon nagy okosság.Search The Internet.zip = metaadatok és borítók keresése a neten egy gombnyomásra
Ez hasznosnak tűnik, fel is dobom.ount Pages.zip = kész könyv oldalszámlálása a Calibre-ben
lugin_apnx_generator-1.1.0.zip = oldalszám generálása már a gépen található könyvekhezItt a kettő között mi a különbség? Illetve mikor generálja az oldalszámot, amikor mobi-t csinálok belőle?
-
snowdog
veterán
Hogy miért az ne kérdezd (már nem mindet tudom miért is telepítettem), de nálam ezek a plugin-ek vannak telepítve:
Antikvarium_hu_1.0.1.zip
Calibre-DOCX-Input.v0.0.22.zip
Count Pages.zip
DeDRM.zip
Extract ISBN.zip
Favourites Menu.zip
Find Duplicates.zip
Goodreads.zip
Import List.zip
Kindle Collections.zip
Libri_hu_1.0.4.zip
Manage Series.zip
Moly_hu_1.0.1.zip
plugin_apnx_generator-1.1.0.zip
Reading List.zip
Search The Internet.zipIlletve a leghasznosabbak a következők:
Antikvarium_hu_1.0.1.zip, Libri_hu_1.0.4.zip, Moly_hu_1.0.1.zip = metaadatok letöltése
Count Pages.zip = kész könyv oldalszámlálása a Calibre-ben
Find Duplicates.zip = egy könyvtárban dupla könyvek kiszűrése
Favourites Menu.zip = saját menü készítése (egy menügomb alatt több menüpont nyílik meg
Search The Internet.zip = metaadatok és borítók keresése a neten egy gombnyomásra
plugin_apnx_generator-1.1.0.zip = oldalszám generálása már a gépen található könyvekhez
... és így tovább. -
drmotto
őstag
Az biztos, mert én csak a metaadatok leszedéséhez tettem fel plugint + a DRM plugint.
Én is csak úgy vettem észre, hogy miután töröltem a 000 fájlt és újra beimportáltam az epubot, benne volt pont ugyanaz, mint előtte. Akkor belenéztem a fájlba, és így vettem észre.HA van valami ajánlott plugin, akkor szívesen veszem.

-
snowdog
veterán
Headers and Footers [link]
You can insert arbitrary headers and footers on each page of the PDF by specifying header and footer templates. Templates are just snippets of HTML code that get rendered in the header and footer locations.
For example, to display page numbers centered at the bottom of every page, in green, use the following footer template:...Ezek szerint PDF állományoknál használatos például oldalszám megjelenítésére.
-
snowdog
veterán
Csak tököltem vele még egy kicsit, és megvan a megoldás. Nem kell hozzá bat file, egyetlen paranccsal akár több száz könyvből eltávolíthatod a jacket oldalt (vagy bármi mást, amit csak akarsz).

Windows alatt ezt az egy parancsot kell kiadni egy parancssor (dos) ablakban abban a mappában, ahol a zip kiterjesztésűre átnevezett epub könyvek találhatók (előtte természetesen telepíteni kell a 7-Zip programot [link] ):
for /r %x in (*.epub.zip) do "C:\Program Files\7-Zip\7z.exe" d -r "%x" *_split_000.html
Minden könyvből eltávolítja a jacket oldalt. Ezt követően már csak vissza kell nevezni a könyveket valami.epubra. Ezt a műveletet a TotalCommander egy lépésben elvégzi.
-
snowdog
veterán
Kipróbáltam, és működik:
for /r %x in ("Rizsetelek - Klement Andras.epub.zip") do "C:\Program Files\7-Zip\7z.exe" d -r %x Rizsetelek_split_000.htmlÉs kiszedte a zip állományból a "Rizsetelek_split_000.html" fájlt.
Az az érdekes, ha ugyan ezt a sort beteszem egy bat fájlba, akkor hibaüzenettel leáll:
Files\7-Zip\7z.exe" d -r x Rizsetelek_split_000.html most nem használható.Vagyis a bat parancs a "Program Files" részt szétvágja annak ellenére, hogy az útvonal idézőjelek között van.
Parancssoros ablakban meg végrehajtja. Egyenlőre ennyire futotta, most több időm nincs rá. A lényeg hogy megoldható, csak még görcsölni kell vele egy kicsit. -
snowdog
veterán
Mondom én hogy nem lehetetlen, például.
I have at least 40 archive files, 100 MB each, which also includes many .jpg files within.
How I can delete the .jpg files from these archives easily?On Windows, install 7zip, and run following command in the folder with the zip files:
for /r %x in (*.zip) do "C:\Program Files (x86)\7-Zip\7z.exe" d -r %x *.jpg -
snowdog
veterán
Az esetleg működő megoldás lehet, hogy újrakonvertálom a könyveket, ezúttal szerkesztve az említett xml fájlt, hogy mit tegyen bele, mit ne?
Ha nem távolítod el a régi jacket oldalt, akkor úgy fog kinézni, hogy ott marad az eredeti, és megjelenik mögötte az újonnan kialakított. Vagyis két jacket oldal lesz a könyvben. Szóval egy lépésben nem fog menni.
Inkább abba az irányba kellene menni, hogy melyik az a program, ami egy zip állományból képes egy adott állományt eltávolítani. És még akkor sem lesz egyszerű, mert a fájl neve mindig változik. Bár ha az eleje megegyezik a könyv címével, akkor előre ellehet készíteni egy listát, amit átlehetne adni a programnak. A számítástechnika segítségével szinte mindent meglehet oldani, gondolom ezt is. Csak az a kérdés, hogy mennyi ideig tart a megfelelő programot megtalálni.
-
drmotto
őstag
Nem hibás, mind jó, én tettem rendbe az összeset.
Csak valahogy nem találom odavalónak azt hogy "Címkék: sci-fi", ezért gondoltam, hogy esetleg van egy egyszerű módszer rá.(#114) snowdog:
Nyilván nem, így nem is fogok nekikezdeni.
Az esetleg működő megoldás lehet, hogy újrakonvertálom a könyveket, ezúttal szerkesztve az említett xml fájlt, hogy mit tegyen bele, mit ne?
-
snowdog
veterán
Calibre-vel ki lehet szedni valahogy a könyvel elejéről a metaadatokat, vagy csak úgy, ha word-be konvertálom, törlöm, majd vissza?
Tettem egy próbát, és a módszer nálam bevált. Nálam ez egy mobi formátumú könyv volt. Tehát adott egy könyv, aminek az elején már ott van a metaadat oldal (jacket page).
1. A könyvet átkonvertáltam epub formátumra. A konvertálás során mikor felugrik a konvertálás beállításai oldal a "Struktúra felismerés" pontban a "Metaadatok beszúrása a könyv elejére külön oldalként" check box elől kivettem a pipát.
2. Ezt követően a megfelelő mappában megkerestem az újonnan konvertált valami.epub fájlt, és átneveztem valami.epub.zip-re. A TotalCommander-rel megnyitottam a zip állományt, és eltávolítottam a valami_split_000.html állományt. Nem árt F3-al belenézni, hogy valóban az-e a jacket oldal.
3. A valami.epub.zip-et visszaneveztem valami.epub-ra.
4. A valami.epub-ot a Calibre-vel most már metadatok beszúrás nélkül újrakonvertáltam mobi-ba.Nem azt mondom hogy biztosan ez a legegyszerűbb megoldás, de amíg nincs jobb ezt a módszert lehet használni.
-
snowdog
veterán
Mert pl. a fülszöveg jó ha ott van, de pl. a címke felesleges.
Első lépésben próbáld ki következőt: a Calibre\resources\jacket\template.xhtml fájlból töröld ki a
{tags_label}: {tags}
sort. Szerintem ha a programot frissíted, akkor ez az állomány visszaáll az eredeti formátumra, tehát minden frissítés után újra módosítanod kell. Vagy nem frissítesz, és akkor megmarad.
-
snowdog
veterán
Kiszedni talán a Calibre "Keresés és csere" funkciójával lehetne. Pontosan nem tudom hogyan, mert nem próbáltam. De a leírásokból ezt szűrtem le.
You might be able to make a 'hacked' copy (put THEM in <the config folder>\resources\jacket of the template found in the calibre2\resources\jacket\
Itt [link] azt olvastam, hogy meg lehet hekkelni a forrás állományt, de nem biztos hogy minden formátumban jól fog működni. Minden esetre egy próbát megérne a dolog. Az első ránézésre egyszerűnek tűnik, ha valamit ki akarunk hagyni. Ha hozzá is szeretnénk tenni valami újat, azt már bonyolultabbnak találom. Ha jutottál vele valamire, az eredményről szívesen olvasnánk.
-
drmotto
őstag
Üdv!
Calibre-vel ki lehet szedni valahogy a könyvel elejéről a metaadatokat, vagy csak úgy, ha word-be konvertálom, törlöm, majd vissza?
Illetve, lehet valahol állítani, hogy amikor mobiba konvertálom, akkor a metaadatok közül mi kerüljön bele? Mert pl. a fülszöveg jó ha ott van, de pl. a címke felesleges.Köszi.
-
snowdog
veterán
Erre többféle lehetőség van, az egyik amit Degeczi is említett, a PDFTOEPUB. De van más lehetőség is. [link]
Nekem a legjobban az ABBYY PDF Transformer 3.0 (fizetős) vált be. Szinte hiba nélkül konvertál. Ennek segítségével készítek a pdf-ből Word rtf-et, majd szerkesztés után abból készítek a Calibre-vel mobi-t.
-
Degeczi
nagyúr
nem gondolhatod komolyan, h ha nem kezelné, akkor ilyen népszerű lenne...
az teljes használhatatlanságot jelentenevalszeg hülye kódolású PDF-el próbálkozol, ami nem a Calibre-n múlik, mert ez csak a külön meghívott PDF2HTML segédlet kimenetén dolgozik tovább: ha ez a segédlet elbukik a szerencsétlen anyagon (pl. a Search/Replace funkció alatt a varázspálca ikonnal nézhető meg, milyen HTML-t kapott tőle a Calibre), akkor nincs más megoldás, először vmi másik alkalmazással (pl. PDFTOEPUB) kell emészhető formába rázni a könyvet
-
Degeczi
nagyúr
ne keverd mappákkal a collectiont: nem az!
egy egyszerű címke, semmi más...
ebből adódóan míg egy könyv csak egyetlen mappába tartozhatna, címke több is ragasztható rá (pl. "sci-fi" és "angol" is)
ezért van értelme, h az alap nézetekben (olvasás, szerző vagy cím szerinti) mutatja a címkével már ellátottakat is
ha vmiért zavar, válaszd a "collection" nézetet fönn -

nfernc
csendes tag
Sziasztok!
Előre is bocsi, ha már elhangzott a kérdés, biztos átsiklottam felette.
A kindle 4-emen (No-Touch) szerettem volna rendezgetni a könyveimet mappákba az említett programmal, azonban belefutottam egy furcsaságba. Amellett, hogy az elkészült collection-ban megjelennek a kívánt elemek, a ömlesztve elérhetőek az eszköz főkönyvtárában is.
Olyan mintha a mappában szerepló könyvek csak hivatkozások lennének, mert habár működnek, ha törlöm a mappán kívülről a könyvet, akkor a mappából is törlődik.Ennek így kellene működnie? Van ötletetek a dolog megoldására?


















Új hozzászólás Aktív témák

- Samsung Galaxy A12 64GB, Kártyafüggetlen, 1 Év Garanciával
- BESZÁMÍTÁS! Apple MacBook Air 15 M3 8GB 256GB SSD garanciával hibátlan működéssel
- Beszámítás! Lenovo Legion Slim 5 16AHP9 notebook - R7 8845HS 16GB RAM 512GB SSD RTX 4060 8GB Win11
- Beszámítás! HP Victus 16-R1002NF Gamer notebook - i7 14700HX 16GB RAM 1TB SSD RTX 4070 8GB WIN11
- BESZÁMÍTÁS! Asus Rog Zephyrus G14 notebook - R9 4900HS 16GB RAM 512GB SSD RTX 2060 6GB Max-Q WIN10
- AlzaPower CAT6 UTP 40m, szürke kábel
- ÁRGARANCIA!Épített KomPhone Ryzen 7 7700X 32/64GB RAM RX 9070 16GB GAMER PC termékbeszámítással
- Csere-Beszámítás! RTX Számítógép játékra! I5 13400F / 32GB DDR5 / RTX 4070 Super / 1TB SSD
- Bomba ár! HP EliteBook 820 G3 - i5-6GEN I 8GB I 256GB SSD I 12,5" FHD I Cam I W10 I Garancia!
- Csere-Beszámítás! Asztali számítógép játékra! I5 14400F / RX 6900 XT 16GB / 32GB DDR5 / 1TB SSD
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest