Hirdetés
A Kepler architektúra mélylélektana
A bevezető után itt az ideje ízekre szedni a 28 nm-es gyártástechnológiával készülő, GK104-es cGPU-t. A 3,54 milliárd tranzisztorból felépülő lapka sokban hasonlít tehát a Fermihez, már ami az alapokat illeti. A rendszerbe 8 darab streaming multiprocesszort sikerült beépíteni, amit az NVIDIA hangzatosan SMX-nek hív; lényegében ezek a modulok felelnek a Kepler képességeiért. A streaming multiprocesszorok felépítése rendkívül komplex: mindegyik ilyen egység 192 darab, úgynevezett CUDA magot tartalmaz két nagyobb csoportba rendezve, így az utasításszavak csoportonként 3 darab, 32 utas feldolgozón lesznek párhuzamosan végrehajtva. Mindegyik CUDA mag rendelkezik egy IEEE754-2008-as szabványnak megfelelő, 32 bites lebegőpontos végrehajtóval, melyek támogatják a MAD (Multiply-Add) és az FMA (Fused Multiply-Add) instrukciókat. A regiszterek szempontjából a Fermi köszön vissza, így a rendszer közös regiszterterületet használ egy streaming multiprocesszoron belül, melynek kapacitása 256 kB. A feldolgozók számának drasztikus növekedésével a feladatirányító egységek (dispatch) számát is növelni kellett, így már nyolc található egy-egy SMX modulban. Ezzel egyetemben a warp ütemezők száma is négyre nőtt.
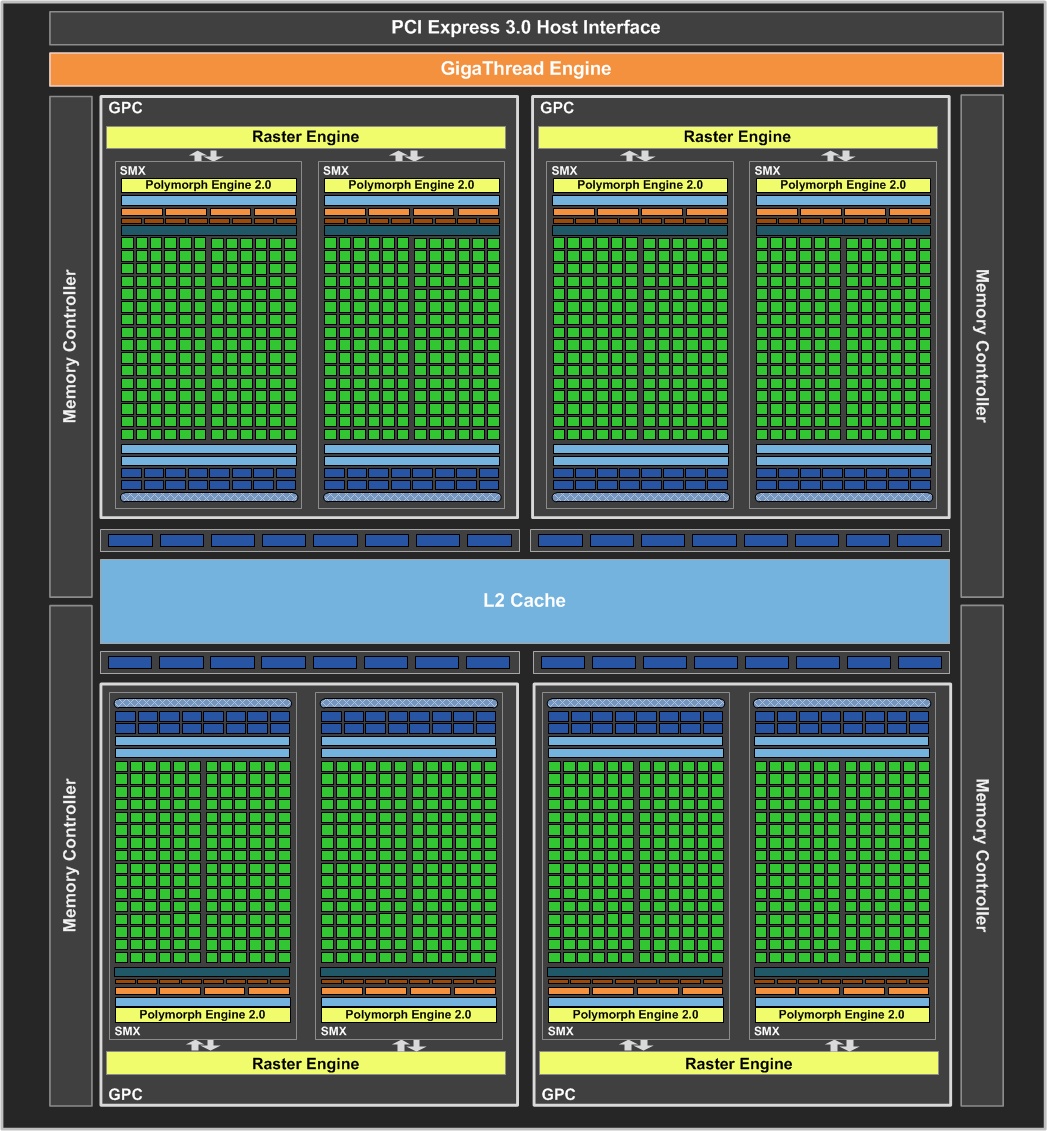
A GK104 logikai felépítése [+]
Az SMX modulon belül a két feldolgozócsoport 16-16 darab, a speciális funkciókért felelő egységet (SFU) kapott, a Kepler architektúrában ezek végzik a trigonometrikus és transzcendens utasítások mellett az interpoláció feladatát is. Utóbbi jelentős erősítésen esett át a Fermihez képest, ami kellett is, ugyanis így a teljes lapkát nézve már 256 interpolátorról van szó, szemben a GF100, GF104, GF110 és GF114 kódnevű GPU-k 64 darab egységével. Az interpoláció során érdemes megjegyezni, hogy az AMD emulációval dolgozik, ami a mai játékok rendkívül eltérő igényei mellett kiegyensúlyozottabb eredményeket ad. Az NVIDIA továbbra is a fixfunkciós interpolátorok mellett teszi le a voksát, de a számuk jelentős növelésével a Kepler is kiegyensúlyozottabban teljesít majd. Igazából mindkét elgondolás járható út, és egyaránt rendelkeznek előnyös és hátrányos hatásokkal. Az NVIDIA még az emuláláson is elgondolkodhat emellett, hiszen mostmár a shaderek oldaláról is elég erős lett a rendszer ehhez.

Streaming multiprocesszor, avagy SMX [+]
A GK104 a textúrázási képességek területén is belehúz. Az egyes streaming multiprocesszorok mostantól négy darab textúrázó blokkot tartalmaznak, melyekben egyenként négy textúracímző és textúraszűrő található, és ezekhez csatornánként négy mintavételező tartozik. Ez a fejlesztés szükséges lépés volt, hiszen a CUDA magok száma jelentősen nőtt a streaming multiprocesszorokon belül. Újítás még a textúrázási modell áttervezése. A Fermi esetében maximum 128 egyedi textúra volt beköthető egy shader kódon belül. Ebből a szempontból a Kepler változtat, és egymillió fölé emeli ezt az értéket. Itt persze meg kell jegyezni, hogy az egyedi textúrák 128-ra való limitálása a shader kódokban a DirectX 11 API sajátossága, vagyis ahhoz, hogy a Keplerhez bonyolultabb shader kódokat lehessen írni, egy kiterjesztés szükséges a Windows 8-ban megjelenő DirectX 11.1 API-n belül. Természetesen ugyanez szükséges az OpenGL oldaláról is.
Az előbbi bekezdésben részletezett technológiát az NVIDIA bindless textúrázásnak hívja. Itt érdemes megjegyezni, hogy az AMD is bevezetett egy hasonló megoldást a GCN architektúrára épülő termékekben, ahol az egyes CU-kban található skalár feldolgozók kiolvashatják az erőforrás állandókat, és ezzel vezérelhetik a textúrázást. Mindez elméletben végtelen mennyiségű egyedi textúra bekötésének lehetőségét jelentheti egy adott shader kódban. Sőt, az AMD még ennél is továbbment a Partially Resident Textures eljárással, mely lehetővé teszi a hardveres virtuális textúrázást (ismertebb néven megatextúrázást) és a hardveres textúra streaming algoritmusok kreálását.
Memóriahierarchia szempontjából a Kepler architektúra szinte teljesen a Fermit másolja. A GK104 egy 512 kB kapacitású, megosztott L2 gyorsítótárat alkalmaz, mely minden streaming multiprocesszor számára elérhető, és a CUDA magok írhatnak is bele. Maguk az SMX modulok 64 kB-os L1 gyorsítótárral rendelkeznek, mely a feladatnak megfelelően dinamikusan szétosztható egy 16 és egy 48 kB-os részre, illetve újítás, hogy mostantól 32-32 kB-os szeletelés is lehetséges, attól függően, hogy mekkora megosztott memóriát igényelnek a CUDA magok. Természetesen a grafikus feldolgozás során a DirectX 11 specifikációinak megfelelően kötelező minimum 32 kB-os helyi adatmegosztást (Local Data Share) alkalmazni. A megújult textúrázó csatornák természetesen most is külön gyorsítótárat kapnak.
Az NVIDIA a GK104 dupla pontosság melletti képességeiről nem beszélt. Egyrészt ez nem olyan fontos a GeForce által megcélzott piacon, másrészt a lapka ebből a szempontból nem éppen erős. Az SMX-eken belül egy 32 utas tömb fogható be dupla pontosságra, eközben pedig a modulon belüli további öt 32 utas tömb dolgozhat bármi máson. A dupla pontosság a tömb elméleti kapacitásának negyedével valósul meg. Ez összesítve a GK104 esetében lényegében 130 GFLOPS-ot jelent, ami tényleg nem sok. A konkurens Tahiti cGPU például 947 GFLOPS-os tempóra képes.
A memóriavezérlő tekintetében az NVIDIA továbbra is maradt a crossbarnál. A GK104 256 bites szélességű buszt használ, mely 64 bites csatornákra van szétosztva. Egy-egy csatornához két ROP-blokk tartozik. Utóbbiból összesen 8 darab van, ami 32 blending és 256 Z mintavételező egységet eredményez.
A cikk még nem ért véget, kérlek, lapozz!






