Hirdetés
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- Az Intel mindent feltesz az Intel 14A node-ra
- Nvidia GPU-k jövője - amit tudni vélünk
- Nagyon bízik az Instinct MI450-ben az AMD alelnöke
- Milyen egeret válasszak?
- Mini-ITX
- NVIDIA GeForce RTX 5080 / 5090 (GB203 / 202)
- SSD kibeszélő
- MILC felhasználók szakmai topikja
- Fejhallgató erősítő és DAC topik
Új hozzászólás Aktív témák
-
#741
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
Szerintem ez megér egy linket: Zen L3$ elemzés
Az inspiráció
Lényegében azt mondja, hogy szintetikus 1 szálas cache tesztelő programmal csak 8MB cache használat mérhető, mivel 1 processzor közvetlenül csak 8MB L3$-hez fér hozzá, egész pontosan a saját maga adataival csak 8MB-ot tud megtölteni és onnan újrahasznosítani.
A leírás szerint amit eddig inter-CCX latency-nek, vagy CCX-ek (L3$-ek) közti késleltetésnek gondoltunk a rendelkezésre álló mérések szerint, az csupán azt képezi le, hogy egyszálas felhasználás esetén az elsőkézből rendelkezésre álló 8MB-on túl mennyire sok esetben nincs is benne a másik CCX L3$-ében az adat, aminek folytán a memóriához kell nyúlni.
Vagy másként megfogalmazva az, hogy egy CCX egyik magja egy kért adatot egy másik CCX L3$-ében megtaláljon az elég esetleges. Akkor fordulhat elő leggyakrabban, ha - rossz optimizáció következtében - egy programszál egy másik CCX-re pattan át.
Sajnos a videóban és a leírásban nem mutatnak meg ilyen esetet (egyik CCX teleírja a cache-t, a másik CCX egyik magja pedig olvas.)
Bennem őszintén szólva felvetődött annak gondolata is, hogy talán az egyik CCX-ből a másik CCX L3$-éhez nem is nyúlRémlik egy ábra még régről, hogy ha nem találha a zen az adatot a saját L3$-ben, akkor párhuzamos kérést küld a DDR vezérlő és a szomszédos L3$ irányába és ahonnan előbb érkezik, azt használja, de nem tudom felidézni ennek helyét.
TAláltam viszont egy Inteles ábrát, ahol az intel tudni véli ezeket a számokat:
L3$ "Far": 98ns
DDR4: 102nsEz a különbség annyira kicsi, és ha a fenti leírás igaz, mindenképpen meg a kérés mindkét irányba. Viszont a különbség annyira kicsi,hogy őszintén felvetődik bennem az kérdés, hogy van-e értelme az elvileg a CCX-eket összekötő IF-et ezzel terhelni? Amikor általánosságban nagyon kicsi az esélye annak, hogy a másik L$3-ben benne van az adat, a kérés a DDR vezérlő felé úgyis biztosan elment, és a DDR irányából az adat úgyis biztosan megérkezik.
Én simán el tudom képzelni, hogy a zen1-ből a CCX-ek ilyen jellegű összekötését, tehát ami a másik CCX L3$-éhez való átnyúlást lehetővé tenné egyszerűen kihagyták.
És akkor most a predikció
Így néz ki a zeppelin CCX :

Számos latency test utal arra, hogy 1 mag lokális L3$ egyes szeleteit sem egységes késleltetéssel éri el. Mondjuk úgy, hogy a 8MB-tól az utolsó 2, néha 4MB elérése lassabb. Nyilván azzal áll összefüggésben, hogy a fenti "ábrán a lila" sávokon mennyit kell utaznia az adatnak.
Hasonló kommunikációs csatorna a CCX-ek között nem látszik:

Ellentétben ezzel a képpel:
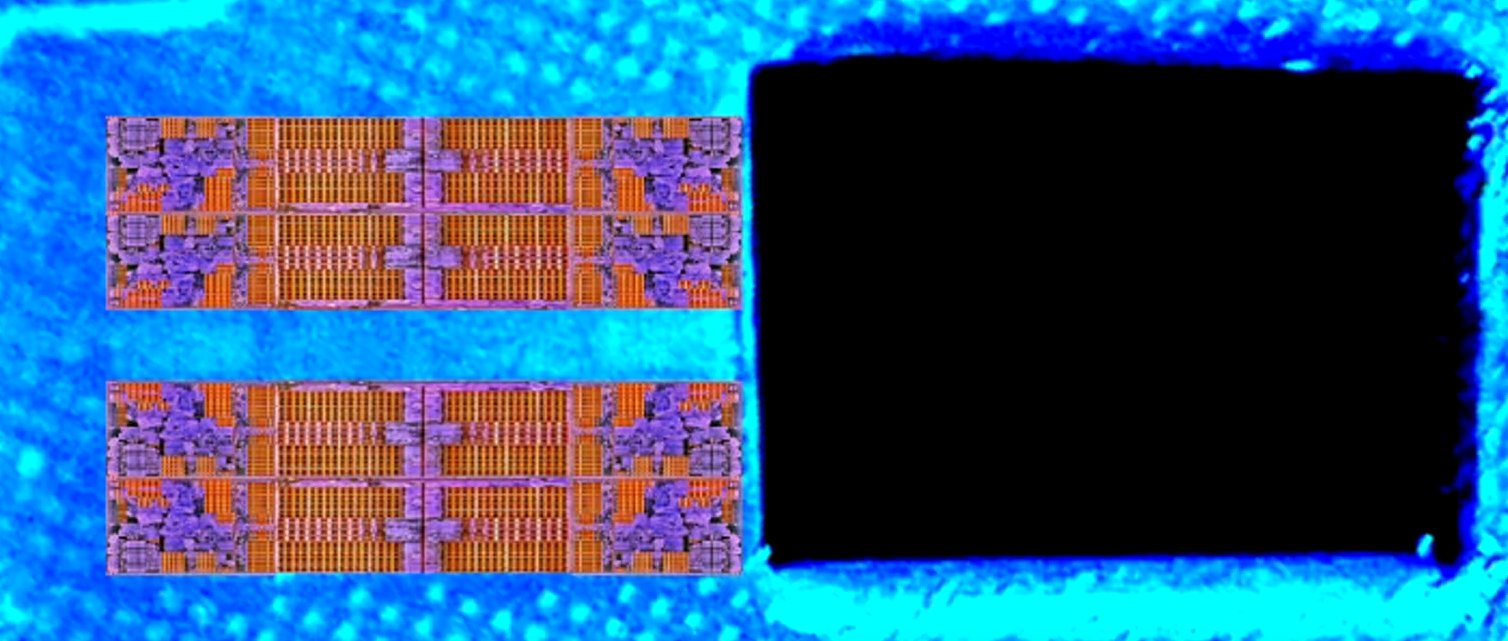
AdoredJim vetette fel, hogy esetleg a CCX-ek között az alábbi módon crossbar lenne:

Vagy esetleg valami más, de a lényeg, hogy tényleg ott van egy csomó olyan hely, ami végigfut kereszt formában a lapkán és függőlegesen mintha összekötné a két CCX L3$-ét és vízszintes irányban is lehetővé teheti másik lapkával a CCX-ek és azok L3$-ének összekapcsolását. (Ez megmagyarázná, miért vannak párosával egymáshoz közel a Rome-on)
Ha - ellentétben a zeppelinnel - a zen2 esetén esetleg tényleg működik CCX-ek között adatmegosztási lehetőség, ami gyorsabb, mint a memóriába irányába történő kérés, akkor az a userbenchmark latency mérésében egyáltalán nem mutatkozna meg, hiszen egy mag továbbra is a neki dedikált 16MB L3$-t tudja megtölteni és újrahasznosítani.
Ellenben enyhítene/megoldana minden olyan - jellemzően játékokban megjelenő problémát, ami a szálak egyik magról a másikra való átpattogásának, vagy megosztott adatfelhasználásnak késleltetéséből fakad.

Új hozzászólás Aktív témák
- Borderlands 4
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- Gurulunk, WAZE?!
- Az Intel mindent feltesz az Intel 14A node-ra
- sziku69: Szólánc.
- sziku69: Fűzzük össze a szavakat :)
- Luck Dragon: Asszociációs játék. :)
- Kerti grill és bográcsozó házilag (BBQ, tervek, ötletek, receptek)
- Vicces képek
- iPhone topik
- További aktív témák...

- Apple iPhone 15 128 GB Kék 12 hónap Garancia Beszámítás Házhozszállítás
- BESZÁMÍTÁS! 1000W Sesonic FOCUS GX-1000 Gold tápegység garanciával hibátlan működéssel
- OLCSÓBB!!! Dell Latitude Precision XPS Üzleti gépek, 2-in-1 gépek, Vostro 8-12. gen.
- Telefon felvásárlás!! Samsung Galaxy S21/Samsung Galaxy S21+/Samsung Galaxy S21 Ultra
- LG 55CS6 - 55" OLED - 4K 120Hz 1ms - NVIDIA G-Sync - FreeSync Premium - HDMI 2.1 - PS5 és Xbox!
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest