Hammertől Huskyig
Az előző oldalakon szándékosan nem esett túl sok szó a Llano CPU-magjairól. Az eddigiek olvasatában annyit már mindenképpen tudnunk kell, hogy a Stars, azaz a K10 vonalat vitte tovább a Husky. A K10, mint olyan, asztali vonalon leginkább az első, 65 nanométeres Phenom X4 processzorokkal vált ismertté. Ezt követte a 45 nanométeres Phenom II (K10.5), mely az elődhöz képest jóval alacsonyabb fogyasztással és magasabb órajelekkel került piacra.

Egy Husky mag
A Husky tehát gyakorlatilag egy kissé módosított K10.5, vagy ismertebb nevén Athlon II. Azért áll közelebb inkább az utóbbihoz, mint a Phenom II-höz, mert nem tartalmaz L3 cache-t. A K10.5-ös egyenes ági rokonságának köszönhetően a Husky a K8 (azaz az első Athlon 64) dédunokájának is tekinthető. Most aggassuk a K12 nevet a Husky-re! Egyrészt azért, mert az AMD technikai dokumentációjában ilyen néven emlegetik, másrészt talán valamivel egyszerűbb lesz átlátni a következő bekezdéseket.
Az AMD 2003-ban indította útjára a K8 családot, amely a megelőző, 3-utasítás széles K7 processzormag továbbfejlesztett változatán kívül integrált memóriavezérlőt és egy (vagy három) HyperTransport linket tartalmazott; ez(ek)en keresztül a rendszerrel, illetve további két CPU-val tarthatta a kapcsolatot. Az azóta megjelent AMD processzormagok olyannyira erre az alapvető felépítésre alapoznak, hogy egyetlen ábrán bemutatható a K8 (fekete), a K10/K10.5 (kék) és a K12 (piros) működése. Tekintsük át ezen mikroarchitektúrák jellemzőit!
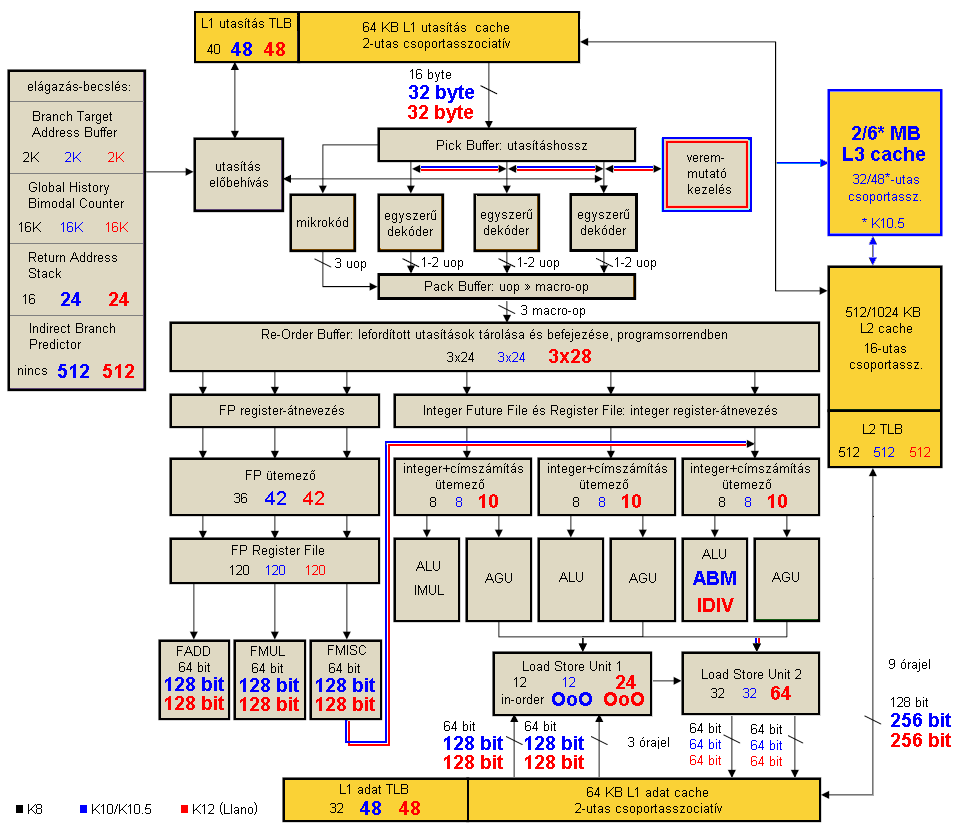
[+]
A processzor 64 KB-os, 2-utas L1 utasításcache-t tartalmaz, amelyből az elágazásbecsléssel együttműködve órajelenként 16 bájtot fogad a processzor Pick Buffer (Scan/Align) egysége, amely a változó hosszúságú x86/x64 utasítások kezdetét, végét és bonyolultságát meghatározza. Innen két úton juthatnak tovább az utasítások:
- órajelenként 3 egyszerű utasítás kerülhet a 3 teljesen megegyező egyszerű dekóderbe, amelyek órajelenként 1-1 x86/x64 utasítást fordítanak le belső, uopnak nevezett RISC-műveletekre (DirectPath);
- a bonyolult, legalább 3 uopra fordítható utasításokból órajelenként legfeljebb 1-et továbbít a mikrokódmotor felé (VectorPath).
A két lehetséges út a Pack Bufferben találkozik újra, amely az összetartozó, aritmetikai és memóriát kezelő uopokat "összecsomagolja" 1-1 macro-opnak nevezett egységgé, és ezekből legfejlebb 3-at programsorrendben továbbít a Re-Order Bufferbe, amely 24 ilyen hármast tud tárolni, azaz legfeljebb 72 macro-op fér el benne. Innen attól függően, hogy milyen jellegű műveletről van szó, vagy az integer vagy az FPU egységbe kerülnek végrehajtásra a műveletek. Egészen addig maradnak itt a lefordított műveletek, amíg be nem fejeződik a végrehajtásuk, majd órajelenként 1 összetartozó, kész macro-op hármas programsorrendben törlődik. Elágazástévesztés esetén ezen puffer teljes tartalma érvénytelenítésre kerül, és a kiszámolt helyes memóriacímről származó dekódolt macro-opokkal fog feltöltődni.
Hirdetés
Az integer egység végzi el az egész számokkal dolgozó számításokat és kezeli a memóriaműveleteket is: 3 megegyező egységből áll, amelyeket 1 ALU (aritmetikai-logikai egység), 1 AGU (címszámító egység) és a hozzájuk tartozó közös 8 macro-op méretű ütemező alkot. Egyetlen utasításcsoport nem hajtható végre bármelyik egységen: ezek az szorzó utasítások, amelyek kizárólag az 1. végrehajtóba kerülhetnek; a többi utasításnál annak macro-op hármason belüli helye – vagyis az eredeti programsorrend – dönti el, hogy melyik egységben kerül végrehajtásra. Az osztásokon és az említett szorzásokon kívül a 8-64 bites egész számokon végzett bármely műveletet – ha annak minden bemeneti értéke registerben van és nem kell a memóriából beolvasni – 1 órajel alatt képesek végrehajtani az ALU-k.
A memóriacímek az AGU-kban kerülnek kiszámításra, és párhuzamosan dolgoznak az ALU-kkal. Mindhárom AGU órajelenként 1-1 címet továbbíthat a kétszintes Load Store Unitba, amely programsorrendben órajelenként 2 db 64 bites olvasást vagy 2 db 64 bites írást vagy 1-1 64 bites olvasást és 64 bites írást tud küldeni a 64 kB-os, 2-utas L1 adatcache felé, vagy ha abban nem található a keresett memóriaterület, akkor továbbítja az L2 cache-nek. Az L1 adatcache késleltetése 3 órajel, az L2-é ezen felül további 9 órajel.
Az FPU-egységnek a lebegőpontos és a SIMD-műveletek a felségterülete; 36-elemű ütemezőből és 3 darab, 64 bites végrehajtóból áll, amelyek specializáltak:
- az FADD az összeadás jellegű műveleteket hajtja végre;
- az FMUL a szorzásokat, osztásokat és gyökvonásokat kapja;
- az FSTORE vagy FMISC a többi, ritkább műveletet (pl. integer<->FP konverzió) kezeli.
A 128 bites SSE és SSE2 utasítások két 64 bites lépcsőben, egymás után kerülnek végrehajtásra.

Egyetlen K8 mag L2 cache nélkül
A 2007-ben piacra dobott K10 mikroarchitektúra alapvetően nem rajzolta át felépítést, viszont számos ponton kiegészítette azt:
- jelentősen okosodott az elágazásbecslő egység, egyrészt növelték a munkaterületeit, valamint kiegészítették az indirekt ugrások címjegyzékével;
- az L1 utasításcache-ből órajelenként kétszer annyi, 32 bájtnyi utasítás kerül feldolgozásra;
- a dekódolási lépcsőfok kiegészült egy veremmutatót kezelő egységgel, amely a veremkezelő utasítások manipulált lefordításával segíti azok párhuzamos végrehajtását;
- a 3. integer ALU dedikált ABM egységet kapott a bemutatkozó SSE4A utasításkészlet bitszámláló utasításaihoz;
- a Load Store Unit 1. szintjét a memóriaolvasásokra specializálták, viszont azokat out-of-order módon képes végrehajtani, órajelenként akár 2 db 128 bites olvasást kiadva az L1 adat cache-nek; kizárólag a 2. szint foglalkozik a memóriaírásokkal, valamint az L1-tévesztő memóriaolvasásokkal;
- az FPU-végrehajtók 128 bitesre bővültek, csökkentve ezzel a végrehajtáshoz szükséges időt; bevezettek továbbá egy 64 bit széles FP-to-int buszt, amely közvetlen adatkapcsolatot teremt az integer egységgel (pl. konverziós utasításoknál vagy adatmásolásnál);
- az L1 és az L2 közötti buszszélességet megkétszerezték;
- bemutatkozott a 2 MB méretű L3 cache, mellyel együtt a magonkénti L2 cache mérete fixen 512 KB-ra csökkent;
- az integrált kétcsatornás memóriavezérlő a korábbi 128 bites összekapcsolt (ganged) mód mellett új, 2 x 64 bites "független" (unganged) üzemmódot is kapott, amelynek előnye főleg a több magot használó, memóriaintenzív programokban mutatkozott meg.

Egyetlen K10 mag L2/L3 cache nélkül
A 2009-ben megjelent, sok helyen csak K10.5 néven emlegetett 45 nm-es K10 változatokban még tovább csiszolták a felépítést:
- az L3 cache mérete 6 MB-ra növekedett, késleltetése 2 órajellel csökkent, valamint lehetőséget kínál arra, hogy az inaktívvá lekapcsolt magok L1 és L2 cache-ik tartalmát kimásolják belé, majd kiürítsék azokat, csökkentve energiafelhasználásukat;
- növelték a RAM-sávszélességet;
- hatékonyabbá tették az indirekt ugrások becslésének működését;
- növelték a LOCK prefixszel ellátott, atomi x86/x64 utasítások párhuzamos végrehajtási sebességét;
- 36-ról 42-re növelték a lebegőpontos ütemező méretét, valamint finomították a lebegőpontos register->register másolások végrehajtását.

Egyetlen K10.5 mag L2/L3 cache nélkül
A most megjelenő K12 kódnevű Llano CPU-mag ugyancsak nagyban alapoz a megelőző felépítésre, bizonyos helyeken kiegészítve azt:
- a Re-Order Buffer méretét megnövelik, ezáltal 24 helyett 28 macro-op hármast képes tárolni, azaz legfeljebb 84 macro-opnak biztosít helyet; ezzel párhuzamosan az integer ütemezőket is megnövelik 8-ról 10 macro-opra;
- az osztó utasítások dedikált végrehajtó egységet kapnak a 3. ALU-ban, így ezek gyorsabban kiszámíthatók és velük párhuzamosan folyhat további műveletek végrehajtása a másik két ALU-ban;
- Az L1 adatcache valamint az L2 cache a korábbi 6T (6 tranzisztor cellánként) megoldás helyett immáron 8T (8 tranzisztor cellánként) kialakítással készül. Ez a lépés 33%-kal nagyobb cache területet eredményez, viszont alacsonyabb fogyasztást és megbízhatóbb működést kínál cserébe;
- L3 cache-t nem tartalmaz a felépítés, viszont az L2 cache méretét magonként 1 MB-ra növelték.

Egyetlen K12 mag L2 cache nélkül
Ez utóbbi K12-vel a 2003 óta piacon lévő K8 (más néven Hammer) architektúrától és annak közvetlen leszármazottjaitól végleg elbúcsúzunk. A Hammer helyét a közeljövőben debütáló, teljesen újragondolt Bulldozer mikroarchitekúra fogja majd elfoglalni.
(Az oldalon látható, összesen négy különböző magot ábrázoló kép méretarányos egymással.)
A cikk még nem ért véget, kérlek, lapozz!






