Hirdetés
Sandy Bridge (32 nm)
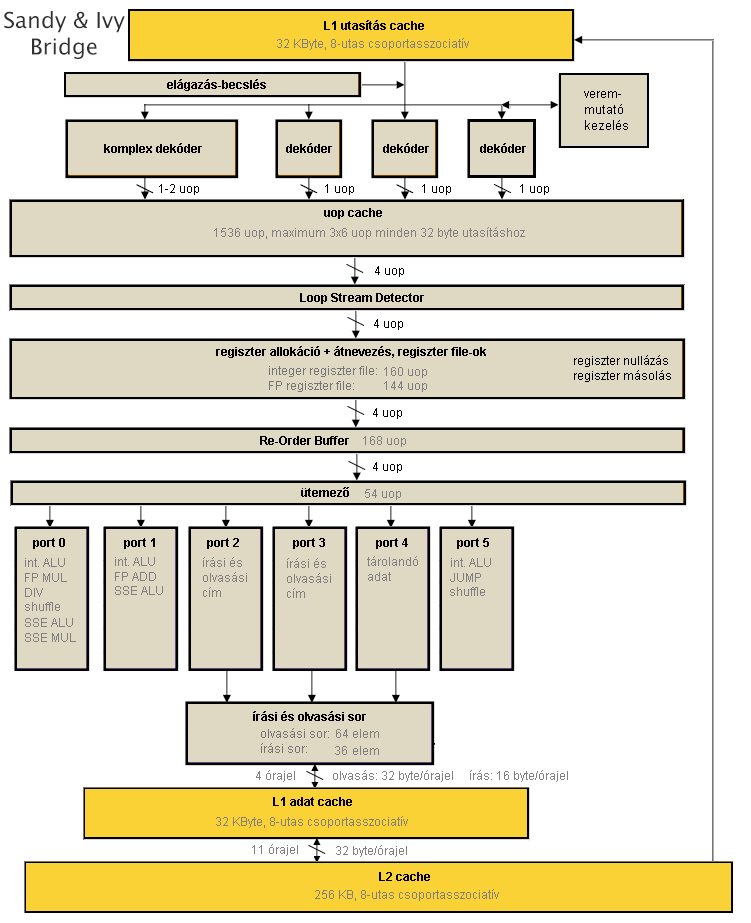
Az előzővel ellentétben ez a generáció jelentős változásokat hoz a processzor szerkezetében, ahogy az a felépítési ábrán is látható.
[+]
- A pipeline elején, a dekóderek után egy nagyméretű, legfeljebb 1536 lefordított µop tárolására alkalmas gyorsítótárat találunk. Ez körülbelül 500 darab x86 utasítás tárolására képes, ezáltal nagyméretű ciklusok vagy teljes függvények, szubrutinok tárolására is alkalmas, amivel egyrészt az idő nagy részében jellemzően munka nélkül hagyja az L1 utasításcache-t és a dekódereket, másrészt garantáltan órajelenként 4 µop-ot küld a végrehajtó egységek felé.
- Továbbhaladva két nagyméretű regiszter fájlt találunk, amelyek bizonyos utasításokat saját hatáskörben végre tudnak hajtani, levéve a terhet a végrehajtó egységek válláról: ha egy regiszterre kiadjuk a SUB reg,reg vagy XOR reg,reg utasítást, azaz önmagából kivonjuk vagy önmagával XOR-ozzuk, akkor az eredmény a regiszter jelenlegi értékétől függetlenül 0 lesz; ráadásul ezen utasítások mérete jóval kisebb, mintha egyéb úton nulláznánk. Az ilyen jellegű utasítások meglehetősen gyakran fordulnak elő a programokban. A regiszter fájlok felismerik ezeket a µop-okat, és azonnal törlik a kérdéses regiszter tartalmát (órajelenként legfeljebb 4-ét), így további munka nincs velük a pipeline további részében.
- Elérkezve a végrehajtó egységekhez, látható, hogy míg a korábbi processzorok 1 db dedikált végrehajtóval rendelkeztek a memóriaolvasásokhoz, addig immár két olyan portot látunk (a korábbi port 2 mellé az eddigi írási címszámító port 3 is felsorakozik), amely képes memóriát olvasni. Továbbá a teljes további memória-alrendszer (olvasási sor, L1 adatcache) fel van készítve arra, hogy órajelenként 2 memóriaolvasást tudjon kezelni. Ez jelentős löketet ad a végrehajtásnak, hiszen általánosságban elmondható, hogy az adatfeldolgozás során sokkal több adat olvasására van szükség, mint amennyi írására, gondoljunk csak a pointerekre, struktúra- és tömbcímekre, ciklusváltozókra.
- Az utasításfúzió szintet lép, mivel a CMP és TEST mellé az összeadás/kivonás (ADD és SUB, illetve INC és DEC) és az AND utasítás is felsorakozik, tehát ezek és az őket közvetlenül követő ugró utasítás egyesíthető a dekóderek által egyetlen belső műveletté; továbbá a dekóderek órajelenként 2 db ilyen párt tudnak "összeboronálni".
- A számítási µop-okat 256 bit széles végrehajtók várják, hiszen ebben a generációban jelenik meg az AVX utasításkészlet támogatása, amely 256 bites vektorokkal, azaz egyszerre 8 egyszeres vagy 4 dupla pontosságú lebegőpontos számmal dolgozik.
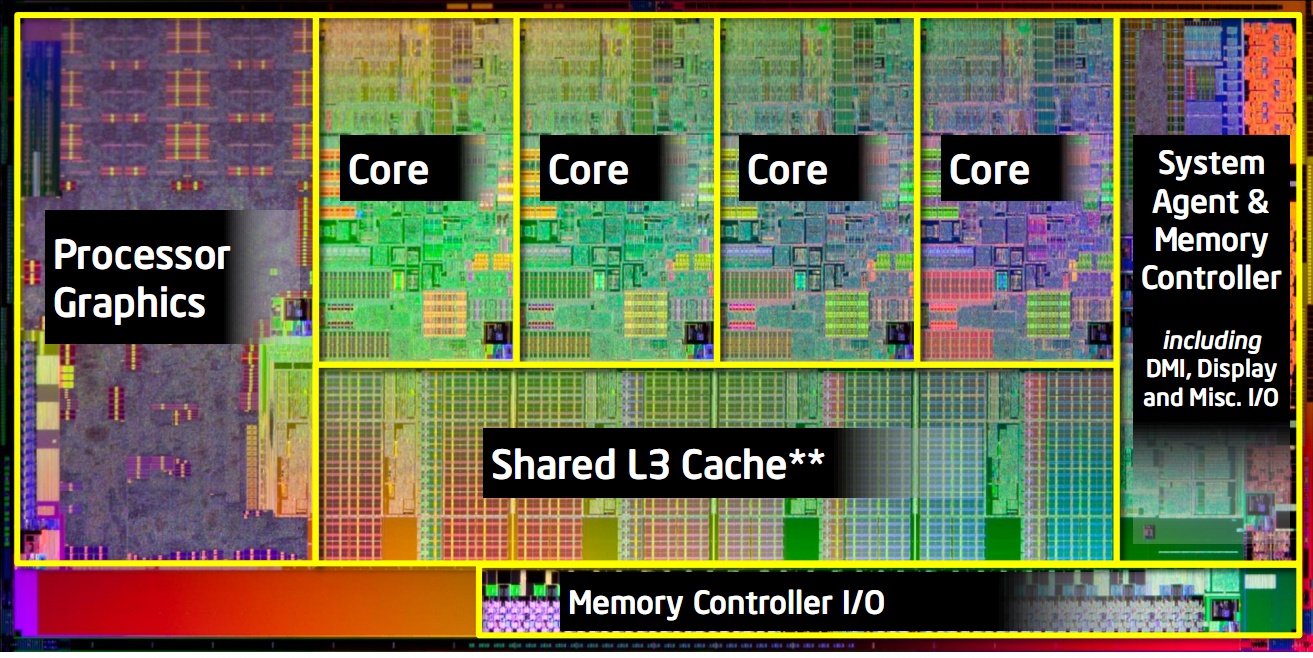
A négymagos Sandy Bridge lapka felépítése [+]
A cikk még nem ért véget, kérlek, lapozz!