Hirdetés
- Ha nem növelnéd feleslegesen a villanyszámlád, a Chieftecnek van pár új ajánlata
- ARC vs eARC — Ilyet is tud a HDMI-d? 🤨
- A következő évtizedbe repíti a NAND hatékonyságát a Samsung új kutatása
- ASUS blog: kisebb, de nem gyengébb – a mini PC-k forradalma
- 5 kilowattos GPU-k előtt nyitná meg az utat az Intel
- AMD Navi Radeon™ RX 9xxx sorozat
- Mini-ITX
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Kivégezheti a kisebb VGA-gyártókat az NVIDIA döntése
- Nyomtató topik
- Gaming notebook topik
- VR topik (Oculus Rift, stb.)
- Milyen belső merevlemezt vegyek?
- Vezeték nélküli fejhallgatók
Új hozzászólás Aktív témák
-
#6878
 Petykemano
veterán
S_x96x_S
#6874
Petykemano
veterán
S_x96x_S
#6874
Petykemano
veterán
válasz
 S_x96x_S
#6874
üzenetére
S_x96x_S
#6874
üzenetére
/zen5/
Ha tippelnem kéne, azt mondanám, hogy az Apple-t követik:
privát L1 + L2 és megosztott L3 (zen3)
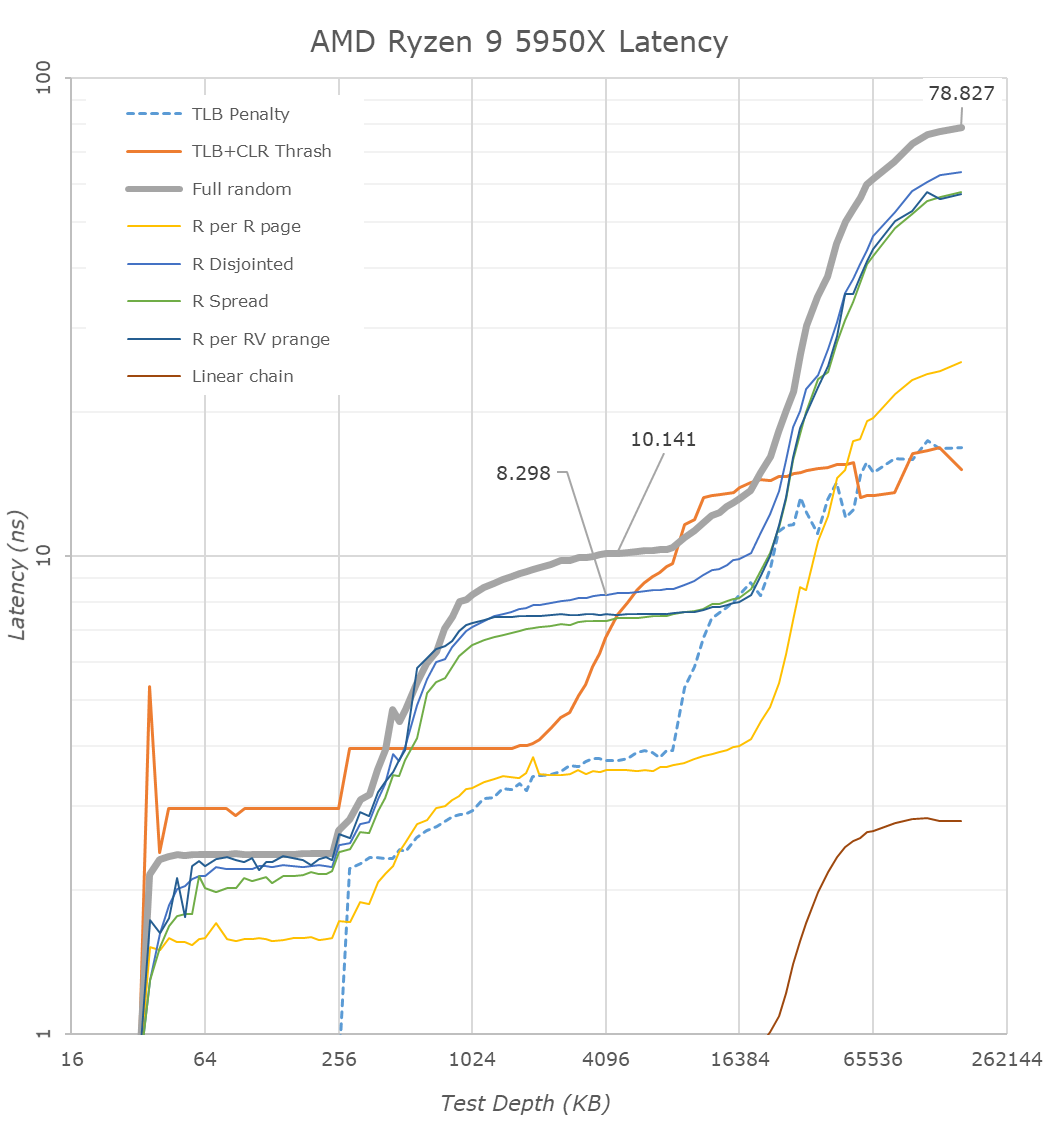 ( [link] )
( [link] )Látszik, hogy 32KB-ig 1ns a késleltetés, aztán az L2$ feléig még mindig alacsony, aztán szépen felkúszik 10ns-ra, ami az L3$ közel eső szeletének késleltetése, majd az is feltörik.
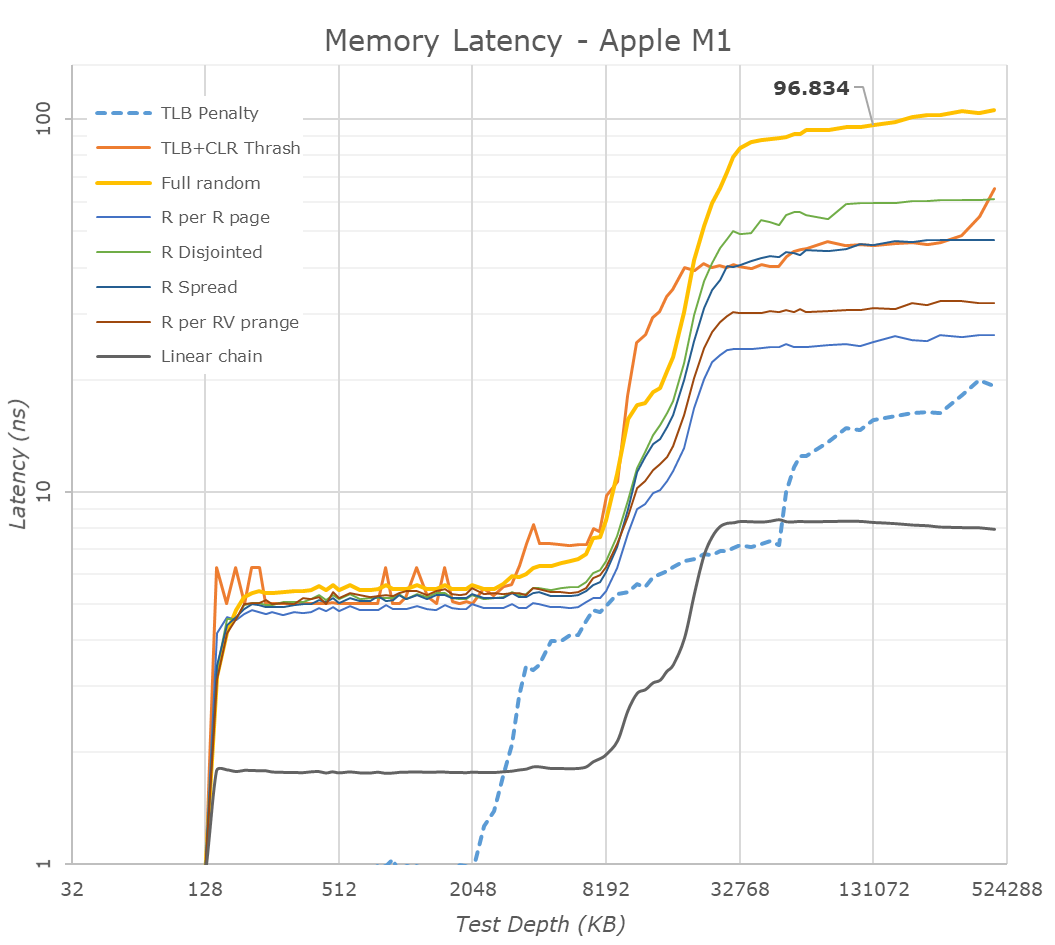
Ehhez képest az M1:
A késleltetés 128KB-ig nagyon alacsony és utána 8MB-ig 5ns (noha valójában 12MB az L2$)
Ha ezt meg tudják csinálni, akkor valóban kevesebb szükség lehet L3$-re.
Bár az Apple is alkalmaz L3$-t (System Level Cache néven), de ha jól emlékszem,. akkor azt már nem csak a CPU, hanem az IGP is tudja használni.Ez viszont csak akkor valósítható meg, ha a az L3$-t kompletten kiemelik a CCX-ből, összecsúsztatják az L2$ részeket és végül egységesítik az L2$-t úgy, hogy stacked L3$ rápakolására még mindig lesz lehetőség. Abban az esetben ha az L3$ stacked azzal sincs probléma, hogy a stacked L3$ rész késleltetése picit magasabb.
Ezzel egyébként egy roadmapet is felvázoltunk.
Szerintem nem volt akkora hülyeség a wccf által publikált rajz [link] [link]
Csak nem arra vonatkozik, amire ők gondolták.
Szóval a roadmap szerintem:
- zen4: az új zen3 architektúra finomítása, megnövelt L2$ (aminek hatására kisebb a nyomás az L3$-en), új gyártástechnológia, FPU duplázás
- zen4c/zen4d: L3$ kiemelése (legalább felezése, de inkább kiemelése) a CCX-ből. Az L2$ összecsúsztatása (privát 1MB vagy 2 mag által megosztott?), 3D Stacked L3$, visszaállás 2 CCX / CCD-ra (16 magra egységesített L3$, vagy 2x 3D stacked L3$ lapka )
- zen5: új architektúra: architektúra szélesítése, megnövelt L1$, L3$ kiemelése a CCX-ből, L2$ összecsúsztatása és egységesítése (=> megosztott, 8MB)Azt gondolom, hogy az L3$ kiemelése a designból és az L2$ összecsúsztatása nem egy nagy kunszt, tehát a zen4d/c és a zen5 fejlesztése ebből a szempontból lehetett párhuzamos. A wccf cikk fő mondanivalója ugye az, hogy két zen4 mag fog osztozni 1MB L2$-n. Ebből a szempontból a zen4d/c egy pilot projekt is lehet(ett) a zen5 egységesített L2$-éhez.
Az a kérdés merült föl bennem, hogy azt mondják, hogy nem véletlen, hogy az Apple M1 olyan, amilyen és a zen valamint az intel processzorok is olyanok, amilyenek cache felépítés szempontjából. Konkrétan: az M1 egy konzumer eszköz, ahol jellemző az egy programos használat (nem feltétlenül egyszálas, de hogy a rendszert döntően egy program veszi igénybe egyszerre), amely esetben jól jöhet, hogy megosztott L2$, amin keresztül az egy programhoz tartozó szálak adatot tudnak megosztani egymással. Ehhez képest a szerverek terén inkább jellemző az, hogy egymástól teljesen független programszálak futnak, amiknél meg inkább a privát cache hasznos. Persze elképzelhető, hogy ki lehet kapcsolni a megosztást. Tehát konzumer termékben 8MB L2$ látható, szerver termékben magonként 1MB L2$.


Új hozzászólás Aktív témák
- Győr és környéke adok-veszek-beszélgetek
- Assassin's Creed: Valhalla
- BestBuy topik
- AMD Navi Radeon™ RX 9xxx sorozat
- Samsung kuponkunyeráló
- Mini-ITX
- Xiaomi 14T Pro - teljes a család?
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Spórolós topik
- További aktív témák...

- Lenovo ThinkPad P15 Gen 1 Tervező Vágó Laptop -50% 15,6" i7-10750H 32/512 QUADRO T1000 4GB
- Dell LAtitude 7490 FHD, TOUCH, i7-8565U CPU, 16GB DDR4, 512GB SSD, 27% ÁFÁS SZÁMLA, 1ÉV GARANCIA!
- Üzletből, Lenovo garanciával ThinkPad E14 Gen 5/ Intel Core i5-1335u/16GRAM/512SSD/FULL HD +kijelző
- HP Elitebook 840 G6 FHD, i7-8565U CPU, 16GB DDR4, 512GB SSD, 27% ÁFÁS SZÁMLA, 1ÉV GARANCIA!
- HP Elitebook 840 G5 FHD, i7-8550U CPU, 16GB DDR4, 512GB SSD, 27% ÁFÁS SZÁMLA, 1ÉV GARANCIA!
- BESZÁMÍTÁS! ASUS H510M i7 10700 16GB DDR4 512GB SSD RTX 3060 12GB GDDR6 Zalman T4 Plus ADATA 600W
- LG 83G4 - 83" OLED evo - 4K 144Hz & 0.1ms - MLA Plus - 3000 Nits - NVIDIA G-Sync - FreeSync Premium
- ÁRGARANCIA!Épített KomPhone Ryzen 5 7600X 32/64GB RAM RTX 5070 12GB GAMER PC termékbeszámítással
- GYÖNYÖRŰ iPhone 14 Pro Max 256GB Space Black -1 ÉV GARANCIA - Kártyafüggetlen, MS3766, 100% Akksi
- BESZÁMÍTÁS! MSI Z690 i9 14900K 32GB DDR5 1TB SSD RTX 3090 OC 24GB Zalman Z1 PLUS Seasonic 750W
Állásajánlatok

Cég: BroadBit Hungary Kft.
Város: Budakeszi

Cég: Laptopműhely Bt.
Város: Budapest