- Milyen TV-t vegyek?
- Multimédiás / PC-s hangfalszettek (2.0, 2.1, 5.1)
- Mini-ITX
- Sugárhajtómű ihlette a Zalman CPU-hűtőjét, de nem az üzemzaj tekintetében
- Apple MacBook
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- Steam Deck
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- AMD Navi Radeon™ RX 9xxx sorozat
- A hardverek is nehezen viselik a kánikulát

Új hozzászólás Aktív témák
-
#1709
 Jester01
veterán
Sk8erPeter
#1708
Jester01
veterán
Sk8erPeter
#1708
Jester01
veterán
válasz
 Sk8erPeter
#1708
üzenetére
Sk8erPeter
#1708
üzenetére
Amilyen gyorsan megtanultad, ugyanolyan gyorsan felejtsd is el

Ugyanis semmilyen hibakezelést nem végez így nagyon kiváló túlcsordulást lehet vele csinálni. Persze tehetsz bele max hosszot, de akkor meg azzal kell külön vacakolni, hogy a pufferben maradt szemetet kiolvasd (ugye a példa szerint is benne marad egy enter ami a következő beolvasást megzavarhatja) illetve hogy értelmes hibaüzenetet adj. Szóval kb házi feladat programokhoz jó, egyébként pedig egész sorokat kell olvasni és aztán szépen értelmezni. Macerás, de ez van. -
Jester01
veterán
válasz
 Gyuri16
#1680
üzenetére
Gyuri16
#1680
üzenetére
man waitpid
POSIX.1-2001 specifies that if the disposition of SIGCHLD is set to SIG_IGN or the SA_NOCLDWAIT flag is set for
SIGCHLD (see sigaction(2)), then children that terminate do not become zombies and a call to wait() or waitpid() will
block until all children have terminated, and then fail with errno set to ECHILD. (The original POSIX standard left
the behavior of setting SIGCHLD to SIG_IGN unspecified. Note that even though the default disposition of SIGCHLD is
"ignore", explicitly setting the disposition to SIG_IGN results in different treatment of zombie process children.)Tehát a 2001-es POSIX szabvány szerint a signal miatt nem lesznek zombik, a waitpid pedig az összes gyereket bevárja és aztán hibát dob (vagyis nem adja vissza a status-t). Más szabványú implementáció esetén még a signal ellenére is szükséges lehet a waitpid a zombik elkerülésére.
-
Jester01
veterán
válasz
Gyuri16
#1677
üzenetére
Valószínűleg ez fájl felülírás, tehát már lehet valami ott. Ha feltételezzük, hogy az olvasás a fájl végéig megy, akkor 0 byte hatására még ha van is utána szemét az C stringként már nem fog látszani.
Pl. ha a fájlban most az van, hogy "makvirag" és azzal akarod felülírni, hogy "rozsa" akkor a 0 byte nélkül az lenne ott átmenetileg, hogy "rozsarag". Ha egy másik program épp ilyenkor olvasná ki akkor hibás adatot kapna. Ha viszont a lezáró nulla byte is bekerül, akkor azt fogja kapni, hogy "rozsa<0>ag". De mivel a C logika szerint a string csak a 0 byteig tart, ezért ez a helyes "rozsa" értékkel egyenértékű. Ezután persze az ftruncate le fogja vágni a fölösleges byteokat, szóval csak egy nagyon rövid ideig fordulhat elő.
-
#1641
Jester01
veterán
Scroll Lock
#1640
Jester01
veterán
válasz
 Scroll Lock
#1640
üzenetére
Scroll Lock
#1640
üzenetére
1) C-ben így nem tudsz dinamikus tömböt csinálni. Pointerekkel és malloc-kal kell játszani.
2) Nem, annak a tömbnek pontosan 1 dimenziósnak kell lennie -
Jester01
veterán
válasz
 Dead_slow
#1626
üzenetére
Dead_slow
#1626
üzenetére
Mivel a legnagyobb különbséget már megtaláltad így semmi más dolgod nincs mint mégegyszer végigmenni a telkeken és kiírni azon telkek jellemzőit amiknél a különbség megegyezik a maximummal. (A feladatkiírás szerint több is lehet, különben elég lenne az első ciklusban egyszerűen megjegyezni az elem indexet is.)
-
Jester01
veterán
válasz
 Dirty_Pio
#1622
üzenetére
Dirty_Pio
#1622
üzenetére
Már az init függvényedben is van egy túlcímzés z[maxlen].next=-1; .
Az add függvényben sem "megy minden jól": if(-1==(k=z[k].next)) z[k].next=*d; Továbbá a temp változót két típusként is használod, egyszer tipnod egyszer meg tiplista. Ezeket javítva látszólag működik a kód, bár a typedef char tipcursor; igen szerencsétlen választás mivel nem tudhatod előjeles vagy nem. Márpedig ha nem az, akkor -1 sose lesz és végtelen ciklusba kerül a program.Láncolt listába beszúráskor amúgy nem kellene az elemeket másolgatni.
-
Jester01
veterán
-
Jester01
veterán
válasz
 grabber
#1559
üzenetére
grabber
#1559
üzenetére
1. a main után hiányzik a zárójelpár
2. a FILE * brain után hiányzik egy pontosvessző
3. a pointerek csillagja ízlés szerint vagy a típushoz vagy a változóhoz írandó, középre semmiképp (mert úgy aztán tényleg szorzásnak néz ki - de szintaktikailag helyes)
4. ha egyszer void a main akkor nem lehet benne return(1)
5. a return nem függvényhívás nem kell oda a zárójel (de ez is helyes szintaktikailag)
6. a Grabber:\ nem tudom micsoda de bízom benne, hogy a géped tudja
7. viszont érdemes lenne azért ellenőrizni a brain pointert is, hátha mégse
8. konstans szöveg kiírásához az (f)puts ajánlott, főleg, ha nem tudod mi a szöveg
9. hibajelzéseket tipikusan az stderr kimenetre küldjük
10. a while(feof(fp)) az esetek többségében hibás struktúra, helyette az adott beolvasó függvény visszatérési értékét kell vizsgálni
11. az fgetc meglepő módon int típust ad vissza, hogy tudja jelezni a fájl végét. Tehát a c változó típusa ez legyen
12. az fwrite hívást gyanítom a fórummotor tette tönkre, tessék szépen használni a Programkód gombot (egy őstagnak magyarázzam? )
)
13. mindazonáltal ha fgetc van, akkor a kiíráshoz fputc ajánlott, mert az a párja
14. a kiírás sikerességét is jó ellenőrizni
15. a kimeneti fájlt nem annyira célszerű bezárni a ciklusban egyetlen karakter kiírása után
#include <stdio.h>
int main()
{
FILE* fp;
FILE* brain;
int c;
fp = fopen("C:\\Tanuljunk meg programozni.txt", "rt");
brain = fopen("Grabber:\\Head\\Brain.txt", "a+t");
if (fp == NULL || brain == NULL) {
fputs("Hiba a fajlok megnyitasakor\n", stderr);
return 1;
}
while((c = fgetc(fp)) != EOF) {
if (fputc(c, brain) == EOF) {
fputs("Hiba iras kozben!\n", stderr);
fclose(brain);
fclose(fp);
return 1;
}
}
fclose(brain);
fclose(fp);
return 0;
} -
#1561
Jester01
veterán
LevyZidane
#1560
Jester01
veterán
válasz
 LevyZidane
#1560
üzenetére
LevyZidane
#1560
üzenetére
Igazából a ciklusmag elején kellene foglalni mindig egy új elemet amit a végén (ha sikerült az összes mezőt beolvasni) hozzáadsz a listához.
-
#1554
Jester01
veterán
Sk8erPeter
#1553
Jester01
veterán
válasz
Sk8erPeter
#1553
üzenetére
Mindenütt számít, úgy hívják operátor precedencia.
 A [ ] index operátor erősebb mint a * dereferencia operátor tehát ha neked előbb kell a * akkor bizony zárójelezni kell.
A [ ] index operátor erősebb mint a * dereferencia operátor tehát ha neked előbb kell a * akkor bizony zárójelezni kell.char** helyiertek[10] 10 elemű tömb melynek minden eleme egy char** pointer
char* (*helyiertek)[10] 1 darab pointer ami egy 10 elemű tömbre mutat melynek elemei char* pointerek (stringek) -
#1552
Jester01
veterán
Sk8erPeter
#1551
Jester01
veterán
válasz
Sk8erPeter
#1551
üzenetére
char* (*helyiertek)[10];
-
#1550
Jester01
veterán
Sk8erPeter
#1546
Jester01
veterán
válasz
Sk8erPeter
#1546
üzenetére
A típust merő gonoszságból direkt hagytam le, hogy legyen min gondolkodni ha valaki akar. De sajnos a te fordítód megmondja
 , ott van a hibaüzenetben: char* (*)[10] Ez kiolvasva azt jelenti, hogy olyan pointer ami egy tíz elemű string tömbre mutat. Vagyis gyakorlatilag a romai mátrix egy sorára. És azért adok hozzá 3-at mert visszafelé megyünk benne tehát az utolsó sorral kezdünk. Ha átrendeznénk a sorokat akkor értelemszerűen ez nem is kellene.
, ott van a hibaüzenetben: char* (*)[10] Ez kiolvasva azt jelenti, hogy olyan pointer ami egy tíz elemű string tömbre mutat. Vagyis gyakorlatilag a romai mátrix egy sorára. És azért adok hozzá 3-at mert visszafelé megyünk benne tehát az utolsó sorral kezdünk. Ha átrendeznénk a sorokat akkor értelemszerűen ez nem is kellene. -
#1539
Jester01
veterán
Sk8erPeter
#1538
Jester01
veterán
válasz
Sk8erPeter
#1538
üzenetére
Elfelejtetted inicializálni a romai tömböt. Márpedig strcat hívása ilyen esetekben rosszat jelent. Nem ellenőrizted, hogy a scanf-nek sikerült-e beolvasni valamit egyáltalán (persze azt sem, hogy esetleg csak egy része volt értelmes a bemenetnek). Valamint hiányzik egy return 0; a végéről.
Egyébiránt pár oldallal korábban már volt itt ilyen kód
-
Jester01
veterán
Tipikus x86 fordító esetén a 32 bit és a 64 bit mód között csak a long más. A char, short, int, float, double az ugyanaz. Ahogy a kollega említette, a limits.h és a float.h megmondja neked a határokat. Egészeket először long-ba olvasd be az strtol függvénnyel. Itt a hibakezelés megmondja nem túl nagy-e a szám vagy van-e vele más baj. Ezután a limits.h alapján már tudod ellenőrizni belefér-e a célváltozóba. Hasonlóan a tizedestörtekre az strtod függvénnyel indulva. Szerintem
-
Jester01
veterán
Más konvenciók meg pont azt mondják, hogy nyugodtan használj annyi returnt amennyit akarsz, az átláthatóság miatt
 Ugyanis adott esetben sok if/else ág lenne illetve segédváltozók és/vagy ciklus lefutás után a feltétel újratesztelése is szükséges lehet.
Ugyanis adott esetben sok if/else ág lenne illetve segédváltozók és/vagy ciklus lefutás után a feltétel újratesztelése is szükséges lehet.int find(int needle, int* haystack, int size)
{
int result = -1;
if (haystack == NULL)
{
fputs("haystack NULL", stderr);
} else {
for(int i = 0; i < size; i++)
{
if (haystack[i] == needle)
{
result = i;
break;
}
}
}
return result;
}-vagy-
int find(int needle, int* haystack, int size)
{
if (haystack == NULL)
{
fputs("haystack NULL", stderr);
return -1;
}
for(int i = 0; i < size; i++)
{
if (haystack[i] == needle)
{
return i;
}
}
return -1;
}Az első esetben hiába van 1 return a függvény végén, ahhoz, hogy megtudd mit ad vissza ígyis-úgyis végig kell nézni a függvényt, hogy hol lesz az a változó beállítva. Akkor meg pont ugyanolyan egyszerű a return utasításokat megkeresni. Ha pedig mondjuk két ciklus van egymásbaágyazva akkor még több macera kijutni belőlük (mivel ugye goto-t sem használunk
) -
Jester01
veterán
C89 szabvány szerinti C nyelvben illetve C++ nyelvben csak fix méretű tömb van. C99-ben van dinamikus is. GCC meg szeret alapból nagyon laza lenni, házi feladat vagy hordozható kód esetén ajánlott a -ansi -pedantic -Wall. Ezen felül bizonyos warningok meg csak bekapcsolt optimalizáció mellett jelenkeznek.
MOD: haha a klónom gyorsabb volt
Sőt tulajdonképpen mindenki. Na mindegy.MOD #sok:
$ gcc -ansi -pedantic -Wall dab.c
dab.c: In function 'f':
dab.c:5: warning: ISO C90 forbids variable length array 'x' -
Jester01
veterán
Az fscanf szintaxisa 2 karakter beolvasására: fscanf(bemeneti fájl neve, "%c %c", &a, &b)
Nem a fájl neve kell oda, hanem a megnyitott fájl pointer. Karakter olvasáshoz az fgetc függvényt kell használni ami szintén a fájl pointert kapja és visszaadja a soron következő karaktert. A getchar() ekvivalens egy fgetc(stdin) hívással, vagyis az a standard inputról olvas ezért nem kell neki fájl.
Példa:
#include <stdio.h>
int main(int argc, char* argv[])
{
FILE* f = fopen(argv[1], "rb");
int ch;
while((ch = fgetc(f)) != EOF) putchar(ch);
fclose(f);
return 0;
} -
Jester01
veterán
Gondolom a tíz elemű tömb definiálása és a tízszer három szám beolvasása nem okoz problémát az ellenőrzéssel együtt sem.
Egy adott koordinátahármas int-be pakolásához először mindegyiket az adott formára kell hozni, pl: if (x < 0) x = 0x80 | -x;. Ezután pedig bit eltolás művelettel egybe lehet őket tenni, pl: int step = (x << 16) | (y << 8) | z; -
Jester01
veterán
Pl. úgy, hogy nem intet használsz, hanem longot, ami mindig 32-bites.
Mindig? Na ne viccelj!kikiáltja C++ programozásnak, pedig ez csak egy C program, C++ fordítóval lefordítva,
Azért mert egy adott program ránézésre esetleg nem annyira objektum-orientált vagy ilyesmi, azért még meg lehet írni c++-ban. És persze semmi akadálya, hogy az implementáció során osztályokat használj pl. a "Program", "Terminal", "Executor" (ez egy absztrakt osztály lenne), "Simulator" (ez meg implementálja az Executor-t). Így ha teszem azt később ki akarod bővíteni azzal, hogy vezéreljen egy usb portra kötött 3D robotot akkor csak egy új osztály kell ami az Executor-t implementálja.cucka: Mivel a feladat specifikálta, hogy ezt a 3 byteot kell belegyömöszölni az int-be ezért feltételezhető, hogy az adott architektúrán legalább 24 bites az int. Ha meg több az tök mindegy. Egyszerű bit műveletekkel meg lehet oldani. Amúgy ha ettől a feladattól elvonatkoztatva valamikor adott bitszámú int-re van szükséged, akkor az stdint.h-ban laknak olyanok, hogy int32_t meg int_least32_t és társaik.
-
Jester01
veterán
Hát ez elég szájbarágósan le van írva. Meg tudod mondani melyik rész okoz problémát?
Votyesz13: te meg lehagytad a feladatot. De a for az ciklus tehát ha valamit ismételni kell akkor használd. A switch meg csak egy felturbózott if amit akkor használunk ha azonos kifejezés különböző értékeit akarjuk vizsgálni.
-
Jester01
veterán
Mégpedig azért, mert a scanf egy borzasztó rossz függvény terminálról olvasáshoz.
Ha debuggerrel vagy egy kiíratást betéve megnézed mi lesz a gyalog változód valószínűleg egyből kiszúrod, hogy bizony a bástya bekérés után a pufferben maradt egy (vagy kettő) soremelés karakter és az kerül oda.Gyors megoldásként ha a második scanf formátumstring elejére teszel egy szóközt akkor már jó lesz. (Persze ahogy cucka kollega mondta, csak simán az értékeket hasonlítsd össze.)
Beolvasáshoz amúgy fgets és sscanf párosa ajánlott, megfelelő hibakezeléssel.
-
Jester01
veterán
Az a veszélye, hogy a szabvány nem rögzíti előjeles vagy nem. Ha valakinek ez fontos, akkor feltétlen írja ki, hogy unsigned char vagy signed char ellenkező esetben érheti meglepetés.
Például az á betű kódja iso8859-2 szerint 225, de ha a char véletlen előjeles akkor a naív if (c == 225) bizony nem lesz jó:
#include <stdio.h>
int main()
{
char c = getc(stdin);
printf("c == 225: %d\n", c == 225);
return 0;
}$ gcc -Wall t.c
t.c: In function 'main':
t.c:6: warning: comparison is always false due to limited range of data type
$ echo á | ./a.out
c == 225: 0
$ gcc -Wall -funsigned-char t.c
$ echo á | ./a.out
c == 225: 1 -
-
#1238
Jester01
veterán
m0h0senator
#1237
Jester01
veterán
válasz
 m0h0senator
#1237
üzenetére
m0h0senator
#1237
üzenetére
A legnagyobb közös osztóhoz a közös prímtényezőket kell venni a legmagasabb közös hatványon. A többszöröshöz meg prímtényezők úniója kell. Legalábbis én így emlékszem.
-
Jester01
veterán
válasz
Dirty_Pio
#1233
üzenetére
Nekem speciel nem kerül végtelen ciklusba csak nem csinál semmit:
while (fgets(buff,250,f))
{
linelen=strlen(buff);
fseek(f,-linelen,1);
fprintf(f,"%s",buff);
};Ugyanis a fenti ciklus szépen beolvas egy sort, majd visszmegy ugyanannak a sornak az elejére és újra kiírja. Vagyis nem csinál semmit csak minden sort rámásol saját magára.
-
#1235
Jester01
veterán
m0h0senator
#1234
Jester01
veterán
válasz
m0h0senator
#1234
üzenetére
Melyik részére kell ötlet? Prímtényezőkre bontáshoz a legfavágóbb módszer ha szépen ciklusban megpróbálod leosztogatni. A végeredmény pedig a tényezőkből már adódik.
-
#1226
Jester01
veterán
Gergőőőőőőőő
#1225
Jester01
veterán
válasz
 Gergőőőőőőőő
#1225
üzenetére
Gergőőőőőőőő
#1225
üzenetére
És melyik részéhez kellene a segítség? Mi tudtál megcsinálni és mit nem?
Nagy vonalakban pl. a string osztály find, find_first_of, find_first_not_of metódusaival megcsinálod a darabolást, simán cin/cout a kérdéshez, és egy ofstream a fájl íráshoz.
-
Jester01
veterán
válasz
 !wannabe
#1214
üzenetére
!wannabe
#1214
üzenetére
Érthető a kérdésem?
Nem
A listádban nevek vannak, tehát az if(current->name == del) értelmetlen.
Vagy név szerint akarsz törölni, vagy index szerint. Ha név szerint akkor nyilván nem egy int paramétert kell átadni, ha meg index szerint akkor nem a name mezővel kell összehasonlítani. -
Jester01
veterán
1) megnézted, hogy a GetLastError mit mond?
2) van joga a felhasználónak a desktophoz? ("The application must add permission for the specified user account to the specified window station and desktop, even for WinSta0\Default.")
3) esetleg nem unicode stringeket adsz be neki? -
Jester01
veterán
válasz
 skylaner
#1165
üzenetére
skylaner
#1165
üzenetére
A valgrindban van egy "massif" eszköz is, az nem jó?
#-----------
snapshot=64
#-----------
time=124348
mem_heap_B=8
mem_heap_extra_B=8
mem_stacks_B=1008
heap_tree=detailed
n1: 8 (heap allocation functions) malloc/new/new[], --alloc-fns, etc.
n0: 8 in 1 place, below massif's threshold (01.00%) -
Jester01
veterán
válasz
skylaner
#1163
üzenetére
Hát a globális (illetve statikus) változók azok benne vannak a program fejlécében (objdump -h kimenetben data+bss). Lokális változók méreténél (ideértve a függvényargumentumokat is) nem tudom mit szeretnél tudni, esetleg a maximális verem méretet? Mivel ismereteim szerint linux alatt a verem nem csökken, ezért azt elvileg ki lehet nyomozni a futás végén. Például gdb-vel breakpoint az exit függvényre és a /proc/<pid>/maps fájlban a stack bejegyzésből.
-
Jester01
veterán
válasz
skylaner
#1161
üzenetére
Igen, a lezáró nulla csak akkor megy át, ha 14 byteot küldesz. Jelen esetben amúgy nem is kell lezárni: if (len == 13 && strncmp(msg, "download_over", 13) == 0) ....
Ja és a recv visszaadhat hibakódot (-1) vagy éppenséggel BUFF_SIZE értéket is és ezekben az esetekben a msg[len]='\0'; felettéb szerencsétlen lenne (de gondolom a hibakezelést csak innen a postból hagytad ki).
-
Jester01
veterán
válasz
skylaner
#1148
üzenetére
Viszont nincs benne hossz korlátozás ezért használata erősen ellenjavalt (buffer overrun). Helyette általában az fgets ajánlott, de vigyázat, az viszont eltárolja a sorvég jelet is. Jelen esetben azonban teljesen felesleges sorokat olvasni, mivel a feladat karakter-orientált.
-
#1135
Jester01
veterán
Sk8erPeter
#1133
Jester01
veterán
válasz
Sk8erPeter
#1133
üzenetére
1. azért mert unicode (akár utf8 akár utf16/ucs2) esetén nem 1 byte 1 karakter. Utf16 esetén továbbá sok 0 byte is előfordul ami C-ben sajnos a string végét jelzi.
2. nem fontos, de ha egyszer konstans, akkor miért ne
3-4. lásd a kollega válaszát fentebb
5. jó
-
#1113
Jester01
veterán
Sk8erPeter
#1107
Jester01
veterán
válasz
Sk8erPeter
#1107
üzenetére
Na itt az én verzióm, hogy ti is kötözködhessetek. Amit még én magamba belekötök, hogy lehetne még:
1. függvényekre szétszedni
2. a hosszú fájlneveket is (láncolt listával) kezelni
3. a tab-okat kezelni
4. locale beállításokat figyelembe venni
5. a kimenő fájlnevet szebben előállítani
6. parancssori argumentumokat kezelni -
#1112
Jester01
veterán
Sk8erPeter
#1107
Jester01
veterán
válasz
Sk8erPeter
#1107
üzenetére
Szerintem a fájlod esetleg unicode lehet, az bekavarhat.
-
Jester01
veterán
válasz
 Benmartin
#1109
üzenetére
Benmartin
#1109
üzenetére
5. Nem, de miért nem írod egyből jóra a programot? Azért, hogy extra pénzt kaszálj majd a professional verzióért ami nagyobb fájlokat is tud kezelni? Igen, lefordul, csak esetleg nem működik. Ráadásul a változó argumentumot használó függvényeknek ansi C szerint is kötelező a prototípus (pl. fscanf, printf) tehát általában az stdio.h bizony nem elhagyható. Az meg, hogy egy adott fordító esetleg mit eszik meg és mit nem, abszolút nem befolyásolja hogy mi van a szabványban vagy hogy mi a helyes.
6-7. melyik részének mondasz ellent? Annak, hogy int a prototípus nélküli függvények visszatérési értéke vagy annak, hogy pl. 64 biten piszkosul megszívod ha int-et használsz pointer helyett?
A többire pedig továbbra is csak azt tudom mondani, hogy lehetőleg ne ezt tanítsd egy kezdőnek.
-
Jester01
veterán
válasz
Benmartin
#1105
üzenetére
Azért kötözködtem, mert tanuláshoz rossz példa.
2. Izé, kipróbáltad? Mert nem működik, mivel a feof csak azután lesz igaz, hogy túlmész a fájl végén. Tehát előfordulhat, hogy eggyel többször fut a ciklusod és az utolsó alkalommal ki tudja milyen adatra. Ehhez csak az kell, hogy az utolsó sor végén is legyen egy soremelés (márpedig ez normális dolog). Egyébként is pl. %d esetén vagy bonyolultabb formátumstringnél abból tudod, hogy sikerült-e beolvasni valamit. ellenkező esetben könnyen végtelen ciklus lehet (ugyanis olyankor a fscanf nem eszi meg a hibás adatot, de feof sem lesz)
3. sajnos de. sőt, még ékezeteket is. sokat szívok ezekkel én is a munkám során, főleg linux-windows közötti másolgatás nagy élmény (meg a kalapos vs. rendes ő/ű)
4. az azért van, hogy annyit kezel a programod, addig ok. de sehol nem biztosítod, hogy ne is legyen több. Az fscanf jelen formájában vidáman megesz többet is és szép buffer overflow lesz belőle. Ezt is jobb idejekorán megtanulni.
5. igen, és ez a rossz. már miért is ne lehetne egy 120GB-os fájlt feldolgozni csak azért mert nincs 120GB memóriám.
6-7. már hogyne kellene. Amelyik függvénynek nincs prototípusa, azt alapból int visszatérési értékkel feltételezi a fordító. Márpedig sem a malloc sem pedig az strcat nem int-tel tér vissza. És ha az int véletlen nem binárisan kompatibilis a void* illetve a char* típusokkal (pl 64 bites rendszer esetén) akkor az instant segfault.
10. szerintem nem fölösleges, jobb ha az újonc azt látja hogy a változókat a lehető legszűkebb körben deklaráljuk
11. azt te honnan tudod? És ha 5GB-os fájlra akarom futtatni? Vagy 128kB-osra 16 bites rendszeren?
12. ja és akkor nem kell. pl ha egy fájl (vagy sor) véletlen nincs 4 karakter akkor a program összeomlása az rendben van? -
Jester01
veterán
válasz
Benmartin
#1102
üzenetére
Ajjjaj ilyen rossz példával ne kábítsuk szegény tanulókat
Hirtelen ennyi:1. te nem a sorok elejéről szedted le az első 4 karaktert
2. az fscanf visszatérési értékét célszerű ellenőrizni, nem pedig a feof-ot
3. %s formátummal nem olvasunk fájlneveket (sem) mert megáll a szóközöknél
4. az fscanf-ben nincs hossz limit
5. teljesen felesleges betölteni a memóriába a fájlt
6. strcat-hoz hiányzik a megfelelő #include
7. malloc-hoz hiányzik a megfelelő #include
8. a malloc void*-ot ad vissza, csúnyán néznek azokra akik ezt cast-olják
9. a lefoglalt memóriát nem szabadítod fel
10. a változók globálisak nem lokálisak
11. az ftell nem unsigned int-et ad vissza
12. hibakezelés teljes hiánya -
Jester01
veterán
Ok, az OpenProcess tényleg NULL-t ad vissza (de hogy miért, azt csak a microsoft tudja).
Azt, hogy miért csak kettőt indít el, így ránézésre nem tudom. Tipp 2 dolog lehet: vagy nem megy bele a while-ba háromszor vagy nem sikerül elindítani a CreateProcess-sel. Debuggold és/vagy tegyél bele kiíratást no meg hibakezelést.Az üres sort elég egyszerű felismerni, mert a hossza nulla. A levágott sort meg az jelzi, hogy a végén nem soremelés van.
-
Jester01
veterán
Hát ez sajnos elég szörnyűre sikerült

Amivel mindenképpen baj van:
* 3 processznek van helyed statikusan, és sehol nem ellenőrzöd nem lesz-e esetleg több
* az fgets-nél nem nézed nem üres sor jött-e illetve, hogy az egész sor megvan-e
* az OpenProcess nem NULL-t fog visszaadni, hanem INVALID_HANDLE_VALUE-t.
* a CloseHandle akkor is fut, ha a handle null (invalid)
* a while(1) ciklusban a "current" változó elmegy a végtelenbe (és nem is nulláról indul)A többi hiba ezekhez képest elhanyagolható.
-
Jester01
veterán
Na így már jobban hasonlít, bár a feladatkiírás szerint minden szót pontosan egy szóköz választ el egymástól, te meg mindenféle mást is elválasztójelnek tekintesz. Ez okozhat problémát.
De ami biztos rossz, hogy a fájl végén ha éppen soremelés után vagyunk (ami pedig szokás) akkor beszúrsz egy üres szót is a fába. Ettől eltekintve az általam használt tesztadatra jól működött.
-
Jester01
veterán
Ez meg nem is hasonlít a feladatkiírásra. Eleve egész számokról van szó. A fa elemeknél nem is értem a mezőket. A két bejárást sehol nem látom, ahogy a kiírandó igen és nem szavakat sem. A beolvasás meg úgy látom tetszőleges számú fájlból akar olvasni és sehová nem ír, pedig a feladat szerint egy darab bemeneti és egy darab kimeneti fájl van.
Biztos, hogy ez a program ehhez a feladathoz tartozik?
-
-
Jester01
veterán
Már majdnem megdícsértelek, hogy milyen ügyesen használod a valgrind-ot.

Az első hiba amit a vg talált, hogy az 57-es sorban nem inicializált változót használsz. Ez konkrétan az strlen(sz) és nyilván azért mert az sz nincs inicializálva. Ráadásul a cikluson belül is csupa szóközzel akarod feltölteni, 0 byteok helyett.
A második az az első folyománya, ha azt javítod, ez is eltűnik.
A harmadik a 37. sorban a main-ben inicializálatlan fej változók miatt van.
A következő a 42. sorban gondolom a fordított while feltétel miatt van.
#1000

-
#977
Jester01
veterán
Sk8erPeter
#975
Jester01
veterán
válasz
Sk8erPeter
#975
üzenetére
Azért növelgetük egy tetszőleges számig, mert annyi darab pontot teszünk ki. Vagyis a kört 100 részre osztjuk. A teljes kör ugye 2*PI radián, ezért lesz a fi annyi amennyi.
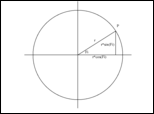
A P futó pont koordinátái nyilvánvalóan azok, amik a setpixel hívásban szerepelnek.
Ha a képpont rajzolás már megvan (a setpixel, vagy bármi ami azzal ekvivalens) akkor a fenti for ciklus kirajzolja a kört, semmi egyebet nem kell csinálni.
-
#974
Jester01
veterán
Sk8erPeter
#973
Jester01
veterán
válasz
Sk8erPeter
#973
üzenetére
Hát mert elírtam!
 Nyilván nem az r megy 0-tól 2PI-ig, mert az állandó, hanem a fi. Uppsz.
Nyilván nem az r megy 0-tól 2PI-ig, mert az állandó, hanem a fi. Uppsz.
Annyi lépésben amennyi pontra szükséged van. Ez is a kör egyenlete, ha behelyettesíted a tiedbe, akkor látszik (a sin^2 fi + cos^2 fi = 1 azonosság alapján)
Tehát pl. így lehetne ezzel kört rajzolni:for(i = 0; i < 100; i++)
{
double fi = i / 100.0 * 2 * M_PI;
setpixel(r * cos(fi) + u, r * sin(fi) + v);
}Ez a lépésszám függvényében lehet, hogy lukacsos lesz kicsit.
Van persze másik módszer is, de az szerintem macerásabb. -
Jester01
veterán
A másoláshoz eleve tudnod kellene hol kezdődik és hol végződik. És ha azt tudod, akkor már nem is kell átmásolni

int next_word(const wchar_t** start, const wchar_t** end)
{
/* az előző szó végétől indulunk */
*start = *end;
/* keressük meg a következő szó elejét */
while(**start != 0 && !iswalnum(**start)) *start += 1;
/* ha a string vége, akkor kész */
if (**start == 0) return 0;
/* keressük meg a szó végét */
*end = *start + 1;
while(iswalnum(**end)) *end += 1;
return 1;
}Az előző példához képest ez most pointeres, de ugyanaz a logika.
-
Jester01
veterán
Ja, ha soronként egy mondat van az jó.
Tulajdonképpen átmásolni felesleges, elég pozíció alapján nézegetni a mondatot. Tehát nyilvántartod a szó elejét és a végét és az alapján ellenőrzöl. Valami ilyesmivel:
int start = 0;
int end;
int found = 0;
while(next_word(&start, &end))
{
if (end - start >= 5 && is_palindrome(start, end))
{
found = 1;
break;
}
}Értelemszerűen a next_word és is_palindrome függvényeket neked kell megírni. Az előbbi sorban visszaadja a szavak kezdő és végpozícióját, az utóbbi pedig megnézi, hogy az adott szó palindróma-e.
-
Jester01
veterán
Azért kínálgatják a wchar.h-t, hogy az ékezetes karaktereket helyesen tudd kezelni. Éppen csak azt felejtették el megmondani, hogy milyen kódolásban van a fájl.
Igen, ha mondatonként olvasol be, az jó megoldás lehet. Figyelned kell arra, hogy esetleg nem fér bele a pufferbe, ezért dinamikusan kell méretezni. Vagy, ha nagyon csúnyán akarod, akkor egyszerre be is olvashatod az egész fájlt
 Mindenesetre azt kellene tudni, mi határoz meg egy mondatot - erre jó lenne ha a specifikáció kitért volna. Márcsak azért is, mert bizonyos esetkben igen nehéz eldönteni. Például az Apám neve id. Kiss János. az hány mondat is? Ennek hiányában egyszerű szabályként például azt lehet használni, hogy a mondat vége ott van ahol egy vagy több ., ! vagy ? áll ami után a következő betű nagy. De ezt mindenképp rögzíteni kell a dokumentációban. Összességében ez egy igen rosszul specifikált probléma, szerintem ne vállald el
Mindenesetre azt kellene tudni, mi határoz meg egy mondatot - erre jó lenne ha a specifikáció kitért volna. Márcsak azért is, mert bizonyos esetkben igen nehéz eldönteni. Például az Apám neve id. Kiss János. az hány mondat is? Ennek hiányában egyszerű szabályként például azt lehet használni, hogy a mondat vége ott van ahol egy vagy több ., ! vagy ? áll ami után a következő betű nagy. De ezt mindenképp rögzíteni kell a dokumentációban. Összességében ez egy igen rosszul specifikált probléma, szerintem ne vállald el A másik kérdésre: valamilyen alkalmas adatszerkezetben nyilván kell tartani a szavakat. Ahogy olvasod a bemenetet, a megfelelő szó előfordulásainak számát növeled. Tipikusan erre a hash tábla a célszerű, de mivel C-ben ilyen nincs, ezért például egy láncolt lista vagy egy bináris fa is megteszi. MOD: persze ilyenek sincsenek, de könnyebb csinálni
-
#962
Jester01
veterán
Sk8erPeter
#959
Jester01
veterán
válasz
Sk8erPeter
#959
üzenetére
Persze, hogy nem tanultál a setpixel függvényről, azt neked kellene megírni
Induláshoz: a setpixelnek semmi más dolga nincs, mint a megfelelő tömbelembe egy X-et tenni. Kört legegyszerűbb az x = r cos fi, y = r sin fi, r=0..2 PI paraméteres egyenletből csinálni, téglalapot meg simán a négy egyenesből.
Az egészet nem fogom megírni helyetted, de ha elakadsz valahol akkor segítek.
MOD: de lassú vagyok
-
#958
Jester01
veterán
Sk8erPeter
#957
Jester01
veterán
válasz
Sk8erPeter
#957
üzenetére
A platformfüggetlen megoldás az lenne, hogy csinálsz egy tömböt a memóriában ami a rajzfelületed. Implementálsz egy csoda setpixel függvényt ami kitesz egy képpontot ebben a tömbben. A rajzolás végén pedig sorban végigmész a tömbön és kiteszed a képernyőre. Azért kell ilyen körülményesen, hogy elkerüljük a kurzorpozícionálás problémáját.
Innentől kezdve a kör és a téglalapok rajzolása már triviális. -
Jester01
veterán
-
Jester01
veterán
Na hát a baj az, hogy a második szám összes jegyét végigszorozza nullával, és ezért lesz annyi nullád. Ha más probléma nincs, akkor egyszerűen speciális esetként lehet kezelni ha bármelyik szám 0, és simán 0-t írni ki.
Egyébként én személy szerint inkább úgy csinálnám, hogy egyáltalán nem törődnék a nullákkal csak a legvégén a kiírásnál szépen elhagynám őket. A szorzást abszolúte nem zavarja, ugye, csak kicsit tovább tart.
-
-
Jester01
veterán
Itt van egy ciklussal ... van helyette viszont rekurzió
(a ciklus gyorsabb)int factor(int x, int start, int depth)
{
int count = 0;
int max = sqrt(x);
int i;
for(i = start; i <= max; i++)
{
div_t q = div(x, i);
if (q.rem == 0)
{
count += (depth > 1) ? factor(q.quot, i, depth - 1) : 1;
}
}
return count;
}A feladat eredményét a factor(terfogat, 1, 3) adja.
Ez az én gépemen (2.2GHz) kevesebb mint 5ms alatt lefut bármit is adtam be neki eddig. Na jó, 2 milliárdra már 12ms -
Jester01
veterán
Hirtelen csak a prímtényezőkre bontás jut eszembe mint alternatíva.
MOD: ha konkrétan nem mondták, hogy a 3 ciklus baj, akkor azon még lehet csiszolni. Nyilván elég akkor futtatni a belső ciklust, ha a külső változó osztója a térfogatnak. Ha osztója, akkor gyorsan le is kell osztani és belső ciklusban már csak ezt felbontani.
-
Jester01
veterán
válasz
Dirty_Pio
#903
üzenetére
1 byteos számot olvasd (un)signed char változóba, aztán csinálj vele amit akarsz. Ha mindenképp short-ba olvasod, akkor eleve azt is tudnod kell, hogy melyik felébe (endianness). A másik felét pedig neked kell nullázni (akár úgy, hogy a beolvasás előtt az egészet nullázod).
MOD: ja és negatív számoknál még sign extension is kell. Szóval macerás, jobb ezt a fordítóra bízni. -
Jester01
veterán
A const-nak annyi jelentősége van, hogy a string literal az const (csak olvasható memóriaterületen van). Tulajdonképp nem is értem, miért fordul le (-Wwrite-strings és akkor van warning). De próbálj csak meg beleírni, lesz szép segfault
A szám/egyéb valóban nem volt feladat, de mivel egy tömböt indexelsz a beadott karakterekkel azért jó ha ellenőrzöd.
Csak azért kötözködtem, hogy ha valaki meglátja azért tudja, hogy még lehet rajta mit csiszolni. Gondoltam, hogy neked nem okozna problémát
-
Jester01
veterán
Ja, ilyesmi lenne a tömbös. Csak nem jó
Mert azt kell nézni, hogy a leképezett számjegy ugyanaz-e mint az előző, nem pedig a betű. Ha "a" betű után jön "b" betű, akkor is kell a szóköz, ugyebár. Becsúszott néhány nev[0] a nev [ i ] helyett, de ez gondolom csak elírás, ugyanúgy mint a felesleges \0 a tömbben.Ha nagyon kötözködni akarnék akkor további észrevételek (nem rosszindulatból
 ):
):
* az a tömb igazából const char* tomb[] kellene legyen
* A gets annyira rossz, hogy a gcc szól is érte (fgets helyette)
* while feltételbe strlen nem jó ötlet hatékonyság miatt
* printf helyett fputs/fputc és tsai (ha egyszer semmi formázás nincs, akkor minek a printf)
* toupper/tolower valamelyike (vagy ha nagyon trükkös valaki, akkor bit művelet)
*.ellenőrizni kellene, hogy betű jött-e egyáltalán -
Jester01
veterán
Van egy felesleges bezáró kapcsos zárójeled és hiányzik egy #include <string.h> Ettől mondjuk még nem működik, de legalább lefordul.
Ezek így nem jók: if (nev[ i ]=='a' || 'A') helyette if (nev[ i ]=='a' || nev[ i ] == 'A') kell. Így talán jó lesz.
Amúgy a tömbös megoldásnál egyszerűen mejegyzed mi volt az előző lenyomott gomb és ha a mostani ugyanaz, akkor kiteszed a szóközt.
-
Jester01
veterán
Ahogy Benmartin írta, az a baj, hogy az enter amit a felhasználó lenyom szintén bekerül a pufferbe. A %c önmagában nem ugorja át a whitespace-t (mi ennek a magyar neve?) de a szóköz az igen.
Tehát pl. ha a következő két sort adta be a felhaszáló: A<szóköz>B<enter>C<szóköz>D<enter> akkor a "%c %c" mit csinál? Berakja az A-t az első változóba, a szóköz miatt átugorja a bemenetben lévő szóközt, majd a B-t berakja a második változóba. Eddig szép és jó. Na de ha most még egy "%c %c" olvasás következik, az szembetalálja magát a pufferben lévő soremeléssel és azt teszi be az első változóba a C helyett. A formátumban lévő szóköz most a C karakterrel foglalkozik, de mivel az nem whitespace ezért nem történik semmi. A második változóba ezután szépen bekerül a C a D helyett. Ha viszont van egy szóköz a formátum elején is, akkor az megeszi a soremelést és minden megint jó.











 Ránézésre jó ha a makró tulajdonképpen ezt csinálja:
Ránézésre jó ha a makró tulajdonképpen ezt csinálja:



 )
)
 , ott van a hibaüzenetben: char* (*)[10] Ez kiolvasva azt jelenti, hogy olyan pointer ami egy tíz elemű string tömbre mutat. Vagyis gyakorlatilag a romai mátrix egy sorára. És azért adok hozzá 3-at mert visszafelé megyünk benne tehát az utolsó sorral kezdünk. Ha átrendeznénk a sorokat akkor értelemszerűen ez nem is kellene.
, ott van a hibaüzenetben: char* (*)[10] Ez kiolvasva azt jelenti, hogy olyan pointer ami egy tíz elemű string tömbre mutat. Vagyis gyakorlatilag a romai mátrix egy sorára. És azért adok hozzá 3-at mert visszafelé megyünk benne tehát az utolsó sorral kezdünk. Ha átrendeznénk a sorokat akkor értelemszerűen ez nem is kellene.


 Ugyanis adott esetben sok if/else ág lenne illetve segédváltozók és/vagy ciklus lefutás után a feltétel újratesztelése is szükséges lehet.
Ugyanis adott esetben sok if/else ág lenne illetve segédváltozók és/vagy ciklus lefutás után a feltétel újratesztelése is szükséges lehet.





















 Mindenesetre azt kellene tudni, mi határoz meg egy mondatot - erre jó lenne ha a specifikáció kitért volna. Márcsak azért is, mert bizonyos esetkben igen nehéz eldönteni. Például az Apám neve id. Kiss János. az hány mondat is?
Mindenesetre azt kellene tudni, mi határoz meg egy mondatot - erre jó lenne ha a specifikáció kitért volna. Márcsak azért is, mert bizonyos esetkben igen nehéz eldönteni. Például az Apám neve id. Kiss János. az hány mondat is? 
 ):
):Új hozzászólás Aktív témák
Hirdetés
● olvasd el a téma összefoglalót!
● ha kódot szúrsz be, használd a PROGRAMKÓD formázási funkciót!
- Windows 10
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Okos Otthon / Smart Home
- DOOM - The Dark Ages
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Luck Dragon: Asszociációs játék. :)
- Vigneau interaktív lokálblogja
- iPhone topik
- Magga: PLEX: multimédia az egész lakásban
- Diablo IV
- További aktív témák...

- Bomba ár! Dell Inspiron 5405 - Ryzen5 4500U I 8GB I 256SSD I 14" FHD I HDMI I Cam I W11 I Garancia!
- Apple iPhone 13 128GB, Kártyafüggetlen, 1 Év Garanciával
- AKCIÓ! MSI B450 R5 5500 16GB DDR4 512GB SSD RTX 2060 Super 8GB GDDR6 Rampage Shiva Zalman 500W
- Apple iPhone 13 128GB, Kártyafüggetlen, 1 Év Garanciával
- ÁRGARANCIA!Épített KomPhone Ryzen 7 5800X 32/64GB RAM RX 7800 XT 16GB GAMER PC termékbeszámítással
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: CAMERA-PRO Hungary Kft
Város: Budapest