
A Haswell és a grafika
Az Intel a Haswell fejlesztése során igen sok erőforrást fektetett az integrált grafikus vezérlőbe. Új architektúra ugyan nincs, így az Ivy Bridge-ben található Gen7-es rendszer felújított, Gen7.5-ös verzióját kaptuk meg, de előbbiben igen sok hiba volt, amit orvosoltak a mérnökök. A legfontosabb szempont azonban, hogy az Intel először szembesülhetett azzal, hogy miben rejlik a jó grafikus processzor titka. Megfelelő GPU-architektúrát fejleszteni ugyanis nem túl nagy munka, ugyanakkor a skálázható architektúra már kemény dió.
Hirdetés
Az Intel első próbálkozása ebből a szempontból a Larrabee kódnevű projekt volt, mely végül a süllyesztőben végezte, mivel a grafikai számítások mellett nem skálázódott. Megmaradt azonban a tapasztalat, amit a cég fel is használt. A Haswell IGP-jébe épített architektúra természetesen nem mutat majd olyan extrém használhatóságot, mint az AMD és az NVIDIA architektúrái, így nem fog rá épülni 2 és 300 watt között majdnem lineárisan skálázódó termékskála, de valahol mindig el kell kezdeni. A tervezők például konkrétan képesek voltak megtöbbszörözni a shader és a render tömbök számát. Bár ezt igen tranzisztorpazarló módon tették meg, de egyrészt a jelenlegi architektúra működése igen limitált, másrészt sokan alábecsülik az egész jelentőségét, pedig a teljesítmény skálázása a grafikus vezérlők tervezésénél konkrétan a legnehezebb feladat.
Az Intel a fentiek mellett egy igen logikus evolúciót követ. A Larrabee kapcsán megtanulták, hogy mindent egyben bevetni nem lehetséges, mivel ehhez komoly, akár több évtizedes tapasztalat kell, amit pénzért nem lehet megvásárolni. A HD Graphics sorozat már lépésről lépésre fejlődött. A Sandy Bridge-ben bevetett Gen6-os architektúra gyakorlatilag kijelölt egy járható ösvényt, az Ivy Bridge Gen7-es IGP-je előkészítette a terepet a skálázhatóságra, így az Intel több részre osztotta fel a rendszert a felépítés szempontjából. Az új Haswell Gen7.5-ös fejlesztés az előző generáció alapjaira építve végre skálázza a felosztott blokkokat, vagyis már nem csak két verziója lesz az IGP-nek a termékekben, hanem három. Az eddigi tesztek szerint az új IGP hozzávetőleg 10 és 40 wattos tartományban skálázható úgy, hogy a tempó közel lineárisan nő az extra blokkok beépítésével. Ez az Intel szempontjából egy mérföldkőnek tekinthető, és a jövőben már arra törekedhetnek, hogy a teljesítményskálázást tranzisztorok százmillióinak pazarlása nélkül kivitelezzék.
[+]
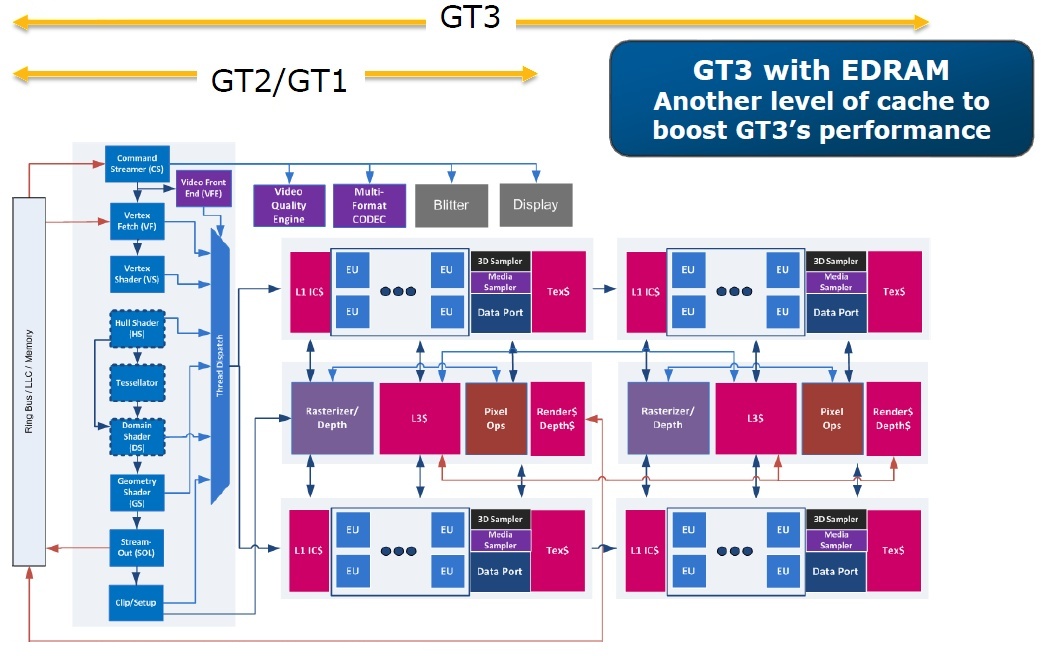
A grafikus számítások szempontjából a Gen7.5 architektúra is három jól elkülöníthető részre osztható. A kalkulációkért továbbra is a shader tömb felelős, de ahogy fentebb leírtuk, már nem csak egy ilyen kaphat helyet a rendszerben, hanem maximum négy. A shader tömbön belül azért voltak változások, bár ezek a funkciókat nem érintik, de a működés hatékonyságát igen. Az Ivy Bridge IGP-je esetében 16 darab shader processzor volt egy tömbben, amit az Intel Execution Unit néven emlegetett mindig is, de ez csak formalitás. Ez a felépítés az úgynevezett ALU:Tex arány szempontjából nagyjából megegyezik azzal, amit az AMD is használ a saját architektúráinál.
Az Intel viszont ma már úgy gondolja, hogy ez sok a saját architektúrájukat figyelembe véve, így a Haswell IGP-je még az NVIDIA Kepler architektúrájánál is kisebb ALU:Tex arányt használ. Bár ez a módosítás kiugróan nagy változást nem eredményez majd, de az látszik belőle, hogy az Intel tervezői végre saját útjukra léptek, és nem másolják az AMD grafikus megoldásainak paraméterezéseit. Ez egy nagy előrelépés, mivel alapesetben mindenképp logikus azt mondani egy rendszer tervezésénél, hogy ha nekik működik, akkor nekünk miért ne lenne ugyanaz az összeállítás hatékony, de valójában az architektúrák eltérő működése ebbe nagyon beleszól.
A Gen7.5 IGP esetében egy shader tömb mostantól maximum 10 darab Execution Unitot tartalmaz. Ezek továbbra is komplex feldolgozók, így két darab 128 bites vektormotorból állnak. Utóbbiak közül az egyik felel az általános operációk feldolgozásáért, míg a másik a speciális, trigonometrikus és transzcendens utasításokat támogatja, de kapott FMA támogatást is, ami rögtön utat ad a 4+4 co-issue képességnek. Ezzel tehát az Execution Unitok órajelenként nyolc darab, egymástól független FMA utasítást képesek végrehajtani. Természetesen a függőség kezelése itt kulcsfontosságú, mivel az egymástól függő operációk párhuzamos feldolgozása nem lehetséges. Erről a Thread Dispatch egység gondoskodik, mely igyekszik megfelelően etetni a vektormotorokat, hogy minél többször hasznosítható legyen a 4+4 co-issue feldolgozás.
A shader tömbökben szokás szerint található még egy 256 kB-os kapacitást kínáló URB, azaz a Unified Return Buffer, mely egy gyorsan elérhető, írható és olvasható megosztott memória az Execution Unitok között, emellett a 32 kB-os L1 utasítás-gyorsítótár is megosztott.
A textúrázás szempontjából szintén javult a rendszer. Egy shader tömb két darab megosztott textúrázó blokkot tartalmaz, melyek egyenként négy darab Gather4-kompatibilis textúrázó csatornát alkalmaznak. A javulás itt abban rejlik, hogy a Gather4 már nem csak formális jellegű. Az Ivy Bridge IGP-jének az egyik legnagyobb hibája az volt, hogy egy csatornához csak egy mintavételező tartozott, ami teljesen eliminálta a Gather4 utasítások alkalmazásának előnyét. Mivel a DirectX 11-es játékok aktívan használják ezt a funkciót, így az Intel a korábbi logikátlan döntését korrigálta, és mostantól minden csatornához négy mintavételező tartozik. Így már kihasználható az a tempóelőny, amit a Gather4 utasítások bevetése jelent az alkalmazásokban. Természetesen jelen van a blokkonkénti textúrázó gyorsítótár is, mely egy 4 kB-os elsődleges és egy 24 kB-os másodlagos szintből áll.
A shader tömbök mellett található a render tömb, mely a data porton keresztül érhető el. Utóbbi tartalmazza a ROP-blokkot is, melyben négy blending és négy Z mintavételező egység dolgozik. Ezen a ponton tehát nincs változás a korábbi IGP-khez képest. Megmaradt a 256 kB-os L3 gyorsítótár is, ami továbbra is azt a célt szolgálja, hogy az IGP ebbe írjon ki fontos adatokat, és ne szemetelje össze a utolsó szintű gyorsítótárat (LLC), ami jelentősen hátráltatná a processzormagokat a feladatok feldolgozásában. Természetesen a fejlesztő kiírhatja az adott szál eredményét az LLC-be is, így azt a processzormagok gyorsan elérhetik, de mindezt csak rendkívül szigorú szoftveres kontroll mellett érdemes megtenni. Emellett persze az IGP az LLC tartalmát továbbra is olvashatja. Itt megjegyezzük még, hogy az önálló L3 gyorsítótár felel majd a DirectX 11-ben megkövetelt Local Data Share (LDS) funkció ellátásáért is.
A cikk még nem ért véget, kérlek, lapozz!







