- NVIDIA GeForce RTX 4080 /4080S / 4090 (AD103 / 102)
- NVIDIA GeForce RTX 4060 / 4070 S/Ti/TiS (AD104/103)
- Fejhallgató erősítő és DAC topik
- AMD Navi Radeon™ RX 7xxx sorozat
- Home server / házi szerver építése
- Milyen TV-t vegyek?
- 3D nyomtatás
- Azonnali notebookos kérdések órája
- Notebook hibák
- Micro Four Thirds
Hirdetés
-


Spyra: akkus, nagynyomású, automata vízipuska
lo Type-C port, egy töltéssel 2200 lövés, több, mint 2 kg-os súly, automata víz felszívás... Start the epic! :)
-


Sokat fogyaszt az AI, egyre több az adatközpont, kell az atomenergia
it Az AI-t kiszolgáló adatközpontok olyan nagy energiaigénnyel bírnak, hogy egyre több atomenergiára van szükség.
-


Egyre nagyobb a balhé a Helldivers II körül
gp Úgy tűnik, hogy egyre több sötét felhő kezd gyűlni a játék körül a Sony döntése miatt.






-

PROHARDVER!
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#57651
 paprobert
senior tag
Petykemano
#57649
paprobert
senior tag
Petykemano
#57649
paprobert
senior tag
válasz
 Petykemano
#57649
üzenetére
Petykemano
#57649
üzenetére
Az AMD rendelkezik a default library-vel.
A "nagy tempó, nagy fogyasztás" piacot célozza jelenleg az AMD. Valamekkora fogyasztáshátrány szinte biztosan megmaradna az ARM-mal szemben, egy teljesen más filozófia szerint felépített új x86 CPU-val is.
De ha belegondolsz, a Bergamo (Zen dense) tekinthető egyfajta szélesítésnek-sűrítésnek, package és mag szinten.

640 KB mindenre elég. - Steve Jobs
-
#57653
 Petykemano
veterán
paprobert
#57651
Petykemano
veterán
paprobert
#57651
Petykemano
veterán
válasz
 paprobert
#57651
üzenetére
paprobert
#57651
üzenetére
> Az AMD rendelkezik a default library-vel.
Nyilván, persze> De ha belegondolsz, a Bergamo (Zen dense) tekinthető egyfajta
> szélesítésnek-sűrítésnek, package és mag szinten.
Abból a szempontból, ahogy én kérdeztem nem. A frekvencia és az IPC is hatással van egy processzor mag egyszálas teljesítményére. A Bergamo lehet, hogy alacsonyabb frekvenciát célozva ugyanúgy magasabb tranzisztorsűrűséget fog hozni, de csak a magszámot fogja emelni.Találgatunk, aztán majd úgyis kiderül..
-
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
Az előző tweet júni 15: [link]
"There seems to be 16384SP 8SE navi3x, but I don't know if it really exists or if it's a gaming card?"Mai tweet: 2023 Specifications to be determined.[link]
"It was planned in response to the AD102's huge power consumption model, so there is a lot of uncertainty about power consumption and scale, if the N31 is good enough to deal with the AD102, it may not come out, just like the GH202."ezért emelik a fogyasztását a kész tervezett SKU-knak. vajon elég lesz a felső házban NV ellen?
lehet korai volt még az MCM váltás, jensen megint jól gondolta ki a dolgokat.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#57659
 Alogonomus
őstag
b.
#57658
Alogonomus
őstag
b.
#57658
Alogonomus
őstag
A tweet arról szól, hogy az AMD esetleg nem is lesz rákényszerítve az MCM kialakításra ahhoz, hogy az AD102 "huge power consumption" változatával felvehesse a versenyt most ősszel.
Az MCM váltás maximum azért tekinthető korainak, mert a tweet alapján a konkurenciát már MCD kialakítással is belekényszerítette egy "huge power consumption model" létrehozásába.
Ez mondjuk megkérdőjelezi annak a széles körben terjesztett állításnak a valóságtartalmát, hogy a konkurensek állítólag eléggé pontosan tudják a másik termékének a képességeit. -

GeryFlash
veterán
-
#57662
Petykemano
veterán
Alogonomus
#57659
Petykemano
veterán
válasz
 Alogonomus
#57659
üzenetére
Alogonomus
#57659
üzenetére
Greymon mai tweetjében (megint) azt állíttotta, hogy a jelenlegi állás szerint 1GCD + cache+IO kialakítású, a korábbiakhoz képest visszafogottabb specifikációval rendelkező Navi31 nem a csúcs RDNA3 modell lesz. Hanem egy 2023-ban érkező modell (2GCD?) lesz a zászlóshajó.
Meglátásom szerint a chipletes megoldás elsősorban a gyárthatóságon segít. Egy adott teljesítményű processzor amennyiben elkészíthető monolitikus felépítéssel, valószínűleg átlagosan* kisebb fogyasztással rendelkezhet.
* Direkt írtam, hogy átlagosan. Mert ha már kisebb chipletekkel számolunk, mint amilyen az Epyc esetén a Zen CCD, úgy már a lapkák minőségbeli válogatása is sokat nyomhat a latba, de a pletykált 1GCD + körítés esetén ez nem játszik.
Amiben a chiplet design segít az az, hogy mondjuk az AMD - mivel kevesebb N5 wafert használ egy adott lapkához, ezért elképzelhető, hogy ugyanannyi N5 waferből kétszer annyi lapkát legyárt. Más kérdés, hogy az Nvidia általában több wafert foglal és többet gyárt, de ha az AMD-nek kapacitás problémái lennének, akkor ez egy olyan lépés, ami azon enyhíthet.
Találgatunk, aztán majd úgyis kiderül..
-
#57663
Alogonomus
őstag
Petykemano
#57662
Alogonomus
őstag
válasz
Petykemano
#57662
üzenetére
A chipletes megoldás a minőségbeli válogatáson felül a célhoz igazodó optimális node kiválasztását is lehetővé teszi.
Míg egy monolitikus GPU egységesen egy bizonyos nodeon készül, vagyis szükségtelenül nagy kapacitást emészt fel a rendelkezésre álló drága node kapacitásból, addig a chipletes kialakítással csak a feltétlenül szükséges részegységek (jellemzően a compute egységek) készülnek a drága node alkalmazásával, míg a többi elem (IO, SRAM) simán készülhet 7/6, de az IO talán még 14/12 nm-en is. Ez pedig nem csak a legyártható mennyiséget növeli, de a legyártási költséget is csökkenti.
Sőt adott esetben a kártya "tuningját" is egyszerűsíti, mert chipletes kialakítás esetén sokkal könnyebb később "hozzácsapni" egy extra külső - de az MCD/MCM fizikai keretein belüli - gyorsítótárat, ahogy az például az 5800X3D esetén is történt. -
#57664
Petykemano
veterán
Alogonomus
#57663
Petykemano
veterán
válasz
Alogonomus
#57663
üzenetére
Igen, ez igaz.
Én abból az aspektusból kívántam körbejárni a kérdést, hogy vajon a látott eredmények a szokásos mutatók (perf, perf/W, perf/$) alapján fogják-e egyértelműen megválaszolni azt a kérdést, hogy előnyös volt-e már chipletre menni, vagy helyes döntés volt-e még várni vele. b ugyanis sommásan mintha az utóbbit állapította volna meg (többedszer).Találgatunk, aztán majd úgyis kiderül..
-
#57665
 b.
félisten
Petykemano
#57664
b.
félisten
Petykemano
#57664
válasz
Petykemano
#57664
üzenetére
Az hogy helyes döntés a chiplet nem kérdés,ez a jövő.Az hogy korai e és erre rátervezni egy egész generácíót mindjárt az elején az a kérdés főleg üzletileg..Kockázatos.Miért nem elég egy csúcs MCM tapasztalatszerzésnek alá pedig biztosra menni?
.A példa azt mutatja hogy nem sikerül kompletten kihozni a tervezett SKU kat és így 2022 ben kiadni a csúcs RDNA3 at tehát ha a pletyka igaz nem nehéz sommás véleményt alkotni,ha AMD ezzel fél év előnyt ad a felsőházban az Nvidiának,aki közben nyugissan elesz a csúcson és fejlesztgeti a Hoppert MCM dizájnt.
Ha a pletyka nem igaz akkor persze más az aspektus de akkor is még nagyon sok a kérdőjel teljesítmény ,ár és egyéb mutatók szempontjából és nem csak AMD nél,Nvidiánál is.Egyre több jel utal afelé,hogy(pletykák szerint )a kezdeti lemaradásuk már előnnyé vált.Tehát nem látom mi értelme van kockáztatni.
Ráadásul azért az a tsmc 5 nem lett azért igazi.Az öreg és Intel is kisebb csíkszélre tervezik az MCM hatékony megvalósithatóságát.3nm?[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-

Abu85
HÁZIGAZDA
A TSMC-nek az 5 nm-es node-ja (plusz ennek a 4 nm-es half-node-ja) azért elég jól sikerült. Igen kellemes már a kihozatal is a kisebb lapkáknál, a nagyobbaknál nem tökéletes, de ez benne van eleinte. Sokkal több baja van a 3 nm-en a TSMC-nek. Ott már kezd visszaütni, hogy a FinFET túlment a határon.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Lényegében igen. A 3 nm problémája az, hogy a Samsungnál GAAFET van, ami ismeretlen, tehát kockázatos, míg a TSMC-nél még nincs GAAFET, miközben a FinFET már nem skálázódik ilyen csíkszélességre, ami megint kockázatos. Nyilván átváltanak majd, de most nem túl jó döntés ezt elsietni.
Egyébként a Samsung 3 nm-je jobban áll, ami nyilván azért van, mert ők már nem FinFET-et használnak. És valószínű, hogy gyorsabban is fog javulni nekik a kihozataluk.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#57670
 szmörlock007
aktív tag
Yutani
#57669
szmörlock007
aktív tag
Yutani
#57669
szmörlock007
aktív tag
válasz
 Yutani
#57669
üzenetére
Yutani
#57669
üzenetére
Amd amúgy simán átvihetne pár dolgot (pl. laptop cpu-k) a Samsung 3nm-re, amúgy is együtt dolgoznak, hiszen ők adják a Samsungnak az igp-t a csúcstelefonokba. Emiatt gondolom alapból van információjuk az aktuális legfrissebb node-ról is. És akkor a kínzó gyártásbeli hiányt kb ki is ütnék.
[ Szerkesztve ]
-
#57671
Petykemano
veterán
szmörlock007
#57670
Petykemano
veterán
válasz
 szmörlock007
#57670
üzenetére
szmörlock007
#57670
üzenetére
Annak látnám némi esélyét és előnyét, hogy bizonyos chipleteket a samsungnál ggyártsanak
De az az igazság, hogy a Samsung gyártástechnilógia bár tr sűrűségben versenyképes, high perf fogyasztásban és talán kihozatalban nem.
Ebben lehet, hogy az EUV és az ahhoz kapcsolódik szűrőfólia késése játszik szerepet.Találgatunk, aztán majd úgyis kiderül..
-
-
#57674
Alogonomus
őstag
olymind1
#57672
Alogonomus
őstag
válasz
 olymind1
#57672
üzenetére
olymind1
#57672
üzenetére
A hitelesebb leakerek már régóta utalnak rá, hogy az AMD is be fog vetni csak a saját kártyájában elérhető funkciókat az FSR technológiához, ahogy az Intel is pluszként adja az XMX megoldást a saját kártyáiban, míg a többi gyártónak ott van a DP4a az XeSS használatához.
Kérdés, hogy az állítólagos kb. 150% gyorsulás az ilyen WMMA típusú optimalizálások eredményeként jelentkezik, vagy ez csak még további gyorsulást hoz a kompatibilis alkalmazásokban?[ Szerkesztve ]
-
-
#57678
 Hellwhatever
aktív tag
Hellwhatever
aktív tag
Hellwhatever
aktív tag
-
#57679
Petykemano
veterán
Petykemano
veterán
Greymon szerint a Navi31 GCD chiplet mérete: 350mm2
Ez elég kicsinek tűnik, de persze ehhez még hozzájön 6db N6-on gyártott MCD.Találgatunk, aztán majd úgyis kiderül..
-
#57680
Alogonomus
őstag
Alogonomus
őstag
Ez a 8 GB-os RX 6500 XT kártya megkavarhatja az állóvizet a belépőszinten. Persze nem lesz ettől RTX 3050 erejű, de a kártya legjelentősebb gyengeségét ezzel orvosolják is.
-
#57681
Petykemano
veterán
Alogonomus
#57680
Petykemano
veterán
-
#57682
 Yutani
nagyúr
Alogonomus
#57680
Yutani
nagyúr
Alogonomus
#57680
Yutani
nagyúr
válasz
Alogonomus
#57680
üzenetére
Jó lenne egy tesztet látni, mennyire segíti meg a 8GB memória.
#tarcsad
-

Devid_81
nagyúr
-
#57684
Alogonomus
őstag
Devid_81
#57683
Alogonomus
őstag
válasz
 Devid_81
#57683
üzenetére
Devid_81
#57683
üzenetére
Azok a 320 és 384 bites modellek érdekes új spekulációk. Eddigi pletykákban csak 256 bites 16 és 32 GB-os modelleket emlegettek. A jelenlegi generációban szerintem a 384 bit helyett csak 256 bites memóriabusz okozhatja a 4K-ban jelentkező lemaradás nagy részét, mert 4K-hoz már kevés az Infinity Cache kapacitása.
Az alsóbb felbontásokban az új 8-as és 9-es kártyákhoz várt 384 vagy akár 512 MB-os Infinity Cache valószínűleg továbbra is eldönti majd a versenyt. Sőt egyes pletykák szerint a csúcs Navi 31 esetén az MCM kialakítás eredményeként több részre lehet majd bontva az IC, így többszörözött sávszélességet biztosít. -
#57685
Petykemano
veterán
Petykemano
veterán
Korszakos lehetőséghez érkezett az AMD.
Nem, vagy nem feltétlenül a chiplet miatt. Az biztosan sokat segít majd a válogathatóságban és így hozzájárulhat, hogy megbízhatóan jó minőségű sku-kat is össze tudjanak rakni.
Valamint persze javíthat a selejtarányon, összességében segítheti az AMD-t abban, hogy egy kellően jó kártya esetén ne annyira kelljen kapacitás-problémákkal küzdeni, amiatt magasan.árazni, és/vagy lemondani piaci részésedésről.Még csak nem is feltétlenül azért, mert a pletykák szerint az RDNA3 energiahatékonysága jobb lesz. Ez lehet, hogy csak a túlhajtott legmagasabb szféra esetén lesz igaz. De ha igaz, akkor az lehetővé teheti, hogy az AMD benyomuljon az OEM piacokra. - ahonnan szerintem az nvidia meghatározó piaci részesedése származik.
Hanem amiatt, hogy az elmúlt hetekben kiadott az AMD egy újraírt DX11 és egy újraírt openGL illesztőt. Régóta ismert, hogy az nvidia ezeken a területeken brillírozott nagyon és ha DX12/Vulkan terén egálban is voltak, akkor.számos régi.játék eredménye ronthatta az összképet, ami miatt lehetett az a konklúzió, hogy aki régebbi játékkal is akar játszani, annak.azért előnyösebb az nvidia kártyát választani.
Most a jónak ígérkező RDNA3-mal és a új driverekkel az AMDnek törtélmi esélye nyílik, hogy a benchmarkokban megszabaduljon a régi játékok lehúzó terhétől és a teljes palettán győzelmet arasson.
Találgatunk, aztán majd úgyis kiderül..
-
-
#57687
Alogonomus
őstag
Devid_81
#57686
Alogonomus
őstag
válasz
Devid_81
#57686
üzenetére
Minimum meglepő az AMD jelenlegi sorozatának komoly előnyt biztosító Infinity Cache méretének negatív irányú változása. Vagy az állítólagos OREO technológia mellé nagyon kevés Infinity Cache is elég, vagy valami nagyon nem stimmel a leak kapcsán.
Eddig ilyen 384, vagy akár 512 MB-os Infinity Cache meglétét jósolták, ami abszolút logikus is lett volna a megcélzott 4K és 8K mellé, valamint a játékok egyre méretesebb textúracsomagjaihoz igazodva. -
#57688
Yutani
nagyúr
Alogonomus
#57687
Yutani
nagyúr
-
#57689
Devid_81
nagyúr
Alogonomus
#57687
Devid_81
nagyúr
válasz
Alogonomus
#57687
üzenetére
Sztem van ott meg valami amire a leakerek sem latnak ra.

AMD-tol nagyon keves info jon, az RDNA2.0-rol is vegig keves info jott es egy jo eros RTX2080Ti szintig vartuk a vacak 256bitjevel, aztan mi lett belole?
...
-
#57690
Petykemano
veterán
Devid_81
#57689
Petykemano
veterán
válasz
Devid_81
#57689
üzenetére
Biztosan most is többféle variációt kipróbáltak.
Ez a 96/192MB lehet szegmentációs célzatú is.
A raytracingben pl tudtommal sokat számít. Tehát pl a 192MB-os változat lehet PRO, vagy valamilyen más célzattal feláras.De az sem kizárt, hogy változott a cache hierarchia.
(Abu azt mondta, az oo$ eddig nem is volt része.) Csupán egy victim cache volt. Ha ezen változtattak, akkor kevesebb is elég lehet.A leírás szerint az AMD PPA-ra optimalizált, vagyis vagy kellően szűkösek a kapacitásaik, vagy az AMD piaci részesedés szerzését tervezi.
Ezek a lapkák tényleg elég kicsik. Reméljük ez az áraikban is reflektálódni fog.
Találgatunk, aztán majd úgyis kiderül..
-
#57691
Alogonomus
őstag
Devid_81
#57689
Alogonomus
őstag
válasz
Devid_81
#57689
üzenetére
Igen, az biztos, hogy végül használat közben rendben lesz az RDNA 3 kártyák teljesítménye, mert egyébként nem a kis IC irányába mentek volna el, hanem maradtak volna a 256 bit és 384 MB IC vonalán. Talán tényleg az az AMD szándéka, hogy a chiplet design miatt nagyon olcsón kiadható kártyákkal piaci részarányt javítson, és nem kezd el versenyezni a rengeteget fogyasztó Lovelace csúcskártyával. Majd talán a refresh kapcsán.
Érdekes ősznek nézünk elébe. Egyedül a Navi 33 specifikációi lehangolóak, mert a 128 bites memóriabusz egyértelműen kizárja a 12 GB-os pletykált verzió létezését, a "Navi33 outperforms Intel’s top end Alchemist GPU" pedig azt jelzi, hogy nagyjából egy RX 6600 XT lesz erőben, bár a fogyasztása valószínűleg kedvező lesz, de egyáltalán nem Navi 21 teljesítményszintre jön.
-
#57692
Petykemano
veterán
Alogonomus
#57691
Petykemano
veterán
válasz
Alogonomus
#57691
üzenetére
Ezen infók alapján én a navi33-at a 6700XT / 3070/Ti szintre várnám.
Egy 237mm2-es navi23 teljesítményét hozni N6-on gyártott ~200mm2 navi33-mal nem lenne nagy kunszt.Gondolom a dupla mennyiségű ALU azért valahol érezteti majd a hatását.
Ha a 335mm2-es lapkájú navi22-t elérnék az már szép eredmény lenne. Ha ez Így történne, akkor szerintem oda áraznák, ahol most a 6600XT van (nem számolva recessziós árkedvezménnyel)
Találgatunk, aztán majd úgyis kiderül..
-

hokuszpk
nagyúr
ahha !
szóval>> Infinity Cache 96MB (0-hi), 192MB (1-hi) <<
lesz "sima" Navi 31 és 3dcaches verzió.
sőt.
>>>
There were early plans for a version with 288MB of Infinity Cache (2-hi), but this was shelved as the cost-benefit was not worth it.
<<<kár volt dobni.
Első AMD-m - a 65-ös - a seregben volt...
-
válasz
 hokuszpk
#57694
üzenetére
hokuszpk
#57694
üzenetére
Szerintem mérlegelnek a kihozatal/ teljesítmény / árazás koordinátákon és ez lett az origo.
Okosan hoznak mostanában fejlesztési döntéseket, nincs kétségem afelől ,hogy felső házas termék lesz így is a konkurenciával szemben és ha így jobb áron jöhet egyben kihúzza a használt piac méregfogát is. Legalább is mérsékli a hatását az új genre."A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#57696
Petykemano
veterán
hokuszpk
#57694
Petykemano
veterán
válasz
hokuszpk
#57694
üzenetére
csökkenő határhasznosság
Lehet, hogy úgy lesz majd a szegmentálás, hogy az (esetleg később jövő) YY50XT megkapja a plusz sávszélt és vagy "true 4K"-val vagy RayTracinggel, vagy épp PRO kékséggel fogják eladni, míg a kisebb IC-vel rendelkező példányok mennek a kevésbé vájtszemű kispolgároknak.
Találgatunk, aztán majd úgyis kiderül..
-
#57697
hokuszpk
nagyúr
Petykemano
#57696
hokuszpk
nagyúr
válasz
Petykemano
#57696
üzenetére
kamu duma. ha beletolnának 16GB infinity cachet, 100% hit rate.
[ Szerkesztve ]
Első AMD-m - a 65-ös - a seregben volt...
-
#57698
Petykemano
veterán
hokuszpk
#57697
Petykemano
veterán
válasz
hokuszpk
#57697
üzenetére
Idővel lesz 16GB cache 😃
Viszont érdekesek a számok.
Az angstronomics cikk alapján az MCD 37mm2 (legyen 35-40)
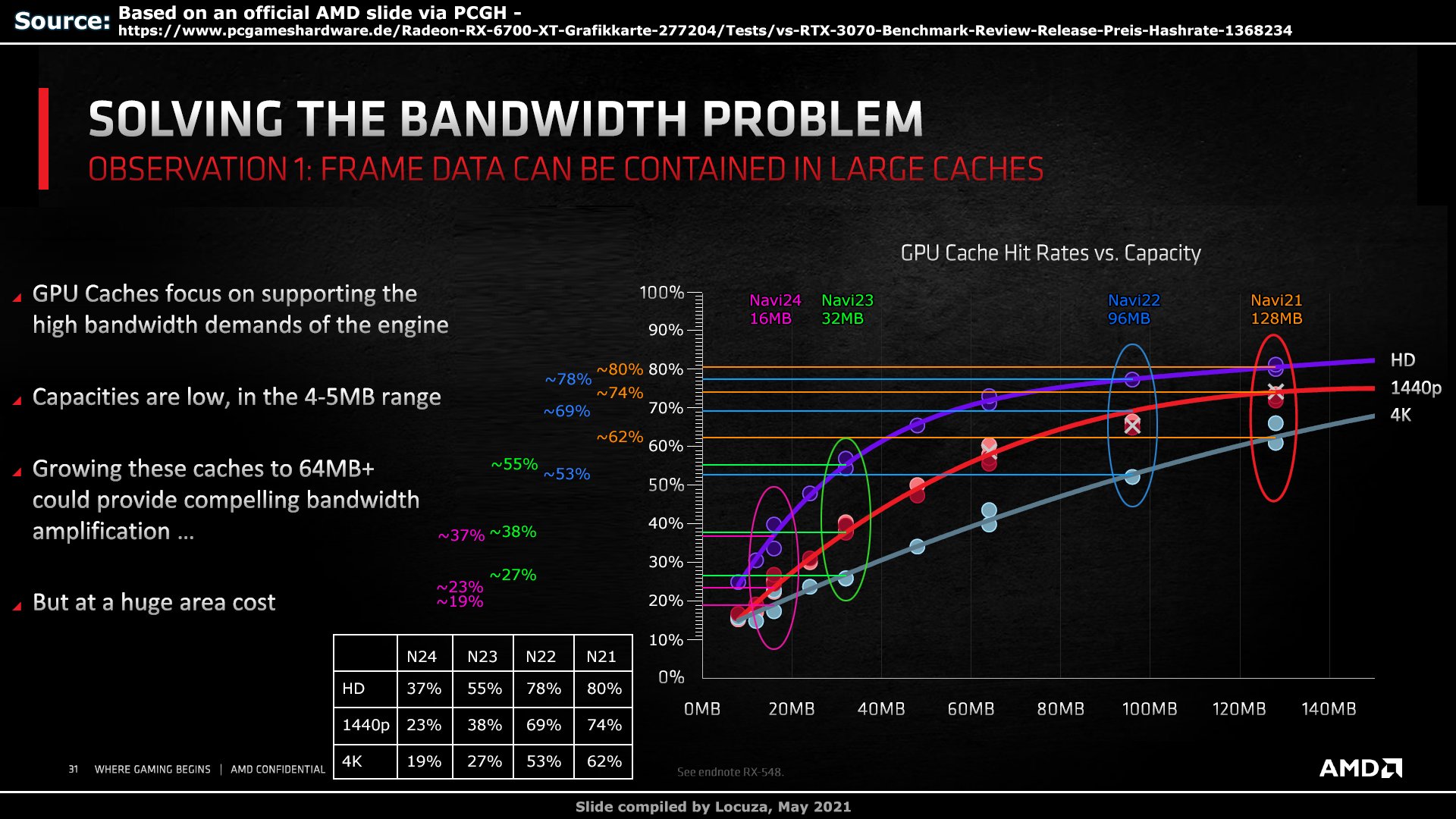
Azt állítják, hogy ebben már benne van 16MB Infinity Cache.Locuza Navi21-es számai alapján 64bit GDDR6 ~13mm2, 32MB IC pedig ~23mm2, vagyis 35-40mm2-ből nagyjából 32MB is kijön és akkor még nem is beszéltünk arról, hogy ez N7 számok, az MCD pedig N6.
Miért és hogyan kerülne bele csak 16MB?Az a fura, hogy külön gyártva lényegesen nagyobb sűrűséget értek el a V-cache esetén - ott 64MB belefért ~36mm2-be. Tehát ha az MCD v-cache-t kapna, annak is valamivel kisebbnek kéne lennie a 23mm2-nél, ha csak 32MB, vagy ha nincs kitöltő szilícium, akkor 64MB is kijöhetne az MCD teljes méretéből.
Így meg aztán tényleg érthetetlen a spórolás.Ezzel együtt hihetőnek tűnik az, hogy nem skálázódik jól tovább a cache. Szerintem az infinity cache nem egybefüggő volt eddig se. Legjobb esetben is 2db 64MB-os szelet volt, de valószínűbb, hogy 32MB-os szelet szolgált ki 64bit memóriavezérlőt (sőt, lehet, hogy 16MB egy 32bites sávot)
A grafikon alapján látható, hogy 1080p-hez a felezett mennyiség is.elég. 1440p lehet,.hogy vállalható felezett cache mellett. De a 4K-Nak jót.tenne a több cache.
Kissé érthetetlen, hogy az AMD miért döntött a jó iránynak tűnő.cache helyett a memóriabusz szélesítése mellett.
Két dologra tudok gondolni:
- nem csak az számít, hogy mennyi a cache méret. Tehát mondjuk hiába lenne nagyobb a cache mérete, ha a csatoló (InFO_oS) által kínált sávszéleség limitált.
Ez Megmagyarázná miért döntött az amd a több cache helyett a több MCD mellett.
- a GCD-ben az nvidiához.hasonlóan növelték az L2$ méretét (sajnos itt a kitöltő szilícium szükségessége miatt valószínűtlen a 3D megoldás), ami jelentősen enyhítette a L3$-re nehezedő nyomást.Találgatunk, aztán majd úgyis kiderül..
-
#57699
 kisfurko
senior tag
Petykemano
#57698
kisfurko
senior tag
Petykemano
#57698
kisfurko
senior tag
válasz
Petykemano
#57698
üzenetére
Lehet, hogy azért kisebb a cache az MCD-ben, hogy csökkentsék a latencyt. Azt se tudjuk, hogy a GCD-vel való kapcsolat mennyi helyet igényel. Simán valami gazdaságossági dolog is lehet, hogy pl. 10-20 százalék die area aránytalanul több időt/pénzt igényelne, vagy sokkal nagyobb kihozatalt akarnak.
Eddig a cache chipen belül volt, nyilván a belső busz gyorsabb, mint a két chip közötti, tehát valamivel kompenzálniuk kell a sávszélesség-veszteséget, ezért a másfélszeres busz, szerintem.


































Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- World of Tanks - MMO
- Politika
- Automata kávégépek
- Filmvilág
- Lakáshitel, lakásvásárlás
- Atomenergia
- Feltörték a PROHARDVER!-es regisztrációmat! (vagy elvesztettem a belépési emailcímemet)
- Kerékpárosok, bringások ide!
- Hálózatokról alaposan
- NVIDIA GeForce RTX 4080 /4080S / 4090 (AD103 / 102)
- További aktív témák...

- Gainward Phoenix RTX3080
- Rog 4070 Ti //KERESEM!!//
- Hibátlan - GIGABYTE GTX 1660Ti Windforce OC 6G 6GB GDDR6 VGA videókártya dobozos
- ELADÓ 32 DB Nvidia RTX 3060 Ti és 8 DB Zotac Gaming Geforce RTX 3080 Trinity / KOMPLETT BÁNYAGÉP
- ASUS ProArt GeForce RTX 4080 SUPER 16GB GDDR6X OC (ASUS-VC-PRO-RT4080S-O16G) Bontatlan új 3 év gar!
Állásajánlatok

Cég: Ozeki Kft.
Város: Debrecen

Cég: Promenade Publishing House Kft.
Város: Budapest