Újabb utasításkészletek
A mikroarchitektúra módosítása mellett természetesen új utasításkészletek is költöztek a processzorba, a választék bővítésének tekintetében viszont a Haswell kiemelkedik a korábbi generációk közül.
Tranzakcionális memóriakezelés
Azon többszálú programoknak, amelyek nem statikusan felosztott adathalmazokon dolgoznak – pl. 2 mag esetén az adatok felén, 4 mag esetén a negyedén stb. –, általános problémája annak biztosítása, hogy ugyanazt az adatot egyszerre csak az egyik szál módosíthassa. Az x86/x64 architektúra az egyetlen egész számot tartalmazó változó közvetlen vagy akár feltételes atomi módosítására – amely lehet 1, 2, 4, 8 vagy 16 bájtos – kényelmes lehetőséget biztosít a LOCK utasításprefix vagy a CMPXCHG-utasításcsoport révén; előbbi a 'betöltés-módosítás-kiírás' típusú utasításoknál alkalmazható.

Amennyiben egynél több adat atomi módosítására van szükség, nehezebb a helyzet: ilyen esetben a teljes adathoz való hozzáférést egyetlen szinkronizációs változóval kell levédeni, ennek módosításáért (azaz birtoklásáért) majd visszaállításáért versengenek a szálak, és amelyik szál sikeresen módosítja a szinkronizációs változót, az hajthatja végre a módosításait a teljes adathalmazon; a többi szál eközben várakozik tétlenül. Sűrűn előfordul azonban, hogy a különböző szálak adatmódosításai nem ütköznek egymással, általában más-más adatot módosítanak, így a várakozások nagy része felesleges lenne. E teljesítményromboló állási idők elkerülésére fejlesztették ki a tranzakcionális memóriakezelési technikákat, melynek első kereskedelmi forgalomba kerülő megvalósítása – mivel a néhai Sun Rock nevű processzort végül nem dobták piacra – a Haswellben debütál.
A Haswell rögtön két megoldást is kínál a tranzakciók kezelésére: az egyik teljesen kompatibilis a régebbi processzorokkal (HLE, Hardware Lock Elision) – bár hatása nem érvényesül azokon, de érvényes utasításként elfogadják őket –, a másik (TSX-utasításkészlet) három új utasítás bevezetését jelenti: XBEGIN, XEND és XABORT. Mindkettő működési mechanizmusa azonos:
- a tranzakció elejét és végét egy-egy utasítás jelzi;
- a tranzakció végrehajtása közben a processzor feljegyzi, hogy mely memóriaterületekről történt olvasás és melyekre írás, valamint a módosítások csak az L1D és L2 cache-be kerülnek, miközben az L3 az eredeti adatokat tartalmazza, így a többi programszál ezeket látja;
- a tranzakció végén a processzor ellenőrzi, hogy a feljegyzett memóriaterületek még mindig az eredeti értékeket tartalmazzák-e – azaz amikkel a program a tranzakció alatt számolt, más szál nem módosította-e őket időközben –; ha igen, akkor az adatmódosítások egyszerre lesznek láthatóak a teljes rendszer számára (commit); ha viszont változás történt, akkor az L1/L2 cache-ben levő a módosított értékeket felülírja az aktuális értékekkel (rollback), és újra megpróbálkozik a teljes tranzakció lefuttatásával.
Ily módon hardveresen biztosított az, hogy nem módosítja több szál egyszerre az adathalmaz azonos elemét, viszont figyelembe kell venni, hogy az adatmódosítások számának limitáló tényezője elsősorban a 256 kB-os L2 cache: túl sok felhasznált és/vagy módosított adat esetén a processzor önhatalmúlag megszakíthatja a tranzakciót (abort; erre a programozó is utasítást adhat bizonyos körülmények fennállása esetén); ilyen esetekre a TSX használatával külön 'menekülőút' írható a programba, míg HLE alkalmazása esetén újra lefut a tranzakció, immár az említett várakozás kikényszerítésével.
FMA3
A Haswell megérkeztével az AMD után immár az Intel is bevezette a lebegőpontos FMA-utasításokat (fused multiply+add), mégpedig háromparaméteres változatukat, amely egyik bemenő adatát felülírja az eredménnyel. Ezen 5 órajel alatt végrehajtódó utasítások 256 bites vektorokon is dolgozhatnak, továbbá órajelenként 2 kerülhet végrehajtásra, így – mivel egy FMA két FLOP-nak felel meg – az elődök 128, illetve 256 bites lebegőpontos végrehajtásához képest a Haswell 2-4-szeres elméleti számítási teljesítménynövekedést ígér.

AVX2
A Sandy Bridge-ben bemutatkozó, 256 bites vektorokon dolgozó lebegőpontos AVX utasítások után a Haswell AVX2 elnevezésű készletével az egész számos SIMD végrehajtást is kibővítette a korábbi 128-ról 256 bites vektorokra, leváltva/kiegészítve a koros 128 bites, Pentium 4-gyel bemutatkozó SSE2 készletet, valamint a Core 2 CPU-kban megjelent, ugyancsak 128 bites SSE4.1 egész számos SIMD-utasításainak nagy részét. Ennek előnyeit elsősorban a kép-, hang- és videofeldolgozó és -megjelenítő programok élvezhetik, de – tekintve az SSE2 mai elterjedtségét – számos különféle programban várható idővel a megjelenése.

[+]
Gather memóriaolvasás
Az eddigi x86/x64 SIMD műveletek végrehajtásához előre kellett gondoskodni arról, hogy a vektorok elemei egymás után sorakozzanak a memóriában, mivel egy-egy vektor egy folyamatos memóriaterületet jelent. A Haswellben bemutatkozó 'gather' típusú betöltési utasítás önállóan képes szétszórt elemekből önállóan összeállítani egy vektort, mivel paraméterként a kezdőcímet, valamint az elemek e címtől számított távolságát kapja meg. Bár technikailag ez a processzoron belül több külön memóriaolvasásként van megvalósítva, számottevően gyorsítja az ismétlődő minták szerinti memóriahozzáféréseket.
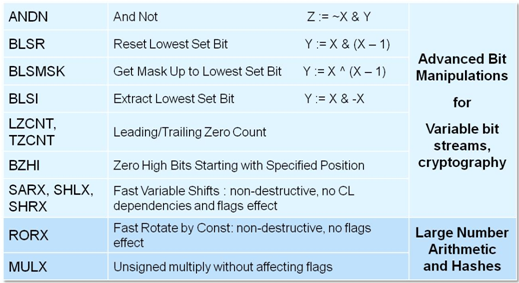
Bitmanipulációs utasítások
A Haswell új bitközpontú utasításokkal is gazdagodott, amelyek egész értékeken (szorzás, shiftelés/forgatás), illetve azok bitcsoportjain végzett bonyolult műveletek végrehajtását gyorsítja fel, külön utasításokként rendelkezésre bocsátva a korábban több instrukcióból álló műveletsorokat.
A cikk még nem ért véget, kérlek, lapozz!







