
A Zen 3 és az RDNA 2 házassága
Az AMD a Raven Ridge SoC APU bevetésével jelentkezett be igazán a notebookpiacra, ugyanis ez a fejlesztés a megjelenésekor igencsak versenyképesnek bizonyult. Azóta a vállalat hozta a továbbfejlesztésnek tekinthető Picasso, a Zen 2 magokat bevető Renoir, illetve a Zen 3-ra szavazó Cezanne SoC APU-kat is, de ezek közös jellemzője volt, hogy amíg a processzorrész látványosan fejlődött, addig az IGP maradt a Vega architektúránál. A nagy váltást a cég a Rembrandt kódnevű SoC APU-ra tartogatta, amely immáron az IGP-t is RDNA 2 dizájnra cserélte, míg a processzorrész továbbfejlesztett Zen 3+ magokat kapott.

[+]
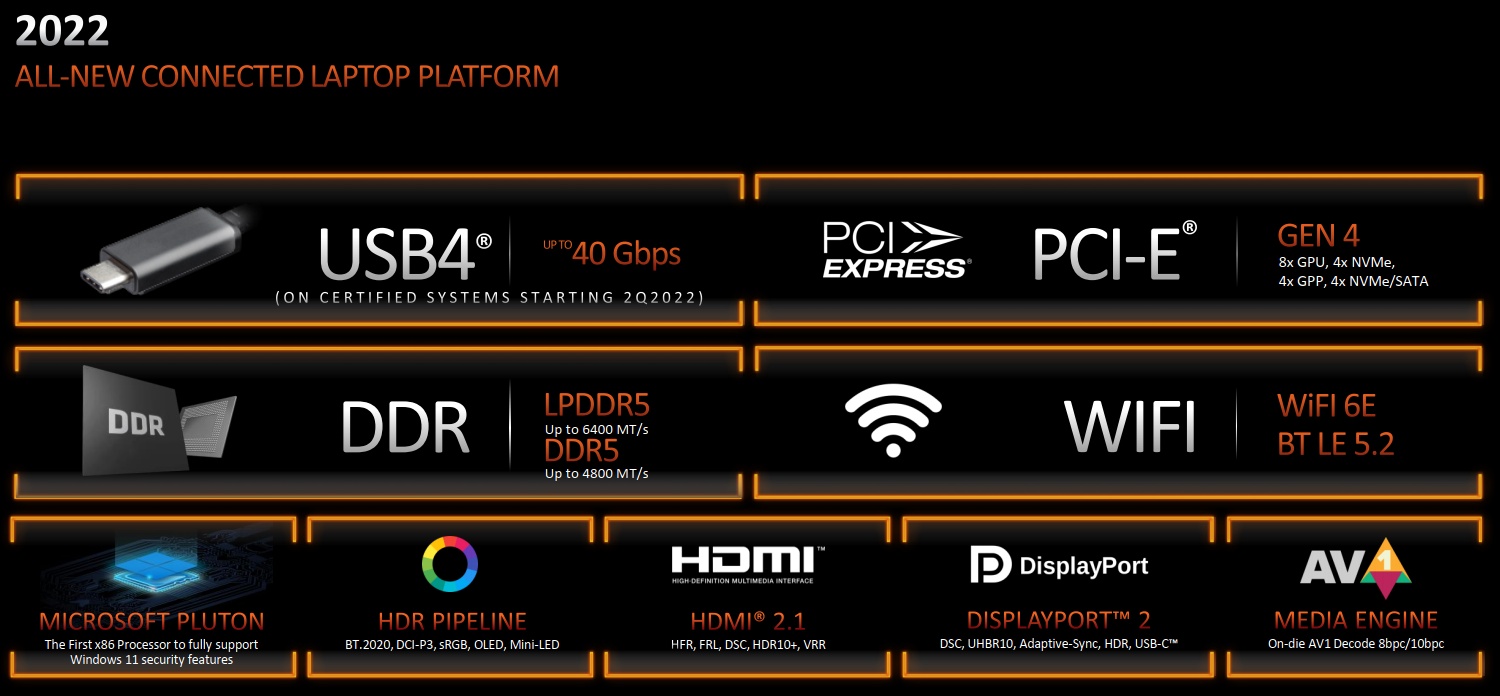
A friss lapka a TSMC 6 nm-es gyártástechnológiájára épít, amely a korábban használt 7 nm-es eljárás half-node-jának számít. Az előző generációhoz viszonyítva a processzorrész alig változott, mivel az AMD csak alapvető optimalizálást alkalmazott, ami nagyobb órajeleket és alacsonyabb fogyasztást tesz lehetővé, és emiatt a Zen 3 magok megkapták Zen 3+ jelzőt. Az előbbiek következtében a Zen 3-ra vonatkozó írásunk nagyrészt igaz a Rembrandtra is. A kialakítást tekintve marad a nyolc mag, amelyek egyenként 512 kB-os L2 gyorsítótárral bírnak, míg a megosztott L3 cache kapacitása 16 MB. Módosult ugyanakkor a memóriavezérlő, amely immáron támogatja az LPDDR5, illetve a DDR5 szabványt is. A memóriabusz 128 bites marad, de a gyorsabb memóriákkal így is lényegesen nő az elérhető memória-sávszélesség. A rendszer DDR5 mellett 4,8 GHz-es effektív órajelet is képes biztosítani, de ez LPDDR5-tel 6,4 GHz-re nő.
[+]
A lapkán belül PCI Express 4.0-s vezérlőre alapoz az AMD, méghozzá maximum 24 sávval, és két port erejéig az USB4 is tiszteletét teszi a korábbi USB opciók mellett. Az NVMe és a SATA szokás szerint alapfelszereltség, továbbá a SoC rendelkezik két darab 10 gigabites Ethernet vezérlővel, de ezek a végfelhasználóknak szánt verziókban nem lesznek aktívak, pusztán a később érkező, beágyazott piacra szánt megoldásokban használhatók majd.

[+]
További újítás a Microsoft Pluton architektúrájának teljes implementálása, így az AMD friss fejlesztése megfelel a FIPS 140-3 Level 2 hitelesítésnek, illetve az x86/AMD64-es platformok között jelenleg egyedüliként támogatja a Windows 11 összes biztonsági szolgáltatását. Ez a rendszer az AMD Secure Processor (AMD-SP) mellett lesz elérhető, de csak akkor, ha mobil Ryzen PRO sorozatú modellt választ a vásárló.
Az RDNA 2 kicsiben
Ahogy az előző oldalon ecseteltük, az egyik legnagyobb változás az IGP teljes megújítása, ugyanis a Rembrandt SoC APU megkapta az RDNA 2 architektúrát, pontosabban ennek 6 nm-es node-ra portolt változatát, ami leginkább optimalizálásnak számít a hatékonyabb működés érdekében.

Az RDNA 2 architektúra alapvető működéséről korábbi cikkünkben már bővebben írtunk, és az alapdizájnt tekintve nagy különbség nincs is. A multiprocesszorok felépítése például nem változott, de számuk igen, így a friss IGP-ben 6 darab úgynevezett WGP (Workgroup Processor) található, amelyek két darab CU-t, azaz Compute Unitot tartalmaznak, és ezekben belül van két darab, egymástól teljesen független, saját skalár egységekkel dolgozó, 32 utas, azaz 1024 bites, multiprecíziós SIMD motor. Egy WGP-ben 128 kB-os Local Data Share (LDS) található, amelyen a négy darab, egyenként 128 kB-os regiszterterülettel rendelkező SIMD motor osztozik. A helyi adatmegosztás mellett CU-nként egy darab 16 kB-os L0 adat gyorsítótár is fellelhető.

[+]
A WGP-n belül a saját regiszterterülettel és wave pufferrel rendelkező skalár egységekhez tartozik egy közös 16 kB-os skalár és egy 32 kB-os utasítás gyorsítótár. Előbbit csak a skalár feldolgozó éri el, míg utóbbit az összes feldolgozó hasznosíthatja, és természetesen mindkét gyorsítótár írható és olvasható is. Ezek mellett a textúrázást CU-nként egy blokk oldja meg, amely négy darab, csak szűrt mintákkal visszatérő, Gather4-kompatibilis textúrázó csatornát rejt. Az SFU-k, vagyis a speciális funkciókért felelős egységek összesített száma sem változott, azaz SIMD-enként nyolc feldolgozóról beszélünk.
A dedikált GPU-k által alkalmazott RDNA 2-höz viszonyítva nagy különbség, hogy a Rembrandt SoC APU nem alkalmaz Infinity Cache-t. Egyszerűen be kell érni egy 2 MB-os írható és olvasható másodlagos gyorsítótárral, és ehhez van hozzákötve a négy ROP blokk. Ezek a részegységek továbbra is a másodlagos gyorsítótár kliensei, vagyis a pixel- és textúraadatokra vonatkozó memóriaelérések koherensek, továbbá minden ROP blokk saját RB gyorsítótára egy olyan 128 kB-os L1 gyorsítótárhoz kapcsolódik, amelyet még 6 darab WGP is elér, és ezek az egységek a raszterizálóval együtt ezen osztoznak. Mindemellett az L1 gyorsítótárhoz kapcsolódik a CU-khoz tartozó L0 is.

[+]
A ROP blokkok továbbra is úgynevezett pixelmotorokat tartalmaznak, egészen pontosan kettőt, és egy pixelmotor négy blending, illetve nyolc Z mintavételező egységből áll, ami a Rembrandt IGP-je esetében összesen 32 blending és 64 Z mintavételezőt jelent. Természetesen a VRS (variable rate shading) támogatása adott, ahogy megmaradt a Delta Color Compression technika is.
Felezve, nem megvágva!
Logikai felépítés tekintetében a Rembrandt IGP-jében két darab shader motor található, és ez azért nagyon fontos információ, mert a Radeon 660M és 680M jelzésű IGP konfigurációk között a fő különbség, hogy az előbbiben csak az egyik shader motor aktív. Ergo nem csak a WGP-k fele kerül letiltásra a gyengébb teljesítményű dizájnban, hanem az ezeket tartalmazó shader motor is, az összes ROP blokkjával, L0 és L1 gyorsítótárával, illetve raszterizálójával. Az átláthatóság érdekében a két IGP konfiguráció paramétereit táblázatban részletezzük.
| Típus | 660M | 680M |
|---|---|---|
| SoC APU kódneve | Rembrandt | |
| Architektúra | RDNA 2 | |
| CU-k száma (WGP-k száma) | 6 (3) | 12 (6) |
| Shader részelemek száma | 384 | 768 |
| Textúrázó csatornák száma | 24 | 48 |
| Blending egységek száma | 16 | 32 |
Jó hír viszont, hogy mindkét dizájnban négy ACE dolgozik, amelyek egy HWS (Hardware Scheduler) fennhatósága alá tartoznak. Ezzel a rendszer összességében 32 compute parancslistát kezel egy grafikai parancslista mellett. Természetesen megmaradt a finomszemcsés preempció és a QoS (Quality of Service) támogatása. Előbbi felel azért, hogy a kritikus fontosságú feladatok előnyt élvezzenek, míg utóbbi a többfelhasználós környezet hatékony kezelését teszi lehetővé, ráadásul továbbra is virtualizálható a teljes lapkára, mindezt teljesen automatikus hardveres ütemezés mellett. Természetesen továbbra is a rendszer része a 64 kB-os globális adatmegosztás, vagy más néven Global Data Share (GDS), és az előző generációban bevezetett priority tunneling szintén elérhető.

[+]
A multimédiás blokk is fejlődött, így ez már támogatja az AV1-es formátumú videók dekódolásának gyorsítását, illetve beépítésre kerül egy friss kijelzőmotor, amely a DisplayPort 2.0 mellett a HDMI 2.1-et is kezeli. Ez azonban nem minden, ugyanis a lapka kapott egy olyan audió koprocesszort, amely képes az AI zajszűrésre, ugyanakkor ezt az adott notebookgyártónak kell engedélyezni.

 [+]
[+]
Technikai képességek terén ez az első IGP a piacon, amely teljes mértékben támogatja a DirectX 12 Ultimate API-t. Ez lényegében a sugárkövetés gyorsítását is magában foglalja, amivel nem biztos, hogy lehet kezdeni valamit ezen a teljesítményszinten, de legalább a lehetőség adott. Itt számításba vehető, hogy a sugárkövetés nem csak teljesítménygyilkos lehet, például a FidelityFX-féle Hybrid Shadows Sample eljárás lényege pont a raszterizálással szembeni memóriakímélése és tempóelőnye. Tehát nem teljesen hasztalan hardverelemek ezek még egy IGP-ben sem, de tény, hogy a manapság elérhető játékoknál nem nagyon lehet mit kezdeni velük.
Energiatakarékosság lapkaszinten...
Az előbbiekből leszűrhető, hogy az AMD az elérhető legújabb komponenseket alkalmazta a Rembrandt SoC APU tervezésénél, de a vállalat célja volt az is, hogy hatékonyság tekintetében is egy teljesen új szintet ostromoljanak a teljesítmény/watt és a teljesítmény/mm² arány tekintetében. Ezek kulcstényezők ahhoz, hogy elérhető legyen az egy teljes napig tartó üzemidő, amit értékelhető teljesítmény mellett eddig csak az ARM-os megoldások tudtak abszolválni Windows operációs rendszeren.

 [+]
[+]
Ez a célkitűzés teszi igazán érdekessé az új fejlesztést, mert az AMD a problémát ötszintű energiaoptimalizálással kezeli. Az alapot nyilván a TSMC 6 nm-es node-ja adja, amely kifejezetten kedvez a rendszerchipeknek, de önmagában nem adna jelentős előnyt a Cezanne SoC APU-hoz képest, ami még a TSMC 7 nm-es node-ján készült. Emiatt teljesen újratervezték az eredeti Zen 3 magot. A logikai működésében nincs eltérés, de a Zen 3+ fizikai dizájnja ötvennél is több, hatékonyságot célzó módosítást tartalmaz. A legfontosabb, hogy az újratervezett magnál a szivárgási áram jóval kisebb problémát jelent, de eközben az L3 gyorsítótár inicializálása késleltetett, hardveresen segített az egyes magok ébresztésének a folyamata, illetve ezeket a korábbitól eltérő módon is alvó állapotba lehet küldeni, sőt, a kihasználási adatokból kiindulva a felesleges ébresztések is ritkábbak.

 [+]
[+]
A fentiek mind előnyösek a késleltetés, illetve az energiafelhasználás szempontjából, de van három kiemelkedően fontos fejlesztés. Egyrészt a Zen 3+ magokat már szálszinten is menedzselheti az operációs rendszer ütemezője, ami némileg nagyobb teljesítményt is lehetővé tesz a korábbi magszintű menedzseléshez viszonyítva, de ennek igazán a hatékonyság javításában van haszna. Másrészt az áramerősség szabályozása jóval finomabb lett, amivel igen sok energiát lehet spórolni, harmadrészt pedig a túl sok cache miss magával vonja az erőforrások lekapcsolásának ideiglenes tilalmát. Utóbbi nehezen érthető lépés, mert a logika azt diktálná, hogy ha az adatért a memóriáig kell menni, akkor az a jó, ha addig spórol a rendszer, de hosszabb távon valójában ez hátrányos az olyan hatékonyan működő dizájnokkal, mint amilyen a Zen 3+ mag. Emiatt az AMD úgy döntött, hogy beáldozza a pillanatnyi hátrányt a hosszabb távú előnyért, és összességében ez a koncepció vezet visszafogottabb fogyasztáshoz.

 [+]
[+]
A Zen 3+ a változásokkal rendkívül hatékonyan dolgozik, de ez igaz a teljes Rembrandt SoC APU-ra, mivel lapkaszinten is rengeteg olyan újítást alkalmaz az AMD, ami hatékony működést tesz lehetővé, és a rendszer energiamenedzsmentjét a firmware is aktívan segíteni tudja.

[+]
A nagy kérdés persze az, hogy mit jelent ez a gyakorlatban. A Rembrandt SoC APU második leggyorsabb alternatívája a Ryzen 9 6900HS lesz, amit az ASUS ROG Zephyrus G14-es notebook 35 wattos fenntartott, CPU-ra vonatkozó energialimit mellett képes üzemeltetni, és ilyen paraméterekkel 5733 pontot ér el a Cinebench R20-as tesztprogram többszálú tesztjében. Ugyanitt az MSI Raider GE76-os notebookba épített Intel Core i9-12900HK jelzésű csúcsmodell 6849 pontra volt képes, de ehhez ennek a mobil processzornak 110 wattos fenntartott, CPU-ra vonatkozó energialimit szükséges. Az AMD mérése szerint tehát a Rembrandt SoC APU 2,62-szer hatékonyabb, mint inteles konkurense, és a cég elmondása alapján ez a hatékonyság teszi lehetővé, hogy 15 wattos fogyasztási osztályon is nyolc darab nagy teljesítményű magot tudjanak biztosítani a notebookgyártóknak, szemben az Intel 15 wattos Alder Lake megoldásainak két darab nagy teljesítményű magjával – amit nyolc, kisebb tempóra képes alternatíva egészít ki.
…és platformszinten
A lapkaszintű fogyasztás ugyan előny, de a mobil megoldásoknál platformszinten érdemes gondolkodni, hiszen végeredményben a vásárló notebookokat vesz. Itt jön képbe az előző oldalon említett öt energiaoptimalizálási szint közül az ötödik. Ide tartozik minden olyan energiatakarékossági technológia, amelyet ugyan a Rembrandt SoC APU lehetővé tesz, de a gyártóknak is tenni kell az implementálásukért.

[+]
Mivel a notebookok egyik legnagyobb fogyasztója a kijelző, az AMD is főleg erre fókuszált, és a megnyert hatékonyság zöme innen ered. Ennek egyik alapja a PSR, azaz a Panel Self Refresh, ami önmagában nem tekinthető újdonságnak, hiszen évek óta elérhető a mobil eszközökben. Ennek a technológiának a célja az, hogy amikor az adott gépen statikus tartalom jelenik meg, akkor igazából felesleges a kijelzőmotort működtetni, mert ugyanazt a képet küldené ki magára a panelra. Emiatt egy ilyen rendszerben maga a kijelzőmotor lekapcsolható, és a panel ellátja a saját frissítését. Ezzel némi energiát lehet megspórolni, amíg nincs új tartalom, miközben a módszernek a felhasználó nem látja a kárát, nem is veszi észre.
Az előbbi megoldás kiegészítése a PSR-SU, vagyis a Selective Update, ami különböző helyzetekben kontrollálja, hogy mikor történjen frissítés. Például videólejátszásnál a tartalomhoz közeli értékre csökkenti a panel frissítésének gyakoriságát, illetve FreeSync alkalmazása mellett ez a technológia nem frissíti a panelnek azokat a részeit, amelyeken a tartalom statikus, azaz nem változik. Ettől ugyan a kijelzőmotornak működnie kell, de elég csak a változó részeket kiküldeni a panel felé, amivel szintén lehet némi energiát spórolni.
A fentieken túl a Rembrandt SoC APU – elődjéhez hasonlóan – kínál DSC-t (Display Screen Compression) és FEC-t (Forward Error Correction) a DisplayPort sávokon bekötött panelek felé, amivel a sávok száma csökkenthető, OLED panelek mellett pedig elérhető a Vari-Bright, aminek köszönhetően automatikusan kontrollálható a kijelző fényereje még akkor is, ha a notebook nem rendelkezik környezeti fényt érzékelő szenzorral. Mindkettő a fogyasztást csökkenti, továbbá utóbbi funkció a Radeon Software-ben paraméterezhető.

 [+]
[+]
Az AMD szerint ezekkel az energiatakarékosságot célzó fejlesztésekkel akár 24 órás üzemidő is elérhető videólejátszás során ultramobil kategóriás Ryzen 6000U sorozatú rendszerchippel. Ultramobil vonalon maradva, egy 15 wattos fogyasztási osztályú Ryzen 5000U megoldáshoz képest egy szintén 15 wattos Ryzen 6000U akár 17%-kal jobb tempót ígér CPU és 81%-kal gyorsabbat IGP tekintetében, miközben három órával is növelheti az üzemidőt ugyanolyan akkumulátort alkalmazva.

[+]
A konkrét termékstartot tekintve először a Ryzen 6000HS sorozat érkezik, az erre épülő notebookok gyakorlatilag bármikor befuthatnak. Ezt követi majd a 6000HX és 6000U sorozat március elején, és utóbbi kategóriába várhatók USB 4.0-t használó mobil gépek is. Végül az üzleti szintre fejlesztett Ryzen PRO vonal zárja a sort, erre március közepétől jönnek a hordozható rendszerek.
Abu85












