A Haswell
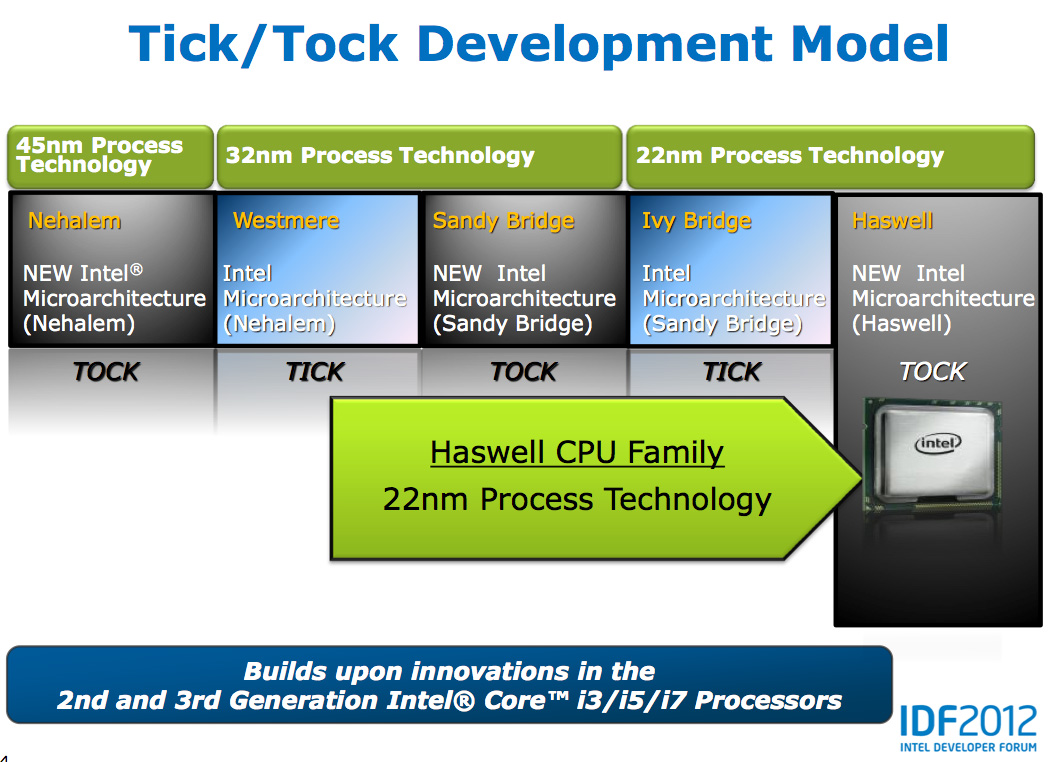
A Intel tick-tock elve szerint új gyártástechnológia bevezetésekor először a már meglévő, aktuális mikroarchitektúrára alkalmazzák azt, mely elsősorban gazdaságosabb gyártást eredményez. Ezen termékvonal felfuttatása elegendő időt biztosít a tervezőcsapatok számára, hogy a csíkszélesség csökkentésével előálló, a gazdaságosan gyártható lapkaméretbe beleférő többlet tranzisztormennyiséget a következő mikroarchitektúrában átgondoltan költsék el.
[+]
A "tick" lépcső keretein belül debütált Ivy Bridge tavaly április végén elhozta a 22 nanométeres csíkszélességet, melyen azt megelőzően több mint egy évtizedet munkálkodott az óriásvállalat. Kissé rendhagyó módon mikroarchitekturális változásokat is eszközölt az Intel, melyről korábbi elemzésünkben részletesen beszámoltunk. Ezzel CPU oldalon 3-8% javulást ért el az Ivy Bridge, míg az integrált GPU tekintetében a korábbi HD Graphics 3000-hez képest durván 30%-ot gyorsult a HD 4000-es IGP. Bár utóbbi jelentős mértékű előrelépésnek számított, bizonyos esetekben még mindig nem volt elég a konkurens csúcs AMD APU-k grafikus teljesítményének beéréséhez, vagy éppen felülmúlásához.

[+]
Utóbbi okán nem is lehetett kérdés, hogy a következő generáció egyik célkitűzése az integrált grafikus mag képességeinek további javítása lesz. Ezzel párhuzamosan az x86-os CPU magok tempójának javítása sem kerülhetett le napirendről, hiszen ez a "tock" lépcső egyik kötelező eleme. Az Intel részéről a Haswell azonban sokkal többről szól, mint a termékkategória puszta frissítéséről: üzleti szempontból az új architektúrának igen komoly küldetése van. Ebből az aspektusból társoldalunk, az IT café cikke foglalkozik az újdonsággal.
A Haswell lapka

Haswell és Ivy Brige [+]
(nem méretarányos)
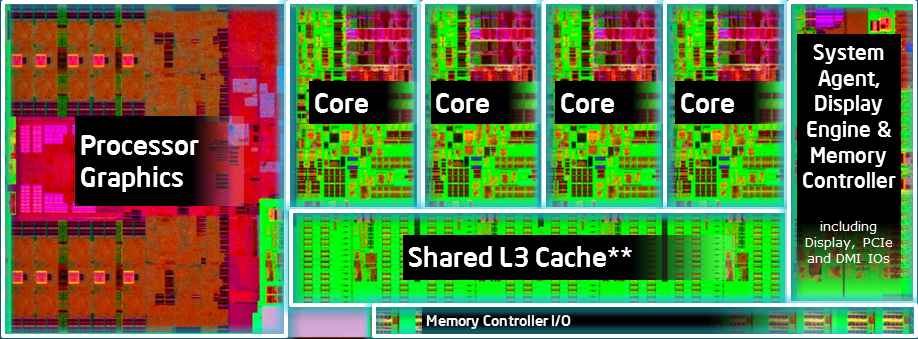
A fenti, négymagos lapkákat ábrázoló képekből megállapíthatjuk, hogy az új lapka alapvető felépítése a Sandy Bridge által lerakott "soros" elrendezést követi. A két dizájnt összehasonlítva láthatjuk, hogy tovább hízott a grafikus szekció, illetve a jobb szélen látható "System Agent" kezdetű terület is megnőtt. Ennek egyik oka, hogy immáron a digitális kijelzők interfésze az alaplapi chipkészletből (PCH) beköltözött a processzorba. Ahogy már utaltunk rá, a gyártástechnológia nem változott, ergo maradt a tavaly debütált 22 nm-es Tri-Gate technológia.

Itt még az alaplapon [+]
A Haswell lapka második új lakója a feszültségszabályzó kis chip (voltage regulator), mely korábban valahol a CPU-foglalat közelében volt megtalálható, és annak típusáról az alaplap tervezője gondoskodott. Ennek kiviteléről és ezzel együtt képességeiről mostantól az Intel gondoskodik. Ezzel ismét egy komponenssel kevesebb kerül fel az alaplapokra, ami a gyártási költségekre, illetve a szükséges területre minden bizonnyal jó hatással van, ugyanakkor az alaplapok tervezőinek kezét kissé megkötheti.
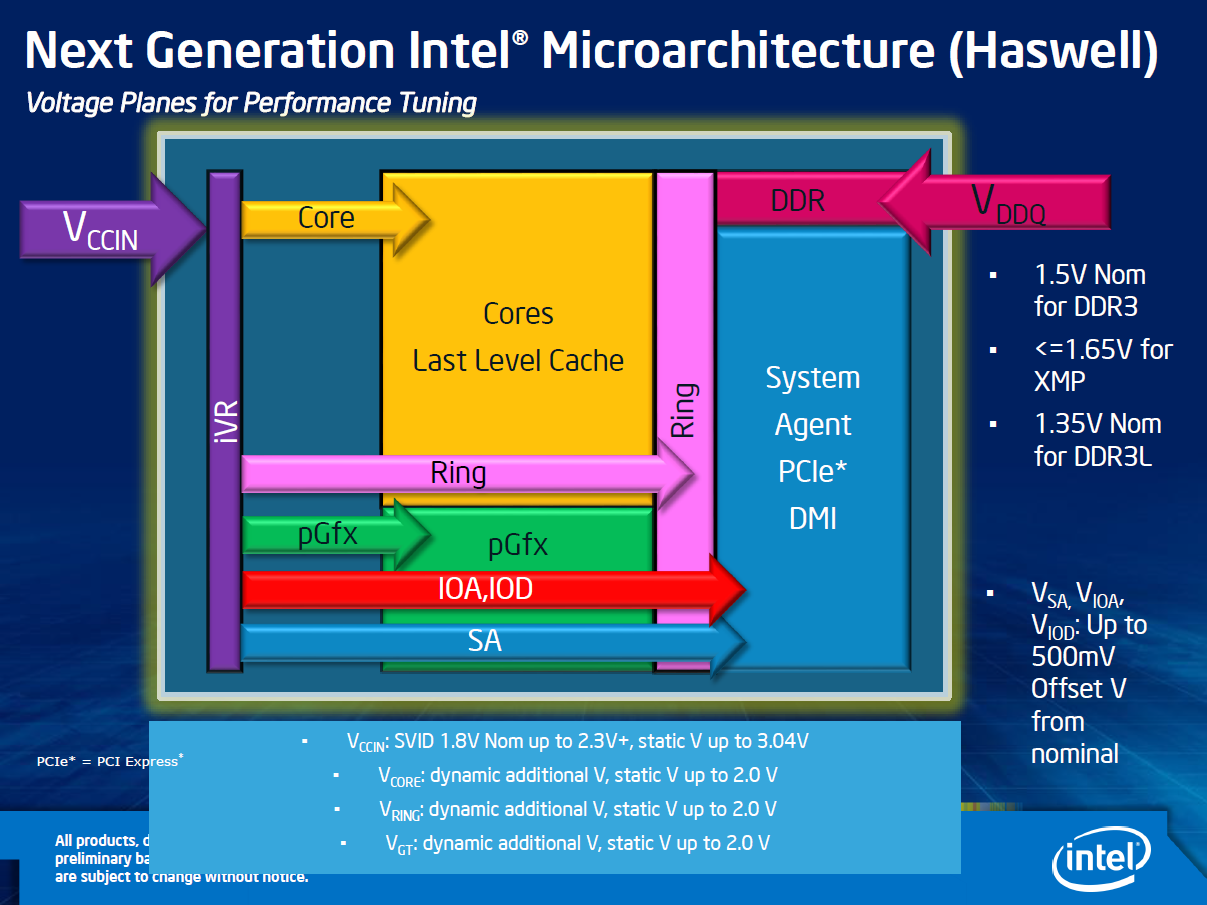
iVR: integrated Voltage Regulator [+]
Pozitív hozomány, hogy az Intel mostantól pontosan tudja, mire képes a vezérlő, így ő magabiztosabban építkezhet rá, nem kell tartania esetleges kompatibilitási vagy képességbeli problémáktól. Minden bizonnyal ezen újításnak köszönhető, hogy újabb energiatakarékossági módokkal gazdagodott a Haswell.

A fenti ábrán látható S0i1 és S0i3 módokon felül megjelentek a C6 és C7 jelzésű energiatakarékossági szintek is, bár előbbieket csak az Y és U szériás mobil megoldások estében lesznek aktívak.

[+]
Az újabb módokkal alacsony terhelés vagy teljes üresjárat mellett további wattok takaríthatóak meg. Mint azt már korábban elmondtuk, az Intel elmúlt néhány processzorcsaládja már elsősorban az akkumulátorokról üzemelő, mobil gépek igényeinek megfelelően került kialakításra, itt pedig minden egyes megspórolt watt sok perces üzemidőt jelenthet. Ennek ellenére természetesen asztali környezetben is használhatóak az új módok, melyek közül a C7-hez már olyan tápegység szükséges, ami a rendkívül csekély, 0,05 ampert is képes stabil feszültség mellett biztosítani.
[+]
További említésre érdemes különbség, hogy visszatért a Nehalem esetében már látott, úgynevezett "Uncore" (vagy "Ring") órajel. Ez elsősorban az L3 cache, illetve az azon keresztül futó körbusz órajelét takarja. A Sandy, illetve Ivy Bridge esetében ez a szekció a CPU-magok mindenkori órajelén futott, de a tervezők a Haswell-lel ismét kettéválaszották az egyes üzemi frekvenciákat. Ezzel a magoktól eltérő órajelen futtatható a meglehetősen méretes L3 cache (is), amivel további energia takarítható meg. Egy lehetséges további előny, hogy a GPU az esetlegesen alvó x86-os magok órajelétől függetlenül igényelhet gyorsabb cache-t (magasabb órajelet), mivel mostantól a gyorsítótár különálló frekvencián üzemel. Mint sok minden másnak, ennek is megvan a hatránya, ugyanis ezzel a CPU-magok oldaláról megnőtt az L3 cache hozzáférési ideje, ami bizonyos esetekben negatívan befolyásolhatja a végrehajtás tempóját.
| Lapka kódneve | Gyártástechnológia | Magok száma | L2 + L3 mérete | Tranzisztorszám | Lapka területe |
|---|---|---|---|---|---|
| Haswell | 22 nm Tri-Gate | 4 (+ IGP) | 9 MB | 1,4 milliárd | 177 mm2 |
| Ivy Bridge | 22 nm Tri-Gate | 4 (+ IGP) | 9 MB | 1,48 milliárd | 160 mm2 |
| Sandy Bridge | 32 nm HKMG | 4 (+ IGP) | 9 MB | 995 millió | 216 mm2 |
| Sandy Bridge-E | 32 nm HKMG | 6 | 16,5 MB | 2,27 milliárd | 435 mm2 |
| Gulftown | 32 nm HKMG | 6 | 13,5 MB | 1,17 milliárd | 240 mm2 |
| Lynnfield | 45 nm HKMG | 4 | 9 MB | 774 millió | 296 mm2 |
| Bloomfield | 45 nm HKMG | 4 | 9 MB | 731 millió | 263 mm2 |
| Trinity | 32 nm HKMG SOI | 4 (+ IGP) | 4 MB | 1,303 milliárd | 246 mm2 |
| Llano | 32 nm HKMG SOI | 4 (+ IGP) | 4 MB | 1,45 milliárd | 228 mm2 |
| Orochi/Vishera | 32 nm HKMG SOI | 8 (4 modul) | 16 MB | ~1,2 milliárd | 315 mm2 |
| Thuban | 45 nm SOI | 6 | 9 MB | 904 millió | 346 mm2 |
| Deneb | 45 nm SOI | 4 | 8 MB | 758 millió | 258 mm2 |
A lapkához visszakanyarodva, a fenti táblázatból láthatjuk, hogy annak területe csupán minimálisan, 17 négyzetmilliméterrel nőtt, míg ugyancsak az Intel által szolgálatott adatok alapján a tranzisztorszám csökkent.
Haswell lapkák egy 300 mm átmérőjű ostyán [+]
A CPU-magok újításai
Megszokottnak nevezhető, hogy a generációról generációra finomított elágazásbecslés mellett a tranzisztorbüdzsé egy részét az out-of-order végrehajtást biztosító, illetve elősegítő pufferek növelésére költik.
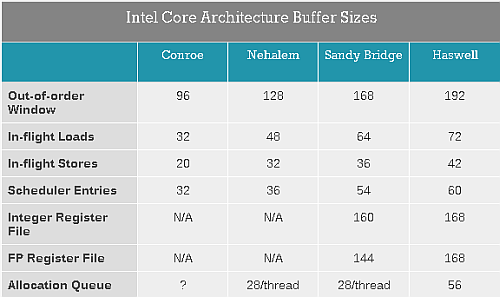
forrás: Anandtech
Mint a fenti táblázatban látható, a Re-Order Buffer (azaz előrelátási ablak), az ütemező, egyszerre kezelhető, L1 cache-t tévesztő memóriaolvasási és -írási műveletek sorai mind-mind folyamatosan nőnek a mikroarchitektúra-váltások során, és a jövőben is gyarapodni fognak: ezeknél a puffereknél a végtelen méret lenne ideális, tehát növelésük útjába nem áll praktikus akadály, csak 5-10 bájt nagyságrendű elemméretük és a hozzájuk tartozó vezérlőlogika tranzisztorigénye.
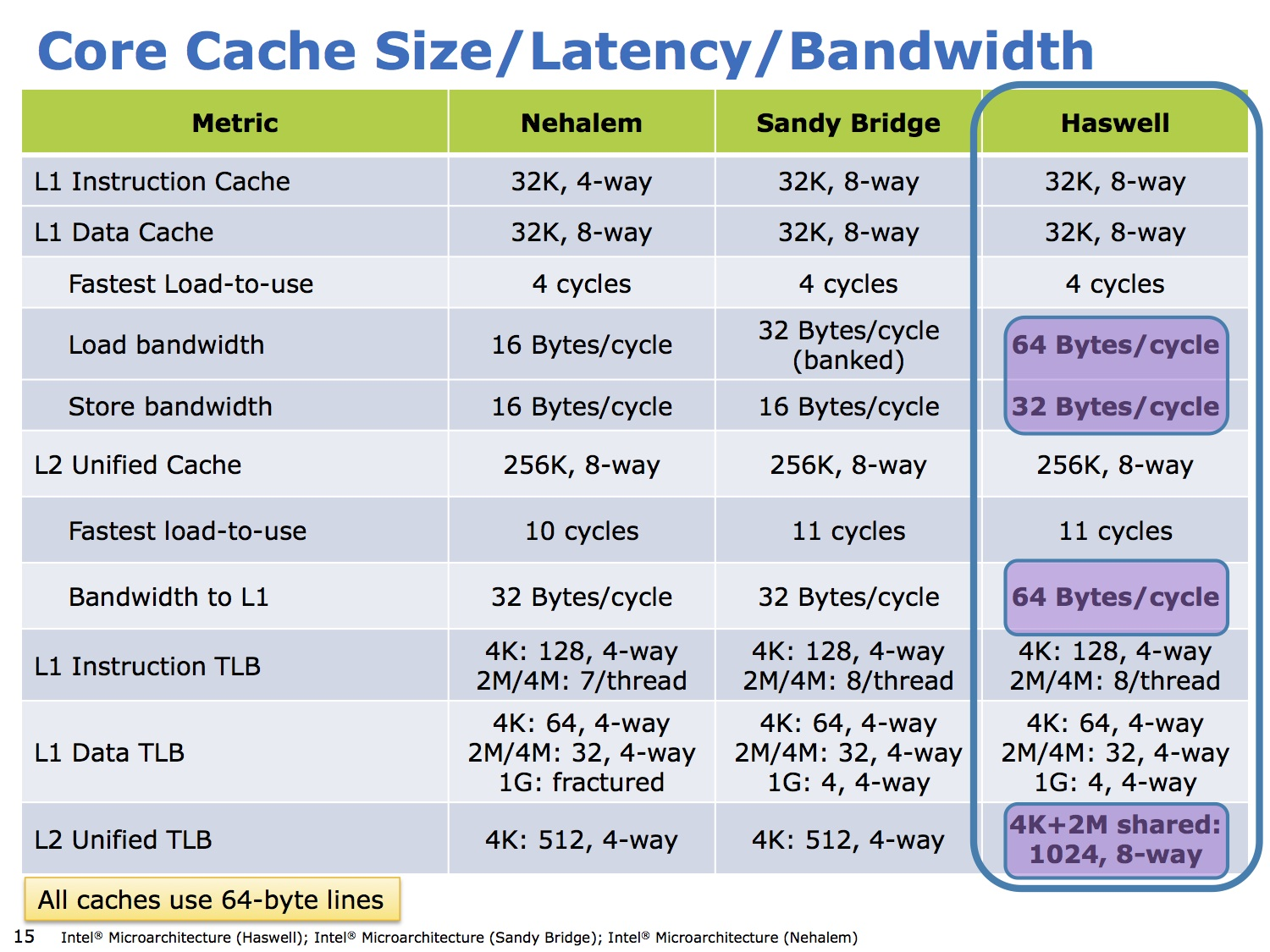
Bár az első- és másodszintű gyorsítótárak növekedése megállt, a hozzájuk vezető adatút szélességének növelése kritikus a végrehajtó egységek megfelelően ütemezett adatokkal való ellátásának szempontjából. A Haswell immár 2 x 256 bitet olvashat ki órajelenként az L1D-ből, továbbá az L2-ből az L1 cache-be is órajelenként 64 bájtot (azaz egy teljes cache-vonalat) mozgathat.
[+]
Hosszú idő után bővülést láthatunk a végrehajtó egységek számában: az Intel a Core 2 processzorok megjelenése óta az Ivy Bridge-ig bezárólag 6 műveletvégző egységgel operált, amelyek szerepköre ugyan változott az idők folyamán, de alapvetően a következő felosztás általánosan igaz:
- 3 műveletvégző egység (port 0, 1 és 5)
- 2 címszámító egység (port 2 és 3)
- 1 adattárolási egység (port 4)
A Haswell két további porttal bővíti a repertoárt: egyrészt a két címszámító mellé egy harmadikat (port 7) is alkalmaz, kifejezetten a tárolási műveletek címszámításainak részére, így a másik kettő elláthatja beolvasott adatokkal a két 256 bites lebegőpontos egységet (port 0 és 1), valamint az új 6. portot kifejezetten egyszerű integer műveletek részére tartja fenn, biztosítva azt, a SIMD-ciklusok végrehajtása közben a mutató-, számláló- és ciklusműveletek ne vegyék el az erőforrásokat a vektorműveletektől. Ezen új portok jótékony hatása az egyszálas végrehajtásnál is tetten érhető, de a HyperThreading által lehetővé tett kétszálas működésnél mutatkozik meg igazán.

[+]
Újabb utasításkészletek
A mikroarchitektúra módosítása mellett természetesen új utasításkészletek is költöztek a processzorba, a választék bővítésének tekintetében viszont a Haswell kiemelkedik a korábbi generációk közül.
Tranzakcionális memóriakezelés
Hirdetés
Azon többszálú programoknak, amelyek nem statikusan felosztott adathalmazokon dolgoznak – pl. 2 mag esetén az adatok felén, 4 mag esetén a negyedén stb. –, általános problémája annak biztosítása, hogy ugyanazt az adatot egyszerre csak az egyik szál módosíthassa. Az x86/x64 architektúra az egyetlen egész számot tartalmazó változó közvetlen vagy akár feltételes atomi módosítására – amely lehet 1, 2, 4, 8 vagy 16 bájtos – kényelmes lehetőséget biztosít a LOCK utasításprefix vagy a CMPXCHG-utasításcsoport révén; előbbi a 'betöltés-módosítás-kiírás' típusú utasításoknál alkalmazható.
Amennyiben egynél több adat atomi módosítására van szükség, nehezebb a helyzet: ilyen esetben a teljes adathoz való hozzáférést egyetlen szinkronizációs változóval kell levédeni, ennek módosításáért (azaz birtoklásáért) majd visszaállításáért versengenek a szálak, és amelyik szál sikeresen módosítja a szinkronizációs változót, az hajthatja végre a módosításait a teljes adathalmazon; a többi szál eközben várakozik tétlenül. Sűrűn előfordul azonban, hogy a különböző szálak adatmódosításai nem ütköznek egymással, általában más-más adatot módosítanak, így a várakozások nagy része felesleges lenne. E teljesítményromboló állási idők elkerülésére fejlesztették ki a tranzakcionális memóriakezelési technikákat, melynek első kereskedelmi forgalomba kerülő megvalósítása – mivel a néhai Sun Rock nevű processzort végül nem dobták piacra – a Haswellben debütál.
A Haswell rögtön két megoldást is kínál a tranzakciók kezelésére: az egyik teljesen kompatibilis a régebbi processzorokkal (HLE, Hardware Lock Elision) – bár hatása nem érvényesül azokon, de érvényes utasításként elfogadják őket –, a másik (TSX-utasításkészlet) három új utasítás bevezetését jelenti: XBEGIN, XEND és XABORT. Mindkettő működési mechanizmusa azonos:
- a tranzakció elejét és végét egy-egy utasítás jelzi;
- a tranzakció végrehajtása közben a processzor feljegyzi, hogy mely memóriaterületekről történt olvasás és melyekre írás, valamint a módosítások csak az L1D és L2 cache-be kerülnek, miközben az L3 az eredeti adatokat tartalmazza, így a többi programszál ezeket látja;
- a tranzakció végén a processzor ellenőrzi, hogy a feljegyzett memóriaterületek még mindig az eredeti értékeket tartalmazzák-e – azaz amikkel a program a tranzakció alatt számolt, más szál nem módosította-e őket időközben –; ha igen, akkor az adatmódosítások egyszerre lesznek láthatóak a teljes rendszer számára (commit); ha viszont változás történt, akkor az L1/L2 cache-ben levő a módosított értékeket felülírja az aktuális értékekkel (rollback), és újra megpróbálkozik a teljes tranzakció lefuttatásával.
Ily módon hardveresen biztosított az, hogy nem módosítja több szál egyszerre az adathalmaz azonos elemét, viszont figyelembe kell venni, hogy az adatmódosítások számának limitáló tényezője elsősorban a 256 kB-os L2 cache: túl sok felhasznált és/vagy módosított adat esetén a processzor önhatalmúlag megszakíthatja a tranzakciót (abort; erre a programozó is utasítást adhat bizonyos körülmények fennállása esetén); ilyen esetekre a TSX használatával külön 'menekülőút' írható a programba, míg HLE alkalmazása esetén újra lefut a tranzakció, immár az említett várakozás kikényszerítésével.
FMA3
A Haswell megérkeztével az AMD után immár az Intel is bevezette a lebegőpontos FMA-utasításokat (fused multiply+add), mégpedig háromparaméteres változatukat, amely egyik bemenő adatát felülírja az eredménnyel. Ezen 5 órajel alatt végrehajtódó utasítások 256 bites vektorokon is dolgozhatnak, továbbá órajelenként 2 kerülhet végrehajtásra, így – mivel egy FMA két FLOP-nak felel meg – az elődök 128, illetve 256 bites lebegőpontos végrehajtásához képest a Haswell 2-4-szeres elméleti számítási teljesítménynövekedést ígér.

AVX2
A Sandy Bridge-ben bemutatkozó, 256 bites vektorokon dolgozó lebegőpontos AVX utasítások után a Haswell AVX2 elnevezésű készletével az egész számos SIMD végrehajtást is kibővítette a korábbi 128-ról 256 bites vektorokra, leváltva/kiegészítve a koros 128 bites, Pentium 4-gyel bemutatkozó SSE2 készletet, valamint a Core 2 CPU-kban megjelent, ugyancsak 128 bites SSE4.1 egész számos SIMD-utasításainak nagy részét. Ennek előnyeit elsősorban a kép-, hang- és videofeldolgozó és -megjelenítő programok élvezhetik, de – tekintve az SSE2 mai elterjedtségét – számos különféle programban várható idővel a megjelenése.

[+]
Gather memóriaolvasás
Az eddigi x86/x64 SIMD műveletek végrehajtásához előre kellett gondoskodni arról, hogy a vektorok elemei egymás után sorakozzanak a memóriában, mivel egy-egy vektor egy folyamatos memóriaterületet jelent. A Haswellben bemutatkozó 'gather' típusú betöltési utasítás önállóan képes szétszórt elemekből önállóan összeállítani egy vektort, mivel paraméterként a kezdőcímet, valamint az elemek e címtől számított távolságát kapja meg. Bár technikailag ez a processzoron belül több külön memóriaolvasásként van megvalósítva, számottevően gyorsítja az ismétlődő minták szerinti memóriahozzáféréseket.
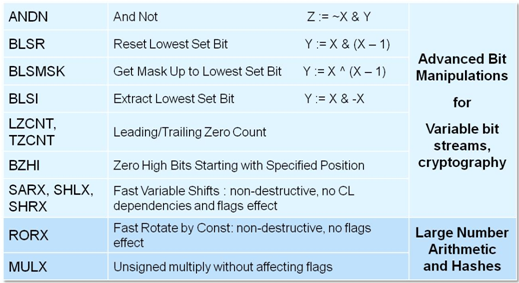
Bitmanipulációs utasítások
A Haswell új bitközpontú utasításokkal is gazdagodott, amelyek egész értékeken (szorzás, shiftelés/forgatás), illetve azok bitcsoportjain végzett bonyolult műveletek végrehajtását gyorsítja fel, külön utasításokként rendelkezésre bocsátva a korábban több instrukcióból álló műveletsorokat.
A Haswell és a grafika
Az Intel a Haswell fejlesztése során igen sok erőforrást fektetett az integrált grafikus vezérlőbe. Új architektúra ugyan nincs, így az Ivy Bridge-ben található Gen7-es rendszer felújított, Gen7.5-ös verzióját kaptuk meg, de előbbiben igen sok hiba volt, amit orvosoltak a mérnökök. A legfontosabb szempont azonban, hogy az Intel először szembesülhetett azzal, hogy miben rejlik a jó grafikus processzor titka. Megfelelő GPU-architektúrát fejleszteni ugyanis nem túl nagy munka, ugyanakkor a skálázható architektúra már kemény dió.
Az Intel első próbálkozása ebből a szempontból a Larrabee kódnevű projekt volt, mely végül a süllyesztőben végezte, mivel a grafikai számítások mellett nem skálázódott. Megmaradt azonban a tapasztalat, amit a cég fel is használt. A Haswell IGP-jébe épített architektúra természetesen nem mutat majd olyan extrém használhatóságot, mint az AMD és az NVIDIA architektúrái, így nem fog rá épülni 2 és 300 watt között majdnem lineárisan skálázódó termékskála, de valahol mindig el kell kezdeni. A tervezők például konkrétan képesek voltak megtöbbszörözni a shader és a render tömbök számát. Bár ezt igen tranzisztorpazarló módon tették meg, de egyrészt a jelenlegi architektúra működése igen limitált, másrészt sokan alábecsülik az egész jelentőségét, pedig a teljesítmény skálázása a grafikus vezérlők tervezésénél konkrétan a legnehezebb feladat.
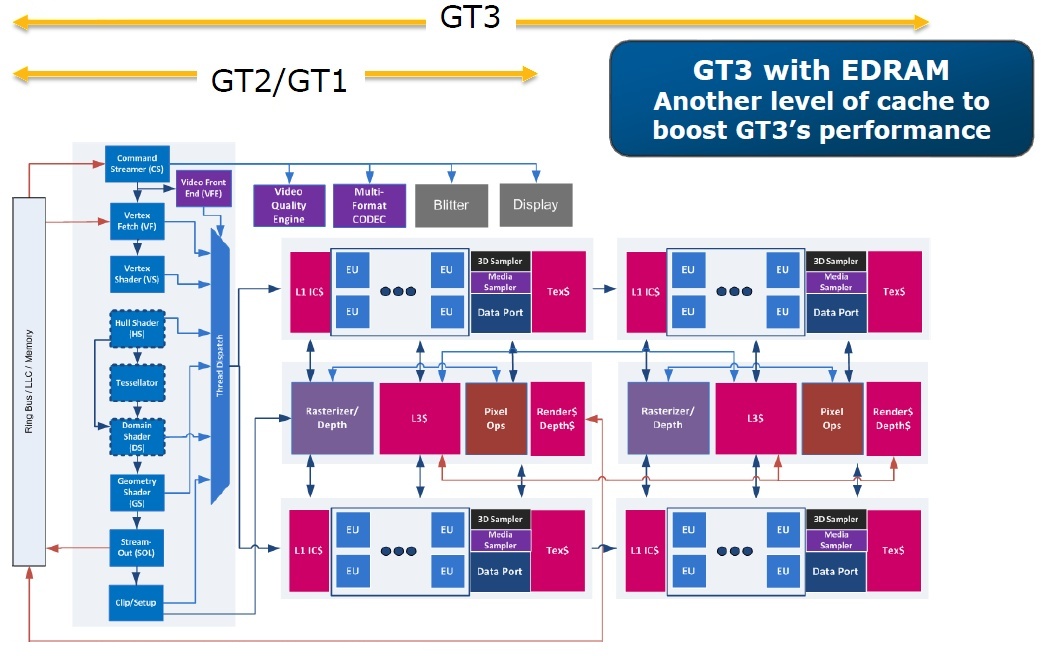
Az Intel a fentiek mellett egy igen logikus evolúciót követ. A Larrabee kapcsán megtanulták, hogy mindent egyben bevetni nem lehetséges, mivel ehhez komoly, akár több évtizedes tapasztalat kell, amit pénzért nem lehet megvásárolni. A HD Graphics sorozat már lépésről lépésre fejlődött. A Sandy Bridge-ben bevetett Gen6-os architektúra gyakorlatilag kijelölt egy járható ösvényt, az Ivy Bridge Gen7-es IGP-je előkészítette a terepet a skálázhatóságra, így az Intel több részre osztotta fel a rendszert a felépítés szempontjából. Az új Haswell Gen7.5-ös fejlesztés az előző generáció alapjaira építve végre skálázza a felosztott blokkokat, vagyis már nem csak két verziója lesz az IGP-nek a termékekben, hanem három. Az eddigi tesztek szerint az új IGP hozzávetőleg 10 és 40 wattos tartományban skálázható úgy, hogy a tempó közel lineárisan nő az extra blokkok beépítésével. Ez az Intel szempontjából egy mérföldkőnek tekinthető, és a jövőben már arra törekedhetnek, hogy a teljesítményskálázást tranzisztorok százmillióinak pazarlása nélkül kivitelezzék.
[+]
A grafikus számítások szempontjából a Gen7.5 architektúra is három jól elkülöníthető részre osztható. A kalkulációkért továbbra is a shader tömb felelős, de ahogy fentebb leírtuk, már nem csak egy ilyen kaphat helyet a rendszerben, hanem maximum négy. A shader tömbön belül azért voltak változások, bár ezek a funkciókat nem érintik, de a működés hatékonyságát igen. Az Ivy Bridge IGP-je esetében 16 darab shader processzor volt egy tömbben, amit az Intel Execution Unit néven emlegetett mindig is, de ez csak formalitás. Ez a felépítés az úgynevezett ALU:Tex arány szempontjából nagyjából megegyezik azzal, amit az AMD is használ a saját architektúráinál.
Az Intel viszont ma már úgy gondolja, hogy ez sok a saját architektúrájukat figyelembe véve, így a Haswell IGP-je még az NVIDIA Kepler architektúrájánál is kisebb ALU:Tex arányt használ. Bár ez a módosítás kiugróan nagy változást nem eredményez majd, de az látszik belőle, hogy az Intel tervezői végre saját útjukra léptek, és nem másolják az AMD grafikus megoldásainak paraméterezéseit. Ez egy nagy előrelépés, mivel alapesetben mindenképp logikus azt mondani egy rendszer tervezésénél, hogy ha nekik működik, akkor nekünk miért ne lenne ugyanaz az összeállítás hatékony, de valójában az architektúrák eltérő működése ebbe nagyon beleszól.
A Gen7.5 IGP esetében egy shader tömb mostantól maximum 10 darab Execution Unitot tartalmaz. Ezek továbbra is komplex feldolgozók, így két darab 128 bites vektormotorból állnak. Utóbbiak közül az egyik felel az általános operációk feldolgozásáért, míg a másik a speciális, trigonometrikus és transzcendens utasításokat támogatja, de kapott FMA támogatást is, ami rögtön utat ad a 4+4 co-issue képességnek. Ezzel tehát az Execution Unitok órajelenként nyolc darab, egymástól független FMA utasítást képesek végrehajtani. Természetesen a függőség kezelése itt kulcsfontosságú, mivel az egymástól függő operációk párhuzamos feldolgozása nem lehetséges. Erről a Thread Dispatch egység gondoskodik, mely igyekszik megfelelően etetni a vektormotorokat, hogy minél többször hasznosítható legyen a 4+4 co-issue feldolgozás.
A shader tömbökben szokás szerint található még egy 256 kB-os kapacitást kínáló URB, azaz a Unified Return Buffer, mely egy gyorsan elérhető, írható és olvasható megosztott memória az Execution Unitok között, emellett a 32 kB-os L1 utasítás-gyorsítótár is megosztott.
A textúrázás szempontjából szintén javult a rendszer. Egy shader tömb két darab megosztott textúrázó blokkot tartalmaz, melyek egyenként négy darab Gather4-kompatibilis textúrázó csatornát alkalmaznak. A javulás itt abban rejlik, hogy a Gather4 már nem csak formális jellegű. Az Ivy Bridge IGP-jének az egyik legnagyobb hibája az volt, hogy egy csatornához csak egy mintavételező tartozott, ami teljesen eliminálta a Gather4 utasítások alkalmazásának előnyét. Mivel a DirectX 11-es játékok aktívan használják ezt a funkciót, így az Intel a korábbi logikátlan döntését korrigálta, és mostantól minden csatornához négy mintavételező tartozik. Így már kihasználható az a tempóelőny, amit a Gather4 utasítások bevetése jelent az alkalmazásokban. Természetesen jelen van a blokkonkénti textúrázó gyorsítótár is, mely egy 4 kB-os elsődleges és egy 24 kB-os másodlagos szintből áll.
A shader tömbök mellett található a render tömb, mely a data porton keresztül érhető el. Utóbbi tartalmazza a ROP-blokkot is, melyben négy blending és négy Z mintavételező egység dolgozik. Ezen a ponton tehát nincs változás a korábbi IGP-khez képest. Megmaradt a 256 kB-os L3 gyorsítótár is, ami továbbra is azt a célt szolgálja, hogy az IGP ebbe írjon ki fontos adatokat, és ne szemetelje össze a utolsó szintű gyorsítótárat (LLC), ami jelentősen hátráltatná a processzormagokat a feladatok feldolgozásában. Természetesen a fejlesztő kiírhatja az adott szál eredményét az LLC-be is, így azt a processzormagok gyorsan elérhetik, de mindezt csak rendkívül szigorú szoftveres kontroll mellett érdemes megtenni. Emellett persze az IGP az LLC tartalmát továbbra is olvashatja. Itt megjegyezzük még, hogy az önálló L3 gyorsítótár felel majd a DirectX 11-ben megkövetelt Local Data Share (LDS) funkció ellátásáért is.
Az IGP új képességei és a skálázás gyakorlata
Az új IGP általános felépítése mellett érdemes rátérni az extra tudásra, amit az Intel belepréselt. A Gen7.5 architektúra támogatja a DirectX 11.1-es, a DirectCompute 5.0-s, az OpenGL 4.0-s és az OpenCL 1.2-es API-t. Az OpenGL-támogatással még mindig nagyon mostohán bánik az Intel, de a többi szempontból nem érheti panasz a rendszert.
Javult a setup motor is, ami az előző körben is komoly fejlődésen ment keresztül. Alapvetően a sebesség változott, mivel az egyes fixfunkciós egységek teljesítményét megduplázta az Intel, amire azért volt szükség, mert mostantól egynél több shader és render tömböt is ki kell szolgálnia a rendszernek. A tesszellátor továbbfejlődött, de ennek teljesítményével eddig sem volt lényeges probléma. Azzal viszont már van, hogy az Intel továbbra sem figyel a hierarchikus Z túlterhelésére, így kis háromszögek mellett a feldolgozás teljesítménye nagyon visszaesik. Erre az AMD és az NVIDIA már alkalmaz egyfajta megoldást, aminek a titka abban rejlik, hogy a rendszer a raszterizálást hierarchikus Z nélkül hajtja végre a teljes képkockát több egyenlő méretű, viszonylag kicsi mozaikra osztva, és biztosítva a renderelés megfelelő sorrendjét. A hierarchikus Z algoritmus a mozaikokon lesz lefuttatva, amelyeket tovább lehet küldeni, vagy éppen el lehet dobni, ha nem tartalmaznak látható információt. Erre az Intelnek később figyelnie kell, mert nem sokat ér a gyors tesszellátor, ha nincs megfelelő körítés hozzá.
A Haswell IGP-je két órajelenként dolgoz fel egy háromszöget, ami a megcélzott kategóriában manapság vérszegénynek számít. A rendszer ugyan kellően magas órajelen jár, hogy ez ne legyen nagyon limitáló hatású, de lassan illene valami combosabb setup motort fejleszteni, lépést tartva a kor igényeivel. A raszter motor a raszterizálást négyes pixelblokkokon hajtja végre (ez általánosnak mondható a mai PC-s GPU-kon vagy IGP-ken), a teljesítménye pedig órajelenként 8 képpont. Utóbbi érték már megfelelő az IGP-k között, és ennek hála két render tömb mellett is kiegyensúlyozott a rendszer. Egy render tömbbel már sok is a raszterizálás teljesítménye, de itt a ROP úgymond túletetése a jobbik eshetőség, így ez nem jelenthet problémát.
Változás érte még a CS rövidítésű Command Streamer egységet, ami kibővült pár új funkcióval, melyek apró módosításoknak tűnnek, de radikális fordulatot eredményeznek az Intel tervezési koncepcióját tekintve, egészen pontosan a processzormagok és a grafikus vezérlő kommunikációjában. Évek óta nincs egyetértés abban, hogy érdemes-e pont a processzormagokat használni a grafikus teljesítmény maximalizálása érdekében, vagy éppenséggel a grafikus hardver parancsait kell megközelítőleg olyan egyszerűvé tenni, amilyenek az API parancsai. A grafikus processzorok fejlesztésével foglalkozó cégek az előző évtized közepe óta egyetértenek abban, hogy utóbbi elv a nyerő stratégia, így például az AMD és az NVIDIA is ezt a tervezési filozófiát követi, miközben az Intel korábbi véleménye az volt, hogy akármekkora teljesítmény beáldozható a grafikus driver egyszerűségének fenntartása érdekében.
Függetlenül attól, hogy a teljes iparág magára hagyta az Intelt fenti véleményével, nem lehet elmenni szó nélkül amellett, hogy a Santa Clara-i óriáscégnek sok szempontból igaza van az egyszerűséget illetően. A mai grafikus driverek túl bonyolultak, túl sok erőforrást kell a fejlesztésükbe ölni, és a tesztelésük is nagyon nehéz. Az Intel eddig az előbbi problémáktól teljesen mentesült pusztán azért, mert más elveket vallottak a processzormagok és a grafikus vezérlő kommunikációja szempontjából. Meggyőződésünk, hogy a vállalat véleménye ma sem változott meg, továbbra is az egyszerűséget tartják jobb iránynak, de nem nézhetik, hogy a konkurensek csupán a driver felépítésének elvi eltéréséből akár hatszoros tempóelőnyre tesznek szert egy-egy játékban.
Ezt a különbséget a hardver fejlődése sose hozná be, így az Intel a büszkeségét sutba vetve beállt a többi cég mögé, így a Haswell IGP-jének tervezésénél már azt a nézetet vallották, hogy a grafikus hardver parancsait kell megközelítőleg olyan egyszerűvé tenni, amilyenek az adott API parancsai. Ennek értelmében változott meg a Command Streamer egység, ezzel pedig esélyt ad a cég magának, hogy minimalizálják a driver többletterhelését, amivel sebességet nyerhetnek. Ennek hozományaként viszont mostantól sokkal bonyolultabb meghajtókat kell írniuk. Fontos megjegyezni, hogy az Ivy Bridge IGP-je ebből a váltásból nem vagy csak nagyon keveset profitál majd, mivel más működésre tervezték a hardvert, míg a régebbi integrált grafikus processzorokat az Intel már nem támogatja folyamatosan frissülő driverekkel.
A hardverek
A Gen7.5 architektúra részletezése után érdemes megnézni, hogy milyen konfigurációk épülnek majd a rendszerre. A legegyszerűbb ezt táblázatos formába önteni, mivel így jól láthatók az eltérések:
| IGP kódneve | GT1 | GT2 | GT3 | GT3e |
|---|---|---|---|---|
| IGP típusjelzése | HD Graphics | HD Graphics 4200/4400/4600 | HD Graphics 5000 / Iris Graphics 5100 | Iris Pro Graphics 5200 |
| Shader tömbök száma | 1 | 2 | 4 | 4 |
| Render tömbök száma | 1 | 1 | 2 | 2 |
| Execution Unitok száma | 10 | 20 | 40 | 40 |
| Textúrázó csatornák száma | 8 | 16 | 32 | 32 |
| Blending egységek száma | 4 | 4 | 8 | 8 |
| eDRAM | - | - | - | 128 MB |
| Az eDRAM sávszélessége | - | - | - | ~50 GB/s |

[+]
Az adatok magukért beszélnek, de érdekes újítás az eDRAM az Iris Pro Graphics 5200 esetében. Ez funkcionálisan egy L4 gyorsítótárként működik, és a belső gyűrűs adatbusszal van összekötve. Ennek megfelelően a processzormagok és a grafikus vezérlő is írhat bele, illetve olvasható belőle. A koncepciónak előnyei és hátrányai is vannak. Előnye, hogy az IGP gyorsabban jut adatokhoz, így mindenképp tempósabban végzi majd a feladatát. Hátránya azonban, hogy az IGP szálanként 32 kB adatot írhat bele, ráadásul oda ahova akar. Némi szoftveres kontrollt azért biztosíthat a programozó. Ez hasonlít arra a megoldásra, amit az Intel a Sandy Bridge esetében vezetett be az utolsó szintű gyorsítótárra (LLC), miközben az Ivy Bridge esetében alapértelmezett működés mellett letiltották ezt a funkciót, mert az IGP gyakorlatilag kontroll nélkül elkezdte használni az LLC-t, és a processzormagok által kiírt adatokat sorra felülírta. Ez komoly probléma volt, mivel azok eléréshez a processzormagoknak a rendszermemóriához kellett fordulnia, ami mindig jelentős időveszteség.
Az eDRAM 128 MB-os mérete mellett ez elvben ugyan még mindig probléma, de a gyakorlatban már nem, hiszen az LLC-t az IGP érintetlenül hagyja, így a processzormagok számára a legfontosabb adatok gyorsan elérhetők. Eközben az IGP lényegében kisajátíthatja a gyorsítótárként funkcionáló eDRAM-ot. Persze a rendszernek azért némi hátránya még így is van, mivel a processzormagok szempontjából rontja nagyméretű tartományokon tárolt adatok eléréséhez szükséges időt, de ez vállalható kompromisszumnak tűnik.
A Haswell és a multimédia
Multimédiás újítások is kerültek a rendszerbe. A legnagyobb újdonságként az MJPEG dekódoló említhető meg. Mint ismeretes, ez a formátum kódolt, azaz ha a felhasználó meg akarja tekinteni az adott fájlt, akkor azt ki kell kódolnia egy programnak, mely rendszerint a processzor teljesítményét használja ehhez. Az Intel lényegében ezt kerüli meg egy fixfunkciós motorral, mely gyorsabban és hatékonyabban dolgozik. Persze a fixfunkciós egységet támogatni kell, így konkrétan program is szükséges hozzá, ami ki tudja használni a hardver által kínált előnyöket.
Más szempontból túlzott előrelépés nem történt, így a Haswell IGP-je nagyjából arra képes, amire az Ivy Bridge megoldása. Ennek megfelelően marad a Quick Sync Video szolgáltatás, mely egy videók transzkódolására kihegyezett fixfunkciós motor, ami továbbra is a H.264, az MPEG2 és a VC-1 kodekeket támogatja, ám az új egység valamivel gyorsabb, mint az előző verzió. Emellett a transzkódolás minősége is javult.
A dekódolásért felelős motor lényegében nem változott, de megjegyzendő, hogy a Haswell már támogatja a DisplayPort 1.2 HBR2-es kimenetet, így az új IGP a konkurens megoldásokat beérve képes a 4K-s videók lejátszására egyetlen kimenet felhasználása mellett.
Többmonitoros móka újratöltve
Az Intel még az Ivy Bridge esetében vezette be azt a lehetőséget, miszerint az IGP képes három kijelzőt kezelni, melyeken a felhasználó különféle tartalmakat jeleníthet meg. Ennek a szoftveres megvalósítása elég vérszegény volt, hiszen gyakorlatilag nem volt hozzá vezérlőszoftver. Ez azt eredményezte, hogy a Windows kijelzőkezelőjében kellett kiterjeszteni a monitorokat, ami rendkívül kellemetlen működést eredményezett, hiszen így csak az első megjelenítő gyorsítható.

[+]
Az Intel a Haswell esetében megoldotta a problémát, mivel az új driver bevezeti a Collage módot, ami gyakorlatilag egy logikai megjelenítőnek hazudja az operációs rendszer felé a három csatlakoztatott monitort. Gyakorlatilag ugyanilyen elven működik az AMD Eyefinity és az NVIDIA Surround technikája is, így újdonságról most sincs szó, de ez a normális működése ennek a többmonitoros koncepciónak, így pedig használata kellemes lesz, nem pedig kínszenvedés.
Sajnos ez a vezérlőszoftver csak a Haswell IGP-ire érhető el. Mivel szimplán szoftveres változásról van szó, így illene az Ivy Bridge IGP-jén is engedélyezni ezt, de erre egyelőre semmi garancia. Az Intel terméktámogatására jellemző, hogy az új generációnál régebbi hardverek már nem kapnak új funkciókat, még akkor sem, ha a rendszer elvben képes támogatni. Ebben az esetben viszont igazán lehetne egy kivételt tenni, mivel az Ivy Bridge is megfelelne a felhasználók számára a több monitor megfelelő kezelése szempontjából.
Új platform: Shark Bay
A processzor lapkájába költözött újabb részegységek okán elkerülhetetlen volt a foglalatváltás, így az LGA1155 búcsúzik, és helyét az LGA1150 (Socket H3) veszi át.

[+]
Az új foglalat első ránézésre kiköpött mása az LGA1155-nek. Ez nem is csoda, hisz az alapvető kialakítás megmaradt, így a processzorok fizikai mérete sem változott, csupán 5 érintkezővel kevesebbet számolhatunk azokon.

LGA1150 - LGA1155 [+]
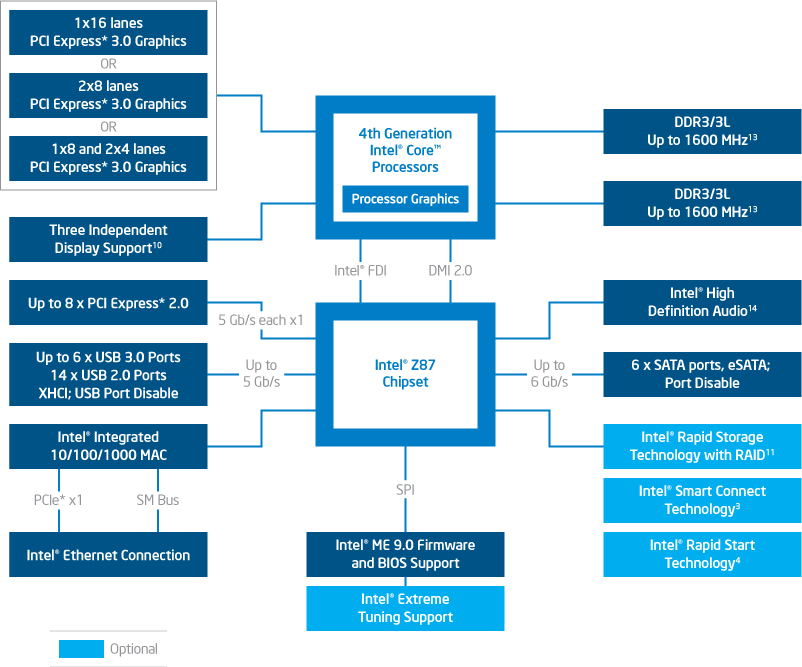
Természetesen ezzel bármilyen kompatibilitás kizárt a két tokozás, illetve foglalat között. Az LGA1150 mellé Lynx Point néven új chipkészlet (PCH) család is érkezett, így a korábbi nevezéktannak megfelelően Z87, H87, H81, B85, Q87, illetve Q85 modellekre számíthatunk, melyek közül az otthoni felhasználók körében valószínűleg az első 3-4 modell lesz a legnépszerűbb.

[+]
Ahogy korábban már megjegyeztük, a mai chipkészletek eléggé limitált fejlesztési potenciállal rendelkeznek, hisz jó néhány funkció már átköltözött a processzorba. Ebből fakadóan röviden összefoglalhatóak a 8x család főbb újításai: mostantól mind a 6 darab SATA port képes 6 Gb/s sebességre, illetve az USB 3.0 portok száma négyről hatra nőtt. Ezen felül csak apróbb módosításokat láthatunk, mint például a PCI támogatás teljes száműzését.
[+]
Említésre érdemes, hogy a hivatalosan támogatott memóriák szabványa nem változott, így a Shark Bay is legfeljebb DDR3-1600-as tempóra képes modulokat kezel.

[+]
A fogyasztás, illetve a gyártási költségek szempontjából lényeges, hogy az új PCH-k már 32 nm-es gyártástechnológiával készülnek, ami a korábbi 65 nm-hez képest meglehetősen nagy előrelépés. Véleményünk szerint ennek ismételten csak a mobil szegmensben lehet igazán jelentősége, hisz a PCH-k korábban sem rendelkeztek túl nagy TDP-vel (4-6 watt), így ebből fakadóan az asztali gépeknél nem számíthatunk jelentősebb fogyasztásmérséklésre.

[+]
Tesztkonfig, fogyasztás, specifikációk
Tesztünkben korábban már alkalmazott CPU és VGA (IGP) tesztrendszerünket vetettük be, melyben a már megszokott alkalmazások kaptak helyet. Ennek pontos listája a következőképpen fest:
- WinRAR 4.20 (64-bit)
- 7-Zip 9.20 (64-bit)
- Cinebench R11.5 (64-bit)
- Autodesk 3ds Max 2012 (64-bit)
- Indigo Renderer v2.4.13 (64-bit)
- Adobe After Effects CS5 (64-bit)
- Adobe Premiere Pro CS5.5 (64-bit)
- Adobe Photoshop CS5.1 (64 Bit)
- Sony Vegas Pro 10.0e (64-bit)
- CyberLink PowerDirector 9 (64-bit)
- Sorenson Squeeze 7 (32-bit)
- DivX Encoder 6.9.2 (32-bit)
- XviD Encoder 1.3.2 (64-bit)
- x264 build 2200 (64-bit)
- Cockos REAPER v4.0 (32-bit)
- Apache 2.2.19 (32-bit)
- AVG Antivirus Free 2012 (64-bit)
Az alkalmazások döntő többsége képes 4-6 vagy akár több magot/szálat is kihasználni, de akadnak kivételek. Az XviD Encoder például csak egyetlen magot vagy szálat tud megtornáztatni, de a DivX is megáll valahol 2 és 3 között. A WinRAR az utóbbihoz hasonlóan működik, és a két fájltömörítő közül ilyen szempontból a 7-Zip kicsit jobban viselkedik. Az előbbi alkalmazáshoz kapcsolódik, hogy jelen tesztünkben 4.20-as verziót használtuk, ami számottevően gyorsabb a korábban kipróbáltaknál. Az AVX utasításkészleteket biztosan kihasználó x264 nevű enkóder természetesen most sem maradhatott ki, melyből továbbra is a 2200-as build került bevetésre.
- Anno 2070 (DirectX 11) – motor: InitEngine / műfaj: stratégia
- DiRT Showdown (DirectX 11) – motor: EGO Engine / műfaj: autóverseny
- Hitman: Absolution (DirectX 11) – motor: Glacier 2 / műfaj: TPS
- Sleeping Dogs (DirectX 11) – motor: United Front Engine / műfaj: TPS/akció
- Tomb Raider (DirectX 11) – motor: Crytal Engine / műfaj: TPS/kaland
- Sniper Elite V2 (DirectX 11) – motor: Asura Engine / műfaj: TPS
Az IGP-k tesztelésénél a felbontásokat illetően egy szinttel feljebb léptünk, így immáron 1680x1050-ben és 1920x1200-ban futtattuk le a méréseket. A könnyebb és pontosabb mérés, valamint összevetés érdekében a Sniper Elite V2, DiRT Showdown, Hitman, Sleeping Dogs és Tomb Raider benchmark toolt használtuk, míg az Anno 2070-et FRAPS-szel mértük le.
| LGA1150 tesztplatform | Intel Core i7-4770K (3,5 GHz) processzor MSI Z87 MPOWER alaplap (Z87 chipset, BIOS: V1.3B1) 2 x 4 GB G.Skill RipjawsX DDR3-1866 F3-14900CL9Q-16GBXL memória DDR3-1600 beállítás, 9-10-9-28-1T időzítések |
|---|---|
| LGA1155 tesztplatform | Intel Core i7-3770K (3,5 GHz) processzor Intel Core i7-2600K (3,4 GHz) processzor ASUS P8Z77-V DELUXE alaplap (Z77 chipset, BIOS: 1504) 2 x 4 GB G.Skill RipjawsX DDR3-1866 F3-14900CL9Q-16GBXL memória DDR3-1600 vagy DDR3-1333 beállítás, 9-10-9-28-1T/9-9-9-28-1T időzítések |
| FM2 tesztplatform | AMD A10-5800K (3,8 GHz) processzor MSI FM2-A85XA-G65 alaplap (A85X chipset, BIOS: 1.4B5) 2 x 4 GB G.Skill RipjawsX DDR3-1866 F3-14900CL9Q-16GBXL memória DDR3-1866 beállítás, 9-10-9-28-2T időzítések |
| AM3/AM3+ tesztplatform | AMD FX-8350 (4,0 GHz) processzor AMD Phenom II X6 1100T (3,7 GHz) processzor ASUS Crosshair V Formula-Z alaplap (990FX chipset, BIOS: 1201) 2 x 4 GB G.Skill RipjawsX DDR3-1866 F3-14900CL9Q-16GBXL memória DDR3-1866 vagy DDR3-1333 beállítás, 9-10-9-28-2T/9-9-9-28-1T időzítések |
| Videokártya | AMD Radeon HD 7970 3 GB GDDR5 – Catalyst 13.4 |
| Háttértárak | Intel SSD 510 250 GB SSDSC2MH250A2 (SATA 6 Gbps) Kingston SSDNow M Series 80 GB SNM225-S2/80 GB (Intel X25-M G2) SSD Seagate Barracuda 7200.12 500 GB (SATA, 7200 rpm, 16 MB cache) merevlemez |
| Processzorhűtő | Prolimatech Megahalems Rev.C |
| Tápegység | Cooler Master Silent Pro M600 – 600 watt |
| Monitor | Samsung Syncmaster 305T Plus (30") |
| Operációs rendszer |
Windows 7 Ultimate SP1 64 bit |
Kíváncsiak voltunk, hogy a Sandy és Ivy Bridge családokhoz mérten mennyivel tud többet az új, Haswell-alapú i7-4770K, így a korábbi i7-2600K és i7-3770K is bekerült a mérésekbe. A konkurens AMD oldaláról az aktuálisan elérhető leggyorsabb CPU és APU vett részt a megmérettetésben, ami név szerint az FX-8350-et és az A10-5800K-t takarja. Ezen túlmenően, referencia gyanánt még a korábbi X6 1100T-t is bevettük a CPU-tesztekbe. Az új Haswellt az MSI Z87 MPOWER alaplapjában mértük le, melyet később részletesen is bemutatunk majd alaplaptesztünkben.

i7-4770K ES [+]
A bevett procedúrának megfelelően most is mindent a gyári specifikációk alapján állítottunk be. A turbó funkciók kivétel nélkül az összes platform esetében be voltak kapcsolva. Érdekesség, hogy alapállásban az inteles alaplapok minden esetben az összes magra azonnal a maximális 3900 MHz-es turbót lőtték be, még akkor is, ha éppen 100%-on volt terhelve a teljes CPU. Ez ellentmond a gyári specifikációknak, hisz a 3900 MHz-hez tartozó turbó szorzót csak egy vagy maximum két terhelt mag esetében lehet aktiválni.
Szokás szerint először a fogyasztást vettük górcső alá. Ennek mérését egy konnektorba dugható, digitális VOLTCRAFT Energy Check 3000 készülékkel végeztük, és minden esetben a monitor nélküli teljes konfiguráció értékeit vizsgáltuk. Mivel a Haswell, illetve a Sandy és Ivy Bridge-alapú Core i7, de még AMD APU is tartalmaz IGP-t, ezért ezek fogyasztását kétféle módszerrel is megvizsgáltuk. Az első esetben egy diszkrét Radeon HD 7970 került a rendszerekbe, amivel a processzorba integrált GPU inaktívvá vált, majd később ezt kivettük, és nélküle is elvégeztük a méréseket. Mind az Intel, mind pedig az AMD platformon be volt kapcsolva az összes lehetséges energiagazdálkodási funkció (EIST, C'n'Q, C1E, C6, stb.).
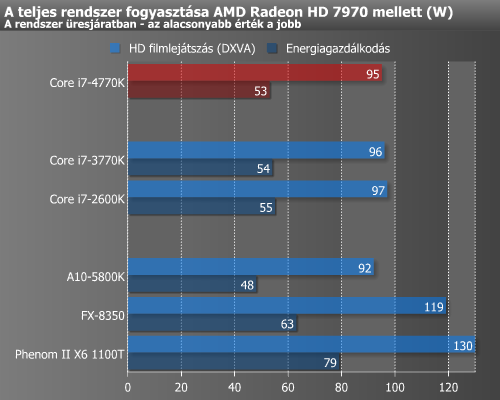

Üresjáratban előrelépés elsősorban az IGP-vel mért értékeknél látható. Az üresjárati fogyasztást az operációs rendszer is befolyásolja, és minden bizonnyal Windows 8 alatt jobb eredmények várhatóak. Ennek a közeljövőben megpróbálunk utánajárni.
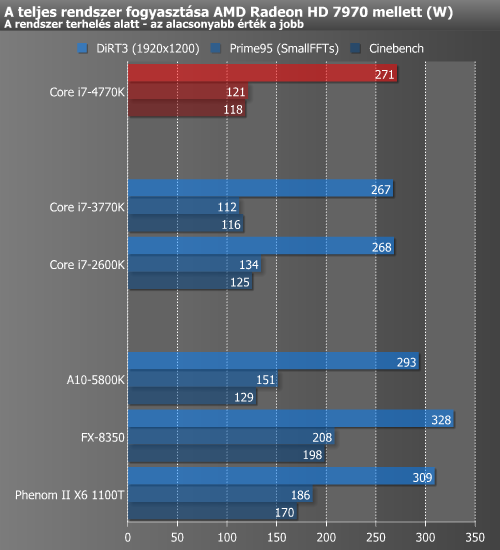
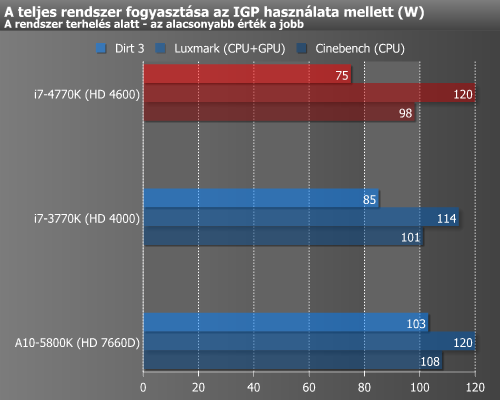
Terhelés mellett a HD 7970-nel társítva valamivel többet fogyaszt a 4770K, de ne feledjük, hogy az új Intel processzor TDP-je magasabb elődjéénél. IGP-vel kissé változik a kép, ugyanis ebben a felállásban DiRT alatt 10 wattal kért magának kevesebbet a Haswell.
| Processzor típusa | Intel Core i7-4770K | Intel Core i7-3770K | Intel Core i7-2600K |
|---|---|---|---|
| Kódnév | Haswell | Ivy Bridge | Sandy Bridge |
| Tokozás | LGA1150 | LGA1155 | |
| Alap magórajel | 3500 MHz | 3400 MHz | |
| Magok / szálak | 4 / 8 | ||
| Max. hivatalos memória-órajel | DDR3-1600 (DC) | DDR3-1333 (DC) | |
| Turbo Boost v. Turbo Core | 3,7-3,9 GHz (4-től 1 magig) |
3,5-3,8 GHz (4-től 1 magig) |
|
| L1D/L1I cache mérete | 4 x 32/32 kB | ||
| L2 cache mérete | 4 x 256 kB | ||
| L3 cache mérete | 8 MB | ||
| L3/IMC órajele (uncore/NB) | 3500 MHz | magórajel | |
| Kommunikáció a chipsettel | DMI (5 GT/s) + FDI (az IGP-hez) |
||
| Integrált PCIe vezérlő | 16 sáv (3.0) | 16 sáv (2.0) | |
| Utasításkészletek | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AES-NI, AVX, AVX2, FMA3 | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AES-NI, AVX | |
| Egyéb technológiák | EIST, C1E, C-states Execute Disable Bit, Hyper-Threading, Quick Sync, VT-x |
||
| Gyártástechnológia / feszültség | 22 nm Tri-Gate 1,05 V (rev. C0) |
22 nm Tri-Gate 1,15 V (rev. E1) |
32 nm HKMG 1,251 V (rev. D2) |
| TDP | max. 84 watt | max. 77 watt | max. 95 watt |
| Tranzisztorok száma Mag mérete |
1,40 milliárd 177 mm2 |
1,48 milliárd 160 mm2 |
995 millió 216 mm2 |
| Integrált GPU (IGP) | HD Graphics 4600 | HD Graphics 4000 | HD Graphics 3000 |
| Grafikus mag kódneve | Gen7.5 | Gen7 | Gen6 |
| Végrehajtóegységek | 20 Execution Unit | 16 Execution Unit | 12 Execution Unit |
| Órajel | 650(?) MHz | 650 MHz | 850 MHz |
| Turbo Boost v. Core órajel | 1250 MHz | 1150 MHz | 1350 MHz |
| Támogatott DirectX verzió | DirectX 11.1 | DirectX 11 | DirectX 10.1 |
| Támogatott OpenGL verzió | OpenGL 4.0 | OpenGL 3.0 | |
| Támogatott OpenCL verzió | OpenCL 1.2 | nem támogatott | |
| Multi-GPU opció | nem támogatott | ||
| HD anyagok hardveres támogatása | Intel ClearVideo HD (H.264, VC-1, MPEG-2) |
||
| HDMI Audio | Dolby TrueHD és DTS-HD Master | ||
| Processzor típusa | AMD A10-5800K | AMD A10-5700 | AMD A8-5600K | AMD A8-5500 |
|---|---|---|---|---|
| Kódnév | Trinity | |||
| Tokozás | FM2 | |||
| Alap magórajel | 3800 MHz | 3400 MHz | 3600 MHz | 3200 MHz |
| Magok / szálak | 4 / 4 | |||
| Max. hivatalos memória-órajel |
DDR3-1866 (DC) | |||
| Turbo Core (alap/max.) | 4,0/4,2 GHz | 3,7/4,0 GHz | 3,8/3,9 GHz | 3,5/3,7 GHz |
| L1D/L1I cache mérete | 4 x 16 kB / 2 x 64 kB | |||
| L2 cache mérete | 2 x 2 MB | |||
| L3 cache mérete | nincs | |||
| L3/IMC órajele (uncore/NB) | 1800 MHz | 1600 MHz | 1500 MHz | 1600 MHz |
| Kommunikáció a chipsettel | UMI (5 GT/s) | |||
| Integrált PCIe vezérlő | 20 sáv (2.0) | |||
| Utasításkészletek | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, SSE4A, AES, AVX, XOP, FMA4, FMA(3), F16C, BMI, TBM | |||
| Egyéb technológiák | APM, HTC, C1E, C6, EVP, AMD-V, VCE | |||
| Gyártástechnológia / feszültség | 32 nm HKMG SOI 1,375 V (rev. A1) |
32 nm HKMG SOI 1,212 V (rev. A1) |
32 nm HKMG SOI 1,400 V (rev. A1) |
32 nm HKMG SOI 1,262 V (rev. A1) |
| TDP | max. 100 watt | max. 65 watt | max. 100 watt | max. 65 watt |
| Tranzisztorok száma Lapka mérete |
1,303 milliárd 246 mm2 |
|||
| Integrált GPU (IGP) | Radeon HD 7660D | Radeon HD 7560D | ||
| Grafikus mag kódneve | Devastator | |||
| Végrehajtóegységek | 384 Radeon Core | 256 Radeon Core | ||
| Órajel | 800 MHz | 760 MHz | ||
| Turbo Boost v. Core órajel | nincs | |||
| Támogatott DirectX verzió | DirectX 11 | |||
| Támogatott OpenGL verzió | OpenGL 4.2 | |||
| Támogatott OpenCL verzió | OpenCL 1.2 | |||
| Multi-GPU opció | Dual Graphics | |||
| HD anyagok hardveres támogatása | AVIVO HD (UVD3), (H.264, VC-1, MPEG-2, MPEG-4 ASP/DivX) | |||
| HDMI Audio | Dolby TrueHD és DTS-HD Master | |||
Renderelés, tömörítés (CPU)
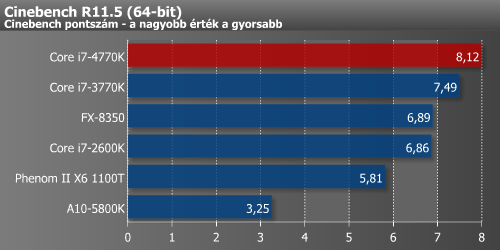
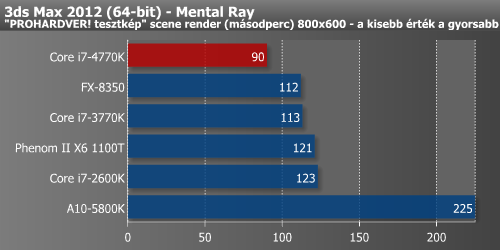
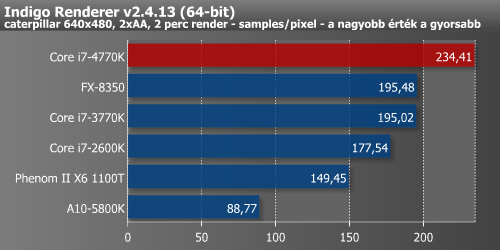
Korábbi tesztjeinkben már elmondtuk, hogy a renderelés tipikusan az a nagyon jól párhuzamosított folyamat, ami nem igazán profitál sem a méretes L3 cache-ből, sem pedig az esetleges nagyobb memória-sávszélességből. Ez a terület nagyon fekszik az új mikroarchitektúrának, hisz 3ds Max és Indigo alatt majd 20%-kal gyorsabb a 4770K a 3770K-nál.
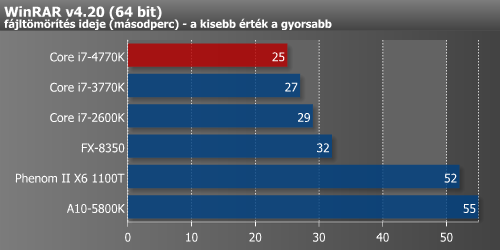
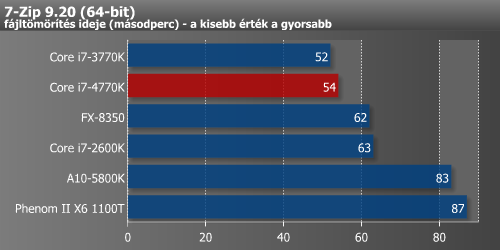
A fájltömörítők a renderelő alkalmazásokkal ellentétben kedvelik a minél nagyobb memória-sávszélességet és L3 cache-t. A WinRAR nem túl sokat, 2 másodpercet gyorsult, míg a 7-Zip lassult. Utóbbi minden bizonnyal az első oldalon említett módosított L3 cache hozzáférés számlájára írható.
Videóvágás, szerkesztés (CPU)
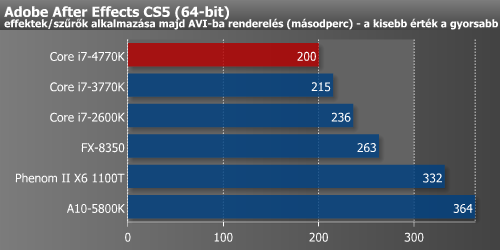
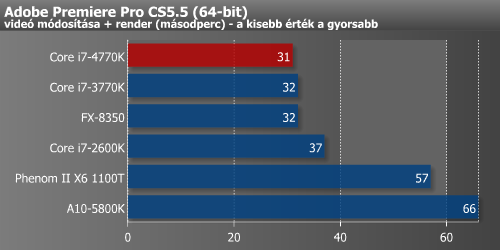
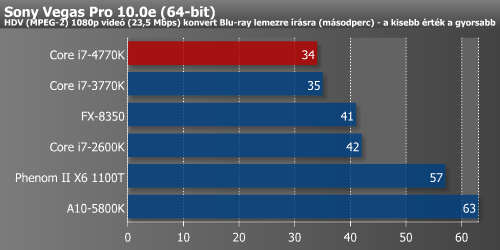
A különféle videóvágó és -konvertáló alkalmazások egyelőre nem profitálnak jelentősen a Haswell képességeiből.
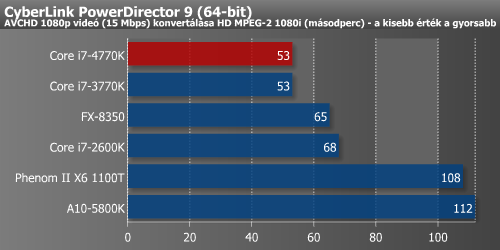
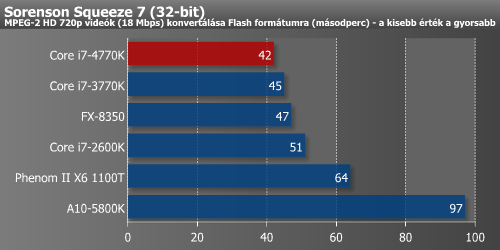

A Powerdirector, Sorenson Squeeze, Cockos Reaper trió sem gyorsult jelentősen. A három alkalmazás közül egyedül az utóbbi gyorsult viszonylag nagyobb mértékben, 10%-ot.
Videókódolás, egyéb (CPU)
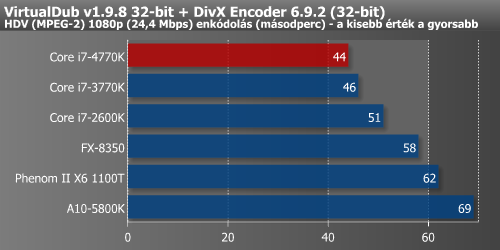
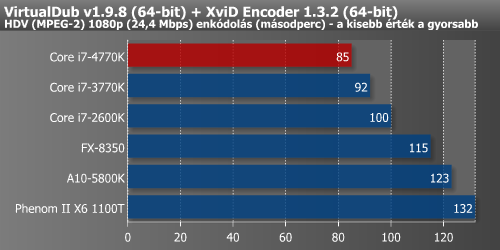

Az DivX-alapú kódolás és az XviD sem gyorsult jelentősen a Haswell-lel. Ezzel szemben az AVX, AVX2 és FMA3 utasításkészleteket alkalmazó x264 12%-os pluszt produkált a 4770K-val.
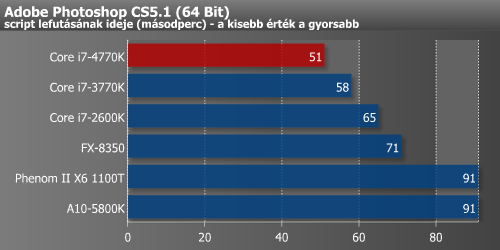


A Photoshop a fenti x264-hez hasonlóan szintén 12%-ot profitált a Haswell-ből. Tesztünk egyik kakukktojása az Apache, amiben a 4770K jelentősen lassult a korábbi Intel processzorokhoz képest. Korábban hasonló tendenciát véltünk felfedezni az AMD Bulldozer-alapú megoldásainál, amit a modulos felépítésnek tulajdonítottunk. Úgy fest, hogy valami más lehet a háttérben, hisz többszöri újraindítás, illetve mérés után sem produkált jobb eredményt ez a teszt.
Játékok (CPU)
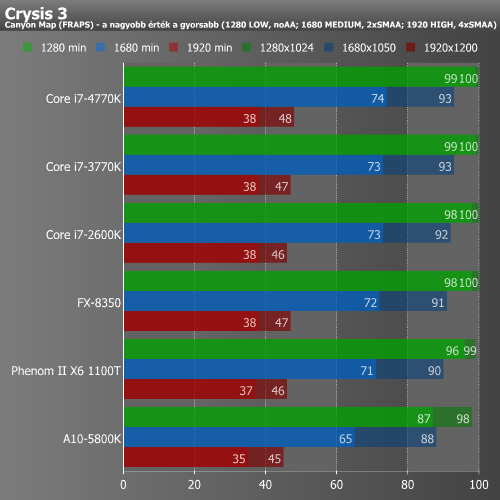
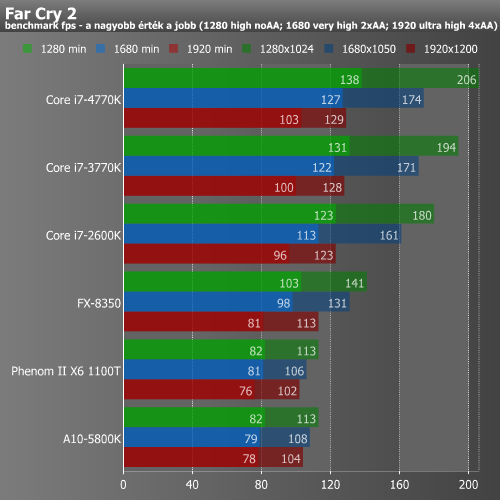
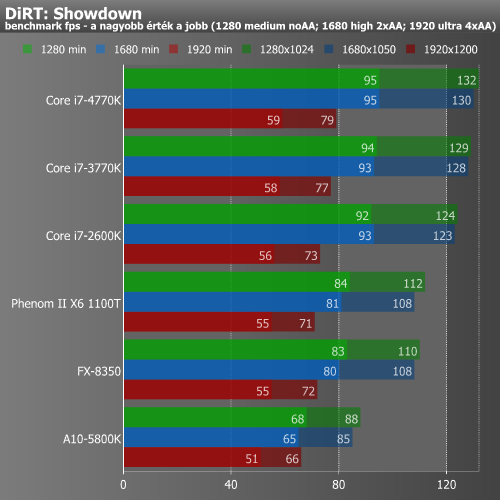
A Radeon HD 7970-nel párosítva, játékok alatt továbbra sem láttunk különösebb meglepetést. A meglehetősen újnak számító Crysis 3 alatt még az A10-5800K is képes volt jól játszható eredményt produkálni. A már igencsak korosnak számító Far Cry 2 esetében nagyobb különbségeket láthatunk, pusztán az a kérdés, hogy ez a mai játékok esetében mennyire számít reprezentatívnak. A DiRT esetében alacsonyabb felbontás, illetve részletesség mellett vannak különbségek, ami Full HD esetében már igencsak beszűkül. Ebből újfent az következik, hogy 1920x1080-hoz és a fölé az esetek döntő többségében elsősorban erős VGA, nem pedig erős CPU szükséges.
Sleeping Dogs, DiRT, Anno 2070 (IGP)
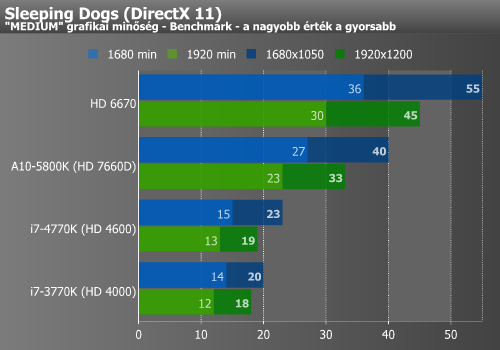
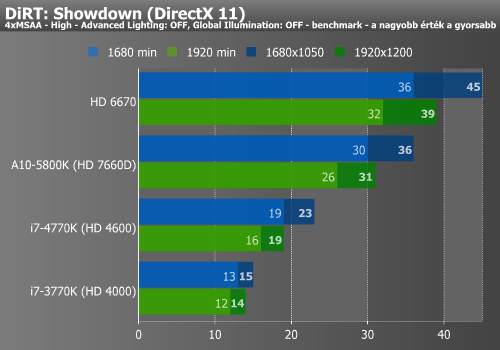
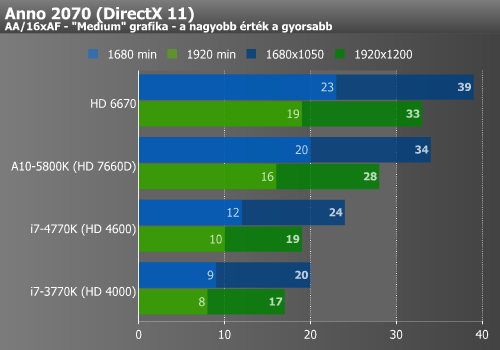
Sleeping Dogs alatt nem túl sokat gyorsult a HD 4600 a HD 4000-hez képest. Ezzel szemben a DiRT már jelentősen profitált az újabb IGP-ből, bár az AMD aktuális leggyorsabb megoldását még így sem érte be. Az Anno 2070 ismételten csak jól reagált a HD 4600-ra.
DiRT alatt tettünk próbát a memória órajelének emelésére. Korábbi tesztjeinkben az a kép rajzolódott ki, hogy az Intel IGP-k egyelőre nem támaszkodnak jelentősen a DDR3-as modulok által nyújtott sávszélességre. Kíváncsiak voltunk, hogy a Haswell esetében ez változott-e. A modulok órajelét 1600 MHz-ről 1866 MHz-re emeltük, de ez csupán egyetlen fps javulást eredményezett az említett játék alatt.
Hitman, Tomb Raider, Sniper Elite (IGP)
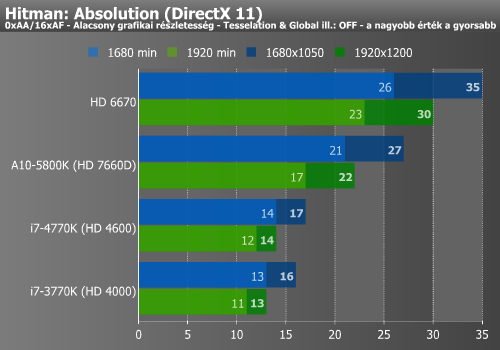
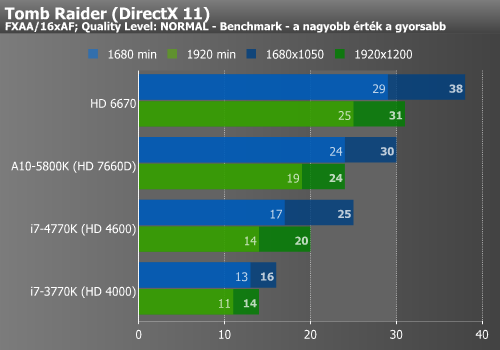
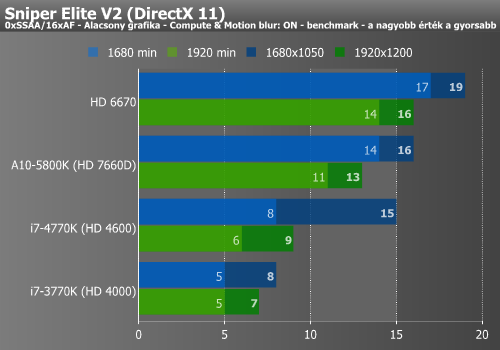
A Hitman mérése nem mutatott jelentős különbséget az elődhöz képest, míg a Tomb Raider már igen nagymértékű gyorsulást produkált a HD 4600 hatására.
LuxMark v2.0, winZip (OpenCL)
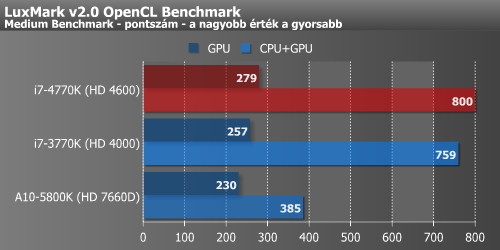
A Luxmark esetében az érdekesség kedvéért a méréseket két különböző módban is elvégeztük: először csak a GPU számolt, a második esetben a CPU-magok és a GPU közösen végezte a kalkulációkat. Ez a folyamat eléggé fekszik az Intel grafikus megoldásainak, amire a CPU-magok csak rátesznek egy további nagy lapáttal.
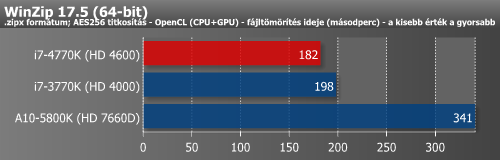
A WinZip néhány verzió óta támogatja az OpenCL-t, bár sajnos nem minden esetben tudja kamatoztatni a GPU erejét, így egyelőre sok esetben csak a CPU-magokra támaszkodik.
Tuning és clock 2 clock összevetés
Szokás szerint most is megnéztük, hogy mekkora órajeltartalék lapul még a főszereplő processzorban. Az i7-4770K esetében szerencsére viszonylag könnyű dolgunk volt, hisz a "K" jelölésből adódóan a főszereplő szorzózármentes.

i7-4770K ES [+]
Tuning terén nem sok újítást hozott a Haswell. Megjelentek a Sandy Bridge-E esetében már látott BCLK szorzók, de mi egyelőre nem tudtuk munkára fogni azokat, így maradtunk a jól bevált szorzóállítgatásnál.
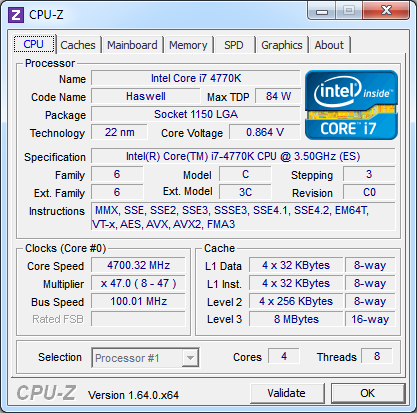
Végül 4700 MHz-et értünk el, ami megegyezik a Sandy és Ivy Bridge esetében látottakkal, ergo ezen a téren már jó ideje nincs változás az Intel háza táján. A stabil órajelhez 1,25 voltos feszültség volt szükséges, amivel maximális terhelés mellett 80 Celsius-fok környékén működtek a magok.
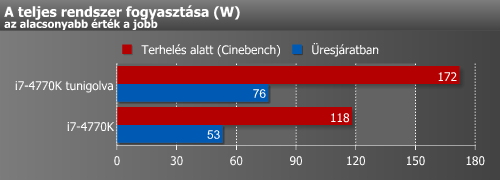
A feszültség és az órajel emelésének hatására természetesen most is alaposan megugrott a fogyasztás.
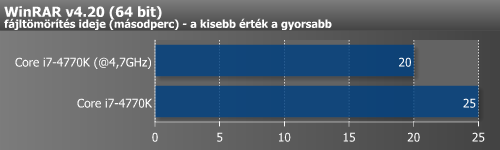
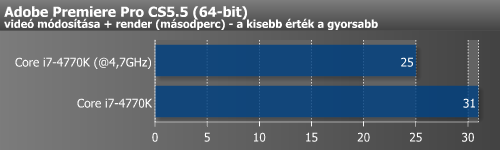
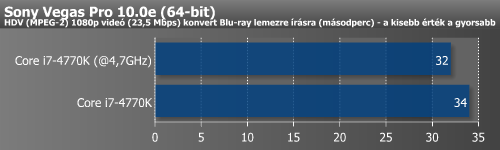
Végül a tuning hatását különböző alkalmazások alatt is megmértük.


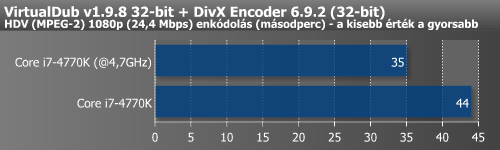
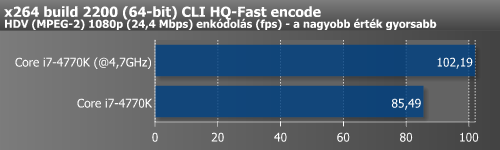
Legvégül azt is megnéztük, hogy teljesen azonos körülmények között mennyivel gyorsabb a Haswell elődjénél. A processzorok órajelét 3500 MHz-re fixáltuk, a turbót kikapcsoltuk, valamint a memória órajelét mindkét CPU esetében 1600 MHz-re állítottuk be.
| Alkalmazás | Ivy Bridge @3,5 GHz (DDR3-1600) |
Haswell @3,5 GHz (DDR3-1600) |
Különbség a Haswell javára |
|---|---|---|---|
| WinRAR tömörítés (mp) | 27 | 26 | 4,3% |
| 7-Zip tömörítés (mp) | 54 | 56 | -3,7% |
| Cinebench R11.5 (pont) | 7,14 | 7,64 | 7,0% |
| 3ds max 2012 (mp) | 119 | 94 | 21,0% |
| Indigo v2.4.13 (pont) | 185,58 | 221,42 | 19,3% |
| Adobe After Effects (mp) | 218 | 204 | 6,4% |
| Adobe Premier Pro (mp) | 34 | 32 | 5,9% |
| Adobe Photoshop (mp) | 60 | 54 | 10,0% |
| Sony Vegas 10.0e (mp) | 36 | 35 | 2,8% |
| Powerdirector 9 (mp) | 54 | 53 | 1,8% |
| Sorenson Squeeze (mp) | 48 | 45 | 6,3% |
| DivX kódolás (mp) | 47 | 45 | 4,3% |
| XviD kódolás (mp) | 100 | 93 | 7,0% |
| x264 (fps) | 72,31 | 79,38 | 9,8% |
| Cockos Reaper (mp) | 29 | 26 | 10,4% |
| Apache (pont) | 3792 | 2703 | -40,3% |
| AVG Antivirus (mp) | 96 | 87 | 9,4% |
Összegzés
Cikkünk végéhez közeledve térjünk rá az eredmények összesítésére!
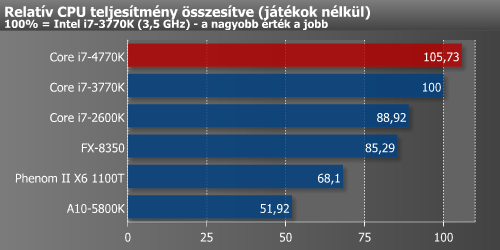
Jól kivehető, hogy méréseink alapján az Intel Core i7-4770K majd 6%-kal gyorsabb az i7-3770K-nál. Apache nélkül a Haswell helyzete valamivel jobb, ugyanis így 8,4%-os az előny. Soknak ez utóbbi sem nevezhető, így minden bizonnyal újrafordított és/vagy optimalizált alkalmazásokra lesz szükség a nagyobb előny eléréséhez.
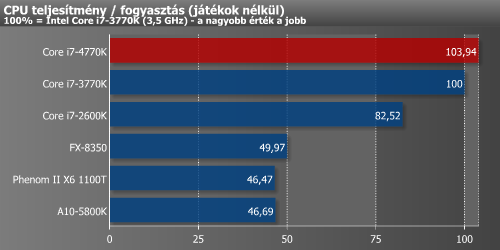
Mivel a gyártástechnológia nem változott, így nem számítottunk jelentősebb javulásra a teljesítmény/fogyasztás mutató esetében. Ez így is lett, ugyanis a Haswell csak minimálisan múlja felül az Ivy Bridge-et.
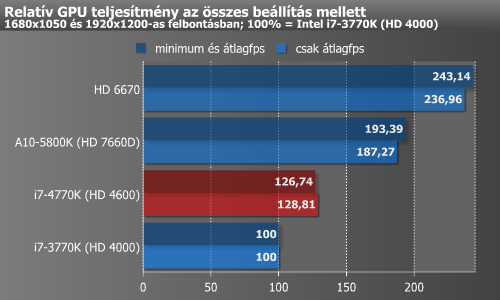
Az integrált GPU tekintetében már jóval nagyobb az előrelépés, ugyanis itt 27-29%-os átlagos előrelépést mértünk az Ivy Bridge-hez képest. Ennek ellenére az AMD jelenleg legerősebb, Trinity kódnevű megoldása továbbra is utcahosszal vezet.
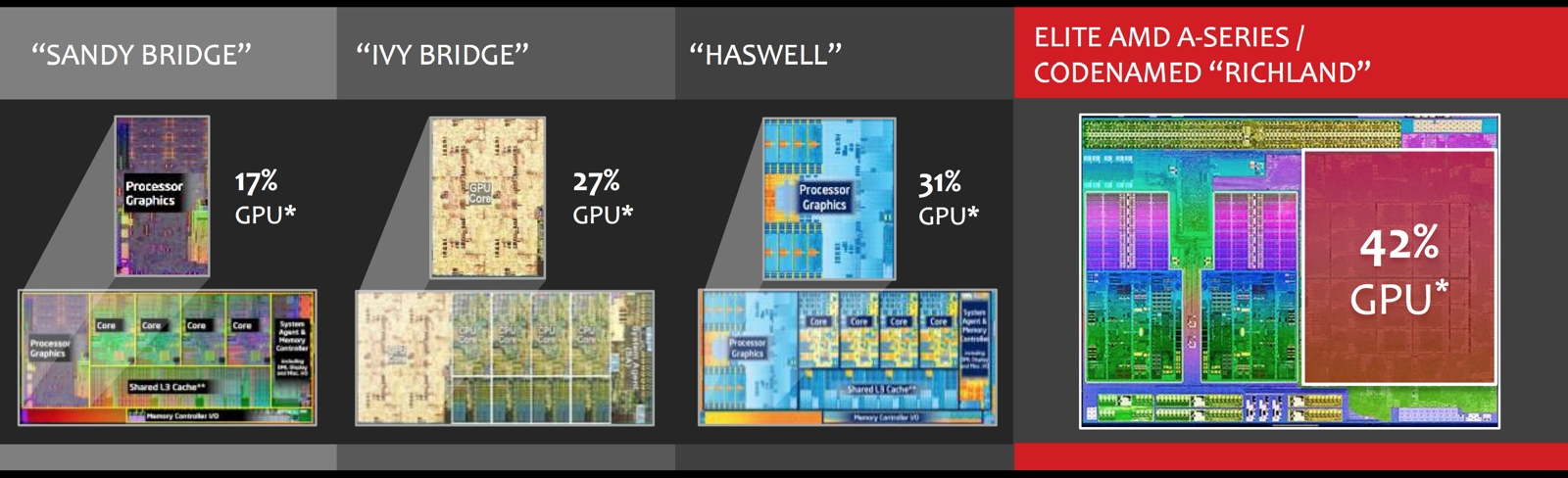
[+]
Ugyanakkor ne feledjük, hogy a GT3 és a GT3e személyében erősebb IGP-ket is várhatunk. Kérdés, hogy ezek a gyakorlatban mekkora előrelépést fognak jelenteni, illetve addig mivel rukkol elő a konkurencia.
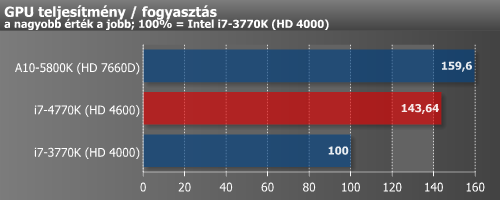
Az IGP teljesítmény/fogyasztásának tekintetében jól áll a Haswell, hisz a grafikus teljesítmény nőtt, miközben a fogyasztás némileg csökkent.
Mindent összevetve mi kicsit többet vártunk a Haswelltől, pláne ami a CPU-t illeti. Ahogy elmondtuk, minden bizonnyal az újabb, optimalizált szoftverekkel gyorsulhatnak az újdonságok, már csak az a kérdés, hogy mikor és mekkora mértékben.

[+]
Ettől függetlenül bizonyos helyzetekhez talán még sok is az i7-4770K ereje, ami jelenleg bőségesen elég lehet a legtöbb otthoni felhasználónak. Mindenesetre szerintük i7-3770K-ról, de még i7-2600K-ról is csak speciális esetben éri meg váltani, amennyiben a legfőbb szempont a CPU x86-os számítási teljesítménye. Az IGP már egy másik kérdés, bár a HD 4600 még mindig nem az, amire igazán vártunk, de talán az 5000-es széria már egy nagyobb ugrás lesz – kíváncsian várjuk.
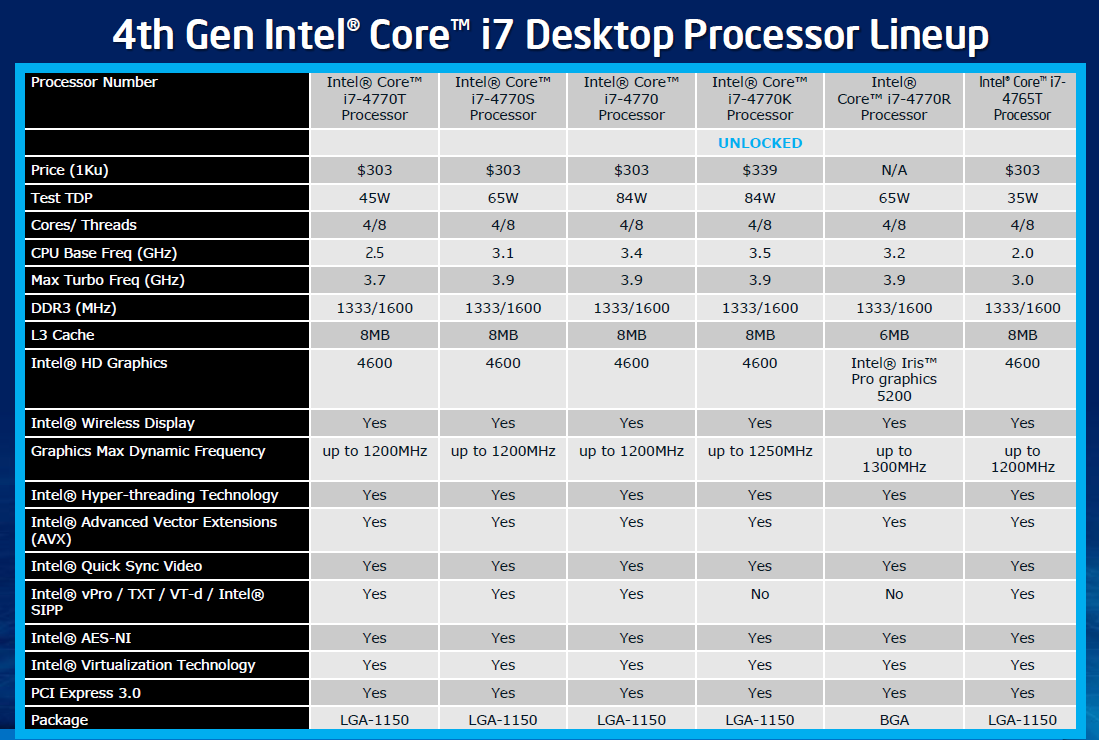
[+]
Az újabb nagy tűzijáték ugyan elmaradt, de ettől függetlenül az i7-4770K egy jó processzor, amit egyelőre leginkább azoknak ajánlanánk, akik 3 éves vagy annál régebbi rendszerről szeretnének újítani.

Intel Core i7-4770K processzor
Oliverda és Abu85
Az Intel Core i7-4770K-t az Intel bocsátotta rendelkezésünkre, a teszteléséhez használt MSI Z87 MPOWER alaplapot pedig az MSI biztosította.