

Hirdetés
AIDA64: szintetikus tesztek (folytatás)
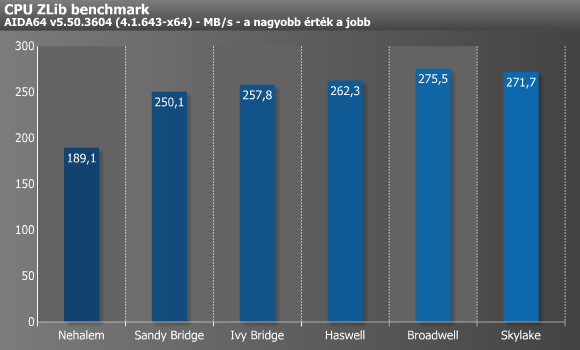
A CPU ZLib is egy integer benchmark, amely a publikusan elérhető 1.2.5-ös ZLib fájltömörítési algoritmussal méri le a processzor és a memória-alrendszer teljesítményét. A teszt magonként/szálanként 32 MB-ot tömörít egy masik 32 MB-os bufferbe, miközben csak és kizárólag alap x86-os utasításokat használ. Itt inkább a CPU sebessége, illetve képességei számítanak (dekódolás szélessége, out-of-order load támogatása, ugrásbecslés, reordering ablak mérete), mintsem a memória sebessége. Ebben a tesztben a Sandy Bridge óta nem sokat gyorsultak az egyes mikroarchitektúrák, csupán kisebb előrelépéseket tudtunk kimérni.
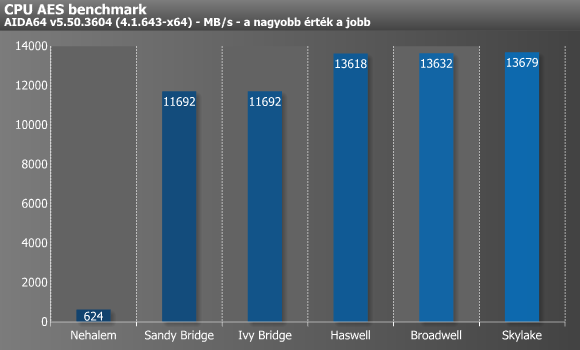
A CPU AES is egy integer benchmark, amely az AES (azaz Rijndael) adattitkosító algoritmust használja. A teszt Vincent Rijmen, Antoon Bosselaers és Paulo Barreto publikusan elérhető C kódját használja ECB módban. A benchmark alap x86-os utasításokat, MMX-et, valamint SSE4.1-et használ, és és magonként/szálanként 8 kB-nyi adatot kódol át egy másik 8 kB-os bufferbe. Elsősorban itt is inkább a CPU sebessége a fontos, illetve kiugróan az out-of-order load képesség számít (a hardveres AES támogatást leszámítva persze). Ennek hatását jól szemlélteti a Nehalem és a Sandy Bridge közötti különbség, ugyanis utóbbi már támogatja az AES-NI utasításkészletet.
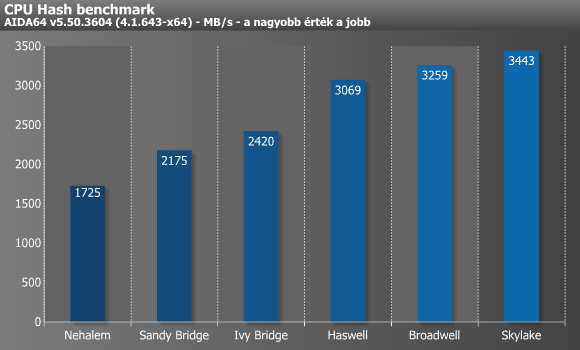
A CPU Hash az SHA1 hasító algoritmus segítségével méri le a processzor képességeit, melynek kódját assemblyben írták a készítők. A teszt képes kihasználni az MMX, MMX+/SSE, SSE2, SSSE3, AVX, AVX2, XOP, BMI, és BMI2 utasításkészletek nyújtotta előnyöket a VIA PadLock Security Engine-jével egyetemben. A BMI és BMI2 által nyújtott pluszt jól szemlélteti a Haswell, melybe anno mindkét utasításkészlet bekerült.
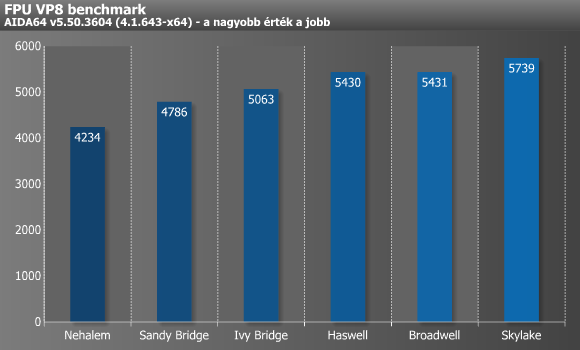
A következő, FPU VP8 nevű teszt már kifejezetten egy lebegőpontos mérés, mely az FPU képességeire fókuszál, és egész adatokat használ XMM vektorregiszterekkel. Ahogy nevéből is sejthető, ez a Google VP8-as kodekjének 1.1.0-es verziójával operál, melynek hathatós közreműködésével tömörít egy 1280x720-as felbontású, 8192 kbps bitrátájú videót a legjobb minőségi beállítások mellett, melynek képkockáit az FPU Julia fraktál modulja állítja elő. A SIMD-utasításkészletek közül az MMX, SSE2, SSSE3, és SSE4.1 kiterjesztésekből képes profitálni. Itt az egyes Intel mikroarchitektúrák relatíve lassú, de folyamatos gyorsulást produkáltak, a Broadwellt leszámítva.
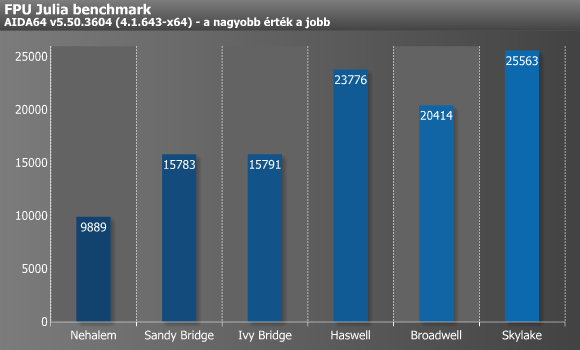
Az imént már említett FPU Julia a processzorok 32 bites (egyszeres pontosságú) lebegőpontos teljesítményét méri le a közismert „Julia” fraktál segítségével, amit magonként/szálanként 1024x1024 pixel méretben, 1000 iteráció mélységig számol. A benchmark kódja itt is assemblyben íródott, és extrém mértékben használja ki az egyes SIMD-utasításkészleteket (x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA3). A Sandy Bridge és a Haswell esetében érthető a két nagy ugrás, ugyanakkor a Broadwell visszaesésének bizarr anomáliájára még az AIDA64 fejlesztői sem tudják a pontos választ. Annyi legalább már kiderült, hogy a mikroarchitektúra sajátosságából fakadó lassulás csak különféle FMA utasítások bizonyos sorrendjénél jön elő.
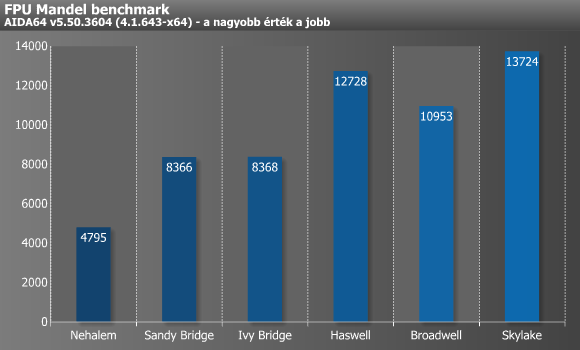
Az FPU Mandel a 64 bites (kétszeres pontosságú) lebegőpontos teljesítményt (FP64) méri le a „Mandelbrot” fraktál egyes frame-jeinek kiszámolása révén, melyeket az előzőhöz hasonlóan magonként/szálanként 1024x1024 pixel méretben, 1000 iteráció mélységig számol. Ez a benchmark is assemblyben íródott, és akárcsak az FPU Julia, hatékonyan használja ki az egyes SIMD-utasításkészleteket (x87, SSE2, AVX, AVX2, FMA3 es FMA4). A két teszt hasonlóságai az eredményekben is visszatükröződnek, hisz szinte ugyanaz a tendencia mutatkozott meg, mint a Julia esetében.
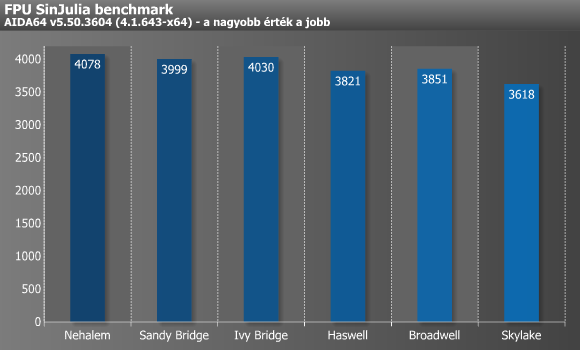
Az FPU SinJulia a 80 bites (kiterjesztett pontosságú) lebegőpontos teljesítményt méri le a „Julia” fraktál módosított változatának (256x256 pixel, 70 iteráció) kiszámolásával. A kód assemblyben íródott, és erősen kihasználja a trigonometrikus és exponenciális x87-es utasításokat. Míg a Juliánál a raw 32 bites lebegőpontos MUL/ADD/MOV képességek számítanak, addig a SinJuliánál a legpontosabb 80 bites mód kihajtása a lényeg, és a transzcendens utasítások (sin, cos, ex) megvalósítása. Teljes végrehajtási idő szempontjából az utóbb említett sin, cos, ex sebessége a döntő, amiben például a Skylake lassabb, mint az Ivy Bridge vagy a Nehalem. Általánosságban elmondható, hogy az Intel már jó ideje nem fejleszti az x87-es képességeket, sőt ahogy az eredmények is jól mutatják, ezen a téren már inkább visszafele lépdelnek, ami bár első ránézésre furcsán hangozhat, ugyanakkor a jelen kor követelményeinek fényében meglepőnek már sokkal kevésbé nevezhető.
A cikk még nem ért véget, kérlek, lapozz!





