Amit tudni érdemes
Átlagfelhasználóként csak ámulunk és bámulunk, amikor új processzorcsalád jelenik meg a piacon. A megannyi kódnév és típusjelzés teljesen összezavarja az embert, és fogalma sincs, hogy mit vegyen. Ez alól a most év elején az Intel által bevezetett új processzorcsalád sem kivétel, elég ha azt vesszük alapul, hogy nem kevesebb, mint 29 új típus jelenik meg idővel a boltok kínálatában: fogadja gratulációnkat, aki mindet meg tudja jegyezni. Erre persze nincs szükség, de azért nem árt, ha van némi fogalmunk arról, hogy mire adunk ki több tízezer forintot. Nos, az Intelben szerencsére ezúttal sem kellett csalódnunk, ugyanis olyan processzorokkal álltak elő, amelyek valóban megérnek egy kisebb misét.

Aki olvassa a hardverrel kapcsolatos híreket/cikkeket már valószínűleg tudja, hogy az Intel egy úgynevezett tikk-takk "kódnéven" futó stratégia alapján dolgozik, ami azt jelenti, hogy kétévente új architektúrát jelent be, kétévente pedig új gyártástechnológiára áll át. Ennek utolsó állomása a Westmere volt (többségünk Core i3/i5 - Clarkdale - néven ismeri, illetve a csúcskategóriás Gulftown (hatmagos Core i7) is ide tartozik), amely 32 nm-es csíkszélességre ültette az előzőleg új architektúraként megismert Nehalemet (Core i7-9xx - Bloomfield és Lynnfield). Most 2011 elején (pici késéssel, ugyanis elvileg tavaly lett volna esedékes) elérkeztünk egy újabb takk-állomáshoz, vagyis amikor egy új architektúra jelenik meg, ez pedig a Sandy Bridge nevet viseli. A Sandy Bridge alapjában véve a jelenleg kapható két- és négymagos Core i3/i5/i7 processzorok leváltására érkezik, elméletileg középre pozicionálva, de elég széles terjedelemben, hiszen a most megjelenő CPU-k kb. 20-25 000 forinttól 70-80 000 forintig lesznek kaphatóak.
Hirdetés
Hogy megkönnyítsük az "átállást", pontokba szedtük, hogy a Sandy Bridge miről is szól, melyek azok a szempontok, amelyek alapján megkülönböztethetjük elődeitől:
- egy lapkán (szíliciumszeleten) elterülő CPU és GPU
- továbbfejlesztett (pontosabban módosított) CPU-architektúra
- új SIMD-utasításkészlet (AVX)
- magasabb órajelek
- alacsonyabb fogyasztás
- továbbfejlesztett Turbo Boost mód
- továbbfejlesztett GPU
- tuningzár
- új CPU-foglalat

Az egyes pontok elég egyértelműek, de lássuk, mivel állunk szemben! A Sandy Bridge az első olyan asztali processzor, amely a CPU-magokon felül egy GPU-t is tartalmaz. A jelenleg még kapható Core i3/i5 is tartalmaz GPU-t, de ezeken a processzorokon a GPU egy különálló lapka a kupak alatt. Miért is jó ez nekünk és az Intelnek? Alapjában véve ez jó és rossz is. Az Intelnek jó, mert az egyes részegységek vezérlése egyszerűbb, és gyorsabb az adatkommunikáció, ebből következően elvileg nekünk is jobb, mert magasabb teljesítményre számíthatunk. A GPU és a CPU összekötéséért felelős útvonal eltűnik, tehát csökken a fogyasztás és a gyártási költség is. Ugyanakkor azonos csíkszélességet feltételezve eleinte ez hátrány is, hiszen könnyebb két kisebb lapkát (a Clarkdale CPU-ja és GPU-ja) hiba nélkül legyártani, mint egy nagyobbat, de ez idővel nyilván elhanyagolható tényezővé fog válni, miután az Intel újra csökkenti majd a gyártási csíkszélességet (és ez lesz majd az Ivy Bridge, de az még odébb van). Az egy lapkán elterülő CPU-magok és a GPU együttesen használhatják a harmadszintű gyorsítótárat, ami egy nagyon gyors elérésű memóriának fogható fel; ezt a processzormagok asztali környezetben elég ritkán használják, ezért a GPU sebességét komolyan meg tudja dobni. A CPU egyes részegységei (magok, GPU, L3 cache, memóriavezérlő) között egy körforgalmi adatbusz (ring bus) található, ezen vándorolnak az adatok így biztosítva minden egyes részegység számára az azonos idejű hozzáférést.
Az architektúra, illetve a futószalag minden egyes lépcsőfoka megváltozott kisebb-nagyobb mértékben. A front-end, azaz az utasításbehívást és dekódolást végző rész kiegészült egy, a Pentium 4-es éra alatt megismert trace-cache-szerű kis tárral, amely a már dekódolt mikroutasítások (Uop) eltárolására képes. Ez kb. 1500 mikroutasítást képes tárolni: ha a behívás (fetch) során egy már a Uop-cache-ben található utasításra kerülne a sor, akkor azt nem kell újra dekódolni, tehát lekapcsolható a front-end, ezzel pedig nemcsak gyorsul a parancsok végrehajtása, de némi energiát is meg lehet takarítani. Továbbfejlesztették az elágazásbecslést is, ami egyébként minden egyes újonnan megjelenő architektúráról elmondható; ezen a részen mindig csiszolnak valamit a gyártók.
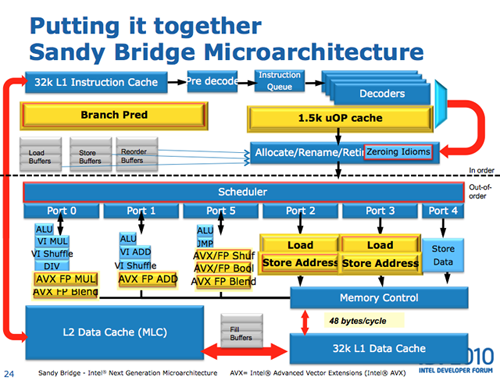
Már az ütemezést érinti és ennél érdekesebb, hogy nem csak hogy megnövelték a ROB (Re-Order Buffer) méretét, de "beszúrtak" mögé két fizikai regiszterfájlt (egy FP és egy Int) is. A ROB alapvetően az utasítások sorrendjét állítja vissza az eredeti állapotba, miután az OoO-feldolgozás megtörtént, ugyanis ebben tárolódnak az egyes műveletek végeredményei. A két nagy regiszterfájl bevezetésére a Sandy Bridge-ben bemutatkozó AVX (Advanced Vector Extensions) SIMD-utasításkészlet miatt volt szükség, amely 256-bit széles utasítások feldolgozását teszi lehetővé. Az AVX alapvetően a lebegőpontos feldolgozás gyorsítására lett kitalálva, és az egyik legérdekesebb újítása, hogy lehetővé teszi a háromoperandusos műveletvégzést, tehát az a:=a+b helyett immár használhatjuk a c:=a+b formát is (igaz, megkötésekkel).
A lebegőpontos teljesítmény csak egy megfelelő szélességű back-enddel aknázható ki. A Sandy Bridge minden egyes 256-bites AVX utasítást egyetlen Uop-ként hajt végre, az új végrehajtók pedig lehetővé teszik, hogy órajelenként egy 256-bites FP szorzást, egy 256-bites FP összeadást és egy 256-bites eltolást (shuffle) hajtson végre. Az utasítások végrehajtása után a Load és Store gyorstárak lépnek működésbe. Itt is komoly fejlődésnek lehetünk a szemtanúi, ugyanis a Nehalem Load és Store gyorstárait, amelyek vagy csak loadot vagy csak store-t voltak képesek tárolni, felváltotta két szimmetrikus tár, amelyek a Load és a Store utasításokat is képesek végrehajtani.
A cikk még nem ért véget, kérlek, lapozz!









