Hirdetés
Rövid visszatekintő
A szinte éppen egy éve debütált, Bulldozer-alapú AMD FX asztali processzorcsalád nem váltotta be a hozzá fűzött, talán túlzó reményeket. Ez több különböző okra vezethető vissza. Egyrészt néhány korábbi termékéhez hasonlóan az AMD ezt a fejlesztést is egy hosszabb távú célnak rendelte alá, ami nem más, mint az x86-os CPU-magok, valamint az általános számításokra is befogható GPU egyre szorosabb összefűzése. Akik olvasták tavalyi tesztünket, azok tudhatják a Bulldozerről, hogy felépítése radikálisan eltér mind elődeiétől, mind jelenlegi versenytársaiétól. A mikroarchitektúra tervezését jó néhány évvel ezelőtt, szinte nulláról kezdték a mérnökök, ami valószínűleg nagyban közrejátszott abban, hogy az első, 2009-es céldátum helyett csak tavaly, azaz 2011-ben lett kézzelfogható termék a munkagépről elnevezett fejlesztésből.
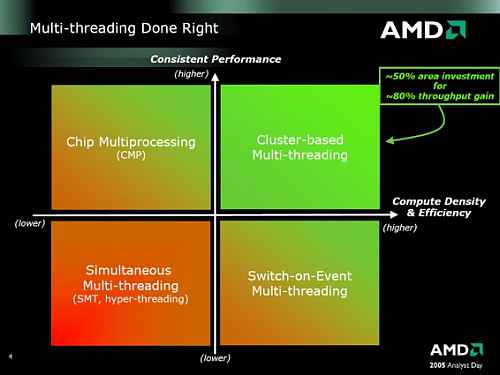
A teljes rendszer alappilére a cluster-based multi-threading (klaszteralapú többszálúsítás). A multi-threading (magyarul többszálúsítás) röviden valamilyen speciális hardveres megoldást takar, melyben a végrehajtószálak minden esetben osztoznak bizonyos erőforrásokon. Az, hogy ezek a bizonyos egységek pontosan mit takarnak, az mindig a koncepciótól függ. A többmagos megoldásokkal (multi-core) szemben – mely több önálló, teljes értékű magot kapcsol egy lapkába a számítási teljesítmény növelése érdekében – ezen eljárás fő célja a már rendelkezésre álló erőforrások minél hatékonyabb kihasználása.
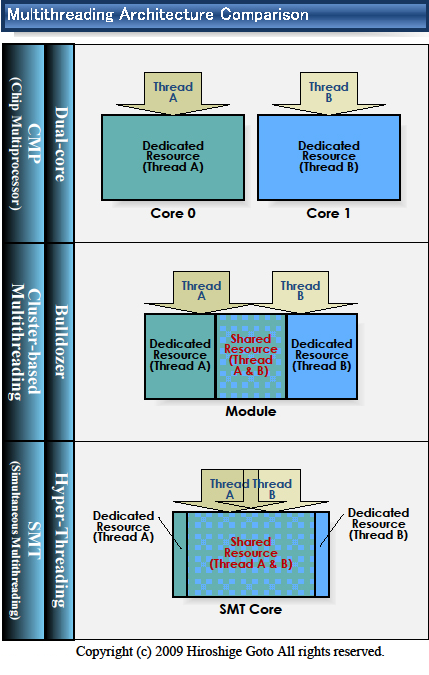
A cluster-based multi-threading koncepció félig-meddig a Sun által tervezett SPARC architektúrás (azaz nem x86!) UltraSPARC T1 és T2 esetében bevezetett, "chip multi-threading" nevű rokonra hasonlít. Ennek dióhéjban az a lényege, hogy egy lapkán belül több mag (az említett T1 és T2 kapcsán maximum 8) található, melyek osztoznak bizonyos erőforrásokon (cache, FPU stb.), és emellett egy-mag(juk) képes SMT-szerűen több szálat (4-8) is futtatni, melyeket a rendszer – a Hyper-Threadinghez hasonló módon – különálló végrehajtó egységeknek ismer fel.
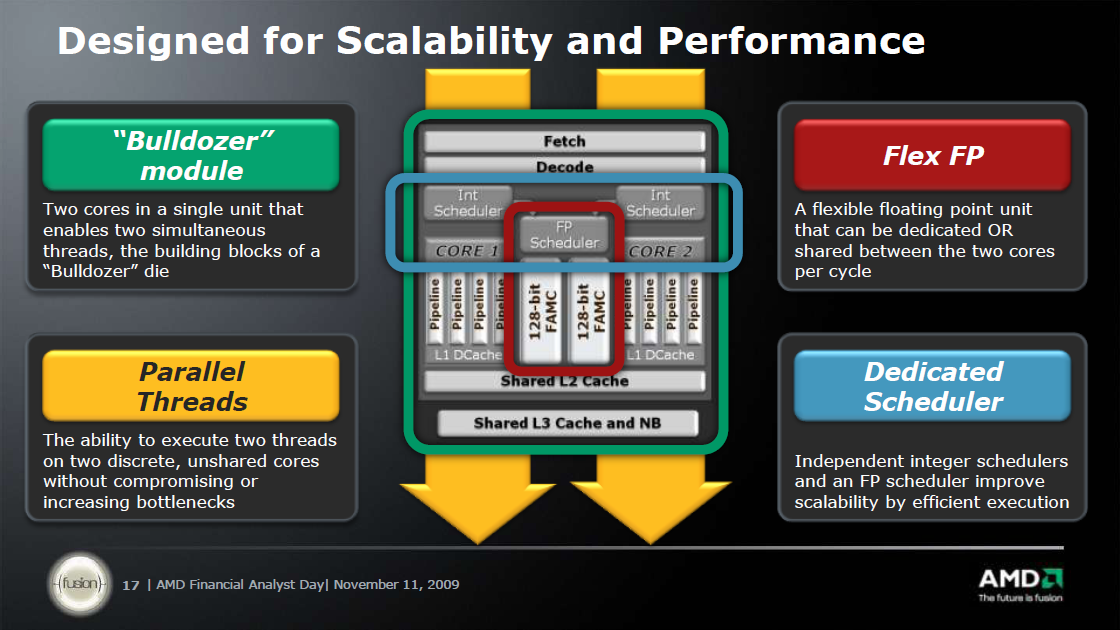
[+]
Az AMD koncepciója a fenti sematikus ábrán figyelhető meg. Abban a tekintetben, hogy a processzoron belül mi az az elemi feldolgozó egység, amely a támogatott utasításkészletek összes utasítását fel tudja dolgozni, a korábban megszokott "mag" kifejezést a Bulldozerben a "modul" vette át. A modulok belül több alegységre bonthatóak, amelyek közül néhányból teljes egészében kettő van, ezek dedikáltan egy-egy szálhoz tartoznak, míg mások mindkét utasításfolyamot kezelik felváltva vagy párhuzamosan. Az utasítások végrehajtása a következő utasítások kiválasztásával, azok előfeldolgozásával és dekódolásával kezdődik, ezeket az összefoglaló néven front-endnek hívott megosztott részegységek végzik, órajelenként váltva a két szál között. A szálak utasításait egyetlen 64 kB méretű, kétutas csoportasszociatív L1 I-cache (utasítás cache) tárolja.
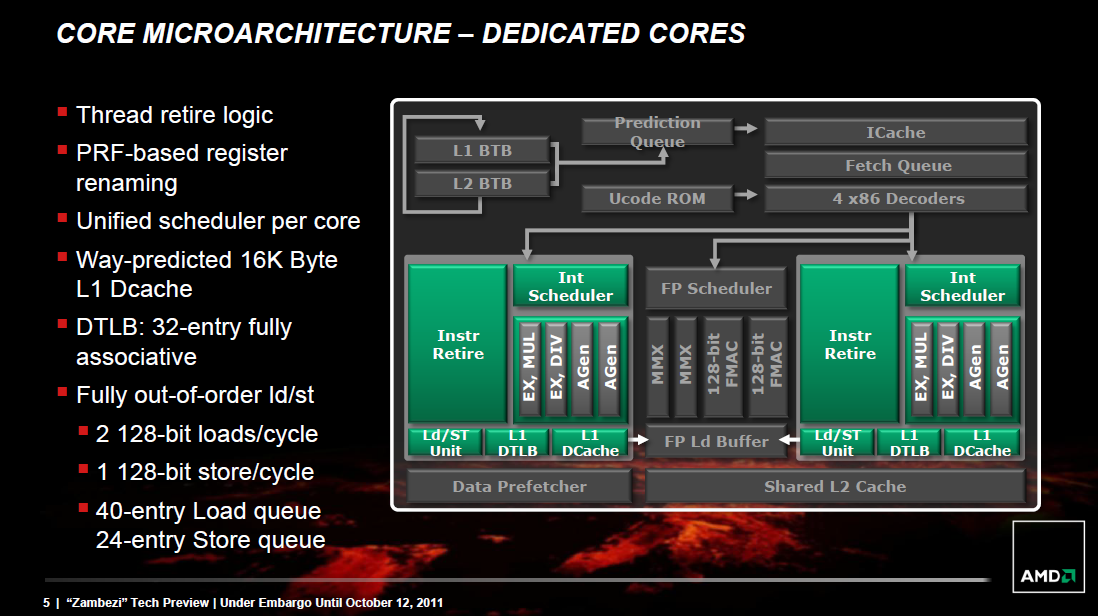
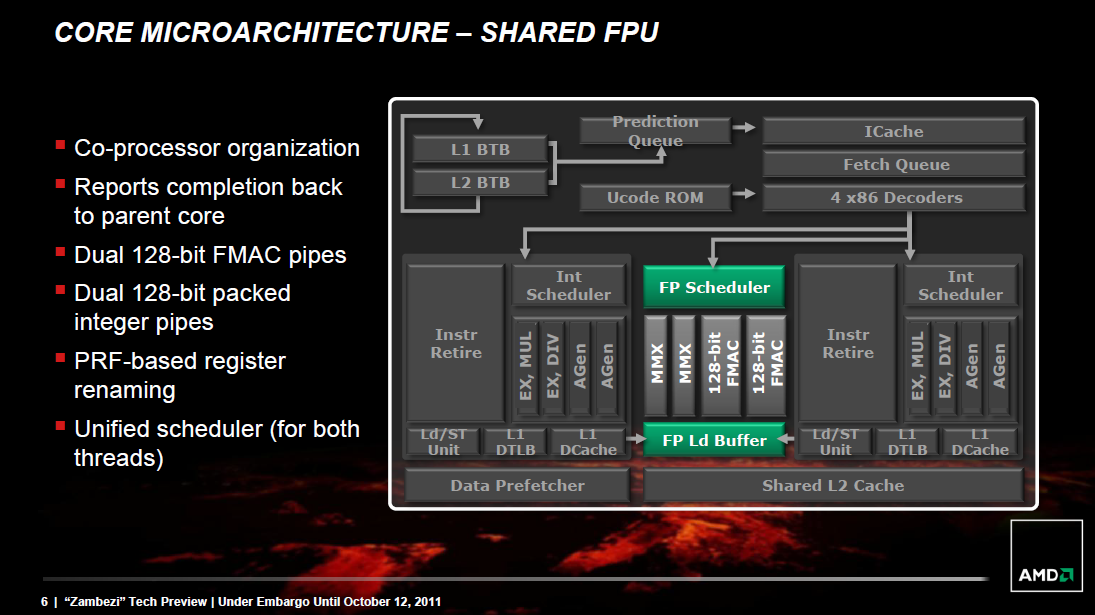
[+]
Mindkét programszálhoz dedikált egész számos műveletvégző egység tartozik, amelyeket az AMD magoknak nevez. Ezek egyrészt az adott szálhoz tartozó összes belső műveletet és azok eredeti programsorrendjét tárolják a Re-Order Bufferben (ROB), másrészt végrehajtják az egész számokon dolgozó SISD utasításokat és kezelik a memória-alrendszert. Külön L1 adatcache-sel rendelkezik a két integer mag, méretük 16-16 kB. Modulonként egyetlen FPU-t találunk, amely megosztott a két programszál között: feladata az összes lebegőpontos számítás, valamint a egész számos SIMD funkciók ellátása. Egy modul 4 db 128 bites végrehajtót tartalmaz, amelyek közül a 2 FMAC jellemzően lebegőpontos számokon dolgozik, kettő pedig egész számokon. Az L2 cache mérete 2 MB, 16 utas asszociativitású és két magja közösen használja, míg a különálló modulokat egy méretesebb (4-8 MB-os), 64 utas asszociativitású L3 cache köti össze egymással.
A cikk még nem ért véget, kérlek, lapozz!









