
AMD Tahiti
Egy új architektúra bevezetésénél nagyon nehéz megfelelni minden szempontnak, ugyanis ami elméletben működik, az nem biztos, hogy a gyakorlatban is fog. A fejlesztés végletekben megszabott célkitűzéseivel az AMD óriási kockázatot is vállalt, hiszen radikális újításokat kellett bevezetni. A Tahiti kódnevű termék végül megfelel a Sweet Spot stratégiának, hiszen a TSMC 28 nm-es gyártástechnológiájával készülő lapka kiterjedése 365 mm², és ebbe a méretbe 4,31 milliárd tranzisztort sikerült bepasszírozni.

A Tahiti cGPU blokkdiagrammja [+]
A rendszer alapja CU, azaz a Compute Unit lesz; lényegében ez váltja a jelenlegi, VLIW utasításokkal dolgozó shader tömböket. Mindegyik CU tartalmaz egy skalár feldolgozót, és négy darab, egymástól teljesen független, 16 utas, azaz 512 bites, multiprecíziós SIMD motort. Ezzel a felépítéssel a jelenlegi, VLIW-alapú rendszert sújtó függőség problémája teljesen kiküszöbölhető, mivel az adatok mostantól komponens folyamonként érkeznek. Egy CU órajelenként négy utasítást képes végrehajtani 16 elemen, melyek négy különböző munkafolyamatból kerülhetnek ki. A Cayman GPU-ban alkalmazott megvalósítás jóval bonyolultabban működött, mivel egy shader tömbön belül 16 darab szuperskalár shader processzor volt, melyek órajelenként négy utasítást hajthattak végre négy elemen, ám ezek nem, illetve csak nagyon speciális esetben függhettek egymástól. Az új architektúrában bevezetett változások a hatékonyságot helyezik előtérbe, így a rendszer jobban kihasználható, és egyszerűbb is rá programozni, vagyis a driverek fejlesztésével, valamint a valós idejű shader fordító optimalizálásával is jóval könnyebb dolga lesz az AMD-nek.

[+]
Egy CU-n belül 64 kB-os Local Data Share (LDS) található, melyeken a négy darab, egyenként 64 kB-os regiszterterülettel rendelkező SIMD motor osztozik. Az LDS-sel egyébként az AMD túlteljesíti a DirectCompute 32 kB-os követelményét, ami valószínűleg azért történt így, mert az architektúrát jelentősen az általános számításokra tervezték. Az LDS mellett egy 16 kB-os adat gyorsítótár is elérhető, melyet a CU írhat és olvashat is. A fentebb már említett skalárfeldolgozó némileg különc a CU-n belül. Ez lényegében egy integer ALU, mely 8 kB-os dedikált regiszterterületet kapott. A textúrázást CU-nként egy blokk oldja meg, mely négy darab, csak szűrt mintákkal visszatérő Gather4-kompatibilis textúrázó csatornát rejt. A rendszeren belül a CU-k négyes tömbökbe rendeződnek, és ezekhez tartozik egy 16 kB-os skalár és egy 32 kB-os utasítás gyorsítótár. Előbbit csak a skalárfeldolgozó éri el, és csak olvasható tárról van szó, ám utóbbi írható is, és a CU összes feldolgozója hasznosíthatja. A Tahiti cGPU-ban egyébként 32 darab CU található, melyekhez kapcsolódik egy Global Data Share (GDS) memória is, amivel a CU-k nagyon gyorsan oszthatnak meg adatokat egymással.

A Compute Unit felépítese [+]
A vezérlés dilemmája
Nem túl nehéz megállapítani, hogy egy cGPU-nál a hatékony működés kulcsa a hatékony vezérlés, így erre a területre az AMD-nek is rá kellett feküdni, azonban figyelembe kellett venni a skálázhatóságot. Példaként érdemes felhozni a Fermi architektúra lapkáit az NVIDIA termékskálájáról. A GF110-es és a GF114-es lapkák úgy-ahogy versenyképesek a chip kiterjedéséhez mért egységnyi sebesség tekintetében, de a kisebb GeForce-okon már meglátszik, hogy a bonyolult vezérlés rengeteg tranzisztort emészt fel. A GF116-os GPU például közel akkora, mint az AMD Barts lapkája, de a GeForce GTX 550 Ti még csak megközelíteni sem tudja a Radeon HD 6870 teljesítményét. Ez persze a termékek árazásában is megnyilvánul az NVIDIA-nál, de a probléma jelen van, és így a rendszer skálázhatósága egy bizonyos szint alatt nagyon nem hatékony.
Lényegében ezen a ponton kellett az AMD mérnökeinek a legtöbb problémával megküzdeni, és úgy döntöttek, hogy egy teljesen moduláris vezérlést vezetnek be, így az úgynevezett Asynchronous Compute Engine (ACE) felel majd a CU-k etetésért. Ez az egység a parancsprocesszorhoz szorosan kapcsolódik, és akármennyi beépíthető az adott lapkába, sőt, akár mellőzhető is. Utóbbi opció azonban nem ajánlott, mivel az ACE a rendszer magas hatékonyságú kihasználásához alapvetően szükséges, ugyanis ez a motor dönt az erőforrás-allokációjával, a kontextusváltással és a feladat prioritásával kapcsolatban. Ráadásul az ACE out of order logikát alkalmaz az erőforrások mielőbbi felszabadítása érdekében. Bár maguk a CU-k in order elven működnek, vagyis az utasításfolyamokat a beérkezés sorrendjében hajtják végre, de alapvetően az ACE eteti a CU-kat, így képes meghatározni a feldolgozás sorrendjét.
A Tahiti cGPU-ba két ACE került. Arról sajnos az AMD nem közölt információkat, hogy két motor mennyire hatékonyan képes kezelni 32 darab CU-t, de az architektúráról kiderült, hogy félelmetesen jól skálázható, így a jövőben annyi ACE-t lehet beépíteni, amennyit az AMD jónak lát.
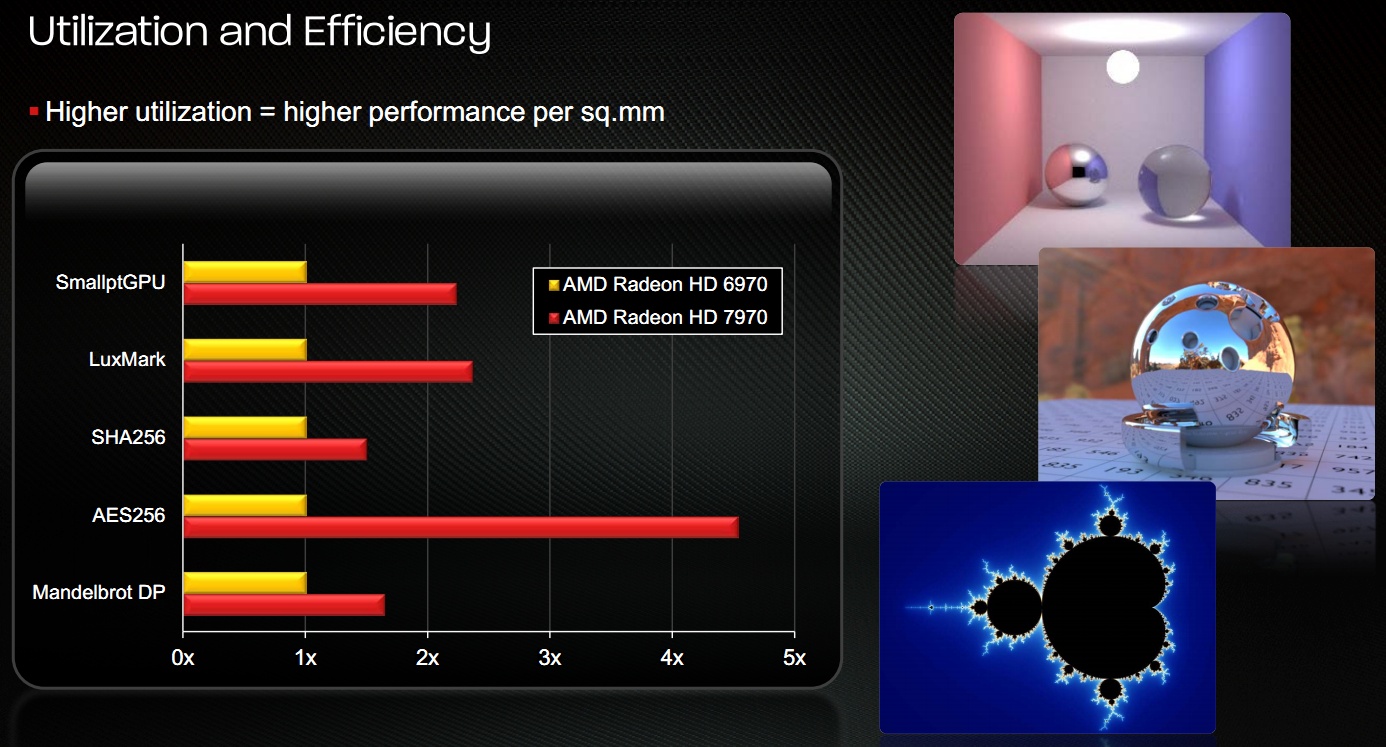
[+]
A gyakorlatban a változások az AMD mérései szerint jól sültek el, mivel a Cayman és a Tahiti lapkák kiterjedése nagyon hasonló, de az utóbbi termék 50-60%-kal nagyobb elméleti számítási teljesítmény mellett több helyen is jobb teljesítményre tett szert. A Cayman architektúrájának tipikusan feküdt az SHA256-os kódolás, mivel ez egy gyorsításra szélsőségesen érzékeny algoritmus. Itt a Tahiti lényegében annyit gyorsult, amennyire a magasabb számítási teljesítményből számítani lehetett, ám a SmallptGPU és a LuxMark esetében jóval nagyobb az előrelépés. A hatékonyság kiugró növekedésével lehet számolni az AES256-os kódolás esetében, ami az algoritmus jellegzetességeiből adódóan jól mutatja, hogy az ACE nagyon jó munkát végez a rendszer vezérlése során. Az AMD dupla pontosság mellett tesztelt Mandelbrot fraktállal is, amit szintén gyorsan dolgozott fel már a Cayman is, így az előrelépés nagyjából a valós gyorsulással egyezik meg. A Tahiti cGPU egyébként az elméleti számítási teljesítmény negyedével képes dolgozni dupla pontosság mellett.
A cikk még nem ért véget, kérlek, lapozz!





