Régi tervek új APU-ja
A tavaly július elején debütált, Llano kódnevű megoldást hosszú várakozás előzte meg. Ezt mi sem bizonyítja jobban, minthogy a 2007-es tervek szerint az AMD az első CPU-t és GPU-t egyaránt tartalmazó processzort még valamikor 2009-ben szerette volna piacra dobni. A napvilágot látott információk alapján azonban a Swift több próbálkozás után sem akart összeállni, és ennek állítólag a gyártástechnológia volt az oka.
Az AMD ugyanis az első, 130 nanométeres Athlon 64 óta úgynevezett SOI (Silicon-On-Insulator – szilícium a szigetelőn) technológiát alkalmaz szinte az összes processzorának gyártásánál, ezzel ellentétben a GPU-k készítésénél azelőtt sosem alkalmazták még ezt a módszert. Ráadásul a grafikus lapkák gyártását korábban a területen jóval nagyobb tapasztalattal rendelkező TSMC végezte, akik egy egyszerűbb, úgynevezett bulk CMOS eljárással termelték és termelik őket mind a mai napig. A szóban forgó, kereskedelmi forgalomba sosem került, Swift fantázianévre hallgató termék annyiban bizonyosan hasonlított volna a Llanóhoz, hogy úgynevezett "Stars", azaz K10 alapú x86-os magokat tartalmazott volna. Végül nagyjából 2 év csúszással – a Swift helyett – 2011-ben végre megérkezett a Llano, melynek születése szintén nem volt zökkenőmentes; ennek fő oka pedig állítólag újfent a gyártástechnológiában rejlett.

[+]
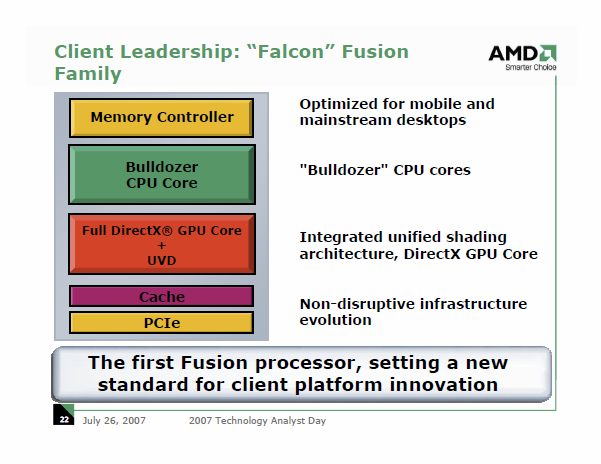
A Swifttel párhuzamosan az AMD már az azt követő, Falcon elnevezésű terméket is betervezte, mely végül szintén valahol a süllyesztőben ért földet. A koncepcióról nagyjából annyit lehetett tudni, hogy Bulldozer magokat tartalmazott volna a GPU és az integrált PCIe vezérlő mellett. A Swifthez és a Falconhoz hasonlóan az első, még 2009-re tervezett első verziós, pusztán x86-os magokat tartalmazó Bulldozer sem látott soha napvilágot. Akik nyomon követik a processzorok világát, azok nyilván jól tudják, hogy végül az első Bulldozer-alapú processzor a Llanóhoz hasonlóan csak tavaly jelent meg, ami szintén bő 2 éves csúszást jelent. Nagyjából egy évvel ezen termékek piacra kerülése után megállapíthatjuk, hogy a kettő közül a Llano sikerült jobban, így nagyobb sikert is aratott.

[+]
Tavalyi megatesztünkből kiderült, hogy az ezen lapkára épülő asztali A8-as és A6-os megoldások x86-os számítási teljesítménye – az Intel i3-as modelljeihez hasonlóan – megfelel a legtöbb átlagfelhasználónak, míg az integrált GPU-teljesítmény közepes részletesség mellett 1440x900-hoz vagy kisebb felbontáshoz is elegendő lehet; tisztességesen optimalizált vagy néhány éves játékok esetén még akár az 1680x1050-hez is. Ez Llanót megelőző integrált grafikai megoldásoknál még szinte teljesen utópisztikusan hangzott. Ezen processzorokkal egy viszonylag költséghatékony, alacsony fogyasztású, valamint csendes konfigurációt lehetett kiépíteni. Utóbbi jó tulajdonságok okán HTPC-hez is sokan választották a Llanót, mivel a talán legszigorúbb HTPC-s elvárásoknak is megfelelt az APU.
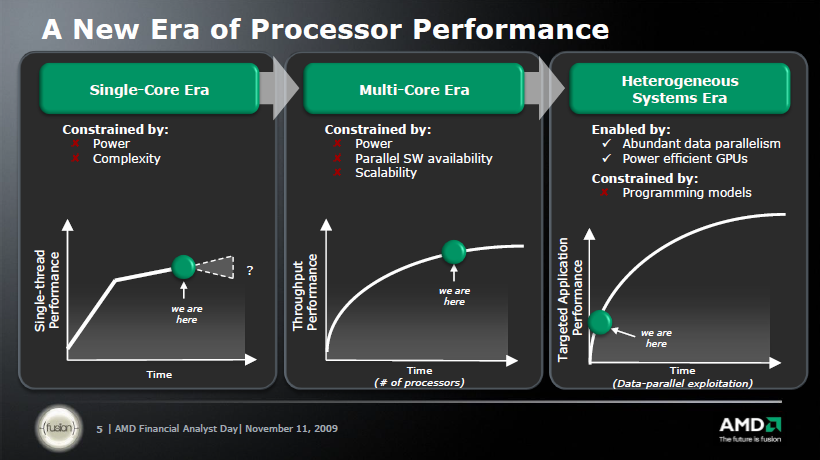
Mielőtt továbbmennénk, elevenítsük fel az APU fogalmát! Az AMD néhány éve úgy döntött, hogy a korábbi Fusion elnevezés égisze alatt megjelenő processzoroknak egy új kategóriát hoz létre, melyet az eddig jól megszokott CPU (Central Processing Unit, azaz központi végrehajtóegység) helyett APU-nak hív. Az APU az Accelerated Processing Unit rövidítése, mely nyers fordítás szerint annyit jelent, hogy gyorsított végrehajtóegység. Az alapötlet olyan processzorok megalkotása volt, amelyek heterogén módon programozhatóak, biztosítva egy belépőt a rendszerszintű integrációba, avagy más néven lassan megkezdődhet a heterogén éra térhódítása.
[+]
A többség egyfajta divathullámnak értékeli a grafikus mag processzorhoz való társítását, de ennél többről van szó, ugyanis a GPU-ban szunnyadó számítási kapacitást általános számításokra is fel lehet használni, ráadásul bizonyos esetekben lényegesen kedvezőbb teljesítmény/fogyasztás mutatót képes ezzel felmutatni a rendszer. Az előző évtized első felében még kemény órajelháború folyt. A processzorok egyetlen x86-os magot tartalmaztak, és a mérnökök ebből próbálták kipréselni a lehető legnagyobb számítási teljesítményt.
Hirdetés
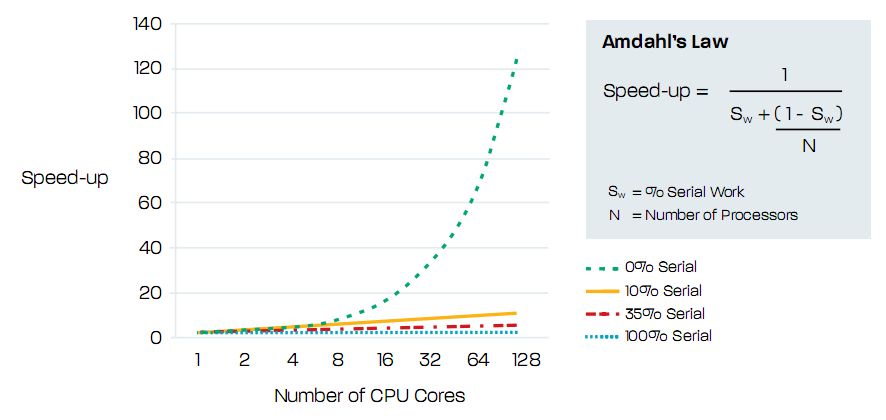
A tervezők idővel belátták, hogy ez az út sokáig nem járható tovább, így inkább az adott processzoron vagy szilíciumlapkán belüli magok számának növelése felé indultak el. Ez egy meglehetősen tranzisztorigényes megoldás, ráadásul probléma, hogy a többmagos processzorok programozása sem egyszerű, mely helyzet a magok számának növelésével csak még tovább romlik. Mindez oda vezet, hogy az extra magok beépítése a teljesítményt alig növeli tovább a megfelelő szoftverek hiányában, vagyis a többmagos elgondolás skálázhatósága jó néhány esetben egyáltalán nem optimális.
[+]
A heterogén rendszerek ezekre a problémákra próbálnak gyógyírt nyújtani. Természetesen a helyzet itt sem olyan egyszerű, hiszen hiába a sok esetben mérföldekkel jobb teljesítmény/fogyasztás mutató, ha mindezt nem lehet kihasználni, ugyanis mindezen erőforrások kiaknázásához szükséges egy újfajta programozási modell, egy megfelelő felület. Ilyen például az OpenCL, mely már jó ideje elérhető, így már "csak" az ezen felületet kihasználni képes alkalmazások tömkelegének érkezésére kell várnunk.
Erőltetett menet
2009 és 2011 között, azaz több mint 2 évig az AMD nem örvendeztette meg a közönséget új mikroarchitektúrával. Ehhez minden bizonnyal hozzájárult az előző oldalon már taglalt csúszások nagy része is, ergo nyilvánvalóan nem egy tervezett hatásszünetről volt szó. Ezzel szemben a grafikus processzorok oldalán az AMD szekere szinte töretlenül robogott az elmúlt időben, amivel sikerült évente felmutatni egy új, számottevő fejlődést hozó GPU-t vagy GPU-családot. Általánosságban elmondható, hogy a grafikus megoldások fejlődése valamivel gyorsabb, mint az x86-os mikroarchitektúráké, amivel evidens módon a gyártók is tisztában vannak.

[+]
Az AMD ennek megfelelően 2009-es Analyst Day nevű rendezvényén elhintette, hogy a Llano debütálását követően minden évben egy megújult grafikus maggal rendelkező APU-t fognak bemutatni.

[+]
Ezzel párhuzamosan a CPU-magok fejlesztésének területén is megpróbált tempót váltani a vállalat. Ennek eredményeképpen – a GPU-k ütemtervéhez hasonló stratégia keretein belül – minden éveben egy frissített x86-os mirkoarchitektúrát szándékozik az újabb APU-kba beültetni az AMD.

[+]
Emellett a cég egyik hosszútávú, igen magas prioritást élvező célja, hogy a CPU és a GPU szekciókat minél inkább összefonja, és közelebb tolja egymáshoz. Erre vonatkozóan már a Llanóban is láthattunk apró csírákat. Egy ilyen volt például az közvetlen buszrendszer, mely a CPU és a GPU kommunikációját hivatott egyszerűsíteni, ezzel együtt meggyorsítani. A folyamat ezen része (is) viszonylag lassan fog végbemenni, hisz meglehetősen bonyolult fejlesztésekről van szó, amelyeknél figyelembe kell venni a piaci igényeket is. X86-os oldalról bizonyos formában már a Bulldozer is ennek a hosszútávú folyamatnak lett alárendelve, vagy ha úgy tetszik, beáldozva, ugyanis már egy jó ideje köztudott, hogy az AMD az integrációnak rendeli alá fejlesztéseit, ezzel szinte egy lapra téve fel mindent.

[+]
Az AMD által lefektetett és propagált, HSA nevű virtuális utasításarchitektúra például legfeljebb 128 bites vektorokon tud SIMD-műveleteket végrehajtani, ehhez pont megfelelnek a Bulldozerben található Flex FP 128 bites egységei, azaz a 256 bites végrehajtók kihasználatlanok maradnának. A következő év/évek megoldásaiban helyet kapó grafikus végrehajtók írható-olvasható L1 adatcache-ei write-through irányelvet követő, 16 kB méretű, 4-utas csoportasszociatív gyorsítótárak csakúgy, mint a Bulldozer magokéi, azaz minden memóriaírás azonnal megjelenik a GPU- vagy a CPU-modul saját L2 cache-ében is. A rendszerszintű cache-koherencia megvalósításához elég tehát ezeket az L2-ket összekötni. Az újabb utasításkészletek beköltözésével a CPU-magok immár ugyanúgy támogatják a különböző bonyolult bitmanipulációs műveleteket, mint a grafikus magok skalár egységei.
Problémás szülők gyermeke
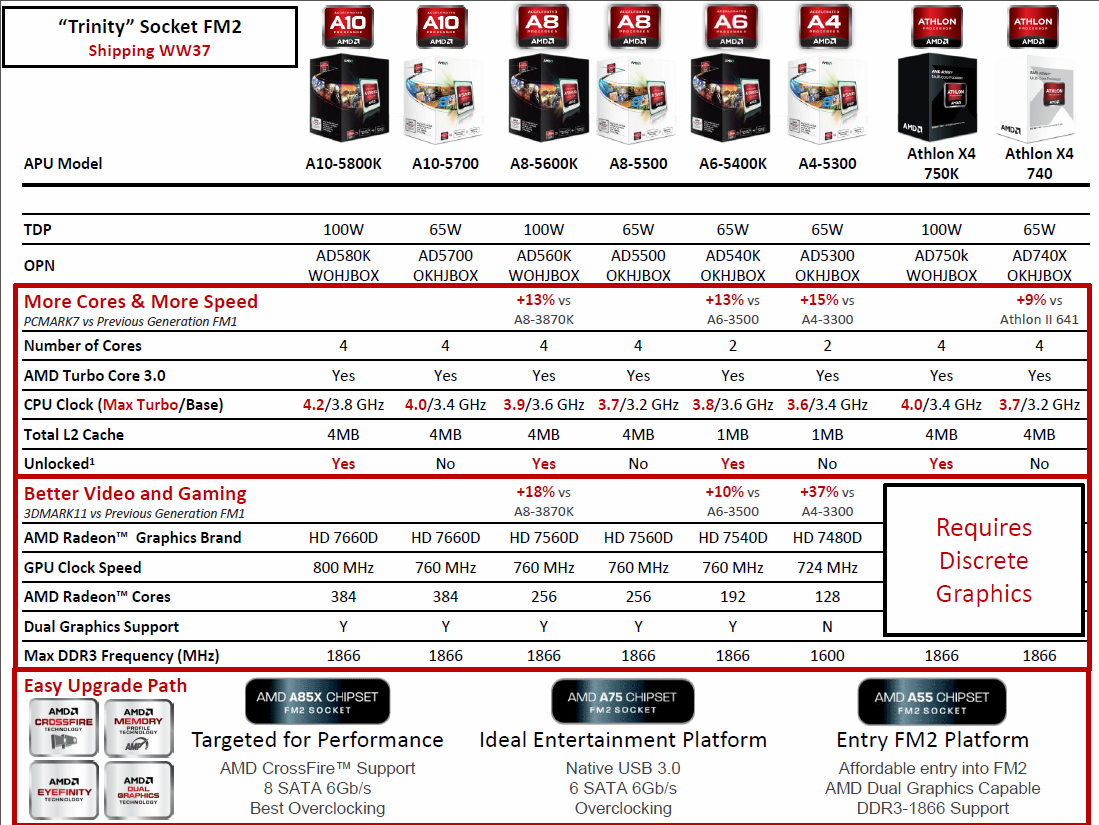
Az Intel, az NVIDIA, valamint még számtalan nagyvállalat úgynevezett útiterv (roadmap) alapján dolgozik; természetesen ezalól az AMD sem képez kivételt. Ez jó esetben azt jelenti, hogy az éppen forgalomban lévő terméket követő második generáció is mindig már bőven a kivitelezési fázisban van. Az AMD Trinity kódnévre hallgató fejlesztéséről például már lassan 2 éve hivatalosan is értesülhetett a nagyközönség, holott akkor még a Llano sem jelent meg. Természetesen az útitervek változhatnak, aminek számos oka lehet. A lenti képen látható 2012-es fejlesztések közül például csak jelen cikkünk főszereplője látta meg a napvilágot, ugyanis a Komodo, valamint a Krishna nevű fejlesztéseket bizonyos okokból kifolyólag végül más termékekre cserélt fel az AMD.
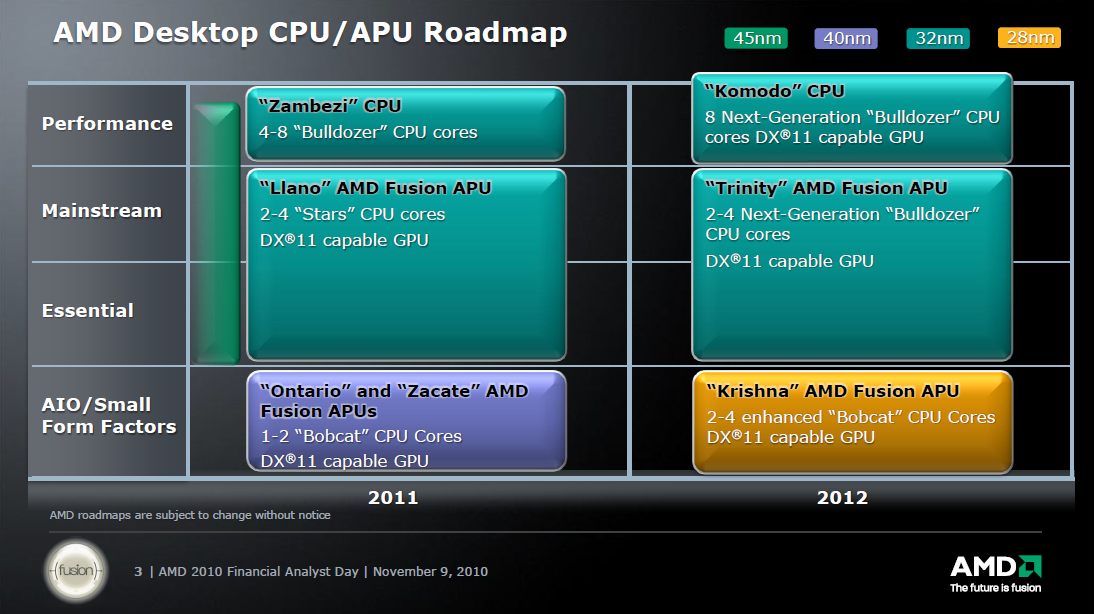
[+]
Azt már tudjuk, hogy mind a Llano, mind pedig a Bulldozer meglehetősen nehéz szülésnek számított az AMD életében. Ebből eredően néhányan kissé szkeptikusan álltak a Trinity kódnevű fejlesztéshez, mely épp a két koncepciót hivatott egyesíteni. A Bulldozerről tudjuk, hogy felépítése radikálisan eltér mind elődeiétől, mind pedig versenytársaiétól, nagyrészt azért, mert már a kezdetektől fogva magas órajeleket szántak hozzá. Ezt a GlobalFoundries 32 nanométeres HKMG SOI gyártástechnológiájának problémái miatt nem sikerült elérnie az AMD-nek, így az arra épülő termékek alulmúlták az előzetes elvárásokat. A szintén ezen gyártósorokról legördülő Llanóval mindeközben folyamatos kihozatali problémákba botlottak a mérnökök, így a vállalat utóbbi fejlesztéssel is rendesen megszenvedett. Mindezen nehézségek ellenére idén májusban a mobil szegmensben debütálhatott a Trinity kódnevű lapka, mely a cikkünk elején említett Falcon alapötletét viszi tovább a Bulldozer és a Llano alapjain.
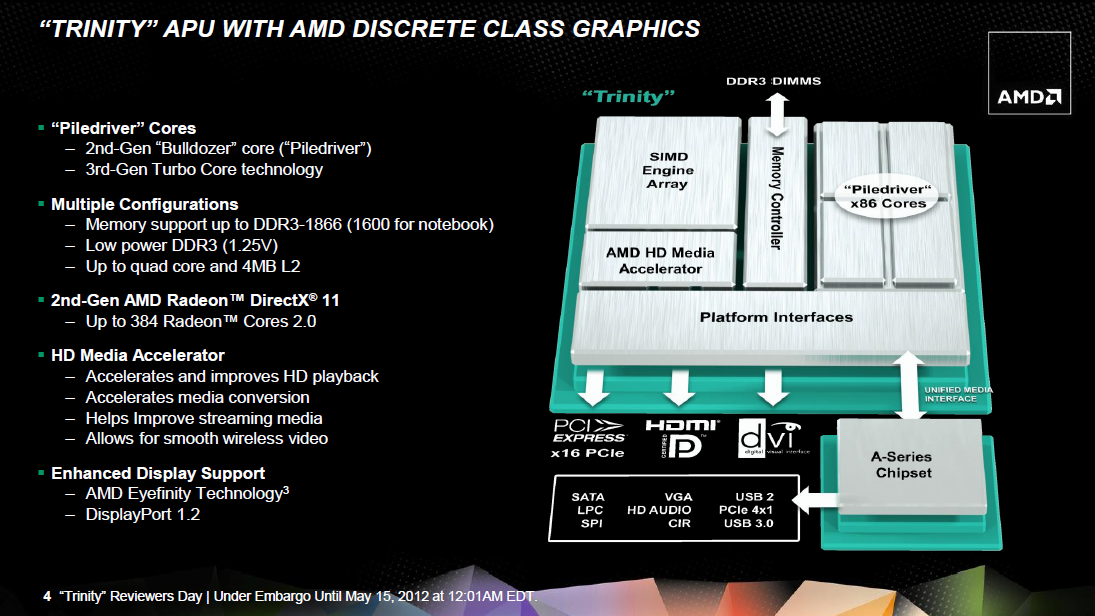
[+]
A különféle gyártástechnológiai problémák nagy részén időközben sikerült úrrá lenni, így a Trinity – a Llanóhoz és a Bulldozerhez hasonlóan – a GlobalFoundries 32 nanométeres HKMG SOI gyártósorain készül. A lapka alapvető felépítése meglehetősen hasonló a Llano esetében látottakhoz. A legnagyobb változás az x86-ps CPU magokat, valamint az integrált grafikus processzort érinti. A négy korábbi, Husky kódnevű, K12-es magot két Piledriver modulra cserélték a tervezők. A két számítási egység mérete szinte pontosan megegyezik a korábbi négy magéval, ráadásul a teljes L2 cache mérete sem változott, azaz maradt 4 MB. A memóriavezérlőt különösebben nem babrálta az AMD, így ez továbbra is 128 bites, és hivatalosan maximum a DDR3-1866 szabványú modulokat támogatja. Az új grafikus szekció immáron a Northern Islands család sarja, de ezt kicsit később taglaljuk. Az UVD motor – újabb híján – a Llanónál már látott, 3-as verziót vonultatja fel. Ezen felül az integrált PCI Express vezérlőt sem érte különösebb módosítás, az egység továbbra is a 2.0-s szabvány szerint dolgozik, így a 3.0 debütálása az AMD-nél csak a jövő évben lesz esedékes.

[+]
A kontroller továbbra is összesen 24 sávból áll, melyből négy darab képezi az úgynevezett UMI (Universal Media Interface) szekciót, amely ebben az esetben a korábban alkalmazott HyperTransport szerepét vette át. Feladata az alaplapi egyetlen vezérlőhíd, vagy más néven FCH (Fusion Controller Hub, erről később) APU-val való összekapcsolása. A négy PCIe 2.0 szabványú sávnak köszönhetően itt 2 GB/s a kapcsolat sávszélessége. Egy másik csokor összesen 16 sávot tartalmaz, és ez elsősorban az esetleges diszkrét grafikus kártya (vagy kártyák) összeköttetéséhez van fenntartva. Ezeket két külön slotra felosztva, x8-x8 konfigurációban akár CrossFire rendszer is kiépíthető. A maradék négy sáv felhasználása már teljesen a gyártókra van bízva, ezekre ültethetnek különféle hálózati, SATA vagy akár USB vezérlőket is, illetve még alaplapi PCIe aljzatok formájában a vásárlókra is bízhatják opcionális kihasználásukat.

[+]
Mindezen változtatásokkal a Llanóhoz képest nagyjából 8%-kal nőtt a lapka mérete, ami 246 mm2-es területet jelent. Ezzel párhuzamosan a tranzisztorszám 1,178-ról 1,303 milliárdra duzzadt.
| Lapka kódneve | Gyártástechnológia | Magok száma | L2 (+ L3) mérete | Tranzisztorszám | Lapka területe |
| Trinity | 32 nm HKMG SOI | 4 (+ IGP) | 4 MB | 1,303 milliárd | 246 mm2 |
|---|---|---|---|---|---|
| Llano | 32 nm HKMG SOI | 4 (+ IGP) | 4 MB | 1,178 milliárd | 228 mm2 |
| Orochi (Bulldozer) | 32 nm HKMG SOI | 8 (4 modul) | 16 MB | ~1,2 milliárd | 315 mm2 |
| Thuban | 45 nm SOI | 6 | 9 MB | 904 millió | 346 mm2 |
| Deneb | 45 nm SOI | 4 | 8 MB | 758 millió | 258 mm2 |
| Ivy Bridge | 22 nm Tri-Gate | 4 (+ IGP) | 9 MB | 1,48 milliárd | 160 mm2 |
| Sandy Bridge | 32 nm HKMG | 4 (+ IGP) | 9 MB | 995 millió | 216 mm2 |
| Sandy Bridge-E | 32 nm HKMG | 6 | 16,5 MB | 2,27 milliárd | 435 mm2 |
| Gulftown | 32 nm HKMG | 6 | 13,5 MB | 1,17 milliárd | 240 mm2 |
| Lynnfield | 45 nm HKMG | 4 | 9 MB | 774 millió | 296 mm2 |
| Bloomfield | 45 nm HKMG | 4 | 9 MB | 731 millió | 263 mm2 |

A Llano és a Trinity méretarányos belső felépítése [+]
A Trinity újításai
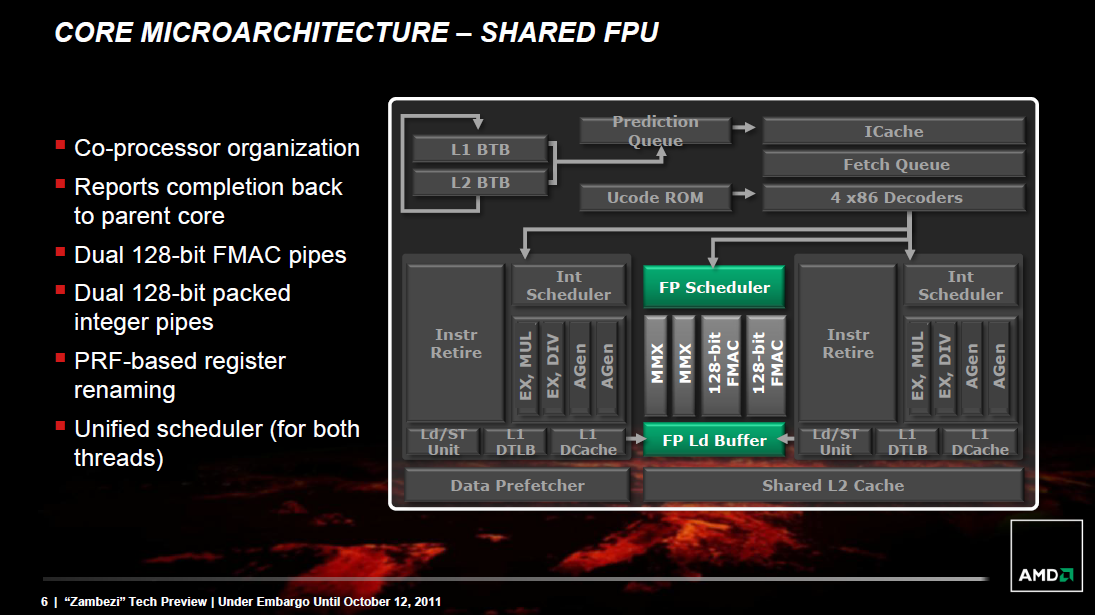
A moduláris Bulldozer mikroarchitecktúra kidolgozása után az AMD előtt állt egy következő nagy feladat: a Piledriverrel olyan szintre javítani a teljestmény/fogyasztás mutatót, hogy az leválthassa a Llanókban alkalmazott K12 felépítést a 2. generációs Trinity APU-kban. Ez elsősorban a fogyasztás lejjebb tornászását jelenti, másodsorban olyan csiszolásokat, amelyek az egy órajel alatt valóban végrehajtható utasítások számát növelik. Mindebből természetesen az ugyancsak Piledriver-alapra építkező, következő FX és Opteron CPU-k is profitálni fognak, melyek bár nem tartamaznak integrált grafikus magot, órajeleiket feljebb lehet tolni vagy még több modult lehet egy lapkába építeni. Mivel az APU-k és a klasszikus sokmagos CPU-k igényei túl széles skálát fednek le, kétféle Piledriver modul készült: a Trinity szerényebb követelményeinek megfelelő Piledriver v1 és a teljesítményorientált v2, mely az újabb FX és Opteron modellekben kap majd helyet. Mindkét modulra építkező lapkákban közös, hogy az órajelelosztás energiaigényét csökkentették a Cyclos által kidolgozott Resonant Clock Mesh technológiára alapozva.
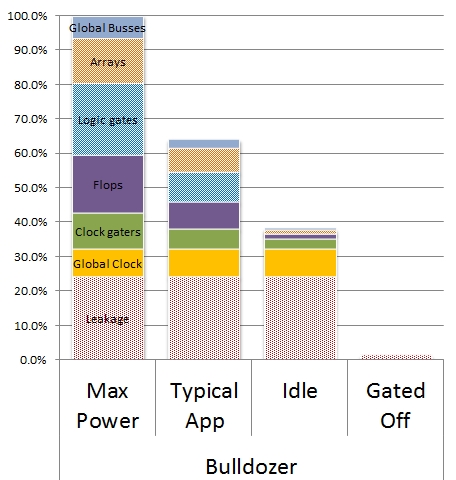
Mint a képen látható, a Bulldozer fogyasztásának 15-35%-áért maga az órajelhálózat a felelős. A Resonant Clock Mesh – amelynek a Trinity az első kereskedelmi forgalomba került megvalósítása – jelentősen csökkenti ezt a fogyasztási tényezőt, ami azonos órajelen kisebb TDP-t, illetve azonos TDP mellett magasabb órajelet jelent. Ennek köszönhetően a AMD termékpalettáján is megjelent az eddigi 25 és 35 W mellett a 17 W-os kategória, lehetővé téve számukra teljesítményorientáltabb ultrahordozható laptopok építését.

A Resonant Clock Mesh megvalósítása a Bulldozer meglevő órajelrendszerére épült a Piledriverben; a Cyclos szerinti optimalizációkkal a következő generációkban akár meg is duplázható a fogyasztási megtakarítás.

[+]
Mindemellé a Llano energiamenedzsmentjét is tovább csiszolták. A Trinity-t az elődhöz hasonlóan elsősorban a mobil szegmensbe szánják, ahol minden egyes wattnak rendkívüli jelentősége van az akkumulátoros üzemidő szempontjából.
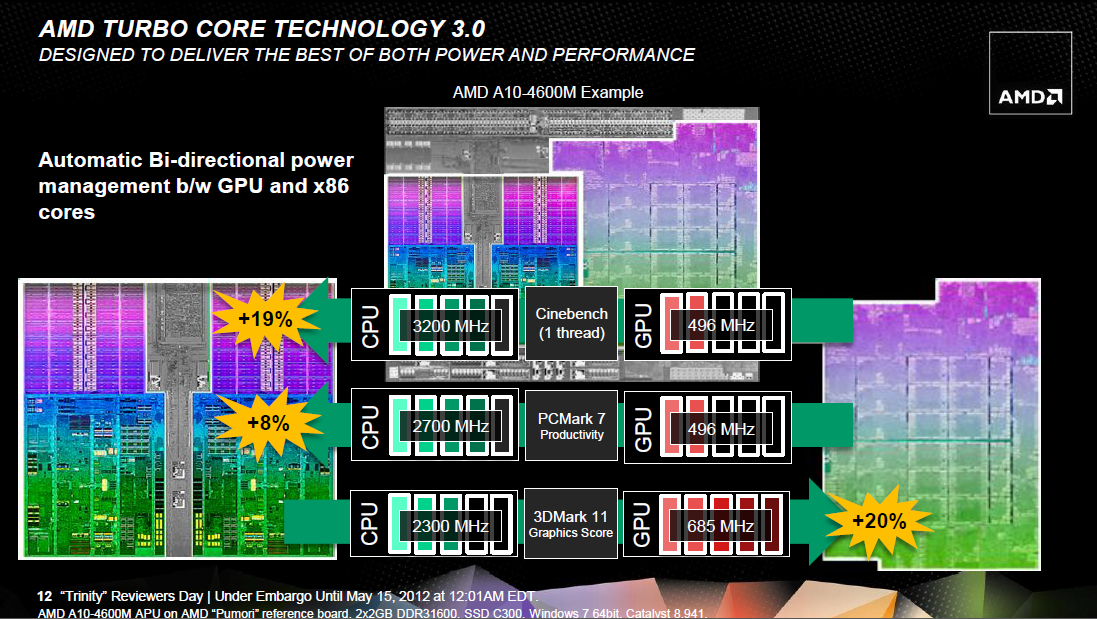
[+]
Alapvető változás, hogy míg a Llano esetében a GPU egy fix fogyasztási kerettel rendelkezett, így annak órajelét a rendszer nem tudta megemelni még akkor sem, ha az épp belefért volna a TDP-keretbe, addig a Trinity a terhelés függvényében már dinamikusan szabályozza az éppen felhasználható értékeket a CPU-magok és a GPU között, ergo az utóbbi üzemi frekvenciája megemelhető, ha szükséges és belefér a keretbe.

[+]
A rendszer vezérlője is változásokon esett át. A Llanónál minden egyes lehetséges magi aktivitáshoz (melyek száma 100 körüli) hozzárendeltek egy fogyasztási mutatót, ami alapján az energiagazdálkodási modul képes volt pontosan kiszámolni az éppen aktuális fogyasztást. A Trinity ezt kiegészítve gyors transzformációkkal, termikus számítások alapján modellezi a hőmérsékletet is, mely adatok felhasználásával gyorsabb órajelváltás mehet végbe. Mindezen felül további lépések is történtek az energiagazdálkodás terén a Piledriver köré építhető infrastruktúrákban:
- az integrált északi híd dinamikusan állítható órajelei mellé megjelent a rendszermemória órajelének állítási lehetősége is. Két ilyen lépcsőt ismer a rendszer, a gyári órajel mellett az alacsony NB-aktivitás esetén beállítható visszavett ütemet;
- az integált PCI Express 2.0 vezérlőt is bevonták a fogyasztás csökkentésébe, mivel az kihasználatlanság esetén képes visszaskálázni az eszközökhöz rendelt nagysebességű (x16, x8 vagy x4) kapcsolatot akár x1-re is, a többi vonalat ideiglenesen lekapcsolva. Többféle metódust is kínál erre a vezérlő, de a legrugalmasabbak csak AMD grafikus kártyákkal működnek együtt;
- az integrált kétcsatornás memóriavezérlő támogatja az 1,25 V alapfeszültségű LPDDR3 memóriamodulokat is.

[+]
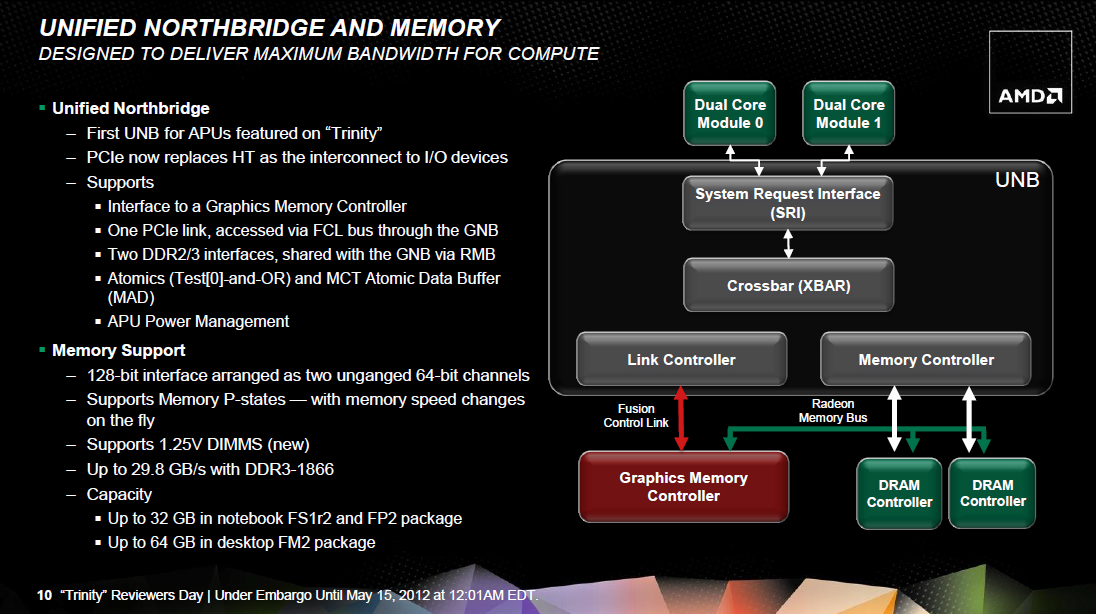
A Trinity integrált északi hídja átdolgozásra került a Llanóéhoz képest: a legnagyobb változást a Garlic és az Onion buszok RMB-re (Radeon Memory Bus) való lecserélése, valamint a 2. generációs IOMMU (IOMMU v2) beépítése jelenti:
- a mindkét irányba 128 bit széles Fusion Control Link ad koherens hozzáférést az IGP-nek a CPU-rész által kezelt memóriához, az I/O-csatornákhoz, továbbá a CPU-nak hozzáférést az IGP-nek dedikált memóriarészhez;
- a mindkét irányba 256 bites Radeon Memory Bus révén közvetlenül kapcsolódik az IGP memóriavezérlője a két 64 bites memóriacsatornához;
- az IOMMU v2 (I/O Memory Management Unit) immár lehetőséget ad arra, hogy a diszkrét kártyák (grafikus kártyák, nagyteljesítményű hálózati kártyák stb.) transzparens módon, a CPU-éval azonos virtuális->fizikai címfordítási mechanizmuson keresztül, de annak közreműködése nélkül érjék el a rendszermemóriát.
[+]
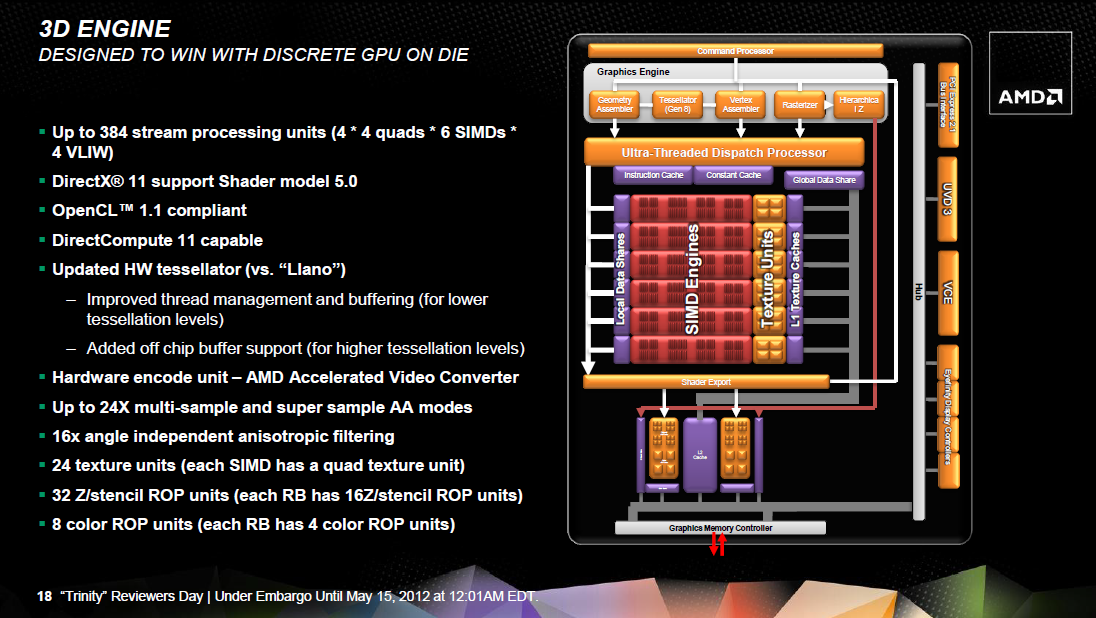
A grafikus mag jelentősnek mondható változáson esett át, mely így tulajdonképpen már a Northern Islands (Cayman – HD 6900) termékcsalád részének tekinthető. A fő különbség a Llano APU IGP-jéhez képest, hogy a szuperskalár shader processzorok úgynevezett VLIW5 felépítését VLIW4-re váltották a mérnökök. Ez összességében jobb kihasználást jelent, illetve a Cayman örökségeként számos értékes technológia is bevetésre került.
Egy shader tömb 16 darab szuperskalár shader processzort rejt, melyhez 32 kB-os Local Data Share, valamint egy 8 kB-os, csak olvasható gyorsítótárral rendelkező textúrázó blokk tartozik. Utóbbi négy darab Gather4-kompatibilis csatornát alkalmaz, melyek csak szűrt mintákkal térnek vissza. Az interpoláció a DirectX 11-es Radeonokhoz hasonlóan emulált, ám a rendszer itt sok optimalizációt kapott, így relatív kevés erőforrás szükséges az interpolálás végrehajtásához. Az új Trinity APU IGP-jében összesen 6 darab shader tömb van, amelyek egy blokkra vannak fűzve. Ez a blokk természetesen egységes Ultra-Threading Dispatch Processzorra támaszkodik. A tömbök közötti adatmegosztást továbbra is egy nagysebességű, 64 kB-os (Global Data Share) tárterület biztosítja.
[+]
Az IGP setup motort is a Caymantől örökölte annak minden előnyével együtt. A tesszellátor az AMD Gen8-as megoldása lesz, míg a raszter motor órajelenként 16 képpontot dolgoz fel. Az igazán értékes újítás azonban a tile-based load balancing, ami a hierarchikus Z algoritmus túlterhelését akadályozza meg. A rendszer a raszterizálást hierarchikus Z nélkül hajtja végre a teljes képkockát több egyenlő méretű, viszonylag kicsi mozaikra osztva. Természetesen itt számos szabályt be kell tartani biztosítva a renderelés sorrendjét. A hierarchikus Z algoritmus a mozaikokon lesz lefuttatva, amelyeket tovább lehet küldeni vagy éppen el lehet dobni, ha nem tartalmaznak látható információt. Ez az elgondolás tesszellálásnál lehet hasznos, mivel a hierarchikus Z motor könnyen túlterhelhető, ami esetenként elég sok problémát jelenthet.

[+]
A memóriavezérlőhöz egy 128 kB kapacitású, csak olvasható másodlagos gyorsítótár és két ROP-blokk kapcsolódik. Ez így összesen 8 blending és 32 Z mintavételező egységet eredményez. Itt a Caymantől megörökölt újítás, hogy a blokkok jelentős fejlődésen mentek keresztül, így a Llano IGP-jéhez képest kétszer gyorsabban végzik a 16 bites unorm és snorm operációkat, valamint a 32 bites lebegőpontos utasítások feldolgozása akár négyszer gyorsabb is lehet. Némi egyenetlenség azért maradt a rendszerben, mivel a raszter motor órajelenként 16 képpontot dolgoz fel, ami sok 8 blending egységhez, de utóbbi inkább legyen túletetve, minthogy adatra várjon.
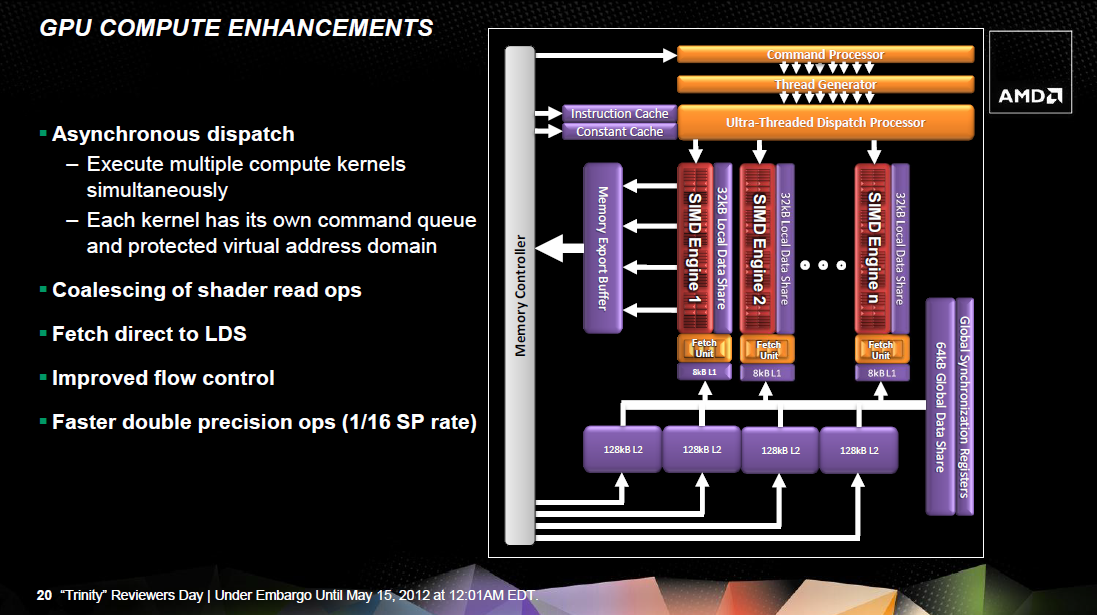
[+]
A Trinity IGP-je abból a szempontból érdekes a Llano megoldásához viszonyítva, hogy a shader processzorok száma 400-ról 384-re csökkent, miközben a textúrázó csatornák száma 20-ról 24-re nőtt. Alapvetően azonban a változás minden szempontból előnyös, ugyanis a Trinity szuperskalár shader processzorainak felépítése kedvezőbb, mivel hatékonyabban "etethetők". További fontos adalék, hogy a Trinity APU IGP-je az integrált megoldások között elsőként támogat dupla pontosságot. Ebben a módban a rendszer teljesítménye az elméleti számítási tempó tizenhatod részével egyezik meg.
A Piledriver v1 fejlesztései
Maguk az x86-os Piledriver-modulok apróbb csiszolásokon estek át a Bulldozer-modulokhoz képest, de az alapkoncepció nem változott. A Trinity-ben helyet kapott verzió újításai a következők:
- az integer magokban és a Flex FP-ben található ütemezők hatékonyságát a végrehajtó egységek kihasználásának növelése érdekében javították;
- az integer magok Load/Store egységében az olvasási sor méretét 40-ről 44-re növelték, azaz 10%-kal több, függőben levő memóriaolvasási műveletet kezelhet egyszerre 1-1 mag;
- az L1 adat TLB és az utasítás Translation Lookaside Buffer mérete egyaránt 32-ről 64 bejegyzésre nőtt, így kevesebb időigényes virtuális->fizikai memóriacím-fordítás szükséges a programok futása közben;
- az elágazásbecslés hatékonyabb lett, kevesebb téves elágazásjóslatot eredményezve: a hibrid branch prediktor két egységből áll, amelyek kétféle szempont szerint elemzik azt, hogy a következő órajelben mely utasítások kerüljenek beolvasásra az utasításcache-ből. Arra az esetre, ha a két jóslat ellentmond egymásnak, egy kis logika nyomon követi, hogy melyik jósol egy-egy adott szituációban korrektebben, és annak eredményét fogja használni legközelebb;
- a lebegőpontos és az egész számos osztó utasítások, a felhasználói és kernel mód között váltó instrukciók, valamint az atomi (LOCK) műveletek végrehajtása gyorsabb lett;
- a Flex FP különböző alegységekből áll, az ezek közötti adattovábbítás további 1 órajellel növeli a művelet végrehajtási idejét; a Piledriver-ben a leggyakoribb ilyen eset, a kiszámított eredmények memóriába írása (amely az adott lebegőpontos számítási alegységből a STORE alegységbe történő továbbítást jelenti) már nem igényli ezt a +1 órajelet;
- négy új utasításkészlet költözik be a CPU-ba: az Intel Haswellben alkalmazandó 3 paraméteres FMA-utasítások (a Bulldozer a rugalmasabb 4 paraméteres utasításokat kezeli); a 32 bites egyszeres és a 16 bites félpontosságú lebegőpontos számok közötti konverziót megvalósító F16C készlet két utasítása; továbbá a BMI- és TBM-készletek, amelyek egyrészt lehetővé teszik egy-egy 16, 32 vagy 64 bites egész érték bizonyos bitjeinek feltételtől függő csoportos 1-re állítását és/vagy törlését – kiváltva ezzel 2-3 korábbi külön utasítást –, másrészt implementálják az ANDNOT műveletet és a BEXTR utasítás révén az ilyen számok összefüggő bitmezőinek kiemelését.

[+]
Az adatokat spekulatívan előbetöltő hardveres elemek (prefetch-erek) működése is megváltozott, ennek megértéséhez merüljünk bele a cache-ek működésébe! Az a kifejezés, hogy "16 kB 4-utas csoportasszociatív cache 64 byte vonalmérettel, LRU cserélési algoritmussal" (angolul: 4-way set-associative cache, 64 byte line size, LRU replacement policy) a következőket jelenti:
- Ez a cache 64 byte-os elemekből álló tömb, jelen esetben 256 ilyen elemből áll. Ha a CPU-nak szüksége van a memóriából akár egyetlen bájtra is, beolvassa a teljes 64 bájtos memóriarészt (64 byte vonalméret, cache line size), amelyben az adott byte van, és elhelyezi a 256 elem egyikébe. Ez a beolvasás akkor is megtörténik, ha csak ír erre a címre a processzor, kivéve, ha speciális tároló utasításokkal (non-temporal store, azaz nem-átmeneti tárolás) kifejezetten tiltja ezt.
- Nem akármelyikbe teheti be, hanem csak 4 elem valamelyikébe (4-utas, 4-way), azaz 4 db 64 byte-os elem alkot egy csoportot (set), azaz ebben a cache-ben 64 ilyen csoport van. Egy-egy memóriacím csak egy-egy meghatározott csoport 4 elemében jelenhet meg, azaz ha a CPU-nak szüksége van egy adatra, akkor csak 4 elemet kell megnéznie a cache-ben, hogy ott van-e, nem kell mind a 256-ot átnéznie, így gyorsabb is a cache (kisebb a késleltetése) és a cache-vezérlő logika is sokkal egyszerűbb.
- Hátránya is van persze ennek, hiszen egy-egy csoport a fizikai memória eléggé nagy – de nem folyamatos – szeletét képezi le, azaz gyakran felülíródnak bennük az adatok; azt, hogy a csoport 4 eleme közül adott pillanatban melyik íródjon felül, azt a Least-Recently-Used (LRU) algoritmus határozza meg. A cache-vezérlő mindegyik csoportra külön-külön karbantart egy-egy sorrendet, hogy a 4-4 db 64 bájtos elem közül melyikre történt legrégebben hivatkozás, melyikre legutóbb; a legrégebben használt adatot írja felül ilyenkor.

[+]
Adatot a memóriából vagy egy lentebbi cache-szintről azonban nem csak a CPU-magok igényelhetnek, hanem az előbetöltők önállóan is olvasnak be adatokat. Ezek olyan részegységek a cache-ek mellett, amelyek autonóm módon figyelemmel követik, hogy a végrehajtó egységek milyen memóriacímekről olvasnak be adatokat, és ezekben szabályosságot találva spekulatív módon betöltik a jövőben valószínűleg igényelt 64 bájtos szeleteket:
- ha sikeres a jóslat, akkor a memóriaolvasásra való várakozást elrejtette, ezzel növekszik a végrehajtási sebesség;
- ha sikertelen, akkor viszont egy értékes adatot írt felül az adott csoportban, amit ráadásul sok esetben vissza is kell olvasni.
Az eddigi prefetch-erek hatására a spekulatívan beolvasott adat került az adott csoport LRU-sora élére, amivel az 'éppen most' használt elem lett a csoportban, tehát egy valóban szükséges adat be- vagy visszaolvasása esetén nem ezt a téves jóslatot, hanem egy másik, ugyancsak értékes elemet írt felül a cache-vezérlő a csoportban, amit aztán megint csak vissza kell olvasni... És így tovább; ezáltal egy kis dominó-effektus indult el az adott 4 x 64 bájtos csoportban. A Piledriver prefetchere azonban a spekulatívan beolvasott adatot azonnal "legrégebben" használtnak jelöli meg:
- ha valóban szüksége van a CPU-magnak az adott adatra, azt azonnal fel is fogja használni;
- ha nincs szükség rá, akkor ezt fogja legközelebb hasznos adat felülírni, a többi értékes adatot nem éri bántódás.
Új platform új foglalattal: Virgo és FM2
Az elmúlt évek alapján elmondhattuk, hogy az AMD mind asztali, mind pedig szerver vonalon elég kegyes volt később bővíteni szándékozó vásárlóihoz, ugyanis a cég a foglalatváltások ellenére is próbált többé-kevésbé visszafelé is kompatibilitást biztosítani új processzoraihoz. A 2006 májusában debütált AM2-es foglalatba az első Phenomok is belementek, de az alaplap gyártójától függően még bizonyos AM3-as tokozású processzorok működése sem volt kizárt. Az AM2-t 2007 novemberében az AM2+ követte, mely foglalattal szerelt alaplapok többsége később gond nélkül befogadta a szűk másfél évvel később érkező AM3-as processzorokat is, amibe még a hatmagos Phenom II X6 is beletartozott. Az AM3 esetében már kevésbé volt egyszerű a helyzet, de mint végül kiderült, a 800-as chipkészletre építkező modellek közül néhány elboldogult az AM3+ tokozású FX processzorokkal is.

FM1 és FM2 [+]
Nos, a most debütált Socket FM2 esetében sajnos az AMD már nem volt ilyen előzékeny, ugyanis az FM2-es Trinity semmilyen formában nem kompatibilis a korábbi alaplapokkal, illetve az FM1-es processzorok sem mennek bele az FM2-vel szerelt termékekbe. Az inkompatibilitásnak fizikai korlátai is vannak, ugyanis a processzoron található érintkezők elhelyezkedése megváltozott.

Véleményünk szerint szerint ennek az az oka, hogy vállalat korábbi tervei alapján idén egyetlen foglalatra egyesítette volna a CPU-kat és az APU-kat, amihez változásokat kellett eszközölni a tápellátás környékén, illetve a megjelenítők kimeneteinek háza táján is történtek apróbb módosítások. Az egyesítés a 2. oldalon említett útiterv változása okán egyelőre várat magára, így a lépés elsőre kissé logikátlannak tűnhet, bár az tény, hogy a foglalatváltással anyagilag jól járnak a cégek. Ennek elsősorban az alaplapok gyártói örülnek nagyon, hiszen így folyamatosan újabb és újabb termékeket értékesíthetnek. Természetesen a chipsetek gyártóinak (aki jelen esetben az AMD) is pénzt hoz a konyhára, bár ez az üzletág ma már nem nevezhető éppen aranybányának. A felhasználók egy részét már kevésbé érinti kellemesen egy ilyen lépés az esetleges plusz kiadás, valamint az ezzel járó macera miatt. Öröm az ürömben, hogy a hűtő felfogatása most sem változott. Az új FM2 foglalatra tehát bármilyen korábbi Socket AM2(+), AM3(+), vagy éppen FM1 kompatibilis hűtő felszerelhető, sőt egyes, a műanyag keretbe kapaszkodó Socket 754-re vagy 939-re megfelelő modellek is tovább alkalmazhatóak.

[+]
Ezzel kissé ironikusan megállapíthatjuk, hogy az FM1 foglalat lett az AMD-féle LGA1156, ugyanis az Intel első, CPU-ba (vagy inkább CPU mellé) integrált grafikát támogató platformja hasonlóan rövid életciklust tudhatott magáénak. Talán épp ezért is igyekezett az AMD már most kihangsúlyozni azt a hivatalos álláspontot, miszerint az FM2-be a jövőre érkező újabb fejlesztés is bepattintható lesz. Természetesen ez a jelenlegi, FM1-es foglalatú termékekkel rendelkező tulajdonosoknak elég sovány vigasz, hisz nekik alaplapcsere nélkül be kell érniük a Llano képességeivel.

[+]
Az új foglalat mellé az A85X (Hudson D4) FCH (azaz Fusion Controller Hub) személyében egy új chipset is érkezett. Ez a modell az FM1-gyel debütált A75-hez képes csak kisebb módosításokat vonultat fel, ami elsősorban a háttértárolók vezérlését érinti. Ez egészen pontosan azt jelent, hogy 6 Gbps kompatibilis natív portok száma 6-ról 8-ra nőtt, valamint a vezérlő a RAID 0 és 1 mellett most már a RAID 5 módot is támogatja. A megnövekedett SATA portok száma elsősorban a komolyabb alaplapok előállítási költségére lehet jó hatással, hisz ezzel a ma már alapfelszereltségnek számító 6 aljzaton túl, plusz vezérlő beiktatása nélkül kínálhatnak extra portokat a gyártók, például eSATA formájában. A tervezők keze nincs megkötve, így arra használják fel ezt a lehetőséget, amire csak szeretnék. A vásárlók szempontjából ez azért lehet jó hír, mert a natív vezérlők szinte minden szempontból jobbak az olcsó külső megoldásoknál. Az A85X FCH megjelenése mellett a korábban debütált A75 (Hudson D3) és A55 (Hudson D2) továbbra is használható, melyek közül az USB 3.0-t nem támogató A55 minden bizonnyal most is a legolcsóbb termékeken fog helyet kapni.

Az AMD A85X FCH – egészen apró a lapka [+]
A két tavaly megjelent FCH-hoz hasonlóan a chip négy darab PCI Express 2.0-s sávot tartalmaz, továbbá három PCI interfész is elérhető. Az A75-hez hasonlóan támogatott az úgynevezett FIS-based switching is, ez a funkció SATA portra kötött elosztó mellett hasznos. Ilyenkor több adattároló működik egy interfészről, de a hagyományos Command-based Switching alkalmazásával egyszerre csak egy meghajtó foglalhatja le a sávszélességet. A FIS-based (Frame Information Structure) megoldással az összes meghajtó működtethető párhuzamosan, a vezérlő gondoskodik a terhelés megfelelő elosztásáról. A költségek csökkentésének érdekében az FCH az órajel-generátort is magában hordozza, de az alaplapok gyártói dönthetnek akár egy külső egység alkalmazása mellett is. Az A85X USB vezérlője összesen 16 natív portot támogat, melyek közül négy 3.0-s, tíz 2.0-s és mindössze két interfész érhető el az 1.1-es felülethez.
Az első fecske: ASUS F2A85-V PRO
Az egyik első AMD A85X FCH-ra épülő alaplap személyében a felsőkategóriás megoldásnak tekinthető, ASUS F2A85-V PRO tette nálunk tiszteletét.

[+]
A dobozban most sem tárulkozik elénk túl sok minden az alaplapon kívül. A szokásos kézikönyv, DVD és hátlap mellett két pár SATA kábel és egy Q-connector nevű kis kiegészítő lapul, mely a ház bizonyos kábeleinek könnyebb csatlakoztatását segíti elő.

[+]
Az alaplapot dobozábol kiemelve nekünk szinte azonnal a tavaly bemutatott, FM1-es ASUS F1A75-V PRO ugrott be, ami nem is csoda, hisz az új modell tulajdonképpen a korábbi evolúciójának tekinthető. Az első szembetűnő változás az elődhöz képest a PCI aljazok terén van, ugyanis az F2A85-V PRO-n a három PCI-ból eltűnt a legalsó, helyét pedig egy teljes hosszúságú, konfigurációtól függően maximum 4 sávot szolgáltatni képes PCI Express vette át. Ezzel a háromkártyás CrossFireX is támogatottá vált. A "rejtett" változások közé tartozik RAM slotokhoz futó vezetékek elrendezése, mely a magasabb, 1866 MHz feletti órajelek elérése érdekében immáron úgynevezett T-topológiát alkalmaz. Az alaplap jobb szélét vizslatva máris láthatjuk, hogy az ASUS kihasználta az újabb natív portokat, ugyanis a hat darab 90 fokban kiforgatott csatlakozó felett egy további aljzat is helyet kapott.

[+]
Az alaplapra most is egybefüggő hűtőrendszer került, mely a tápellátást és az FCH-t köti össze. Azzal vélhetően sokan tisztában vannak, hogy a hőcsövek alapvetően a magasabb hőmérsékletű rész felől szállítják a hőt az alacsonyabb hőmérsékletű pont felé, így a komponensek aktuális hőmérsékletétől függően segít a hűtésben a két bordázott szekció. Néhány fotó erejéig természetesen most sem úszhatta meg az eltávolítást ez a rész, így közelebbről is szemügyre vehettük a tápellátást. A látottak alapján elmondhatjuk, hogy az elődhöz mérten a fázisok száma nem változott, azaz maradt a nyolc (6+2) darab. A tápellátás gyakorlatilag a már jól megszokott, ASUS által alkalmazott komponensekre épül. A rendszer lelke továbbra is a Digi+ névre keresztelt digitális CHiL vezérlőchip, ami a SMART DIGI+ technológiával kiegészülve a korábbiakhoz képest még pontosabb, stabilabb és egyszerűbb szabályozást tesz lehetővé.

A hátlapon a kombó PS2 csatlakozó alatt két USB 2.0 port nyitja a sort, mellettük jobbról egy optikai hangkivezetés kapott helyet, alatta egy 1.4-es HDMI, valamint az immáron 1.2-es szabványú DisplayPort található. Utóbbi már a 4K néven elhíresült, 4096x2160-as felbontást is támogatja. Közvetlenül ezek után a sort egy D-Sub és egy DVI-D folytatja; utóbbi érdekessége, hogy dual-link, azaz a 2560x1600-as felbontást is képes átpréselni magán. A négy különböző videokimenet láttán ismét megállapíthatjuk, hogy a megjelenítők csatlakozóival nem spórolt az ASUS, ami újfent dicséretes. Itt jegyeznénk meg, hogy a Trinity Eyefinity-támogatásának köszönhetően akár három kimenetet is használhatunk egyidőben, és a DisplayPort aljzat bevetésével akár négy kijelző meghajtása is lehetséges. A következő állomás az A85X FCH nyolcadik natív 6 Gbps-es SATA portját vonultatja fel eSATA köntösben, ami alá szintén natív USB 3.0 port páros került. A sor végéhez közelítve a jól ismert Realtek 8111F chipje által vezérelt Gigabit Ethernet portot láthatjuk, mely alatt két újabb USB 3.0-s port található; ezeket az ASMedia chipje vezérli. A sort most is a Realtek márkájú ALC 892 HD audiokodek analóg kimenetei zárják.
Az alaplap támogatja az ASUS-nál már korábban megismert EPU, TPU, MemOK!, USB BIOS Flashback, Remote GO!, Fan Xpert 2, valamint USB Charger+ funkciót is. Ahogy a gyártótól már szinte megszokhattuk, úgy ezen az alaplapon is UEFI kapott helyet, aminek beállítási lehetőségeit a következő képeken igyekszünk bemutatni:















ASUS F2A85-V PRO UEFI
Tesztkonfig, specifikációk
Tesztünkben tavaly ősszel frissített CPU tesztrendszerünket vetettük be, melyben a korábban használt alkalmazások jóval naprakészebb verziói kaptak helyet. Ennek pontos listája a következőképpen fest:
- WinRAR 4.20 (64-bit)
- 7-Zip 9.20 (64-bit)
- Cinebench R11.5 (64-bit)
- Autodesk 3ds Max 2012 (64-bit)
- Indigo Renderer v2.4.13 (64-bit)
- Adobe After Effects CS5 (64-bit)
- Adobe Premiere Pro CS5.5 (64-bit)
- Adobe Photoshop CS5.1 (64 Bit)
- Sony Vegas Pro 10.0e (64-bit)
- CyberLink PowerDirector 9 (64-bit)
- Sorenson Squeeze 7 (32-bit)
- DivX Encoder 6.9.2 (32-bit)
- XviD Encoder 1.3.2 (64-bit)
- x264 build 2200 (64-bit)
- Cockos REAPER v4.0 (32-bit)
- Apache 2.2.19 (32-bit)
- AVG Antivirus Free 2012 (64-bit)
- Crysis Warhead
- Battlefield 3
- Far Cry 2
- DiRT 3
Az alkalmazások döntő többsége képes 4-6 vagy akár több magot/szálat is kihasználni, de akadnak kivételek. Az XviD Encoder például csak egyetlen magot vagy szálat tud megtornáztatni, de a DivX is megáll valahol 2 és 3 között. A WinRAR az utóbbihoz hasonlóan működik, és a két fájltömörítő közül ilyen szempontból a 7-Zip kicsit jobban viselkedik. Az előbbi alkalmazáshoz kapcsolódik, hogy jelen tesztünkben már a legújabb, 4.20-as verziót használtuk, ami számottevően gyorsabb a korábban kipróbáltaknál. Szintén a közelmúltban frissült az x264 nevű enkóder is, melyből a 2200-as build került bevetésre.
| FM2 tesztplatform | AMD A10-5800K (3,8 GHz) processzor AMD A8-5600K (3,6 GHz) processzor ASUS F2A85-V PRO alaplap (A85X chipset, BIOS: 5104) 2 x 4 GB G.Skill RipjawsX DDR3-1866 F3-14900CL9Q-16GBXL memória DDR3-1866 beállítás, 9-10-9-28-2T időzítések |
|---|---|
| FM1 tesztplatform | AMD A8-3870K (3,0 GHz) processzor AMD A8-3820 (2,5 GHz) processzor ASUS F1A75-V PRO alaplap (A75 chipset, BIOS: 2206) 2 x 4 GB G.Skill RipjawsX DDR3-1866 F3-14900CL9Q-16GBXL memória DDR3-1866 beállítás, 9-10-9-28-2T időzítések |
| AM3+ tesztplatform | AMD FX-4170 (4,2 GHz) processzor AMD Phenom II X4 980 (3,7 GHz) processzor ASUS Crosshair V Formula alaplap (990FX chipset, BIOS: 1301) 2 x 4 GB G.Skill RipjawsX DDR3-1866 F3-14900CL9Q-16GBXL memória DDR3-1333 beállítás, 9-9-9-28-1T időzítések |
| LGA1155 tesztplatform | Intel Core i3-3220 (3,3 GHz) processzor Intel Core i3-3225 (3,3 GHz) processzor Intel Core i3-2120 (3,3 GHz) processzor Intel Core i7-3770K (3,5 GHz) processzor Intel Core i7-2600K (3,4 GHz) processzor ASUS P8Z77-V DELUXE alaplap (Z77 chipset, BIOS: 1504) 2 x 4 GB G.Skill RipjawsX DDR3-1866 F3-14900CL9Q-16GBXL memória DDR3-1600 vagy DDR3-1333 beállítás, 9-10-9-28-1T/9-9-9-28-1T időzítések |
| Videokártyák | AMD Radeon HD 7970 3 GB GDDR5 – Catalyst 12.3 Sapphire Radeon HD 6670 1 GB GDDR5 (100326L) – Catalyst 12.8 |
| Háttértárak | Intel SSD 510 250 GB SSDSC2MH250A2 (SATA 6 Gbps) Intel SSD 320 160 GB SSDSA2CW160G3 Seagate Barracuda 7200.12 500 GB (SATA, 7200 rpm, 16 MB cache) merevlemez |
| Processzorhűtő | Prolimatech Megahalems Rev.C |
| Tápegység | Cooler Master Silent Pro M600 – 600 watt |
| Monitor | Samsung Syncmaster 305T Plus (30") |
| Operációs rendszer |
Windows 7 Ultimate SP1 64 bit |
Első körben az AMD A10-5800K és az A8-5600K Trinity APU érkezett tesztlaborunkba. Természetesen kíváncsiak voltunk, hogy a közvetlen elődökhöz képest mit tudnak, így az FM1-es A8-3870K APU nem maradhatott ki a megmérettetésből, mely mellé a 65 wattos A8-3820 is betársult. Míg előbbi az összes tesztben, addig utóbbi csak a CPU-tesztekben vett részt, mivel mindkét APU-ban ugyanaz a HD6550D jelzésű grafikus mag található. AMD oldalról még bevettük a leggyorsabb négymagos, FX-4170 névre hallgató, 4,2 GHz-es Bulldozert, hisz a Trinity CPU-része ehhez áll a legközelebb. Az FX mellé még a szintén négymagos Phenom II X4 is bekerült, melyből szintén a leggyorsabb, 3,7 GHz-es 980-ra esett a választásunk.

[+]
A konkurencia részéről elsősorban most is az azonos árszegmensből szemezgettünk, így csak az i3-ak jöhettek szóba. Ez név szerint a közelmúltban tesztelt, Ivy Bridge alapú i3-3220-ban és i3-3225-ben merült ki, amiből utóbbit a grafikus vezérlő eltérése miatt csak a GPU-tesztekben vizsgáltunk. A korábbi Sandy Bridge szériából épp kéznél volt az i3-2120, így ez sem maradhatott ki a buliból. Ezen felül a GPU tesztekhez még felhasználtuk az aktuálisan leggyorsabb, Core i7-3770K nevű Ivy Bridge-et, valamint i7-2600K jelölésű elődjét is.


A10-5800K – A8-5600K [+]


HD 7660D (A10-5800K) – HD 7560D (A8-5600K) [+]
Természetesen az APU-k egyik fő sajátosságát, a grafikus magot is alaposan megvizsgáltuk. Ahogy a Llano, úgy a Trinity is képes a Turks GPU-s kártyákkal (HD 6600 és 6500) Dual Graphics (~CrossFire) üzemmódban működni. Ezen funkció vizsgálatához most is a tavaly már jó szolgálatot tett Sapphire HD 6670-et hívtuk segítségül.



A Dual Graphics bekapcsolva [+]
| Processzor típusa | AMD A10-5800K | AMD A10-5700 | AMD A8-5600K | AMD A8-5500 |
|---|---|---|---|---|
| Kódnév | Trinity | |||
| Tokozás | FM2 | |||
| Alap magórajel | 3800 MHz | 3400 MHz | 3600 MHz | 3200 MHz |
| Magok / szálak | 4 / 4 | |||
| Max. hivatalos memória-órajel |
DDR3-1866 (DC) | |||
| Turbo Core (alap/max.) | 4,0/4,2 GHz | 3,7/4,0 GHz | 3,8/3,9 GHz | 3,5/3,7 GHz |
| L1D/L1I cache mérete | 4 x 16 kB / 2 x 64 kB | |||
| L2 cache mérete | 2 x 2 MB | |||
| L3 cache mérete | nincs | |||
| L3/IMC órajele (uncore/NB) | 1800 MHz | 1600 MHz | 1500 MHz | 1600 MHz |
| Kommunikáció a chipsettel | UMI (5 GT/s) | |||
| Integrált PCIe vezérlő | 20 sáv (2.0) | |||
| Utasításkészletek | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, SSE4A, AES, AVX, XOP, FMA4, FMA(3), F16C, BMI, TBM | |||
| Egyéb technológiák | APM, HTC, C1E, C6, EVP, AMD-V, VCE | |||
| Gyártástechnológia / feszültség | 32 nm HKMG SOI 1,375 V (rev. A1) |
32 nm HKMG SOI 1,212 V (rev. A1) |
32 nm HKMG SOI 1,400 V (rev. A1) |
32 nm HKMG SOI 1,262 V (rev. A1) |
| TDP | max. 100 watt | max. 65 watt | max. 100 watt | max. 65 watt |
| Tranzisztorok száma Lapka mérete |
1,303 milliárd 246 mm2 |
|||
| Integrált GPU (IGP) | Radeon HD 7660D |
Radeon HD 7660D | Radeon HD 7560D | Radeon HD 7560D |
| Grafikus mag kódneve | Devastator | |||
| Végrehajtóegységek | 384 Radeon Core | 256 Radeon Core | ||
| Órajel | 800 MHz | 760 MHz | ||
| Turbo Boost v. Core órajel | nincs | |||
| Támogatott DirectX verzió | DirectX 11 | |||
| Támogatott OpenGL verzió | OpenGL 4.2 | |||
| Támogatott OpenCL verzió | OpenCL 1.2 | |||
| Multi-GPU opció | Dual Graphics | |||
| HD anyagok hardveres támogatása | AVIVO HD (UVD3), (H.264, VC-1, MPEG-2, MPEG-4 ASP/DivX) | |||
| HDMI Audio | Dolby TrueHD és DTS-HD Master | |||
| Processzor típusa | Intel Core i3-3225 Intel Core i3-3220 |
Intel Core i3-2120 |
Intel Core i7-3770K |
Intel Core i5-3470 |
||
|---|---|---|---|---|---|---|
| Kódnév | Ivy Bridge | Sandy Bridge | Ivy Bridge | |||
| Tokozás | LGA1155 | |||||
| Alap magórajel | 3300 MHz | 3500 MHz | 3200 MHz | |||
| Magok / szálak | 2 / 4 | 4 / 8 | 4 / 4 | |||
| Max. hivatalos memória-órajel |
DDR3-1600 (DC) | DDR3-1333 (DC) | DDR3-1600 (DC) | |||
| Turbo Boost vagy Turbo Core |
nincs | 3,6-3,9 GHz (4-től 1 magig) |
3,3-3,6 GHz (4-től 1 magig) |
|||
| L1D/L1I cache mérete | 2 x 32/32 kB | 4 x 32/32 kB | ||||
| L2 cache mérete | 2 x 256 kB | 4 x 256 kB | ||||
| L3 cache mérete | 3 MB | 8 MB | 6 MB | |||
| L3/IMC órajele (uncore/NB) | magórajel | |||||
| Kommunikáció a chipsettel | DMI (5 GT/s) + FDI (az IGP-hez) | |||||
| Integrált PCIe vezérlő | 16 sáv (2.0) | 16 sáv (3.0) | ||||
| Utasításkészletek | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AES-NI, AVX | ||||
| Egyéb technológiák | EIST, C1E, C-states, Execute Disable Bit, Hyper-Threading, Quick Sync, VT-x | |||||
| Gyártástechnológia / feszültség | 22 nm Tri-Gate 1,075 V (rev. E1) |
32 nm HKMG 1,14 V (rev. D2) |
22 nm Tri-Gate 1,15 V (rev. ?) |
22 nm Tri-Gate 1,10 V (rev. ?) |
||
| TDP | max. 55 watt | max. 65 watt | max. 77 watt | |||
| Tranzisztorok száma Lapka mérete |
ismeretlen ~118 mm2 |
624 millió 149 mm2 |
1,48 milliárd 160 mm2 |
|||
| Integrált GPU (IGP) | HD Graphics 4000 HD Graphics 2500 |
HD Graphics 2000 | HD Graphics 4000 | HD Graphics 2500 | ||
| Grafikus mag kódneve | Gen7 | Gen6 | Gen7 | |||
| Végrehajtóegységek | 16 Execution Unit 6 Execution Unit |
6 Execution Unit | 16 Execution Unit | 6 Execution Unit | ||
| Órajel | 650 MHz | 850 MHz | 650 MHz | |||
| Turbo Boost v. Core órajel | 1050 MHz | 1100 MHz | 1150 MHz | 1100 MHz | ||
| Támogatott DirectX verzió | DirectX 11 | DirectX 10.1 | DirectX 11 | |||
| Támogatott OpenGL verzió | OpenGL 3.3 | OpenGL 3.0 | OpenGL 3.3 | |||
| Támogatott OpenCL verzió | OpenCL 1.1 | nem támogatott | OpenCL 1.1 | |||
| Multi-GPU opció | nem támogatott | |||||
| HD anyagok hardveres támogatása | Intel ClearVideo HD (H.264, VC-1, MPEG-2) |
|||||
| HDMI Audio | Dolby TrueHD és DTS-HD Master | |||||
Deneb, Llano, Bulldozer, Trinity
A teszteket kissé rendhagyó módon a négy utoljára megjelent, AMD mikroarchitektúrára épülő processzorral kezdtük. Célunk az volt, hogy azonos magszám, valamint órajel mellett hasonlítsjuk össze a Deneb (K10.5), Llano (K12), Bulldozer (Bulldozer), valamint Trinity (Piledriver) megoldást. Mindezt elsősorban egyfajta érdekességnek szánjuk, hisz a végleges termékek számítási teljesítményét éppúgy határozza meg az órajel is, mint az egységnyi órajelciklus alatt végrehajtható utasítások száma. Mint azt már jól tudjuk, a Bulldozert és annak leszármazottait a korábbi generációknál jóval magasabb órajelre tervezte az AMD, emellé még a "mag" fogalmát is alaposan átértelmezték.

Deneb, Llano, Bulldozer, Trinity: a négy muskétás [+]
A mérések ezen köréhez összesen négy processzort választottunk: Phenom II X4 980, A8-3870K, FX-4170 és A10-5800K. Mindegyik modell kivétel nélkül négymagos megoldás, melyek órajeleit az UEFI segítségével fixen 3000 MHz-re lőttük be. Az egyes platformokhoz a hivatalosan támogatott maximális memória-órajelet állítottuk be, ami a Phenom kivételével a másik három processzornál 1866 MHz volt.
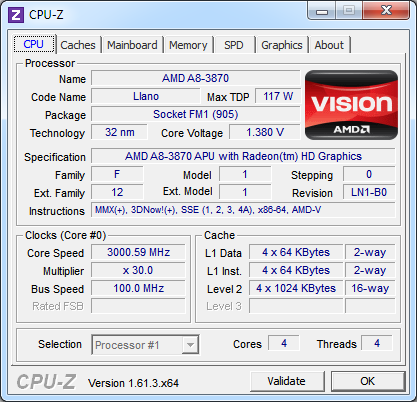

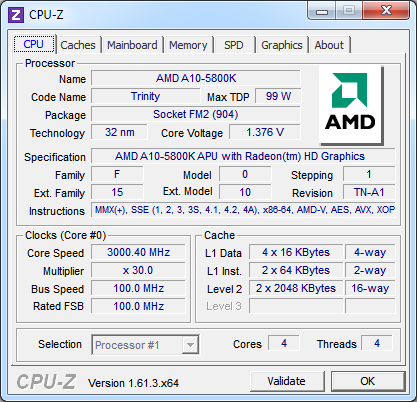
Deneb – Llano – Bulldozer – Trinity [+]
| CPU Megnevezése | Phenom II X4 980 | A8-3870K | FX-4170 | A10-5800K |
|---|---|---|---|---|
| Kódnév | Deneb | Llano | Bulldozer (Orochi) | Trinity |
| Architektúra | K10.5 | K12 | Bulldozer | Piledriver v1 |
| Tokozás | AM3 | FM1 | AM3+ | FM2 |
| Gyártástechnológia | 45 nm SOI | 32 nm HKMG SOI | ||
| Stepping | C3 | B0 | B2 | A1 |
| Beállított magórajel | 3000 MHz | |||
| Szorzó és ref. órajel | 15 x 200 MHz | 30 x 100 MHz | 15 x 200 MHz | 30 x 100 MHz |
| NB/IMC(/L3) órajele | 2000 MHz | 900 MHz | 2200 MHz | 1500 MHz |
| L1 cache / mag | 64 kB adat és 64 kB utasítás (2-utas) | 16 kB adat (4-utas) és 64 kB utasítás két magra (2-utas) |
||
| L2 cache / mag | 512 kB (16-utas) | 1 MB (16-utas) | 2 MB két magra (16-utas) | |
| L3 cache | 6 MB (48-utas) | nincs | 8 MB (64-utas) | nincs |
| Utasításkészletek | 3DNow!(+), MMX, SSE, SSE2, SSE3, SSE4a | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, SSE4A, AES, AVX, XOP, FMA4 | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, SSE4A, AES, AVX, XOP, FMA4, FMA3, F16C, BMI, TBM | |
| Rendszerbusz | 4 GT/s HyperTransport | 5 GT/s UMI | 4,4 GT/s HyperTransport | 5 GT/s UMI |
| Támogatott RAM | DDR3-1333 | DDR3-1866 | ||


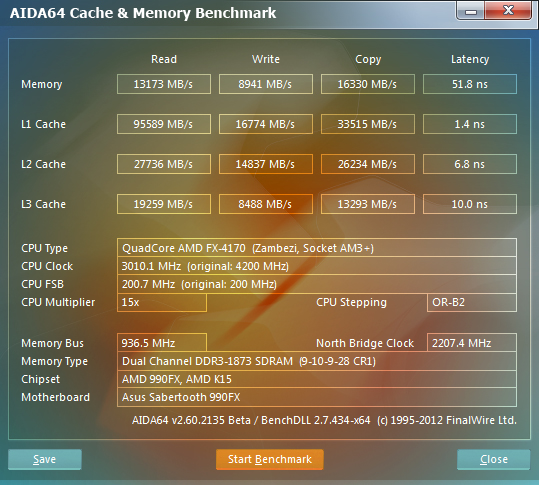

AIDA64 Cache and Memory Benchmark eredmények [+]
| CPU Megnevezése | A8-3870K | FX-8350 | A10-6800K | A10-7850K |
|---|---|---|---|---|
| Kódnév | Llano | Vishera | Richland | Kaveri |
| Architektúra | K12 | Piledriver v2 | Piledriver v1 | SteamrollerB |
| Tokozás | FM1 | AM3+ | FM2 | FM2+ |
| Gyártástechnológia | 32 nm HKMG SOI | 28 nm HKMG | ||
| Stepping | B0 | C0 | A1 | A1 |
| Beállított magórajel | 3000 MHz | |||
| Szorzó és ref. órajel | 30 x 100 MHz | 15 x 200 MHz | 30 x 100 MHz | |
| NB/IMC(/L3) órajele | 900 MHz | 2200 MHz | 1800 MHz | |
| L1 cache / mag | 64 kB adat és 64 kB utasítás (2-utas) | 16 kB adat (4-utas) és 64 kB utasítás két magra (2-utas) |
16 kB adat (4-utas) és 96 kB utasítás két magra (3-utas) |
|
| L2 cache / mag | 1 MB (16-utas) | 2 MB két magra (16-utas) | ||
| L3 cache | - | 8 MB (64-utas) | - | - |
| Utasításkészletek | 3DNow!(+), MMX, SSE, SSE2, SSE3, SSE4a | MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, SSE4A, AES, AVX, XOP, FMA4, FMA3, F16C, BMI, TBM | ||
| Rendszerbusz | 5 GT/s UMI | 5,2 GT/s HyperTransport | 5 GT/s UMI | |
| Támogatott RAM | DDR3-1866 | DDR3-2133 | ||
A négy muskétás – eredmények



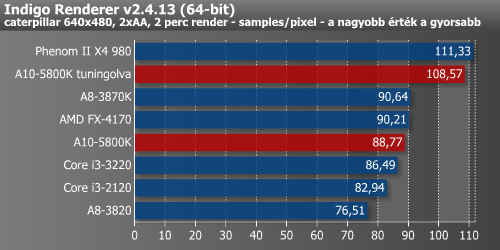
A gyökeresen új kialakítás miatt a Bulldozer egyik rákfenéje épp a renderelés volt. Ahogy látszik is, azonos órajel és magszám mellett jóval lassabb, mint a Deneb vagy a Llano, amin a Trinity Piledriver moduljai csak kismértékben tudtak szépíteni.


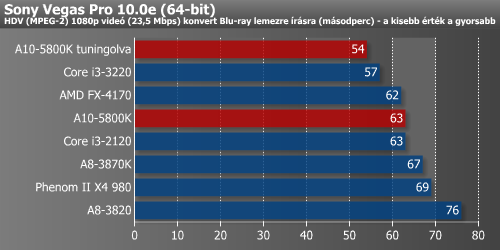
A Premier Pro esetében már lényegesen jobb a helyzet. Itt a Bulldozer még lassabb volt, mint az azt megelőző mikroarchitektúrák, de a Piledriver v1 alapú Trinity nagyon lendített az eredményen, és határozottan az élre állt. Ezzel szemben Photoshop alatt csak kisebb ugrást látunk, amivel majdnem a Deneb szintjére állt vissza a Trinity. Az After Effects a Premier Próhoz kissé hasonló képet fest annyi különbséggel, hogy a Trinity azonos órajelen egyelőre nem volt elég a négymagos Deneb és Llano befogásához.


A Sony Vegas alatt nem mutatkoztak túl nagy különbségek. Itt egyelőre AMD-vonalon a Llano a legjobb, utána a Trinity és a Deneb következik. A Cyberlink Powerdirector nevű alkalmazás kedveli az AMD új irányvonalát, így a Trinity itt a leggyorsabb volt. Ezzel ellentétben a DivX már annyira nem rajong a modulos rendszerért, míg az egyetlen szálon dolgozó XviD nagyon hasonló eredményeket mutatott a négy különböző architektúránál.
A négy muskétás – további eredmények


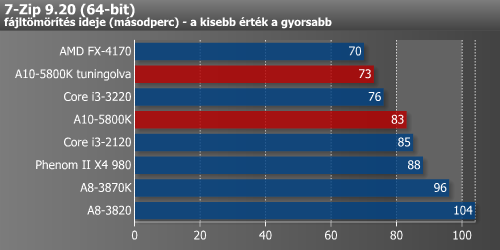
A x264-es enkódolás ugyan fekszik a Trinity-nek, de egyelőre ez nem elég az elődök azonos órajelen való beéréséhez. A fájltömörítés már egy teljesen más történet, ugyanis ezek preferálják a minél nagyobb memória-sávszélességet és cache-t. Így nem is meglepő, hogy 7-Zip alatt a nagy L3 révén a Bulldozer a nyerő, melyet a Trinity követ. A WinRAR az XviD-hez hasonlóan viszonylag közeli eredményeket adott a négy megoldásra.



A Sorenson Squeeze és az AVG hasonló grafikonokat rajzol fel nekünk. Jól látható, hogy egyik alkalmazás sem nagyon kedveli a modulos négymagos megoldást. Az Apache ebből a szempontból a tesztek közül szinte messze a legrosszabb eredményt adta, ami szerintünk valamilyen alapvető problémára vezethető vissza. Ennek a jövőben megpróbálunk alaposabban utánajárni.

Az összesítésből könnyedén leolvasható, hogy azonos órajel és magszám mellett a korábbi Llano átlagosan 17,5%-kal gyorsabb, mint a Trinity. Ez így elsőre meglehetősen rosszul hangzik, de ne feledjük, hogy ezt órajellel részben vagy teljesen kompenzálni lehet. Pusztán elméleti síkon mozogva, tökéletes skálázódás esetén egy 3525 MHz-es Trinity hozná a 3 GHz-es A8-3870K számítási teljesítményét. Ezzel szemben az A10-5800K 3800, míg az A8-5600K 3600 MHz-es alapórajelen ketyeg, így a további eredmények ismerete nélkül még kissé korai lenne temetni az új megoldásokat.
Fogyasztás
A Trinity összesen nyolc darab, úgynevezet CPU PSTATE-tel (Processor Performance State) rendelkezik, melyek között az éppen aktuális terheléstől függően váltogat a rendszer. Emellett az integrált memóriavezérlő, valamint a RAM-ok két ilyen állapotból gazdálkodhatnak. Terhelés hiányában természetesen a GPU is képes csökkenteni az órajelét, modelltől függően 300 MHz környékére.


A10-5800K – A8-5600K [+]
A turbó funkció egyszerű monitorozására az AMD az Intel mintájára készített egy kis alkalmazást, mely egyszerűen csak Turbo Core Monitor névre hallgat.

A fogyasztás mérését egy konnektorba dugható, digitális VOLTCRAFT Energy Check 3000 készülékkel végeztük, és minden esetben a monitor nélküli teljes konfiguráció értékeit vizsgáltuk. Mivel a Sandy és Ivy Bridge-alapú processzorok, valamint a Llano-alapú A8 is tartalmaz IGP-t, ezért ezek fogyasztását kétféle módszerrel is megvizsgáltuk. Az első esetben egy diszkrét Radeon HD 7970 került a rendszerekbe, amivel a processzorba integrált GPU inaktívvá vált, majd később ezt kivettük, és nélküle is elvégeztük a méréseket. Mind az Intel, mind pedig az AMD platformon be volt kapcsolva az összes lehetséges energiagazdálkodási funkció (EIST, C'n'Q, C1E, C6 stb.).


Az eredmények alapján elmondhatjuk, hogy az AMD fejlesztései derekasan megtérültek, ugyanis üresjárat mellett 3-7 wattos előrelépést láthattunk, a hasonló szituációban már amúgy is jó értékeket produkáló Llanóhoz képest. A HD 7970 mellett nagyobb volt a differencia, ami szerintünk a Virgo platform dinamikus PCI Express sávkiosztásának köszönhető.


Terhelés mellett az A8-5600K nagyjából a korábbi csúcs Llano, az A8-3870K szintjét hozta. A hasonló, 100 wattos TDP-osztály ellenére az A10-5800K már többet kért magának, ami szerintünk azt jelenti, hogy ennek a modellnek az áramfelvétele a hatékony Turbo Core miatt sok esetben már a 100 watt körüli limit közelében mozgott. A konkurenciával összevetve itt az AMD nem áll jól, ami a 35-45 wattos TDP-eltérés alapján minket különösebben nem lepett meg. Fontos még megjegyeznünk, hogy a HD 6670 fogyasztását az A10-5800K mellett mértük, egymagában és Dual Graphics bekapcsolása mellett is.
Renderelés, tömörítés
Akkor nézzük mostmár szigorúan gyári beállítások mellett a teljes mezőnyt!



A renderelés tipikusan az a jól párhuzamosított folyamat, ami nem igazán profitál sem az esetlegesen nagyobb L3 cache-ből, sem a nagyobb memória-sávszélességből. Ahogy várható is volt, itt csak az i3-akat tudta megelőzni a két főszereplő, mivel a K10.5- és K12-alapú megoldások nagyon jók renderelésben.


Ahogy már elmondtuk, a fájltömörítők a renderelő alkalmazásokkal ellentétben kedvelik a minél nagyobb memória-sávszélességet és L3 cache-t, ezért az FX-en kívül sikerült lenyomni az elődöket, ugyanakkor az Ivy Bridge kissé meglépett.
Videóvágás, szerkesztés



After Effects alatt viszonylag jól szerepletek az új jövevények, bár az Ivy Bridge-nek itt is volt némi egérútja. A Premiere Pro nagyon feküdt a Trinity-nek, és a Sony Vegasban sem volt különösebb szégyellnivalója.



A Powerdirector a Sony Vegashoz hasonlóan szépen profitál a nagy memória-sávszélességből, ami ismét megmutatkozott. Sorenson Squeeze alatt megint sikerült lenyomni az Intelt, de a Phenom II-t már senki sem tudta utolérni. Korábbi tesztünkben már megfigyeltük, hogy a Bulldozernek finoman fogalmazva nem fekszik Cockos Reaper tesztünk, ez sajnos a Trinity esetében is megmutatkozott.
Videókódolás, egyéb



A DivX-alapú kódolás nem igazán feküdta Trinity-nek, bár a Llanót sikerült megelőzni. Ezzel szemben az egyszálas XviD jobb képet mutatott. Az x264-es eredmények szintén nem nevezhetőek rossznak.



A Trinity-nek összességében tetszett a Photoshop, és itt igen nagy előnyt hozott össze a Llanóhoz képest, sőt az Ivy Bridge sem volt messze. Néhány oldallal ezelőtt már kitértünk az Apache-ra, ahol a Bulldozer-alapú megoldások eléggé gyengélkednek, ez itt is visszaköszönt. Az AVG által adott eredmény itt már jobbnak nevezhető, bár ez most is "csak" arra volt elég, hogy az Intelek elé keveredjen a Trinity-alapú A10.
Játékok (CPU)




A Radeon HD 7970-nel párosítva, játékok alatt az előzetes elvárásainknak megfelelően szerepelt a Trinity. Alacsonyabb felbontás, valamint részletesség mellett meglehetősen nagy volt a differencia az Intel és az AMD újabb processzorai között, ami alól csak a Battlefield 3 képzett kivételt. Ennek ellenére Full HD-ban, nagy részletesség mellett mindegyik processzor képes volt játszható szintet produkálni, azaz most is elmondhatjuk, hogy 1920x1080-hoz és a fölé az esetek döntő többségében elsősorban erős VGA, nem pedig erős CPU szükséges.
Crysis Warhead, DiRT 3, Anno 2070 (IGP)
A második menetben a két főszereplő grafikus képességeit vetettük össze az előddel, valamint a konkurencia aktuális megoldásaival.

A Crysis Warheadről tudjuk, hogy magas részletesség mellett még az erősebb mai diszkrét videokártyákat sem kíméli, így természetesen az integrált megoldások sem kapnak kegyelmet. Az új A10 ennek ellenére 1440x900-ban játszható szintet produkált, de még a nagyobb felbontásban sem ment rosszul. A Trinity A8 szinte pontosan a legerősebb Llano sebességét mutatta. A Dual Graphics itt jól muzsikált.


A DiRT 3-ról (és az egész sorozatról) tudjuk, hogy nagyon fekszik a Radeon-oknak. Ez most sem volt másképp, mert az A10 már tökéletesen játszható szintet produkált. Ezen felbuzdulva meg is emeltük a felbontást 1920x1200-ra, ahol 30 minimum és 34 átlag képkockaszámot kaptunk másodpercenként. Dual Graphics mellett ez a szám 49/58 volt, ami bizony már igen tisztességesnek nevezhető. Az Anno 2070-ben az A10 a kisebb felbontásban még játszhatónak nevezhető szintet hozott, míg a két A8 ismét azonos eredményt produkált.
Battlefield 3, Deus Ex, Batman, Starcraft 2 (IGP)
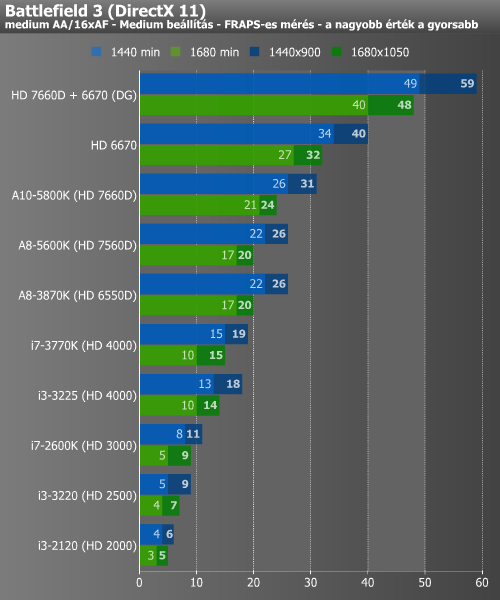
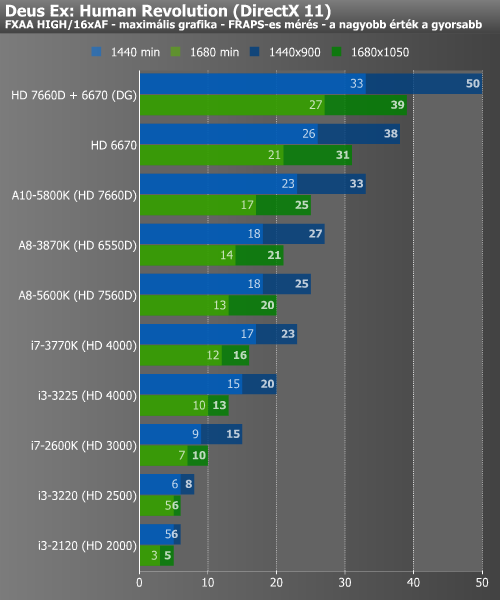
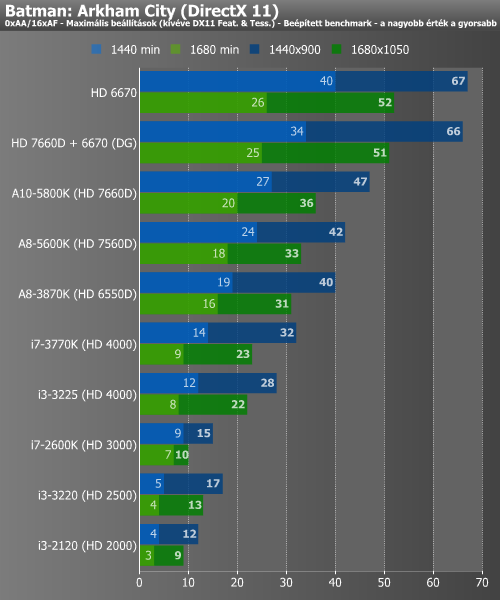
A Battlefield 3 alatt ismét élvezhető szintet mutatott fel 1440x900-ban az A10, a Dual Graphics megint hatékonyan végezte a dolgát. A Deus Ex alatt elért eredmény ugyan annyira már nem volt jó, de az A10-zel a kisebbik felbontásban itt sem álltunk messze az élvezhető szinttől. Utóbbi Batman alatt összejött, viszont a Dual Graphics elhasalt, ami valószínűleg valamilyen kezdeti szoftveres problémára vezethető vissza.
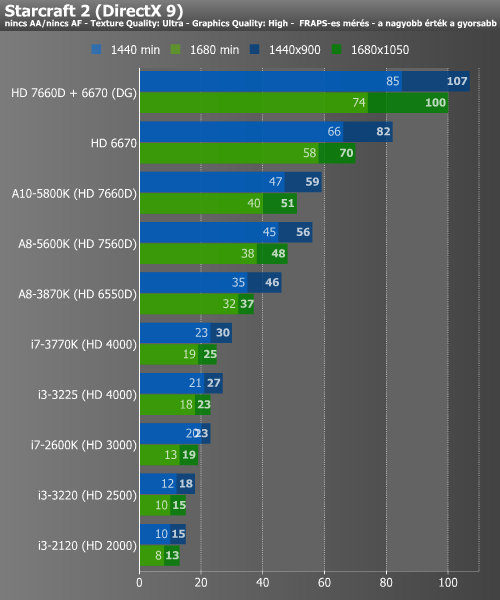
Végül a DirectX 9 alapú Starcraft 2-t néztük meg, ami eléggé feküdt a Trinity-nek. Olyannyira, hogy itt az új és régi A8 közötti, korábbi kis rés is kitágult. Az eredményeken újfent felbátorodva ismét beállítottuk az 1920x1200-as felbontást, itt az A10 34 minimum és 44 átlag fps-t produkált. A Dual Graphics hasonló beállítások mellett 68/90-es eredményt hozott.
ComputeMark, LuxMark v2.0, Handbrake (OpenCL)
A közelmúlt VGA-tesztjeihez hasonlóan két, általános számítási feladatokat tartalmazó benchmark is bekerült méréseink közé. Mivel félig-meddig szintetikus tesztekről van szó, túl messzemenő következtetéseket szerintünk nem érdemes levonni ezek eredményeiből.


A ComputeMark egyszerűbb DirectCompute shaderekkel operál, amelyekkel főleg a játékok alatt lehet találkozni. A LuxMarkból a legújabb verzióra váltottunk, ahol az alapértelmezett Medium Benchmarkkal mértünk. Az érdekesség kedvéért ezt a mérést két különböző módban is elvégeztük: először csak a GPU számolt, a második esetben a CPU-magok és a GPU közösen végezte a kalkulációkat. Látható, hogy a Llano A8 és a Trinity A10 között pusztán a GPU számítási kapacitásában közel 50%-os előrelépést mutatott a LuxMark. További érdekesség, hogy az A10 még a HD 6670-et is majdnem befogta, valamint a CPU és GPU erejét összedobva megelőzte a tisztán csak CPU-erőből gazdálkodó i7-2600K-t. A Dual Graphics itt is jól működött.

A népszerű és ingyenes, grafikus felülettel ellátott Handbrake konvertáló a tesztünkben szintén oszlopos tagnak számító x264-re épül. A fejlesztők már egy ideje munkálkodnak egy OpenCL-támogatással rendelkező verzión is, ami egyelőre még nincs végleges stádiumban. Ennek ellenére mi kaptunk egy verziót, amit nem voltunk restek kipróbálni. A LuxMarkhoz hasonlóan mértünk, azaz először a Handbrake publikus, pusztán CPU-erőt használó verziójával konvertáltunk, majd ezután jött az OpenCL-re is felkészített verzió, ahol a GPU ereje is beszállt a játékba.
A kapott eredmények önmagukért beszélnek. Az A10 az integrált GPU erejének köszönhetően az első helyen végzett, ezzel szemben a létező OpenCL támogatás ellenére sem tudtuk munkára fogni az Intel HD 4000 és HD 2500-zal szerelt processzorait, ami a számokból jól látszik. Egyelőre nem tudjuk, hogy a hiba az Intel meghajtóprogramjában vagy a Handbrake korai verziójában keresendő, de optimális esetben nyilván az Ivy Bridge alapú modelleknél is tapasztalnunk kellett volna egy bizonyos mértékű gyorsulást. További probléma, hogy utóbbihoz hasonlóan a Dual Graphics sem működött.

Munkában az AMD System Monitor [+]
A Handbrake-es méréshez elővettük az első APU-kkal debütált AMD System Monitor nevű szoftvert, mely valós időben képes megmutatni a heterogén végrehajtás közbeni erőforrás-megosztást. A fenti animáció az A10-5800K mérése közben született.
Az A10-5800K APU gyors tuningja
A Llano megjelenésének időpontjában nem kínált szorzózármentes APU-t az AMD; ez az állapot csak az év utolsó negyedévében változott meg az A6-3670K és A8-3870K modell debütálásával. A tunigot kedvelők szerencséjére a Trinity épp két ilyen zármentes (Black Edition) APU-val nyitott, amiből mi az idő szűkössége miatt csak az A10-et vetettük bele a túlhajtás feketelevesébe. Viszonylag könnyű dolgunk volt, hisz kizárólag a szorzókkal és a feszültségekkel kellett machinálnunk.
[+]
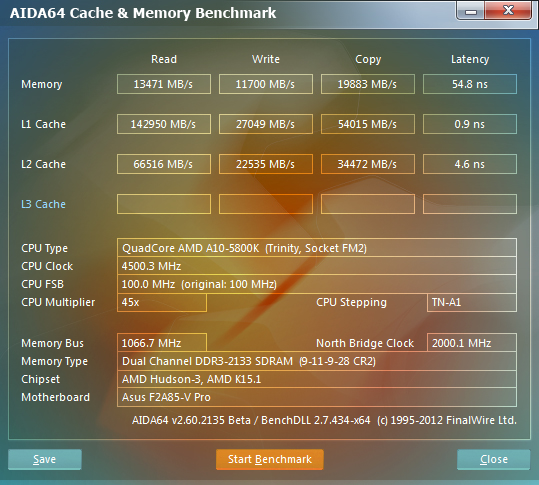
Gyors kísérletünk során a CPU-magokat 4500 MHz-ig tudtuk stabilan felhúzni, amihez 1,5 voltos magfeszültség volt szükséges, ami konkrétan 0,125 voltos emelést jelent. Az integrált északi híd üzemi frekvenciáját ezzel párhuzamosan 2000 MHz-ig húztuk fel. Ezután az IGP következett, amit 800 MHz-ről 1013 MHz-ig emeltünk, végül a memóriákat is megkínoztuk egy kicsit. Az ASUS alaplapja a Trinity-vel karöltve egészen 2400 MHz-ig kínálja a memóriaszorzókat, ám ezt G.Skill moduljaink már nem tolerálták, így meg kellett elégednünk a stabil 2133 MHz-cel.
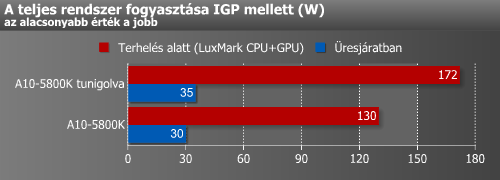
A viszonylag nagy feszültségemelés ellenére nem ugrott meg vészesen a fogyasztás. A CPU-t és GPU-t egyaránt nagyon terhelő LuxMark alatt 42 wattos pluszt tapasztaltunk, míg DiRT 3 alatt csak 22 wattos volt a többlet. A hőmérsékleti érték ennek megfelelően 47 Celsius-fok környékén mozgott az alaplap szerint.
Természetesen néhány mérés erejéig azt is megnéztük, hogy a számítási teljesítményre mekkora hatással vannak az órajel-emelések.

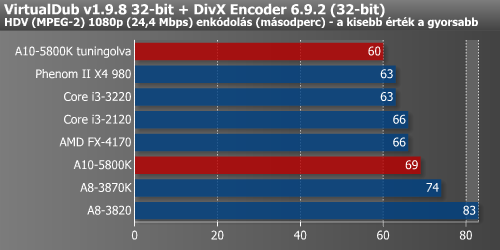
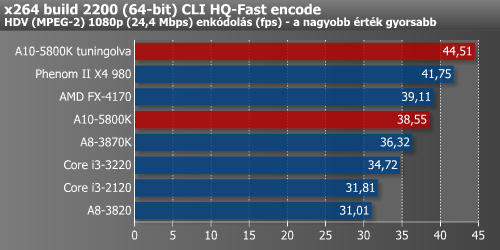
Ezt követően ismét előkerült a DiRT 3 és a Crysis Warhead, melyekkel megnéztük, hogy a túlhajtás mennyit jelentett a képkockák másodpercenkénti számában.
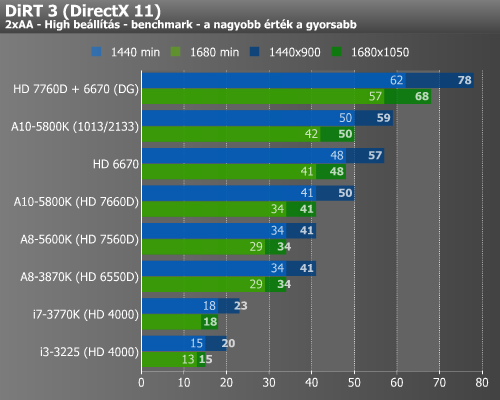
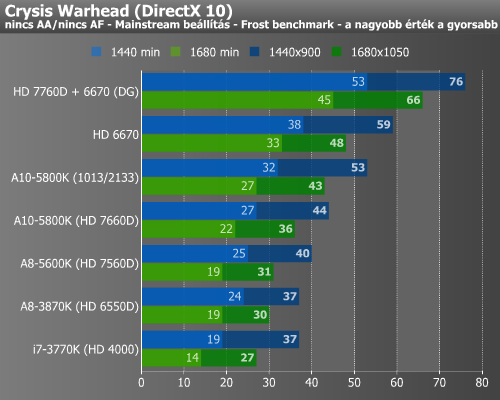
A DiRT 3 olyannyira meghálálta tuningot, hogy a húzott A10-5800K már a diszkrét HD 6670-et is megelőzte, ami szerintünk nagy fegyverténynek nevezhető. Ugyan Crysis Warhead alatt már nem ismétlődött meg a bravúr, de a hatás ott is szemmel látható volt.
Végszó
Kissé hosszúra nyúlt cikkünk végéhez érkezve jöjjenek az összesített eredmények!
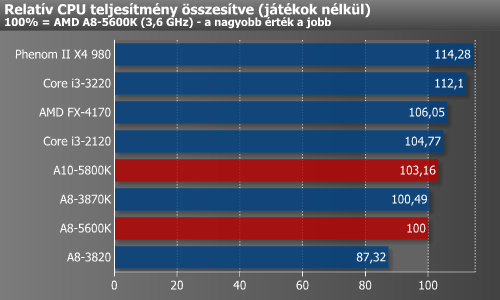
Az összesítésből kiderül, hogy tisztán x86-os alapú számításokban az A10 szűk 3%-kal gyorsabb a korábbi csúcs Llano A8-3870K-nál. Ezzel szemben a régi Intel Core i3-2120-tól csak 1,5%-kal, míg az i3-3220-tól már nem egész 9%-kal marad el. Az A8-5600K szinte pontosan az A8-3870K sebességét produkálta, miközben így az A10-es nagytesótól csak bő 3%-kal maradt el. Ahogy már megjegyeztük, a Bulldozer és legújabb leszármazottja különösen lemaradt Cockos Reaper, valamint Apache tesztünkben, ezek számításba vétele nélkül a két újdonság valamivel jobban állna.

Ahogy a terheléses fogyasztásmérésben, úgy az ezen értékre alapozó teljesítmény/fogyasztás mutató esetében sem tündököl a két 100 wattos Trinity. A három darab, azonos TDP osztályba tartozó modell szépen együtt van, míg a 65 wattos Llano 3%-kal előttük végzett. Természetesen a Trinity-ből is készülni fog 65 wattos verzió, amit lehetőségeinkhez mérten a jövőben majd megpróbálunk bemutatni olvasóinknak.

Az integrált grafikus megoldás 3D-s megjelenítési sebességét tekintve az AMD az asztali megoldások között tovább növelte előnyét. A korábbi csúcsmodell A8-3870K-hoz képest az új A10-es zászlóshajó APU 23%-ot gyorsult. Figyelembe véve, hogy a támogatott memória sebessége nem változott és a lapka mérete csak minimális mértékben nőtt, valamint a gyártástechnológia csíkszélessége és a fogyasztási keret is azonos maradt, a 23% szerintünk több, mint ami ilyen feltételek mellett elvárható volt. Az A8 5%-os gyorsulása ezzel szemben nem túl sok, de tartsuk szem előtt, hogy az új csúcsmodell immáron A10 névre hallgat, hisz az AMD egy új kategóriával bővítette az "A" szériás palettát.
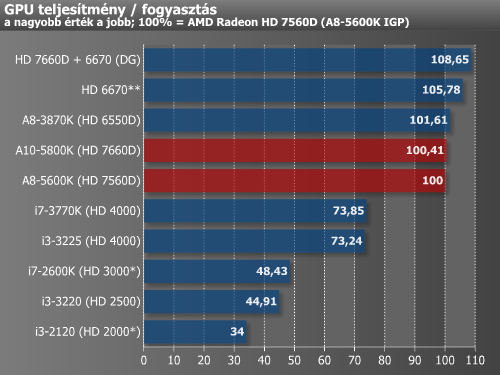
A remek GPU-teljesítménynek köszönhetően – még a magasabb fogyasztás ellenére is – továbbra is vezeti a GPU teljesítmény/fogyasztási mutatókat az AMD.
Verdikt
Egyelőre úgy fest, hogy az AMD viszonylag zavartalanul tud tovább robogni az általuk megnyitott fúziós ösvényen. Amennyiben különösebb csúszások nélkül képesek lesznek tartani az ütemtervet, úgy érdekes néhány év állhat előttünk. Természetesen az igazi sikerhez szükséges lesz az OpenCL, valamint a HSA elterjedése is, mellyel az időközben egyre inkább összefonódó CPU- és GPU-magok kapcsolatának gyümölcse több területen is kihasználható lesz.

[+]
A jövőre érkező Steamroller modulokra, valamint GCN grafikus végrehajtókra épülő Kaveri egy nagyobb ugrást prognosztizál. Amennyiben – kissé ironikusan – az Intel stratégiájával akarjuk érzékeltetni a konkurens AMD terveit, akkor elmondhatjuk, hogy a Trinity csak egy kisebb "tick" állomás volt, míg a Kaveri lesz a "tock", azaz a gyökeresebb, és ezzel várhatóan nagyobb előrelépés. Utóbbi eszmefuttatás fényében, valamint az elődök problémáinak ismeretében szerintünk a Trinity egy jól sikerült fejlesztés gyümölcse lett. CPU-erőben kisebb, míg GPU terén jóval nagyobb ugrást mutat. Ez valahol megfelel az AMD terveinek, aki inkább a GPU-ra hárítaná a számításokat, bár ennek ellenére a CPU-magok/modulok fejlesztését sem hanyagolhatják, hisz az x86-os végrehajtókra még nagyon sokáig szükség lesz! Ennek fényében készült a Steamroller, mely az előzetes beharangozók alapján egy nagyobb előrelépés lesz, mint amit a Bulldozer->Piledriver(v1) esetében ma bemutattunk, ergo a java még csak ezután jön!
[+]
Visszakanyarodva a főszereplőkhöz: a Trinity A10-5600K és A10-5800K szerintünk két legalább olyan jól sikerült termék, mint amilyen a tavaly nyáron bemutatott Llano A8-3850 volt. Tisztán a CPU erőt tekintve ugyanazt mondhatjuk, mint az eddigi i3-ak esetében, azaz mind az A8, mind pedig az A10 elégséges teljesítményt nyújt a legtöbb otthoni, extra igényekkel nem rendelkező felhasználónak.

[+]
Az árazás sarkalatos pont. Egyelőre pontos hazai adatokkal nem tudunk szolgálni, így csak az amerikai dollárban megadott értékekből kalkulálhatunk. Az előző héten bemutatott Intel i3-3220 hivatalos árát 117 dollárban, míg az erősebb, HD 4000-es IGP-vel szerelt i3-3225-ét 134 dollárban szabta meg az Intel. Ezzel szemben az AMD 122 dollárt adott meg a csúcsmodell A10-5800K-ra, míg a kisebb A8-5600K egy 101 dolláros címkét kapott. Ebből, valamint az Intel Core i3-ak hazai árára alapozva szerintünk az A10 34-35 000 forintba fog kerülni, az A8 pedig 27-28 000-be.
Azt már tudjuk, hogy pusztán CPU-teljesítményben, valamint fogyasztásban az Intel a jobb, ellenben a GPU-t tekintve az AMD nagyon vezet. Ennek fényében mi a Llano-hoz hasonlóan leginkább azoknak ajánljuk az új A10-5800K új Trinity APU-t, akik valamilyen módon ki tudják aknázni a grafikus teljesítményt is. Ez jelenleg elsősorban különféle játékokkal, alacsonyabb felbontás mellett lehetséges, de a Handbrake tesztből kiderült, hogy ha lassan is, de érkeznek olyan alkalmazások, amelyek általános számításoknál is ki tudják használni GPU-ban rejlő nagy potenciált. Az A8-5600K egyelőre az ára miatt nem ajánlott, hisz az A8-3870K nagyjából 2000 forinttal olcsóbb, így a nálunk járt kisebbik Trinity APU egyelőre csak a tetszett kategóriánkat gyarapíthatja. Ezzel együtt azt is megerősítenénk, hogy alapesetben szinte mindig érdemes kihagyni a fejlesztési verseny legalább egy lépcsőjét, hisz igazán nagy ugrást általában csak így tapasztalhattunk a processzorunk, grafikus kártyánk, vagy éppen más egyéb hardverünk cseréje után.
 |
 |
| AMD A10-5800K APU | AMD A8-5600K APU |
Oliverda
Az AMD A10-5800K és A8-5600K APU-kat az AMD biztosította, míg az ASUS F2A85-V PRO alaplapot az ASUS magyar képviselete adta kölcsön. A teszteléshez használt AMD FX-4170 processzort Gianni bazárjának köszönhetjük.








