
A Nehalemhez vezető út
A nyár végén megjelent Skylake processzorok alapja, a Nehalem már lassan 7 éve került piacra, a két mikroarchitektúra között pedig sok mindent történt. Ahhoz, hogy átlássuk pontosan, miként jutott el a Skylake-ig az Intel, első lépésként ugorjunk vissza az időben cirka 15-20 esztendőt.
A P6 család
A Core processzorcsalád nagyban alapoz az Intel által csak P6 családnak nevezett Pentium Pro (1995) - Pentium 2 (1997) - Pentium III (1999) triumvirátus felépítésére, ezért először érdemes áttekinteni ezek működését.
Ez a család az Intel első out-of-order szemlélettel készült dizájnja, amely belül a műveleteket soron kívül, azaz nem programsorrendben dolgozza fel. Természetesen kívülről úgy kell látszódjon, mintha a végrehajtás a program szerinti sorrendben történne, ezért a processzor a beérkező utasításokat dekóderek segítségével belső, elemi egységekre, úgynevezett mikrooperációkra, azaz µop-okra bontja, majd ezeket azonnal végrehajtja, amint rendelkezésre állnak a szükséges paramétereik, végül pedig újra programsorrendbe állítva őket véglegesíti az eredményeket. Ekkor természetesen kiderülhet, hogy a kiszámított eredményekre mégsem lesz szükség, például mert az elágazásbecslés rosszul jósolt, így figyelmen kívül kell hagyni ezeket, majd a helyes ágon újraindítani a végrehajtást; ezáltal a belső működés spekulatívvá válik.
Az x86-os utasítások alapvetően memóriából beolvasó (load), műveletvégző (operation vagy op) és memóriába tároló (store) műveletekből állhatnak, illetve mivel CISC, azaz komplex utasításkészletről van szó, ezek kombinációi is lehetségesek egy utasításon belül, load-op vagy load-op-store utasítások formájában. A P6 processzorcsalád tagjai dekóderek segítségével ezeket az utasításokat primitív µop-okra bontják, majd továbbhaladva a pipeline-ban a primitíveknek megfelelő végrehajtókat találunk, melyek kezelik ezeket, párhuzamosan. A primitív műveletek a következők lehetnek:
- a load, azaz adatbetöltés egy megadott memóriacímről, 1 µop;
- a tárolás, azaz adatírás egy megadott memóriacímre, 2 µop; az egyik a cím kiszámításához szükséges, a második a kiírandó adatot juttatja erre a címre;
- op, azaz számítási műveletek, ebből egy utasításban általában 1 van, ami 1 µop-ot jelent, de bizonyos utasításokban akár több is lehet.

[+]
A fentiek alapján látható, hogy egy load-op vagy egy store utasítás 2 µop-ra, egy load-op-store utasítás általában 4 µop-ra bomlik, míg az adatbetöltés (load), illetve a regisztereken dolgozó számítási műveletek 1 µop-ra fordulnak le. Bizonyos utasítások 4-nél több µop-ra fordulnak, ezeket vektorutasításoknak nevezzük.
A processzor 3 dekódert biztosít, amelyek közül az első tudja kezelni az összes 1-4 µop-ra lefordítható utasítást 1 órajel alatt, a másik kettő pedig csakis az 1 µop-ra forduló utasításokat tudja fogadni, így együtt órajelenként legfeljebb 3 utasítást tudnak lefordítani, maximum 6 µop-ot létrehozva.
A lefordított µop-ok programsorrendben a Re-Order Bufferbe kerülnek, ami továbbítja őket az ütemezőbe, amint – függőségeik figyelembevételével – rendelkezésre áll az összes bemenő paraméterük. Az ütemező ezek közül minden órajelben igyekszik mindegyik portra 1-1 µop-ot továbbítani, ahol azok végrehajtása megtörténik. Amint elkészülnek, az µop-ok eredménye újra a Re-Order Bufferbe kerül, ahonnan programsorrendben ellenőrzésre kerülnek legfeljebb 3 µop/órajel ütemben azért, hogy nem történt-e illegális művelet (például nullával való osztás vagy az olvasás/írás memóriacíme érvénytelen), majd véglegesítődnek: eredményük valóban tárolásra kerül, vagy kiváltódik a megfelelő kivétel.
Az µop-ok végrehajtása tehát spekulatív, és nem programsorrendben történik. A számítási és a memóriaolvasó műveletek lefuttatása "veszélytelen", így egymás közt korlátlanul átrendezhetőek és érvényteleníthetők, viszont a memóriába írások nem hajthatók végre ilyen módon, mivel a) a korábbi memóriaolvasásoknak mindenképp kiírás/felülírás előtt kell lefutniuk; b) az azonos címre történő memóriaírásoknak programsorrendben kell megtörténniük; c) az írásokat nem lehet visszavonni a cache-ből, illetve RAM-ból. Így az írások programsorrendben hajtódnak végre, tekintettel a programsorrendben őket megelőző memóriaolvasásokra, valamint eredményük először egy speciális pufferbe kerül (cím-adat-méret hármasonként), és a programsorrendbeli véglegesítés folyamán történik meg tényleges kiírásuk; ezáltal visszavonhatóvá válnak, és helyes sorrendbe kerülnek.
Pentium M, Conroe, Penryn
Pentium M
A Core processzorok közvetlen elődjének a Netburst termékvonallal párhuzamosan fejlesztett Pentium M processzorok tekinthetők. Ezek szerkezeti ábrájukban nagyrészt megegyeznek a P6 processzorokkal, viszont több ponton is jelentősen fejlődtek.
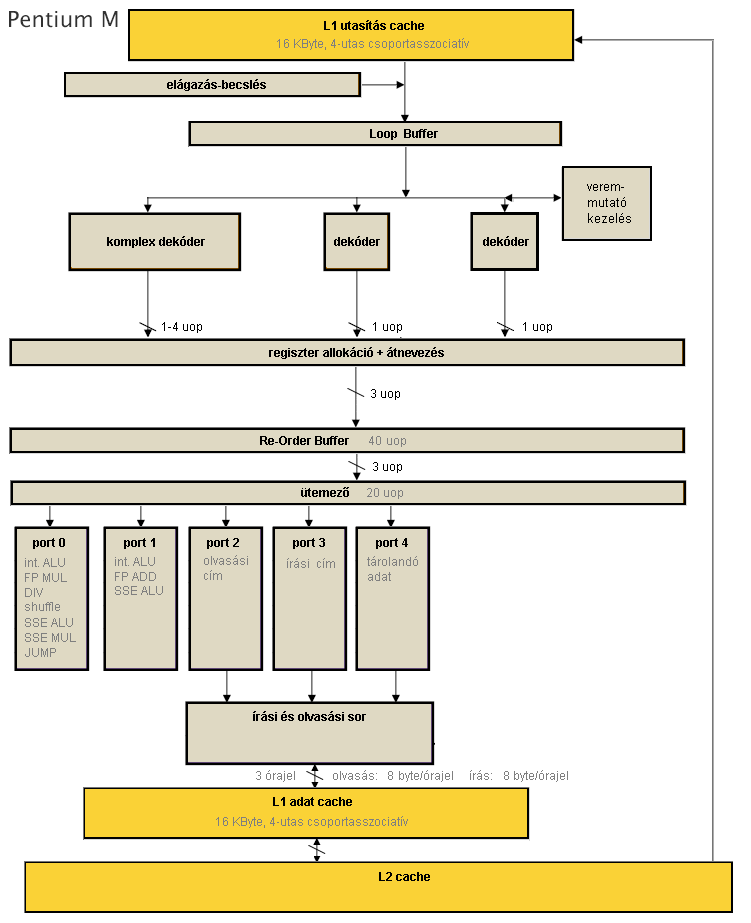
[+]
- Bevezetésre kerül az µop-fúzió (micro fusion): a load-op, illetve a store jellegű utasítások 2-2 µop-ját egyetlen egységben dekódolja és tárolja a ROB-ban, majd azok csak az ütemezőben válnak szét és kerülnek külön végrehajtóba. Ennek jelentősége egyrészt, hogy így a két egyszerű dekóder is tudja ezeket az utasításokat kezelni, így sokkal több utasítás kerülhet dekódolásra órajelenként, sokkal kötetlenebb a korábbi szigorú 4-1-1 µop mintájú optimális utasítássorrend; másrészt a változatlan elemszámú belső pufferek effektíve akár kétszer annyi tennivalót is tárolhatnak. Ez a fúzió itt még csak az integer és MMX utasításokra érvényes, az SSE utasításokra nem működik.
- Ugyancsak a dekódolás gyorsítása miatt egy 64 bájtos loop buffert alkalmaznak, miáltal a kisméretű ciklusok utasításcache-olvasás nélkül futtathatók.
- A harmadik jelentős módosítás a veremmutató-kezelő megjelenése a dekódolás során: a függvények paraméterátadására és hívására alkalmas PUSH, POP, CALL és RET utasítások mindegyike hatással van a veremmutató értékére, csökkentik vagy növelik azt. A veremmutató-kezelő egy olyan számláló, amely tárolja a csökkentés/növekedés mértékét, így a veremmutató változatlan maradhat, a tényleges módosítását nem kell végrehajtani, csak a dekóderek belefordítják a veremíró, illetve veremolvasó µop-ba a számláló értékét is.
- Ugyancsak jelentős, a magoknál nagyobb léptékű változás, hogy a Pentium M család kései termékeiben megjelennek a natív többmagos megoldások, amelyek között a nagyméretű megosztott, azaz mindkét mag által közösen használt L2 cache teremt kapcsolatot.
Conroe és Penryn, azaz az 1. generációs Core processzorok
A Pentium 4 processzorok fejlesztésének megszakítása után az Intel asztali felhozatalát az előbb ismertetett Pentium M felépítésre alapozta, ugyanakkor számos ponton "kiszélesítette" azt.
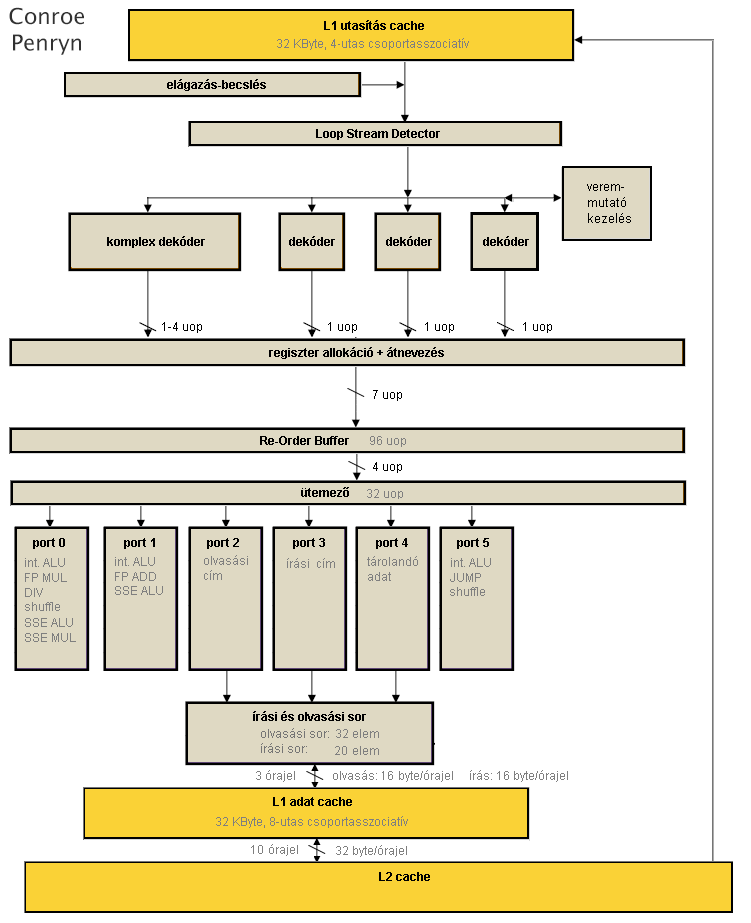
[+]
- A teljes processzor 4 utasítás széles, ennek érdekében 4 dekódert találunk a front-endben, az újonnan beépített fordító is egyszerű, mivel ezzel órajelenként 4 utasítás feldolgozása lehetséges: 1 komplexebb, legfeljebb 4 µop-ot generálóé, és utána közvetlenül sorakozó 3 egyszerű, 1 µop-ra leképezett utasításé.
- Megjelenik az utasítás-fúzió (macro fusion), így két speciális esetben lehetséges 2 db egymást követő x86 utasítás egyetlen µop-ra fordítása: az első instrukció vagy két integer érték összehasonlítása (CMP), vagy két integer érték AND művelettel való tesztelése (TEST); a második pedig az azt közvetlenül követő ugró utasítás. Ezen párok egyetlen CMPJMP vagy TESTJMP belső műveletté fordíthatók le; ez a későbbiekben is elemi belső művelet, nem válik ketté a végrehajtás során sem. Ezt a fúziót a 4 dekóder bármelyike képes megcsinálni, de órajelenként csak 1 ilyen esemény történhet; továbbá ebben a processzorgenerációban csak 32 bites programkódon működik és csak előjeltelen szemantikájú ugrásokra, 64 bites utasításokra még nem, illetve előjeles feltételkódokra sem.
- Teljessé válik a µop-fúzió: immár az összes load-op és store utasítás 2-2 µop-ja egyesítődik, beleértve az SSE utasításokat is.
- A korábbi processzorcsaládok 64 biteseivel szemben az összes SSE utasítás 128 bites végrehajtókat kap, beleértve a memóriahozzáféréseket is.
- Lehetővé válik a memóriaírási műveletek out-of-order módon történő végrehajtása: természetesen a korábbi konvencióknak meg kell felelni, de immár a processzor képes belül teljesen spekulatívan átrendezni egymás között a memóriaolvasási és -írási µop-ok feldolgozását, és ha a véglegesítés közben kiderül, hogy sorrendsértés történt, akkor – egy téves elágazásbecsléshez hasonlóan – újraindítja az utasításvégrehajtást a legutolsó helyes utasítástól.
- A korábbi két, számítási µop-okat végrehajtó egység mellé felsorakozik egy újabb, ezáltal három port között lehet elosztani a kalkulációkat. Számos egyszerű integer µop-ból immár órajelenként 3 futtatható, valamint ezen egység futtatja az összes ugró és fuzionált ugró utasítást.
Nehalem (45 nm), Westmere (32 nm)
A második generációs Core processzorok felépítését leginkább a korábbi Core 2 család ráncfelvarrásaként jellemezhetjük: a tervezők fő célja az volt, hogy az immár 4 szélesre kibővített felépítés erőforrásait minél jobban kihasználhassák a programok.

[+]
- Az Intel palettáját tekintve ebben a generációban költözik be először a processzor lapkájába a memóriavezérlő, amely jelentős lendületet adott a RAM-kezelésnek, később pedig a szintén Nehalem mikroarchitektúrás Lynnfield kódnevű lapkában jelenik meg először az integrált PCI Express vezérlő.
- A cache-hierarchia megváltozik: a korábbi megosztott L2 cache helyét a megosztott L3 cache veszi át, míg a magok egy-egy saját, 256 kB méretű, kicsi, de igen gyors L2-vel gazdagodnak.
- Visszatér a Pentium 4-ből már ismert Hyper-Threading, amely által egy-egy magon az operációs rendszer két programszálat futtathat, jobban kihasználva annak erőforrásait, lehetőségeit, ezzel pedig jobban leterhelve azt. Míg ennek értelmét a Netburstön a hosszú futószalag miatti gyakori üresjáratok adták, itt az erőforrások gazdag tárháza teszi ezt lehetővé, ugyanis egy programszál sokszor csak a végrehajtóknak és puffereknek csak egy bizonyos részét képes dolgoztatni.
- A loop buffer szerepe és helye is megváltozik: míg korábban utasításbájtokat tárolt, ettől kezdve lefordított µop-okat tartalmaz, így kisméretű ciklusok esetén nem csak az L1 utasításcache, hanem a dekóderek is tehermentesíthetőek.
- Az utasításfúziót immáron 64 bites üzemmódban is képes elvégezni a processzor, illetve ugyanez igaz az előjeles feltételes ugrásokra is.
- A Westmere esetében megjelenik az AES-NI utasításkészlet, mely az AES-algoritmus gyorsításáért felel.
A Lynnfield lapka felépítése
Sandy Bridge (32 nm)
Az előzővel ellentétben ez a generáció jelentős változásokat hoz a processzor szerkezetében, ahogy az a felépítési ábrán is látható.
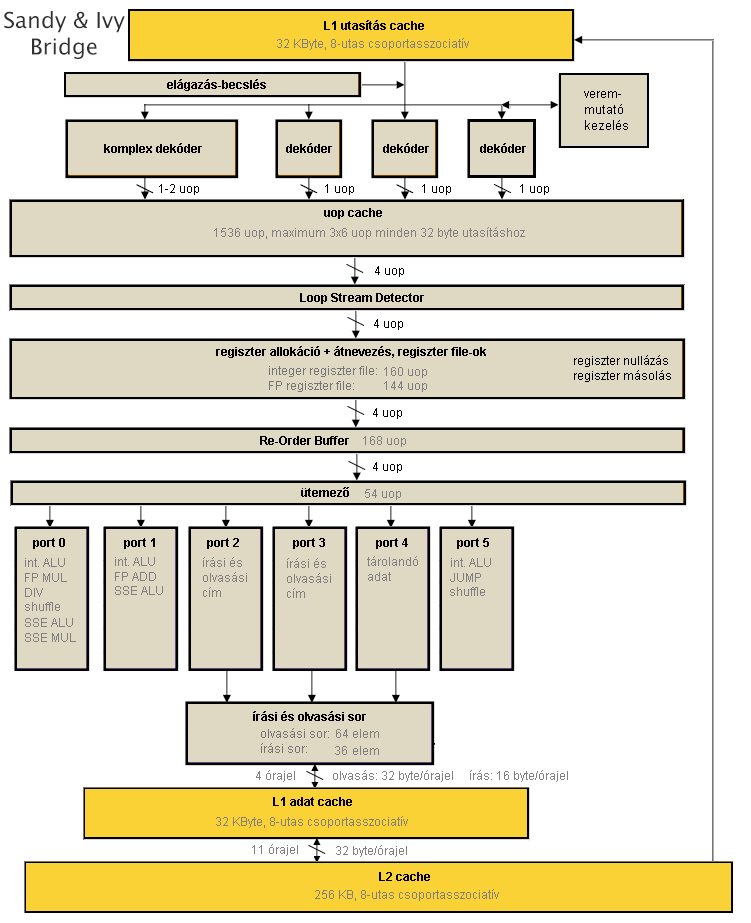
[+]
- A pipeline elején, a dekóderek után egy nagyméretű, legfeljebb 1536 lefordított µop tárolására alkalmas gyorsítótárat találunk. Ez körülbelül 500 darab x86 utasítás tárolására képes, ezáltal nagyméretű ciklusok vagy teljes függvények, szubrutinok tárolására is alkalmas, amivel egyrészt az idő nagy részében jellemzően munka nélkül hagyja az L1 utasításcache-t és a dekódereket, másrészt garantáltan órajelenként 4 µop-ot küld a végrehajtó egységek felé.
- Továbbhaladva két nagyméretű regiszter fájlt találunk, amelyek bizonyos utasításokat saját hatáskörben végre tudnak hajtani, levéve a terhet a végrehajtó egységek válláról: ha egy regiszterre kiadjuk a SUB reg,reg vagy XOR reg,reg utasítást, azaz önmagából kivonjuk vagy önmagával XOR-ozzuk, akkor az eredmény a regiszter jelenlegi értékétől függetlenül 0 lesz; ráadásul ezen utasítások mérete jóval kisebb, mintha egyéb úton nulláznánk. Az ilyen jellegű utasítások meglehetősen gyakran fordulnak elő a programokban. A regiszter fájlok felismerik ezeket a µop-okat, és azonnal törlik a kérdéses regiszter tartalmát (órajelenként legfeljebb 4-ét), így további munka nincs velük a pipeline további részében.
- Elérkezve a végrehajtó egységekhez, látható, hogy míg a korábbi processzorok 1 db dedikált végrehajtóval rendelkeztek a memóriaolvasásokhoz, addig immár két olyan portot látunk (a korábbi port 2 mellé az eddigi írási címszámító port 3 is felsorakozik), amely képes memóriát olvasni. Továbbá a teljes további memória-alrendszer (olvasási sor, L1 adatcache) fel van készítve arra, hogy órajelenként 2 memóriaolvasást tudjon kezelni. Ez jelentős löketet ad a végrehajtásnak, hiszen általánosságban elmondható, hogy az adatfeldolgozás során sokkal több adat olvasására van szükség, mint amennyi írására, gondoljunk csak a pointerekre, struktúra- és tömbcímekre, ciklusváltozókra.
- Az utasításfúzió szintet lép, mivel a CMP és TEST mellé az összeadás/kivonás (ADD és SUB, illetve INC és DEC) és az AND utasítás is felsorakozik, tehát ezek és az őket közvetlenül követő ugró utasítás egyesíthető a dekóderek által egyetlen belső műveletté; továbbá a dekóderek órajelenként 2 db ilyen párt tudnak "összeboronálni".
- A számítási µop-okat 256 bit széles végrehajtók várják, hiszen ebben a generációban jelenik meg az AVX utasításkészlet támogatása, amely 256 bites vektorokkal, azaz egyszerre 8 egyszeres vagy 4 dupla pontosságú lebegőpontos számmal dolgozik.
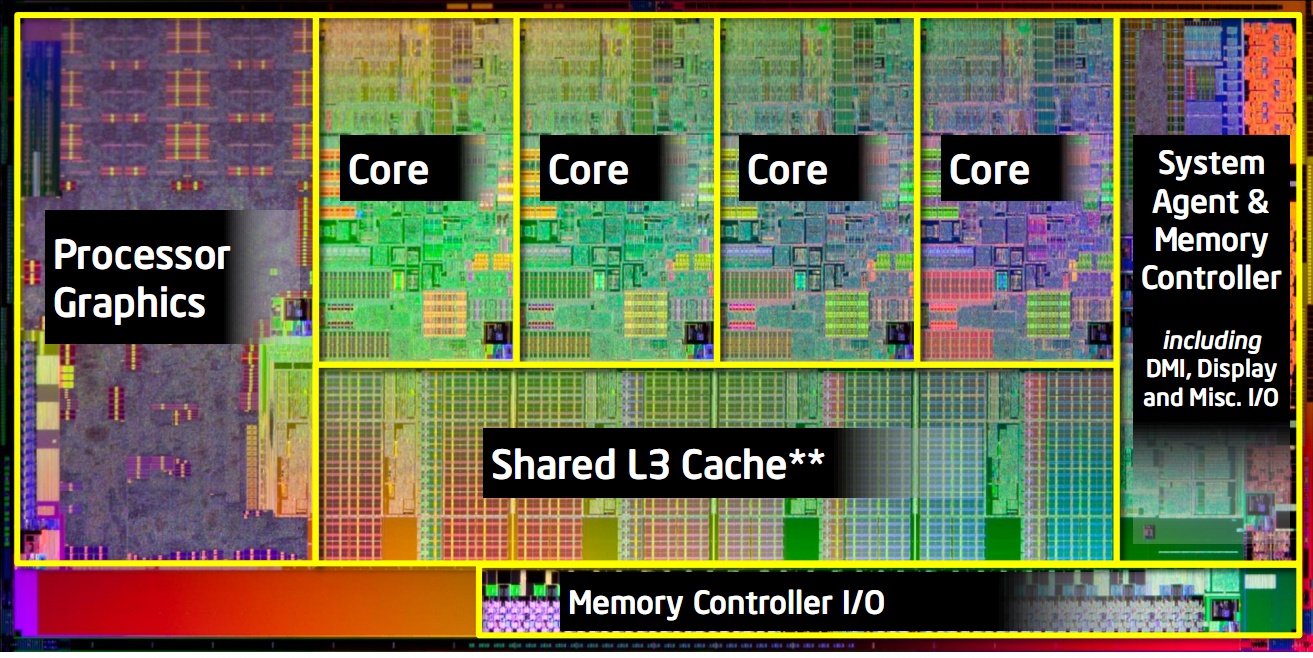
A négymagos Sandy Bridge lapka felépítése [+]
Ivy Bridge (22 nm)
Az Ivy Bridge processzormagok a "tick-tock" stratégia "tick" állomásaként a 22 nm-es gyártástechnológiára való áttérés mellett nem sok változást mutatnak az előző oldalon ecsetelt Sandy Bridge-hez képest; konkrétan három fő újdonsággal találkozhatunk.
- A processzor új utasításokat kínál a 16 bites félpontosságú és a 32 bites egyszeres pontosságú lebegőpontos számok közti konvertáláshoz.
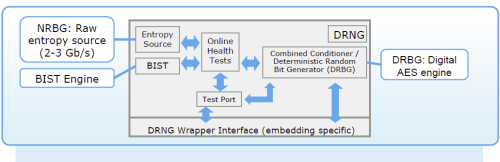
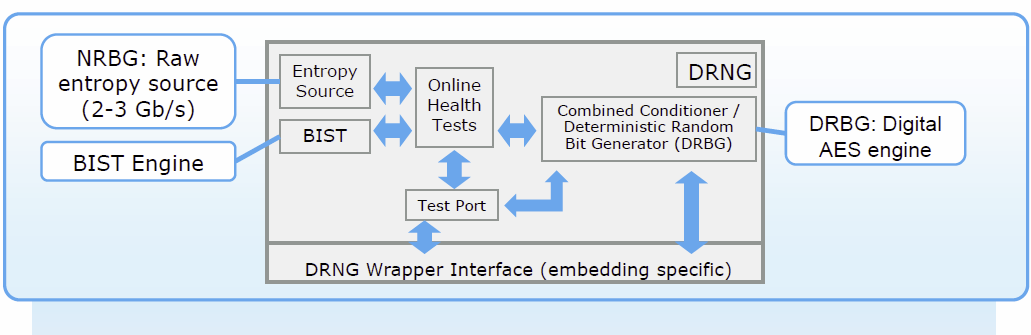
- Az RDRAND utasítás formájában nagyteljesítményű véletlenszám-generátort (Digital Random Number Generator – DRNG) kapott, amely 16, 32 vagy 64 bites számok létrehozására alkalmas.
-
[+] - A legérdekesebb újítást a Supervisory Mode Execute Protection (SMEP) névvel illetett védelem jelenti, amely a következőt takarja: a processzor négyféle védelmi körbe (Ring0, Ring1, Ring2, Ring3) tudja sorolni a programokat aszerint, hogy azok mit tehetnek meg, mihez van jogosultságuk. A modern operációs rendszerek ezek közül legalább kétfélét használnak, ezek a felhasználói (User, Ring3) és a kernel (Supervisor, Ring0) mód. A felhasználói módban futó programoknak pl. nincs jogosultságuk közvetlenül hozzáférni a hardverekhez vagy módosítani a teljes rendszer futási körülményein, az ezekhez szükséges úgynevezett privilégizált gépi utasítások nem engedélyezettek, a program hibával leáll, ha ilyenre fut. Ezen utasítások csak kernel módban engedélyezettek, az ebben a módban futó programok (operációs rendszer, driver-ek, virtualizációs rétegek stb.) megbízható forrásból származnak. Ha egy program hozzá szeretni férni valamely hardverhez, pl. olvasni akar egy fájlt a háttértárról, akkor meghívja az OS megfelelő függvényét, amely ilyenkor átvált kernel módba, végrehajtja a kért cselekményt pl. a megfelelő driver segítségével, majd visszavált felhasználói módba, és a program futása folytatódik.

[+]
A kernel módban levő programkód viszont mindezidáig lefuttathatott csak felhasználói jogkörrel rendelkező programkódokat is, ennek megakadályozására született meg a SMEP: bár maga a kernel-módú kód megbízható forrásból származik, eddig sikerülhetett rávenni (pl. egy biztonsági rés miatt) arra, hogy futása átirányítódjon egy rosszindulatú felhasználói programra; bekapcsolt SMEP mellett viszont ilyen esetekben azonnal megáll a program futása, és elmarad a károkozás.
Mindezeken felül a Sandy Bridge-hez képest kisebb mértékű gyorsulás történt a következők miatt: javulás látható a mikrokód-alapú memóriamásoló és -inicializáló utasítások teljesítményében, 4 új utasítás segítségével gyorsítható az egyes programszálak privát adatait tartalmazó területre mutató FS és GS szegmensregiszterek elérése; a legnagyobb horderejű változás azonban az, hogy – az AMD Bulldozerben bevezetett Move Elimination-hoz hasonlóan, de annál általánosabban akár lebegőpontos, akár integer regiszterre – a regiszterből regiszterbe történő másolásokat a regiszterfájl saját hatáskörében elvégzi, ezen műveletek nem igényelnek végrehajtó egységet. Ezzel tovább okosodott ez az egység, mivel a Sandy Brigde-ben még csak a regiszterek nullázását végezte el önállóan.
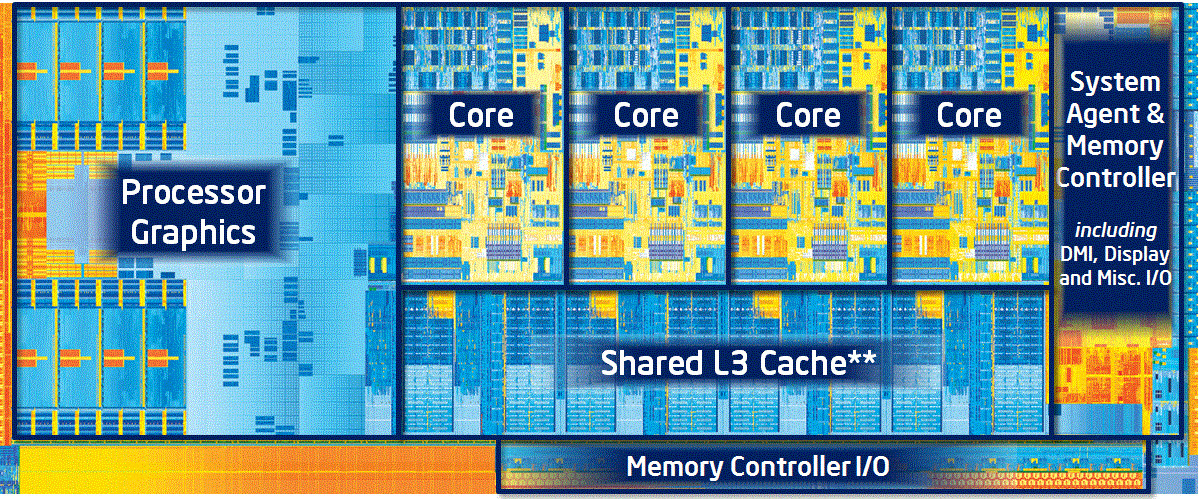
A négymagos Ivy Bridge lapka felépítése [+]
Haswell (22 nm)
Megszokottnak nevezhető, hogy a generációról generációra finomított elágazásbecslés mellett a fejlettebb gyártástechnológiából származó tranzisztorbüdzsé egy részét az out-of-order végrehajtást biztosító, illetve elősegítő pufferek növelésére költik. A Re-Order Buffer (azaz előrelátási ablak), az ütemező és az L1 cache-t tévesztő memóriaolvasási és -írási műveletek sorai mind-mind folyamatosan nőttek a nagyobb (tock) mikroarchitektúra-váltások során, és a jövőben is gyarapodni fognak: ezeknél a puffereknél a végtelen méret lenne ideális, tehát növelésük útjába nem áll praktikus akadály, csak 5-10 bájt nagyságrendű elemméretük és a hozzájuk tartozó vezérlőlogika tranzisztorigénye. A Haswell esetében a ROB (Re-Order Buffer) a Sandy és Ivy Bridge esetében rendelkezésre álló 168-ról 192 µop-ra nőtt.
Mivel az első- és másodszintű gyorsítótárak méretét a Nehalemmel kvázi bebetonozták, ezért a hozzájuk vezető adatút szélességének növelése kritikus a végrehajtó egységek megfelelően ütemezett adatokkal való ellátásának szempontjából. A Haswell immár 2 x 256 bitet olvashat ki órajelenként az L1D-ből, továbbá az L2-ből az L1 cache-be is órajelenként 64 bájtot (azaz egy teljes cache-vonalat) mozgathat.

[+]
Hosszú idő után bővülést láthatunk a végrehajtó egységek számában: az Intel a Core 2 processzorok megjelenése óta az Ivy Bridge-ig bezárólag 6 műveletvégző egységgel operált, amelyek szerepköre ugyan változott az idők folyamán, de alapvetően a következő felosztás általánosan igaz:
- 3 műveletvégző egység (port 0, 1 és 5);
- 2 címszámító egység (port 2 és 3);
- 1 adattárolási egység (port 4).
A Haswell két további porttal bővíti a repertoárt: egyrészt a két címszámító mellé egy harmadikat (port 7) is alkalmaz, kifejezetten a tárolási műveletek címszámításainak részére, így a másik kettő elláthatja beolvasott adatokkal a két 256 bites lebegőpontos egységet (port 0 és 1), valamint az új 6. portot kifejezetten egyszerű integer műveletek részére tartja fenn, biztosítva, hogy a SIMD-ciklusok végrehajtása közben a mutató-, számláló- és ciklusműveletek ne vegyék el az erőforrásokat a vektorműveletektől. Ezen új portok jótékony hatása az egyszálas végrehajtásnál is tetten érhető, de a Hyper-Threading által lehetővé tett kétszálas működésnél mutatkozik meg igazán.
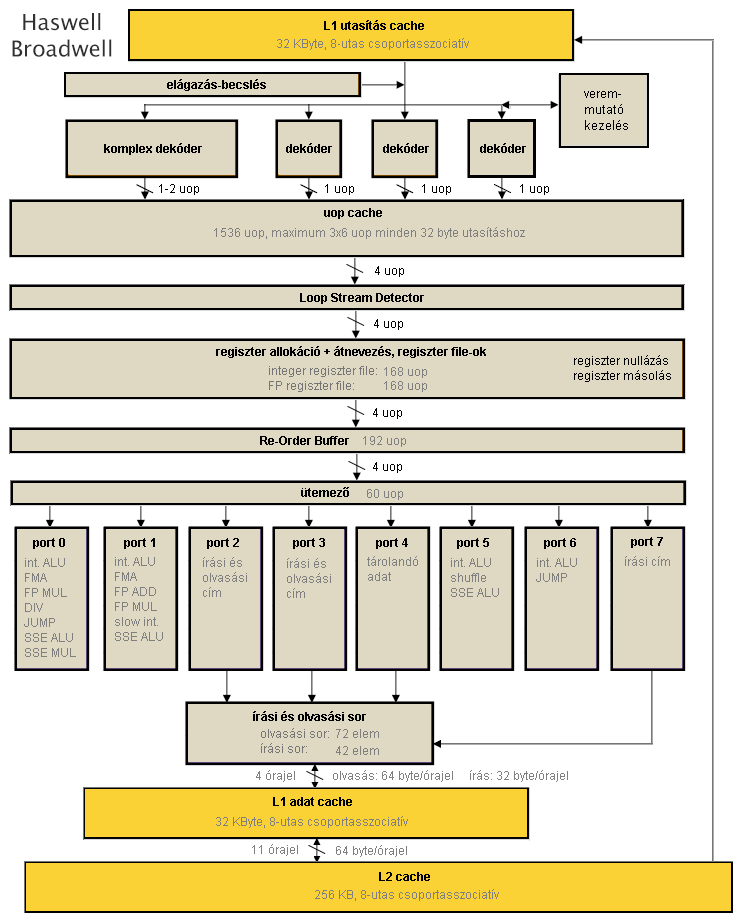
A négymagos Haswell felépítése [+]
A mikroarchitektúra módosítása mellett új utasításkészletek is költöztek a processzorba, a választék bővítésének tekintetében viszont a Haswell kiemelkedik a korábbi generációk közül.
Tranzakcionális memóriakezelés
Azon többszálú programoknak, amelyek nem statikusan felosztott adathalmazokon dolgoznak – pl. 2 mag esetén az adatok felén, 4 mag esetén a negyedén stb. –, általános problémája annak biztosítása, hogy ugyanazt az adatot egyszerre csak az egyik szál módosíthassa. Az x86/x64 architektúra az egyetlen egész számot tartalmazó változó közvetlen vagy akár feltételes atomi módosítására – amely lehet 1, 2, 4, 8 vagy 16 bájtos – kényelmes lehetőséget biztosít a LOCK utasításprefix vagy a CMPXCHG-utasításcsoport révén; előbbi a 'betöltés-módosítás-kiírás' típusú utasításoknál alkalmazható.
Amennyiben egynél több adat atomi módosítására van szükség, nehezebb a helyzet: ilyen esetben a teljes adathoz való hozzáférést egyetlen szinkronizációs változóval kell levédeni, ennek módosításáért (azaz birtoklásáért), majd visszaállításáért versengenek a szálak, és amelyik szál sikeresen módosítja a szinkronizációs változót, az hajthatja végre módosításait a teljes adathalmazon; a többi szál eközben várakozik tétlenül. Sűrűn előfordul azonban, hogy a különböző szálak adatmódosításai nem ütköznek egymással, általában más-más adatot módosítanak, így a várakozások nagy része felesleges lenne. E teljesítményromboló állási idők elkerülésére fejlesztették ki a tranzakcionális memóriakezelési technikákat, melynek első kereskedelmi forgalomba kerülő megvalósítása – mivel a néhai Sun Rock nevű processzort végül nem dobták piacra – a Haswellben debütál.
A Haswell rögtön két megoldást is kínál a tranzakciók kezelésére: az egyik teljesen kompatibilis a régebbi processzorokkal (HLE, Hardware Lock Elision) – bár hatása nem érvényesül azokon, de érvényes utasításként elfogadják őket –, a másik (TSX utasításkészlet) három új utasítás bevezetését jelenti: XBEGIN, XEND és XABORT. Mindkettő működési mechanizmusa azonos:
- a tranzakció elejét és végét egy-egy utasítás jelzi;
- a tranzakció végrehajtása közben a processzor feljegyzi, hogy mely memóriaterületekről történt olvasás és melyekre írás, valamint a módosítások csak az L1D és L2 cache-be kerülnek, miközben az L3 az eredeti adatokat tartalmazza, így a többi programszál ezeket látja;
- a tranzakció végén a processzor ellenőrzi, hogy a feljegyzett memóriaterületek még mindig az eredeti értékeket tartalmazzák-e (azaz amikkel a program a tranzakció alatt számolt, azt más szál nem módosította-e időközben); ha igen, akkor az adatmódosítások egyszerre lesznek láthatóak a teljes rendszer számára (commit); ha viszont változás történt, akkor az L1/L2 cache-ben levő a módosított értékeket felülírja az aktuális értékekkel (rollback), és újra megpróbálkozik a teljes tranzakció lefuttatásával.
Ily módon hardveresen biztosított az, hogy nem módosítja több szál egyszerre az adathalmaz azonos elemét, viszont figyelembe kell venni, hogy az adatmódosítások számának limitáló tényezője elsősorban a 256 kB-os L2 cache: túl sok felhasznált és/vagy módosított adat esetén a processzor önhatalmúlag megszakíthatja a tranzakciót (abort; erre a programozó is utasítást adhat bizonyos körülmények fennállása esetén); ilyen esetekre a TSX használatával külön 'menekülőút' írható a programba, míg HLE alkalmazása esetén újra lefut a tranzakció, immár az említett várakozás kikényszerítésével.
Bár a TSX minden Haswell lapkában megtalálható, a megjelenés után bő 1 évvel az Intel egy problémára hivatkozva az összes termékben letiltotta az utasításkészlet használatát.
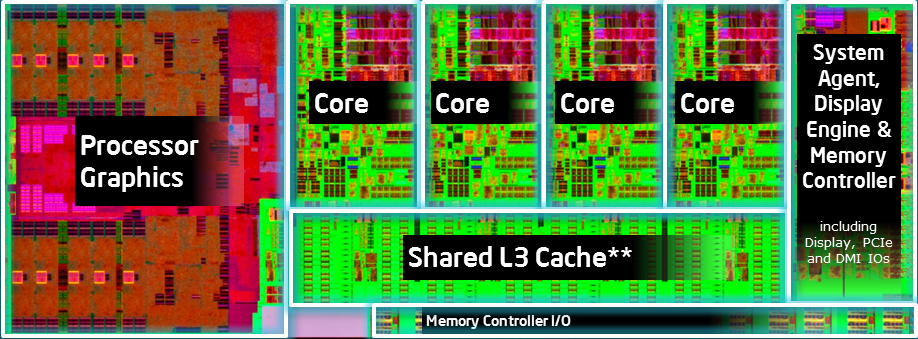
A négymagos Haswell lapka felépítése [+]
FMA3
A Haswell megérkeztével az AMD után az Intel is bevezette a lebegőpontos FMA utasításokat (fused multiply + add), mégpedig háromparaméteres változatukat, amely egyik bemenő adatát felülírja az eredménnyel. Ezen 5 órajel alatt végrehajtódó utasítások 256 bites vektorokon is dolgozhatnak, továbbá órajelenként 2 kerülhet végrehajtásra, így – mivel egy FMA két FLOP-nak felel meg – az elődök 128, illetve 256 bites lebegőpontos végrehajtásához képest a Haswell 2-4-szeres elméleti számítási teljesítménynövekedést ígér.
AVX2
A Sandy Bridge-ben bemutatkozó, 256 bites vektorokon dolgozó lebegőpontos AVX utasítások után a Haswell AVX2 elnevezésű készletével az egész számos SIMD végrehajtást is kibővítette a korábbi 128-ról 256 bites vektorokra, leváltva/kiegészítve a koros 128 bites, Pentium 4-gyel bemutatkozó SSE2 készletet, valamint a Core 2 CPU-kban megjelent, ugyancsak 128 bites SSE4.1 egész számos SIMD-utasításainak nagy részét. Ennek előnyeit elsősorban a kép-, hang- és videófeldolgozó és -megjelenítő programok élvezhetik, de – tekintve az SSE2 mai elterjedtségét – számos különféle programban várható idővel a megjelenése.
Gather memóriaolvasás
Az eddigi x86/x64 SIMD műveletek végrehajtásához előre kellett gondoskodni arról, hogy a vektorok elemei egymás után sorakozzanak a memóriában, mivel egy-egy vektor egy folyamatos memóriaterületet jelent. A Haswellben bemutatkozó 'gather' típusú betöltési utasítás önállóan képes szétszórt elemekből összeállítani egy vektort, mivel paraméterként a kezdőcímet, valamint az elemek e címtől számított távolságát kapja meg. Bár technikailag ez a processzoron belül több külön memóriaolvasásként van megvalósítva, számottevően gyorsítja az ismétlődő minták szerinti memóriahozzáféréseket.
Bitmanipulációs utasítások
A Haswell új bitközpontú utasításokkal is gazdagodott, amelyek egész értékeken (szorzás, shiftelés/forgatás), illetve azok bitcsoportjain végzett bonyolult műveletek végrehajtását gyorsítja fel, külön utasításokként rendelkezésre bocsátva a korábban több instrukcióból álló műveletsorokat.
Broadwell (14 nm)
A Broadwell-alapú processzorok felépítésének alapját a megelőző generációs, 22 nm-es technológiával gyártott Haswell mikroarchitektúra adja, amelyet néhány ponton csiszoltak, kisebb módosításokat végeztek rajta:
- 60-ról 64 eleműre bővül az out-of-order ütemező mérete;
- másfélszeresére, azaz 1536 eleműre nő a másodszintű TLB (virtuális -> fizikai címfordítást végző/gyorsító egység) mérete a 4 kB-os és 2 MB-os lapokra, és új, 16 elemű TLB-t kapnak az 1 GB-os lapok;
- ugyancsak a címfordítást gyorsítja a bevetett második címfordító, melynek segítségével két címfordítás végezhető párhuzamosan, amennyiben azokra nincs találat a gyorstárban;
- az indirekt ugrások címét megjósoló prediktor munkaterülete nő.
A fenti változások mellett nagyobb mértékű fejlesztések érintik a lebegőpontos számítások végrehajtását:
- a szorzások végrehajtási időidénye 5 órajelről 3 órajelre csökken, így immár ugyanannyi, mint a lebegőpontos összeadásé/kivonásé;
- az osztások gyorsítását szolgálja az 1024 Radix osztómű, amely lehetővé teszi 2,5 órajelenként új egyszeres vagy 4 órajelenként új dupla pontosságú osztás kiszámításának elindítását.

A négymagos Broadwell (GT3e) lapka felépítése [+]
Ugyancsak jelentős, körülbelül 60%-os sebességelőnyre tesznek szert a Haswellben bevezetett gather memóriaolvasások.
Fejlesztések történtek a titkosítási/biztonsági algoritmusokat érintően is:
- az ADC (ADd with Carry: x=x+y+Carry Flag) és SBB (SuBtract with Borrow: x=x-y-Carry Flag) utasítások végrehajtása gyorsul;
- új utasításként bemutatkozik az ADCX és ADOX, amelyek az ADC-hez eltérően csak 1 flaget (az előbbi a Carry-t, utóbbi az Overflow-t) módosít, ebből veszi, illetve ebbe helyezi a túlcsordulást, így párhuzamosan két utasításlánc hajtható végre belőlük;
- gyorsult a számos hash/CRC algoritmusban használt PCLMULQDQ utasítás végrehajtása;
- ugyancsak új utasítás a nem determinisztikus random számok generálására alkalmas RDSEED.
Újdonság továbbá az Ivy Bridge-ben bevezetett SMEP védelem párja, az SMAP (Supervisor Mode Access Protection): ennek aktiválásakor a kernel módban futó programkód nemcsak hogy nem hívhat meg felhasználói módú programrészt – ezt akadályozza meg az SMEP –, hanem felhasználó által hozzáférhető/módosítható adatterületről nem is olvashat be adatot.
Az F0 steppinges Broadwell processzoroktól kezdődően ismét elérhetővé vált a Haswell esetében bevezetett, majd később letiltott TSX (tranzakcionális memóriakezelés). Emellett a virtualizációs, valamint az imént említett tranzakcionális memóriakezelést biztosító utasítások végrehajtását is módosították; utóbbi elsősorban nagyobb lehetséges tranzakcióméretben nyilvánul meg.
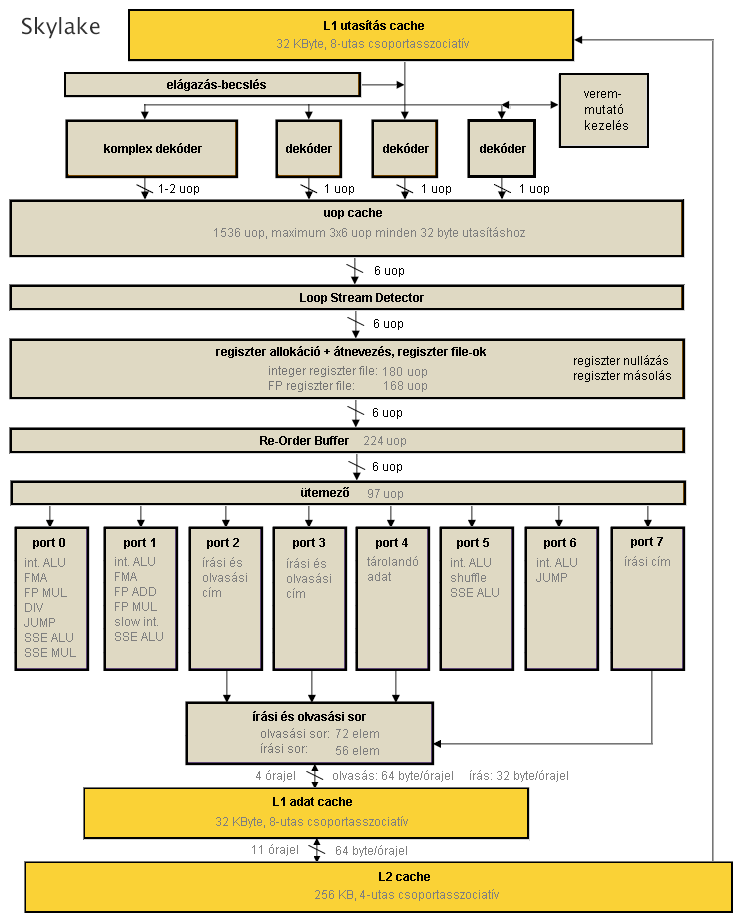
Skylake (14 nm)
A Core-generációk legújabb tagja az idén megjelent Skylake. Végigtekintve rajta egyszerre láthatunk teljesítménynövelő fejlesztést és néhány fogyasztáscsökkentő visszalépést is. Mivel az egészen alacsony fogyasztású mobillapkáktól a nagy teljesítményre kihegyezett szerverprocesszorokig igen széles skálát kell lefednie a Skylake-nek, így az utóbbi "egy lépéssel vissza" megoldások azt a célt szolgálják, hogy a korábbi teljesítmény kisebb étvággyal legyen elérhető.
[+]
- Az out-of-order végrehajtás pufferei – szokás szerint – nőnek, ez a gyarapodás érinti a ROB-ot, az ütemezőt, az integer regiszter file-t és a tárolási sort is.
- A tárak növekedésével együtt a köztük haladó adatutak is kiszélesednek, így a front-end immár órajelenként a 6 µop-ot tud a végrehajtó egységekhez juttatni a korábbi órajelenkénti 4-gyel szemben.
- Visszalépésnek tekinthető viszont, hogy bár a Haswellhez képest a Broadwellben 5-ről 3-ra csökkent a lebegőpontos szorzás időigénye, a Skylake-ben az érték emelkedik, 4 órajelre.
- Ugyancsak meglepő, hogy a 256 kB méretű L2 cache asszociativitása 8-ról 4-re csökkent. Mivel mérete azonos maradt, ez a csökkenés a korábbi generációkhoz képest kisebb találati arányt jelent. Mindezt ellensúlyozandó a Skylake kétszeresére növeli az L2 tévesztések kezelésének sávszélességét.
- Lökést adhat viszont a Hyper-Threading által lehetővé tett kétszálas feldolgozásnak az, hogy míg az elődök órajelenként, magonként legfeljebb 4 µop eredményét tudták véglegesíteni (a spekulatív végrehajtásuk utáni programsorrendben történő ellenőrzésük és eredményük érvényesítése), a Skylake programszálanként képes 4 µop kezelésére.
- Az energiafelhasználás alacsonyan tartását elősegítendő a még nem túl elterjedt AVX2 utasításkészletért felelős végrehajtó hardver teljes egésze lekapcsolható, amennyiben arra épp nincs szükség.
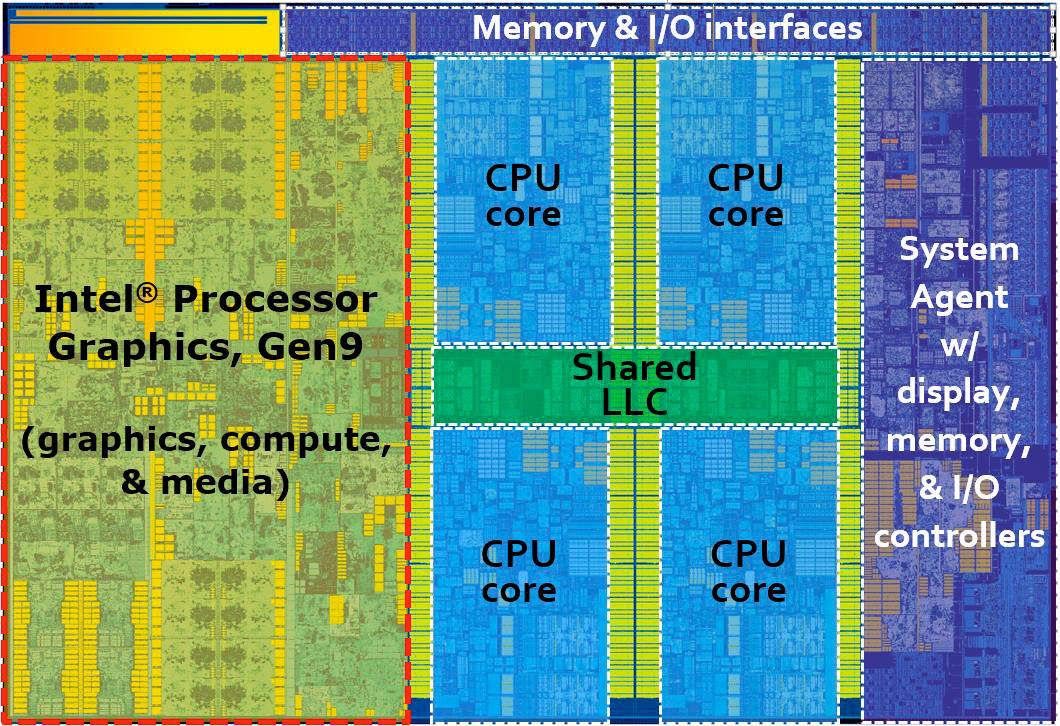
A négymagos Skylake lapka felépítése [+]
Új utasításkészletek
- A Software Guard Extension (SGX) készlet használatával az adott program saját sandboxot hozhat létre, amelyből egyrészt nem tud kilépni, másrészt a rendszeren futó többi program sem képes hozzáférni.
- A Memory Protection Extensions (MPX) az adott program saját memóriájának használata során – legyen szó veremről vagy dinamikusan foglalt memóriáról – ellenőriztetheti, hogy a cím ténylegesen érvényes címterületen van-e, megelőzendő a puffertúlcsordulásos biztonsági hibákat
Összehasonlító táblázat
| Mikroarchitektúra neve | Nehalem (tock) |
Sandy Bridge (tock) |
Ivy Bridge (tick) |
Haswell (tock) |
Broadwell (tick) |
Skylake (tock) |
|---|---|---|---|---|---|---|
| L1D mérete | 32 kB | |||||
| L1D asszociativitása | 8-utas | |||||
| L1D olvasási sebessége | 128 bit | 256 bit | 512 bit | |||
| L1D írási sebessége | 128 bit | 256 bit | ||||
| L1D késleltetése | 4 órajel | |||||
| L1D TLB | 4 kB lapokhoz 64 db (4 utas), 2/4 MB lapokra 32 db (4 utas) |
4 kB lapokhoz 64 db (4 utas), 2/4 MB lapokra 32 db (4 utas), 1 GB lapokhoz 4 db (4 utas) |
||||
| L1I mérete | 32 kB | |||||
| L1I asszociativitása | 4 utas | 8 utas | ||||
| L1I kiolvasási sebessége | 16 bájt/órajel | |||||
| L1I TLB | 4 kB lapokhoz 128 db (4 utas), 2/4 MB lapokra szálanként 7 db |
4 kB lapokhoz 128 db (4 utas), 2/4 MB lapokra szálanként 8 db | ||||
| L2 mérete | 256 kB | |||||
| L2 asszociativitása | 8 utas | 4 utas | ||||
| L2 átviteli sebessége | 32 bájt/órajel | 64 bájt/órajel | ||||
| L2 késleltetése | 10 órajel | 11 órajel | ||||
| L2 TLB | 4 kB lapokhoz 512 db (4 utas) | 4 kB és 2 MB lapokhoz közösen 1024 db (8 utas) |
4 kB és 2 MB lapokhoz közösen 1536 db (8 utas), 1 GB lapokhoz 16 db (4 utas) |
|||
| x86 dekóderek száma | 4 | |||||
| µop buffer mérete | nincs | 1536 µop | ||||
| ROB mérete | 128 | 168 | 192 | 224 | ||
| Ütemező mérete | 36 | 54 | 60 | 64 | 97 | |
| Végrehajtóportok száma | 6 | 8 | ||||
| Integer végrehajtók száma | 3 | 4 | ||||
| Memória címszámítók száma | 2 | 3 | ||||
| Olvasási sor mérete | 48 | 64 | 72 | |||
| Írási sor mérete | 32 | 36 | 42 | 56 | ||
| Lebegőpontos végrehajtók száma | 3 | |||||
| SIMD INT végrehajtók szélessége | 128 bit | 256 bit | ||||
| SIMD FP végrehajtók szélessége | 128 bit | 256 bit | ||||
| FLOPS (egyszeres pontosság) | 8 | 16 | 32 | |||
| FLOPS (dupla pontosság) | 4 | 8 | 16 | |||
Felsorakoznak a résztvevők
A töményebb elméleti rész után valószínűleg már sokakat érdekel, hogy a gyakorlatban mennyit számítanak az egyes mikroarchitektúrák eltérései, újításai. Ennek kiderítésére azonos magszám és órajel mellett hasonlítottuk össze a résztvevő processzorokat. A meccsbe így végül összesen hat mikroarchitektúra került be: Nehalem (Lynnfield), Sandy Bridge, Ivy Bridge, Haswell, Broadwell, Skylake.

Hat különféle processzor, hat különböző mikroarchitektúra [+]
A hat tesztelt Intel processzor listája a következőképpen alakult: Core i7-870, Core i7-2600K, Core i7-3770K, Core i7-4770K, Core i7-5775C, Core i7-6700K. A felsorolt modellek kivétel nélkül négy maggal rendelkeznek, illetve támogatják a Hyper-Threading technológiát, valamint integrált PCI Express kontrollerrel is felvértezték őket. A hat darab CPU-ból öt esetében a gyorsítótárak mérete is megegyezik, az egyetlen kivételt a Broadwell-alapú Core i7-5775C jelenti, melynek L3 cache mérete 8 MB helyett csupán 6 MB, ugyanakkor jókora kompenzáció gyanánt ott a lassabb, ugyanakkor sokkal nagyobb, 128 MB-os eDRAM. Ezzel a Core i7-5775C-t, illetve annak eredményeit bizonyos esetekben érdemes fenntartással kezelni, ugyanis ahol kapóra jön a hatalmas eDRAM, ott bizony a mikroarchitektúrától független előnyre tehet szert a Broadwell, de más piacon lévő opció híján ezzel kellett beérnünk.
| CPU megnevezése | Core i7-870 | Core i7-2600K | Core i7-3770K | Core i7-4770K | Core i7-5775C | Core i7-6700K |
| Kódnév | Lynnfield | Sandy Bridge-DT | Ivy Bridge-DT | Haswell-DT | Broadwell-H | Skylake-S |
|---|---|---|---|---|---|---|
| Mikorarchitektúra | Nehalem | Sandy Bridge | Ivy Bridge | Haswell | Broadwell | Skylake |
| Tokozás | LGA1156 | LGA1155 | LGA1150 | LGA1151 | ||
| Gyártástechnológia | 45 nm HKMG | 32 nm HKMG | 22 nm Tri-Gate | 14 nm Tri-Gate | ||
| Stepping | B1 | D2 | E1/L1 | C0 | E0/G0 | R0 |
| Beállított magórajel | ~3000 MHz | |||||
| Beállított szorzó és BCLK | 22 x 136 MHz | 30 x 100 MHz | ||||
| NB/IMC(/L3) órajele | 2448 MHz | 3000 MHz | ||||
| L1 cache / mag | 32 kB adat (8 utas) és 32 kB utasítás (4 utas) |
32 kB adat (8 utas) és 32 kB utasítás (8 utas) |
||||
| L2 cache / mag | 256 kB (8 utas) | 256 kB (4 utas) | ||||
| L3 cache | 8 MB (16 utas) | 6 MB (12 utas) | 8 MB (16 utas) | |||
| Utasításkészletek | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2 |
MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, SSE4A, AES, AVX | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, SSE4A, AES, AVX, AVX2, FMA3, TSX* |
|||
| Rendszerbusz | 2,5 GT/s QPI | 5 GT/s DMI | 8 GT/s DMI | |||
| Leggyorsabb támogatott RAM | DDR3-1333 MHz (Dual Channel) | DDR3-1600 MHz (Dual Channel) | DDR3L-1600 (DC) DDR4-2133 (DC) |
|||
| *A TSX támogatását az Intel a Haswell processzorokban végül letiltotta. | ||||||
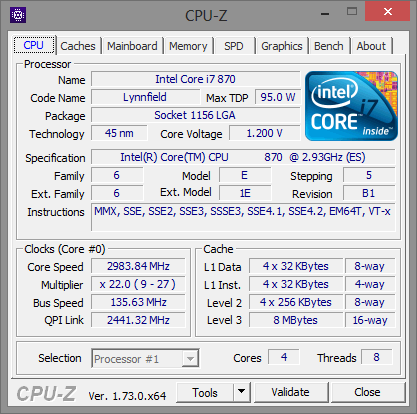
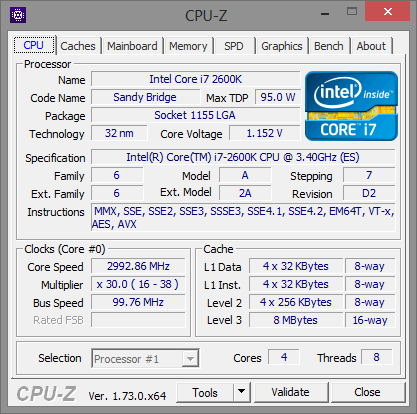
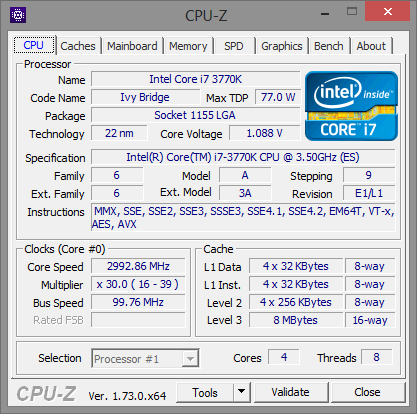
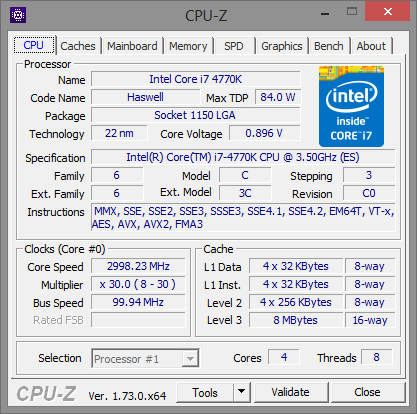
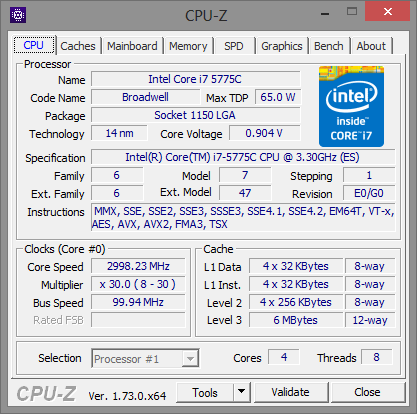
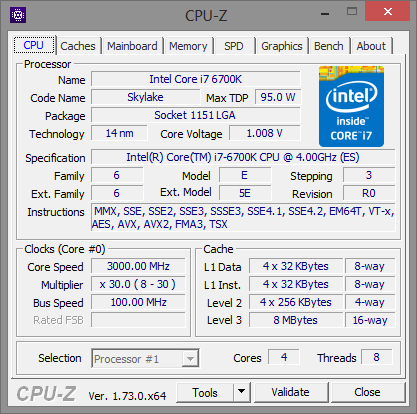

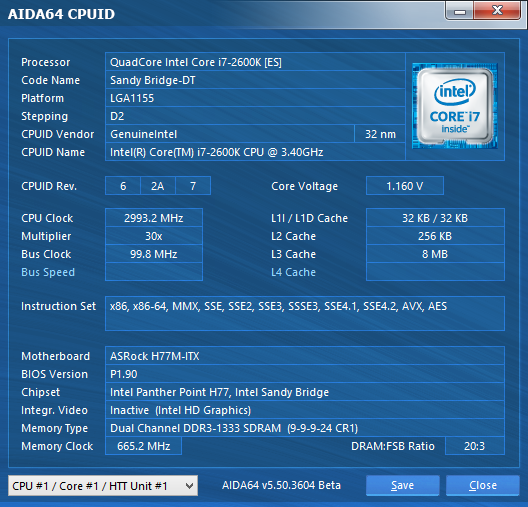
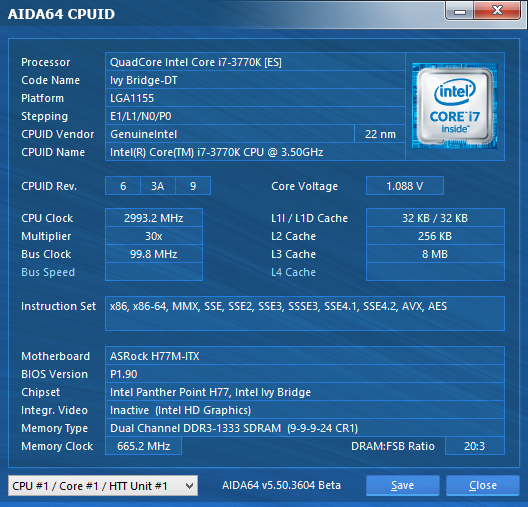
Intel Core i7-870, Core i7-2600K, Core i7-3770K, Core i7-4770K, Core i7-5775C, Core i7-6700K [+]
Az egyes processzorok órajelét egységesen 3000 MHz-re, azaz 3 GHz-re próbáltuk belőni, ami csak a Core i7-870 esetében igényelt egy minimális tuningot. Ez a modell még alacsonyabb szorzót, illetve 133 MHz-es BCLK-t alkalmaz, melyet végül 136 MHz-re emelve értük el a kívánt célértéket.
| LGA1156-os tesztplatform | Intel Core i7-870 2,93 GHz (~3000 MHz-en járatva) MSI P55-GD80 (P55 chipset, BIOS: V1.12) 2 x 4 GB Kingston HyperX Predator DDR3-2400 memória DDR3-1333 beállítás, 9-9-9-24 CR1 időzítések |
|---|---|
| LGA1155-ös tesztplatform | Intel Core i7-2600K 3,4 GHz (~3000 MHz-en járatva) Intel Core i7-3770K 3,5 GHz (~3000 MHz-en járatva) ASRock H77M-ITX (H77 chipset, BIOS: P1.90) 2 x 4 GB Kingston HyperX Predator DDR3-2400 memória DDR3-1333 beállítás, 9-9-9-24 CR1 időzítések |
| LGA1150-es tesztplatform | Intel Core i7-4770K 3,5 GHz (~3000 MHz-en járatva) Intel Core i7-5775C 3,3 GHz (~3000 MHz-en járatva) ASRock Z97 Extreme6 (Z97 chipset, BIOS: P2.40) 2 x 4 GB Kingston HyperX Predator DDR3-2400 memória DDR3-1333 beállítás, 9-9-9-24 CR1 időzítések |
| LGA1151-es tesztplatform | Intel Core i7-6700K 4,0 GHz (~3000 MHz-en járatva) Asus Z170-P D3 (Z170 chipset, BIOS: 0407) 2 x 4 GB Kingston HyperX Predator DDR3-2400 memória DDR3-1333 beállítás, 9-9-9-24 CR1 időzítések |
| Videokártya | NVIDIA GeForce GTX 980 Ti – GeForce driver 358.50 |
| Háttértárak | Intel SSD 510 250 GB SSDSC2MH250A2 (SATA 6 Gbps) Seagate Barracuda 7200.12 500 GB (SATA, 7200 rpm, 16 MB cache) |
| Tápegység | Seasonic Platinum Fanless 520 – 520 watt |
| Monitor | Acer B326HUL (32") |
| Operációs rendszer |
Windows 8 Pro 64 bit |
A még kiegyenlítettebb környezet érdekében a memóriákat is próbáltuk egységesen beállítani. Ebben az esetben a DDR3-1333 volt a cél, amit végül mind a hat processzor esetében sikerült elérni, igaz a Skylake, azaz az i7-6700K-nál ehhez egy DDR3-a modulokat kezelő LGA1151-es alaplapra volt szükségünk.
AIDA64: szintetikus tesztek
Első körben szintetikus méréseket végeztünk a hat különböző processzorral és platformmal, melyhez most is a jól ismert, és nem utolsósorban teljesen hazai fejlesztésű AIDA64-et hívtuk segítségül. Kezdésnek a gyorsítótárak maximálisan elérhető sávszélességét vizsgáltuk meg. A tesztprogram ehhez magonként/szálanként az adott cache kapacitásának pontosan megfelelő méretű adatot ír, illetve olvas, miközben az x86/x64, x87, MMX, MMX+, 3DNow!, SSE, SSE2, SSE4.1, AVX és AVX2 utasításkészleteket is képes kihasználni.

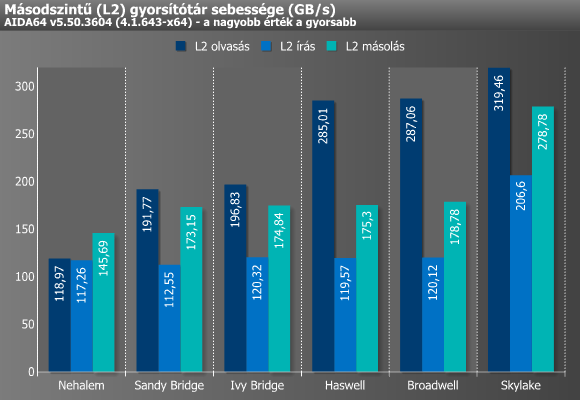

A fenti grafikonok, illetve a számok önmagukért beszélnek, hisz jól mutatják a már említett, a gyorsítótárak sávszélességének növelése érdekében tett különféle módosítások hatásait.
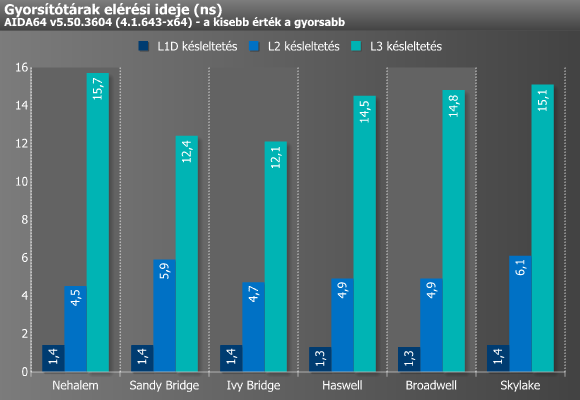
A késleltetés méréséhez alkalmazott teszt már csak egyetlen magot/szálat használ. Ez egy TLB-nyi memóriaablakban véletlenszerűen lépdel végig minden cacheline-on, mielőtt egy újabb ablakba váltana át. Akárcsak a sávszélesség esetében, itt is az adott gyorsítótárszint méretének megfelelő adattal dolgozik a teszt.
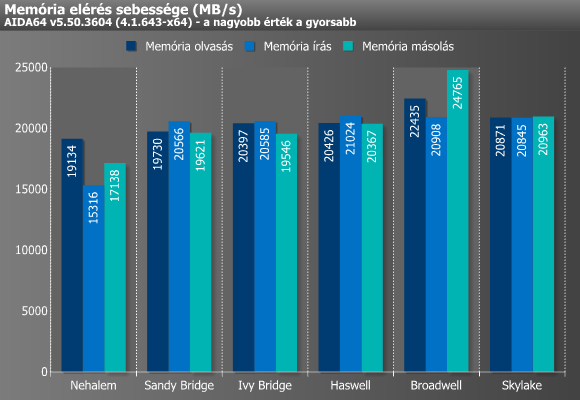

A memóriával kapcsolatos mérések a fentiekhez hasonló módszerrel működnek, csupán az adatok mérete nagyobb. Sávszélesség esetén magonként/szálanként 64 MB adatot olvas, illetve ír a teszt, míg másoláskor 32 MB-ot olvas és 32 MB-ot ír. A késleltetés mérésénél a tesztadat mérete minden esetben az utolsó cache-szint négyszerese. Az eredményeket tekintve megállapíthatjuk, hogy a Sandy Bridge óta nem történt komolyabb változás, hisz már ez a mikroarchitektúra is majdnem képes volt kiaknázni a kétcsatornás DDR3-1333 által nyújtott maximális sávszélességet. Ezt egyedül a Broadwell tudta átlépni, melynek oka minden bizonnyal az eDRAM környékén keresendő.

Ezt követően az AIDA benchmark moduljai felé vettük az irányt, melyekből összesen kilenc (5 integer, 4 lebegőpontos) különféle teszttel mértük meg a processzorokat. Az egyik ilyen a CPU Queen, mely egy egyszerű, egész számokkal dolgozó benchmark, mely a processzorok elágazásbecslési képességeire fókuszál, és a „nyolc királynő egy sakktáblán” feladványra épül (10 x 10-es sakktáblán). A teszt x86-, MMX-, SSE-, SSE2- és SSSE3-optimalizált, és kevesebb mint 1 MB memóriát foglal le. Nemcsak a branch prediction táblák és a becslés pontossága, illetve a return stack mérete számít, hanem az is, hogy az adott utasításkészlet valamilyen módon támogatja-e maguknak az elágazásoknak az elkerülését (van-e CMOV vagy PABSB utasítás), illetve képes-e egyszerre párhuzamosan több bábu helyzetével számolni. Itt a Haswellig még többé-kevésbé javultak az eredmények, majd a Skylake esetében visszaesett a pontszám, amire (egyelőre) nincs teljesen biztos magyarázat, de valószínűleg a Skylake futószalagjának hossza körül rejtőzhet a megoldás.
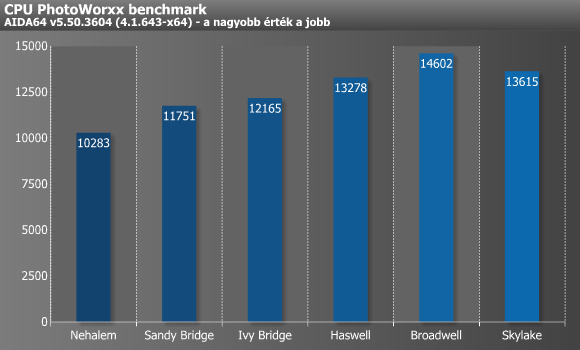
A következő teszt a CPU PhotoWorxx, amely különböző digitális fotófeldolgozási műveleteket hajtat végre a processzorral (SWRandom kitöltes, 90 és 180 fokos forgatás, difference, RGB2YUV konverzió). Ez a teszt elsősorban a processzorok integer számolási végrehajtási egységeit dolgoztatja meg a memória-alrendszerrel egyetemben, és nem skálázódik kifejezetten jól több processzormag esetén. Ezzel szemben meglehetősen sok különféle utasításkészletből képes profitálni, így az x87, MMX, MMX+, 3DNow!, 3DNow!+, SSE, SSE2, SSSE3, SSE4.1, SSE4A, AVX, és AVX2 mellett még az XOP is támogatott. A PhotoWorxx egy igen összetett teszt, többféle méretű képpel dolgozik, sok minden számít benne, de leginkább az átlagos memóriaelérés ideje a meghatározó, illetve sokat jelentenek a jobb prefetcherek, és itt számít a legtöbbet a cache-ek hatása is. Itt nem túl meglepő módon elsősorban a Sandy Bridge és a Haswell esetében láthatunk 1-1 nagyobb ugrást, míg a Broadwellnél már bejön a képbe az eDRAM, mely nélkül valószínűleg csak alig gyorsulna a Haswellhez képest.
AIDA64: szintetikus tesztek (folytatás)
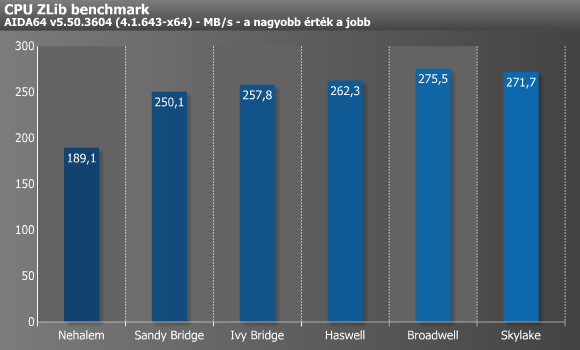
A CPU ZLib is egy integer benchmark, amely a publikusan elérhető 1.2.5-ös ZLib fájltömörítési algoritmussal méri le a processzor és a memória-alrendszer teljesítményét. A teszt magonként/szálanként 32 MB-ot tömörít egy masik 32 MB-os bufferbe, miközben csak és kizárólag alap x86-os utasításokat használ. Itt inkább a CPU sebessége, illetve képességei számítanak (dekódolás szélessége, out-of-order load támogatása, ugrásbecslés, reordering ablak mérete), mintsem a memória sebessége. Ebben a tesztben a Sandy Bridge óta nem sokat gyorsultak az egyes mikroarchitektúrák, csupán kisebb előrelépéseket tudtunk kimérni.
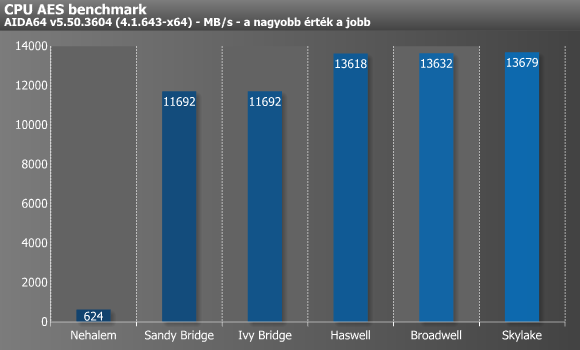
A CPU AES is egy integer benchmark, amely az AES (azaz Rijndael) adattitkosító algoritmust használja. A teszt Vincent Rijmen, Antoon Bosselaers és Paulo Barreto publikusan elérhető C kódját használja ECB módban. A benchmark alap x86-os utasításokat, MMX-et, valamint SSE4.1-et használ, és és magonként/szálanként 8 kB-nyi adatot kódol át egy másik 8 kB-os bufferbe. Elsősorban itt is inkább a CPU sebessége a fontos, illetve kiugróan az out-of-order load képesség számít (a hardveres AES támogatást leszámítva persze). Ennek hatását jól szemlélteti a Nehalem és a Sandy Bridge közötti különbség, ugyanis utóbbi már támogatja az AES-NI utasításkészletet.
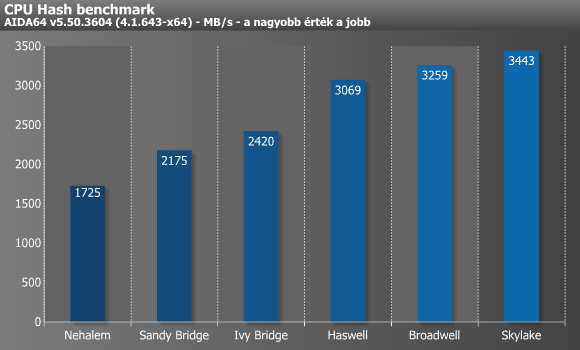
A CPU Hash az SHA1 hasító algoritmus segítségével méri le a processzor képességeit, melynek kódját assemblyben írták a készítők. A teszt képes kihasználni az MMX, MMX+/SSE, SSE2, SSSE3, AVX, AVX2, XOP, BMI, és BMI2 utasításkészletek nyújtotta előnyöket a VIA PadLock Security Engine-jével egyetemben. A BMI és BMI2 által nyújtott pluszt jól szemlélteti a Haswell, melybe anno mindkét utasításkészlet bekerült.
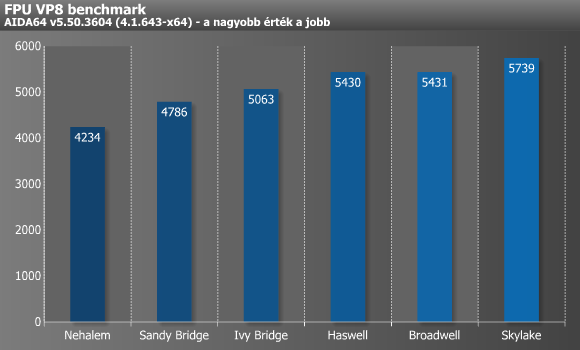
A következő, FPU VP8 nevű teszt már kifejezetten egy lebegőpontos mérés, mely az FPU képességeire fókuszál, és egész adatokat használ XMM vektorregiszterekkel. Ahogy nevéből is sejthető, ez a Google VP8-as kodekjének 1.1.0-es verziójával operál, melynek hathatós közreműködésével tömörít egy 1280x720-as felbontású, 8192 kbps bitrátájú videót a legjobb minőségi beállítások mellett, melynek képkockáit az FPU Julia fraktál modulja állítja elő. A SIMD-utasításkészletek közül az MMX, SSE2, SSSE3, és SSE4.1 kiterjesztésekből képes profitálni. Itt az egyes Intel mikroarchitektúrák relatíve lassú, de folyamatos gyorsulást produkáltak, a Broadwellt leszámítva.
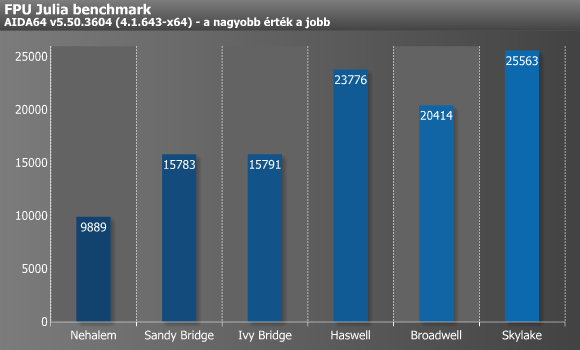
Az imént már említett FPU Julia a processzorok 32 bites (egyszeres pontosságú) lebegőpontos teljesítményét méri le a közismert „Julia” fraktál segítségével, amit magonként/szálanként 1024x1024 pixel méretben, 1000 iteráció mélységig számol. A benchmark kódja itt is assemblyben íródott, és extrém mértékben használja ki az egyes SIMD-utasításkészleteket (x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA3). A Sandy Bridge és a Haswell esetében érthető a két nagy ugrás, ugyanakkor a Broadwell visszaesésének bizarr anomáliájára még az AIDA64 fejlesztői sem tudják a pontos választ. Annyi legalább már kiderült, hogy a mikroarchitektúra sajátosságából fakadó lassulás csak különféle FMA utasítások bizonyos sorrendjénél jön elő.
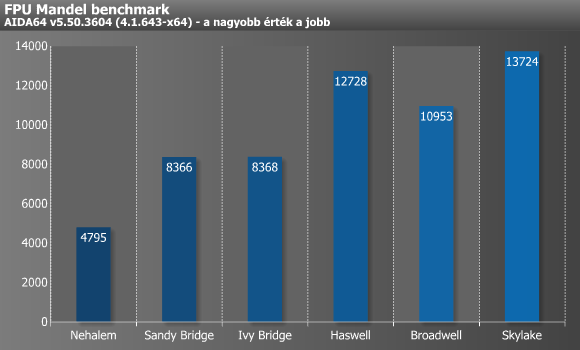
Az FPU Mandel a 64 bites (kétszeres pontosságú) lebegőpontos teljesítményt (FP64) méri le a „Mandelbrot” fraktál egyes frame-jeinek kiszámolása révén, melyeket az előzőhöz hasonlóan magonként/szálanként 1024x1024 pixel méretben, 1000 iteráció mélységig számol. Ez a benchmark is assemblyben íródott, és akárcsak az FPU Julia, hatékonyan használja ki az egyes SIMD-utasításkészleteket (x87, SSE2, AVX, AVX2, FMA3 es FMA4). A két teszt hasonlóságai az eredményekben is visszatükröződnek, hisz szinte ugyanaz a tendencia mutatkozott meg, mint a Julia esetében.
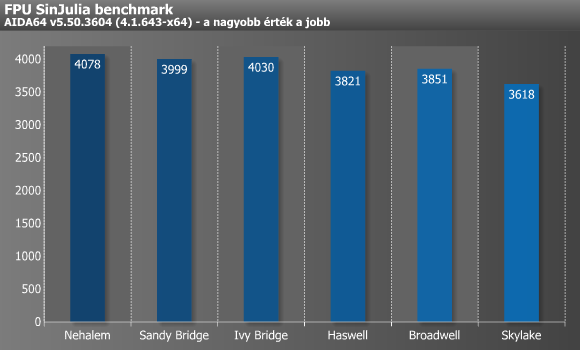
Az FPU SinJulia a 80 bites (kiterjesztett pontosságú) lebegőpontos teljesítményt méri le a „Julia” fraktál módosított változatának (256x256 pixel, 70 iteráció) kiszámolásával. A kód assemblyben íródott, és erősen kihasználja a trigonometrikus és exponenciális x87-es utasításokat. Míg a Juliánál a raw 32 bites lebegőpontos MUL/ADD/MOV képességek számítanak, addig a SinJuliánál a legpontosabb 80 bites mód kihajtása a lényeg, és a transzcendens utasítások (sin, cos, ex) megvalósítása. Teljes végrehajtási idő szempontjából az utóbb említett sin, cos, ex sebessége a döntő, amiben például a Skylake lassabb, mint az Ivy Bridge vagy a Nehalem. Általánosságban elmondható, hogy az Intel már jó ideje nem fejleszti az x87-es képességeket, sőt ahogy az eredmények is jól mutatják, ezen a téren már inkább visszafele lépdelnek, ami bár első ránézésre furcsán hangozhat, ugyanakkor a jelen kor követelményeinek fényében meglepőnek már sokkal kevésbé nevezhető.
Renderelés, tömörítés
A szintetikus mérések után most térjünk rá a fontosabb, úgynevezett real-world alkalmazások alatti teljesítmény vizsgálatára! A méréseket szokásos tesztcsomagunkkal végeztük.

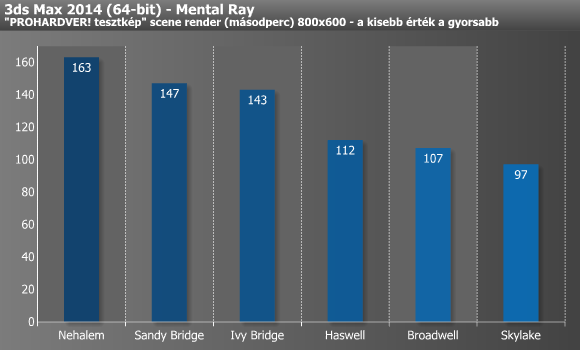
A renderelés tipikusan az a nagyon jól párhuzamosított, sok magot/szálat nagyon hatékonyan kihasználni képes folyamat, ami nem igazán húz hasznot sem a méretes L3 cache-ből, sem az esetlegesen nagyobb memória-sávszélességből. Az IPC, azaz az egységnyi órajel alatt végrehajtható műveletek számából, illetve a magasabb üzemi magfrekvenciából viszont annál inkább képesek profitálni ezek az alkalmazások. Cinebench alatt szépen fejlődtek az Intel architektúrák az elmúlt néhány évben, ami a Nehalemhez képest körülbelül 43%-os pluszt jelent azonos órajel és magszám mellett. 3ds Max alatt hasonló mértékű, 40% körüli a gyorsulás, a grafikonról pedig jól leolvasható, hogy itt a legnagyobb előrelépést a Haswell hozta.
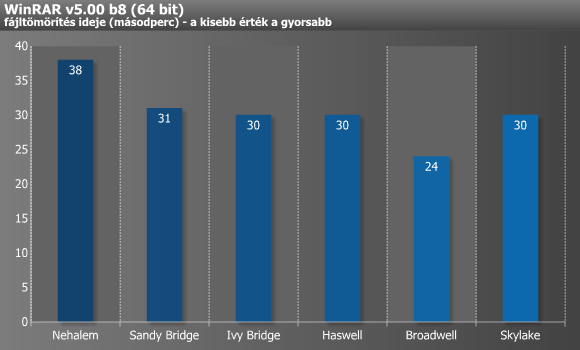
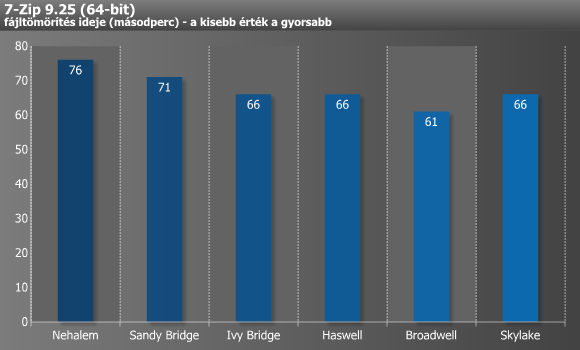
A fájltömörítők a renderelő alkalmazásokkal ellentétben kedvelik a minél nagyobb memória-sávszélességet és az alacsony késleltetést, illetve a minél nagyobb, illetve gyorsabb cache-t. Ebben az esetben az Ivy Bridge-ig történt előrelépés, majd azóta gyakorlatilag semmi sem változott. A Broadwell eredménye ne tévesszen meg senkit, ugyanis az i7-5775C-nek sokat segít a 128 MB-os L4 cache (eDRAM), mely nélküli szinte biztosan a Haswell-lel azonos eredményeket láthattunk volna.
Videóvágás, szerkesztés
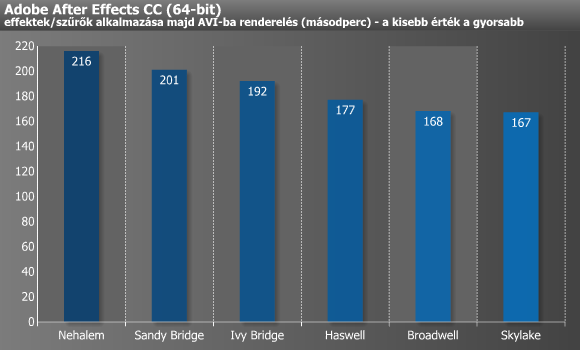


A különféle videóvágó és -konvertáló alkalmazások egyaránt profitálnak a gyorsabb memóriából és a minél több magból/szálból, illetve természetesen a magasabb IPC-ből. After Effects alatt a Broadwellig mértünk számottevő gyorsulást, és szinte ugyanez volt a helyzet Premier Pro alatt is. Tippünk szerint a Sony Vegas is beállhatna a sorban, ugyanakkor itt megint kissé torzítja az eredményt az i7-5775C eDRAM-ja, ami jó néhány másodperces lökést ad a Broadwellnek.
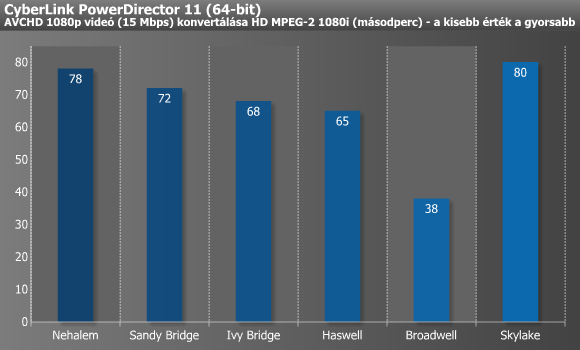
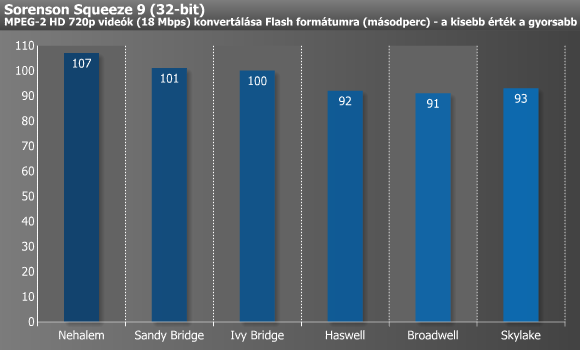
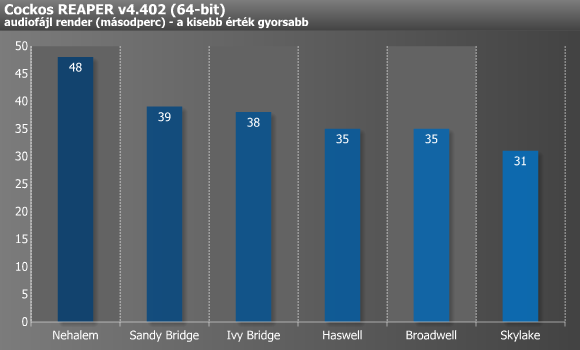
A PowerDirector rendkívül kedveli a minél alacsonyabb memória-késleltetést, amit a Broadwell-alapú i7-5775C eDRAM-ja 128 MB erejéig meg is adott neki, így pedig nem volt kérdéses az első hely, ugyanakkor eDRAM nélkül minden bizonnyal csak valahol a Haswell szintjén végezhetett volna. Ennél sokkal furcsább a Skylake gyenge szereplése, melynek okára még tippünk sincs, mindenesetre többszöri újramérés után is pontosan 80 másodperces eredményt kaptunk. A Sorenson a fenti első trióhoz hasonló képet rajzolt ki, azaz a Haswell után már kvázi nem volt változás, míg a Reaper még a Skylake esetében is gyorsult bő 11%-ot.
Videókódolás, egyéb
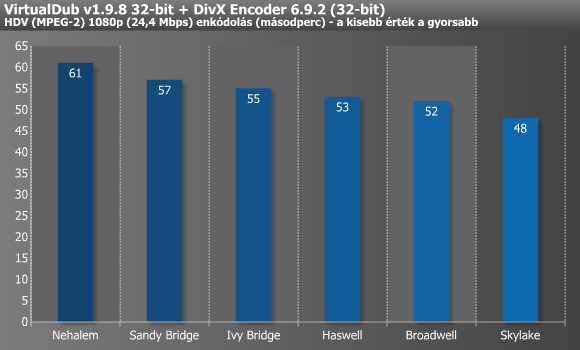
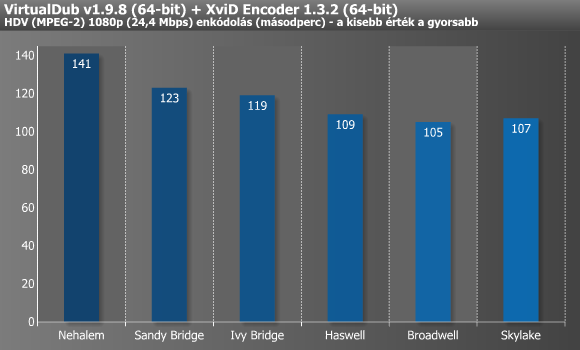
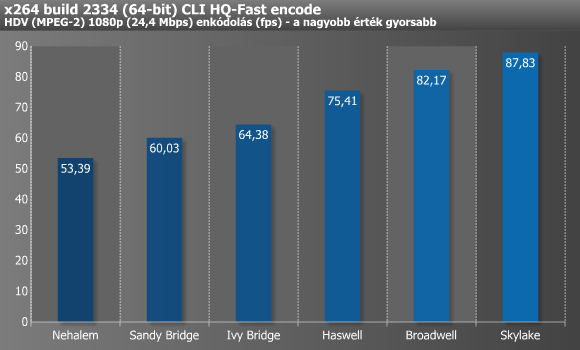
A DivX képes több szálon dolgozni, bár négy felett már egyiket sem terheli maximumra, míg az XviD mindössze egyet tud kihasználni. Ezekkel ellentétben az x264 jóval fejlettebb, hisz a tizenkét vagy több magot/szálat felvonultató processzorokon is képes 100%-os CPU-kihasználtságot mutatni, miközben még a legújabb utasításkészleteket (pl. AVX2) is kihasználja. A DivX-XviD páros alatt tűrhetően skálázódtak az újabbnál-újabb architektúrák, míg x264 esetében már egy kifejezetten szép grafikont rajzoltak ki az eredmények. Utóbbi tesztben mértük a legnagyobb, 64,5%-os gyorsulást a Nehalem és a Skylake között.

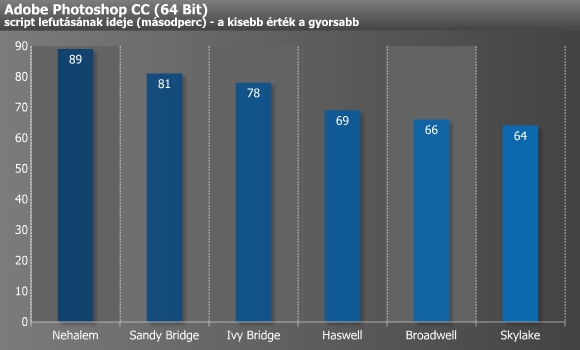

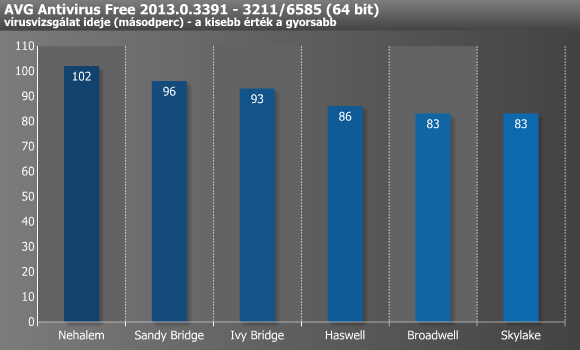
A LameXP alatti konvertálás a Broadwellig minden lépcsőn rendre 1-2 másodpercet gyorsult, a Skylake viszont már nem hatotta meg túlzottan. A Photoshop a Haswellnél ugrott a legnagyobbat, majd attól kezdve lelassult a másodpercek csökkenése. Az Apache szintén nagyot ugrott a Haswell-lel, míg a Skylake esetében továbbra is siralmas eredményt produkál, melynek (lehetséges) okára a következő oldalon rávilágítunk.
A Hyper-Threading hatékonysága
A Hyper-Threading a multi-threading (magyarul többszálúsítás) egyik megvalósítása. Az eljárás fő célja a már rendelkezésre álló részegységek minél hatékonyabb kiaknázása, így az Intel technológiájának lényege, hogy egyetlen fizikai magban a feldolgozás során keletkező üresjáratokat is ki tudják használni egy második szál (angolul thread) hozzáadásával, melyhez a magonként szükséges szilíciumtöbblet minimális, mindössze 5% körüli. A végeredmény két teljesen egyenértékű végrehajtószál, melyeket az operációs rendszer két teljesen különálló processzorként/magként érzékel, azaz a tévhittel ellentétben ezek között sosincs semmiféle alá- vagy mellérendelt szerep, ahogy a "virtuális mag" meghatározás is abszolút helytelen.
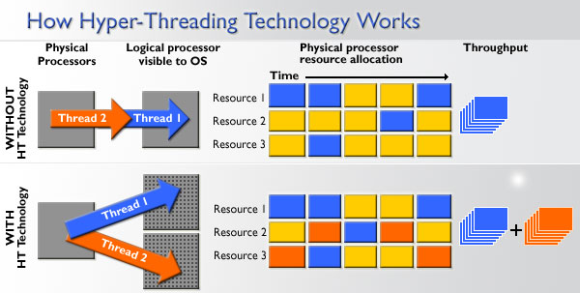
A Hyper-Threading hatékonysága alkalmazás- és architektúrafüggő, ugyanakkor elmondható, hogy out-of-order felépítésnél optimális esetben kb. 20-30% teljesítménynövekedést hozhat. A technológia sajátosságai miatt ugyanakkor bizonyos esetekben előfordulhat, hogy mindez épp semmilyen, vagy szélsőségesebb esetben akár negatív hatással is lehet a végrehajtási sebességre, ezért néhány alkalmazásnál maguk a szoftverek készítői tanácsolják kikapcsolását, amire lényegében minden esetben meg is van a lehetőség.
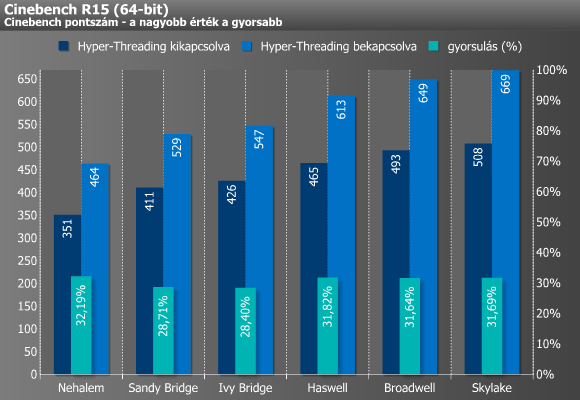
A különféle renderelőkről jól tudjuk, hogy remekül képesek kihasználni a több mag vagy a Hyper-Threading által nyújtott előnyöket, hisz ezek tulajdonképpen annyi különálló egységre osztják fel a kiszámolandó munkát, ahány mag vagy szál épp rendelkezésre áll, így végül minden feldolgozóra egy teljesen saját feladat jut, ily módon pedig az egyes folyamatok nem függenek egymástól, ami szinte tökéletes skálázódást eredményez. A fenti grafikon ezt gyönyörűen alá is támasztja, ugyanis a Sandy és Ivy Bridge közel 29, míg a többi architektúra 32 százalékkal jobb eredményt produkált a Hyper-Threading bekapcsolása mellett, ami a technológia kvázi maximuma.
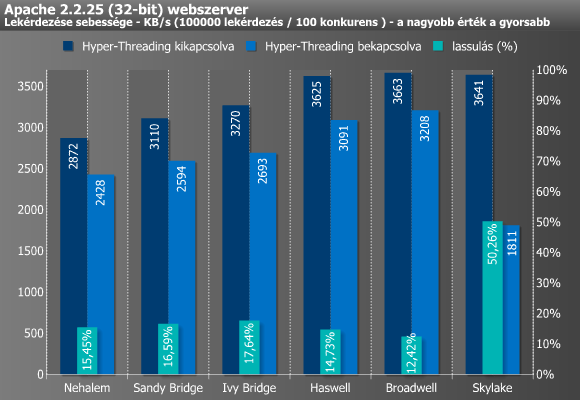
Hogy egy picit árnyaltabb legyen a kép, az Apache személyében egy olyan alkalmazást is megnéztünk, ami kifejezetten "utálja" a Hyper-Threadinget. Jól látszik, hogy itt kivétel nélkül mind a 6 mikroarchitektúra jobban szerepelt Hyper-Threading nélkül, sőt a Skylake szabályosan szárnyakat kapott, ami az előző oldal végén látott gyenge eredményre is válasz lehet. Mindez ugyanakkor újabb kérdéseket vet fel, hisz nem értjük pontosan, mi okozza ezt a hatalmas visszaesést, pláne úgy, hogy a Skylake egyes módosításai épp a Hyper-Threading hatékonyságát hivatottak javítani. Véleményünk szerint az sem zárható ki, hogy valamiféle hiba áll a háttérben, amit az Intel egy mikrokód-frissítéssel még orvosolhat a jövőben. (Hasonló jelenséget anno a Haswell is produkált legelső tesztünkben, majd pár hónappal később a probléma teljesen megszűnt). A Skylake rejtélyétől eltekintve a Broadwell már "csak" 12,42%-ot lassult aktív Hyper-Threading mellett, ergo az előző generációig még látható volt némi javulás.
A játékosok kedvéért: DiRT Rally
Legvégül egy játékkal, a DiRT Rally-val is lemértük a hat processzort. Ehhez a jelenlegi egyik leggyorsabb egyetlen GPU-s grafikus kártyát, az NVIDIA GeForce GTX 980 Ti-t hívtuk segítségül, hisz így szinte biztosak lehettünk abban, hogy a VGA a legkevésbé limitáló tényező. Ezen felül még arról is gondoskodtunk, hogy az Ivy Bridge-től elérhető PCI Express 3.0 miatt ne kerüljön hendikepbe a Nehalem (Lynnfield) és a Sandy Bridge, ugyanis a másik négy platform esetében a BIOS beállítások segítségével 2.0-ra limitáltuk a PCI Express szabványát, azaz a processzorokban található vezérlő és a GM200-as GPU közötti kapcsolat mind a hat esetben azonos sávszélességű volt.
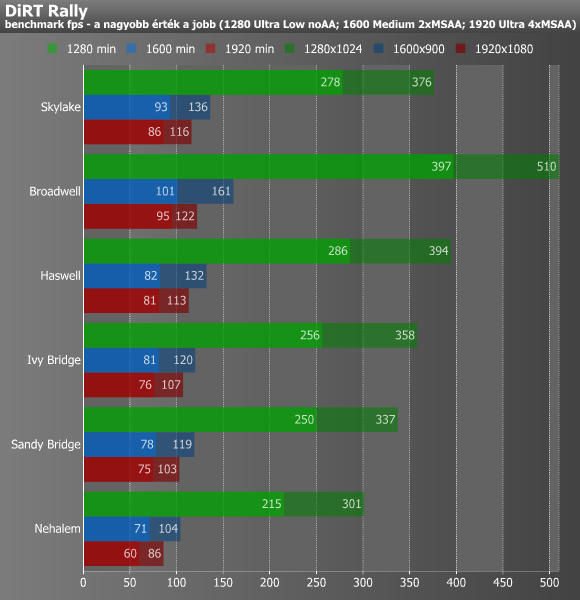
Az eredmény kissé meglepett minket, hisz a 128 MB-os L4 gyorsítótárral felvértezett Broadwell, azaz az i7-5775C mindent vitt. Ennek oka egyértelműen az eDRAM-ban keresendő, melyet valamilyen okból nagyon kedvelt a DiRT Rally. A kakukktojás processzort leszámítva szépen javultak az eredmények az egyes újabb architektúrákkal, ugyanakkor a Sandy Bridge és a Skylake között még így sincs túl nagy különbség. Mindez dióhéjban annyit tesz, hogy a Sandy Bridge még ma, évekkel a megjelenése után is gond nélkül kiszolgálhatja a legtöbb játékos igényeit.
Összegzés, konklúzió
Mindenekelőtt nézzük az eredmények összesítését, amit a Skylake kedvéért elsőként PowerDirector és Apache nélkül, majd később azokkal is megcsináltunk.
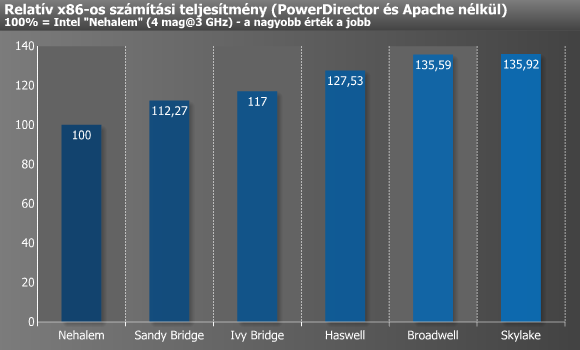
Utóbbi kalkuláció alapján arra jutottunk, hogy az elmúlt 7 évben a Sandy Bridge jelentette a legnagyobb előrelépést, amit a Haswell követ, a dobogó legalsó fokára pedig az idén megjelent Skylake állhat fel. A Broadwell eredménye az eDRAM miatt becsapós, az extra cache nélkül valószínűleg csak 3-5% lenne a Haswellhez mért plusz. A Nehalem és a Skylake között, azaz 2008 és 2015 között ~36% a különbség, tehát tesztcsomagunk alapján azonos magszám, órajel, és memóriabeállítások mellett ennyit gyorsultak az Intel első számú mikroarchitektúrái az elmúlt 7 esztendőben.
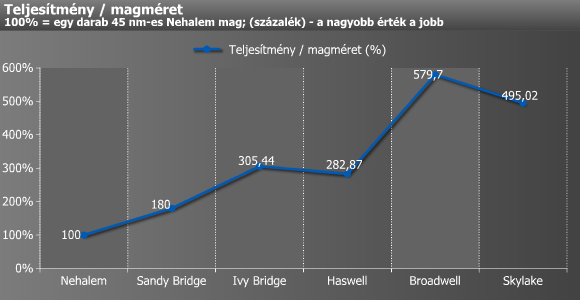
Legvégül egy érdekesség: egyetlen mag területe alapján teljesítmény/magméret grafikont is készítettünk, amely azt hivatott szemléltetni, hogy az egyes mikroarchitekturális fejlesztésekkel, illetve gyártástechnológia-váltásokkal mennyivel vált gazdaságosabbá legyártani az adott számítási teljesítményt.





Nehalem: 29,5 mm², Sandy Bridge: 18,4 mm², Ivy Bridge: 11,3 mm², Haswell: 13,3 mm², Broadwell: 6,9 mm², Skylake: 8,1 mm²
(A hat különböző magot ábrázoló kép méretarányos egymással.)
36% nem sok. Már anno a Haswell esetében is elégedetlenkedtünk kissé, hisz az Intel "tock" váltásának jegyében nagyobb előrelépésre számítottunk, ugyanakkor a Skylake még ennél is kevesebbet hozott, ami az asztali processzorok rajongóinak körében akár csalódással is felérhet. Az Intel elmondása szerint tudatosan nem az IPC-re gyúrták ki a Skylake-et, hisz manapság a Core M és társai, azaz a mobil piac nagyobb profittal kecsegtet, mint az évek óta egyre zsugorodó PC szegmens, itt pedig bizonyos (alacsony) keretek közé vannak beszorítva a fogyasztási (TDP) értékek, melyekből még messze nem tudták kihozni a maximumot.

Tesztünk dobtémaja: tock-tock-tick-tock-tick-tock [+]
Ebben javarészt igazat lehet adni az Intelnek, ugyanakkor ott lesznek még a többutas szerverekbe szánt, méregdrága Xeonok, ahova szinte ugyanez a Skylake mag fog bekerülni valamikor 2017 folyamán. Ebben ugyanakkor már jelen lesz az AVX-512-es utasításkészlet, mely az azt kihasználni képes, megfelelően optimalizált programkód esetében 8%-nál mindenképpen nagyobb lökést adhat, ugyanakkor ennek hiányában majd csak a valamivel magasabb órajeltől, illetve az esetleges plusz magoktól lehet várni nagyobb előrelépést.

P6-tól Skylake-ig (animgif) [+]
A következő 1-2 évben érdekes lesz látni, hogy az Intel miként lesz képes meggyőzni saját korábbi vásárlóit a processzorcseréről. Per pillanat még egy Sandy Bridge-alapú i7-2600K-ról is csak kevés esetben van igazán értelme a váltásnak, ez pedig jövő januárban már bizony egy 5(!) éves processzor lesz. Egy szó mint száz, jelenleg úgy fest, hogy a Nehalemmel elindított vonalból lassan kezd kifogyni a szufla, hisz törvényszerűen egyre csökken a fejlesztési potenciál.
Pusztán idő kérdésre, hogy az Intel sok év után ismét rákényszerüljön egy gyökeresebb váltásra, ami legutóbb a Netburst vonallal igencsak balul sült el, de a közelmúltból említhetnénk akár a konkurens AMD-t is, akinek szintén nem jött be az x86-os körökben igencsak egyedi Bulldozer mikroarchitektúra. A jövő egyik nagy kérdése tehát az, hogy az Intel hány bőrt lesz még képes lehúzni az aktuális vonalról anélkül, hogy jelentősen csökkennének az eladásai, ám a válaszra legalább 1-2, legfeljebb 3-4 évet még várnunk kell.
Oliverda





