
Zen harmadszor
Három és fél éve annak, hogy az AMD bemutatta az első generációs Zen magot, amely sokat javított a cég akkori pozícióján, de az igazi sikerek az előző év nyarán, a Zen 2-vel kezdtek érkezni. Október elején azonban a cég már a Zen 3-mat leplezte le, vagyis kifejezetten őrült fejlesztési tempóra kapcsoltak, köszönhetően az előző generációban behozott chipletfelépítésnek.
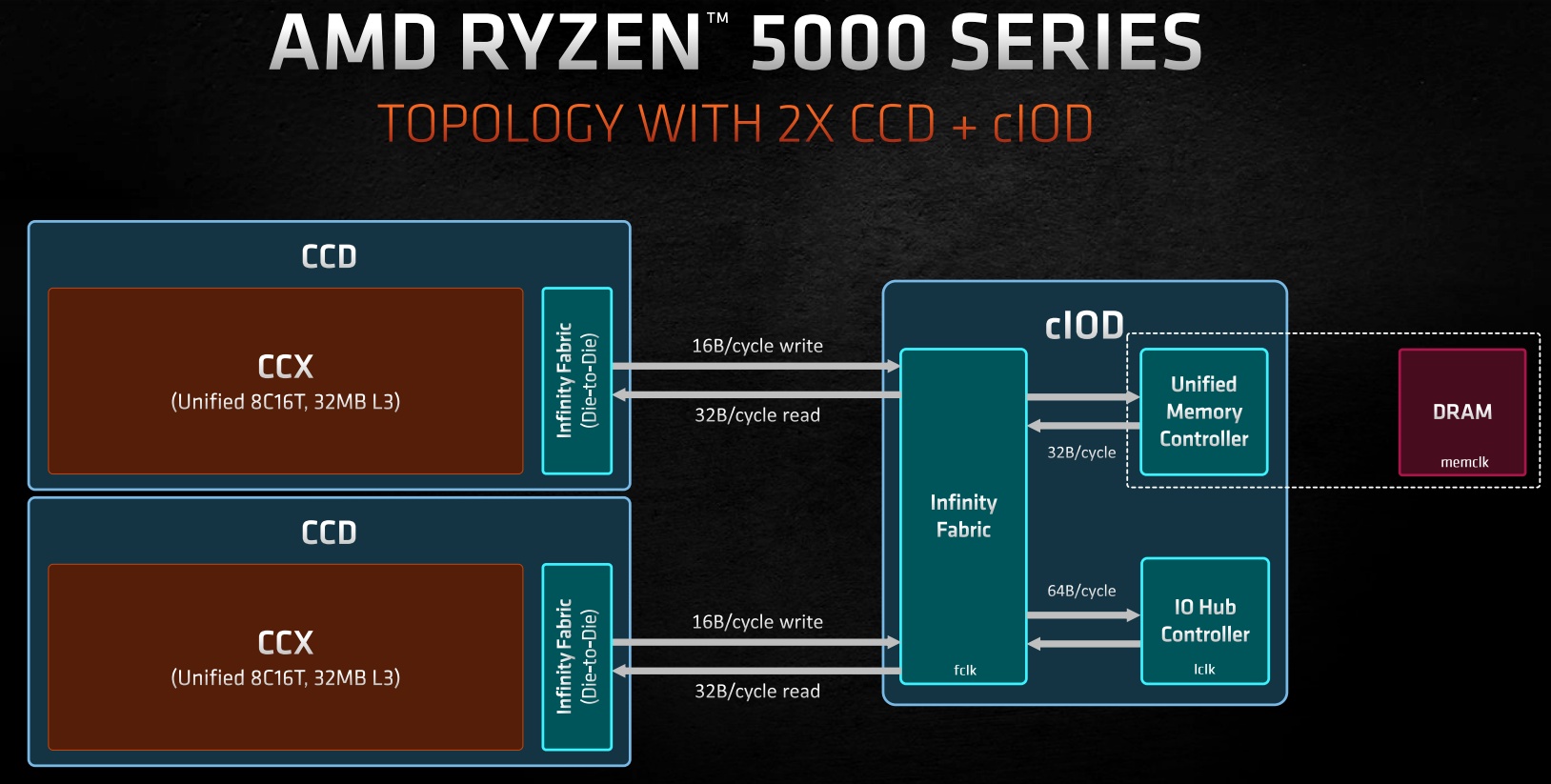
Az AMD a Ryzen 3000-es CPU-kkal két részre bontotta a tervezést, így a tokozásra egy IO lapka (cIOD) mellé került egy vagy két CPU chiplet (CCD). Az IO lapka fontos elem, de nem kell belőle minden generációban újat tervezni, és ezzel a lehetőséggel a vállalat a nemrég leleplezett Ryzen 5000-es CPU-knál él is, vagyis az új, Vermeer kódnevű fejlesztés csak a CPU chiplet tekintetében frissít. Ilyen formában marad a Socket AM4-es tokozás, ami továbbra is 1331 tűvel kapcsolódik az 500-as sorozatú alaplapokhoz. Később a 400-as vezérlőhidakhoz is megérkezik az opcionális támogatás, de ezek alkalmazása az alaplapgyártókon is múlik.

A fejlesztés tehát teljes egészében a CPU chiplet körül forgott, de ezen belül van rendesen újdonság, ugyanis nemcsak a magok, hanem a strukturális felépítés is módosult. Maga az új CCD egyébként továbbra is a TSMC 7 nm-es eljárásán készül, de már 80,7 mm² a kiterjedése és 4,15 milliárd tranzisztorból épül fel.

 [+]
[+]
Ahogy fentebb említettük, egy tokozáson belül egy vagy két CPU chiplet lehet, ezek pedig Infinity Fabric linken keresztül kapcsolódnak az I/O lapkához. Írás során 16, olvasásánál pedig 32 bájt adat mozgatása lehetséges CCD-nként.

[+]
Az igazán mély változások inkább a CCD-n belül találhatók, ez ugyanis a korábbi kettő helyett már csak egy CCX-et, azaz Core Complexet tartalmaz. Ilyen formában a CCD maga a CCX, amiben nyolc darab Zen 3 mag található, és ezekhez 32 MB megosztott, 16 utas L3 gyorsítótár kapcsolódhat a ciklusonként 32 bájtot továbbító buszon keresztül. Ez ráadásul úgynevezett victim cache, vagyis ha a magonkénti 512 kB-os, nyolcutas L2 gyorsítótár megtelik, akkor kerülnek az L3 gyorsítótárba az adatok. Továbbra is megmarad a rendszernek az a tulajdonsága, hogy az L3 gyorsítótár elérésének késleltetése nem csak az adott maghoz tartozó szeletre levetítve alacsony, hanem konkrétan az egész CCX-en belül az, és mivel már négy helyett nyolc mag osztozik rajta, ez hatalmas előnyt jelent a gyakorlati működés során.

[+]
A chipletek összeköttetésével kapcsolatban megjegyzendő, hogy változik az Infinity Fabric órajele. Bár a memóriavezérlő nem módosult, elvégre nem készült új IO lapka, viszont az optimális effektív memória-órajel 4 GHz-re nőtt, vagyis a memória ezen a frekvencián van szinkronban az Infinity Fabric sebességével, így ez adja a legjobb késleltetési értékeket – alatta és fölötte ezek romlani fognak.
A cikk még nem ért véget, kérlek, lapozz!












