
Végre új Radeonok!
Sokat kellett várni az AMD Radeon R9 Fury és Fury X jelzésű VGA-kra. Miközben az NVIDIA előrukkolt a remekül sikerült nagy Maxwell GPU-kkal, addig az AMD látszólag csak ült a babérjain, legalábbis külső szemlélőként ezt gondolhatnánk. Azt hogy pontosan mivel foglalatoskodott a vállalat, miközben a konkurencia vadiúj GPU-kkal állt elő, innen nehéz megmondani, ugyanakkor tény, hogy az AMD az elmúlt időben (jobb híján?) több-kevesebb sikerrel, inkább a szoftveres résszel foglalkozott (API-k), mely befektetésük pontos hozadékát ma még nehéz felmérni. A nagy teljesítményre képes 20 nanométeres gyártástechnológia hiánya kétségkívül rossz hatással volt az AMD versenyképességére, hisz korábban a cég rendre elsőként lovagolta meg az alacsonyabbnál alacsonyabb csíkszélességeket, amivel szinte mindig sikerült kisebb-nagyobb ütéseket bevinnie a konkurens NVIDIA gyomrába.

Egy régi elnevezés tért vissza
Végül ahogy 2013 őszén, úgy az AMD ismét csak a (leg)drágább termékvonalra dobott be teljesen új terméket, hisz az R7 370, R9 380, R9 390, illetve R9 390X gyakorlatilag csak átnevezés, pontosabban már korábban megjelent GPU-k újrapozicionálása, frissítése. Az AMD az új termékskálát az E3-on ugyan megmutatta, illetve maguk a termékek is megjelentek, de górcső alá csak most vehettük őket. A Fiji kódnevű cGPU egy meglehetősen rosszul őrzött titok volt, hiszen rengeteg adat szivárgott ki róla a megjelenés előtt. Ezek azonban nem festették le a teljes képet a technikai oldalt tekintve, amit jelen cikkünkben megtesszük az elmaradhatatlan tesztekkel karöltve.
Az új Radeonok talán az eddig megjelent legkomplexebb VGA-k. Ezt nagyrészt köszönhetik a HBM memóriaszabványnak, amelyről korábban már írtunk egy cikket. Utóbbi miatt nem igazán beszélhetünk csupán egyetlen lapkáról, ugyanis a Fiji kódnevű cGPU mellett még négy darab HBM memória is található, mely lapkák egyetlen interposeren kaptak helyet, illetve összeköttetést. Maga a Fiji cGPU továbbra is a TSMC 2012 januárja óta alkalmazott 28 nm-es gyártástechnológiájával készül, kiterjedése pedig 596 mm², mellyel máris elnyerte a valaha tömegtermelésben legyártott legnagyobb Radeon grafikus processzor címét. Ebbe az igen nagy méretbe 8,9 milliárd tranzisztort sikerült bepasszírozni. A mellette lévő HBM memóriatömbök kiterjedése egyenként 35 mm², és a Hynix gyártja őket.

Jól látható a Fiji cGPU, a négy HBM memória, az interposer, illetve maga a tokozás
Bár a legtöbb olvasó a GPU-ra és a memóriára figyel, mégis a legfontosabb komponens inkább az 1011 mm²-es interposer, amely az ASE, az Amkor és az UMC kooperációjának eredménye. Ez a világ első, tömeggyártásban is elérhető interposere, és az összeköttetést biztosítja a cGPU és a memóriák között, illetve a tokozással is ez áll közvetlen kapcsolatban. Az új irányban az egyik legfontosabb szempont, hogy a különálló lapkák működését összehangolják. Ez drámaian megnöveli a fejlesztés során a hibalehetőségek számát, hiszen mostantól a grafikus processzor mellé szükséges az interposer és a memória gondos megválasztása, és ezek együttes működésének tökéletesítése.
Az AMD a gyártást teljes kooperációban oldja meg. A GPU-t a TSMC készíti el, majd az átkerül az UMC-hez, ahol a Hynixtól megkapott memóriák mellett felkerül az interposerre. Ezután az egész csomag megy a tokozásra, és megtörténik a GPU tesztelése. A továbbiakban a rendszer a Hynixhez kerül a memória tesztelése céljából. Itt válik a teljes tokozás formálisan is véglegessé (rákerül a Made in Korea felirat is), és megy a gyártókhoz, ahol felkerülhet a VGA-kra. Egy szó mint száz, itt egy igen komplex, és ezzel együtt költséges folyamatról van szó, de ez szükséges, ugyanis HBM nélkül kvázi lehetetlen lenne elérni az 512 GB/s-os, illetve annál magasabb memória-sávszélességet.
Utóbbi szám úgy jön ki, hogy egyetlen 1 GB-os HBM memória 1024 bites buszon keresztül kapcsolódik a Fiji cGPU-hoz, és mivel négy darab memória kerül az interposerre, így teljes egészében 4096 bites összeköttetésről beszélhetünk. A memóriák 500 MHz-en üzemelnek, de mivel most is DDR interfészről van szó, így az effektív órajel 1 GHz. Ebből kiszámolható az 512 GB/s-os memória-sávszélesség, amely új csúcsot jelent a VGA-k történelmében.
Hirdetés
A Tonga átmentett tudása
Az AMD a Fiji lapkában is a GCN architektúrát alkalmazza, ezen belül is a Tonga cGPU-ban már bemutatkozott GCN3 (V.I. azaz Volcanic Islands) verziót, amelynek publikus dokumentációja egy ideje már elérhető.
A grafikus vezérlőben 64 darab CU van, és ezek egyenként tartalmaznak egy skalár feldolgozót, illetve négy darab, egymástól teljesen független, 16 utas, azaz 512 bites, multiprecíziós SIMD motort. Egy CU-n belül 64 kB-os Local Data Share (LDS) található, melyen a négy darab, egyenként 64 kB-os regiszterterülettel rendelkező SIMD motor osztozik. Az LDS-sel az AMD – szokásához híven – túlteljesíti a DirectCompute 32 kB-os követelményét, aminek az a magyarázata, hogy az architektúrát általános számításokra tervezték, illetve a manuális interpoláció számára is szükséges némi gyorsan elérhető memóriaterület. Az AMD az LDS-t szokás szerint virtualizálja, tehát a különböző feladatok egymás adatait nem bánthatják, ezzel egyetemben a rendszer megörökölte a korábbi lapkáktól azt a tulajdonságot, amelynek hála a CU-kon belüli LDS-t a geometry shaderek adatainak mentésére is lehet használni. Az LDS mellett természetesen egy 16 kB-os adat gyorsítótár is elérhető, melyet a CU írhat és olvashat is.
A fentebb már említett skalár feldolgozó némileg különc a CU-n belül. Ez lényegében egy integer ALU, mely 8 kB-os dedikált regiszterterületet kapott. A textúrázást CU-nként egy blokk oldja meg, mely négy darab, csak szűrt mintákkal visszatérő Gather4-kompatibilis textúrázó csatornát rejt. A lapkán belül négy CU egy tömbbe rendeződik, és ehhez tartozik egy 16 kB-os skalár és egy 32 kB-os utasítás gyorsítótár. Előbbit csak a skalár feldolgozó éri el, míg utóbbit a CU összes feldolgozója hasznosíthatja, de természetesen mindkét gyorsítótár írható és olvasható is.

A Fiji cGPU blokkdiagrammja [+]
A Fiji az órajelenként négy háromszöggel dolgozó setup motort is megörökölte a Tonga cGPU-ból, annak minden előnyével együtt. A négy darab tesszellátor tizenegyedik generációs megoldás, míg a szintén négy darab raszter motor egyenként, órajelenként 16 képpontot dolgoz fel, vagyis összesen 64 képpontot. A memóriavezérlőhöz egy 2 MB kapacitású, írható és olvasható másodlagos gyorsítótár és 8 darab ROP-blokk kapcsolódik, ami így összesen 64 blending és 256 Z mintavételező egységet eredményez. Látható az is, hogy a blending egységek száma, illetve a raszter motorok teljesítménye szinkronban van.
Fontos megjegyezni, hogy a HBM memóriára való áttérés miatt a memóriavezérlőt némi átalakítás érte. Ezzel kapcsolatban megtudtuk, hogy az AMD a korábbi döntéseknek hála könnyen átállhatott, mert az évek óta alkalmazott control hub nagyon illik a HBM-hez. Mint ismeretes, a korábbi memóriaszabványoknál maguk a memóriák 32 bites busszal kapcsolódtak a lapkához, persze párosával, így a memóriavezérlők 64 bitesek voltak. Ezt relatíve egyszerű volt crossbar módszerrel kezelni, hiszen kis szélességű összeköttetésekre volt szükség, és ebből bőven elfért egy csomó az adott lapkán belül. Még olyan tranzisztorkímélő optimalizálásokat is be lehetett vetni, hogy a keresztirányú összeköttetések nem 64, hanem csak 32 bitesek, és ez a gyakorlatban nem igazán jelentet teljesítményhátrányt.
Az AMD-nek a control hubra vonatkozó ötlete, vagyis az, hogy legyen egy nagy széles busz a memóriavezérlők és az L2 gyorsítótárak között ugyan nem volt rossz, hiszen így is lehetett vele tranzisztorokat spórolni lényegében mindenféle negatív mellékhatás nélkül, de radikális előrelépést nem jelentett a DDR3 és a GDDR5 memóriák mellett. Ez a HBM-mel azonban teljesen megváltozik, mivel mostantól a memóriavezérlők egyenként 512 bitesek, vagyis a crossbar módszer itt már rendkívül tranzisztorpazarló lenne, de a control hubbal lényegében ezt a hátrányt nem kell felvállalnia az AMD-nek.
A dupla pontossággal kapcsolatban a hardver képes az elméleti számítási teljesítmény tizenhatod részével elvégezni a feladatokat, vagyis ebből a szempontból elég korlátozott megoldásnak számít, de erre a lapkára csak Radeon fog épülni, tehát nincs jelentősége a döntésnek. Van viszont támogatás a 16 bites lebegőpontos utasítások teljes értékű feldolgozására vonatkozóan, ami már a játékosok számára is lényeges szempont, hiszen számos feladat nem igényel 32 bites precizitást, így energiát lehet spórolni, miközben gyorsul is a hardver. Utóbbi egyébként opcionális DirectX 12-es követelmény, amit az AMD annyira nem szokott hangoztatni, de az Intel nagyon erősen kardoskodik használatáért a fejlesztőknél.
Szintén megjegyzendő, hogy a Fiji is megkapta a Tonga cGPU-ban bemutatkozott Delta Color Compression technikát a temérdek memória-sávszélesség és pixelkitöltési sebesség mellé, ami növeli a rendszer hatékonyságát.
A Fiji funkcionalitásban a többi GCN architektúrára épülő megoldást másolja, így támogatja a DirectX 11.2-es, a DirectX 12-es, az OpenGL 4.5-ös, az OpenGL ES 3.0-s és a Mantle API-t, emellett kezeli a C++ AMP-t és az OpenCL 2.0-es felületet. Később támogatni fogja a Vulkan API-t is.
A lapka kapott új UVD motort, mely a Tonga cGPU-ban bevezetett 6-os verzióhoz képest már támogatja a HEVC formátumú 4K-s videók dekódolását is. A VCE 3.1-es blokk lényegében ugyanazt tudja, amit a Tonga cGPU megoldása, vagyis a legtöbb korábbi Radeon VGA-hoz képest 12-szer gyorsabban dolgozik, illetve képes 4K-s H.264-es videókat is kódolni. Mindemellett természetesen a TrueAudio hangprocesszor is a lapka része, amelyhez jelen állás szerint az év későbbi részében új játékok is érkeznek.
Virtuális valóságra tervezve
Az általános számítások szempontjából a Fiji egy igazi monstrum. A lapkán belül megmarad a nyolc darab ACE egység a grafikus parancsprocesszor mellett, ahol előbbi csak compute, míg utóbbi compute és grafikus feladatokat képes feldolgozni. Eközben továbbra is a rendszer része a 64 kB-os globális adatmegosztás, vagy más néven Global Data Share (GDS), emellett megmaradt a két DMA motor. A rendszer összességében 64 compute parancslistát kezel 1 grafikai parancslista mellett, ami egyébként általánosan jellemző az újabb Radeonokra.
Az általános számításokhoz kapcsolódóan viszont az egyik legfontosabb információ, hogy ez az első igazán nagy teljesítményű grafikus vezérlő a piacon, amelyet a technikai tudás tekintetében is a virtuális valósághoz terveztek. Utóbbi szegmens az AMD reményei szerint a következő év elején hatalmas népszerűségre tesz majd szert, és nem véletlen, hogy ennyire kampányolják az újszerű élményt, hiszen a GCN architektúra, különösen a Fiji harmadik generációs iterációja abszolút kiszolgálja a virtuális valóság legfőbb igényeit, olyan fontos funkciókra alapozva, amelyeket más még nem épített be. Nyilván az sem véletlen, hogy az E3-on a virtuális valóságot bemutató demonstrációkat az AMD rendszerén futtatták.
Ha már ennyire ki van emelve a virtuális valóság a Fiji cGPU szempontjából – nyilván nem ok nélkül –, akkor érdemes megvizsgálni, hogy mitől is olyan különleges ez a lapka, vagy másképp fogalmazva mi kell a jó élményt kínáló virtuális valósághoz.

[+]
A Fiji legfontosabb képessége ebből a szempontból az úgynevezett finomszemcsés preempció támogatása, amely lehetővé teszi, hogy az architektúra tetszőlegesen leállítson és későbbi folytatásra elmentsen egy feladatot, ha időközben befut egy magasabb prioritású feladat. Erre természetesen a AMD Radeon R9 285 is képes, de a Tonga cGPU számítási teljesítménye nem kiemelkedő, persze nem is tekinthető rossznak. Az azonban kétségtelen, hogy a Fiji jóval erősebb, és a Tonga tudásával kiegészítve rendkívül hatékony az asynchronous timewarpok kezelése szempontjából.
Hogy ez az egész érthetőbb legyen, érdemes leírni, hogy a virtuális valóság teljesen más követelményekkel rendelkezik, mint egy normál, fogalmazzunk úgy, hogy monitoron történő szórakozás. Egyrészt a képkocka/másodpercre vonatkozó értékek részben irrelevánsak lesznek. A virtuális valóságban állandó a vertikális szinkron, vagyis arra van szükség, hogy legyen minden másodpercben megfelelő mennyiségű elkészült képkocka. Az Oculus Rift esetében ez például 90-et jelent, hiszen a szemüveg 90 Hz-en frissít. A vertikális szinkron miatt azonban kialakul egy szinkronablak, vagyis – maradva az Oculus Rift hardverének vizsgálatánál – muszáj 11,1 ezredmásodpercen belül új sztereó 3D-s képkockát számolni. Ebben az lesz a nehézség, hogy ha jó minőséget akar a fejlesztő, akkor az említett időkereten belül a sztereó 3D következtében két darab 1920x1080 pixeles képkocka kell, ráadásul négymintás MSAA és mellette még szintén négymintás SSAA élsimítással, plusz szükség van még némi utófeldolgozásra is.
Rögtön észrevehető, hogy az igények miatt a nyers erőre alapozni tévút lesz, és itt jön képbe az Oculus korábbi felfedezése, hogy valójában a virtuális valóságnál csak folyamatosság kell, és nem feltétlenül szükséges minden képkockát különálló jelenetből számítani. Sőt elég minden második képkockát a nulláról kalkulálni, vagyis effektíve 45 jelenetet kap a felhasználó másodpercenként, és a hézagokat az előbbi említett timewarpok töltik ki. Ez ugyan nagymértékű trükközés, de a gyakorlatban fantasztikusan működik, tehát a végeredmény tekintetében helytáll a koncepció.
A timewarpok számítása viszont teljes egészében a grafikus vezérlő feladata, méghozzá az előző képkocka adataira építve. A jelenet természetesen nem változik, de a számításhoz a grafikus vezérlő kap egy új fejpozíciót, hogy az eredeti képkocka adataiból számoljon egy olyan sztereó 3D-s képet, amely elmozdul az új fejpozíciónak megfelelően. Ez teljes egészében compute feladat, de minden előnye ellenére vannak problémák. Ahhoz, hogy ez működjön, aszinkron módon kell futtatni a timewarp kalkulációját az éppen számolt, tényleges új jelenetre épülő képkockával. Innen is kapta az asynchronous timewarp nevet. Ehhez viszont igen modern architektúra kell, mert a korábbi grafikus API-k sosem követelték meg a grafikus vezérlőtől, hogy az egyes futószalagokat párhuzamosan futtassák. Ezek most szép sorban megérkeznek a hardverre és egymás után lefutnak. Ennek megfelelően alig van olyan grafikus architektúra a piacon, amely tényleg úgy lett megtervezve, hogy képes legyen egymás mellett futtatni egy grafikai és egy compute futószalagot, ráadásul tegye ezt tényleg hatékonyan.
De mitől fog működni ez az egész?
Az AMD a virtuális valósághoz három fontos szempontot értékel egy hardverben, és pontosan ez az Oculus általános álláspontja is. Többek között legyen nagy számítási teljesítmény, legalább 4-5 TFLOPS, aminek a Fiji bőven megfelel. Nyilván nem kell magyarázni, hogy a virtuális valóság számításigényes, tehát gyors hardver szükséges hozzá, bár ez azért függ az adott alkalmazás terhelésétől, így ebből a szempontból nagy lesz a szórás, de igazán komoly grafikai minőséghez szükséges a sok TFLOPS.
Fontos, hogy legyen az architektúra úgynevezett stateless compute elvű. Ez ahhoz szükséges, hogy a compute futószalagok futtatásához ne kelljen speciális hardverállapot, egyszerűen ezeket kezelje annyira általánosan a rendszer, hogy bármilyen hardverállapot mellett futtathatók legyenek. Így működik mindegyik AMD GCN verzió, tehát ebből a szempontból a Fiji szintén megfelel. A hardverállapottól való függetlenség egyébként azért fontos, mert ilyen formában a timewarp bármilyen grafikai futószalag mellett futhat aszinkron módban, míg ha a compute futószalag futtatása hardverállapothoz kötődik, mondjuk például a pixel feldolgozáshoz, akkor a compute futószalagok futtatásával meg kell várni, amíg a hardver beállítja a szükséges állapotot, vagyis például nem lehetséges a timewarp futtatása a vertex feldolgozással vagy a tesszellálással párhuzamosan.
Végül a már említett finomszemcsés preempció az egyik leglényegesebb igény, mivel a timewarp számítására kevés idő van, tehát jobb az, ha a következő, ténylegesen új jelenethez tartozó képkocka számításához szükséges feladatokat igény esetén manuálisan és ideiglenesen félbehagyja a grafikus vezérlő, és a magas prioritású timewarp futószalagokat elindítja a felszabaduló erőforrásokon, hogy azoknak minél hamarabb legyen eredménye.

[+]
Ezek összességének általános előnye lesz, hogy drámaian megnő annak az esélye, hogy egy sztereó 3D-s képkocka, legyen az nulláról számolt vagy szimplán timewarp, még a szinkronablakon belül kész lesz, így az Oculus Riftnek vagy más, virtuális valóságra tervezett szemüvegnek nem kell kiraknia újból az előző képkockát. Ez csökkenti a mikroakadások számát, amely a virtuális valóság esetében okvetlenül fontos, ugyanis amíg a monitoron látott apró akadásokon csak mérgelődünk, addig a virtuális valóságon belül ezeknek komoly kockázatai is lehetnek általános egészségi állapotunkra. Többek között, ha a képkockák sokszor lekésik a szinkronizációt, akkor elég általános lesz a fejfájás, illetve szédülés, de legrosszabb esetben hányás is bekövetkezhet, ami mondanunk sem kell, hogy roppant kellemetlen az ember számára. Utóbbi a legfőbb indoka az AMD-nek arra, hogy a virtuális valósághoz miért nem csak szimplán erős hardvert terveznek, hanem rendszerhez igazított, alacsony késleltetésű feldolgozást is az architektúrába épített extra tudás által.
Ez a tudás természetesen kihasználható a LiquidVR SDK-val, ami a Mantle API virtuális valósághoz tervezett verziójára épül, és számos fejlesztő jelentette be az E3-on a támogatását. Ez az egész csomag nemcsak az AMD, hanem az ipar számára is nagyon fontos, hiszen a kiépülő, virtuális valósághoz igazán jó PC-s konfigurációktól nagyon függ a virtuális valóságra tervezett szemüvegek, illetve tulajdonképpen az egész irány sorsa.
Az AMD Radeon R9 Fury X
Elsőként az erősebbik kártyát, azaz Radeon R9 Fury X-et vettük szemügyre. Ebből a modellből (egyelőre) csak az AMD által tervezett referencia verzió létezik, azaz az egyes gyártók megoldásai között legfeljebb a csomagolás és a matrica térhet el.

[+]
Ami azonnal szembetűnik, hogy az elmúlt sok év trendjeinek ellentmondóan a kártya mérete jelentősen csökkent, mivel a hossza mindössze 19,5 centiméter.

[+]
Oldalról feltűnik egy Radeon felirat, mely működés közben piros színben pompázik. E fölött a kis lyukban egy DIP kapcsoló található, mely a szokásos, két BIOS chip közötti átváltást segíti elő. A kártya végébe két darab 8 tűs tápcsatlakozó került, melyen keresztül legfeljebb 375 wattot vehet fel a Fury X.

[+]
Az aljzatok felett 9 LED húzódik, melyek a kártya aktuális áramfelvételét, és ezzel annak terhelését mutatják, továbbá egy LED a ZeroCore funkció visszajelzését szemlélteti. Ezek színe két kapcsolóval szintén variálható. A fenti képen jól látható, hogy a megoldás egy fém hátlapot is kapott, így a NYÁK kvázi teljesen burkolva van.


[+]
A refrencia R9 Fury X kompakt vízhűtéssel rendelkezik, melyhez hasonlót tavaly már láthattunk a két GPU-s Radeon R9 295X2 esetében. A hűtés a Cooler Master műhelyéből érkezett, radiátora 12 x 15,5 x 6,5 centiméter méretű. A D1225C12B7ZP-62 típusjelzésű ventilátort a Nidec szállítja, melyről túl sok információt nem találtunk.

[+]
A külső, 12 centiméteres ventilátor helyére beépíthető egység két harisnyázott csövön, illetve egy kábelen keresztül csatlakozik a kártyában, a fedlap alatt található pumpához. A hűtés egyértelmű előnye, hogy rendeltetésszerű elhelyezés esetén a házon kívülre vezeti a meleg levegőt, míg hátránya, hogy elfoglalja a ház egyik 12 centiméteres ventilátorhelyét, ami például akkor lehet probléma, ha ezt már megteszi egy hasonló kialakítású, kompakt CPU-hűtés.

[+]
Mélyebre ásva már a csupasz NYÁK-ot is szemügyre vehetjük. A rövid nyomtatott áramkörről eltűntek a GDDR5-ös chipek, így jóval szellősebb lett az elrendezés. A tápellátás összesen 6 fázist vonultat fel, melyek vezérléséért az International Rectifier IR 3567 jelölésű chip felel.

[+]
A némi túlzással nagyjából fél kilogramnyi hűtőpaszta nehézkes eltávolítása után megcsodálhattuk a Fiji GPU-t, mely, mint említettük, a Radeon kártyák történelmében rekord nagy alapterületű. Szabad szemmel is remekül látható a négy, darabonkánt 1 GB-os Hynix HBM chip, illetve az azokat a GPU-val összekötő inteposer. A HBM további apró előnye, hogy ezzel a kialakítással már elég könnyű megoldani a memóriák hűtését is, melyek felülete egy síkban van a GPU-éval. Egyébiránt maga a grafikus processzor legfeljebb 1050 MHz-en ketyeghet, míg a HBM memóriák 500 MHz-en (effektív 1000 MHz).

[+]
A kártyák hátlapjára három darab DisplayPort 1.2a-s aljzat, illetve egy HDMI 1.4-es interfész került, ergo az öregecske DVI port alapértelmezetten már lemaradt. Ezt a gyártók egyénileg pótolhatják, de csakis a Radeon R9 Fury esetében. Tekintve, hogy mindkét kártyát 4K-ra tervezték, a DVI hiánya nem akkora érvágás, nem is beszélve arról, hogy a HDMI-re köthető átalakító. A HDMI 1.4-es interfész azonban már lényegesebb limitáció, mert ez ugyan a 4K-s felbontásra képes, de maximum 30 Hz-es frissítéssel, tehát a Radeon R9 Fury modellekkel leginkább a DisplayPort interfészeket érdemes használni, ezek ugyanis tudnak 4K-t 60 Hz-en is, illetve járulékos extra, hogy támogatják a FreeSync technológiát, miközben erre a HDMI egyik verziója sem alkalmas.
Az ASUS Strix Radeon R9 Fury
Az "X" nélküli, tehát a sima Radeon R9 Fury kínálatból az Asus Strix megoldása landolt szerkesztőségünkben.

[+]
A kártyához most sem jár terülj, terülj asztalkám, hisz a dobozban egy 8 tűs tápátalakítón kívül mást nem találtunk.

[+]
A kártyát kézbe véve azonnal feltűnhet, hogy az Asus néhány konkurense korábbi példáját követve felpakolt egy harmadik ventilátort az évek óta jól megszokott két darab mellé, amivel egy csapásra megszületett a DirectCU III hűtés. Míg az AMD-féle Fury X egyik fő ismeretőjegye a kompakt kivitel, addig az Asus láthatóan továbbra is a "méret a lényeg" elvét valja, hisz a kártya 30 centiméter hosszú, miközben legmagasabb pontján 15 centimétert mértünk.

[+]
A kártya hátlapja masszív fémlapot kapott, illetve a GPU-t egy GPU-Fortifier nevű, piros színű merevítő kerettel illeték, mely megakadályozza a NYÁK esetleges meghajlását. A díszkivilágítás ebben az esetben sem hiányzik, ugyanis az oldalt elhelyezett Strix felirat szépen, diszkréten pulzál.
 />
/>
A Strix R9 Fury hátlapja felé eső egyik sarokban feszültségmérő pontokat találunk, ahol a VDDCI, MVDD és VDDC értékeit tudjuk nyomon követni multiméter segítségével.

[+]
A DirectCU III hűtés öt darab, 10, 8, és 6 milliméter átmérőjű hőcsövet vonultat fel, ugyanakkor furcsálltuk, hogy ezekből gyakorlatilag csak három érintkezik a GPU, illetve a HBM memóriák felületével, ami a rendhagyó állagú hővezető anyagon hagyott nyomból is jól látható. Mint később a gyártótól megtudtuk ez nem véletlen, ugyanis a két szélső hőcső amolyan kiegészítő funkciót tölt be.

[+]
A tápellátás hűtése is megoldott, melynek komponensei közvetlenül a bordához érintkeznek. Az első Strix kártyával bevezetett innováció természetesen innen sem hiányzik, azaz a légkavarók egy bizonyos hőmérsékletig nem pörögnek fel, ergo addig a kártya kvázi passzív hűtésűnek tekinthető. Miután a terhelés megszűnik és lehűlt a GPU, a ventilátorok ismét leállnak, majd a folyamat később kezdődhet elölről.

[+]
Bár az R9 Fury alapvetően kisebb áramfelvételt kíván meg, mint a nagytestvér, ennek ellenére az Asus jóval nagyob NYÁK-ot pakolt a GPU alá, melynek egy részét a néggyel több, összesen 10 fázist magában foglaló tápellátás emészti fel. Ezek vezérlését most is a Digi+ chip végzi. A kártya végébe ebben az esetben is két darab 8 tűs tápcsatlakozó került, melyeken keresztül legfeljebb 375 wattot vehet fel a Strix Fury.

[+]
A Fiji GPU közeli fotóján jól megfigyelhető az Asus által alkalmazott furcsa hővezető szivacs(?), melyhez hasonlót eddig még nem láttunk. Az "X" nélküli Fury enyhén megnyirbált központi egységet kapott, így a végrehajtók 1/8-ad részét, azaz 512 darabot letiltottak. A GPU maximális üzemi órajele 1000 MHz, míg az összesen 4 GB HBM memória frekvenciája ebben az esetben is 500 Mhz.

Hátlap tekintetében az ASUS Strix Radeon R9 Fury máris eltér az előző oldalon látottaktól, és sokkal inkább hasonlít a legújabb csúcs GeForce-okra. Mindez azt jelenti, hogy DVI-ból (ami jelen esetben dual-link DVI-D típust jelent) egyetlen darab került a kártyára, a többi helyet a DisplayPort 1.2a és a HDMI 1.4 oltárán áldozták fel: előbbiből három, utóbbiból egy darabot kapunk.
Tesztkonfig, fogyasztás, hűtés, tuning
Komoly frissítésen ment keresztül több mint két esztendőt futott tesztrendszerünk. Az alaplap szerepét egy ASUS X99 PRO modell vette át, míg a processzor feladatát egy fixen 4 GHz-re tuningolt Intel Core i7-5960X kapta meg, hogy minél többet ki tudjunk passzírozni a VGA-kból. A rendszermemória mérete is nőtt, egész pontosan duplázódott, így már 32 GB-ból gazdálkodhat a rendszer. A HyperX Fury típusú DDR4 modulból összesen négy található az alaplapban, így azok négycsatornás üzemmódban, 2666 MHz-en hasítanak. Az egyre csak hízó játékok okán SSD-ből már kénytelenek voltunk egy 500 GB-os modellt választani, egészen konkrétan egy Samsung 850 EVO-t.
| Videokártyák | AMD Radeon R9 Fury X 4096 MB (Catalyst 15.7 WHQL) ASUS Strix Radeon R9 Fury 4096 MB (Catalyst 15.7 WHQL) Sapphire Radeon R9 390X 8192 MB (Catalyst 15.7 WHQL) Sapphire Radeon R9 290X 4096 MB (Catalyst 15.7 WHQL) NVIDIA GeForce GTX 980 Ti 6144 MB (GeForce driver 353.30) NVIDIA GeForce GTX 980 4096 MB (GeForce driver 353.30) |
|---|---|
| Processzor | Intel Core i7-5960X (3 GHz) – túlhajtva 4 GHz-en EIST bekapcsolva; C1E / C-state kikapcsolva; Turbo Boost kikapcsolva |
| Alaplap | ASUS X99 PRO (BIOS: 1702) – Intel X99 chipset |
| Memória |
HyperX Fury 32 GB (4 x 8 GB) DDR4-2666 (HX426C15FBK4/32) |
| Háttértár | Samsung 850 EVO 500 GB MZ-75E500 (SATA 6 Gbps) |
| Processzorhűtő | Noctua NH-D14 SE2011 |
| Tápegység | Seasonic Platinum Fanless 520 – 520 watt |
| Monitor | Acer B326HUL (32") és Acer XB280HK (28") |
| Operációs rendszer | Windows 8.1 64 bit |

A tesztkörnyezet [+]
Ami a meghajtóprogramokat illeti, a Radeon kártyákat a Catalyst 15.7 WHQL driverrel teszteltük, míg a GeForce kártyához a 353.30-es WHQL drivert került feltelepítésre. A játékokat a tesztben szereplő kártyákban lapuló számítási teljesítmény miatt 1920x1080-as (Full HD) és 3840x2160-es (4K vagy UHD) felbontásban teszteltük. A képminőséget játéktól függetlenül maximálisra állítottuk. A meghajtóprogramban mindent alapértelmezett beállításokon hagytunk, az anizotropikus szűrést, illetve az élsimítást pedig mindig az adott játékban aktiváltuk. Korábbi szavazásunk eredménye alapján mostantól, ahol lehet, DirectX helyett a Mantle renderert választjuk a GCN-alapú Radeon kártyák esetében, azaz HD 7000-től felfelé.
Játékok
- Batman: Arkham Origins (DirectX 11) – motor: Unreal Engine 3 / műfaj: TPS
- Company of Heroes 2 (DirectX 11) – motor: Essence Engine 3.0 / műfaj: stratégia
- DiRT Rally (DirectX 11) – motor: EGO Engine 3.0 / műfaj: autóverseny
- GTA V (DirectX 11) – motor: EGO R.A.G.E. / műfaj: TPS/akció
- Metro: Last Light (DirectX 11) – motor: 4A Engine / műfaj: FPS
- Middle-earth: Shadow of Mordor (DirectX 11) – motor: LithTech Jupiter EX / műfaj: TPS
- Thief (DirectX 11/Mantle) – motor: Unreal Engine 3 / műfaj: FPS/akció
- Tomb Raider (DirectX 11) – motor: Crystal Engine / műfaj: TPS/kaland
- Sniper Elite 3 (DirectX 11/Mantle) – motor: Asura / műfaj: FPS/akció
A mérésekhez használt játékok palettáját újfent megváltoztattuk kissé. Fontosnak tartjuk, hogy viszonylag naprakész és/vagy népszerű címeket alkalmazzunk, ezért a GRID Autosport helyét a DiRT Rally vette át, korábban a Sniper Elite 3 a Crysis 3 helyére ugrott be, a Hitman: Absolutiont a Middle-earth: Shadow of Mordor című TPS-re cseréltük le, míg a legutóbbi Alien: Isolation-t a GTA V váltotta.
A könnyebb és pontosabb mérés, valamint összevetés érdekében minden játéknál a beépített benchmark toolt használtuk. A grafikonokat a minimum képkockák értékei alapján rendeztük csökkenő sorrendbe, ahol alapértelmezetten a mindenkori nagyobbik felbontás az elsődleges szempont.
Fogyasztás
A fogyasztást konnektorba dugható, digitális VOLTCRAFT Energy Logger 4000 készülékkel vizsgáltuk. A grafikonon az egyes videokártyákkal kiegészített rendszerek fogyasztása látható alaplappal, processzorral, táppal és a többi alkatrésszel együtt, de természetesen a monitor nélkül. A méréseket a Metro: Last Light benchmarkja alatt végeztük, mely 1920x1080-as felbontásban került lefuttatásra. Játékkal terhelt mérés közben meglehetősen sűrűn és gyorsan ingadozik a fogyasztás, ezért ide egy olyan értéket próbáltunk regisztrálni, ami a legtöbbször villant fel az eszköz kijelzőjén, vagyis nem a csúcsértéket jegyeztük fel.

Fogyasztás tekintetében nem kérnek keveset a Fury kártyák, hisz játék alatt mindkettő többet evett a GTX 980 Ti-nél. Az Asus kártyájával 19 wattal mutatott többet a műszer, míg az AMD Fury X esetében 72 wattal. Öröm az ürömben, hogy végre előrelépés történt videólejátszás alatt, ugyanis itt eddig rendre sokkal többet fogyasztottak a Radeon kártyák, pláne ha felsőkategóriás modellről volt szó, amit a 290X és 390X húzós értéke jól mutat. Az Asus Fury VGA-ja DXVA gyorsítás mellett már beéri 83 wattal, míg az AMD Fury X 93 wattot fogyasztott a teszt alatt, ami már legalább egy elfogadható érték.
Hűtés


AMD R9 Fury X – Asus Strix R9 Fury [+]
Az AMD vízhűtéses megoldásának egyetlen, 12 centiméteres ventilátora üresjáratban egy nagyon picit hallatta a hangját, ugyanakkor a zajszint terhelés mellett sem változott szinte semmit, ami viszont már egy igen jó (halk) eredmény, ráadásul mindeközben a GPU hőmérséklete nem ment 55 Celsius-fok fölé, ami bizony megsüvegelendő. Ennek ellenére mégsem voltunk maradéktalanul boldogok, ugyanis a pumpa terheléstől függetlenül sípoló hangot adott ki magából, amit az asztalon felépített nyitott rendszerből folyamatosan hallani lehetett. Ez egy idő után számunkra már zavaróvá is vált, ettől pedig bennünk kezdett el felmenni a pumpa. Ahogy a közelmúltban hírt adtunk róla, a legújabb sorozat módosított szivattyúval érkezik, mely elvileg orvosolja a hibát, ugyanakkor ezt mi egyelőre sem cáfolni, sem pedig megerősíteni nem tudjuk; mindenesetre ez egy kisebb baki az amúgy remek hatásfokú hűtésben.
Az Asus felújított Strix hűtésétől az elődök alapján joggal várhattunk jó teljesítményt. Üresjáratban nem is volt semmi gond, hisz ilyenkor szépen leállnak a ventilátorok, és a kártya teljesen néma. A probléma terhelésnél kezdődött, ahol egy idő után némi meglepetésre bizony zajossá váltak a légkavarók, miközben a GPU hőmérséklete sem volt kifejezetten alacsony a maga 70 Celsius-fok körüli értékével, pláne ha azt az amúgy több hőt termelő Fury X értékéhez viszonyítjuk. Egy szó mint száz, most először nem voltuk elkápráztatva a Strix hűtéstől, plusz egy ventilátor ide, nagyobb átmérőjű hőcsövek oda.
Tuning
Természetesen a kártya túlhajtási lehetőségeire is vetettünk egy pillantást, melyhez a Catalyst, azaz az AMD saját szoftvere állt rendelkezésünkre. Ebben egyelőre nincs opció a HBM memóriák órajelének piszkálására, így csak a GPU-t tudtuk megizzasztani.


AMD R9 Fury X – Asus Strix R9 Fury [+]
Végül némi kísérletezgetés után az AMD R9 Fury X esetében 1135 MHz-es, míg az Asus Strix R9 Fury példánynál 1090 MHz-es GPU órajelet értünk el, ami 85, illetve 90 MHz-es emelés.
| VGA megnevezése | Radeon R9 Fury X |
Radeon R9 Fury | Radeon R9 390X | GeForce GTX 980 | GeForce GTX 980 Ti |
|---|---|---|---|---|---|
| Kódnév | Fiji | Grenada | GM204 | GM200 | |
| Gyártástechnológia | 28 nm (TSMC) | ||||
| Mikroarchitektúra | GCN | Maxwell | |||
| Tranzisztorok száma | 8,9 milliárd |
6,2 milliárd | 5,2 milliárd | 8 milliárd | |
| GPU lapka mérete | 596 mm2 | 438 mm2 | 398 mm2 | 601 mm2 | |
| GPU alap/turbó órajel | 1050 MHz | 1000 MHz | 1050 MHz | 1126/1216 MHz | 1000/1075 MHz |
| GPU/shader órajele üresjáratban | 300 MHz | 324 MHz | |||
| Shader processzorok típusa | multiprecíziós vektor | stream | |||
| Számolóegységek száma | 4096 | 3584 | 2816 | 2048 | 2816 |
| Textúrázók száma | 256 textúracímző és -szűrő |
224 textúracímző és -szűrő |
176 textúracímző és -szűrő |
128 textúracímző és -szűrő |
176 textúracímző és -szűrő |
| ROP egységek száma | 16 blokk (64) | 4 blokk (64) | 6 blokk (96) | ||
| Memória mérete | 4096 MB | 8192 MB | 4096 MB | 6144 MB | |
| Memóriavezérlő | 4096 bites hubvezérelt | 512 bites hubvezérelt | 256 bites crossbar | 384 bites crossbar | |
| Memória órajele terhelve | 500 MHz (HBM) | 1500 MHz (GDDR5) | 1752 MHz (GDDR5) | 1752 MHz (GDDR5) | |
| Üresjáratban | 500 MHz | 150 MHz | 162 MHz | ||
| Max. memória-sávszélesség | 512 000 MB/s | 384 000 MB/s | 224 000 MB/s | 336 600 MB/s | |
| Támogatott DirectX | 12 | ||||
| Dedikált HD transzkódoló | VCE | NVENC | |||
| HD képanyagok lejátszásának hardveres támogatása | AVIVO HD (UVD) | Purevideo HD (VP4) | |||
| Hivatalos fogyasztási adat | ~275 watt | ~165 watt | ~250 watt | ||
Shadow of Mordor, DiRT Rally, Company of Heroes 2
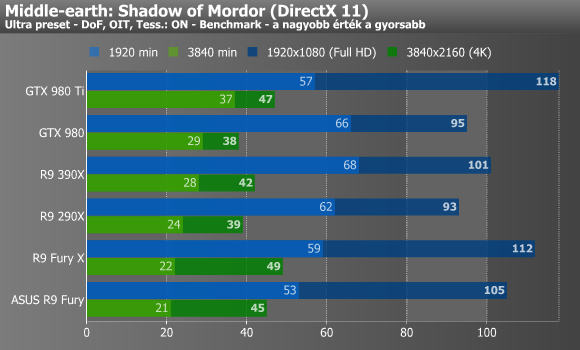
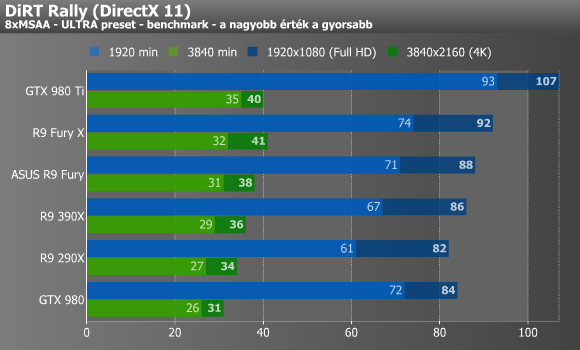
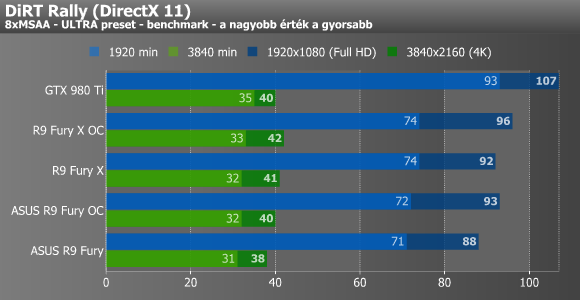
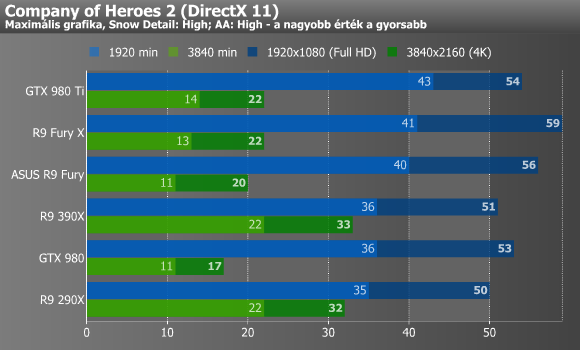
Mordor alatt nem muzsikáltak jól a Fury kártyák, már ami a minimum fps-t illeti, így még a 290X-390X kettős is megelőzte őket. A Dirt esetében már jobb volt a helyzet, pláne a nagyobbik, 4K-s felbontást tekintve. A Company of Heroes 2 4K-ban valamiért csak a Hawaii GPU-s kártyákat kedvelte igazán, ugyanis a többi VGA esetében többszöri mérésre sem kaptunk 11-14 fps-nél többet. A fejlesztőktől megtudtuk, hogy ennek az oka az új GPU-kra történő optimalizálás hiánya, ami rosszabb hatékonyságú memóriaallokációt von maga után.
Metro: Last Light, Tomb Raider, Thief




Metro alatt nem sikerült elcsípni a 980 Ti-t, ugyanakkor az R9 Fury felülmúlta a 980-at, és Tomb Raider esetében is hasonló volt a helyzet. A Thief esetében már komoly csatát folytattak a csúcskártyák, amiből végül a Fury-k kerültek ki győztesen.
Batman, Sniper Elite 3, GTA V



Batman alatt Full HD felbontásban a 980 Ti igen nagy előnnyel végzett az élen, míg 4K-ban szépen feljött, kvázi holtversenybe a Fury X. A Sniper Elite benchmarkjában ismét jól mentek a Fury kártyák, míg GTA V-ben, ha nem is nagy előnnyel, de a 980 Ti nyert.
ComputeMark, LuxMark
Az GPU-k általános számítási feladatokra való használatának népszerűsödésével két, ezen képességet vizsgáló benchmark is bekerült méréseink közé. Mivel félig-meddig szintetikus tesztekről van szó, így messzemenő következtetéseket nem érdemes levonni ezek eredményeiből.


A ComputeMark egyszerűbb DirectCompute shaderekkel operál, melyekkel főleg a játékok alatt lehet találkozni. A Luxmark az egyik legelterjedtebb benchmark a ray-tracing tesztelésére.
Összegzés

Az összes játékban elért eredmény alapján a Radeon R9 Fury X 6-8%-kal lassabb a GeForce GTX 980 Ti-nél, míg a kisebbik kártya, a Radeon R9 Fury nagyjából 9%-kal marad el a nagy testvértől.

Csupán a magasabbik, 3840x2160-as (4K) felbontás eredményeit vizsgálva már változik a kép, ugyanis itt jobban kijön a nagyobb memória-sávszélesség áldásos hatása, aminek köszönhetően jobban állnak az új Radeon kártyák. Az átlag értékeket tekintve a Fury X már képes volt beelőzni a GTX 980 Ti-t.

Teljesítmény/fogyasztás tekintetében ugyan előrelépést jelentenek a Fury kártyák, de a nagyobb Maxwell-alapú megoldásoktól még így is lemaradnak némileg.

[+]
Az AMD Radeon R9 Fury X kártya teljesítménye ugyan jó, de az alacsonyabb, 1920x1080-as (Full HD) felbontásban lemarad a rivális GeForce GTX 980 Ti-től, és csak 4K-ban tud igazán versenyre kelni vele. Magát a kártyát tekintve elégedettek voltunk, hisz egy kicsi, kompakt, a legtöbb házba könnyedén beszerelhető VGA-val volt dolgunk, melynek hűtése is remek hatékonyságú, bár a pumpa sípoló hangja némileg árnyalja a képet, de ez az újabb verziókkal remélhetőleg megszűnik. Kétségkívül egy negatív tényező a HDMI 2.0 hiánya, bár az AMD valószínűleg inkább a FreeSync-támogatással rendelkező 4K monitorok irányába szeretné terelni a játékos vásárlókat. Per pillanat a Radeon R9 Fury X ára valahol 230-240 000 forint környékén mozog, ami nagyon hasonlít a GeForce GTX 980 Ti árcédulájához, mely Full HD-ban egyértelműen gyorsabb, illetve 4K-ban sem marad le a Radeontól, ráadásul fogyasztása is alacsonyabb. Mindezek tükrében egyelőre nehéz lenne ajánlani a Radeon R9 Fury X-et, bár maga a kártya kialakítása, illetve az innovatív HBM memória alkalmazása egyértelműen tetszett nekünk.

[+]
Az ASUS Strix Radeon R9 Fury kártya megújult hűtésétől sokat vártunk, de végül sajnos kissé csalódnunk kellett, ugyanis sem hőmérsékletben, sem pedig terhelés alatti zajszintben nem remekelt a szóban forgó modell. Összességében nekünk valamelyest visszalépésnek tűnik a három ventilátoros kivitel, hisz az előző, két légkavaróval operáló Strix hűtések mindegyike remekül muzsikált tesztlaborunkban. Az AMD ajánlása alapján a Fury 100 dollárral, azaz átszámítva nagyjából bruttó 35 000 forinttal olcsóbb az X jelölésű társánál, de mivel egyelőre nem áll rendelkezésünkre pontos hazai ár, így még nem tudunk pontosan ítélkezni Radeon R9 Fury versenyképessége felett. Amint konkrét információt kapunk, frissíteni fogjuk a cikk ezen részét.

AMD Radeon R9 Fury X videokártya
Oliverda és Abu85
Az egyes kártyákat az AMD, illetve az ASUS képviseletétől kaptuk kölcsön.








