- Nyár közepén jön az AOC 540 Hz-es gaming monitora
- AMD APU (AM4 és AM5) topik
- Azonnali informatikai kérdések órája
- HiFi műszaki szemmel - sztereó hangrendszerek
- AMD Ryzen 9 / 7 / 5 7***(X) "Zen 4" (AM5)
- Vezetékes FEJhallgatók
- SONY LCD és LED TV-k
- Melyik tápegységet vegyem?
- Május 7-én lesz az új iPadek bemutatója
- iPad topik
Hirdetés
-


Megjelenési dátumot kapott a Metaphor: ReFantazio
gp A tervek szerint a végső kiadás októberben lesz elérhető PC-re és konzolokra.
-


Május 7-én lesz az új iPadek bemutatója
ma Online termékbemutatót tart az Apple május 7-én, a közvetítésen iPadek és hozzájuk tartozó kiegészítők lesznek a téma.
-


AMD Radeon undervolt/overclock
lo Minden egy hideg, téli estén kezdődött, mikor rájöttem, hogy már kicsit kevés az RTX2060...






-

PROHARDVER!
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#57701
 Alogonomus
őstag
Petykemano
#57692
Alogonomus
őstag
Petykemano
#57692
Alogonomus
őstag
válasz
 Petykemano
#57692
üzenetére
Petykemano
#57692
üzenetére
Kérdés, hogy mit értett "top end Alchemist" alatt, de a 6700XT/3070/Ti az eredetileg is legfeljebb az A780 területe lett volna, amit már elég régen elengedett az Intel.
Jelenleg a csúcs Alchemist az A770 lehet, bár eredményeket még csak az A750 kapcsán közölt az Intel, és azok a 3060 szintjét hozták, plusz azok valószínűleg eleve az Intelnek kedvező játékválogatásból készültek. A 3060-nál bő 10%-kal jobb a 6600XT, amennyit nagyjából az A770 hozhat az A750-hez képest. -
#57702
 kisfurko
senior tag
Petykemano
#57700
kisfurko
senior tag
Petykemano
#57700
kisfurko
senior tag
válasz
Petykemano
#57700
üzenetére
Szerintem is drága mulatság ez az MCD-sdi, de lehet, hogy idővel a GCD-vel a nyereség ezt kompenzálni tudja, ki tudja. Kíváncsian várom az árakat, meg a teszteredményeket.
-
#57703
 b.
félisten
Petykemano
#57700
b.
félisten
Petykemano
#57700
válasz
Petykemano
#57700
üzenetére
Valószínűleg a 31 nél a 3D is rátesz egy lapáttal a költségekre, de ettől függetlenül meg van a Pro és a gaming vonal közötti átmenet .
Ott ha így csinálják ahogy mondtad, 16 MB felosztással a 3D miatt lesz egy gyorsabb IF cache rész is ?
Az igazán ütős és piacrész szerzésre tervezhető SKU ebből a N32 ami elhagyja az úri( 3D) ficsőrőket és olcsó hatékony , gyors Kártyákat lehet majd erre építeni. Itt nem is a felső szegmens a lényeges a konkurenciával szemben , hanem ez.
Mondjuk nem vagyok benne biztos de ezzel azért még az RT és egyéb DL ficsőrőkben nem tudom be tudja e hoznia konkurenciát. ( lehet nem is kell neki )Volt pletyka arról hogy AMD is tervez Tensor/ ML re kigyúrt egységeket a kártyáiba. Itta cikk nem tér erre ki ,ezek szerint elmarad vagy a Pro szegmens kiváltsága lesz.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#57708
 szmörlock007
aktív tag
b.
#57706
szmörlock007
aktív tag
b.
#57706
szmörlock007
aktív tag
Könnyen lehet, plusz valószínűleg azzal lehet támadni a top1 gaming gpu címet is ha szükséges nekik, meg persze ha jól skálázódik.
#57700
"Az igazán ütős és piacrész szerzésre tervezhető SKU ebből a N32 ami elhagyja az úri( 3D) ficsőrőket és olcsó hatékony , gyors Kártyákat lehet majd erre építeni. Itt nem is a felső szegmens a lényeges a konkurenciával szemben , hanem ez."Elvileg a navi31 se lesz 3d-s, legalábbis a cikkben az van, hogy a sima 96 MB-os lesz az elsődleges gamingre, mert a 192 MB nem éri meg a felárat arányaiban. Szóval elvileg a navi 31 se lesz sokkal-sokkal drágább azért mint a navi 32, ugye 50%-al nagyobb a GCD meg +2 MCD van, a 3d tokozásos verziója valszeg megmarad Pro-ra, meg Refreshre, vagy ha csak 5-10% plusz hiányzik a csúcson, akkor kiadják azt megtámadva.
[ Szerkesztve ]
-
#57709
 vezeralmos2
senior tag
vezeralmos2
senior tag
vezeralmos2
senior tag
Sziasztok,
szerintem elképzelhető hogy nemsokára kijön az új Quantum technológiás AMD GPU, a Radeon HD One. Ezzel az összes többi grafikuskártya gyártónak befellegzett.A Sandy Bridge legendája
-
#57710
 regener
veterán
vezeralmos2
#57709
regener
veterán
vezeralmos2
#57709
regener
veterán
válasz
 vezeralmos2
#57709
üzenetére
vezeralmos2
#57709
üzenetére
Köszönjük az információt

-
#57711
 Pkc83
őstag
vezeralmos2
#57709
Pkc83
őstag
vezeralmos2
#57709
Pkc83
őstag
válasz
vezeralmos2
#57709
üzenetére
16k, 360fps... Nvidia megy is csődbe.
-
#57712
 hokuszpk
nagyúr
vezeralmos2
#57709
hokuszpk
nagyúr
vezeralmos2
#57709
hokuszpk
nagyúr
válasz
vezeralmos2
#57709
üzenetére
tippre a jövőből jöttél, csak valami gixer folytán picit többet ugrottál vissza, mint amennyit akartál
![;]](//cdn.rios.hu/dl/s/v1.gif)
Első AMD-m - a 65-ös - a seregben volt...
-
#57713
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
nézem ezeket a nemhivatalos renderképeket és az jut eszembem, hogy ha az MCD (memóriavezérlő + opcionális 3D tokozott cache) úgyis nagy sávszélességű kapcsolaton keresztül csatlakoztatott tokozási megoldáson keresztül csatlakozik a fő lapkához, akkor vajon ehhez képest mennyivel lett volna drágább vagy rosszabb ,vagy nem tudom ha rögtön HBM-et is tokoznak hozzá/mellé/fölé?
pl:
- nem lehetne a HBM-et 3D tokozni a memóriavezérlő+cache lapkára?
- vagy ha a HBM csak konzervatív módszerekkel működik, vagyis kell az interposer, akkor is elég egy-egy akkora interposer, amire a memóriavezérlő és mellette a HBM elfér, ami lényegesen kisebb, mint ha az egész lapka alá kéne interposer és meghagyja az MCD V-cache -sel való ellátásának lehetőségét.[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
"9 Chiplets navi3 started to be mass-produced. I was wondering what it was and why it was not a 7 but a 9. A navi with 13 Chiplets began development. It's still a long way from mass production, about a year from now."
és egy lehetséges forgatókönyv:
(Skyjuice tipp )
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#57715
Petykemano
veterán
b.
#57714
Petykemano
veterán
A 9 lehet
- egy navi32 + 4 MCD+ 3D IC
vagy
- két navi32 + 2×3 MCD + 1 nagyrészt cache-t tartalmazó cache lapka. Ahhoz hasonlóan, ahogy a kínai BR10X is összekapcsolódik, tehát a kapcsolódás pontja az, ahol az MCD kapcsolódna, és ahol egy IC szelet is lenne. De ott egy nagyobb cache lesz ami azt a célt szolgálja, hogy bridgeljen a másik GPU lapkához tartozó adatok gyors eléréséhez. Így csökken a nyomást a másik lapka belső buszán és persze csökken a késleltetés.A 13 lapkás változat ugyanez csak navi31 lapkákkal és 2×5 MCD-vel.
Én ugyanezt a táblázatot ma egy Coreteks videoban láttam
Találgatunk, aztán majd úgyis kiderül..
-
#57716
b.
félisten
Petykemano
#57715
válasz
Petykemano
#57715
üzenetére
Szerintem is ez 3D V-cache a Navi 31-hez kapcsolva.
Hivatalosan innen van, innen szedték ők is kiegészítve árakkal. [link] Téged szokott jobban érdekelni a téma, nem tudom láttad e a TSMC 5 nm fejtegetését. Tök érdekes és rávilágít egy két dologra. [The TRUTH of TSMC 5nm]
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#57717
Alogonomus
őstag
b.
#57714
Alogonomus
őstag
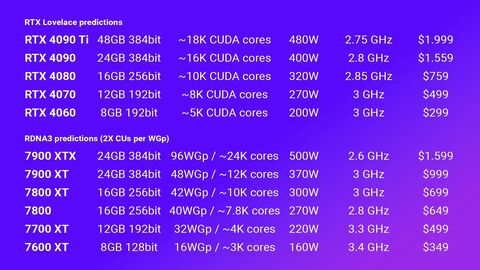
A régóta általánosan elfogadott vélekedés, hogy az RDNA3 jelentősen energiahatékonyabb lesz, mint a Lovelace. Ezek után vagy a 7800 (non XT) már a 4080 szintjét hozza, míg a 7800 XT már a 4090, a 7900 XT pedig a 4090 Ti kihívója lesz, vagy a táblázat mond ellent a közvélekedésnek.
Az 192 bites RTX 4060 pedig szinte biztosan hiba a táblázatban, mert vagy 128 bit, vagy 12 GB a lehetséges. Fölöslegesen nem áldoznak chipterületet az egyébként is nagyon területigényes memóriavezérlőre.
-
#57718
b.
félisten
Alogonomus
#57717
válasz
 Alogonomus
#57717
üzenetére
Alogonomus
#57717
üzenetére
általánosan elfogadott vélekedés= remény hogy jelentősen energiahatékonyabb lesz? Ezek nagy szavak ám .
 két meg sem jelent GPU architektúráról beszélünk a valós teljesítmény ismerete nélkül.
két meg sem jelent GPU architektúráról beszélünk a valós teljesítmény ismerete nélkül.
jelentős energiahatékonyságbeli eltérés utoljára Pascal vs Vega generációnál volt ahol kb 50 % eltérés volt a két gyártó azonos szintű termékei között.
Pont azt látom mindenhol hogy bizonytalan mindenki mit is fog hozni a két gyártó pontosan és nincsen általánosan elfogadott vélekedés azon kívül hogy minkét arc gyors lesz és sokat fog enni. AMD is. és ezzel már kb már lefedték az összes lehetséges forgatókönyvet a leakerek.
A 128 bites forgatókönyvvel egyetértek.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#57719
 paprobert
senior tag
Alogonomus
#57717
paprobert
senior tag
Alogonomus
#57717
paprobert
senior tag
válasz
Alogonomus
#57717
üzenetére
A GCN érában másfél generációs perf/w előnye volt a zöldeknek átlagosan.
Az RDNA megjelenése óta csak tippelgetni lehet az erőviszonyokra. A becsléseket arra alapoztuk, amilyen csata volt a TSMC 12nm vs 7nm, illetve az S8 vs 7-6nm-es kártyák között.
Ez alapján az NV tetemes előnye csökkent, de még mindig van."A régóta általánosan elfogadott vélekedés, hogy az RDNA3 jelentősen energiahatékonyabb lesz, mint a Lovelace."
Pont arról olvashattunk legutóbb híreket, hogy az AMD továbbra is "Area Area Area" felfogással alakítja ki az RDNA3-at.
Tudod, hogy ez mit jelent ez a gyakorlatban?Azt, hogy el fogja rontani a perf/w arányt egy adott terméknél, bármennyire is jó az architektúra.
Azért, mert minden egyes teljesítményszint egy kisebb kategóriás GPU-val van lefedve. (Minden kártya szét van húzva, magas boost órajellel jön, indokolatlanul magas fogyasztással a méretéhez képest. Kicsiben láthattuk ezt már az RDNA2-vel is.)Arról ne is beszéljünk hogy a chipletek közötti adatszinkronizáció segíti-e az energiahatékonyságot.
 Szóval nem, valószínűleg nem lesz energiahatékonyabb az RDNA3.
Szóval nem, valószínűleg nem lesz energiahatékonyabb az RDNA3.
Akkor történhetne meg az előzés, ha van valami trükk az AMD tarsolyában amiről nem tudunk, vagy ha a zöldek valamit bődületesen elrontanak.[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
-
#57720
 Hellwhatever
aktív tag
Hellwhatever
aktív tag
Hellwhatever
aktív tag
Ha már energiahatékonyság, erősen ajánlott olvasmány arról miért is problémás csak a szenzoros mérésekre alapozni AMD-nél: https://www.igorslab.de/en/graphics-cards-and-their-consumption-read-out-rather-than-measured-why-this-is-easy-with-nvidia-and-nearly-impossible-with-amd
[ Szerkesztve ]
-
#57721
b.
félisten
Hellwhatever
#57720
válasz
 Hellwhatever
#57720
üzenetére
Hellwhatever
#57720
üzenetére
Ezt anno linkeltem a Vs ben is. nem semmi azért hogy 20 -33 % kal több a valós fogyasztás az RDNA 2 nél.
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#57722
Alogonomus
őstag
paprobert
#57719
Alogonomus
őstag
válasz
 paprobert
#57719
üzenetére
paprobert
#57719
üzenetére
A kisebb chipfelületen ugyanakkora hőmennyiség leadása jelentősebb hőáramot feltételez. Az "Area Area Area" felfogás alapján egyértelműen az AMD-nek lesz nagyobb kihívás egységnyi hőmennyiséget átpasszolni a hűtőbordák felé, így az AMD keze jobban meg van kötve a fogyasztás szabadabbra elengedése kapcsán.
-
#57723
 Abu85
HÁZIGAZDA
Hellwhatever
#57720
Abu85
HÁZIGAZDA
Hellwhatever
#57720
Abu85
HÁZIGAZDA
válasz
Hellwhatever
#57720
üzenetére
Ezért kell konnektorból mérni. Abban még az is benne van, hogy mennyire hatékony a meghajtó a CPU többletterhelését tekintve.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#57725
Petykemano
veterán
b.
#57716
Petykemano
veterán
> Szerintem is ez 3D V-cache a Navi 31-hez kapcsolva
Nem gondolnám, hogy a 3D.vcache nagyobb mértékben növelné a teljesítményt. Lehetnek.bizonyos késleltetés érzékeny folyamatok, amiknél persze igen. Például szerintem az RT ilyen.
Ehhez képest a GCD duplázás biztosan nagy hallelúja lenne.Szóval bármennyire is szeretném, hogy az $1500-2000 példányok inkább ezek a böhöm állatok legyenek, valóban az tűnik reálisnak, hogy ha most 3D cache alapján történik a szegmentáció és lesz Radeon RX és Radeon RTX. Meg persze a PRO szoftvereknél ki tudja hol jön jól az alacsony késleltetés?
Aztán jövőre lehet egy olcsón megúszható refresh az összekapcsolt lapkákból. És akkor nem marad ki év a 2024-re ígért RDNA4-ig.
Találgatunk, aztán majd úgyis kiderül..
-
#57727
b.
félisten
Petykemano
#57725
válasz
Petykemano
#57725
üzenetére
Természetesen az lenne teljesítmény centrikus megközelítés.Kérdés az hogy hova és mire,mert nem tartom elképzelhetetlennek a Tensor/DL műveletekre való egységeket,ami megadná a 3d cache fontosságának az okát.
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
#57728
 Busterftw
veterán
Hellwhatever
#57720
Busterftw
veterán
Hellwhatever
#57720
Busterftw
veterán
válasz
Hellwhatever
#57720
üzenetére
Erről az AMD anti-consumer tevékenységről lehetne hír itt is.
-
Abu85
HÁZIGAZDA
válasz
 Busterftw
#57728
üzenetére
Busterftw
#57728
üzenetére
Milyen anti-consumer tevékenység. Az AMD hardverei régóta így működnek. És azért működnek így, mert így sokkal gyorsabb lehet egy hardver. Amikor bevezették az AVFS-t, akkor sokszor hangsúlyozták, hogy 15 éve dolgoznak egy ilyenen, és a célja ennek az, hogy ne csak 1 perces turbókat kapj, hanem kitartott, 4-7 percig dolgozókat is. A DVFS-hez viszonyítva az AVFS +10-20%-os extra teljesítményt is jelent a felhasználónak. Az, hogy nem lehet normálisan kimérni? Sosem tervezték arra, hogy ki lehessen. Aki valós fogyasztási adatokat akar, olvassa a fogyasztásmérőt a konnektorból. A többi megoldásban mindig is sok volt a hibalehetőség. De nem fognak 10-20%-nyi teljesítményről lemondani azért, mert a user nem tudja pontosan mérni a fogyasztását a hardvernek.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
Specifikusan külön ilyen egység nem lesz benne. Egyszerűen nincs értelme egy feladatért tranzisztorok tízmilliárdjait elkölteni, amit lehet, hogy xy cím alatt be sem lehet kapcsolni. Ráadásul ezek az eljárások jó darabig gyártóspecifikusak lesznek, tehát face-to-face tesztben be sem fogják őket kapcsolni, ami azért nagy baj, mert tranzisztorok tízmilliárdjai rögtön mennek a kukába az irányadó teszteknél. És akkor jöhet a gyártó azzal, hogy nem jól tesztelsz, mert amúgy a hardver gyors.

Az RDNA 3 egyszerűen csak kap egy úgynevezett WMMA operációcsoportot. Ez ugyanaz, mint ami a CDNA architektúrákban van, azzal a különbséggel, hogy sokkal korlátozottabb a mátrixok kezelése, de ugye az RDNA csak grafikai dizájn. Ennek a módszernek az az előnye, hogy mindössze csak a dekódolót és az ütemezést kell átalakítani, külön ALU-t nem igényel, vagyis az operációk futhatnak a normál számításra használt SIMD motorokon. Ilyen formában ezért a képességért nem tízmilliárdos, hanem inkább százmilliós nagyságrendben kell tranzisztorral fizetni, így a megnyert tranyókat el lehet költeni olyan feldolgozókra, amelyeket minden program hasznosít, és amelyekre majd a tesztekben is építenek.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Gondolom Nvidiáról beszélsz, természetesen. ( Tudtam amúgy hogy ezt fogod írni ha hozzászólsz) Nagyon béna egy cég, semmihez nem értenek. Az elpazarolt tensor és RT magok miatt vannak lemaradásban mindenben is.
Amúgy az íróniát félretéve, nem a gaming vonalra gondoltam a tensor vonal nem tudom mennyire értelmezhető még a továbbiakban illetve fognak e rá építeni valamit.
Amúgy Semmi kivetni valót nem látok a gyártóspecifikus dolgokban. Az hogy tesztekben nem kapcsoljak be a cikkírók nem jelenti azt hogy otthon ezt ne tenné meg egy felhasználó de sok esetben volt és van értelme a dedikált hardvernek lásd RT. Az IFC is egy dedikált hardver, még ha megkerülhetetlen is de helyet foglal költséget emel a teljesítmény céljából biztos vagyok benne hogy sok szoftver jobban kihasználja ha direkt optimalizáljak rá a szoftvert vagy a játékot meg sok esetben nincs előnye abból az RDNA 2 nek, hogy van benne nagy cache.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
Abu85
HÁZIGAZDA
Meg az Intelről is. Ők is külön egységgel oldják meg. Nagyon messze is vannak a versenyképességtől.
Én sem, de megvan a maga átka. És nyilván nyomós indokkal nem akar az AMD tranzisztortízmilliárdokat költeni egy olyan dologra, aminek a hatása a tesztekben nem fog látszódni.
Az Infinity Cache csak egy egyszerű victim cache. Eleinte voltak particionálási kísérletek optimalizálás gyanánt, de az AMD egy ideje egyáltalán nem ajánlja. Egyszerűen csak az a javaslat, hogy hagyják automatikusan dolgozni, ne is foglalkozzanak azzal, hogy van, tudja a dolgát magától.Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Busterftw
#57735
üzenetére
Akkor leírom még egyszer. Mindig azt mondtuk a PH-n, hogy ezekben a mérésekben nem lehet bízni. Ezért mérünk fogyasztásmérővel. Az, hogy az igazunk rendre újra és újra bebizonyosodik, hát basszus, ezért mondjuk jó ideje azt, hogy csak a konnektorból mért fogyasztási adat a megbízható. Minden más potenciálisan tévúthoz vezethet. Ha van valaki, aki még 2022-ben sem értette ezt meg, nos, ő már sosem fogja.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
Abu85
HÁZIGAZDA
válasz
Busterftw
#57737
üzenetére
Az nem zavar, hogy mi évekkel korábban is azt mondtuk, amit Igor, csak korábban még kinevettek?
Persze lehet bízni 2022-ben szoftveres mérésben, de már régóta nem mérvadó. És ennél világosabban nem tudom leírni. Mi már évekkel korábban is azt mondtuk, hogy csak a konnektorból mért adat a mérvadó, mert az vesz figyelembe mindent. Az, hogy valakinek ez 2022-ben esik le... hát, jó reggelt.
Persze felőlem rácsodálkozhatunk minden évben, hogy szoftveresen a fogyasztás nem kimérhető, csak ne tegyünk úgy, hogy ez nem 10-15 éve ismert tény.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
válasz
Busterftw
#57735
üzenetére
A hardveres mérést semmi nem tudja helyettesíteni. Az otthon mért szoftveres fogyasztásadatok valójában magasabb értékkel bírnak de az nem mindegy hogy ez Nvidiánál 3 % AMD nél meg 20-33 % is lehet.
Mondjuk abban mindenképpen igazad van hogy el lehet menni ez mellett így is hogy konektorból kell mérni aztán rálegyinteni,meg úgy is hogy ez azért nem túl fair dolog egy gyártótól, hogy erre nem fegyelmezteti a felhasználóit hogy csókolom az a 220 W valójában 270W és egy részletes elemző cikk kell ahhoz hogy ez kiderüljön.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
válasz
 #32839680
#57741
üzenetére
#32839680
#57741
üzenetére
Nem értem amúgy ezt miért nem teszik meg meg. Ráadásul a ventik fogyasztását sem veszi figyelembe. Értem én hogy a GPU-t és memóriát montírozza mint az állat de a valós teljes áramfelvétel meg becsült érték szofveres mérésnél?
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
Busterftw
veterán
"meg úgy is hogy ez azért nem túl fair dolog egy gyártótól, hogy erre nem fegyelmezteti a felhasználóit hogy csókolom az a 220 W valójában 270W és egy részletes elemző cikk kell ahhoz hogy ez kiderüljön."
Helo 2022 tevuton vagy, a PH-n ezt mar megirtak. Bar keresem ezt az elemzo cikket, nem talaltam meg meg.
[ Szerkesztve ]
-

Pakmara
őstag
Konnektornal a hw környezet ugyanúgy bejön mint torzító hatás: táp hatásfok, akt. kapacitas kihasználtsága, milyen cpu. Szvsz Igornál pont ez volt a lényeg, hogy a megmutatta a kettő közötti (fogyasztas mérő felöl vs sw felöl) értéket, és azt, hogyan aranylik a felhasználó által legkönnyebben elérhető sw-es adatokhoz a kártya tényleges fogyasztasa.
-
#57746
Petykemano
veterán
Pakmara
#57745
Petykemano
veterán
válasz
 Pakmara
#57745
üzenetére
Pakmara
#57745
üzenetére
Ugyanabban a gépben mérve nagyjából ugyanolyan torzító hatások jelentkezhetnek, amelyek ugyanúgy hatnak a különböző gpukra.
Ha ez mégsem így lenne, akkor az meg pont az adott gpu jellegezetessége / hatása, amit figyelembe kell venni. Szerintem reális, hogy ha a CPU-t jobban vagy kevésbé veszi igénybe a gpu, akkor amikor a perf/W mutatót nézzük, akkor az is számítson bele.De Abu állítása szerint mindig is így mérték, sosem próbálták az AMD kártyák fogyasztását a hamiskás szoftveres mérésekkel kozmetikázni. Szerintem emiatt nem jogos Neki felróni azt, hogy erről (Igor felfedezéséről) Ő miért nem írt tájékoztató cikket hivatalból. Azoknál lehetne pampogni, akik (eddig vagy ezután) szoftveresen mért adatokkal tájékoztatják félre a potenciális vásárlókat.
Találgatunk, aztán majd úgyis kiderül..
-
#57747
 awexco
őstag
Petykemano
#57746
awexco
őstag
Petykemano
#57746
awexco
őstag
válasz
Petykemano
#57746
üzenetére
Lehet mérni konektorbol de akkor felmerül a kérdés mennyi volt a cosφ ?
I5-6600K + rx5700xt + LG 24GM77
-
#57748
Petykemano
veterán
awexco
#57747
Petykemano
veterán
válasz
 awexco
#57747
üzenetére
awexco
#57747
üzenetére
A konnektoros mérésből egy olyan értéket fogsz kapni, amit nem tudsz összehasonlítani más weboldalak/csatornák akár azonos módszertannak, de más konfigurációval mért értékeivel.
De feltételezem, hogy a cosφ (már amennyiben a táp hatásfokára célzol ezzel), szerintem azonos lehet, ha azonos kategóriájú GPU termékeket mérsz. Tehát lehet, hogy egy 75W-os és egy 350W-os TDP-vel rendelkező kártyáról a nagyon kicsi és nagyon nagy leadott teljesítmény mellett esetleg tapasztaható eltérő hatásfok miatt nem lesz pontos a mérés, nem lesz a két nagyon eltérő kártyára egy pontos szám az áramfelvétel különbségére. De hasonló kategóriájú kártyák esetén szerintem ez a veszély nem áll fenn.
Találgatunk, aztán majd úgyis kiderül..
-
#57749
Pakmara
őstag
Petykemano
#57746
Pakmara
őstag
válasz
Petykemano
#57746
üzenetére
Nem kérdőre vonás akart lenni, csak megjegyeztem h számomra miért volt érdekes az a cikk: mert felhívja a figyelmet egy olyan jelenségre amin sokan (akar teszteket közreadók is "átsiklanak").
A bújtatott kritika az így hangzik: mi falból mérünknél egy fokkal beszédesebb/szerencsésebb tudna lenni: a mi falból mérünk mert ctrl+v a fenti komment (félre visz., cpu többlet stb). Lehet szájbarágós de az egyszeri olvasót így talan jobban eligazítja az eletérő eredmények között.
-

Yutani
nagyúr
Nem tudom, hogy az itt jelen lévők nem szokták nézni a TPU fogyasztás adatait? Ők a PCIe power connector és PCIe busz fogyasztását mérik, tehát csak a kártya fogyasztását. Nem szoftveres bohóckodás, mert annak egyébként is ki hisz? Persze, csúnya AMD, dádá, ezt mindenképpen be kell írni.
#tarcsad
















![;]](http://cdn.rios.hu/dl/s/v1.gif)



 két meg sem jelent GPU architektúráról beszélünk a valós teljesítmény ismerete nélkül.
két meg sem jelent GPU architektúráról beszélünk a valós teljesítmény ismerete nélkül.
 Szóval nem, valószínűleg nem lesz energiahatékonyabb az RDNA3.
Szóval nem, valószínűleg nem lesz energiahatékonyabb az RDNA3.













Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Nintendo Switch
- Samsung Galaxy S23 Ultra - non plus ultra
- Ukrajnai háború
- E-roller topik
- Nintendo Switch 2 vagy amit akartok (találgatós topik most még)
- Nyár közepén jön az AOC 540 Hz-es gaming monitora
- Luck Dragon: Asszociációs játék. :)
- Sweet.tv - internetes TV
- AMD APU (AM4 és AM5) topik
- Robotporszívók
- További aktív témák...
